目录
1.最小梯度下降(Mini-batch SGD)
2.激活函数
2.1 sigmoid
2.2 tanh
2.3 ReLU
2.4 Leaky ReLU
2.5 ELU
2.6 最大输出神经元
2.7 建议
3.数据预处理
4. 如何初始化网络的权值
5. 批量归一化
6.超参数的选择
1.最小梯度下降(Mini-batch SGD)
我们之前讲过如何训练一个模型:给定一个数据集,建立好它的网络模型,然后初始化学习参数,利用前向传播计算学习结果,利用反向传播进行梯度下降不断的找到代价函数最优解。但是,在一次迭代过程中,我们最小化代价函数是在整个数据集上运行的,如果一个数据集很大,上百亿上千亿,那么我们机器的内存会爆炸,因此我们对于一个海量数据集不可能将全部数据读入内存进行梯度下降,那我们怎么办?
我们可以一次读取一批(batch)的数据集,用这小批量的数据集去进行反向传播更新参数,这个想法我们叫它Mini-batch,本节中,我们将讲述融入最小梯度下降法思想的深度学习并且讨论以下问题:
①如何建立神经网络
②选择怎样的激活函数
③怎样对数据进行预处理
④权重初始化
⑤正则化
⑥梯度检查
⑦如何监控这个训练过程
⑧超参数优化...
2.激活函数
对于任意一层来说(全连接层或者卷积层),我们将输入乘上权重值
,然后将结果输入一个激活函数或者非线性单元。
这里有一些激活函数的例子:


2.1 sigmoid
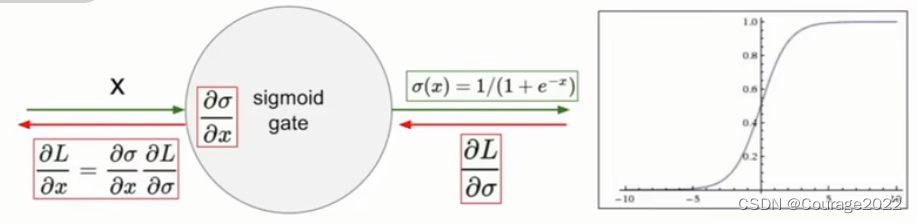
每一个元素输入到sigmoid非线性函数中使每个元素被压缩到
范围内,如果你有一个非常大的输入值,那么输出将会十分接近于1;如果你有一个绝对值很大的负的输入值,那么输出将会十分接近于0。
但实际上他有若干问题:
①首先是饱和神经元将使得梯度消失:
它所返回的梯度流是什么样的呢?
当输入是一个绝对值很大的负数时,梯度取值是什么呢?此时梯度为0,是因为这个太过接近sigmoid函数的负饱和区域,这个区域本质上是平的所以梯度
会变为0,因此我们将返回的上游梯度
等于一个约等于0的数,因此经过链式法则后会让梯度流消失,因此零梯度便会传递到下游的节点导致梯度消失。
当输入是一个接近0的数时,你将会得到一个很好的梯度并可以很好的进行反向传播。
当输入是一个很大的正数时,同理,也会导致梯度消失。
②sigmoid是一个非零中心的函数,这会导致什么样的问题呢?
考虑一下当输入神经元的数值始终为正的时侯会发生什么:
考虑一下这个线性层的局部梯度是多少?我们用L对任何激活函数求偏导损失传递了下来,然后我们的局部梯度实际上就是
的梯度因为他们或者全是正数或者全是负数,那么它们总是朝着同一个方向移动,当你在做参数更新的时候你可以选择增加它们,你就将用正数去增加/减少所有
假设我们的
因此我们为了解决这个问题,我们通常使用均值为0的数据,这样我们就能得到正的和负的数值。
③sigmoid的计算代价稍微有点高(但相比于卷积的乘法不值得一提)


2.2 tanh
它和sigmoid函数差不多,只不过现在它被挤压到
的范围内,tanh函数是以0为中心的,所以我们就不会有sigmoid函数的第二个问题,但是当它饱和的时候依然会出现梯度消失的问题。

2.3 ReLU
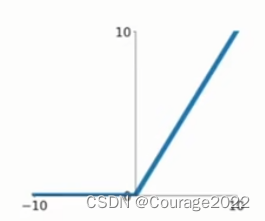
ReLU函数的形式是:
根本来讲,它在你的输入上按元素进行操作;如果你的输入是负数,将会得到结果0,如果输入的是正数,结果还是你输入的数。
它是目前最为流行的激活函数。然而对于ReLU仍然存在问题,就是它不再是以0为中心的了,我们可以看到sigmoid也不是以0为中心的,tanh解决了这个问题但现在ReLU又产生了这个问题。另外输入正半轴的时候我们没有产生饱和。
当
在

2.4 Leaky ReLU
Leaky ReLU函数的形式是:
解决了ReLU的梯度消失问题。

2.5 ELU
ELU函数的形式是:
它具有所有ReLU的优点且它的均值,此外,它的输出均值还接近为0。

2.6 最大输出神经元
它的形式是这样的:
但这会将神经元的参数翻倍,原来是用一组参数训练,现在变成了两组,但它可以规避掉ReLU所有的问题。
2.7 建议
最好用ReLU,但要控制学习率。
尝试Leaky ReLU/Maxout/ELU
尝试tanh但不要对它抱有太多希望
不要尝试sigmoid
3.数据预处理
要对数据归一化处理。对于图像要对像素进行归一化或者零均值化再方差均一化处理。
还可以用PCA与白化给数据做预处理:
具体来说, 在训练阶段我们会决定我们的均值,然后我们会将一样的均值应用到测试数据中去,所以我们会用从训练数据中使用相同的均值来归一化。总结说来,一般对于图像
我们就是做零均值化的预处理,并且我们可以减去整张均值图像的值,从训练数据数据可以计算均值图像,其尺寸和你的每张图像都是相同的,例如对于一张RGB图像,然后我们的图像假设为的,所以我们会有一个红色通道的均值、一个绿色通道的均值以及一个蓝色的。我们求出整个训练集的R、G、B的均值然后用这个均值去归一化我们的图像,零均值化处理它的每一层。


4. 如何初始化网络的权值
一般来说将权重初始化一个非常小的随机数,但这有很大的问题。
在此,我们有标准的双层神经网络,我们看到所有这些用来学习的权值都需要给他们赋值初值,然后我们再用我们的梯度更新来更新他们。
第一个问题,当我们使用0为权值初始化
会发生什么呢?
所有神经元参数相同,1个和N个没有区别。所有的神经元都在做相同的事情,由于你的权重都是零,给定一个输入每个神经元将在你的输入数据上有相同的操作接着它们将输出相同的数值并且得到相同的梯度。它们用相同的方式更新,最后得到完全相同的神经元,这并不是我们想要的。
第二个问题,我们将所有权重是一个小的随机数,我们可以从一个概率分布中抽样:W = 0.01 * np.random.randn(D,H)这个例子中,我们从标准高斯函数抽样,均值为0,方差为
,然后乘以0.01。这样给定了很多小的随机参数,这样的参数在小型网络中适用,但在结构深一点的网络可能会存在问题。
简单来讲就是正向传播时,由于权重
又是取决于
那如果我们尝试用增大权重来解决这个问题呢?
和前面所说的一样,会使神经元处于饱和状态(tanh、sigmiod)导致梯度消失或者梯度爆炸(ReLU)。
那么太小也不行太大也不行到底要我怎么样?
一个很好的经验是Xavier初始化:fan_in、fan_out对应所输入/输出层的神经元数量
w=np.random.randn(fan_in,fan_out)/ np.sqrt(fan_in)我们观察这里的W,我们需要从标准的高斯分布中取样然后根据我们拥有的输入的数量来进行缩放,我们要求输入的方差等于输出的方差。
如果我们有少量的输入,那么我们将除以较小的数,从而得到较大的权重。我们需要较大的权重因为我们有少量的输入,用每一个输入值乘以权重那么你需要一个更大的权重来得到一个相同的输出方差;如果我们有大量的输入,我们想要更小的权重以便让它在输出中得到相同的方差。

5. 批量归一化
我们想要在高斯范围内保持激活,我们要对数据进行批量归一化:(为什么要在高斯范围内保持激活?为了避免经激活函数激活后使神经元饱和从而导致梯度消失梯度爆炸等问题)
Batch归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更庞大工作效果也很好。
那么批量归一化是怎么工作的呢?让我们考虑一下在某一层上的批量激活,如果我们想要正确地激活单位高斯函数,我们可以取目前批量处理的均值然后我们可以用均值和方差来进行归一化,所以我们在训练开始时才设置这个值而不是在权重初始化的时候以便我们能够在每一层都有很好的单位高斯分布希望在训练的时候能够一直保特。
下图中,如果你想训练这些参数比如
,那归一化
的平均值和方差可以有效的避免神经元饱和的问题。
因此批量归一化可以使
值,可以快速地训练
。这就是Batch归─化的作用。
但严格来说我们真正归一化的是输入到激活函数前的数据,因此需要归一化的数据不是
。因为归一化激活前的数据这样就可以避免因为数据分布问题(比如这一层神经元权重过大)导致的梯度消失或者梯度爆炸(激活函数不同可能导致梯度消失或者梯度爆炸)。我们具体是这么做的:
未经激活的该层数据为
求出均值和方差:
通过求出的均值和方差归一化该层数据:
这里的
是一个超参数,是一个较小的值,作用是防止输入数据相似导致方差为0。
我们最后要进行激活的
为:
其中,
也是待训练参数。作用是可以随意设置
的平均值,而不是死板的让它的均值为0,方差为1。这可以适用于不同的激活函数,比如sigmoid激活函数不是原点对称,我们可以将它的均值设置为0.5,但是对于ReLU,tanh激活函数,就可以将均值设置为0。作为参数学习也会让系统性能变得更好。
在测试阶段,批量归一化层BN减去了训练数据中的均值和方差,我们在测试阶段不用重新计算,我们只是把这当成了训练阶段。

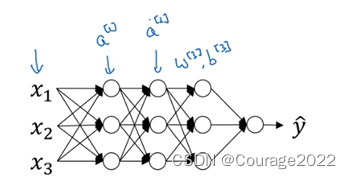
6.超参数的选择
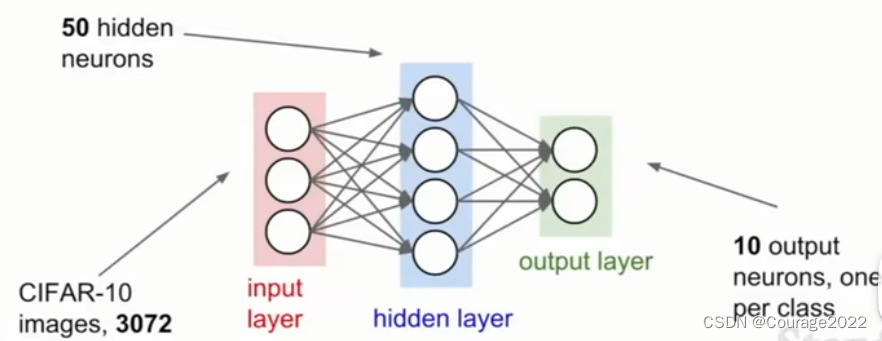
一直以来,我们要做的第一步是数据预处理,然后我们选择网络结构,假设下图是一个简单的神经网络,开始它具有一个含有50个神经元的隐藏层。
接下来我们要初始化我们的网络,网络进行前向传播,用我们选择的损失函数计算我们的损失,我们先从一个小数据集开始,加入正则化,如果我们能够得到非常小的损失,我们关闭正则化,观察下我们是否能把训练损失降为0。
现在可以用全部数据进行训练了,我们加上一个小的正则化项,让我们确定下什么才是最优的学习率,学习率是我们首先要调整的参数,我们通过交叉验证来调整,交叉验证是在训练集上训练然后在验证集验证,观察这些超参数的实验效果。
那么我们现在为超参数选择一个合理的取值范围吧:
随机取值可以提升你的搜索效率,但随机取值并不是在有效值范围内的随机均匀取值,而是选择合适的标尺用于研究这些超参数。假设你要选取隐藏单元(某一隐藏层有多少节点)的数量
,假设你选择的取值范围是从50到100中某点。这种情况下观察这个50-100的数轴。
你可以随机在其上取点,这是一个搜索特定超参数的很直观的方式。
如果你要选取神经网络的层数我们称之为字母L,也许会选择层数为2~4中的某个值, 2.3.4是可能的值,这是几个在你的考虑范围内随机均匀取值的例子,在这个例子中很合理。
但是这对某些超参数而言并不适用。
假设你在搜索超参数
即梯度下降学习速率假设你怀疑其值最小是0.0001,最大值为1。要保证取值均匀。如果你画一条从0.0001到1的数轴,沿其随机均匀取值,那90%的数值将会落在0.1到1之间。结果就是在0.1到1之间应用了90%的资源。而在0.0001到0.1之间只有10%的搜索资源。
对于学习率的选取用对数标尺搜索超参数的方式会更合理,因此这里不使用线性轴,分别依次取0.0001 0.001 0.01 1,在对数轴上均匀随机取点,这样在0.0001到0.001之间就会有更多的搜索资源可用。
我们要做的就是在
区间随机均匀地给r取值,这个例子中r∈[-4,0],然后你可以设置α的值基于随机取样的超参数值α = 10^r,所以总结一下在对数坐标上取值,取最小值的对数就得到a值,取最大值的对数就得到b值,所以现在你在对数轴上的10^a到10^b区间取值,在a、b间随意均匀的选取r值,将超参数设置为10^r这就是在对数轴上取值的过程。
另外一个就是计算β用于计算指数的加权平均值,假设你认为β是0.9到0.999之间的某个值,当计算指数的加权平均值时,取0.9就像在10个值中计算平均值,而取0.999就是在1000个值中取平均,如果你想在0.9到0.999区间搜索那就不能用线性轴取值,所以考虑这个问题最好的方法就是我们要探究的是1-β,此值在0.1到0.001区间内,所以我们会给1-β取值大概是从0.1到0.001,这是10^(-1)这是10个(-3),所以你要做的就是在[-3,-1]里随机均匀的给r取值,你设定了1-β=10^r所以β=1-10^r,然后这就变成了你的超参数随机取值。
我们如何组织我们的超参数搜索过程呢?
一种是你照看一个模型通常是有庞大的数据组,但没有许多计算资源或足够的CPU和GPU的前提下,基本而言你只可以一次负担起试验一个模型或一小批模型,这种情况下即使当它在试验时你也可以逐渐改良,比如第0天你将随机参数初始化开始试验,然后你逐渐观察自己的学习曲线也许是损失函数J,或者数据设置误差或其他的东西在第一天内逐渐减少,那这一天末的时候你可能会说看它学习得真不错。我要试着增加一点学习速率看看它会怎样也许结果证明它做得更好,两天后你会说它依旧做得不错,也许我现在可以填充下momentum或减少变量,然后第三天,每天观察他不断调整你的参数,也许有一天你会发现你的学习率太大了,所以你可能又回归之前的模型,但那通常是因为你没有足够的计算能力。不能在同一时间试验大量模型时才采取的办法。
另一种方法则是同时试验多种模型,我们设置了一些超参数,尽管让它自己运行或者是一天甚至多天,我们会得到一条学习曲线,这可以是损失函数J或实验误差的损失或数据设置误差的损失但都是你曲线轨迹的度量。同时,你可以开始一个有着不同超参数设定的不同模型,所以你的第二个模型会生成一个不同的学习曲线也许是像紫色的一条,与此同时你可以试验第三种模型……然后只是最后快速选择工作效果最好的那个。