文章目录
- 前言
- 一、ER模型
- 二、数据类型
- 三、字段命名规范
- 四、数据库创建与管理
- 4.1、创建数据库
- 4.2、删除数据库
- 4.3、列出数据库
- 4.4、备份数据库
- 4.5、还原数据库
- 4.6、使用某个数据库
- 五、数据表创建与管理
- 5.1、创建表、结构
- 5.2、查看表结构
- 5.3、查看数据表
- 5.4、复制表结构
- 5.5、复制表数据
- 5.6、修改表名
- 5.7、增加字段
- 5.7.1、将添加的字段放入首位
- 5.7.2、将添加的字段放入 test2字段之后
- 5.8、删除字段
- 5.9、修改字段的数据类型
- 5.10、修改字段的名称
- 5.11、设置主键
- 5.12、删除主键
- 5.13、外键
- 5.14、删除外键
- 六、数据更新
- 6.1、insert 插入记录
- 6.1.1、插入单条记录
- 6.1.2、插入多条记录
- 6.1.3、子查询,插入多条记录
- 6.2、delete 删除记录
- 6.3、update 更新记录
- 七、数据查询
- 7.1、单表查询
- 7.1.1、where常用关键字
- 7.1.2、通配符
- 7.1.3、order by子句
- 7.1.4、聚集函数
- 7.1.5、group by子句
- 7.2、连接查询
- 7.2.1、简单连接
- 7.2.2、JOIN连接
- 7.2.2.1、内连接(inner join)
- 7.2.2.2、外连接(left join 、right join)
- 7.3、嵌套查询
- 7.3.1、带有IN谓语的子查询
- 7.3.2、带有比较运算符的子查询
- 7.3.3、带有ANY(SOME)或ALL谓语子查询
- 7.3.4、带有EXISTS谓语的子查询
- 7.4、合并查询
- 八、索引
- 8.1、为已经创建好的表建立索引
- 8.2、创建新表时创建索引
- 九、视图
- 9.1、创建视图
- 9.2、修改视图
- 9.3、删除视图
- 十、存储过程
- 10.1、创建存储过程
- 10.2、调用存储过程
- 10.3、删除存储过程
- 10.4、创建带参数的存储过程
- 10.4.1、in
- 10.4.2、out
- 10.4.3、inout
- 十一、自定义函数
- 11.1、创建函数
- 十二、触发器
- 12.1、创建触发器
- 12.2、查看触发器
- 12.3、删除触发器
- 12.4、NEW和OLD的应用
- 12.4.1、流程图
- 12.4.2、案例
- 十三、 事务
- 13.1、介绍
- 13.2、提交、回滚事务
- 13.3、事务包括4个特性
- 13.4、案例
- 十四、用户管理与权限管理
- 14.1、用户管理
- 14.1.1、创建用户
- 14.1.2、修改用户密码
- 14.1.3、删除用户
- 14.2、权限管理
- 14.2.1、授予权限
- 14.2.1.1、查看权限
- 14.2.2、撤销权限
- 十五、备份、恢复数据库
- 15.1、备份
- 15.2、恢复
- 十六、日志
- 16.1、错误日志
- 16.2、查询日志
- 16.3、慢查询日志
- 16.4、二进制日志
- 总结
前言

大家好,我是秋意临。
一学期快结束了,结束前总结一篇MySQL,篇幅内容很多,所以是一篇收藏级,因为内容覆盖面比较广、比较浅、好理解非常适合正在学习mysql同学的新手,可以当作msyql命令手册大全,覆盖了mysql基本操作的所有内容(相信看到目录结构的一瞬间就会明白)。
常看常新,常看常新,常看常新哦!!~
记得收藏+关注免得迷了路。
欢迎加入云社区
一、ER模型
实体-联系模型(简称E-R模型)它提供不受任何DBMS约束的面向用户的表达方法,在数据库设计中被广泛用作数据建模的工具。
我们在做一个项目是就需要提前使用ER模型来绘制ER图,从而使其数据库结构清晰、合理。
DBMS 中的约束,约束强制限制可以从表中插入、更新、删除的数据或数据类型。约束的整个目的是在更新、删除、插入表中时保持数据完整性。
约束的类型
- 非空、独特、默认、校验、键约束 – 主键,外键、域约束、映射约束
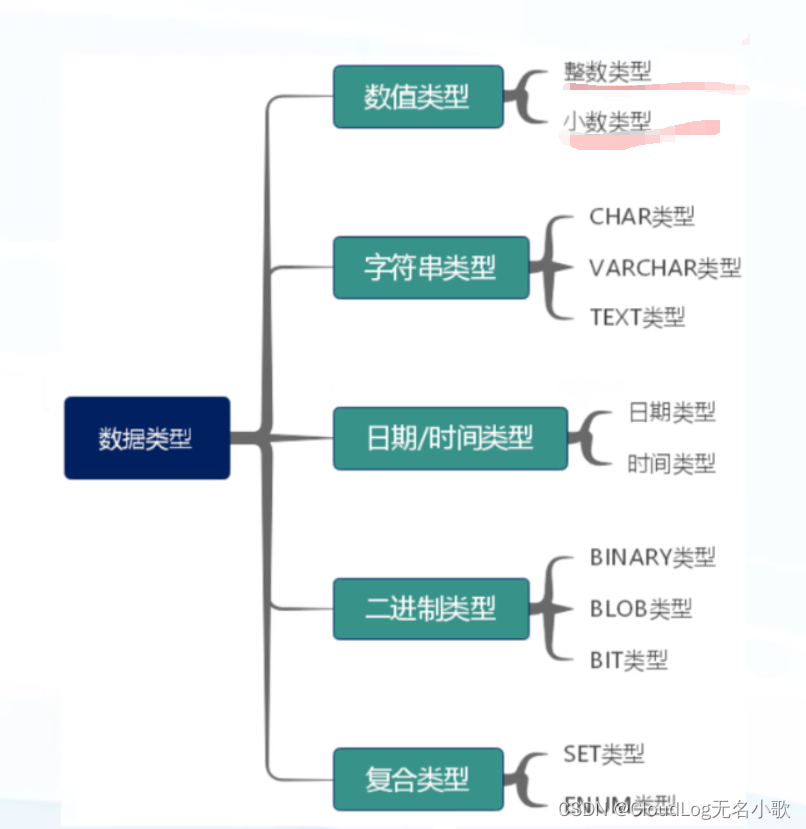
二、数据类型
三、字段命名规范
1.采用26个英文字母(区分大小写)和0-9的自然数(经常不需要)加上下划线_'组成,命名简洁明确,多个单词用下划线_'分隔。
2.—般采用小写命名。
3.禁止使用数据库关键字,如: table, time, datetime, primary等。
4.字段名称一般采用名词或动宾短语,如user_id,is_good。
5.采用字段的名称必须是易于理解,一般不超过三个英文单词。
四、数据库创建与管理
帮助
说明:
- table_name:数据表表名
col_name:字段名
data_type:字段的数据类型
查看创建过程
语法:show create 关键字(table database) 名称;
show create table t_teacher;
4.1、创建数据库
语法:create database db_name;
create database db_test;
4.2、删除数据库
语法:drop database db_name;
drop database db_test;
4.3、列出数据库
语法:show databases;
show databases;
4.4、备份数据库
如果在宿主机操作,可省略 -h 参数。
语法:mysqldump -h 主机名 -u 用户名 -p 密码 数据库名称 > 脚本文件路径;
mysqldump -uroot -p000000 test > test.sql;
4.5、还原数据库
语法:mysql -h 主机名 -u 用户名 -p 密码 数据库名称 < 脚本文件路径;
mysql -uroot -p000000 test < test.sql;
或者
source test.sql;
4.6、使用某个数据库
语法:use db_name;
use db_test;
五、数据表创建与管理
5.1、创建表、结构
语法:create table table_name(col_name1 data_type1,col_name2 data_type2,....);
创建t_test数据表,字段为id,name(数据类型中的数字是字段长度)
create table t_test(id char(20),name char(10));
5.2、查看表结构
语法:describe table_name;
desc table_name;
describe可以缩写为desc。
describe t_test;
desc t_test;
5.3、查看数据表
语法:show tables;
show tables;
5.4、复制表结构
如果是复制其他数据库的表结构,在table_name2前加上数据库的名称
语法:create table new_table_name1 like old_table_namme2;
将数据库db_test中的t_test1表结构复制到当前数据库,命名为表结构t_test2。
create table t_test1 like t_test2;
5.5、复制表数据
表结构一致
insert into table_name_new select * from table_name_old;
表结构不一致
insert into table_name_new(column1,column2...) select column1,column2... from table_name_old;
5.6、修改表名
语法:alter table old_table_name (旧名字) rename new_table_name(新名字);
alter table t_test1 rename t_test2;
5.7、增加字段
语法:alter table table_name add col_name1(添加字段名)data_type (字段类型);
alter table t_test add test_address varchar(255);
5.7.1、将添加的字段放入首位
语法:alter table table_name add col_name1(添加字段名)data_type (字段类型) first;
alter table t_test add test_address varchar(255) first;
5.7.2、将添加的字段放入 test2字段之后
语法:alter table table_name add col_name1(添加字段名)data_type (字段类型) after test2(字段);
alter table t_test add test1 varvhar(20) after test2;
5.8、删除字段
语法:alter table t_reader drop reader_qq (删除的字段名);
alter table t_test drop test1;
5.9、修改字段的数据类型
语法:alter table table_name modify col_name1(字段名) data_type (字段类型);
将test2的数据类型由varchar改为char。
alter table table_name modify test2 char(100);
5.10、修改字段的名称
语法:alter table table_name change old_col_name(字段名) new_col_old(新字段名) data_type(字段数据类型);
alter table t_test change test_address address char(100);
5.11、设置主键
作用:保证输入记录唯一性
方式:
- 创建表时设置
- 创建表之后设置
语法:create table table_name(xs_id char(12),xs_name char(10) primary key (xs_id));
创建studnet表时,将xs_id设置为主键。
create table studnet (xs_id char(12),xs_name char(10),primary key(xs_id));
创建studnet表时,将xs_id和xs_name设置为主键。这种将多个字段设为主键的方式称为:组合主键。组合主键也是一个主键(唯一性)。
create table studnet (xs_id char(12),xs_name char(10),primary key(xs_id,xs_name));
5.12、删除主键
语法:alter table table_name drop primary key;
alter table studnet drop primary key;
5.13、外键
作用:确保数据完整性。如:
- 实体完整性
- 用户定义完整性
- 参照完整性
只有当某个字段成为了主键后,该字段才能在其它表中成为外键。
语法:alter table table_name add constraint 外键名称 foreign key (设为外键的字段名)references t_table2(主键字段名);
将t_test1表中id字段设为主键,t_test2表中id字段设为外键。
alter table t_test2 add constraint fk1 foreign key (id) references t_test1(id);
5.14、删除外键
语法: show create table table_name;
获取外键名称:
show create table t_test2;
语法:alter table t_test2 drop foreign key 外键名称;
alter table t_test2 drop foreign key fk1;
六、数据更新
6.1、insert 插入记录
6.1.1、插入单条记录
语法:insert [into] 表名 [字段1,字段n] values(值1,值n);
insert into test values(123,'tt');
insert into test(pid) values(124);
6.1.2、插入多条记录
insert into test values(125,'ttww'),(126,'ttwwe'),(127,'ttqqq');
6.1.3、子查询,插入多条记录
使用select查询出来的内容字段,插入到inert对应的字段
语法:insert [into] 表名1 [字段1,字段n] select [字段1,字段n] from 表名2 [where语句];
insert into test-1 select * from test-2;
insert into test-1(pid,name) select pid,name from test-2;
6.2、delete 删除记录
语法:delete from 表名 [where <条件>];
delete from test; ## 删除所有记录
delete from test where pid==123; #删除id为123的这条记录。
6.3、update 更新记录
语法:update 表名 set 列名1 = 值1,列名2 = 值2,…[where 条件];
七、数据查询
7.1、单表查询
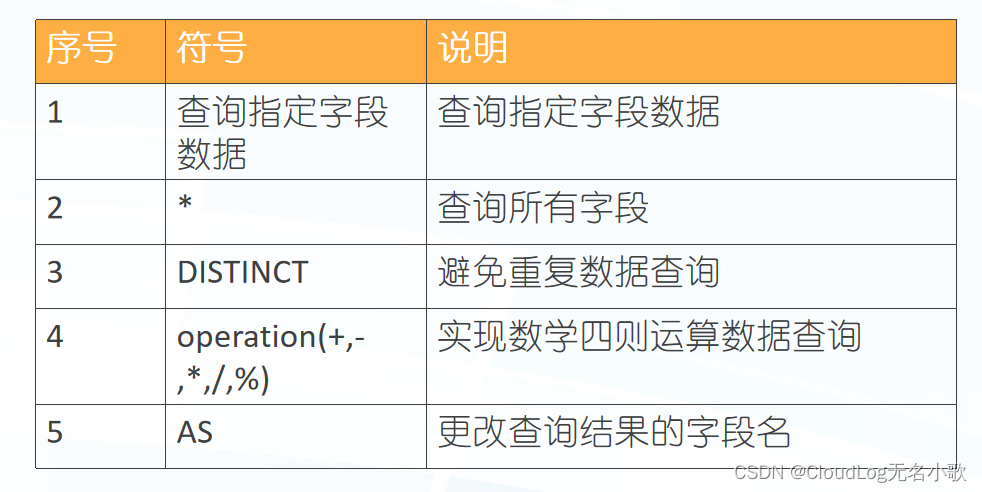
1、语法:select <[列名1,列名n 或通配符 [as 别名] ]> from 表名;
as:将某个字段取个别名
2、语法:select distinct <[列名1,列名n 或通配符]> from 表名;
去掉重复项,对应的字段前加
符号表达:
7.1.1、where常用关键字
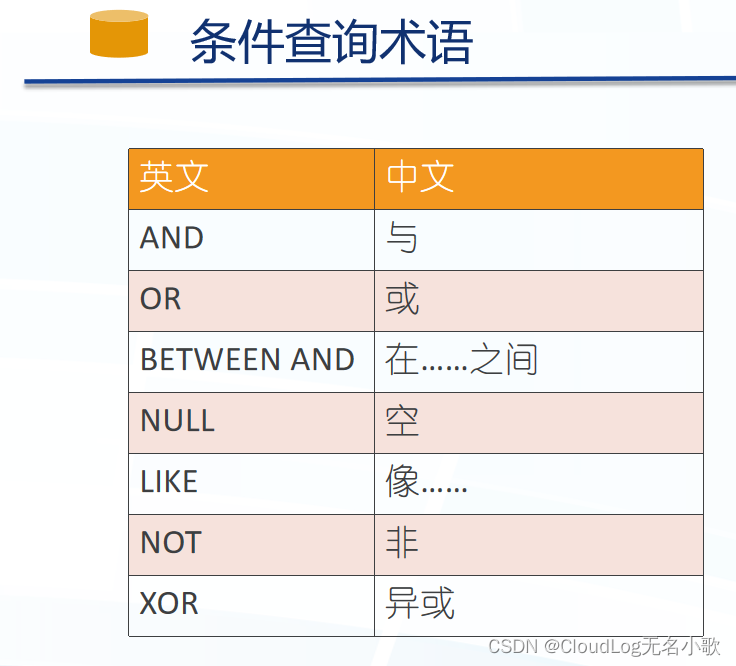
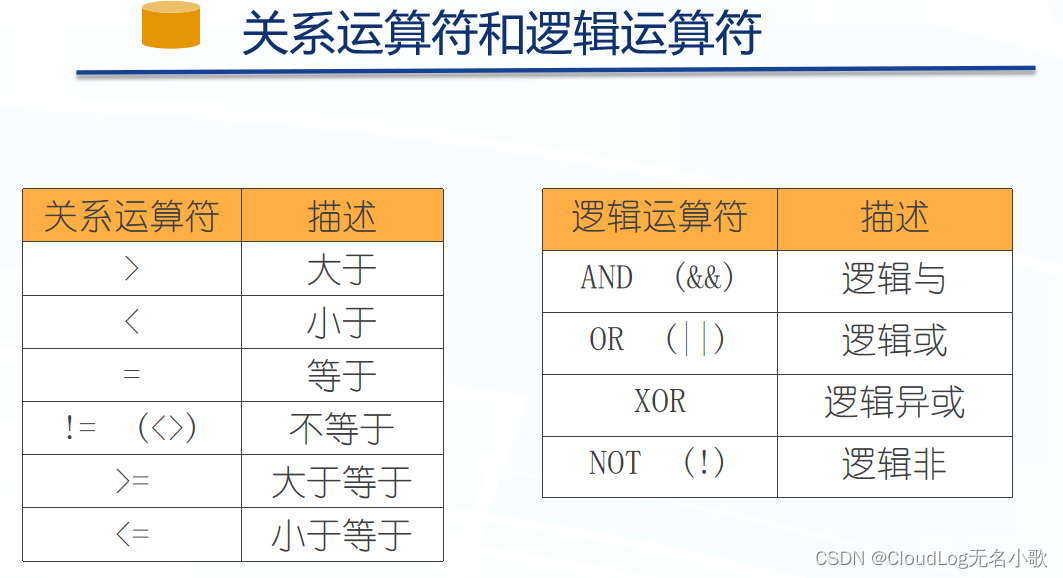
- AND、OR:连接多个条件
BETWEEN AND:在…之间
IS NULL:查询空值
IN:查询在某个集中中
LIKE:模糊查询
7.1.2、通配符
”*“通配符:匹配任意列名
“_"通配符:匹配单个字符
“%”通配符:匹配任意字符
7.1.3、order by子句
可以使用order by子句对查询结果安装一个或多个属性列(多个属性逗号隔开)的升序(ASC)或降序(DESC)排列,默认为升序。
--查询结果按照bookPrice列值的降序排列
select * from books order by bookPrice desc;
7.1.4、聚集函数
例:
#查询book表中年龄最大的
select max(age) from book;
7.1.5、group by子句
将查询结果按某一列或多列的值分组,值相等的为一组。
select count(*),pressName from books group by pressName;
如:下列表中,叫 “人民邮电出版社” 名字的有1个,叫 ”清华大学出版社“ 的有6个。

7.2、连接查询
根据两个表或多个表的列之间的关系来查询数据,即连接查询。
7.2.1、简单连接
连接查询实际是通过表与表之间相互关联的列进行数据的查询,对于关系数据库来说,连接是查询最主要的特征。
简单连接使用逗号将两个或多个表进行连接,也是最常用的多表查询形式。
例:
select b.reader_id,br.book_name from books b,borrow_record br where b.ISBN=br.ISBN;
7.2.2、JOIN连接
除了使用逗号连接外,也可使用JOIN连接。
7.2.2.1、内连接(inner join)
1)等值连接
select * from books b inner join borrow_record br where b.ISBN=br.ISBN;
2)不等连接
select * from books b inner join borrow_record br where b.ISBN<>br.ISBN;
7.2.2.2、外连接(left join 、right join)
1)左连接
on后面也可使用 where执行条件判断
select * from books b left join borrow_record br on b.ISBN=br.ISBN;
2)右连接
on后面也可使用 where执行条件判断
select * from books b right join borrow_record br on b.ISBN=br.ISBN;
7.3、嵌套查询
SQL语言中,一个select-from-where语句被称为一个查询块。将一个查询块嵌套在另一个查询块的where子句或having短语的条件中的查询被称为嵌套查询。
语法:select <字段名或通配符> from <表或视图名> where [表达式] (select <字段名或通配符> from <表或视图名> where [表达式] )
7.3.1、带有IN谓语的子查询
select * from books where isbn in (select * isbn from brrowrecord where reader_id='201801');
7.3.2、带有比较运算符的子查询
指父查询与子查询之间用比较运算符连接。可以用 >、<、=、>=、<=、!=、<> 等比较运算符。
select * from books where isbn=(select * isbn from brrowrecord where reader_id='201801');
7.3.3、带有ANY(SOME)或ALL谓语子查询
子查询返回值单值时可以用比较运算符,但返回多值时要用ANY(有的系统用SOME)或ALL谓语,使用ANY或ALL谓语时必须同时使用比较运算符。
谓语释义:
例:
#查询读者编号为"201801"的学生未借阅的所有图书的详细信息;
select * from books where isbn <> all(select isbn from brrowwrecord where reader_id="201801");
7.3.4、带有EXISTS谓语的子查询
EXISTS谓语的子查询不返回任何数据,是一个布尔值(true或false)逻辑判断。使用存在量词EXISTS后,若内层查询结果为空,则外层的WHERE子句返回ture,否则取反。
例:
#查询读者编号为201801的读者没有借阅过的图书信息
select * from books where not exists (select * from borrowrecord where isbn=books.isbn and reader_id="201801");
7.4、合并查询
#两个表字段合并显示,两个表相同字段合并后显示一次
select * from t_major1 union select * from t_major;
八、索引
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。
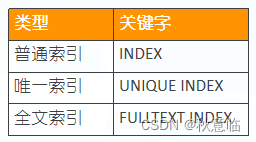
8.1、为已经创建好的表建立索引
1)用CREATE INDEX方法在已经创建好的表 t_student 上为其字段名 stu_id 创建普通降序索引。
语法:create [unique | fulltext] index index_name on table_name(co_name ase|desc , [co_name ase|desc] ) #多字段索引使用逗号(,)隔开
create index index_student on t_student(stu_id desc)
2)用ALTER TABLE…ADD INDEX方法为表t_course的字段列course_name 创建全文索引。
语法:alter table table_name add [unique | fulltext] index index_name(co_name ase|desc , [co_name ase|desc] ) #多字段索引使用逗号(,)隔开
alter table t_course add fulltext index index_course_name(course_name)
8.2、创建新表时创建索引
创建表 t_teacher2,与 t_teacher 结构一致(不能复制表结构),在创建表的过程中创建索引,为 teacher_id 创建一个唯一升序索引。
create table t_teacher2(teacher_id char(10),teacher_name char(50),index index_tea_id(teacher_id asc));
九、视图
视图(View)其实是从一个或多个关系表(或视图)当中导出的表,是一个虚表类似一个软链接。
9.1、创建视图
建一个视图view_basic_info,数据来源于t_student表
语法:create view <视图名> as select_statement
create view view_basic_info as select * from t_student;
9.2、修改视图
语法:create view <视图名> as select_statement
alter view view_basic_info as select * from t_student;
9.3、删除视图
drop view view_basic_info;
十、存储过程
存储过程和程序中的函数非常相似,它可以将某些需要多次调用、实现某个特定任务的代码段编写成一个过程,将其保存在数据库中,并通过过程名来调用,这些过程称为存储过程。
DELIMITER 定义:设置语句结束后使用的分隔符,MYSQL的默认结束符为";"。
10.1、创建存储过程
mysql> delimiter $
mysql> create procedure p1()
-> comment '读者信息'
-> begin
-> select * from t_reader;
-> end $
mysql> delimiter ;
10.2、调用存储过程
mysql> call p1;
10.3、删除存储过程
mysql> drop procedure p1;
10.4、创建带参数的存储过程
10.4.1、in
- 创建一个带输入参数的存储过程,查询某个学号对应的学生信息。
mysql> delimiter $
mysql> create procedure p3(in stuid char(10))
comment "查询某个学号对应的学生信息"
begin
select * from t_student where stu_id=stuid;
end $
mysql> delimiter ;
mysql> call p3(1631607102); #调用存储过程
10.4.2、out
- 创建一个带输出参数的存储过程,查询所有学生的人数。
注意:变量名前加@表示:会话变量
会话变量:不局限于存储过程内部
mysql> delimiter $
mysql> create procedure p6(out stucount int)
begin
select COUNT(stu_id) into stucount from t_student;
end $
mysql> delimiter ;
mysql> call p6(@stucount); #调用存储过程
mysql> select @stucount; #查看输出变量
10.4.3、inout
- 创建一个带输入输出参数的存储过程,对某个成绩加20分。
mysql> delimiter $
mysql> create procedure p9(inout testname int)
begin
update t_score set grade=grade+20 where score_id=testname;
select grade into testname from t_score where score_id=testname;
end $
mysql> delimiter ;
mysql> set @testname=1001;
mysql> call p9(@testname);
mysql> select @testname;
@pra:会话变量不局限于存储过程内部
十一、自定义函数
11.1、创建函数
语法:
create function func_name(parameters)
returns type
body
create function:创建函数的关键字
func_name:函数名称
type:函数放回值类型,如:int、char(50)等。
body一般格式为,如下:
begin
retrun(select 查询语句);
end
例子:
创建一个函数,查询某读者的年龄。
delimiter $
create function func_reader_age2(name char(50))
returns int
begin
return(select year(curdate())-year(reader_birthday) from t_reader where reader_name=name);
end $
delimiter ;
select func_reader_age2("肖华");
十二、触发器
触发器自动执行时,以响应特定事件的存储程序。(特定事件:对数据库表的增删改)
触发器可以被定义在INSERT、UPDATE、DELETE语句更改数据表之前或之后被自动执行。
12.1、创建触发器
语法:CREATE TRIGGER trigger_name trigger_time trigger_event ON table_name FOR EACH ROW [trigger_order] trigger_body
参数详解:
trigger_time:中发器执行的时间:AFTER(之后) | BEFORE(之前)
trigger_event:触发器触发的事件:DELETE | UPDATE | INSERT
FOR EACH ROW:表示任何一条记录上的操作满足触发事件都会触发该触发器
table_name:表元触发事件操作表的名字
trigger_body:创建触发器的SQL语句
(1)创建Insert触发器,每向t_student中插入一条记录后,则向t_log表中插入该表的表名t_student和插入的时间。
CREATE TABLE t_log
(logno int AUTO_INCREMENT primary key,
tname varchar(20),
logtime datetime);
SELECT * FROM t_log;
create trigger tr_insert after insert on t_student for each row
insert into t_log (tname,logtime) VALUES('t_student',now());
insert into t_student(stu_id) values("0123456789");
select * from t_student;
select * from t_log;
(2)创建一个t_score1表的插入触发器,当向t_score1表中插入一条数据时,在t_student1自动添加一条stu_id对应的记录,在t_cours1e中自动添加一条course_id对应的记录。
create table t_score1 like t_score;
insert into t_score1 select * from t_score;
//创建触发器
create trigger t_insert3 after insert on t_score1 for each row
begin
insert into t_student1(stu_id) VALUES("1123456789") ;
insert into t_course1(course_id) VALUES("12345678") ;
end
//验证
insert into t_score1(score_id,stu_id,course_id) values(1018,1631607101,16610001);
select * from t_student1 where stu_id = "1123456789";
select * from t_course1 where course_id = "12345678";
12.2、查看触发器
show triggers;
12.3、删除触发器
drop trigger trigger_name;
12.4、NEW和OLD的应用
MySQL中定义了NEW和OLD两个临时表,用来保存触发器修改之前和之后的表,方便引用。
12.4.1、流程图

12.4.2、案例
(1)修改表t_student1中一个学生的生日时,向另一个表t_backup(需新建)表中插入修改前的生日与修改后的生日。
//创建触发器
create trigger t_updata1 after update on t_student1 for each row
begin
insert into t_backup(old_birthday,new_birthday) values(old.stu_birthday,new.stu_birthday);
end
//测试
update t_student1 set stu_birthday="1999-12-12" where stu_name="王伟";
(2)删除t_major1表中的一条记录时,将删除的这条记录插入到另一个表(需新建表)中。
//创建触发器
create trigger t_delete1 after delete on t_major1 for each row
begin
insert into t_major_back values(old.major_id,old.major_name);
end
//测试
delete from t_major1 where major_name="计算机应用技术";
十三、 事务
语法:
START TRANSACTION | BEGIN
DML语句
COMMIT 或 ROLLBACK
START TRANSACTION、BEGIN:可以开始一项新的事务
DML语句:insert、delete、update
COMMIT、ROLLBACK:定义提交、回滚事务
13.1、介绍
事务是一个完整的业务逻辑,是一个工作单元。如:
假设转账,从A账户向B账户中转账10000。
- 将A账户的钱减去10000 (update语句)
将B账户的钱加上10000 (update语句)这就是一个完整的业务逻辑。这两个updata语句要求必须同时成功或同时失败。
只有DML语句才会有事务这一说,其它语句和事务无关! ! !
insert、delete、update
只有以上的三个语句和事务有关系,其它都没有关系。
所以,事务就是批量的DML语句同时成功,或者同时失败
13.2、提交、回滚事务
提交事务:commit; 语句 ,代表事务结束。
回滚事务:rollback; 语句(回滚永远都是只能回滚到上一次的提交点!)
13.3、事务包括4个特性
A(原子性):
说明事务是最小的工作单元。不可再分。
C(一致性):
所有事务要求,在同一个事务当中,所有操作必须同时成功,或者同时失败,以保证数据的一致性。
I(隔离性)重点:
A事务和B事务之间具有一定的隔离。
教室A和教室B之间有一道墙,这道墙就是隔离性。
A事务在操作一张表的时候,另一个事务B也操作这张表会那样? ? ?
D(持久性):
事务最终结束的一个保障。事务提交,就相当于将没有保存到硬盘上的数据保存到硬盘上!
13.4、案例
将学生学号为“1631607101”的C语言成绩加10分,如果发现加10分后的成绩大于100分,则执行事务的回滚操作,否则提交事务。
mysql> select * from t_score1;
+----------+------------+-----------+-------+
| score_id | stu_id | course_id | grade |
+----------+------------+-----------+-------+
| 1001 | 1631607101 | 16610001 | 92 |
| 1002 | 1631607101 | 16610002 | 75 |
| 1003 | 1631607101 | 16610003 | 88 |
| 1004 | 1631607102 | 16610004 | 100 |
| 1005 | 1631607102 | 16610005 | 99 |
| 1006 | 1631611104 | 16610003 | 76 |
| 1007 | 1631611104 | 16610004 | 107 |
| 1008 | 1631611104 | 16610005 | 97 |
| 1009 | 1631611104 | 16610006 | 90 |
| 1010 | 1731613106 | 16610009 | 75 |
| 1011 | 1731613107 | 16610009 | 97 |
| 1012 | 1631601101 | 16610002 | 86 |
| 1013 | 1631601102 | 16610003 | 85 |
| 1014 | 1631601103 | 16610004 | 90 |
| 1015 | 1631601104 | 16610005 | 80 |
| 1016 | 1631601105 | 16610006 | 79 |
| 1017 | 1631601105 | 16610007 | 98 |
| 1018 | 1631607101 | 16610001 | NULL |
+----------+------------+-----------+-------+
18 rows in set (0.00 sec)
mysql> begin;
mysql> update t_score1 set grade=grade+10 where stu_id="1631607101";
mysql> select * from t_score1 where stu_id="1631607101" and grade < 100;
+----------+------------+-----------+-------+
| score_id | stu_id | course_id | grade |
+----------+------------+-----------+-------+
| 1002 | 1631607101 | 16610002 | 85 |
| 1003 | 1631607101 | 16610003 | 98 |
+----------+------------+-----------+-------+
--回滚后,数据就没有改变
mysql> rollback; --如果这里换成commit; 代表事务结束。
mysql> select * from t_score1 where stu_id="1631607101" and grade < 100;
+----------+------------+-----------+-------+
| score_id | stu_id | course_id | grade |
+----------+------------+-----------+-------+
| 1001 | 1631607101 | 16610001 | 92 |
| 1002 | 1631607101 | 16610002 | 75 |
| 1003 | 1631607101 | 16610003 | 88 |
+----------+------------+-----------+-------+
3 rows in set (0.00 sec)
--执行commit;后,就无法回到commit之前,代表事务结束。
mysql> commit;
十四、用户管理与权限管理
语法:CREATE USER user_name [IDENTIFIED BY [PASSWORD] “user_password”]
user_name:创建的账号名,完整的账号由用户名和主机组成,形式为
'user_name'@'localhost'。
14.1、用户管理
14.1.1、创建用户
1、默认所以主机
create user test_1 identified by '123456';
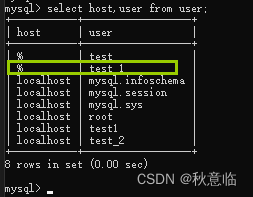
2、 指定用户的主机为localhost
create user test1@localhost identified by '123456';
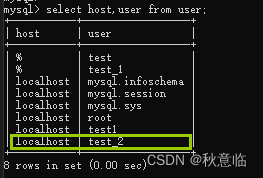
14.1.2、修改用户密码
14.1.3、删除用户
drop user user_name;
14.2、权限管理
14.2.1、授予权限
GRANT priv_type[(column_list)] ON database.table TO user [IDENTIFIED BY [PASSWORD] 'password'] [,user IDENTIFIED BY [PASSWORD] 'password'] ... [WITH with-option['with-option']...]
priv_type:授权类型(ALL表示所有的权限)。
column_list:指定列名,表示权限作用在那些列上,不指定作用于整个表。
database.table:指定数据库和表。
user:用户名,完整的账号由用户名和主机组成,形式为'user_name'@'localhost'。
IDENTIFIED BY:指定为账户设置密码,已经存在的用户可不指定密码。
password:表示用户新密码,已经存在的用户可以不用密码。
WITH with-option[‘with-option’]:指定授权选项。
1、使用grant语句创建用户soft,密码为123456,并授予对所有数据库所有表的select,insert,update权限和转授权限(grant option)
grant select,insert,update on *.* to soft@localhost identified by '123456' with grant option;
2、使用grant语句,并授予对所有数据库所有表的select,insert,update权限
grant select,insert,update on *.* to soft;
14.2.1.1、查看权限
语法:GRANT priv_type[(column_list)] ON [object_type]{table_name | * | *.* | db_name.*} FROM user [,user]...
select * from user;
普遍用户也可执行
show grants for ‘user'@'host';
14.2.2、撤销权限
revoke select,insert,update on *.* from soft@localhost;
十五、备份、恢复数据库
15.1、备份
语法:
E:\db_backup>mysqldump
Usage: mysqldump [OPTIONS] database [tables]
OR mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...]
OR mysqldump [OPTIONS] --all-databases [OPTIONS]
For more options, use mysqldump --help
备份一个数据库
MYSQLDUMP -u user_name -p db_name table_name1 table_name2... > backup_name.sql
user_name:用户名
db_name:选择备份的数据库
table_name:选择备份数据库里面的表
backup_name:生成的备份文件名
备份多个数据库
MYSQLDUMP -u user_name -p --databases db_name1 db_name2... > backup_name.sql
备份所以数据库
MYSQLDUMP -u user_name -p --all-databases > backup_name.sql
15.2、恢复
MYSQL -u user_name -p [db_name] < backup_name.sql
db_name:用来指定数据库的名称,指定数据库时,还原该数据库下的表。不指定时,表示还原备份文件中的所有数据。
十六、日志
MySQL四种日志类型:错误日志、查询日志、慢查询日志、二进制日志
四种类型的日志对应的文件,保存在mysql数据目录data目录下,可以使用show variables命令查看
错误日志默认开启,其它三种日志默认打开。
16.1、错误日志
错误日志记录着 MySQL服务启停及运行时的报错信息, 如:运行的sql语句语法错误。
错误日志功能默认开启且无法被禁止。
查看“错误日志”是否开启
--使用show variables命令后可以看到日志文件存放位置:D:\APP\Pro_Software\MYSQL\data\
show variables like "%log_erro%";
+----------------------------+----------------------------------------------------+
| Variable_name | Value |
+----------------------------+----------------------------------------------------+
| binlog_error_action | ABORT_SERVER |
| log_error | D:\APP\Pro_Software\MYSQL\data\DESKTOP-T92IEER.err |
| log_error_services | log_filter_internal; log_sink_internal |
| log_error_suppression_list | |
| log_error_verbosity | 2 |
+----------------------------+----------------------------------------------------+
5 rows in set, 1 warning (0.00 sec)
16.2、查询日志
查询日志记录着MySQL服务器的启停信息、客户端连接信息、增删查改数据记录的SQL语句。
查询日志默认关闭,由于查询日志会记录用户的所有操作,故如若开启查询日志,会占用较多磁盘空间,查询日志建议定义清理,以节省磁盘空间。
查看“查询日志”是否开启
--使用show variables命令后可以看到日志文件存放位置:D:\APP\Pro_Software\MYSQL\data\
mysql> show variables like "%general%";
+------------------+----------------------------------------------------+
| Variable_name | Value |
+------------------+----------------------------------------------------+
| general_log | OFF |
| general_log_file | D:\APP\Pro_Software\MYSQL\data\DESKTOP-T92IEER.log |
+------------------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
--开启
mysql> set global general_log = ON;
Query OK, 0 rows affected (0.00 sec)
--关闭
mysql> set global general_log = OFF;
Query OK, 0 rows affected (0.00 sec)
16.3、慢查询日志
慢日志记录执行时间超过指定时间的各种操作。
通过分析慢查询日志能有效定位MySQL各指令执行的性能瓶颈。
查看“慢查询日志”是否开启
--使用show variables命令后可以看到日志文件存放位置:D:\APP\Pro_Software\MYSQL\data\
mysql> show variables like "%slow%";
+-----------------------------+---------------------------------------------------------+
| Variable_name | Value |
+-----------------------------+---------------------------------------------------------+
| log_slow_admin_statements | OFF |
| log_slow_extra | OFF |
| log_slow_replica_statements | OFF |
| log_slow_slave_statements | OFF |
| slow_launch_time | 2 |
| slow_query_log | OFF |
| slow_query_log_file | D:\APP\Pro_Software\MYSQL\data\DESKTOP-T92IEER-slow.log |
+-----------------------------+---------------------------------------------------------+
7 rows in set, 1 warning (0.01 sec)
--开启
mysql> set global slow_query_log=on;
Query OK, 0 rows affected (0.00 sec)
--关闭
mysql> set global slow_query_log = off;
Query OK, 0 rows affected (0.00 sec)
--测试
mysql> select sleep(10);
+-----------+
| sleep(10) |
+-----------+
| 0 |
+-----------+
1 row in set (10.01 sec)
16.4、二进制日志
二级制日志以二进制的形式记录数据库除了查询以外的各种操作也叫变更日志。主要用于记录修改数据或有可能引起数据改变的MySQL语句,并且记录着语句发生时间、执行时长、操作的数据等。
查看“二进制日志”是否开启
--使用show variables命令后可以看到日志文件存放位置:D:\APP\Pro_Software\MYSQL\data\
mysql> show variables like "%log_bin%";
+---------------------------------+---------------------------------------------+
| Variable_name | Value |
+---------------------------------+---------------------------------------------+
| log_bin | ON |
| log_bin_basename | D:\APP\Pro_Software\MYSQL\data\binlog |
| log_bin_index | D:\APP\Pro_Software\MYSQL\data\binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+---------------------------------------------+
6 rows in set, 1 warning (0.00 sec)
--查询binlog文件名
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000119 | 57106 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
总结
我是秋意临,欢迎大家一键三连、加入云社区
我们下期再见(⊙o⊙)!!!