本文内容组织形式
- Block的基本信息
- 作用
- 示意图
- 举例说明
- 源码解析
- Footer
- 格式
- 写入&读取
- 编码&解码
- 元数据块(Meta Block)
- 构建&读取
- 元数据索引块
- 构建&读取
- 索引块
- 定义
- 构建&读取
- 核心方法-FindShortestSeparator&FindShortSuccessor
- 作用:
- 举例说明
- FindShortestSeparator
- FindShortSuccessor
- 猜你喜欢
- PS
Block的基本信息
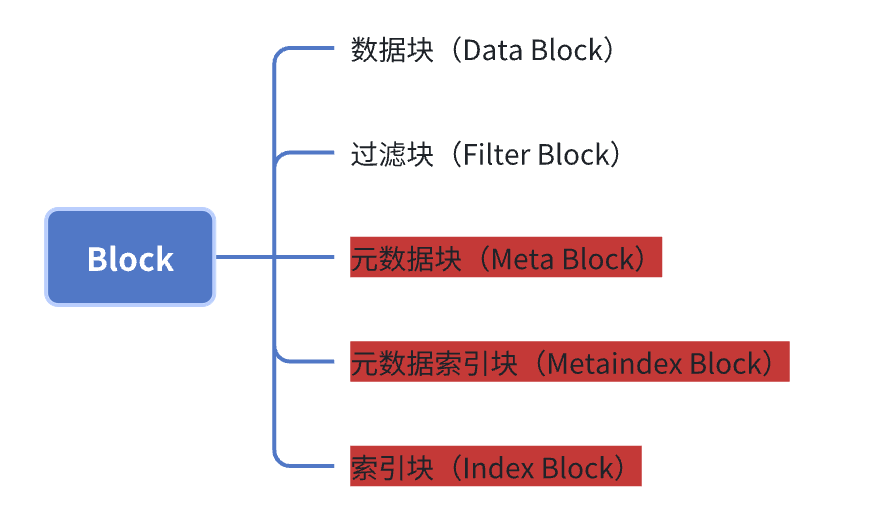
Block 是组成SSTable文件中的基本单元,主要有以下类型
- 数据块(Data Block):存储实际的键值对数据,按键排序并使用前缀压缩减少空间占用。
- 过滤块(Filter Block):包含布隆过滤器,用于快速判断一个键是否可能存在,避免不必要的磁盘读取。
- 元数据块(Meta Block):存储关于SSTable文件的额外元数据信息,如统计数据或特定功能的配置。
- 元数据索引块(Metaindex Block):保存指向各个元数据块的索引,方便查找特定类型的元数据。
- 索引块(Index Block):存储数据块的索引信息,记录每个数据块的最大键和偏移量,用于定位特定键所在的数据块。
作用
这里的元数据块,元数据索引块,索引块,本质上就是在做加速检索的事情,接下来我们先说说这些索引块在数据检索中的实际作用
示意图
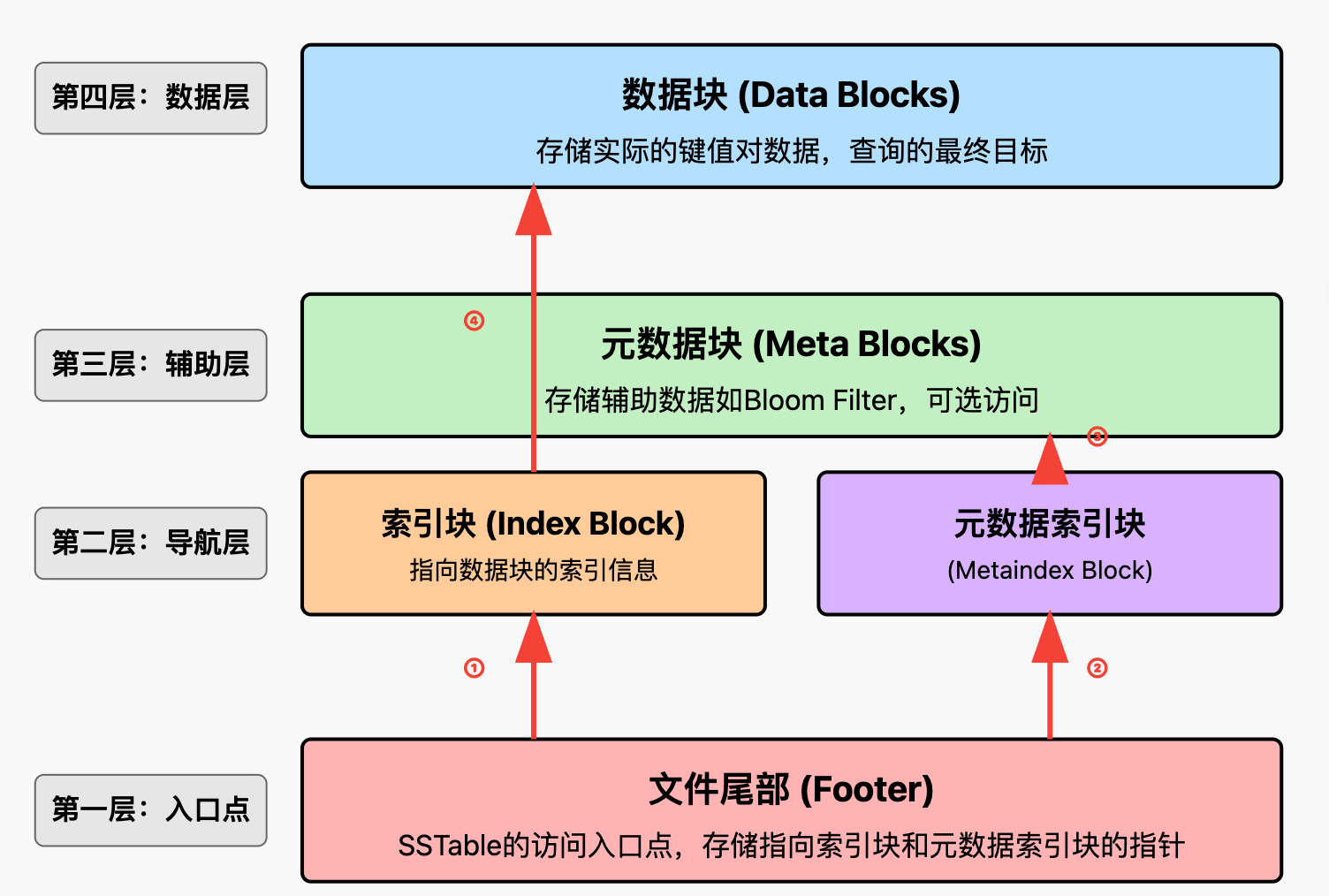
数据访问流程:
① 从Footer获取索引块位置 → ② 获取元数据索引块位置(可选) → ③ 检查元数据(可选) → ④ 定位并读取目标数据
举例说明
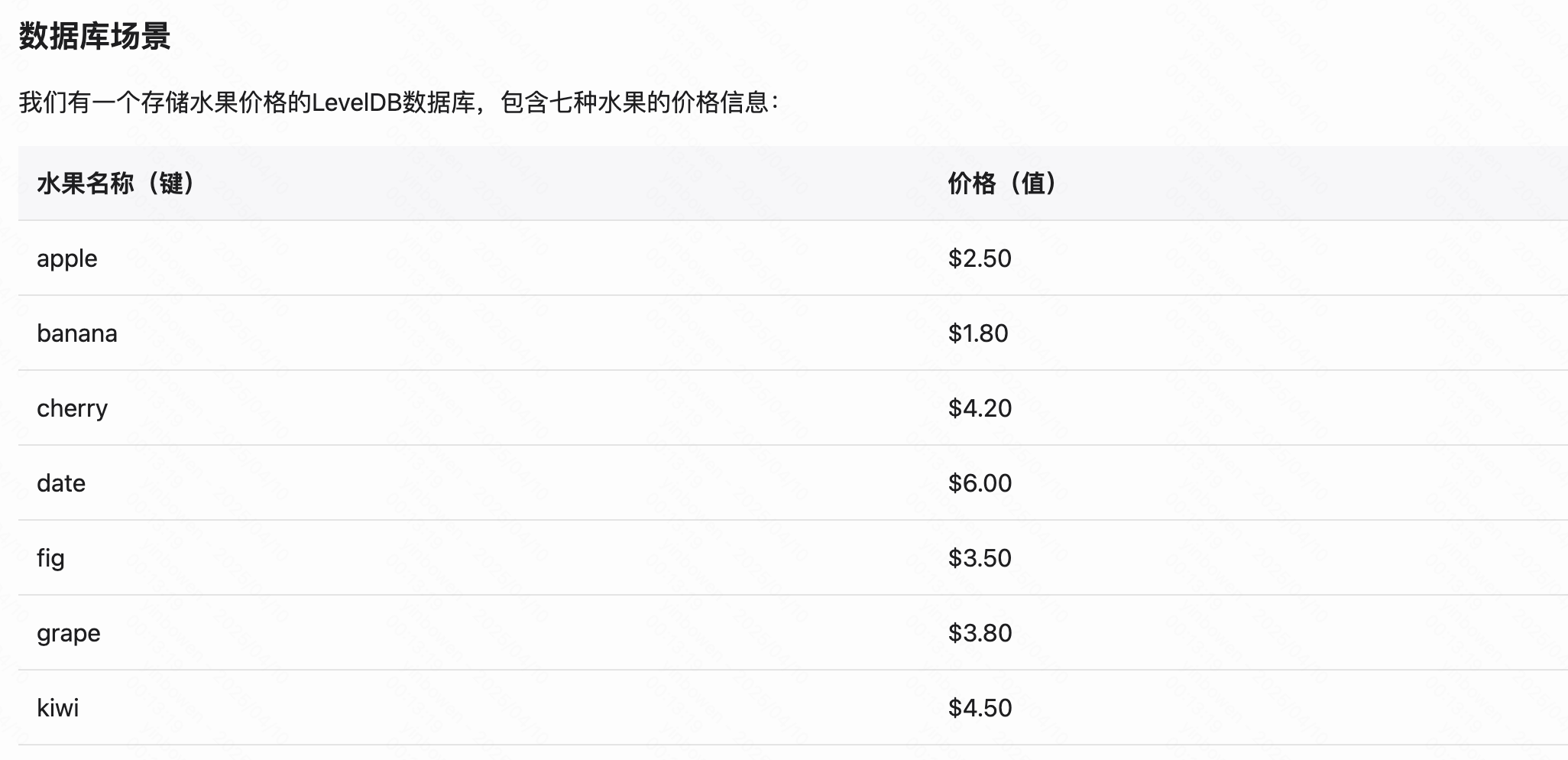
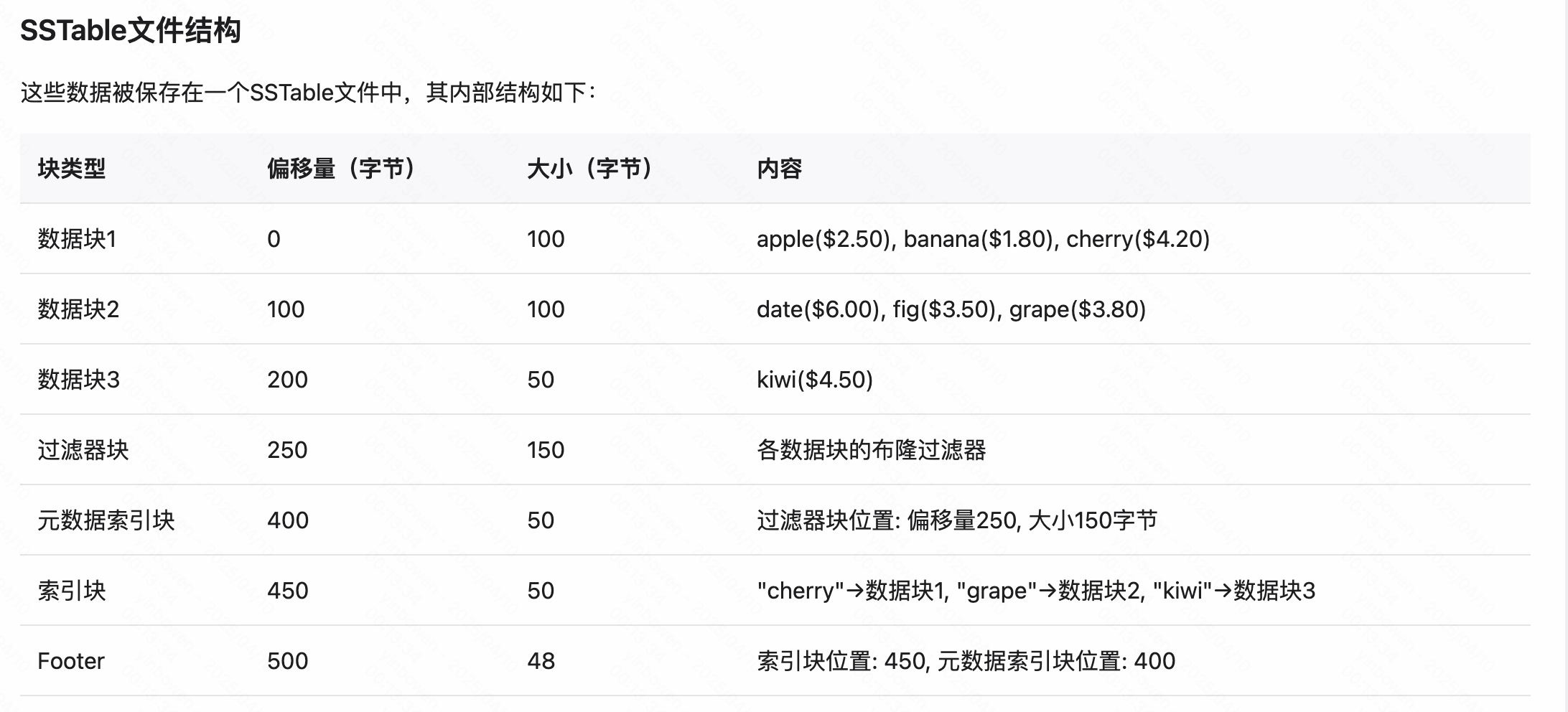
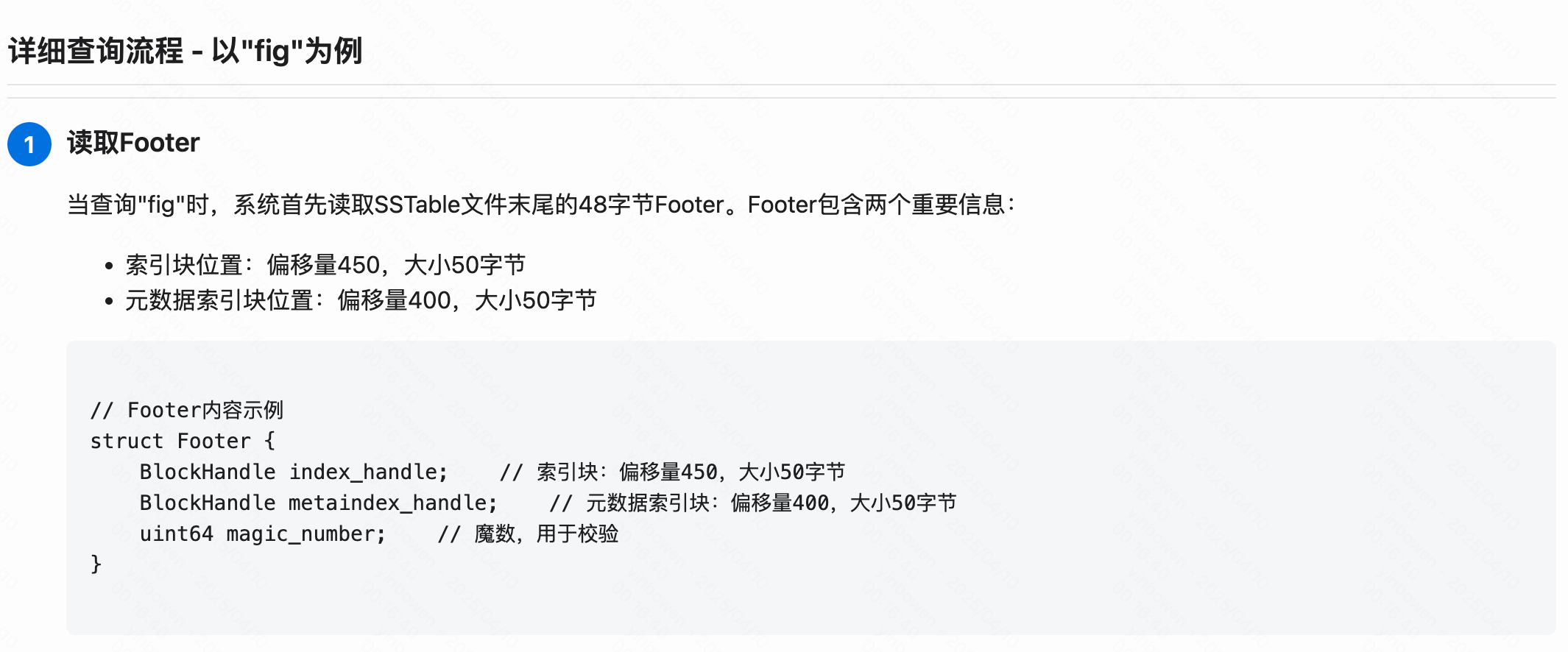



源码解析
Footer
Footer 重点作用就是存位置信息
- 元数据索引块位置信息
- 数据索引块位置信息
格式
class Footer {
public:
enum { kEncodedLength = 2 * BlockHandle::kMaxEncodedLength + 8 }; // Footer的固定长度
Footer() = default;
const BlockHandle& metaindex_handle() const { return metaindex_handle_; }
void set_metaindex_handle(const BlockHandle& h) { metaindex_handle_ = h; }
const BlockHandle& index_handle() const { return index_handle_; }
void set_index_handle(const BlockHandle& h) { index_handle_ = h; }
void EncodeTo(std::string* dst) const;
Status DecodeFrom(Slice* input);
private:
BlockHandle metaindex_handle_; // 元数据索引块句柄
BlockHandle index_handle_; // 数据索引块句柄
};
写入&读取
Status TableBuilder::Finish() {
...
// Write footer
if (ok()) {
Footer footer;
// handle 是对应位置的信息
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
// 对footer的信息进行编码
footer.EncodeTo(&footer_encoding);
// 进行写入逻辑
r->status = r->file->Append(footer_encoding);
if (r->status.ok()) {
r->offset += footer_encoding.size();
}
}
...
}
tatus Table::Open(const Options& options, RandomAccessFile* file,
uint64_t size, Table** table) {
if (size < Footer::kEncodedLength) {
return Status::Corruption("file is too short to be an sstable");
}
char footer_space[Footer::kEncodedLength];
Slice footer_input;
// 从文件中读取
Status s = file->Read(size - Footer::kEncodedLength, Footer::kEncodedLength,
&footer_input, footer_space);
if (!s.ok()) return s;
Footer footer;
// 对数据进行解码,并返回
s = footer.DecodeFrom(&footer_input);
if (!s.ok()) return s;
// ...
}
编码&解码
使用魔数 来进行校验当前的数据
void Footer::EncodeTo(std::string* dst) const {
const size_t original_size = dst->size();
metaindex_handle_.EncodeTo(dst);
index_handle_.EncodeTo(dst);
dst->resize(2 * BlockHandle::kMaxEncodedLength); // 填充
// 写入魔数 用作验证
PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber & 0xffffffffu));
PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber >> 32));
assert(dst->size() == original_size + kEncodedLength);
}
Status Footer::DecodeFrom(Slice* input) {
const char* magic_ptr = input->data() + kEncodedLength - 8;
const uint32_t magic_lo = DecodeFixed32(magic_ptr);
const uint32_t magic_hi = DecodeFixed32(magic_ptr + 4);
const uint64_t magic = ((static_cast<uint64_t>(magic_hi) << 32) |
(static_cast<uint64_t>(magic_lo)));
if (magic != kTableMagicNumber) {
return Status::Corruption("not an sstable (bad magic number)");
}
Status result = metaindex_handle_.DecodeFrom(input);
if (result.ok()) {
result = index_handle_.DecodeFrom(input);
}
if (result.ok()) {
const char* end = magic_ptr + 8;
*input = Slice(end, input->data() + input->size() - end);
}
return result;
}
元数据块(Meta Block)
元数据块 主要用来存储过滤块的信息, 在当前版本的levelDB中等同于filter block,用来帮助当前sstable文件快速检索。
PS: 具体filter_block的信息, 可参考:https://editor.csdn.net/md/?articleId=147023029
构建&读取
// Write metaindex block
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
// Add mapping from "filter.Name" to location of filter data
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
void Table::ReadMeta(const Footer& footer) {
if (rep_->options.filter_policy == nullptr) {
return;
}
ReadOptions opt;
if (rep_->options.paranoid_checks) {
opt.verify_checksums = true;
}
BlockContents contents;
// 读取当前文件的元数据信息
if (!ReadBlock(rep_->file, opt, footer.metaindex_handle(), &contents).ok()) {
return;
}
Block* meta = new Block(contents);
Iterator* iter = meta->NewIterator(BytewiseComparator());
std::string key = "filter.";
key.append(rep_->options.filter_policy->Name());
iter->Seek(key);
if (iter->Valid() && iter->key() == Slice(key)) {
ReadFilter(iter->value()); // 这里拿到对应的过滤器
}
delete iter;
delete meta;
}
元数据索引块
构建&读取
Status TableBuilder::Finish() {
...
// 写入元数据索引块
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
// 添加过滤器的位置信息到元数据索引,这里只添加索引位置信息
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
WriteBlock(&meta_index_block, &metaindex_block_handle);// 这里添加元数据索引信息和具体的元数据信息
}
...
}
Status Table::Open(const Options& options, RandomAccessFile* file,
uint64_t size, Table** table) {
// ... 读取Footer
// 读取索引块
BlockContents index_block_contents;
s = ReadBlock(file, opt, footer.index_handle(), &index_block_contents);//
if (s.ok()) {
Block* index_block = new Block(index_block_contents);
Rep* rep = new Table::Rep;
rep->options = options;
rep->file = file;
rep->metaindex_handle = footer.metaindex_handle();
rep->index_block = index_block;
// ... 其他初始化
*table = new Table(rep);
(*table)->ReadMeta(footer); // 读取元数据
}
}
// 读取元数据
void Table::ReadMeta(const Footer& footer) {
if (rep_->options.filter_policy == nullptr) {
return;
}
ReadOptions opt;
BlockContents contents;
// 这里是读取具体的元数据索引信息
if (!ReadBlock(rep_->file, opt, footer.metaindex_handle(), &contents).ok()) {
return;
}
Block* meta = new Block(contents);
Iterator* iter = meta->NewIterator(BytewiseComparator());
// 查找过滤器信息,这里是根据读取到的元数据索引信息 来找对应的过滤器信息
std::string key = "filter.";
key.append(rep_->options.filter_policy->Name());
iter->Seek(key);
if (iter->Valid() && iter->key() == Slice(key)) {
ReadFilter(iter->value());
}
delete iter;
delete meta;
}
索引块
定义
class BlockBuilder {
private:
const Options* options_; // 配置选项
std::string buffer_; // 存储实际数据
std::vector<uint32_t> restarts_; // 重启点数组
int counter_; // 计数器
bool finished_; // 是否已完成
std::string last_key_; // 上一个键
};
struct TableBuilder::Rep {
Rep(const Options& opt, WritableFile* f)
: options(opt),
index_block_options(opt), // 索引块选项
// ... 其他初始化
index_block(&index_block_options), // 创建索引块
// ...
{
index_block_options.block_restart_interval = 1; // 索引块的重启点间隔为1
}
// ...
BlockBuilder index_block; // 索引块构建器
};
构建&读取
void TableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
// 处理待处理的索引条目
if (r->pending_index_entry) {
assert(r->data_block.empty());
// 找到最短分隔符作为索引键
r->options.comparator->FindShortestSeparator(&r->last_key, key);// 因为这里需要使用到后一个key作为生成最短分隔符,所以可能存在最后一个数据块没有办法生成分割符的情况
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
// 将索引条目添加到索引块
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
// ... 其他处理
}
Status TableBuilder::Finish() {
// ... 其他处理
if (ok()) {
// 这里处理的是最后的一个数据块,
if (r->pending_index_entry) {
// 处理最后一个待处理的索引条目
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
// 写入索引块
WriteBlock(&r->index_block, &index_block_handle);
}
// ... 写入footer等
}
核心方法-FindShortestSeparator&FindShortSuccessor
作用:
- 为每个数据块找到一个最短的键,该键大于当前块中的所有键,但小于下一个块中的所有键
- 通过这种方式可以减少索引块的大小,因为不需要存储完整的键
举例说明
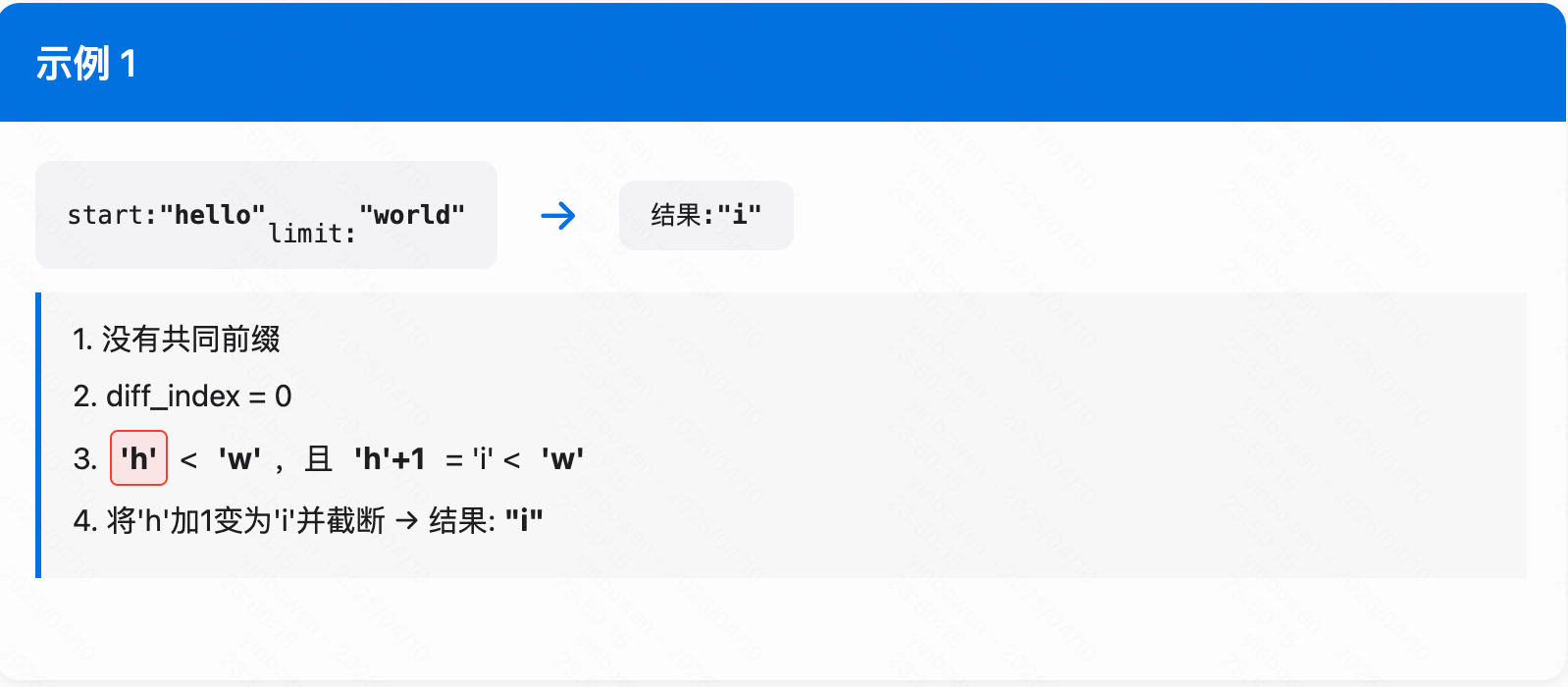
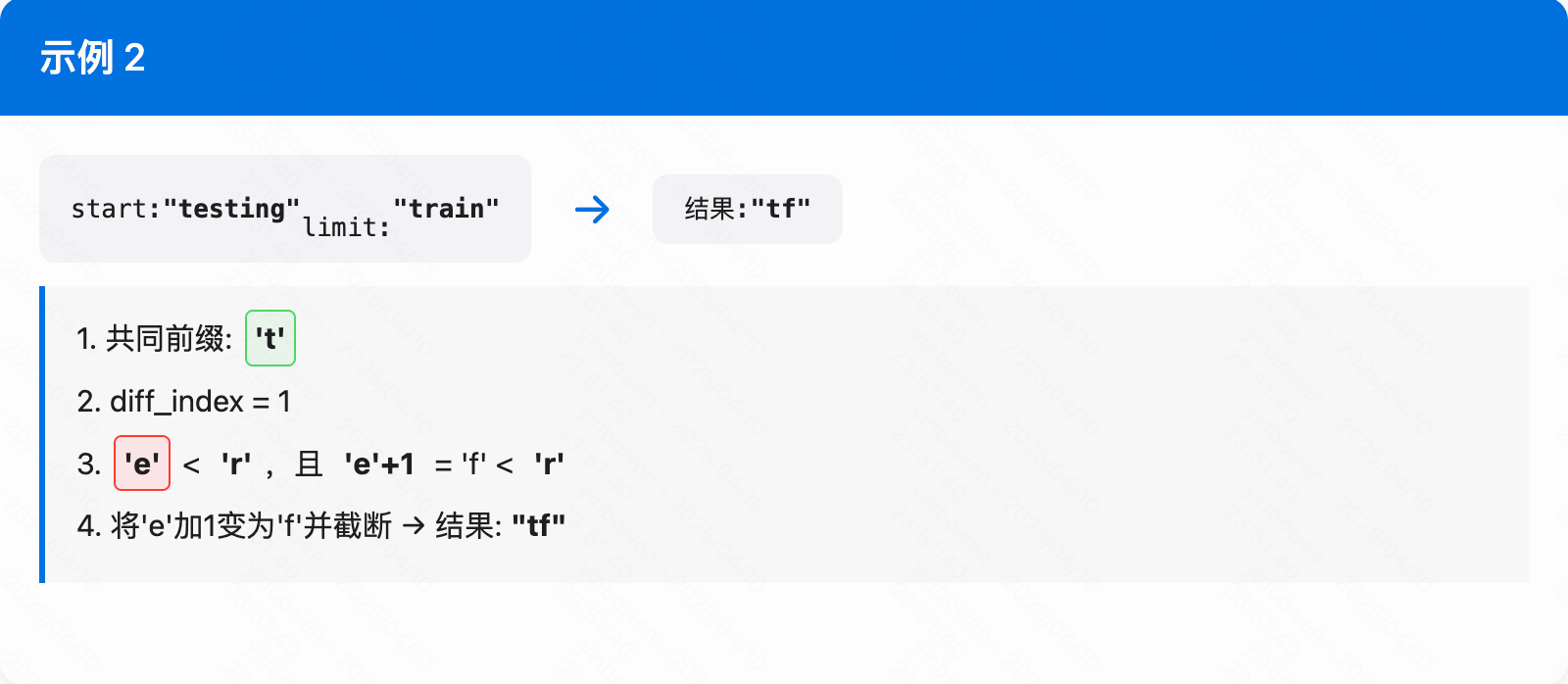
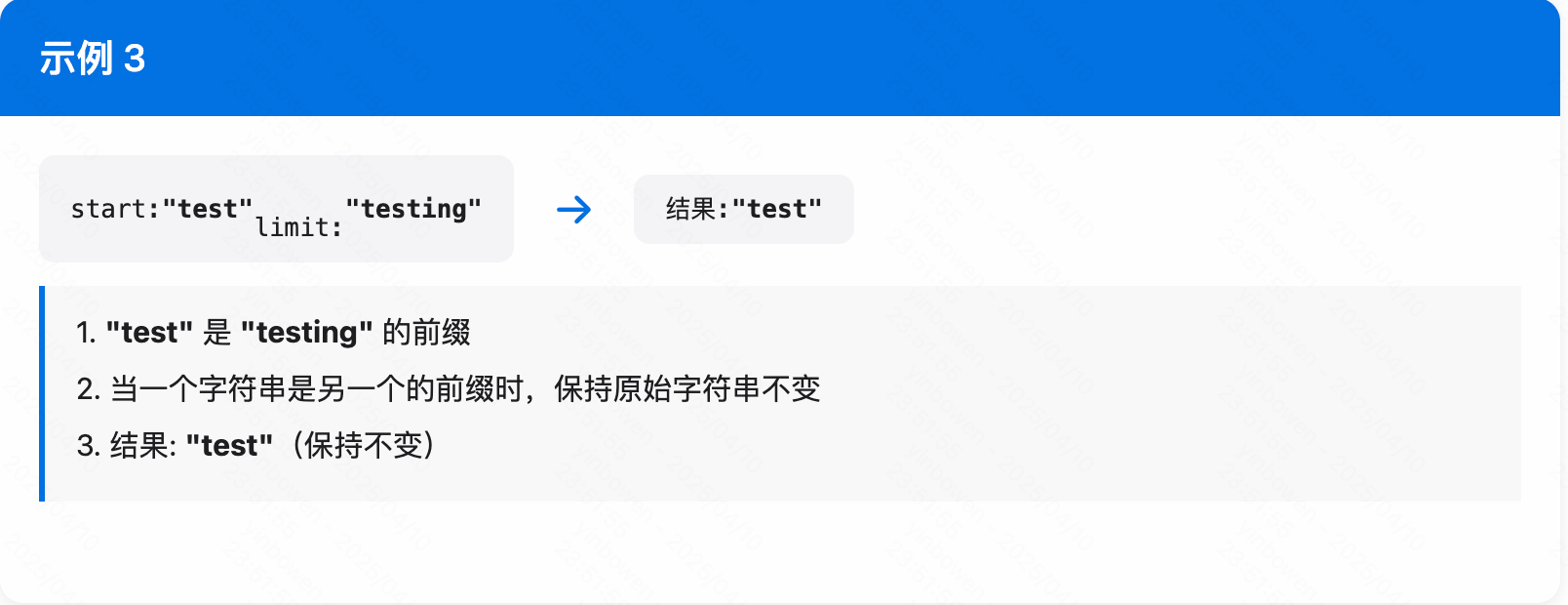
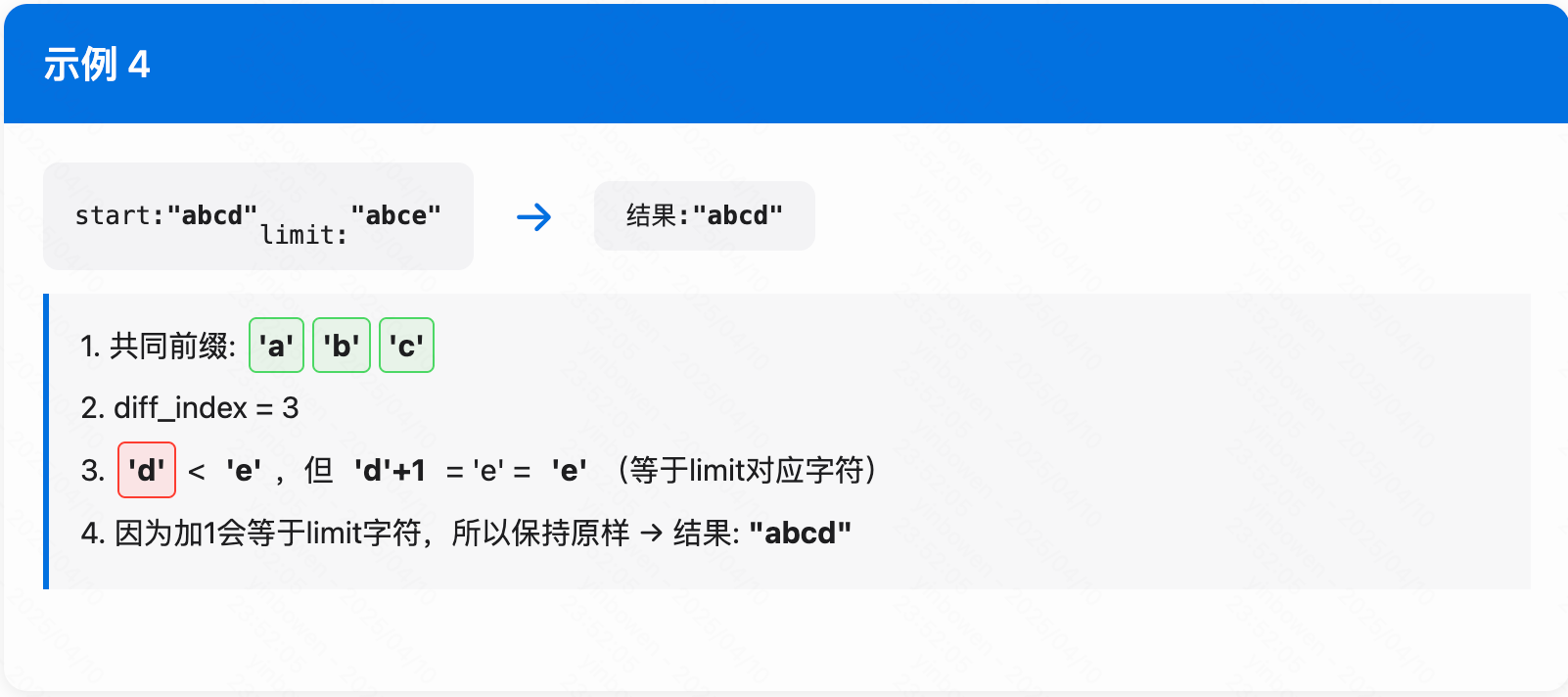
FindShortestSeparator
简单说下这个逻辑,本质上就是找到第一个出现diff index的字符然后生成自己的索引字符
/**
第一步找到第一个不同的字符位置。这是必要的,因为:
分隔符必须保持共同前缀不变(否则可能会小于start)
只能在第一个不同的位置上做修改
**/
void FindShortestSeparator(std::string* start,
const Slice& limit) const override {
// Find length of common prefix
// 找到 start 和limit 之间的最短分隔符
size_t min_length = std::min(start->size(), limit.size());
size_t diff_index = 0;
while ((diff_index < min_length) &&
((*start)[diff_index] == limit[diff_index])) {
diff_index++;
}
/**
然后对第一个出现diff的区域+1 (ps: 当 < oxff 时,担心出现溢出问题)
**/
if (diff_index >= min_length) {
// Do not shorten if one string is a prefix of the other
} else {
uint8_t diff_byte = static_cast<uint8_t>((*start)[diff_index]);
// < oxff 的原因 是因为担心 +1 出现溢出问题
if (diff_byte < static_cast<uint8_t>(0xff) &&
diff_byte + 1 < static_cast<uint8_t>(limit[diff_index])) {
(*start)[diff_index]++;
start->resize(diff_index + 1);
assert(Compare(*start, limit) < 0);
}
}
}
FindShortSuccessor
这个函数很简单: 找到一个比当前key大的最小字符串
void FindShortSuccessor(std::string* key) const override {// 用于找到 key的下一个字典序最小的字符串
// Find first character that can be incremented
size_t n = key->size();
for (size_t i = 0; i < n; i++) {
const uint8_t byte = (*key)[i];
// 找到第一个不是0xFF的字符
if (byte != static_cast<uint8_t>(0xff))
// 将这个字符加1
{
(*key)[i] = byte + 1;
// 截断后面的所有字符
key->resize(i + 1);
return;
}
}
// *key is a run of 0xffs. Leave it alone.
}
猜你喜欢
C++多线程: https://blog.csdn.net/luog_aiyu/article/details/145548529
一文了解LevelDB数据库读取流程:https://blog.csdn.net/luog_aiyu/article/details/145946636
一文了解LevelDB数据库写入流程:https://blog.csdn.net/luog_aiyu/article/details/145917173
关于LevelDB存储架构到底怎么设计的:https://blog.csdn.net/luog_aiyu/article/details/145965328?spm=1001.2014.3001.5502
PS
你的赞是我很大的鼓励
我是darkchink,一个计算机相关从业者&一个摩托佬&AI狂热爱好者
本职工作是某互联网公司数据相关工作,欢迎来聊,内推或者交换信息
vx 二维码见: https://www.cnblogs.com/DarkChink/p/18598402