摘要
知识图(KG)以其代表和管理海量知识的独特优势,为各种下游知识感知任务(如推荐和智能问答)提供了高质量的结构化知识。KGs的质量和完整性在很大程度上决定了下游任务的有效性。但由于知识产权制度的不完备性,知识产权制度中仍有大量有价值的知识缺失,因此有必要对现有知识产权制度进行完善,以补充缺失的知识。知识图谱补全(KGC)是一种流行的知识补充技术。因此,人们对KGC技术的关注日益增加。近年来,对KGC领域的研究越来越多。为了深入了解和掌握KGC研究的主要思想和成果,并进一步突出当前KGC研究的进展,本文对当前KGC研究的最新进展进行了全面的综述。
根据KGC方法所使用的信息源,我们将现有的KGC方法分为两大类:依赖于结构信息的KGC方法和使用其他附加信息的KGC方法。进一步,将每个类别细分为不同的粒度,以便对它们进行总结和比较。此外,还介绍了针对特殊字段KGs的其他KGC方法(包括时间KGC、常识KGC和超关系KGC)。特别是,我们将在概述中讨论每个类别的比较和分析。最后,对未来的研究进行了讨论和展望。
1.介绍
知识图(KGs)以结构化的三重形式描述概念、实体及其关系,提供了更好的组织、管理和理解世界上大量信息的能力[1]。近年来,KG在许多知识感知任务中发挥着越来越重要的作用,特别是为智能问答、信息提取等人工智能任务带来了活力[1-3]。有许多大规模的KGs,如DBPedia[4]、Freebase[5]、WordNet[6]和YAGO[7](如表1所示),它们在许多知识感知的应用程序中得到了广泛的利用。这些KGs中的事实通常以三重形式表示:(主语、谓语、宾语),作为KGs的基本数据结构,保留了KGs的基本语义信息[8]。
虽然知识图谱在应用上有很大的价值,但由于知识图谱中隐含或遗漏了大量有价值的知识,因此知识图谱具有不完备性。有数据表明,在目前的大KG中,一些共同的基本关系的缺乏率超过70%[9],而其他不太普遍的关系更是缺乏。知识图补全(KGC)的目的是预测和补充三元组中缺失的部分。知识图嵌入(Knowledge Graph Embedding,简称KGE,知识图表示学习)作为知识图谱补全的热门研究方向之一,迅速得到了广泛关注。KGE将KG组件(如实体和关系)嵌入到连续向量空间中,以简化操作,同时保留KG的固有结构[10-15]。近年来,对KGC领域的研究越来越多。为了便于对KGC任务的研究和跟踪KGC领域的发展,越来越多的综述文章对最近的KGC技术进行了整理和总结。
相应地,提供了以前关于KGC技术的一些概述:
- Wang等人[16]对2012年至2016年的KGC研究进行了最相关的回顾。他们首先根据输入数据(输入数据只包含事实或包含附加信息)粗略地对KGE模型进行分组。[16]中的附加信息包括实体类型、关系路径、文本描述、逻辑规则和一些其他信息,如实体属性和时间信息)。然后,他们在上述分组的基础上进一步进行细粒度的分类(例如,只考虑事实的方法涉及两个类别,基于距离的KGC方法和基于语义匹配的KGC)。但是,工作[16]并不是KGC任务的具体概述,这个概述只是将KGC作为KGE技术可以支持的下游应用程序之一。
- Gesese等人[17]对KGC任务做了一个简短的总结,与[16]相比,只增加了不到10篇最新的文章。此外,[17]的工作主要关注与文字信息相关的KGE技术。[17]中的文字信息表示文本描述、数值、图像或它们的组合。
- Rossie等人[18]总结了16种基于KG嵌入的最新链路预测(LP)模型。然而,[18]工作并不涉及其他KGC任务,如三元组分类(TC)和关系预测(RP)(我们将在第2.1节中对这些KGC任务进行具体介绍)。
- 另外,其他两篇综述[19,20]简要列出和陈述了几个与kgc相关的研究。它们既没有对具体的KGC技术细节进行全面和仔细的介绍,也没有涵盖主要的KGC方法。此外,一些调查[21-23]关注KG领域,但没有讨论KGC的具体工作。
随着过去几年里诸如Transformer和预训练语言模型(例如BERT)等技术的发展,出现了大量新的KGC技术,这些技术在现有的调查中没有被详细介绍或总结。此外,除了[16,17]中提到的信息外,KGC字段还使用了更多的附加信息,如实体邻居、多跳关系路径、第三方数据源等。直观地说,基于附加信息的KGC方法应该被划分为更广泛的范围和更多的细节。
与上述概述相比,本文提出了一种更全面、更细粒度的知识图谱补全(KGC)划分概述。我们的论文涵盖了到目前为止几乎所有的主流KGC技术。我们的概述为不同级别的KGC类别提供了更仔细的分类。具体而言,我们做出了以下主要贡献:
- 从全面性的角度,对KGC领域进行了较为全面、系统的研究。我们特别关注2017年至今的文献,这些文献要么没有在[16]中总结,要么没有在之前的其他综述[17,19,20]和[18]中详细介绍。此外,我们还考虑了一些特殊的KGC技术,包括时间知识图补全(TKGC)、常识知识图补全(CSKGC)和超关系知识图补全(HKGC)。
- 从详细的分类和总结的角度来看,根据是否依赖KGs附加信息,我们将近年来的KGC研究归纳为两大类:仅依赖KGs结构信息的KGC和含有附加信息的KGC。对于前一类,KGC方法分为三类:张量/矩阵分解模型、平移模型和神经网络模型。在引入基于内部信息的KGC方法时,我们考虑了五类信息,包括节点字面量、实体相关信息、关系相关信息、邻域信息和关系路径信息。另外,基于额外信息的KGC包括两大类:基于规则的KGC和基于第三方数据源的KGC。
- 从比较分析的角度出发,针对各个KGC类别,对所介绍的KGC方法在理论和实验上进行了不同粒度的详细比较。并对其进行了深入的分析和总结。在此基础上,对未来的研究方向进行了全面的讨论和展望。
本文的其余部分结构如下:我们首先概述KG符号、定义、工艺过程、数据集、评价标准以及我们在第2节中的分类标准;然后利用第3节和第4节的附加信息,讨论了两类基于KG的结构信息的KGC方法;接下来,我们将在第5节中回顾KGC的三种特殊技术。第六部分对展望的研究方向进行了讨论。最后,我们在第7节中做出了结论。
2.知识图补全的符号表示与我们的分类标准
我们首先在第2.1节给出了KGC的一些符号。然后我们进一步介绍了KGC的一般过程(见2.2节),其中提供了KGC的几个关键步骤。此外,我们在2.3节中总结了KGC的主要数据集和KGC的评价标准。我们还简要介绍了与KGC相关的知识图细化(KGR)技术(见第2.4节)。最后,我们给出了我们的分类标准(见2.5节)。
2.1. KGC的符号

KGC可分为三个子任务:三元组分类、链接预测和关系预测。三元组分类是KGC的一项重要任务,它通过估计这个三重分类是否正确来决定是否将三重分类添加到KGs中。链接预测任务是指当三元组中头实体或尾实体缺失时,寻找缺失实体的过程。关系预测判断两个实体之间建立特定关系的概率。KGC的三个子任务可以表述如下:

2.2. KGC过程概述
本部分在第2.2.1节中对KGC的整个工艺流程进行了简要介绍。此外,我们在2.2.2节中描述了两种训练技巧:负抽样和排名设置。图1说明了KGC过程的典型工作流。
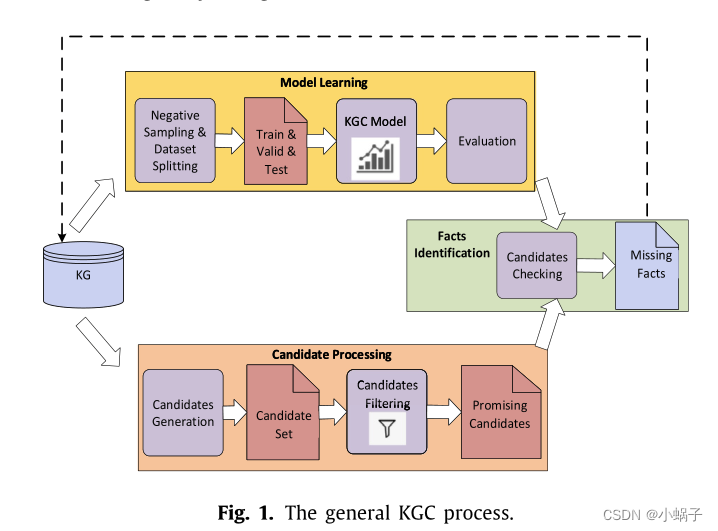
2.2.1. 一般KGC过程
从图1可以看出,一般来说,KGC过程包括三个部分:模型学习、候选处理和事实识别。
模型学习:首先,在建立KGC模型之前,通常有一个负责数据准备的预处理步骤,包括负采样(有时不是必要的步骤,也可以在模型训练时在线完成)和数据集拆分。负采样的目的是在原KG中加入可变数量的反例,以应对KG只包含正例[24]的问题。数据集拆分负责将KG数据拆分为一个训练集、一个验证集和一个测试集。分裂的数据集接下来将用于训练和评估KGC模型。然后,KGC模型通常是一个分类模型或排序模型,其目标是预测候选三元组对KG是否正确。通常,学习到的KGC模型倾向于经历一个评估过程,通过各种评估指标进行评估。一个满意的评估结果通常意味着一个良好的KGC模型。
候选处理:候选处理的目的是获得可验证的三元组。在模型学习中,学习到的KGC模型将对这些三元组进行检查。候选处理从候选集生成开始,它依赖算法或手工工作生成一个候选集(候选集是可能正确但在KG中不存在的三元组)。由于初始生成的候选人集往往非常大,无论候选人是否有希望,它必须进一步进行候选人过滤[25]步骤,以先发制人地删除那些不太可能的候选人,同时保留尽可能多的有希望的候选人。通常,过滤工作是通过生成几个过滤规则(也称为“修剪策略”)来完成的,并将这些规则应用于候选集,以生成最有希望的候选集[26]的候选集。
事实识别:最后,将模型学习中学习到的KGC模型应用于上述候选对象处理生成的有希望候选对象集,得到被认为是正确的、很可能被添加到KG[26]中的缺失三元组集。
2.2.2. 两种训练技巧:负抽样和排名设置
(1)负采样
负抽样的基本思想

采样策略
本文介绍了三种常用的抽样策略:均匀抽样(unif)、伯努利负抽样(bern)[15]和基于生成对抗网络(GAN)的负抽样[27]。
- 均匀抽样(unif)是一种比较简单的抽样策略,其目的是根据抽样的均匀分布对负三元组进行抽样。通过这种方式,所有实体(或关系)都以相同的概率进行抽样。
- 伯努利负抽样法(“bern”)[15]:由于某一关系对应的头实体和尾实体的数量分布不平衡,即存在“一对多”、“多对一”、“多对多”等多种关系类型,用统一的方式替换头实体或尾实体是不合理的。因此,在不同概率下,“bern”策略[15]替代了一个三元组的头部实体或尾部实体。形式上,对于某个关系r,“bern”用关系r计算所有三元组中每个尾实体对应的头实体的平均数(记作hpt)和每个头实体对应的尾实体的平均数(记作tph),然后对每个头实体以
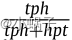 的概率进行抽样,同样,对每个尾实体也以
的概率进行抽样,同样,对每个尾实体也以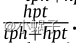 的概率进行抽样。“bern”采样技术在许多任务中表现良好,它比“unif”更能减少假阴性标记。
的概率进行抽样。“bern”采样技术在许多任务中表现良好,它比“unif”更能减少假阴性标记。 - 基于GAN的负采样[27]:受生成对抗网络(GAN)[27]广泛应用的启发,Cai等[28]将生成负样本的方式改为以强化学习的方式基于GAN的采样,其中GAN生成器负责生成负样本,而鉴别器可以使用平移模型获得实体和关系的向量表示,然后对生成的负三组进行评分,并将相关信息反馈给生成器,为其负样本的生成提供经验。最近出现了一系列基于GAN的负采样技术(如[29-31]),相关实验表明,这类方法能够获得高质量的负样本,有利于在知识表示模型的训练过程中对三元组进行正确的分类。
(2)排名设置
在链接预测(LP)任务中,评估是通过对所有测试三元组进行头部预测或尾部预测,并为每个预测计算目标实体与所有其他实体的排名。通常,模型期望目标实体产生最高的似是而非的可能性。在计算预测的排名时,应用了两种不同的设置,原始场景和过滤场景。实际上,一个预测可能有不止一个有效的答案:以尾预测为例(巴拉克·奥巴马,父母,娜塔莎·奥巴马),KGC模型可能会将玛利亚·奥巴马的得分高于娜塔莎·奥巴马,也就是说,可能存在其他预测事实已经包含在KG中,例如(巴拉克·奥巴马,父母,玛利亚·奥巴马)。根据有效答案是否被认为是可接受的,设计了两个独立的设置[18]:

2.3. 数据集和评估指标
这里我们介绍一些最常用的KGC数据集(见第2.3.1节)和KGC的几个评估指标(见第2.3.2节)。
2.3.1. 数据集
我们描述了主要在Freebase和WordNet两个KG上开发的数据集,并在表2中报告了它们的一些重要属性。
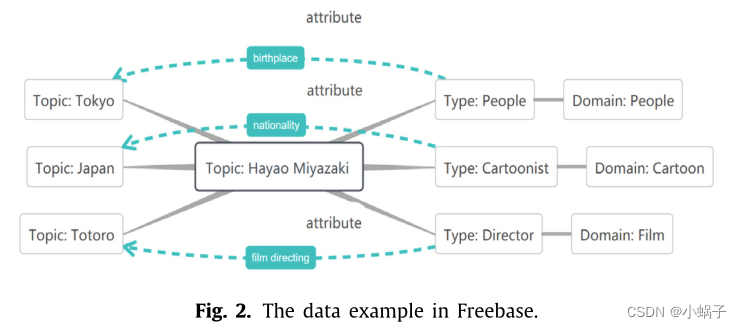
Freebase: Freebase是一个公共KG,其内容全部由用户添加。此外,Freebase还从开KGs中提取知识作为[26]的补充。Freebase中的基本数据项包括‘‘Topic’’, ‘‘Type’’, ‘‘Domain’’, ‘‘Property’’“主题”、“类型”、“域”、“属性”等。我们给出了一个演示来说明Freebase中的数据,如图2所示。 Miyazaki Hayao宫崎骏是漫画领域的漫画家,却是电影领域的导演。可以看出,Freebase是一个由主题扩展的多个域组成的数据库,每个主题的图结构由其类型和类型属性控制。通常,在KGC中,通常使用Freebase的FB15k和FB13子集,以及在FB15k基础上改进的FB15k-237作为方法检测的实验基准:
- FB15k: FB15k是通过选择Wikilinks数据库中涉及的实体子集来创建的,并且这些实体在Freebase[11]中至少有100次提及。此外,FB15K删除了反向关系(其中反向关系如' !/people/person/nationality '只是与' /people/person/nationality '的关系颠倒了首尾。FB15k描述同义集之间的三元关系,出现在验证集和测试集中的同义集也出现在训练集中。此外,FB15k将用物化表示的n元关系转换为二进制边的团,这极大地影响了图的结构和语义[18]。FB15K有592213个三元组,14951个实体和1345个关系,随机拆分如表2所示。
- FB15k-237:Toutanova和Chen[32]构建的FB15k的一个子集,由于FB15k存在近似相同关系或反向关系而引起的测试泄漏问题。在此背景下,FB15k-237被构建为一个更具挑战性的数据集,首先从FB15k中选择涉及401个最大关系的事实,并删除所有等价或反向关系。然后,他们确保在训练集中连接的实体中没有一个也直接链接在验证和测试集中,以过滤掉所有平凡的三元组[18]。
WordNet [6]: WordNet是一个基于认知语言学的大型KG本体,也可以看作是一个英语词典知识库,其构建过程考虑单词的字母顺序,进一步形成英语单词的语义网。在WordNet中,实体(称为同义词集)对应于语义,关系类型定义这些语义之间的词汇关系。此外,WordNet不仅包含一词多义、类别分类、同义词、反义词等多种类型的词汇,还包含实体描述。此外,还有从WordNet中提取的各种后期生成的子集数据集,如WN11、WN18和WN18RR:
- WN11:它包括11个关系和38696个实体。此外,WN11的训练集、验证集和测试集分别包含112 581、2609和10 544三重组[11]。
- WN18:它以WordNet为起点,然后迭代地过滤掉提及太少的实体和关系[11,18]。注意,WN18涉及到可逆关系。
- WN18RR: WN18RR是由Dettmers等人[33]为解决WN18中测试数据在训练时被模型看到的测试泄漏问题而构建的。它是通过应用类似于FB15k-237[32]所使用的管道来构建的。最近,他们承认测试集中有212个实体没有出现在训练集中,这使得大约6.7%的测试事实无法合理预测。
2.3.2. 评价指标
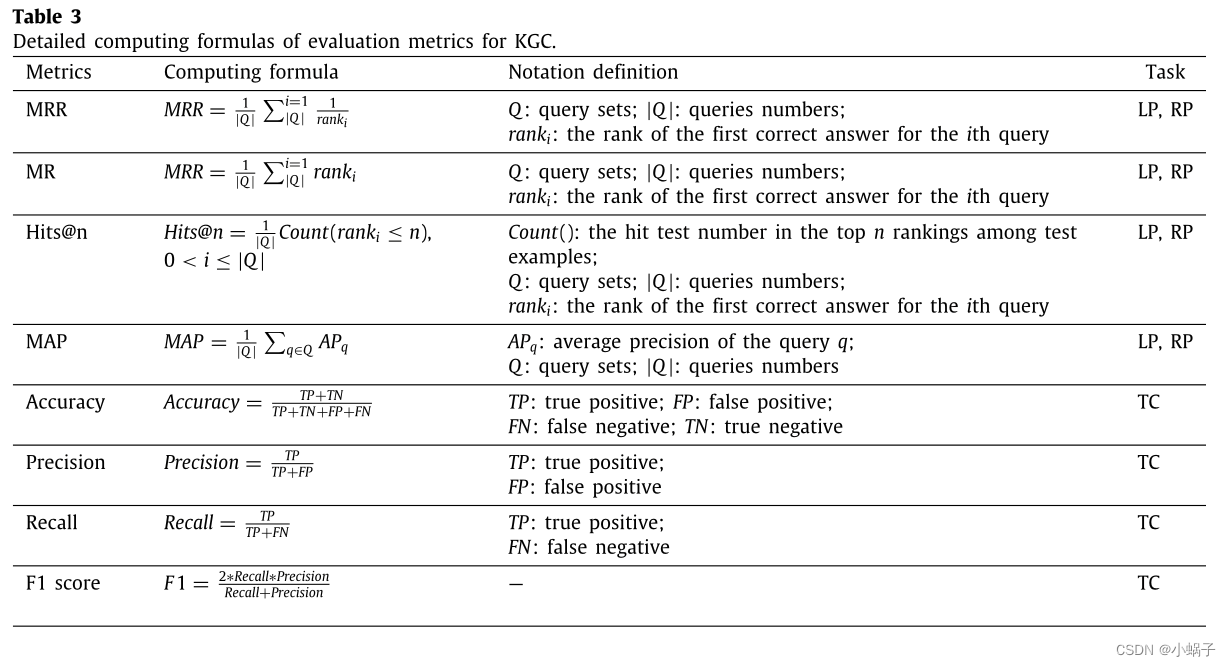 在本节中,我们将推荐KGC中通常使用的评估指标。上述指标的详细计算公式如表3所示。
在本节中,我们将推荐KGC中通常使用的评估指标。上述指标的详细计算公式如表3所示。
Mean Reciprocal Rank 平均倒数排名(MRR)
MRR在KGC的LP和RP任务等倾向于返回多个结果的排序问题中被广泛应用。在处理这类问题时,评价系统将根据结果的分数从高到低进行排序。MRR根据排序算法对目标答案的排序来评估排序算法。目标答案排名越高,排序算法越好。在公式视图中,对于查询,如果目标答案排在第n位,那么MRR评分计算为1/n(如果返回的结果中没有目标答案,则评分为0)。
Mean-Rank (MR) and Hits@n 平均排名(MR)和Hits@n

准确率:准确率是指正确预测的三元组与总预测三元组的比值,通常用于评价KGC在TC任务中分类模型的质量,其计算公式如表3所示。
其他评价指标:对于KGC任务还有其他的评价指标,如平均平均精度(MAP)在排序问题中关注返回结果的相关性。在测量分类问题时,有些指标与“准确性”密切相关,如“召回率”、“精确度”和“F1分数”。与MR、MRR、Hits@n和“accuracy”相比,这些指标在KGC领域中并没有被持续使用。上述指标的具体计算公式见表3。
2.4. 知识图谱细化(KGR) vs. KGC
Knowledge Graph Refinement
大规模知识体系的构建过程导致知识体系中的形式化知识不能合理地同时达到“全覆盖”和“完全正确”。kg通常需要在完整性和正确性之间进行良好的权衡。知识图细化(Knowledge Graph refine, KGR)用于推断并将缺失的知识添加到图中(即KGC),并识别错误的信息片段(即错误检测)[24]。最近,KGR被纳入到推荐系统[34]中。Tu等人[34]利用KG来捕获推荐系统中特定于目标的知识关系,方法是提取KG以保留有用信息,精炼知识以捕获用户的偏好。
基本上,KGC是KGR子任务之一,用于对丢失的三元组进行推断和预测。错误检测(如[35,36])是KGR的另一个子任务,用于识别KGs中的错误。Jia等人。[36]建立了一个知识图三重可信度度量模型,该模型量化了三重的语义正确性和表达的三重的真度。但是需要注意的是,KGC是一项相对独立的任务,它是为了增加KGs的覆盖率,以缓解KGs的不完整性。在我们目前的概述中,我们关注的是KGC技术,关于KGR的问题可以参考[24,34]。
2.5. 我们的分类原则
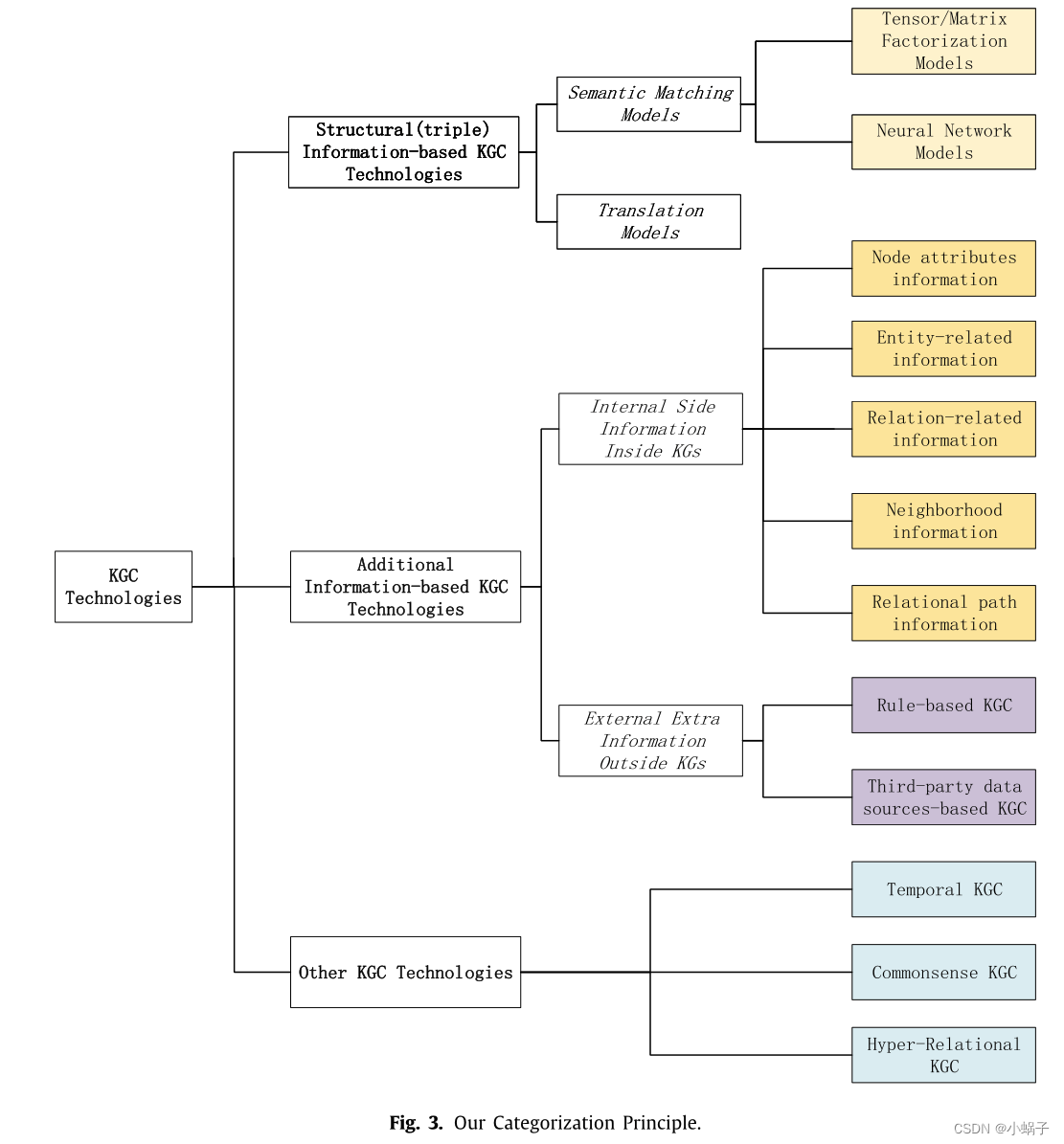
我们对KGC研究综述的主要全视图分类如图3所示。
随着KGC模型的快速发展,我们对先进的KGC技术的新兴研究进行了广泛的报道。我们尽可能全面地包括了KGC研究开始以来的主要文献,并详细地关注了影响深远和显著的方法。根据是否使用附加信息,我们将KGC方法分为两大类:基于结构(三重)信息的KGC方法和基于附加信息的KGC方法(附加信息通常是指除结构信息外包含在KGs内部或外部的一些其他信息,如文本描述、人工规则)。此外,我们进一步考虑了附加信息的来源——根据它是否来自内部KG,我们将附加信息分为两个更细的子类:KG内部的内部侧信息和KG外部的外部额外信息。此外,我们引入了一些针对特定领域的KGC技术,如时间知识图补全(TKGC)、CommonSense KGC (CSKGC)和超关系KGC (HKGC)。我们还对各个小类别的方法做了详细的比较和总结。对未来的研究方向进行了全面的讨论和展望。具体来说,我们的分类原则如下:
基于结构信息的KGC方法:仅利用KGs中内部事实的结构信息,针对这类方法,根据语义匹配模型和翻译模型的评分函数性质,对KGC方法进行了评述。语义匹配模型一般采用基于语义匹配的评分函数,进一步由张量/矩阵分解模型和神经网络模型组成。翻译模型采用基于距离的评分函数;
基于附加信息的KGC方法:与附加信息(除结构信息外的KGs内部或外部信息)协同实现KGC。对于这个类别,我们进一步提出了细粒度分类法,分别分为内部信息和外部信息使用的两种视图:
- KGs涉及的KGs内部侧信息,包括节点属性信息、实体相关信息、关系相关信息、邻域信息、关系路径信息
- KGs外的外部额外信息,主要包括基于规则的KGC和基于第三方数据源的KGC两个方面
其他KGC技术:我们特别关注其他一些KGC技术,如临时KGC、常识KGC和超关系KGC。
4. 附加的基于信息的KGC技术
基于附加信息的KGC研究近年来受到越来越多的关注。第3节所介绍的技术主要依靠KGs的结构信息(即简单的三重结构信息)进行KGC,当然,第3节中提到的几种方法也同时利用了KGC的附加信息。例如,KBAT[91]考虑给定实体的多跳邻域信息来捕获实体和关系特征,而DrWT[45]利用KGs以外实体的附加维基百科页面文档。在本节中,我们将重点关注基于附加信息的KGC技术,并进行全面和细粒度的总结和比较。
我们特别关注两种附加信息的合并,包括kg内部的内部附加信息和kg外部的外部附加信息:
- 我们在4.1节中介绍了kg内部侧信息的使用,它由五个子类组成:节点属性信息(章节4.1.1)、实体相关信息(章节4.1.2)、关系相关信息(章节4.1.3)、邻域信息(章节4.1.4)和路径信息(章节4.1.5)。
- 关于在KGs之外合并外部信息的研究在第4.2节,涉及到两个方面的内容:第4.2.1节基于规则的KGC和第4.2.2节基于第三方数据源的KGC。
4.1 KG内部的内部附加信息
KG学习过程中经常使用KG内部固有的丰富信息(即内部信息),这些不可忽略的信息在为KGC和知识感知应用捕获知识嵌入的有用特征方面发挥着重要作用。一般来说,kg内部的通用内部侧信息包括节点属性信息、实体相关信息、关系相关信息、邻域信息和关系路径信息。
4.2KG外部的外部附加信息
本节梳理利用外部信息的KGC研究,主要包括两个方面:第4.2.1节的基于规则的KGC和第4.2.2节的第三方数据源辅助KGC。
4.2.1. 基于规则的KGC
KGs中的逻辑规则是不可忽视的,因为它们可以为KGC提供专家和声明性信息,它们已被证明在推理中发挥关键作用[185-187],因此对KGC至关重要。在本节中,我们将系统地介绍使用各种规则的KGC任务,我们还列出了表21所示的基于规则的KGC方法汇总表。
4.2.1.1. 逻辑规则的引入
4.2.2. 基于第三方数据源的KGC
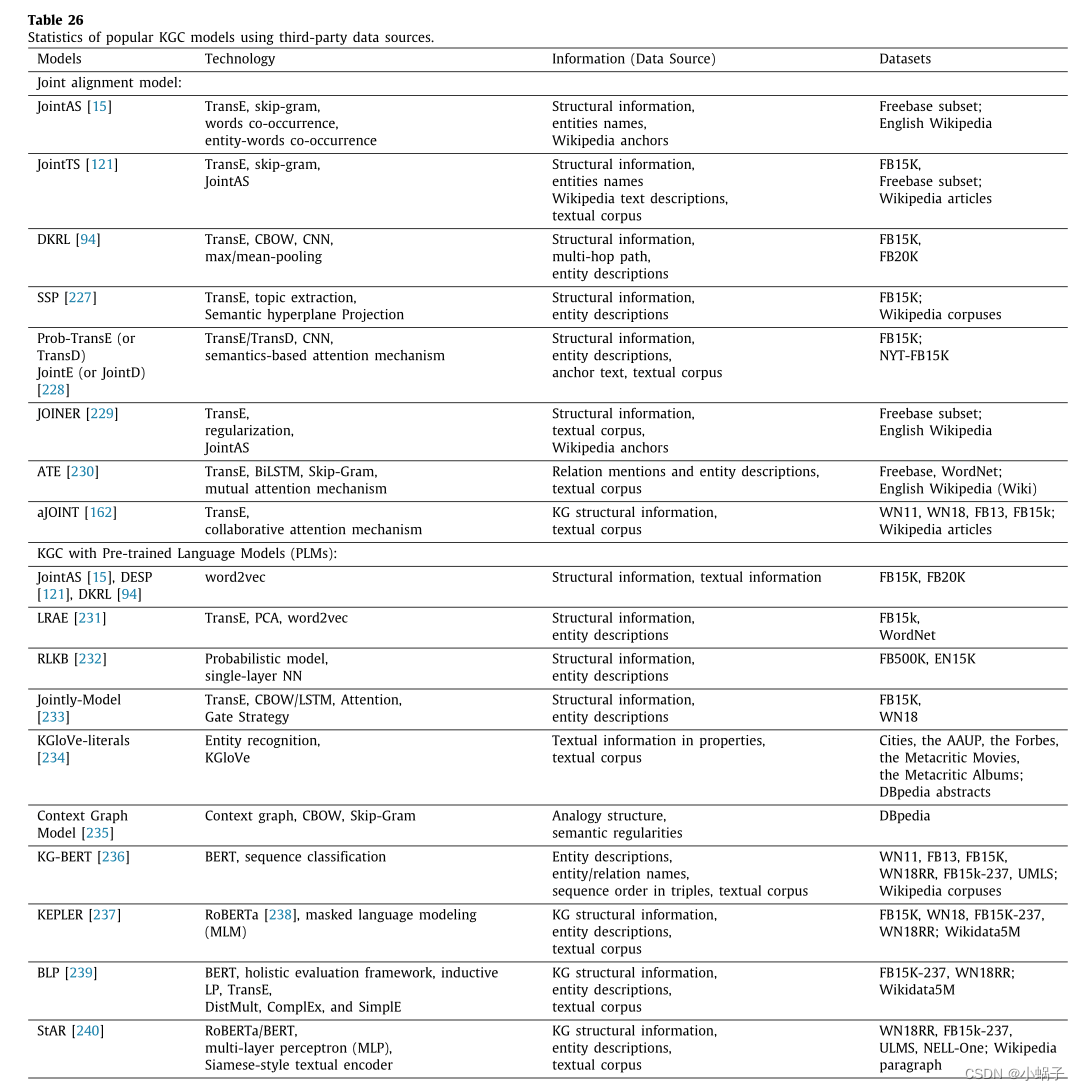
一些相关技术与第三方数据源一起从KG中的三元组学习实体/关系嵌入,特别是使用附加的文本语料库(例如,维基百科文章),以从相关的丰富语义信息中获得帮助。接下来,我们将系统地介绍使用第三方数据源的KGC研究,我们也将它们列在表26中直接展示。
4.2.2.1. 研究的灵感
这一方向受到以下三个关键项目的启发:首先,预训练语言模型(PLMs),如Word2Vec[75]、ELMo[241]、GPT[242]和BERT[243],引起了自然语言处理(NLP)领域的热潮,它可以有效地捕获文本中的语义信息。它们起源于一个令人惊讶的发现,从大型训练语料库中学习到的单词表示以线性向量翻译的形式显示语义规律[75],例如,king−man + woman≈queen。这样的结构很有吸引力,因为它通过词汇-语义类比推理提供了对分布向量空间的解释。其次,在开放世界假设下,一个缺失的事实通常包含KG之外的实体,例如,一个或多个实体是出现在web文本中但尚未包含在KG中的短语[15]。虽然仅依靠内部结构信息很难对该场景进行建模,但第三方文本数据集可以为处理这些kg外事实提供满意的帮助。第三,与上一点类似,实体描述等辅助文本信息有助于稀疏性实体的学习,稀疏性实体作为这些在KG中缺乏足够信息支持学习的实体的补充信息。
最显著的文本信息是实体描述,很少有KG包含每个实体或短语的现成的简短描述或定义,如wordnet和Freebase,通常它需要额外的词汇资源来提供文本训练。例如,在一个有许多技术词汇的医学数据集中,维基百科页面、字典定义或通过诸如“medilexicon.com”这样的网站进行的医学描述都可以作为词汇资源[236]。
4.2.2.2. 联合对齐模型