随着持续集成的引入,项目中的自动化测试用例越来越多,每轮执行所消耗的时间也越来越久。
要提高自动化测试用例执行的效率,以下几点是需要考虑的根本点。
(1)公司项目的交付策略如何
首先,测试团队服务于公司项目,因此我们必须根据公司项目的交付策略做对应的调整。例如你所在的团队会在发版前两天进行封版,那么就有足够的时间去执行自动化测试;如果你所在的团队在临上线前一小时还在改代码,这时想要去执行所有编写的自动化测试用例,必然会时间短缺。
(2)测试团队的自动化测试策略如何
- 自动化测试的开展策略
UI自动化测试和接口测试有不同的优缺点。根据公司项目实际情况,合理规划自动化测试的组织形式,用接口测试去验证易变的业务逻辑,用UI自动化测试来覆盖业务主流程,将两者相结合,才能发挥最大的测试效应。
- UI自动化测试的执行策略
结合公司、项目实际情况,测试经理应该控制研发人员提交版本的节奏,然后根据该节奏合理安排自动化测试的执行策略。自动化测试一定要在平时的测试版本经常执行,以便提早发现问题,这也符合测试左移的大思想。千万不要等到封版以后才去执行该版本的自动化测试用例。
(3)合理划分测试用例等级
在自动化测试用例设计之初就要确定好用例标记。测试用例可以按优先级来划分,也可以按照模块来划分。有了这些工作的铺垫,在需要快速执行测试用例的时候,我们就可以根据需要选择合适范围的用例来执行,从而提升测试效率。这有点符合精准测试的思想。
(4)测试用例步骤是否精简
精简的测试用例脚本是指通过采用合理的请求方式,跳过不必要的操作,从而达到减少操作步骤、加快执行速度的效果。
下面举个例子,正常的业务操作如图所示。

如果B操作后的页面对应URL2,那么我们就可以对测试步骤进行简化,如图所示。

对比我们可以发现,前者两个元素定位及操作的动作被一个get(url2)所代替,整个脚本的执行时间变短且更加稳定。
(5)测试用例等待是否合理
这里再次提醒,千万别随意使用强制等待(sleep)。
自动化测试经验分享:
(1)验证码
CAPTCHA是Completely Automated Public Turing Test to Tell Computers and Humans Apart(全自动区分计算机和人类的图灵测试)的简称。CAPTCHA是区分计算机和人类的一种程序算法,是一种区分用户是计算机还是人的计算程序,这种程序必须能生成并评价人类能很容易通过但计算机通不过的测试。
简单来说,验证码存在的目的就是防止自动化,所以请不要尝试用各种方法去识别验证码。一般来说,我们可以通过以下两种方式避免项目中遇到“验证码”。
- 测试环境中关闭验证码功能。
- 使用万能验证码功能。
(2)双因子验证
双因子验证(2 Factor Authentication,2FA)是一种安全密码验证方式。传统的密码验证由一组静态信息组成,如字符、图像、手势等,其很容易被获取,相对不安全。2FA会基于时间、历史长度、实物(信用卡、SMS手机、令牌、指纹)等自然变量结合一定的加密算法组合出一组动态密码,一般每60秒刷新一次,不容易被获取和破解,相对安全。
在Selenium中,如果遇到2FA类型的验证方式,一般来说可以采取以下方式避免。
- 在测试环境中为某些用户禁用2FA,以便可以在自动化中使用这些用户凭据。
- 在测试环境中禁用2FA。
- 设置某特定IP请求不进行2FA,这样我们就可以配置测试机IP来避免2FA。
(3)文件下载
尽管可以在Selenium中通过单击浏览器的链接来开始下载,但该API不会获取下载进度,这使其不适合测试下载的文件。所以,应尽量避免使用Selenium来验证项目的下载功能,或者你应该和需求方确认清楚“他想要验证的到底是什么”。
(4)测试用例依赖
需要强调一下,你的测试用例应该能够以任何顺序执行(测试用例之间没有耦合关系),并且某个用例能否执行成功不应该依赖于其他测试用例的执行结果。
(5)性能测试
不要尝试用Selenium来做性能测试,性能测试追求的是相同时间节点上模拟众多用户发送给服务器端大量的请求。Selenium官方强调过这并非其擅长的场景,所以请使用其他专业的性能测试工具,如JMeter、Gatling等。
(6)抓取信息
网络上,有部分文章介绍如何借助Selenium来抓取某某网站的信息。Selenium确实可以实现该功能,但官方有声明,基于WebDriver的实现原理,它绝不是最理想的工具。也许我们可以尝试使用“BeautifulSoup”之类的库,因为这些库中的方法不依赖于创建浏览器和导航页面,这样可以节省大量的时间。
(7)登录邮箱、账号
网络上,有部分文章介绍如何借助Selenium实现登录邮箱、登录12306抢票、登录京东网站参加整点抢购商品活动。实际上,这有点“哗众取宠”,因为:第一,通过页面的操作方式去抢购的速度绝对没有直接发请求来得快;第二,这会在无形中违反了一些网站的使用条款,有可能会面临账户被关闭的风险。
一、测试环境准备
1、Selenium简介
Selenium是一个用于Web应用程序的测试工具。在浏览器中可直接运行Selenium测试,就像真正的用户在操作一样。
1. Selenium具有以下特点
- 免费、开源。
- 支持多语言(C、Java、Ruby、Python、C#)。
- 支持多平台(Windows、macOS、Linux)。
- 支持多浏览器(IE、Firefox、Chrome、Safari、Opera等)。
- 分布式(可以把测试用例分布到不同的测试机器上执行,相当于分发机的功能)。
- 技术支持(成熟的社区、大量的文档支持)。
总之,Selenium是一个成功的开源软件,其在发展过程中获得了很多公司和独立开发者的支持,同时也被众多公司和项目组选为UI自动化测试的工具。
2. Selenium 3包含的3个部分
- Selenium WebDriver
WebDriver是Selenium的核心部分,其提供了各式各样的接口,供用户实现Web UI自动化测试的功能。
- Selenium IDE
Chrome和Firefox浏览器有对应的Selenium IDE插件。借助插件,我们可以录制和回放浏览器操作,从而快速创建自动化测试。
- Selenium Grid
为了提升测试效率,需要将自动化测试脚本分发到不同的测试机器上执行,此操作可以借助Selenium Grid来实现。
3. Selenium 3的新特性
- Selenium 3去掉了RC。
- 支持Java 8及以上版本。
- 不再提供默认浏览器支持,所有浏览器均由浏览器官方提供支持。例如,Firefox官方提供geckodriver来驱动Firefox浏览器。
- 在Windows 10上可以对Edge浏览器进行自动化测试。
- Apple提供了SafariDriver,以支持macOS中的Safari浏览器。
- Selenium 3支持IE 9.0及以上版本。
4. WebDriver组件
使用WebDriver构建测试之前,我们先要了解相关的组件。
- 本地执行
本地执行的最基础结构如图所示,WebDriver通过Browser Driver与浏览器通信,并且以同样的路径来接收浏览器返回的信息。
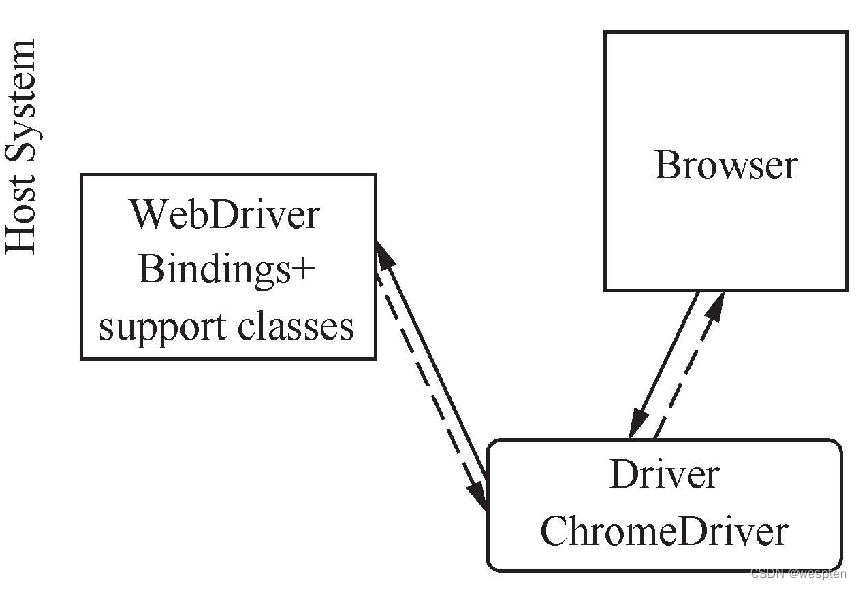
注意:不同的浏览器需要不同的Browser Driver来驱动。
- 远端执行
如果不想在本地执行测试,我们还可以借助Remote WebDriver实现在远端执行测试,如图所示。
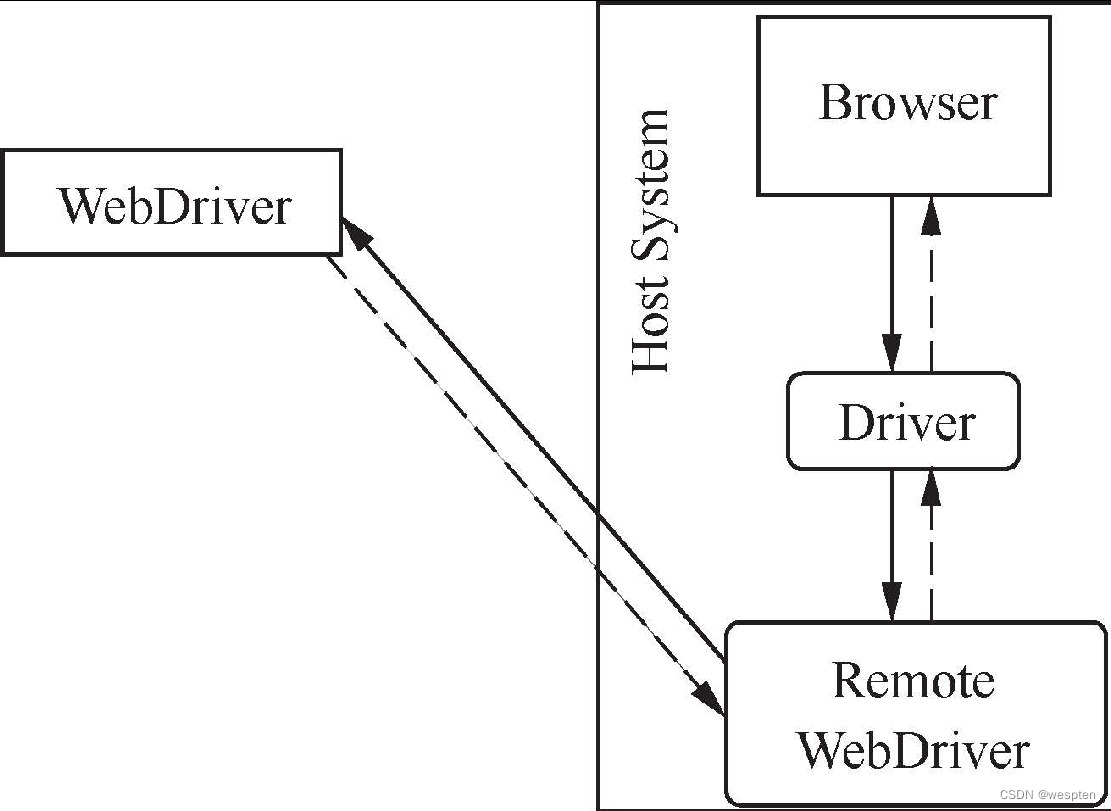
注意:Remote WebDriver、Browser Driver与浏览器在同一系统上。
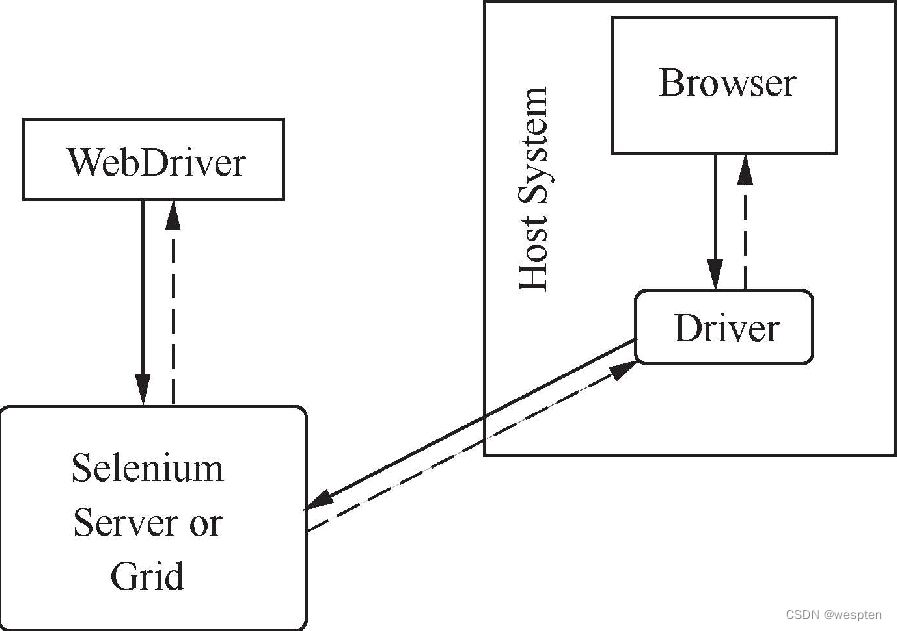
- 集群执行
借助Selenium Server或Selenium Grid,我们可以实现集群执行的效果,如图所示。
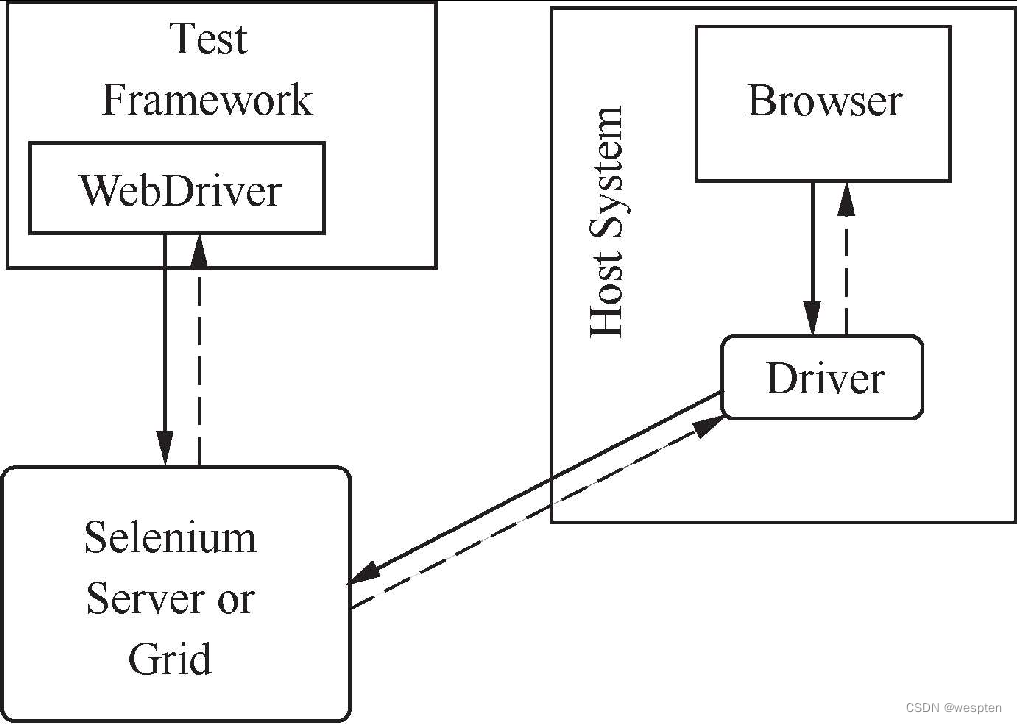
- 框架执行
WebDriver的长处是可以配合Browser Driver与浏览器进行通信。但WebDriver对测试相关事情不太擅长,例如它不知道如何比较事物,如何断言成功或失败。这些问题是需要各种框架来解决的,因此需要选择一种与开发语言相关的测试框架。
如果以Python作为开发语言,可以选择unittest和Pytest框架。测试框架负责执行WebDriver中与测试相关的步骤,如图所示。
5. Selenium IDE
如果你想快速创建一个缺陷回归测试,或者创建自动化测试脚本来进行探索测试,那么你就可以使用Selenium IDE,它可以简单地记录和回放与浏览器的交互行为。
Selenium IDE分别提供了Firefox和Chrome两种浏览器的插件,这里我们以Firefox的插件为例,讲解一下插件安装、脚本录制的过程。
对于Selenium IDE存在的价值,笔者是这样理解的:因为IDE很难满足自动化测试的复杂场景,所以借助IDE来完成整个项目的自动化测试很不现实;但是IDE录制完成后,可以查看、导出测试脚本,这有助于我们了解官方推荐的脚本编写思路,为后续我们编写测试脚本提供指导。
遗憾的是,官方IDE在3.0后的版本中不再提供脚本导出的功能,替代的是另外一款非官方插件——Katalon Recorder,该插件能够提供脚本导出功能。
1)Selenium Firefox IDE
(1)安装Firefox IDE
- 打开Firefox浏览器,访问Selenium官网。
- 单击Selenium IDE下方的“DOWNLOAD”按钮,进入下载页面,如图所示。
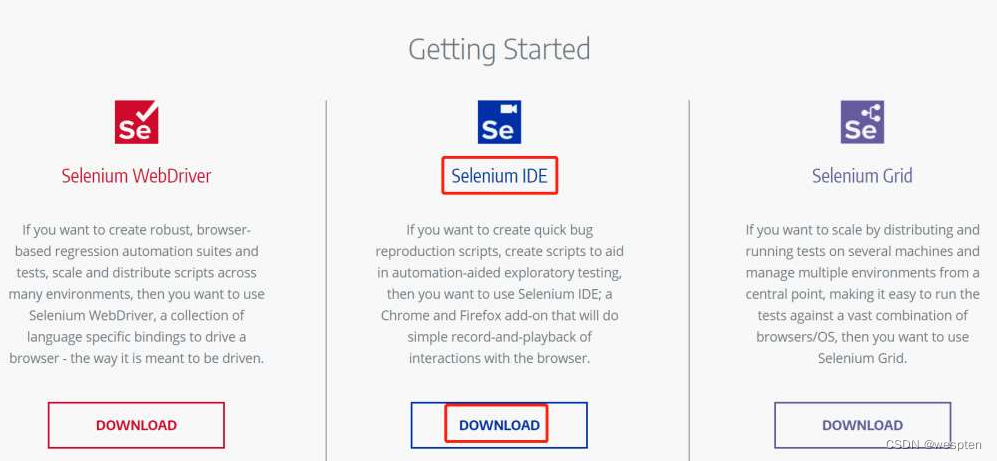
- 单击“+Add to Firefox”按钮,开始安装插件,如图1-6所示。
- 安装过程中,会弹出图1-7所示的提示框。此时,单击“添加(A)”按钮。
- 浏览器右上角出现提示框,提示Selenium IDE已经被添加到Firefox浏览器,并且我们可以选择Firefox浏览器菜单中的“附加组件”选项来管理相关插件,如图所示。
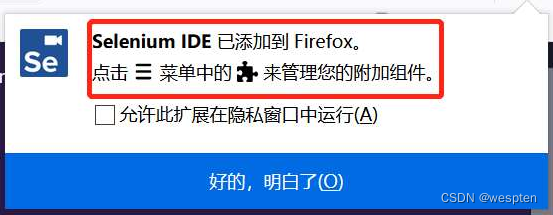
(2)Selenium IDE录制
- 单击插件图标,打开图所示的对话框。
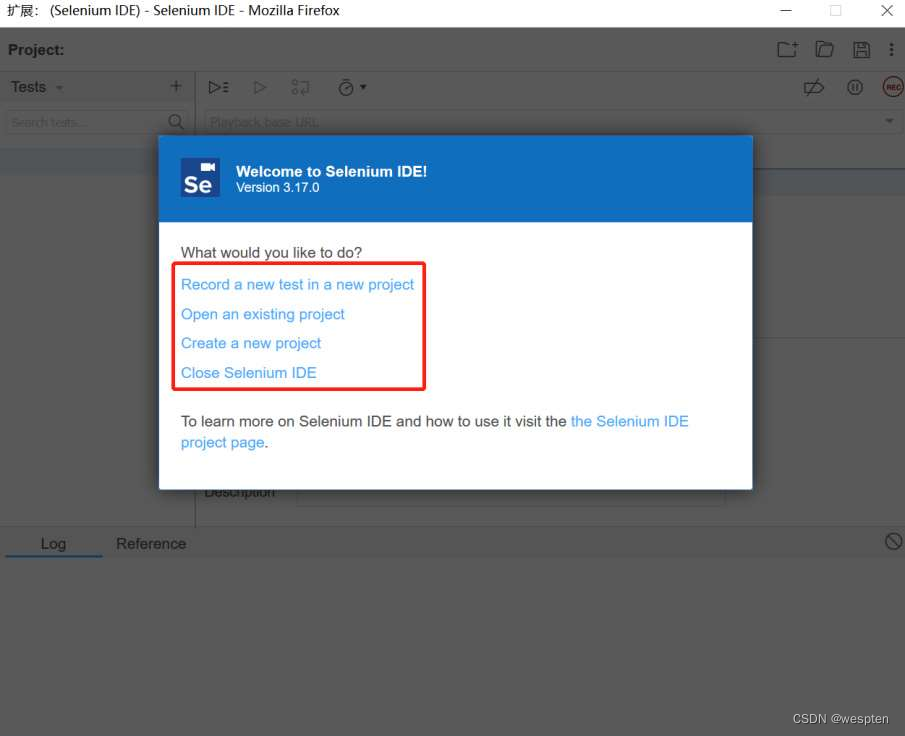
- 根据实际需要选择在新项目中录制新测试或打开一个已存在的项目等。这里,我们单击第一项“Record a new test in a new project”。
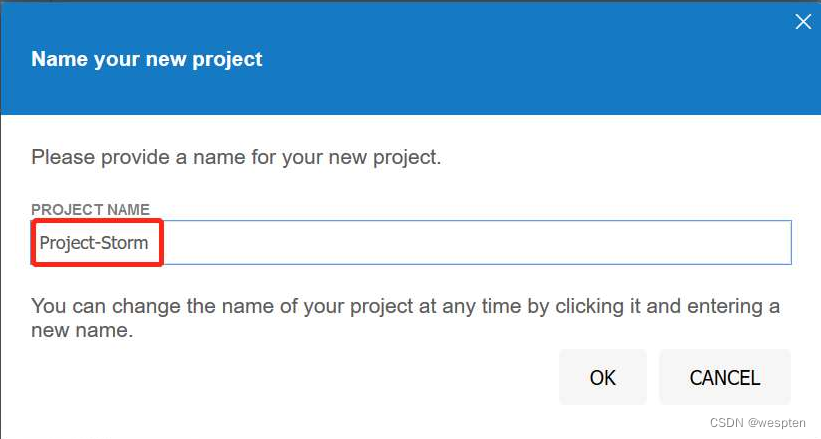
- 弹出的对话框中输入项目名称,然后单击“OK”按钮。
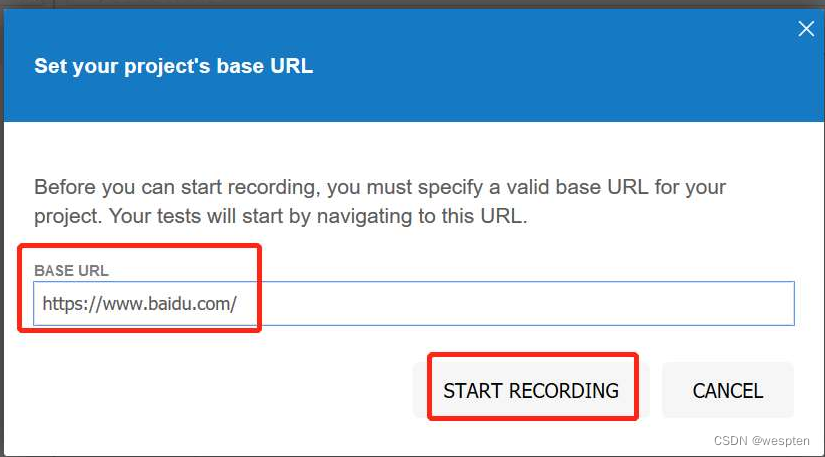
- 在开始录制之前,先要输入起始的URL(这里我们输入了百度的URL),然后单击“START RECORDING”按钮,如图所示。
- 这时候,会打开一个Firefox浏览器并访问上一步骤中输入的URL(在浏览器的右下方会显示“Selenium IDE is recording”)。
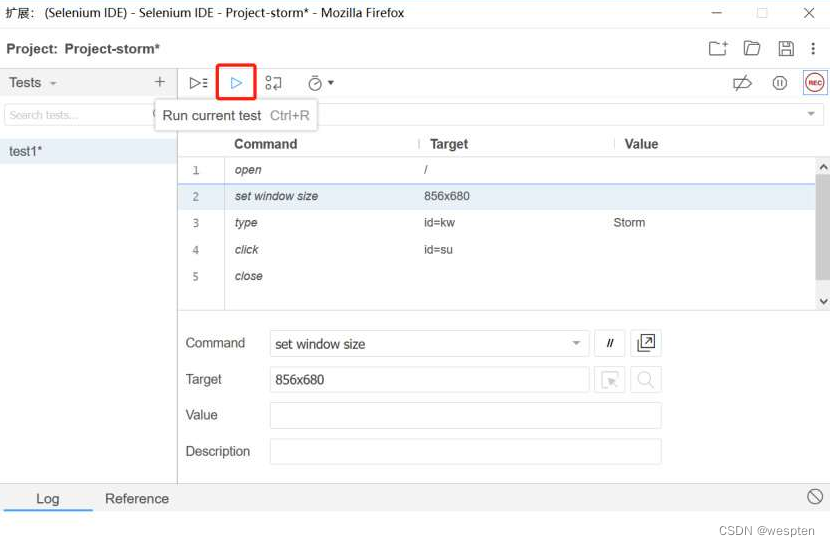
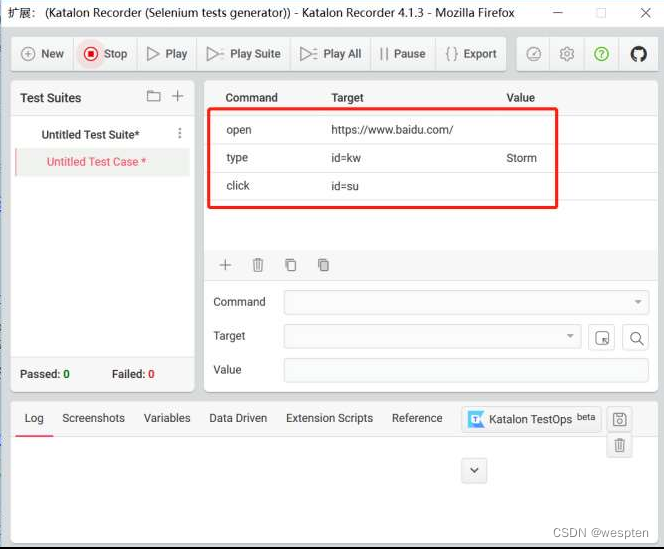
- 然后我们对浏览器所做的所有操作都会被录制下来,这里我们做3个动作:在百度搜索框中输入关键字“Storm”,单击“百度一下”按钮,关闭浏览器。
- 在IDE窗口中单击右上角的“Stop recording”按钮,结束录制。

- 输入该测试脚本(用例)的名字,这里输入“test1”,然后单击“OK”按钮。
- 单击图中的三角按钮,可以回放录制的动作。
前面我们说过Selenium IDE的重点在于其脚本导出功能,不过官方新版本IDE不再提供脚本导出功能,如果有兴趣的话,可以自行研究(整个IDE的操作都相对比较简单)。
2)Katalon Recorder插件
接下来,我们安装并使用Katalon Recorder插件,重点看一下官方推荐的测试脚本编写风格和思路。
(1)安装Katalon Recorder插件
- 打开Firefox浏览器,然后打开菜单,选择“附加组件”,再搜索“Katalon Recorder”,最后选择图所示的搜索结果。
- 单击“添加到Firefox”按钮,完成插件的安装,如图所示。

(2)使用Katalon Recorder插件
- 打开Firefox浏览器,单击菜单栏中的“Katalon Recorder”图标,打开Katalon Recorder窗口。
- 单击“Record”按钮即可开始录制,这里我们还是做3个操作:打开百度首页,在搜索框中输入“Storm”,单击“百度一下”按钮。录制结果如图所示。
(3)Katalon Recorder导出脚本
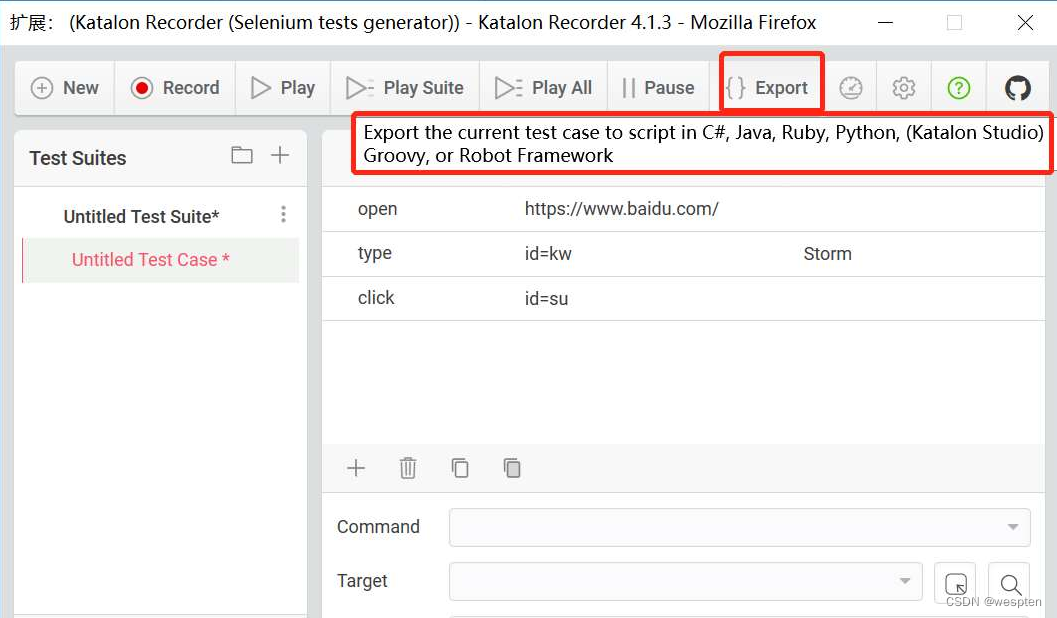
- 单击“Export”按钮,可以选择导出脚本的语言。
- 这里我们选择“Python 2(WebDriver+unittest)”。
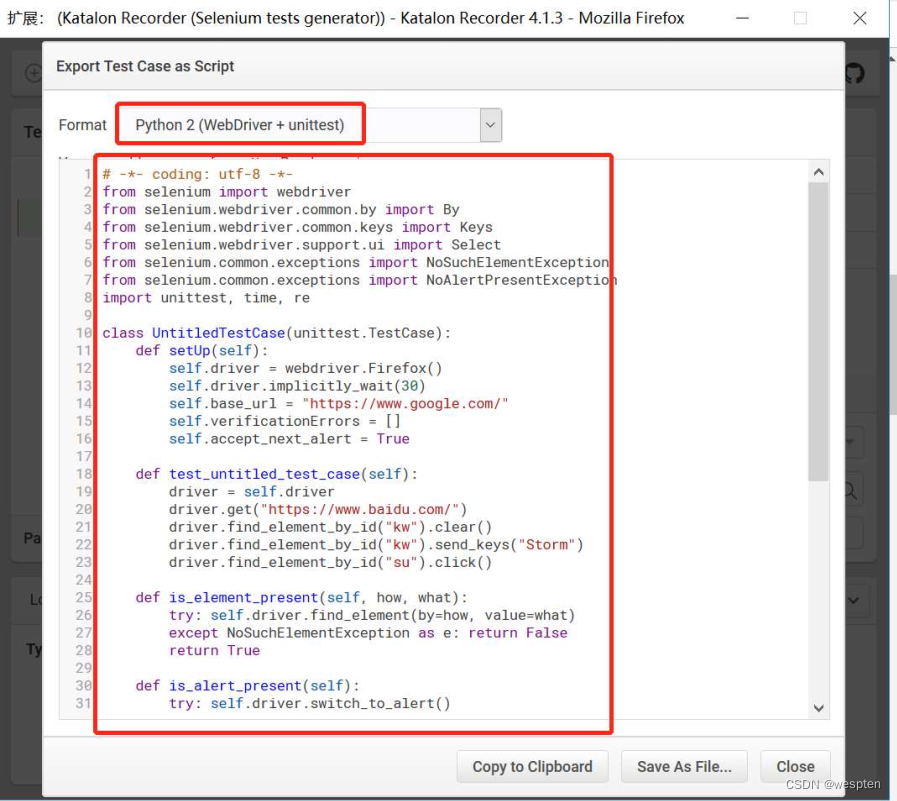
最后再强调一下,IDE所能提供的脚本功能实在有限,我们学习它的目的,是了解其脚本编写风格,再无其他。
注意:Katalon Recorder插件不支持导出Python 3版本格式脚本。Python 2和Python 3在语法上有部分差异,不过我们还是可以参考脚本的unittest框架风格。
6. WebDriver脚本示例
WebDriver是Selenium的核心组成部分,先带大家浏览一下测试脚本的样式。
from selenium import webdriver
import unittest
class VisitPTPress(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
def test_open_ptpress(self):
self.driver.get('https://www.ptpress.com.cn/') # 打开人民邮电出版社官网
self.assertIn('图书', self.driver.page_source) # 断言:网页中有“图书”字样
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()上述脚本采用Python unittest框架编写,整个操作流程如下:
- 导入WebDriver的包。
- 打开Chrome浏览器。
- 访问人民邮电出版社官网。
- 判断打开的网页中是否有“图书”字样。
- 退出浏览器。
2、Selenium安装
1. 通过Python的pip工具安装
pip是Python的包管理工具,该工具提供了对Python包的查找、下载、安装、卸载等功能。最新版本Python的安装包自带该工具,pip工具的默认安装目录为Python安装目录下的Scripts文件夹,如图所示。
同样,我们在DOS窗口中输入“pip3--version”并按“Enter”键,假如显示了pip版本信息,证明pip工具可以使用,如图所示。

接下来,我们使用“pip install selenium”命令来安装Selenium,如图所示。
安装完成后,我们可以使用“pip show selenium”命令来查看Selenium的版本,如图所示。
另外,还有如下命令供大家参考:
- pip install -U selenium:将Selenium升级到最新版本。
- pip uninstall selenium:卸载Selenium。
下载安装包安装
- 访问Selenium官网,下载Selenium安装包(setup.py文件)。
- 切换到安装包目录,使用“python setup.py install”命令即可完成安装。
2. 下载Browser Driver
安装完Selenium后,我们还需要下载Browser Driver才能操控浏览器。
- 下载Browser Driver
对于Selenium 3及以后的版本,各个浏览器的Browser Driver由各浏览器厂商自己维护,因此大家可以去浏览器官网下载对应的Browser Driver。
注意:很多浏览器都会开启自动升级功能,部分情况下,浏览器升级后,需要下载新的Browser Driver。
- 放置目录
将下载的Browser Driver放置到Python安装目录下(如D:\python),解压即可。当然也可以将其放置到任意目录下,然后将该目录添加到环境变量PATH中。添加环境变量的方法参考如下。
在Windows操作系统中以管理员身份打开命令提示符,然后执行以下命令将目录永久添加到环境变量中。
setx /m path "%path%;C:\WebDriver\bin\"在macOS/Linux操作系统中打开终端,使用如下命令添加环境变量。
export PATH=$PATH:/opt/WebDriver/bin >> ~/.profile3、Python安装
1. 安装Python
- 访问Python官网,如图所示。
将鼠标指针悬浮在“Downloads”上,单击右侧“Python 3.8.2”即可开始下载,如图所示。
- 双击下载的安装包进行安装,注意勾选“Add Python 3.8 to PATH”复选框,将Python添加到系统环境变量,单击“Customize installation”按钮,开始自定义安装。
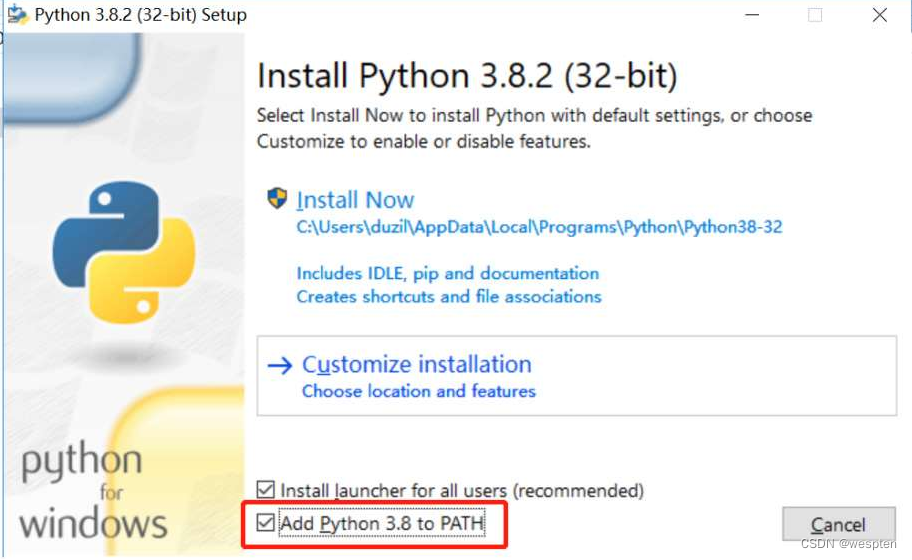
- 在安装过程中单击“Next”按钮,在“Advanced Options”界面中勾选“Install for all users”复选框,自定义Python的安装目录(注意,目录中不要出现中文)。最后单击“Install”按钮,如图所示。
- 如果显示“Setup was successful”,则证明安装成功。
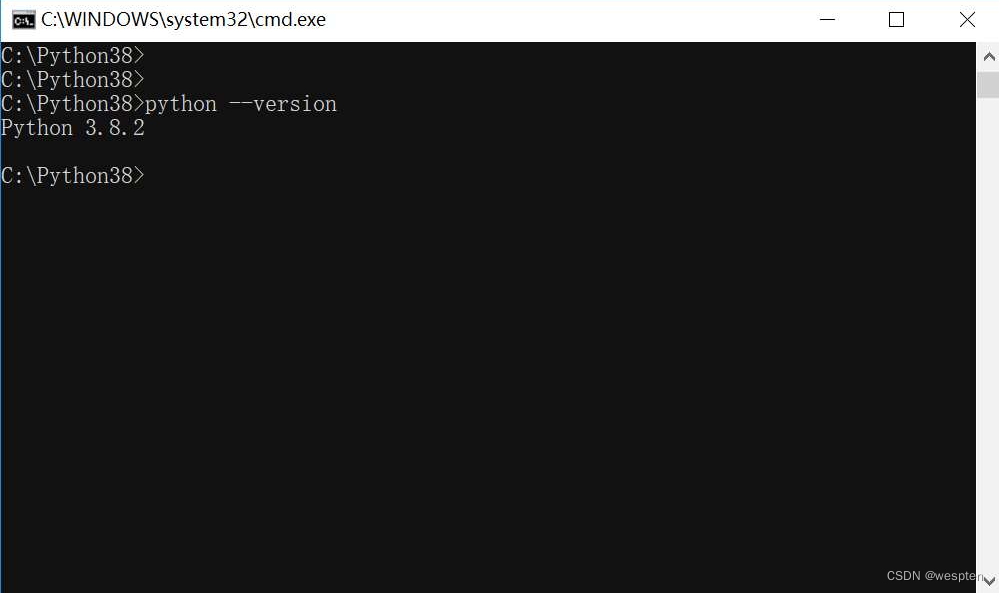
- 按“Win+R”组合键打开“运行”窗口,输入“cmd”并按“Enter”键,打开DOS窗口,输入命令“python --version”并按“Enter”键,查看Python版本,如图所示。
安装过程中有以下注意事项:
- 下载安装包时,注意选择相应的操作系统的种类和位数(目前Python官网会自动判断用户的操作系统的种类和位数)。
- 注意安装路径中不要出现中文。
2. Python目录结构解析
访问Python的安装目录,可以看到类似图所示的结构。

下面对Python的目录进行简单介绍:
- Doc:存放Python帮助文档的文件夹。
- Lib:将来安装的第三方库都会存放在该文件夹下。
- libs:包含一些内置库(可以直接引用的模块,如time、os等)。
- Scripts:包含可执行的文件,如pip。
3. Python IDLE
IDLE是Python内置的开发与学习环境。我们可以在Windows菜单中找到它,如图所示。
- IDLE的特性
- 完全用Python编写,使用名为tkinter的图形用户界面工具。
- 跨平台,在Windows、UNIX和macOS平台上均能运行。
- 提供输入/输出高亮和错误信息的Python命令行窗口(交互解释器)。
- 提供多次撤销操作、Python语法高亮、智能缩进、函数调用提示、自动补全等功能的多窗口文本编辑器。
- 能够在多个窗口中检索、在编辑器中替换文本,以及在多个文件中检索(通过grep工具)。
- 提供持久保存的断点调试、单步调试、查看本地和全局命名空间功能的调试器。
- 提供配置、浏览以及其他对话框。
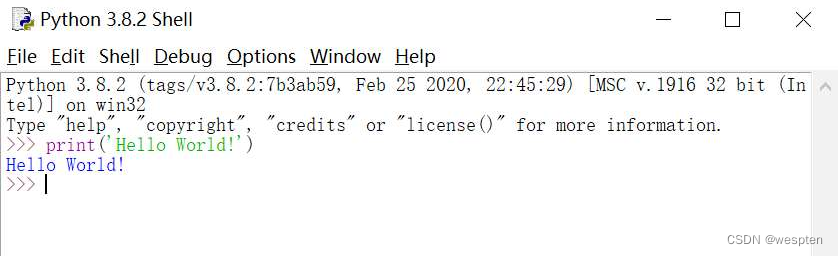
- IDLE试用
在Python的IDLE中,使用print语句输出字符串“Hello World!”,如图所示。
4、PyCharm安装
PyCharm是由JetBrains公司打造的一款Python IDE,带有一整套可以帮助用户在使用Python语言开发程序时提高效率的工具,例如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。PyCharm有两个版本,分别是Professional版和Community版。前者为专业版,支持更多的功能;后者为社区版,是免费的。
1. 安装PyCharm
进入PyCharm官方下载页面,选择对应的操作系统,单击“下载”按钮,如图所示。
下载完成后,双击“.exe”文件,然后多次单击“Next”按钮,完成安装。
2. 设置PyCharm
- 创建新项目
安装完成后,首次打开PyCharm时会提醒你选择界面风格,然后创建新项目。如图2-15所示,你可以单击“+Create New Project”按钮来创建一个新项目。
在“Location”处设置项目的保存地址,并单击“Project Interpreter: New Virtualenv environment”,展开后,勾选“Inherit global site-packages”和“Make available to all projects”复选框,如图所示。

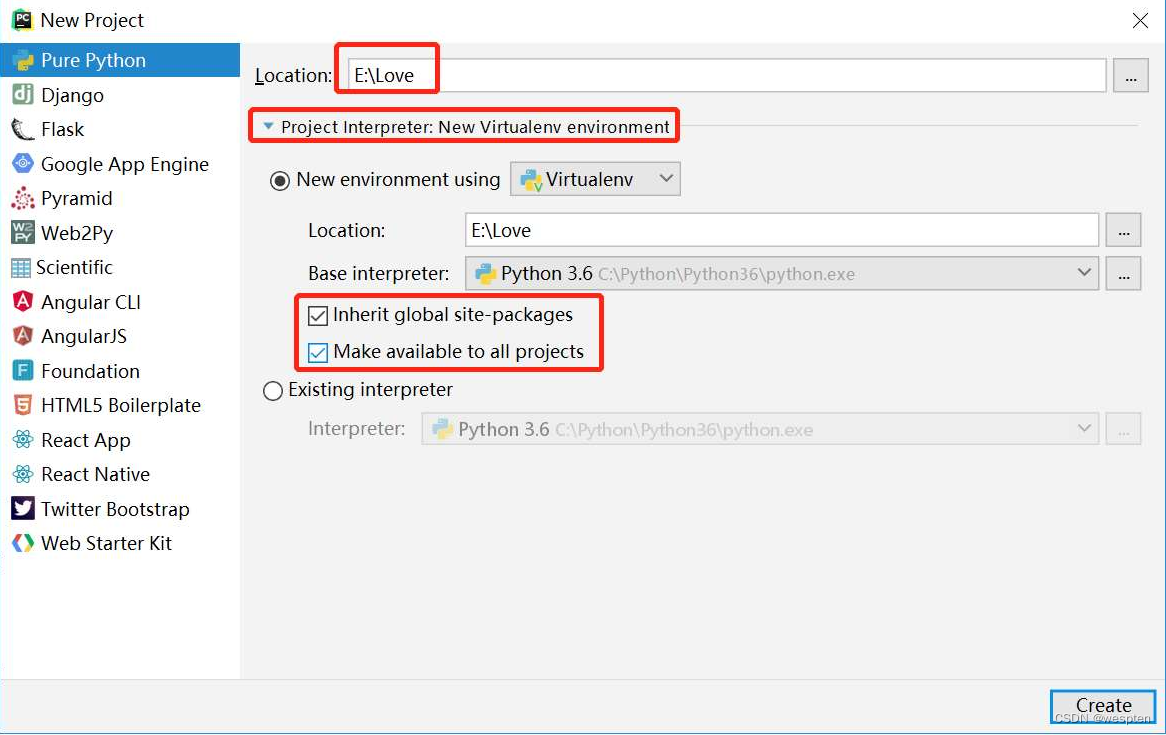
注意:这里建议选择非C盘目录,因为C盘的写保护可能会带来一些不必要的麻烦。
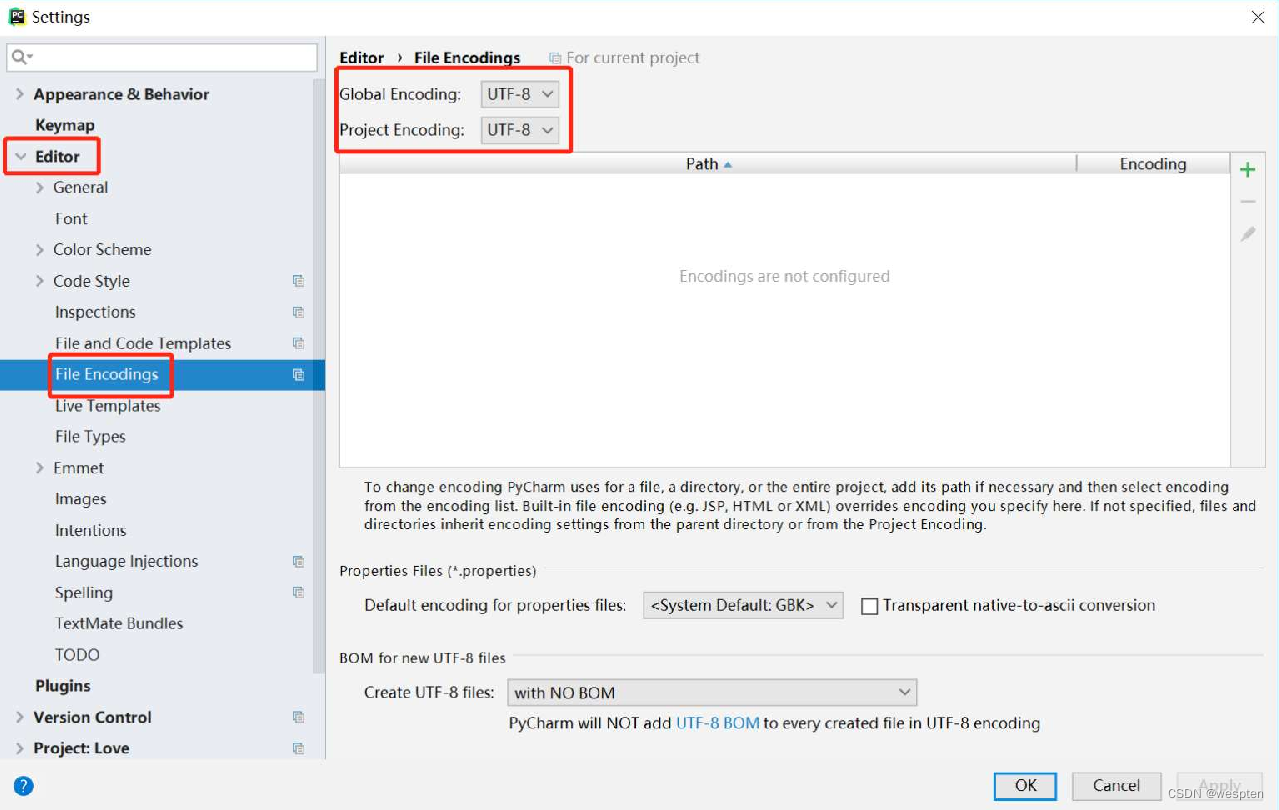
- 设置PyCharm的默认编码格式
选择PyCharm的菜单栏中的“File→Settings→Editor→File Encodings”命令,将“Global Encoding”和“Project Encoding”设置为“UTF-8”,如图所示。
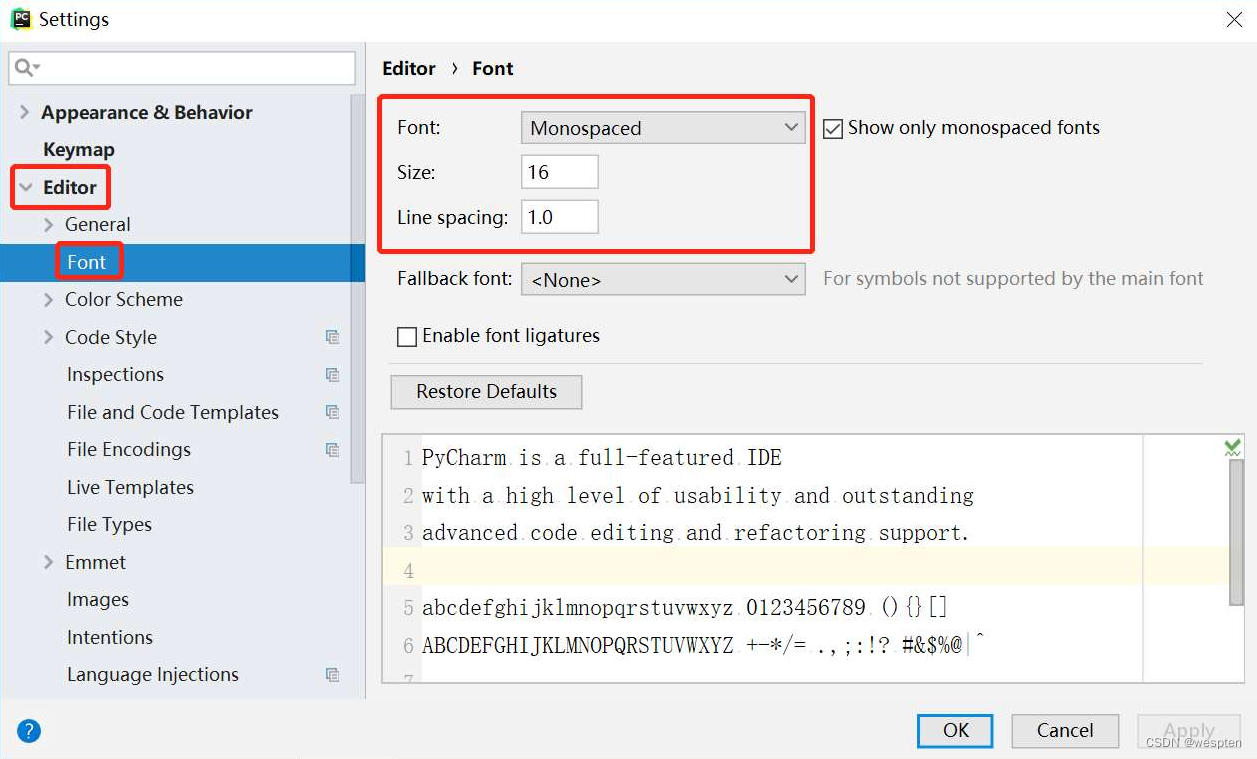
- 设置字体、文字大小和行间距
打开“Font”窗口,根据自己的需要设置“Font”“Size”“Line spacing”,如图所示。
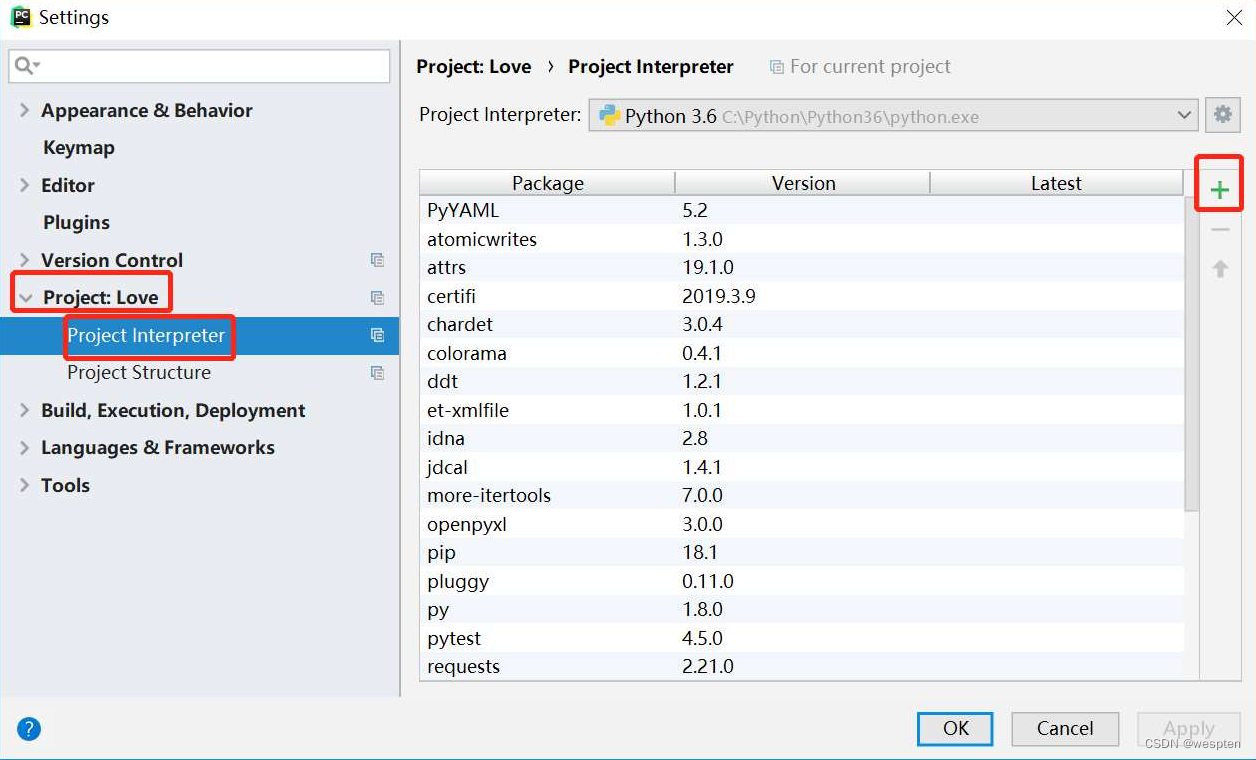
- 安装第三方包
我们可以通过PyCharm来安装第三方包,首先进入“Project Interpreter”窗口,然后单击右侧的“+”按钮,如图所示。
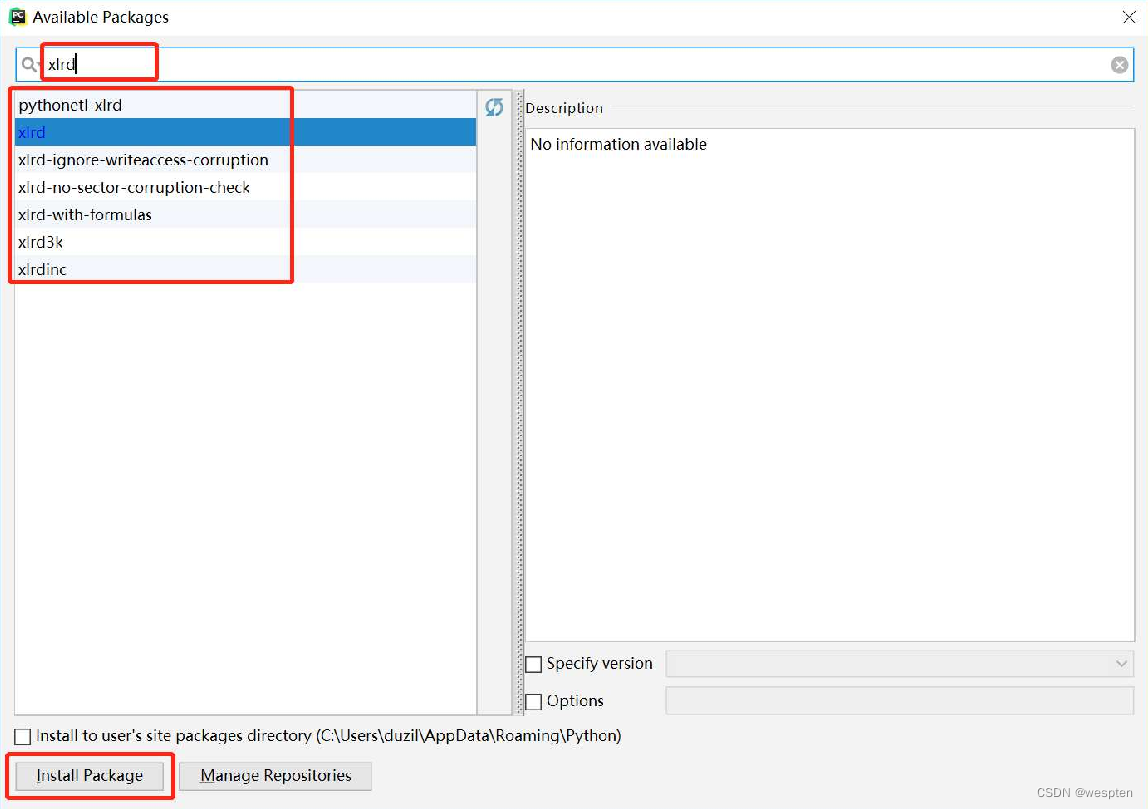
打开“Available Packages”窗口,在搜索框中输入关键字,如“xlrd”,此时下方会显示所有包含该关键字的包名,单击选中要安装的包,然后单击左下角的“Install Package”按钮,即可开始安装,如图所示。
- 创建Package
接下来,我们通过PyCharm创建一个“Package”。右击项目“Love”,从弹出的快捷菜单中选择“New→Python Package”命令,然后在弹出窗口的文本框中输入“package name”,再按“Enter”键,即可完成创建,如图所示。
注意:“Package”的中文意思是“包”,你可以简单理解为我们需要将一组具有相似功能的Python文件放置到一个“Package”中。
- 创建Python文件
在项目或“Package name”上右击,在弹出的快捷菜单中选择“New→Python File”命令,然后在弹出的窗口的文本框中输入文件名“test0”,再按“Enter”键,即可创建一个Python文件,如图所示。
- 执行Python文件
在新建的Python文件中编写脚本,这里使用print语句输出“Hello World!”。在代码输入区的空白处右击,在弹出的快捷菜单中选择“Run‘test0’”命令,即可执行该Python文件,如图所示。
注意:也可以按组合键“Ctrl+Shift+F10”执行当前Python文件。
- 查看执行结果
在PyCharm窗口的下方会出现执行结果,如图所示。
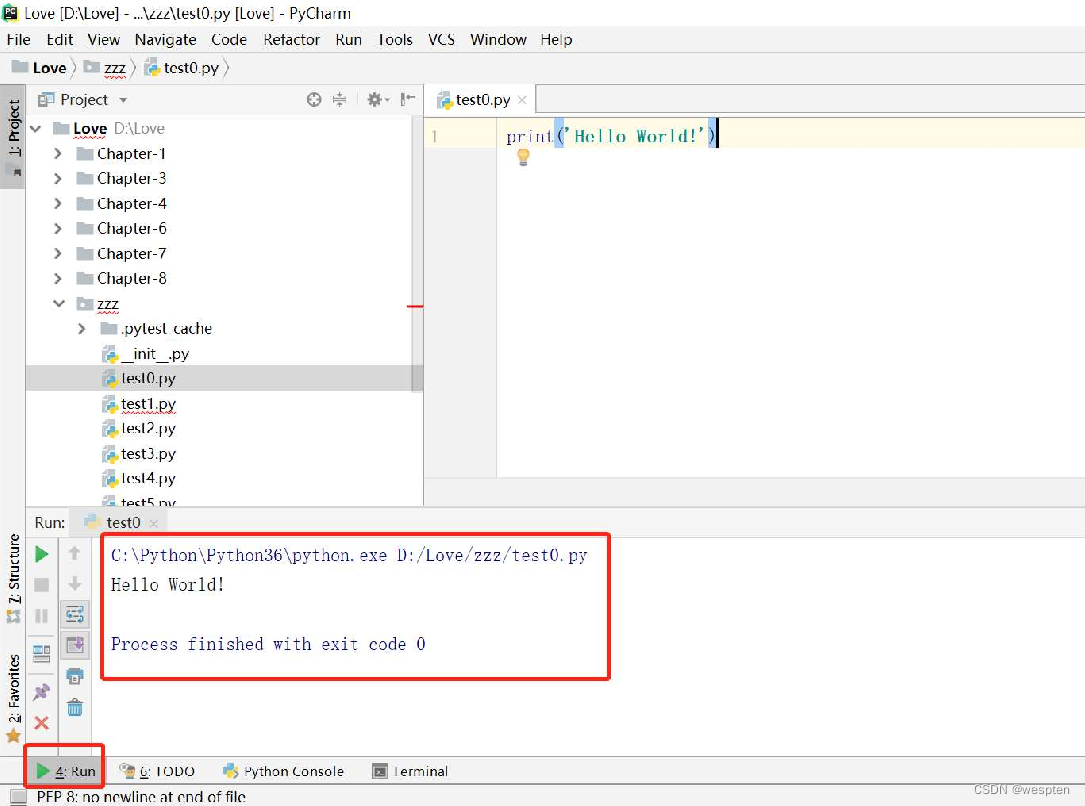
到目前为止,我们的Windows操作系统已经安装了所有的Web UI自动化测试所需要的软件。
5、Linux环境快速搭建
1. 安装Python
通常macOS默认安装了Python 2。我们需要重新访问官网,下载Python 3,如图所示。
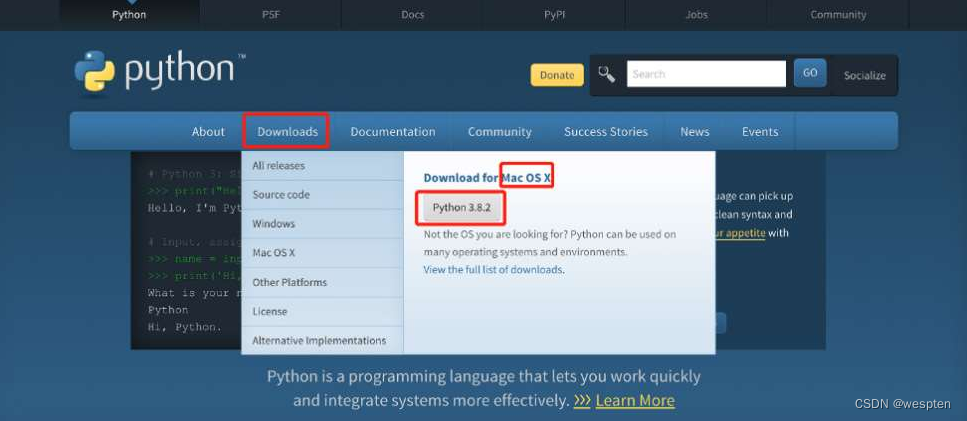
下载文件的名称格式为“python-×××.pkg”,双击该文件,按照提示逐步安装即可。
接下来,我们使用下面的命令将Python 3设置为默认Python。
export PATH=/Library/Frameworks/Python.framework/Versions/3.8/bin:${PATH}
source ~/.bash_profile注意:上述命令的作用是将新安装的Python 3环境加入环境变量,用户需要根据自己的实际安装目录进行调整。
2. 安装Selenium
同样,使用“pip install selenium”命令来安装即可,这里不再赘述。
下载浏览器Driver,放置到Python根目录即可。
3. 安装PyCharm
同样,去PyCharm官网下载对应的macOS版本安装即可,这里不再赘述。
4. 开发者工具简介
因为在编写Web UI自动化测试脚本的过程中,我们需要查看、使用页面元素,所以我们以Chrome和Firefox为例,介绍一下浏览器开发者工具的元素识别功能。
1)Chrome DevTools
(1)如何打开浏览器开发者工具
我们可以通过以下几种方式打开浏览器开发者工具。
- 按快捷键“F12”(笔记本电脑的话需要按组合键“Fn+F12”)。
- 按组合键“Ctrl+Shift+I”。
- 在浏览器页面中右击,在弹出的快捷菜单中选择“检查”命令。
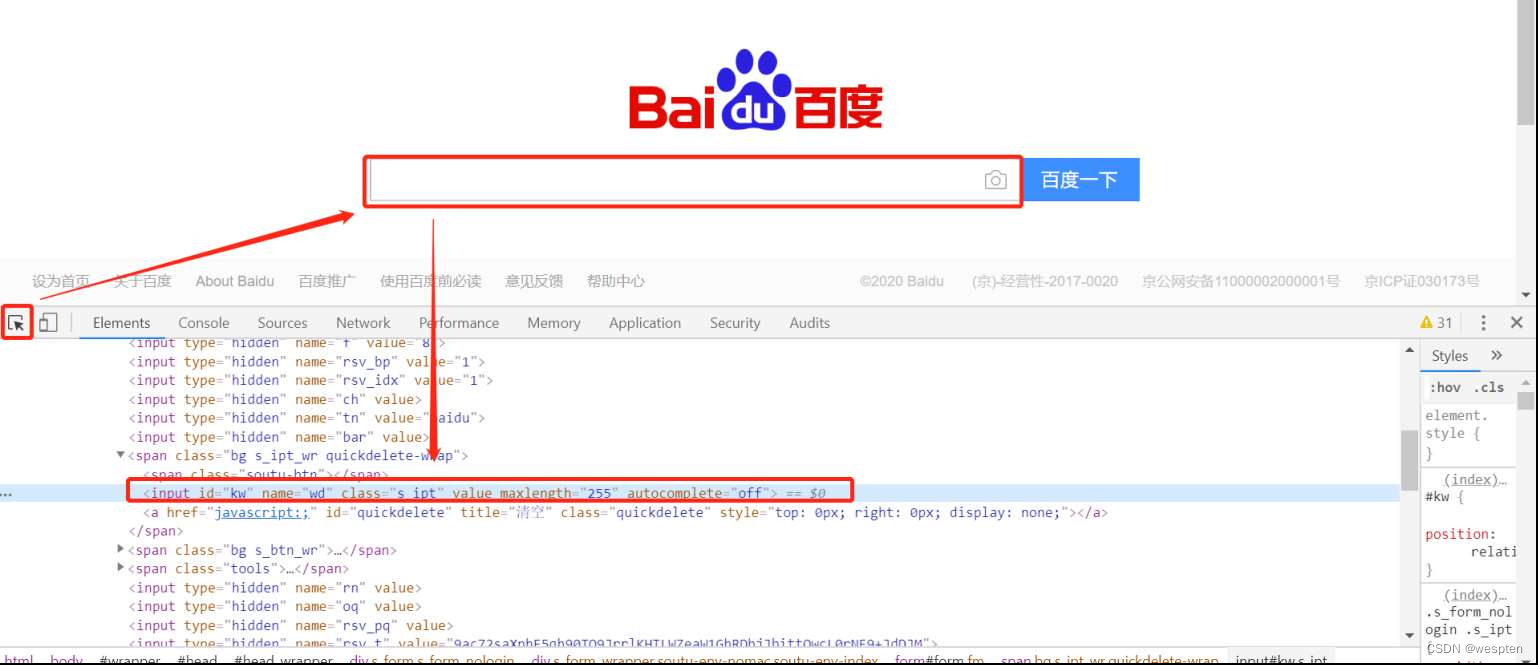
(2)使用页面元素查看器
单击图所示的开发者工具左侧框中的按钮,当其变为蓝色时,再单击页面中的元素。例如百度的搜索框,下方“Elements”标签中将以蓝底显示该元素对应的HTML代码。此时,我们能定位到该元素,图片长框中显示元素的相关属性,例如:标签名称为“input”。
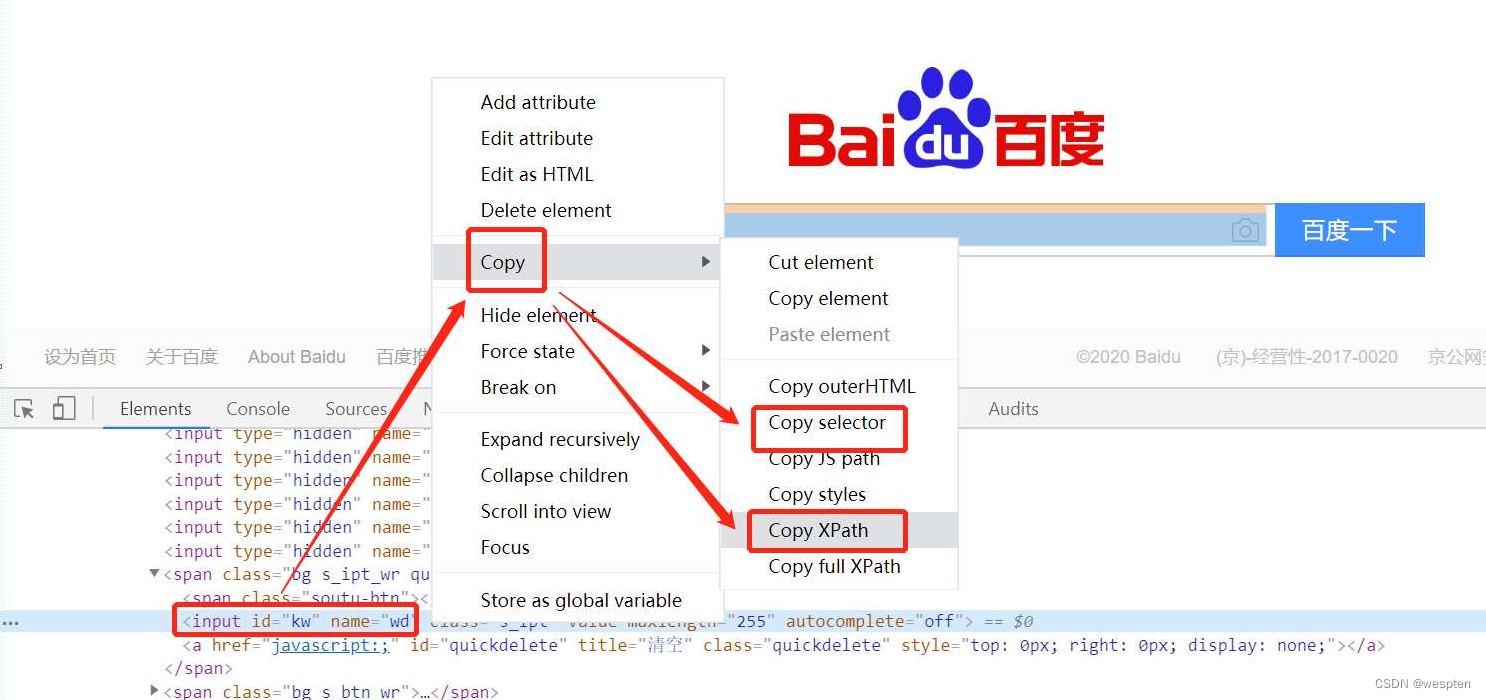
(3)复制元素XPath和CSS selector
在元素代码上右击,在弹出的快捷菜单中选择“Copy”命令,选择“Copy XPath”或“Copy selector”命令即可复制XPath或CSS selector,如图所示。
Chrome DevTools还有很多重要的功能,是帮助开发调试、测试确认结果的重要工具。大家可以根据实际需要,自行深入学习。
2)Firefox DevTools
Firefox DevTools和Chrome DevTools的使用方法大同小异,这里不再过多讲解。需要提醒的是,2017年Firebug插件的功能全部集成到了DevTools,Firebug已经退出了历史舞台。在网络上搜索Selenium相关知识的时候,你可能会看到较多关于Firebug和Firepath插件的介绍,但是你已经无法再搜索和安装这些插件了,当然你也没有必要安装它们。
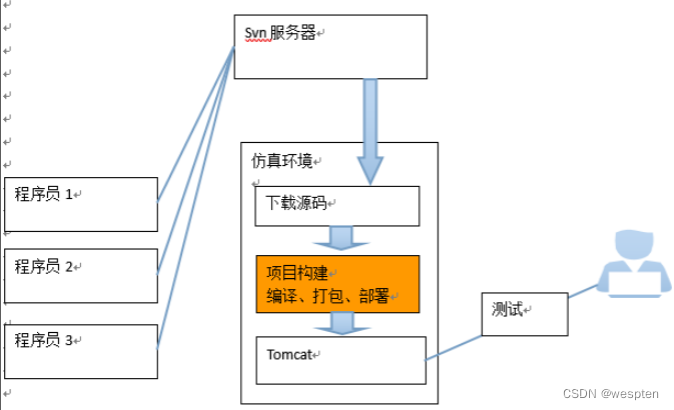
二、持续集成简介
1、持续集成的作用
随着互联网的蓬勃发展,软件生命周期模型也经历了几个比较大的阶段,从最初的瀑布模型,到 V 模型,再到现在的敏捷或者 devops,不论哪个阶段,项目从立项到交付几乎都离不开以下几个过程,开发、构建、测试和发布,而且一直都在致力于又好又快地完成软件的交付。
然而大多数互联网公司面临的常态却是,临近上线日全员待命,如临大敌,通宵达旦,生怕出现上线事故导致版本回滚,即使暂时上线成功后也可能会出现明明测试环境全部通过了,却依然有各种线上质量问题频发。这些现象的主要原因就是代码合并的太晚,而且每次改动未经过充分的测试,代码合并时出现冲突,为了解决冲突重新修改代码,新修改的代码又有可能会引发新的问题,进入了恶性循环。
那么如何才能快速地合并代码,快速地构建,快速地测试,快速地发布高质量的代码呢?持续集成就应运而生了,它的宗旨就是多次合并代码,合并完成后在各种环境下进行多次充分的测试,保证版本的可用性和代码更改的正确性。
2、持续集成的定义
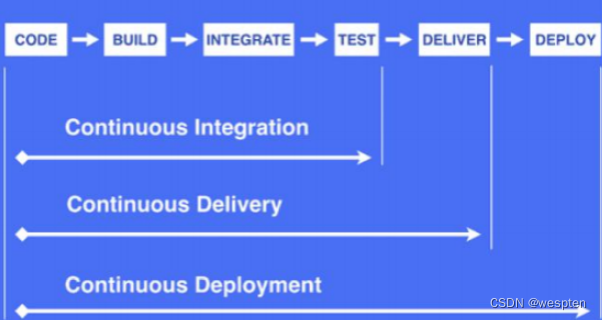
我们经常听到的持续工程方法有 3 个,分别为持续集成(Continuous Integration,CI)、持续交付(Continuous Delivery,CD)和持续部署(Continuous Deploy,CD)。
- 持续集成:指的是在一定时间内,开发人员多次将代码合并到同一主干上。代码入库后将代码编译打包成可以发布的形式,先发布到测试环境进行详细全面的测试(如果是代码修复的情况下可以根据实际情况只进行精准的测试),测试环境通过后再发布到预生产环境,最终部署到线上环境。目的就是频繁的集成以便发现其中的错误。
- 持续交付:强调的是短时间内完成可以随时发布的软件产品,对每一个进入主干分支的代码提交后,构建打包,测试环境验证通过,预发布环境进行验证,保证产品是可发布的状态。目的是快速地得到市场的反馈,以便更好地进行开发和设计。
- 持续部署:将每一次代码提交后,都构建出产品直接上线,交付给用户使用。
以上 3 个流程的本质都是为了保证每一次代码合并后都能经过一系列的验证,保证这些变更的质量。
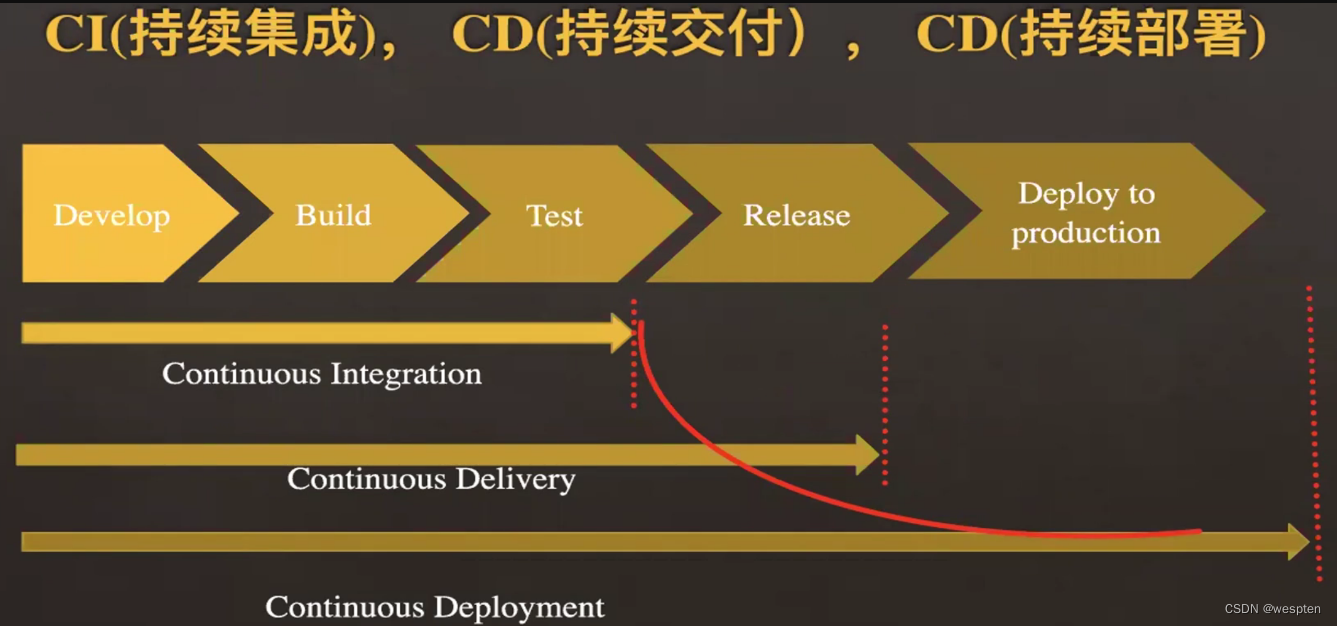
以下是 3 个持续过程的流水线示意图:

3、持续集成的原则
1. 测试要尽量得充分
因为持续集成最终的目的是保证版本的可用性,而且由于多人协作,合并后的代码有可能对整个的软件都会有影响,所以一般情况下需要把所有的测试流程都走一遍,比如静态代码扫描、单元测试、功能测试、接口测试、性能测试等等;如果只是修复了一些 bug,代码改动不大的情况下,可以只做一些针对性测试。
2. 测试的速度要尽可能得快
持续集成中每天都会有代码合并,甚至一天有好几次合并,如果测试的效率不够高的话很可能会出现一个打包的版本还未测试完成,新的版本就已经出现了,甚至积压几个版本,这样的话就不能及时的发现是哪个版本出现的问题,而且开发一直是在有问题的版本上进行的修改,所以这就要求测试的速度要快,自动化测试肯定是不可或缺的,甚至还要并行或者分布式执行测试。
3. 尽量使用和生产环境类似的环境进行测试
如果持续集成采用的测试环境和线上环境差异太大的话,测试的结果很可能是不准确的,有些线上的问题也是很难发现的,特别是关于性能测试的结果,资源和锁等问题。所以采用和线上环境完全一样的环境时最理想的,如果条件不允许的话要尽可能采用同比例缩小的环境进行测试,以保证测试结果的准确性。
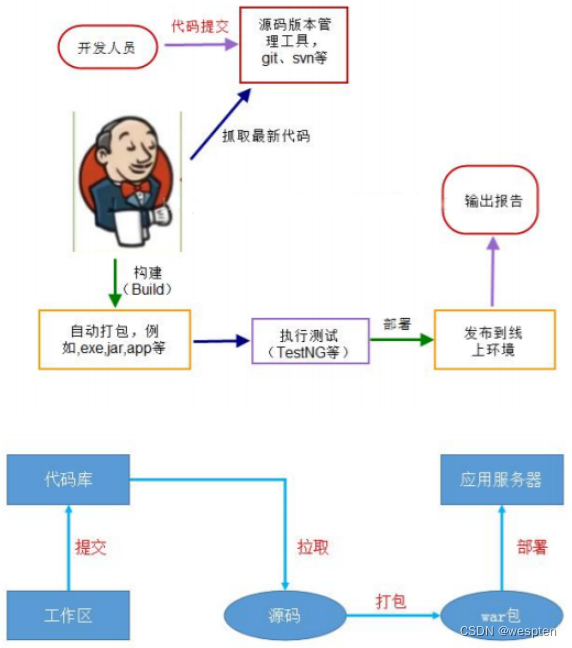
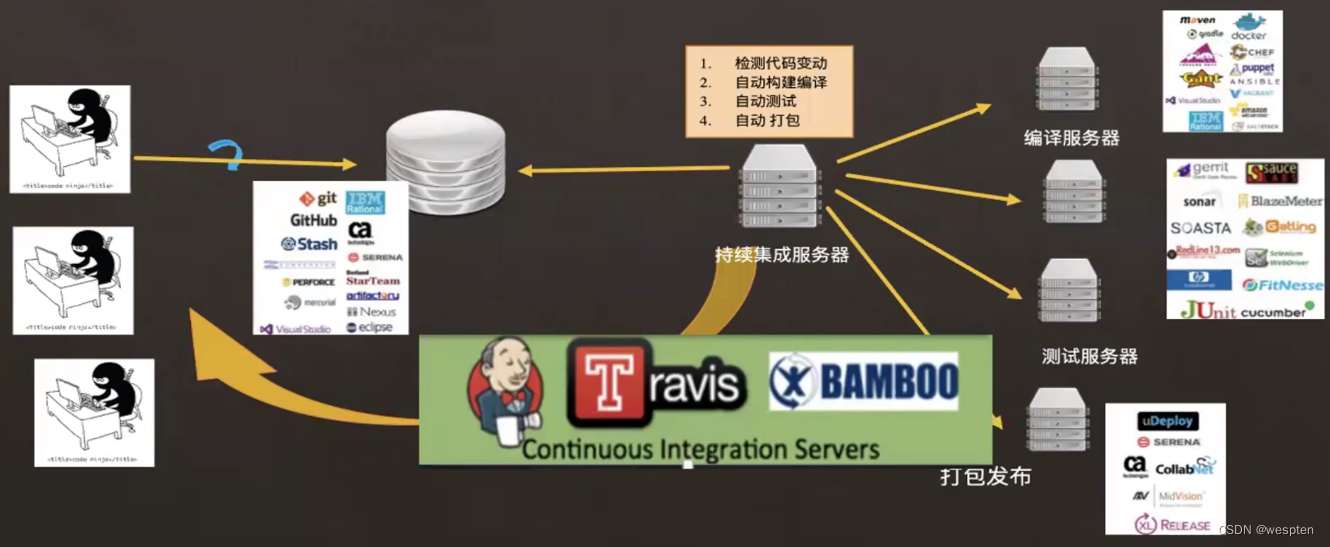
4、整体流程
三、持续集成环境搭建
环境说明:Win10 + Jenkins 2.277.2 + JDK 1.8 + Maven + Git + Tomcat
1、Git 安装
1. 登录官网下载安装包
官网:Git - Downloading Package
下载完成后双击安装,如下图所示:
双击 exe 文件,一路 next 即可。
2. 配置环境变量
将 Git 的 bin 目录 添加到环境变量。
3. 注册 github 账号
登录 GitHub: Where the world builds software · GitHub 注册账号。
2、JDK 1.8 安装
1. 登录官网,下载 jdk 1.8
Java Downloads | Oracle
先选择 Accept,然后根据自己电脑 选择对应 windows 下的文件:
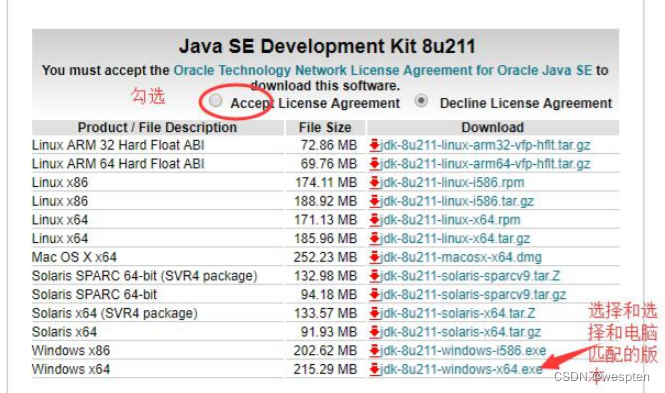
下载完成后的文件为 jdk-8u211-windows-x64.exe。
2. 安装
单击 jdk-8u211-windows-x64.exe。
3. 配置 java 环境变量
配置JAVA_HOME:

配置 path:
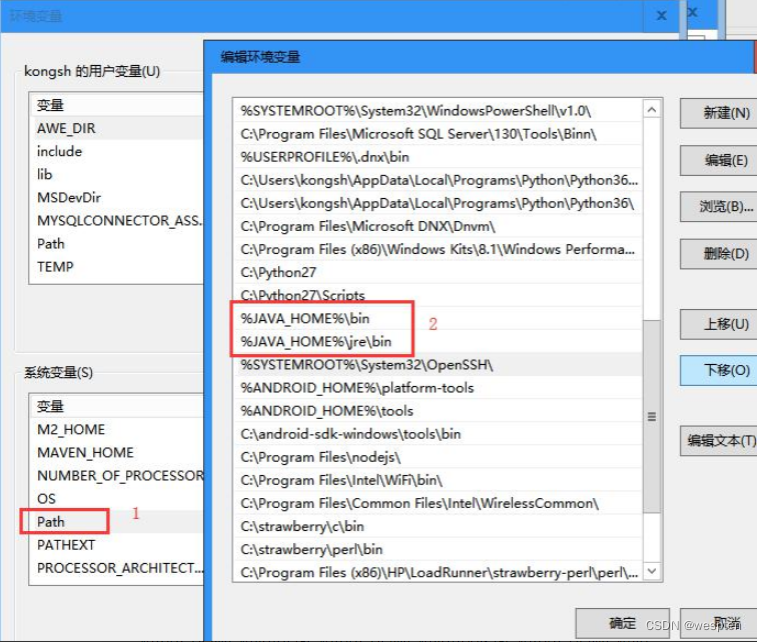
新增环境变量 CLASSPATH:
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;%JAVA_HOME%\lib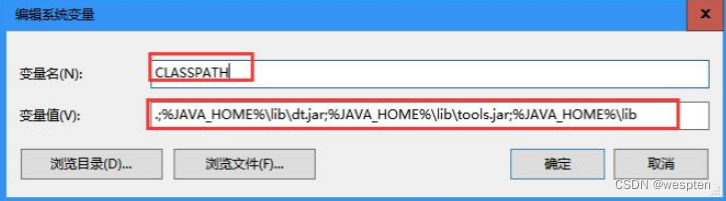
配置完成后点击所有的确定按钮。
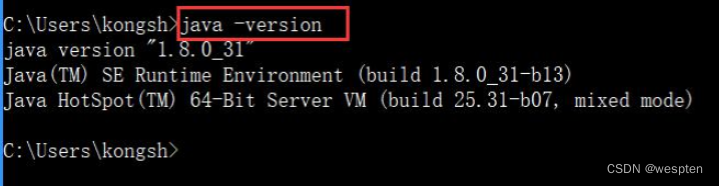
4. 确认安装成功
启动 cmd,输入 java -version,如下结果表示安装并配置成功:
3、Tomcat 安装
这里选择 tomcat8 为示例。
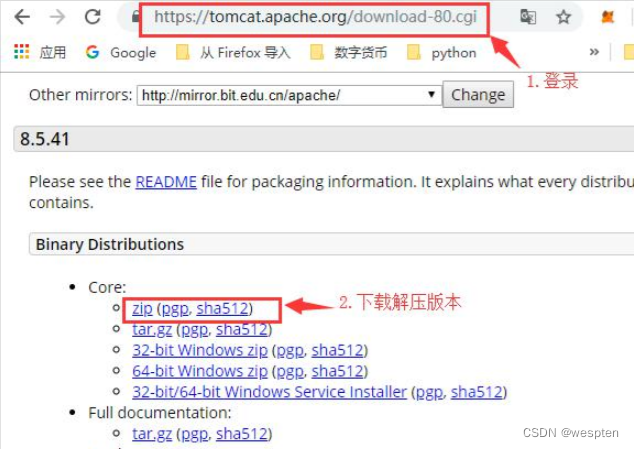
1. 登录官网下载解压版本
Apache Tomcat® - Apache Tomcat 8 Software Downloads
2. 解压缩
将下载后的文件解压到指定的目录,比如:D:\program2.5.3.
3. 修改编码方式
Jenkins 建议在 tomcat 中使用 utf-8 编码 , 配置 tomcat 下 conf 目录的 server.xml 文件:

4. 在 windows 下用浏览器访问
浏览器输入:127.0.0.1:8080

5. 修改 tomcat 配置文件
接下来我们在 Jenkins 的 maven 任务中采用 Deploy war/ear to a Container 的方式,而要将 war 包到 tomcat 下,需要配置 tomcat 的配置文件 tomcat/conf/tomcat-users.xml,将名为 tomcat 的用户配上以下四个角色:admin-gui、manager-gui、manager-script 和 manager-jmx,这样才可以使用 tomcat 这个用户完成远程部署的功能。
打开 tomcat 安装目录下的 tomcat-users.xml 文件,在文件底部加入如下内容:
<role rolename="tomcat"/>
<role rolename="role1"/>
<role rolename="manager-gui" />
<role rolename="manager-script" />
<role rolename="manager-status" />
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="role1" password="tomcat" roles="role1"/>
<user username="deploy" password="tomcat" roles="manager-gui,manager-script,manager-status" />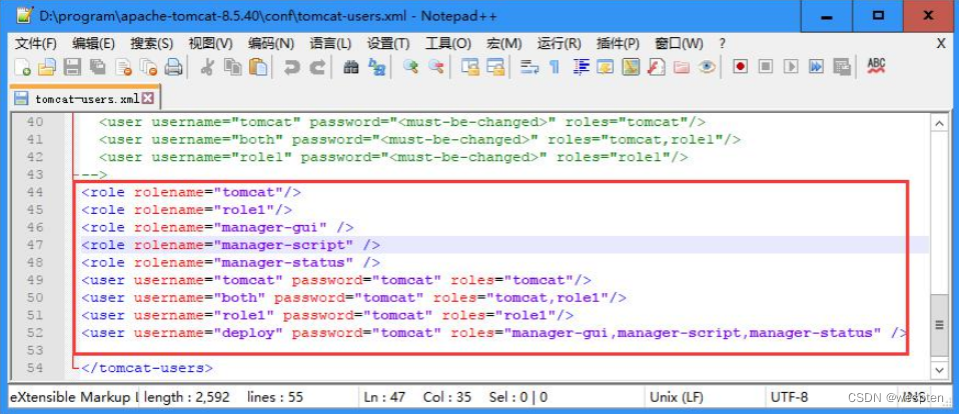
4、Maven安装配置
1. Maven 简介
定义:
- Maven 基于 POM(工程对象模型),通过一小段描述来对项目的代码、报告、文件进行管理的工具。
- Maven 是一个跨平台的项目管理工具,它使用 java 开发,依赖于 jdk1.6 及以上。
- Maven 主要有两大功能:管理依赖(依赖指的就是 jar 包) 、项目构建。
什么是构建?
构建过程:

项目构建的方式:
- Eclipse:使用eclipse进行项目构建,相对来说,步骤比较零散,不好操作。
- Ant:它是一个专门的项目构建工具,它可以通过一些配置来完成项目构建,这些配置要明确的告诉 ant,源码包在哪?目标 class 文件应该存放在哪?资源文件应该在哪等。
- Maven:它是一个项目管理工具,也是一个项目构建工具。通过使用 maven,可以对项目进行快速简单的构建,它不需要告诉 maven 很多信息,但是需要按照 maven 的规范来进行代码的开发。也就是说 maven 是有约束的。
2. Maven 安装
1)登录官网下载解压版本
进入官网:http://maven.apache.org/download.cgi,下拉页面找到 files,如下所示:
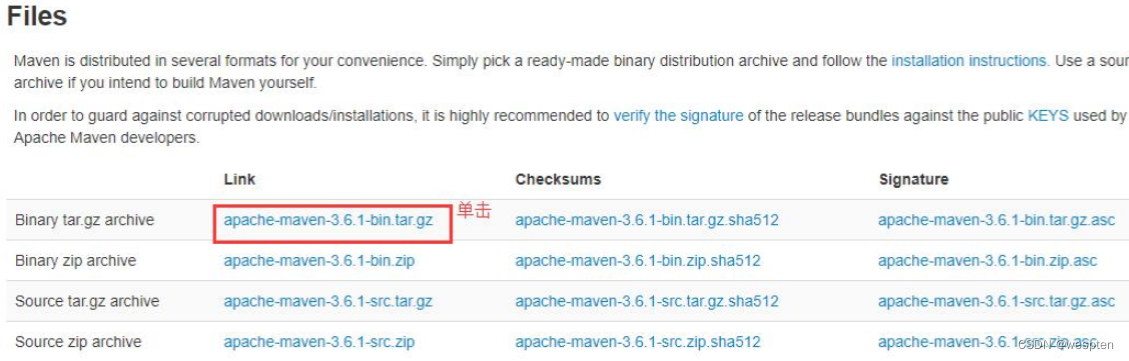
2)解压缩
3)配置环境变量 MAVEN_HOME
maven 的安装过程中会自动添加 %M2_HOME%(Jenkins 中使用的也是 M2_HOME,所以务必添加到环境变量),并且将 %M2_HOME%\bin 加入到 path 中。但是有一些项目仍引用 MAVEN_HOME,为了保险起见,也将其配置到环境变量中。
4)验证安装成功
启动命令行,输入:
mvn --version 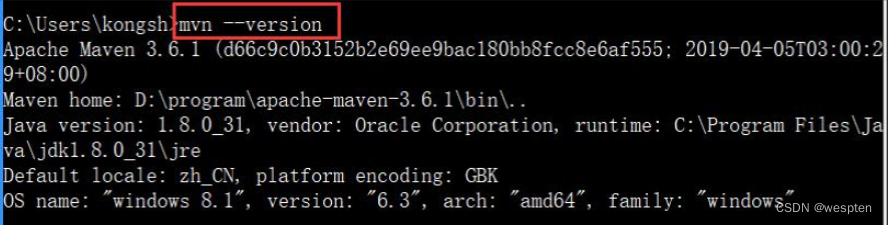
5、Jenkins 安装和基础配置
1. 下载 Jenkins 的 war 包
官网链接:Jenkins download and deployment
向下滑动页面,可以看到有 LTS 和 Weekly 两种版本,版本建议下载 LTS 版本,Weekly 版本每周都会更新,更新频率太快。
2. 将 war 包放到 tomcat 的 webapps 下
3. 启动 tomcat
上一步已经把 war 包放到了 tomcat 的 webapps 目录下,进入 tomcat 的 bin 目录,单击 startup.bat,启动 tomcat 后就可以直接在浏览器中访问了:http://127.0.0.1:8080/Jenkins
4. 解锁 Jenkins
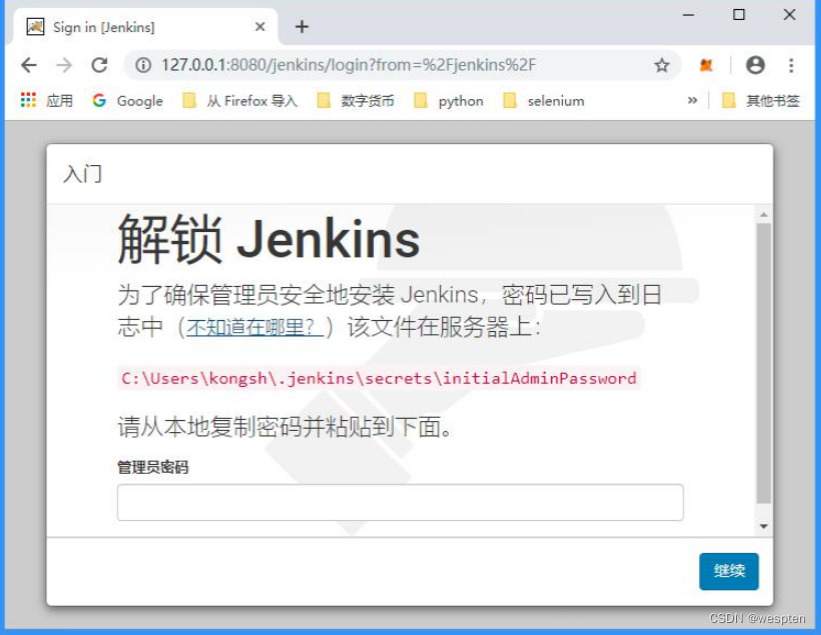
根据提示打开以下文件,将管理员密码粘贴到网页中:
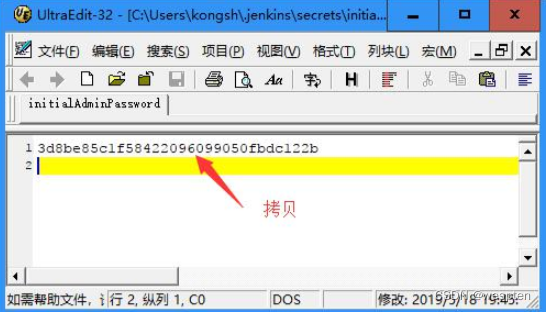
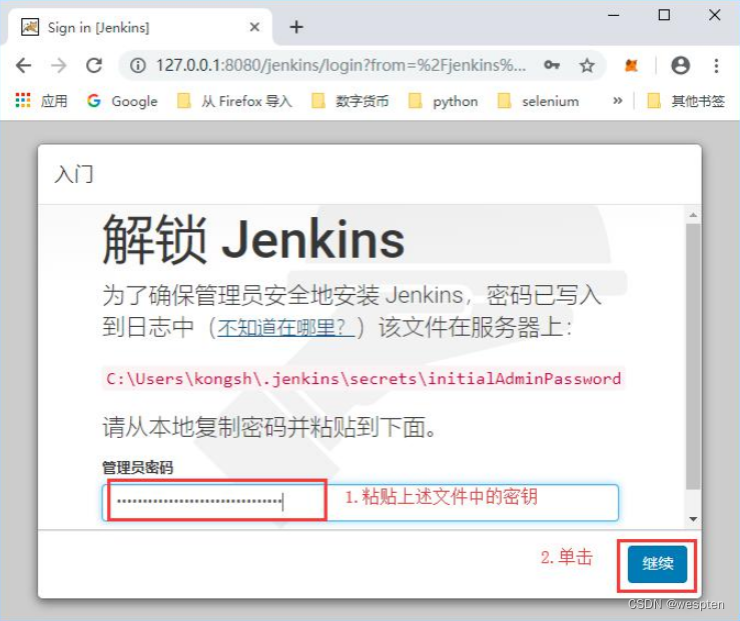
或使用命令行:type + 文件名:

5. 解决离线问题(没有提示离线,直接跳过此步)
弹出的页面显示离线,如下所示:
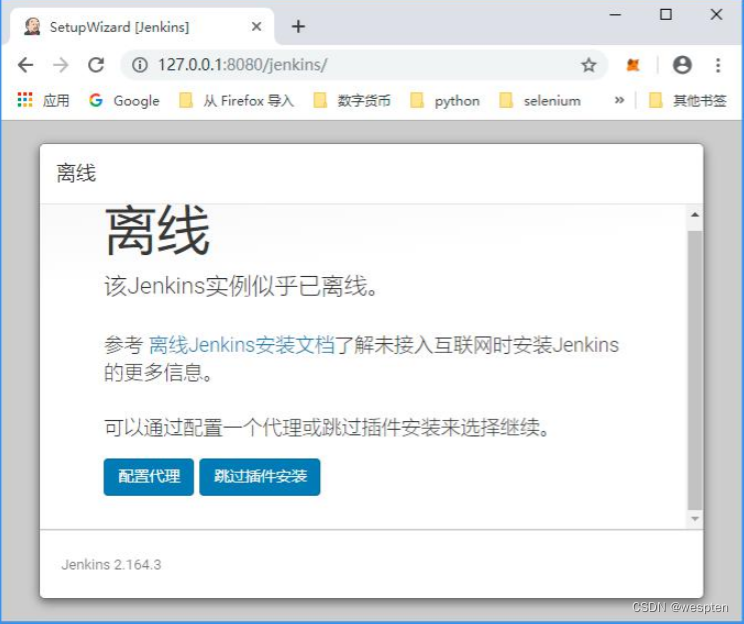
有以下两种解决方案:
A)选择跳过插件安装,进入 Jenkins 后根据需要自行安装,但是安装插件前也是需要进入到插件管理修改配置。
B)修改配置文件:
将 C:\Users\kongsh\.Jenkins\hudson.model.UpdateCenter.xml 文件中的 url 更改为如下值:https://mirrors.tuna.tsinghua.edu.cn/Jenkins/updates/update-center.json
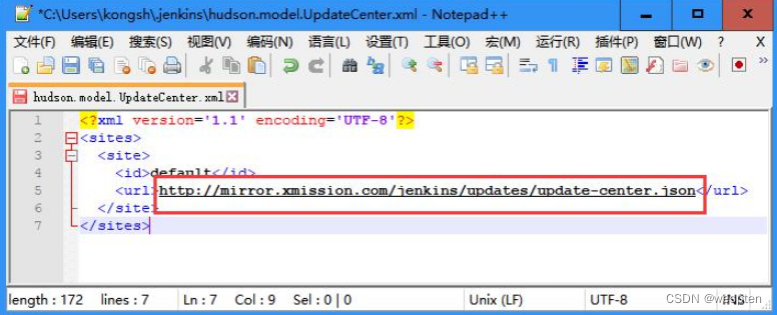
或者更改为 http://updates.Jenkins.io/update-center.json ,即去掉 s(采用),如下:
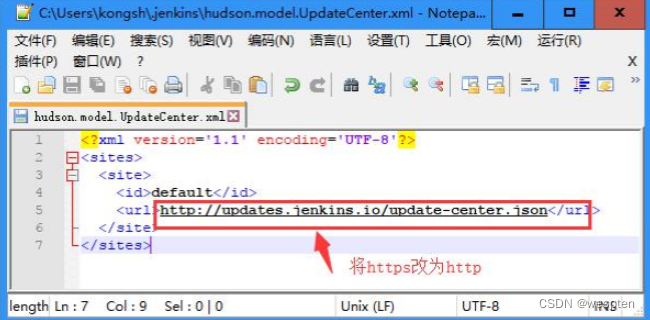
解决方案 B 是推荐的, 可彻底解决插件安装慢问题, 不过要先安装中文插件, 可以先通过前面两种方法安装该插件:Jenkins 插件安装失败解决办法__星辰夜风的博客-CSDN博客_jenkins插件安装失败。
重启 tomcat,刷新页面后,显示正常:
选择默认安装插件的话,此过程需要一段时间,而且根据网络不同有些插件安装不成功,但是之后可以自己再安装即可;也可以自定义选择指定的插件。接下来我们安装推荐的插件。
6. 安装推荐的插件
单击左侧的安装推荐的插件按钮:
安装过程如下:
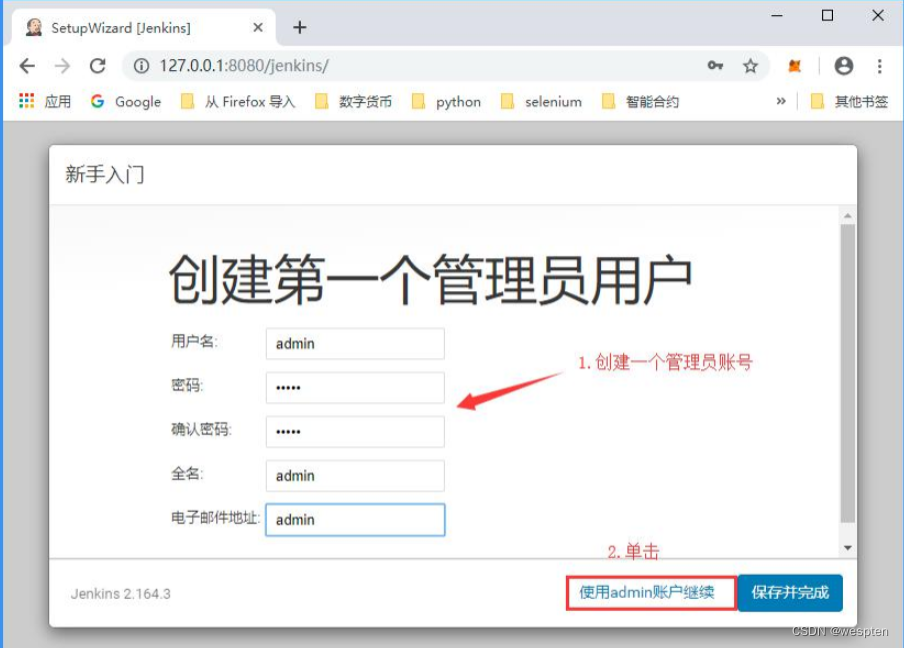
7. 创建管理员账号
8. 设置 Jenkins 访问地址 URL
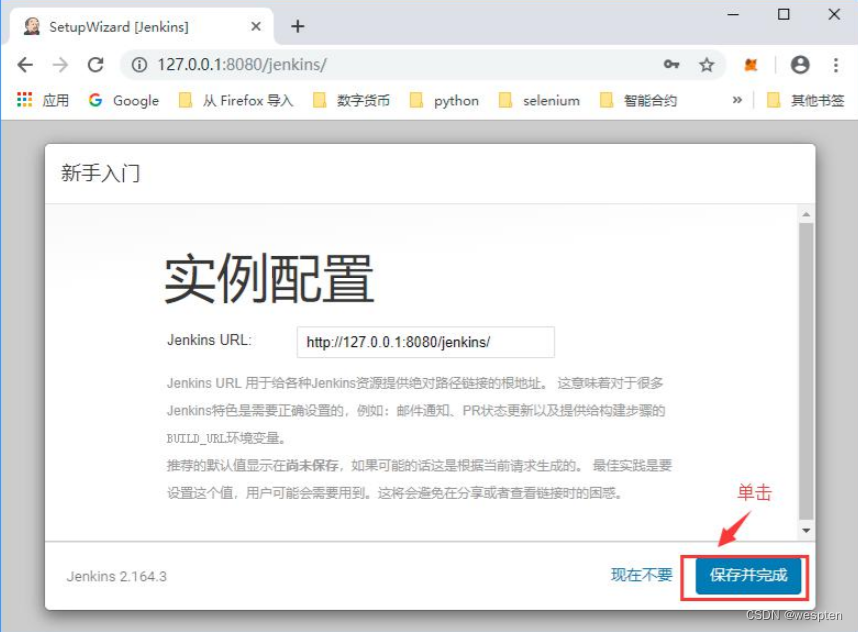
我们会有直接想通过 http 方式运行 Jenkins job 的需求,这样就不需要每次都进入 Jenkins 的页面了(本机的话就是 127.0.0.1)。
9. 进入 Jenkins
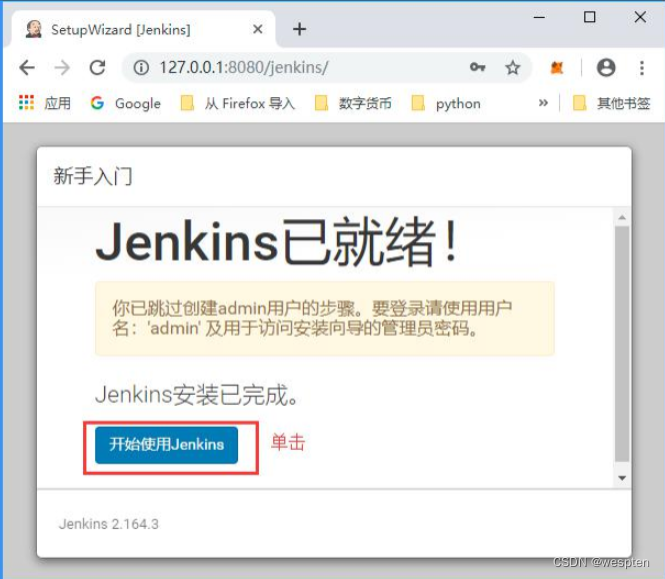
若之后 Jenkins 卡住,则重启 tomcat 即可。
10. 进入登录页面,输入用户名和密码即可
6、Ngrok 安装
GitHub 收到提交的代码后要主动通知 Jenkins,所以 Jenkins 所在服务器一定要有外网 IP,否则 GitHub 无法访问,解决方法:下载 ngrok,将 IP 暴露到网络(类似的工具还有 holer)。
1. 下载
登录到 https://ngrok.com/download 下载 ngrok 压缩包,选 windows 版本:
2. 解压缩
将 ngrok-stable-windows-amd64.zip 文件解压到指定的目录,比如:F:\ngrok-stable-windows-amd64
3. 获取 ngrok 的 token
切换到官网并进行登录(可用 github 账号登录):
获取 token:
4. 认证 token
切换到解压后的目录,执行命令进行认证:ngrok authtoken <your token>

5. 启动 ngrok
在 ngrok 所在的目录执行:ngrok http 8080(8080 是 tomcat 的监听端口),拷贝 forwarding 指示的 ip,后续会用到(注意:cmd 的窗口不要关闭)。
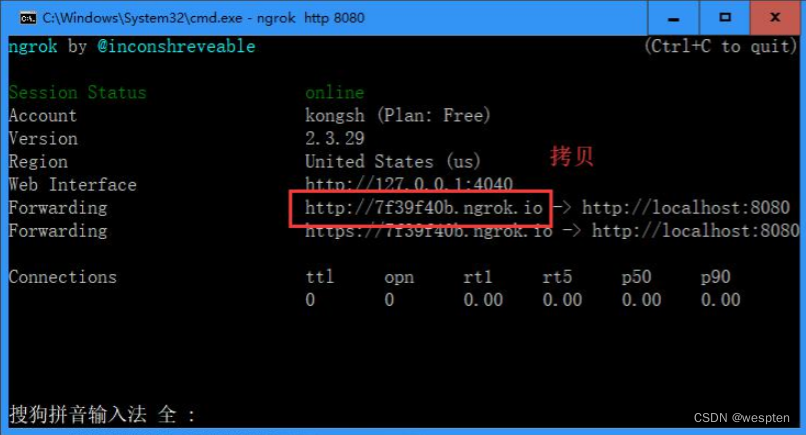
注意:关机或重启后就要重新进入 ngrok 所在的目录执行 ngrok http 8080 命令生成新的 IP,同时 Jenkins 和 github 中的 webhook 对应的 ip 也要修改。
7、Gradle安装
Gradle 是一个基于Apache Ant和Apache Maven概念的项目自动化构建开源工具。它使用一种基于Groovy的特定领域语言(DSL)来声明项目设置,目前也增加了基于 Kotlin 语言的 kotlin-based DSL,抛弃了基于 XML 的各种繁琐配置。
Gradle 面向Java应用为主。当前其支持的语言C++、Java、Groovy、Kotlin、Scala和Swift,计划未来将支持更多的语言。
Gradle 和 Maven 两者都是项目工具,但是 Maven 现在已经是行业标准,Gradle 是后起之秀,很多人对它的了解都是从 Android Studio 中得到的。Gradle 的优点主要如下:
- 其一:简洁。Gradle 抛弃了 Maven 的基于 XML 的繁琐配置,众所周知 XML 的阅读体验比较差,对于机器来说虽然容易识别,但毕竟是由人去维护的。取而代之的是 Gradle 采用了领域特定语言 Groovy 的配置,大大简化了构建代码的行数。
- 其二:灵活。各种在 Maven 中难以下手的事情,在 Gradle 中就是小菜一碟,比如修改现有的构建生命周期,几行配置就完成了,同样的事情,在 Maven 中你必须编写一个插件,那对于一个刚入门的用户来说,没个一两天几乎是不可能完成的任务。
1. 登录官网下载解压版本
进入官网:Gradle Build Tool
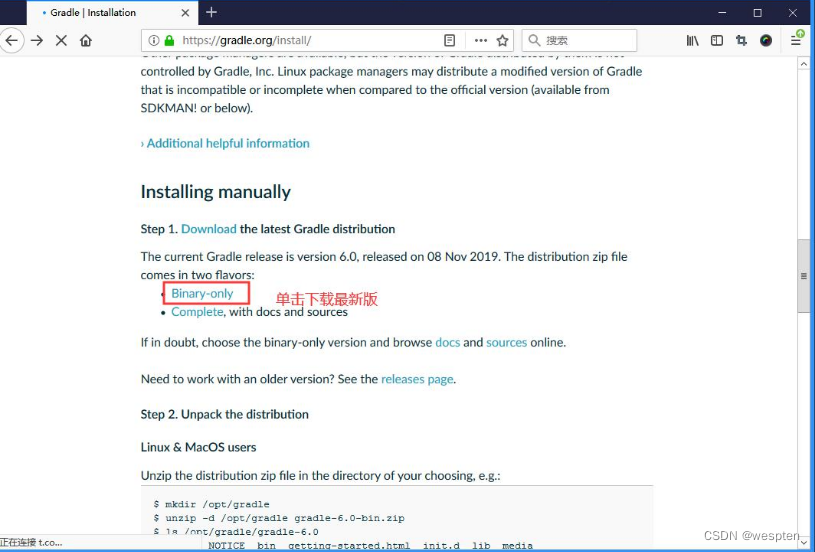
单击 Install Gradle 之后,下拉页面,单击如下链接,下载最新版本:
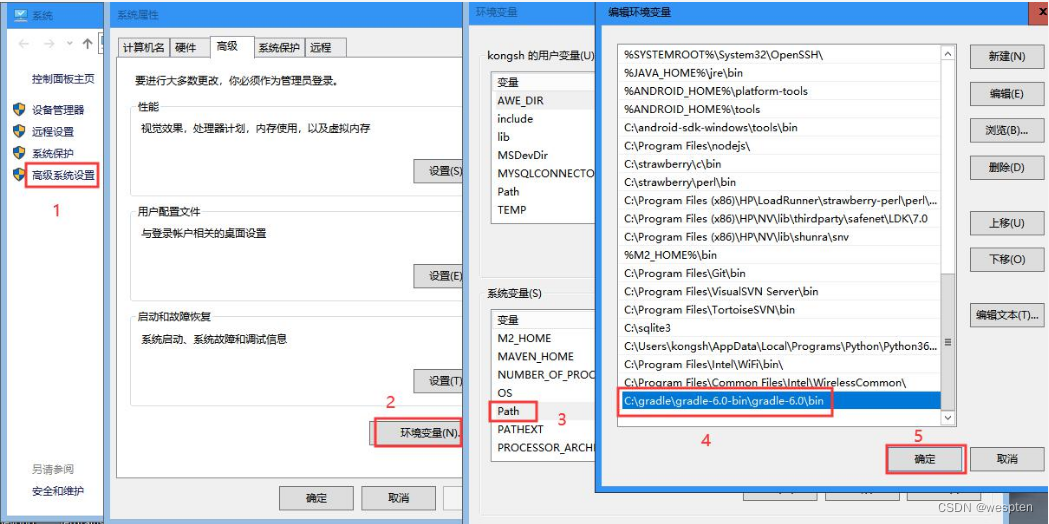
2. 解压并配置环境变量
将下载后的压缩文件解压到指定位置,并配置环境变量。如下:
3. 验证安装成功
启动命令行,输入:gradle
四、Jenkins项目管理与配置
1、Jenkins插件安装
方式一:通过插件管理下载指定的插件
进入 Jenkins 首页-->系统管理-->插件管理-->可选插件页面,在右上角的过滤框中输入插件部分或全部名称并回车,在搜索出的内容中查找待安装的插件。
按照以下步骤在 filter 中输入想要安装的插件部分命名,比如我们想安装 GitHub Branch Source,输入 github 后回车,在筛选后的页面中找到想要的插件,勾选左侧的方框后,选择 install without restart 或者 Download now and install after restart。
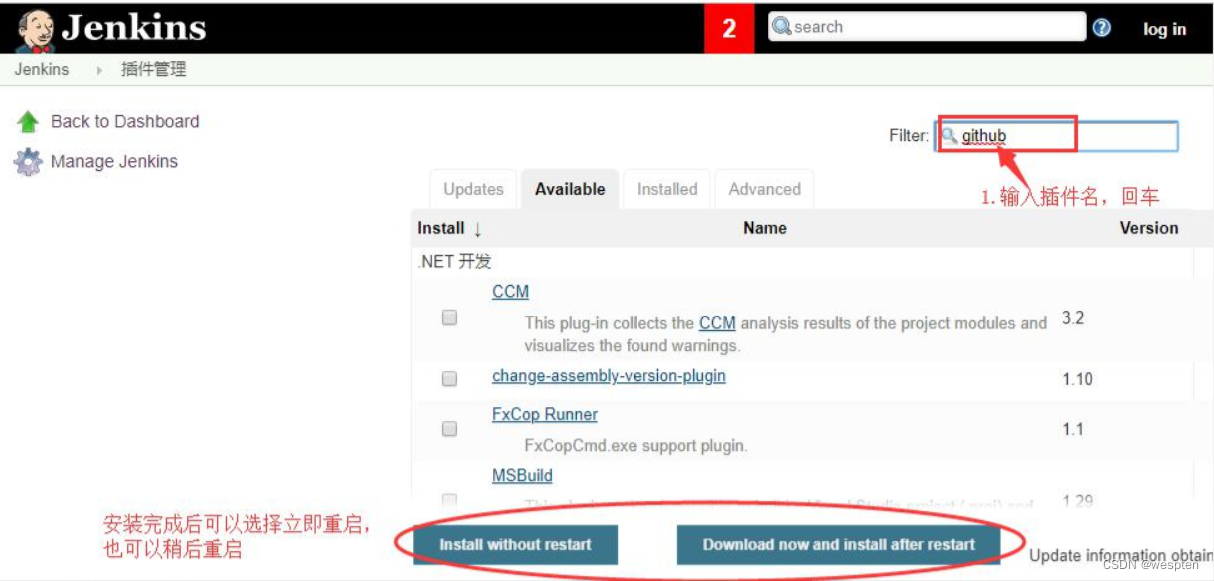
(若已经安装过该插件,则显示不出来 github 的插件)如下提示表示安装成功:

方式二:上传已下载好的 .hpi 文件
进入 Jenkins 首页-->系统管理-->插件管理-->高级,将页面拉到最后,按如下操作:

如下提示表示安装成功:

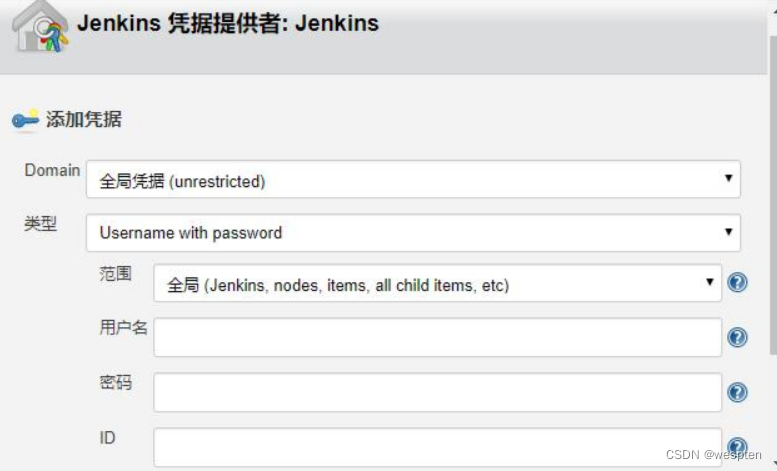
2、添加凭证
Jenkins 访问 tomcat 或者 github 是有可能会需要这些工具能够识别的凭证才能访问,Jenkins 也提供了设置 Credentials 的功能,有 2 种方法添加凭据:
方法一:在 Jenkins 首页的凭据中进行添加
进入 Jenkins 首页-->单击凭据:
如果之前添加过的话会显示所有添加的凭据,类似于以下内容:

添加新的凭据:
凭据类型说明:
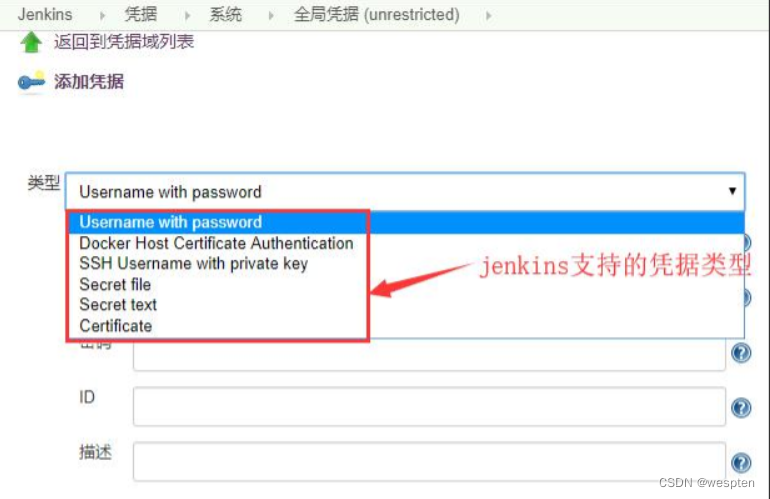
- Secret text:例如 API token(例如 GitHub 的个人 access token)。
- Username with password:用户名和密码 ,可以作为单独的组件处理,也可以作为 username:password 格式的冒号分隔字符串来处理(请参阅处理凭据中的更多信息)。
- Secret file:包含密钥的文件 SSH Username with private key:一个 SSH 密钥对。注意:直接选择回车可以复制私钥的文本并将其粘贴到生成的密钥文本框中。
- Certificate:一个 PKCS#12 证书文件 和可选的密码。
为 github 添加 Username with password 类型的凭据:
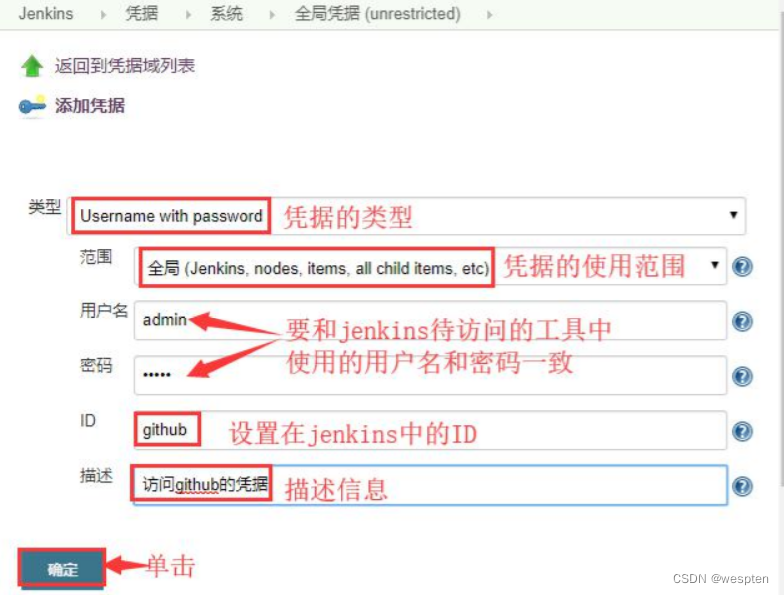
- 用户名和密码:如果该凭证是为 Jenkins 访问 github 使用的话,那么用户名和密码就是 github 登录的用户名和密码。
- ID:在 Jenkins 中使用的一个变量名。
方法二:新建任务后,配置过程中出现类似的操作按钮

直接单击 Add 添加凭据即可,出现如下的对话框,和方法一的一致:
3、全局工具配置
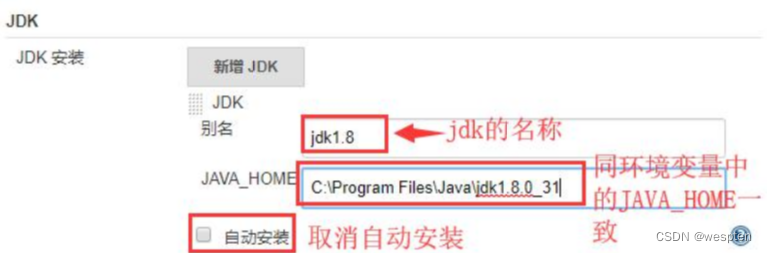

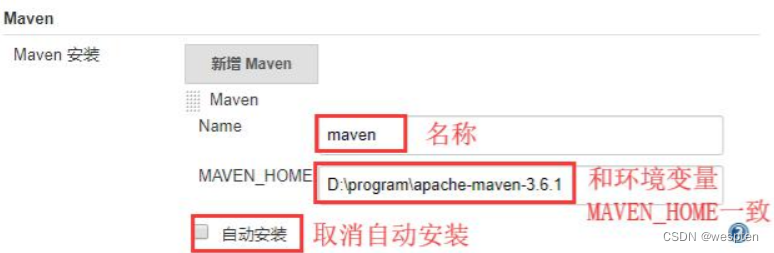
以上工具都有自动安装的选项,不过建议手动安装。
以上配置完成后,将页面拉到最后,单击 Save 保存即可。
4、系统设置
1. 主目录
默认的主目录如下,可以点开右上角的问号,按照提示信息修改,一般不用改。

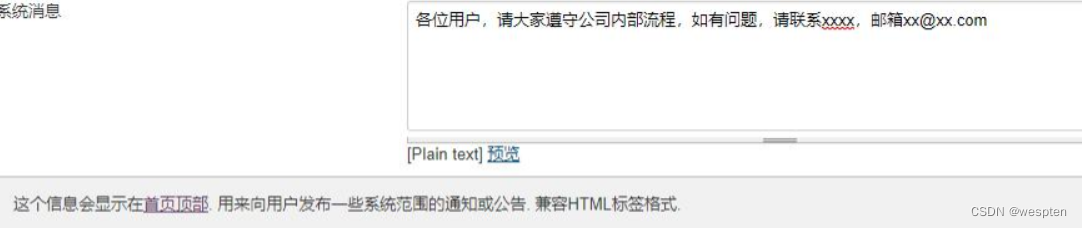
2. 系统消息
可以点开右侧的问号,看到系统消息的作用就是显示在首页顶部的一些公告信息,比如输入内容如下:
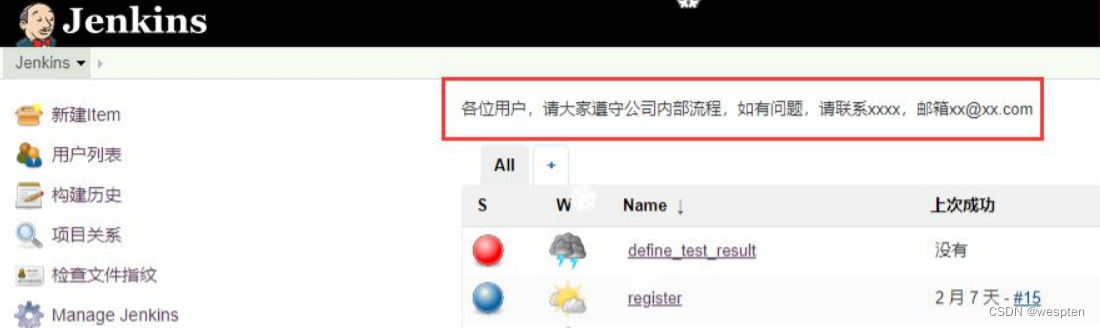
单击保存后,回到 Jenkins 首页,可以看到如下内容:
该内容默认是纯文本形式的,如果想要更高级的可以使用 HTML 格式控制显示内容的格式,但是需要切换到设置-->Configure Global Security 中,标记格式器,选择 Safe HTML,如下:
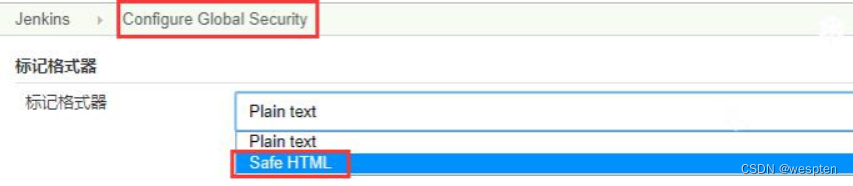
再进入到系统管理-->系统设置,输入 HTML 格式的文本,保存。

在 Jenkins 首页显示的内容如下:

3. Maven 项目配置
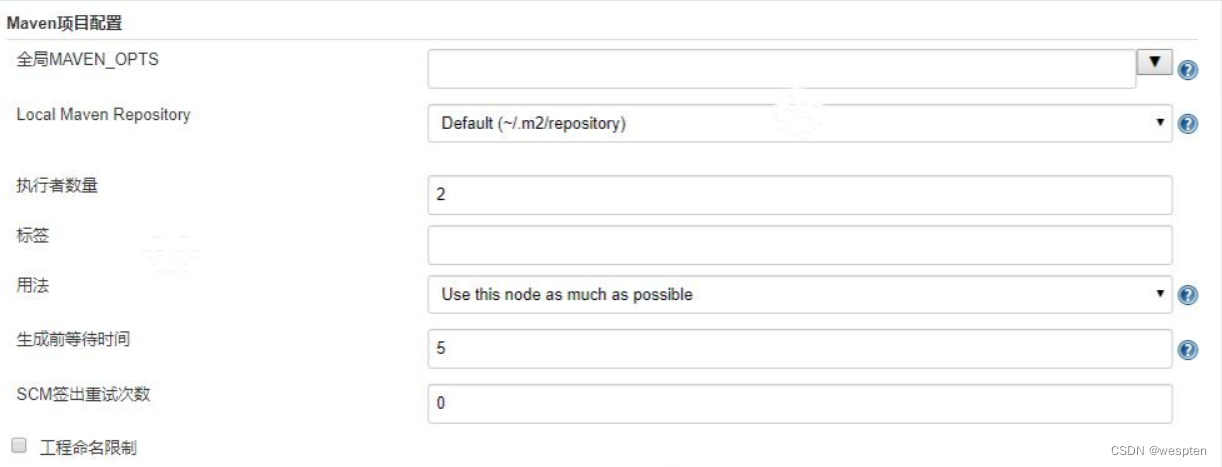
- 执行者数量
默认值为 2,表示最多可以同时跑 2 个 job(有的版本叫 item)。
- 用法
有两个选项:

当 Jenkins 有多个执行节点情况下的使用规则:
尽可能的使用这个节点:这是默认和常用的设置。在这种模式下,Jenkins 会尽可能地使用这个节点。任何时候如果一个构建能使用这个节点构建,那么 Jenkins 就会使用它。
只允许运行绑定到这台机器的 Job:这种模式下,Jenkins 只会构建哪些分配到这台机器的 Job。这允许一个节点专门保留给某种类型的 Job。例如,在 Jenkins 上连续的执行测试,你可以设置执行者数量为 1,那么同一时间就只会有一个构建,一个实行者不会阻止其它构建,其它构建会在另外的节点运行。
- 生成等待时间
默认值是 5 秒,表示创建一个 job 或 item 中的构建在开始之前需要等待的秒数,一般不做修改。
- SCM 签出重试次数
默认为 0,表示 Jenkins 从 git 或者其他源代码管理工具中拉取代码失败时的尝试次数,也可以在具体的项目中进行设置。
- 工程命名限制
如果勾选了此项,并且选择的是 Pattern,那么创建 job(或者 item)时要满足此规则才能创建成功。如下:
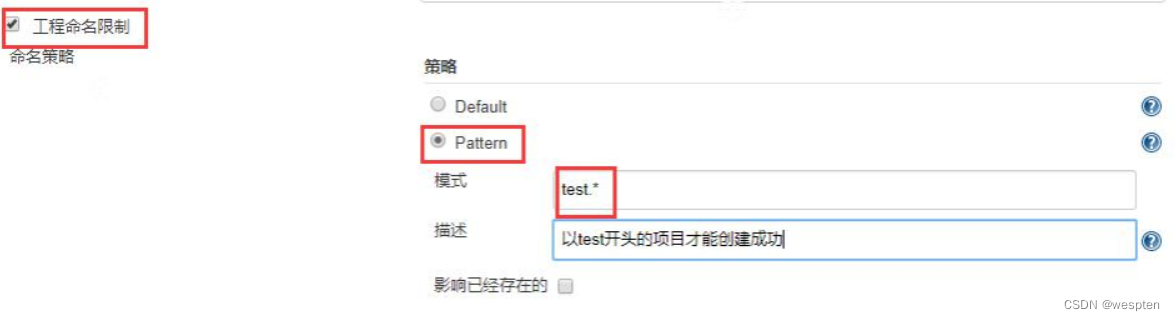
创建项目时不满足以上规则会提示以下信息:

- Jenkins Location
Jenkins URL:我们只是演示用,不做修改,实际工作中 Jenkins URL 是需要改成具体的 IP 地址,这样才能让别人访问。
管理员邮箱:测试完成后用来发送邮件或者一些警告信息,还有更灵活的发邮件规则需要借助第 3 方的插件。
4. 配置 Jenkins 自带的邮件功能
配置完成后,单击页面最下方的保存按钮:

5、常用插件
1. Extended E-mail Notification
Jenkins 默认的邮件通知,能在构建失败、构建不稳定等状态后发送邮件。但是它本身有很多局限性,比如邮件通知无法提供详细的邮件内容、无法定义发送邮件的格式、无法定义灵活的邮件接收配置等等。而 Jenkins Email Extension Plugin 能允许你自定义邮件通知的方方面面,比如在发送邮件时你可以自定义发送给谁,发送具体什么内容等等。
这里的发件人邮箱地址切记要和系统管理员邮件地址保持一致。
注意事项:
- 如果设置 QQ 邮箱的话,密码必须为授权码,开启方法:登录 QQ 邮箱,在”设置”-->“帐户”里开启“POP3/SMTP”并获取授权码(否则报错 535)。
- 必须勾选【Use SMTP Authentication】【Use SSL】。
- 用户名必须与系统管理员邮件地址保持一致(否则报错 501)。
- 设置接收人(Recipients),多个接收人时用英文空格分隔。
1)Job 中使用 Extended E-mail
在任务的配置中,“构建后操作”中选择“Editable Email Notification”选项即可使用 Extended E-mail Notification 插件。
基本配置:
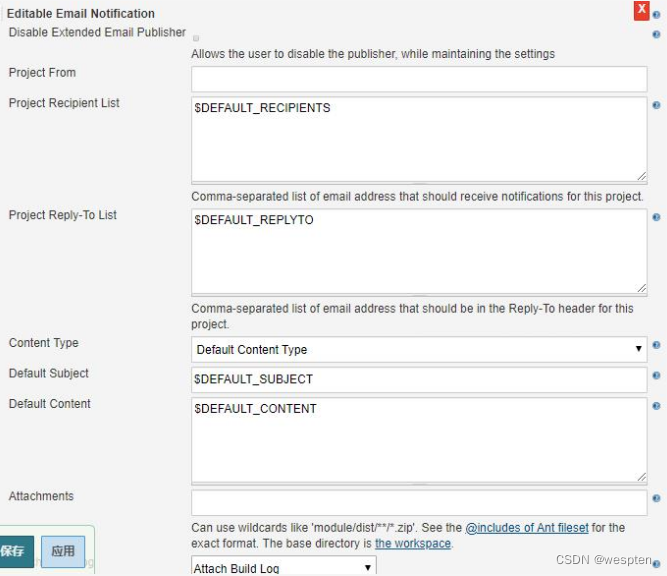
参数说明(这里只列出常用的参数):
- Project Recipient List:这是一个以逗号(或者空格)分隔的收件人邮件的邮箱地址列表。如果想在默认收件人的基础上添加收件人:$DEFAULT_RECIPIENTS,<新的收件人>
- Default Subject:邮件主题,默认为 Extended E-mail Notification 配置的主题。
- Default Content:跟 Default Subject 的作用一样,但是是替换邮件内容。
- Attach Build Log:将构建日志作为附件发送
- Compress Build Log before sending:发送压缩格式的日志(zip 格式)
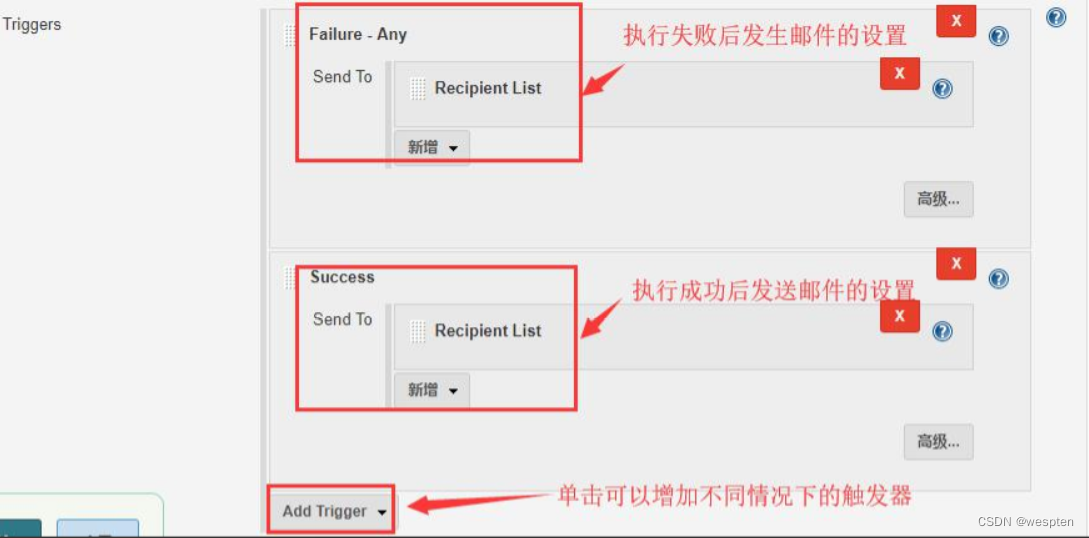
高级配置:
单击 Advanced Settings...,可以用来进行更细化的设置,比如:执行成功和执行失败分别发送给不同的邮箱。
注意:默认情况下是没有配置触发器的,任务构建成功后会提示:No emails were triggered.。
参数说明:
在每个 Trigger 中都有高级配置项目,可以配置的内容和 Extended E-mail Notification 配置项目类似,这里修改的话会覆盖之前的默认设置,具体不再赘述,配置项如下:
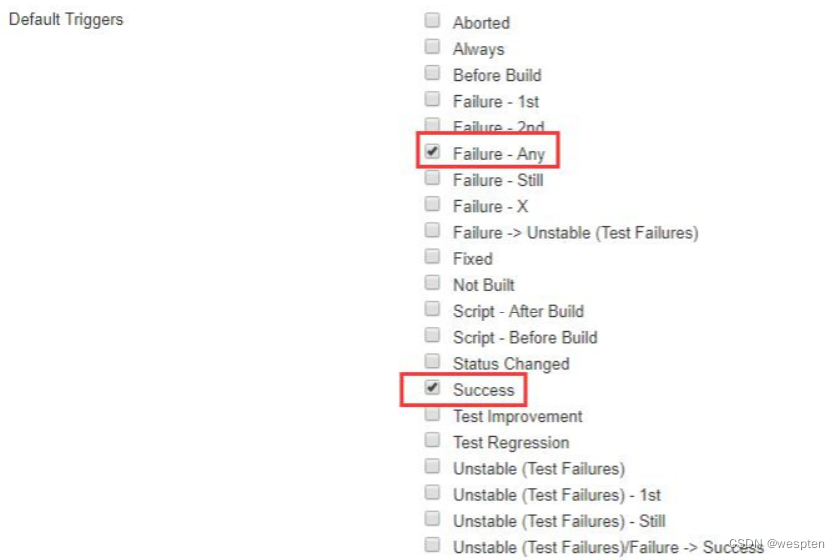
触发器类型:
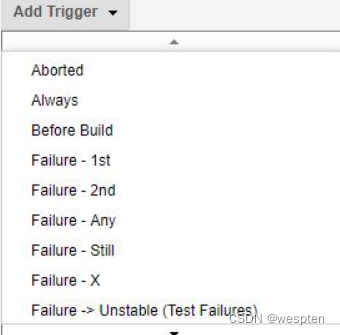
注意:触发器都只能配置一次。
- Aborted:终止时发邮件,比如构建过程中手动停止构建,配置后就会给指定邮箱发邮件。
- Always:不管什么构建情况都会发邮件。
- Before Build:当构建开始时发送邮件。
- Failure - 1st:第 1 次构建失败时发送构建失败的邮件。如果“Still Failing”触发器已配
- 置,而上一次构建的状态是“Failure”,那么“Still Failing”触发器将发送一封邮件来替代(它)。
- Failure Still :如果两次或两次以上连续构建的状态为“Failure”,发送该邮件。
- Unstable:即时发送构建不稳定的邮件。如果”Still Unstable”触发器已配置,而上一次构建的状态是“Unstable”,那么“Still Unstable”触发器将发送一封邮件来替代(它)。
- Success:如果构建的状态为“Successful”发送邮件。如果“Fixed”已配置,而上次构建的状态为“Failure”或“Unstable”,那么”Fixed”触发器将发送一封邮件来替代(它)。
- Fixed:当构建状态从“Failure”或“Unstable”变为“Successful”时发送邮件。
- Still Unstable:如果两次或两次以上连续构建的状态为“Unstable “,发送该邮件。设置好以上内容后,点击保存。即 Job 中使用 Extended E-mail 设置完成。
2)全局设置
进入系统管理- 系统设置 - Extended E-mail Notification
SMTP 基础设置:
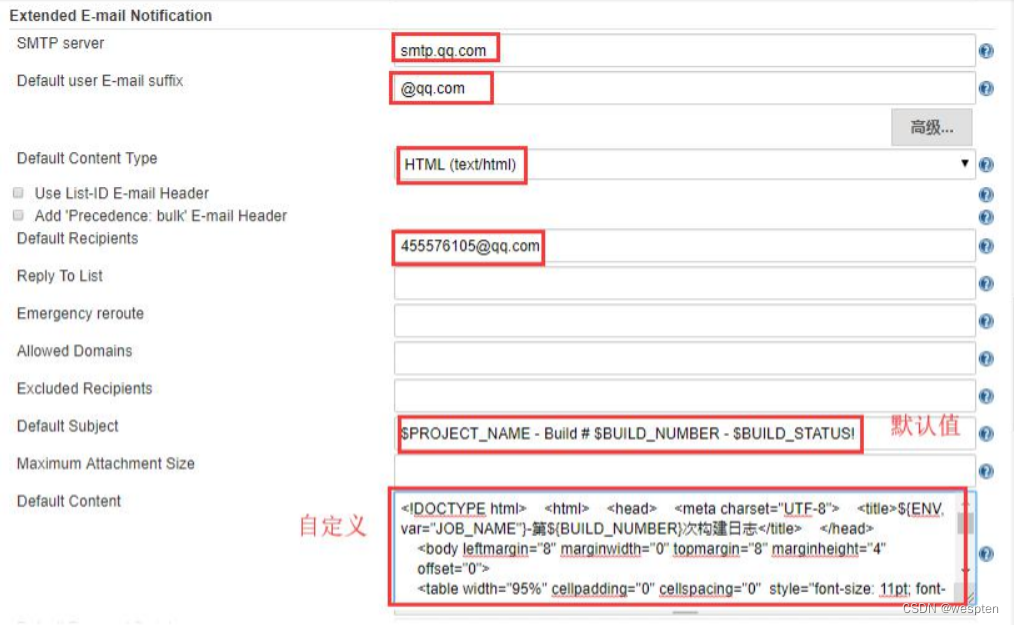
- SMTP server:邮件协议服务器。如 qq 邮箱则为 smtp.qq.com。
- Default user E-mail suffix:邮箱的后缀名。如 qq 邮箱则为 @qq.com。
- Default Content Type:默认的发送的邮件内容类型,默认是 text,我们选择 HTML(test/html)。
- Default Recipients:默认的收件人列表,多个的话用逗号隔开。如果没有被项目中的配置覆盖的话,该插件会使用这个列表。可以在项目配置使用$ DEFAULT_RECIPIENTS,其参数包括此默认列表,也可以根据实际需要添加新的地址。
- Reply To List:回复列表。
- Emergency reroute:如果不为空的话,所有的邮件将只发送到指定的邮箱列表。
- Allowed Domains:允许发送的域名。比如:@domain1.com,domain2.com,那么任何匹配*@domain1.com 和*@*.domain2.com 都可以发送。
- Excluded Recipients:禁止发送邮件的邮箱地址Default Subject:默认的邮件主题。可以使用 Jenkins 自带的一些全局变量。
- Maximum Attachment Size:最大的附件大小。
- Default Content:默认的邮件内容。
- Default Pre-send Script:默认发送前执行的脚本。
- Default Post-send Script:默认发送后执行的脚本。
- Default Triggers:当任务构建完成后选择 Editable Email Notification 的话,满足以下触发的条件就会发送邮件。
- Content Token Reference:邮件中可以使用的变量。点击右侧的问号可以查看:
高级设置:
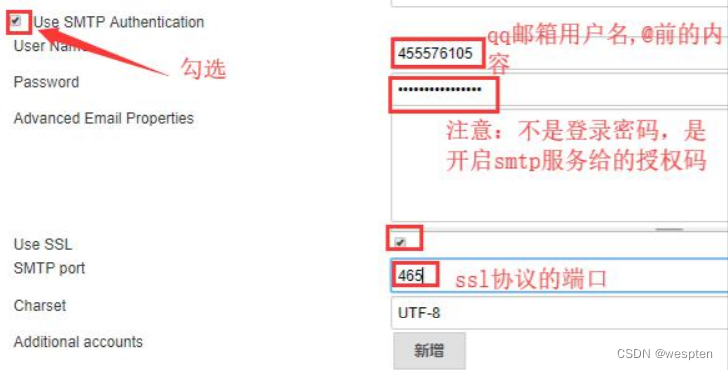
- Use SMTP Authentication:勾选后才能看到用户名和密码。
- User Name:qq 邮箱用户名(@qq.com 可以不写)。
- Use SSL:使用安全连接。
- SMTP port:qq 邮箱 SSL 启用就是 465/587,不启用 ssl 就是 25。
设置好以上内容后,点击保存。即全局设置完成。
3)Default Content
以下是网上找的 Default Content,供参考:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>${ENV,
var="JOB_NAME"}-第${BUILD_NUMBER}次构建日志</title> </head>
<body leftmargin="8" marginwidth="0" topmargin="8" marginheight="4"
offset="0">
<table width="95%" cellpadding="0" cellspacing="0" style="font-size: 11pt; font-family:
Tahoma, Arial, Helvetica, sans-serif">
<tr>
本邮件由系统自动发出,无需回复!<br/>
各位同事,大家好,以下为${PROJECT_NAME }项目构建信息</br>
<td><font color="#CC0000">构建结果 - ${BUILD_STATUS}</font></td>
</tr>
<tr>
<td><br /><b><font color="#0B610B">构建信息</font></b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td>
<ul>
<li>项目名称 : ${PROJECT_NAME}</li>
<li>构建编号 : 第${BUILD_NUMBER}次构建</li>
<li>触发原因: ${CAUSE}</li>
<li>构建状态: ${BUILD_STATUS}</li>
<li>构建日志: <a
href="${BUILD_URL}console">${BUILD_URL}console</a></li>
<li>构建 Url : <a href="${BUILD_URL}">${BUILD_URL}</a></li>
<li>工作目录 : <a
href="${PROJECT_URL}ws">${PROJECT_URL}ws</a></li>
<li>项目 Url : <a href="${PROJECT_URL}">${PROJECT_URL}</a></li>
</ul>
<h4><font color="#0B610B">失败用例</font></h4><hr size="2" width="100%" />
$FAILED_TESTS<br/>
<h4><font color="#0B610B">最近提交(#$SVN_REVISION)</font></h4><hr size="2"
width="100%" /><ul>
${CHANGES_SINCE_LAST_SUCCESS, reverse=true, format="%c", changesFormat="<li>%d
[%a] %m</li>"}</ul>
详细提交: <a href="${PROJECT_URL}changes">${PROJECT_URL}changes</a><br/>
</td>
</tr>
</table> </body> </html>效果如下:
2. Deploy war/ear to a container
这种方式能够将生成的 war 包自动发布到指定 IP 的 Tomcat 中,前提是需要 Tomcat 已经启动。
Tomcat Manager 是 Tomcat 自带的、用于对 Tomcat 自身以及部署在 Tomcat 上的应用进行管理的 web 应用。Tomcat Manager 需要以用户角色进行登录并授权才能使用相应的功能,由于 Tomcat Manager 在默认的情况下是禁用的,因此需要我们进行相应的用户配置之后才能使用 Tomcat Manager。用户角色如下:
- manager-gui:允许访问 html 接口(即 URL 路径为 /manager/html/*)。
- manager-script:允许访问纯文本接口(即 URL 路径为 /manager/text/*)。
- manager-jmx: 允许访问 JMX 代理接口(即 URL 路径为 /manager/jmxproxy/*)。
- manager-status:允许访问 Tomcat 只读状态页面(即 URL 路径为 /manager/status/*)。
1)添加角色
新安装的 tomcat,访问 tomcat 的 Server Status、Manager App、Host Manager 三个页面均显示 403,需要在 conf/tomcat-users.xml 里添加配置。
如果想要访问 manager 页面,需要添加配置项:
<role rolename="manager-gui"/>
<user username="admin"password="password" roles="manager-gui"/>如果需要使用到远程部署等功能,需要添加配置项:
<role rolename="manager-script" />
<user username="admin" password="password" roles="manager-gui,manager-script"/>2)限制远程访问的解决方案
Tomat7 不需要修改下面这两个文件,只有 Tomcat7 以上才需要修改。
在 webapps 下的 host-manager 和 manager,都有名为 META-INF 的文件夹,里面都有 context.xml 文件,部分内容为:
<Context antiResourceLocking="false" privileged="true" >
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="127.d+.d+.d+|::1|0:0:0:0:0:0:0:1" /><Value> 此代码的作用是限制来访 IP 的,127.d+.d+.d+|::1|0:0:0:0:0:0:0:1 是正则表达式,表示 IPv4 和 IPv6 的本机环回地址,所以这也解释了,为什么我们本机可以访问管理界面,但是其他机器访问返回 403。要修改为所有人都可以访问,可以直接注释掉或者改成这样:
<Context antiResourceLocking="false" privileged="true" >
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="^.*$" />
</Context>3)配置示例
如果 tomcat 在 linux 下的话,需要做如下配置,然后重启 tomcat 即可。
在 tomcat/conf/tomcat-users.xml 追加以下内容:
<role rolename="tomcat" />
<role rolename="role1" />
<role rolename="manager-gui" />
<role rolename="manager-script" />
<role rolename="manager-status" />
<user username="tomcat" password="tomcat" roles="tomcat" />
<user username="both" password="tomcat" roles="tomcat,role1" />
<user username="role1" password="tomcat" roles="role1" />
<user username="deploy" password="tomcat" roles="admin,manager,manager-gui,manager-script,manager-status" />tomcat/webapps/manager/META-INF/context.xml 如下图所示,注释掉 <valve> 标签:
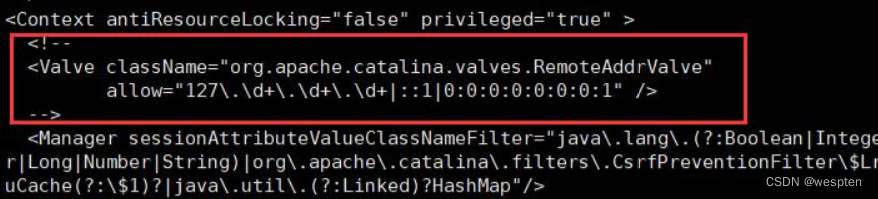
如果发布过程中提示:
Caused by: org.codehaus.cargo.container.tomcat.internal.TomcatManagerException: The username you provided is not allowed to use the text-based Tomcat Manager (error 403)则检查以上 2 个文件是否正确配置。
3. Publish over SSH
- 利用此插件可以将编译好的 war/jar 文件上传到远程 linux 指定的目录下,在远程执行脚本将拷贝的文件复制到 tomcat 的 webapps 文件夹下,重启 tomact。
- 可以采用用户名和密码的方式登录,也可以采用公钥认证的方式。
1)插件说明
进入 Jenkins 主页,系统管理 --> 全局工具配置,下拉到最后。
主配置项:
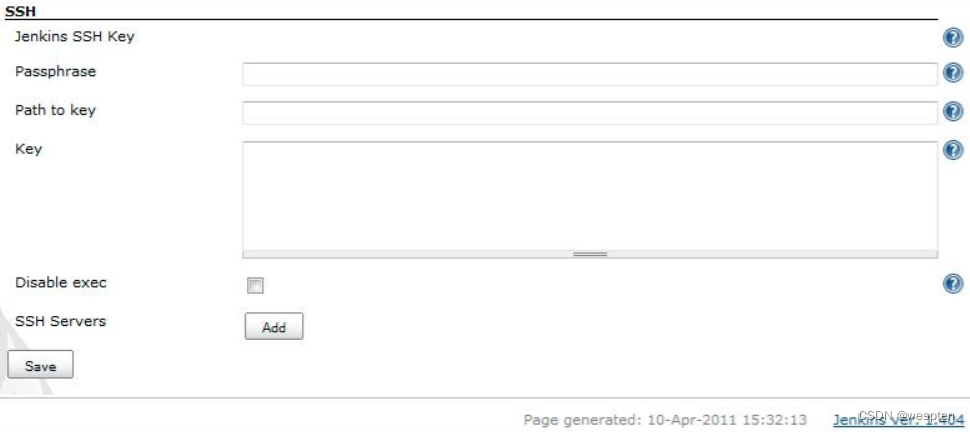
- Passphrase:linux 下生成 ssh key 时加密使用的密码,没有的话不用填。
- Path to file:Jenkins 所在主机上保存 ssh 私钥文件的路径,可以是绝对路径也可以是相对于 Jenkins_HOME 的路径。
- Key:ssh 私钥(包含头尾----的内容),如果 key 和 path to file 均填写了,那么以 key 中的内容为准。
- Disable exec:勾选此项后,此插件将不能执行指定的命令,默认即可。
Add an SSH Server:单击“新增”按钮:
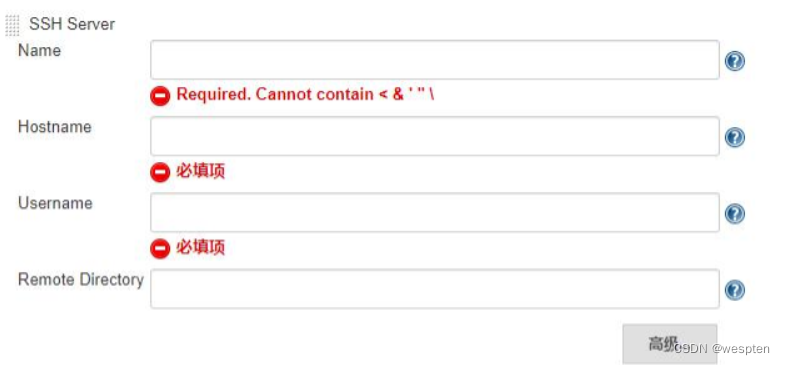
- Name:标识的名字,随便写,能方便区分即可。
- Hostname:需要连接 ssh 的主机名或 ip 地址(建议 ip)。
- Username:远程主机登录的用户名,点击高级后才能填写密码。
- Remote Directory:远程目录,指的是 ssh 文件上传后,文件在远程服务器上的保存路径,路径需要预先建立好。同时,如果上传了文件后,需要执行命令的话,这也是 bat、shell 等命令的工作目录。
高级配置项:单击高级...按钮:
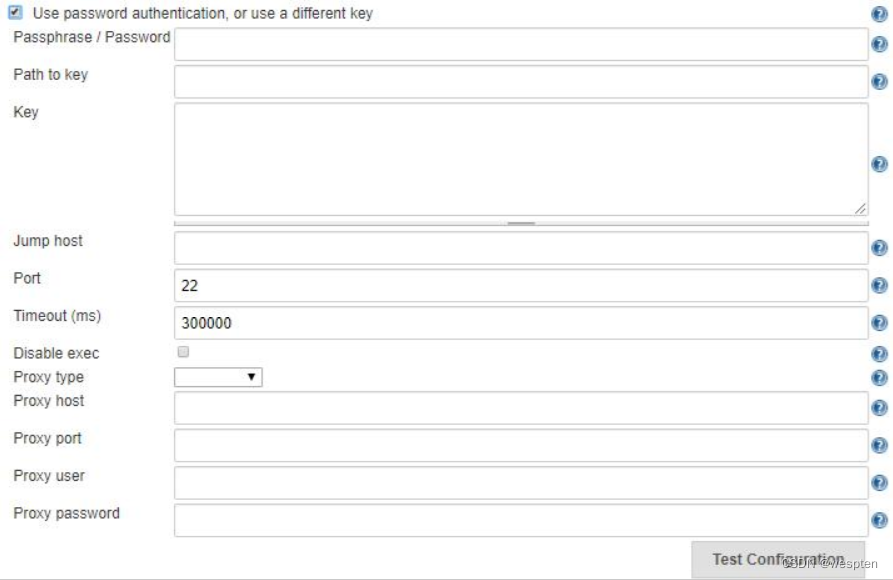
- Use password authentication, or use a different key:可以替换公共配置(选中展开的就是公共配置的东西,这样做扩展性很好,不同的服务器有不同的密钥)。
- Passphrase / Password:如果 Path to key 和 key 两项有一个配置的话,此配置项表示密钥加密时使用的 passphrase,如果 key 对应的输入框是空的话,此配置项表示登录的密码。
- Path to key:同上。
- Key:同上。
- Port:端口(默认 22)。
- Timeout (ms):超时时间(毫秒)默认即可。
- Disable exec:同上。
- Test Configuration:测试是否可以链接到远程服务器。
- Add more server configurations (if required):添加更多的服务器配置。
2)系统配置
用户名和密码方式连接
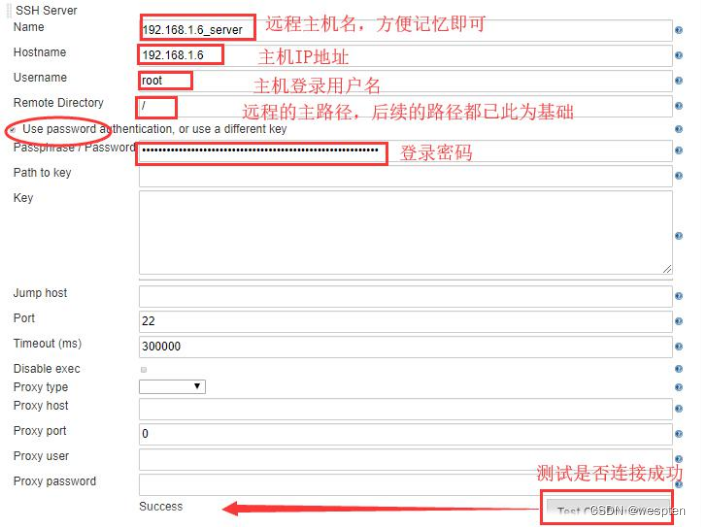
ssh 私钥认证方式登录:
登录 linux 系统,生成 SSH-key,SSH-key 是一对密钥,一个公钥,一个私钥,用来在不同的电脑之间通过安全的连接进行数据交换。
cd /root
ls -al ~/.ssh //查看 id_rsa.pub 或 id_dsa.pub 是否存在
ssh-keygen //连续三次回车,即在本地生成了公钥和私钥,在生成过程中可以根据需要设置一个 passphrase,也可以不设置,生成的公钥私钥在~/.ssh 目录下,id_rsa 是私钥,d_rsa.pub 是公钥
cat id_rsa.pub //可以看到生成的公钥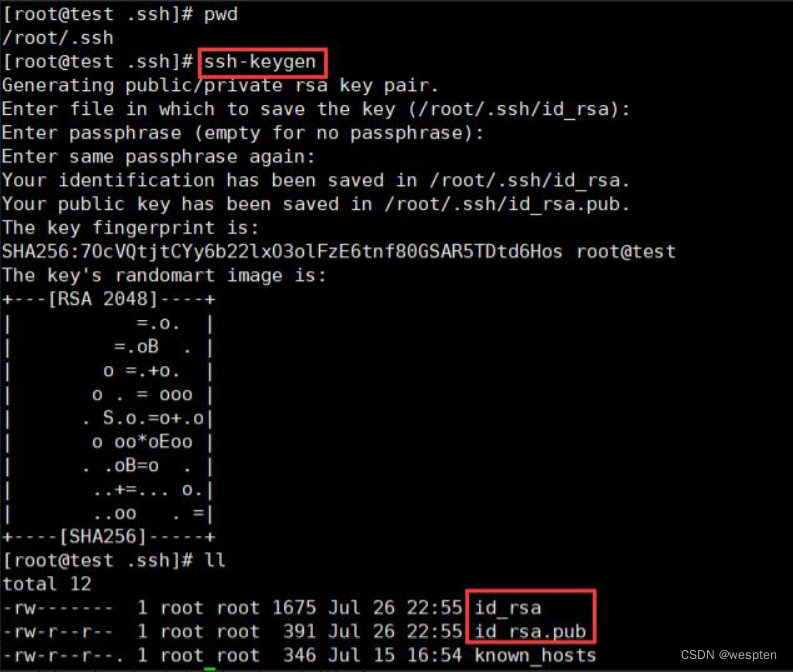
补充:Linux CentOS 7 下 ssh 操作相关命令。
重启服务不再通过 service 操作,而是通过 systemctl 操作:
- systemctl status sshd.service:查看 sshd 服务是否启动
- systemctl start sshd.service:如果没有启动,则需要启动该服务
- systemctl restart sshd.service:重启 sshd 服务
- systemctl enable sshd.service:设置服务开机自启
3)项目配置
构建后操作→增加构建后操作步骤→Send build artifacts over SSH
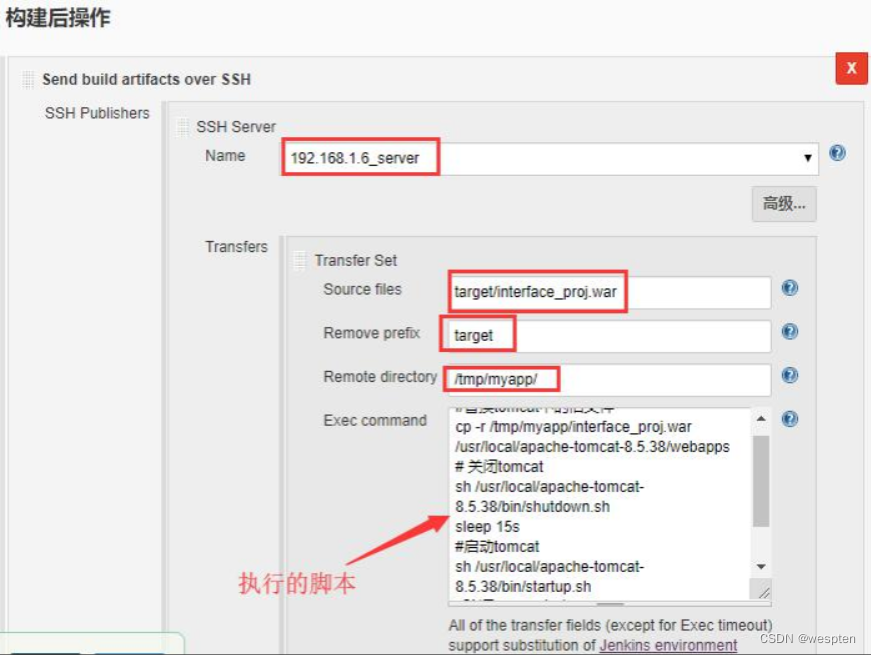
- SSH Server Name:选一个在系统设置里配置的配置的名字。
- Transfer Set Source files:需要上传的文件(注意:相对于工作区的路径。看后面的配置可以填写多个,默认用,分隔)。
- Remove prefix:移除目录(只能指定 Transfer Set Source files 中的目录)。
- Remote directory:远程目录(根据你的需求填写,默认会继承系统配置)。
- Exec command:把你要执行的命令写在里面,脚本内容示例如下:
#替换 tomcat 中的旧文件
cp -r /tmp/myapp/interface_proj.war /usr/local/apache-tomcat-8.5.38/webapps
# 关闭 tomcat
sh /usr/local/apache-tomcat-8.5.38/bin/shutdown.sh
sleep 15s
#启动 tomcat
sh /usr/local/apache-tomcat-8.5.38/bin/startup.sh
#验证 tomcat 启动
ps -ef|grep tomcat|grep start|grep -v 'grep'|awk '{print $2}'高级设置:
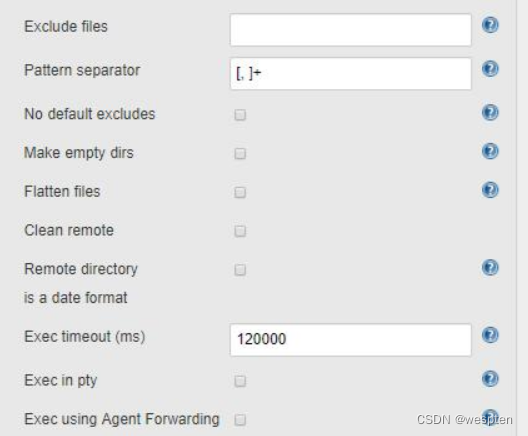
- Exclude files :排除的文件(在传输目录的时候很有用,使用通配 符,例 如:**/*.log,**/*.tmp,.git/)。
- Pattern separator:分隔符(配置 Transfer Set Source files 的分隔符。如果这儿更改了,上面的内容也需要更改)。
- No default excludes:禁止默认的排除规则(具体的自己看帮助)。
- Make empty dirs:此选项会更改插件的默认行为。默认行为是匹配该文件是否存在,如果存在则创建目录存放。选中此选项会直接创建一个目录存放文件,即使是空目录。(个人理解)
- Flatten files:只上传文件,不创建目录(除了远程目录)。
- Remote directory is a date format:远程目录建立带日期的文件夹(需要在 Remote directory 中配置日期格式),具体格式参考下表:
| Remote directory | Directories created |
| 'qa-approved/'yyyyMMddHHmmss | qa-approved/20101107154555 |
| 'builds/'yyyy/MM/dd/'build-${BUILD_NUMBER}' | builds/2010/11/07/build-456 (if the build was number 456) |
| yyyy_MM/'build'-EEE-d-HHmmss | 2010_11/build-Sun-7-154555 |
| yyyy-MM-dd_HH-mm-ss | 2010-11-07_15-45-55 |
- Exec timeout (ms):脚本运行的超时时间(毫秒)。
- Exec in pty:模拟一个终端执行脚本。
- Add Transfer Set:增加配置。
4. 其他
Jenkins 第一次启动时会有推荐安装的插件,以下插件不包含在推荐安装列表中。
| 序号 | 插件名称 | 作用 |
| 1 | Maven Integration | 用来创建 Maven 项目,不安装的话不能创建 Maven 项目 |
| 2 | Deploy to container | 用来将 war 包部署到 tomcat 服务器上 |
| 3 | Generic Webhook Trigger | 用来创建 webhook,获取源码仓库改动信息,自动触发部署 |
| 4 | Email Extension | 邮件的扩展插件,可以定义不同构建结果情况下收件人,邮件 内容等 |
| 5 | Publish Over SSH | 用来实现远程的自动部署 |
| 6 | Role-based Authorization Strategy | 实现基于角色的安全机制 |
| 7 | Performance | 将 jtl 文件展示为图表 |
| 8 | HTML Publisher | 用来将 HTML 的测试结果展示到项目首页 |
| 9 | Startup Trigger | 用来在 Jenkins 节点(master/slave)启动时触发构建,做一些 初始化工作 |
| 10 | Groovy | 用来在项目构建步骤中直接执行 Groovy 代码 |
| 11 | Pipeline Utility Steps | pipeline 中类似于的 jdk 的插件,提供一些常用的方法 |
| 12 | Docker-build-step | 用来集成 Docker 相关操作 |
| 13 | Docker | 用来将 Docker 配置为云 |
6、环境变量
环境变量这个词我们并不陌生,安装完 java 或者 python 之后,为了在任意位置使用都需要将其安装路径加入到系统的环境变量中。类似的,Jenkins 也有环境变量,而且还可以分为内置的和自定义的环境变量。
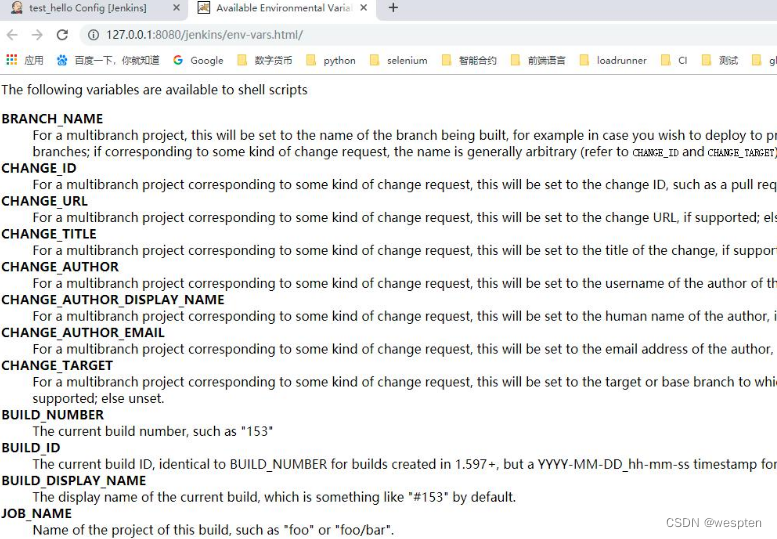
1. 内置环境变量
Jenkins 通过一个名为 env 的全局变量可以访问内置的环境变量。在构建配置项下方,有项目可以使用的环境变量超链接,如下:
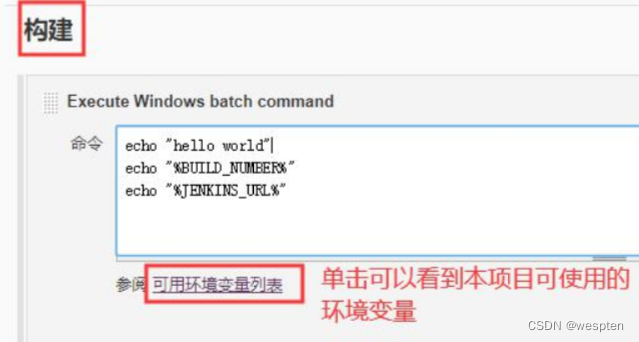
点击之后,可以看到如下页面内容(注意,不同的项目类型可以使用的环境变量会有些差异):
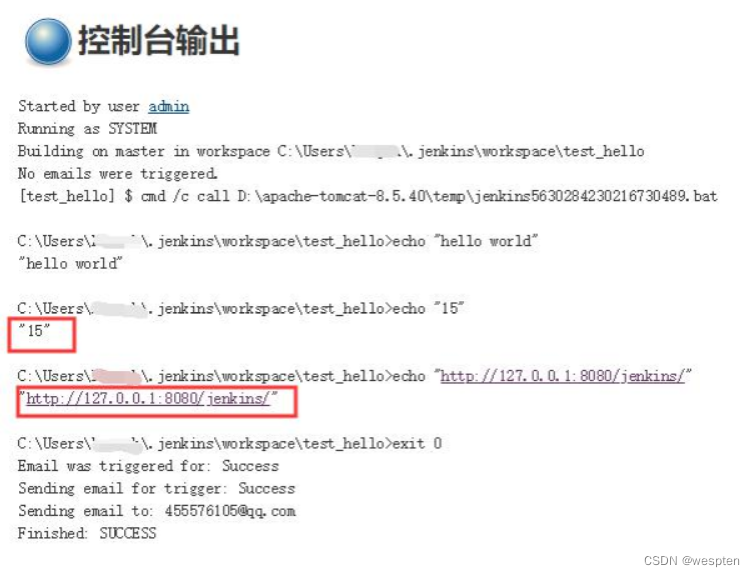
环境变量使用格式:
- windows:%变量名%,如 echo "%BUILD_NUMBER%",echo "%Jenkins_URL%"
- linux:$变量名或者${变量名},如 echo "{env.BUILD_NUMBER}",echo "$Jenkins_URL"
2. 自定义全局环境变量
如果内置的环境变量不能满足项目的需要,也可以自定义全局的环境变量。进入 Manage Jenkins-->Configure System 页,下拉查找全局属性,选中“Environment variables”,单击 Add 按钮可以在出现的框中添加变量名和变量值。如下所示:
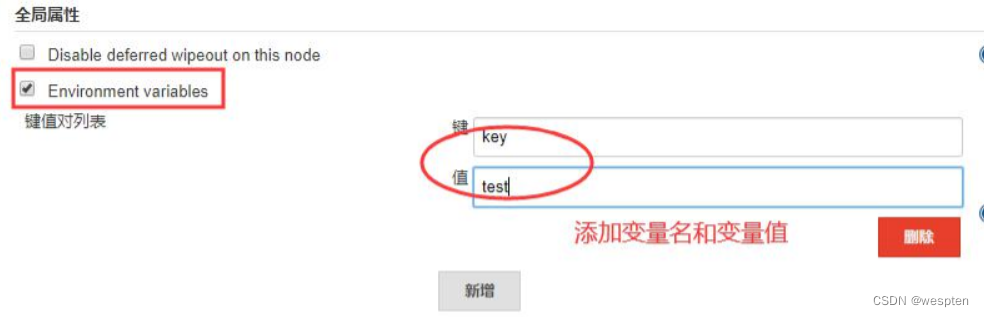
自定义的全局变量也会被加入到 env 属性列表中,像使用内置的环境变量一样去使用。
7、用户登录与权限设定
一个项目涉及到的人员有多个,比如开发、测试和运维,测试又有测试经理和普通测试工程师,他们的权限一般都是不一样的,而且如果 Jenkins 集成的项目很多很复杂的时候,可能需要使用更细粒度的方式进行授权,不同的角色拥有不同的权限,如全局角色拥有所有项目的增删改查权限;项目角色只是针对参与的项目有特定的权限。
Jenkins 默认的权限管理体系不支持用户组或角色的配置,因此需要安装第三发插件来支持角色的配置,我们采用的是 Role-based Authorization Strategy 插件(https://github.com/Jenkinsci/role-strategy-plugin/blob/master/README.md)。
1. 安装插件
Jenkins 首页-->系统管理-->插件管理-->可选插件页面,搜索 Role-based Authorization Strategy:
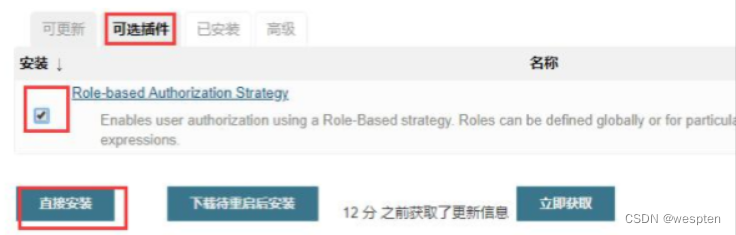
安装成功后再已安装的标签页就可以看到此插件:
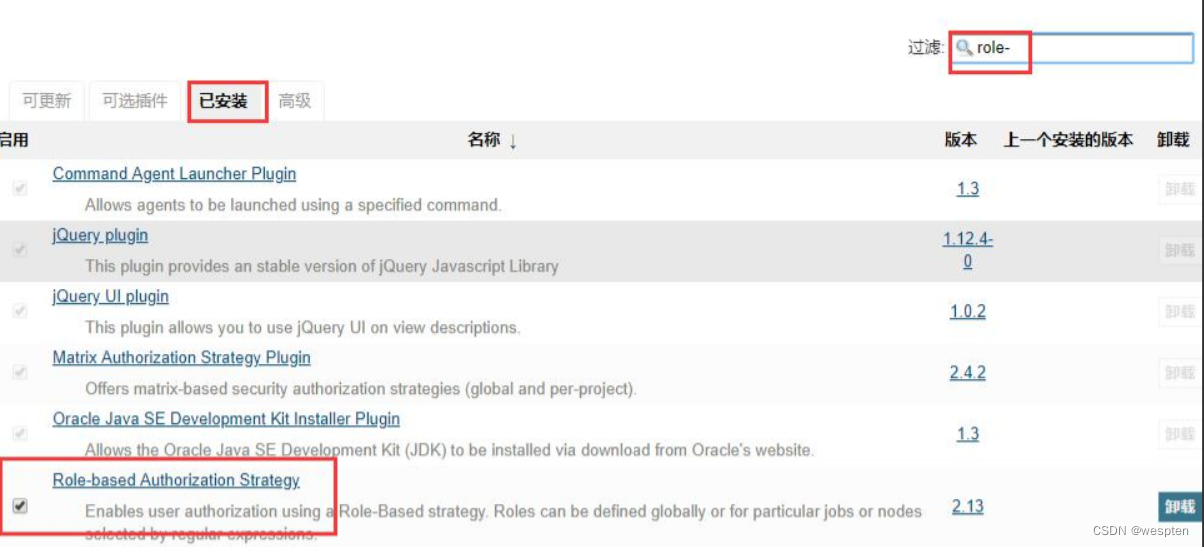
2. 添加用户
需要先添加用户,才能给用户分别权限。
进入 Jenkins 首页-->系统管理-->Manage Users:
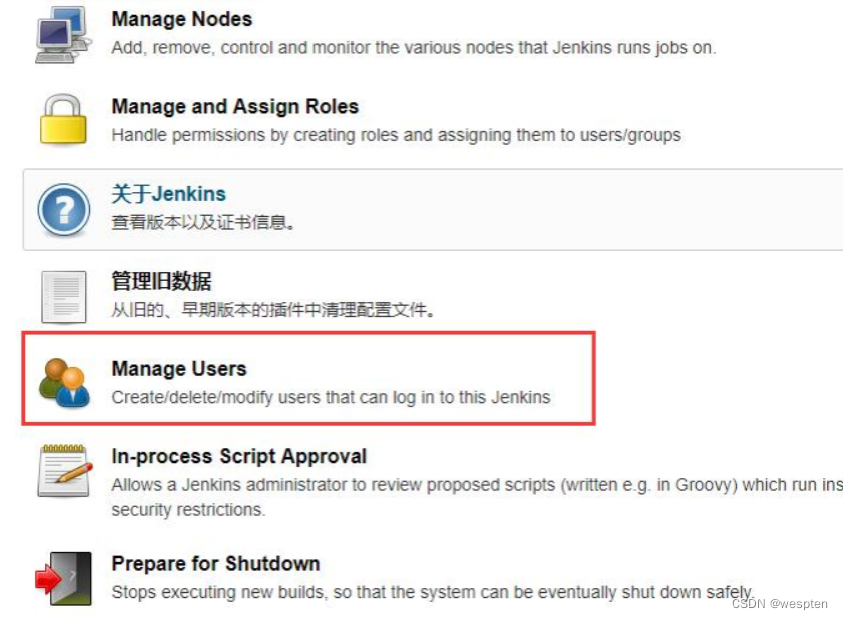
创建新用户:

3. 配置全局安全策略
进入 Jenkins 首页,单击系统管理-->Configure Global Security,勾选 Role-Based Strategy:
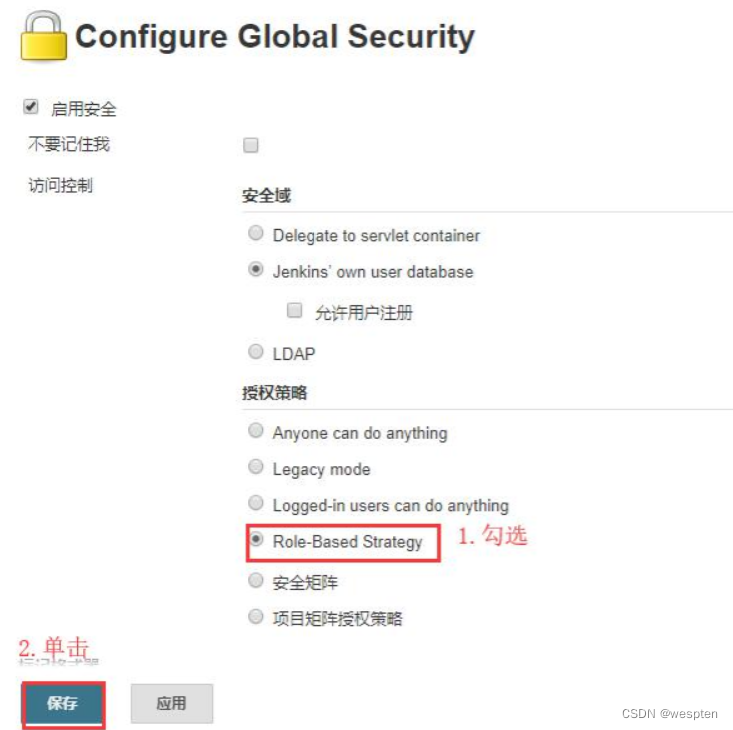
开启授权策略后,可以在系统管理页面看到 Manage and Assign Roles 选项:
4. 配置 Manage and Assign Roles 策略
使用 admin 登录,进入 Jenkins 首页,单击系统管理-->Manage and Assign Roles,可以看到以下界面:

需要进行 Global roles、Project roles 两个配置:
- Global roles 是一个整体权限的配置;Project roles 是项目权限的配置,类似于从大到小的原则进行分配。
- 项目角色与全局角色的区别就是:项目角色是用来管理项目的,没有对 Jenkins 的管理权限;而全局角色更加侧重于对于 Jenkins 的管理。
1)Manage Roles
- global roles
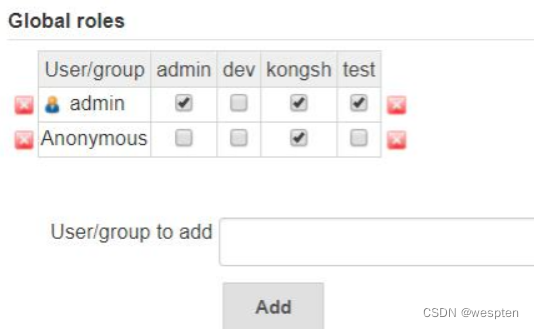
可以看到 admin 是超级用户,拥有所有的权限。点击 Add 按钮添加用户,然后对该用户的权限进行配置。注意:一般用户要有 Overall 的 read 权限,不添加的话使用该用户登录,则 Jenkins 会提示:用户没有 Overall/read 权限。

- Project roles
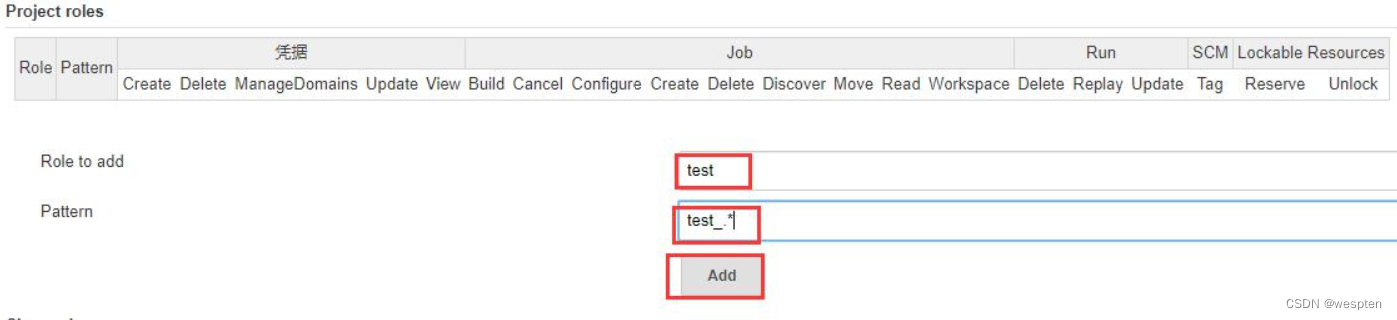
- Role to add:要添加的角色,相当于一个组名。
- Pattern:匹配的规则,支持正则表达式。比如:
- test_.*:表示以 test_开头的所有项目。
- (?i):表示大小写不敏感,如 (?i)roger-.* 可以匹配 Roger-.* 和 roger-.*。
- ^foo/bar.*:用来匹配文件夹。
- |:匹配多个,比如 abc|bcd|efg”直接匹配多个项目。
单击 Add 添加完成后,再分配权限:

2)Assign Roles
将定义好的规则分配给具体的用户。在 Manage Roles 只是对不同的角色分配了不同的权限,这一步是将这个权限和具体的用户匹配起来。

单击 Assign Roles,进入之后可以看到有两个和 Manage Roles 对应的配置项:Global roles 和 Item roles。
- global roles
- Item roles
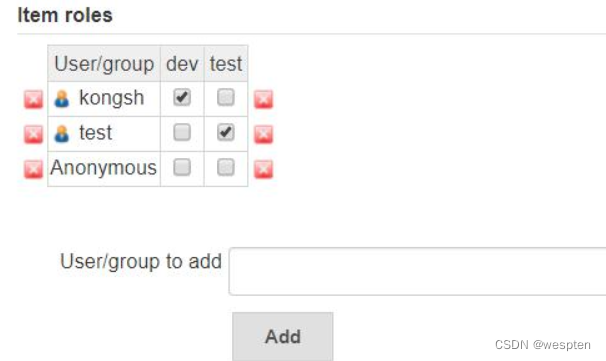
- 将 dev 规则分配给用户 kongsh,也就是只有对 pipe 开头的项目的读权限。
- 将 test 规则分配给用户 test,也就是对所有以 test_ 开头的项目有 Build、Configure、Create、Read、Workspace 权限。
5. 权限验证
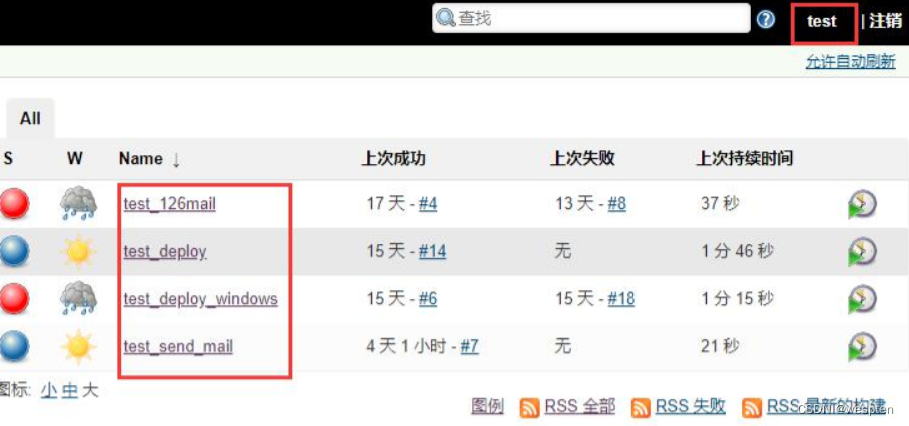
以 test 用户登录:
- 能看到所有以 test_ 开头的项目,而且有执行权限
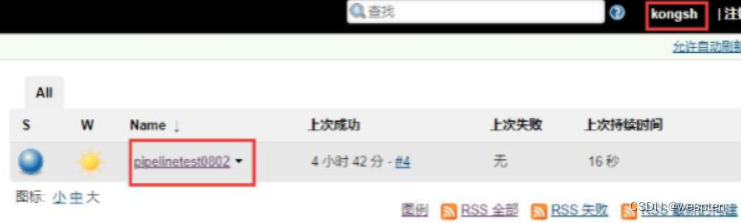
以 kongsh 用户登录:
- 只能看到以 pipe 开头的项目
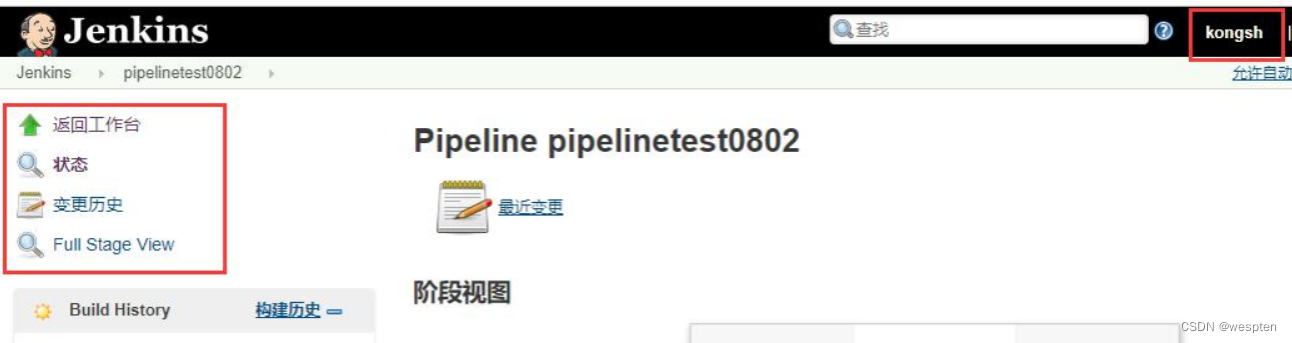
- 进入项目后,只有 read 的权限,没有修改和执行的权限
8、使用视图
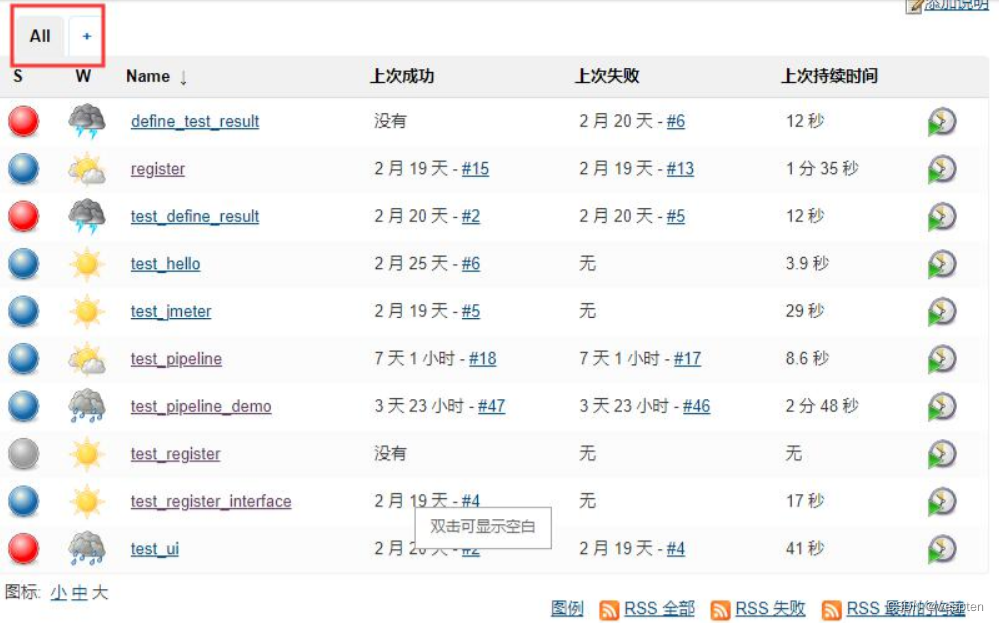
默认情况下创建的项目都是在 Jenkins 首页一个名为 ALL 的视图中,当项目很多或者所有团队共用一个 Jenkins 的话,想找到目标项目就会很吃力,要么使用浏览器自带的搜索功能,要么使用 Jenkins 的搜索功能。这时我们就可以使用视图来对项目进行分类管理。
未使用视图分类时的项目组织情况:
1. 新建视图
单击左侧的 New View 或者 All 后面的 + 号都可以用来创建视图:
单击后的配置页面如下:

单击确定后进入视图配置页面,如下:
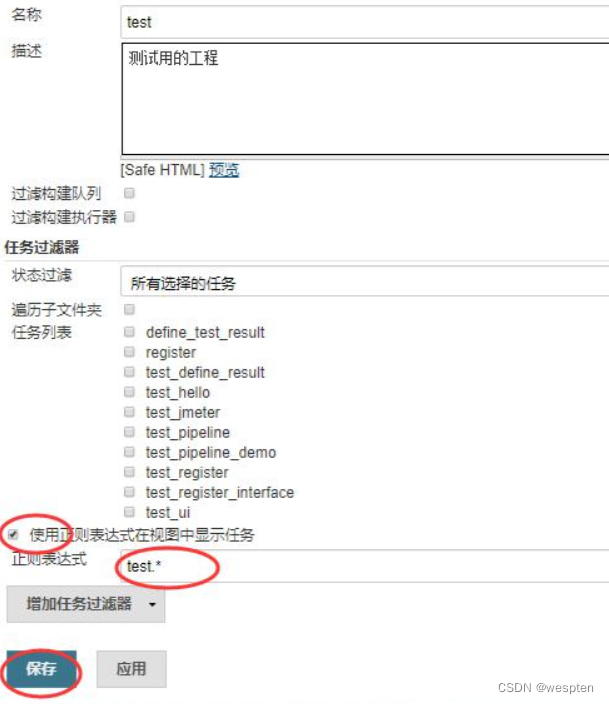
勾选“使用正则表达式在视图中显示任务”,然后输入正则表达式:test.*,表示所有以 test 开头的项目,和正则表达式匹配的项目就会出现在此视图中,如下:
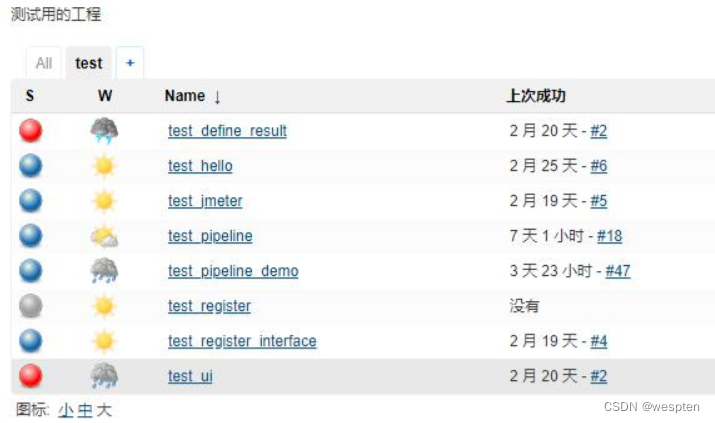
如果不想使用正则表达式的话,也可以手动选择指定的项目到此视图中。
2. 设置默认视图
如果有多个视图的话,可以把某一个设置为默认视图,方法如下:
进入 Manage Jenkins-->Configure System 页,下拉找到默认视图配置项:

可以根据需要选择默认的值。
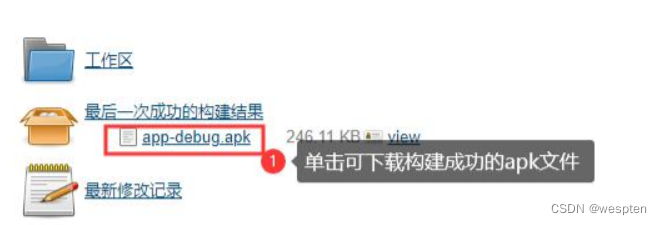
9、归档构建产物
这个是指将每次构建之后会在当前的工作空间中产生 war 包、jar 包、apk 或者一些日志文件等二进制文件展示到项目的构建首页中,方便需要时下载或者查看。Jenkins 提供了 Archive the Artifacts 的插件以满足以上要求。
在项目中构建后操作配置中选择 Archive the Artifacts:
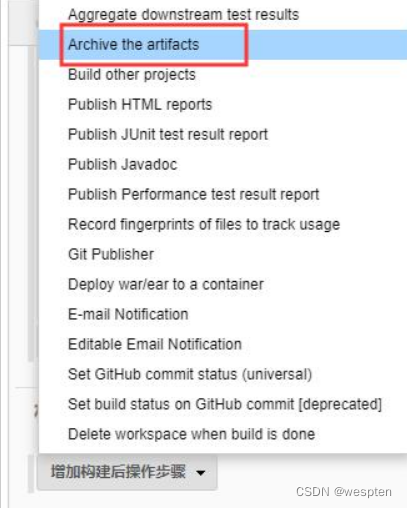
Archive the artifacts 配置中,输入归档产物的目录。
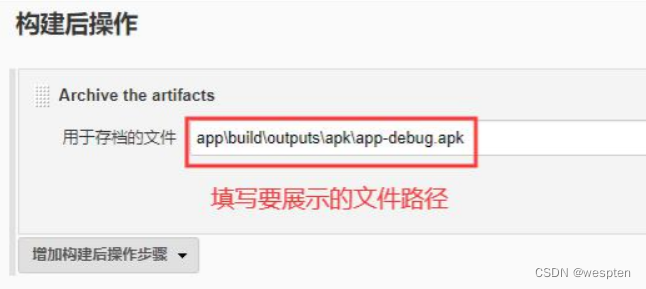
构建后在项目首页看到的结果:
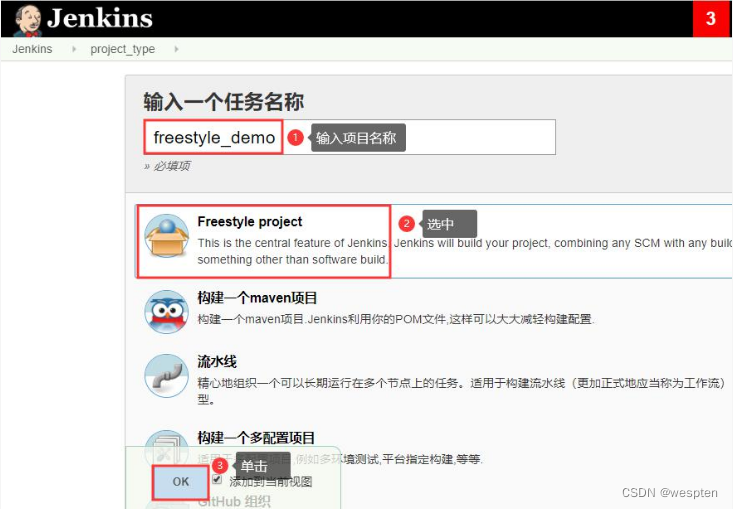
10、Freestyle project
Jenkins 根据不同的项目需求对项目类型进行了分类,对于大多数项目类型,配置页面上都有常见的选项,比如基础设置、构建、源码管理等等。
下面简单的介绍下 Jenkins 支持的项目类型以及最常用项目的配置项,有些项目类型必须安装相应的插件后才能看到,比如 maven 项目。如果在第 1 次配置 Jenkins 时安装了推荐的插件后,在 Jenkins 首页单击新建 item 可以看到以下几种项目:

自由风格的项目:
1. General
用来为项目设定一些全局性的选项。
- Discard old build(丢弃旧的构建)
作用:用来设置 Jenkins 的 jobs 保留最近几次的构建结果,可以避免占用大量的磁盘空间。
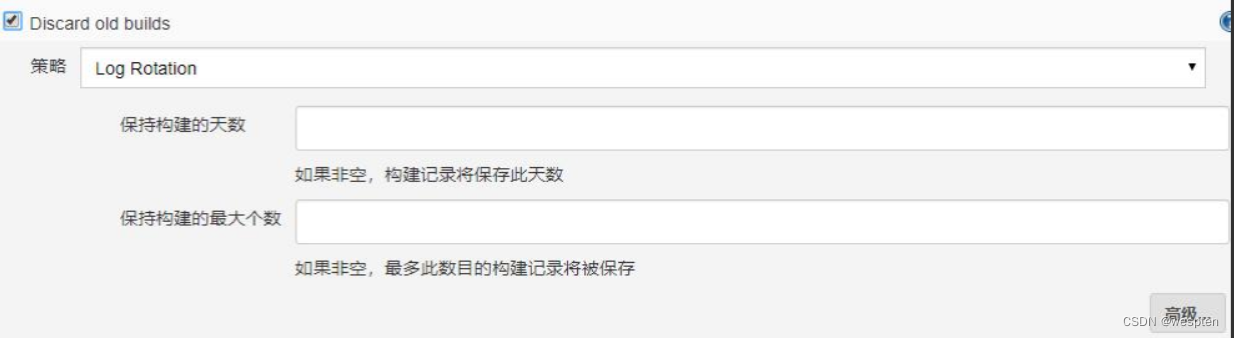
参数:
- 策略:只有一个默认值选项 Log Rotation,无须修改;
- 保持构建的天数:设置保留最近几天的构建结果;保持构建的最大个数:设置保留最近几次的构建结果。
- 高级:也可以进一步对制品的删除策略进行设置。一般不用设置
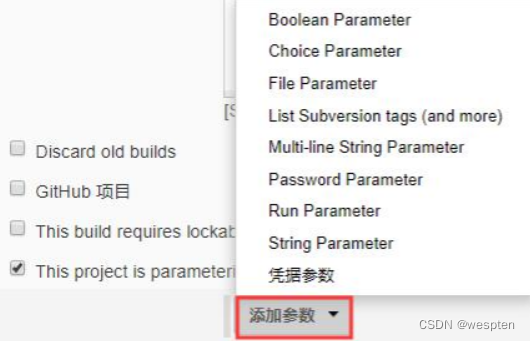
- This project is parameterized(参数化构建)
作用:参数化构建,可以单击添加参数,在每次构建之前需要用户给参数赋值,根据不用的参数值执行不同的处理流程。
- Throttle build(节流构建)
作用:允许在一个指定的时间段内进行构建的次数。

参数:
- Number of builds:构建的次数
- Time period:设置指定的时间段,单位可以是年、月、日、周、时、分、秒
- 关闭构建
作用:勾选此复选框后,此项目不会再执行。
- 在必要的时候并发构建
作用:默认情况下,不允许同一个项目执行并发构建。
勾选此复选框后,并且有足够的执行节点的话,就会执行并行构建。这一功能对长时间的构建项目或者是多场景的项目会很有用。
注意:在并发构建时,工作空间名称会附加 @#(其中 # 是一个数字)用于区分工作空间。但是如果没有使用默认工作空间的话,则所有并发构建都是在同一工作空间运行。
- 限制项目的运行节点
勾选此复选框后,允许你通过标签表达式来指定某一个或多个“标签”指定的节点来运行此项目。注意:标签是添加节点时设置的名称。
单击限制项目的运行节点选项下方的高级按钮,可以设置一些附件选项,具体如下:
Quiet period(安静期):
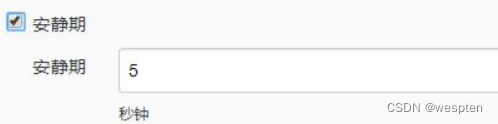
作用:设置在项目构建前等待的秒数。如果这里没有设置,则使用系统默认的全局安静期。
此项主要用于支持遗留问题,比如 CVS,需要等待所有文件提交完成后才能开始构建,而不是在系统看到第一个时就开始执行。
重试次数:
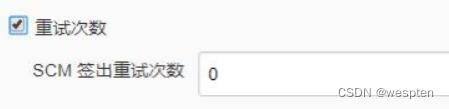
作用:用于重试 SCM( Source Control Management)的检出次数。两次尝试之间有 10s 的间隔。
当上游项目正在构建时阻止构建:
作用:勾选此复选框后,如果此项目的某个依赖的上游项目正在构建或处于队列中时,则不允许构建该项目。
当下游项目正在构建时阻止构建:
作用:勾选此复选框后,如果其中的一个子项目正在构建或处于队列中,时,则不允许构建该项目。
使用自定义工作空间:
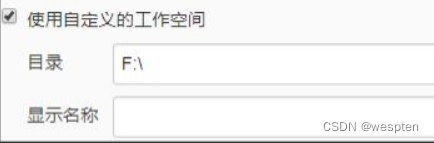
作用:Jenkins 默认的工作空间是在“C:\Users\xxx\.Jenkins\workspace\项目名称”目录下,也可以在此处指定自定义的工作空间。
参数:
- 目录:指定工作空间的位置,可以是绝对路径也可以是相对路径,如果是相对路径,则相对的是节点的根目录。注意:千万不要直接写磁盘的根目录,否则执行构建时会将目录下所有的内容删除!!
- 显示名称:在 Jenkins web 界面中显示的值。
保留依赖的构建日志:
为了保留有上下游依赖的构建日志,此配置会覆盖日志循环策略。
2. 源码管理
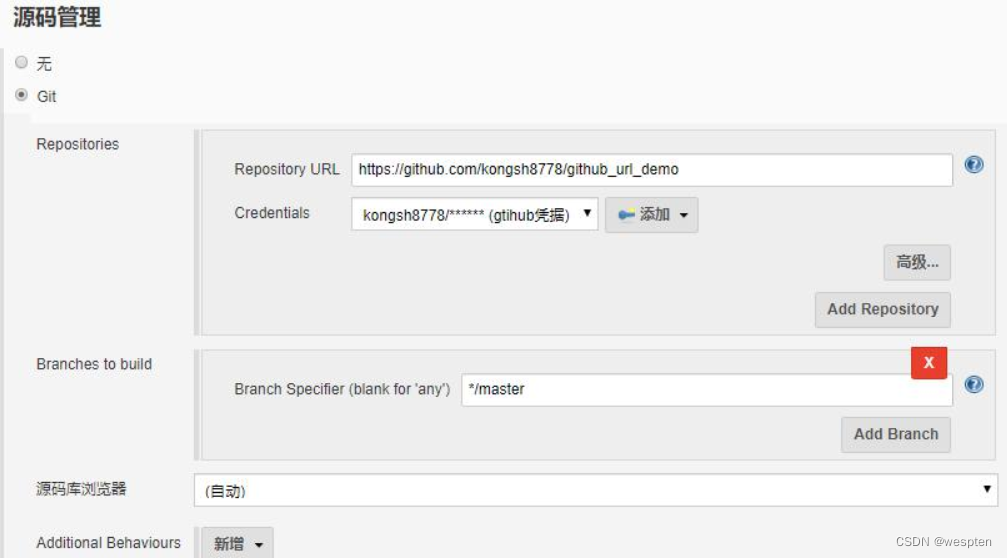
根据安装的插件不同,界面中看到的配置项会有所差异,但是也都是大同小异,最常见的配置如下:
- 仓库 URL:设置项目中能够访问的仓库位置,比如源码的存放位置,或者测试脚本的存放位置等。
- 凭证:用于访问 SCM 的用户名密码、ssh 密钥、token 等凭证。
- 版本:配置要使用的代码的具体版本。
- git 仓库的配置项。
3. 构建触发器
构建触发器用来设置触发项目构建的时间或者事件。
- 触发远程构建

勾选此复选框之后,Jenkins 会提供一个特定的 URL 用来触发项目的自动构建,可以看下面的那行提示信息。为了安全起见,可以看到在 URL 之后还会要求有一个用于授权的 Token 字段(需要在 Manage Jenkins-->Manage Users 中对用户进行设置)。这样就可以使用 wget 或 curl 这样的工具触发构建。
- Build after other projects are built(其它项目构建完成后构建)
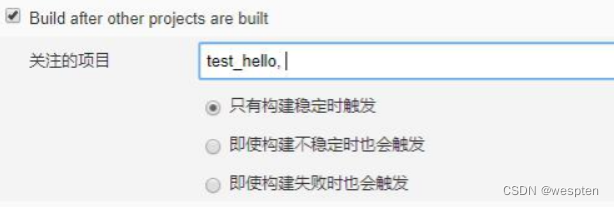
用来设置在某个项目构建完成后才能触发本项目的构建。而且可以对其它项目的具体构建结果进行设定,比如,稳定的(成功),不稳定的,失败的。比如我们需要在 war 包发布成功后,再进行测试脚本的执行,这种场景下就可以配置此项。
- Build periodically(周期性构建)
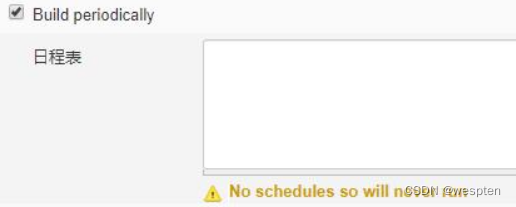
这是一种类似于 crontab 命令的功能,可以指定在某个或某些具体时间自动进行项目的执行。包含 5 个字段,这些字段以空格或者 Tab 键分割,用来指定多久去执行一次构建。格式为:
- MINUTES:一小时内的分钟,取值范围(0-59)
- HOURS:一天内的小时,取值范围(0-23)
- DAYMONTH :一个月中的某一天,取值范围(1-31)
- MONTH :月份,取值范围(1-12)
- DAYWEEK:一周中的星期几,取值范围(0-7)。0 和 7 都表示星期日
还可以使用特殊的字符一次指定多个值:
- *:匹配所有的值
- N:匹配 M-N 之间的值
- M-N/<VALUE> 或者 */<value>:表示每隔 <value>,比如 */5 每隔 5 分钟
- A,B,...Z:多个枚举值
- 5H:可以用于任何字段,用来告诉 Jenkins 在一个范围内使用该项目名的散列值计算出一个唯一的偏移量,这个偏移量于范围内的最小值相加后定义为实际的执行时间。注意:这个值是项目名的散列值,那么每一个值都与其他项目是不同的,但是同一个项目的值是不变的。
H 符号在实际的项目中是非常推荐使用的,因为在大型的项目中可能存在多个同一时刻需要执行任务,比如(0 0 * * *),都需要在半夜零点启动,那么使用 H 后,从散列算法获得的偏移量,就可以错开执行具有相同 cron 时间的项目。
示例:
# every fifteen minutes (perhaps at :07, :22, :37, :52).
H/15 * * * *
# every ten minutes in the first half of every hour (three times, perhaps at :04, :14, :24).
H(0-29)/10 * * * *
# once every two hours at 45 minutes past the hour starting at 9:45 AM and finishing at 3:45 PM every weekday.
45 9-16/2 * * 1-5
# once in every two hours slot between 9 AM and 5 PM every weekday (perhaps at 10:38 AM, 12:38 PM, 2:38 PM, 4:38 PM).
H H(9-16)/2 * * 1-5
# once a day on the 1st and 15th of every month except December.
H H 1,15 1-11 *- Generic Webhook Trigger
一种通用的生成 webhook 的插件,不局限于 github。
- Github hook trigger for GITScm polling
专门针对于 github 仓库的配置项,需要安装 Github Integration plugin 插件才能看到。
这种方式要求设置一个 github 服务,以便在 github 仓库中有指定的事件发生时,向 Jenkins 发送通知,而无需 Jenkins 不断的轮询。
- Poll SCM(轮询 SCM)
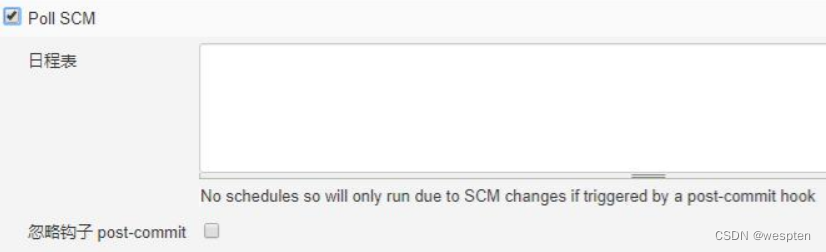
就是定期到指定的代码仓库查询是否有变化,如果有变化就执行。语法同 cron 是一样的。
与周期性构建的区别就是,让 Jenkins 在指定的时间去检查代码仓库是否有变化,有变化了才运行项目,而不是直接到点了就运行项目。
注意:最下面一行有一个复选框,忽略 post-commit 钩子,就是告诉 Jenkins 要忽略来自钩子的信号,目的就是为了防止重复触发操作。
4. 构建环境
可以用来对项目指定某些全局操作和集成设置。这些选项有很多,根据安装的插件不同,显示出来的也不同。
- Delete workspace before build starts(构建前删除工作空间)
就是在构建前先将工作空间删除。
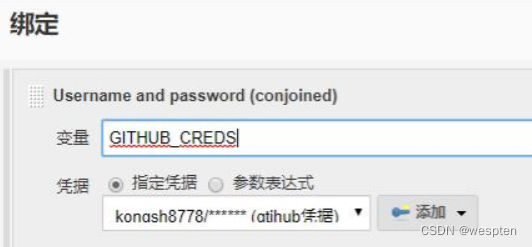
- Use secret text(s) or file(s)(使用机密文本或文件)

安装了凭证绑定插件(Credentials Biding plugin)才会看到此配置项。创建凭证时会为其指定一个全局变量名,然后就可以在任务中使用此全局变量代替凭证中的敏感信息,在执行构建时,会将实际值对全局变量进行替换。
下图以用户名和密码为例:
- Abort the build if it's stuck
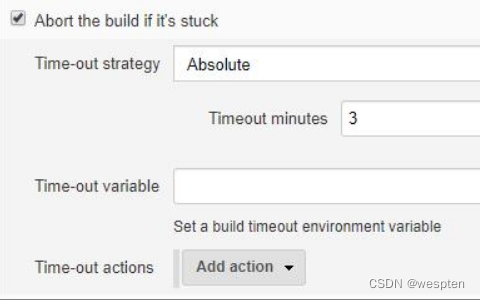
用来配置超时的策略和指定值,以便在构建时间过长时停止构建,有 3 个可以配置的参数:
1)Time-out strategy:可以使用的策略有 5 种:
- Absolute(绝对的):根据固定的超时时间中止构建;
- Deadline(截止时间):截止时间格式为 HH:MM:SS
- Elastic(弹性):定义终止构建前的等待时间,以最后 n 次成功构建的平均持续时间的百分比表示
- Likely stuck(可能卡住):当任务运行的时间比以前多很多倍时,终止构建
- No Activity(没有活动):自上次日志输出后,经过指定的秒数后触发超时
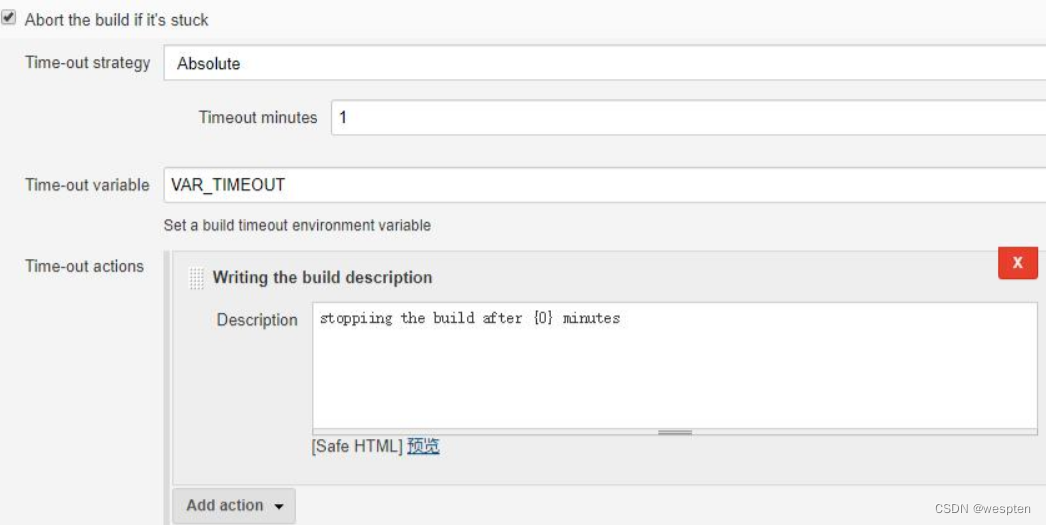
2) Time-out variable:定义一个自动填充超时的环境变量,以 ms 为单位,可以在任务中引用此变量,如:
3) Time-out actions:用来定义超时之后采取的行动,包括终止构建、构建失败以及将信息写入到正在运行任务的描述字段中。
示例:
- Add timestamps to the Console Output
顾名思义,就是在控制台打印执行日志的时候加上时间戳显示,如下:

- 其它构建环境选项
如果安装了其它插件,可能会看到更多的环境选项,比如 Ant、gradle 或者 Maven,需要的话可以单击选项右侧的蓝色问号查看帮助信息即可。
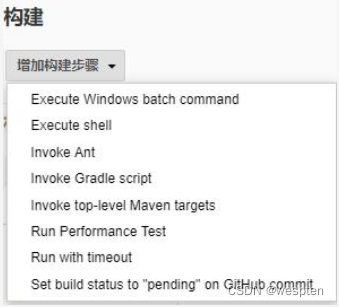
5. 构建
此部分是项目中的主要实现逻辑,根据项目类型的不同,在此配置项目中看到的功能也会有所不同,最常用的就是 shell 命令或者 windows 下的批处理命令。在后续的项目实战中会对此配置做具体的说明。
6. 构建后操作
用来设置在项目执行完毕后做的一些操作,比如,发邮件,将构建结果发布到指定的目录等等。有些是需要安装特定的插件才能看到对应的配置项,如下:
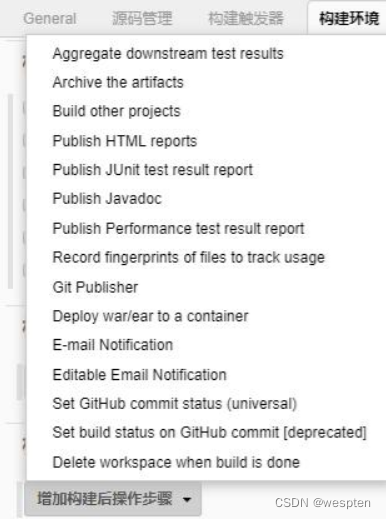
同样地,此部分在后续的项目实战中会对此配置做具体的说明。
11、Maven项目
创建Maven项目:

1. 所有配置项

可以看出,大部分的配置项和自由风格的项目类似,只是将构建的步骤拆分为了 3 个,分别为:Pre Step、Build 和 Post Steps。将一些传统的非 Maven 构建步骤移到 Pre Step 和 Post Steps 中,这两步支持的步骤都是相同的。

2. Build
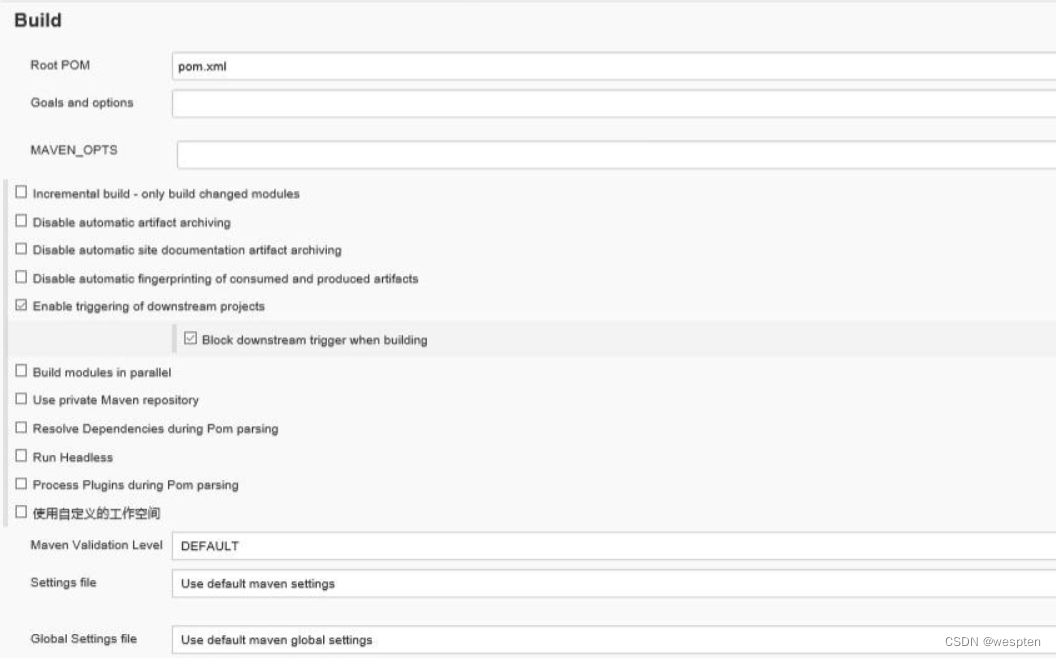
默认使用项目根 POM 文件名,也就是 pom.xml 名,也可以指定实际适使用的具体的文件路径,比如 parent/pom.xml。在 maven 项目中会自动对制品进行归档。
12、流水线
流水线项目是将来主流的 Jenkins 任务实现方式,也是 Jenkins 社区极力推崇的,目的是将任务中的步骤和逻辑使用 Groovy 脚本实现,而不用繁琐的表单配置,更符合程序员的思维。
1. 所有配置项
有一个专门的流水线配置项,其它项可参考自由风格项目中的配置说明。

2. 流水线
有 2 种定义方式,分别为:
Pipeline script :默认值,可以在富文本框中直接输入 pipeline 脚本。
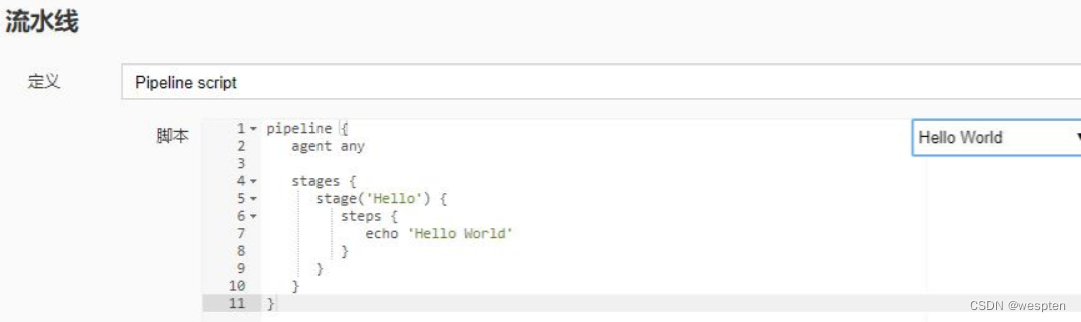
Pipeline script from SCM:需要制指定 Jenkinsfile 的仓库位置轻量级检出项的作用是,开始时只检查 Jenkinsfile 文件而不是整个项目,然后通过 Jenkins file 执行 checkout scm 语句,可避免两次检出整个项目,提升效率。
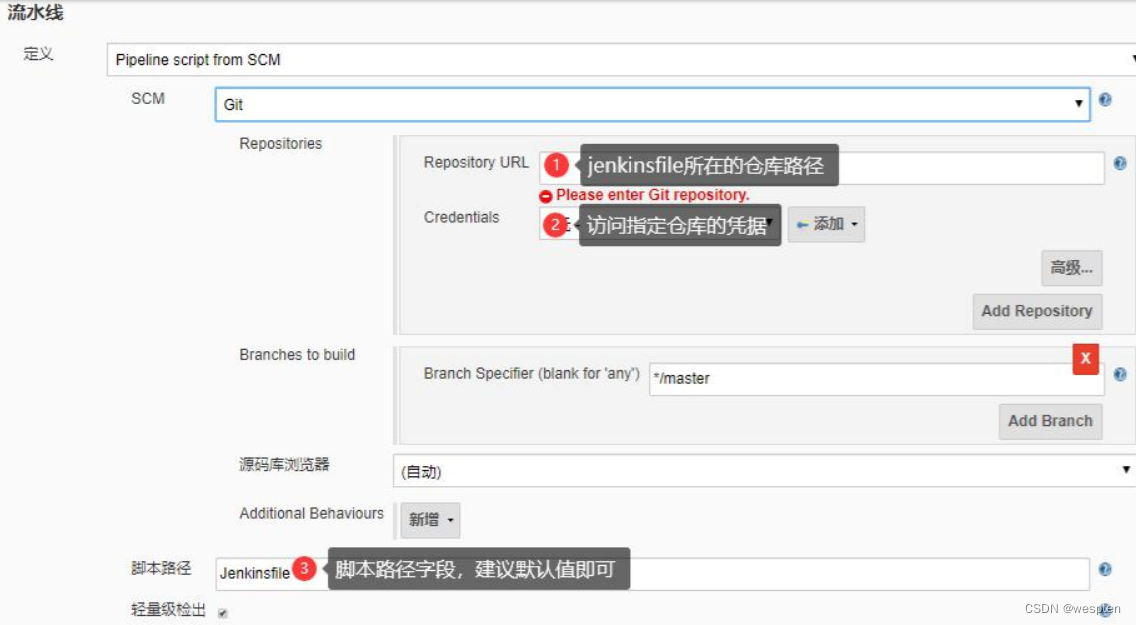
注意:通过配置项目中我们可以看到,在流水线项目中也会有一些简单的表单配置项,比如参数化构建,这些参数可以在流水线部分定义的脚本中进行访问,但是如果使用的是 Jenkins file 的话,文件本身和配置是分开的,使用起来会不方便,这时最好是在 Jenkins file 中定义此功能。
13、多配置项目
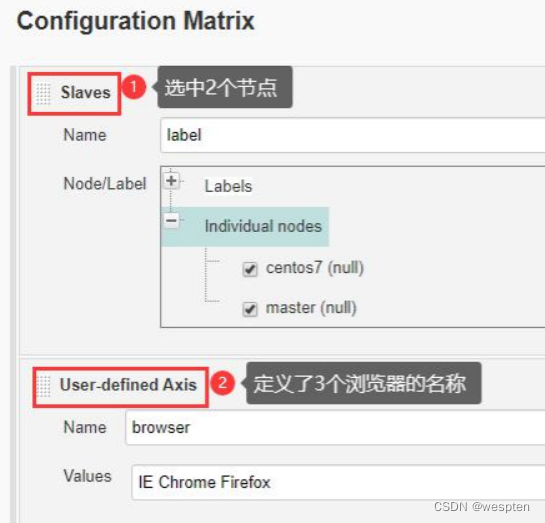
此类型的项目和自由风格的项目配置比较类似,主要是多了一个 Configuration Matrix 项。
此类项目用来做多场景多配置的混合测试,比如说要使用 Chrome、Firefox 和 IE 浏览器分别测试,还要使用 Windows、MAC 等系统运行测试构建。如果没有这种项目类型,那么需要 3*2 也就是 6 个任务来重复做同样的流程。
1. 所有配置项

可以看到多配置的项目和其它项目类似,重点是多了 Configuration Matrix 项。
2. Configuration Matrix
可以在此项中定义 3 种类型的坐标轴,每个坐标轴有 1 个名称,每个名称对应一个环境变量。可以添加到配置矩阵中的坐标轴类型有以下 4 种:
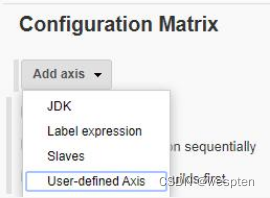
- JDK:用来定义不同的 JDK 版本的标签,如果项目需要在不同的 JDK 下测试可以添加此种来下的坐标轴。
- Label expression:用来使用高级语法选择要包含哪个节点的集合。例如,node1$$node2 表示只有具有这两个标签的节点才有资格包含在内。
- Slaves:指定所使用节点的名称,或者节点的标签。
- User-defined Axis:用户自定义的一组值,用来在构建任务时进行迭代。
示例:
Configuration Matrix 添加 2 个坐标轴,分别为:
构建部分的内容如下:
echo "******************start"
echo "Executing Configuration Matrix %browser% for %label%"
echo "******************end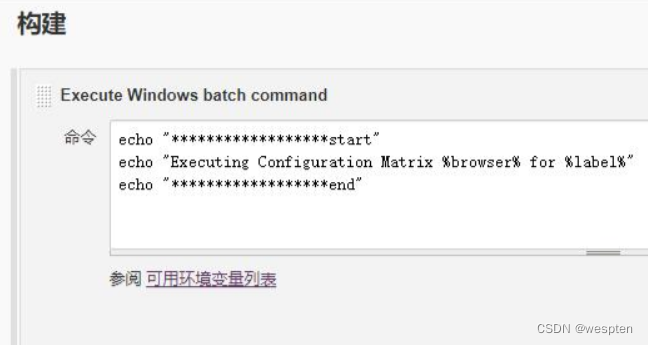
配置成功后,在项目首页看到的任务矩阵如下:

相当于会执行 6 遍,分别使用 6 个不同的配置。
14、Jenkins使用小技巧
1. 查看帮助信息
点击右侧的蓝色问号,这是 Jenkins 的上下文帮助按钮,可以查看详细的帮助信息。
2. 变量的使用
内置环境变量可以在配置 Jenkins Job 的时候用得到,也可以用在 Execute shell、Execute Windows batch command、文本框等加上编辑好的 shell 脚本。
- Windows:%BUILD_NUMBER% %变量名%
- Linux:${BUILD_NUMBER} ,也可以直接使用 $BUILD_NUMBER
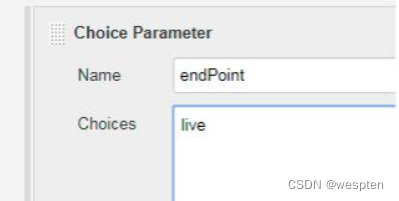
自己定义的参数化(Parameter)在调用时可以直接用 $参数名,比如调用这个时直接 $endPoint。
在 Maven 中使用(参考 Jenkins 内置环境变量的使用):
- Maven:直接使用:${env.WORKSPACE}
- Ant:需要增加 <property environment="env"/> 节点,再使用 ${env.WORKSPACE}
3. 工作空间
在 Jenkins 节点机器的运行目录为:C:\Users\G\.Jenkins\workspace\项目名,如果 Jenkins 的任务上没有用 github 方式拉取代码,而是直接构建运行代码的话,所有运行 job 不会自动在 Jenkins 机器上创建当前这个 Jenkins job 名称的文件夹路径。
4. 永久解决 HTML 文件样式丢失的问题
Jenkins 为了避免受到恶意 HTML/JS 文件的攻击,默认的配置下只允许加载 Jenkins 服务器上托管的 CSS 文件和图片文件 。 默认的安全策略 CSP 设置为 :sandbox; default-src 'none'; img-src 'self'; style-src 'self';
也有一种解决方法是在 Jenkins 的脚本命令行执行一条关闭默认的设置。但是这种方法的缺点就是 Jenkins 关闭之后就会失效,必须重新执行一次该命令。本节介绍一种永久性的解决方法,即使 Jenkins 重启也不用担心。
需要提前安装好以下 2 个插件:
- Startup Trigger:用来在 Jenkins 节点(master/slave)启动时触发构建。
- Groovy:用来在项目构建步骤中直接执行 Groovy 代码。
新建一个自由风格的项目,在构建触发器选项中选中 Build when job nodes start:
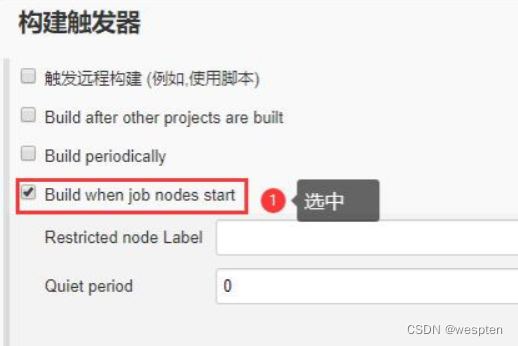
在构建步骤中选择 Execute Groovy script,输入以下命令:
System.setProperty("hudson.model.DirectoryBrowserSupport.CSP","script-src 'unsafe-inline'")
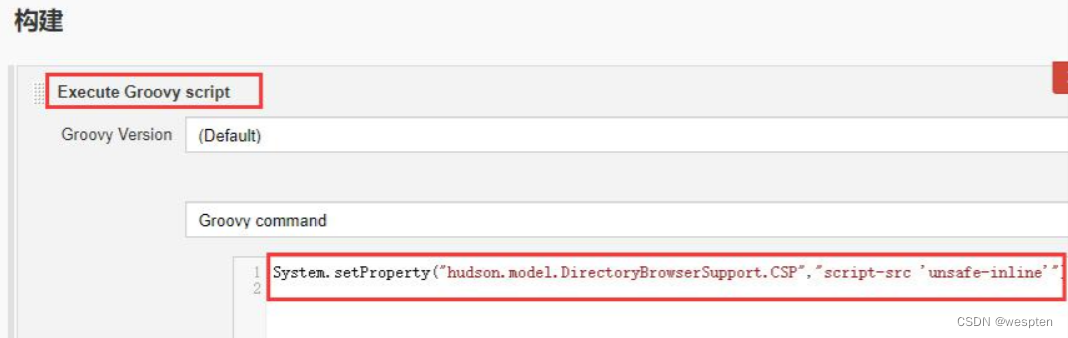
保存即可。相当于把脚本的执行集成在项目中,这样就不用担心 Jenkins 重启了。
5. 忘记管理员密码
如果不小心忘记了管理员密码,我们该怎么办呢?过程如下:
1)修改<passwordHash>
进入到 C:\Users\kongsh\.Jenkins\users\admin 目录下,打开 config.xml 文件,找到 <passwordHash> 所在的行,如下:
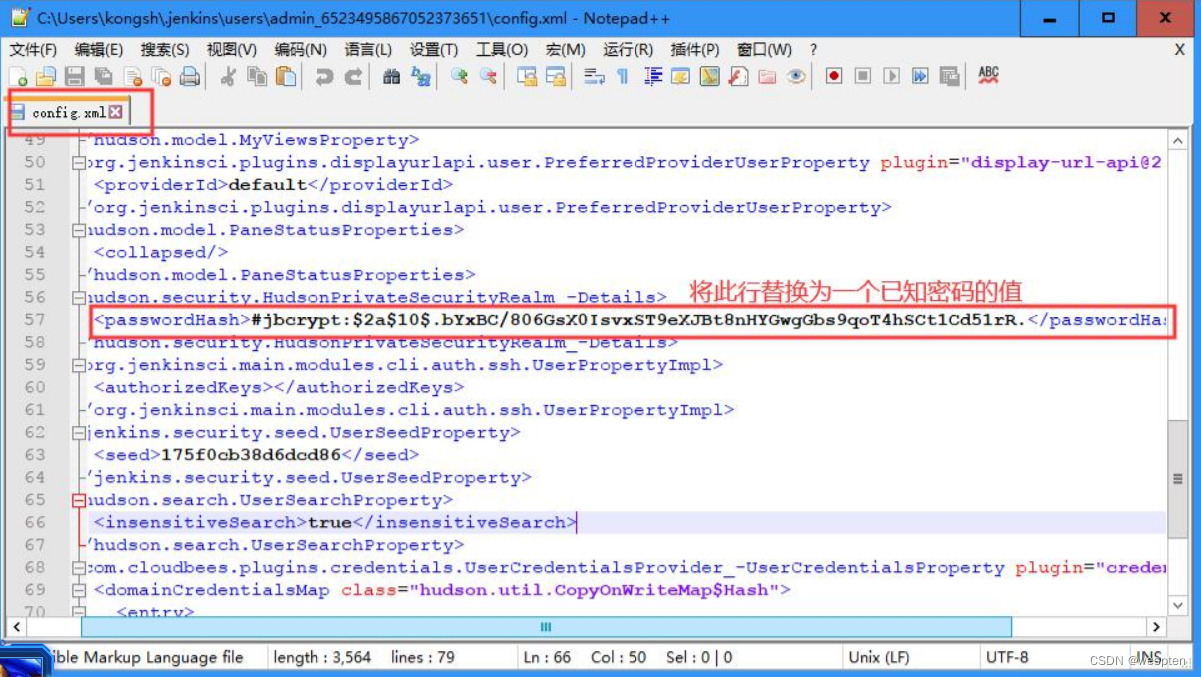
将其替换为一个已知密码的值,比如:<passwordHash>#jbcrypt:$2a$10$eJAMBW3qb/ijrFsSxkJnDOB747e0mFWSR03UmLCn96E4N7vL5BYzC</passwordHash>,这样密码就会被重置为 123456。
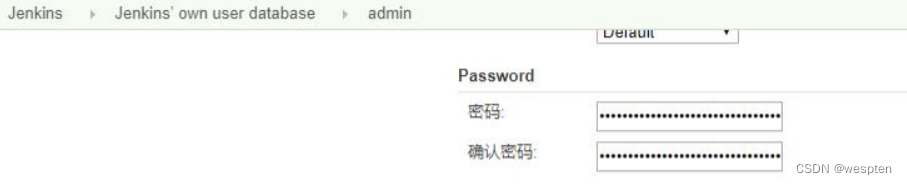
2)重启 Jenkins 服务
3)进入浏览器界面修改新的管理员密码
Manage Jenkins → Manage Users → admin 右侧设置齿轮图标,设置新的管理员密码,应用、保存即可。

五、Jenkins Pipeline语法
1、pipeline简介
Jenkins2.x 的核心是使用 pipeline 来构建项目,也就是流水线,将 Jenkins1.0 版本中基于表单的配置信息比如 JDK/SVN 以及参数的配置都转变成了代码,即 pipeline as Code。
传统的表单方式有以下缺点:
- 需要大量的 web 表单交互,有时候需要进行很多次的切换,比较繁琐。
- 不能进行版本管理。
- 可重用性差。
而采用 pipeline 的方式,项目的所有流程和配置都写在 Jenkinsfile 文件中,移植时只要将此文件拷贝即可,无须繁琐的配置;而且 pipeline 可以很直观的看到每个阶段的构建情况,再结合上 Blue Ocean 可以进行强大的流水线监控,方便、直观、及时地获取到构建结果。
在 Jenkins 中,把每一段管道比作是不同的 Job,不同 Job 的链接就需要用到 Pipeline 插件。Jenkins 的工作流程可以简单概括为 build-deploy-test-release,每个流程之间我们都可以用 Pipeline 来连接,大致如下效果图:

Jenkins pipeline 是基于 Groovy 语言实现的一种 DSL(Domain-Specific Language,领域特定语言),可以理解为适用于 Jenkins 的编程语言。
pipeline 支持两种语法:脚本式语法(scripted pipeline)和声明式语法(declarativepipeline)。早期的 pipeline plugin 只支持脚本式语法,声明式语法是在 pipeline2.5 之后新增加的,相对而言,声明式语法更简单,即使没有 groovy 语言的基础也能进行基本的操作。Jenkins 社区的动向也是偏向于声明式语法,所以以声明式语法为例进行说明。
2、pipeline基本语法
pipeline{
agent any
stages{
stage('build'){
steps{
echo 'build steps'
}
}
}
}以上是最最基本的一个 pipeline 结构,具体的含义如下:
- pipeline:后面用一对 {} 也就是闭包,表示整条流水线,里面是流水线中具体的处理流程。
- agent:用来指定整个流水线或者某一个阶段在哪个机器节点上执行。如果是 any 的话表示该流水线或者阶段可以运行在任意一个定义好的节点上。这个指令必须要有,而且一般会放在顶层 pipeline{...} 的下一层,在 stage{...} 中也可以使用 agent,但是一般不这么用。
- stages:后面跟一对 {},类似于一个容器,封装了一个或多个 stage,也就是将不同的阶段组织在一起;例如 build 是一个 stage, test 是第二个 stage,deploy 是第三个 stage。通过 stage 隔离,让 Pipeline 代码读写非常直观。
- stage:后面跟一对 {},流水线中的某个阶段,其中封装了多个执行步骤,每个阶段都需要有个名称。
- steps:封装了在一个阶段中的一个或多个具体的执行步骤。在本例中 echo 就是一个步骤。
接下来我们一一介绍上面提到的 pipeline 中包含的最基本的几个 section,以及另外一些可选的 section。
3、agent
用来指定 pipeline 的执行节点,一般放在顶层的 pipeline 中。agent 部分支持几种不同的参数以此来适应不同的应用场景。
1. any
作用:表示可以在任意的节点或者代理上执行此 pipeline。
代码示例:
pipeline {
agent any
}2. none
作用:在 pipeline 的顶层应用中使用此参数的话表示不会为整个 pipeline 指定执行的节点,需要在每个 stage 部分用 pipeline 指定执行的节点。
代码示例:
pipeline {
agent none
stages {
stage('test'){
agent {
label '具体的节点名称'
}
}
}
}3. label
作用:在标签指定的可用代理上执行 pipeline 或 stage,比如 agent {label "label"} 表示流水线或者阶段可以运行在任何一个具有 label 标签的代理节点上。
代码示例:
pipeline {
agent {
label '具体的一个节点 label 名称'
}
}4. 自定义工作空间
作用:代理节点的标签新增了一个特性,允许为流水线或阶段指定一个自定义的工作空间,用 customWorkspace 指令来指定。和 label 功能类似。
代码示例:
pipeline {
agent {
node {
label "xxx-agent-机器"
customWorkspace "${env.JOB_NAME}/${env.BUILD_NUMBER}"
}
}
}此处的 node 可以换成 label,但是为了避免 Docker 代理节点中的 label 用法混淆,一般用 node 表示。这种类型的 agent 在实际工作中的使用场景是最多的。
测试代码:
pipeline {
agent {
node {
label "xxx-agent-机器"
customWorkspace "${env.JOB_NAME}/${env.BUILD_NUMBER}"
}
}
stages {
stage ("Build") {
bat "dir" //执行windows下的bat命令
}
stage ('test') {
echo ${JAVA_HOME} //打印JAVA_HOME
}
}
}可以将以上代码段放到 Jenkinsfile 中或者在 Jenkins ui 中去执行。
4、post
post 部分用来指定 pipeline 或者 stage 执行完毕后的一些操作,比如发送邮件、环境清理等。post 部分在 Jenkins 代码中是可选的,可以放到顶层,也就是和 agent 同级,也可以放到stage 中。在 post 代码块中支持多种指令,比如:always、success、failure、aborted、unstable、changed 等等,我们一一来介绍。
1. always
作用:当 pipeline 执行完毕后一定会执行的操作,不管成功还是还失败。比如说文件句柄的关闭或者数据库的清理工作等。
代码示例:
pipeline {
agent any
stages {
stage ("Build") {
bat "dir"
}
}
post {
always {
script {
//写相关清除/恢复环境等操作代码
}
}
}
}2. success
作用:当 pipeline 执行完毕后且构建结果为成功状态时才会执行的操作。
代码示例:
pipeline {
agent any
stages {
stage ("Build") {
bat "dir"
}
}
post {
success{
script {
//写相关清除/恢复环境等操作代码
}
}
}
}3. failure
作用:当 pipeline 执行完毕后且构建结果为失败时执行的操作,比如发送错误日志给相关人员。
4. changed
作用:当 pipeline 执行完毕后且构建状态和之前不一致时执行的操作。
5. aborted
作用:当 pipeline 被手动终止时执行的操作。
6. unstable
作用:当 pipeline 构建结果不稳定时执行的操作。
7. 以上命令的组合
在 post 部分是可以包含多个条件块,也就是以上命令的组合,比如:
pipeline {
agent any
stages {
stage ("Build") {
bat "dir"
}
}
post {
always {
script {
echo "post always "
}
}
success{
script {
echo "post success"
}
}
failure{
script {
echo "post failure"
}
}
}
}5、stages/stage/steps
- stages:Pipeline 中单个阶段的操作封装到 stages 中,stages 中可以包含多个 stage。
- stage:一个单独的阶段,实际上所有实际工作都将包含在一个或多个 stage 指令中。stage{…} 里面有一个强制的字符串参数,用来描述这个 stage 的作用,这个字符串参数是不支持变量的,只能你自己取名一个描述字段。
- steps:一个 stage 下至少有一个 steps,一般也就是一个 steps。可以在 steps 下写调用一个或者几个方法,也就是两三行代码。
有以下注意点:
- 在声明式 pipeline 脚本中,有且只有一个 stages。
- 一个 stage{…} 必须有且只有一个 steps{…}, 或者 parallel{…} 或者 stages {…},多层嵌套只支持在最后一个 stage{…} 里面。
- 在声明式语法中只支持 steps,不支持在 steps {…} 里面嵌套写 step{…}。
代码示例:
pipeline {
agent any
stages {
stage('build') {
steps { echo 'build' }
}
stage ('test') {
steps { echo "${JAVA_HOME}" } //打印 JAVA_HOME
}
}
}6、environment
作用:通过键值对的方式定义整个 pipeline 或者 stage 中使用的环境变量。
代码示例:
pipeline {
agent any
environment {
test = true
}
stages {
stage('build') {
steps {
script{
if(test == true) {
// 一些特定的操作
echo 'sucess'
}
}
}
}
}
}7、options
options 指令在 pipeline 也是可选的。用来指定一些属性和值,这些预定义的选项可以应用到整个流水线中,可以理解为在 Jenkins web 表单里一个项目的基本配置中定义的事情。
1. retry
作用:表示 Jenkins 中的 job 执行失败后继续进行几次尝试。可以放到顶层的 pipeline 中也可以放到 stage 中。注意:这个次数是指总次数,包括第 1 次失败。
pipeline {
agent any
options {
retry(3)
}
stages {
stage('test') {
steps {
// 步骤
}
}
}
}2. buildDiscarder
作用:保留指定数量的流水线执行,包含控制台输出以及制品。当 pipeline 指定完毕后,会在工作空间中保存制品和执行日志,如果执行次数太多的会话,这些内容会占用很多的存储空间,使用该参数后会只保留最近指定次数的构建结果,自动清理之前的内容。
代码示例:
pipeline {
agent any
options {
buildDiscarder(logRotator(numToKeepStr:'3'))
}
stages {
stage('test') {
steps {
// 步骤
}
}
}
}说明:logRotator 元素并没有什么作用,主要是历史原因。
3. checkoutToSubdirectory
作用:指定检出到工作空间的子目录中。Jenkins 从代码管理库中拉取代码时默认检出到工作空间的根目录,如果想修改的话可以用此参数。
代码示例:
pipeline {
agent any
options {
checkoutToSubdirectory('subdir')
}
stages {
stage('test') {
steps {
// 步骤
}
}
}
}4. disableConcurrentBuilds
作用:阻止 pipeline 同时执行。默认的情况下 pipeline 是可以同时执行多次的,如果为了防止同时访问共享资源或者防止一个较快的并发执行把较慢的并发执行给碾压的场景可以使用此参数禁止并发执行。
代码示例:
pipeline {
agent any
options {
disableConcurrentBuilds()
}
stages {
stage('test') {
steps {
// 步骤
}
}
}
}5. timeout
作用:为流水线的执行设置一个超时时间。如果超过这个值就会把整个流水线终止。时间单位可以是 SECONDS(秒),MINUTES(分钟),HOURS(小时)。
代码示例:
pipeline {
agent any
options {
timeout(time:10, unit:'HOURS')
}
stages {
stage('test') {
steps {
// 步骤
}
}
}
}6. skipDefaultCheckout
作用:删除隐式的 checkout scm 语句,因此可以从 Jenkinsfile 定义的流水线中跳过自动的源码检出功能。
代码示例:
options {
skipDefaultCheckout()
}8、parameters
parameters 用来在 pipeline 中实现参数化构建,也就是根据用户指定的不同参数执行不同的操作。pipeline 支持很多种类型的参数,有字符串参数,布尔选择参数,下拉多选参数等。
1. 字符串参数
作用:开始构建前需要用户输入字符串,比如 ip 或者 url。
代码示例:
pipeline {
agent any
parameters {
string(name: 'DEPLOY_ENV', defaultValue: 'release', description: '')
}
}2. 布尔值参数
作用:定义一个布尔类型参数,在执行构建前用户在 Jenkins UI 上选择是还是否,选择是执行这部分代码,否则会跳过这部分。比如:执行完毕后环境的清理工作。
代码示例:
pipeline {
agent any
parameters {
booleanParam(name: 'DEBUG_BUILD', defaultValue: true, description: '')
}
}3. 文本参数
作用:支持写很多行的字符串。
代码示例:
pipeline {
agent any
parameters {
text(name: 'Welcome_text', defaultValue: 'One\nTwo\nThree\n',description: '')
}
}4. 选择参数
作用:支持用户从多个选择项中选择一个值用来表示这个变量的值。比如:选择服务器类型、选择版本号等。
代码示例:
pipeline {
agent any
parameters {
choice(name: 'ENV_TYPE', choices: ['test', 'dev', 'product'], description: 'testmeans test env,….')
}
}5. 文件参数
作用:参数化构建 UI 上提供一个文件路径的输入框,Jenkins 会自动去根据用户提供的网络路径去查找并下载。
代码示例:
pipeline {
agent any
parameters {
name: 'FILE', description: 'Some file to upload')
}
}6. 密码参数
作用:密码(password)参数就是在 Jenkins 参数化构建 UI 提供一个暗文密码输入框。
例如,需要登录到服务器做自动化操作,为了安全起见,就不能用名为的 string 类型参数,而是 password 方式。
代码示例:
pipeline {
agent any
parameters {
password(name: 'PASSWORD', defaultValue: 'test', description: 'A secret password')
}
}测试执行:
注意:
保存之后,左侧菜仍然单是 Build now,而并不是 Build with Parameters,这个是正常的,需要先点击 Build now,先完成第一个构建,Jenkins 第二个构建才会显示代码中的三个参数。刷新之后,就可以看到参数化构建这个菜单。

9、tool
作用:定义自动安装和放置工具的路径。
对于 agent none,这个关键字将被忽略,因为没有任何节点或者代理可以用来安装工具。此指令主要是为了三大工具(jdk、gradle、maven)提供环境变量服务。一旦配置完成,tools 指令可以让我们指定的工具需要在我们已经选择的代理节点上自动安装在配置路径下。
代码示例 1:
pipeline {
agent any
tools {
jdk 'jdk1.8'
}
stages {
stage('test') {
steps {
sh 'java -version'
}
}
}
}说明:
tools {
jdk 'jdk1.8'
}左侧的 jdk 是流水线模型中定义的特殊字符串,目前,在声明式流水线中可以指定的合法的工具类型如下:ant、git、gradle、jdk、maven、jgit 等。
右侧的 jdk8 映射的是全局工具配置中的名称字段(管理 Jenkins → Global ToolConfiguration 中预配置)。例如,上面代码我写了 jdk1.8,那么必须在 Jenkins 管理-->全局工具配置中有别名为 jdk1.8 配置。
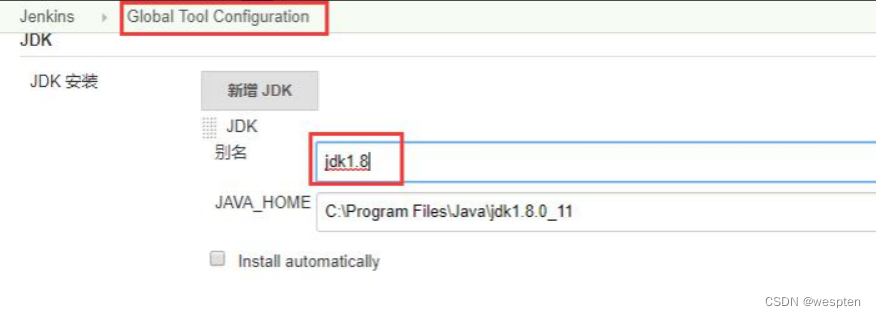
一旦这样设置后,jdk 工具会被自动安装到指定的路径下,然后我们可以在流水线步骤中简单的使用 jdk1.8 字符串替代 JAVA_HOME 路径,Jenkins 会把它映射到我们系统中安装的 JDK。
代码示例 2:
pipeline{
agent any
parameters {
string(name: 'gradleTool', defaultValue: 'gradle3', description: 'gradle version')
}
tools{
gradle "${params.gradleTool}"
}
}说明:如果需要输入一个特定的版本来使用,这个 tools 指令可以使用一个参数的值。
注意:当前生命式语法有一个局限就是当这个流水线第一次运行时,Jenkins 不能识别出该构建需要一个参数,需要先手动构建一次。
10、when
when{…} 是写在 stage{…} 里面一层条件控制,允许 pipeline 根据给定的条件来决定是否执行某个阶段。when 指令必须至少包含一个条件,也可以含多个条件,这与子条件嵌套在一个 allOf 条件中一样。
更复杂的条件结构可使用嵌套条件建:not,allOf 或 anyOf,嵌套条件可以嵌套到任意深度。下面来看看 when{…} 支持的一些内置条件命令。
1. branch
作用:当正在构建的分支与给出的分支模式匹配时执行。注意,仅适用于多分支 pipeline。
代码示例:
when { branch 'master' }
2. environment
作用:当指定的环境变量与给定的值相同时执行。
代码示例:
when { environment name: 'DEPLOY_TO', value: 'production' }
3. expression
作用:当给定的 Groovy 表达式返回 true 时执行。
代码示例:
when { expression { return params.DEBUG_BUILD } }
4. not
作用:当嵌套条件为 false 时执行,必须包含一个条件。
代码示例:
when { not { branch 'master' } }
5. allOf
作用:当所有嵌套条件都为真时执行,必须至少包含一个条件。
代码示例:
when {
allOf {
branch 'master';
environment name: 'DEPLOY_TO',
value: 'production'
}
}6. anyOf
作用:当至少一个嵌套条件为真时执行,必须至少包含一个条件。
代码示例:
when { anyOf { branch 'master'; branch 'staging' } }
7. buildingTag
作用:如果 pipeline 所执行的暧昧被打了 tag 则执行。
代码示例:
when { buildingTag() }
测试代码:
pipeline {
agent any
environment {
quick_test = false
}
stages {
stage('Example Build') {
steps {
script {
echo 'Hello World'
}
}
}
stage('Example Deploy') {
when {
expression {
return (quick_test == "true" )
}
}
steps {
echo 'Deploying'
}
}
}
}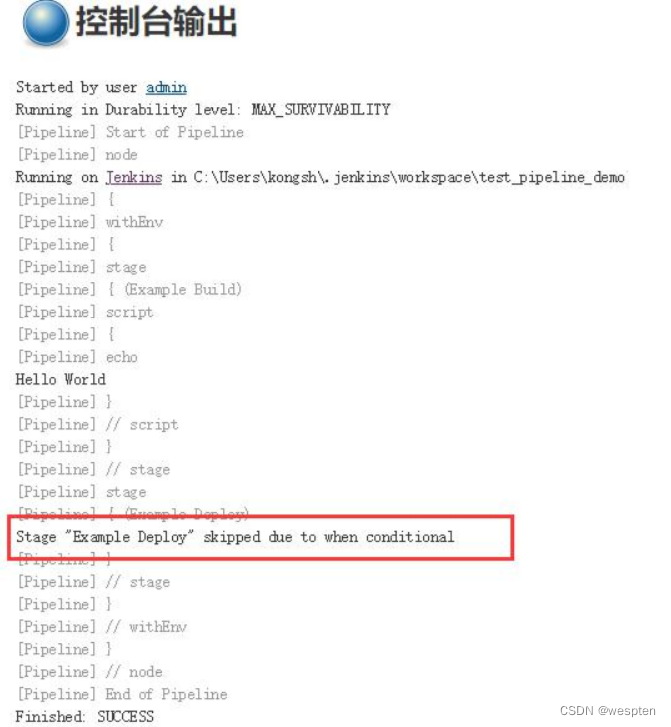
environment 里面定义了一个键值对“quick_test = false”, 第二个 stage('ExampleDeploy') 因为不满足 when{…}里面的条件就不会执行。
11、scripts
作用:用来在声明式流水线中写非声明式代码的地方,允许你定义一定代码块/闭包用来囊括非声明式的语法,其实就是在 script 中写 Groovy 代码。比如 if...else 等语句。
代码示例:
pipeline {agent any
stages {
stage('test') {
steps {
script{
def browsers=['chrome','firefox']
for(int i=0;i<browsers.size();i++){
echo "testing the ${browsers[i]} browser"
}
}
}
}
}
}12、triggers
用来指定使用什么类型的触发器来自动启动流水线构建。注意:这些触发器并不适合用于多分支流水线、github 组织等类型的任务。我们介绍 4 种不同的触发器:cron、pollSCM、upstream 以 githubPush。
1. cron
作用:按照指定的周期有规律的执行流水线,就是闹钟一样,一到时间点就执行。
代码示例:
pipeline {
agent any
triggers {
cron ('0 0 * * *')
}
stages {
stage('test') {
steps {
// 步骤
}
}
}
}说明:
cron 包含 5 个字段,这些字段以空格或者 Tab 键分割,用来指定多久去执行一次构建。格式为:
- MINUTES:一小时内的分钟,取值范围(0-59)
- HOURS:一天内的小时,取值范围(0-23)
- DAYMONTH :一个月中的某一天,取值范围(1-31)
- MONTH :月份,取值范围(1-12)
- DAYWEEK:一周中的星期几,取值范围(0-7)。0 和 7 都表示星期日
还可以使用特殊的字符一次指定多个值:
- *:匹配所有的值
- N:匹配 M-N 之间的值
- M-N/<VALUE>或者*/<value>:表示每隔<value>,比如*/5 每隔 5 分钟
- A,B,...Z:多个枚举值
- H:可以用于任何字段,用来告诉 Jenkins 在一个范围内使用该项目名的散列值计算出一个唯一的偏移量,这个偏移量于范围内的最小值相加后定义为实际的执行时间。注意:这个值是项目名的散列值,那么每一个值都与其他项目是不同的,但是同一个项目的值是不变的。
H 符号在实际的项目中是非常推荐使用的,因为在大型的项目中可能存在多个同一时刻需要执行任务,比如(0 0 * * *),都需要在半夜零点启动,那么使用 H 后,从散列算法获得的偏移量,就可以错开执行具有相同 cron 时间的项目。
2. upstream
作用:由上游的任务构建完毕后触发本任务的执行。比如说需要先执行完编译打包和发布后才能执行测试脚本。
代码示例:
triggers {
upstream threshold: 'UNSTABLE', upstreamProjects: 'jobA,jobB'
}说明:
upstreamProjects:指定上游任务的名称,有多个任务时用逗号分隔 。
threshold:指定上游任务的执行结果是什么值时触发,是枚举类型 hudson.model.Result 的某一个值,包括:
- SUCCESS:构建成功;
- UNSTABLE:存在一些错误,但不至于构建失败;
- FAILURE:构建失败。
注意:需要手动触发一次 pipeline 的执行,让 Jenkins 加载 pipeline 后,trigger 指令才会生效。
3. pollSCM
作用:轮询代码仓库,也就是定期到代码仓库询问代码是否有变化,如果有变化就执行。语法和 cron 是一样的。理论上轮询的越频繁越好,但是在一定的构建时间内,如果有多次代码提交,当构建失败时无法马上知道是哪一次的提交导致的,所以这个指令不是很常用,一般是用 webhook,当有代码提交的时候主动通知到 Jenkins。
代码示例:
pipeline {
agent any
triggers {
pollSCM('h/5 * * * *')
}
stages {
stage('test') {
steps {
// 步骤
}
}
}
}4. Generic Webhook Trigger
需要安装 Generic Webhook Trigger(简称 GWT)插件才能使用,安装方式见 3.3 节。安装完之后,Jenkins 会暴露一个 API:http://<Jenkins_URL>/generic-webhook-trigger/invoke,当 GWT 插件接收到 JSON 或者 XML 的 HTTP POST 请求后,根据请求的参数和 Jenkins 中项目的匹配情况来决定执行哪个 Jenkins 项目。注意:项目创建完成后,一定要手动执行一次,这样 pipeline 的触发条件才会生效。
1)Generic Webhook Trigger 触发条件的结构
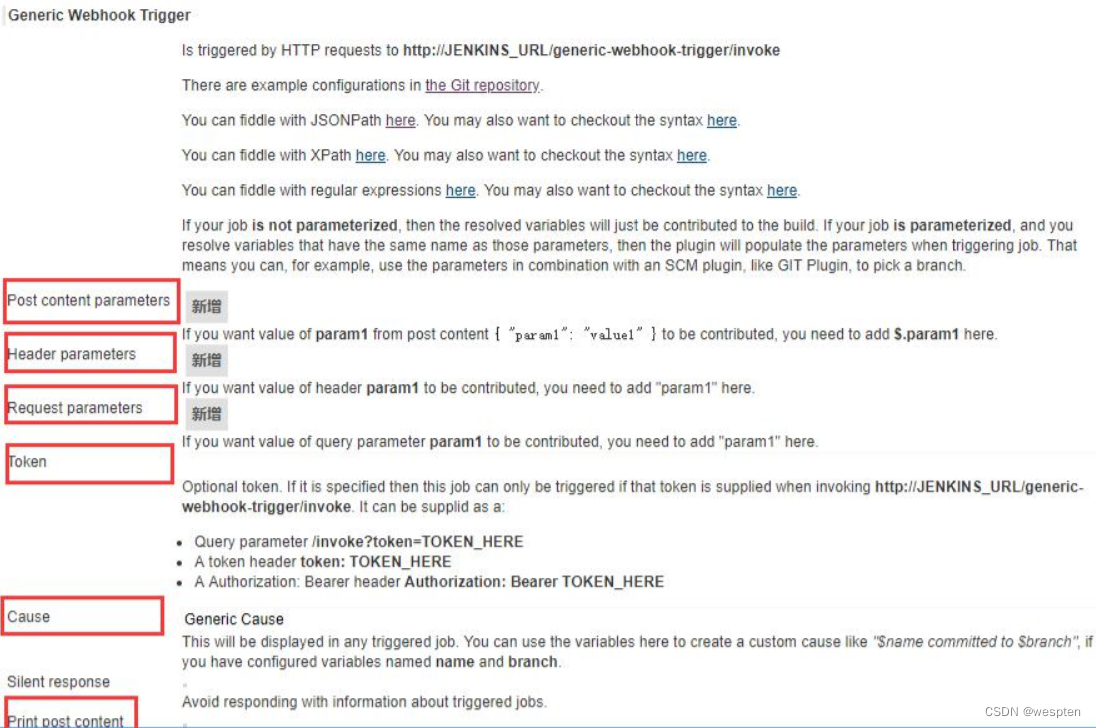
代码格式:
triggers {
GenericTrigger
causeString: 'Generic Cause',
genericHeaderVariables: [[key: 'header', regexpFilter: '']],
genericRequestVariables: [[key: 'request', regexpFilter: '']],
genericVariables: [[defaultValue: '', expressionType: 'XPath', key: 'ref', regexpFilter:'', value: '$.ref']],
printContributedVariables: true,
printPostContent: true,
regexpFilterExpression: '',
regexpFilterText: '',
token: 'secret'
}总结起来可以分为 5 部分:
- genericVariables/genericHeaderVariables/genericRequestVariables:从 HTTP POST 请求提取参数。
- token:用于标识待触发的 Jenkins 项目。
- regexpFilterExpression/regexpFilterText:根据请求参数判断是否触发 Jenkins 项目的执行。
- printContributedVariables/printPostContent/causeString:日志打印控制。
- webhook:响应控制。
2)提取请求参数
genericVariables:提取 POST body 中的请求参数
用法:
genericVariables: [[defaultValue: '', expressionType: 'XPath', key: 'ref', regexpFilter: '',value: '$.ref']]
说明:
- expressionType: 可选,'XPath'默认是 JSONPath,采用默认值的话不会有此参数,还可以设置为 XPath。
- value:JSON 表达式或者 XPath 表达式,取决于 expressionType 的类型。
- key:一个变量名,用来存储从 POST body 提取出的值,可以用于 pipeline 其它步骤。
- defaultValue:可选,当没有提取到时使用此值返回。
- regexpFilter:可选,过滤表达式,用来对提取出的值进行过滤。
genericHeaderVariables:从 URL 中提取参数
用法: genericHeaderVariables: [[key: 'header', regexpFilter: '']]
说明:
- key:一个变量名,用来存储从 URL 提取出的值,可以用于 pipeline 其它步骤。
- regexpFilter:对提取出的值进行过滤。
- genericRequestVariables:从 HTTP Header 中提取参数。和 genericHeaderVariables 用法类似。
3)token
用法: token: 'secret'
说 明 : 用 来 标 识 一 个 pipeline 在 Jenkins 中 的 唯 一 性 。 当 Jenkins 接 收 到generic-webhook-trigger/invoke 接口的请求时,会将请求传递给 GWT 插件,GWT 插
件内部会遍历 Jenkins 中所有的项目,找到 Generic Webhook Trigger 配置 token 和请求中相同 token 的项目,触发这些项目的执行。
4)触发请求参数
如果配置了以下 2 项,即使 token 值匹配了,还要继续判断以下条件是否满足,才能真正触发项目的执行。
- regexpFilterExpression:正则表达式。
- regexpFilterText:需要匹配的 key。
5)日志打印控制
- printContributedVariables:布尔类型,打印提取后的变量和变量值。
- printPostContent:布尔类型,打印 webhook 请求信息。
- causeString:字符串类型,用来表示 pipeline 被触发执行的原因,一般引用直接提取的变量。
13、共享库
当 Jenkins 上建立很多个 pipeline 项目的时候,就会有一些公共的代码在每个项目中都要去重复的编写,当这些代码需要做一些扩展或者修改的时候就需要把所有项目中全部改一遍,维护的成本太高,编写的效率太低。比如发送邮件的功能是所有项目都需要的,邮件模板都写在每个 pipeline 项目中的话视觉效果极差。可以使用 pipeline 共享库(shared library)的技术解决这一问题。
1. 共享库的代码结构
共享库有 3 个部分组成:resources 目录、src 目录和 vars 目录。示例如下:
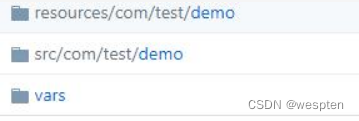
- resources 目录:一般将非 groovy 文件存放在此目录中,比如 XML 文件或者 JSON文件,可以通过外部库中的 libraryResource 步骤加载。
- src 目录:是使用标准 java 目录结构的 groovy 文件,目录中的类称为库类(Library class),这些类必须实现 Serializable 接口,以此保证在流水线停止或者重新启动时能正确的恢复。在流水线中使用 src 目录中的类时,需要注意要使用包名,同时因为是 groovy 代码,所以还要用 script 命令包起来。
- vars 目录:这个是我们要介绍的重点。此目录下存放的可以在 pipeline 中直接调用的全局变量,在 pipeline 中使用的函数名就是文件名,当文件中定义了 call 方法时,它可以像常规流水线步骤一样被调用。这个call方法就相当于这个公共方法的main方法。记住一个原则,一个公共方法,写一个 groovy 类文件,这个 groovy 文件的名称就是这个公共方法的函数名称,在其他 pipeline 项目中调用这个方法就是直接写这个groovy 类名称。
共享库的定义和使用一般分为以下 4 步:
- 根据工作实际需要编写共享库的源代码;
- 将源代码放到代码管理仓库中;
- 在 Jenkins 全局配置中定义共享库;
- 在 pipeline 项目或中 Jenkinsfile 中通过@Library 引用共享库。
2. 编写共享库文件
注意:库文件中包含中文的话一定要保存为 ANSI 格式,否则可能会出现乱码的情况。
我们主要将常用的一些功能封装到 vars 目录来演示,其它高级的用法可以根据实际的需要进一步研究。在 vars 目录下创建 2 个文件,分别名为 command.groovy 的文件,如下:

再创建名为 say.groovy 的文件,内容如下:
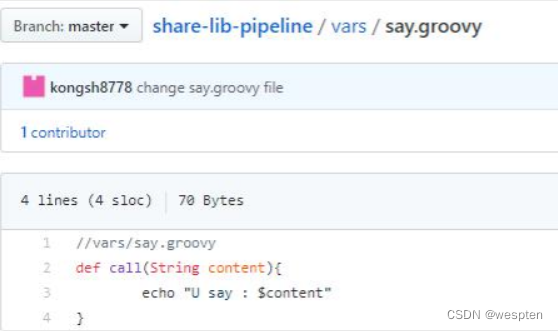
3. Jenkins中配置共享库

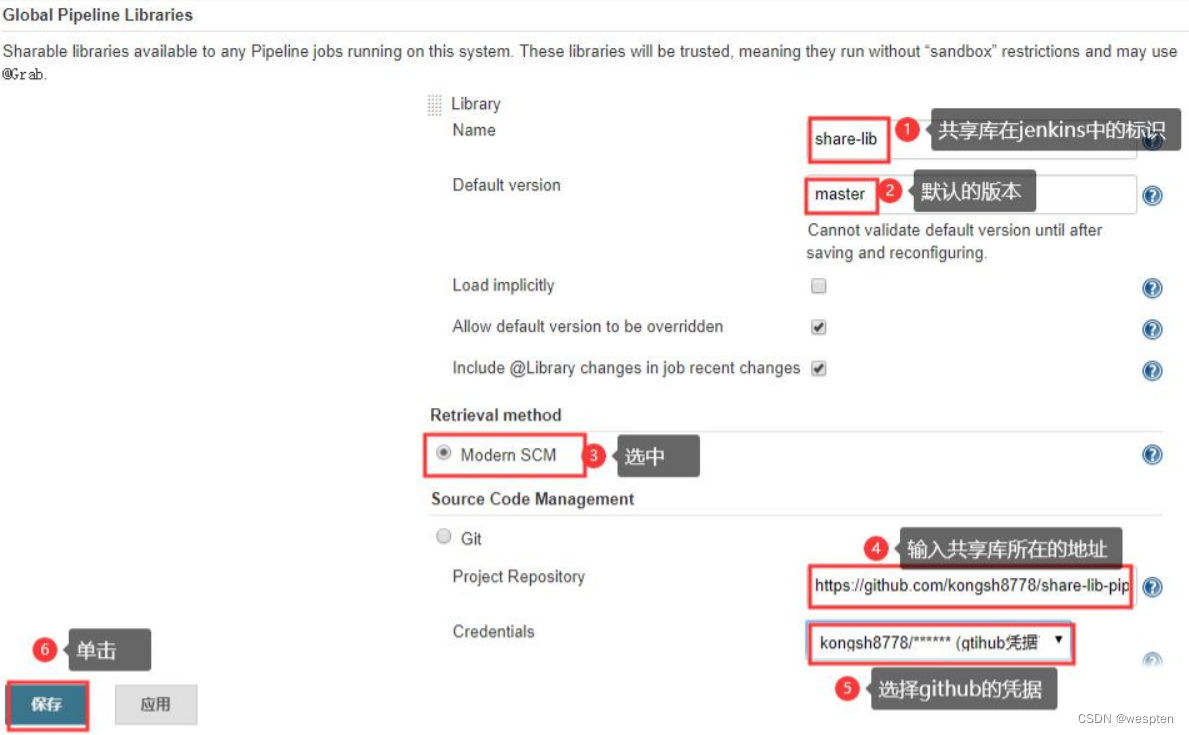
4. 通过@Library 注解使用共享库
在 pipeline 的上方使用@Library 引入共享库。
语法:@Library('<libname>[@<version>]')_ [<import statement>]
说明:
- libname:表示库名,必须要有。
- version:版本号以@开头,可以是代码仓库的标签、分支名或者其他规范。
- _:下划线,表示一次性静态加载 src 目录下所有的代码到 classpath 中,如果没有后面的 import 语句,就必须有此下划线。
- import:可以没有,表示导入指定的方法,如果没有指定表示导入共享库中所有的方法。
使用示例:
//加载一个库的默认版本
@Library('share-lib')_
//加载一个库的指定版本
@Library('share-lib@2.0')_
//加载多个库
@Library(['share-lib@release1.0','myLib'])_
//带导入语句
@Library('share-lib@2.0') import static org.demo.Utils.*14、Pipeline Basic Steps 插件用法
pipeline basic steps 是 pipeline 最基础的一个插件,在安装 pipeline 的时候默认会自动安装,可以在 Jenkins 环境,插件管理下的 installed 下面找到这个插件。
1. readFile
作用:读取指定文件的内容,以字符串的形式返回。
参数说明:
- file:相对于当前工作空间的文件路径,也可以用绝对路径表示;
- encoding:读取文件时的编码方式,默认是根据你当前平台的编码去解析。如果读取的是二进制文件,会采用 Base64 转码的字符串输出。
import hudson.model.*;
println env.JOB_NAME
println env.BUILD_NUMBER
pipeline{
agent any
stages{
stage("init") {
steps{
script {
file = "../../jobs/test_pipeline_demo/demo.txt"
file_contents = readFile file
println file_contents
}
}
}
}
}说明:将 jobs/test_pipeline_demo 目录下的 demo.txt 文件内容读出并打印。
2. writeFile
作用:writeFile 和 readFile 类似,是简单的文本文件进行写操作。如果明确知道是 json 或其他类型文件,那么就可以用其他插件的 readJson 来读取。
参数说明:
- file:相对于当前工作空间的文件路径,也可以用绝对路径表示,路径不存在会创建。
- text:要写入的文件内容。
- encoding:写入文件时的编码方式,默认使用的是当前平台的编码。
3. deleteDir() 方法
作用:默认递归删除 WORKSPACE 下的文件和文件夹,这个方法是没有参数,一般与 dir 一起使用。当执行完每一个 stage 里面的代码,需要在 post{...}里面写一些 clean up 操作,如果这个操作是清空 WORKSPACE 的话,就可以使用 deleteDir()。特别是生产环境,需要节约 Jenkins 服务器的磁盘空间,清空 WORKSPACE 是很有必要的操作。
用法:deleteDir()
4. mail
邮件功能在 Jenkins 中是非常有用的,当构建完成后无论成功还是失败都需要将构建结果通知到相关人员,邮件是最常见的选择。在 pipeline 中发送邮件之前,需要先按照 3.3.7 部分配置完毕。我们可以借助片段生成器查看该插件支持的参数:

需要注意的是 Body MIME Type 这个选项默认就是 text/plain,可以指定为 text/html。
5. dir
作用:切换操作目录。
代码示例:
import hudson.model.*;
println env.JOB_NAME
println env.BUILD_NUMBER
pipeline{
agent any
stages{
stage("dir") {
steps{
println env.WORKSPACE
dir(".."){
echo "pwd"
}
}
}
}
}6. echo("message")和 error("error_message")
作用:echo和 groovy 中的 println 没有任何区别。一般来说使用 echo 就是打印 info debug级别的日志输出用,如果遇到错误,就可以使用 error(“error message”),如果出现执行到 error 方法,Jenkins job 会退出并显示失败效果。
7. fileExists
作用:判断一个文件是否存在,返回值是布尔类型,true 就表示文件存在,false 表示文件不存在。
8. isUnix()
作用:判断当前运行的 Jenkins node 环境是 linux 还是 windows,如果返回是 true 表示是 linux/mac 系统,如果返回是 false,表示当前 Jenkins job 运行在 windows 的系统上。
import hudson.model.*;
println env.JOB_NAME
println env.BUILD_NUMBER
pipeline{
agent any
stages {
stage("isUnix") {
steps{
script {
if(isUnix() == true) {
echo("this Jenkins job running on a linux-like system")
}else {
error("the Jenkins job running on a windows system")
}
}
}
}
}
}9. pwd()
作用:返回当前所在的目录。由于 Jenkins 支持 windows 和 linux,但是 linux 是 pwd,windows 上是 dir。所以这个插件就干脆支持一个方法,统称为 pwd()。
15、git plugin 插件用法
作用:使用 git 命令 checkout 出项目的代码,在 pipeline 代码中,很常见在不同 stage 中使用不同 git 仓库地址的代码,所以 git SCM 操作,可以写在不同 stage 中。
import hudson.model.*;
println env.JOB_NAME
println env.BUILD_NUMBER
pipeline{
agent any
stages{
stage("test") {
steps{
script {
println "test"
}
}
}
stage("git checkout") {
steps{
script {
checkout([$class: 'GitSCM',
branches: [[name: '*/master']],
doGenerateSubmoduleConfigurations: false,
userRemoteConfigs: [[credentialsId: 'gtihub', url:
'https://github.com/kongsh8778/pipelinetest']]])
}
}
}
}
}16、publish html report 插件用法
作用:将测试完成后生成的 html 格式的测试报告展示在 Jenkins 中,无需再切换到目录用浏览器打开。
import hudson.model.*;
pipeline{
agent any
parameters {
string(name: 'BROWSER_TYPE', defaultValue: 'chrome', description: 'Type a
browser type, should be chrome/firefox')
string(name: 'TEST_SERVER_URL', defaultValue: '', description: 'Type the
test server url')
string(name: 'NODE', defaultValue: 'win-anthony-demo', description:
'Please choose a windows node to execute this job.')
}
stages{
stage("test"){
steps{
script{
browser_type = BROWSER_TYPE?.trim()
test_url = TEST_SERVER_URL?.trim()
win_node = NODE?.trim()
echo 'test'
}
}
}
}
post {
always{
script{
publishHTML (target: [
allowMissing: false,
alwaysLinkToLastBuild: false,
keepAll: true,
reportDir: '../../jobs/test_pipeline_demo/report',
reportFiles: '接口测试报告.html',
reportName: "接口测试报告"
])
}
}
}
}插件参数说明:
- reportDir:项目中保存 html 文件的地方,这里写的是一个相对路径写法,相对于当前工作目录的路径,不写的话默认是项目根目录。
- reportFiles:需要展示的 html 文件名,也可以同时写多个 html 文件,逗号隔开。
- reportName:这个参数指定的字符串会在 Jenkins 构建 Job 页面显示的菜单名称,后面会看到这个名称,这个名称可以随意修改。
构建结果:
手动构建后,在项目首页左侧的导航栏可以看到上一步 reportName 值指定的菜单名:
单击接口测试报告,可以看到如下展示结果:

17、借助 Jenkins 生成 pipeline 代码
通过之前的介绍我们对 pipeline 常用的语法有了初步的印象,但是如果完全记住所有的指令还有第 3 方插件的指令也是不太现实的事情。其实 Jenkins 为我们提供了流水线语法在线生成的功能,我们基于表单的格式填好后,会 Jenkins 会帮助我们生成 pipeline 的代码。
进入任意一个 pipeline 项目,单击配置选项:
进入流水线选项卡,单击左下角的流水线语法:
选择“片段生成器”,可以查看所有内置的和已安装插件支持的命令:
以 dir 为例:
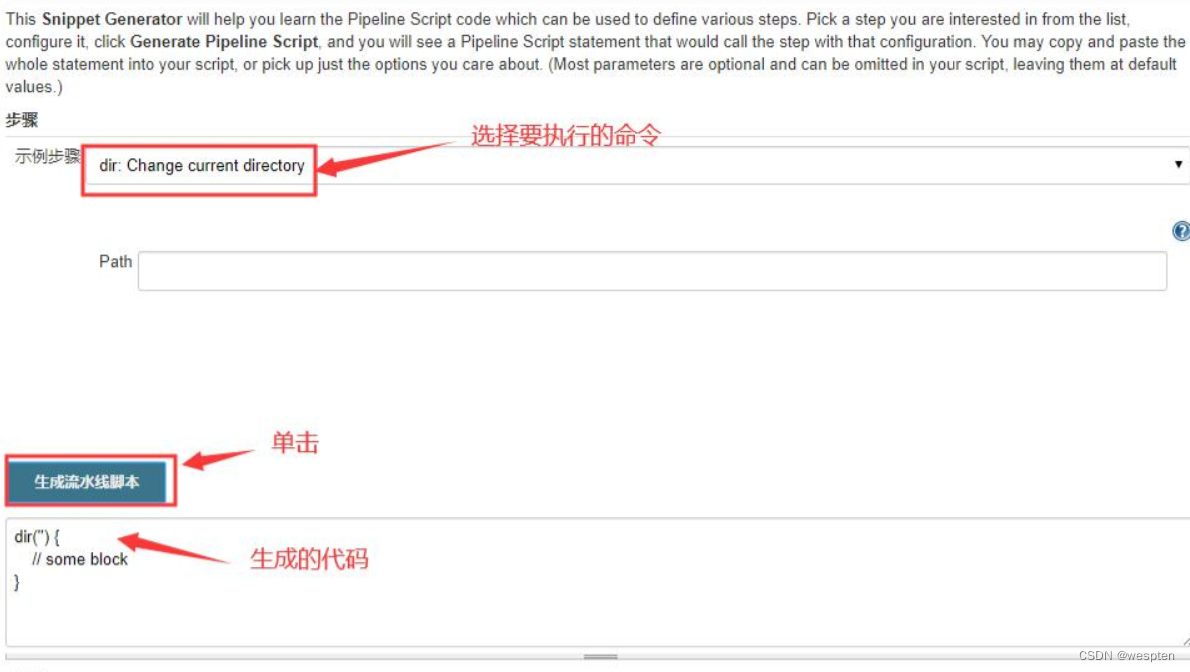
选择“Declarative Pipeline directive”,可以查看声明式 pipeline 的语法:
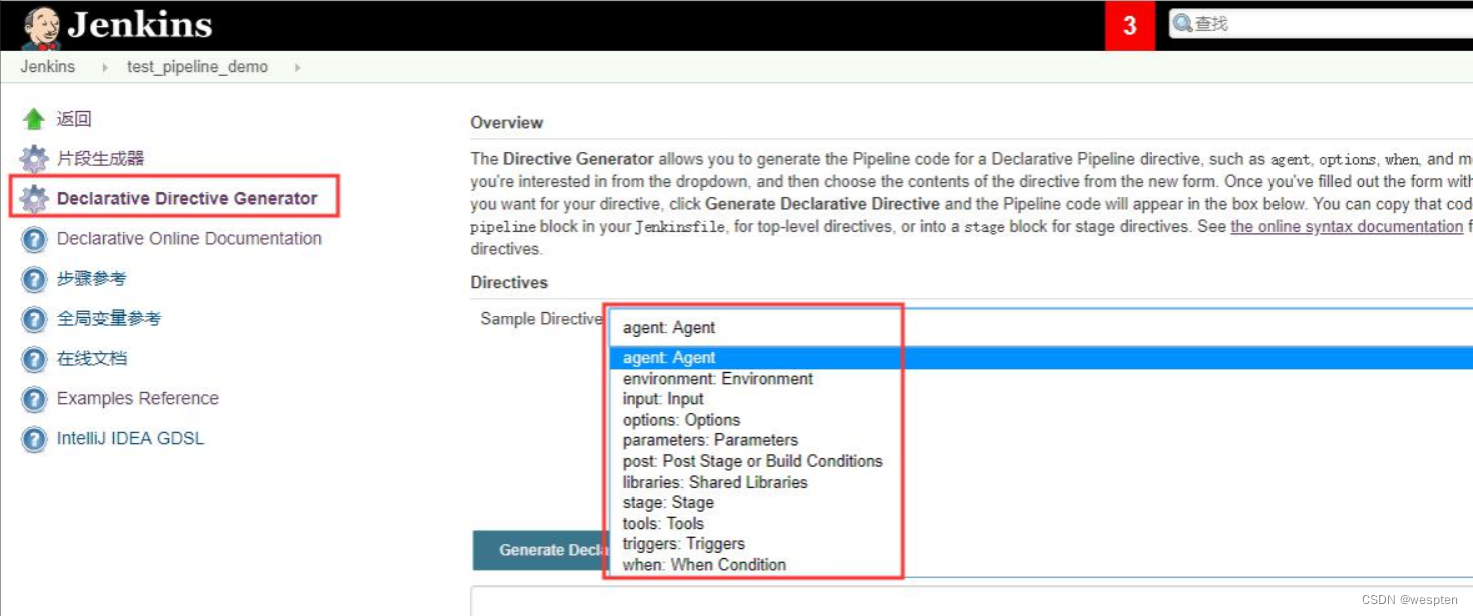
六、Jenkins自动构建与分布式并发构建
1、Jenkins构建原理
Jenkins 的构建成功和脚本执行成功是两个事情,脚本执行成功与否并没有通知 Jenkins,所以会出现明明脚本执行失败了,但是 Jenkins 中显示的依然是 Success。这就是需要我们自行判断脚本的执行结果去通知 Jenkins。
Jenkins 通过退出代码是否为 0 判断 build 是否成功。
2、脚本执行失败立即停止执行
1. 方法 1
在脚本中每一行语句的下一行添加以下语句,表示如果文件执行失败就直接 exit,后面的命令不会再执行。
@IF NOT %ERRORLEVEL% == 0 EXIT /b %ERRORLEVEL%
说明:
- if %errorlevel% >= 值 cmmand 句式时,它的含义是:如果返回的错误码值大于或等于值时,将执行 cmmand 操作;
- if %errorlevel% == 值 cmmand 句式时,它的含义是:如果返回的错误码值等于值时,将执行 cmmand 操作。
一般上一条命令的执行结果返回的值只有两个,"成功"用 0 表示,"失败"用 1 表示。实际上,errorlevel 返回值可以在 0~255 之间。
示例脚本:
py -3 a.py
@IF NOT %ERRORLEVEL% == 0 EXIT /b %ERRORLEVEL%
javac ./java/HelloWorld.java
@IF NOT %ERRORLEVEL% == 0 EXIT /b %ERRORLEVEL%
cd java
@IF NOT %ERRORLEVEL% == 0 EXIT /b %ERRORLEVEL%
java HelloWorld
@IF NOT %ERRORLEVEL% == 0 EXIT /b %ERRORLEVEL%
2. 方法 2
在脚本中每一行语句的末尾追加下述表达式:
&& echo success || exit 1
- &&:只有 && 前面的命令成功时,才会执行该符号后面的命令。
- ||:只有前面命令执行错误时才执行后面命令。
示例脚本:
py -3 a.py && echo success || exit 1
javac ./java/HelloWorld.java && echo success || exit 1
cd java
java HelloWorld && echo success || exit 1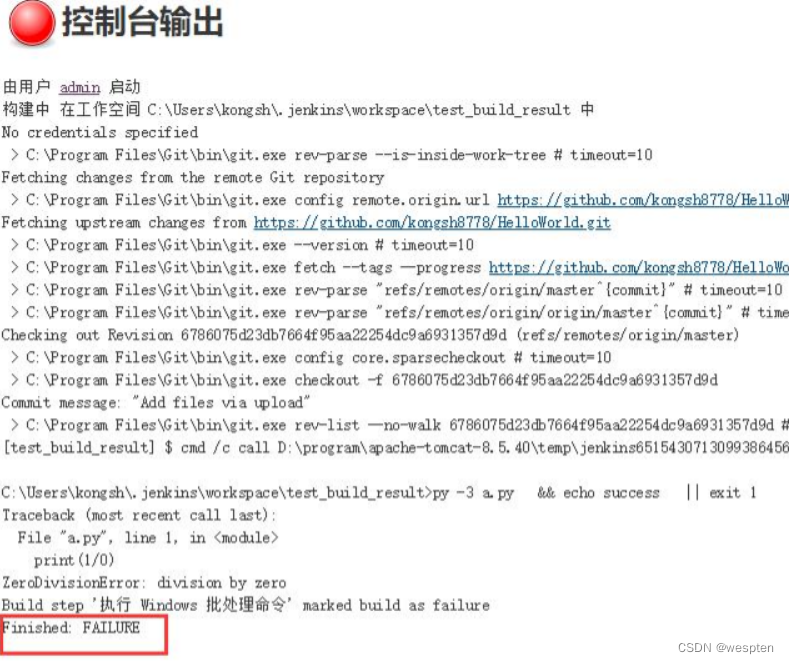
3、脚本执行失败继续后面的执行
执行失败继续后面的执行,但最终的结果是构建失败。
思路:
- 在工作空间中创建一个文件,文件名为 result.txt。
- 判断所有指令的执行结果,如果执行失败就写入 fail 到这个文件中。
- 命令执行完毕后打开 result.txt 文件,如果有 fail 的会直接返回 1 给 Jenkins。
echo off
ping 0.0.0.0 -n 3 > null
echo on
# 创建文件 result.txtecho "">result.txt
# py 文件执行失败的话将 fail 写到 result 文件中
py -3 test.py && echo success || echo fail>result.txt
# py 文件执行失败的话将 fail 写到 result 文件中
py -3 registerTest_hotpoint.py 127.0.0.1:8080/IDEAmaven && echo success || echo
fail>result.txt
# 如果 result 文件中有 fail 说明有执行失败的案例,直接 exit 1 通知 Jenkins 构建失败
find /i "fail" result.txt && exit 1 || exit 0
echo "">result.txt
py -3 a.py && echo success || echo fail>result.txt
javac ./java/HelloWorld.java && echo success || echo fail>../result.txt
cd java
java HelloWorld && echo success || echo fail>../result.txt
cd ..
findstr /i "fail" result.txt && exit 1 || exit 0
4、Jenkins自动触发执行的配置
Jenkins 中建立的任务是可以设置自动触发,更进一步的实现自动化。Jenkins 的触发条件可以分为两种:时间触发和事件触发。
1. 时间触发

到了指定的时间就触发构建,默认的时间触发包括定时构建和轮询 SCM。
- 定时构建:指的是一到指定的时间就自动执行,类似于 linux 下的 crontab,通常用在周期性构建的场景下,比如说半夜构建。
- 轮询 SCM:每隔指定的时间询问代码库是否有变化,比如说 push、pull、update 等操作,操作类型是可以配置的,如果有的话就会自动执行任务。
2. 事件触发
事件触发指的就是发生了某个事件就触发构建,事件可以是手动构建、上游任务的主动触发、HTTP API Webhook 等。
- 由其他工程构建后触发:比如我们打包、部署完 war 包并发布到 tomcat 记做任务 A,测试脚本的任务记做任务 B,当我们想任务 A 构建成功后自动执行测试的话,就可以在任务 B 的 config 中将 A 作为 B 的触发工程。
- GitHub hook trigger for GITScm polling:github 专用,当 github 上代码有变动时用来主动通知 Jenkins 进行项目的构建。该插件默认是没有的。
- 触发远程构建(例如,使用脚本):会提供一个接口,可以用来在代码层面触发构建。
5、jenkins和github 同步配置
1. Ngrok 安装
GitHub 收到提交的代码后要主动通知 Jenkins,所以 Jenkins 所在服务器一定要有外网 IP,否则 GitHub 无法访问,解决方法:下载 ngrok,将 IP 暴露到网络(类似的工具还有 holer)。
1)下载
登录到 https://ngrok.com/download 下载 ngrok 压缩包,选 windows 版本:
2)解压缩
将 ngrok-stable-windows-amd64.zip 文件解压到指定的目录,比如:F:\ngrok-stable-windows-amd64
3)获取 ngrok 的 token
切换到官网并进行登录(可用 github 账号登录):
获取 token:
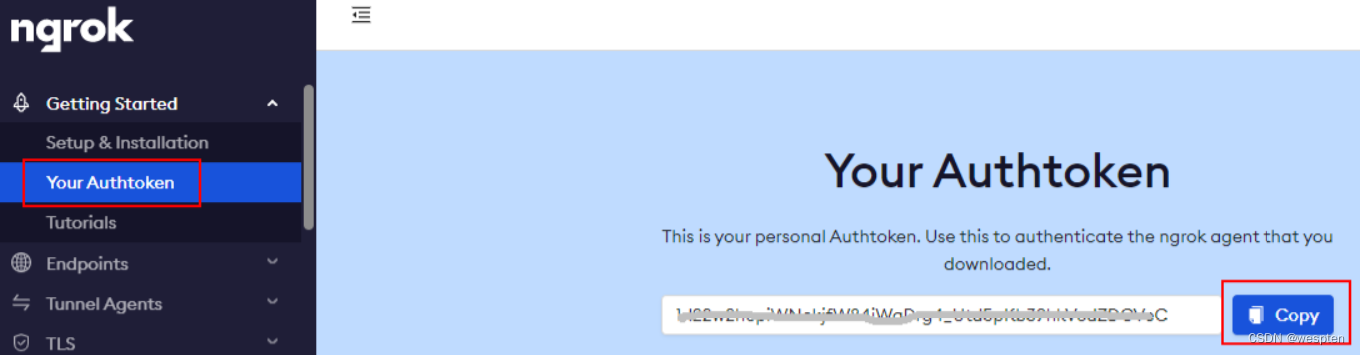
4)认证 token
切换到解压后的目录,执行命令进行认证:ngrok authtoken <your token>

5)启动 ngrok
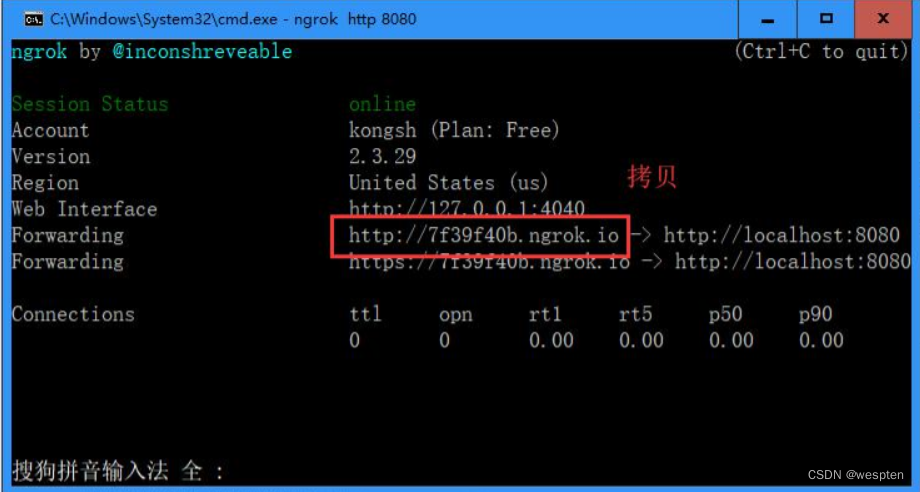
在 ngrok 所在的目录执行:ngrok http 8080(8080 是 tomcat 的监听端口),拷贝 forwarding 指示的 ip,后续会用到(注意:cmd 的窗口不要关闭)。
注意:关机或重启后就要重新进入 ngrok 所在的目录执行 ngrok http 8080 命令生成新的 IP,同时 Jenkins 和 github 中的 webhook 对应的 ip 也要修改。
2. 配置 webhook
在整个流程中关键的一步就是 github 监控到指定的仓库有 push 事件时,就会通知 Jenkins 启动与该仓库关联的任务自动构建,这就需要用到 webhook。
webhook 是一个 HTTP 回调,当有 push 事件发生时,github 可以发起一个 HTTP 请求到 webhook 配置的 URL 通知 Jenkins 发生了 push 事件,这样只要开发人员提交代码后,都会触发编译、打包、发布以及测试任务的构建。
需要在 GitHub 中配置 webhook,然后在 Jenkins 中添加此 webhook,流程如下:
1)登录到 github,进入到需要监控的仓库
点击 settings:
点击 Webhooks-->Add webhooks:
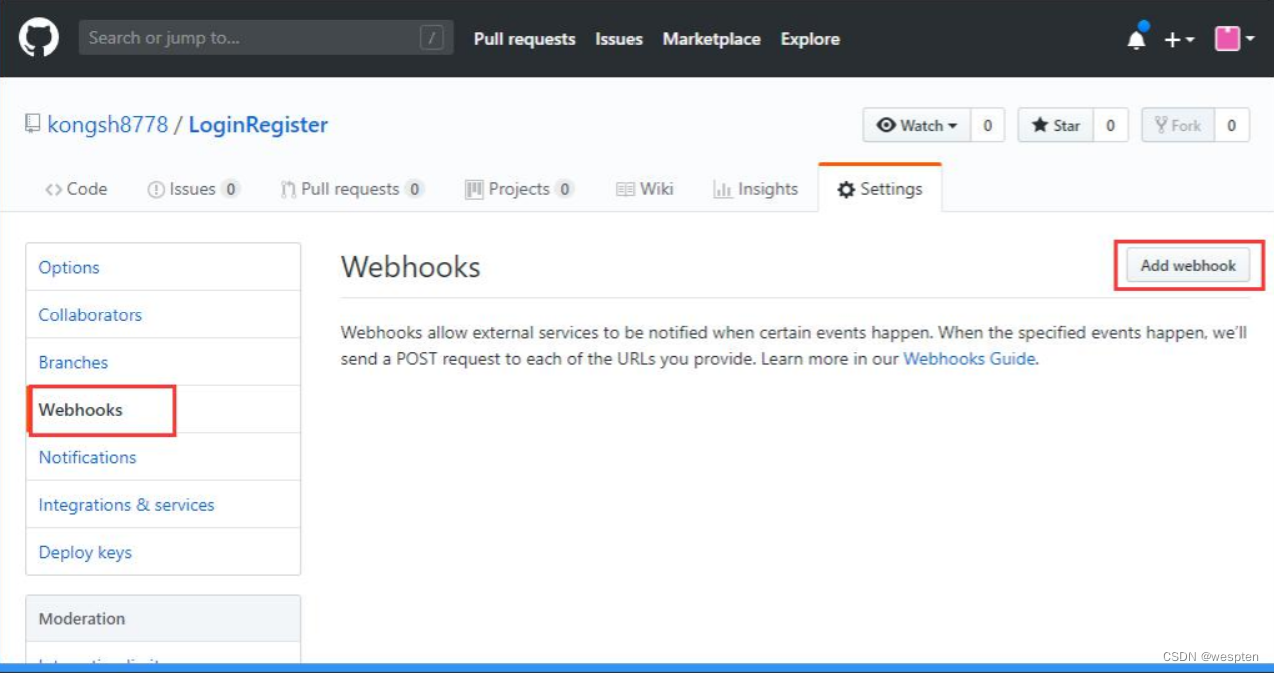
2)设置 Payload URL
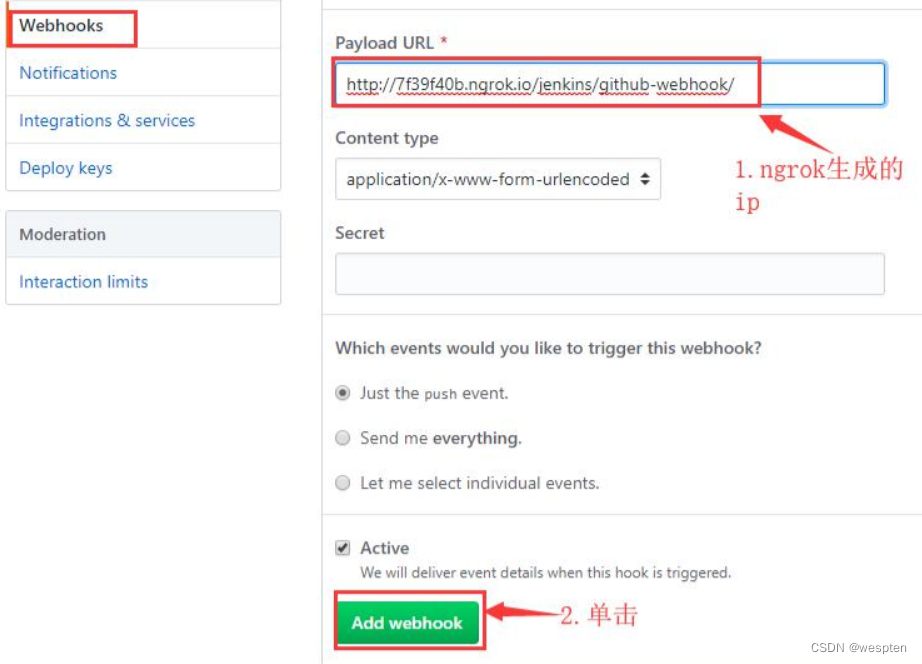
填写 Jenkins 的服务所在 IP 地址 + Jenkins/github-webhook/,如:https://7f39f40b.ngrok.io/Jenkins/github-webhook/
标黄的部分是用 ngrok 生成的 IP 地址,其它值默认即可。
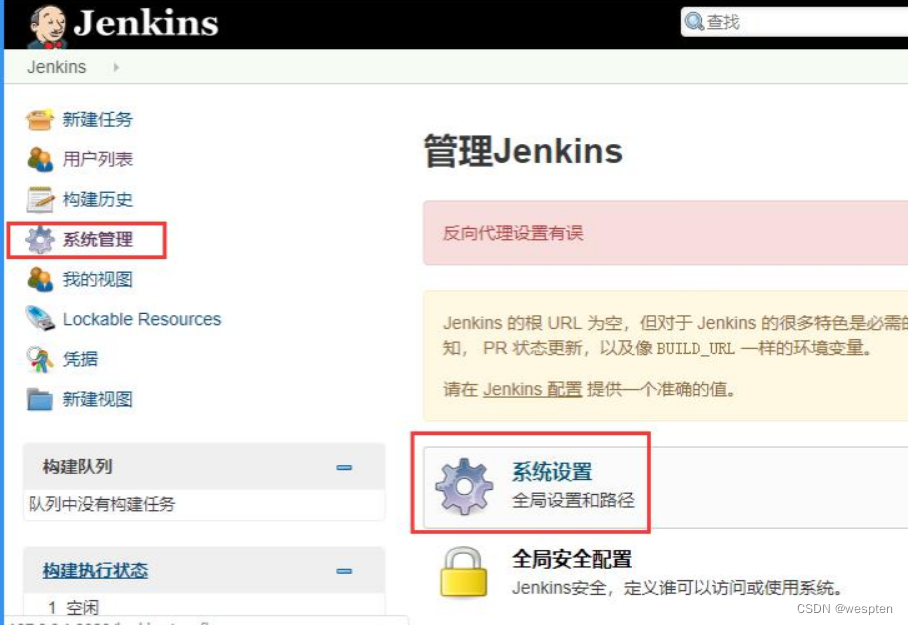
3)进入到 Jenkins,单击系统管理-->系统设置
找到 GitHub,单击 Advanced...
4)添加 webhook
注意:post 地址一定是 http://your_Jenkins_url/github-webhook/ ,不能去掉最后的“/”。

单击页面最底部的 save 按钮,完成配置。
6、Jenkins分布式构建
当持续集成系统管理了特别多的项目时,所有的任务都在主节点上同时执行,那么默认一个节点只能有 2 个 executor 执行任务,其他的就必须等待,这样会大大影响执行的效率,同时也不能满足在不同环境下的兼容性测试。
这里主要介绍如何用 Jenkins 进行分布式构建任务。Jenkins 的分布式也是基于 master-slave 模式的,我们演示用的 master 节点在 windows 上,分别添加一个 linux 的从节点和 windows 的从节点。
1. 添加 linux 节点
1)Jenkins-->Manage Jenkins-->Manage Nodes

2)新建节点

3)配置节点名称
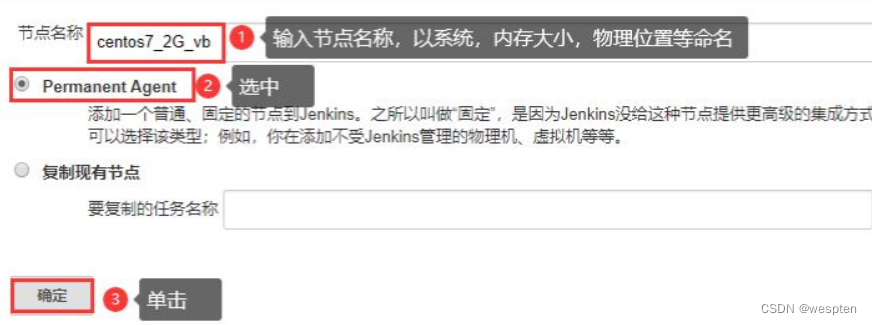
Permanent Agent 表示的是常驻代理客户端。
4)节点详细配置
- 名称:上一步创建的节点名称。
- 并发构建数:指的是该节点最多有多少个执行器(executor),执行器是真正工作的单元,一个执行器就是一个单独的线程。
- 远程工作目录:代理或者从节点上的工作目录,尽量使用绝对路径;目录不存在的话会自动创建,而且必须有写权限,否则会报错:hudson.util.IOException2: Failed to copy xxxx。
- 标签:也叫 tag,用来区分或者标识某类节点,经常以工具链,操作系统等信息标识。
- 用法:标识代理或者从节点的使用策略,有两种方式:
- Use this mode as much as possible:尽可能的使用此节点。
- Only build jobs with label expression matching this node:构建任务时指定的标签匹配本节点时才使用。
- 启动方法:有 3 种方法启动:
- Launch agent agents via SSH:通过 SSH 通道连接节点(安装了 SSH Slaves plugin 插件才能看到)。
- Launch agent by connecting it to the master:通过 jnlp,javaweb 的方式连接。
- Launch agent via execution of command on the master:通过主节点的控制台连接子节点。
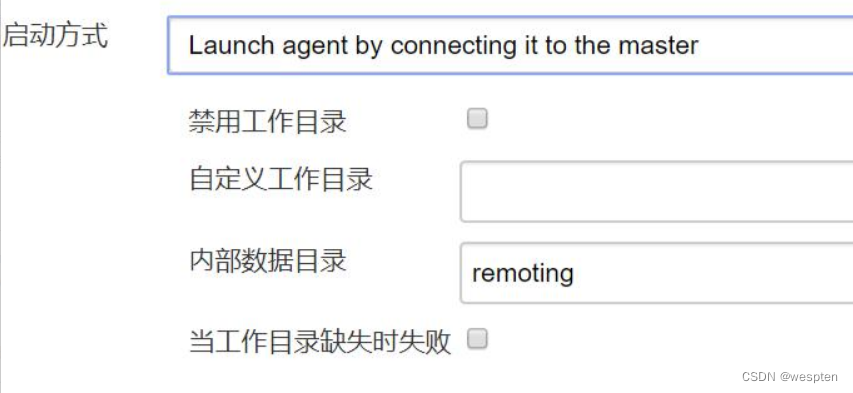
- 我们选择的第 2 种方式,对应的配置如下:
-
-
- 注意:如果定义了自定义工作目录,就不会使用代理的根目录,执行的日子信息会存到主节点中。而且该选项目前无法使用环境变量,因此建议使用绝对路径。
-
- 可用性:决定 Jenkins 的启动和停止:
- 1)Keep this slave on-line as much as possible:尽可能保持节点在线【推荐】
- 该模式下,Jenkins 会尽可能让代理保持在线。
- 如果该代理由于临时性网络故障,Jenkins 会定期尝试重启它。
- 2) Bring this agent online according to a schedule:让代理在特定的时间段内在线或者离线
- 该模式下,Jenkins 会根据一个计划表来启动代理,并保持指定的时长。如果在计划周期内代理掉线,Jenkins 会定期尝试重启它。
- 当代理在线时间达到字段计划启动的时间,它将会被下线。
- 如果勾选了当有构建时保持在线,并且根据计划表应该下线,Jenkins 会等所有的构建任务完成后再下线。
- 3)Bring this agent online when in demand,and take offline when idle:当代理被需要时保持在线,空闲时离线。
- 该模式下,当代理被需要时 Jenkins 将会让代理上线,例如有排队的构建任务满足下列条件:
- 在队列中排队时间达到需求延迟时间限制。
- 被构建任务指定(例如有一个匹配的标签表达式)。
- 如果发生下述情况,代理将会被下线:
- 代理没有需要构建的任务。
- 该代理已经空闲了指定的时间。
- 该模式下,当代理被需要时 Jenkins 将会让代理上线,例如有排队的构建任务满足下列条件:
- 1)Keep this slave on-line as much as possible:尽可能保持节点在线【推荐】
- 节点属性:根据需要配置即可:
- Disable deferred wipeout on this node:在当前节点上,是否开启延迟清理;
- Environment variables:配置环境变量,可以在脚本中引用;
- Tool Locations:工具的目录【推荐】。可以替换系统设置的各种工具目录。如:JDK 目录、Ant 目录、Maven 目录等。好处就是在不更改 Job 配置的情况下,不同环境(如 Windows 和 Linux)的 Job 配置通用。
5)配置完成后节点状态
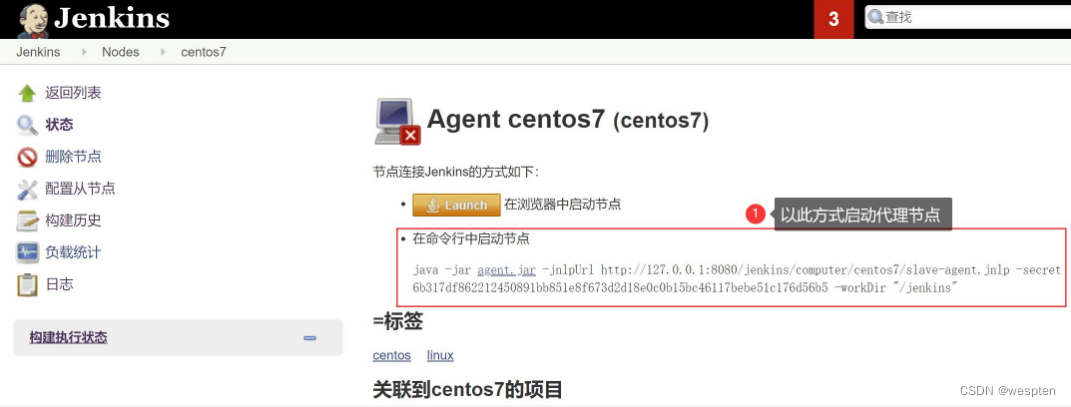
Jenkins 提供了两种方式让 agent 和 master 进行连接,我们选择第 2 种,因为命令行的形式更方便自动化。
6)下载 agent.jar
文件可通过此网址 http://127.0.0.1:8080/jenkins/jnlpJars/agent.jar 或者单击以下超链接:
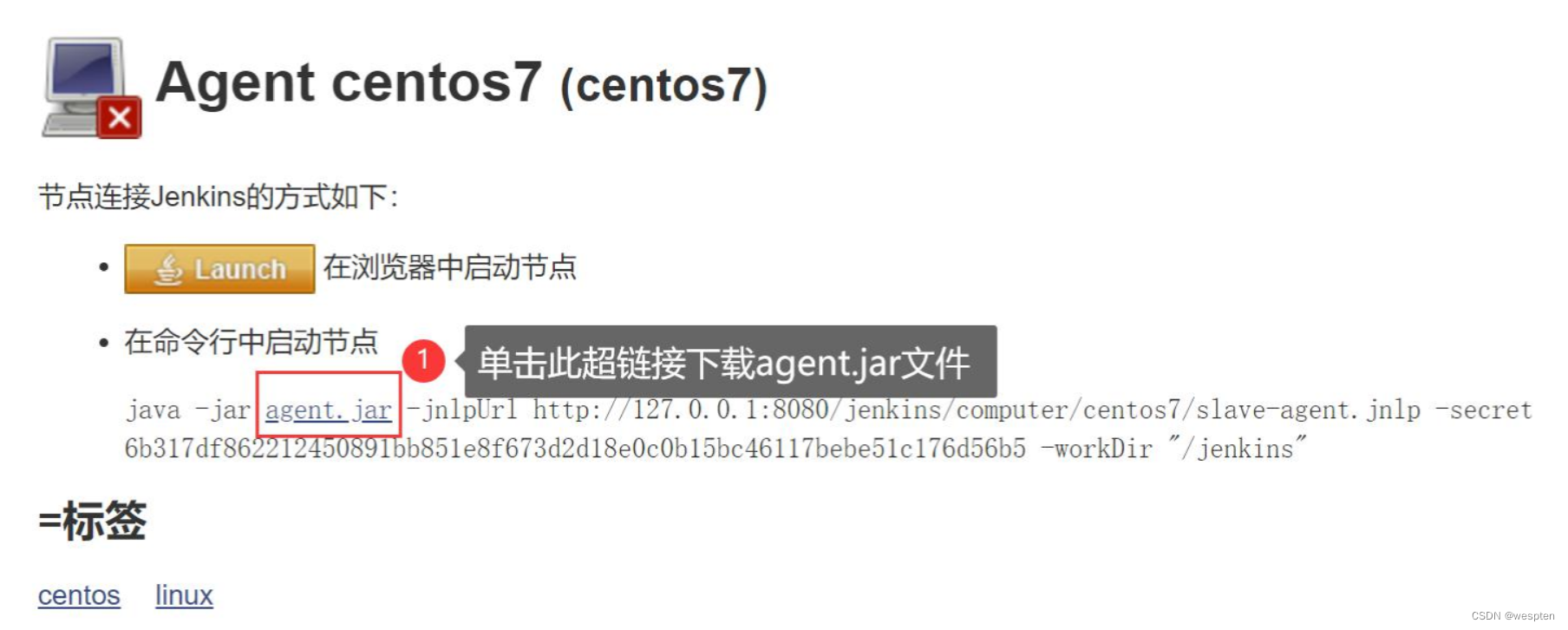
7)将 agent.jar 文件上传到 linux 节点中
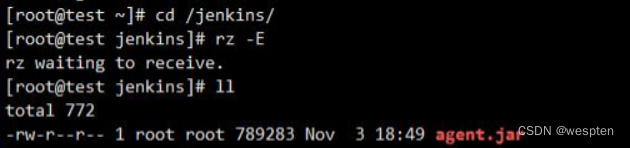
进入到代理节点的工作目录 jenkins 下,执行 rz 命令上传文件。注意:远程的代理节点中一定已经安装好了 jdk。
8)获取 windows 主节点的 IP 地址
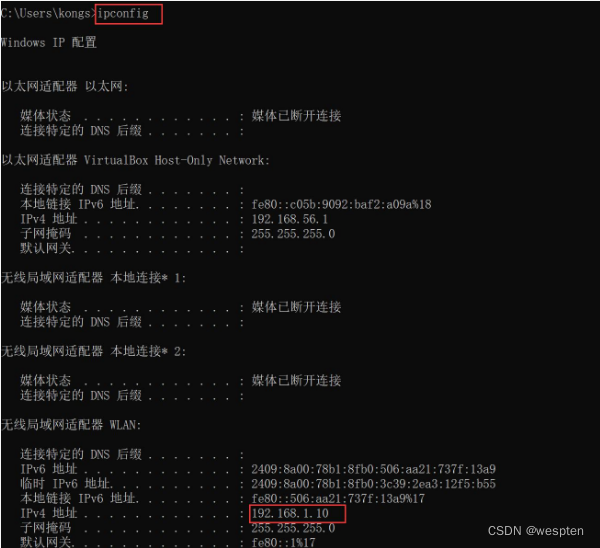
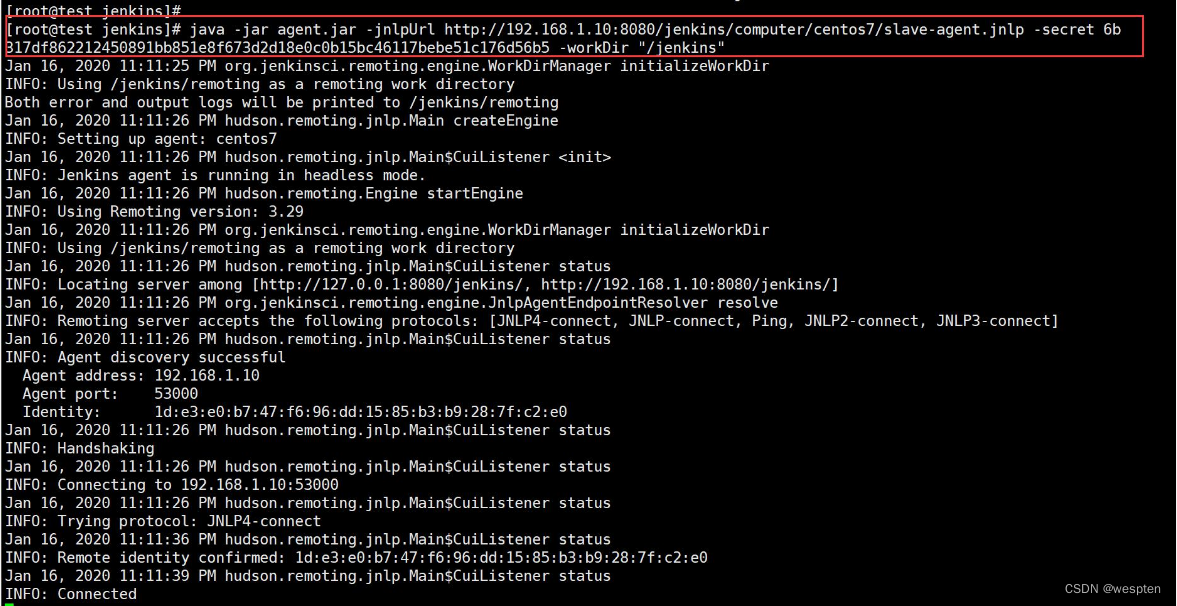
9)linux 节点执行以下命令启动节点
java -jar agent.jar -jnlpUrl http://192.168.1.10:8080/jenkins/computer/centos7/slave-agent.jnlp -secret 6b317df862212450891bb851e8f673d2d18e0c0b15bc46117bebe51c176d56b5 -workDir "/jenkins"
注意:以上 IP 为主节点的 IP 地址。
10)执行 pineline 脚本
pipeline {
agent {
label 'linux'
}
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
}
}
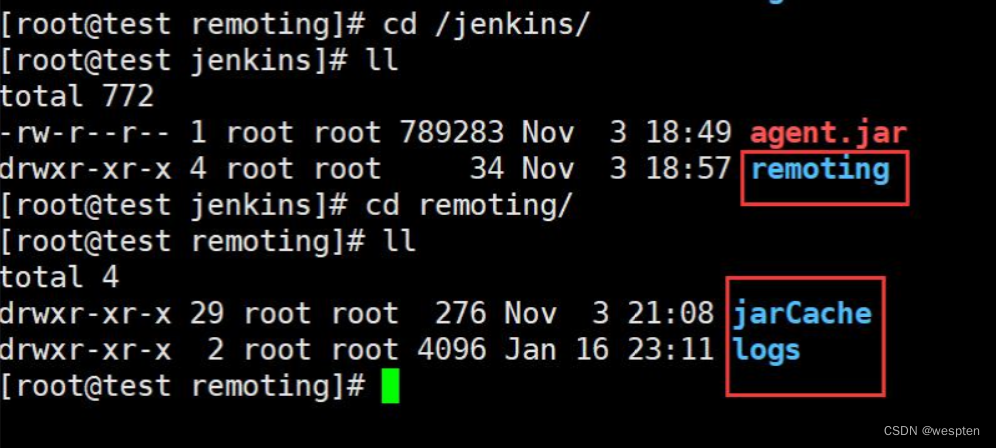
}构建日志:

切换到 linux 节点中 Jenkins 的工作目录,可以看到配置节点时指定的 remoting 目录,下面有节点的执行日志:
2. 添加 windows 节点
和上述添加 linux 节点的步骤大同小异,此处不再赘述。
一般 Jenkins 都是部署到 linux 系统,因为 windows 系统相当不稳定。
7、Jenkins并发构建
1. 原理
并行构建指的是某个 stage 或者 step 同时执行,比如说我们的 UI 测试脚本要在 Chrome、IE 和 Firefox 3 种浏览器下同时执行,或者是 APP 需要在不同型号的手机上执行,或者执行不同分支的代码等等,以上场景如果是顺序执行的话,显然效率是很低的,而且这些场景也都是相对独立的,并无依赖关系,那么我们能不能实现并行执行呢?在 pipeline 中并行构建需要用到 parallel 指令。
parallel{} 里面包含多个 stage{…},只有最后一个 stage{…} 内部支持嵌套多个 stages{…}。在 parallel{…} 中如果要设置只要里面有一个 stage{…} 运行失败就强制停止,可以使用表达式 failFast true 来进行控制。
pipeline 脚本如下:
pipeline {
agent any
stages {
stage('Non-Parallel Stage') {
steps {
echo 'This stage will be executed first.'
}
}
stage('Parallel Stage') {
failFast true
parallel {
stage('并行一') {
steps {
echo "并行一"
}
} stage('并行二') {
steps {
echo "并行二"
}
} stage('并行三') {
stages {
stage('Nested 1') {
steps {
echo "In stage Nested 1 within Branch C"
}
}
stage('Nested 2') {
steps {
echo "In stage Nested 2 within Branch C"
}
}
}
}
}
}
}
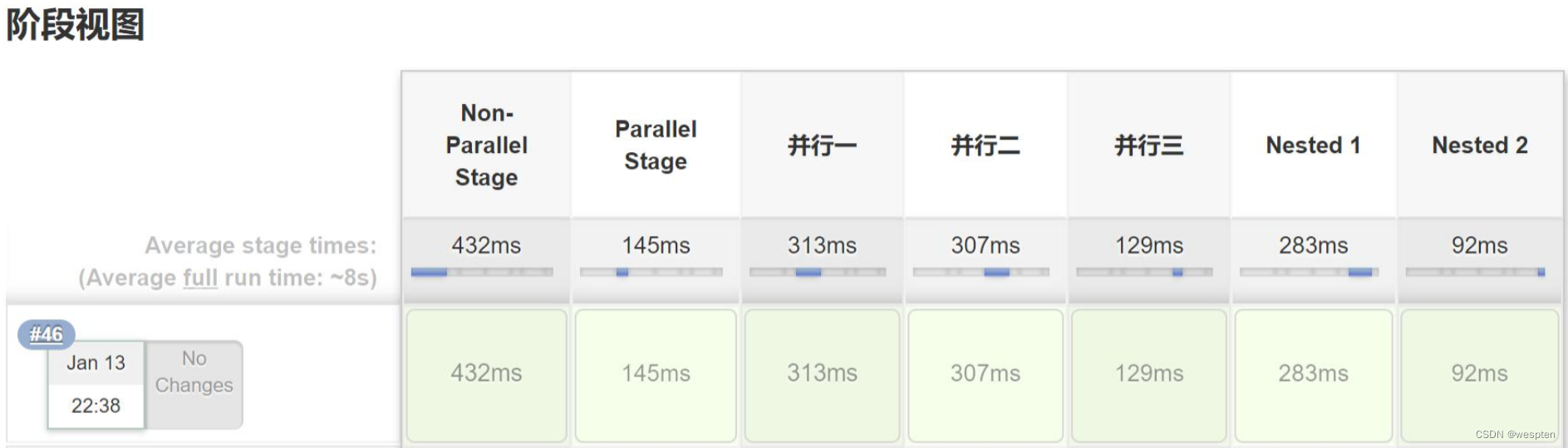
}成功执行结果:
并行 1、并行 2 和并行 3 三个 stage 之间的关系是并行的,下图显示都执行成功。
失败执行结果:
将并行 2 中 echo 改为 printf 指令,查看 pipeline 执行结果,如下。

如果有需要一个不通过,无须执行后面 pipeline 脚本的场景,可以使用 failFast true 语句。
如上图所示,原本并行一、并行二和并行三下面两个嵌套的 stage 都在同一时间并发执行,由于设置了 failFast true,在并行二这个 stage 发生了报错后,导致并行三下面两个前提的 stage 都显示 aborted 了,从控制台日志也可以看出来。
2. 示例
分别用 chrome/IE/Firefox 并行测试:
@Library('share-lib') _
pipeline{
agent any
options {
buildDiscarder(logRotator(numToKeepStr:'3'))
}
environment {
config_file = "\\Config\\ProjVar.py"
}
stages{
//从 github 拉取测试脚本
stage("checkout test script") {
steps{
script {
checkout([$class: 'GitSCM',
branches: [[name: '*/master']],
doGenerateSubmoduleConfigurations: false,
extensions: [[$class: 'CloneOption', noTags: false, reference: '',
shallow: true, timeout: 20]],
submoduleCfg: [],
userRemoteConfigs: [[credentialsId: 'gtihub', url: 'https://github.com/kongsh8778/keywordFramework']]])
}
}
}
//执行测试
stage("Parallel Selenium Test"){
failFast true
parallel {
//firefox 浏览器
stage("firefox"){
steps{
script{
//修改配置文件中浏览器类型
try{
setkey.setKeyValueByWriteFile("browser", "firefox", config_file)
file_content = readFile config_file
//println file_content
}catch (Exception e) {
error("Error met:" + e)
}
//执行测试
bat("py -3 main.py")
}
}
}
//chrome 浏览器
stage("chrome"){
steps{
script{
//修改配置文件中浏览器类型
try{
setkey.setKeyValueByWriteFile("browser", "chrome", config_file)
file_content = readFile config_file
//println file_content
}catch (Exception e) {
error("Error met:" + e)
}
//执行测试
bat("py -3 main.py")
}
}
}
}
}
}
post{
always {
echo 'This will always run'
//workspace 下的临时目录
deleteDir()
}
success {
echo 'This task is successful!'
//记录日志信息
script {
emailext attachLog: true, body: text, compressLog: true, mimeType: 'text/html', subject: '$PROJECT_NAME - Build # $BUILD_NUMBER - $BUILD_STATUS!', to: '455576105@qq.com'
}
}
}
}七、Jenkins持续交付实战
1、实战项目简介
实战项目 - JeeSite:
- 基于Spring Boot 2.0
- 数据存储mysql
- 技术选型:主流
- 语言:Java
- 规模适中,不大不小
- 适合初学者的教学项目
-
实战项目- JeeSite
- 源码位置:https://github.com/princeqjzh/JeeSite4
- 原始工程的位置:https://gitee.com/thinkgem/jeesite4
- 社区版项目,我们拿来学习
-
Demo
- 源码库演示
- 运行应用演示
-
实战项目小结
- 多模块组合项目
- 基础公共引擎模块:common
- 核心系统模块:core
- 模块示例模板:template
- 模块父节点:parent
- 入口模块:root
- web模块:web
- Deploy:部署代码
Spring Boot 框架:
- 目的
- 不是为了学习开发Spring Boot,先了解一下SpringBoot的样子,增强一些亲密感
- 感性认识,为学习Spring Boot项目持续交付做准备
- 框架
- 从写程序到做软件的必经之路
- Copy->建筑工程学的理论,Paste->软件工程学
- Spring框架
- J2EE轻量级开源框架
- EJB开发太麻烦,代码量很重;Spring简化了企业应用的开发难度,少写代码专注业务
- Spring容器管理对象生命周期,简化应用开发难度
- Spring Boot框架
- 比一般Spring还要方便的快速框架
- 方便集成大量第三方库,降低集成难度
- 学习方法建议:别从“0”开始学,可以基于一个现有的项目,然后做扩展
- 找一个适合学习的项目很重要
2、环境准备
- 准备了环境,才能运行程序
- 初学者常见的痛点
- 环境配置关键点:配置过程,验证方法,错误日志
- SpringBoot项日运行配置mysql+java+maven
1. MySQL的部署
- 首推Docker部署,实在太方便了无法拒绝
- 下载docker镜像:
docker pull mysql - 启动mysql docker container实例
docker run -d --name <your container name> -e MYSQL_ROOT_PASSWORD=<your root password> -p 3306:3306 mysql:<tag> - MySQL客户端工具
- MySQL Workbench
- 新建Server Connection,输入Host、Port、Username、Password
-
尝试连接,能成功就说明输入的参数无误
创建jeesite数据库:
create database jeesite 
2. Java开发环境安装方法
- 安装包下载路径:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
- 命令安装
- CentOS:
yum install java-1.8.0-openjdk* -y - Ubuntu:
apt-get install oracle-java8-installer - Mac:
brew cask install java
- CentOS:
- 解压安装
- 将JDK运行程序直接解压缩到本地路径,然后配置环境变量
-
JAVA_HOME=<jdk root path> -
export PATH=$PATH:$JAVA_HOME/bin
- Java环境安装正确的验证:
java -version
3. Maven环境安装方法-Demo
-
下载位置:http://maven.apache.org/download.cgi
-
下载文件:zip 或者tar格式压缩包,带bin字样的表明是可以直接运行的二进制文件
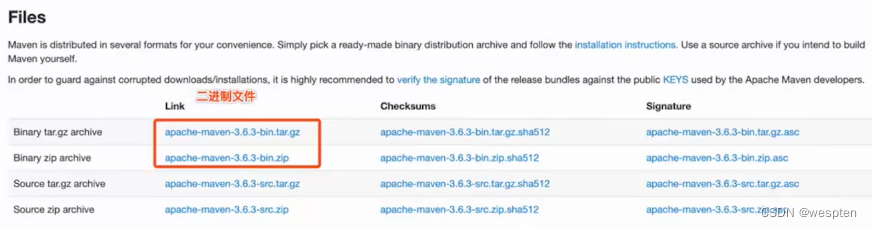
-
Maven环境安装方法
- 将安装包解压到本地路径,然后配置环境变量
-
export M2_HOME=<maven root path> -
export PATH=$PATH:$M2_HOME/bin
-
验证Maven安装成功的方法:
mvn -version

- 加速依赖包下载方法,在
settings.xml中添加阿里云镜像
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>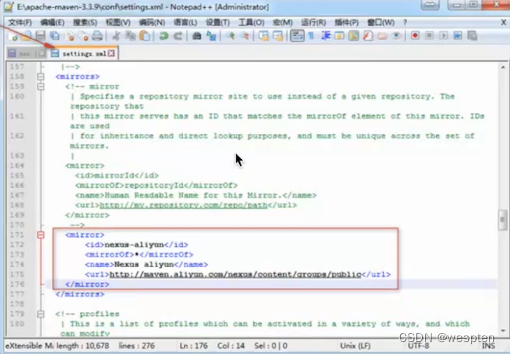
3、项目配置、调试、运行
1. 数据库准备
- 创建jeesite数据库
- SQL语句:
create database jeesite - 检查数据创建结果
2. 初始化数据导入
-
打开
jeesite4/web/src/main/resources/config/application.yml,填写数据库配置(IP 端口、用户名、密码)
-
进入项目路径
jeesite4/web/bin -
运行数据初始化脚本程序
init-data.sh( windows batch command:init-data.bat)
3. IDE里配置项目
- 添加 jeesite4/root/pom.xml Maven根节点到IDE的maven view中
- 其余依赖module会根据配置一起导入
-
添加 jeesite4/root/pom.xml Maven根节点到IDE的maven view中
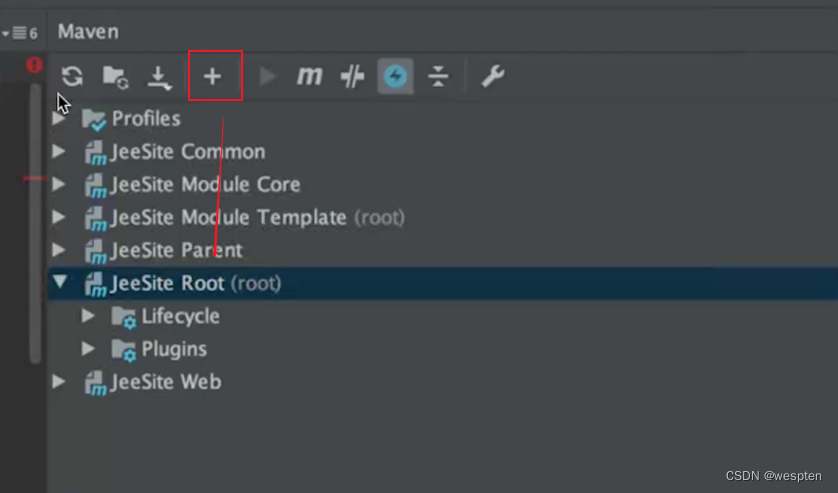
4. IDE里Maven编译、打包项目
-
在Maven View中选中JeeSite Root 下Lifecycle中的Clean + Install,然后单击运行按钮
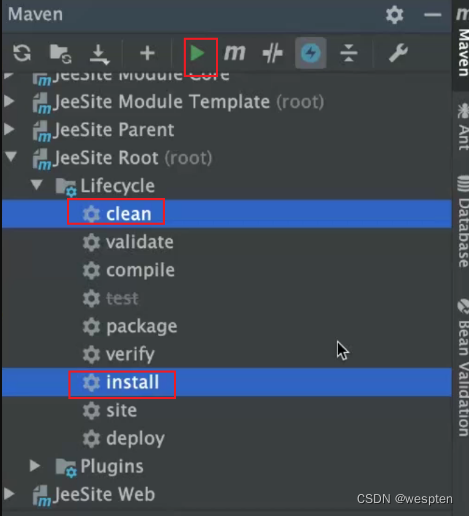

5. IDE里直接运行项目
-
在Run/DebugConfigurations中添加SpringBoot
- 配置Main class:
com.jeesite.modules.Application
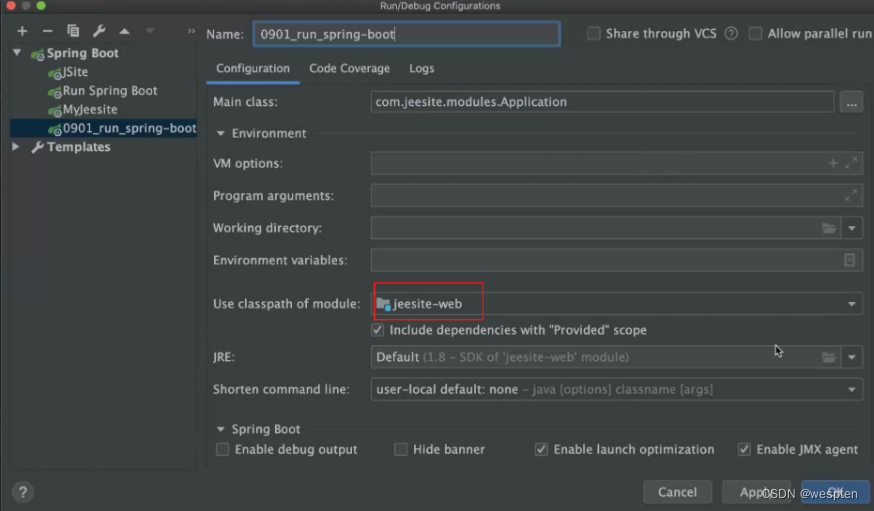
- 运行Demo ~~~~
- 访问8980端口
6. 命令行里编译、打包项目
- 进入项目的root模块所在的目录,然后运行
mvn clean install命令执行项目编译
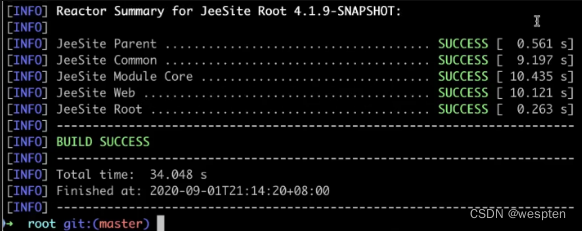
7. 命令行里运行项目
-
进入jeesite4/web目录下,运行:
mvn clean spring-boot:run -Dmaven.test.skip=true
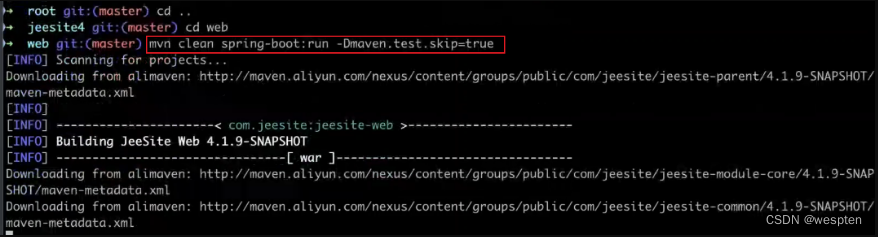
- 访问8980端口
8. 编写部署脚本
- 将部署动作“翻译”成shell脚本,然后部署到Jenkins中进行持续交付部署
- Demo:代码讲解
deploy/start_spring-boot.sh
#!/usr/bin/env bash
## 检查系统类型
export os_type=`uname`
## 停止spring-boot函数
killSpringBoot()
{
pid=`ps -ef|grep spring-boot|grep java|awk '{print $2}'`
echo "spring-boot list :$pid"
if [ "$pid" = "" ]
then
echo "no spring-boot pid alive"
else
kill -9 $pid
fi
}
## Kill 当前正在运行的spring-boot
killSpringBoot
## Maven 编译
cd ${WORKSPACE}/root
mvn clean install
## Maven 运行
cd ${WORKSPACE}/web
nohub mvn clean spring-boot:run -Dmaven.test.skip=true &4、Jenkins部署
- 创建Jenkins任务,设定部署任务
- Demo Jenkins任务执行
1. 创建任务
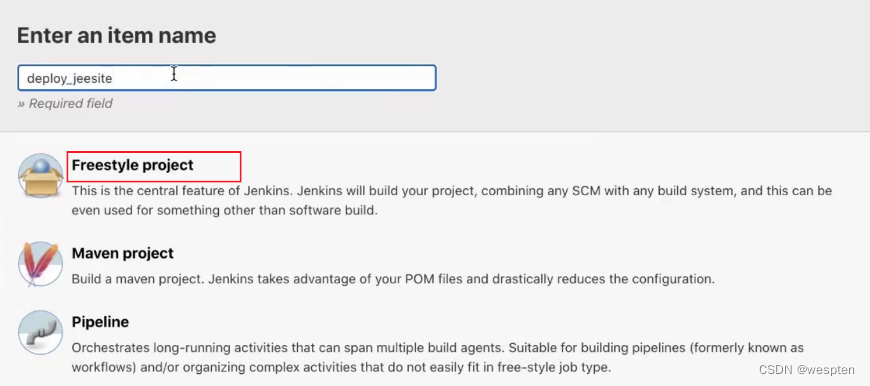
2. 添加项目地址
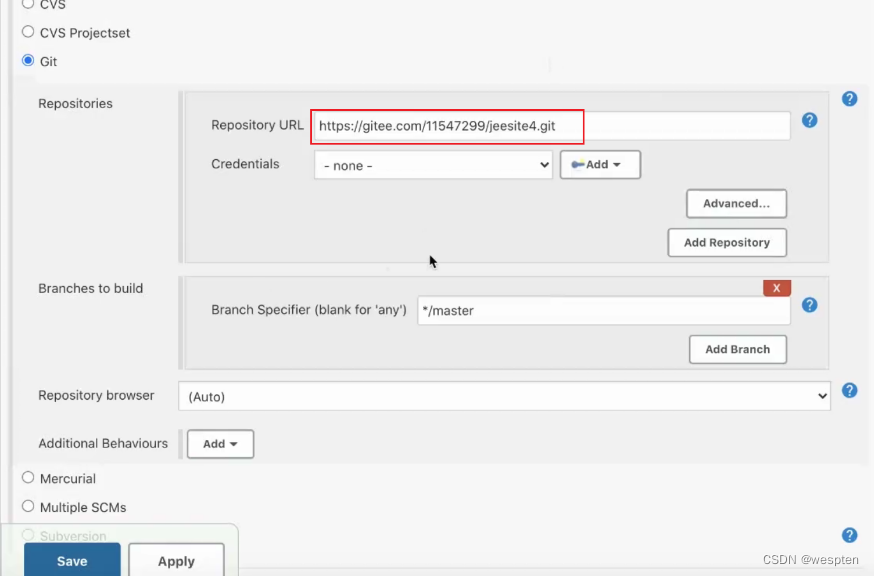
3. 添加运行代码
. ~/.bash_profile:获取环境变量sh deploy/start_spring-boot.sh
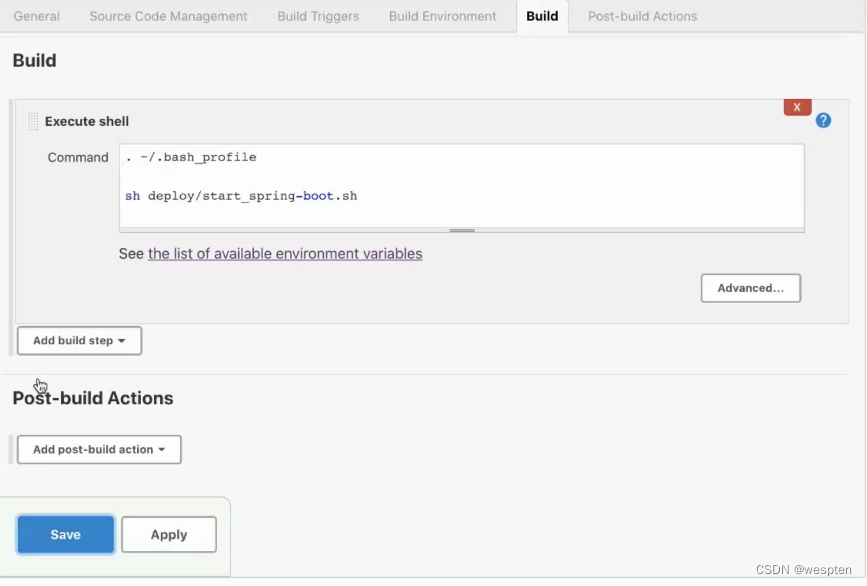
4. 构建任务
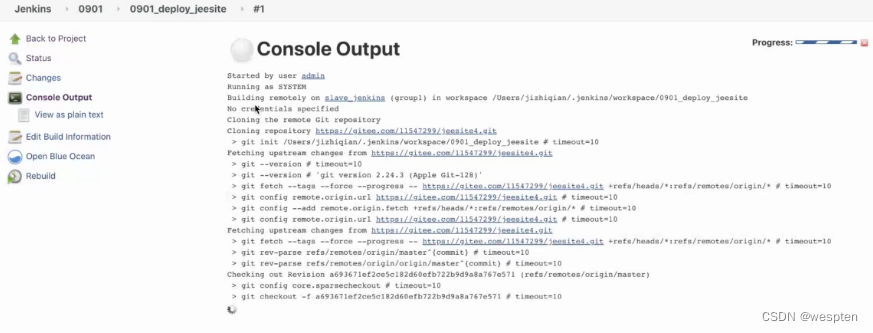
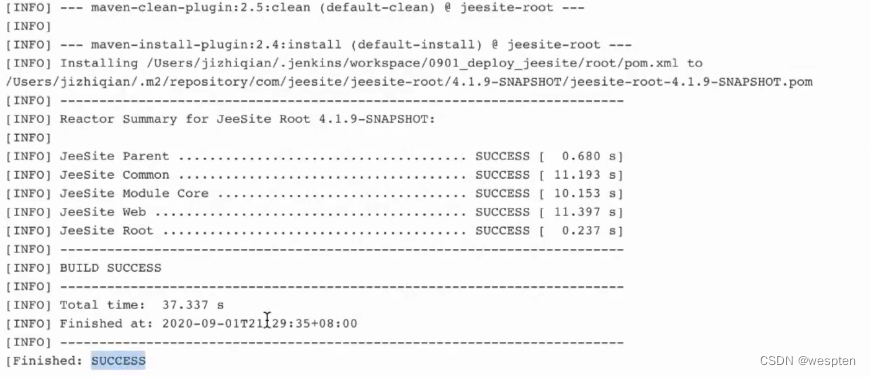
5. 构建完成后发现spring-boot并没有运行起来

原因是:Jenkins运行时有子进程和父进程的关系,Jenkins运行完spring-boot中的代码后会将子进程给kill掉,所以当Jenkins中的job构建完成后spring-boot中的项目也会结束运行。解决方法是在运行代码中添加:BUILD_ID=DONTKILLME
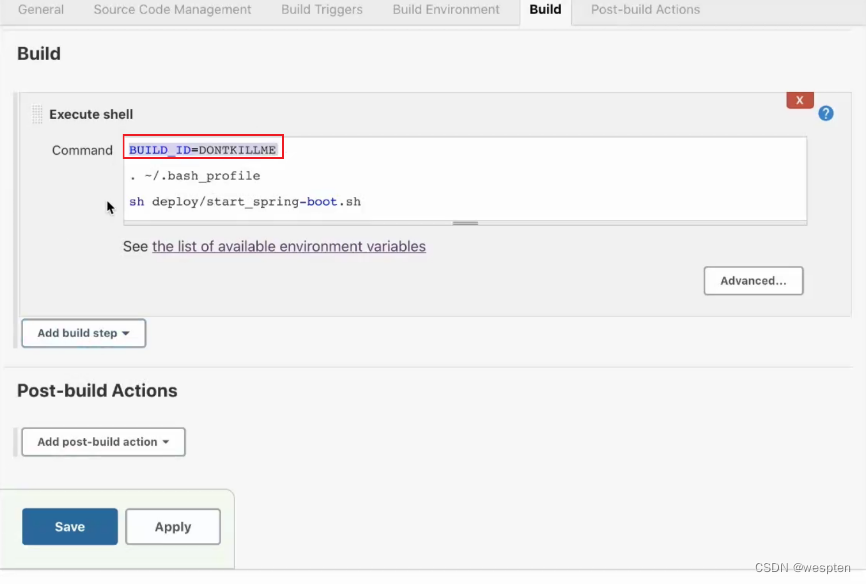
6. 再次查看进程并进入8980端口

5、Tomcat部署持续交付实战
1. Tomcat安装配置
- Tomcat简介
-
- 开源应用服务器
- 支持Servlet,JSP,..... Java系Web应用
- 入门简单
-
运行和配置入门
-
启动:
bin/startup.sh -
停止:
bin/shutdown.sh -
配置文件:
conf/server.xml,进入后:set number可添加行号,/8080可定位到8080位置
-
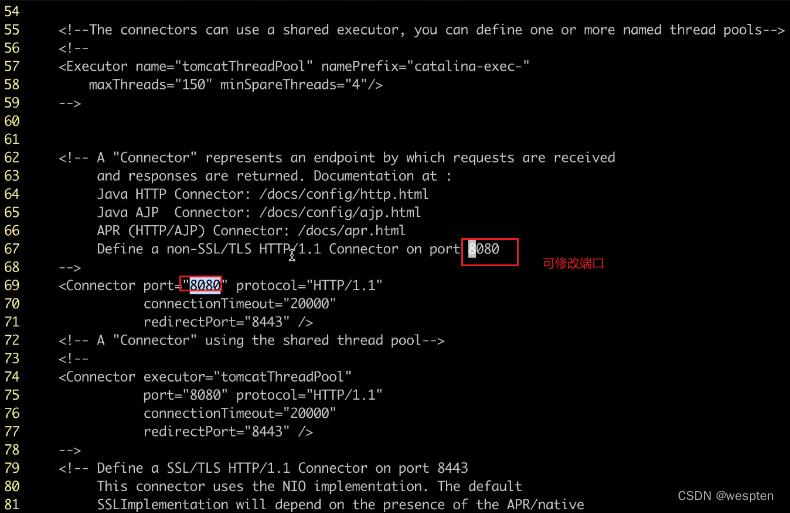
-
-
日志:
logs/catalina.out
-
-
下载位置:https://tomcat.apache.org/
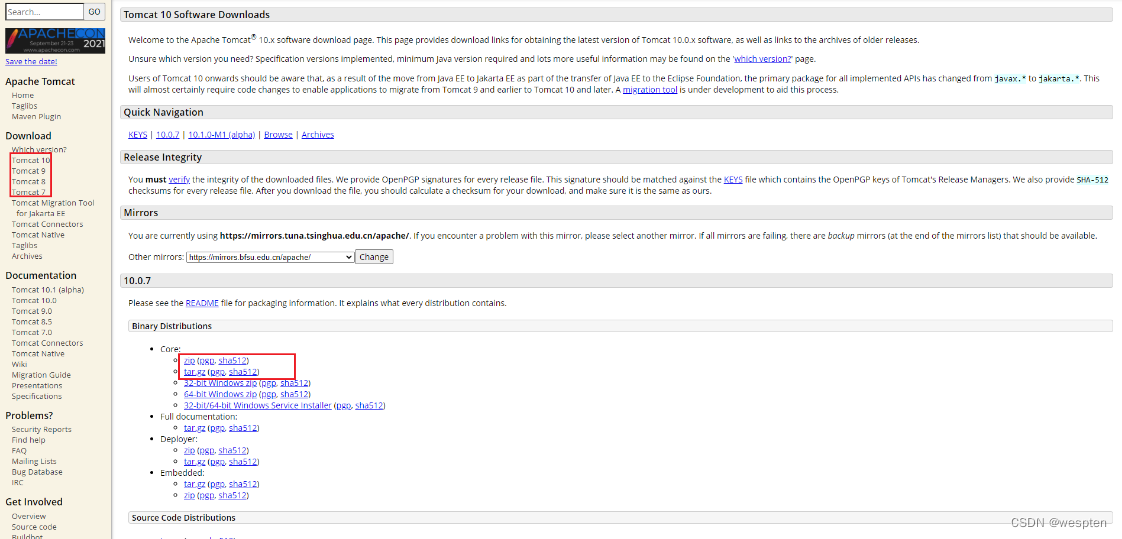
安装方法:直接解压unzip apache-tomcat-xxx.zip
修改文件权限:chmod -R a+x ../apache-tomcat-xxx
查看Tomcat进程是否起来:ps -ef | grep java | grep tomcat

访问8080端口:
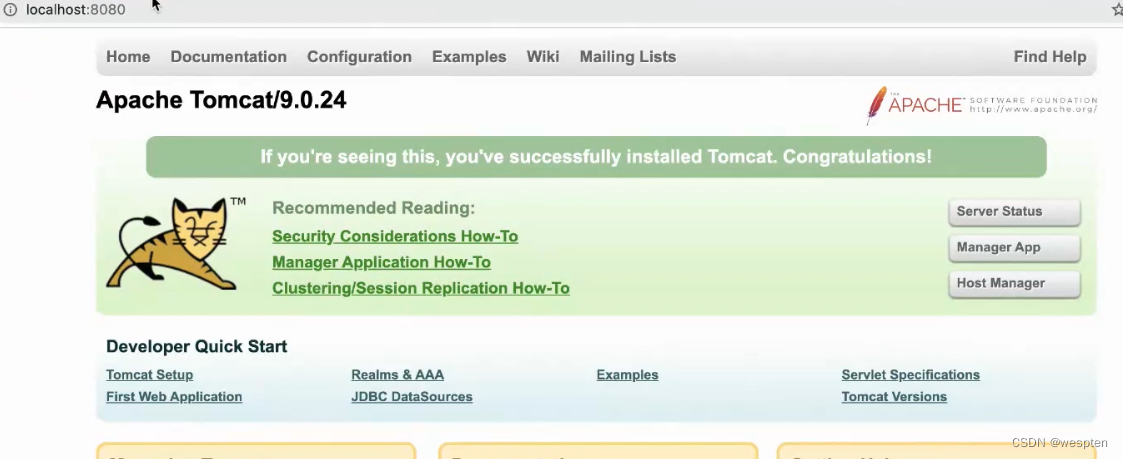
2. Pipeline任务部署Spring应用到Tomcat
-
任务描述:
- 使用Script Pipeline将Spring boot应用部署到Tomcat中运行
-
将整体任务进行分解拆分,独立出任务子模块
-
在Script Pipeline中使用Git
-
在Script Pipeline中使用Maven
-
在Script Pipeline中引用变量
-
在Script Pipeline中控制Tomcat
-
部署流程:将spring-boot的打包成web应用的package放到tomcat中运行
-
清洗环境是因为在持续交付过程中,可能会有之前版本的spring-boot应用,所以在持续迭代的过程中需要清理环境,删除之前的版本。所以部署之前需要停止Tomcat,部署完成后再启动Tomcat。
-
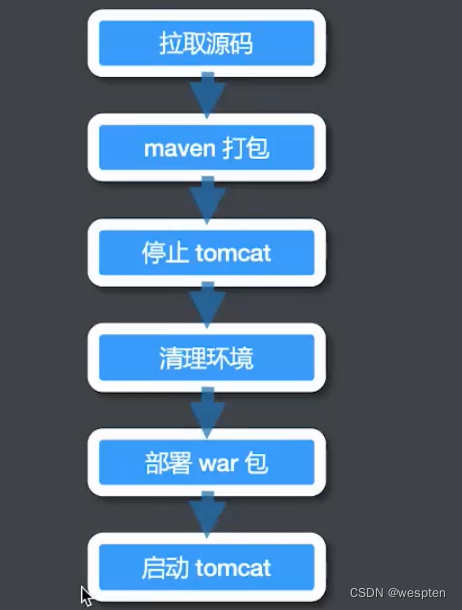
配置pipeline 部署任务:
设置pipeline代码路径:
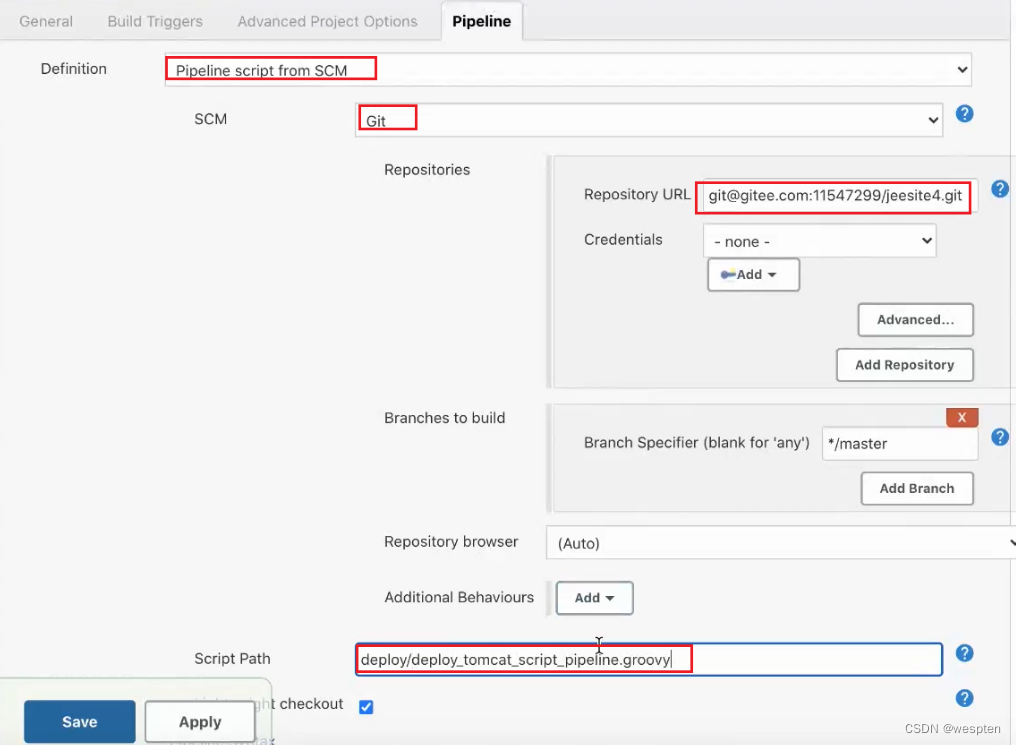
参数配置:
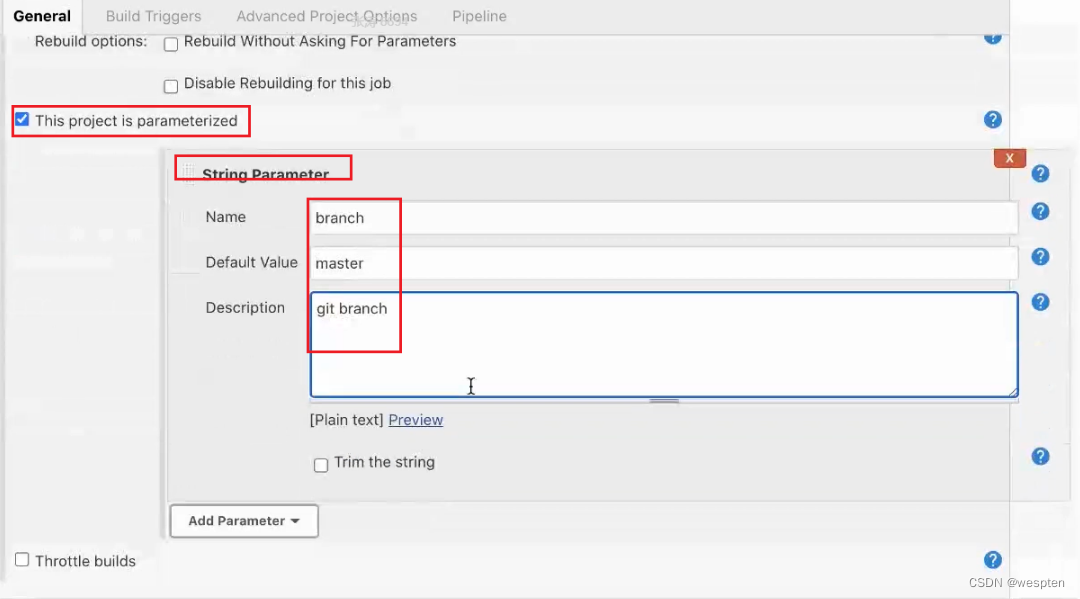
进行构建:
访问8080端口:
Pipeline代码讲解:
deploy_tomcat_script_pipeline.groovy node('master') {
stage('同步源码') {
git([url: 'git@gitee.com:11547299/jeesite4.git', branch: '${branch}'])
}
stage('maven编译打包') {
sh '''
. ~/.bash_profile
export pwd=`pwd`
export os_type=`uname`
cd web/src/main/resources/config
if [[ "${os_type}" == "Darwin" ]]; then
sed -i "" "s/mysql_ip/${mysql_ip}/g" application.yml
sed -i "" "s/mysql_port/${mysql_port}/g" application.yml
sed -i "" "s/mysql_user/${mysql_user}/g" application.yml
sed -i "" "s/mysql_pwd/${mysql_pwd}/g" application.yml
else
sed -i "s/mysql_ip/${mysql_ip}/g" application.yml
sed -i "s/mysql_port/${mysql_port}/g" application.yml
sed -i "s/mysql_user/${mysql_user}/g" application.yml
sed -i "s/mysql_pwd/${mysql_pwd}/g" application.yml
fi
cd $pwd/root
mvn clean install -Dmaven.test.skip=true
cd $pwd/web
mvn clean package spring-boot:repackage -Dmaven.test.skip=true -U
'''
}
stage('停止 tomcat') {
sh '''
## 停止tomcat的函数, 参数$1带入tomcat的路径$TOMCAT_PATH
killTomcat()
{
pid=`ps -ef|grep $1|grep java|awk '{print $2}'`
echo "tomcat Id list :$pid"
if [ "$pid" = "" ]
then
echo "no tomcat pid alive"
else
kill -9 $pid
fi
}
## 停止Tomcat
killTomcat $tomcat_home
'''
}
stage('清理环境') {
sh '''
## 删除原有war包
rm -f $tomcat_home/webapps/ROOT.war
rm -rf $tomcat_home/webapps/ROOT
'''
}
stage('部署新的war包') {
sh '''
cp web/target/web.war $tomcat_home/webapps/
cd $tomcat_home/webapps
mv web.war ROOT.war
'''
}
stage('启动tomcat') {
sh '''
JENKINS_NODE_COOKIE=dontkillme
cd $tomcat_home/bin
sh startup.sh
'''
}
}6、Docker部署持续交付实战
1. Pipeline任务部署Spring Docker应用
- 任务描述
- 使用Declared Pipeline技术,将Spring boot项目部署Docker镜像中
- 涉及知识点
- Declared Pipeline 任务中对Spring boot应用编译、打包
- Declared Pipeline任务中制作Spring Docker镜像
- Declared Pipeline 任务启动Docker实例
- Declared Pipeline 参数与环境变量
- Declared Pipeline容错控制
任务流程图:
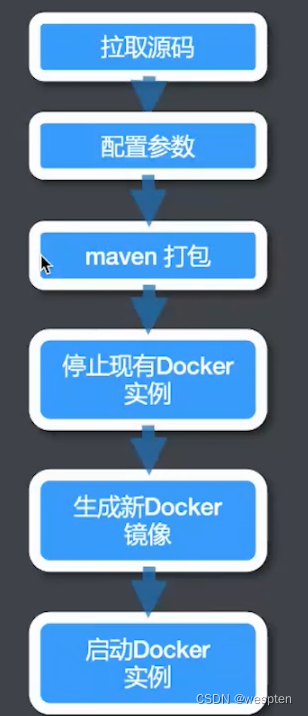
部署过程代码:
- deploy_docker_pipline.groovy 文件
pipeline {
agent {
label 'master'
}
environment {
docker_image_name = 'jeesite4'
docker_container_name = 'iJeesite4'
}
parameters {
string(name: 'branch', defaultValue: 'master', description: 'Git branch')
}
stages{
stage('同步源码') {
steps {
git url:'git@gitee.com:11547299/jeesite4.git', branch:"$params.branch"
}
}
stage('设定配置文件'){
steps{
sh '''
. ~/.bash_profile
export os_type=`uname`
cd ${WORKSPACE}/web/bin/docker
if [[ "${os_type}" == "Darwin" ]]; then
sed -i "" "s/mysql_ip/${mysql_docker_ip}/g" application-prod.yml
sed -i "" "s/mysql_port/${mysql_port}/g" application-prod.yml
sed -i "" "s/mysql_user/${mysql_user}/g" application-prod.yml
sed -i "" "s/mysql_pwd/${mysql_pwd}/g" application-prod.yml
else
sed -i "s/mysql_ip/${mysql_docker_ip}/g" application-prod.yml
sed -i "s/mysql_port/${mysql_port}/g" application-prod.yml
sed -i "s/mysql_user/${mysql_user}/g" application-prod.yml
sed -i "s/mysql_pwd/${mysql_pwd}/g" application-prod.yml
fi
'''
}
}
stage('Maven 编译'){
steps {
sh '''
. ~/.bash_profile
cd ${WORKSPACE}/root
mvn clean install -Dmaven.test.skip=true
cd ${WORKSPACE}/web
mvn clean package spring-boot:repackage -Dmaven.test.skip=true -U
'''
}
}
stage('停止 / 删除 现有Docker Container/Image '){
steps {
script{
try{
sh 'docker stop $docker_container_name'
}catch(exc){
echo 'The container $docker_container_name does not exist'
}
try{
sh 'docker rm $docker_container_name'
}catch(exc){
echo 'The container $docker_container_name does not exist'
}
try{
sh 'docker rmi $docker_image_name'
}catch(exc){
echo 'The docker image $docker_image_name does not exist'
}
}
}
}
stage('生成新的Docker Image'){
steps {
sh '''
cd ${WORKSPACE}/web/bin/docker
rm -f web.war
cp ${WORKSPACE}/web/target/web.war .
docker build -t $docker_image_name .
'''
}
}
stage('启动新Docker实例'){
steps {
sh '''
docker run -d --name $docker_container_name -p 8981:8980 $docker_image_name
'''
}
}
}
}- application-prod.yaml 文件
#======================================#
#========== Project settings ==========#
#======================================#
# 产品或项目名称、软件开发公司名称
productName: JeeSite 生产环境
companyName: ThinkGem
# 产品版本、版权年份
productVersion: V4.1
copyrightYear: 2020
#是否演示模式
demoMode: false
#======================================#
#========== Server settings ===========#
#======================================#
server:
port: 8980
servlet:
context-path: /
tomcat:
uri-encoding: UTF-8
# 将请求协议转换为 https
schemeHttps: false
#======================================#
#========== Database sttings ==========#
#======================================#
# 数据库连接
jdbc:
# Mysql 数据库配置
type: mysql
driver: com.mysql.jdbc.Driver
url: jdbc:mysql://mysql_ip:mysql_port/jeesite?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&allowPublicKeyRetrieval=true
username: mysql_user
password: mysql_pwd
testSql: SELECT 1
# MyBatis 相关
mybatis:
# Mapper文件刷新线程
mapper:
refresh:
enabled: false
# 文件相关
file:
# 文件上传根路径,设置路径中不允许包含“userfiles”,在指定目录中系统会自动创建userfiles目录,如果不设置默认为contextPath路径
baseDir: /root/jeesite2. Dockerfile 代码
- 起点
alpine-java:jdk8-slim镜像 - 加载应用web.war
- 解压缩web.war
- 配置java启动参数
- 添加yml配置文件
- 配置应用启动命令
- 添加暴露端口
FROM frolvlad/alpine-java:jdk8-slim
MAINTAINER ThinkGem@163.com
ENV TZ "Asia/Shanghai"
ENV LANG C.UTF-8
VOLUME /tmp
WORKDIR /app
ADD web.war .
RUN jar -xvf web.war
WORKDIR /app/WEB-INF
ENV JAVA_OPTS "-Xms256m -Xmx1024m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m"
ENV JAVA_OPTS "$JAVA_OPTS -Dspring.profiles.active=prod"
ADD application-prod.yml ./classes/config
ENTRYPOINT java -cp /app $JAVA_OPTS org.springframework.boot.loader.WarLauncher
EXPOSE 8980创建Pipeline任务,部署Spring Docker应用:
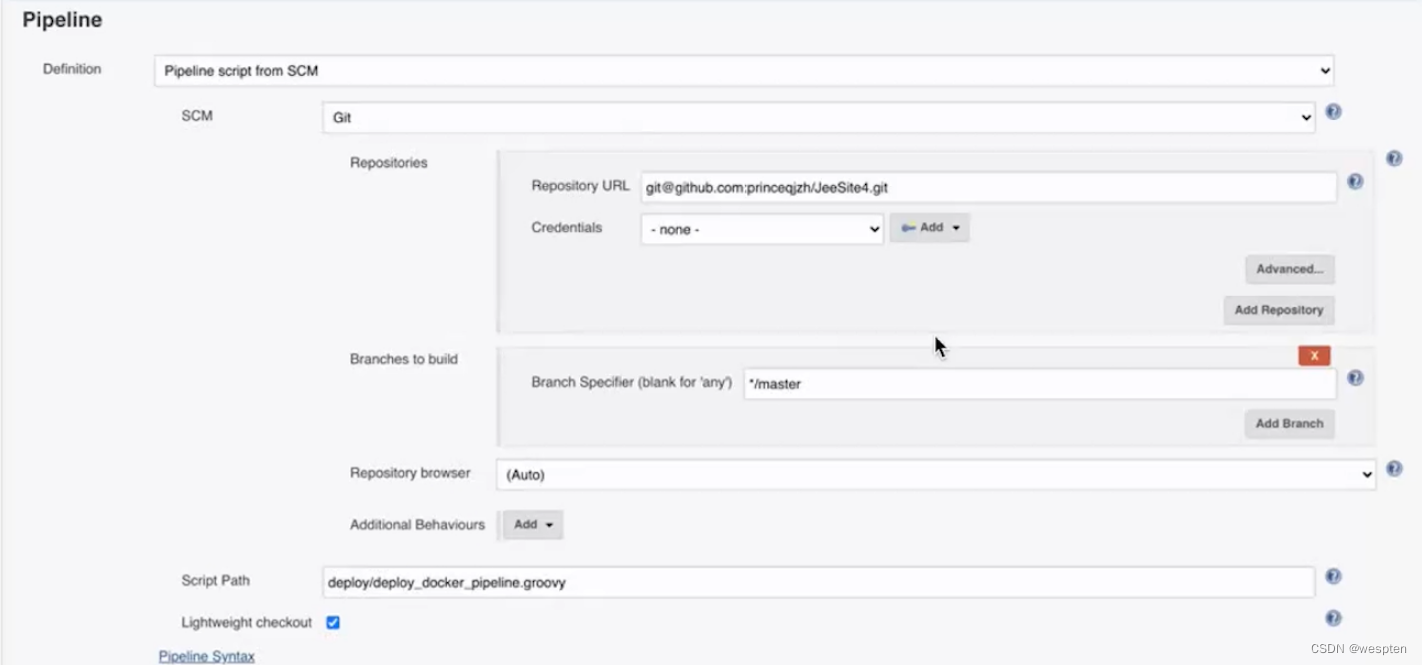
构建任务:
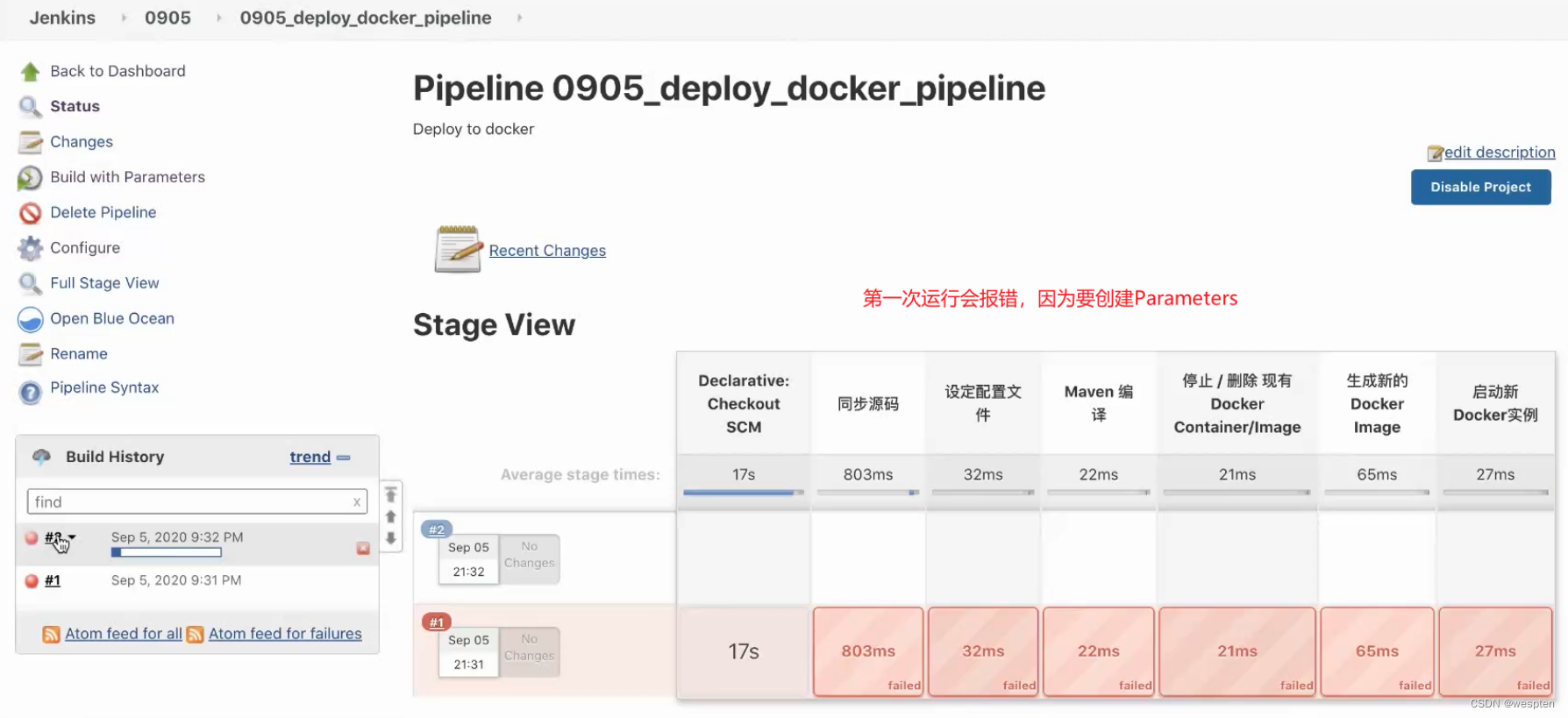
访问8981端口:
八、Unittest测试框架
unittest框架是Python语言内置的单元测试框架。我们用Python语言编写的Web UI自动化测试脚本可以借助该框架来组织和执行。
1、unittest框架结构
unittest是Python语言的内置模块,这意味着我们不需要再进行安装。unittest支持自动化测试、测试用例间共享setUp(测试前的初始化工作)和tearDown(测试结束后的清理工作)代码块,可以将测试用例合并为集合执行,然后将测试结果展示在报告中。
1. unittest框架的4个重要概念
在学习unittest框架之前,我们先要了解4个非常重要的概念。
- 测试固件(test fixture)
对于测试固件,你可以将其理解为在测试之前或者之后需要做的一些操作。例如测试执行前,可能需要打开浏览器、创建数据库连接等;测试结束后,可能需要清理测试环境、关闭数据库连接等。unittest中常用的test fixture有setUp、tearDown、setUpClass、tearDownClass。前面两个是在每个用例执行之前或之后执行,后面两个是在类执行之前或之后执行(简单了解即可,后续我们会用实例详细介绍)。
- 测试用例(test case)
测试用例是在unittest中执行测试的最小单元。它通过unittest提供的assert方法来验证一组特定的操作或输入以后得到的具体响应。unittest提供了一个名为TestCase的基础类,可以用来创建测试用例。unittest中测试用例的方法必须以test开头,并且执行顺序依照的是方法名的ASCII值排序。
- 测试套件(test suite)
测试套件就是一组测试用例,作用是将多个测试用例放到一起,执行一个测试套件就可以将这些测试用例全部执行。
- 测试运行器(test runner)
测试运行器用来执行测试用例,并返回测试用例执行的结果。它还可以用图形、表格、文本等方式把测试结果形象地展现出来,如HTMLTestRunner。
2. unittest用例示例
下面通过代码来看一下unittest用例的基本样式。
test_1.py:
import unittest
class TestStorm(unittest.TestCase):
def setUp(self):
print('setUp')
def test_first(self):
self.assertEqual('storm', 'storm')
def tearDown(self):
print('tearDown')
if __name__ == '__main__':
unittest.main()下面简单总结一下unittest测试框架的“习惯”:
- 首先需要导入unittest包:import unittest。
- 导入包的语句和定义测试类中间要隔两个空行(虽然不加空行也不会报错,但还是建议大家养成好习惯)。
- 新建一个测试类,测试类的名称建议每个单词的首字母大写。另外有的人习惯以Test开头,有的人习惯以TestCase结尾,建议团队保持一致。
- 测试类必须继承unittest.TestCase。
- 接下来就可以编写setUp(注意大小写),当然setUp方法并非必须有。
- 再接下来就可以编写测试用例了,测试用例名称以“test_”开头。
- self.assert×××是unittest提供的断言方法(断言方法有很多,后续详细介绍)。
- 用例写完后就可以编写tearDown(注意大小写),tearDown也非必须有。
- tearDown写完后空两行,就可以使用unittest.main进行测试了。
注意:其实,无论setUp和tearDown摆放在哪里,都不影响其执行的顺序。不过一个团队最好有个约定,大家共同遵守。
尝试执行代码,结果如下。
Testing started at 23:15 ...
C:\Python\Python36\python.exe "C:\Program Files\JetBrains\PyCharm 2018.1.4\helpers\pycharm\_jb_unittest_runner.py" --path D:/Love/Chapter_8/test_1.py
Ran 1 test in 0.000s
OK
Launching unittests with arguments python -m unittest D:/Love/Chapter_8/
test_1.py in D:\Love\Chapter_8
setUp
tearDown
Process finished with exit code 0下面简单解释一下unittest测试框架用例执行的结果信息:
- 第1行显示测试开始执行的时间。
- 第2、第3行显示测试执行的文件。
- 第4行显示执行一个测试用例共花费了多长时间。
- “OK”代表断言成功。
- “setUp”“tearDown”为程序执行的输出信息。
2、测试固件
我们了解到unittest框架共包含4种测试固件:
- setUp:在每个测试方法执行前执行,负责测试前的初始化工作。
- tearDown:在每个测试方法结束后执行,负责测试后的清理工作。
- setUpClass:在所有测试方法执行前执行,负责单元测试前期准备。必须使用@classmethod装饰器进行修饰,在setUp函数之前执行,整个测试过程只执行一次。
- tearDownClass:在所有测试方法执行结束后执行,负责单元测试后期处理。必须使用@classmethod装饰器进行修饰,在tearDown函数之后执行,整个测试过程只执行一次。
测试固件本身就是一个函数,和测试用例分别负责不同的工作。测试固件和测试用例更多的区别在于其在整个class中的执行次序和规律不同。接下来,我们通过一个示例来看一下上述4种测试固件执行的次序。
test_2.py:
import unittest
class TestStorm(unittest.TestCase):
@classmethod # 注意,必须有该装饰器
def setUpClass(cls): # 在整个class开始前执行一次
print('setUpClass')
def setUp(self): # 在每个测试用例执行前执行一次
print('setUp')
def test_first(self): # 第一个测试用例
print('first')
self.assertEqual('first', 'first')
def test_second(self): # 第二个测试用例
print('second')
self.assertEqual('second', 'second')
def tearDown(self): # 在每个测试用例结束后执行一次
print('tearDown')
@classmethod
def tearDownClass(cls): # 在整个class最后执行一次
print('tearDownClass')
if __name__ == '__main__':
unittest.main()执行结果如下:
Ran 2 tests in 0.003s
OK
Launching unittests with arguments python -m unittest test_2.StormTest in D:\Love\Chapter_8
setUpClasssetUp
first
tearDown
setUp
second
tearDown
tearDownClass
Process finished with exit code 0根据上述结果,我们可以看到这4种测试固件的执行顺序:
- 先执行“setUpClass”,整个class只执行一遍。
- 执行“setUp”,第一个测试用例调用。
- 执行第一个测试用例。
- 执行“tearDown”,第一个测试用例调用。
- 执行“setUp”,第二个测试用例调用。
- 执行第二个测试用例。
- 执行“tearDown”,第二个测试用例调用。
- 最后执行“tearDownClass”,整个class只执行一遍。至此,整个class执行结束。
3、编写测试用例
测试用例是通过def定义的方法。测试用例的方法名建议使用小写字母,且必须以“test”开头。
测试用例包含用例执行过程和对执行结果的断言。
test_3.py:
import unittest
first = 20
class TestStorm(unittest.TestCase):
def setUp(self): # 在每个测试用例执行前执行一次
print('setUp')
def test_age(self): # 方法名使用小写字母,且以test开头
second = first + 5 # 用例操作
self.assertEqual(second, 25) # 操作结果断言
def tearDown(self): # 在每个测试用例后执行一次
print('tearDown')
if __name__ == '__main__':
unittest.main()测试用例的定义非常简单,如何合理地组织测试用例以及如何添加合适的断言非常关键,有如下建议。
- 多个测试用例文件尽量不要存在依赖关系,否则一旦被依赖的测试用例执行失败,后续有依赖关系的测试用例也会执行失败。
- 一个测试用例文件只包含一个class,一个class对应一个业务场景。
- 一个class类可以包含多个def定义的测试用例。
- 一个def测试用例下面可以添加多个断言,类似于你在做功能测试的时候一个步骤可能需要检查多个点。
4、执行测试用例
unittest框架给我们准备了多种执行测试用例的方法。这里我们来学习一些日常工作中经常用到的操作。
1. 脚本自测
unittest.main会自动收集当前文件中所有的测试用例来执行。
test_4.py:
import unittest
first = 20
class TestStorm(unittest.TestCase):
def setUp(self): # 在每个测试用例执行前执行一次
print('setUp')
def test_age(self): # 方法名使用小写字母,且以test开头
second = first + 5 # 用例操作
self.assertEqual(second, 25) # 操作结果断言
def tearDown(self): # 在每个测试用例后执行一次
print('tearDown')
if __name__ == '__main__':
unittest.main()注意:
- if __name__ == '__main__':,这里的name和main前后都有两个下划线。你可以在PyCharm中直接输入main来快速输入这行代码。
- unittest.main(),main后面需要加上括号,否则无法正常执行。
- unittest.main(),是对上方脚本进行自测,不影响其他文件的调用。
2. 通过class构造测试集合
我们可以通过unittest.TestLoader().loadTestsFromTestCase加载某个class下面的所有用例。
test_6.py:
import unittest
from Chapter_8 import test_5
if __name__ == '__main__':
testcase2 = unittest.TestLoader().loadTestsFromTestCase(test_5.TestSecond)
suite = unittest.TestSuite([testcase2])
unittest.TextTestRunner().run(suite)运行结果如下:
4
..
3
----------------------------------------------------------------------
Ran 2 tests in 0.001s上方代码先将test_5文件中的内容通过import导入,然后使用unittest提供的unittest.TestLoader().loadTestsFromTestCase方法传入test_5文件中的第二个class,即“TestSecond”;接下来通过unittest.TestSuite([testcase2])组装测试用例集合;最后通过unittest.TextTestRunner提供的run方法来执行组装好的集合。
注意:直接在test_5.py文件中使用这种方法去加载测试用例的话,还是会执行所有的用例,示例代码如下所示。
test_5.py:
import unittest
'''
演示如何通过TestLoader来构造Test Suite
'''
class TestFirst(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_one(self):
print('1')
self.assertEqual(1,1)
def test_two(self):
print('2')
self.assertEqual(2,2)
class TestSecond(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_three(self):
print('3')
self.assertEqual(3,3)
def test_four(self):
print('4')
self.assertEqual(4,4)
if __name__ == '__main__':
testcase2 = unittest.TestLoader().loadTestsFromTestCase(TestSecond)
suite = unittest.TestSuite([testcase2])
unittest.TextTestRunner().run(suite)运行结果如下:
1
2
4
33. 通过addTest构建测试集合
我们可以通过addTest将某个class下面的测试用例添加到集合,然后执行测试集合。
test_7.py:
import unittest
from Chapter_8 import test_5
if __name__ == '__main__':
suite = unittest.TestSuite()
suite.addTest(test10_5.TestFirst("test_one"))
suite.addTest(test10_5.TestSecond("test_four"))
unittest.TextTestRunner().run(suite)上述代码从TestFirst类中取了test_one测试用例,从TestSecond类中取了test_four测试用例,两者组成了一个测试用例集合,运行结果如下。
1
44. 通过discover构建测试集合
我们还可以通过unittest.TestLoader().discover('.')在指定目录中寻找符合条件的测试用例,从而组成测试集合。
关于discover的用法请参考下方示例代码:test_8.py。
import unittest
if __name__ == '__main__':
testSuite = unittest.TestLoader().discover('.')
unittest.TextTestRunner(verbosity=2).run(testSuite)这里的discover,我们传递的目录是一个“.”,代表文件所在目录。执行该文件的话,就会从该文件所在目录中去寻找所有符合条件的测试用例。
5、用例执行次序
如果你细心观察test_5.py文件的运行结果会发现,4个测试用例执行的顺序为“test_one”“test_two”“test_four”“test_three”。该顺序和测试用例的摆放顺序并不相同。为什么测试用例按照这样的顺序来执行呢?其实测试用例执行的顺序依照的是方法和函数名的ASCII值排序。
test_5.py文件中包含两个类(class),分别是“TestFirst”和“TestSecond”,前4个字符相同(都是Test),从第五个字符开始不同,“F”排在“S”前面,因此“TestFirst”类先执行。“TestFirst”类中有两个测试用例,用例名分别是“test_one”和“test_two”,按ASCII值来排序的话“test_one”比“test_two”先执行,同理“test_four”比“test_three”先执行。
那么问题来了,如果我想让测试用例按照从上到下的顺序来执行,应该怎么办呢?这里介绍两种方法。
1. 将用例按顺序添加到集合
这里我们新建一个测试文件。示例代码:test_9.py。
import unittest
from Chapter_8 import test_5
if __name__ == '__main__':
suite = unittest.TestSuite()
suite.addTest(test10_5.TestFirst("test_one"))
suite.addTest(test10_5.TestFirst("test_two"))
suite.addTest(test10_5.TestSecond("test_three"))
suite.addTest(test10_5.TestSecond("test_four"))
unittest.TextTestRunner().run(suite)我们按照“one”“two”“three”“four”的顺序把测试用例组装成测试集合,然后再执行这个测试集合,运行结果如下。
1
...
2
3
----------------------------------------------------------------------
Ran 4 tests in 0.001s
4
测试用例执行的顺序和我们组合测试集合的顺序是一致的。但是当测试用例非常多的时候,我们不可能人工去判断每条用例名的ASCII值,况且一条条地将测试用例加到测试集合中
也是不小的工作量。因此,应对该问题我们有更合适的解决方案——请看方案(2)。
2. 调整测试用例名称
既然测试用例默认的执行顺序依照的是ASCII值的排序,那么我们构造合适的类名和方法名就可以了。
我们在test_5.py文件的基础上调整类名或者方法名,在“test”和用例名中间加上数字,形成文件test_10.py。
import unittest
'''
演示如何通过TestLoader来构造Test Suite
'''
class TestFirst(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_001_one(self):
print('1')
self.assertEqual(1,1)
def test_002_two(self):
print('2')
self.assertEqual(2,2)
class TestSecond(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_003_three(self):
print('3')
self.assertEqual(3,3)
def test_004_four(self):
print('4')
self.assertEqual(4,4)
if __name__ == '__main__':
unittest.main()执行结果如下:
1
2
3
4同样,我们在一个目录下新建的测试用例文件也是按照文件名的ASCII值的排序来编排和执行的,你也可以通过在文件名中添加数字来指定测试用例的执行顺序。
有的朋友可能会问:为什么要纠结测试用例的执行顺序呢?在实际项目中,部分测试用例可能存在前后的依赖关系,这时候你就会期望它们按照顺序执行。
6、内置装饰器
在自动化测试过程中,你可能会遇到这样的场景:在某些情况下,测试用例虽然不需要执行,但是你“舍不得”删掉它。下面来看看unittest提供的装饰器功能。
1. 无条件跳过装饰器(示例代码:test_11.py)
下面的代码借助@unittest.skip('skip info')装饰器,演示无条件跳过执行某个方法。
import unittest
'''
@unittest.skip('skip info'),无条件跳过
'''
class MyTest(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
@unittest.skip('skip info')
def test_aaa(self):
print('aaa')
def test_ddd(self):
print('ddd')
def test_ccc(self):
print('ccc')
def test_bbb(self):
print('bbb')
if __name__ == '__main__':
unittest.main()运行结果如下:
Skipped: skip info
bbb
ccc
ddd2. 满足条件跳过装饰器(示例代码:test_12.py)
下面的代码借助@unittest.skipIf(a>3, 'info')装饰器,演示当满足某个条件时,跳过执行某个方法。
import unittest
import sys
'''
满足条件跳过
'''
class MyTest(unittest.TestCase):
a = 4
def setUp(self):
pass
def tearDown(self):
pass
def test_aaa(self):
print('aaa')
@unittest.skipIf(a>3, 'info')
def test_ddd(self):
print('ddd')
def test_ccc(self):
print('ccc')
def test_bbb(self):
print('bbb')
if __name__ == '__main__':
unittest.main()因为变量a=4,满足a>3的条件,所以跳过执行test_ddd用例,运行结果如下。
aaa
bbb
ccc3. 不满足条件跳过(示例代码:test_13.py)
下面的代码借助@unittest.skipUnless(a==5,'info')装饰器,演示当不满足某个条件时,跳过执行某个方法。
import unittest
import sys
'''
不满足条件跳过
'''
class MyTest(unittest.TestCase):
a = 4
def setUp(self):
pass
def tearDown(self):
pass
def test_aaa(self):
print('aaa')
def test_ddd(self):
print('ddd')
@unittest.skipUnless(a==5,'info')
def test_ccc(self):
print('ccc')
def test_bbb(self):
print('bbb')
if __name__ == '__main__':
unittest.main()因为a=4,不满足a==5的条件,所以跳过test_ccc用例,运行结果如下。
aaa
bbb
Skipped: info
ddd
10.77、命令行执行测试
unittest框架支持命令行模式执行测试模块、类,甚至单独的测试方法。通过命令行模式,用户可以传入任何模块名、有效的测试类和测试方法参数列表。
1. 通过命令直接执行整个测试文件
打开DOS窗口,首先切换到目标文件目录(注意,必须切换到要执行的文件目录),本节的目标文件在“D:\Love\Chapter_8”目录。
C:\Users\duzil>d:
D:\>cd D:\Love\Chapter_8输入“python -m unittest -v 文件名”,按“Enter”键。
D:\Love\Chapter_10>python -m unittest -v test10_5
test_one (test_5.TestFirst) ... 1
ok
test_two (test_5.TestFirst) ... 2
ok
test_four (test_5.TestSecond) ... 4
ok
test_three (test_5.TestSecond) ... 3
ok
----------------------------------------------------------------------
Ran 4 tests in 0.014s
OK注意:
-m参数,代表执行的方法是unittest;-v参数,代表输出结果的详细模式。
2.通过命令执行测试文件中的某个测试类
打开DOS窗口,输入“python -m unittest -v文件名。类名”后按“Enter”键。
D:\Love\Chapter_8>python -m unittest -v test_5.TestSecond
test_four (test_5.TestSecond) ... 4
ok
test_three (test_5.TestSecond) ... 3
ok
----------------------------------------------------------------------
Ran 2 tests in 0.009s
OK3. 通过命令行执行某个文件的某个类下的某个测试用例
打开DOS窗口,输入“python -m unittest -v文件名。类名。方法名”后按“Enter”键。
D:\Love\Chapter_8>python -m unittest -v test_5.TestSecond.test_three
test_three (test_5.TestSecond) ... 3
ok
----------------------------------------------------------------------
Ran 1 test in 0.002s
OK通过命令行,我们可以方便地指定要执行的测试文件、方法、用例。
8、批量执行测试文件
介绍一下如何批量执行测试文件。
在Chapter_8目录下,我们新建一个Python Package:“Storm_8_1”。然后在下面新建3个文件,内容如下。
第一个测试用例文件:test_001.py。
import unittest
class MyTest(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_aaa(self):
print('aaa')
def test_bbb(self):
print('bbb')
if __name__ == '__main__':
unittest.main()第二个测试用例文件:test_002.py。
import unittest
class MyTest(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_ddd(self):
print('ddd')
def test_ccc(self):
print('ccc')
if __name__ == '__main__':
unittest.main()创建一个名为“run.py”的文件,内容如下。
import unittest
if __name__ == '__main__':
testsuite = unittest.TestLoader().discover('.')
unittest.TextTestRunner(verbosity=2).run(testsuite)“run.py”文件的运行结果如下:
aaa
test_aaa (test_001.MyTest) ... ok
bbb
ccc
test_bbb (test_001.MyTest) ... ok
ddd
test_ccc (test_002.MyTest) ... ok
test_ddd (test_002.MyTest) ... ok
----------------------------------------------------------------------
Ran 4 tests in 0.000s
OK具体分析如下:
- testsuite = unittest.TestLoader().discover('.')的意思是,通过unittest的TestLoader提供的discover方法去寻找目录中符合条件的测试用例。
- “.”代表当前目录,也可以构造、传递其他目录。
- 以“test”开头的测试文件名为符合条件的测试用例。
另外,我们还可以在命令行模式下面执行命令“python -m unittest discover”,如下所示。
D:\Love\Chapter_8\Storm_8_1>python -m unittest discover
aaa
.bbb
.ccc
.ddd
.
----------------------------------------------------------------------
Ran 4 tests in 0.010s
OK9、测试断言
断言是为了检查测试的结果是否符合预期。unittest单元测试框架中的TestCase类提供了很多断言方法,便于检验测试结果是否达到预期,并能在断言失败后抛出失败的原因。这里我们列举了一些常用的断言方法,如下表所示。
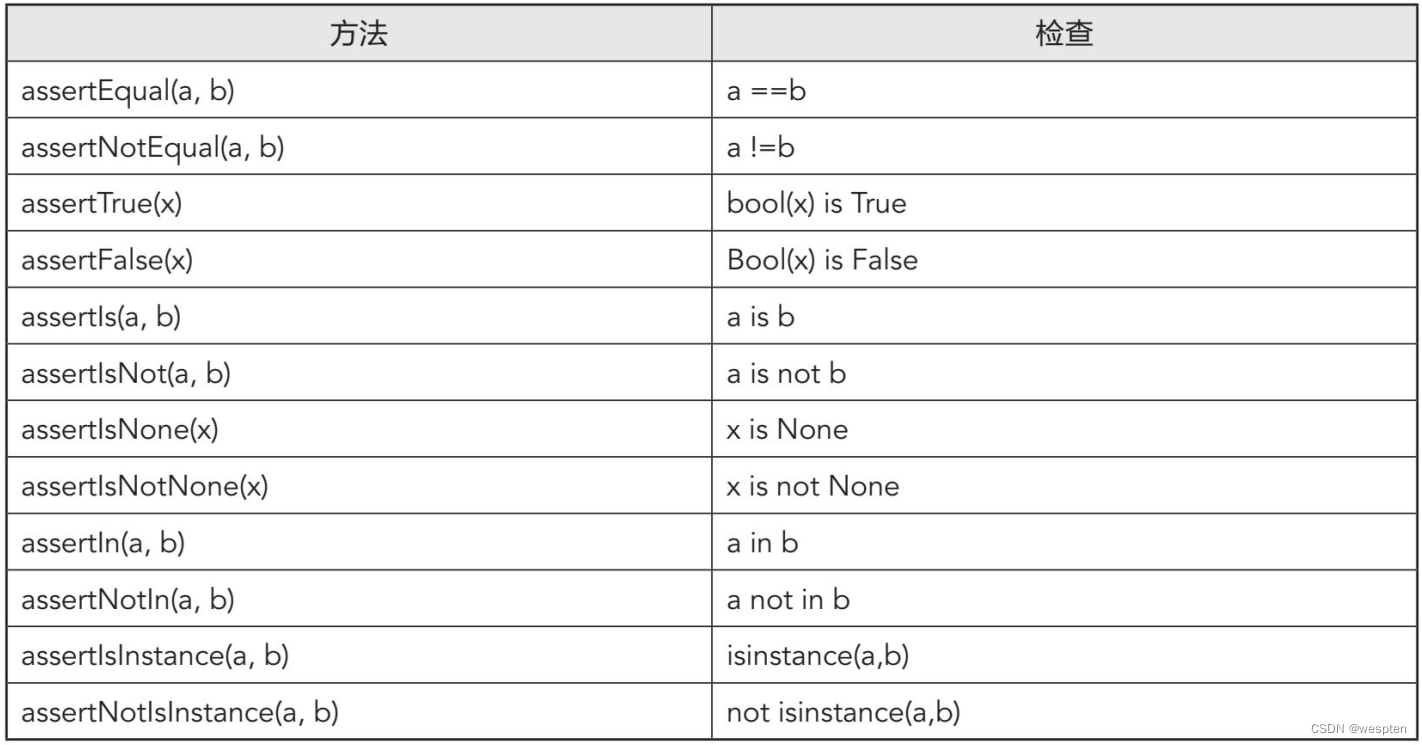
接下来,我们通过示例来演示一下这些断言方法该如何使用。示例代码:test_14.py。
import unittest
class TestMath(unittest.TestCase):
def setUp(self):
print("test start")
def test_001(self):
j = 5
self.assertEqual(j + 1, 6) # 判断相等
self.assertNotEqual(j + 1, 5) # 判断不相等
def test_002(self):
j = True
f = False
self.assertTrue(j) # 判断j是否为True
self.assertFalse(f) # 判断f是否为False
def test_003(self):
j = 'Storm'
self.assertIs(j, 'Storm') # 判断j是否是"Storm"
self.assertIsNot(j, 'storm') # 判断j是否是"storm",区分大小写
def test_004(self):
j = None
t = 'Storm'
self.assertIsNone(j) # 判断j是否为None
self.assertIsNotNone(t) # 判断t是否不是None
def test_005(self):
j = 'Storm'
self.assertIn(j, 'Storm') # 判断j是否包含在"Storm"中
self.assertNotIn(j, 'xxx') # 判断j是否没有包含在"xxx"中
def test_006(self):
j = 'Storm'
self.assertIsInstance(j, str) # 判断j的类型是否是str
self.assertNotIsInstance(j, int) # 判断j的类型是否是int
def tearDown(self):
print("test end")
if __name__ == '__main__':
unittest.main()借助unittest框架提供的断言方法,我们可以方便地实现测试用例断言的需求。更为关键的是,这些封装好的断言有完善的报错信息,还支持用测试报告来统计测试用例执行的结果。
10、测试报告
到目前为止,我们所有的测试结果都是直接输出到PyCharm控制台的。这不利于我们查看和保存测试结果。这里介绍如何借助HTMLTestRunner生成HTML测试报告。
准备工作如下:
- 大家可以自行搜索下载“HTMLTestRunner.py”文件。
- 将“HTMLTestRunner.py”文件复制到Python安装目录下的Lib文件夹中。
- 在Python交互模式下导入模块,测试是否成功。
>>> import HTMLTestRunner没有报错,说明导入成功。
接下来,我们在Chapter_8下面新建一个Python Package,并取名为“Storm_8_2”。然后在下面新建3个文件,文件名及内容如下。
文件一:test_001.py。
import unittest
class MyTest(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_aaa(self):
print('aaa')
self.assertEqual('a','a')
def test_bbb(self):
print('bbb')
self.assertEqual('b','b')
if __name__ == '__main__':
unittest.main()文件二:test_002.py。
import unittest
class MyTest(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_ddd(self):
print('ddd')
self.assertEqual('d','d')
def test_ccc(self):
print('ccc')
self.assertEqual('c','c')
if __name__ == '__main__':
unittest.main()文件三:run.py。
import unittest
import HTMLTestRunner
import time
if __name__ == '__main__':
# 查找当前目录的测试用例文件
testSuite = unittest.TestLoader().discover('.')
# 定义一个文件名,文件名以年月日时分秒结尾,方便查找
filename = "D:\\Storm_{}.html".format(time.strftime('%Y%m%d%H%M%S',time.localtime (time.time())))
# 以with open的方式打开文件
with open(filename, 'wb') as f:
# 通过HTMLTestRunner来执行测试用例,并生成报告
runner = HTMLTestRunner.HTMLTestRunner(stream=f,title='这里是报告的标题', description='这里是报告的描述信息')
runner.run(testSuite)重点看一下“run.py”文件,有以下几点需要注意。
- 通过unittest.TestLoader().discover('.')构造测试集合。
- 通过格式化日期时间拼接一个文件名。
- 通过with open的方式打开、写入文件。好处是不需要手动关闭文件。
- 通过调用HTMLTestRunner.HTMLTestRunner来生成测试报告。
当我们执行“run.py”文件后,程序会在指定的目录(上方代码指定的目录为D盘根目录)下生成一个测试报告文件,我们通过浏览器打开,效果如图所示。

通过该报告,我们可以清晰地看到以下内容。
- 测试报告的标题。
- 执行开始的时间。
- 执行用时。
- 执行状态——测试用例通过个数、失败个数。
- 测试报告的描述信息。
- 测试用例执行的表格。
11、线性测试脚本
1. Redmine系统
Redmine是一个项目管理和缺陷跟踪系统,其功能和我们常见的项目管理和缺陷跟踪系统类似,如禅道、Bugzilla、Jira等。这里推荐大家使用Bitnami Redmine安装包进行安装。
1)下载和安装
大家跟我一起来安装、部署一下目标系统吧。操作非常重要,后续内容都将借助该系统来讲解。
(1)下载安装包
在浏览器中搜索关键字“Bitnami”,打开Bitnami官网,单击进入Redmine详情页,然后单击“Win/Mac/Linux”,如图所示。
单击对应的操作系统,如图所示,将安装包下载到本地。

(2)安装Redmine(以Windows 10为例)
双击“bitnami-redmine-4.1.1-1-windows-x64-installer.exe”文件,弹出系统语言选择窗口。
这里我们从下拉列表中选择“简体中文”,单击“OK”按钮进入下一步,如图所示。

单击“前进”按钮,进入“选择组件”界面。
单击“前进”按钮,进入“安装文件夹”(即安装目录)界面,如图所示。
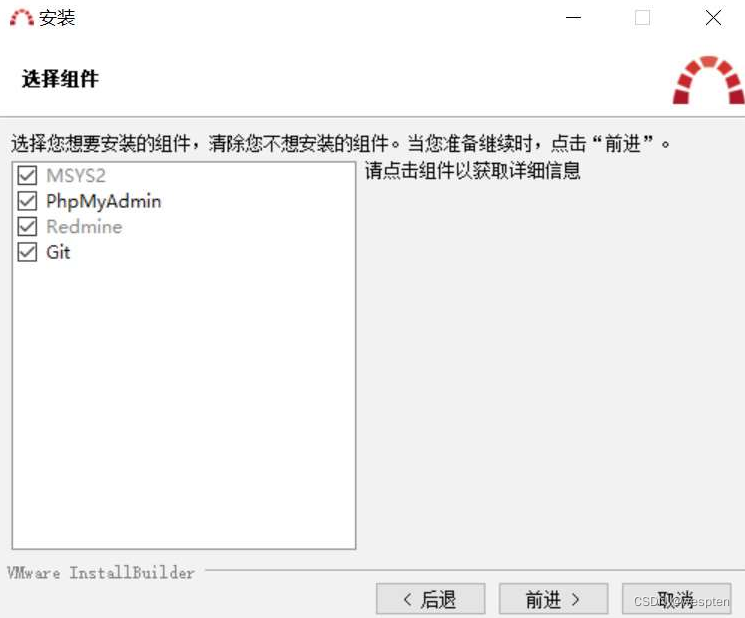

可以使用默认安装目录或者自定义安装目录,单击“前进”按钮,进入“创建管理员账户”界面。
输入“您的真实姓名”“Email地址”“登录”(账号名)“密码”“请确认密码”,注意密码最少8位。单击“前进”按钮,进入“Web服务器端口”界面。
保持默认的“81”端口,单击“前进”按钮,进入“Web服务器端口”界面。
保持默认SSL端口“444”,单击“前进”按钮,进入“MySQL信息”界面。
保持默认MySQL服务端口“3307”,单击“前进”按钮,进入“缺省(即默认)数据配置语言”界面,如图所示。
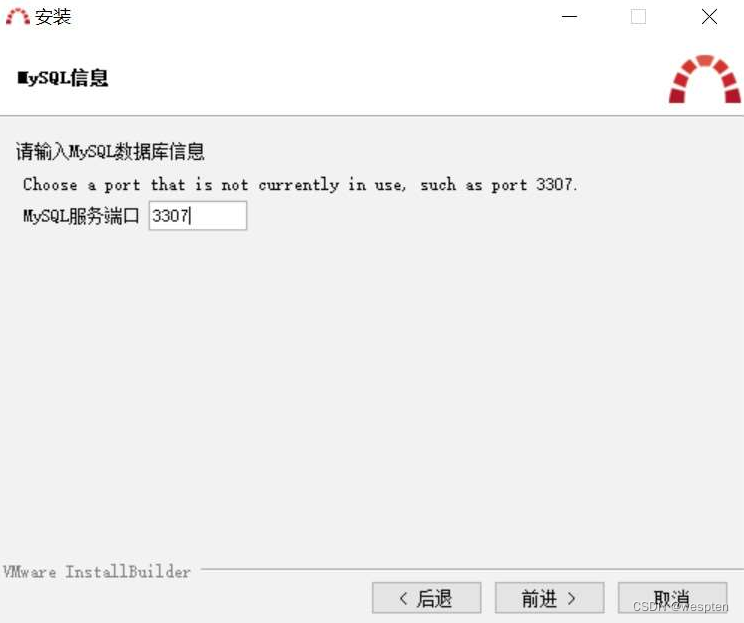
选择“中文”,单击“前进”按钮,进入“配置SMTP设置”界面。
接下来,保持默认设置并多次单击“前进”按钮,直到开始安装。

2)常见错误
虽然Bitnami为我们准备了安装包,但是在安装的过程中,可能还是会遇到一些问题。
问题一:安装过程中,出现弹窗“Microsoft Visual C++2017 x64 Minimum Runtime”,如图所示。
Visual C++安装失败:
解决思路:卸载旧版本“Microsoft Visual C++”,安装“2017版本”。
注意:
大家可以通过控制面板搜索、卸载对应的软件,这里不再赘述。
问题二:Apache Web Server未启动(Apache Web Server not running)。
单击“Welcome”标签下的“Go to Application”按钮,提示“Servers not running”,如图所示。
单击“Manage Servers”标签,查看各组件运行情况,显示“Apache Web Server Stopped”,如图所示。

解决思路一:确定服务端口无冲突。
- 打开DOS窗口,使用命令“netstat -aon|findstr "81"”确认81端口是否被其他应用程序占用(因为安装过程中我们使用的Web服务器端口是“81”)。
- 然后使用如下命令结束占用端口的应用:taskkill /pid 2152。
- 还可以更改Redmine使用的端口。
解决思路二:修改httpd.conf。
进入Redmine的安装根目录,依次进入“apache2”→“conf”文件夹,找到“httpd.conf”文件,如图所示。
用写字板打开该文件,如图所示。

在最后一行前加“#”将其注释掉,然后在下方增加一行:
SetEnv PATH "%PATH%;C:\Bitnami\redmine-4\apache2\bin"注意:
将上面语句中的Redmine安装目录替换为你自己的安装目录。
原因分析:这是因为“${PATH}”是Linux操作系统中的用法,在Windows操作系统中,应该使用“%PATH%”。
3)Redmine系统的启动和关闭
接下来,我们简单看一下如何启动、关闭、重启Redmine系统,以及如何修改各服务器端口。
(1)访问系统
在Windows开始菜单中找到安装程序“Bitnami Redmine Stack Manager”,如图所示。
单击“Bitnami Redmine Stack Manager”按钮,打开Redmine系统控制台,如图所示。
单击“Welcome”标签中的“Go to Application”,即可打开图所示的界面。
单击“Access Redmine”,进入Redmine系统首页,如图所示。
单击右上角“登录”按钮,输入用户名、密码。首次登录后,需要修改密码,如图所示。
后续访问的话,我们可以直接在浏览器地址栏输入“localhost+端口+/redmine/”,例如http://localhost:81/redmine/,又或者可以将“localhost”替换为本机的IP地址。
(2)修改服务器端口
打开“Bitnami Redmine Stack”控制窗口,单击“Manage Servers”标签,选择要修改的服务器端口,单击“Configure”按钮,在弹出的窗口中修改端口为目标端口,单击“OK”按钮保存,如图所示。
(3)启动、关闭服务
打开“Bitnami Redmine Stack”控制窗口,单击“Manage Servers”标签,单击右侧的“Start”“Stop”“Restart”按钮可以启动、关闭、重启单个选中的服务,单击下方的“Start All”“Stop All”“Restart All”按钮来启动、关闭、重启所有服务,如图所示。
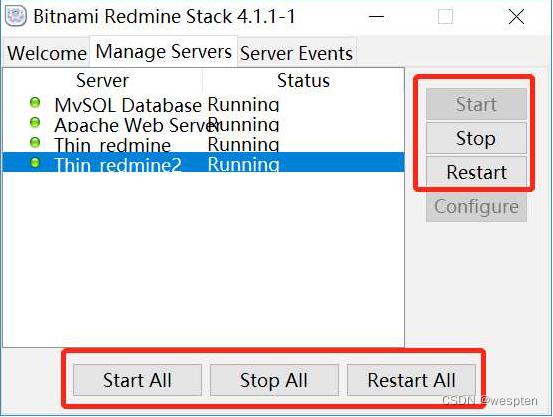
4)Redmine简单使用
缺陷管理系统是每个测试人员一定会接触的系统,这里我们来简单看几个业务场景。
(1)登录
打开浏览器,输入地址“http://localhost:81/redmine/”,打开Redmine首页。单击右上角“登录”按钮进入“登录”页面,输入用户名、密码后单击“登录”按钮即可登录。登录成功后,页面右上角会显示用户名。
(2)新建项目
登录成功后,单击左上角“项目”链接,进入“项目列表”页面,单击右上角“新建项目”链接,可以跳转到“新建项目”页面,如图所示。
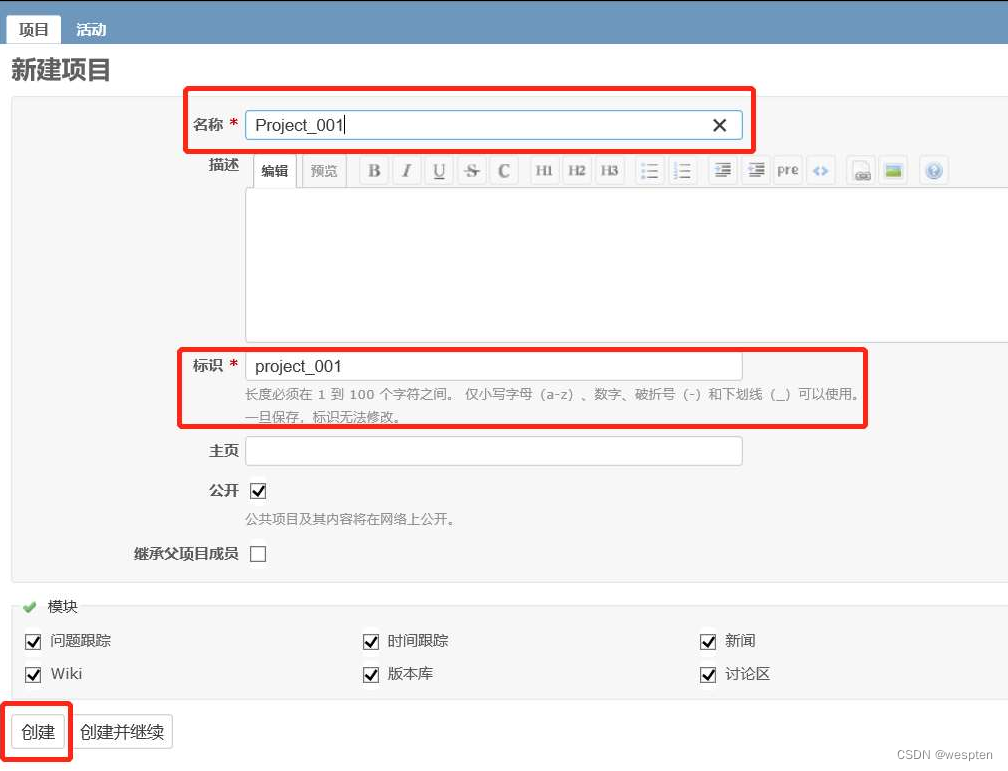
输入项目名称和标识,单击“创建”按钮,项目创建成功。页面会显示“创建成功”的字样,如图所示。

注意事项:
- 只有登录后才能创建项目,未登录只能查看项目信息。
- 项目标识默认和项目名称一致,可以自行修改,项目标识有字符长度和字符类型的要求。
- 项目标识在系统中是唯一值,即项目名称可重复,但项目标识不能重复。
(3)新建问题(缺陷)
登录后选择某个项目,单击“问题”标签,进入“问题”页面,如图所示。

单击右上角“新建问题”,进入“新建问题”页面,如图所示。
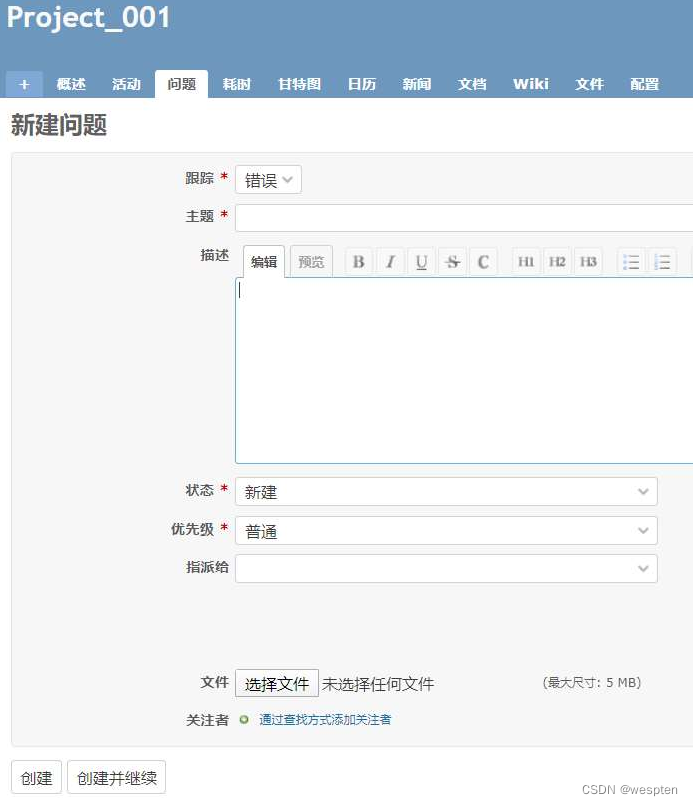
输入主题和描述等信息,单击“创建”按钮即可创建一个问题(缺陷)。
如图所示,问题创建成功后,页面会显示“问题#1已创建”。

(4)关闭问题(缺陷)
登录后选择某个项目,单击“问题”标签,然后单击问题列表中的问题“ID”或者“主题”,打开“问题详情”页面。单击“编辑”按钮打开“编辑”页面,在“状态”下拉列表中修改问题状态为“已关闭”,如图所示。
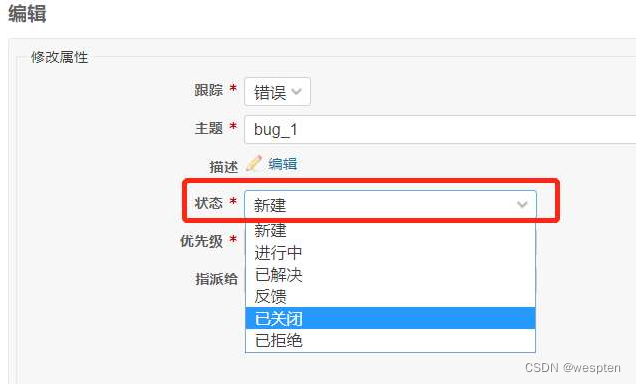
单击左下角“提交”按钮更新问题状态,页面显示“更新成功”,如图所示。
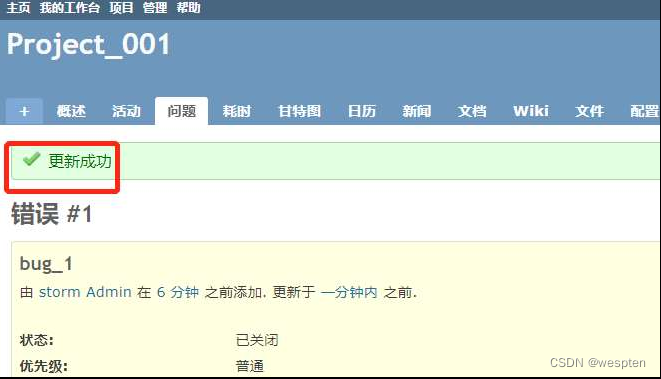
2. 线性脚本
至此前期工作已经准备完毕,我们来编写几个自动化测试用例。
首先来看一下要测试的内容,如下表所示。
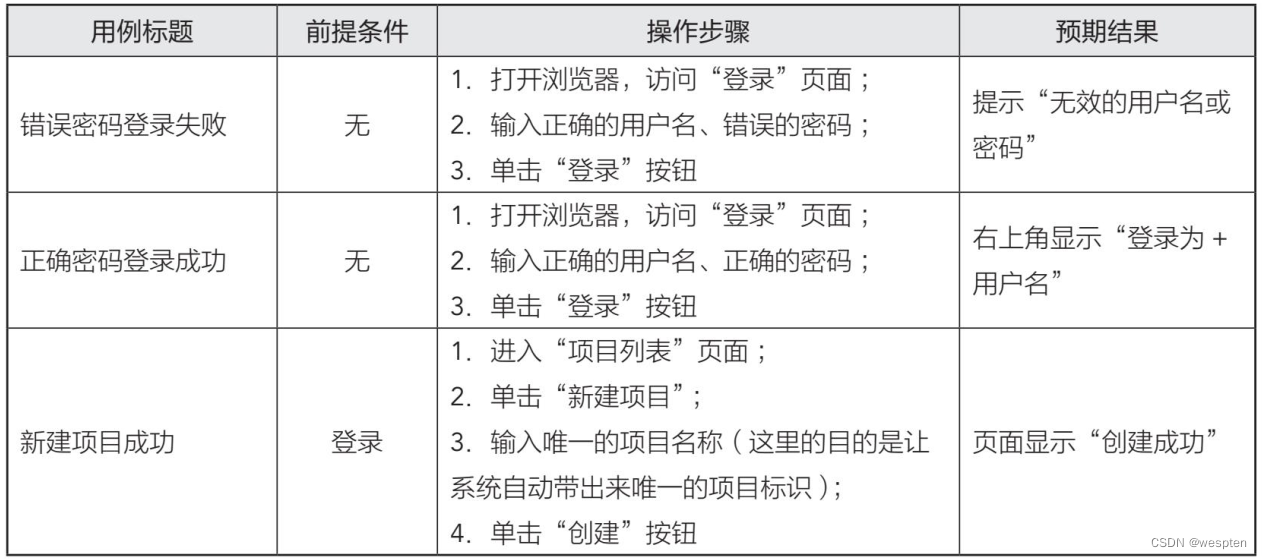
注意:
上面的表格并不是一个完整版的测试用例,我们只是为了说明要测试的内容。
接下来我们在Chapter_8目录下创建测试用例。因为前两个测试用例都是关于登录功能的,所以我们都放到test_login.py文件中。
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(20)
# 访问"登录"页面
driver.get('http://localhost:81/redmine/login')
# 用例一:错误密码登录失败
# 登录名
login_name = driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
# 登录密码
login_pwd = driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('error')
# "登录"按钮
login_btn = driver.find_element_by_id('login-submit')
login_btn.click()
# 登录失败后的提示信息
ele = driver.find_element_by_id('flash_error')
if '无效的用户名或密码' in driver.page_source:
print('pass')
else:
print('fail')
# 用例二:正确密码登录成功
# 登录名
login_name = driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
# 登录密码
login_pwd = driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('rootroot')
# "登录"按钮
login_btn = driver.find_element_by_id('login-submit')
login_btn.click()
# 登录后显示的用户名
name = driver.find_element_by_link_text('admin')
# 断言
if name.text == 'admin':
print('pass')
else:
print('fail')
driver.quit()再来编写第三个测试用例:test_new_project.py。
from selenium import webdriver
import time
# 通过时间戳构造唯一的项目名称
project_name = 'project_{}'.format(time.time())
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(20)
# 访问"登录"页面
driver.get('http://localhost:81/redmine/login')
# 登录
login_name = driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
login_pwd = driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('rootroot')
login_btn = driver.find_element_by_id('login-submit')
login_btn.click()
# 访问"项目列表"页面
driver.get('http://localhost:81/redmine/projects')
# "新建项目"按钮
new_project = driver.find_element_by_link_text('新建项目')
new_project.click()
# 输入项目名称
pj_name = driver.find_element_by_id('project_name')
pj_name.send_keys(project_name)
# "提交"按钮
commit_btn = driver.find_element_by_name('commit')
commit_btn.click()
# 新建项目成功后的提示信息
ele = driver.find_element_by_id('flash_notice')
if ele.text == '创建成功':
print('pass')
else:
print('fail')
driver.quit()我们编写了两个看似还不错的自动化测试用例,测试用例自动执行,并且还能自动去对比实际结果和预期结果,如果执行成功,就输出“pass”,反之输出“fail”。
抛开代码的冗余、代码稳定性、后续的维护成本等问题,我们还可以用同样的方法编写更多的用例。如果要一次性执行所有的测试用例,我们可以单独编写脚本,用来收集、执行符合条件的测试用例;还可以编写代码实现统计用例的执行结果,并生成测试报告。
12、unittest与Selenium
unittest测试框架相关的内容我们已经学习完成。接下来,我们借助unittest来改写一下上面编写的线性自动化测试脚本。
我们在Chapter_8下面新建一个Python Package,名为“Storm_8_3”。然后将前面的两个文件“test_login.py”“test_new_project.py”复制过来并改写代码。
将“test_login.py”改写,内容如下所示。
from selenium import webdriver
import unittest
class TestLogin(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
def test_001_login_err(self):
# 用例一:错误密码登录失败
# 登录名
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
# 登录密码
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('error')
# "登录"按钮
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
# 登录失败后的提示信息
ele = self.driver.find_element_by_id('flash_error')
self.assertIn('无效的用户名或密码', self.driver.page_source)
def test_002_login_suc(self):
# 用例二:正确密码登录成功
# 登录名
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
# 登录密码
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('rootroot')
# "登录"按钮
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
# 登录后显示的用户名
name = self.driver.find_element_by_link_text('admin')
self.assertEqual(name.text, 'admin')
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()对于登录这两个测试用例来说,打开浏览器访问Redmine的“登录”页面是测试前的准备工作,因此我们将相应代码放到setUp中。输入用户名和密码,单击“登录”按钮,然后进行断言,显然是测试用例的主体工作,因此我们将相应代码放到了test开头的方法中。测试完成后,我们要退出浏览器是收尾工作,因此将相应代码放到tearDown中。
接下来,将“test_new_project.py”改写,内容如下所示。
from selenium import webdriver
import time,unittest
# 通过时间戳构造唯一项目名
project_name = 'project_{}'.format(time.time())
class TestNewProject(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
# 登录
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('rootroot')
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
def test_new_project(self):
# 访问"项目列表"页面
self.driver.get('http://localhost:81/redmine/projects')
# "新建项目"按钮
new_project = self.driver.find_element_by_link_text('新建项目')
new_project.click()
# 输入项目名称
pj_name = self.driver.find_element_by_id('project_name')
pj_name.send_keys(project_name)
# "提交"按钮
commit_btn = self.driver.find_element_by_name('commit')
commit_btn.click()
# 新建项目成功后的提示信息
ele = self.driver.find_element_by_id('flash_notice')
self.assertEqual(ele.text, '创建成功')
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()对于新建项目这个用例来说,打开浏览器和完成登录动作都属于前期的准备工作,因此我们将相应代码放到了setUp固件中。
新建“run.py”文件,内容如下。
import unittest
import HTMLTestRunner
import time, os
if __name__ == '__main__':
# 查找当前目录的测试用例文件
testSuite = unittest.TestLoader().discover('.')
# 这次将报告放到当前目录
filename = os.getcwd() + os.sep + "Storm_{}.html".format(time.strftime ('%Y%m%d%H%M%S',time.localtime(time.time())))
# 以with open的方式打开文件
with open(filename, 'wb') as f:
# 通过HTMLTestRunner来执行测试用例,并生成报告
runner = HTMLTestRunner.HTMLTestRunner(stream=f,title='Redmine测试报告', description='unittest线性测试报告')
runner.run(testSuite)上述代码还是在当前文件目录搜寻测试用例,报告命名的方式是当前文件所在目录与当前时间拼接的字符串。
执行“run.py”文件后,会在当前目录生成测试报告,报告的文件名类似“Storm_20200515211544.html”,打开该文件后,内容如图所示。

13、unittest参数化
在“test_login.py”文件中,我们编写了两个测试用例:一个是登录成功,另一个是登录失败。两个测试用例的步骤其实是一样的,只不过传递的数据(这里是密码不同)不一样。如果我们想降低代码的冗余性,可以将脚本中的数据抽取出来,实现数据与代码的分离。这里我们介绍测试数据参数化,也称为“数据驱动”。
unittest本身不支持参数化,我们需要借助第三方插件实现。这里我们介绍两种常见的方法。
1. unittest+DDT
DDT的全称是Data-Driven Tests,意思是数据驱动测试。虽然unittest没有自带数据驱动功能,但DDT可以与之完美地结合。
1)安装DDT
这里我们使用pip3安装DDT,命令如下。
C:\Users\duzil>pip3 install ddt
Requirement already satisfied: ddt in c:\python\python36\lib\site-packages (1.2.1)2)参数化后的代码
我们在Chapter_8下创建一个名为“Storm_8_4”的Package,然后将“test_login.py”文件复制过来,将内容修改为如下所示。(注意看脚本中的注释。)
from selenium import webdriver
import unittest
import ddt
@ddt.ddt
class TestLogin(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
'''
1.@ddt.data,括号中可以传递列表或元组
2.这里传递了两个列表,代表两个测试用例
3.每个测试用例包含了3个参数
(1)第一个是用户名的取值
(2)第二个是密码的取值
(3)第三个是登录成功与否:我们约定0代表登录失败,1代表成功
'''
@ddt.data(['admin', 'error', '0'],['admin', 'rootroot', '1'])
@ddt.unpack
def test_001_login(self, username, password, status):
# 登录名
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys(username)
# 登录密码
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys(password)
# "登录"按钮
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
if status == '0':
# 登录失败后的提示信息
ele = self.driver.find_element_by_id('flash_error')
self.assertIn('无效的用户名或密码', self.driver.page_source)
elif status == '1':
# 登录后显示的用户名
name = self.driver.find_element_by_link_text(username)
self.assertEqual(name.text, username)
else:
print('参数化的状态只能传入0或1')
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()具体分析如下:
- 代码头部导入ddt模块:import ddt。
- 测试类TestLogin(unittest.TestCase)前声明使用:@ddt.ddt。
- 测试方法test_001_login(self, username, password, status):前使用@ddt.data来定义数据,并且定义的数据的个数和顺序必须与测试方法的形参一一对应;然后使用@unpack进行修饰,也就是对测试数据进行解包,将每组数据的第一个传给username,第二个传给password,第三个传给status。
- 这里要解释一下,为什么要定义一个status参数。原因是我们登录成功和失败断言的语句不一样。测试代码经过参数化精简了很多,并且代码的可维护性和可扩展性大大提高了。
- 假如要调整登录过程中的语句(def test_001_login(self, username, password, status)),我们只需要更改一次就好了,而不是要修改两个测试方法中的相同语句。
- 如果你还想测试其他数据的话,只需要在“@ddt.data(['admin', 'error', '0'],['admin','rootroot', '1'])”这里新增其他参数即可,不需要再复制、粘贴编写一个用例。
2. unittest+parameterized
让我们再来看另一种实现参数化的方式。parameterized是一个第三方的库,可以支持unittest的参数化。
1)安装parameterized
依然使用pip3来安装,安装命令如下所示。
C:\Users\duzil>pip3 install parameterized
Collecting parameterized
Downloading https://×××/0130989901f50de41fe85d605437a0210f/parameterized-0.7.4-py2.py3-none-any.whl
Installing collected packages: parameterized
Successfully installed parameterized-0.7.42)示例代码
这里借助parameterized包来完成unittest的参数化,示例代码:test_login_2.py。
from selenium import webdriver
import unittest
from parameterized import parameterized, param
class TestLogin(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
'''
1.@parameterized.expand,括号中传递列表
2.列表中传递元组,每个元组代表一个测试用例
3.每个测试用例包含了3个参数:
(1)第一个是用户名的取值
(2)第二个是密码的取值
(3)第三个是判断登录成功与否:我们约定0代表登录失败,1代表成功
'''
@parameterized.expand([('admin', 'error', '0'),('admin', 'rootroot', '1')])
def test_001_login(self, username, password, status):
# 登录名
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys(username)
# 登录密码
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys(password)
# "登录"按钮
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
if status == '0':
# 登录失败后的提示信息
ele = self.driver.find_element_by_id('flash_error')
self.assertIn('无效的用户名或密码', self.driver.page_source)
elif status == '1':
# 登录后显示的用户名
name = self.driver.find_element_by_link_text(username)
self.assertEqual(name.text, username)
else:
print('参数化的状态只能传入0或1')
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()具体分析如下:
- 代码头部使用语句“from parameterized import parameterized, param”导入两个包。
- 类不需要装饰。
- 在方法处装饰“@parameterized.expand([('admin', 'error', '0'),('admin', 'rootroot', '1')])”。
- 无论是DDT还是parameterized,配合unittest都可以方便地实现参数化,并且两种方法都非常简单,大家根据自己的习惯选择其一即可。当然如果是“团队作战”的话,建议还是保持统一。
九、Pytest测试框架
Pytest框架的组织形式更灵活一些。另外,Pytest配合插件可以实现失败用例再次执行的功能,这在某些情形下非常有用。最后Pytest支持Allure测试报告,该类报告的页面更加美观一些。
1、Pytest框架简介
1. 安装Pytest
Pytest并没有集成在Python包中,需要手动安装。
- DOS窗口安装
我们借助pip3来安装Python的第三方包,命令如下。
pip3 install -U pytest如果安装失败的话,可以尝试使用国内镜像来安装。例如,我们使用清华大学的镜像源,命令如下。
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pytest如果显示“Successfully installed……”,则说明安装成功,如图所示。
接着,我们可以使用“pip3 show pytest”命令来查看安装的Pytest版本。
C:\Users\duzil>pip3 show pytest
Name: pytest
Version: 5.4.2
Summary: pytest: simple powerful testing with Python
Home-page: https://docs.pytest.org/en/latest/
Author: Holger Krekel, Bruno Oliveira, Ronny Pfannschmidt, Floris Bruynooghe, Brianna Laugher, Florian Bruhin and others
Author-email: None
License: MIT license
Location: c:\python\python36\lib\site-packages
Requires: pluggy, importlib-metadata, colorama, wcwidth, atomicwrites, attrs, more-itertools, py, packaging
Required-by:或者也可以使用下面的命令来查看Pytest的版本。
C:\Users\duzil>pytest --version
This is pytest version 5.4.2, imported from c:\python\python36\lib\site-packages\pytest\__init__.py- PyCharm安装
另外,你还可以通过PyCharm的Settings来安装Pytest。
2. Pytest规则
- 文件命名:默认以“test_”开头或者以“_test”结尾(和unittest有差别,unittest默认以“test”开头或结尾)。
- 测试类(class)命名:默认以“Test”开头。
- 测试方法(函数)命名:默认以“test_”开头。
- 断言:直接使用Python语言的断言assert。
示例一:class风格代码(示例代码:test_11_1.py)
先来看一个class风格的Pytest框架代码,整体和unittest非常相似。
import pytest
# class TestStorm: # 这种写法也是可以的
class TestStorm(object):
def test_a(self):
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "test_11_1.py"])运行结果如下:
collected 2 items
test_11_1.py aaaa
.bbbb
.
============================== 2 passed in 0.04s ==============================和unittest一样,“.”代表断言成功,“F”代表断言失败。
示例二:函数风格代码(示例代码:test_11_2.py)
当然,对于Pytest框架代码,你可以不把测试用例放置到class中,而是直接定义函数。示例代码如下。
import pytest
def test_a():
print('aaaa')
assert 'a' == 'a'
def test_b():
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s"])2、Pytest测试固件
unittest提供了setUp、tearDown、setUpClass、tearDownClass等测试固件。
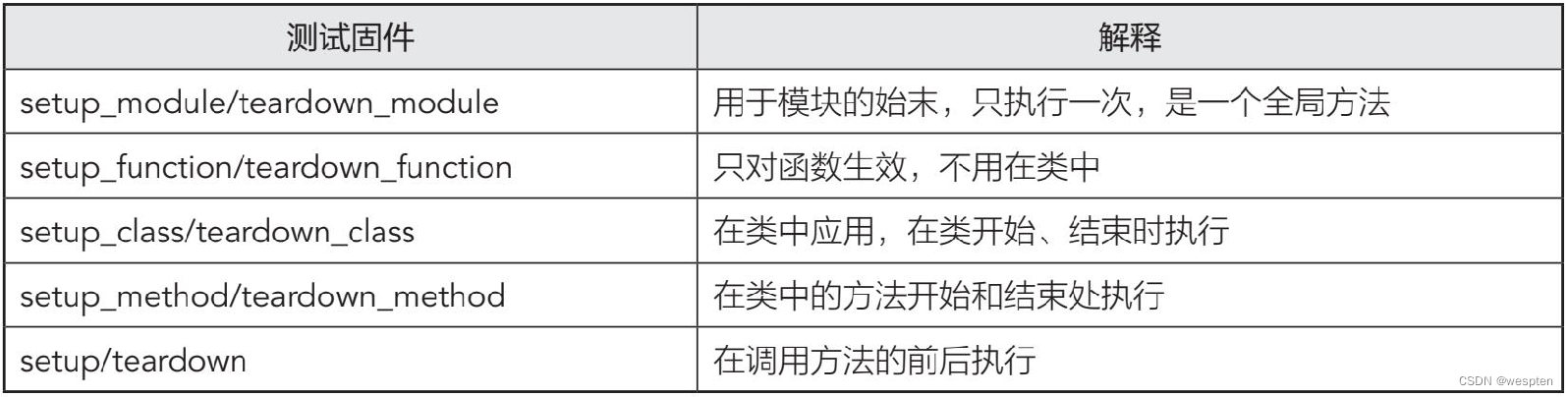
我们通过示例来验证一下效果。
1. 函数中的测试固件(示例代码:test_11_3.py)
- setup_module、teardown_module,在整个文件的开始和最后执行一次。
- setup_function和teardown_function,在每个函数开始前后执行。
import pytest
'''
在函数中使用
1.setup_module、teardown_module,在整个文件的开始和最后执行一次
2.setup_function和teardown_function,在每个函数开始前后执行
'''
def setup_module():
print('setup_module')
def teardown_module():
print('teardown_module')
def setup_function():
print('setup_function')
def teardown_function():
print('teardown_function')
def test_a():
print('aaaa')
assert 'a' == 'a'
def test_b():
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_3.py"])运行结果如下:
test_11_3.py setup_module
setup_function
aaaa
.teardown_function
setup_function
bbbb
.teardown_function
teardown_module2. class中的测试固件(示例代码:test_11_4.py)
- setup_class、teardown_class,在整个class的开始和最后执行一次。
- setup_method和teardown_method,在每个方法开始前后执行。
import pytest
'''
在class中使用
1.setup_class、teardown_class,在整个class的开始和最后执行一次
2.setup_method和teardown_method,在每个方法开始前后执行
'''
class Test01():
def setup_class(self):
print('setup_class')
def teardown_class(self):
print('teardown_class')
def setup_method(self):
print('setup_method')
def teardown_method(self):
print('teardown_method')
def test_a(self):
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_4.py"])运行结果如下:
test_11_4.py setup_class
setup_method
aaaa
.teardown_method
setup_method
bbbb
.teardown_method
teardown_class3. setup和teardown
setup和teardown既可以应用在函数中,也可以应用在class中,作用对象是函数或方法。和unittest中的setUp和tearDown不同,在代码中,“pytest”中的字母都是小写。
来看在函数中的应用(示例代码:test_11_5.py)。
import pytest
def setup_module():
print('setup_module')
def teardown_module():
print('teardown_module')
def setup():
print('setup')
def teardown():
print('teardown')
def test_a():
print('aaaa')
assert 'a' == 'a'
def test_b():
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_5.py"])运行结果如下:
test_11_5.py setup_module
setup
aaaa
.teardown
setup
bbbb
.teardown
teardown_module在class中的应用代码(示例代码:test_11_6.py)如下:
import pytest
class Test01():
def setup_class(self):
print('setup_class')
def teardown_class(self):
print('teardown_class')
def setup(self):
print('setup')
def teardown(self):
print('teardown')
def test_a(self):
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_6.py"])运行结果如下:
test_11_6.py setup_class
setup
aaaa
.teardown
setup
bbbb
.teardown
teardown_class总结:
- 假如你的测试文件中没有定义class,而是直接定义的函数,那么就使用“setup_module/teardown_module”和“setup_function/teardown_function”。
- 假如测试文件中定义了class,就使用“setup_class/teardown_class”和“setup_method/teardown_method”。
- 无论是否定义class,你都可以使用“setup”或“teardown”来实现在每个方法(或函数)的前后执行。
- 建议在一个项目中约定好是定义class来组织测试用例,还是直接定义函数来组织用例。
3、Pytest测试用例和断言
本节我们来看下Pytest组织测试用例及断言的方法。
1. 定义测试用例
Pytest和unittest的框架风格基本一致,但需要注意以下几点。
- 注意函数或方法名以“test_”开头。
- 直接通过函数定义测试用例的话,def后面的括号中没有self
- 通过class中的方法定义测试用例的话,def后面的括号中有self。
下面这个“示例代码:test_11_7.py”中,既包含函数定义的测试用例test_c,又包含class中的测试用例test_a和test_b,大家注意观察def后面的括号中的不同。
import pytest
def test_c(): # 这里没有self
print('cccc')
assert 'c' == 'c'
class Test01():
def test_a(self): # 这里有self
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_7.py"])2. 断言
unittest提供了专门的断言方法,而Pytest直接使用Python的assert关键字进行断言,更加灵活一些。
示例代码:test_11_8.py。
import pytest
'''
pytest的断言更灵活
'''
class Test01():
def setup_class(self):
print('setup_class')
def teardown_class(self):
print('teardown_class')
def setup_method(self):
print('setup_method')
def teardown_method(self):
print('teardown_method')
def test_a(self):
print('aaaa')
assert 5 > 3 # Python比较运算符
def test_b(self):
print('bbbb')
assert 'Storm' in 'Hello Storm' # 成员运算符
if __name__ == '__main__':
pytest.main(["-s", "./test_11_8.py"])在上述代码的测试用例test_a中,我们直接使用了算术运算符;在测试用例test_b中,我们直接使用了Python中的包含运算符in。当然,你还可以使用Python语言支持的任意运算符来返回True或False。
4、Pytest框架测试执行
接下来,我们看一下Pytest框架测试执行的常用方式。
1. 使用main函数执行
与unittest框架类似,Pytest框架也支持使用main函数来进行脚本的自测。
1)执行同级和下级目录所有符合条件的测试
使用pytest.main(["-s"])执行当前文件所在目录下所有符合条件的测试用例。这点和unittest不同。
示例代码:test_11_9.py。
import pytest
def test_b():
print('bbbb')
assert 'Storm' in 'Hello Storm'
if __name__ == '__main__':
pytest.main(["-s"])脚本执行的时候,并不会只执行test_11_9.py中的测试用例,而是会执行test_11_9.py文件所在目录下的所有符合条件的测试用例。
注意:
- unittest中直接使用unittest.main(),括号中不需要提供参数,默认执行当前文件中符合条件的测试用例。
- Pytest中,pytest.main()的括号中不需要提供参数,默认执行该文件同级和下级目录中所有符合条件的测试用例。
- -s参数,关闭捕捉,输出信息。使用-v参数则不会在控制台输出信息。
- main()括号中传递的参数必须放到列表中。
2)pytest.main(["-s", "test_11_10.py"])
在调试脚本的时候,如果我们希望脚本只执行当前文件,那么可以再多传递一个文件名的参数,示例代码:test_11_10.py。
import pytest
def test_b():
print('test_11_10')
assert 'Storm' in 'Hello Storm'
if __name__ == '__main__':
pytest.main(["-s", "test_11_10.py"])3)pytest.main(["-s", "./test_11_11.py::Test02"])
在class风格的脚本中,调试的时候还可以通过在文件名后加两个冒号和class名来指定执行某个class。
示例代码:test_11_11.py。
import pytest
class Test01():
def test_a(self):
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
class Test02():
def test_c(self):
print('cccc')
assert 'c' == 'c'
def test_d(self):
print('dddd')
assert 'd' == 'd'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_11.py::Test02"])2. 在命令行窗口中执行
同样,我们还可以在命令行窗口中执行Pytest框架测试脚本。
1)执行当前目录所有测试用例
首先进入目标目录,然后直接执行“pytest”即可自动寻找当前目录下的测试用例,如下所示。
D:\Love\Chapter_9>pytest
==================== test session starts =====================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1
rootdir: D:\Love\Chapter_9
collected 16 items
bbb_test.py .. [ 12%]
test_11_1.py .. [ 25%]
test_11_2.py .. [ 37%]
test_11_3.py .. [ 50%]
test_11_4.py .. [ 62%]
test_11_5.py . [ 68%]
test_11_6.py . [ 75%]
test_11_7.py .... [100%]
===================== 16 passed in 0.13s =====================2)执行指定的用例文件
“pytest+文件名”用来执行指定用例文件,如下所示。
D:\Love\Chapter_9>pytest test_11_7.py
====================== test session starts =======================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1
rootdir: D:\Love\Chapter_9
plugins: allure-pytest-2.8.13, rerunfailures-9.0
collected 3 items
test_11_7.py ... [100%]
====================== 3 passed in 0.02s ====================
D:\Love\Chapter_9>
(3)执行指定的用例类
我们可以通过“文件名+::+类名”的方式来执行指定的用例类,如下所示。
D:\Love\Chapter_9>pytest test_11_7.py::Test01
=========================== test session starts ===========================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1
rootdir: D:\Love\Chapter_9
plugins: allure-pytest-2.8.13, rerunfailures-9.0
collected 2 items
test_11_7.py .. [100%]
============================ 2 passed in 0.02s ============================
D:\Love\Chapter_9>总结:
- Pytest提供了多种用例执行的方式,受限于篇幅,这里无法完整地介绍,大家可以根据自己的需要研究。
- 在执行测试的时候,你还可以指定结果输出的参数。例如前面我们用到的“-s”。另外还有很多,例如:“-k”表示执行包含某个字符串的测试用例;“pytest -k add XX.py”表示执行XX.py中包含add的测试用例;“q”表示减少测试的运行冗长;“-x”表示出现一条测试用例失败就退出测试,这在调试阶段非常有用,当测试用例失败时,应该先调试通过,而不是继续执行测试用例。
5、Pytest框架用例执行失败重试
Pytest本身不支持测试用例执行失败重试的功能。我们需要安装一个插件——pytest rerunfailures。然后就可以通过“--reruns重试次数”来设置测试用例执行失败后的重试次数。
1. 安装插件
这里我们还是使用pip3来安装,如下所示。
D:\Love\Chapter_9>pip3 install pytest-rerunfailures
Collecting pytest-rerunfailures
Downloading https://files.pythonhosted.org/packages/25/91/a0d1ff828e6da1915e4972d76ea2b5f9a1b520f078b4197ef93eb8427b65/pytest_rerunfailures-9.0-py3-none-any.whl
…
Installing collected packages: pytest-rerunfailures
Successfully installed pytest-rerunfailures-9.0当命令行窗口显示“Successfully……”,则代表安装成功。
2. 设置重试次数
这里我们准备一个示例代码:test_11_12.py。将文件中test_c方法的断言修改为执行失败的情况,代码如下所示。
from selenium import webdriver
import unittest import pytest
class Test01():
def test_a(self):
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
class Test02():
def test_c(self):
print('cccc')
assert 'c' == 'c3' # 让其执行失败
def test_d(self):
print('dddd')
assert 'd' == 'd'在命令行使用“pytest test_11_12.py --reruns 2”语句执行测试用例,结果如下。
collected 4 items
test_11_12.py ..RRF. [100%]
================================ FAILURES =================================
______________________________ Test02.test_c ______________________________
self = <Chapter_9.test_11_12.Test02 object at 0x038B3530>
def test_c(self):
print('cccc')
> assert 'c' == 'c3' # 让其执行失败
E AssertionError: assert 'c' == 'c3'
E - c3
E + c
test_11_12.py:16: AssertionError
-------------------------- Captured stdout call ---------------------------
cccc
-------------------------- Captured stdout call ---------------------------
cccc
-------------------------- Captured stdout call ---------------------------
cccc
========================= short test summary info =========================
FAILED test_11_12.py::Test02::test_c - AssertionError: assert 'c' == 'c3'
================== 1 failed, 3 passed, 2 rerun in 0.09s ===================从上面的执行结果来看,test_c第一次断言失败后重试了两次,但都失败了。整个文件1个用例failed,3个用例passed。
另外,我们还可以指定断言失败后的重试间隔时间。例如当test_11_12.py文件断言失败的时候,我们要重试两次,重试的时间间隔为2秒,并且可以增加“---reruns-delay”参数,结果如下所示。
D:\Love\Chapter_9>pytest test_11_12.py --reruns 2 --reruns-delay 2
=========================== test session starts ===========================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1
rootdir: D:\Love\Chapter_9
plugins: allure-pytest-2.8.13, rerunfailures-9.0
collected 4 items
test_11_12.py ..RRF. [100%]
================================ FAILURES =================================
______________________________ Test02.test_c ______________________________
self = <Chapter_9.test_11_12.Test02 object at 0x0411D990>
def test_c(self):
print('cccc')
> assert 'c' == 'c3' # 让其执行失败
E AssertionError: assert 'c' == 'c3'
E - c3
E + c
test_11_12.py:16: AssertionError
-------------------------- Captured stdout call ---------------------------
cccc
-------------------------- Captured stdout call ---------------------------
cccc
-------------------------- Captured stdout call ---------------------------
cccc
========================= short test summary info =========================
FAILED test_11_12.py::Test02::test_c - AssertionError: assert 'c' == 'c3'
================== 1 failed, 3 passed, 2 rerun in 4.10s ===================最后,必须要注意:使用该功能要谨慎。这里简单分析一下其带来的好处和存在的弊端。无论是线上环境还是测试环境,网络或其他某些不可预测的情况可能会导致某个测试用例在执行的时候失败,但是当手动确认的时候,发现该功能是正常的。于是大家开始喜欢这种“重试”的功能。
好多人在吹捧它的时候说:“为了提高测试用例执行的稳定性,为了这个,为了那个……”,这些话不能说错,但要加个前提,或者说符合哪些条件才需要这样做。如果你编写的脚本没有合理地使用等待,以及没有合理地捕获异常,单纯靠这种“重试”机制去帮你“擦屁股”,我觉得有点“饮鸩止渴”,这会降低脚本的执行效率。
另外,在项目中可能有这样的情况:登录后,只有第一次进入某个页面时是空白页面。这种情况下用“重试”机制的话,就会“完美”地错过本来应该发现的缺陷。好在我们可以通过Pytest清晰地看到哪些测试用例是经过“重试”才通过的,建议在时间允许的情况下对测试用例进行人工验证。
总之,你可以借助“重试”功能去避开一些讨厌的偶然因素,但是也应该时刻提醒自己,对那些总是需要该功能才能通过的测试用例保持清醒。
6、标记机制
Pytest提供了标记机制,借助“mark”关键字,我们可以对测试函数(类、方法)进行标记。
1. 对测试用例进行分级
我们可以对测试用例进行分级,例如某些主流程的用例可以标记为L1,次要流程的用例标记为L2等。这样有一个好处,我们可以在不同的情况执行不同的测试用例,例如,在做冒烟测试的时候,只需要执行L1级别的用例就行了。
- 一个测试函数(类、方法)可以有多个标记。
- 一个标记也可以应用于多个函数(类、方法)。
- 执行参数使用:pytest -m mark名。
- 执行多个标记:pytest -m "L1 or L2"。
示例代码:test_11_13.py。
import pytest
class Test01():
@pytest.mark.L1
@pytest.mark.L2
def test_a(self):
print('aaaa')
assert 'a' == 'a'
@pytest.mark.L2
def test_b(self):
print('bbbb')
assert 'b' == 'b'
class Test02():
@pytest.mark.L1
def test_c(self):
print('cccc')
assert 'c' == 'c'
@pytest.mark.L3
def test_d(self):
print('dddd')
assert 'd' == 'd'其中,我们给test_a用例增加了两个标签L1和L2,test_b用例只有一个L2标签,test_c用例只有一个L1标签,test_d用例只有一个L3标签。
接下来,我们可以用“pytest -s "test_11_13.py" -m "L1"”命令只执行L1级别用例。
D:\Love\Chapter_9>pytest -s "test_11_13.py" -m "L1"
============================== test session starts ==============================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1
rootdir: D:\Love\Chapter_11
plugins: allure-pytest-2.8.13, rerunfailures-9.0
collected 4 items / 2 deselected / 2 selected
test_11_13.py aaaa
.cccc
.还可以同时执行L1和L2级别用例:
D:\Love\Chapter_9>pytest -s "test_11_13.py" -m "L1 or L2"
============================== test session starts ==============================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1
rootdir: D:\Love\Chapter_9
plugins: allure-pytest-2.8.13, rerunfailures-9.0
collected 4 items / 1 deselected / 3 selected
test_11_13.py aaaa
.bbbb
.cccc
.还可以执行非L1级别的用例:
D:\Love\Chapter_9>pytest -s "test_11_13.py" -m "not L1"
============================== test session starts ==============================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1
rootdir: D:\Love\Chapter_9
plugins: allure-pytest-2.8.13, rerunfailures-9.0
collected 4 items / 2 deselected / 2 selected
test_11_13.py bbbb
.dddd
.在根据标记执行用例的时候可能会报如下的错误:
========================== warnings summary ================================
test_11_13.py:5
D:\Love\Chapter_9\test_11_13.py:5: PytestUnknownMarkWarning: Unknown pytest.
mark.L1 - is this a typo? You can register custom marks to avoid this warning - for
details, see https://docs.pytest.org/en/latest/mark.html
@pytest.mark.L1想解决该问题的话,可以将marks配置到pytest.ini文件中。
2. 跳过某些用例
前面我们介绍了unittest所支持的用例跳过装饰器。Pytest同样可以实现类似功能,简单来看一下吧。
1)使用skip(reason=None)实现无条件跳过
import pytest
class Test01():
@pytest.mark.skip(reason='这里是原因')
def test_a(self):
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_14.py"])运行结果如下:
collected 2 items
test_11_14.py sbbbb
.
======================== 1 passed, 1 skipped in 0.03s =========================2)使用skipif(condition, reason=None)实现满足条件跳过
mport pytest
class Test01():
@pytest.mark.skipif(2>1, reason='这里是原因')
def test_a(self):
print('aaaa')
assert 'a' == 'a'
def test_b(self):
print('bbbb')
assert 'b' == 'b'
if __name__ == '__main__':
pytest.main(["-s", "./test_11_14.py"])因为条件2>1是满足的,所以跳过test_a用例,运行结果如下。
collected 2 items
test_11_14.py sbbbb
.
======================== 1 passed, 1 skipped in 0.02s =========================7、全局设置
前面我们介绍的配置信息要么是在文件的main方法中,要么是在命令行。这里我们还可以在测试目录下面创建一个pytest.ini文件,文件中可以设定一些执行规则,借助该文件可以修改Pytest的默认行为,即可以修改Pytest的执行规则。
这里我们先准备一个测试目录。在Chapter_9下面新建一个Python Package:test_Storm_11_1,然后在下面新建一个Python Package:testcases,同时新建一个pytest.ini文件,接着在testcases目录下新建两个测试用例:test_storm_1.py和test_storm_2.py。
整体目录结构如图所示:
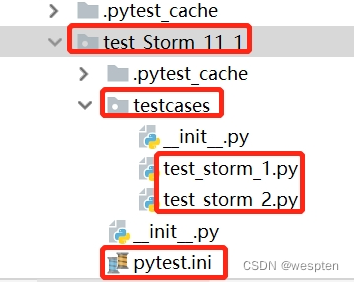
然后,我们就可以将一些配置信息写入pytest.ini文件。这里需要注意以下3点。
- 文件名必须是pytest.ini。
- 文件内容必须以“[pytest]”开头。
- 文件内容不能包含中文。
1. 命令行参数
通过关键字“addopts”来设置命令行参数,如“-s”或“-v”监控、失败重试的次数、重试的时间间隔、按标签来执行,多个参数之间用空格分隔。
示例如下:
addopts = -v --reruns 2 --reruns-delay 2 -m "L1"2. 自定义标签
我们可以将自定义标签添加到pytest.ini文件中。注意,第二个标签需要换行且缩进。这里我们定义了两个标签,第一个L1代表level 1 case,第二个L2代表level 2 case。格式如下所示。
markers = L1:level_1 testcases
L2:level_2 testcases3. 自定义测试用例查找规则
- 在当前文件目录中的testcases目录下查找测试用例:testpaths = testcases。
- 查找文件名以“test_”开头的文件,也可以修改为以其他文件名开头:python_file =test_*.py。
- 查找以“Test*”开头的类,也可以修改为以其他类名开头:python_classes = Test*。
- 查找以“test_”开头的函数,也可以修改为以其他函数名开头:python_functions = test_*。
testpaths = testcases
python_file = test_*.py
python_classes = Test*
python_functions = test_*示例代码:test_storm_1.py。
import pytest
class TestStorm1(object):
@pytest.mark.L1
def test_01(self):
print('aaa')
assert 'a'=='a'
if __name__ == '__main__':
pytest.main(["-s", "test_storm_1.py"])示例代码:test_storm_2.py。
import pytest
class TestStorm2(object):
@pytest.mark.L2
def test_02(self):
print('bbb')
assert 'b' == 'c' # 断言失败pytest.ini文件内容如下:
[pytest]
addopts = -v --reruns 2 --reruns-delay 2 -m "L1 or L2"
markers = L1:level_1 testcases
L2:level_2 testcases
testpaths = testcases
python_file = test_*.py
python_classes = Test*
python_functions = test_*接下来我们在命令行执行,得到的结果如下。
D:\Love\Chapter_9\test_Storm_11_1>pytest
================ test session starts =================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1 -- c:\python\python36\python.exe
cachedir: .pytest_cache
rootdir: D:\Love\Chapter_9\test_Storm_11_1, inifile: pytest.ini, testpaths: testcases
plugins: allure-pytest-2.8.13, rerunfailures-9.0
collected 2 items
testcases/test_storm_1.py::TestStorm1::test_01 PASSED [ 50%]
testcases/test_storm_2.py::TestStorm2::test_02 RERUN [100%]
testcases/test_storm_2.py::TestStorm2::test_02 RERUN [100%]
testcases/test_storm_2.py::TestStorm2::test_02 FAILED [100%]
====================== FAILURES ======================
_________________ TestStorm2.test_02 _________________
self = <Chapter_9.test_Storm_11_1.testcases.test_storm_2.TestStorm2 object at 0x03E02F50>
@pytest.mark.L2
def test_02(self):
print('bbb')
> assert 'b' == 'c'
E AssertionError: assert 'b' == 'c'
E - c
E + b
testcases\test_storm_2.py:8: AssertionError
---------------- Captured stdout call ----------------
bbb
---------------- Captured stdout call ----------------
bbb
---------------- Captured stdout call ----------------
bbb
============== short test summary info ===============
FAILED testcases/test_storm_2.py::TestStorm2::test_02
======= 1 failed, 1 passed, 2 rerun in 25.82s ========
D:\Love\Chapter_9\test_Storm_11_1>合理使用pytest.ini文件能方便地控制测试用例执行的情况。
8、测试报告
Pytest框架支持多种形式的测试报告。本节我们将分别介绍pytest-html和Allure两种测试报告。
1. pytest-html测试报告
先来学习一个轻量级的测试报告。
1)安装包
借助pip3来安装pytest-html的包,命令如下。
D:\Love\Chapter_9\test_Storm_11_1>pip3 install pytest-html
Collecting pytest-html
Downloading https://×××.org/packages/×××
…
Installing collected packages: pytest-metadata, pytest-html
Successfully installed pytest-html-2.1.1 pytest-metadata-1.9.02)在main方法中使用
在Chapter_9下面新建一个Python Package:test_Storm_11_2,然后将test_Storm_11_1中的文件复制过来。在test_storm_1.py文件的main方法中增加“"--html=./report.html"”参数,用来生成测试报告,示例代码如下。
import pytest
class TestStorm1(object):
@pytest.mark.L1
def test_01(self):
print('aaa')
assert 'a'=='a'
if __name__ == '__main__':
pytest.main(["-s", "test_storm_1.py", "--html=./report.html"])在PyCharm中执行,程序会在当前目录生成一个report.html文件,其内容如图所示。
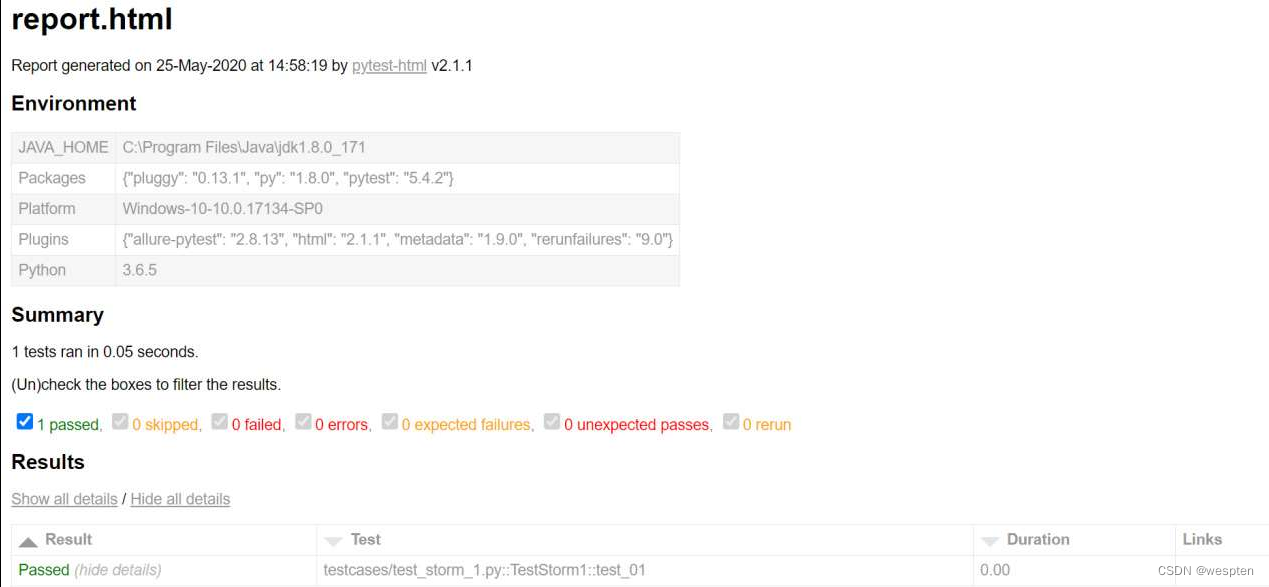
报告包括以下内容。
- 报告生成的日期、时间。
- 测试环境:Java目录、平台等。
- 测试小结:执行了多长时间和多少用例,用例通过、失败、跳过的个数等。
- 具体测试结果。
3)在pytest.ini文件中使用
我们也可以将测试报告的配置项放到pytest.ini文件中,示例代码如下。
[pytest]
addopts = -v --reruns 2 --reruns-delay 2 -m "L1 or L2" --html=./report.html
markers = L1:level_1 testcases
L2:level_2 testcases
testpaths = testcases
python_file = test_*.py
python_classes = Test*
python_functions = test_*接下来,在命令行窗口执行测试用例。
D:\Love\Chapter_9>cd test_Storm_11_2
D:\Love\Chapter_9\test_Storm_11_2>pytest
=================== test session starts ===================
platform win32 -- Python 3.6.5, pytest-5.4.2, py-1.8.0, pluggy-0.13.1 -- c:\python\python36\python.exe
cachedir: .pytest_cache
metadata: {'Python': '3.6.5', 'Platform': 'Windows-10-10.0.17134-SP0', 'Packages':
{'pytest': '5.4.2', 'py': '1.8.0', 'pluggy': '0.13.1'}, 'Plugins': {'allure-pytest':
'2.8.13', 'html': '2.1.1', 'metadata': '1.9.0', 'rerunfailures': '9.0'}, 'JAVA_HOME':
'C:\\Program Files\\Java\\jdk1.8.0_171'}
rootdir: D:\Love\Chapter_9\test_Storm_11_2, inifile: pytest.ini, testpaths: testcases
plugins: allure-pytest-2.8.13, html-2.1.1, metadata-1.9.0, rerunfailures-9.0
collected 2 items
testcases/test_storm_1.py::TestStorm1::test_01 PASSED [ 50%]
testcases/test_storm_2.py::TestStorm2::test_02 RERUN [100%]
testcases/test_storm_2.py::TestStorm2::test_02 RERUN [100%]
testcases/test_storm_2.py::TestStorm2::test_02 FAILED [100%]
======================== FAILURES =========================
___________________ TestStorm2.test_02 ____________________
self = <Chapter_9.test_Storm_11_2.testcases.test_storm_2.TestStorm2 object at 0x046C2ED0>
@pytest.mark.L2
def test_02(self):
print('bbb')
> assert 'b' == 'c'
E AssertionError: assert 'b' == 'c'
E - c
E + b
..\test_Storm_11_1\testcases\test_storm_2.py:8: AssertionError
------------------ Captured stdout call -------------------
bbb
------------------ Captured stdout call -------------------
bbb
------------------ Captured stdout call -------------------
bbb
- generated html file: file://D:\Love\Chapter_9\test_Storm_11_2\report.html -
================= short test summary info =================
FAILED testcases/test_storm_2.py::TestStorm2::test_02 - A...
========== 1 failed, 1 passed, 2 rerun in 4.17s ===========
D:\Love\Chapter_9\test_Storm_11_2>测试报告的内容如图所示:
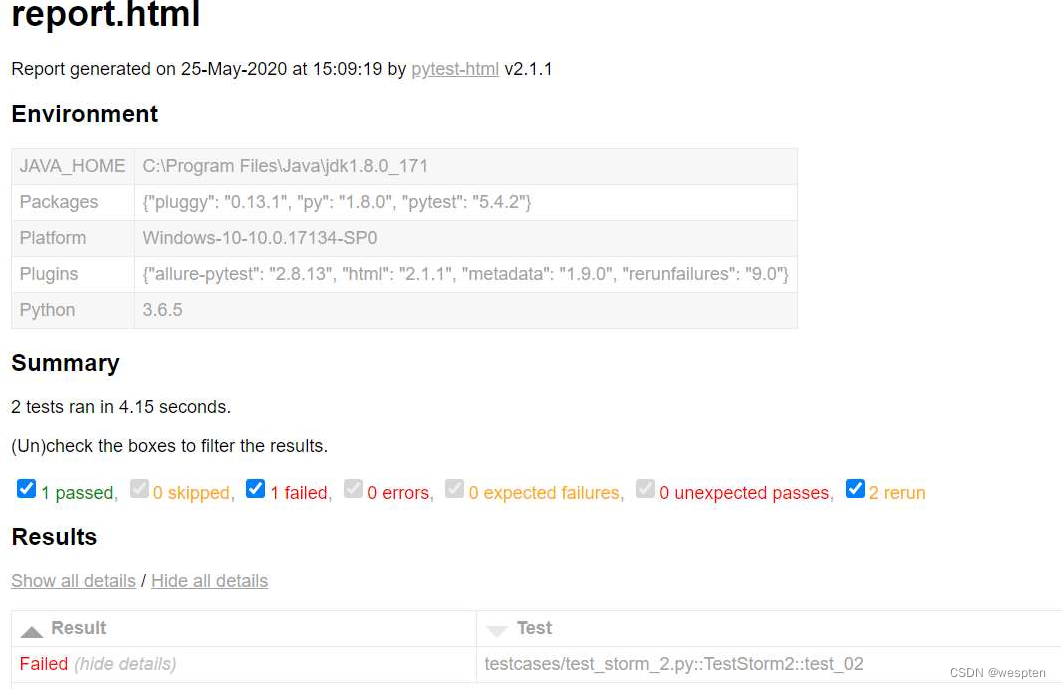
2. Allure测试报告
Allure是一个灵活、轻量级、支持多语言的测试报告工具,来一起了解下吧。
1)环境准备
Allure基于Java开发,因此我们需要提前安装Java 8或以上版本的环境。安装Java以及设置环境变量的方法这里不再赘述,大家自行准备。
- 安装allure-pytest插件
在DOS窗口输入命令“pip3 install allure-pytest”,然后按“Enter”键。
代码如下所示:
D:\Love\Chapter_9>pip3 install allure-pytest
Collecting allure-pytest
Downloading https://files.pythonhosted.org/packages/9a/e3/9cea2cf25d8822752f55c9df16f0d0ef54ca6b369e3ccd0f51737f5288d3/allure_pytest-2.8.13-py3-none-any.whl
Collecting allure-python-commons==2.8.13 (from allure-pytest)
…
Installing collected packages: allure-python-commons, allure-pytest
Successfully installed allure-pytest-2.8.13 allure-python-commons-2.8.13- 安装Allure
确认Java已安装并配置好了环境变量,代码如下。
C:\>java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)下载安装Allure:你可以从GitHub下载安装文件“allure2-2.13.3.zip”,解压后,将bin目录配置到环境变量中,然后在DOS窗口中输入“allure”,并按“Enter”键,如果显示“Usage”的话,说明设置成功。
import unittest C:\Users\duzil>allure
Usage: allure [options] [command] [command options]
Options:
--help
…注意:
你还可以先安装scoop,然后通过scoop来安装Allure。scoop是一个Windows的包管理工具,有点类似pip与Python的关系。
2)执行测试用例
使用如下命令执行:pytest.main(["-m","login","-s","-q","--alluredir=./report"])。
- “-m”:标记用例。
- “login”:被标记需要执行用例。
- “-s”:允许终端在测试执行时输出某些结果,例如你想输入print的内容,可以加上“-s”。
- “-q”:简化输出结果。
- “--alluredir”:生成Allure指定语法。
- “./report”:生成报告的目录。
- “--clean-alluredir”:因为这个插件库allure-pytest生成了报告文件,你第二次执行时不会清理掉里面的东西,所以你需要删除这个report文件夹,然后执行重新新建report文件夹命令。
- 说明:命令执行后,程序会在report文件夹里面生成文件。
3)定制化报告
- eature:标注主要功能模块。
- story:标注features功能模块下的分支功能。
- severity:标注测试用例的重要级别。
blocker级别:致命缺陷。
critical级别:严重缺陷。
normal级别:一般缺陷,默认为这个级别。
minor级别:次要缺陷。
trivial级别:轻微缺陷。
- step:标注测试用例的重要步骤。
- attach:用于向测试报告中输入一些附加的信息,通常是一些测试数据信息。
- name就是附件名称,body就是数据,attachment_type就是传类型。附件支持的类型有TEXT、HTML、XML、PNG、JPG、JSON、OTHER。
- issue:这里传的是一个连接,记录的是你的问题。
- testcase:这里传的是一个连接,记录的是你的用例。
- description:描述用例信息。
接下来,我们在Chapter_9下面新建一个Python Package:test_Storm_11_3,然后在下面新建一个report文件夹,再新建两个Python文件:test_1_storm.py和test_2_storm.py。
整体的目录结构如图所示:
文件test_1_storm.py的内容如下(这里需要大家对比着后面的测试报告看代码中的注释)。
import pytest,allure
@allure.feature("测试场景1") #标记场景
class TestDemo():
@allure.story("测试用例1-1") # 标记测试用例
@allure.severity("trivial") # 标记用例级别
def test_1_1(self): # 用例1
a = 1 + 1
assert a == 2
@allure.story("测试用例1-2")
@allure.severity("critical")
@allure.step('用例2:重要步骤')
def test_1_2(self):
assert 2 == 2文件test_2_storm.py的内容如下。
import pytest,allure
@allure.feature("测试场景2") #标记代码
class TestDemo():
@allure.story("测试用例2-1")
@allure.severity("minor")
def test_2_1(self):
"""
用例描述:这是第一条用例的描述
"""
#allure.MASTER_HELPER.description("11111111111111")
a = 1 + 1
assert a == 3 # 断言失败
@allure.story("测试用例2-2")
@allure.severity("minor")
@allure.step('用例2:重要步骤')
def test_2_2(self):
assert 2 == 2
if __name__ == '__main__':
pytest.main(['-s', '-q', '--alluredir', './report/'])然后我们通过main来执行测试用例,这时候程序会在report文件夹中生成一些JSON格式的文件,如图所示。
接下来回到DOS窗口,进入Storm_11_1这个目录下面,执行“allure generate --clean report”命令,结果如下所示。
D:\Love\Chapter_9\Storm_11_1>allure generate --clean report
Report successfully generated to allure-report按“Enter”键后,可以看到“Report successfully generated to allure-report”。然后我们回到PyCharm,你可以看到新生成了一个allure-report文件夹,展开后如图所示。

这时候你就可以用浏览器打开index.html文件了。
文件打开后默认显示“Overview”菜单,如下图所示。
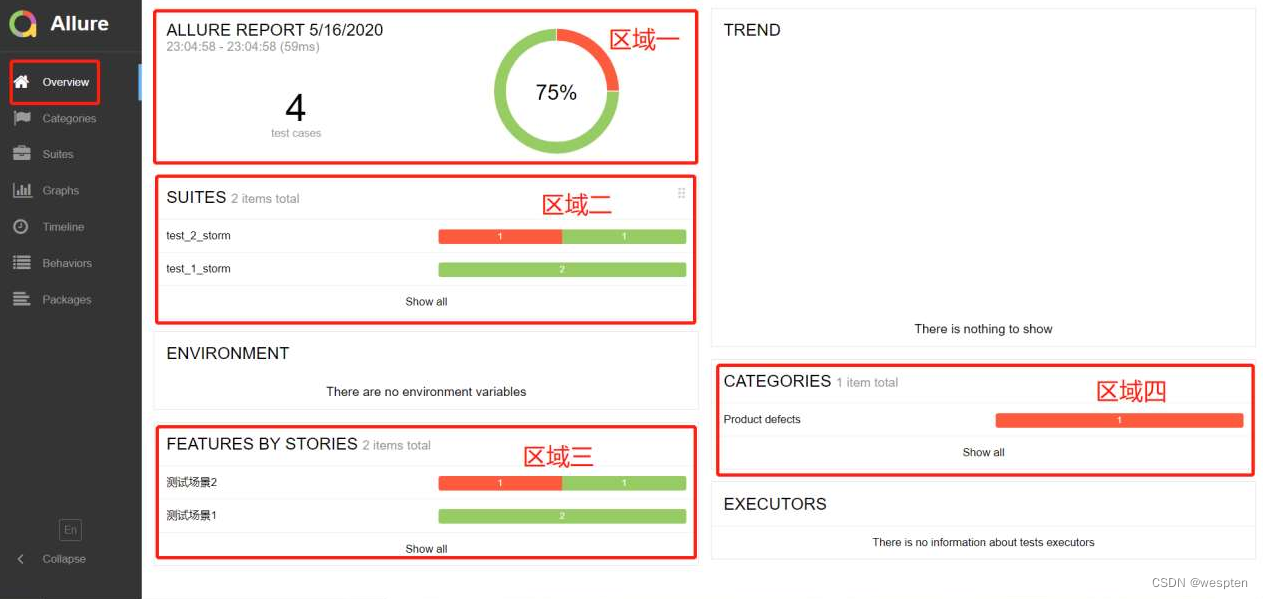
默认打开的“Overview”菜单包括以下内容。
- 区域一:显示报告生成的时间,执行的时间,一共执行了多少个测试用例,环状图显示用例通过的比例。
- 区域二:显示的是测试集合(class)情况。
- 区域三:显示的是测试场景(@allure.feature)。
- 区域四:显示失败用例的信息。
再来看一下“Categories”菜单,我们可以看到断言失败的具体信息,如图所示。
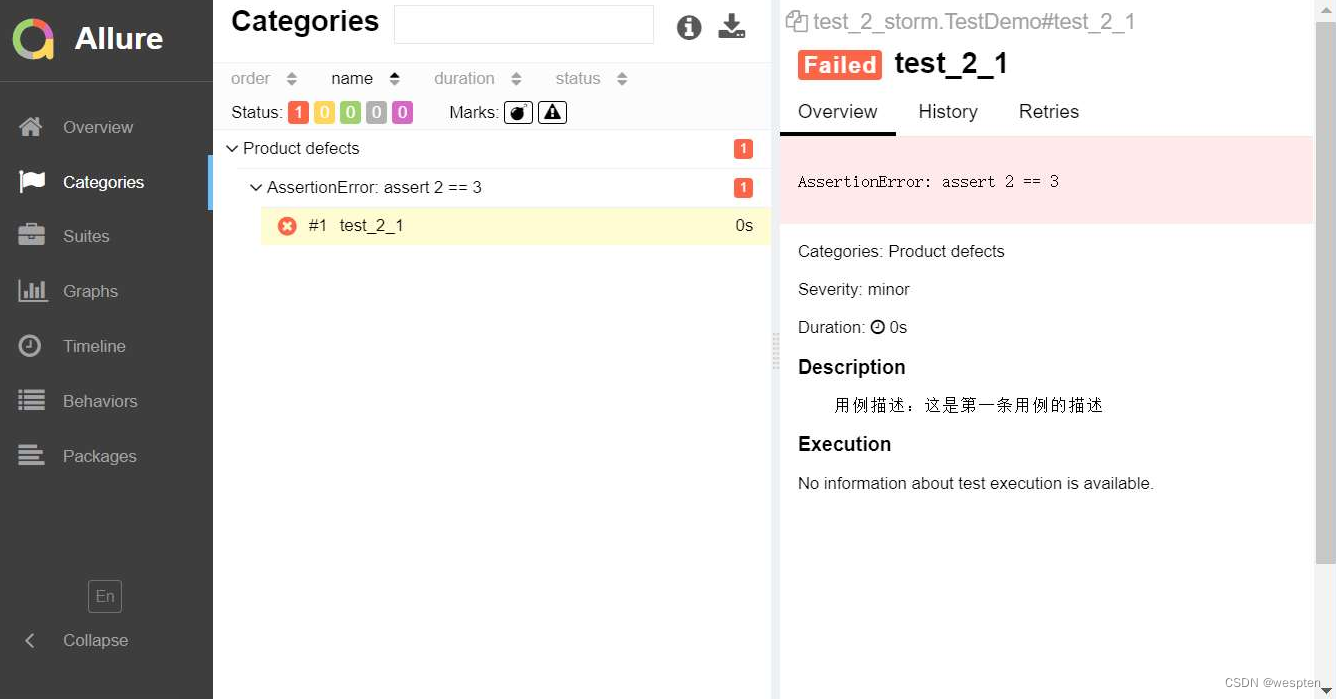
通过“Suites”菜单,我们可以以测试集合树的形式查看用例执行的结果,如图所示。
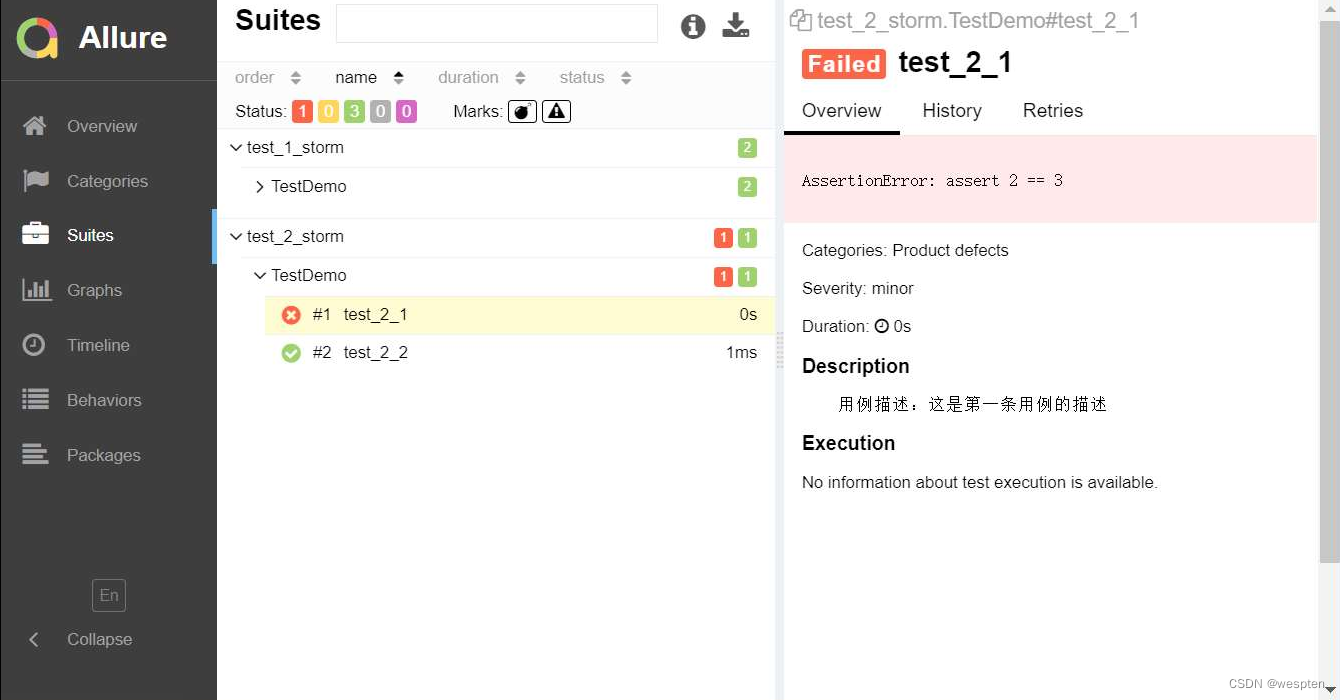
在“Graphs”菜单中,我们可以看到用例执行状态的环状图、用例级别的柱状图、用例执行时间的柱状图,如图所示。
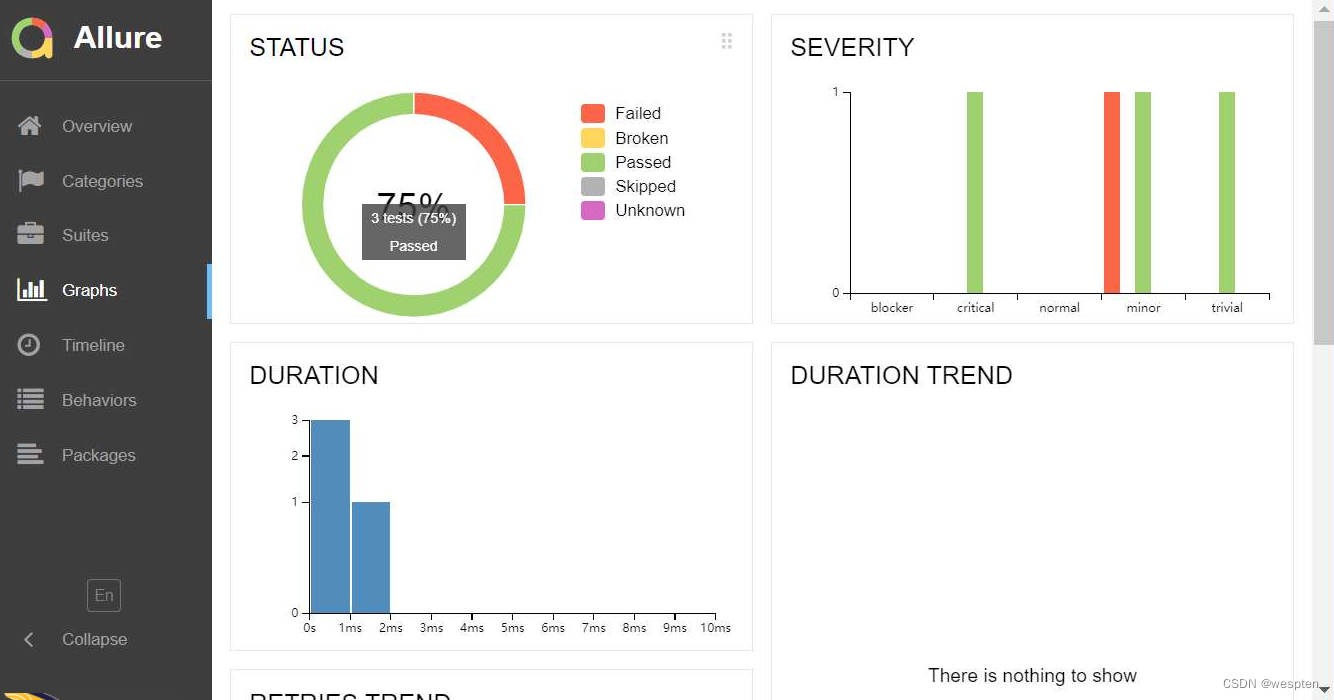
9、Pytest与Selenium
我们将两个测试用例以pytest class的方式改写一下,让大家体验一下Pytest风格的自动化测试脚本,两种方式大同小异。
我们在Chapter_9目录下面新建Python Package:test_Storm_11_4。在其中新建两个测试用例文件,内容如下。
测试用例一:测试登录功能(示例代码:test_001_login.py)。
from selenium import webdriver
import pytest
class TestLogin():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
def teardown(self):
self.driver.quit()
def test_001_login_err(self):
# 用例一:错误密码登录失败
# 登录名
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
# 登录密码
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('error')
# "登录"按钮
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
# 登录失败后的提示信息
ele = self.driver.find_element_by_id('flash_error')
assert '无效的用户名或密码' in self.driver.page_source
def test_002_login_suc(self):
# 用例二:正确密码登录成功
# 登录名
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
# 登录密码
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('rootroot')
# "登录"按钮
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
# 登录后显示的用户名
name = self.driver.find_element_by_link_text('admin')
assert name.text == 'admin'
if __name__ == '__main__':
pytest.main(['-s', '-q', '--alluredir', './report/'])测试用例二:新建项目(示例代码:test_002_new_prjoject.py)。
from selenium import webdriver
import time, pytest
# 通过时间戳构造唯一项目名
project_name = 'project_{}'.format(time.time())
class TestNewProject():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
# 登录
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys('admin')
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys('rootroot')
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
def test_new_project(self):
# 访问"项目列表"页面
self.driver.get('http://localhost:81/redmine/projects')
# "新建项目"按钮
new_project = self.driver.find_element_by_link_text('新建项目')
new_project.click()
# 输入项目名称
pj_name = self.driver.find_element_by_id('project_name')
pj_name.send_keys(project_name)
# "提交"按钮
commit_btn = self.driver.find_element_by_name('commit')
commit_btn.click()
# 新建项目成功后的提示信息
ele = self.driver.find_element_by_id('flash_notice')
assert ele.text == '创建成功'
def teardown(self):
self.driver.quit()
if __name__ == '__main__':
pytest.main(['-s', '-q', '--alluredir', './report/'])Pytest风格用例和unittest风格用例的差异非常小,总结如下:
- 引入的包不同。
- 类方法不再需要继承特定的基础类。
- Test Fixture不同,这是大小写的问题。
- 断言的关键字不同。
10、Pytest参数化
我们来编写Pytest的参数化脚本。Pytest自身支持参数化,使用方法为@pytest.mark.parametrize("argnames",argvalues)。
- argnames:参数名称,单个参数用参数名,多个参数可以拼接到一个元组中。
- argvalues:参数对应值,类型必须为可迭代类型,一般为列表。
我们在Chapter_9下面新建Python Package:test_Storm_11_5。然后在下面新建文件:test_001_login.py。
文件内容如下:
from selenium import webdriver
import pytest
data = [('admin', 'error', '0'), ('admin', 'rootroot', '1')]
@pytest.mark.parametrize(("username", "password", "status"), data)
class TestLogin():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
def teardown(self):
self.driver.quit()
def test_001_login(self, username, password, status):
# 登录名
login_name = self.driver.find_element_by_id('username')
login_name.clear()
login_name.send_keys(username)
# 登录密码
login_pwd = self.driver.find_element_by_id('password')
login_pwd.clear()
login_pwd.send_keys(password)
# "登录"按钮
login_btn = self.driver.find_element_by_id('login-submit')
login_btn.click()
if status == '0':
# 登录失败后的提示信息
ele = self.driver.find_element_by_id('flash_error')
assert '无效的用户名或密码' in self.driver.page_source
elif status == '1':
# 登录后显示的用户名
name = self.driver.find_element_by_link_text(username)
assert name.text == username
else:
print('参数化的状态只能传入0或1')
if __name__ == '__main__':
pytest.main(['-s', '-q', '--alluredir', './report/'])可见Pytest框架实现参数化的方法非常简单。
十、PO设计模式
到目前为止,我们已经掌握了在unittest和Pytest两种单元测试框架中编写Selenium WebDriver测试脚本的方法。然而随着时间的推移,自动化测试用例愈加丰富,项目的易变性导致测试用例的维护成本越来越高,主要介绍其解决方式——PO设计模式。
开发可维护性高的测试脚本,对自动化测试持续集成非常重要。如何去解决这些问题呢?经过在项目中不断实践,前辈们总结出来一套基于Page Object模式(PO模式)的脚本设计方法。目前PO模式被广大测试同行所认可。PO模式是指将页面元素的定位以及元素的操作分离出来,测试用例脚本直接调用这些封装好的元素操作来组织测试用例,从而实现了测试用例脚本和元素定位、操作的分离。
这样的模式带来的好处如下:
- 抽象出页面对象可以在很大程度上降低开发人员修改页面代码对测试的影响。
- 可以在多个测试用例中复用一部分测试代码。
- 测试代码变得更易读、灵活、可维护。
- 测试团队可以分工协作,部分人员封装测试元素对象和操作,部分人员应用封装好的元素操作来组织测试用例。
我们看个实际的场景。在前面,我们编写了3个测试用例——两个登录用例、一个新建项目用例。随着时间的推移,你的测试用例脚本会越来越多。某天项目重构,或者需求调整等原因,导致“登录”页面的用户名输入框id的值发生了变化,不巧的是你可能有几百个用例都用到了该元素。
此时,要维护前期的测试脚本,就会是一个非常巨大的工作量。如果我们借助PO的思想,将测试元素定位和操作从测试用例脚本中分离出来,在遇到前面的问题的时候,就能从容应对。
虽然PO的思想被广大测试同行认可,但是不同团队在项目实践过程中还是采用了不同的分层模式,这里我们介绍两种方案供大家参考。
接下来,我们将在PO方案一中使用unittest风格的测试脚本,在PO方案二中使用Pytest风格的测试脚本。
1、PO方案一
先来看下整体规划,将系统代码分为3层:
- 第一层:将所有元素对象定位器放到一个文件。
- 第二层:将所有元素操作放到一个文件。
- 第三层:将公共的业务场景封装到一个文件中。
接下来,我们看一下具体的实现方式。在Chapter_10目录下创建一个Python Package:Storm_12_1,接着在这个Package下面创建3个Python Package:PageObject、Scenario、TestCase。
这3个Package分别用来保存页面元素对象类、业务场景和测试用例。
目录结构如图所示:
1. 封装定位器层
我们在PageObject目录下面新建一个Python文件:redmine_locators.py。
文件内容如下:
from selenium.webdriver.common.by import By
class LoginPageLocators():
'''
"用户登录"页面
'''
UserName = (By.ID, 'username') # 登录名
PassWord = (By.ID, 'password') # 登录密码
LoginButton = (By.ID, 'login-submit') # "登录"按钮
LoginName = (By.ID, 'loggedas') # 登录后的用户名
LoginFailedInfo = (By.ID, 'flash_error') # 登录失败后的信息
class ProjectListPageLocators():
'''
"项目列表"页面
'''
NewProject = (By.LINK_TEXT, '新建项目') # "新建项目"按钮
class NewProjectPageLocators():
'''
"新建项目"页面
'''
ProjectName = (By.ID, 'project_name') # 项目名称
CommitButton = (By.NAME, 'commit') # "提交"按钮
ProjectCommitInfo = (By.ID, 'flash_notice') # 提交后的信息具体分析如下:
- 一个页面的元素对应一个类。
- 该类下面编写元素定位器。
2. 封装元素操作层
在PageObject目录下面新建一个Python文件:redmine_operations.py。
文件内容如下:
from Chapter_10.Storm_12_1.PageObject.redmine_locators import *
class BasePage():
# 构造一个基础类
def __init__(self, driver):
# 在初始化的时候会自动执行
self.driver = driver
class LoginPage(BasePage):
# "用户登录"页面的元素操作
def enter_username(self, username):
# 输入用户名
ele = self.driver.find_element(*LoginPageLocators.UserName)
ele.clear()
ele.send_keys(username)
def enter_password(self, password):
# 输入密码
ele = self.driver.find_element(*LoginPageLocators.PassWord)
ele.send_keys(password)
def click_login_button(self):
# 单击"登录"按钮
ele = self.driver.find_element(*LoginPageLocators.LoginButton)
ele.click()
def find_login_name(self):
# 查找并返回登录成功后的用户名元素
ele = self.driver.find_element(*LoginPageLocators.LoginName)
return ele
def find_login_failed_info(self):
# 查找并返回登录失败后的提示信息元素
ele = self.driver.find_element(*LoginPageLocators.LoginFailedInfo)
return ele
class ProjectListPage(BasePage):
# "项目列表"页面元素的操作
def click_new_pro_btn(self):
# 单击"新建项目"按钮
ele = self.driver.find_element(*ProjectListPageLocators.NewProject)
ele.click()
class NewProjectPage(BasePage):
# "新建项目"页面的元素操作
def enter_projectname(self, proname):
# 输入项目名称
ele = self.driver.find_element(*NewProjectPageLocators.ProjectName)
ele.send_keys(proname)
def click_com_btn(self):
# 单击"提交"按钮
ele = self.driver.find_element(*NewProjectPageLocators.CommitButton)
ele.click()
def get_pro_commit_info(self):
# 获取提交项目后的提示信息
ele = self.driver.find_element(*NewProjectPageLocators.ProjectCommitInfo)
return ele具体分析如下:
- 首先导入redmine_locators.py文件。
- 定义一个BasePage类,用来初始化一个driver。
- 后续的方法继承BasePage类,获得driver。
- 借助driver和前面封装好的元素定位器,封装这些元素的操作方法,每个类对应一个页面,每个def对应一个元素的操作。
3. 封装业务场景层
在Scenario目录中新建文件:redmine_login.py。该文件用来封装登录的业务场景,内容如下。
from selenium import webdriver
from Chapter_10.Storm_12_1.PageObject import redmine_operations
class LoginScenario(object):
'''
这里是定义"登录"页面的场景
'''
def redmine_login(self):
# 场景一:登录成功
url = 'http://localhost:81/redmine/login'
username1 = "admin"
password1 = "rootroot"
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(20)
driver.get(url)
redmine_operations.LoginPage(driver).enter_username(username1)
redmine_operations.LoginPage(driver).enter_password(password1)
redmine_operations.LoginPage(driver).click_login_button()
return driver
if __name__ == '__main__':
LoginScenario().redmine_login()具体分析如下:
- 这里导入前面封装好的元素操作redmine_operations.py。
- 定义了LoginScenario类,然后在下面定义方法redmine_login,用来实现登录的操作,注意该方法包括3个参数。当前的代码参数虽然抽离了出来,但还是夹杂在代码文件中,后期我们可以继续优化,将其放置到单独的配置文件、数据文件中。
在Scenario目录中新建文件:redmine_new_project.py。该文件用来封装新建项目的业务场景,内容如下。
from Chapter_10.Storm_12_1.PageObject.redmine_operations import *
from Chapter_10.Storm_12_1.Scenario.redmine_login import *
import time
class NewProjectScenario(object):
'''
这里是定义"新建项目"页面场景
'''
def redmine_new_project(self):
# 通过时间戳构造唯一项目名
project_name = 'project_{}'.format(time.time())
# 登录
driver = LoginScenario().redmine_login()
# 访问"项目列表"页面
driver.get('http://localhost:81/redmine/projects')
# "新建项目"按钮
ProjectListPage(driver).click_new_pro_btn()
NewProjectPage(driver).enter_projectname(project_name)
NewProjectPage(driver).click_com_btn()
return driver具体分析如下:
- 这里导入了operations文件和redmine_login的Scenario。
- 新建项目完成后,借助return返回一个driver,该driver可以让后续的脚本继续调用。
4. 重构测试用例
我们在TestCase目录下面新建Python文件:test_001_login.py。
文件内容如下:
import unittest
from selenium import webdriver
from Chapter_10.Storm_12_1.PageObject.redmine_operations import *
from parameterized import parameterized, param
'''
测试用例:验证登录功能
'''
url = "http://localhost:81/redmine/login"
class LoginTest(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.driver.get(url)
@parameterized.expand([('admin', 'error', '0'), ('admin', 'rootroot', '1')])
def test_login(self, username, password, status):
LoginPage(self.driver).enter_username(username)
LoginPage(self.driver).enter_password(password)
LoginPage(self.driver).click_login_button()
if status == '0':
# 登录失败后的提示信息
text = LoginPage(self.driver).find_login_failed_info().text
self.assertEqual(text, '无效的用户名或密码')
elif status == '1':
# 登录成功后显示的用户名
name = LoginPage(self.driver).find_login_name().text
self.assertIn(username, name)
else:
print('参数化的状态只能传入0或1')
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()分析:这里调用operations操作层,完成用户登录的两个测试用例。
接下来,我们编写第二个测试用例——新建项目。在TestCase目录下面新建文件:test_002_new_project.py。
文件内容如下:
import unittest
import time
from Chapter_10.Storm_12_1.Scenario import redmine_login,redmine_new_project
from Chapter_10.Storm_12_1.PageObject.redmine_operations import *
'''
验证新建项目
'''
class AddProjectTest(unittest.TestCase):
def setUp(self):
# 登录,并访问"新建项目列表"页面
self.driver = redmine_login.LoginScenario().redmine_login()
self.driver.get('http://localhost:81/redmine/projects')
def test_add_project(self):
# "新建项目"按钮
_project_name = 'project_{}'.format(time.time())
ProjectListPage(self.driver).click_new_pro_btn()
NewProjectPage(self.driver).enter_projectname(_project_name)
NewProjectPage(self.driver).click_com_btn()
text = NewProjectPage(self.driver).get_pro_commit_info().text
self.assertEqual(text, '创建成功')
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()注意:
将所有项目的元素定位器和操作分别放置到一个文件中,虽然导入较为方便,但是文件将会超级大。
2、PO方案二
接下来我们看PO方案二。该方案和前者最大的不同点在于该方案要将每个页面的元素定位、操作、业务场景封装到一个文件中。
来看下整体规划:将系统按页面分成3层——元素对象层、元素操作层、页面业务场景层。通过调用页面业务场景或者元素操作封装好的方法来组织测试用例。
- 元素对象层:封装定位元素的方法
- 元素操作层:借助元素对象层封装元素的操作方法。
- 页面业务场景层:借助元素操作层封装当前页面的业务场景。
首先,我们在Chapter_10目录下创建一个Python Package:Storm_12_2,接着在这个Package下面创建3个Python Package:pageobject、report、testcases。这3个Package分别用来保存页面元素对象类、测试报告和测试用例。
目录结构如图12-2所示:
其次,我们在pageobject目录下面新建一个Python文件:login_page.py。该文件用来封装“登录”页面所用到的元素对象。
1. 封装第一层:页面元素对象层
这里我们定义一个“查找元素类”,在login_page.py中编写如下代码。
# 页面元素对象层
class LoginPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_username(self):
# 查找并返回"用户名"文本框元素
ele = self.driver.find_element_by_id('username')
return ele
def find_password(self):
# 查找并返回"密码"文本框元素
ele = self.driver.find_element_by_id('password')
return ele
def find_login_btn(self):
# 查找并返回"登录"按钮元素
ele = self.driver.find_element_by_id('login-submit')
return ele
def find_login_name(self):
# 查找并返回登录成功后的用户名元素
ele = self.driver.find_element_by_id('loggedas')
return ele
def find_login_failed_info(self):
# 查找并返回登录失败后的提示信息元素
ele = self.driver.find_element_by_id('flash_error')
return ele对上述代码进行一个简单的分析。
- 首先,定义一个名为“LoginPage”的类(class)。
- 然后,定义一个名为“__init__”的私有方法,这里传入一个“driver”的参数。至于为什么要传入,我们先不解释。
- 接着,定义了5个方法,分别对应该查找“登录”页面要用到的5个页面元素:“登录(用户)名”文本框、“密码”文本框、“登录”按钮、登录成功后右上角显示的用户名、登录失败后显示的提示信息。
2. 封装第二层:页面元素操作层
这里我们定义一个“元素操作类”,继续在上面的文件内容的后面编写如下代码。
# 页面元素操作层
class LoginOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.login_page = LoginPage(driver)
def input_username(self, username):
# 对"用户名"文本框做clear和send_keys操作
self.login_page.find_username().clear()
self.login_page.find_username().send_keys(username)
def input_password(self, password):
# 对"密码"文本框做clear和send_keys操作
self.login_page.find_password().clear()
self.login_page.find_password().send_keys(password)
def click_login_btn(self):
# 对"登录"按钮做单击操作
self.login_page.find_login_btn().click()
def get_login_name(self):
# 返回登录成功后的用户名元素
return self.login_page.find_login_name().text
def get_login_failed_info(self):
# 返回登录失败后的提示信息元素
return self.login_page.find_login_failed_info().text下面对上述代码进行一个简单的分析:
- 首先,定义一个名为“LoginOper”的类。
- 然后,定义一个名为“__init__”的私有方法,这个方法带一个参数“driver”,方法中调用前面定义的元素定位的类“LoginPage”。
- 接着,我们定义了5个方法,分别对应之前找到的元素,并对其进行操作。
3. 封装第三层:当前页面的业务场景层
这里我们定义一个“业务场景类”,继续在上面的文件内容的后面编写如下代码。
# 页面业务场景层
class LoginScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.login_oper = LoginOper(driver)
def login(self, username, password):
# 定义一个登录场景,用到了3个操作
self.login_oper.input_username(username)
self.login_oper.input_password(password)
self.login_oper.click_login_btn()下面对上述代码进行一个简单的分析。
- 首先,定义一个名为“LoginScenario”的类。
- 然后,定义一个名为“__init__”的私有方法,这个方法调用步骤(2)中封装的元素操作类。
- 接着,定义一个实现用户登录场景的方法“login”,这个场景共包含3个操作:输入用户名、输入密码、单击“登录”按钮。
4. 重构登录测试用例
“登录”页面的3层对象已经封装好了,接下来我们在“Chapter_10/Storm_12_2/testcases/”目录下新建文件“test_001_login.py”,用来重构登录的测试用例,代码如下。
from selenium import webdriver
import pytest
# 导入本用例用到的页面对象文件
from Chapter_10.Storm_12_2.pageobject import login_page
data = [('admin', 'error', '0'), ('admin', 'rootroot', '1')]
@pytest.mark.parametrize(("username", "password", "status"), data)
class TestLogin():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
def teardown(self):
self.driver.quit()
def test_001_login(self, username, password, status):
# 登录的3个操作用业务场景方法一条语句代替
login_page.LoginScenario(self.driver).login(username,password)
if status == '0':
# 登录失败后的提示信息,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_failed_info()
assert text == '无效的用户名或密码'
elif status == '1':
# 登录成功后显示的用户名,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_name()
assert username in text
else:
print('参数化的状态只能传入0或1')改进前后的代码差异如下。
- 改进后,我们需要通过import语句导入用例涉及的页面对象。
- 改进后,登录的3个操作仅通过前面封装的用户登录场景来实现。
- 改进后,获取页面元素文本的语句通过前面封装的元素操作来实现。根据改进后的代码,我们再来分析两个问题。
- 测试用例文件中不再包含元素定位和操作的脚本。假如再出现前面说的项目元素定位或操作改变的情况,不管你有多少个测试用例用到了该元素和操作,我们都只需要修改封装元素的页面对象类,而测试用例不需要做任何改变,测试用例的可维护性大大提高。
- 我们在编写测试用例时,setup会实例化一个self.driver,在调用页面对象类中的方法时,我们需要将这个self.driver传递过去才能对页面元素进行操作。这就是我们前面所讲的,在封装页面对象的方法时要定义一个“self.driver”。
接下来,我们再用同样的方法改写test_002_new_project.py测试用例。
首先编写页面对象文件,因为新建项目时我们用到了两个页面——“项目列表”和“新建项目”页面,所以这里封装两个文件,文件内容如下。
第一个页面对象文件:“项目列表”页面(示例代码:project_list_page.py)。
"项目列表"页面
'''
# 页面对象层
class ProjectListPage(object):
def __init__(self, driver):
self.driver = driver
def find_new_pro_btn(self):
ele = self.driver.find_element_by_link_text('新建项目')
return ele
# 对象操作层
class ProjectListOper(object):
def __init__(self, driver):
self.project_list_page = ProjectListPage(driver)
def click_new_pro_btn(self):
self.project_list_page.find_new_pro_btn().click()
# 业务逻辑层
class ProjectListScenario(object):
def __init__(self, driver):
self.project_list_oper = ProjectListOper(driver)
def xxx(self):
# 目前不需要封装业务逻辑
pass
第二个页面对象文件:“新建项目”页面(示例代码:project_new_page.py)。
'''
"新建项目"页面
'''
# 页面对象层
class ProjectNewPage(object):
def __init__(self, driver):
self.driver = driver
def find_pro_name_input(self):
ele = self.driver.find_element_by_id('project_name')
return ele
def find_pro_commit_btn(self):
ele = commit_btn = self.driver.find_element_by_name('commit')
return ele
def find_pro_commit_info(self):
ele = self.driver.find_element_by_id('flash_notice')
return ele
# 对象操作层
class ProjectNewOper(object):
def __init__(self, driver):
self.project_new_page = ProjectNewPage(driver)
def input_pro_name(self, pro_name):
self.project_new_page.find_pro_name_input().send_keys(pro_name)
def click_pro_commit_btn(self):
self.project_new_page.find_pro_commit_btn().click()
def get_pro_commit_info(self):
return self.project_new_page.find_pro_commit_info().text
# 业务逻辑层
class ProjectNewScenario(object):
def __init__(self, driver):
self.project_new_oper = ProjectNewOper(driver)
def new_project(self, pro_name):
self.project_new_oper.input_pro_name(pro_name)
self.project_new_oper.click_pro_commit_btn()然后编写新建项目测试用例,内容如下。
from selenium import webdriver
import time, pytest
from Chapter_10.Storm_12_2.pageobject import login_page, project_new_page, project_list_page
# 通过时间戳构造唯一项目名
project_name = 'project_{}'.format(time.time())
username = 'admin'
password = 'rootroot'
class TestNewProject():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
# 登录
login_page.LoginScenario(self.driver).login(username, password)
def test_new_project(self):
# 访问"项目列表"页面
self.driver.get('http://localhost:81/redmine/projects')
# "新建项目"按钮
project_list_page.ProjectListOper(self.driver).click_new_pro_btn()
project_new_page.ProjectNewScenario(self.driver).new_project(project_name)
# 新建项目成功后的提示信息
text = project_new_page.ProjectNewOper(self.driver).get_pro_commit_info()
assert text == '创建成功'
def teardown(self):
self.driver.quit()
if __name__ == '__main__':
pytest.main(['-s', '-q', '--alluredir', '../report/'])总结:
- 将系统页面分别放到不同的文件中,文件命名的方式需要注意。
- 每个页面文件包含3层:元素定位、元素操作、业务场景。
- 测试用例通过调用公共业务场景和元素操作来完成。
我们学习了两种PO模式的思路,请大家在实际项目中揣摩、实践、评估其优缺点,然后优化、改进,最终形成适合自己项目的PO分层模式。
提示:我们将采用PO方案二+Pytest的方式来进行后续内容的讲解。
3、项目变更应对
在实际项目中,项目的变更是正常的、持续存在的。也正是因为如此,我们才引入了PO模式。那接下来我们通过几个场景来演示PO模型封装的代码,讲解在应对项目变更时,其存在哪些优势。
1. 元素定位器发生改变
元素定位器发生变化是非常常见的一种情况。这里我们假设“登录”页面“用户名”文本框的元素定位发生了变化,如id的值变更了,或者元素没有id了,此时我们该如何处理呢?
我们只需要将login_page.py文件中“用户名”文本框元素的定位方法修改成可用即可。
'''
"登录"页面
'''
# 页面元素对象层
class LoginPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_username(self):
# 查找并返回"用户名"文本框元素
# ele = self.driver.find_element_by_id('username')
ele = self.driver.find_element_by_name('username')
return ele尝试执行测试用例,仍然可以执行成功。因为测试用例并不包含元素定位的方法,都是从封装好的login_page.py文件中读取的,整个脚本维护起来非常简便。
2. 元素操作发生改变
某些情况下,对元素的操作可能会变,如单击变成了双击,这个时候我们只需要调整login_page.py文件中对应的元素操作的代码即可。
from selenium.webdriver import ActionChains
class LoginPage(object):
…
# 页面元素操作层
class LoginOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.login_page = LoginPage(driver)
self.driver = driver
def input_username(self, username):
# 对"用户名"文本框做clear和send_keys操作
self.login_page.find_username().clear()
self.login_page.find_username().send_keys(username)
def input_password(self, password):
# 对"密码"文本框做clear和send_keys操作
self.login_page.find_password().clear()
self.login_page.find_password().send_keys(password)
# def click_login_btn(self):
# 对"登录"按钮做单击操作
# self.login_page.find_login_btn().click()
def click_login_btn(self):
ele = self.login_page.find_login_btn()
ActionChains(self.driver).double_click(ele).perform()这里我们把鼠标的单击动作换成了鼠标的双击动作,因此需要引入ActionChains的包。然后因为ActionChains()的括号中需要传入driver,所以在class的开始处定义了一个self.driver =driver,然后脚本内容就变成了上述内容。不需要对脚本做任何改动,执行脚本,依然成功。
3. 业务发生改变
为了防止系统被暴力破解,假如公司审计部门要求在登录环节增加输入验证码的步骤,因为无法修改Redmine系统登录的功能,这里我们拿伪代码示意(无法执行成功,仅说明意思)。
'''
"登录"页面
'''
# 页面元素对象层
from selenium.webdriver import ActionChains
class LoginPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_username(self):
# 查找并返回"用户名"文本框元素
# ele = self.driver.find_element_by_id('username')
ele = self.driver.find_element_by_name('username')
return ele
def find_password(self):
# 查找并返回"密码"文本框元素
ele = self.driver.find_element_by_id('password')
return ele
def find_login_btn(self):
# 查找并返回"登录"按钮元素
ele = self.driver.find_element_by_id('login-submit')
return ele
def find_login_name(self):
# 查找并返回登录成功后的用户名元素
ele = self.driver.find_element_by_id('loggedas')
return ele
def find_login_failed_info(self):
# 查找并返回登录失败后的提示信息元素
ele = self.driver.find_element_by_id('flash_error')
return ele
def find_verification_code(self): # 新增一个查找验证码的元素
ele = self.driver.find_element_by_id('aaa')
return ele
# 页面元素操作层
class LoginOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.login_page = LoginPage(driver)
self.driver = driver
def input_username(self, username):
# 对"用户名"文本框做clear和send_keys操作
self.login_page.find_username().clear()
self.login_page.find_username().send_keys(username)
def input_password(self, password):
# 对"密码"文本框做clear和send_keys操作
self.login_page.find_password().clear()
self.login_page.find_password().send_keys(password)
# def click_login_btn(self):
# 对"登录"按钮做单击操作
# self.login_page.find_login_btn().click()
def click_login_btn(self):
ele = self.login_page.find_login_btn()
ActionChains(self.driver).double_click(ele).perform()
def get_login_name(self):
# 返回登录成功后的用户名元素
return self.login_page.find_login_name().text
def get_login_failed_info(self):
# 返回登录失败后提示信息元素
return self.login_page.find_login_failed_info().text
def input_verification_code(self, fixed_value=123456): # 输入万能验证码
self.login_page.find_verification_code().send_keys(fixed_value)
# 页面业务场景层
class LoginScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.login_oper = LoginOper(driver)
def login(self, username, password):
# 定义一个登录场景,用到了3个操作
self.login_oper.input_username(username)
self.login_oper.input_password(password)
self.login_oper.input_verification_code() # 增加输入验证码的步骤
self.login_oper.click_login_btn()从上述代码中可以看到,我们总共修改了以下内容。
- 在元素定位层新增了一个验证码元素的定位方法。
- 在元素操作层新增了该元素的输入方法,这里我们定义了一个入参,并且给其设置了一个初始值(如果项目中遇到验证码,让开发人员设置为万能码绕过)。
- 在登录的场景中增加了一个输入验证码的步骤,虽然整体复杂了一些,但是测试用例仍然不需要做改动。
4. 修改测试用例
自动化测试的断言点总是有限的,某些时候自动化测试没有发现问题,人工测试或者生产环境却发现了问题,这个时候我们就要把相关的检查点增加到用例当中。例如我们对登录成功的测试用例要增加一个检查点——登录后页面中要能看到“我的工作台”,如图所示。

这里我们就只需要修改测试用例的断言部分,test_001_login.py文件修改效果如下(部分代码)。
def test_001_login(self, username, password, status):
# 登录的3个操作用业务场景方法一条语句代替
login_page.LoginScenario(self.driver).login(username,password)
if status == '0':
# 登录失败后的提示信息,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_failed_info()
assert text == '无效的用户名或密码'
elif status == '1':
# 登录成功后显示的用户名,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_name()
assert username in text
# 增加一个断言
assert "我的工作台" in self.driver.page_source
else:
print('参数化的状态只能传入0或1')可以从上述的代码中看到,我们在登录成功的状态(elif status == '1')中增加了一个断言(assert "我的工作台" in self.driver.page_source),非常的简单。
当然,如果你的断言用到了新的元素,那么你仍然需要将元素的3层写到对应的PO文件中去,然后再增加断言。
十一、Jenkins UI与接口自动化测试持续集成实战
目标:
- Web UI自动化测试持续集成
- 接口自动化测试持续集成
- 通过参数来控制运行方式
- 控制有界面or无界面运行
- Allure Report展示测试结果报告
- Jenkins + python + allure
1、Selenium UI自动化测试持续集成实战
1. Selenium自动化测试项目介绍
- 用例业务内容:测试百度网首页搜索关键词之后,跳转页面标题的正确性
- python代码实现
- Web UI 测试框架 Selenium (WebDriver)
- 自动化测试框架pytest
- 开发工具 PyCharm
- 源码位置:https://github.com/princeqjzh/iSelenium_Python
测试过程动作:
- 访问首页,搜索“今日头条”,验证正确性
- 访问首页,搜索“王者荣耀”,验证正确性
#######测试代码知识点: - 运行类需继承
unittest.TestCase类 setUp()测试准备方法,用于环境初始化tearDown()测试结束方法,用于环境清理- 所有测试执行方法需要以
test_开头 - 两个测试动作执行方法
test_webui_1(),test_webui_2() get_config()方法读取配置文件- 运行程序之前需要将配置文件
iselenium.ini复制/粘贴到自己测试执行环境的user.home目录下,并按照自己机器的实际路径配置chrome_driver的路径
Demo代码工程:
- 开发工具PyCharm
- 本地IDE运行测试类可以创建py.test运行方法
测试代码
-
目录树
web_ut.py 文件:
import allure
import configparser
import os
import time
import unittest
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
@allure.feature('Test Baidu WebUI')
class ISelenium(unittest.TestCase):
# 读入配置文件
def get_config(self):
config = configparser.ConfigParser()
config.read(os.path.join(os.environ['HOME'], 'iselenium.ini'))
return config
def tearDown(self):
self.driver.quit()
def setUp(self):
config = self.get_config()
# 控制是否采用无界面形式运行自动化测试
try:
using_headless = os.environ["using_headless"]
except KeyError:
using_headless = None
print('没有配置环境变量 using_headless, 按照有界面方式运行自动化测试')
chrome_options = Options()
if using_headless is not None and using_headless.lower() == 'true':
print('使用无界面方式运行')
chrome_options.add_argument("--headless")
self.driver = webdriver.Chrome(executable_path=config.get('driver', 'chrome_driver'),
options=chrome_options)
@allure.story('Test key word 今日头条')
def test_webui_1(self):
""" 测试用例1,验证'今日头条'关键词在百度上的搜索结果
"""
self._test_baidu('今日头条', 'test_webui_1')
@allure.story('Test key word 王者荣耀')
def test_webui_2(self):
""" 测试用例2, 验证'王者荣耀'关键词在百度上的搜索结果
"""
self._test_baidu('王者荣耀', 'test_webui_2')
def _test_baidu(self, search_keyword, testcase_name):
""" 测试百度搜索子函数
:param search_keyword: 搜索关键词 (str)
:param testcase_name: 测试用例名 (str)
"""
self.driver.get("https://www.baidu.com")
print('打开浏览器,访问 www.baidu.com .')
time.sleep(5)
assert f'百度一下' in self.driver.title
elem = self.driver.find_element_by_name("wd")
elem.send_keys(f'{search_keyword}{Keys.RETURN}')
print(f'搜索关键词~{search_keyword}')
time.sleep(5)
self.assertTrue(f'{search_keyword}' in self.driver.title, msg=f'{testcase_name}校验点 pass')iselenium.ini 配置文件:
配置文件需放到系统的家目录下,并添加chromedriver文件路径。
[driver]
chrome_driver=<Your chrome driver path>requirements.txt:
依赖包文件。
allure-pytest
appium-python-client
pytest
pytest-testconfig
requests
selenium
urllib3README.md:
帮助文件。
**Selenium 自动化测试程序(Python版)**
运行环境:
- selenium web driver
- python3
- pytest
- git
配置文件:iselenium.ini
- 将配置文件复制到本地磁盘的[user.home]目录
- 填入设备的chromwebdriver文件的全路径
运行命令:
pytest -sv test/web_ut.py --alluredir ./allure-results代码clone:
- 将iSelenium_Python源码克隆到你的本地
- 可以先Fork然后再克隆你Fork之后的源码项目(源码修改后可以push到github)
- 也可以直接下载(源码修改后不能push到github)
- 克隆参考代码:
git clone git@github.com:princeqjzh/iSelenium_Python.git
chrome driver怎么找:
- 本机需要安装chrome浏览器
- Chrome driver版本与chrome浏览器版本有支持对应关系
- Chrome driver 下载参考网站:http://npm.taobao.org/mirrors/chromedriver/
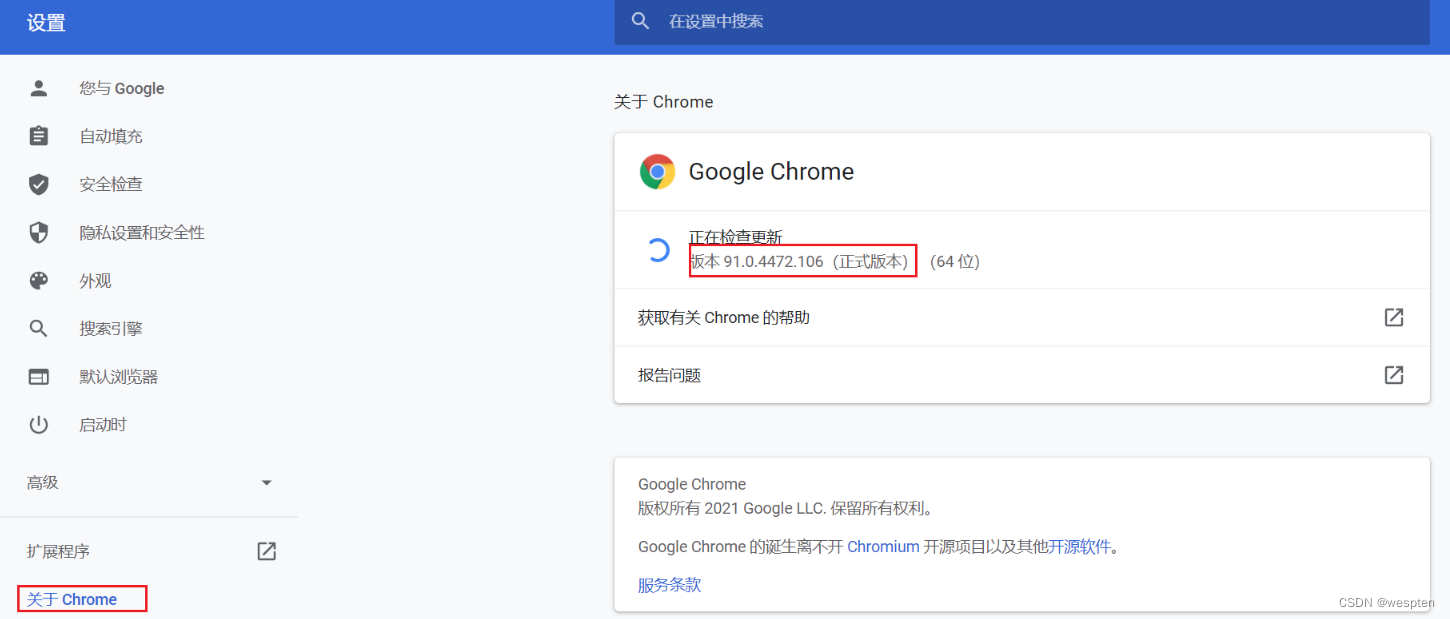
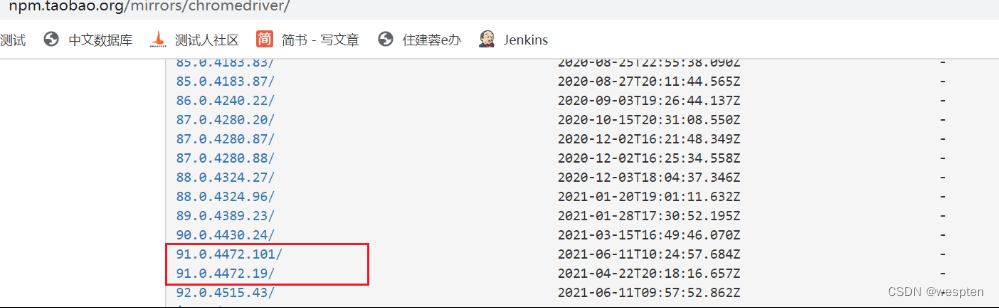
2. Selenium自动化测试实现
- 运行环境可以与Jenkins同一台机器,也可以与Jenkins不同机器
- 实例使用与Jenkins同一台机器便于演示
- 运行环境上需要事先配置python3运行环境,保证pytest可以运行
- 确保环境配置是OK的,可以运行Selenium的web自动化测试程序
3. 配置Allure报告
- Allure Report -更好看一些
- 环境准备:
- 运行环境上需要安装allure report运行环境
- Jenkins allure report 插件
- 环境准备:
- Python依赖准备:
pip install allure-pytest
- Python依赖准备:
- 添加代码:
@allure.feature(' feature name')@allure.story('story name')
- 运行命令:
pytest -sv test/web_ut.py --alluredir ./allure-results
4. Jenkins配置
-
Jenkins中新建一个自由风格的项目
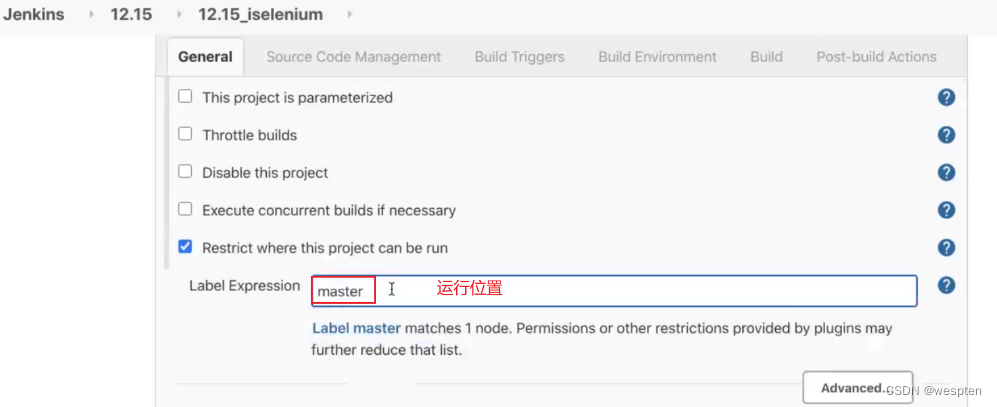
- 配置git 地址链接(ssh格式),添加Checkout to sub-directory
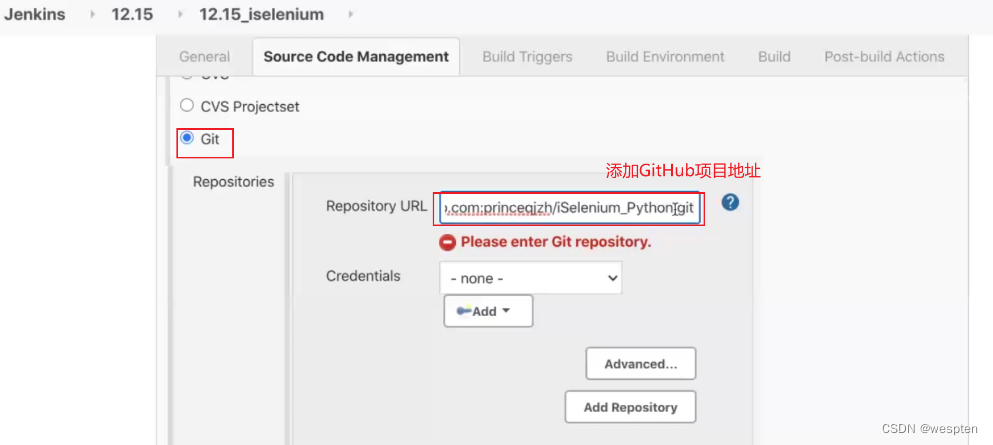
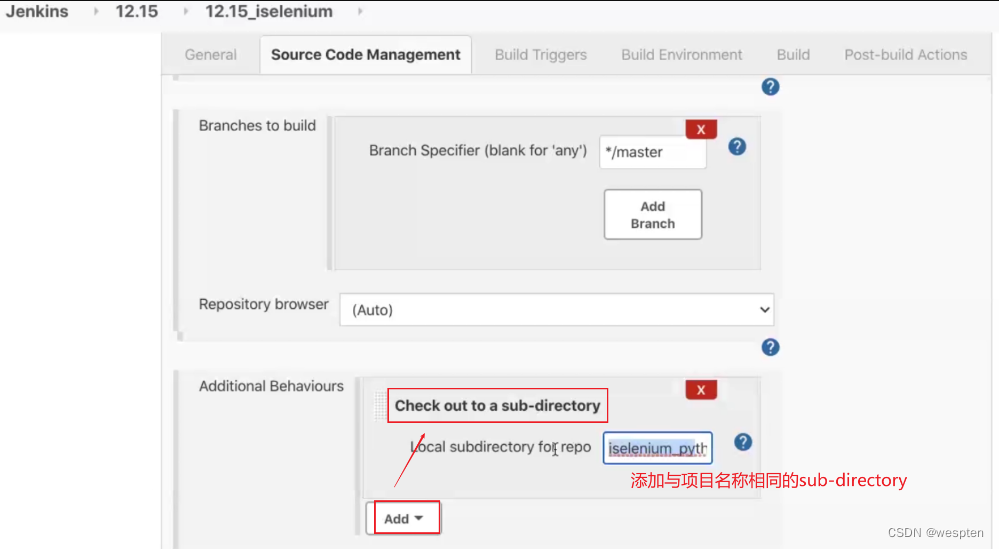
-
添加命令加载python库:
pip install -r requirements.txt -
添加运行命令:
pytest -sv test/web_ut.py- 其中
. ~/.bash_profile是为了获取本机的环境变量 cd iSelenium_Python:切换到项目目录
- 其中
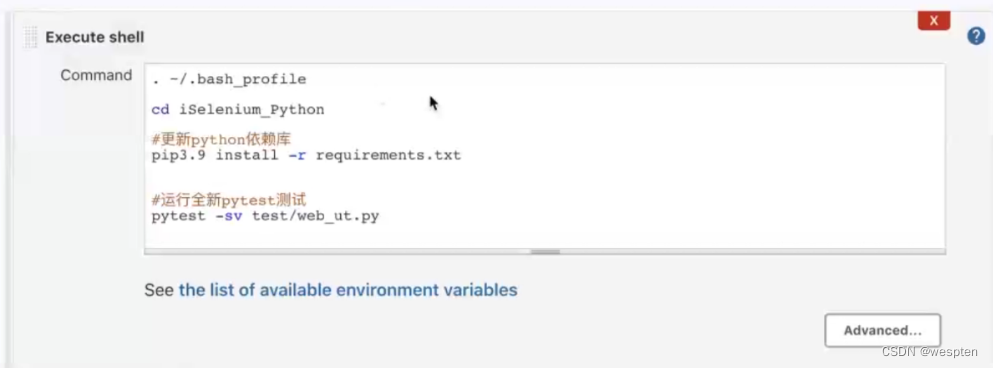
- 添加运行参数,控制是否为有界面运行,此步骤之前可以先试运行程序,没有错误后再添加
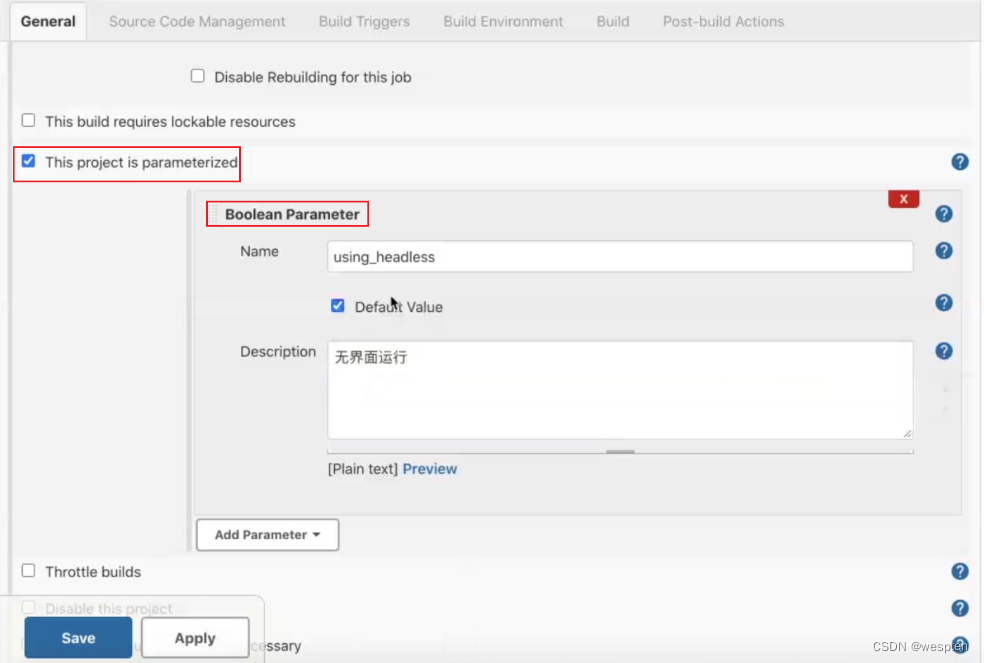
- 添加Allure Report到 Post-build Actions中用于展示测试结果
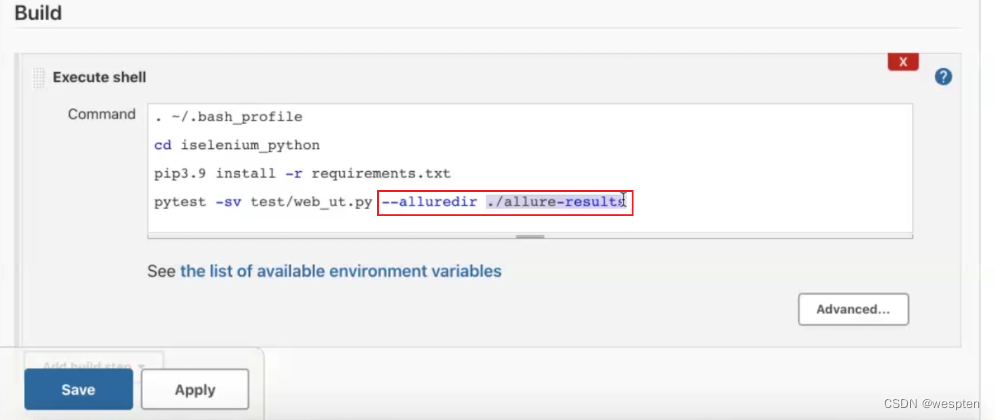
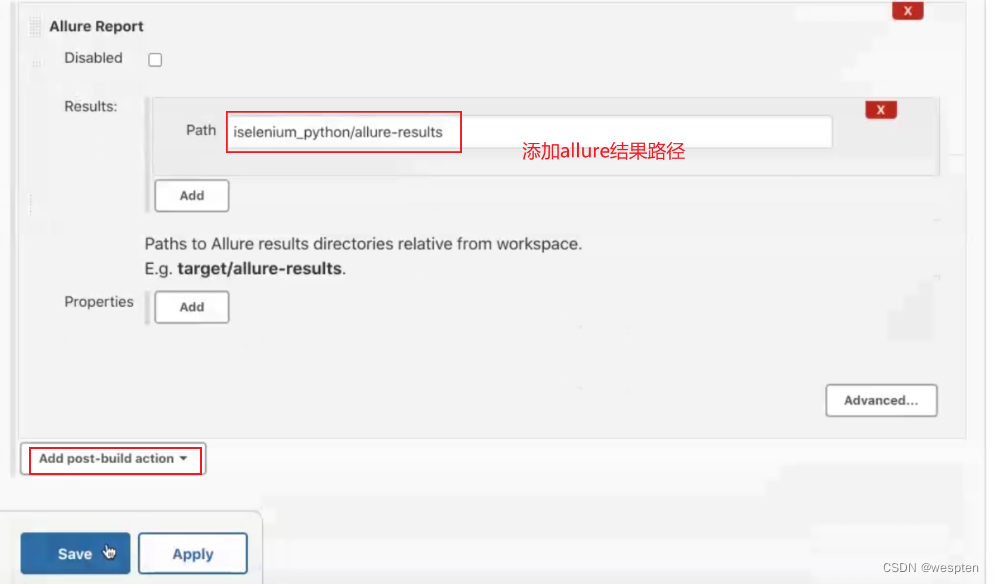
5. 进行构建
查看控制台输出:

查看allure报告:
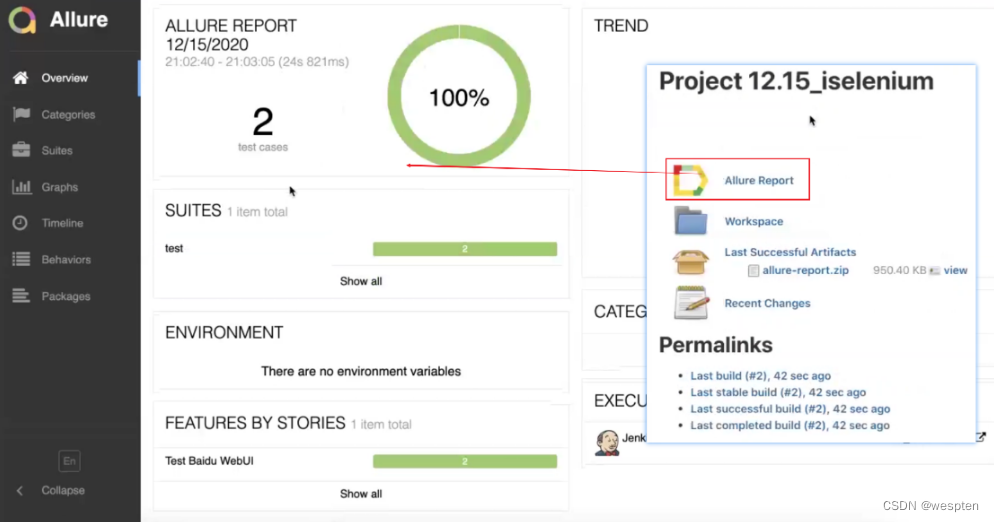
查看allure曲线图(至少运行两次):

总结:
- 利用配置文件记录环境参数,保证相同的代码可以在不同环境上去运行
- Selenium 驱动UI测试运行
- 利用参数控制是否带界面运行
- 自动化测试框架pytest控制测试程序的生命周期
- Allure Report生成测试报告
- Jenkins任务集成整个自动化测试运行过程
2、接口自动化测试持续集成实战
1. 接口自动化测试项目简介
- 接口测试应用:http://www.weather.com.cn/data/cityinfo/
- 接口功能:获得对应城市的天气预报
- 源码:Python
- 功能包:HttpClient
- 请求方法:Get
- 自动化测试框架:pytest
- 开发工具:PyCharm
- 源码位置:https://github.com/princeqjzh/iInterface_python
业务过程:
- 请求接口传入对应参数
- 解析返回JSON串
- 获取对应[城市]返回值
- 校验结果正确性
-
输出报告
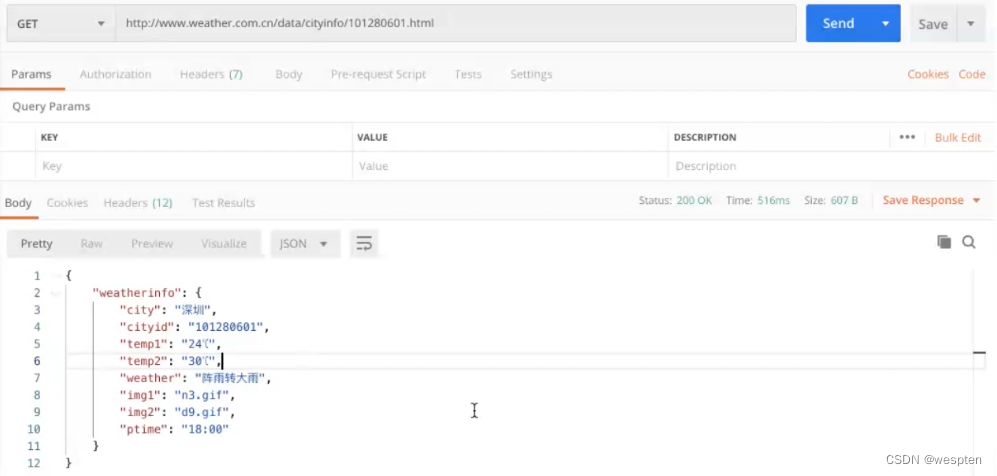
2. 接口自动化测试项目源码
- 打开PyCharm
- HttpClient:网络Http请求类
- Weather():测试用例类
- README.md:说明
- 目录树
jmx是与性能测试相关的,这里忽略。
httpclient.py:
封装和请求方法相关的函数。
import requests
import urllib3
class HttpClient:
"""Generic Http Client class"""
def __init__(self, disable_ssl_verify=False, timeout=60):
"""Initialize method"""
self.client = requests.session()
self.disable_ssl_verify = disable_ssl_verify
self.timeout = timeout
if self.disable_ssl_verify:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def Get(self, url, headers=None, data=None, json=None, params=None, *args, **kwargs):
"""Http get method"""
if headers is None:
headers = {}
if self.disable_ssl_verify:
response = self.client.get(url, headers=headers, data=data, json=json, params=params
, verify=False, timeout=self.timeout, *args, **kwargs)
else:
response = self.client.get(url, headers=headers, data=data, json=json, params=params
, timeout=self.timeout, *args, **kwargs)
response.encoding = 'utf-8'
print(f'{response.json()}')
return responseweather_test.py:
测试文件。
import allure
from unittest import TestCase
from library.httpclient import HttpClient
@allure.feature('Test Weather api')
class Weather(TestCase):
"""Weather api test cases"""
def setUp(self):
"""Setup of the test"""
self.host = 'http://www.weather.com.cn'
self.ep_path = '/data/cityinfo'
self.client = HttpClient()
@allure.story('Test of ShenZhen')
def test_1(self):
city_code = '101280601'
exp_city = '深圳'
self._test(city_code, exp_city)
@allure.story('Test of BeiJing')
def test_2(self):
city_code = '101010100'
exp_city = '北京'
self._test(city_code, exp_city)
@allure.story('Test of ShangHai')
def test_3(self):
city_code = '101020100'
exp_city = '上海'
self._test(city_code, exp_city)
def _test(self, city_code, exp_city):
url = f'{self.host}{self.ep_path}/{city_code}.html'
response = self.client.Get(url=url)
act_city = response.json()['weatherinfo']['city']
print(f'Expect city = {exp_city}, while actual city = {act_city}')
self.assertEqual(exp_city, act_city, f'Expect city = {exp_city}, while actual city = {act_city}')requirements.txt:
依赖库。
allure-pytest
appium-python-client
pytest
pytest-testconfig
requests
selenium
urllib3README.md:
说明文档。
**接口功能自动化测试程序(Python版)**
运行环境:
- python3
- pytest
- allure report
- git
依赖准备:
pip install allure-pytest
运行命令:
pytest -sv test/weather_test.py --alluredir ./allure-results- 模拟接口测试用例通过:actual _value == expect _value
- 模拟接口测试用例失败:actual value != expect_ _value
3. Jenkins配置
- Slave节点配置管理演示
- 权限配置
- Known host操作:Know host 是机器的ssl的校验机制,在机器的home目录下一般有
.ssh的目录,该目录下有known hosts文件,该文件存放的是被当前机器所信任的服务器ip
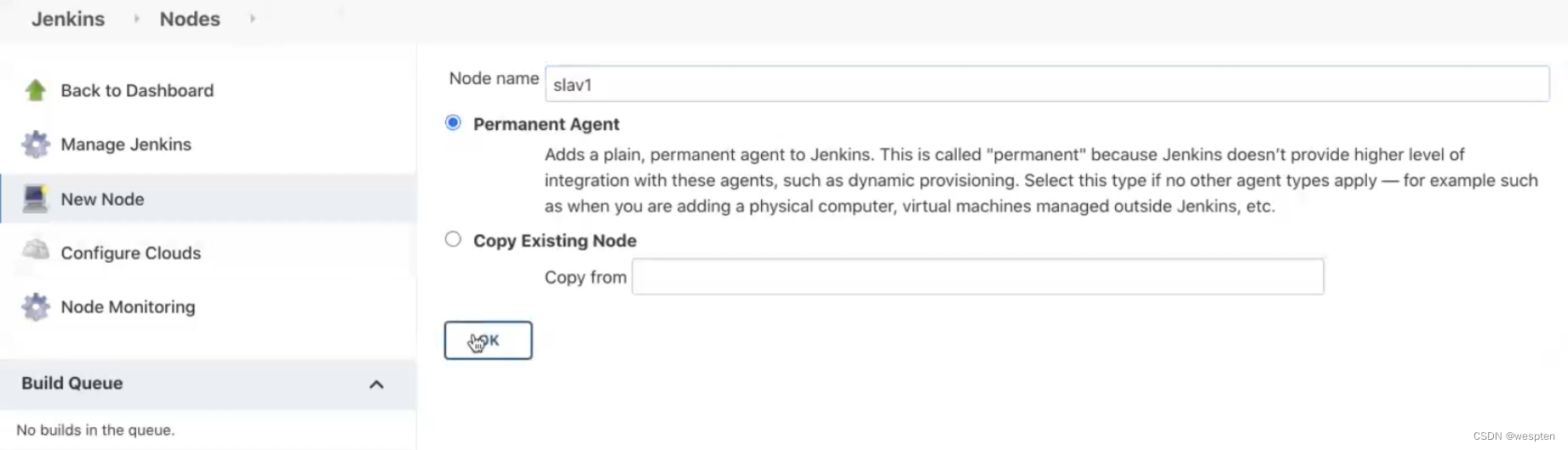



Jenkins中创建自由风格任务:
添加Git地址:
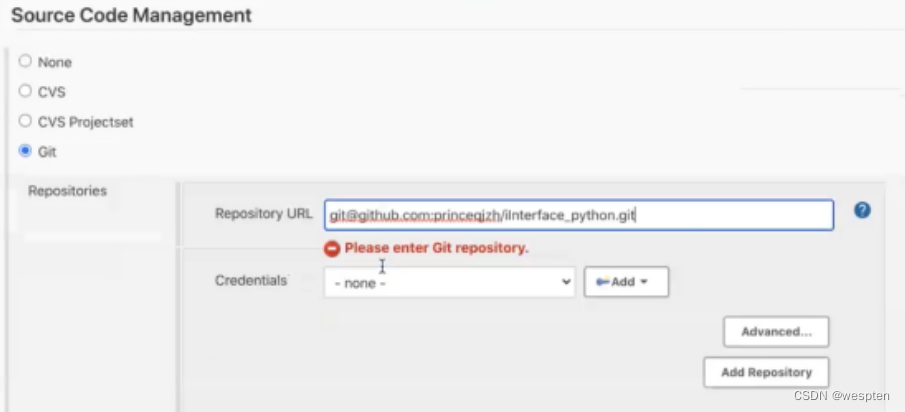
添加sub-directory:
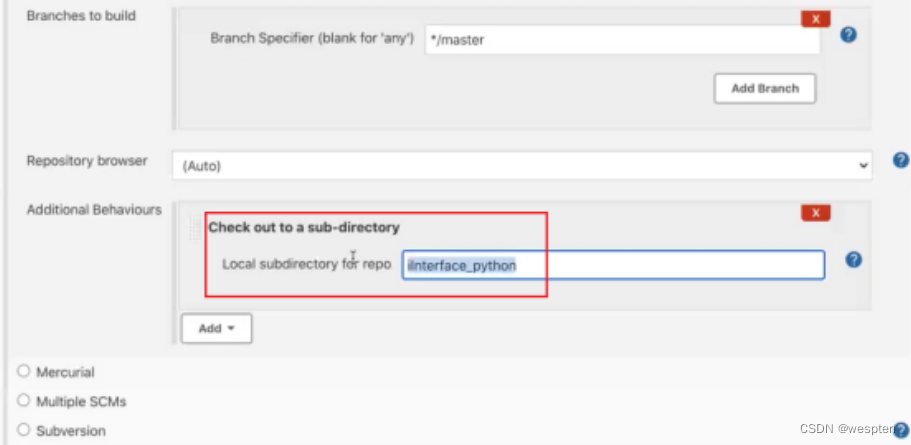
添加命令加载Python库:pip3.9 install -r requirements.txt
添加运行命令:pytest -sv test/weather_test.py -alluredir ./allure-results
配置Allure Report插件:
post-build Actions:
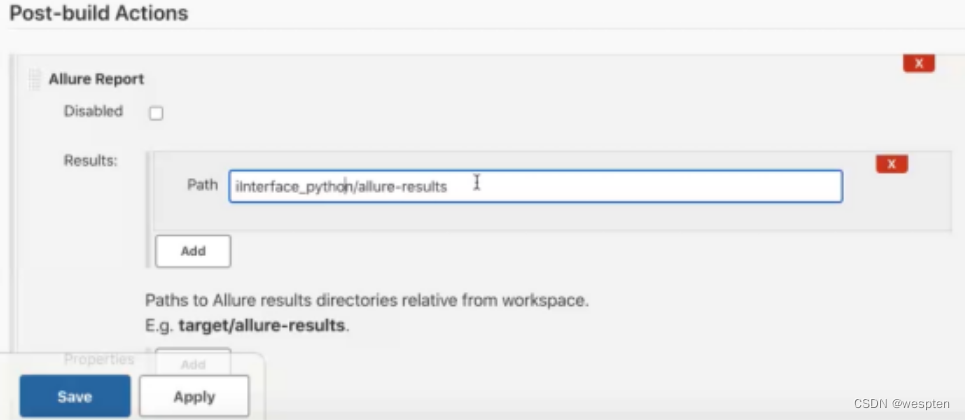
4. 运行Jenkins

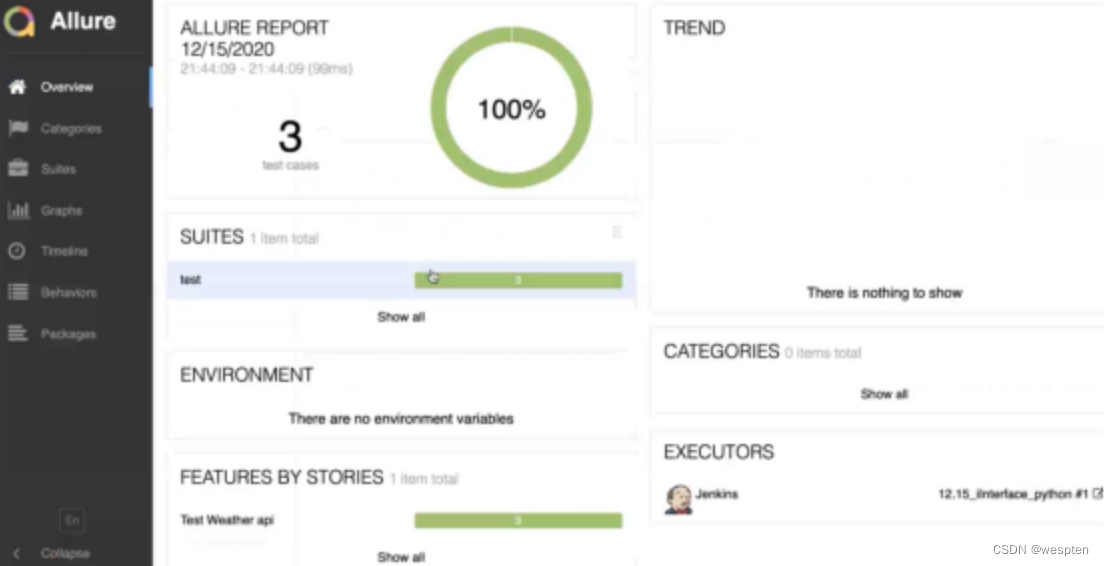
总结:
- 利用Python常用package中的类发起接口请求、获取接口返回值、解析JSON字段、校验结果正确性
- 利用pytest框架来运行接口测试,控制程序的生命周期
- Allure report测试结果展示
- Jenkins任务:源码同步、运行任务、展示测试报告、发送邮件
十二、Jenkins App自动化测试持续集成实战
目标:
- 从源码到可测包,外加自动化测试验证的全流程持续集成体系建设
- 安卓App的构建、打包方法
- Apk文件发布
- 触发自动测试
- Appium UI自动化测试
- 利用Jenkins平台进行持续集成演练
各种自动任务:
- Daily Build打包
- Daily Build发布
- Daily Build UI自动测试(BVT - Build Verification Test)
优势:
- 重复性定式劳动任务,
- 减少人力参与,提升工作效率
- Build不再是阻碍测试进度的因素
- 自动化重用率高,维护频率低
1、安卓App构建、打包、部署与自动化测试
涉及技术点:
- Android App构建
- Android SDK使用
- 安卓模拟器或真机
- Python + Appium自动化测试
- Jenkins持续集成
- Shell脚本开发
- Java程序开发
- Git ( github使用)
1. 测试App构建、打包过程
- Android应用(例子程序)
- 源码位置:https://github.com/princeqjzh/AndroidSampleApp
- 安卓打包的目标文件:app-debug.apk文件
- 安卓打包命令:
gradlew clean assembleDebug - 安卓安装包的输出路径:
/app/build/outputs/apk/debug/app-debug.apk - 关于安卓打包的环境要求
- JDK 1.8
- Android SDK
-
Gradle

2. 安卓App部署
-
前提条件:
- 安卓实体机或者安卓模拟器
- 安卓SDK
-
目标:通过命令安装/卸载App
-
命令控制apk安装与卸载
- 安装:
adb install <file_ path> - 卸载:
adb uninstall <package_ name>
- 安装:
-
查找包名:
adb shell pm list packages | grep sample
3. 安卓UI自动化测试
- Appium app自动测试
- 源码位置:https://github.com/princeqjzh/iAppBVT_Python
- 开发工具:PyCharm
- UI自动化框架:Appium
- 测试执行框架:pytest
- 实现验证点:
- App可安装
- App可启动
- App首页预期的元素存在
- 校验步骤
- 启动App
- 检查Record Event是否存在
-
结束输出结果
4. 测试源码
-
目录树
Readme.me:
**iApp BVT自动化测试程序(Python版)**
运行环境:
- appium server
- python3
- unittest, pytest
- git
配置文件:iAppBVT_Python.json
- 将配置文件复制到本地磁盘
- 填入设备的 deviceName 与 udid
运行命令:
pytest -sv test/bvt_test.py --tc-file /full path/iAppBVT_Python.json --tc-format jsonbvt_test.py 文件:
from appium import webdriver
import unittest
import time
from pytest_testconfig import config
timeout = 30 # 超时
poll = 2 # 轮询
class IAppBVT(unittest.TestCase):
def setUp(self):
desired_caps = {}
appium_server_url = config['appium_server_url']
desired_caps['platformName'] = config['desired_caps']['platformName']
desired_caps['udid'] = config['desired_caps']['udid']
desired_caps['deviceName'] = config['desired_caps']['deviceName']
desired_caps['appPackage'] = config['desired_caps']['appPackage']
desired_caps['appActivity'] = config['desired_caps']['appActivity']
desired_caps['automationName'] = config['desired_caps']['automationName']
desired_caps['noReset'] = config['desired_caps']['noReset']
self.driver = webdriver.Remote(appium_server_url, desired_caps)
def tearDown(self):
self.driver.quit()
def test_bvt(self):
print('BVT test is started!')
status = self.is_record_event_btn_exist()
print(f'The record event button is exist - {status}')
self.assertTrue(status, f'Check record_button result is {status}')
print('Test finished!')
def is_record_event_btn_exist(self):
elem = self._find_elem_by_xpath('//android.widget.Button[contains(@resource-id,"id/trackEventButton")]')
return elem is not None
def _find_elem_by_xpath(self, elem_xpath, time_out=timeout, raise_exception=True):
start = time.time()
elem = None
while time.time() - start < time_out and elem is None:
time.sleep(poll)
try:
elem = self.driver.find_element_by_xpath(elem_xpath)
except Exception:
print('by pass the element not found')
if elem is None and raise_exception:
raise LookupError(f'The element which xpath is {elem_xpath} could not be found')
return elemiAppBVT_Pyhon.json 文件:
获取udid:adb devices。
{
"desired_caps": {
"platformName": "Android",
"deviceName": "<your device name>",
"udid": "<your device udid>",
"noReset": "false",
"automationName": "UiAutomator2",
"appPackage": "com.appsflyer.androidsampleapp",
"appActivity": ".MainActivity"
},
"appium_server_url": "http://localhost:4723/wd/hub"
}requirements.txt:
allure-pytest
appium-python-client
pytest
pytest-testconfig
requests
selenium
urllib32、安卓App持续集成体系建设
- 将之前内容所做事情用Jenkins任务来实现
- Jenkins平台源码构建、打包、发布app测试包
- Jenkins自动部署、测试新app测试包
- Jenkins通知运行结果
实现流程图:
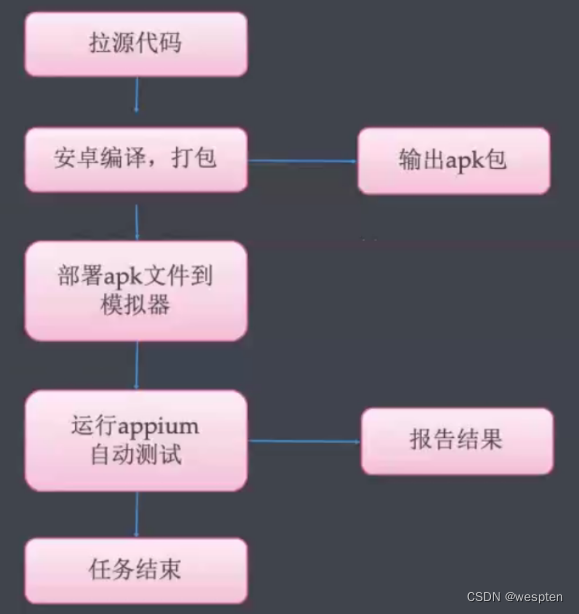
安卓打包任务:
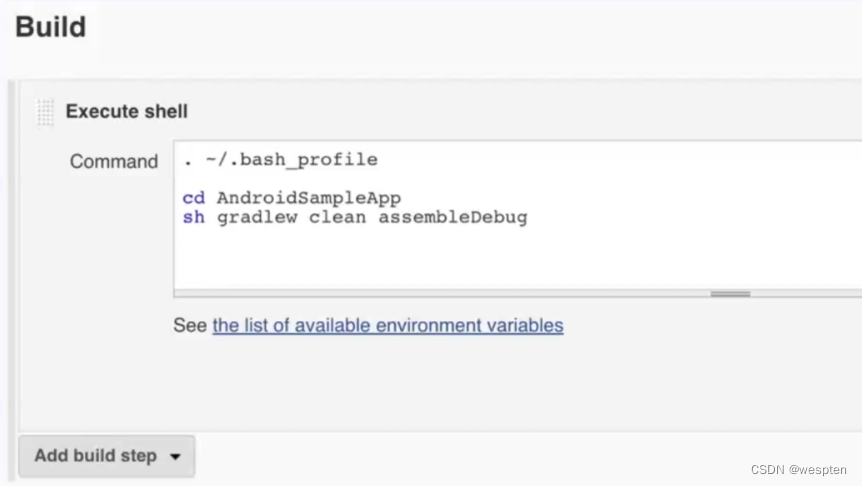
安卓APP发布:
输出apk文件。
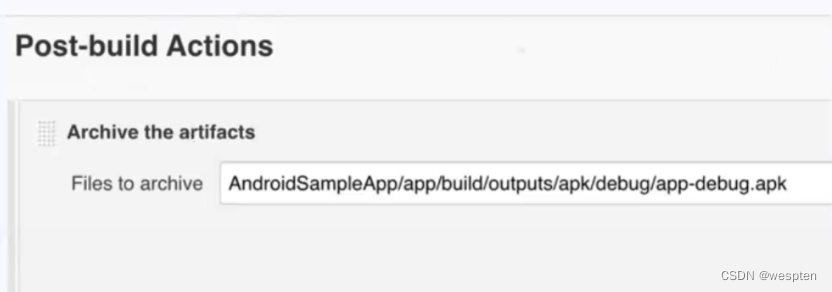
安卓app自动部署、测试任务:
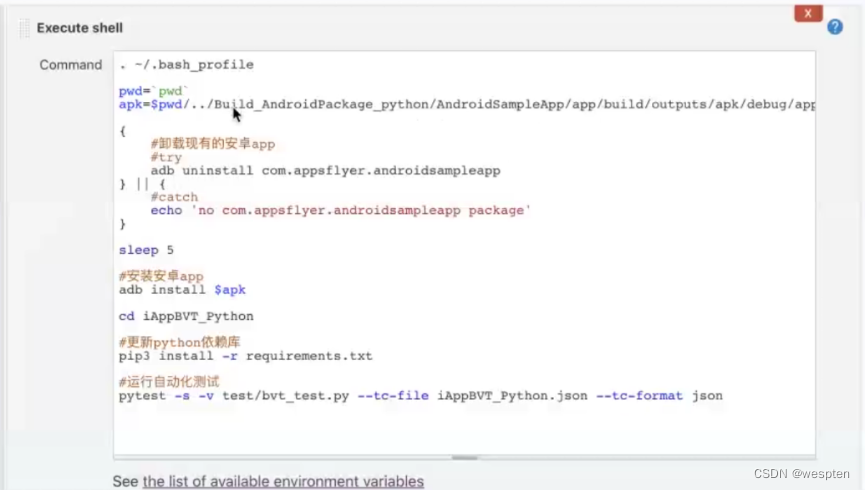
App打包任务与自动部署、测试任务关联:
实现完成打包任务之后,运行自动测试任务,安装新包,并运行UI自动测试验证新安装包的正确性。
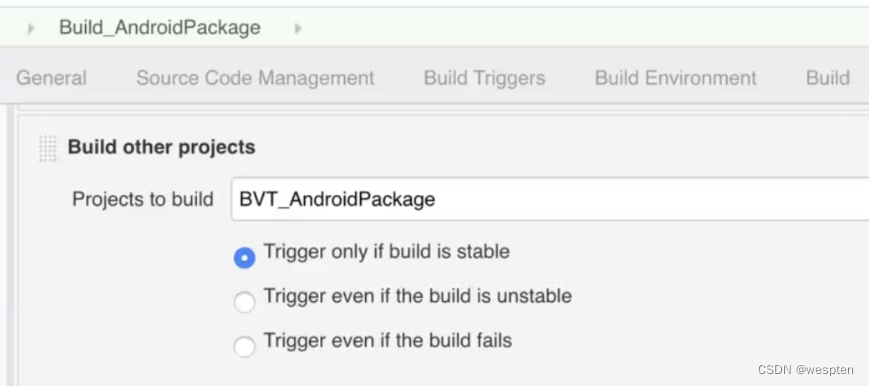
配置任务结果邮件通知:
任务完成之后要把结果周知到相关人员,可以通过email的方式进行通知。
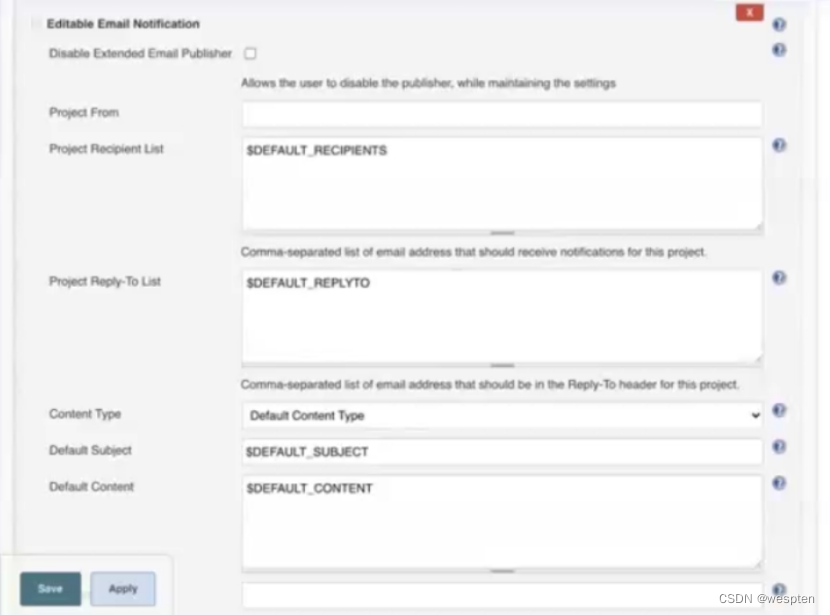
结果通知:任务正确完成。
3、安卓App持续集成实战
1. 创建打包任务
创建job:
选择任务运行的节点-master:

添加项目的GitHub地址,并复制项目名称:
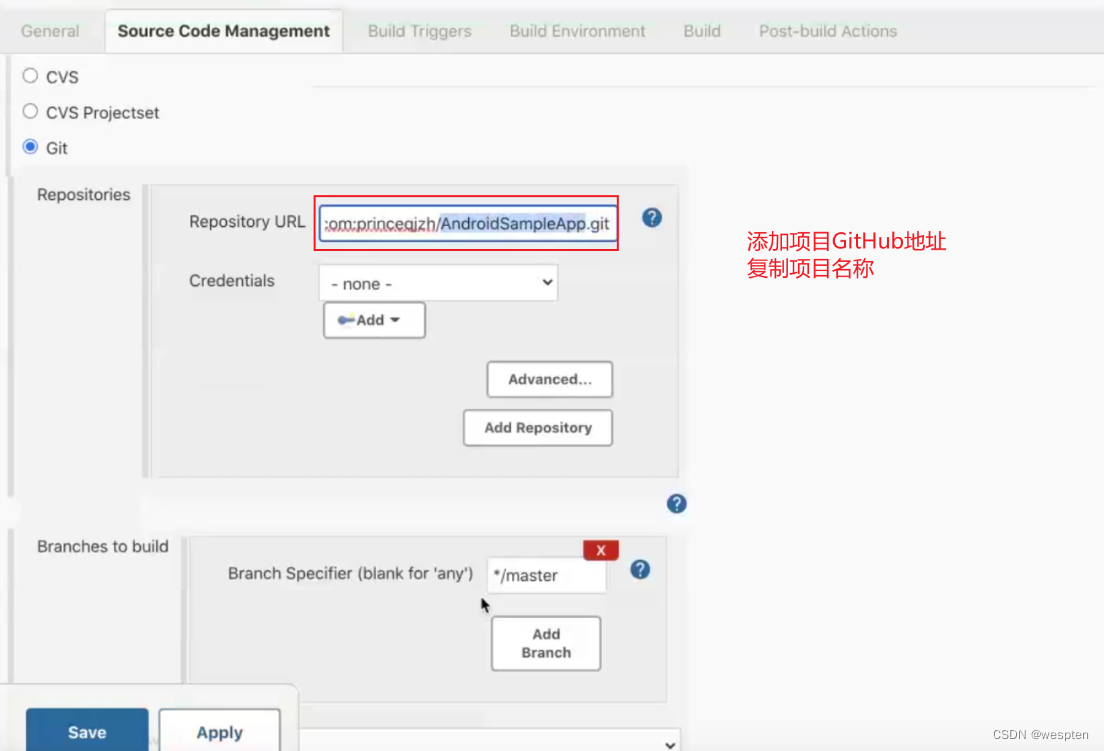
将复制的项目名称复制到sub-directory:
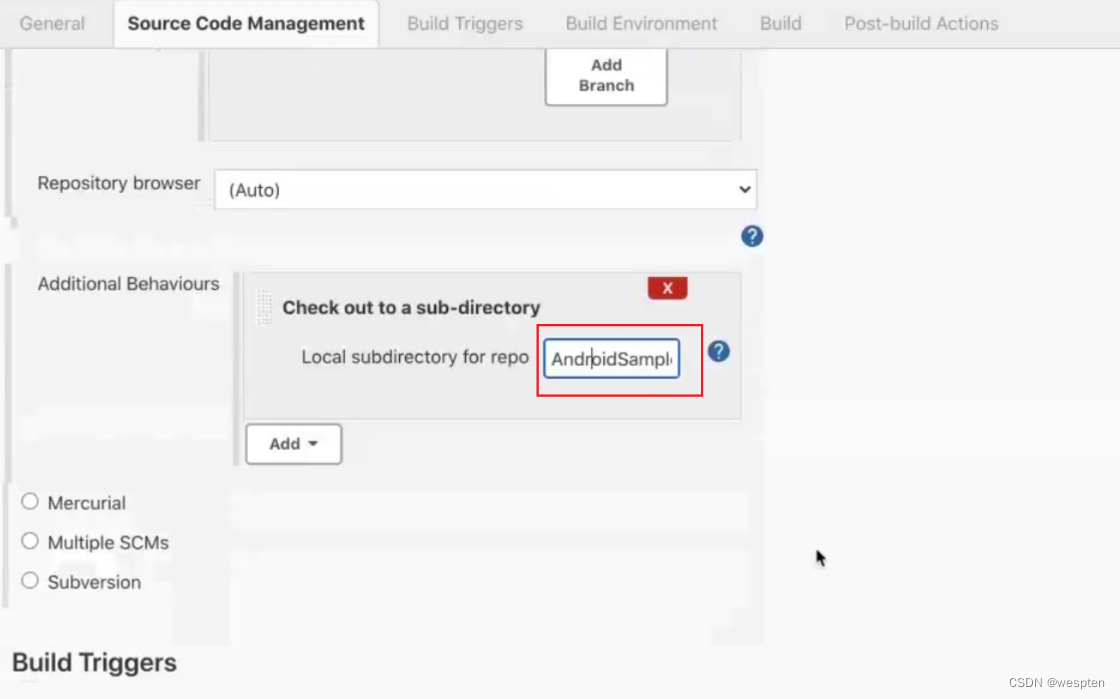
添加shell命令:
. ~/.bash_profile
cd AndroidSampleApp
sh gradlew clean assembleDebug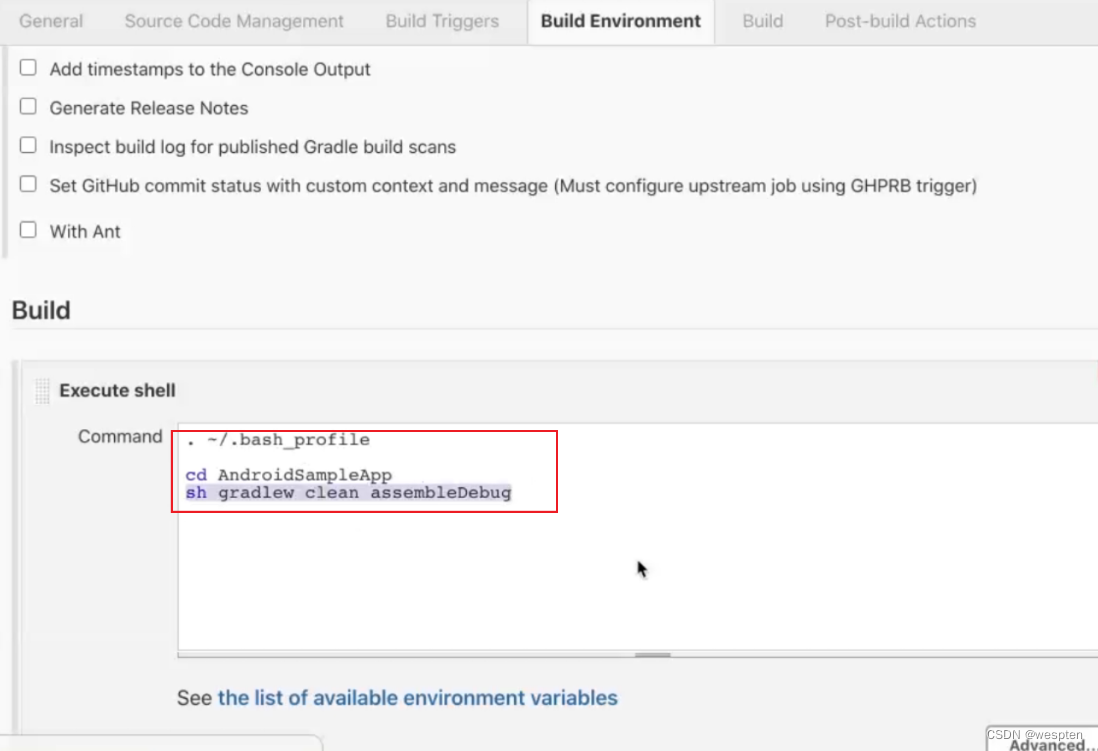
添加发布路径:AndroidSampleApp/app/build/outputs/apk/debug/app-debug.apk

进行构建,查看控制台输出以及运行结果:
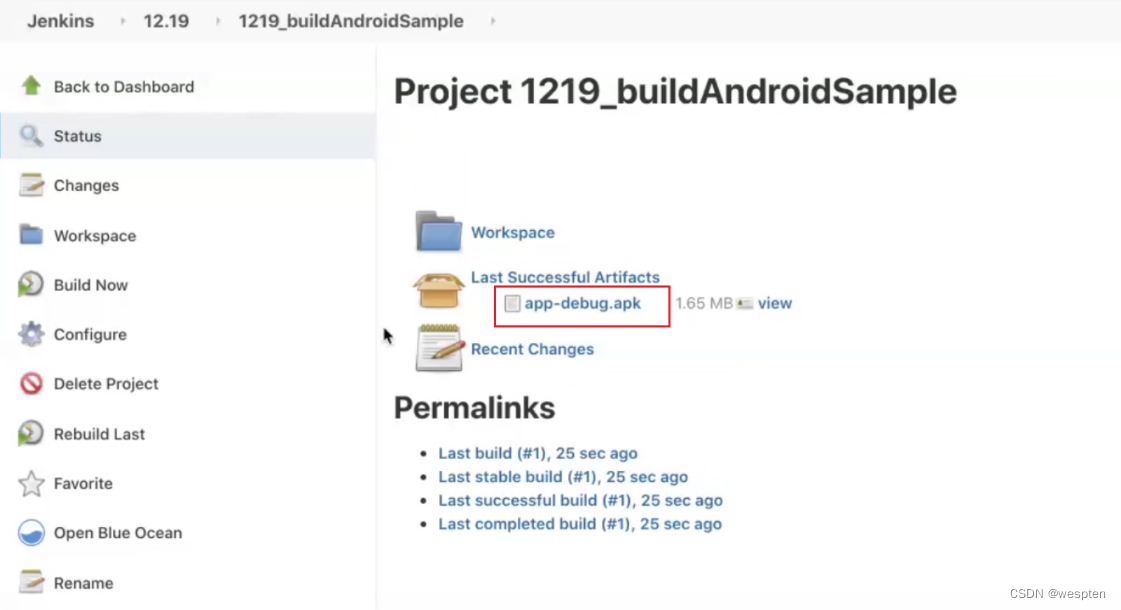
2. 创建自动化测试任务
创建任务:

选择打包的机器:
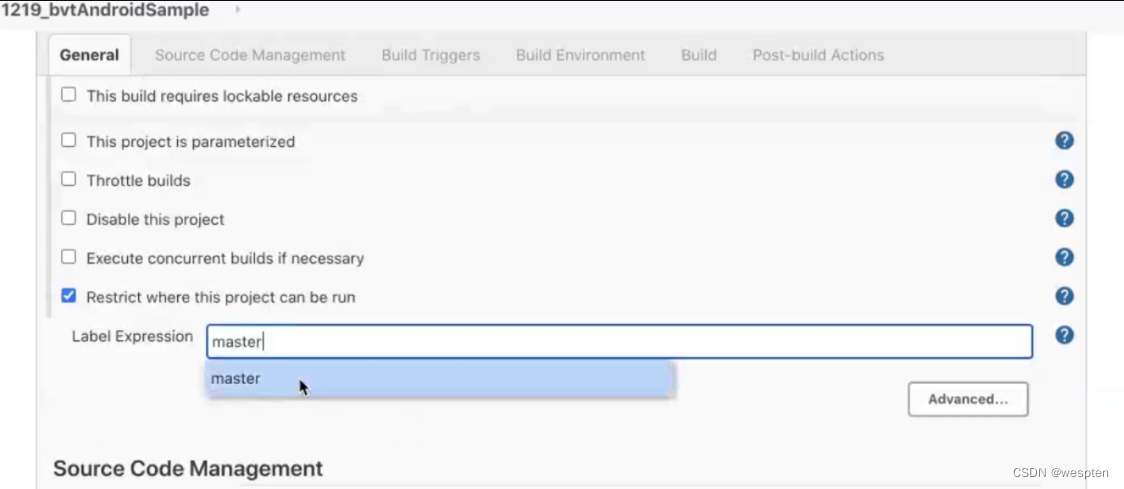
添加项目的GitHub地址,复制项目名称:
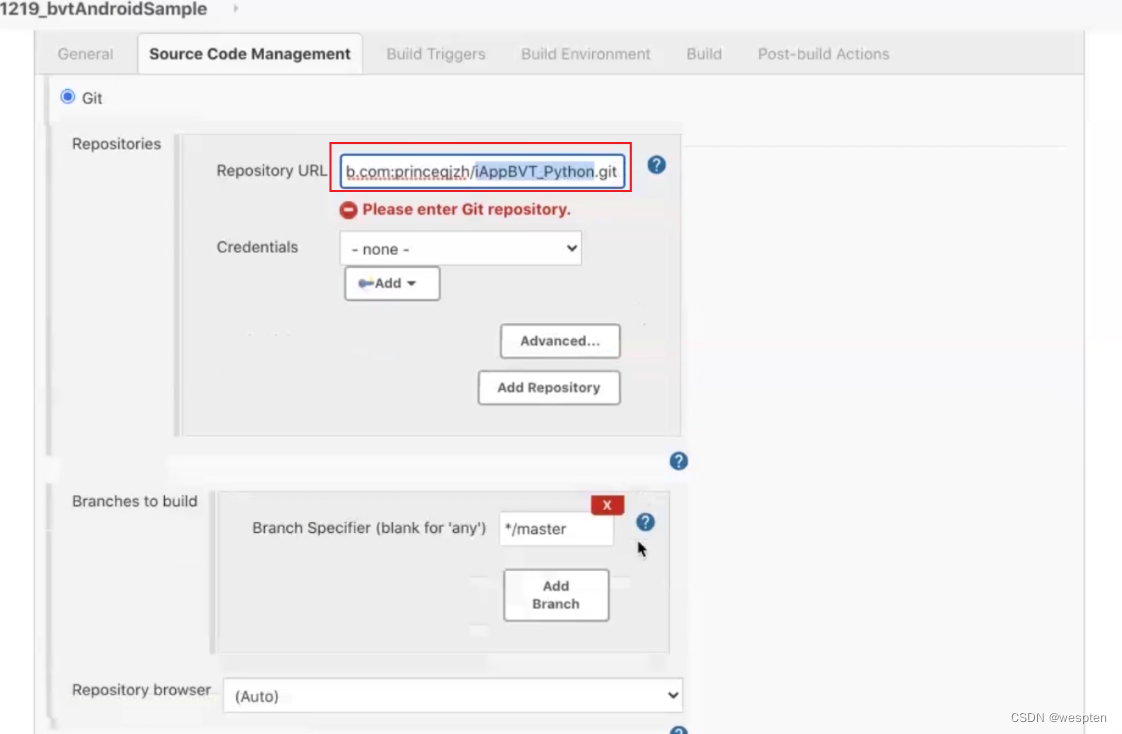
粘贴项目名称到sub-directory:
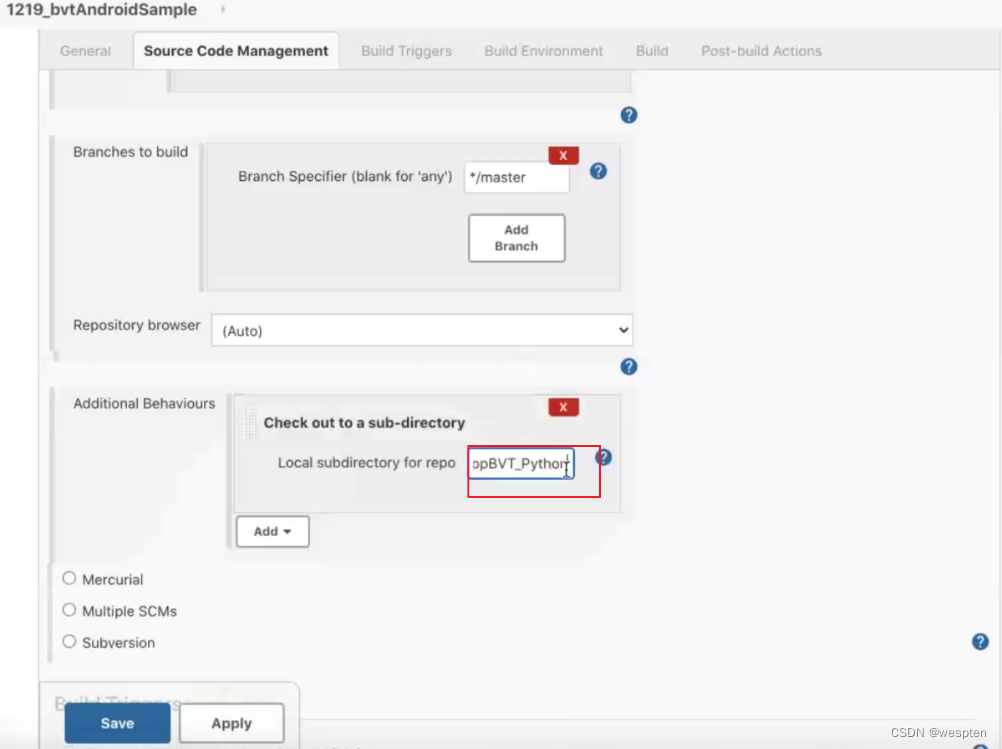
输入shell命令:
如果apk 不存在执行uninstall 命令会报错,可以用以下命令过渡,中间的| |是或者的意思,先之前前面的命令,如果前面的命令报错则执行后面的命令。
{
adb uninstall com.appsflyer.androidsampleapp
} | | {
echo 'no app package installed on the device'
}pwd命令是为了获取当前路径。
. ~/.bash_profilepwd= `pwd`
apk=$pwd/../1219_buildAndroidsample/AndroidSampleApp/app/build/outputs/apk/debug/app-debug.apk
{
adb uninstall com.appsflyer.androidsampleapp
}||{
echo 'no app package installed on the device'
}
adb install $apk
cd iAppBVT_Python
pip3.9 install -r requirements.txt
pytest -sv test/bvt_test.py --tc-file /Users/jizhiqian/iAppBvT_Python.json --tc-format json
构建job,进行运行:
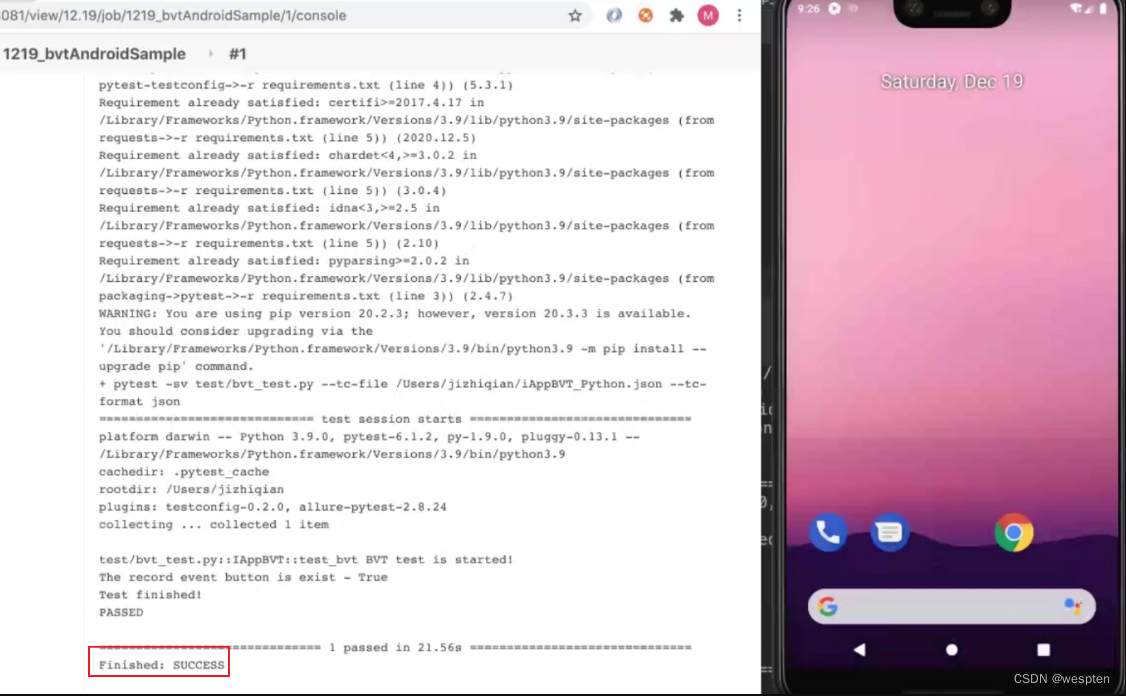
3. 配置消息通知
打包job和自动化测试job添加 Email Notification
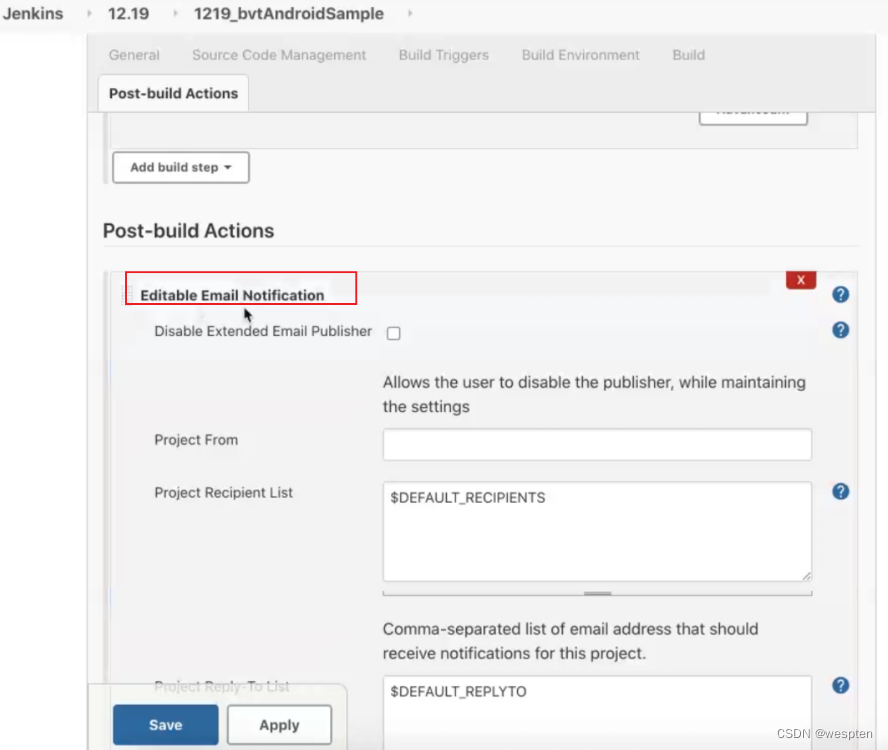
4. 关联任务
在打包job中添加关联,Post-bulid Actions -> Build other projects
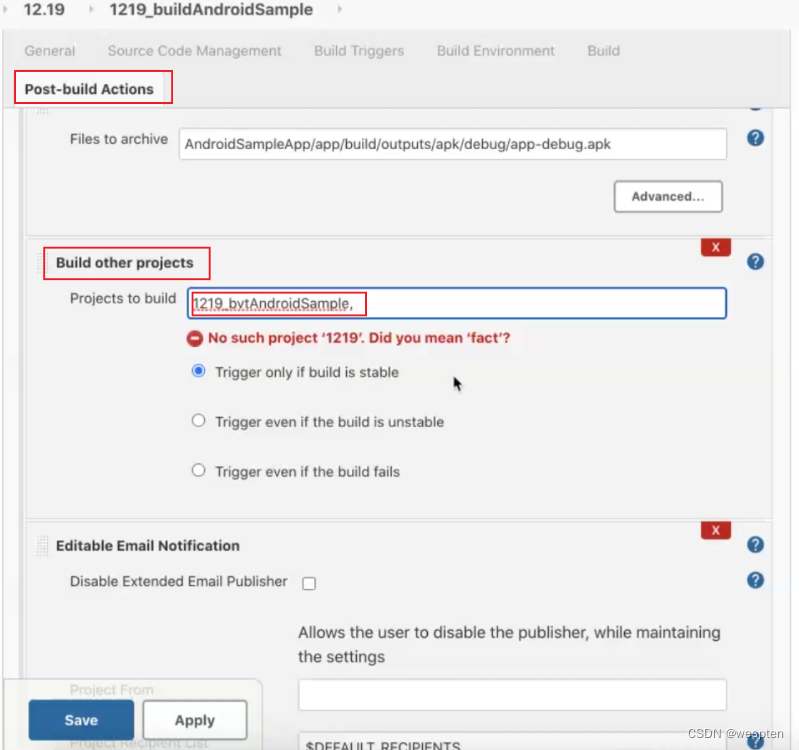
5. 构建打包任务会自动触发自动化测试脚本
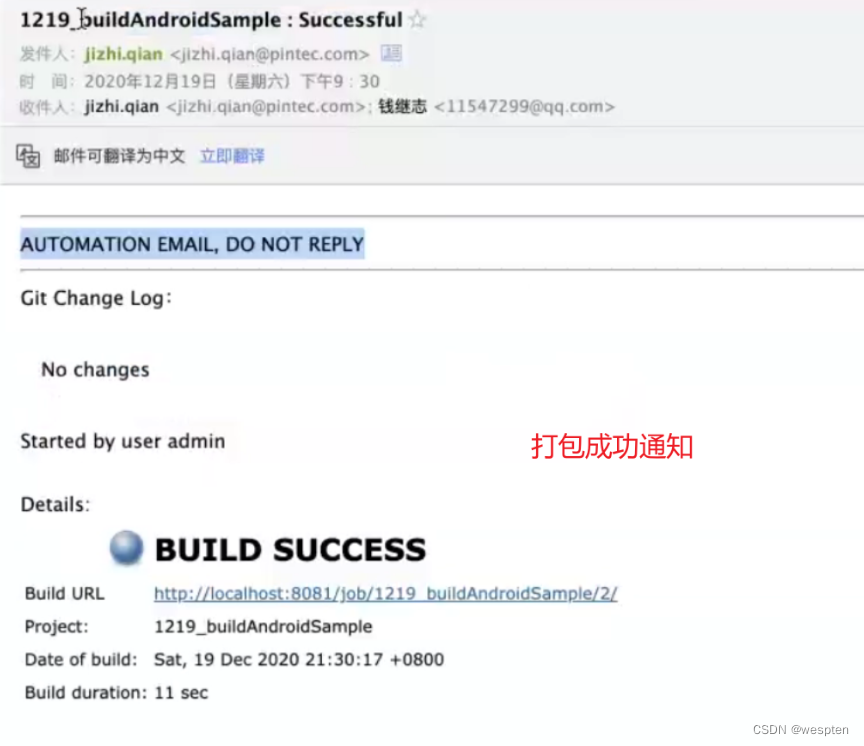
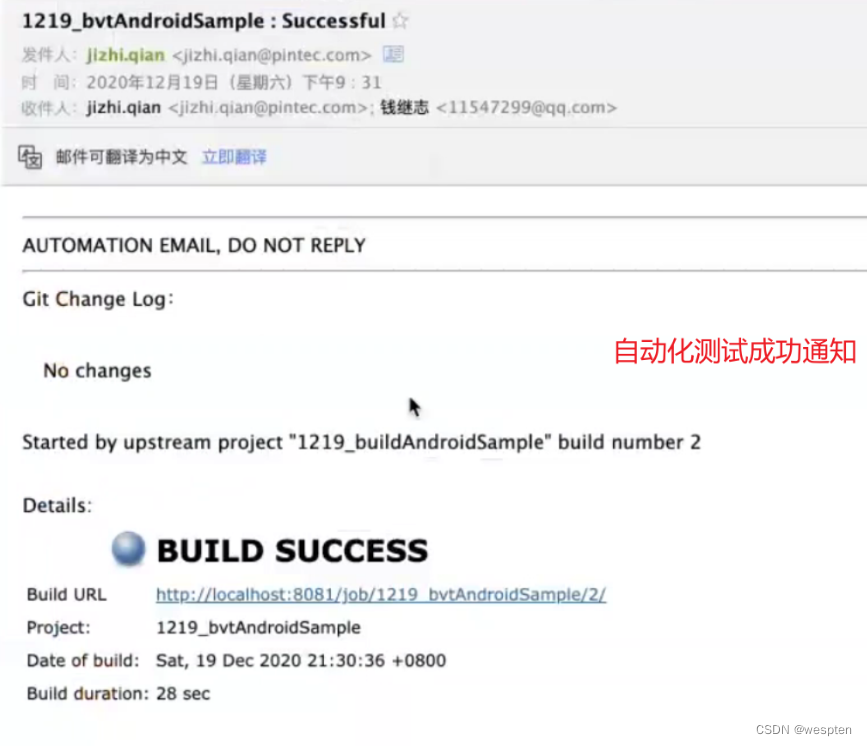
4、FAQ
如何做失败后的自动重试:
- 在job的 Post-build Actions 中添加 Retry build after failure 插件
- Fixed -> Fixed delay:表示延迟多少秒再次构建
- Maximum number of successive failed builds:重试次数
- 可以捕捉错误信息,使用正则表达式,
|表示或
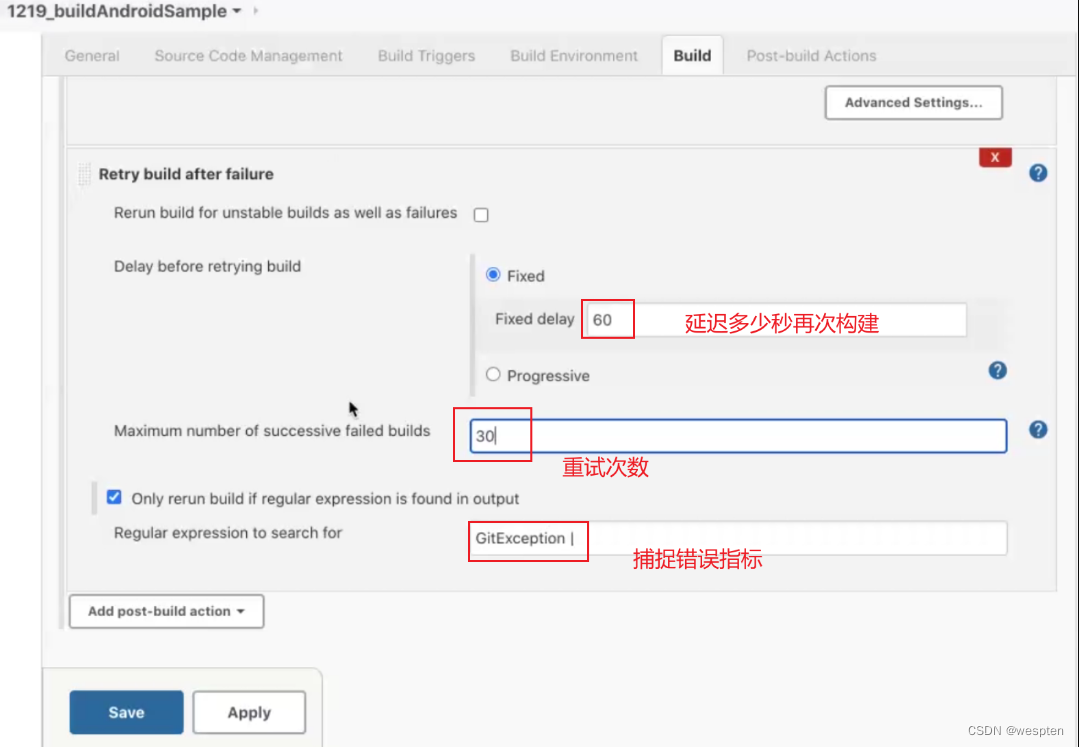
十三、Jenkins UI+接口+App+JMeter自动化测试持续集成实战
1、创建Hello Wordl项目
先牛刀小试,构建一个手动触发的任务(项目名称:test_hello)。
1. 新建任务
选择自由风格的项目:输入任务名称 test_hello:
2. General 配置
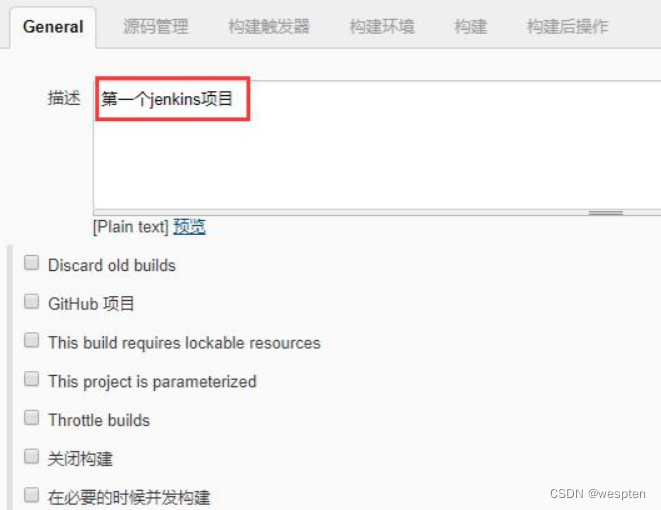
3. 构建配置
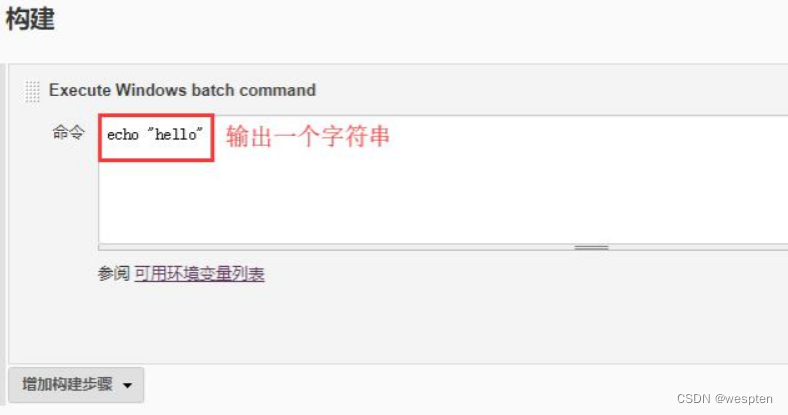
保存后,测试任务配置完毕。
4. 手动触发任务构建
执行日志如下:
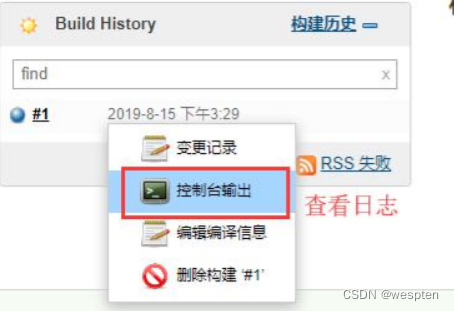

2、构建自动触发的接口测试项目
包含两个项目:
- test_register_interface:用来执行测试脚本的项目。
- build_interface:用来从 github 或者 svn 拉取代码,编译、打包和发布。
其中 test_register_interface 项目的执行由 build_interface 触发,build_interface 的执行是通过 webhook 触发。
1. 新建测试项目(执行测试脚本)
1)General
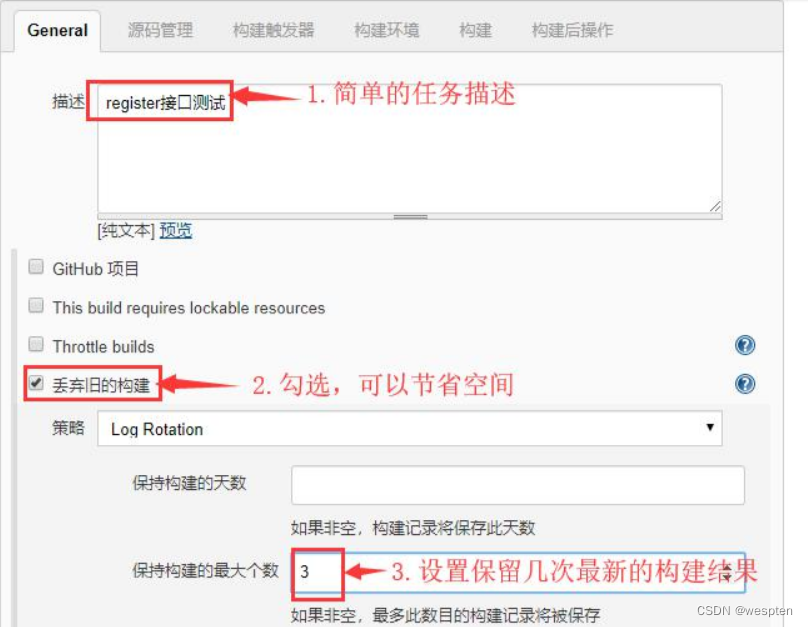
2)源码管理
GitHub - juno3550/RegisterLoginWebProjectTestScript: 测试注册登录web项目(jenkins打包构建后的测试脚本)
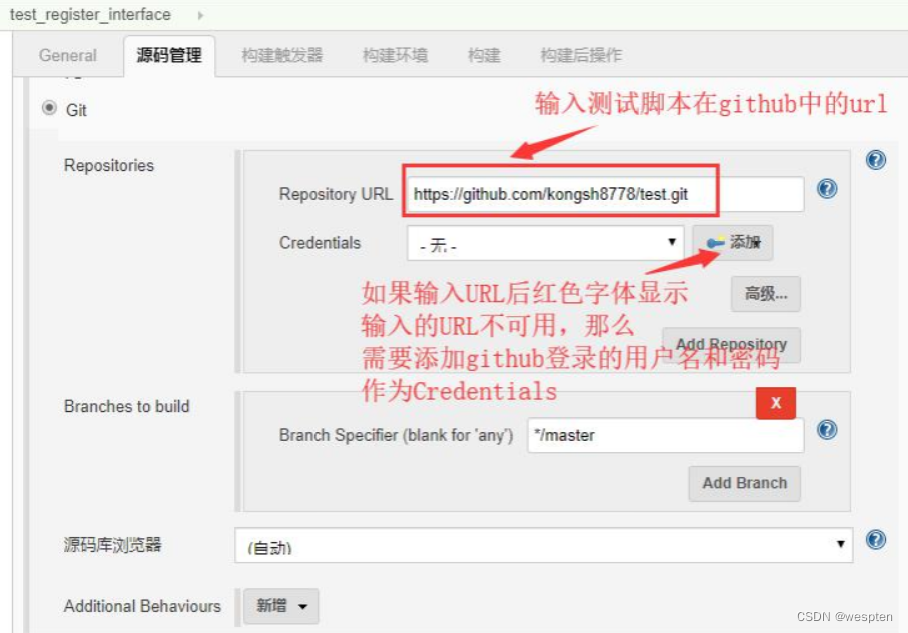
如果输入 URL 后提示类似如下的错误:
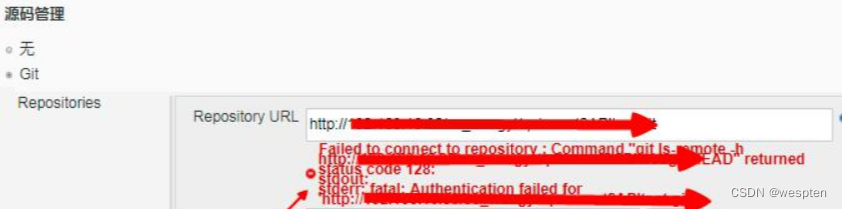
那么需要在 Jenkins 中添加凭证 Credentials,也就是 gtihub 访问的用户名和密码。
可选配置(Advanced clones behaviours):
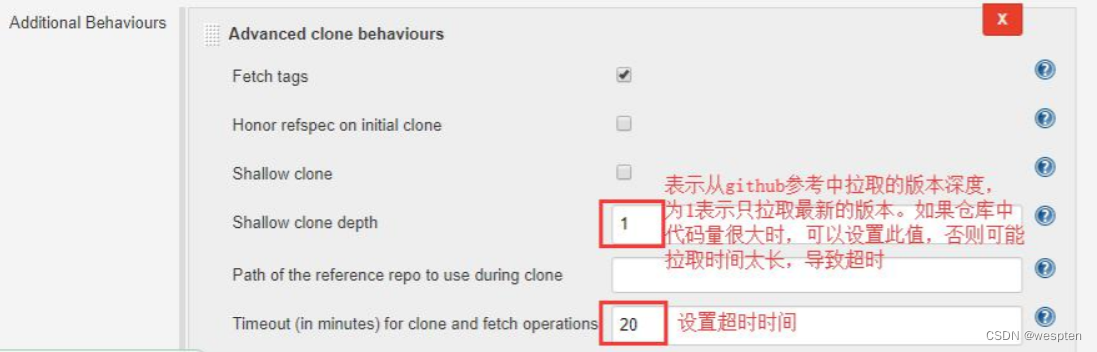
Repository URL 获取方法如下:
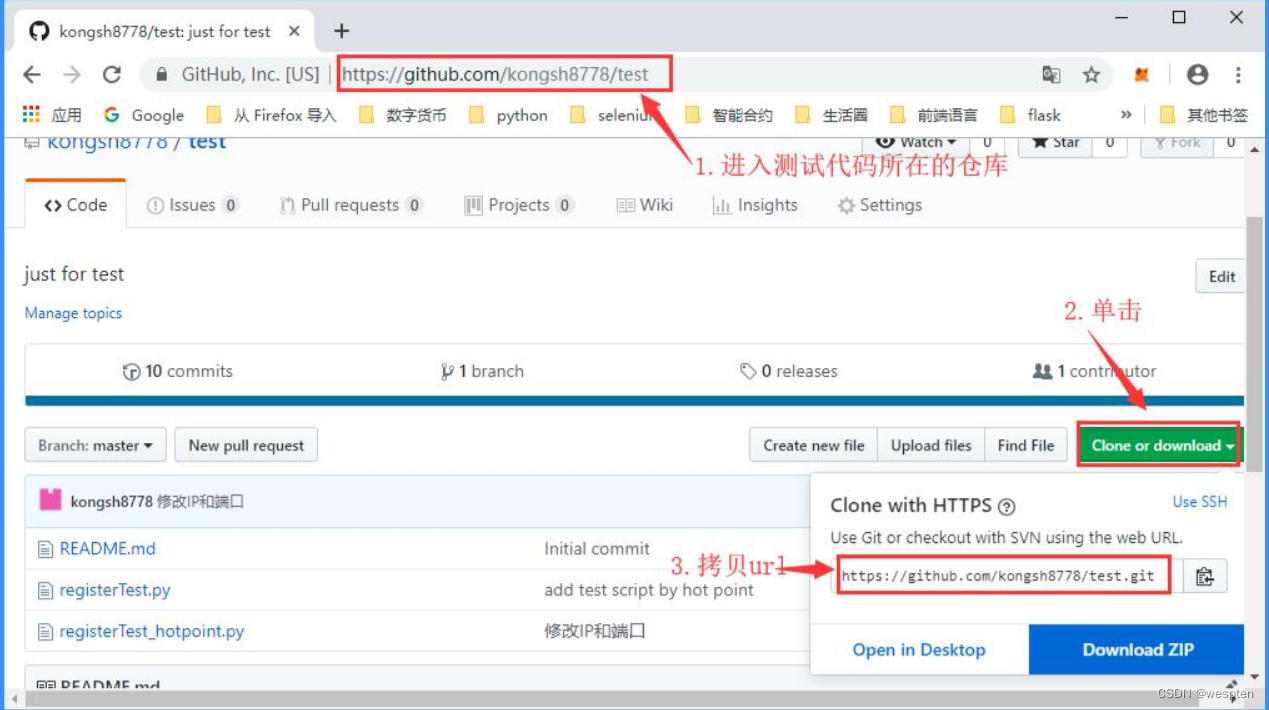
3)构建触发器
用来指定哪个任务执行完毕后自动触发本任务执行。也可以在 build_interface 任务中通过 Post-build Actions 配置项设置。
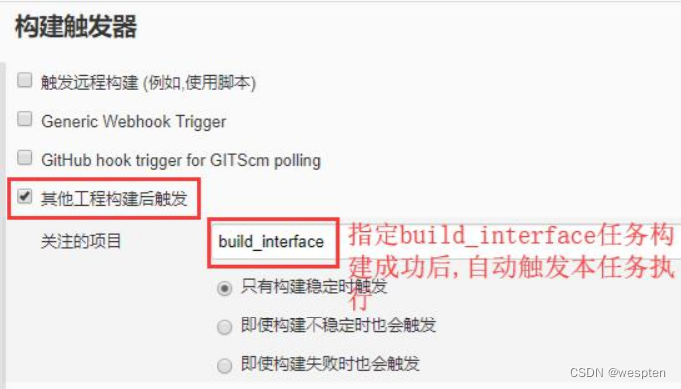
4)构建
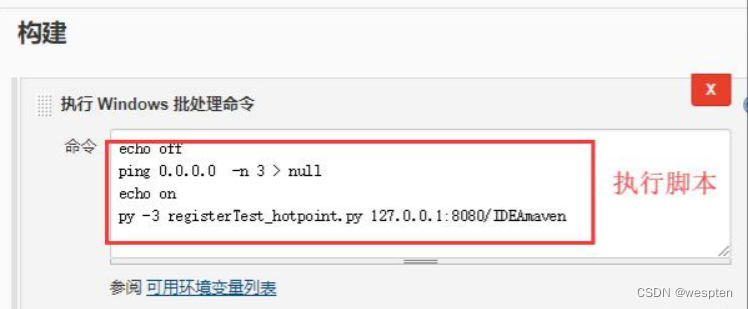
脚本说明:
# windows 下没有 sleep 函数,用以下 3 行间接实现等待 3 秒
echo off
ping 0.0.0.0 -n 3 > null
echo on
# 执行 registerTest_hotpoint.py 脚本
# 参数 127.0.0.1:8080/IDEAmaven,表示访问的网址,测试脚本会拼接为完整的路径
py -3 registerTest_hotpoint.py 127.0.0.1:8080/IDEAmaven保存后,测试任务配置完毕。
2. 新建 Maven 打包项目
1)General
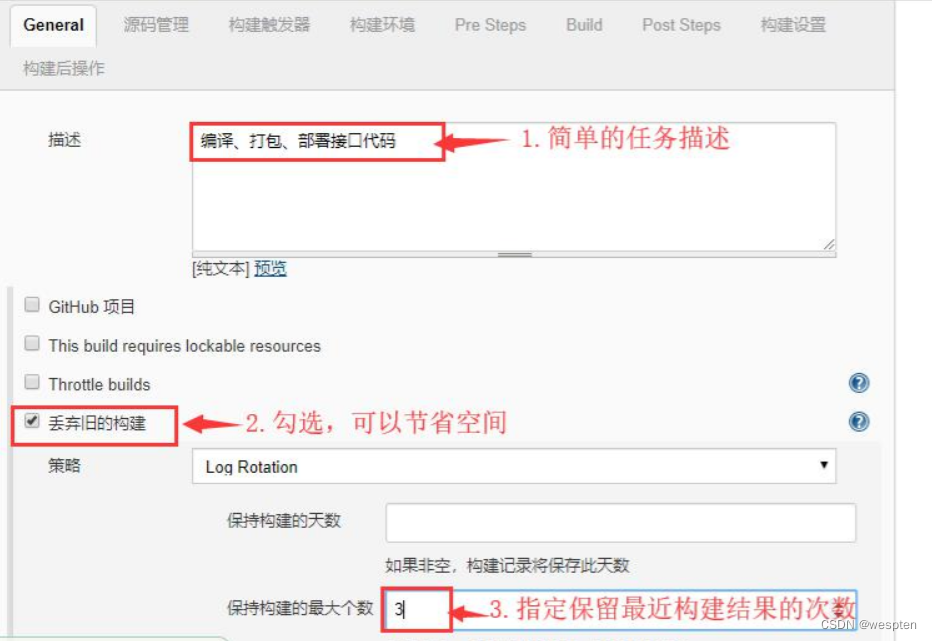
2)源码管理
GitHub - juno3550/RegisterLoginWebProject: 基于springboot的注册登录项目(供jenkins打包构建使用)
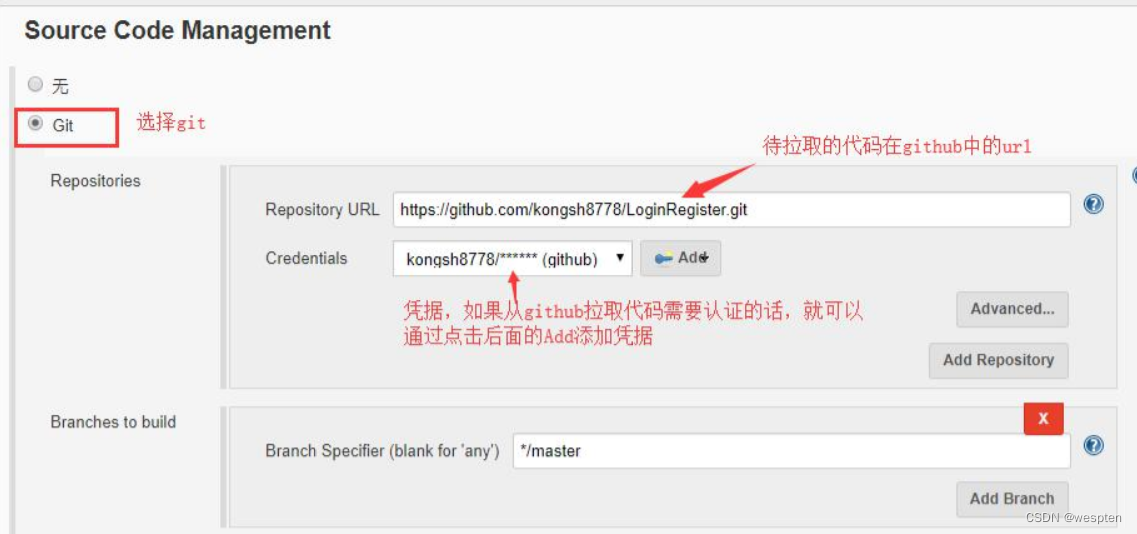
可选配置:
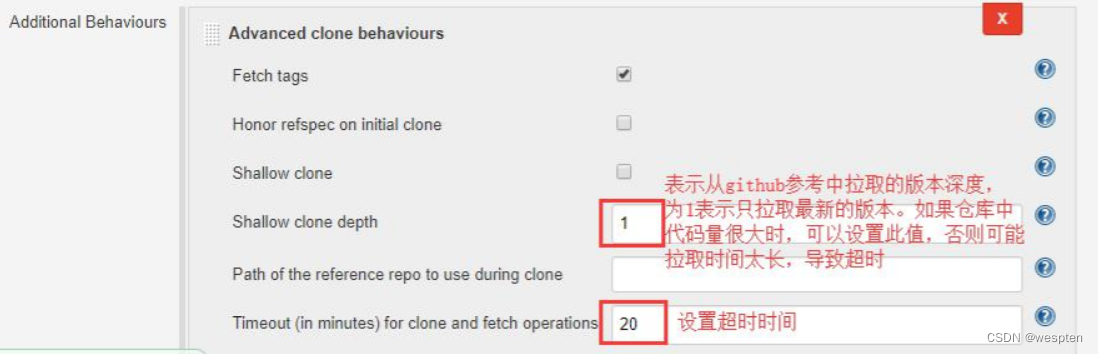
3)构建触发器
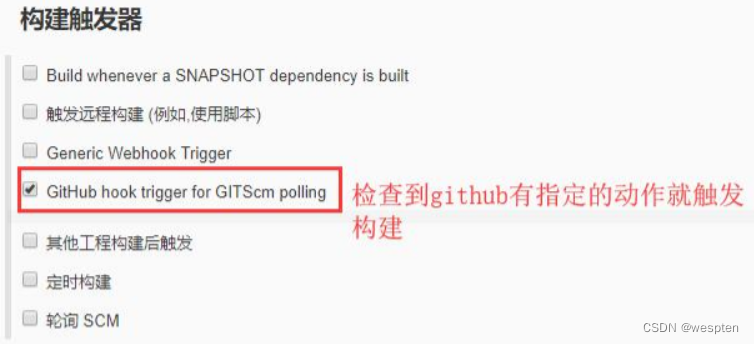
4)Build
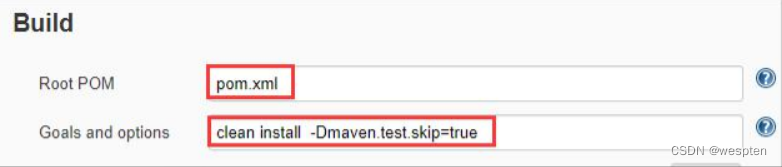
Root POM:指定构建时的 pom.xml,windows 下可以不写绝对路径。如果想配置绝对路径的话一般指定 Jenkins 的工作空间即可,默认的情况下:C:\Users\电脑用户名\.Jenkins\workspace\jenkins项目名称\pom.xml。
Goals and options:以下 3 种任选其一:
- clean package -DskipTests=true
- clean install package '-Dmaven.test.skip=true'
- clean install -Dmaven.test.skip=true
说明:
- clean 表示清除 class 文件;package 表示打包但不发布到本地库;install 表示打包并发布到本地库;-DskipTests 表示跳过单元测试。
- 不配置这一项的话 war 包发布成功后,第 2 次构建再访问会返回 404。
5)构建后操作
我们选择 Deploy war/ear to a container 的方式,将打包后的 war 发布到 tomcat 的 webapps 目录中,步骤如下:
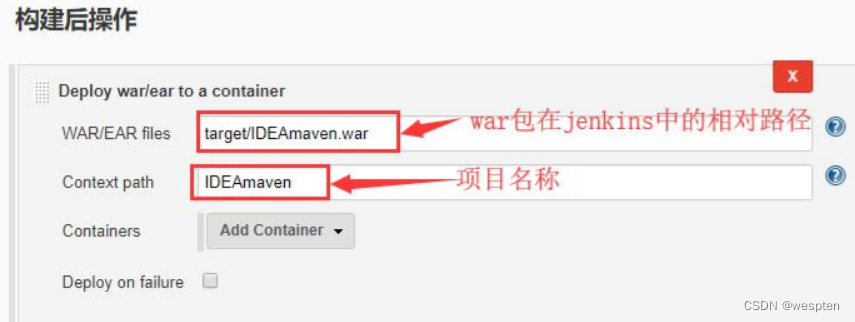
- WAR/EAR files:war 包所在的路径,相对于 Jenkins 项目的 workspace 目录的路径。
- Context path:相对于 tomcat 的 webapps 目录的路径。
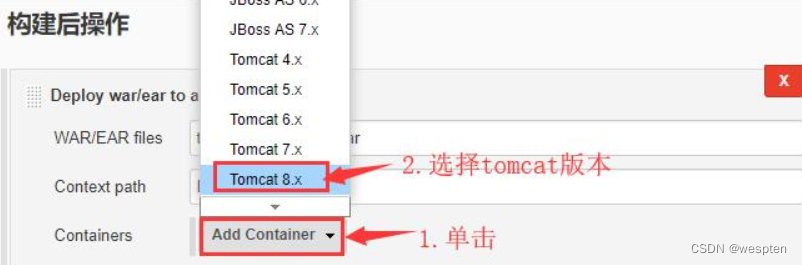
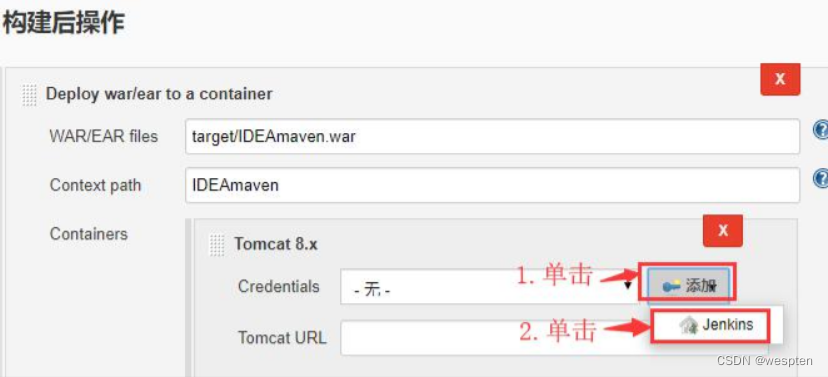
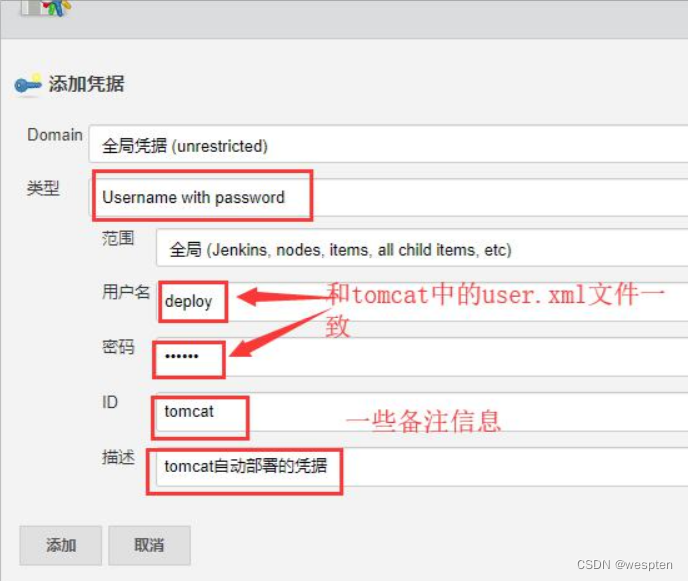
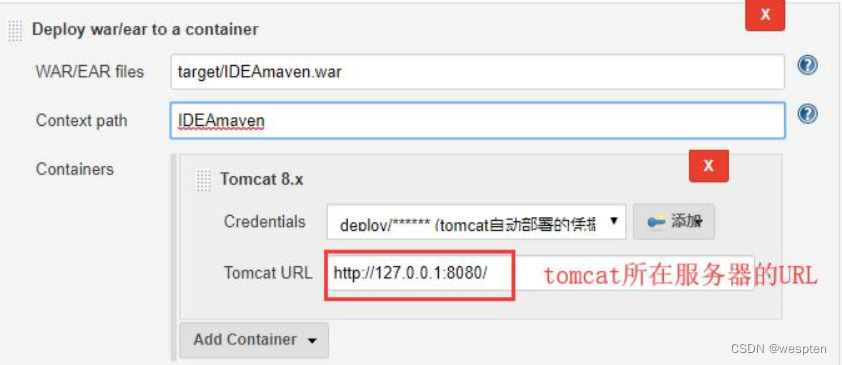
增加扩展的邮件发送功能:
3. 手动执行构建
以上配置完成后,可以在 Jenkins 首页可以看到所有构建的项目:
红色表示构建失败;蓝色表示构建成功。

构建 build_interface 项目(打包部署 war 包,并会自动触发 test_register_interface 项目进行测试),并查看详细的构建过程:
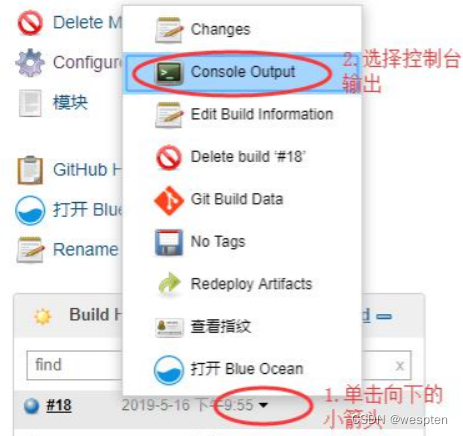
浏览器成功访问 http://127.0.0.1:8080/interface_proj/front/register 表示项目打包部署成功。
查看测试脚本项目日志,验证是否测试通过。
4. 修改 Web 工程代码并 push 到 Github,触发自动构建
1)github push 日志
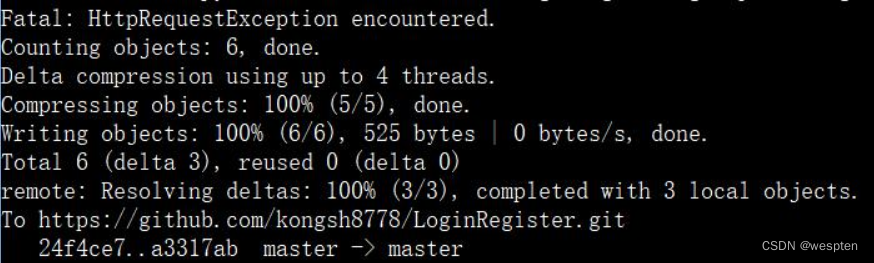
2)触发项目自动构建
触发 build_interface 建立的任务(部署 war):
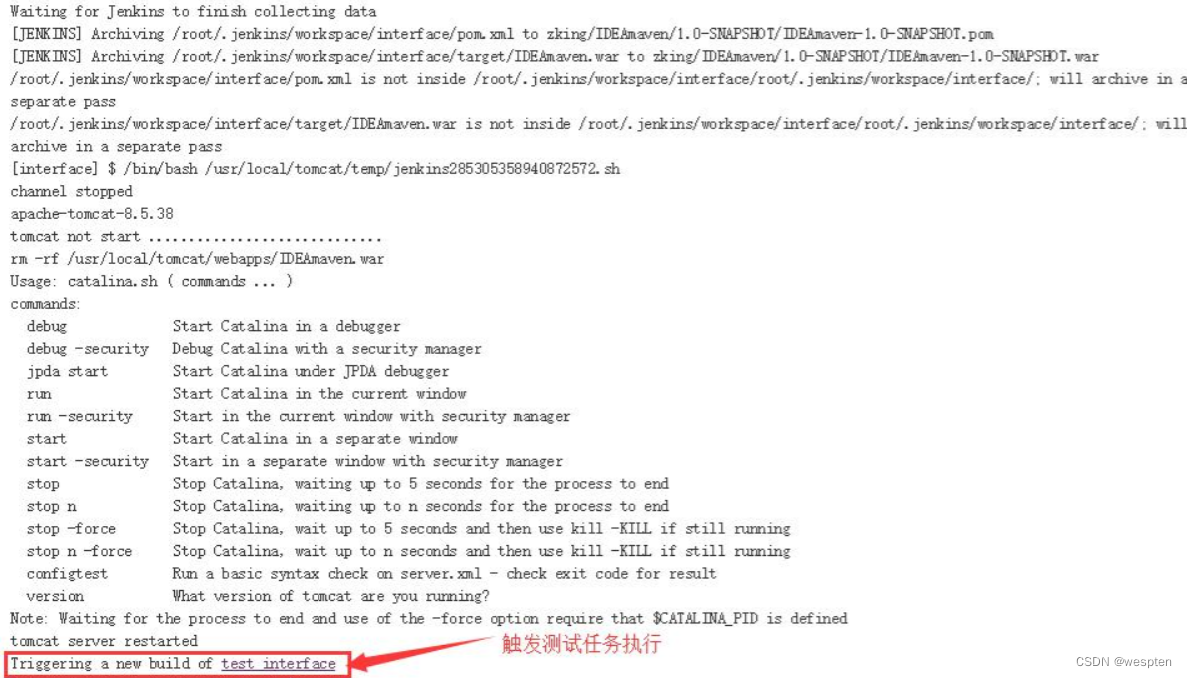
3)触发测试脚本执行
触发的是 test_register_interface(测试项目):

5. 邮件发送的构建日志

6. 补充:构建编译 Java 程序的任务
通过 github 网站,找到构建的工程,在工程下新建一个目录 java(新建目录的方法,直接在输入框后加入\即可),新建一个 HelloWorld.java 的文件,具体代码如下:
class HelloWorld{
public static void main(String[] arr){
System.out.print(" HELLO WORLD");
}
} 在构建界面的输入框中的执行 Windows 批处理命令,为如下:
py -3 a.py
javac ./java/HelloWorld.java
cd java
java HelloWorld3、构建UI测试项目
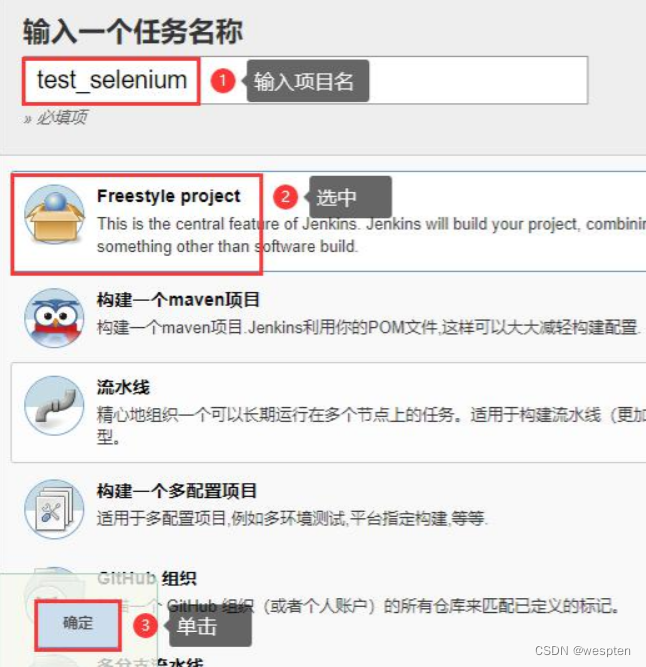
1)General
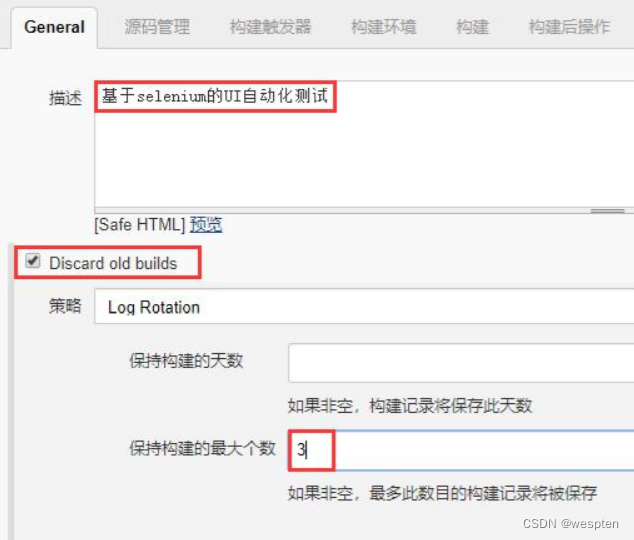
2)源码管理
GitHub - juno3550/UIKeywordFramework: UI自动化测试框架 混合驱动:关键字驱动+数据驱动

3)构建
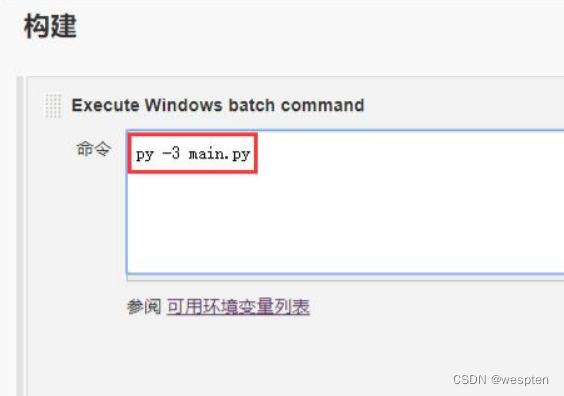
4)构建后操作
这里选择的是扩展的邮件插件,可以根据实际的项目需求定制收件人,邮件内容等信息。

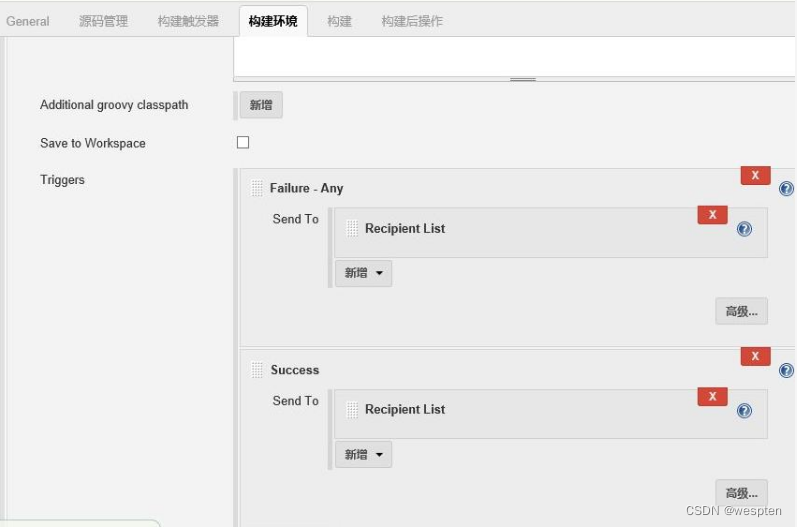
注意:
1. 添加完插件后,需要单击右下角的“Advance settings”按钮,这样才能定制构建失败时的邮件信息,构建成功时的邮件信息等等。
2. 该插件的收件人默认都是 Developers 列表,如果 Jenkins 的全局配置中没有此项的话邮件发送失败,可以在 Manage Jenkins-->Configure System 中进行配置,也可以在此位置直接填写收件人邮箱。
5)构建日志信息

4、构建APP测试项目
1. 新建测试项目(执行测试脚本)
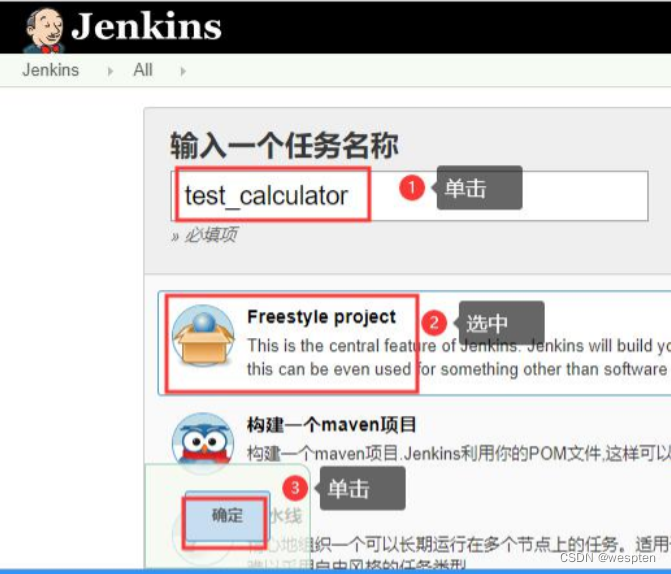
1)General
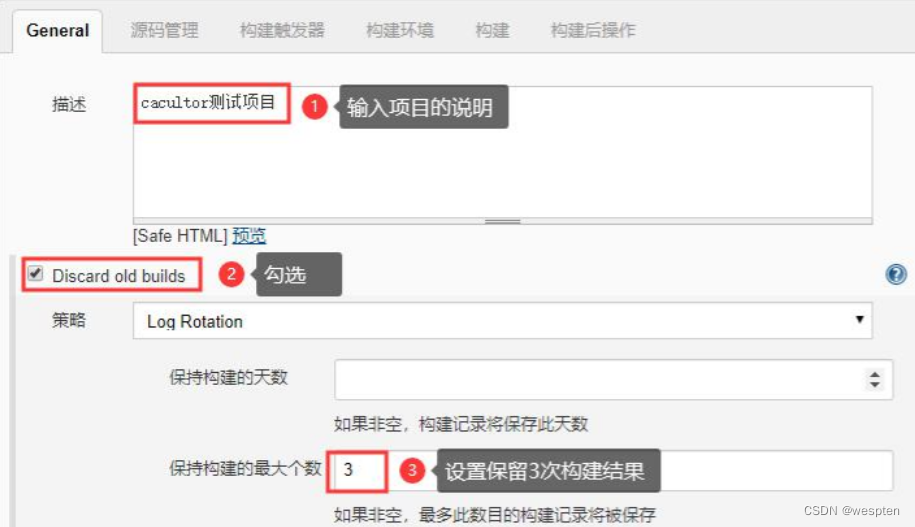
2)源码管理

3)构建触发器
用来指定哪个任务执行完毕后自动触发本任务执行。
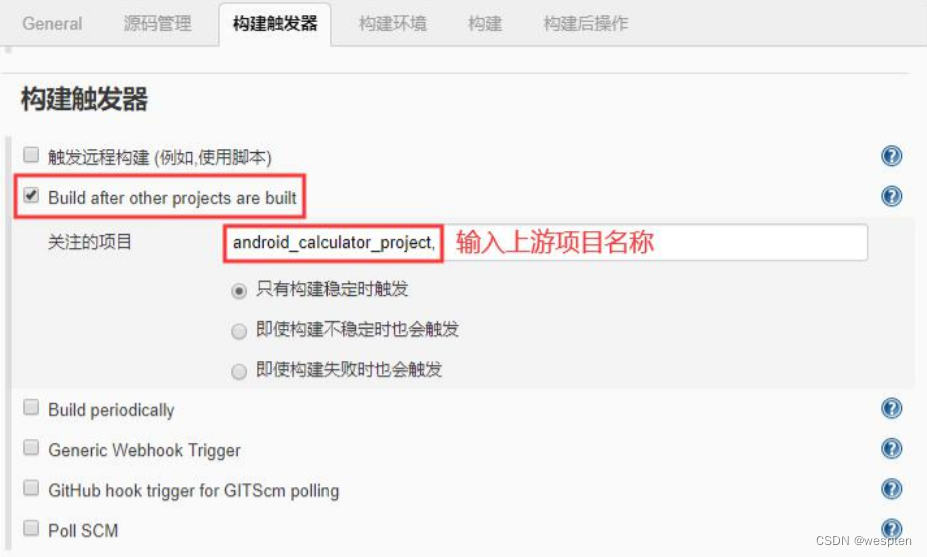
4)构建
py -3 RunTest.py
@IF NOT %ERRORLEVEL% == 0 EXIT /b %ERRORLEVEL%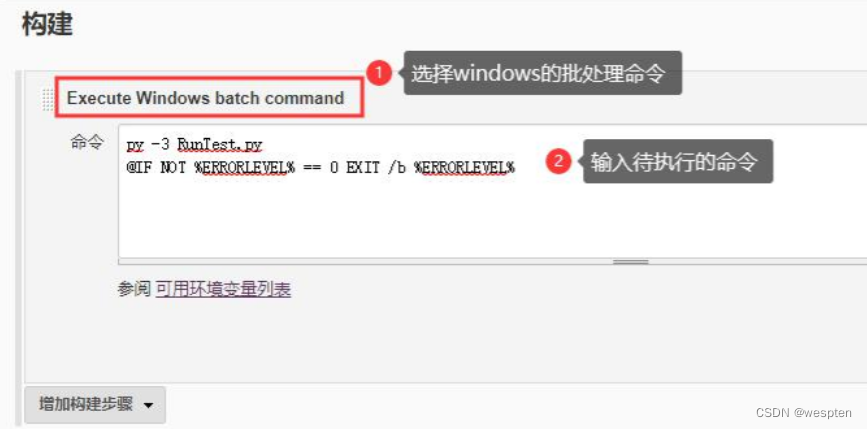
保存后测试任务配置完毕:

2. 新建 Gradle 打包任务
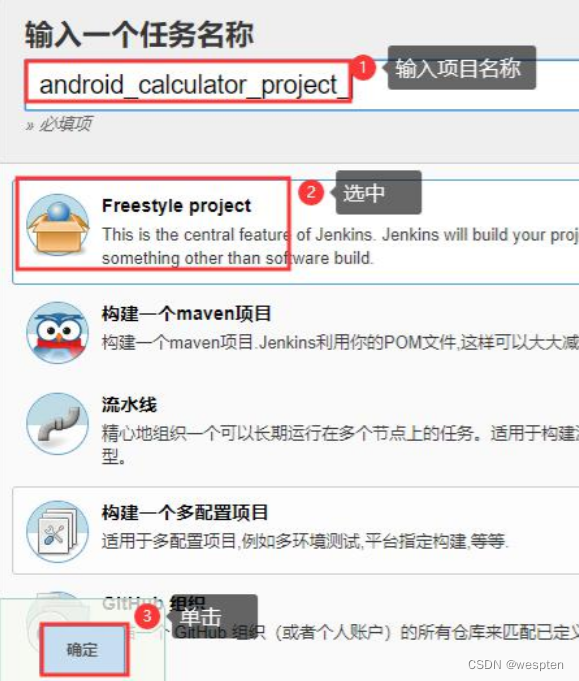
1)General
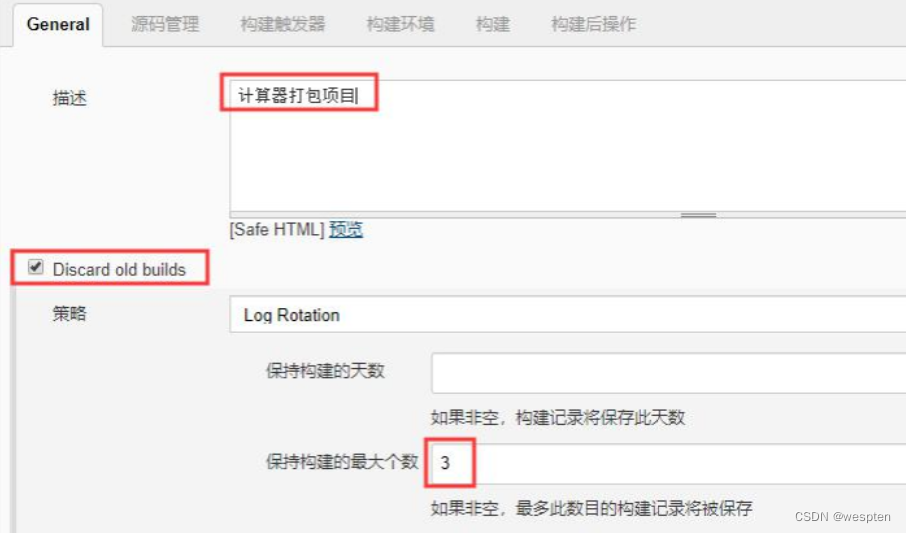
2)源码管理
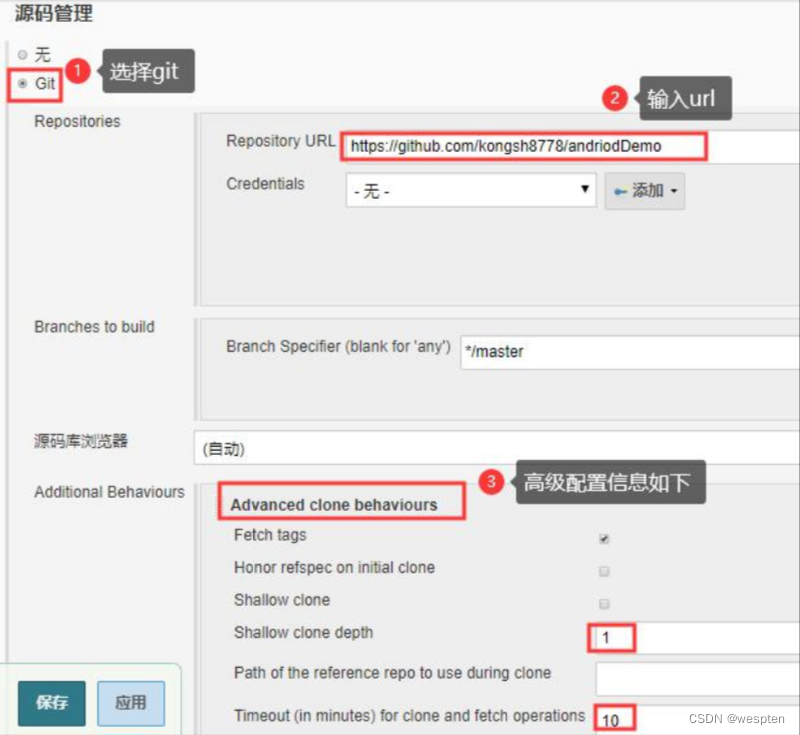
3)构建
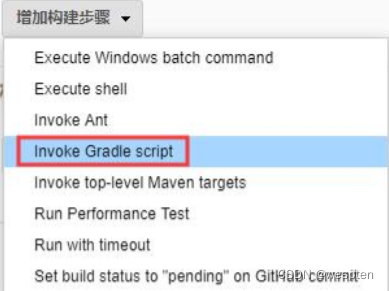
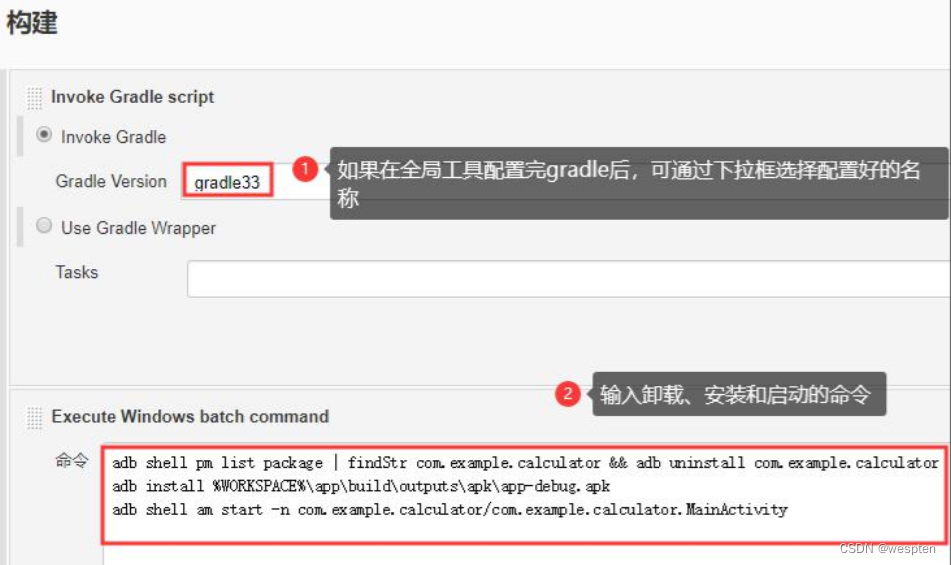
脚本内容如下:
# 判断 com.example.calculator 应用是否已安装,如果已经安装则只先执行 uninstall
adb shell pm list | findStr com.example.calculator && adb uninstall com.example.calculator
# 安装打包的 apk
adb install %WORKSPACE%\app\build\outputs\apk\app-debug.apk
# 启动 app
adb shell am start -n com.example.calculator/com.example.calculator.MainActivity保存后测试任务配置完毕:

3. 构建日志
打包项目构建日志:

执行脚本构建日志:
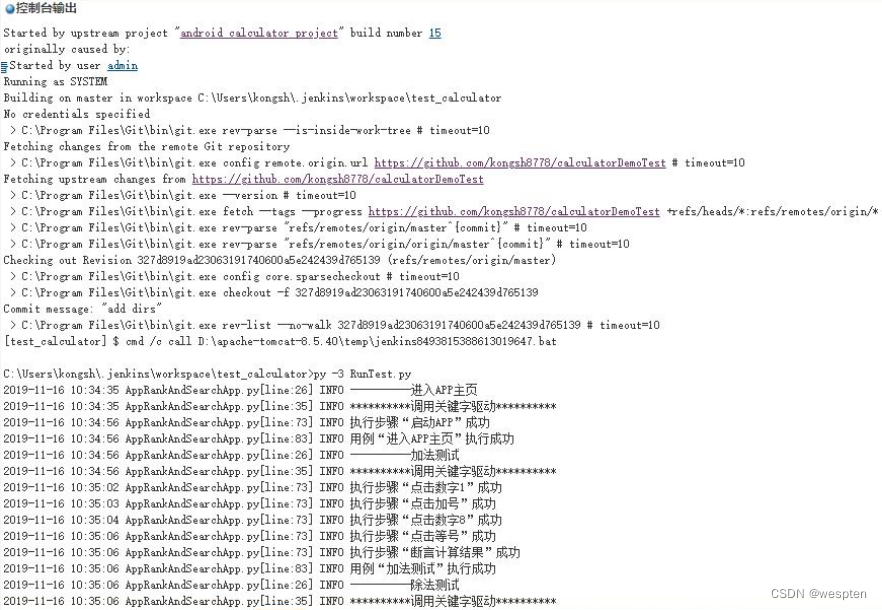
5、构建JMeter性能测试项目
Jenkins 执行 Jmeter 脚本有以下 2 种方式:
- Jmeter 脚本放在负载机中,然后 Jenkins 项目中写 shell 命令。
- Jmeter 脚本放在 Maven 工程中,然后 Jenkins 执行 maven verify,执行 pom.xml(pom 文件配置比较复杂)。
这里以第 1 种方法为例来进行说明。
1. 安装插件
1)performance 插件
作用:将 jtl 文件展示为图表,生成性能测试报告。
安装流程:在“系统管理——插件管理——可选插件”中搜索并安装 performance 插件。

注意:安装过程中可能会超时,安装失败,需要FQ。若不能FQ可在以下网盘下载:
https://pan.baidu.com/s/1YZ0C7ld1R-3RoGsQEZAQYA(提取码:u3vx)
下载完成后,在 Jenkins 界面中系统管理-管理插件下,在管理插件页面点击高级,在高级页面,找到上传插件栏,上传该插件。
2)HTML Publisher 插件
作用:会在新建或者编辑项目时,在【增加构建后操作步骤】出现【Publish HTML reports】的选项,用来生成 HTML 报告。

解决无法正常显示 HTML 报告的方法:
publish html report 由于安全问题,默认不支持 js css 等。这个就是为什么你 extent 报告能在本地浏览器打开,显示很美观,但是到了 Jenkins 页面上就格式很难看。解决方法如下:
进入 Manage Jenkins-->Script Console,输入以下内容,单击右下角的运行:
System.setProperty("hudson.model.DirectoryBrowserSupport.CSP","script-src'unsafe-inline'")
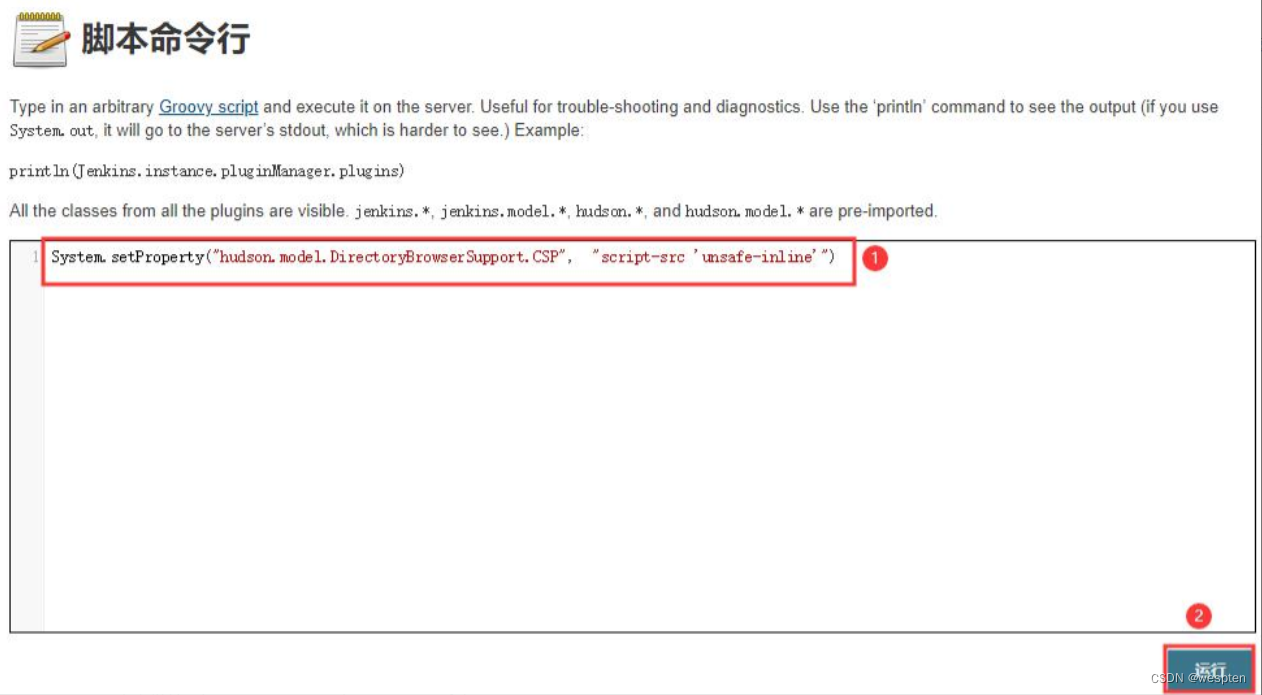
注意:执行完成后,需要多次强制刷新(shift+F5)展示失败的页面。或者重新构建一次该任务。
参考:https://www.jianshu.com/p/16f5b01cc9c0
2. 新建测试项目
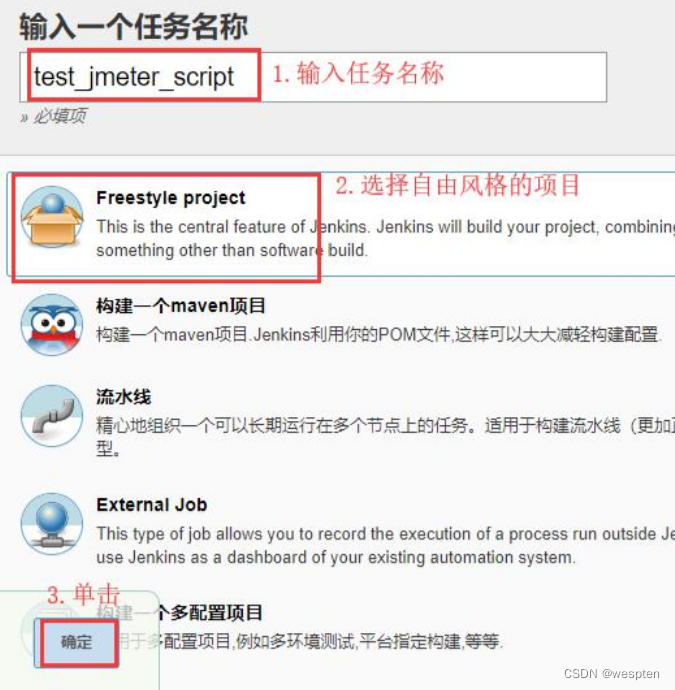
1)General
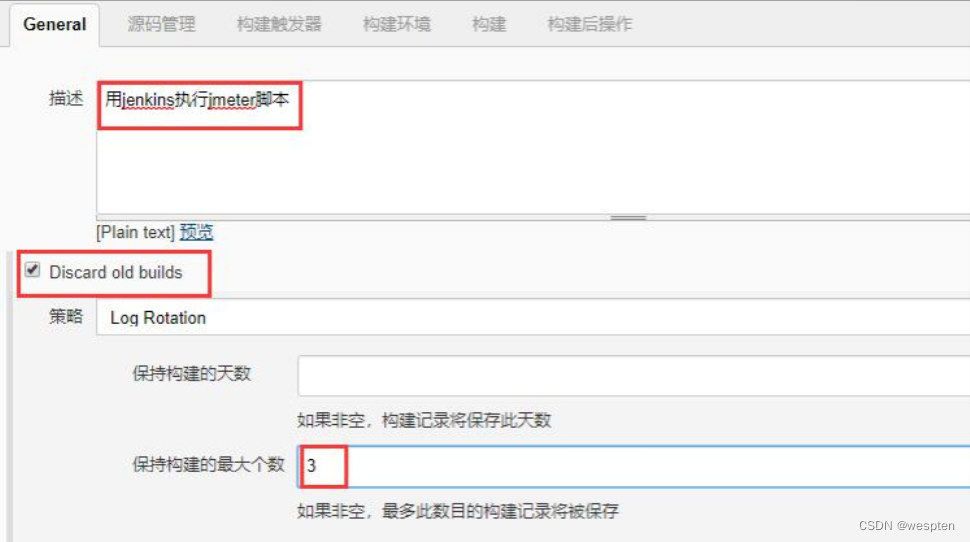
2)构建
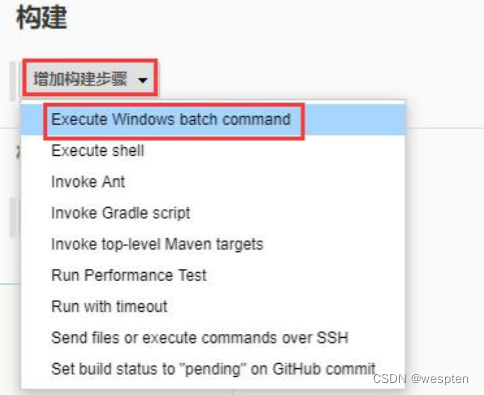
输入执行命令:
# 切换到 d 盘
d:
# 进入 jmeter 安装目录
cd D:\apache-jmeter-5.1.1\bin
# 执行脚本并保存日志
jmeter -n -t ..\20190803\sampler.jmx -l %WORKSPACE%\%JOB_NAME%20190812.jtl
3)构建后操作

此插件在任务运行期间会产生一些图表来保持跟踪整体的响应数据和错误数,每一个 jtl 文件对应生成一个独立的图。
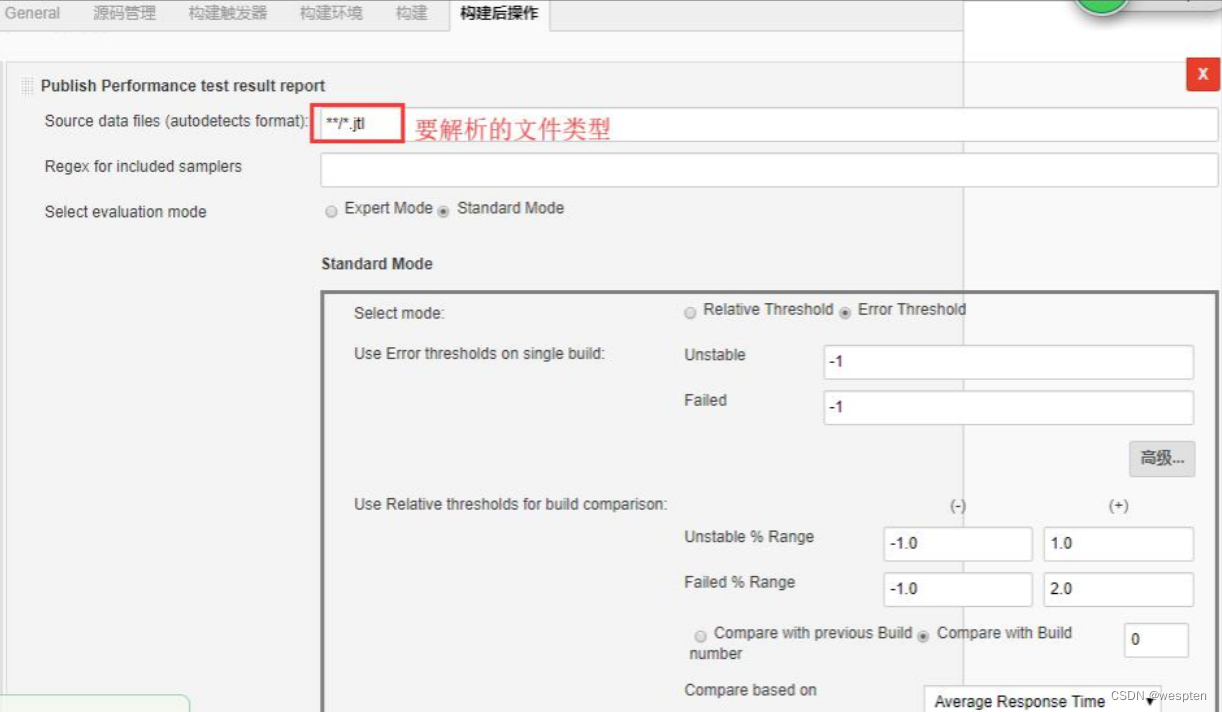
- Source data files (autodetects format) :生成报表的结果文件 **/*.jtl。
- Regex for included samplers:通过正则匹配需要筛选的采样器。
- Select evaluation mode:Expert Mode(专家模式)、Standard Mode(标准模式)。
- Standard Mode:
- Select mode:Relative Threshold(相对阈值)、error threshold(错误阈值)。
- Use Error thresholds on single build:使用单个生成的错误阈值。
- Unstable:不稳定的阈值,默认为 -1 表示忽略。
- Failed:失败的阈值,默认为 -1 表示忽略。
- Average response time threshold:平均响应时间的阈值,例如 JMeterResultsOrders.jtl:2000。
- Use Relative thresholds for build comparison:使用相对阈值进行构建比较。
- Unstable % Range:不稳定范围。
- Failed % Range:失败范围。
- Compare with previous Build:和前一个构建进行比较。
- Compare with Build number:和指定的构建号进行比较。
- Compare based on:在什么基础上比较。可选的下拉列表项有:median response time(中值请求时间)、percentile response time(百分百请求时间)、average response time(平均请求时间)。
3. 性能测试报告
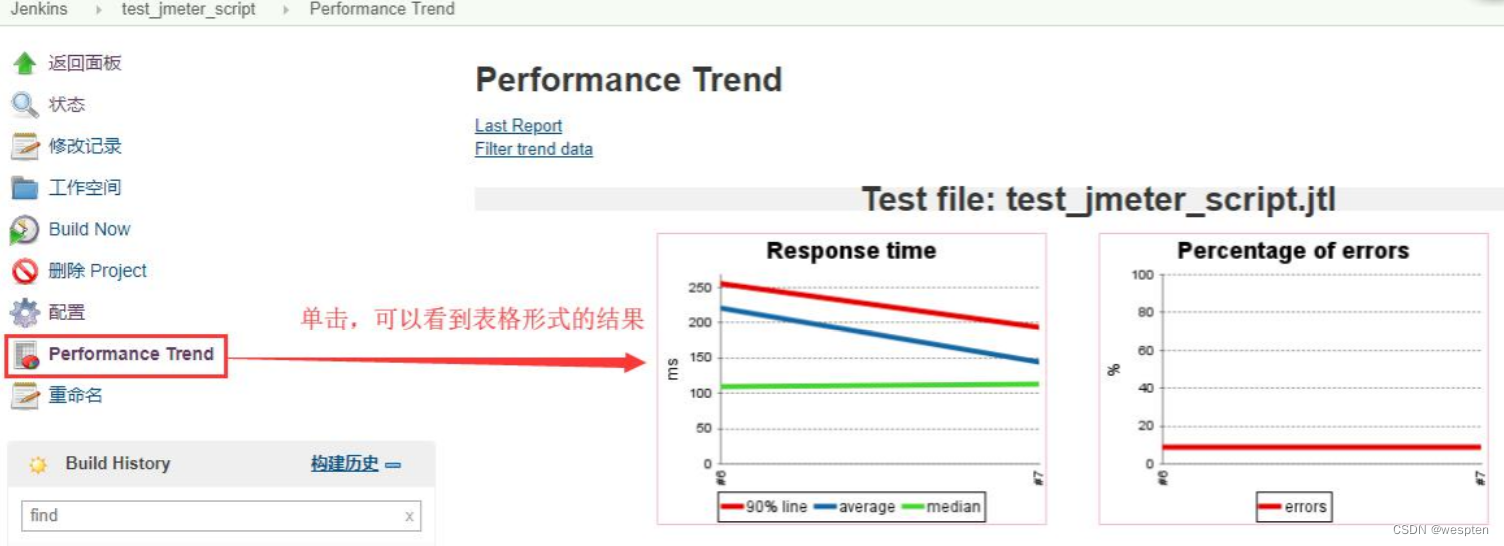
十四、测试框架设计与实现
PO的思想将页面元素的定位、操作、业务场景从测试用例中分离了出来,从而形成了较为健壮的测试用例结构。不过,系统的配置信息、测试数据等仍然夹杂在测试用例中,这部分虽然变化较少,不过一旦出现,还是需要耗费较大的力气去修改测试代码。
另外,在某种情况下,测试团队需要对Selenium提供的API进行二次封装,以便能满足特定的需求。基于这些情况,我们将从实际问题出发,对测试脚本继续分层,最终形成较为完善的测试框架。
主要介绍搭建一个类似下图所示结构的测试框架。
下面简单介绍一下各目录的用途:
- Base:用来对Selenium API进行二次封装。
- Common:用来放置一些公共的函数或方法文件,如前面封装的解析YAML文件、解析CSV文件的函数。
- Config:用来放置测试项目中的配置信息文件,如系统的IP地址、端口。
- Data:用来放置CSV文件,内容是测试用例参数化用到的数据,也可以放置其他类型的数据文件,如Excel和JSON文件。
- Report:用来放置测试执行的报告。
- Test:用来测试相关文件,其中子目录PageObject用来存放页面对象,子目录TestCase用来放置测试用例。
接下来我们做些准备工作:首先根据图创建目录结构,然后将Chapter_10的Storm_12_3目录中的页面对象和测试用例复制到Chapter_14/Test目录下的PageObject和TestCase子目录中。
1、测试数据分离
在实际项目中,我们会遇到两种常见的情况。第一,对于同一个场景,我们需要增加、删除、修改测试数据,以覆盖期望的测试场景,例如我们想增加一个测试场景——验证登录名正确,但密码为空的情况。第二,测试数据需要更改,例如之前的测试账号被同事删除了等。
一旦出现类似的情况,我们就需要查找有哪些脚本应用了这些数据,只有全部更新这些数据才能保证脚本再次执行。为了避免上述情况对自动化测试工作产生影响,我们需要将测试数据从脚本中分离出来。
这里我们以“用户登录数据”为例,演示测试数据与代码分离的操作过程。
首先,我们将test_001_login.py用例中用户登录数据的代码语句放到CSV文件中。
data = [('admin', 'error', '0'), ('admin', 'rootroot', '1')]我们在Data目录中新建一个“test_001_login.csv”文件,内容如下。
name,password,status
admin,error,0
admin,rootroot,1然后,我们将封装的解析CSV文件的函数文件“parse_csv.py”复制到Common目录中。
parse_csv.py:
import csv
def parse_csv(file):
mylist = []
with open(file, 'r', encoding='utf8') as f
data = csv.reader(f)
for i in data:
mylist.append(i)
del mylist[0] # 删除标题行的数据
return mylist
if __name__ == '__main__':
data = parse_csv('my_csv_1.csv')
print(data)接下来,我们改写“test_001_login.py”文件,内容如下。
from selenium import webdriver
import pytest
# 导入本用例用到的页面对象文件
from Chapter_14.Test.PageObject import login_page
from Chapter_14.Common.parse_csv import parse_csv
data = parse_csv("../../Data/test_001_login.csv") #改写
# print(data)
# data = [('admin', 'error', '0'), ('admin', 'rootroot', '1')]
@pytest.mark.parametrize(("username", "password", "status"), data)
class TestLogin():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get('http://localhost:81/redmine/login')
def teardown(self):
self.driver.quit()
def test_001_login(self, username, password, status):
# 登录的3个操作用业务场景方法一条语句代替
login_page.LoginScenario(self.driver).login(username,password)
if status == '0':
# 登录失败后的提示信息,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_failed_info()
assert text == '无效的用户名或密码'
elif status == '1':
# 登录成功后显示的用户名,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_name()
assert username in text
# 增加一个断言
assert "我的工作台" in self.driver.page_source
else:
print('参数化的状态只能传入0或1')
if __name__ == '__main__':
# pytest.main(['-s', '-q', '--alluredir', '../report/'])
pytest.main(['-s', 'test_001_login.py'])大家可以看到,因为我们前面做了很多的准备工作,所以这里改动的代码并不多。
代码变更点如下:
- 导入页面对象的目录改变了。
- 从Common目录导入了解析CSV文件的函数。
- 将data变量的硬数据变成了从Data目录文件中读取。
当测试数据与代码分离后,我们能更好地解决本节开始时抛出的两个问题。
(1)对于同一个场景,我们需要增加、删除、修改测试数据,以覆盖期望的测试场景分支假如我们想验证登录名是否区分大小写,这时候我们设计这样一条测试数据“Admin,rootroot,0”。为了完成该测试用例,我们只需要修改“test_001_login.csv”文件即可,代码如下。
name,password,status
admin,error,0
admin,rootroot,1
Admin,rootroot,0(2)测试数据发生变化
假如准生产环境中的测试账户为root,为了让测试脚本能够支持该环境的测试,我们只需要修改“test_001_login.csv”文件的内容,如下所示。
name,password,status
root,error,0
root,rootroot,1另外,测试数据分离还能带来一个好处,即其他测试人员即便不懂代码,也可以轻松地通过修改对应的测试数据文件来达到测试不同场景的目的。
2、测试配置分离
前面的测试脚本在访问系统不同页面时,都采用的是“IP地址+端口+路径”的形式。在实际项目中,我们可能会遇到这样的情况:测试服务器访问地址或端口发生了变化。遇到这种情况该如何处理?把每个测试用例中的IP地址或端口都改一遍吗?我们有更好的解决办法。接下来我们将以“IP地址+端口”为例,演示如何将测试配置信息从代码中分离出来。
首先,在Config目录创建“redmine.yml”文件,用来存放网站的IP地址和端口信息(这里的localhost代表本机IP地址),内容如下。
websites:
host: localhost:81然后将封装的解析YAML文件的函数文件“parse_yml.py”制到Common目录中。
parse_yml.py:
import yaml
'''
通过传递文件名、section和key,读取YAML文件中的内容
'''
def parse_yml(file, section, key):
with open(file, 'r', encoding='utf8') as f:
data = yaml.load(f, Loader=yaml.FullLoader)
return data[section][key]
if __name__ == '__main__':
value = parse_yml('my_yaml_3.yml', 'websites', 'URL')
print(value)接下来,我们改写“test_001_login.py”文件,内容如下。
from selenium import webdriver
import pytest
# 导入本用例用到的页面对象文件
from Chapter_14.Test.PageObject import login_page
from Chapter_14.Common.parse_csv import parse_csv
from Chapter_14.Common.parse_yml import parse_yml
host = parse_yml("../../Config/redmine.yml", "websites", "host")
url = "http://"+host+"/redmine/login"
data = parse_csv("../../Data/test_001_login.csv")
# print(data)
# data = [('admin', 'error', '0'), ('admin', 'rootroot', '1')]
@pytest.mark.parametrize(("username", "password", "status"), data)
class TestLogin():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get(url)
def teardown(self):
self.driver.quit()
def test_001_login(self, username, password, status):
# 登录的3个操作用业务场景方法一条语句代替
login_page.LoginScenario(self.driver).login(username,password)
if status == '0':
# 登录失败后的提示信息,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_failed_info()
assert text == '无效的用户名或密码'
elif status == '1':
# 登录成功后显示的用户名,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_name()
assert username in text
# 增加一个断言
assert "我的工作台" in self.driver.page_source
else:
print('参数化的状态只能传入0或1')
if __name__ == '__main__':
# pytest.main(['-s', '-q', '--alluredir', '../report/'])
pytest.main(['-s', 'test_001_login.py'])上述内容对代码的改动同样非常小,我们只是导入了解析YAML文件的函数,然后通过配置文件读取系统的host信息。
假如在实际项目中,测试环境发生了变化或者测试的IP地址或端口发生了变化,这个时候我们只需要修改“redmine.yml”文件中的信息即可。例如测试环境IP和端口变成了“192.168.229.33:8080”,我们需要修改的配置文件内容如下。
websites:
host: 192.168.229.33:8080这样就免去修改所有测试用例文件当中IP和端口的信息。
同样,每个测试用例都需要用到登录的步骤,也就是会用到用户名和密码的信息(注意该内容和“test_001_login.py”中用到的测试登录的用户名和密码信息不同)。该信息同样需要放置到配置文件中。现在我们再次修改配置文件,在“redmine.yml”文件当中增加账号的相关信息,代码如下。
websites:
host: localhost:81
logininfo:
username: amdin
password: rootroot然后,我们改写下测试用例“test_002_new_project.py”文件中用到的用户名和密码信息,代码调整如下。
from selenium import webdriver
import time, pytest
from Chapter_14.Test.PageObject import login_page, project_new_page, project_list_page
from Chapter_14.Common.parse_yml import parse_yml
host = parse_yml("../../Config/redmine.yml", "websites", "host")
url_1 = "http://"+host+"/redmine/login"
url_2 = "http://"+host+"/redmine/projects"
# 通过时间戳构造唯一项目名
project_name = 'project_{}'.format(time.time())
username = parse_yml("../../Config/redmine.yml", "logininfo", "username")
password = parse_yml("../../Config/redmine.yml", "logininfo", "password")
class TestNewProject():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get(url_1)
# 登录
login_page.LoginScenario(self.driver).login(username, password)
def test_new_project(self):
# 访问"项目列表"页面
self.driver.get(url_2)
# "新建项目"按钮
project_list_page.ProjectListOper(self.driver).click_new_pro_btn()
project_new_page.ProjectNewScenario(self.driver).new_project(project_name)
# 新建项目成功后的提示信息
text = project_new_page.ProjectNewOper(self.driver).get_pro_commit_info()
assert text == '创建成功'
def teardown(self):
self.driver.quit()
if __name__ == '__main__':
pytest.main(['-s', 'test_002_new_project.py'])当用户名信息发生变化的时候,我们不需要修改所有用例中的用户名信息,而只需要修改配置文件内容,如下所示。
websites:
host: localhost:81
logininfo:
username: storm
password: test12343、Selenium API封装
对Selenium API进行二次封装的目的是简化一些复杂的操作,但是千万不要为了封装而封装。因为新封装的方法名对其他项目人员来说是比较陌生的。但这个话题没有唯一的答案,这里举个例子让大家体会,后面各位如何去封装自己的测试框架,就要靠自己在实际项目中去平衡和取舍了。
显性等待要明显优于隐性等待,且花了很大篇幅去说服你使用显性等待。这里需要解释一下,如果为每个元素都增加显性等待,代码将会变得杂乱。因此,我们暂时借用隐性等待来保障脚本执行的稳定性。在本节内容中,我们将对Selenium提供的元素定位方法进行二次封装,目的是在元素定位的时候增加显性等待的功能。
我们在Base目录下新建一个base.py文件,内容如下。
from selenium.webdriver.support.ui import WebDriverWait
'''
这里我们定义一个名为"Base"的类,对Selenium WebDriver提供的API进行二次封装
'''
class Base(object):
def __init__(self, driver):
'''
调用该类的时候给其传递一个driver
:param driver:
'''
self.driver = driver
def split_locator(self, locator):
'''
分解定位表达式,如"id,kw",拆分后返回定位器"id"和定位器的值"kw"
:param locator: 定位方法+定位表达式组合字符串,如"id,kw"
:return: locator_dict[by], value:返回定位方式和定位表达式
'''
if len(locator.split(',')) == 3:
by = locator.split(',')[0] # 定位器
value = locator.split(',')[1] + ',' + locator.split(',')[2]
else:
by = locator.split(',')[0] # 定位器
value = locator.split(',')[1] # 定位器值
# 这里是为了方便,所以简写了定位器
locator_dict = {
'id': 'id',
'name': 'name',
'class': 'class name',
'tag': 'tag name',
'link': 'link text',
'plink': 'partial link text',
'xpath': 'xpath',
'css': 'css selector',
}
if by not in locator_dict.keys():
raise NameError("Locator Err!'id',only 'name','class','tag','link','plink', 'xpath','css' can be used.")
return locator_dict[by], value
def get_element(self, locator, sec=20):
"""
获取一个元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如"id,kw"
:param sec: 等待秒数
:return: 如果元素可找到则返回element对象,否则返回False
"""
by, value = self.split_locator(locator)
try:
element = WebDriverWait(self.driver, sec, 1).until(lambda x: x.find_element(by=by, value=value))
return element
except Exception as e:
raise e
def get_elements(self, locator, sec=20):
"""
获取一组元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如"id,kw"
:return: elements
"""
by, value = self.split_locator(locator)
try:
elements = WebDriverWait(self.driver, 60, 1).until(lambda x: x.find_elements(by=by, value=value))
return elements
except Exception as e:
raise e
if __name__ == '__main__':
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
a = "id1,kw"
bp = Base(driver)
bp.get_element(a).send_keys('11111')
# bp.get_element("plink,地图").click()
sleep(2)
driver.quit()下面简单对上面的代码做个解释。
- 首先,我们声明了一个名为“Base”的类。
- 然后,我们定义了一个名为“__init__”的方法,该方法起到初始化的效果。该方法包含一个driver形参,并将接收到的driver传递给后续的方法。
- 接着,我们定义了一个名为“split_locator”的方法,该方法包含一个形参locator。locator的传参格式为“定位方法,值”,例如“id,kw”。我们可以通过Python的split函数来将传入的值进行分割,然后将其分别赋给变量by和value。考虑到我们可能会使用模糊匹配的定位方法,所以该定位方法的值中包含逗号(例如“"xpath,//*[starts with(@id,'issue')]"”),这样通过split函数就会分割出来3个值,第一个值是定位器,后两个值拼接起来是定位器的值。因此我们增加了一个判断条件,若split函数分割结果的长度等于3,我们就把后两个值拼接起来作为定位器的值。
- 最后,我们定义了get_element和get_elements方法,分别用来查找并返回一个元素和多个元素。这两个方法和Selenium原始定位元素的API有什么不同呢?可以看到,我们增加了显性等待的方法,这就意味着我们在定位元素的前一步自动地执行显性等待。
借助封装好的元素定位方法,我们修改PageObject目录下的元素定位文件。
将login_page.py的内容修改如下:
'''
"登录"页面
'''
# 页面元素对象层
from selenium.webdriver import ActionChains
from Chapter_14.Base.base import Base
class LoginPage(object):
def _ _init_ _(self, driver):
# 私有方法
self.driver = driver
def find_username(self):
# 查找并返回"用户名"文本框元素
# ele = self.driver.find_element_by_id('username')
# ele = self.driver.find_element_by_name('username')
ele = Base(self.driver).get_element('name,username')
return ele
def find_password(self):
# 查找并返回"密码"文本框元素
# ele = self.driver.find_element_by_id('password')
ele = Base(self.driver).get_element('id,password')
return ele
def find_login_btn(self):
# 查找并返回"登录"按钮元素
# ele = self.driver.find_element_by_id('login-submit')
ele = Base(self.driver).get_element('id,login-submit')
return ele
def find_login_name(self):
# 查找并返回登录成功后的用户名元素
# ele = self.driver.find_element_by_id('loggedas')
ele = Base(self.driver).get_element('id,loggedas')
return ele
def find_login_failed_info(self):
# 查找并返回登录失败后的提示信息元素
# ele = self.driver.find_element_by_id('flash_error')
ele = Base(self.driver).get_element('id,flash_error')
return ele
# def find_verification_code(self):
# ele = self.driver.find_element_by_id('aaa')
# return ele
# 页面元素操作层
class LoginOper(object):
def _ _init_ _(self, driver):
# 私有方法,调用元素定位的类
self.login_page = LoginPage(driver)
self.driver = driver
def input_username(self, username):
# 对"用户名"文本框做clear和send_keys操作
self.login_page.find_username().clear()
self.login_page.find_username().send_keys(username)
def input_password(self, password):
# 对"密码"文本框做clear和send_keys操作
self.login_page.find_password().clear()
self.login_page.find_password().send_keys(password)
# def click_login_btn(self):
# 对"登录"按钮做单击操作
# self.login_page.find_login_btn().click()
def click_login_btn(self):
ele = self.login_page.find_login_btn()
ActionChains(self.driver).double_click(ele).perform()
def get_login_name(self):
# 返回登录成功后的用户名元素
return self.login_page.find_login_name().text
def get_login_failed_info(self):
# 返回登录失败后的提示信息元素
return self.login_page.find_login_failed_info().text
# def input_verification_code(self, fixed_value=123456): # 万能验证码
# self.login_page.find_verification_code().send_keys(fixed_value)
# 页面业务场景层
class LoginScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.login_oper = LoginOper(driver)
def login(self, username, password):
# 定义一个登录场景,用到了3个操作
self.login_oper.input_username(username)
self.login_oper.input_password(password)
# self.login_oper.input_verification_code()
self.login_oper.click_login_btn()上述文件中,我们不再使用WebDriver提供的元素定位API,而是调用base.py中封装好的元素定位方法。同样,我们修改project_list_page.py、project_new_page.py文件中元素定位的代码,然后我们就可以将测试用例中隐性等待的语句“self.driver.implicitly_wait(20)”注释掉了。
最后,尝试执行代码,可以发现仍然执行成功。
4、测试报告
我们将新增“pytest.ini”文件,用来定义Pytest框架的执行策略。
首先,在Chapter_14/Report目录下新建两个Python Package:allure-report和report。report用来保存Pytest执行的结果文件(JSON文件),allure-report用来保存最终的报告文件(HTML文
件)。
然后,在Chapter_14的目录下面新建“pytest.ini”文件,内容如下。
[pytest]
addopts = -v --reruns 2 --reruns-delay 2
testpaths = Test/TestCase
python_file = test_*.py
python_classes = Test*
python_functions = test_*注意:
因为我们修改了目录结构,所以不能再使用Pytest默认的测试用例目录,而需要根据实际目录结构将testpaths设置为Test/TestCase目录。
我们终于封装好了一个相对完善的自动化测试框架。
5、项目实战
接下来,我们将从头到尾演示如何借助封装好的自动化测试框架来完成项目的自动化测试需求。
1. 测试计划
不管采用何种研发模式,项目计划都必不可少。同理,自动化测试也需要编制测试计划,用于指导后续工作的开展。
这里并不打算编写一个具体的测试计划,原因是,不同的项目有不同的目标,自然也就有不同的自动化测试计划。但归根结底,在做自动化测试计划时,我们需要搞明白以下几个问题。
1)项目的特性
- 项目是全新的项目,还是相对稳定的项目。如果是一个全新的项目,则项目本身存在较多的不确定性,页面风格和操作流程并不成熟,这时候并非UI自动化实施的最佳时机;相反,如果项目相对稳定,则应该适度投入人力,开发自动化测试脚本,以便支持项目的快速验证。
- 项目是外包项目,还是公司产品。部分外包项目周期较为紧张,一旦交付则不会继续跟进,开发自动化测试脚本的产出投入比是一个需要考虑的问题;如果是公司自己内部的产品,则可能会长期迭代,自动化测试的产出投入比就会较高。
- 项目开发模式是传统瀑布模型,还是快速迭代、敏捷等类型。传统瀑布模型的项目一般项目周期较长,对快速验证的要求不会太高;而快速迭代、敏捷等新型项目研发模式,则要求测试团队对版本做出较快的质量评估,单靠人力是无法实现的,因此自动化测试必不可少。
- 项目类型是Web项目、App,还是小程序、客户端。一般来说Web项目页面、功能较稳定,适合开展自动化测试;App的迭代速度较快,UI自动化的执行速度较慢,稳定性较差,且后期的维护成本较高,UI自动化测试的产出投入比并不高;客户端程序也比较适合开展自动化测试,不过Selenium对此无能为力,UFT(一种自动化测试工具)相对合适。
2)人力、技术
- 测试团队的人力。项目中预期投入多少测试人力能完成任务是一个非常重要的问题。这里我们参考一下阿里系的测试和研发人员比,阿里系要求:新项目中测试研发比一般在1:5;随着项目越来越成熟,测试研发比将会越来越小,有可能到1:10,甚至更小(关于测试研发比的话题,笔者专门写了一篇博客,感兴趣的朋友可以访问笔者的博客进行查看)。如果你所在项目测试人员较少,则不宜开展较大规模的自动化测试。因为自动化测试并不能节省测试工作的时间,相反,它是拿更多的人力和时间来换取效率的一种活动。
- 技术储备是否足够。自动化测试对测试人员有一定的技术要求,如果团队中有实际项目自动化测试落地经验的成员,那项目自动化测试的成功率要高很多。
3)测试策略
- 整体策略。是否只开展UI自动化测试,还是UI与接口自动化测试相结合。目前,行业中越来越多项目和测试团队在开展自动化测试的时候选择UI和接口自动化测试相结合的策略。
- 目标。自动化测试是用来做冒烟测试,还是用来做场景覆盖测试?是用来辅助功能测试创建数据,还是作为生产环境的监控工具?不同的目标需要采用不同的策略。
- 测试频率。是研发每次提交代码时自动触发自动化测试脚本执行,还是设定每天晚上或每个周末自动执行,这也需要在计划阶段规划清楚。
测试计划切忌贪大求全,一开始不要把摊子铺得过大。从基础做起,先出效果,在得到领导的认可后,后续开展工作的阻力才会更小。这时候再分阶段,逐步支持更多的测试场景。
2. 测试用例
根据功能测试用例编写自动化测试脚本并非最佳选择。更多的时候,我们会参考功能测试用例,抽取适合的用例和检查点来组成自动化测试的用例。在编写自动化测试用例时,有一个至关重要的环节——设置合理的检查点,需要大家格外注意。因为如果检查点设置得不合理,自动化测试报告的成功结果反而会让团队“更放心地”遗漏问题。
这里,我们还是以Redmine项目为例,编写几个测试用例,如下表所示,大家可以参考其格式。
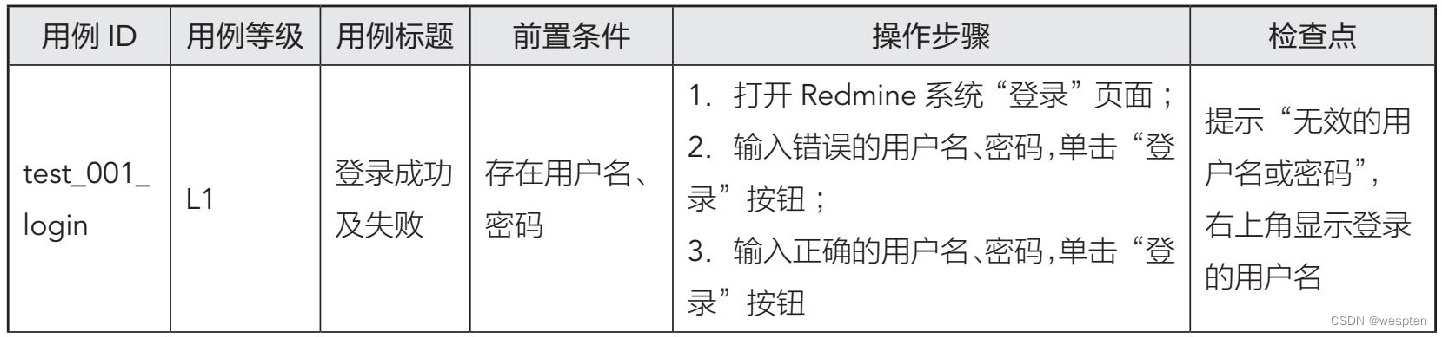
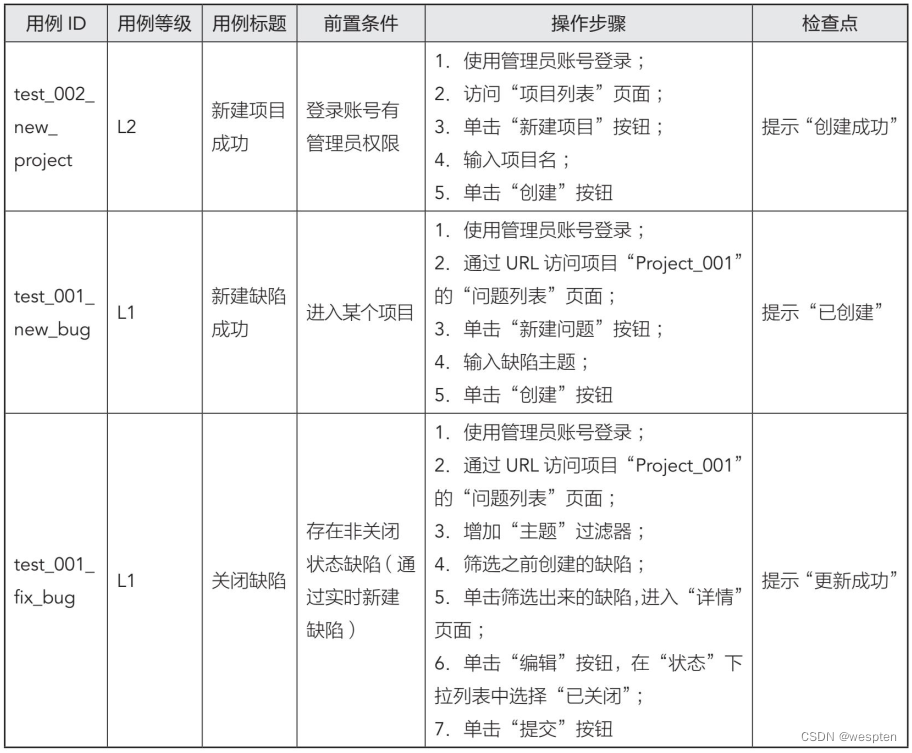
简单解释一下上方的表格:
(1)用例ID
用例的编号,建议和测试脚本的命名保持一致。
(2)用例等级
用例执行的优先级。将来我们可以根据不同的需求,执行不同等级的测试用例,以提高用例执行的效率。
(3)用例标题
用例的标题,用来简单描述用例的目的。
(4)前置条件
用例的前置条件,即要执行该用例需要具备什么条件。
(5)操作步骤
用例的操作步骤。
(6)检查点
对应功能测试用例的预期结果。但是自动化测试的检查点并不能覆盖(或者说不易覆盖),如“页面是否美观”“文字是否重叠”等易用性的检查点。
测试用例的检查点是自动化测试任务的“灵魂”,你需要不断地审视、关注功能测试和生产环境中所发现的问题,并将其增加到自动化测试用例的检查点中。
3. 测试脚本
准备好了测试用例,在项目具备条件后我们就可以编写测试脚本了。
1)准备工作
删除历史项目中的文件,如Report目录下的文件、Test目录的PageObject、TestCase目录下的文件。
因为我们这里的项目和前面测试内容相同,所以我们保留Test目录下的文件,并对文件导入的语句稍做调整即可;如果是新项目的话,删除即可。
2)编写页面对象
接下来,我们根据测试用例编写需要的页面对象文件。为了节省篇幅,前两个测试用例对应的测试脚本我们不再重复演示,直接从新用例开始演示。
- test_003_new_bug——新建缺陷
该用例共涉及两个页面对象:一个是“问题列表”页面,另一个是“新建问题”页面。页面对象文件内容如下。
问题列表页面:bug_list_page.py。
'''
"问题列表"页面
'''
# 页面元素对象层
from Chapter_14.Base.base import Base
class BugListPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_new_bug_btn(self):
# 查找并返回新建缺陷元素
ele = Base(self.driver).get_element('xpath,//*[@id="content"]/div[1]/a')
return ele
# 页面元素操作层
class BugListOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.bug_list_page = BugListPage(driver)
self.driver = driver
def click_new_bug_btn(self):
# 单击"新建问题"按钮
self.bug_list_page.find_new_bug_btn().click()
# 页面业务场景层
class BugListScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.bug_list_oper = BugListOper(driver)
def ×××(self):
pass
“新建问题”页面:new_bug_page.py。
'''
"新建问题"页面
'''
# 页面元素对象层
from Chapter_14.Base.base import Base
class NewBugPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_bug_subject(self):
# 查找并返回"缺陷主题"文本框元素
ele = Base(self.driver).get_element('id,issue_subject')
return ele
def find_commit_btn(self):
# 查找"提交"按钮,并返回元素
ele = Base(self.driver).get_element('name,commit')
return ele
# 页面元素操作层
class NewBugOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.new_bug_page = NewBugPage(driver)
self.driver = driver
def input_bug_subject(self, bug_subject):
# 对"缺陷主题"文本框做clear和send_keys操作
self.new_bug_page.find_bug_subject().clear()
self.new_bug_page.find_bug_subject().send_keys(bug_subject)
def click_commit_btn(self):
# 单击"提交"按钮
self.new_bug_page.find_commit_btn().click()
# 页面业务场景层
class NewBugScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.new_bug_oper = NewBugOper(driver)
def newbug(self, bug_subject):
# 新建bug场景,包括两个动作
self.new_bug_oper.input_bug_subject(bug_subject)
self.new_bug_oper.click_commit_btn()注意:
在第三个测试用例中,“问题列表”页面暂时只用到了一个元素及操作,因此只封装了用到的元素。
- test_004_fix_bug——关闭缺陷
该用例共涉及两个页面对象:第一个是“问题列表”页面,第二个是“问题详情”页面。页面对象文件内容如下。
在上一个“问题列表”页面文件的基础上封装新的元素及操作,示例代码:bug_list_page.py。
'''
"问题列表"页面
'''
# 页面元素对象层
from Chapter_14.Base.base import Base
from selenium.webdriver.support.select import Select
class BugListPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_new_bug_btn(self):
# 查找并返回新建缺陷元素
ele = Base(self.driver).get_element('xpath,//*[@id="content"]/div[1]/a')
return ele
def find_filter_select(self):
# 增加过滤器的下拉列表
ele = Base(self.driver).get_element('id,add_filter_select')
return ele
def find_values_subject(self):
# "主题"文本框
ele = Base(self.driver).get_element('id,values_subject')
return ele
def find_checked_btn(self):
# "应用"按钮
ele = Base(self.driver).get_element('xpath,//*[@id="query_form_with_buttons"]/p/a[1]')
return ele
def find_first_bug(self):
# 找到第一条缺陷
ele = Base(self.driver).get_element("xpath,//*[starts-with(@id,'issue')]/td[6]/a")
return ele
# 页面元素操作层
class BugListOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.bug_list_page = BugListPage(driver)
self.driver = driver
def click_new_bug_btn(self):
# 单击"新建问题"按钮
self.bug_list_page.find_new_bug_btn().click()
def select_filter_select(self, visible_text):
# 按visible_text增加过滤器
ele = self.bug_list_page.find_filter_select()
Select(ele).select_by_visible_text(visible_text)
def input_values_subject(self, subject):
# 输入要过滤的主题
self.bug_list_page.find_values_subject().send_keys(subject)
def click_checked_btn(self):
# 单击"应用"按钮
self.bug_list_page.find_checked_btn().click()
def click_first_bug(self):
# 单击第一条缺陷
self.bug_list_page.find_first_bug().click()
# 页面业务场景层
class BugListScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.bug_list_oper = BugListOper(driver)
def add_filter(self, visible_text):
# 定义一个场景,增加过滤器
self.bug_list_oper.select_filter_select(visible_text)
def filter_subject(self, subject):
# 定义一个场景,按主题筛选
self.bug_list_oper.select_filter_select('主题')
self.bug_list_oper.input_values_subject(subject)
self.bug_list_oper.click_checked_btn()问题详情页面:bug_details_page.py。
'''
"问题详情"页面
'''
# 页面元素对象层
from Chapter_14.Base.base import Base
from selenium.webdriver.support.select import Select
class BugDetailsPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_edit_btn(self):
# 查找并返回"编辑"按钮
ele = Base(self.driver).get_element('xpath,//*[@id="content"]/div[1]/a[1]')
return ele
def find_status_select(self):
# "缺陷状态"下拉列表
ele = Base(self.driver).get_element('id,issue_status_id')
return ele
def find_commit_btn(self):
# "提交"按钮
ele = Base(self.driver).get_element('xpath,//*[@id="issue-form"]/input[6]')
return ele
# 页面元素操作层
class BugDetailsOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.bug_list_page = BugDetailsPage(driver)
self.driver = driver
def click_edit_btn(self):
# 单击"编辑"按钮
self.bug_list_page.find_edit_btn().click()
def select_filter_select(self, visible_text):
# 通过visible_text修改缺陷状态
ele = self.bug_list_page.find_status_select()
Select(ele).select_by_visible_text(visible_text)
def click_commit_btn(self):
# 单击"提交"按钮
self.bug_list_page.find_commit_btn().click()
# 页面业务场景层
class BugDetailsScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.bug_details_oper = BugDetailsOper(driver)
def fix_bug(self):
# 定义一个场景,将缺陷设为已关闭状态
self.bug_details_oper.click_edit_btn()
self.bug_details_oper.select_filter_select('已关闭')
self.bug_details_oper.click_commit_btn()3)编写测试用例
借助步骤(2)中封装好的页面对象,我们来编写测试用例。
第三个测试用例:test_003_new_bug.py。
from selenium import webdriver
import time, pytest
from Chapter_14.Test.PageObject import login_page,bug_list_page, new_bug_page
from Chapter_14.Common.parse_yml import parse_yml
# 解析host
host = parse_yml("../../Config/redmine.yml", "websites", "host")
# 登录url
url_1 = "http://"+host+"/redmine/login"
# 缺陷列表url
url_2 = "http://"+host+"/redmine/projects/project_001/issues"
# 通过时间戳构造唯一bug subject
bug_subject = 'bug_{}'.format(time.time())
# 登录的用户名、密码
username = parse_yml("../../Config/redmine.yml", "logininfo", "username")
password = parse_yml("../../Config/redmine.yml", "logininfo", "password")
@pytest.mark.L1
class TestNewBug():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
# 访问"登录"页面
self.driver.get(url_1)
# 登录
login_page.LoginScenario(self.driver).login(username, password)
self.driver.get(url_2)
def test_new_bug(self):
# 单击"新建问题"按钮
bug_list_page.BugListOper(self.driver).click_new_bug_btn()
new_bug_page.NewBugScenario(self.driver).newbug(bug_subject)
# 新建缺陷成功后的提示信息
assert '已创建' in self.driver.page_source
def teardown(self):
self.driver.quit()
if __name__ == '__main__':
pytest.main(['-s', 'test_003_new_bug.py'])
第四个测试用例:test_004_fix_bug.py。
from selenium import webdriver
import time, pytest
from Chapter_14.Test.PageObject import login_page,bug_list_page, new_bug_page, bug_details_page
from Chapter_14.Common.parse_yml import parse_yml
# 解析host
host = parse_yml("../../Config/redmine.yml", "websites", "host")
# 登录url
url_1 = "http://"+host+"/redmine/login"
# 缺陷列表url
url_2 = "http://"+host+"/redmine/projects/project_001/issues"
# 通过时间戳构造唯一bug subject
bug_subject = 'bug_{}'.format(time.time())
# 登录的用户名、密码
username = parse_yml("../../Config/redmine.yml", "logininfo", "username")
password = parse_yml("../../Config/redmine.yml", "logininfo", "password")
@pytest.mark.L1
class TestFixBug():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
# 访问"登录"页面
self.driver.get(url_1)
# 登录
login_page.LoginScenario(self.driver).login(username, password)
self.driver.get(url_2)
bug_list_page.BugListOper(self.driver).click_new_bug_btn()
new_bug_page.NewBugScenario(self.driver).newbug(bug_subject)
# 新建完缺陷后,要返回到"问题列表"页面
self.driver.get(url_2)
def test_fix_bug(self):
# 先筛选之前创建的缺陷
bug_list_page.BugListScenario(self.driver).filter_subject(bug_subject)
# 单击第一条缺陷(筛选出来那条)
bug_list_page.BugListOper(self.driver).click_first_bug()
# 将缺陷状态变为已关闭
bug_details_page.BugDetailsScenario(self.driver).fix_bug()
# 更新成功后的提示信息
assert '更新成功' in self.driver.page_source
def teardown(self):
self.driver.quit()
if __name__ == '__main__':
pytest.main(['-s', 'test_004_fix_bug.py'])测试脚本编写完成后,你就可以继续调整pytest.ini文件,定制全局执行规则了。
4. 反思:测试数据
在自动化测试过程中,我们避免不了要和测试数据打交道,如登录的用户名。例如,我们要新建一个缺陷的话,需要先选择一个Project ;验证关闭缺陷的话,需要先有一个打开状态的缺陷。另外,自动化测试可能包含新增功能,每执行一轮自动化测试就创建一条数据,久而久之,对测试环境也是一种“污染”。所以,是时候来聊一聊测试数据的问题了。
1)测试数据准备
我们先来看第一个问题——如何准备自动化测试中用到的测试数据。从测试数据是否会被消耗的角度来说,测试数据可以分为两种:一是重复利用型数据,二是消耗型数据。一般来说,针对这两种不同的数据,我们有不同的处理办法。下面我们来具体举例。
(1)重复利用型数据
以“Redmine用户登录”的测试场景为例,我们的目的是测试登录成功或失败后,系统的响应是否正确。测试脚本中用到的用户名“admin”是一种可以重复利用的数据。针对这种测试数据,我们可以采用灵活的方式来准备。通常来说,简单创建一次数据就可反复使用的话,我们完全可以采用手动的方式来创建。假如需要创建多个数据的话,例如,模拟多个数据导致页面出现分页的场景,就可以通过自动化的手段来辅助创建数据。根据实现方式的不同,这些手段可以分为借助UI自动化创建、借助调用接口创建、借助执行SQL语句创建。总之,手段有很多。
对于这种可以循环使用的数据,为什么不推荐实时创建呢?
主要有以下两个原因:
- 降低依赖关系
如果我们在测试用户登录的时候采用实时创建用户的方式,那么要顺利执行用户登录,就得依赖于“用户创建”功能。假如“用户创建”功能出现了缺陷,就会影响其他用例的执行。因此,我们要尽量降低用例或脚本间的依赖关系。
- 提升测试效率
即便是“用户创建”功能一直可用,但每次验证登录功能都去创建用户,也会增加用例执行的时间,降低用例执行的效率。
总之,对于重复利用型数据,我们可以通过各种方式提前将数据准备好,这样既能够降低测试脚本间的依赖性,也能提高测试执行的效率。
(2)消耗型数据
我们再来看一下什么是消耗型数据。假如我们要验证“关闭”缺陷功能的话,就需要一个“打开”(非关闭)状态的缺陷。这时候我们再通过某种方式提前准备数据的话,就不大可行了。因为每次自动化测试执行完都会“消耗”一条“打开状态的缺陷”。因此,我们要验证
“关闭”缺陷功能的话,因为需要使用“消耗型”数据,那么采用实时创建的方式去准备测试数据就会非常合适。
根据这种思路,我们来回顾一下“test_004_fix_bug”这个用例。在用例的setup准备阶段,我们会创建一条缺陷;然后在test_fix_bug这个阶段,我们会通过bug_subject来搜索前面创建的缺陷,再单击该缺陷并将其修改为“关闭”状态。
2)冗余数据处理
之前我们编写了“新建项目”和“新建缺陷”的测试用例。当自动化测试执行多次之后,测试系统就会出现非常多的项目和缺陷。这种情况对于该系统的其他使用者来说是很难接受的,功能测试人员可能会反馈:这么多测试数据,会影响我去查找自己创建的数据。另外,如果测试环境的服务器配置较差,还会引起不必要的性能问题。总之,自动化测试过程中,创建的无用数据最好及时删除掉,以免对测试环境造成“污染”。
要处理自动化测试创建的数据,一般来说有两种方法。
(1)实时删除
以创建缺陷为例,在验证完“新建缺陷”功能正常后,我们就可以将新建的缺陷删除掉。因为后续要验证的缺陷关闭场景是通过实时创建的方式来准备未关闭状态的缺陷的,所以这个时候推荐在“teardown”部分放置删除缺陷的代码。
这里我们将bug_details_page.py文件代码修改如下:
'''
"问题详情"页面
'''
# 页面元素对象层
from Chapter_14.Base.base import Base
from selenium.webdriver.support.select import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from time import sleep
class BugDetailsPage(object):
def __init__(self, driver):
# 私有方法
self.driver = driver
def find_edit_btn(self):
# 查找并返回"编辑"按钮
ele = Base(self.driver).get_element('xpath,//*[@id="content"]/div[1]/a[1]')
return ele
def find_status_select(self):
# "缺陷状态"下拉列表
ele = Base(self.driver).get_element('id,issue_status_id')
return ele
def find_commit_btn(self):
# "提交"按钮
ele = Base(self.driver).get_element('xpath,//*[@id="issue-form"]/input[6]')
return ele
def find_del_btn(self):
# "问题详情"页面中的"删除"按钮
ele = Base(self.driver).get_element('xpath,//*[@id="content"]/div[1]/a[5]')
return ele
# 页面元素操作层
class BugDetailsOper(object):
def __init__(self, driver):
# 私有方法,调用元素定位的类
self.bug_list_page = BugDetailsPage(driver)
self.driver = driver
def click_edit_btn(self):
# 单击"编辑"按钮
self.bug_list_page.find_edit_btn().click()
def select_filter_select(self, visible_text):
# 通过visible_text修改缺陷状态
ele = self.bug_list_page.find_status_select()
Select(ele).select_by_visible_text(visible_text)
def click_commit_btn(self):
# 单击"提交"按钮
self.bug_list_page.find_commit_btn().click()
def click_del_btn(self):
self.bug_list_page.find_del_btn().click()
# 页面业务场景层
class BugDetailsScenario(object):
def __init__(self, driver):
# 私有方法:调用页面元素操作
self.bug_details_oper = BugDetailsOper(driver)
self.driver = driver
def fix_bug(self):
# 定义一个场景,将缺陷设为已关闭状态
self.bug_details_oper.click_edit_btn()
self.bug_details_oper.select_filter_select('已关闭')
self.bug_details_oper.click_commit_btn()
def del_bug(self):
self.bug_details_oper.click_del_btn()
WebDriverWait(self.driver, 10).until(EC.alert_is_present())
self.driver.switch_to.alert.accept()
sleep(2)然后将test_003_new_bug.py文件代码修改如下:
from selenium import webdriver
import time, pytest
from Chapter_14.Test.PageObject import login_page,bug_list_page, new_bug_page, bug_details_page
from Chapter_14.Common.parse_yml import parse_yml
# 解析host
host = parse_yml("../../Config/redmine.yml", "websites", "host")
# 登录url
url_1 = "http://"+host+"/redmine/login"
# 缺陷列表url
url_2 = "http://"+host+"/redmine/projects/project_001/issues"
# 通过时间戳构造唯一bug subject
bug_subject = 'bug_{}'.format(time.time())
# 登录的用户名、密码
username = parse_yml("../../Config/redmine.yml", "logininfo", "username")
password = parse_yml("../../Config/redmine.yml", "logininfo", "password")
@pytest.mark.L1
class TestNewBug():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
# 访问"登录"页面
self.driver.get(url_1)
# 登录
login_page.LoginScenario(self.driver).login(username, password)
self.driver.get(url_2)
def test_new_project(self):
# 单击"新建问题"按钮
bug_list_page.BugListOper(self.driver).click_new_bug_btn()
new_bug_page.NewBugScenario(self.driver).newbug(bug_subject)
# 新建缺陷成功后的提示信息
assert '已创建' in self.driver.page_source
def teardown(self):
self.driver.refresh()
bug_details_page.BugDetailsScenario(self.driver).del_bug()
self.driver.quit()
if __name__ == '__main__':
pytest.main(['-s', 'test_003_new_bug.py'])调整后的代码在执行的时候,既可以完成“新建缺陷”功能的验证,又可以通过teardown中删除缺陷的脚本,实现将新建的缺陷删除掉的效果,从而避免对测试环境造成干扰。
上面的思路没有问题。不过在实际项目中,你可能还会遇到这种情况:某业务只提供新建和停用功能,无法通过UI自动化去删除创建的数据。遇到这种情况,我们就需要根据实际情况来分析了。例如,项目中可以创建多个公司,每个公司的数据是相对独立的,那就可以单独给自动化测试创建一个公司,这样便不会影响功能测试人员的使用等;也可以采取人工干预。
(2)人工干预
当系统某业务不提供删除功能时,或者在某些情况下,自动化删除测试数据的脚本执行失败,这时候就需要我们不定期地人工干预,例如,可以通过执行SQL语句来清除数据库表中的数据。
总之,测试数据的准备和清除是自动化测试绕不开的问题,大家需要结合自己项目的实际情况和具体场景,采取合理的手段,提前准备并及时应对。
十五、Pytest+Unittest+Git+Jenkins+钉钉企业级持续集成自动化测试平台建设
1、Jenkins部署应用
1. 部署Tomcat环境
① 打开Tomcat官网,如图所示。
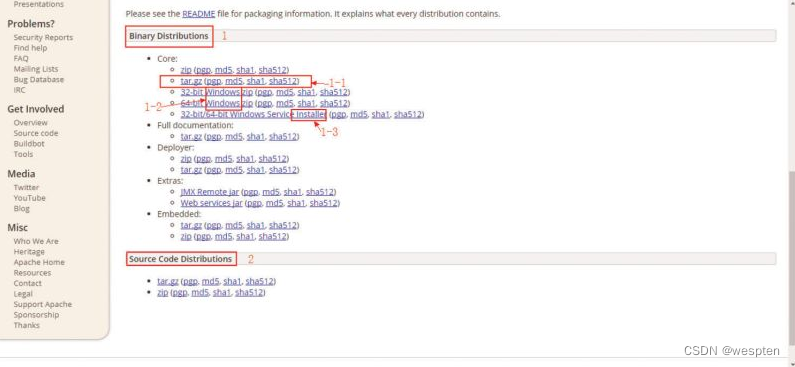
- 1是二进制发行版,2是源码版。
- 1-1是Linux版本。
- 1-2是Windows版本,包括32位和64位版本。
- 1-3是Windows安装版本。
这里在tar.gz的链接上面右击,选择“复制链接地址”,如图所示。
② 登录Linux服务器,使用wget命令下载该gz包。具体命令格式为“wget”+“图6-3复制的链接地址”。
③ 使用gunzip命令解压gz包。具体格式为“gunzip”+“压缩包名称”。
④ 使用tar命令解压tar包。具体格式为“tar-xvf”+“压缩包名称”。
⑤ 启动Tomcat。在Tomcat的bin目录下,通过./startup.sh命令启动Tomcat,如图所示。

⑥ 检查Tomcat服务是否启动成功。访问Tomcat,查看其是否启动成功,在浏览器输入Linux服务器IP地址,加上8080端口,按下“Enter”键,看到类似图的界面,证明Tomcat启动成功。
2. 在Tomcat中部署Jenkins
① 首先进入Jenkins官网,单击“Documentation”下拉菜单中的“Use Jenkins”,在打开界面中单击“Getting started”,然后在“Download Jenkins”上单击鼠标右键,选择“复制链接地址”。最后进入To mcat的webapp目录,使用“wget+链接地址(上一步中以Jenkins复制的具体地址)”命令格式下载Jenkins的war包。
② 重启Tomcat服务。Tomcat会自动解压部署Jenkins,Tomcat启动完成后,可以看到目录中多了一个jenkins的文件夹,如图所示。

③ 访问并配置Jenkins。在浏览器输入地址:192.168.xx.xx:8080/Jenkins,按“Enter”键,可以看到图所示的页面。
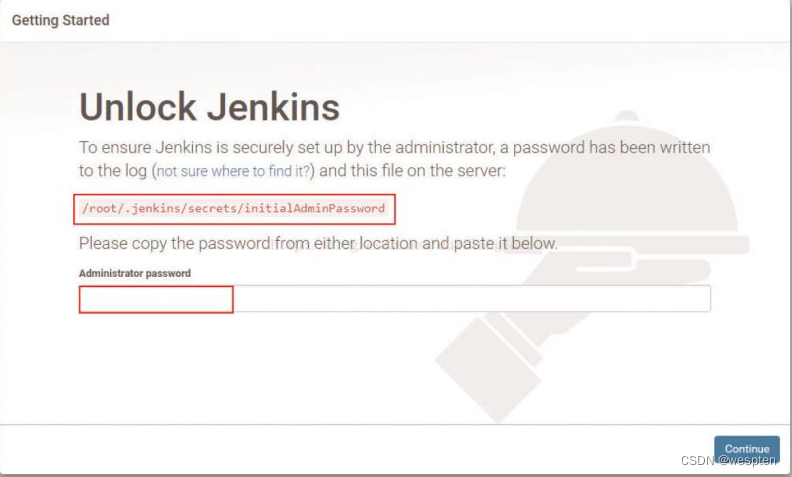
注意:将IP地址替换成你服务器的地址。
拷贝/root/.jenkins/secrets/initialAdminPassword的文件内容,将其粘贴到图中的“Administrator password”框中,单击“Continue”按钮,跳转到自定义Jenkins插件页,如图所示。
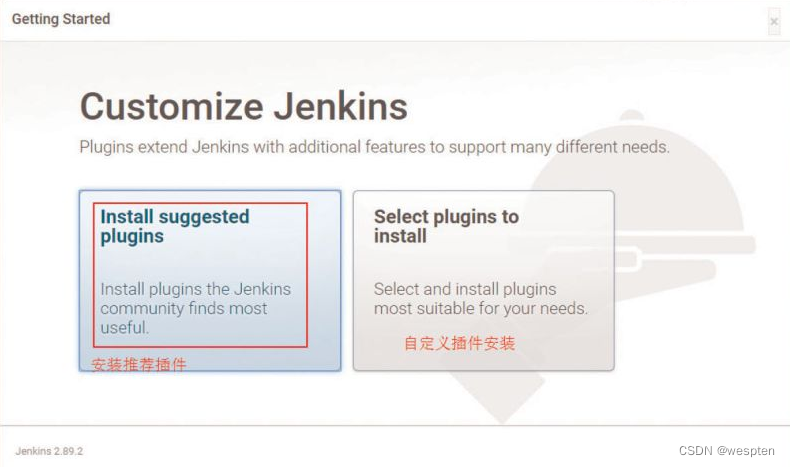
选择安装推荐的插件,需要花费一些时间,等待其自动完成即可。接下来,输入账号信息,创建一个Admin用户(请务必记住账号、密码),如图所示。
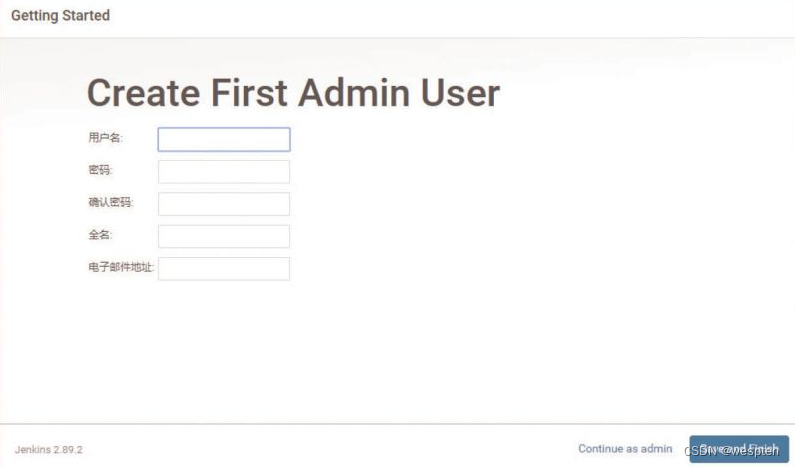
单击“Save and Finish”按钮,打开Jenkins主页面,如图所示。

Jenkins主界面主要分为以下几块区域:
- 左侧上方是功能菜单。
- 左侧下方是构建任务的信息展示。
- 右侧主区域是构建任务的列表。
- 右上角为用户登录信息。
注意:
新版本Jenkins的汉化并不彻底,如果你实在想将其完整汉化的话,可以尝试以下步骤。
- 安装locale plugin插件。
- 安装Localization:Chinese(Simplified)插件。
- 依次选择“系统管理”“系统设置”“Locale”,输入“zh_CN”。
- 重启Jenkins。
假如修改了Tomcat的HTTP访问端口,需要用如下命令开启防火墙允许端口访问。
iptables -I INPUT -p tcp --dport 8899 -j ACCEPTLinux服务器部署Jenkins已经完成。
3. 管理插件
Jenkins提供了数百个插件来支持构建、部署和自动化任何项目。下面介绍管理Jenkins插件的方法。
登录Jenkins后,可以看到图所示的界面。
单击“Manage Jenkins”菜单,然后单击“Manage Plugins”,如图所示。

这里以安装“PowerShell”插件为例,演示如何手动安装插件。单击“可选插件”标签,在搜索框中输入关键字“shell”,勾选对应筛选结果左侧的复选框。根据需要单击“直接安装”按钮或“下载待重启后安装”按钮,如图所示。
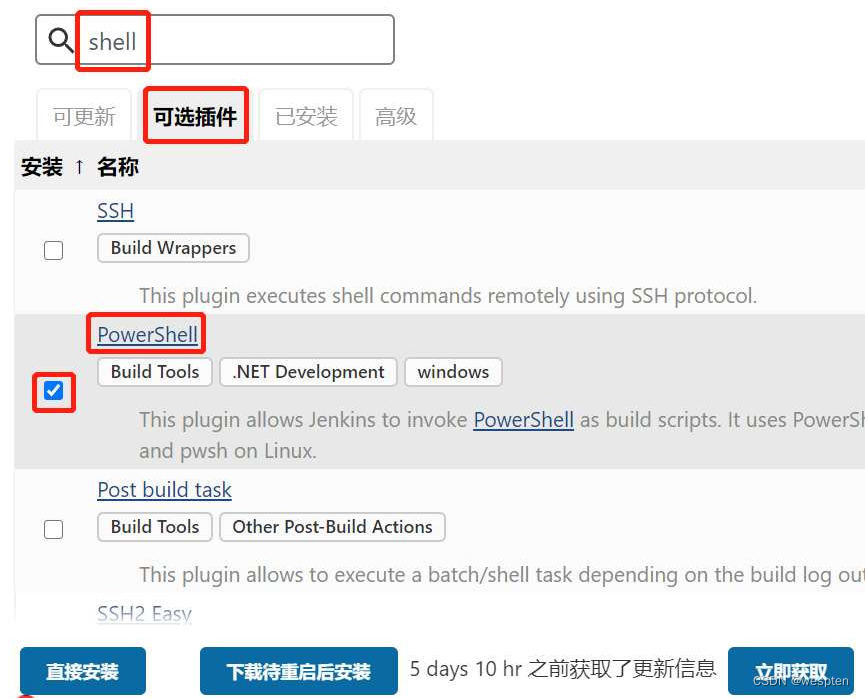
选中“安装完成后重启Jenkins(空闲时)”复选框,如图所示。
这样Jenkins会在插件安装完成后,空闲时自动重启,以使新安装的插件生效。因此,用户只需等待Jenkins重启完成即可,如图所示。
4. 创建任务
借助Jenkins创建任务。
(1)访问Jenkins
使用Windows操作系统上的浏览器访问Jenkins,地址为Linux操作系统的IP地址+端口号,如http://localhost:8080/或http://192.168.229.1:8080/。
(2)创建任务
单击左侧“新建Item”菜单或者界面中间区域的“创建一个新任务”。
在打开的任务创建界面的文本框中输入任务名称“myproject_02”,单击“Freestyle project”(自由风格的软件项目),再单击“确定”按钮。
单击“构建”标签,再单击打开“增加构建步骤”下拉列表,在下拉列表中选择“Linux环境执行shell语句”。然后在“命令”文本框中输入语句“Python D:\A\hello.py”,最后单击“保存”按钮,如图所示。

注意:
- 因为Jenkins部署在Linux环境下,所以执行“shell”命令。如果Jenkins部署在Windows环境下,可以增加一个“Windows batch command”,然后执行“bat”命令。
- 这里我们提前在Linux服务器的“/test-dir/”目录下新建了一个“hello.py”文件,文件内容为“print('Hello Storm')”。
单击“Build Now”,可以立即构建该任务,也就是执行“hello.py”文件,如图所示。
查看任务构建结果。蓝色的球代表本次构建成功,相反红色代表失败;“#8”代表该任务第8次构建;后面的日期和时间代表本次构建的日期和时间,如图所示。
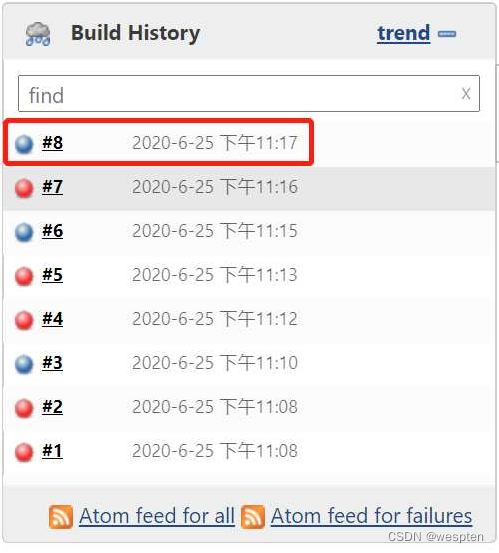
查看控制台日志。将鼠标指针悬浮在某次构建任务上时,会出现下拉倒三角,单击下拉列表中的“Console Output”,如图所示。
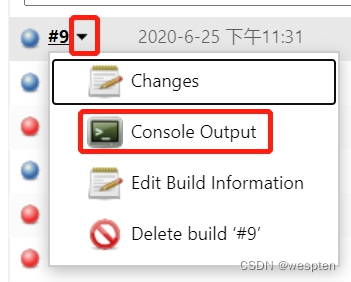
打开控制台输出界面,该界面会显示任务运行的结果输出,这里输入“Hello Storm”。最后一行显示任务构建“SUCCESS”或“FAILED”,如图所示。
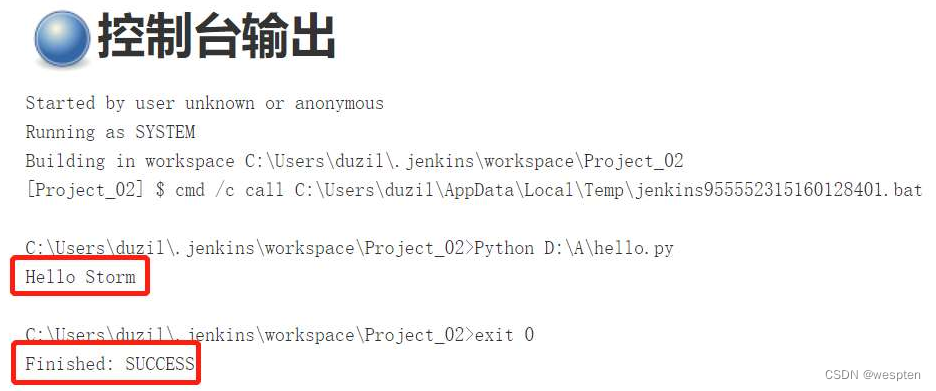
接下来,我们再次创建一个任务,用来执行一个UI自动化测试脚本。构建处的内容为“Python D:\Love\Chapter_1\test1_1.py”,保存后尝试构建。虽然显示构建结果成功,但是Jenkins任务并没有调出浏览器页面。原因是前面的Jenkins是用Windows installer(安装程序)安装的,此时Jenkins是以后台服务启动的,这时候去执行Selenium Cases是不显示浏览器的。
5. 命令行启动Jenkins
为了让Jenkins执行的自动化测试任务能顺利调出浏览器页面,我们需要以命令行的方式启动Jenkins并执行脚本。
请参考以下3个步骤:
(1)关闭Jenkins服务
依次打开“控制面板”“管理工具”“服务”,找到Jenkins。
- 选中Jenkins服务,单击左侧的“停止此服务”,或者在Jenkins服务上右击鼠标,在弹出的快捷菜单中选择“停止”选项,如图所示。
(2)通过命令行启动Jenkins
接下来,我们要使用命令行启动Jenkins,命令如下。
- 使用默认的8080端口启动。
java -jar jenkins.war- 指定启动端口。
java -jar jenkins.war --httpPort 8081注意:
- 以命令行的方式启动Jenkins后,之前的账号和插件将不能使用,并且命令行窗口不能关闭,否则服务也会关闭。
- 以命令行方式启动Jenkins时,使用的环境变量、配置文件等并非安装目录的配置文件。例如,这里Jenkins的安装目录是“D:\Program Files (x86)\Jenkins”,但是使用命令行启动的时候,Jenkins环境初始化使用的目录是“C:\Users\duzil\.jenkins”,如图所示。
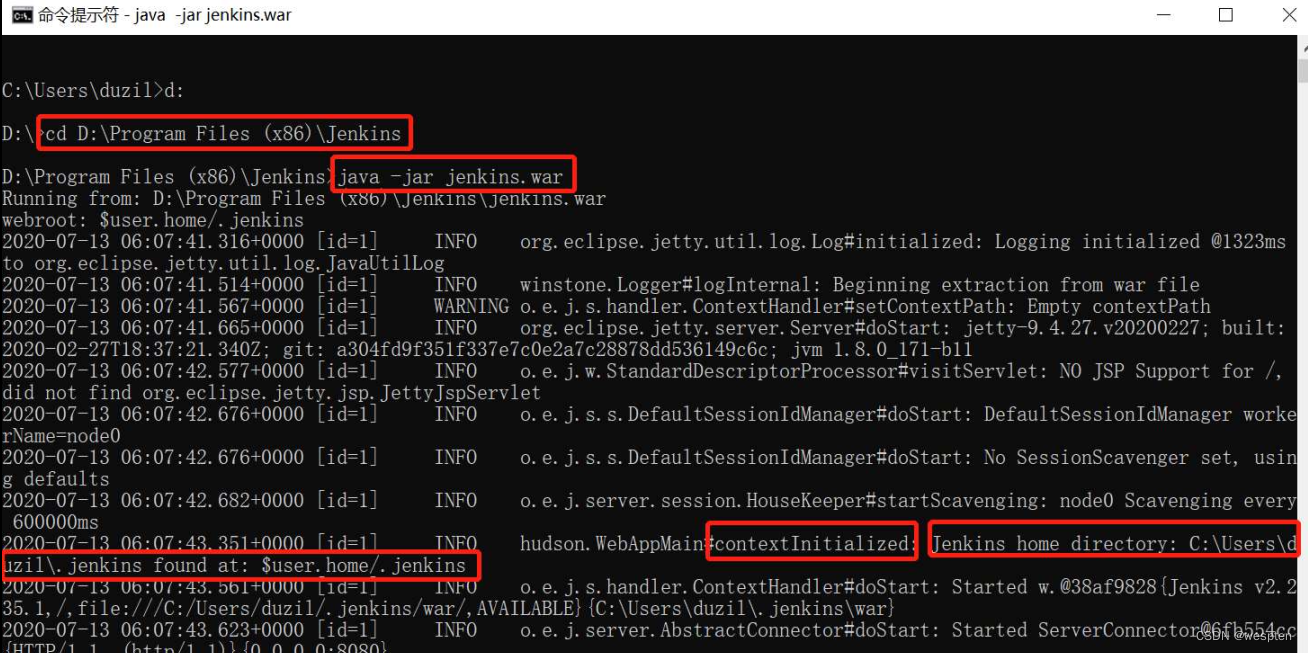
(3)执行Selenium脚本
再次创建Selenium脚本的构建任务,通过手动构建任务,发现能正常地调出浏览器页面。
6. 设置项目执行频率
我们说过可以借助Jenkins帮我们定期地或者按照某种策略来执行创建好的任务。这里我们介绍Jenkins的构建触发器。
单击项目名称,选择“Configure”,单击“构建触发器”标签,进入Jenkins构建触发器的配置界面,如图所示。

Jenkins提供了5种构建触发器,分别如下。
- Build after other projects are built——其他项目构建完成后才开始构建。
- Build periodically——定期构建。
- Build when job Nodes start——当工作任务节点开始时构建。
- GitHub hook trigger for GITScm polling——通过GitHub“钩子”触发构建。
- Poll SCM——通过“钩子”触发构建。
这里,我们重点介绍定期构建触发器。勾选“Build periodically”,在出现的“日程表”文本框中输入“H 1 * * *”,单击文本框外的区域,然后观察下方出现的信息,如图所示。
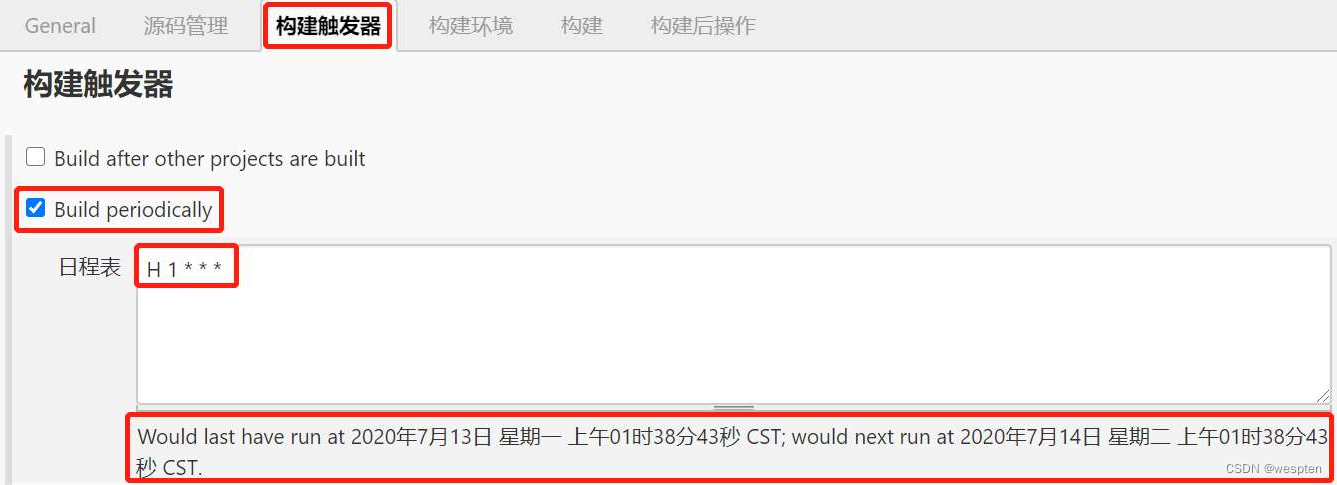
我们来介绍一下这一组“H 1 * * *”共计5个参数分别代表什么意思。
- 分钟:取值区间为0~59(不过Jenkins建议用H来标记,以均匀传播负载)。
- 小时:取值区间为0~23。
- 天:取值区间为1~31。
- 月:取值区间为1~12。
- 星期几:取值区间为0~7。
下面给大家一些参考示例。
- H/30 * * * *表示每隔30分钟执行一次。
- H 1 * * 1-5表示周一到周五凌晨3点执行。
- H 1 1 * *表示每月1号1点执行。
注意:
- * 表示全部,如星期这个标记位是*,表示周一到周日都执行。
- -表示区间,/表示间隔,例如“H 1-17/3 * * *”表示每天的1点到17点,每隔3小时构建一次。
7. 配置邮件
Jenkins能够以既定的策略来构建任务,这非常棒。不过,某些时候你可能还需要将任务构建的结果及时通知相关责任人。。
1)安装邮件插件
安装“Email Extension Template”插件。
2)进行邮件设置
首先进行基础的配置。登录Jenkins,依次单击“Manage Jenkins”“Configure System”。在打开的界面中完成Jenkins Location的配置,包括“Jenkins URL”和“System Admin e-mail address”。

注意:
- Jenkins URL中的IP调整为部署Jenkins的IP地址。
- 邮件地址为发送构建结果的邮件地址。
接着,在下方找到“Extended E-mail Notification”配置项,在“SMTP server”和“Default user E-mail suffix”文本框中输入相应内容,然后单击“Advanced...”按钮,如图所示。

注意:
- SMTP server,邮箱SMTP的服务器。
- Default user E-mail suffix,邮件后缀。
勾选“Use SMTP Authentication”复选框,然后在“User Name”和“Password”文本框中输入相应内容。
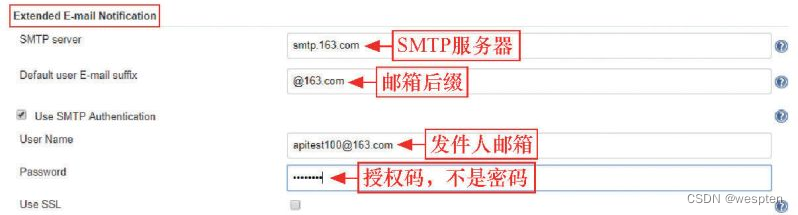
注意:
- 这里的User Name还是邮件发送方的邮件地址,需要和“System Admin e-mail address”的邮件地址保持一致。
- 这里的Password并不是邮箱的登录密码,而是第三方客户端登录时所需要的授权码。你可以登录邮箱,通过“设置”功能开启“POP3/SMTP/IMAP”服务获取授权码,如图所示。注意,授权码需要保密。
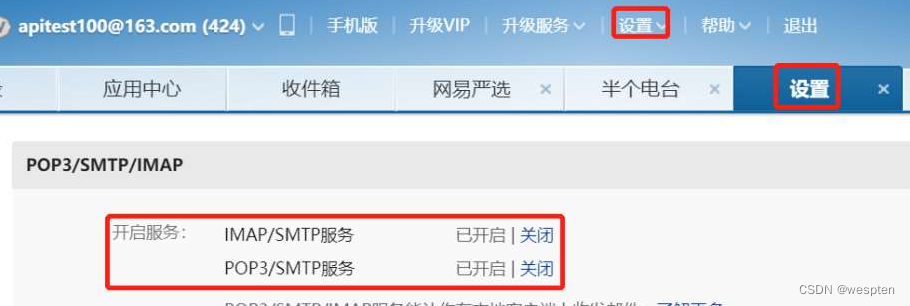
3)添加构建后操作
接下来,我们回到“myproject_02”任务。单击“Post-build Actions”标签,再单击打开“Add post build action”下拉列表,在下拉列表中选择“E-mail Notification”选项,如图所示。
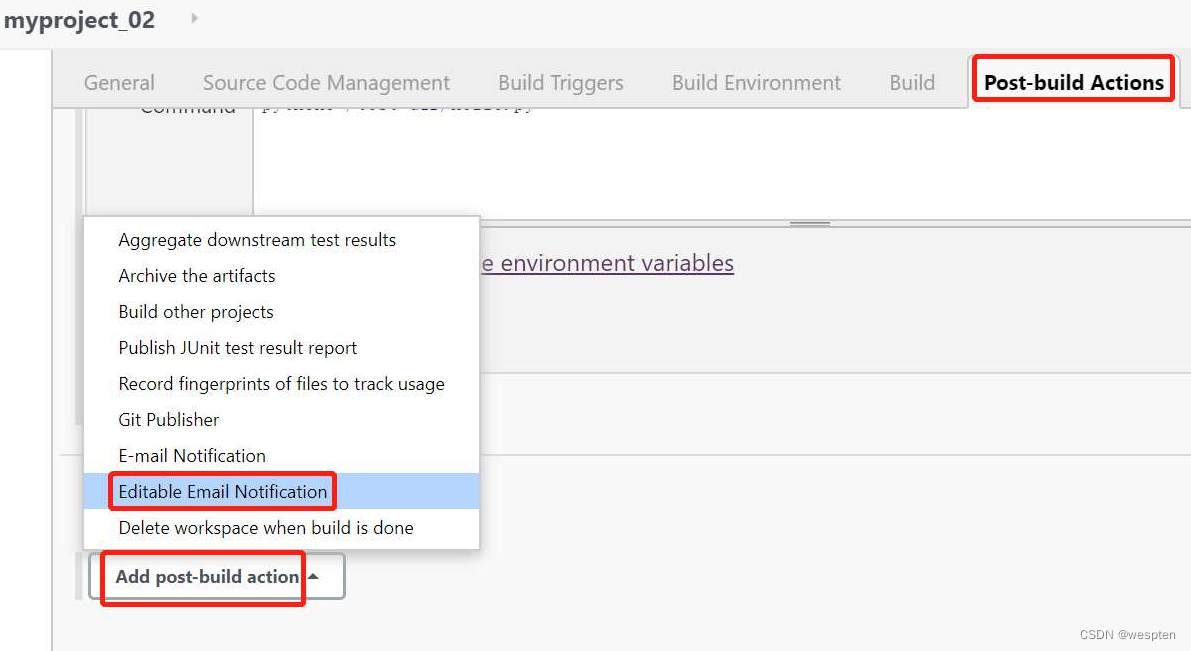
添加邮件接收者邮箱地址,单击“保存”按钮。
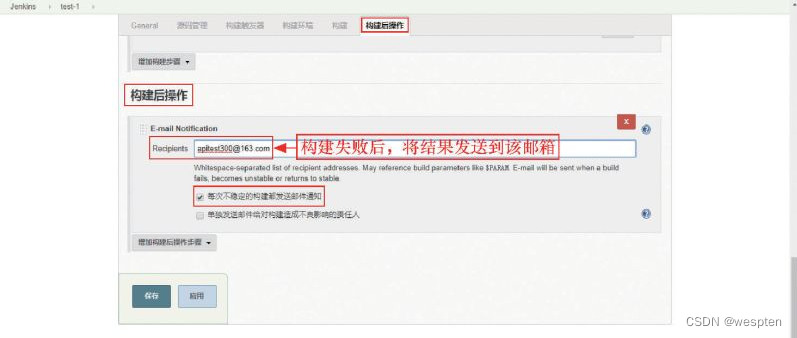
注意:只有构建失败才会发送邮件。
不过大多数情况下,用户会有更复杂的要求,比如,构建成功了发个邮件提醒一下,就需要在“Editable Email Notification”的“Triggers”中添加一个“Always”触发器,接着在“Recipient List”中输入任务结果接收者的邮件地址,如图所示。
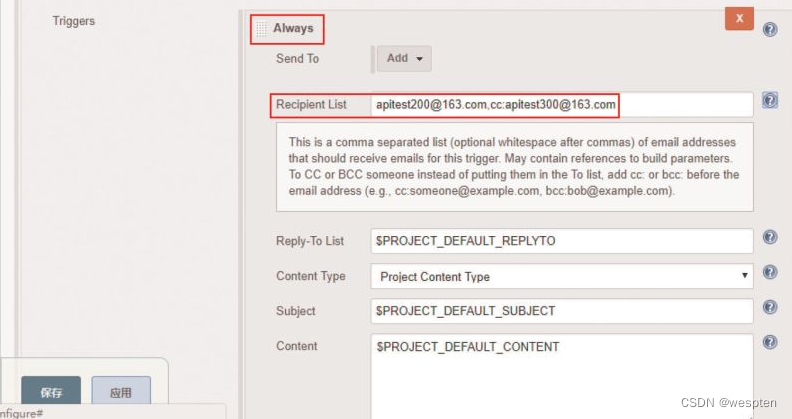
4)构建任务,查看邮件
我们来构建一下“myproject_02”任务。查看任务构建日志,可以看到图所示的类似的信息。
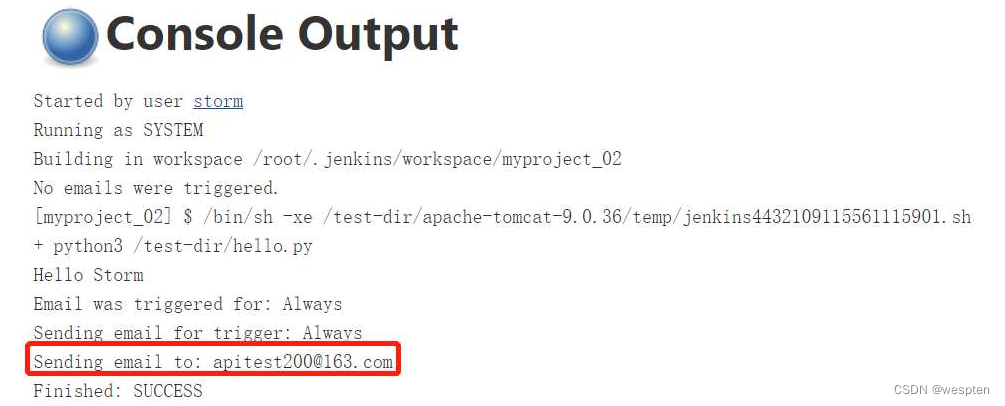
打开邮箱并查收邮件:
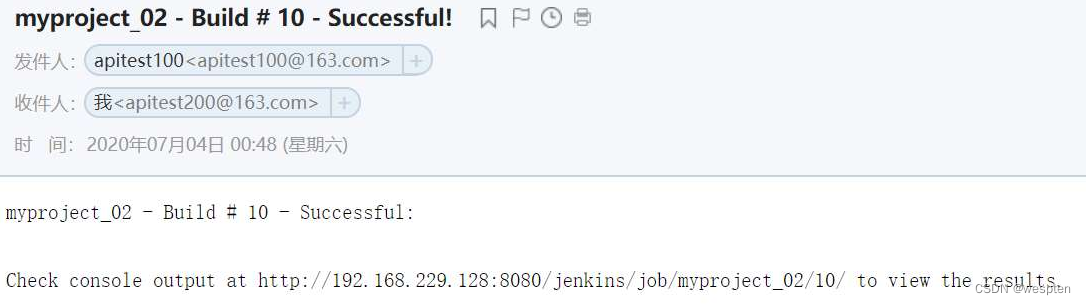
如果在手机上下载了邮箱App,那么就可以在移动端实时查看构建结果了。
2、Git应用
Git是一种分布式版本控制系统(Version Control System,VCS)。版本控制是指在开发过程中管理和备份对文件、目录、工程等内容的修改信息,以方便查看历史记录和恢复以前版本的软件工程技术。Git与SVN(Subversion,一个开发源码的版本控制系统)这种集中式版本控制系统相比,具有这些优点:适合分布式开发,强调个体;公共服务器压力比较小;速度快、操作灵活;任意两个开发者之间可以很容易地解决冲突;支持离线工作。
GitHub和GitLab都是基于Web的Git仓库,二者使用起来差不多。它们都是分享开源项目的平台,为开发团队提供了存储、分享、发布和合作开发项目的中心化云存储的场所。
GitHub作为开源代码库,拥有超过900万的开发者用户,目前仍然是非常火的开源项目托管平台。GitHub同时提供了公共仓库和私有仓库。早期,在GitHub创建私有仓库是要收费的。从2019年开始,GitHub允许普通用户创建私有仓库,不过还是有一点限制,免费私有仓库最多只能添加3个协同操作者。
GitLab允许用户在上面创建免费的私有仓库。GitLab让开发团队对他们的代码仓库拥有更多的控制权。相比较GitHub,它有不少特色。更重要的是,GitLab允许本地化部署。所以,从代码的私有性来看,GitLab是一个更好的选择。但是对于开源项目而言,GitHub依然是全球开发者代码托管的首选。
1. Git安装
1)在Linux操作系统上安装Git
以CentOS为例,推荐大家使用yum工具来安装Git,安装命令如下。
sudo yum install git安装完成后输入“git”,按“Enter”键,若得到图所示的内容,则说明安装成功。
2)在macOS上安装Git
推荐使用macOS的包管理工具Homebrew来安装Git,打开Terminal(终端),输入如下命令。
brew install git
3)在Windows操作系统上安装Git
从Git官网直接下载安装程序,然后双击运行,按默认选项安装即可。安装完成后,在开始菜单里依次找到“Git”和“Git Bash”,若弹出图所示的窗口,则说明Git安装成功。
当安装完Git后,应该做的第一件事就是设置用户名和邮箱地址。因为每次Git的提交都会用到这些信息,并且它会写入你的每次提交中。
我们可以使用“git config --global user.name "storm"”来配置用户名,使用“git config --global user.email "apitest100@163.com"”来配置邮箱地址,如下所示。
Storm@DESKTOP-2VF9P2M MINGW64 ~
$ git config --global user.name "storm"
Storm@DESKTOP-2VF9P2M MINGW64 ~
$ git config --global user.email "apitest100@163.com"
Storm@DESKTOP-2VF9P2M MINGW64 ~配置完成后,你还可以使用“git config --list”来查看当前的配置信息,如下所示。
$ git config --list
…
user.name=storm
user.email=apitest100@163.com2. Git基本操作
我们已经在本地安装好了Git。接下来,我们学习一些Git常用的概念和基本操作。
1)Git工作流程
常用的Git工作流程如下:
- 克隆Git资源作为工作目录。
- 在克隆的资源上添加或修改文件。
- 如果其他人修改了,你可以更新资源。
- 在提交前查看修改。
- 提交修改。
- 在修改完成后,如果发现错误,可以撤回提交并再次修改后提交。
2)Git工作区、暂存区、版本库
我们先来了解Git中3个最基本的概念:工作区、暂存区、版本库。
- 工作区:本地工作目录(你在计算机里能看到的目录)。
- 暂存区:英文叫stage。一般存放在“.git”目录下的index文件(.git/index)中。
- 版本库:工作区有一个隐藏目录“.git”,这个不算工作区,而是Git的版本库。
下图所示为工作区、版本库中的暂存区和版本库之间的关系。
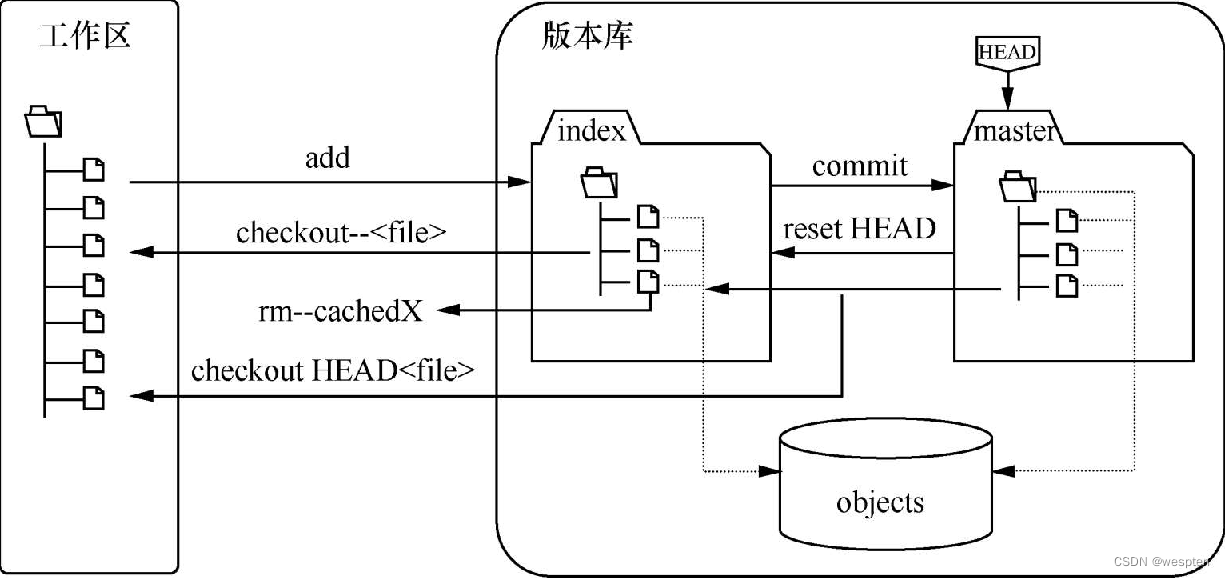
图中左侧为工作区,右侧为版本库。在版本库中标记为“index”的区域是暂存区(stage,index),标记为“master”的区域是master分支所代表的目录树。
从图中我们可以看出,此时HEAD实际指向master分支的一个“游标”,所以图中的命令中出现HEAD的地方可以用master来替换。
图中“objects”标识的区域为Git的对象库,实际位于“.git/objects”目录下,里面包含了创建的各种对象及内容。
当对工作区修改(或新增)的文件执行“git add”命令时,暂存区的目录树会被更新。同时工作区修改(或新增)的文件内容会被写入对象库中的一个新的对象中,而该对象的ID被记录在暂存区的文件索引中。
当执行提交操作“git commit”时,暂存区的目录树写到版本库(对象库)中,master分支会做相应的更新,即master指向的目录树就是提交时暂存区的目录树。
当执行“git reset HEAD”命令时,暂存区的目录树会被重写,并被master分支指向的目录树所替换,但是工作区不受影响。
当执行“git rm --cached <file>”命令时,则会直接从暂存区删除文件,工作区不做出改变。
当执行“git checkout .”或者“git checkout -- <file>”命令时,会用暂存区全部或指定的文件替换工作区中的文件。这个操作很危险,因为会清除工作区中未添加到暂存区的改动。
当执行“git checkout HEAD .”或者“git checkout HEAD <file>”命令时,会用HEAD指向的master分支中的全部或者部分文件替换暂存区以及工作区中的文件。这个操作也是极具危险性的,因为不但会清除工作区中未提交的改动,也会清除暂存区中未提交的改动。
3)初始化本地仓库
接下来,我们通过实际的操作来演示一些Git基础命令的用法。
首先,将已存在的目录(在D盘新建了一个目录“mygit_0”)初始化成仓库。然后进入“mygit_0”目录,右击鼠标,从弹出的快捷菜单中选择“Git Bash Here”,打开图所示的窗口。
接着,使用“git init”命令初始化仓库。在执行完“git init”命令后,Git仓库会生成一个“.git”目录,如图所示。
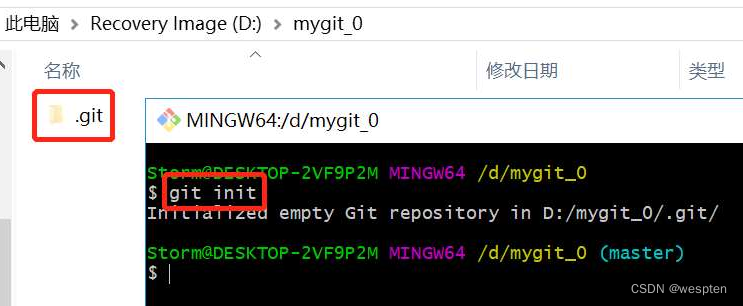
4)查看项目当前状态
我们可以通过“git status”命令来查看项目当前状态。例如,在“mygit_0”目录中新建一个文件“a.txt”,然后通过“git status”命令可以看到图所示的信息。
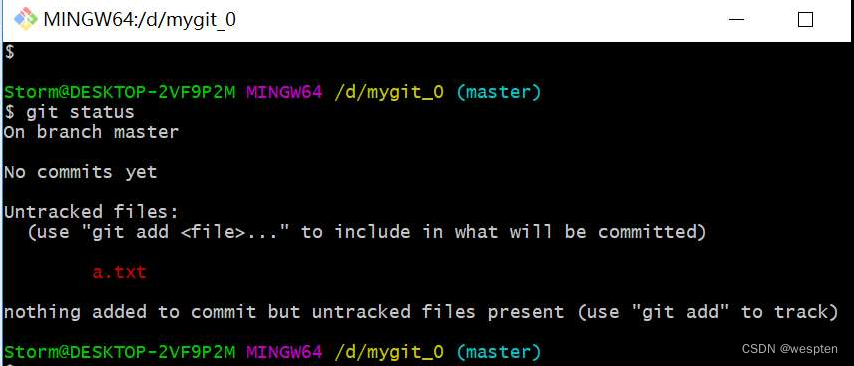
从提示信息中我们可以看到工作区中出现了一个未跟踪(untracked)的文件,你可以使用“git add”命令来跟踪它。
5)将文件添加到暂存区
我们来演示一下如何将工作区中的新文件放到暂存区并进行跟踪。使用“git add a.txt”命令将工作区中的文件放到暂存区,如图所示。
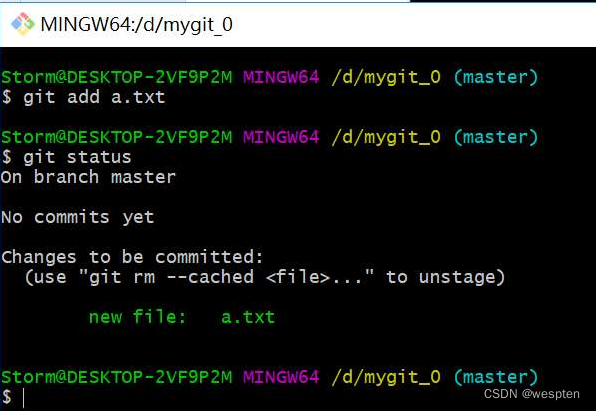
从图的提示信息中我们可以看到,当前的分支是master。虽然工作区中的“a.txt”文件已经被放到了暂存区,但是还未提交(“No commits yet”)到版本库。
6)将文件提交到版本库
我们可以使用“git commit -m "message"”命令将暂存区中的文件提交到当前分支,如图所示。
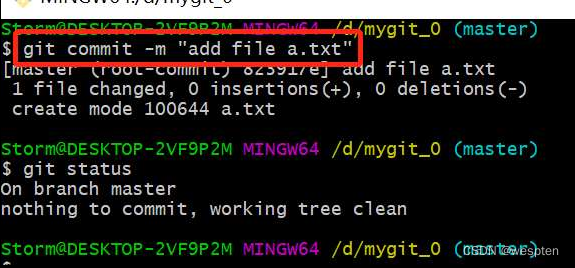
注意:
- 因为提交内容到分支是一件非常严肃的事情,所以请记得一定要添加备注信息(-m “message”)。
- 图中的提示信息显示目前工作区“很干净”(没有需要处理的文件)。
- 在初学阶段,建议经常使用“git status”命令来查看一下工作区的当前状态。
3. GitLab部署
本地的Git仓库不足以支持项目中成员的团队协作。本小节我们讲解搭建适合企业、团队使用的GitLab应用。
一般来说,我们会将GitLab部署到Linux服务器上(注意,部署GitLab的服务器至少需要4GB的内存)。本小节我们将以CentOS 7为例,演示一下如何部署GitLab。
1)更换阿里yum源
因为网络的原因,GitLab的原始yum源可能无法访问,所以我们要先更换到国内yum源。
- 安装wget
yum install -y wget- 备份默认的yum
mv /etc/yum.repos.d /etc/yum.repos.d.backup- 创建新的yum目录
mkdir /etc/yum.repos.d- 下载阿里yum源到创建的目录中
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo- 重建缓存
yum clean all
yum makecache2)部署社区版GitLab
接下来,我们就可以部署GitLab了,步骤如下。
- 安装GitLab的依赖项
yum install -y curl openssh-server openssh-clients postfix cronie policycoreutils-python注意:10.x版本以后开始依赖policycoreutils-python,之前在使用9.x版本时还没有依赖该项。
- 启动postfix,并设置为开机启动
systemctl start postfix
systemctl enable postfix- 设置防火墙
firewall-cmd --add-service=http --permanent
firewall-cmd --reload- 获取GitLab的rpm包
访问清华大学开源软件镜像站查找目标版本的GitLab rpm包,如图所示。

复制链接地址,然后通过wget下载rpm包,如下所示。
wget https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el8/gitlab-ce-12.10.10-ce.0.el8.x86_64.rpm- 安装rpm包
通过“rpm –i”命令来安装下载好的rpm包,如下所示。
rpm -i gitlab-ce-12.10.10-ce.0.el8.x86_64.rpm 当看到图所示的类似显示信息时,则表示GitLab安装成功。

根据提示,继续执行命令配置GitLab。
gitlab-ctl reconfigure- 编辑配置文件gitlab.rb
借助“vi”命令编辑配置文件,如下所示。
vi /etc/gitlab/gitlab.rb将变量external_url的地址修改为GitLab所在Cent OS的IP地址,如图所示。
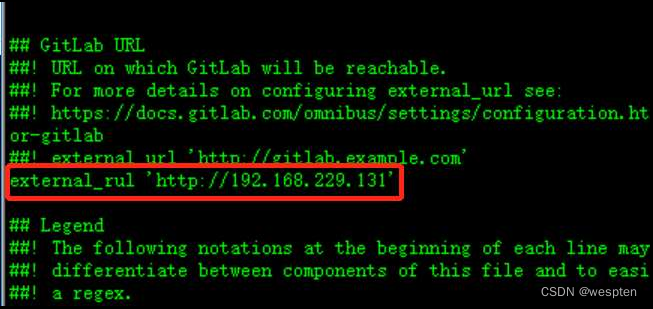
修改配置文件后,需要重新加载配置内容,命令如下。
gitlab-ctl reconfigure
gitlab-ctl restart- 查看GitLab版本
我们可以使用“head -1 /opt/gitlab/version-manifest.txt”命令查看GitLab版本信息,如下所示。
head -1 /opt/gitlab/version-manifest.txt3)设置管理员密码
这里需要注意,虽然登录后管理员的用户名为Administrator,但是实际登录的用户名是root。
- 方法一:网页方式
浏览器访问GitLab所在服务器的IP,首次登录需要修改密码,如图所示。
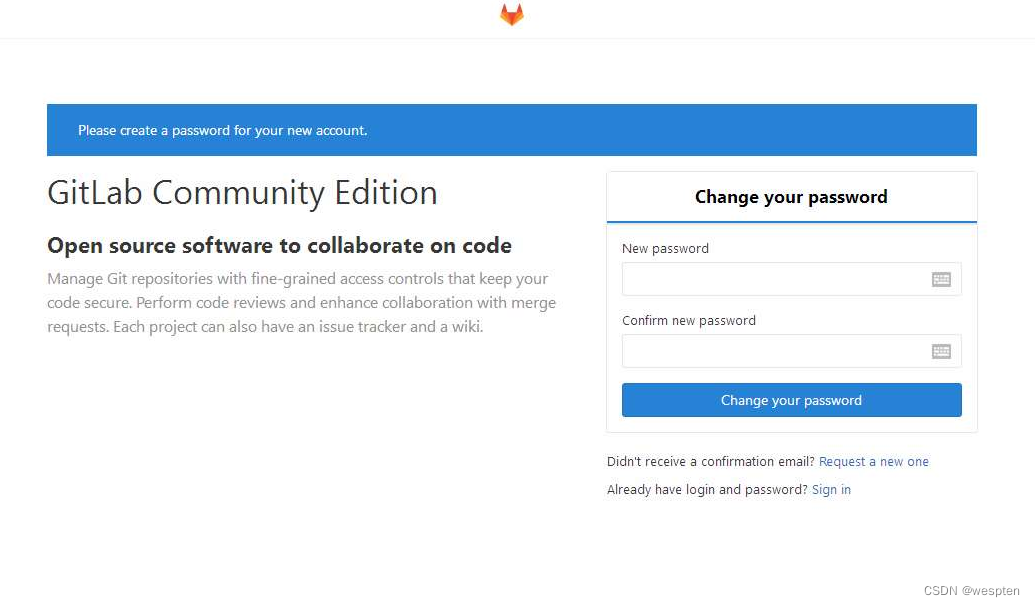
在“New password”“Confirm new password”文本框中输入新的密码,单击“Change your password”按钮,即可完成初始密码修改。
- 方法二:命令方式
我们还可以使用命令设置管理员密码,即在CentOS的命令行窗口中输入如下命令。
gitlab-rails console production稍等一会后会出现图所示的安装提示信息。

接下来,依次输入下面的命令并按“Enter”键,即可设置管理员密码。
irb(main):001:0> user = User.where(id: 1).first // id为1的是超级管理员
irb(main):002:0>user.password = 'yourpassword' // 密码必须至少8个字符
irb(main):003:0>user.save! // 如没有问题,则返回True
exit // 退出4)创建GitLab账号
使用管理员账号登录GitLab后,你可以通过以下步骤为团队成员创建账号。
- 单击“设置”图标。
- 单击左侧“Users”菜单。
- 单击右上角“New user”按钮。
接着,输入用户相关的信息(账号名、用户姓名、用户邮箱),并为其配置权限,最后单击“Create user”按钮,即可成功创建账号。
注意:
- 一定不要多个员工混用账号,也不要每个账号都具有管理员权限。
- 如果组织内用户过多,可以通过对用户进行分组来控制不同用户组的权限。
5)创建项目
使用管理员账号登录GitLab后,你可以通过以下步骤为团队创建项目。
- 单击“设置”图标。
- 单击左侧“Projects”菜单。
- 单击右上角“New Project”按钮。
进入“项目创建”页面后输入项目名,然后设置“项目访问级别”(这里我们选择“Private”,只有具有权限的用户才能访问),单击“Create project”,完成项目创建。
图中所示框中的内容为项目的访问地址:
后续,我们可以通过该地址将GitLab仓库的文件拉取到本地仓库。
4. Git远端仓库
为了方便团队成员的代码合并及管理,我们需要将本地仓库中的代码推送到GitLab保存。这里我们介绍3种场景。
1)将GitLab仓库拉取到本地
一般来说,管理员会负责在GitLab创建项目仓库并创建一些公共文件。当GitLab中已经有了仓库时,我们可以使用以下命令将其拉取到本地仓库。
git clone http://localhost/root/project_01.git
cd project_01
touch README.md
git add README.md
git commit -m "add README"
git push -u origin Master2)将本地文件夹变为GitLab仓库
我们前面所保存的代码都存放在本地文件夹“Love”中,如果现在想借助GitLab来管理代码,那么可以参考以下命令。
cd existing_folder
git init
git remote add origin http://localhost/root/project_01.git
git add .
git commit -m "Initial commit"
git push -u origin Master3)将已有Git仓库变为GitLab仓库
如果本地已经创建了Git仓库,前面我们创建了本地的Git仓库“mygit_0”,那么可以将其推到远端变为GitLab仓库。
参考命令如下:
cd existing_repo
git remote add origin http://localhost/root/project_01.git
git push -u origin --all
git push -u origin --tags3、钉钉应用
如果用户正在使用钉钉办公,那么使用Jenkins的钉钉插件能更方便地接收和处理项目构建信息。
钉钉,阿里巴巴出品,是专为中国企业打造的免费智能移动办公平台,含PC版、Web版和手机版。智能办公电话、消息已读和未读、DING消息任务管理等功能让沟通更高效;移动办公考勤、签到、审批、企业邮箱、企业网盘、企业通讯录等功能让工作更简单。
1. 设置钉钉群组机器人
① 通过浏览器访问钉钉官网,输入用户名和密码登录。
② 单击图中右上方的“添加机器人”图标,创建群组(接收构建消息的人群)。选择“自定义”机器人,如图所示。
设置机器人名字:
单击“添加”按钮后,输入机器人名字。然后进行安全设置,这里我们使用“自定义关键词”,消息中要包含“监控报警”才能够发送。再勾选“我已阅读并同意”复选框。最后单击“完成”按钮,如图所示。

单击“复制”按钮,复制webhook,webhook后面包含access token,如图所示。
2. 集成Jenkins
在Jenkins中设置钉钉的步骤如下。
1)安装钉钉插件
登录Jenkins,选择“系统管理”→“管理插件”→“可选插件”选项卡,搜索“dingding”,安装。
2)配置构建后任务
进入任务配置,在“构建后操作”中添加“钉钉通知器配置”,如图所示。
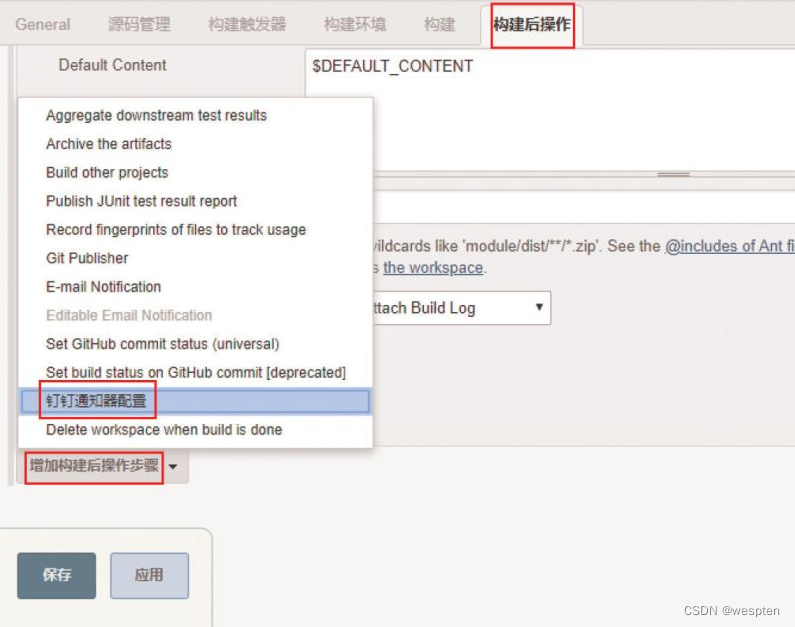
输入从前面webhook处得到的access token,保存,如图所示。
3)接收并处理钉钉消息。
再次构建任务,从Web端和APP端查看构建消息。
能够配合Jenkins的“机器人”有很多,如Slack、BearyChart等。
4、自动化测试持续集成
1. GitHub来维护接口测试文件
① 登录GitHub账号。
② 创建一个repo,取名为douban,如图所示。
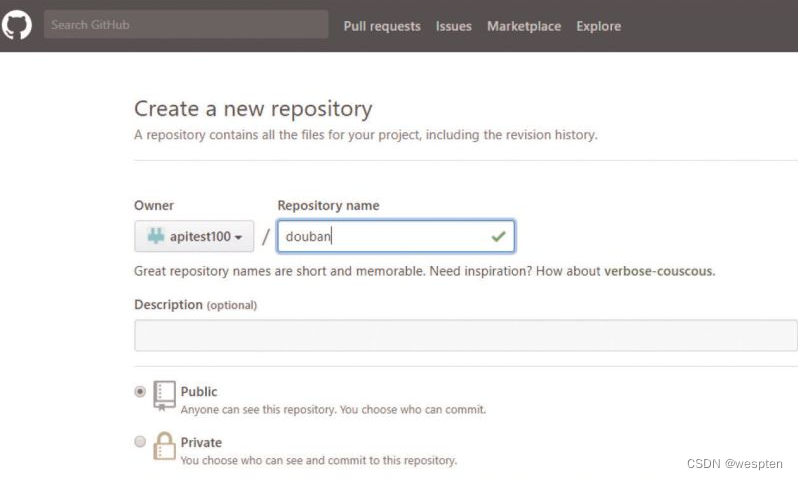
创建成功后,复制项目的SSH Clone地址,如图所示。
③ 进入Windows系统机器D盘的根目录,右键单击Git Bash Here,输入如下命令。
$ git clone git@github.com:apitest100/douban.git按“Enter”键,这样就创建了一个本地Git仓库。
④ 查看目录文件,如图所示。
2. 将集合相关文件推送到远端
① 从Postman导出测试集合及环境文件。
② 将其保存在本地Git文件夹中。
③ 返回Git bash命令行窗口,将文件推送到GitHub,如图所示。
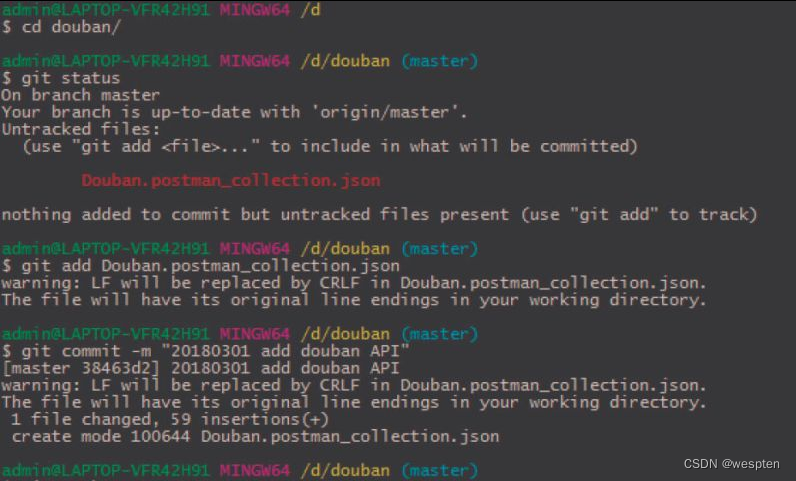
查看GitHub仓库,文件已经推送到了GitHub,如图所示。

注意:
① 为每个特性创建一个分支。
② 测试必须与开发人员代码本身在相同的存储库中进行,从开发环境到所有的生产。所以每个版本的代码都有自己的测试版本。
③ 创建Jenkins构建任务时,将变量参数化。这样,用户可以通过Jenkins轻松地在任何环境中运行相同的测试。
④ 在进行更改之前,一定要确保从主分支或准备分支中获取最新的代码。用户可以通过以下命令进行。
git pull origin master ⑤ 用户可以为特定分支上的每个代码设置测试运行触发器,如果它失败,则不应该对测试环境进行部署。
3. 自动化测试持续集成
接下来,我们利用前面学到的知识,将本地的代码推送到GitLab仓库,然后通过Jenkins来构建自动化测试任务,并将自动化测试的结果通过邮件和钉钉发送给相关责任人。
1)将代码推送到GitLab
我们已经在GitLab创建了一个名为“project_01”的项目。
因为编写好的自动化测试脚本已经存放在本地Windows的文件夹中,并将本地文件夹中的代码文件推送到GitLab。
步骤如下:
Storm@DESKTOP-2VF9P2M MINGW64 /d/Love/Chapter_14 # 进入对应目录
$ git init # Git初始化
Initialized empty Git repository in D:/Love/Chapter_14/.git/
Storm@DESKTOP-2VF9P2M MINGW64 /d/Love/Chapter_14 (Master)
$ git remote add origin http://192.168.229.131/root/project_01.git # 远程仓库
Storm@DESKTOP-2VF9P2M MINGW64 /d/Love/Chapter_14 (Master)
$ git add . # 提交当前目录到暂存区
Storm@DESKTOP-2VF9P2M MINGW64 /d/Love/Chapter_14 (Master)
$ git commit -m "initial commit" # 提交到仓库
[Master (root-commit) f21c01b] initial commit
54 files changed, 691 insertions(+)
…
Storm@DESKTOP-2VF9P2M MINGW64 /d/Love/Chapter_14 (Master)
$ git push -u origin Master # 提交到远程仓库的Master分支
Enumerating objects: 63, done.
Counting objects: 100% (63/63), done.
Delta compression using up to 8 threads
Compressing objects: 100% (62/62), done.
Writing objects: 100% (63/63), 25.47 KiB | 767.00 KiB/s, done.
Total 63 (delta 11), reused 0 (delta 0)
To http://192.168.229.131/root/project_01.git
* [new branch] Master -> Master
Branch 'Master' set up to track remote branch 'Master' from 'origin'.
Storm@DESKTOP-2VF9P2M MINGW64 /d/Love/Chapter_14 (Master)2)安装、配置Allure插件
在创建Jenkins任务之前,我们需要先安装Allure插件。
- 安装Allure插件
搜索“allure”关键字,安装Allure插件,如图所示。
- 配置Allure环境设置
登录Jenkins,依次单击“Manage Jenkins”“Global Tools Configuration”,进入全局工具配置界面,滑动到“Allure Commandline”处,如图所示。

单击“新增Allure Commandline”,如图所示。
输入别名和安装目录,单击“保存”按钮。
3)创建Web UI自动化测试任务
接下来,我们创建一个自动化测试任务,可参考以下步骤。
- 创建任务
这里我们创建一个Freestyle的任务。
- 源码管理
这里我们要对接GitLab来拉取测试脚本进行测试。单击“源码管理”标签,选择“Git”,然后输入Repository URL(GitLab仓库信息),接着输入Credentials(GitLab账户信息),再指定分支为master,如图所示。
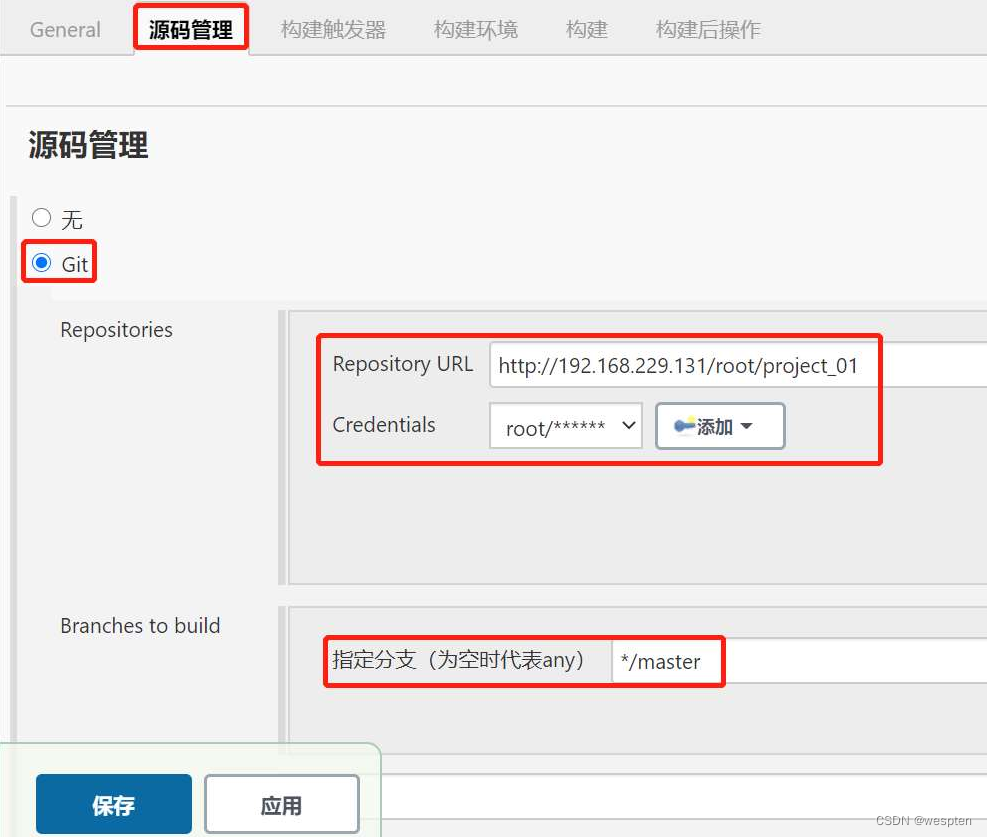
- 添加构建步骤
因为是Windows环境,所以选择“Windows batch command”,输入命令“pytest --alluredir=Report/report”,如图所示。
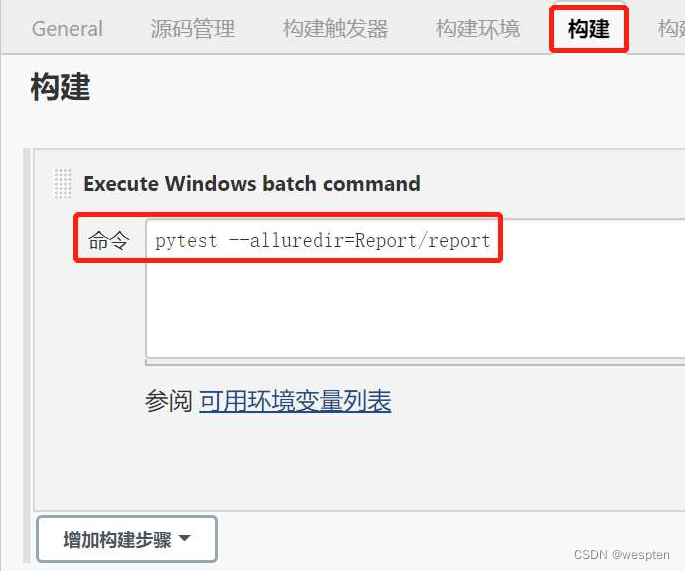
- 添加构建后操作
这里需要注意的是,Results path指的是Allure产生的JSON原始文件的目录,对应“Report/report”,如图所示。
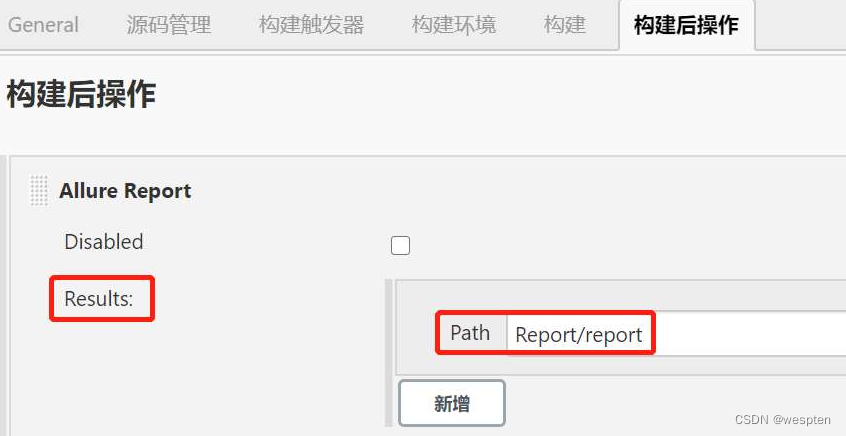
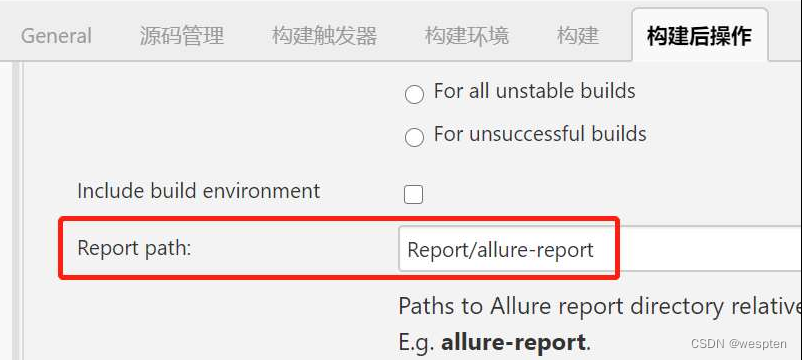
4)构建任务,查看结果
这里我们手动构建任务。等待任务构建完成后,即可通过单击“Allure Report”来查看本次执行的测试报告,如图所示。
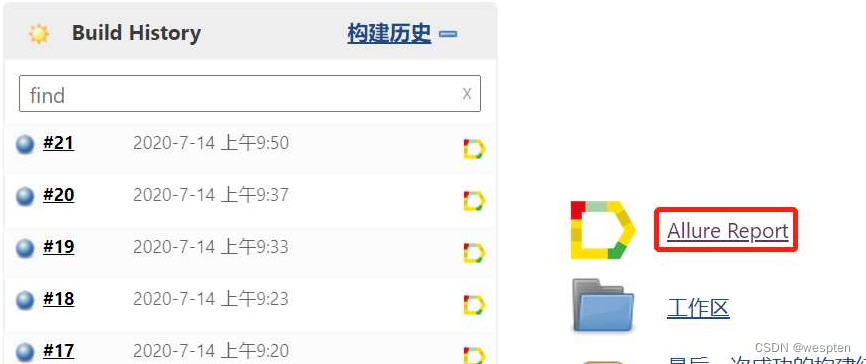
5、接口自动化测试持续集成实战
本项目共提供6个HTTP接口,包含GER、POST请求,涉及键值对(keyvalue)、JSON格式传递参数,涉及Cookies、权限验证、文件上传等。
1. 安装Tornado
使用Python的pip工具安装Tornado,在命令行输入“pip install tornado”,按“Enter”键,出现与下图类似的提示信息,表示安装成功。

2. 安装storm.py
① 可从配套资源中下载相关文件,将其放到E盘根目录(当然也可以放到其他目录,路径中不要有中文字符)。
② 打开命令行,运行python E:\storm.py。
③ 测试。打开浏览器,输入“http://localhost:8081/getuser”,如果浏览器返回如图8-5所示的界面,证明环境部署成功。
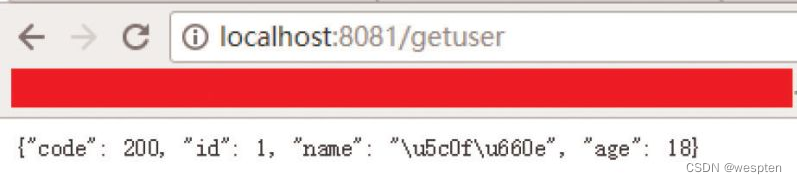
3. 查看接口文档
本地文档如下。
- 1 获取用户信息(一)
1.1 功能描述
获取用户信息:该接口用于通过userid命令获取用户信息。
1.2 请求地址
http://localhost:8081/getuser。
1.3 请求方法
POST/GET。
1.4 入参

1.5 出参
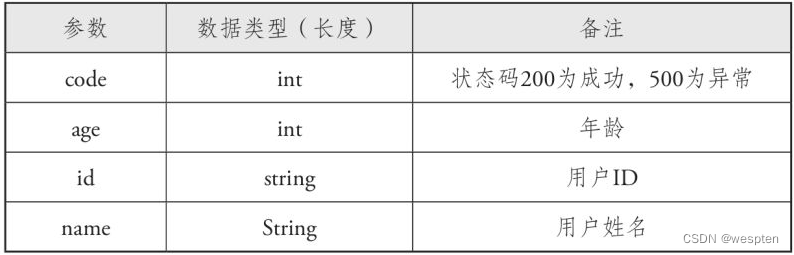
1.6 示例
请求:
http://localhost:8081/getuser?userid=1
返回:
{"age": 18, "code": 200, "id": "1", "name": "小明"}
- 2 获取用户余额
2.1 功能描述
获取用户余额:传入userid获取用户余额。
2.2 请求地址
http://localhost:8081/getmoney。
2.3 请求方法
POST。
2.4 入参

2.5 出参
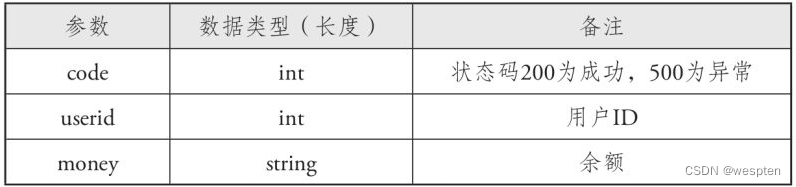
2.6 示例
请求:
http://localhost:8081/getmoney?userid=1
返回:
{'code':200,'userid':1,'money':1000}
- 3 修改用户余额(一)
3.1 功能描述
修改用户余额:需要有HTTP权限验证,账号为admin,密码为123456。
3.2 请求地址
http://localhost:8081/setmoney。
3.3 请求方法
POST。
3.4 入参
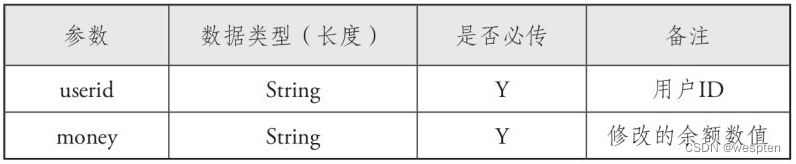
3.5 出参
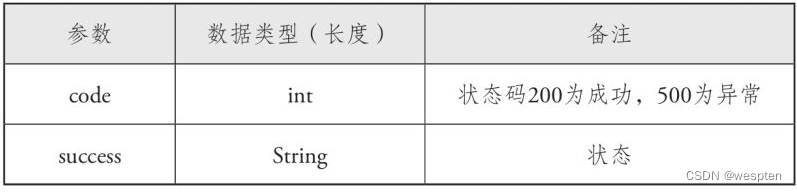
3.6 示例
请求:
http://localhost:8081/setmoney?userid=1&money=5000
返回:
{'code':200,'success':'成功'}
注意,如果调用的时候传入的账号密码不对或者没传的话,返回权限验证失败。
- 4 获取用户信息(二)
4.1 功能描述
获取用户信息:需要添加Headers、Content-Type application/JSON。
头(Headers):服务器以HTTP协议传HTML资料到浏览器前所送出的字串,在头与HTML文件之间尚需空一行分隔。
4.2 请求地址
http://localhost:8081/getuser2。
4.3 请求方法
GET/POST。
4.4 入参

4.5 出参
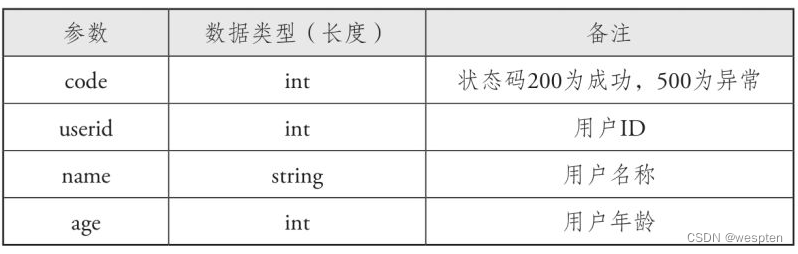
4.6 示例
请求:
http://localhost:8081/getuser2?userid=1
返回:
{'code':200,id':1,'name':'小明','age':18}
- 5 修改用户余额(二)
5.1 功能描述
功能描述:需要添加Cookies,Token Token是固定的token12345。
5.2 请求地址
http://localhost:8081/setmoney2。
5.3 请求方法
POST
5.4 入参
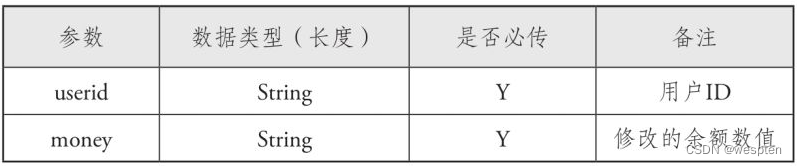
5.5 出参

5.6 示例
请求:
http://localhost:8081/setmoney2?userid=1&money=5000
返回:
{'code':200,'success':'成功'}
注意,和接口3一样,不过是需要传入Cookies,不需要HTTP权限验证了。
- 6 上传文件
6.1 功能描述
上传文件:向服务器(211.149.218)指定目录传送文件。
6.2 请求地址
http://localhost:8081/uploadfile。
6.3 请求方法
POST。
6.4 入参

6.5 出参
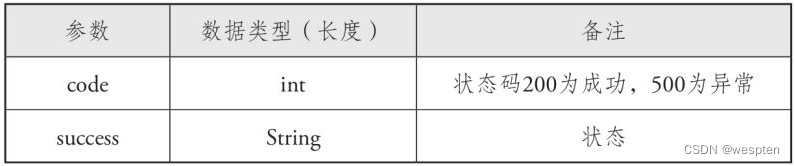
4. 编写接口测试文档
测试计划用于确认需求,确定接口测试范围,是后续接口测试的指导性文件,而接口测试用例则用来指导接口测试工作的具体实施,两者都非常重要。
1)编写接口测试计划
这里提供一份测试计划,供搭建参考。
- 1 概述
1.1 目的
① 确认需求。
② 保证测试进度,确定测试方法和测试环境,为设计测试用例做准备。
③ 通过具体的测试方法,测试该项目接口是否按需求实现相应功能。
1.2 测试范围
① 确认Storm项目接口的基本功能。
② 确认测试交付时间点。
③ 确认接口性能要求。
④ 此计划作为测试依据:控制测试时间、编写测试用例、执行测试阶段及过程、追踪漏洞记录、提交测试报告。
1.3 参考资料
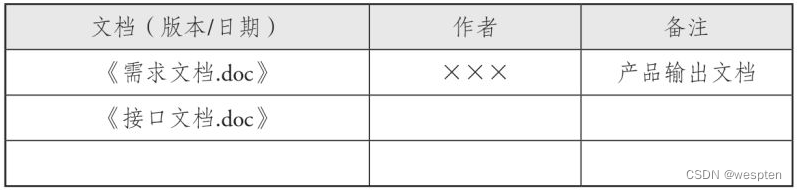
1.4 测试应提交文档
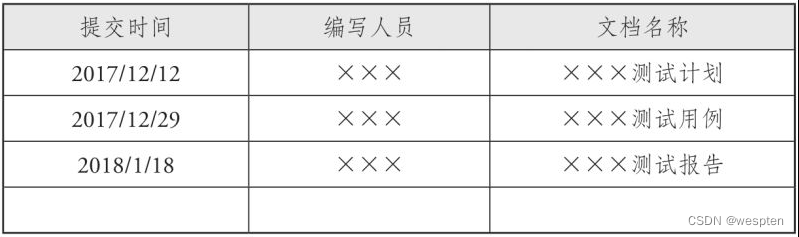
- 2 测试资源
2.1 测试环境
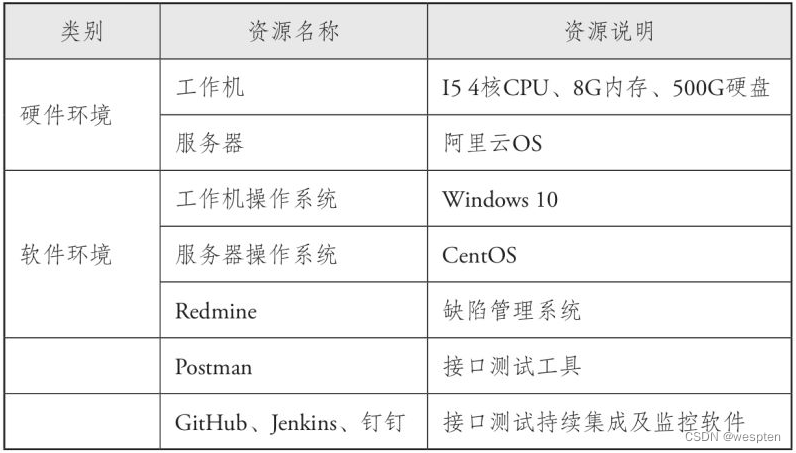
2.2 测试里程碑计划
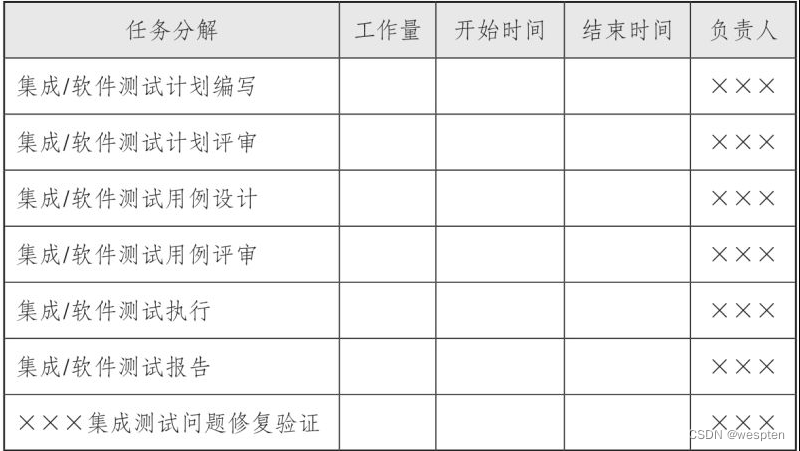
- 3 测试功能以及重点
3.1 测试对象
此次测试组只对接口的功能以及性能做测试,以下所有的功能点均是制作测试用例的大纲。
3.2 测试功能及重点
3.2.1 获取用户信息(一)
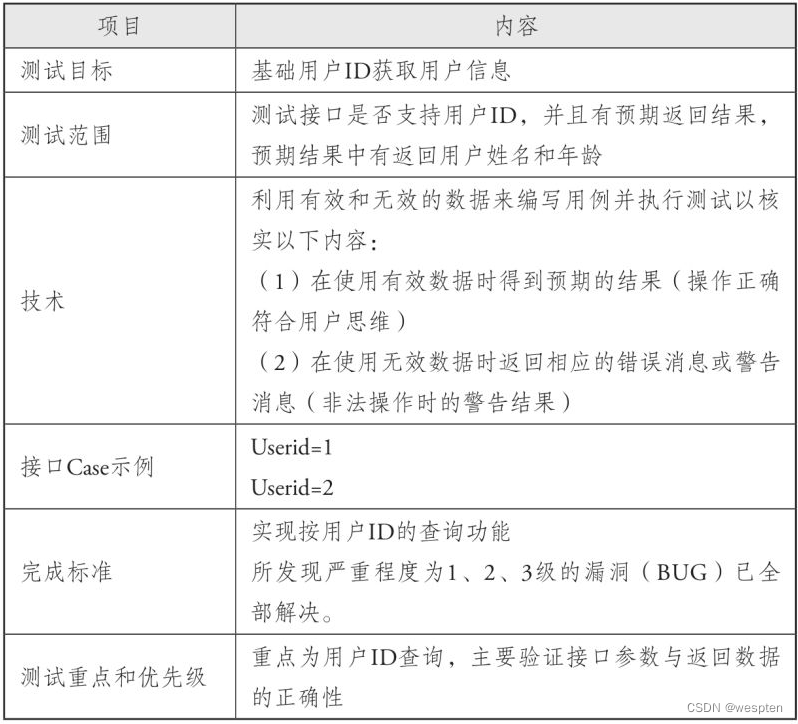
3.2.2 获取用户信息(二)

3.2.3 获取用户余额
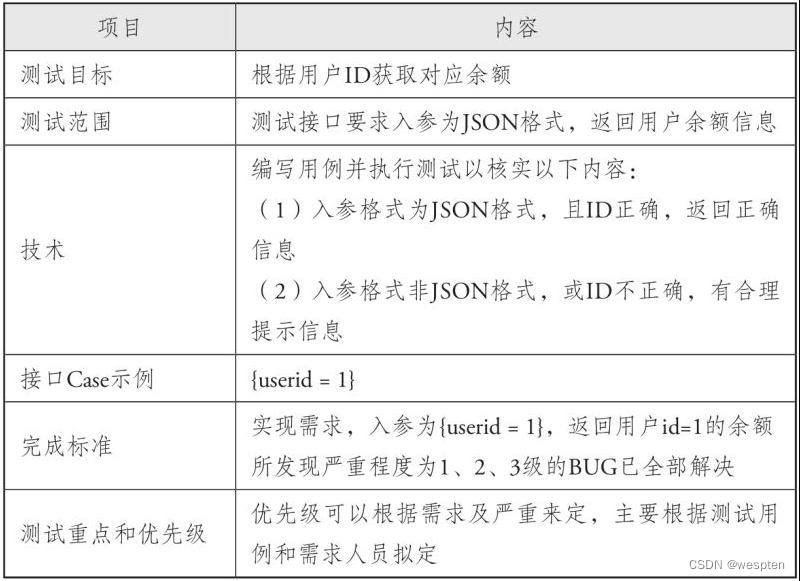
3.2.4 修改用户余额(一)
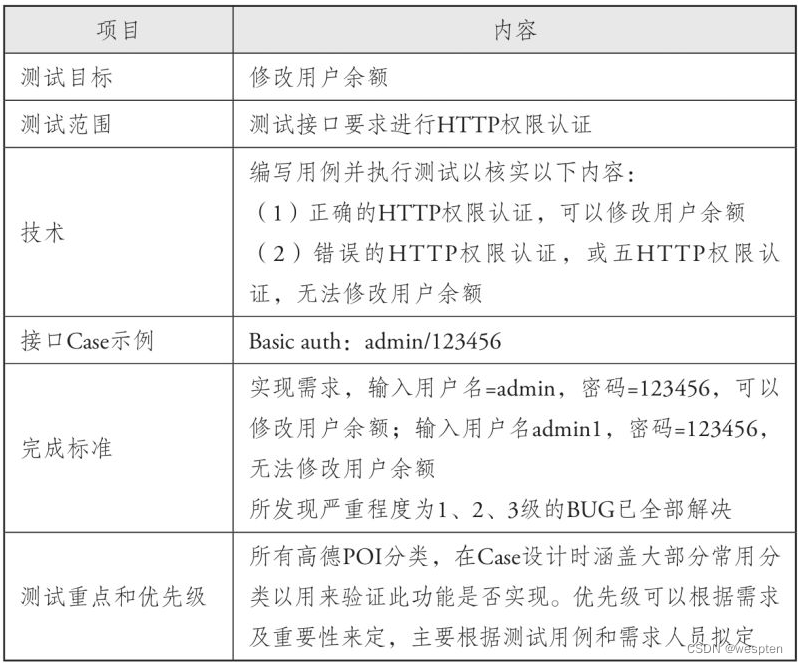
3.2.5 修改用户余额(二)
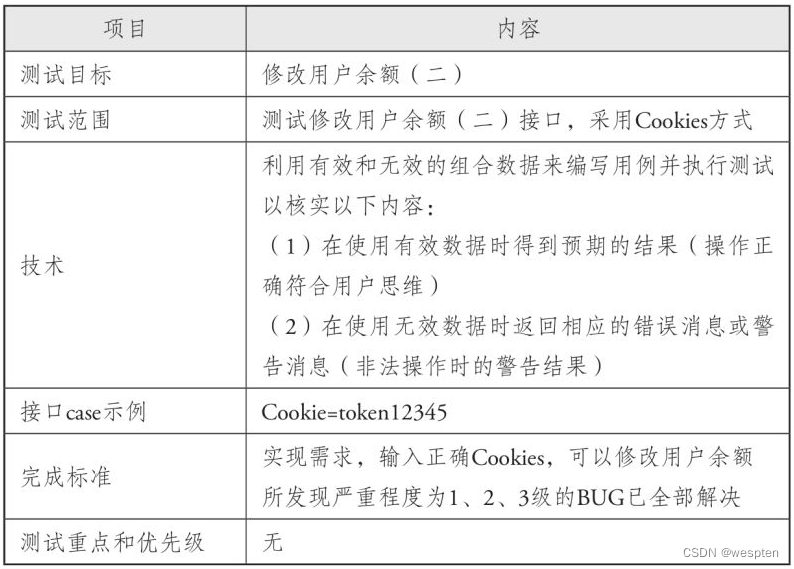
3.2.6 上传文件
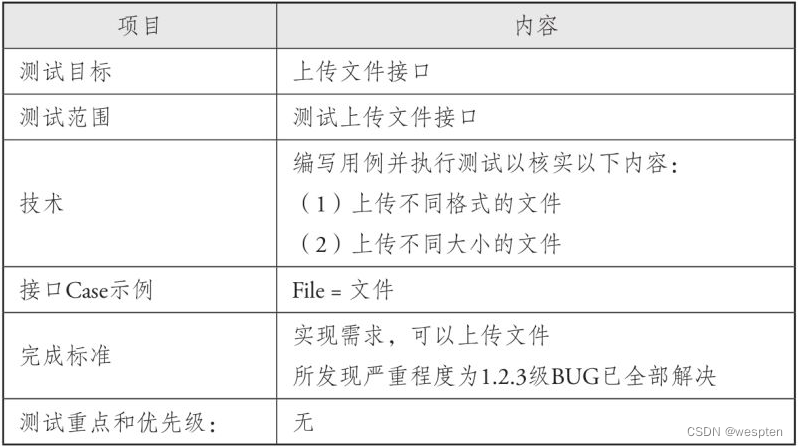
3.3 自动化测试
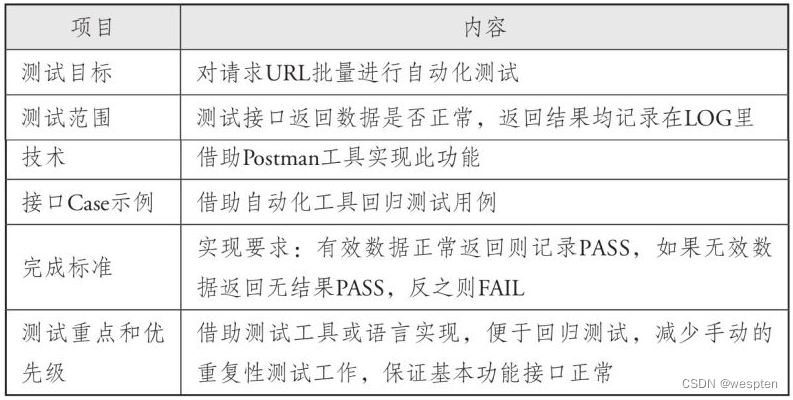
- 4 集成/软件测试策略
整体测试方案:按照测试计划严格控制测试过程,与产品人员讨论需求,编写测试用例,与开发沟通测试中发现的问题,编写测试报告。
测试类型:此次接口测试只做功能测试与性能测试。
性能测试方案:不涉及。
回归测试方案:对上一版本已解决问题和基础功能进行回归验证,基础功能测试用例进行自动化验证,其中手工抽查测试用例加以验证,以此保证原有功能正常。
- 5 测试风险
本次测试过程中,可能出现的风险如下:
① 需求变更导致开发周期延迟从而导致测试日期延后。
② 需求不明确导致开发周期延迟从而导致测试日期延后。
- 6 测试标准
6.1 测试指标
使用Redmine工具进行管理。
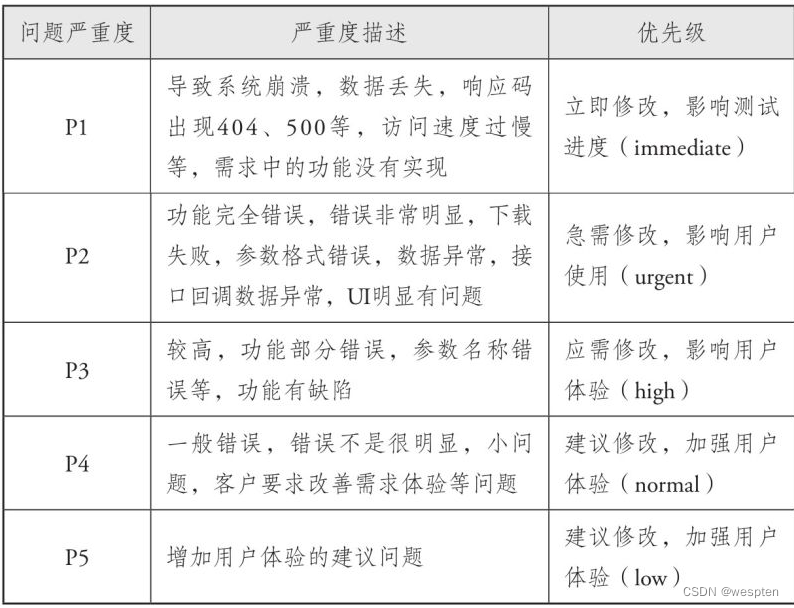
严重程度和优先级都是从1~5,从高到低;在验收环节1、2、3级问题必须全解决或者标注不能及时解决的原因,告知大家,问题可以延后处理。4级问题总数不能超过总量的20%,不然认为BUG过多不允许通过。
6.2 测试通过标准
验收标准如下:
P1级BUG或缺陷必须全部解决,功能级Test Case通过率必须为100%。
P2、P3级BUG或缺陷必须全部解决,功能级Test Case通过率必须为100%。
P4级BUG或缺陷解决80%。
P5级为建议修改,主要为增加体验,在允许的范围内也需尽量修改。
2)编写接口测试用例
集合文件storm.postman_collection.JSON,及对应的环境变量文件storm-test.postman_environment.JSON。
针对上述项目接口,这里列出一份接口测试用例供参考,如下表所示。
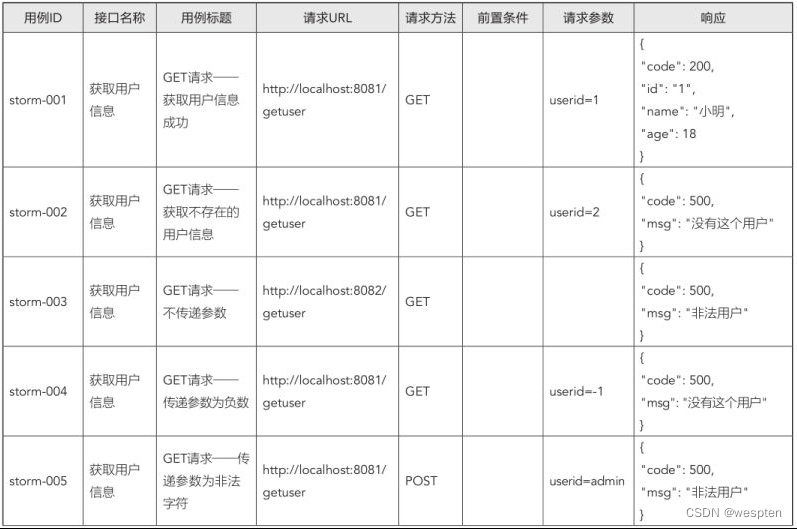
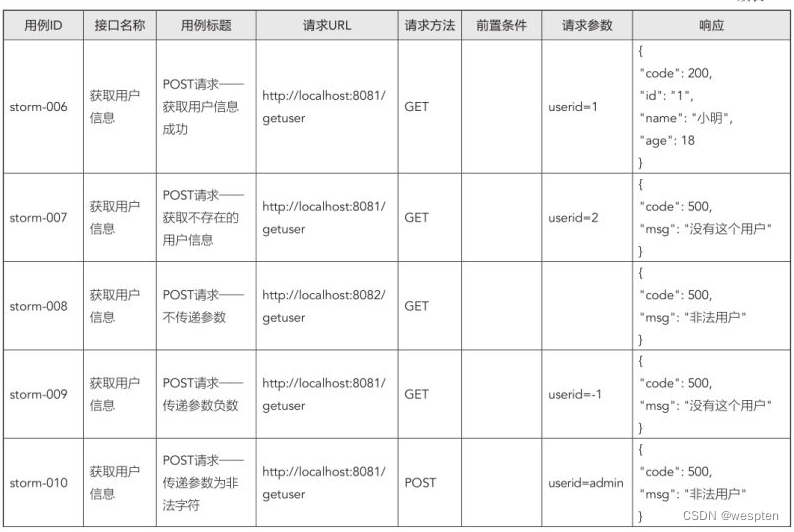
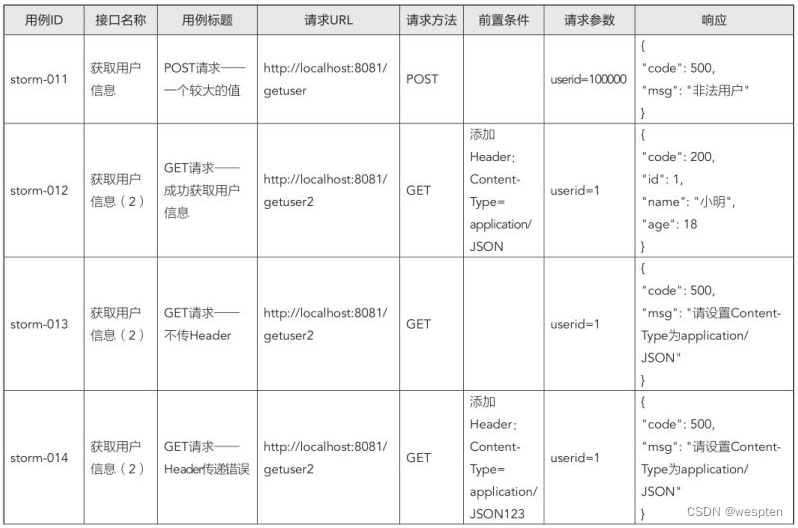
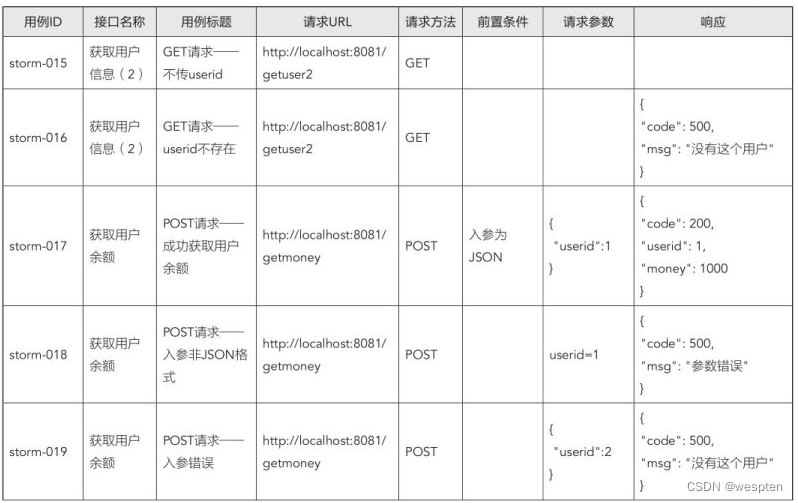
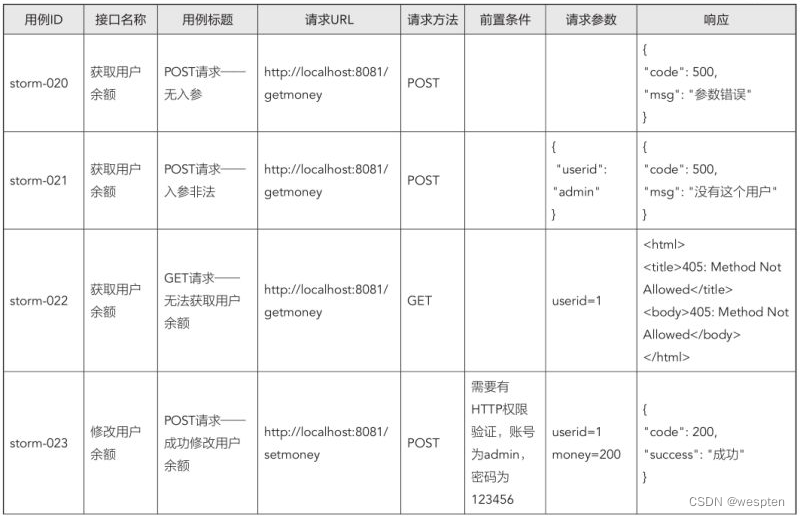
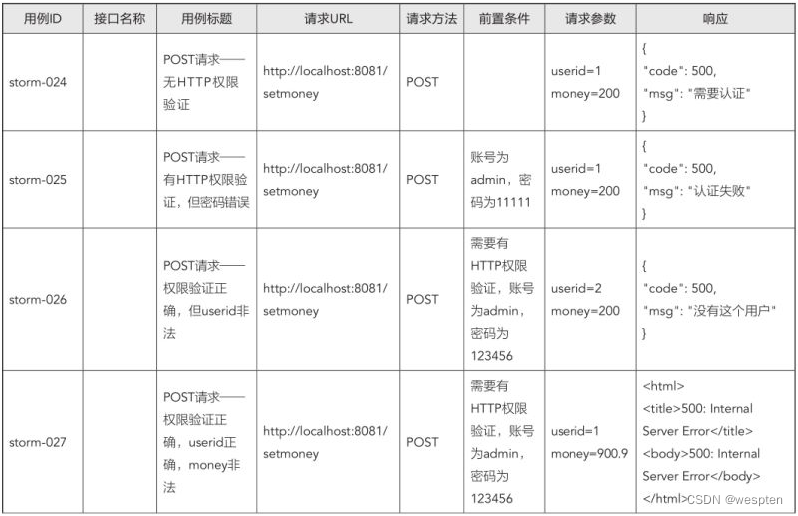
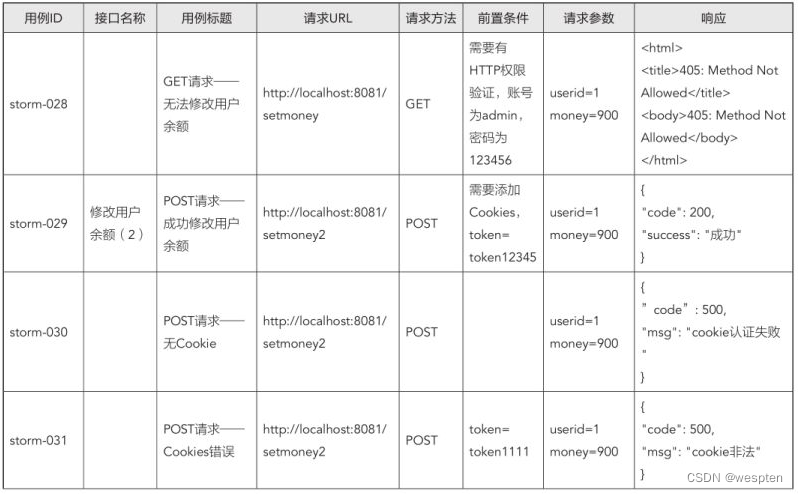
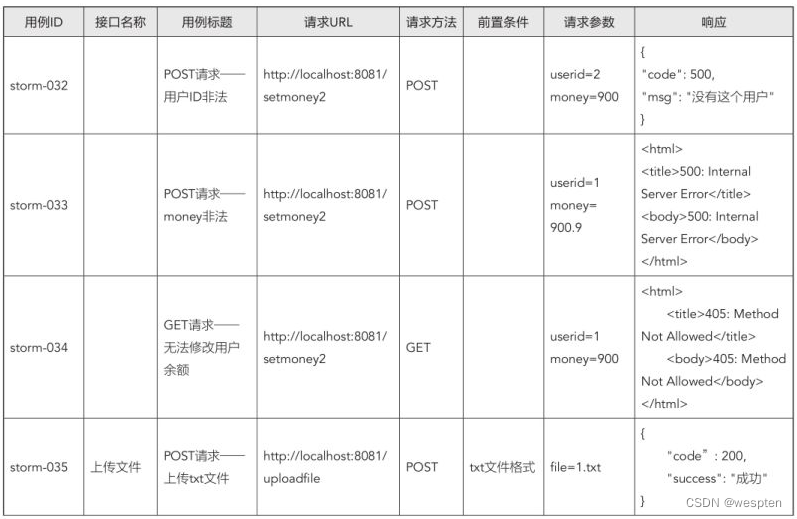
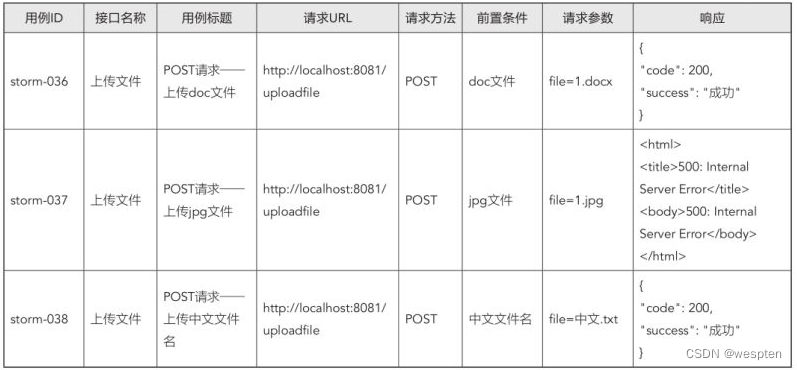
5. 执行接口测试
- 测试用例:storm-001
在Postman中构造接口请求,如图所示。
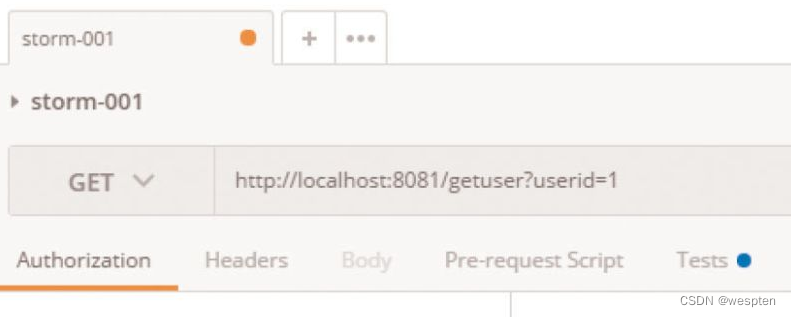
为了使请求更健壮,使用环境变量代替IP地址及端口,设置domain=localhost:8081,如图所示。
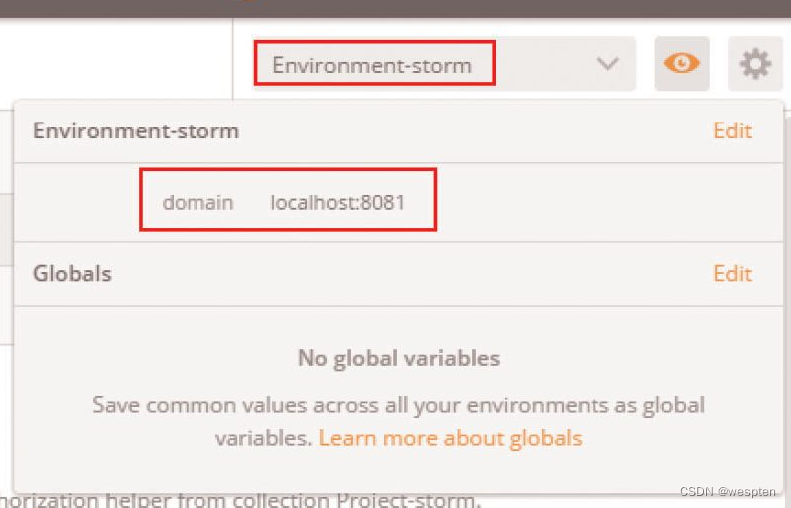
因此,接口请求的URL地址可以变更为下图所示。
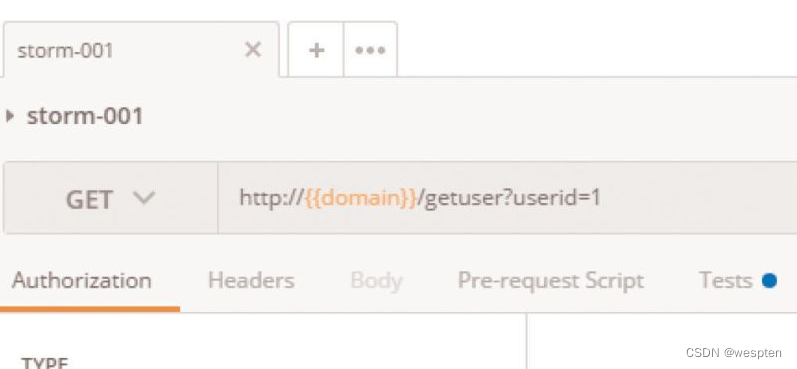
接下来,在Tests中构造测试点,这里选择验证Response响应和预期值一致,如图所示。
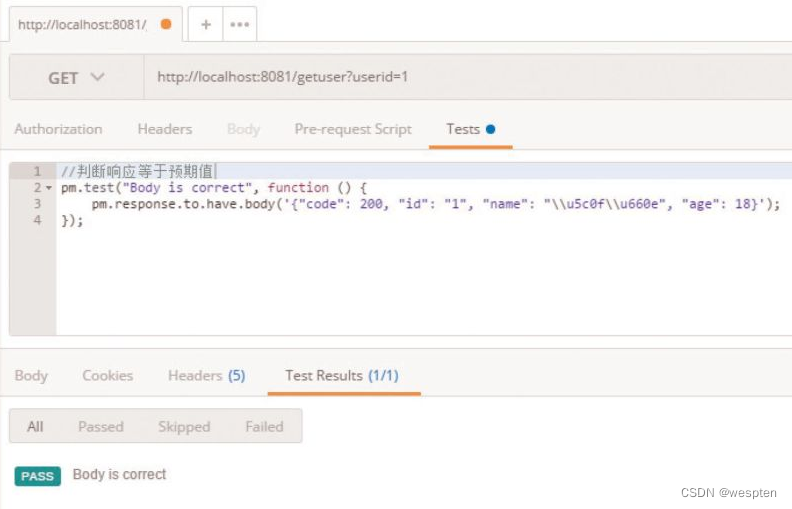
当然,也可以选择其他验证点,如判断Response中的code值等于200(验证响应体相等并不是一个明智的做法,因为不同环境,id=1对应的用户不同,响应体自然也会不同),如图所示。
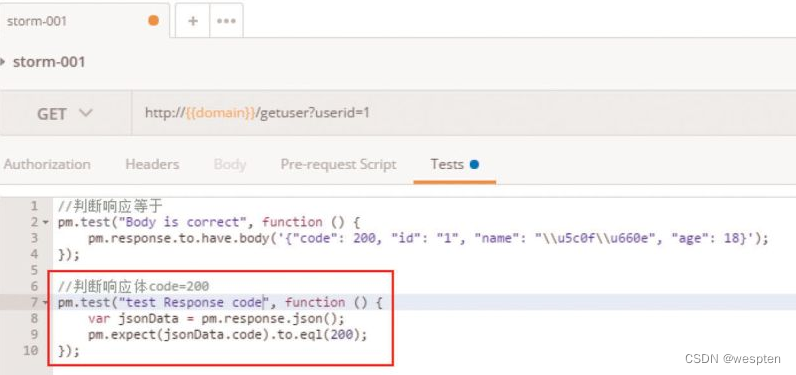
单击Send按钮,发送接口请求,查看测试结果,如图所示。
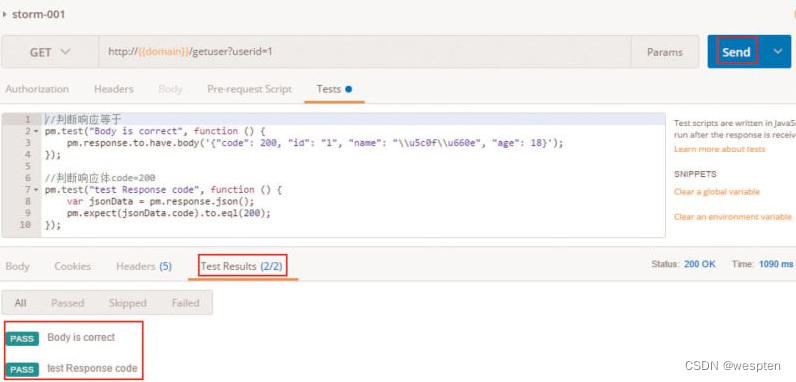
这里设置的2个测试结果都为PASS,该测试用例执行通过。
- 测试用例:storm-002
通过Postman构造接口请求及测试点(期待响应返回提示“没有这个用户”),如图所示。
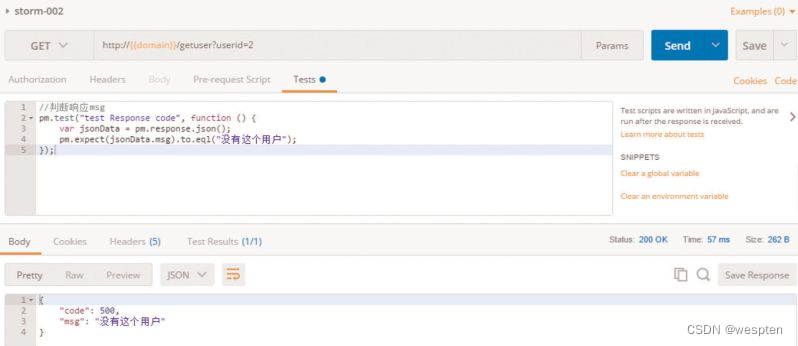
当useid不存在时,接口响应提示“没有这个用户”,测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-003
通过Postman构造接口请求及测试点(不传递参数,接口响应提示“没有这个用户”),如图所示。
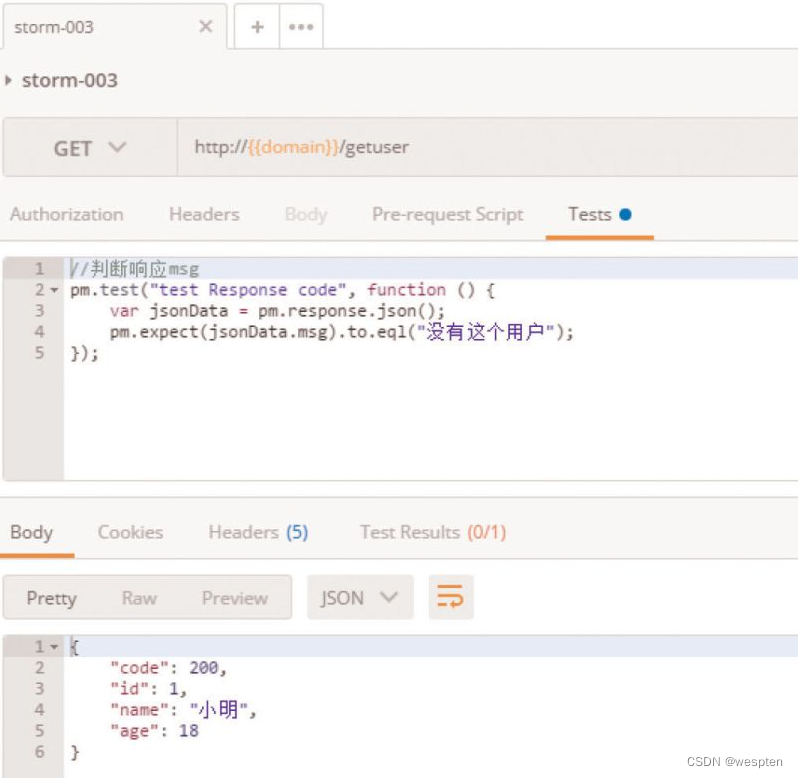
发送接口请求后,没有发送必需参数userid,却返回了用户信息,该测试结果为FAIL,该测试用例执行不通过。
- 测试用例:storm-004
通过Postman构造请求及测试点(userid非法传递参数,期待返回“没有这个用户”),如图所示。
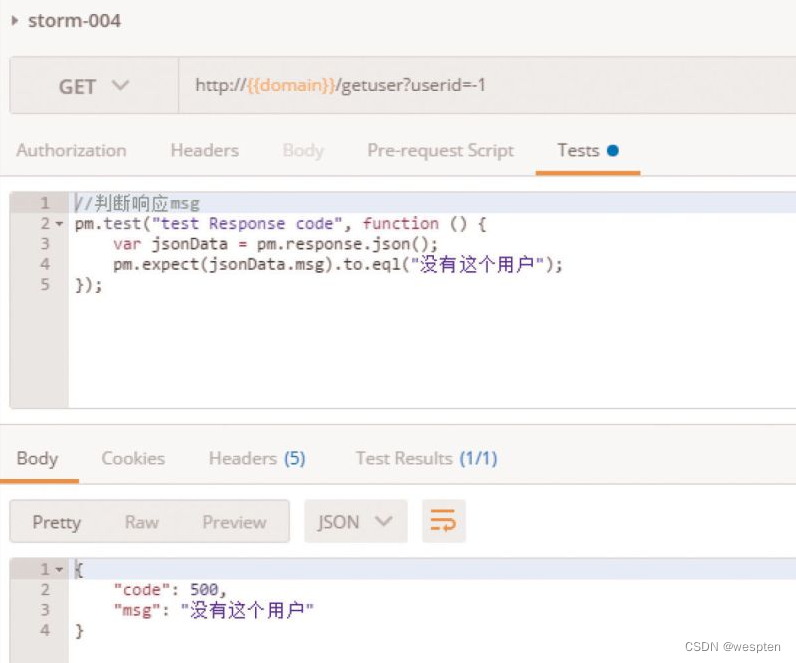
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-005
通过Postman构造请求及测试点(userid非法参数,返回“没有这个用户”),如图所示。
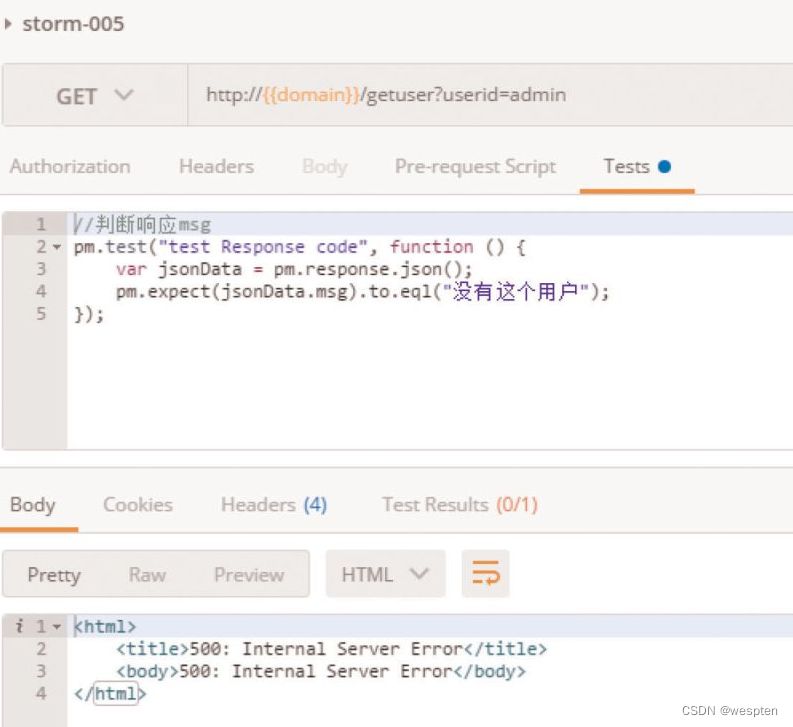
该接口没有正确处理异常参数,测试结果为FAIL,测试用例执行不通过。
- 测试用例:storm-006
通过Postman构造POST请求(接口文档声明该接口支持GET和POST方法),如图所示。
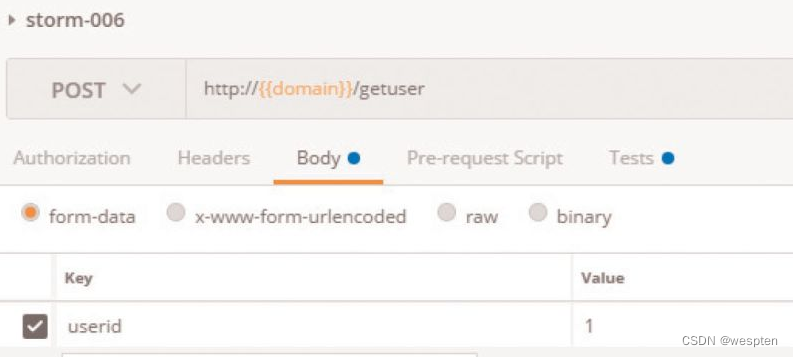
构造测试点,如图所示。
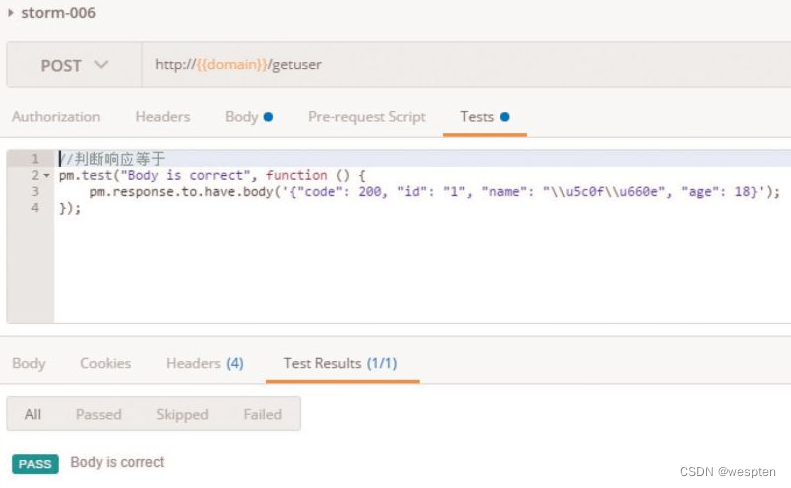
- 测试用例:storm-007
通过Postman构造POST请求(所传递参数userid为不存在ID),如图所示。
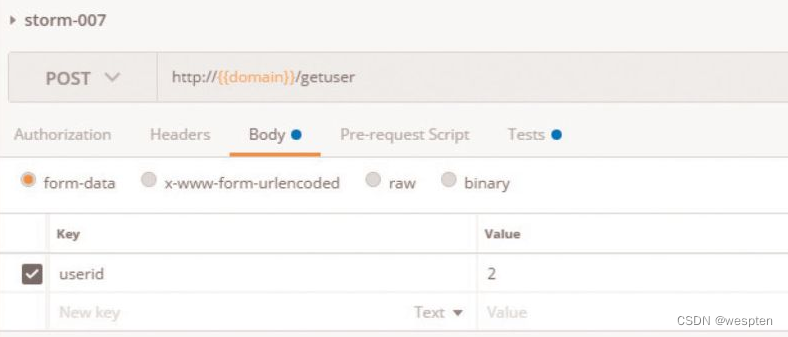
构造测试点,如图所示。
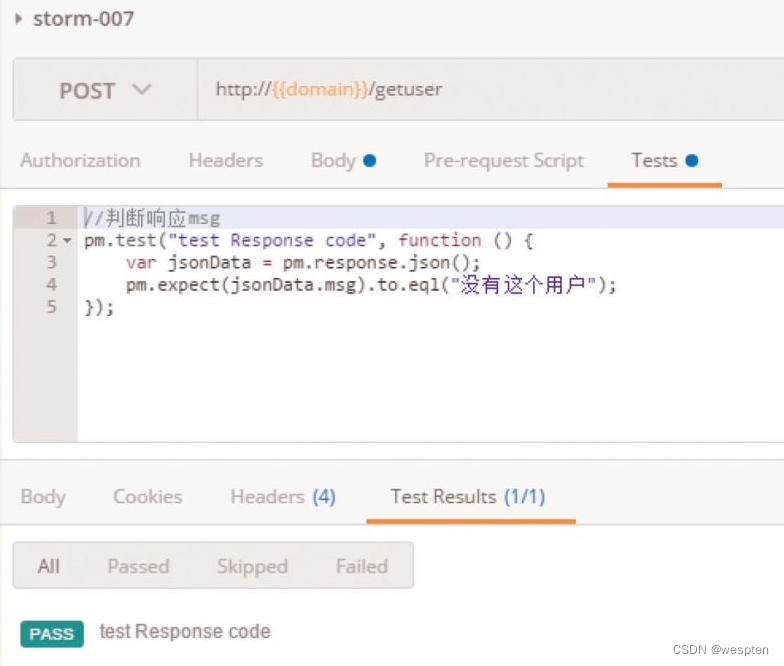
测试结果为PASS,测试用例执行通过。
- 测试用例:storm-008
通过Postman构造POST请求,不传递参数,如图所示。
构造验证点,如图所示。
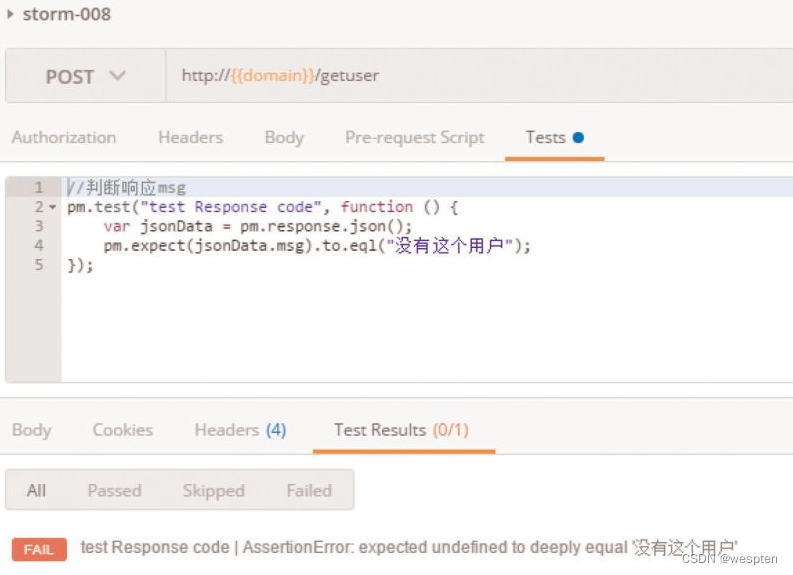
该测试结果为FAIL,测试用例执行不通过。
- 测试用例:storm-009
通过Postman构造POST请求(userid=-1,非法传递参数),如图所示。
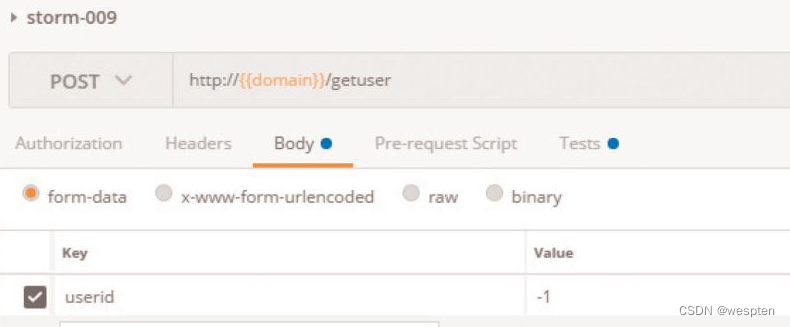
构造测试点,如图所示。
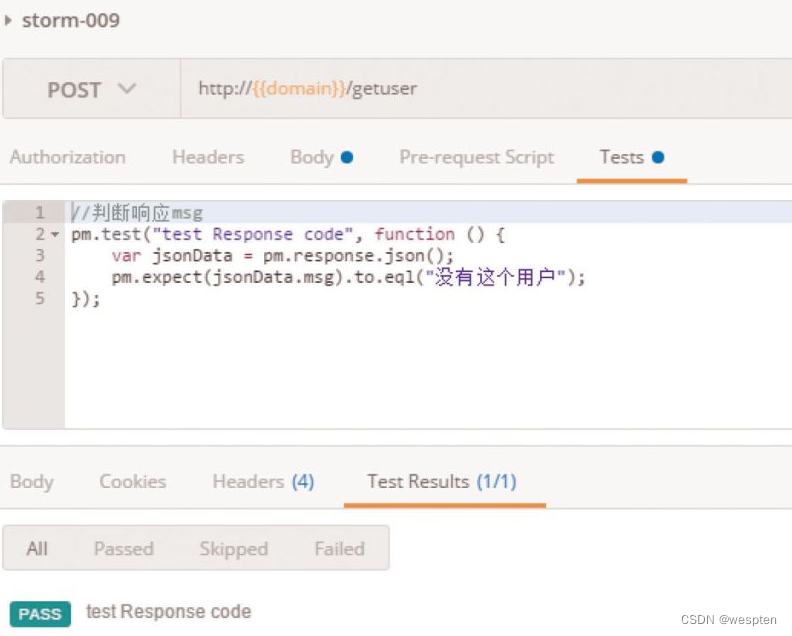
测试结果为PASS,测试用例执行通过。
- 测试用例:storm-010
通过Postman构造请求,userid=amdin,为非法传递参数,如图所示。
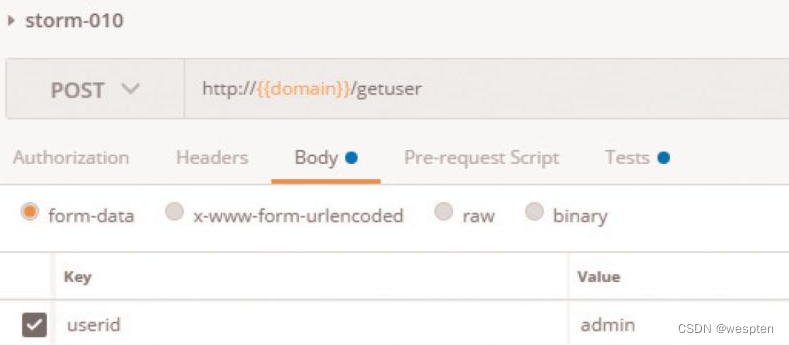
构造测试点如图所示。
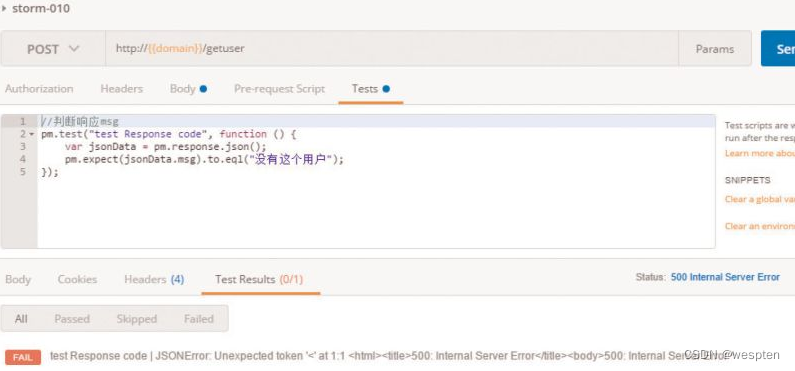
测试结果为FAIL,该测试用例执行不通过。
- 测试用例:storm-011
通过Postman构造请求,正常传递参数,如图所示。
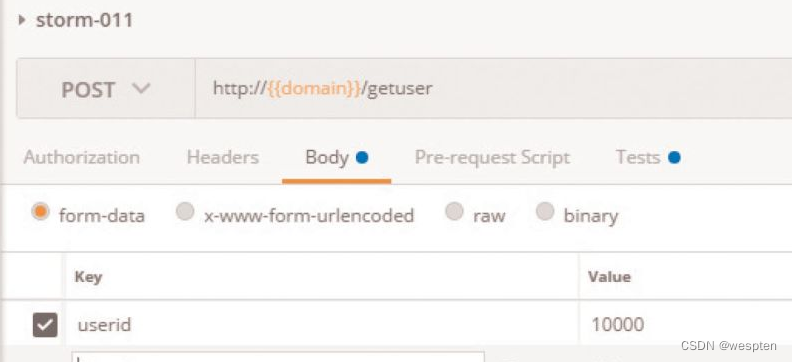
构造测试点,如图所示。
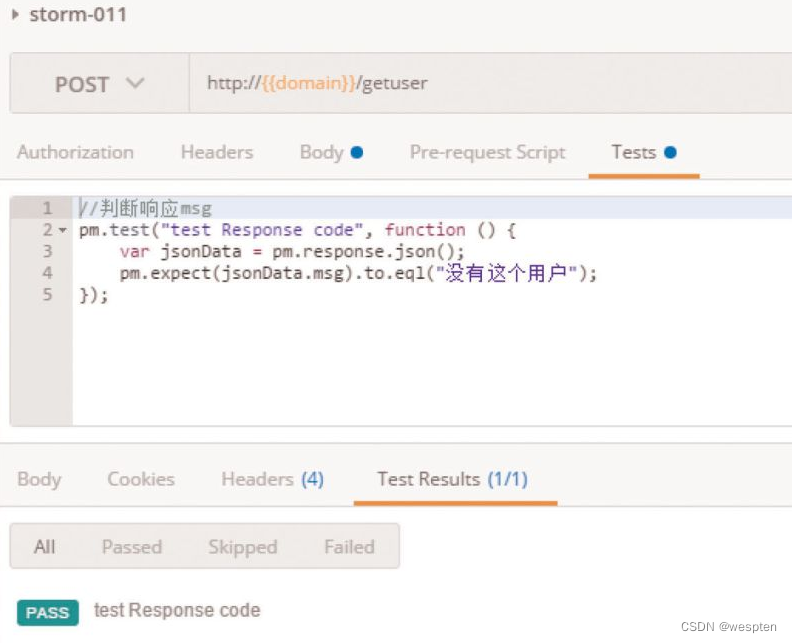
测试结果为PASS,测试用例执行通过。
- 测试用例:storm-012
通过Postman构造请求,如图所示。
构造测试点,如图所示。
测试结果为PASS,测试用例执行通过。
- 测试用例:storm-013
通过Postman构造请求,如图所示。
构造验证点,如图所示。
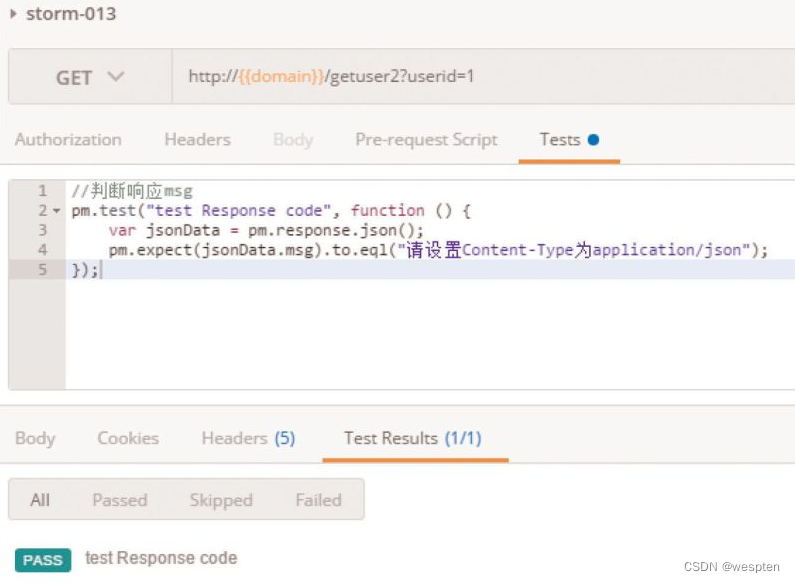
测试结果为PASS,该测试用例通过。
- 测试用例:storm-014
通过Postman构造请求,如图所示。
构造测试点,如图所示。
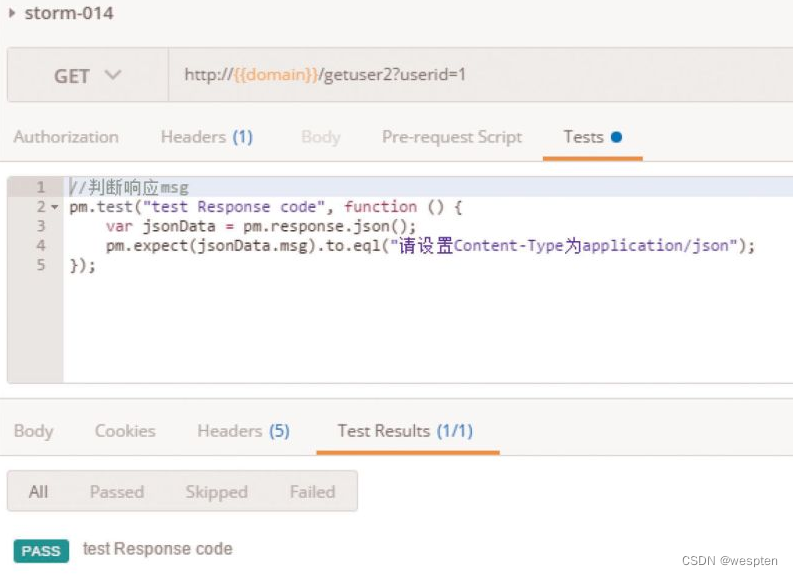
测试结果为PASS,测试用例通过。
- 测试用例:storm-015
通过Postman构造请求,如图所示。
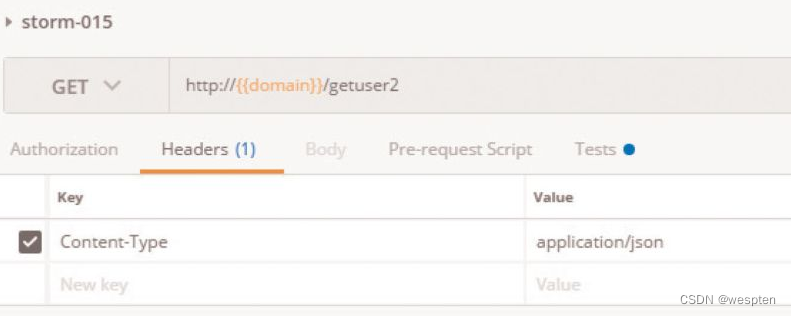
构造测试点,如图所示。
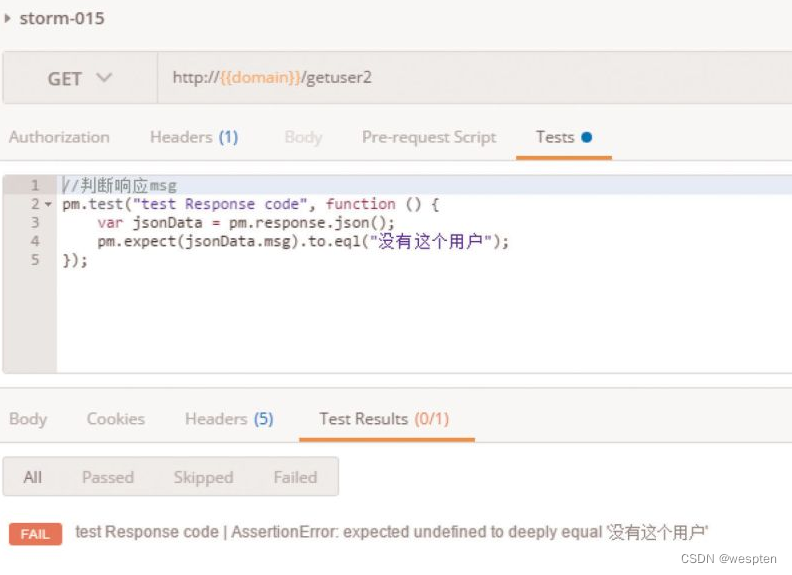
不发送userid,却返回用户信息,测试结果为FAIL,该测试用例不通过。
- 测试用例:storm-016
通过Postman构造请求,如图所示。
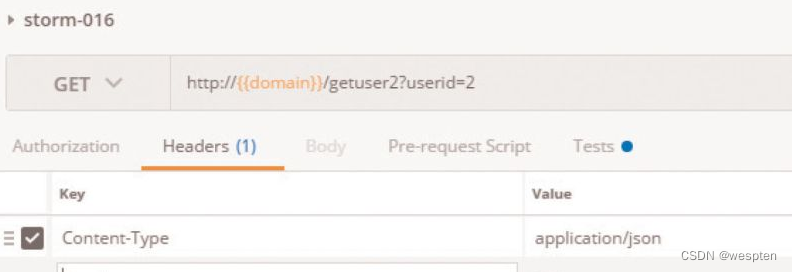
构造测试点,如图所示。
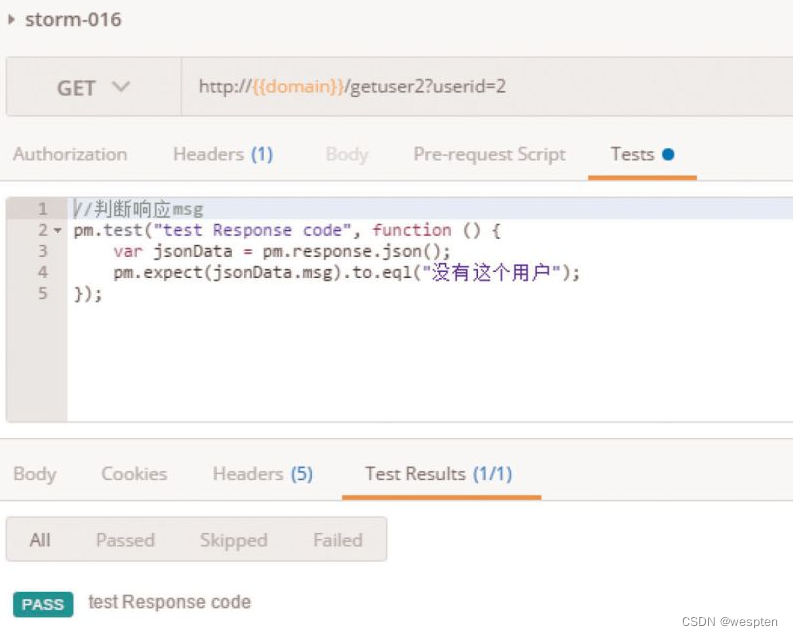
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-017
通过Postman构造请求,如图所示。
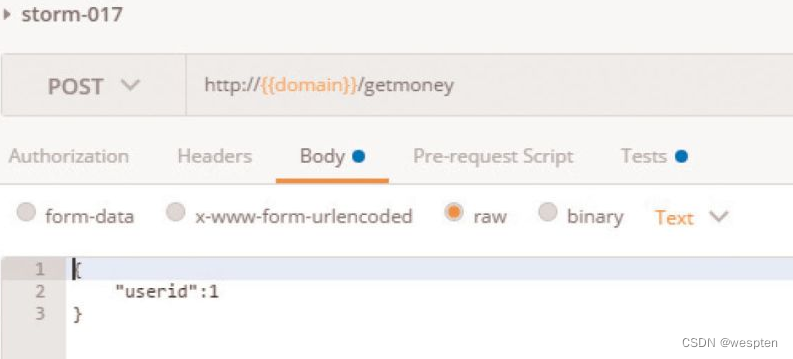
构造测试点,如图所示。
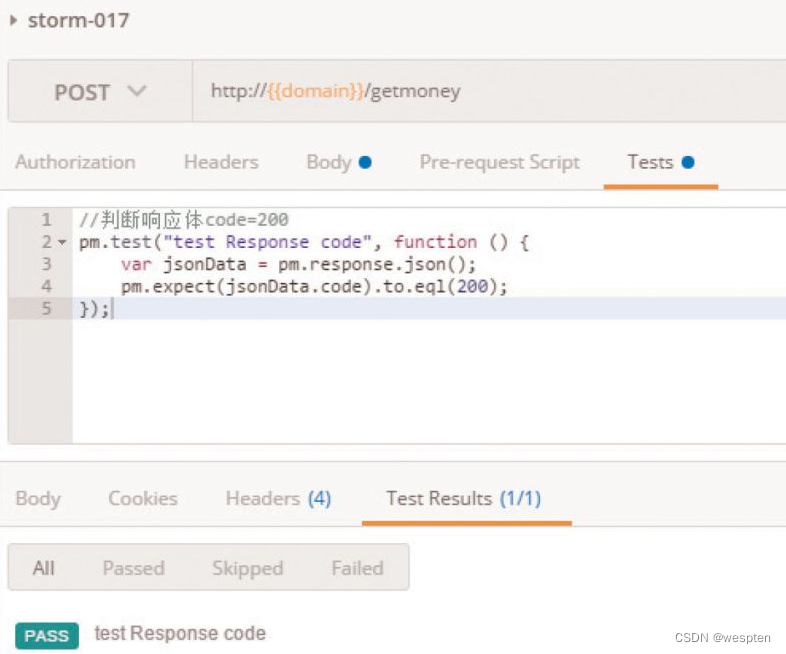
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-018
通过Postman构造请求,如图所示。
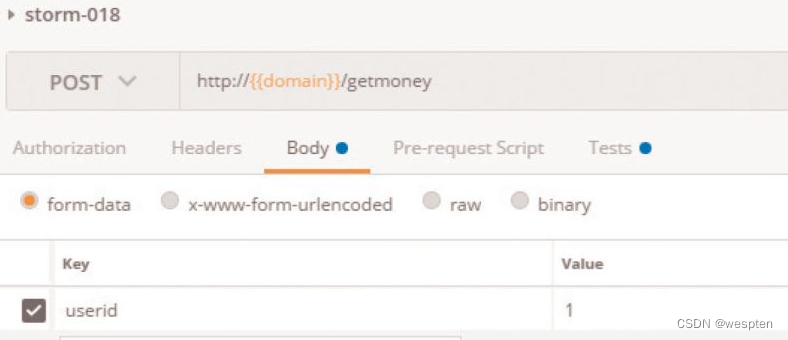
构造测试点,如图所示。

测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-019
通过Postman构造请求,如图所示。
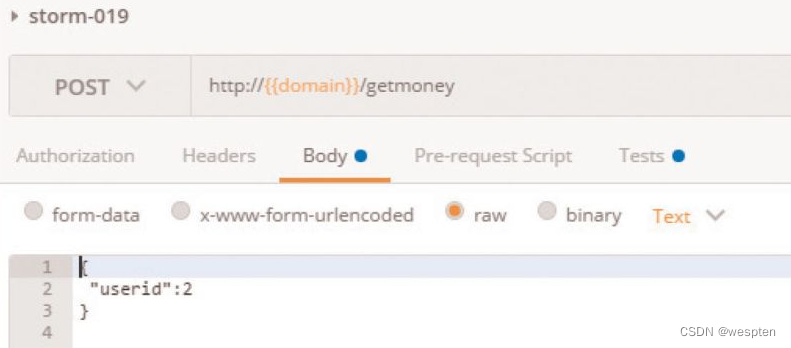
构造测试点,如图所示。
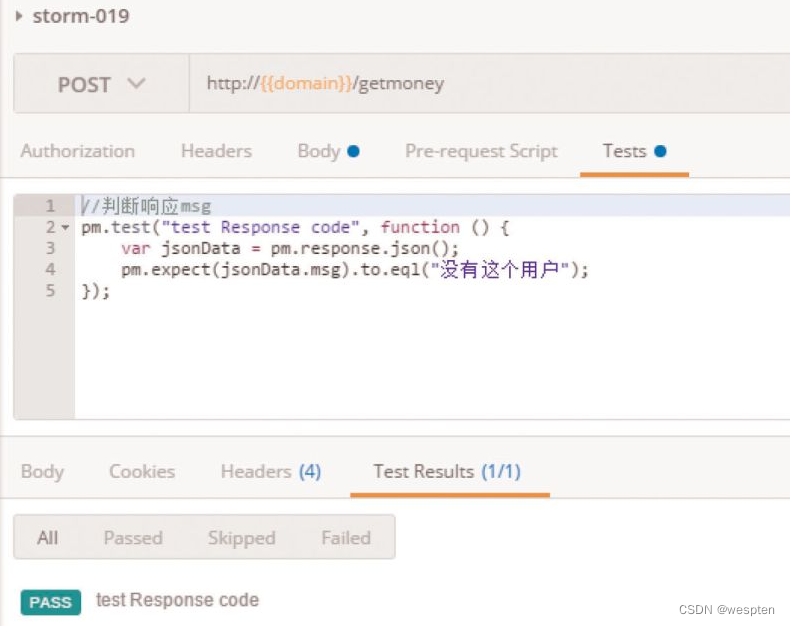
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-020
通过Postman构造请求,如图所示。
构造测试点,如图所示。
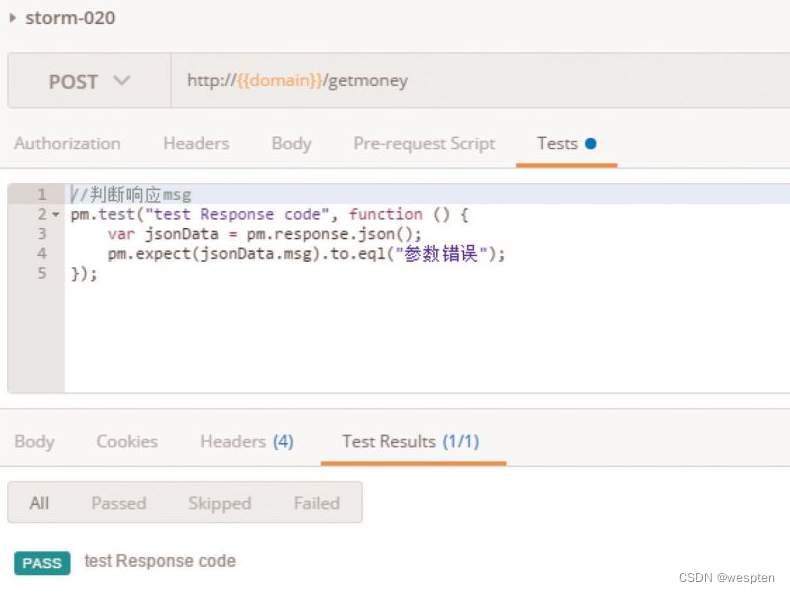
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-021
通过Postman构造请求,如图所示。
构造测试点,如图所示。
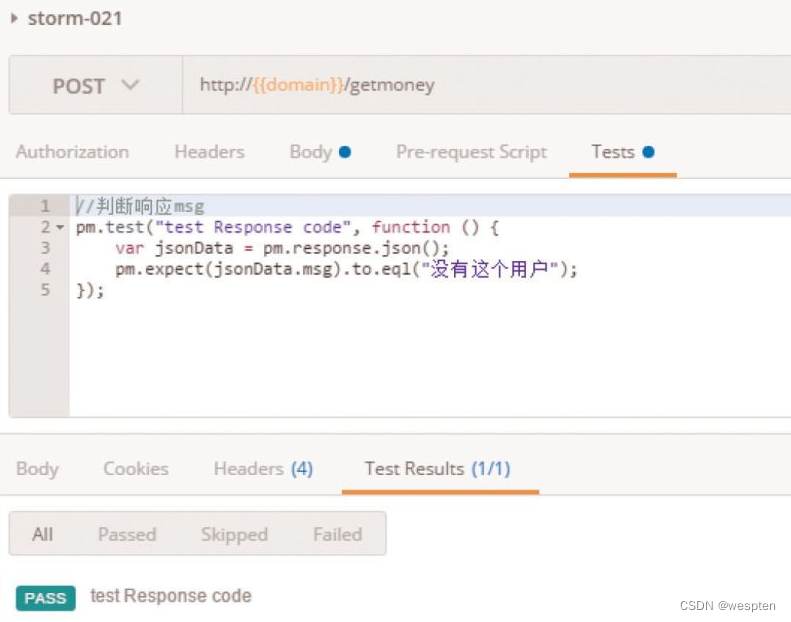
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-022
通过Postman构造请求,如图所示。
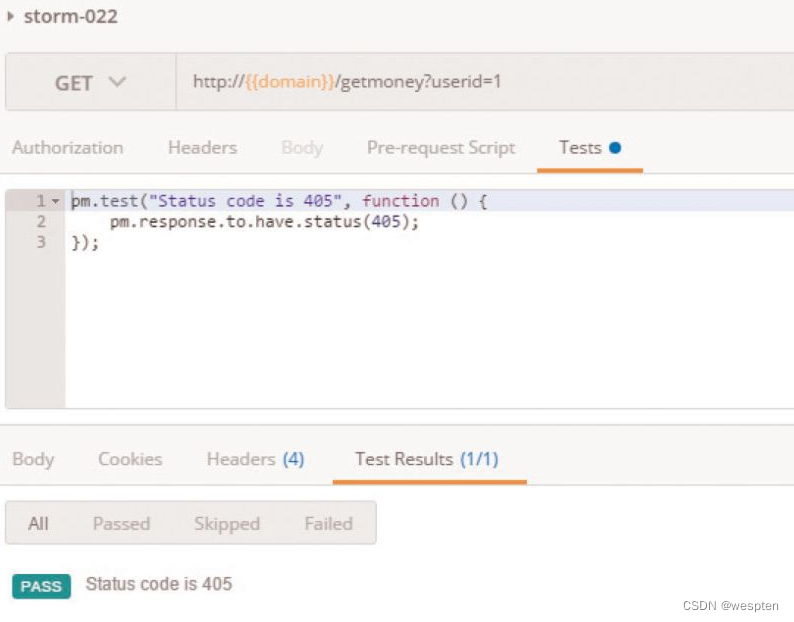
该接口不支持GET请求,Response code=405,测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-023
通过Postman构造请求,如图所示。
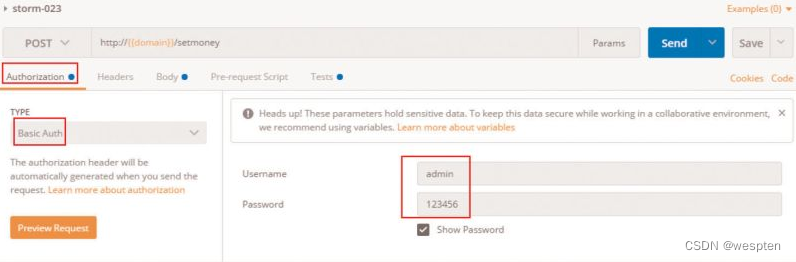
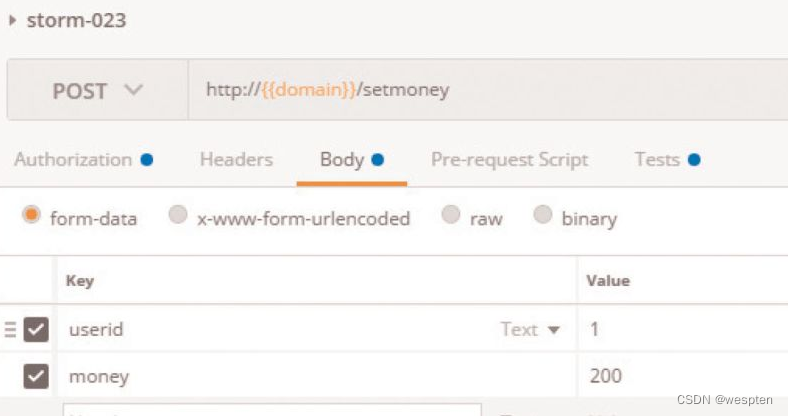
构造测试点,如图所示。
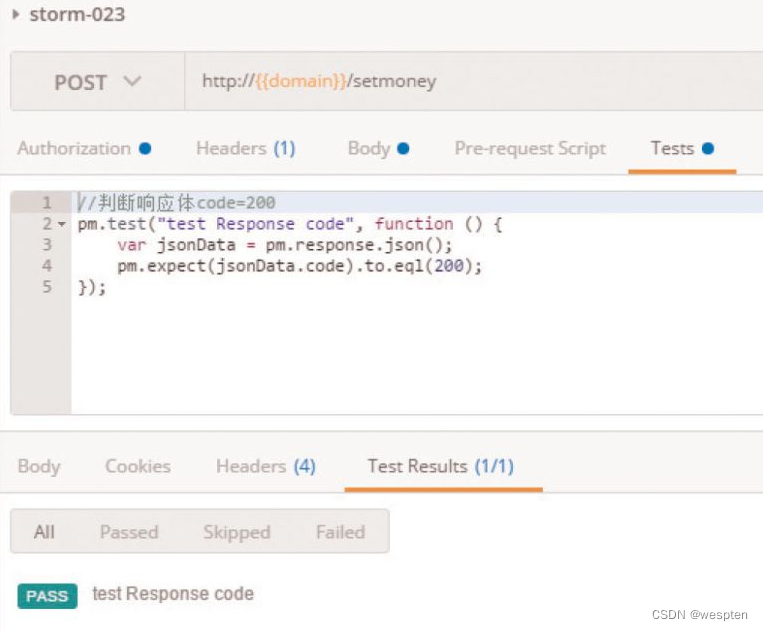
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-024
通过Postman构造请求,如图所示。
构造测试点,如图所示。
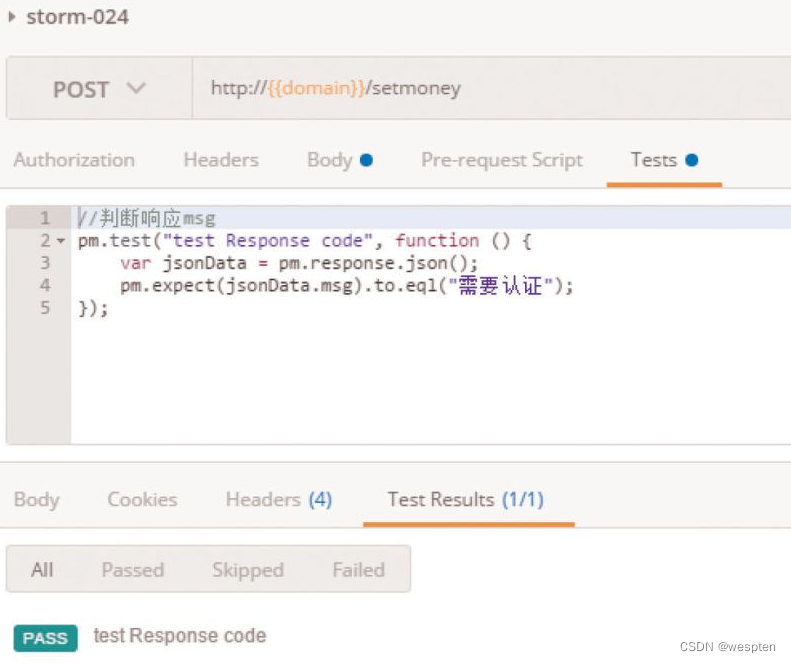
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-025
通过Postman构造请求,如图所示。
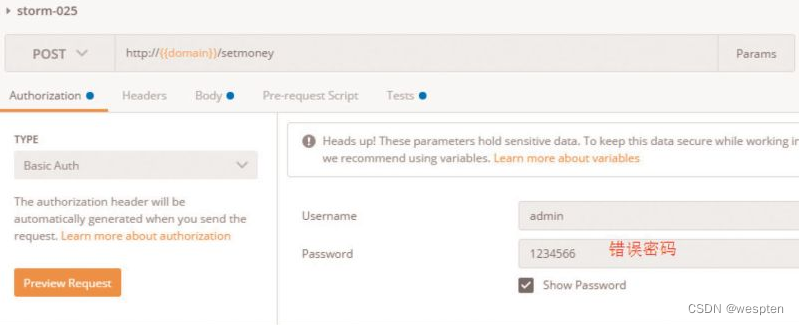
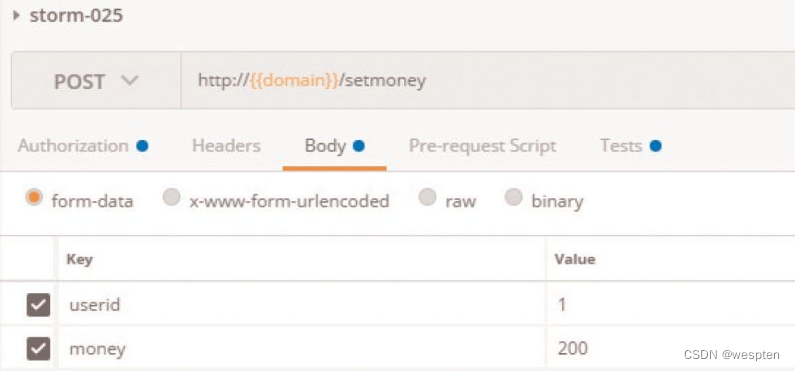
构造测试点,如图所示。
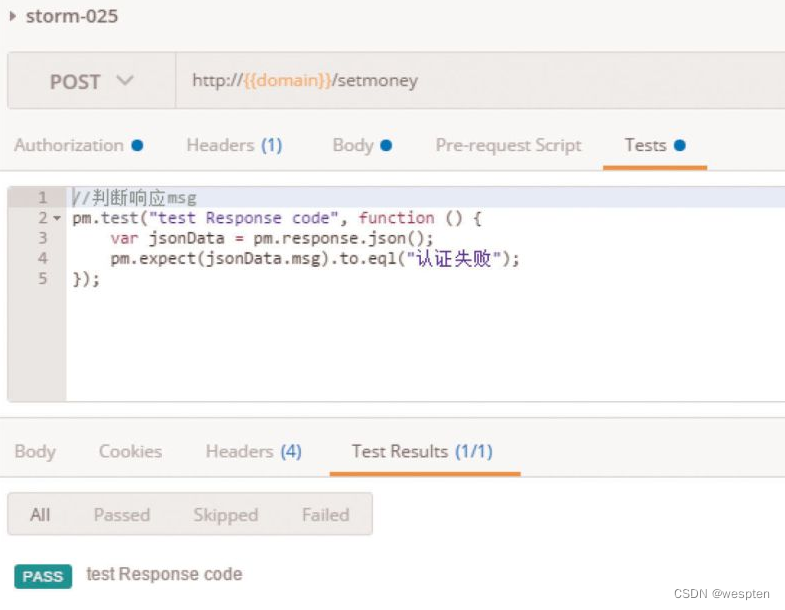
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-026
通过Postman构造请求,如图所示。
构造测试点,如图所示。
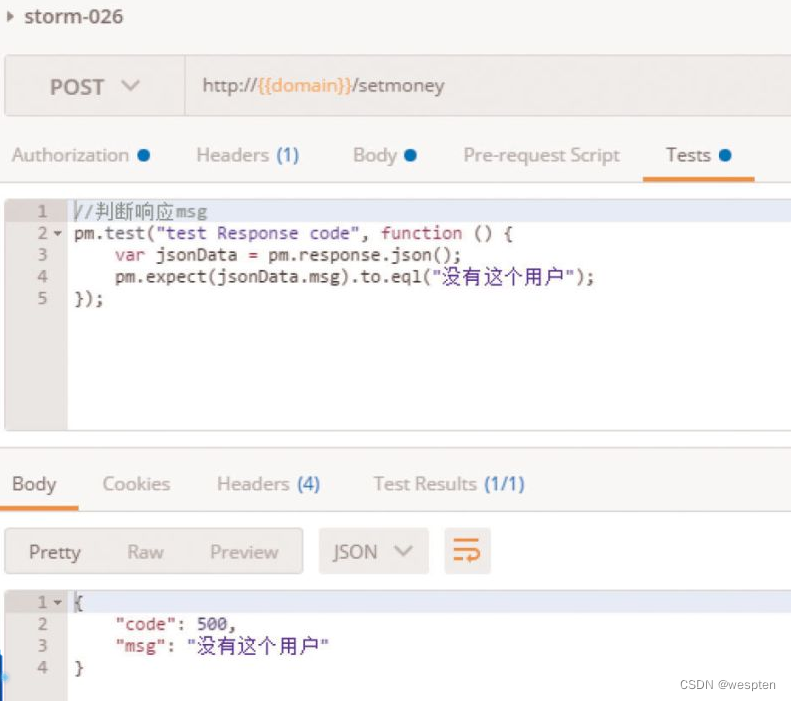
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-027
通过Postman构造请求,如图所示。
构造测试点,如图所示。

当设置金额为小数时,报错,处理异常,测试结果为FAIL,该测试用例不通过。
- 测试用例:storm-028
通过Postman构造请求,如图所示。
构造测试点,如图所示。
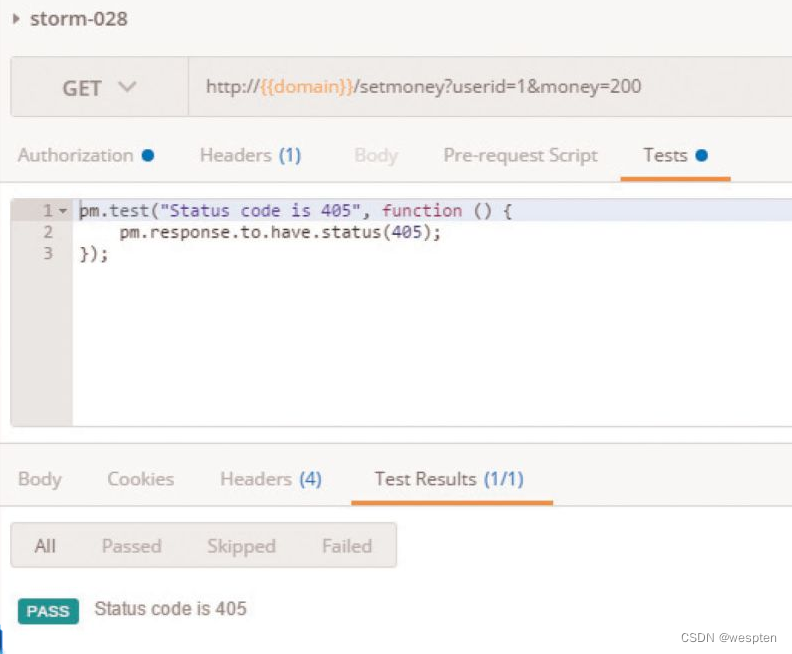
该接口不支持GET请求,测试结果为PASS。
- 测试用例:storm-029
通过Postman构造请求,如图所示。
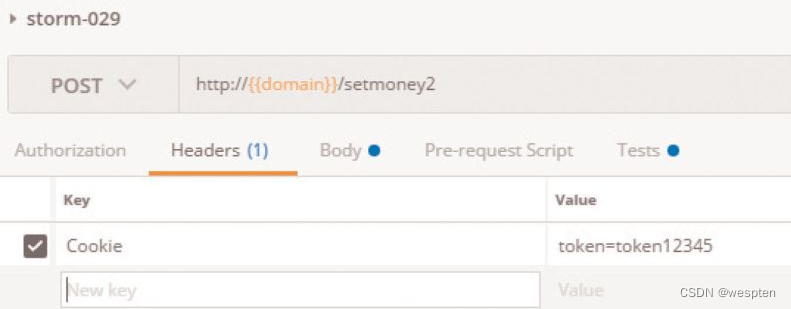
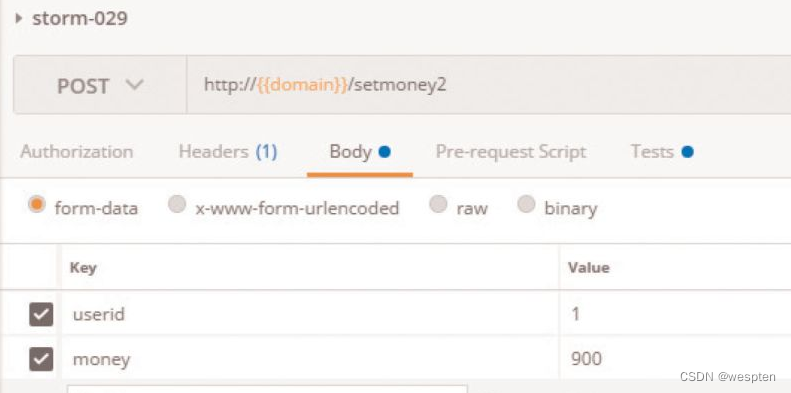
构造测试点,如图所示。
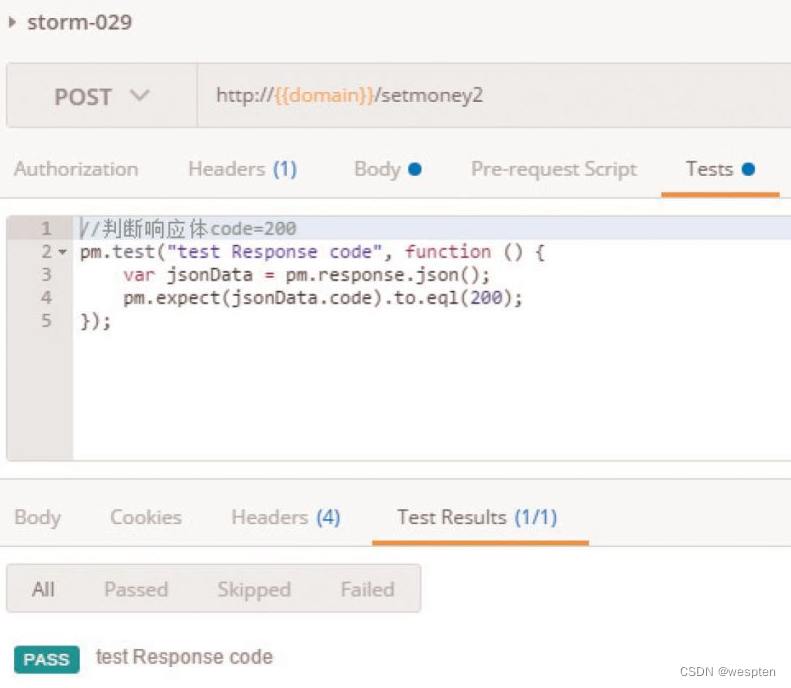
测试结果为PASS,该测试用例执行通过。
- 测试用例:storm-030
通过Postman构造请求,如图所示。

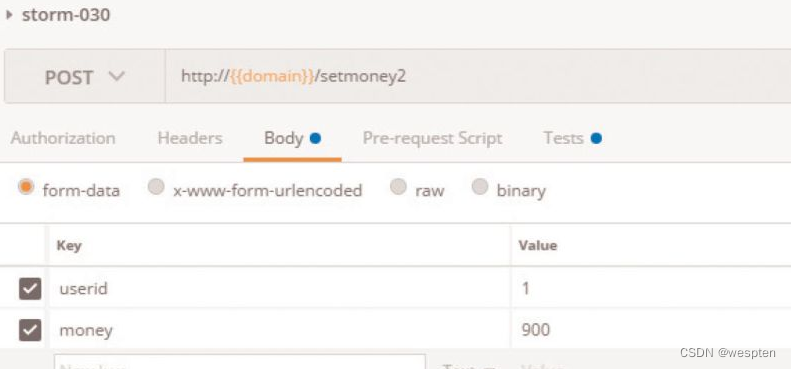
构造测试点,如图所示。
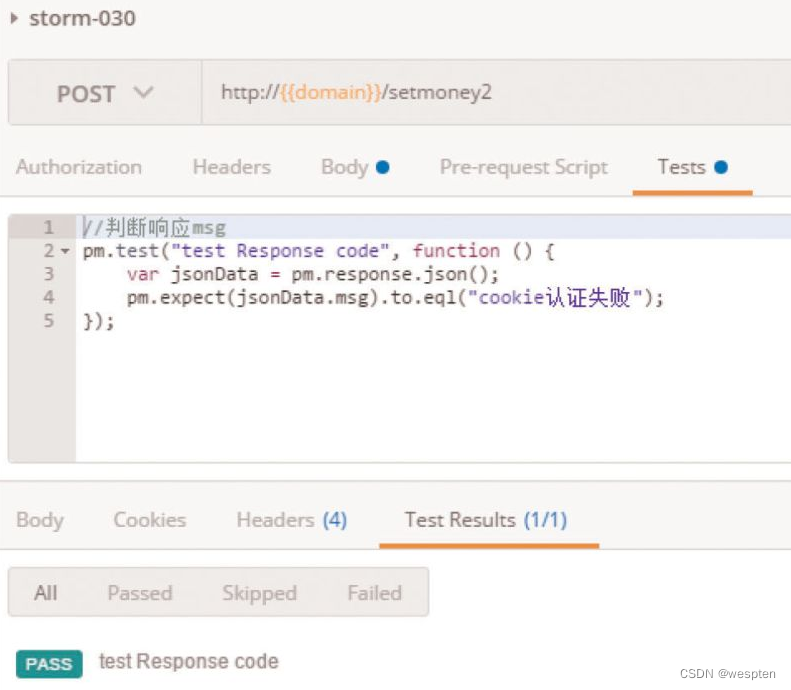
不传Cookies,接口认证失败,测试结果为PASS。
- 测试用例:storm-031
通过Postman构造请求,如图所示。
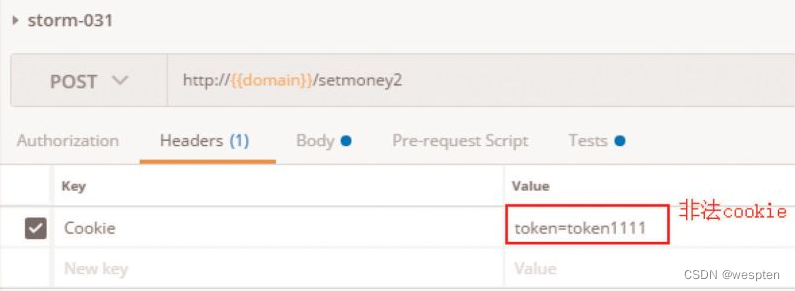
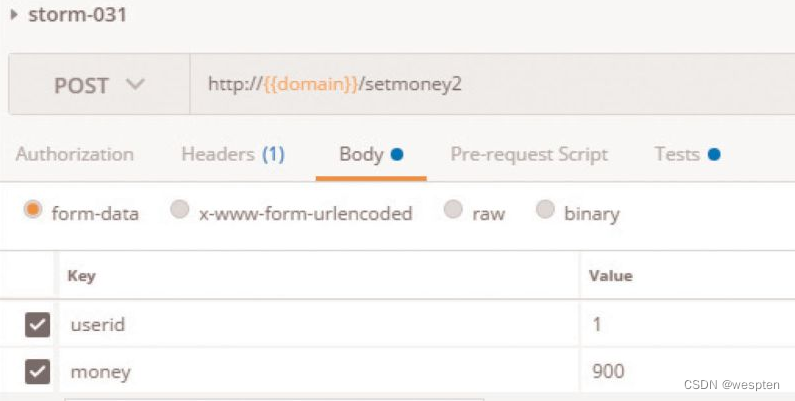
构造测试点,如图所示。
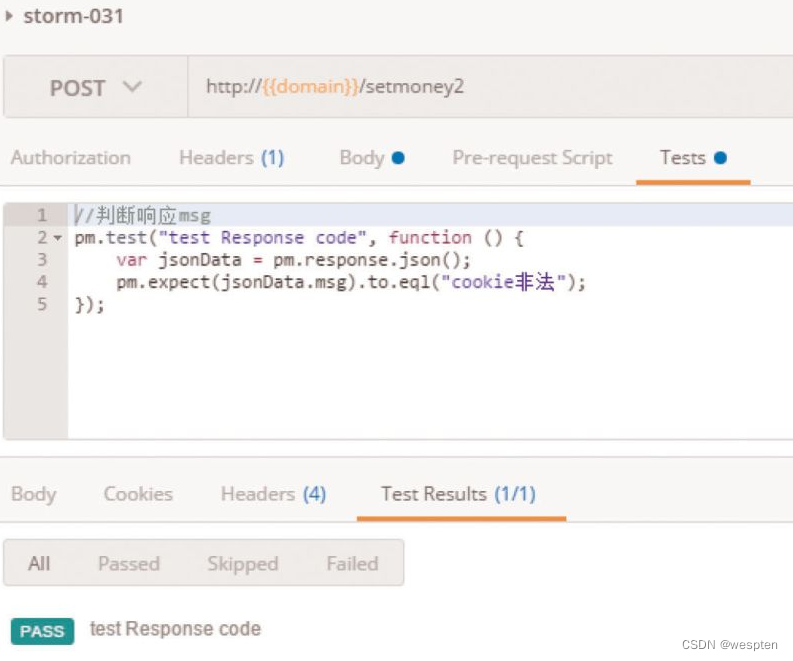
测试结果为PASS。
- 测试用例:storm-032
通过Postman构造请求,如图所示。

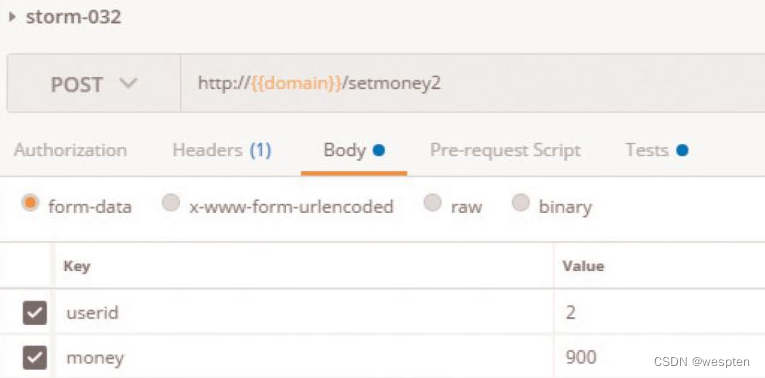
构造测试点,如图所示。
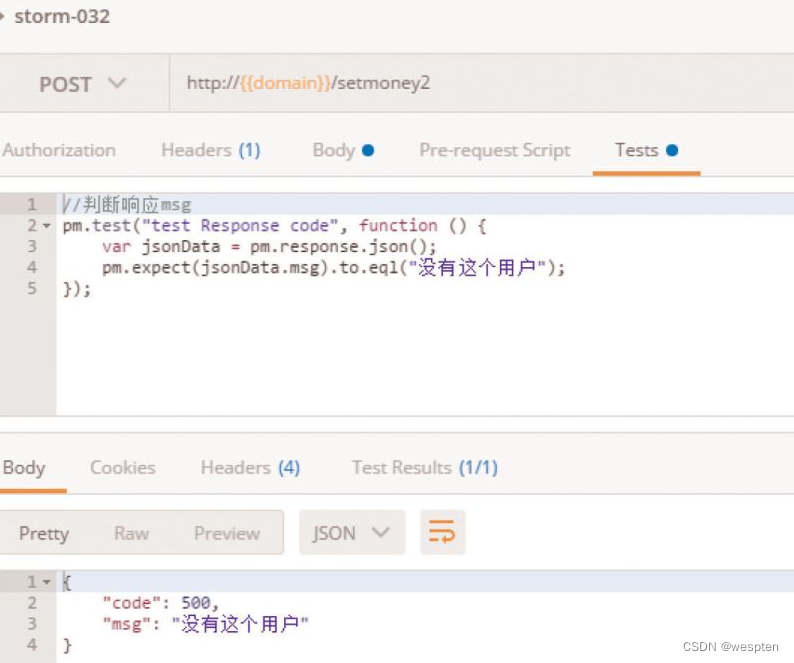
测试结果为PASS。
- 测试用例:storm-033
通过Postman构造请求,如图所示。
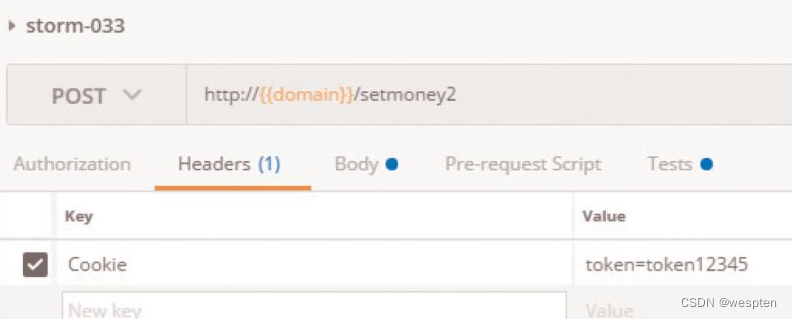

构造测试点,如图所示。

测试失败,结果为FAIL。
- 测试用例:storm-034
通过Postman构造请求,如图所示。
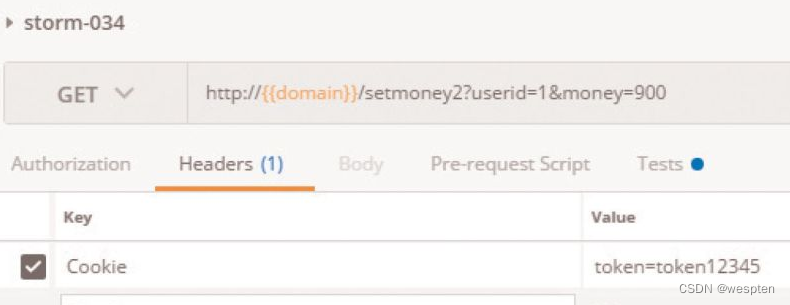
构造测试点,如图所示。
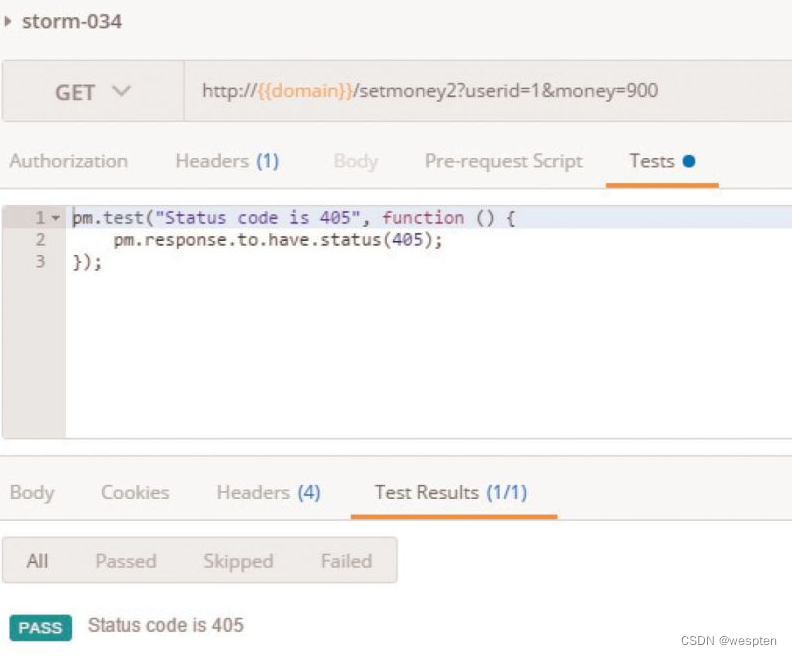
测试结果为PASS。
- 测试用例:storm-035
通过Postman构造请求,如图所示。
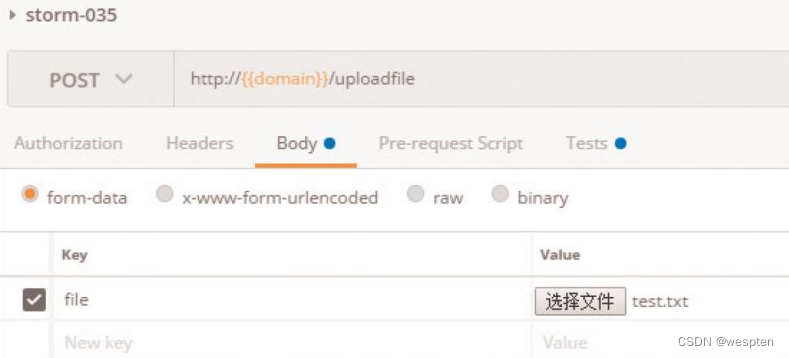
构造测试点,如图所示。
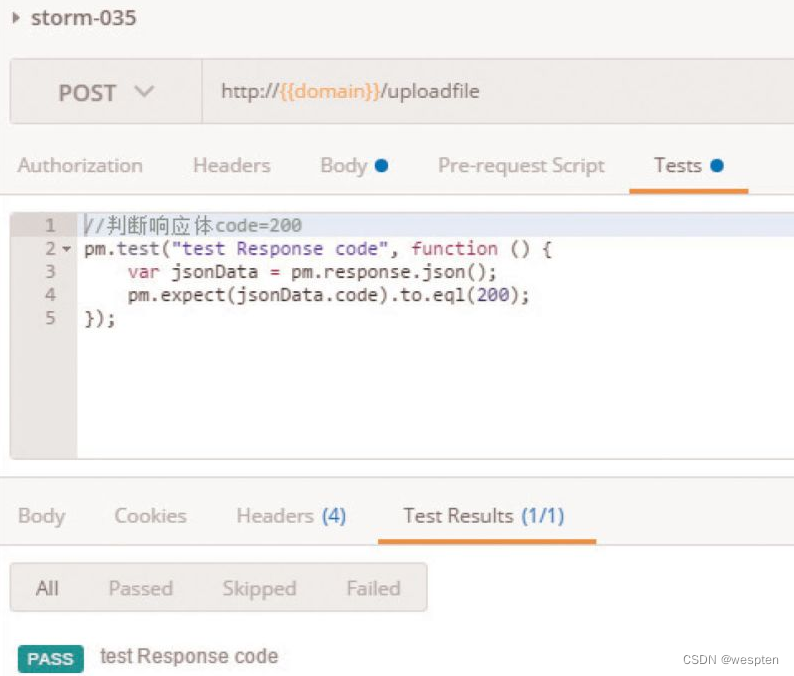
测试结果为PASS。
注意脚本启动目录是否有上传文件权限,如果没有的话会出现上传失败的情况。
下面运行集合Project-storm(包含上述35个接口请求),如图所示。
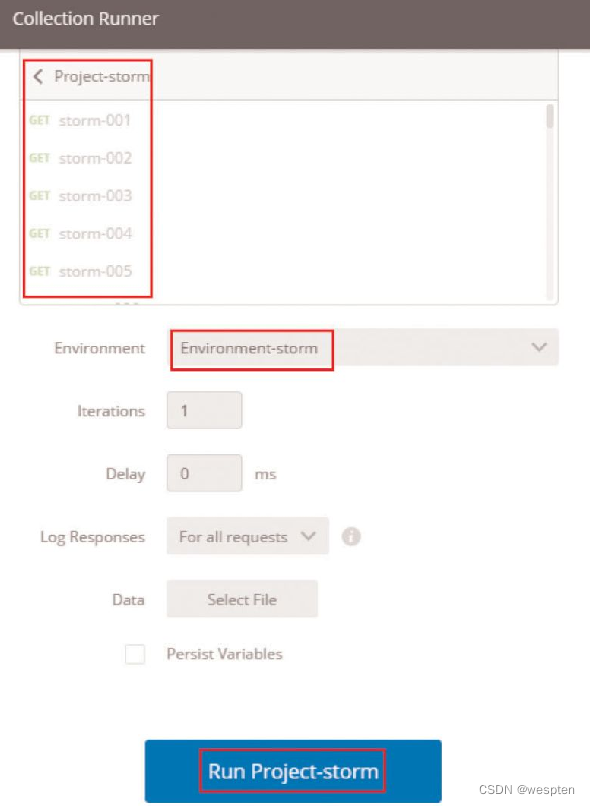
查看运行结果,如图所示。
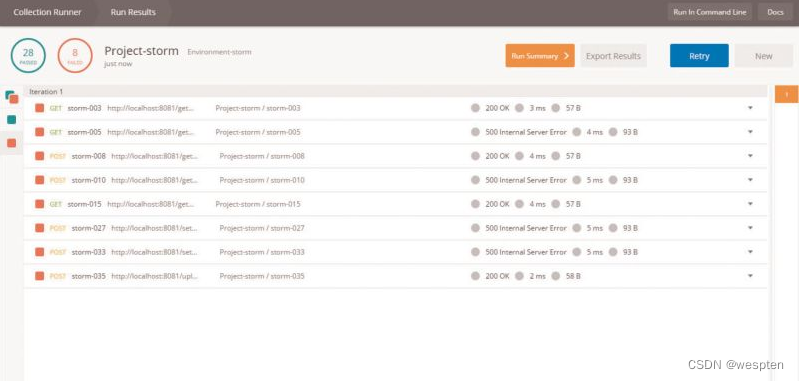
其中测试用例storm-003、storm-005、storm-008、storm-010、storm-015、storm-027、storm-033、storm-035,共8个测试用例执行失败(和我们手动执行接口测试结果一致),storm-035是由于上传文件不能保存导致的,我们暂时忽略。
6. 从Newman执行接口测试
为了可以通过Newman命令行执行接口测试,需要将前面的集合和环境变量保存到本地。导出集合和环境变量的JSON文件,如图所示。

按“Win+R”组合键,输入“cmd”,按“Enter”键,打开“命令提示符”窗口,输入Newman命令运行集合,测试结果如图所示。
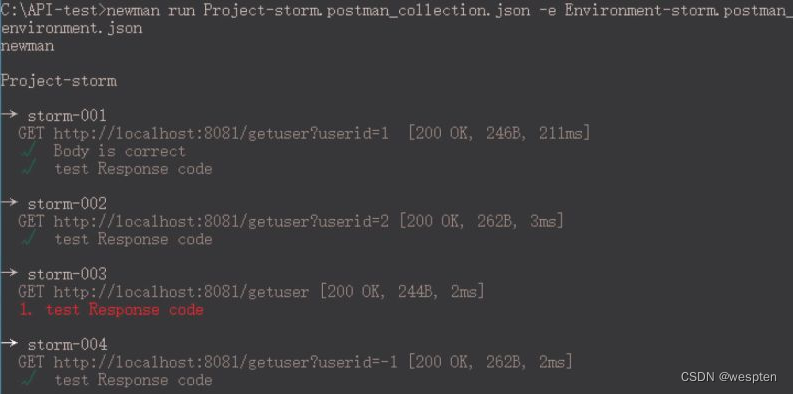
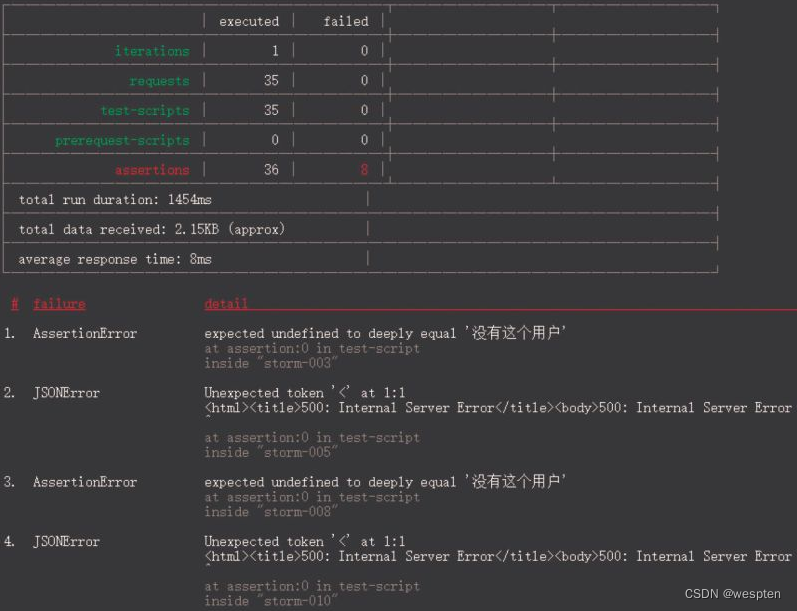
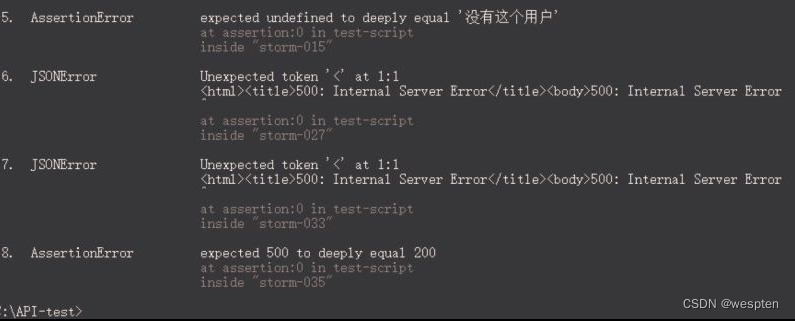
可以看到通过Newman命令行运行集合的测试结果和Postman Runner的运行结果一致。
7. 接口自动化测试持续集成
测试期间,将Postman导出的文件保存到本地Git仓库目录,然后将文件推送到远程GitHub仓库。
使用下面的命令,将其推送到GitHub。
$ git status #查看状态
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: Environment-storm.postman_environment.JSON
no changes added to commit (use "git add" and/or "git commit -a")
admin@LAPTOP-VFR42H91 MINGW64 /c/API-test (master)
$ git add Environment-storm.postman_environment.JSON #添加到暂存区
admin@LAPTOP-VFR42H91 MINGW64 /c/API-test (master)
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: Environment-storm.postman_environment.JSON
admin@LAPTOP-VFR42H91 MINGW64 /c/API-test (master)
$ git commit -m "update Environment" #提交到本地库
[master 31c5830] update Environment
1 file changed, 1 insertion(+), 1 deletion(-)
admin@LAPTOP-VFR42H91 MINGW64 /c/API-test (master)
$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working directory clean
admin@LAPTOP-VFR42H91 MINGW64 /c/API-test (master)
$ git push #同步到GitHub
Counting objects: 3, done
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 290 bytes | 0 bytes/s, done.
Total 3 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
To https://github.com/StormPuck/API-test.git
817ebcc..31c5830 master -> master
admin@LAPTOP-VFR42H91 MINGW64 /c/API-test (master)
$创建Jenkins构建任务:
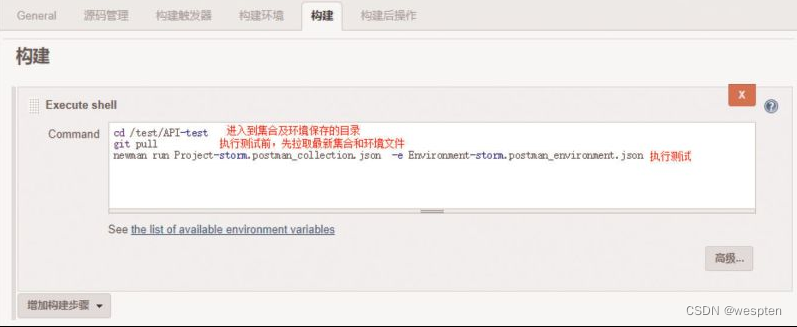
配置构建后操作:
① 添加邮件提醒
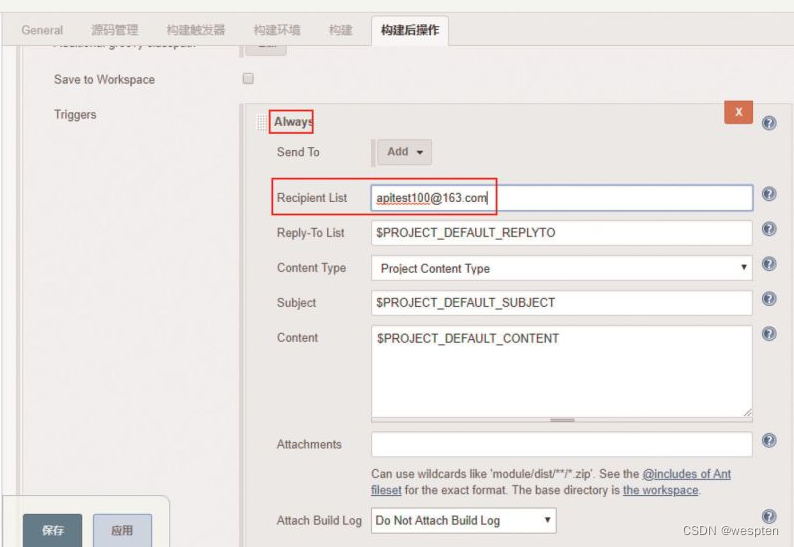
② 添加钉钉提醒,如图所示。

手动执行构建:

该构建结果和本地Newman命令运行结果一致。
查看邮件提醒:
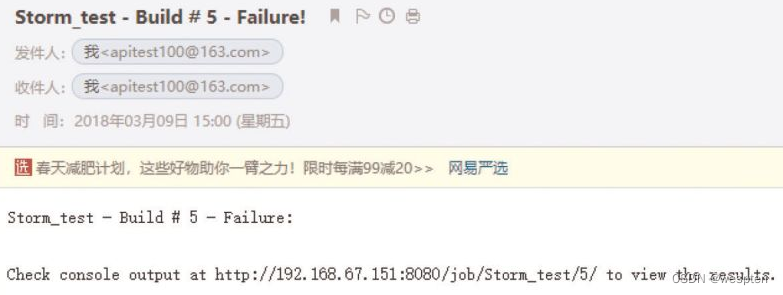
钉钉通知消息:

6、分布式执行
Selenium Grid是Selenium套件的一部分,专门用于将测试用例并行执行在不同的浏览器、操作系统和计算机上。这里我们以Selenium Grid 2为例介绍其用法。
Selenium Grid主要使用Hub/Nodes理念。一个Hub可以对应多个基于Hub注册的子节点(Nodes)。当我们在Master执行测试用例时,Hub会被分发给适当的Node去执行。
1. 什么时候用Selenium Grid
用于兼容性测试,同时在不同的浏览器、操作系统和计算机上执行测试用例。
想减少执行时间。
启动Selenium Grid的3种方式:命令行启动;借助JSON配置文件;使用Docker启动。
2. 命令行启动Selenium Grid
这里将会使用两台计算机,一台运行Hub,另一台运行Node。为了方便描述,将运行Hub的计算机命名为“Machine H”(IP:192.168.1.100),将运行Node的计算机命名为“Machine N”(IP:192.168.1.101)。
前提条件如下:
- 配置Java环境。
- 已安装需要运行的浏览器。
- 下载浏览器driver,放到和Selenium Server相同的目录下,否则在启动Node时要加参数才能启动浏览器(java -Dwebdriver.chrome.driver="C:\your path\chromedriver.exe" -jar selenium-server-standalone-3.141.59.jar -role node -hub http://192.168.1.100:5566/grid/register/,该命令可切换浏览器)。
- 下载Selenium Server,将selenium-server-standalone-X.XX.jar分别放在“Machine H”和“Machine N”上(即放在自定义目录中)
- 启动Hub
在“Machine H”上打开命令行窗口,找到Selenium Server所在的目录,执行“java -jar selenium-server-standalone-3.141.59.jar -role hub -port 5566”命令。
启动成功后你会看到下图所示的类似内容:

或者直接在“Machine H”上的浏览器中(“Machine N”则需要将IP修改为“Machine H”的)打开http://localhost:5566/grid/console,将会看到下图所示的类似页面。
在“Machine N”上打开命令行窗口,找到Selenium Server所在的目录,执行“java -jar selenium server-standalone-3.141.59.jar -role node -hub http://192.168.1.100:5566/grid/register/ -port 5577”命令。
启动成功后你会看到图所示的类似内容:
刷新http://localhost:5566/grid/console,将会看到下图所示的类似页面。

- 启动Node
执行测试脚本,将会看到在“Machine N”上打开了Chrome浏览器,并执行了测试用例,如图所示。
from selenium import webdriver
ds = {'platform': 'ANY',
'browserName': "chrome",
'version': '',
'javascriptEnabled': True
}
dr = webdriver.Remote('http://192.168.1.101:5577/wd/Hub', desired_capabilities=ds)
dr.get("https://www.baidu.com")
print dr.name3. 借助JSON配置文件启动
创建Hub的JSON配置文件的代码如下:
{
"port": 4444,
"newSessionWaitTimeout": -1,
"servlets" : [],
"withoutServlets": [],
"custom": {},
"capabilityMatcher": "org.openqa.grid.internal.utils.DefaultCapabilityMatcher",
"registry": "org.openqa.grid.internal.DefaultGridRegistry",
"throwOnCapabilityNotPresent": True,
"cleanUpCycle": 5000,
"role": "Hub",
"debug": False,
"browserTimeout": 0,
"timeout": 1800
}将上述代码保存为Hub_config.json文件,放在“Machine H”上和Selenium Server相同的目录下。
创建Nodes的JSON配置文件的代码如下:
{
"capabilities":
[
{
"browserName": "firefox",
"marionette": True,
"maxInstances": 5,
"seleniumProtocol": "WebDriver"
},
{
"browserName": "chrome",
"maxInstances": 5,
"seleniumProtocol": "WebDriver"
},
{
"browserName": "internet explorer",
"platform": "WINDOWS",
"maxInstances": 1,
"seleniumProtocol": "WebDriver"
},
{
"browserName": "safari",
"technologyPreview": False,
"platform": "MAC",
"maxInstances": 1,
"seleniumProtocol": "WebDriver"
}
],
"proxy": "org.openqa.grid.selenium.proxy.DefaultRemoteProxy",
"maxSession": 5,
"port": -1,
"register": True,
"registerCycle": 5000,
"Hub": "http://192.168.1.100:4444",
"NodeStatusCheckTimeout": 5000,
"NodePolling": 5000,
"role": "Node",
"unregisterIfStillDownAfter": 60000,
"downPollingLimit": 2,
"debug": false,
"servlets" : [],
"withoutServlets": [],
"custom": {}
}将上述代码保存为Node_config.json文件(注意将Hub对应的值改为“Machine H”的IP),放在“Machine N”上和Selenium Server相同的目录下(当存在多个Node时,需将该文件放在多个Node计算机上或者在同一个计算机上启动多个Node)。
- 启动Hub
在运行Hub的计算机的命令行窗口执行命令:java -jar selenium-server-standalone-3.141.59.jar-role Hub -HubConfig Hub_config.json。
- 启动Node
在运行Node的计算机的命令行窗口执行命令:java -jar selenium-server-standalone-3.141.59.jar -role Node -NodeConfig Node_config.json。
通过之前的验证方法和脚本查看代码是否正确
7、Docker应用
Selenium Grid虽然帮助我们实现了分布式运行,但是每个Node都需要下载相关软件并进行配置,一旦出现问题,还需要逐个分析解决。总之,配置软件的过程非常痛苦。
借助Docker来启动Selenium Grid能帮我们简化操作过程。Docker上已经有Selenium官方的Selenium Grid镜像,只要你安装了Docker,就可使用。
1. 启动Hub
命令:Docker run -d -p 4444:4444 --name selenium-Hub selenium/Hub。
2. 启动Node(Chrome和Firefox)
命令:Docker run -d --link selenium-Hub:Hub selenium/Node-chrome。
命令:Docker run -d --link selenium-Hub:Hub selenium/Node-firefox。
执行命令将会下载内置镜像文件(包括Java、Chrome、Firefox、selenium-server-standaloneXXX.jar等运行Selenium所需的环境),此时你可以访问http://localhost:4444/grid/console,如图所示。
如果需要多个Chrome Node则继续执行这个命令:Docker run -d --link selenium-Hub:Hub selenium/Node-chrome。刷新一次则会看到多了一个Chrome实例。
执行命令:Docker ps。程序会显示正在运行的容器,如图所示。

关闭Docker-grid的命令:Docker stop $(Docker ps -a -q),Docker rm $(Docker ps -a -q)。
Docker已经简化了Selenium Grid的搭建流程,但是还是有很多的手动工作,需要一个一个地启动和关闭Hub/Nodes。
- Docker组件启动Selenium Grid
Selenium Grid通常需要启动一个Hub,多个Nodes(如Chrome、Firefox等)。我们可以把它们定义到一个名为“Docker-compose.yml”的文件中,并通过一个命令来整体启动,Docker提供了一个这样的工具——Docker-Compose。
安装Docker-Compose工具,一旦安装成功,就创建一个新的文件夹,并创建文件Docker compose.yml,文件内容如下。
version: “3”
services:
selenium-Hub:
image: selenium/Hub
container_name: selenium-Hub
ports:
- "4444:4444"
chrome:
image: selenium/Node-chrome
depends_on:
- selenium-Hub
environment:
- Hub_PORT_4444_TCP_ADDR=selenium-Hub
- Hub_PORT_4444_TCP_PORT=4444
firefox:
image: selenium/Node-firefox
depends_on:
- selenium-Hub
environment:
- Hub_PORT_4444_TCP_ADDR=selenium-Hub
- Hub_PORT_4444_TCP_PORT=4444Docker-compose的命令如下:
- 启动(到Docker-compose.yml目录下):Docker-compose up -d。
- 查看启动是否成功:Docker-compose ps。
- 创建更多实例:Docker-compose scale chrome=5。
- 关闭:Docker-compose down。
浏览器打开http://localhost:4444/grid/console,将会看到类似图所示的信息。
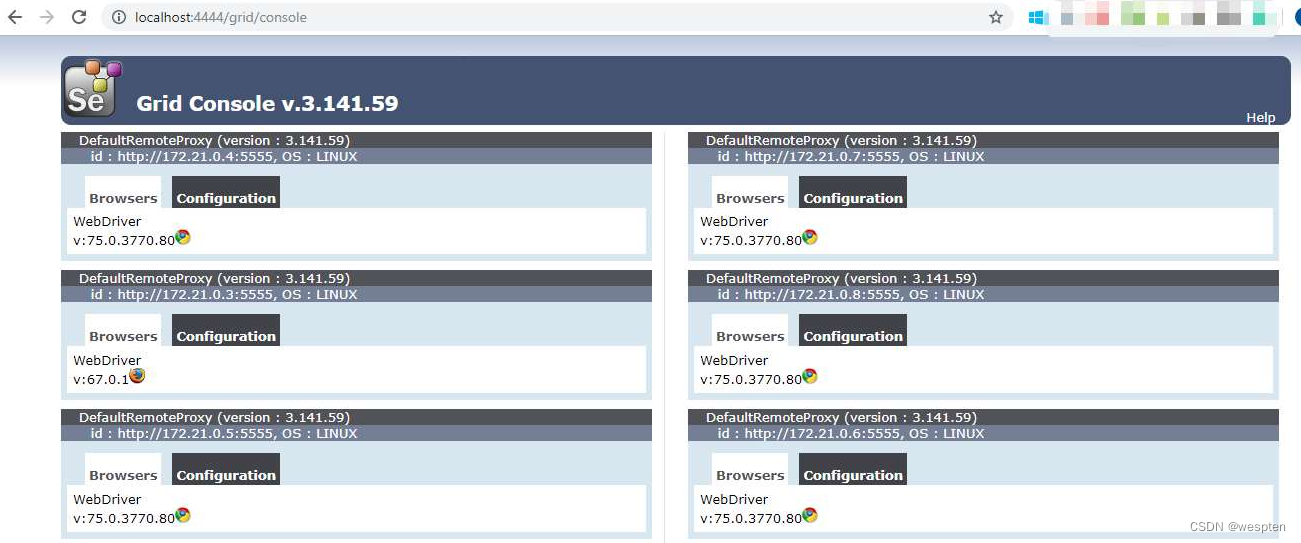
接下来直接执行脚本即可:
import unittest
from selenium import webdriver
class MyTestCase(unittest.TestCase):
def setUp(self):
ds = {'platform': 'ANY',
'browserName': "chrome",
'version': '',
'javascriptEnabled': True
}
self.dr = webdriver.Remote('http://localhost:4444/wd/hub', desired_capabilities=ds)
def test_something(self):
self.dr.get("https://www.baidu.com")
self.assertEqual(self.dr.name, "chrome")
def test_search_button(self):
self.dr.get("https://www.baidu.com")
self.assertTrue(self.dr.find_element_by_id("su").is_displayed())
def tearDown(self):
self.dr.quit()
if __name__ == '__main__':
unittest.main()注意:
使用Docker启动Selenium Grid和前面两种启动方法不太一样,这里不会打开浏览器(即在容器内部执行)。
8、其他补充
1. 无头浏览器
无头的浏览器(headless browser),即没有图形用户界面(GUI)的Web浏览器,通常是通过编程或命令行窗口来控制的。
无头浏览器最早被自动化测试引入的原因是,自动化测试从业者们希望测试机器能够在执行自动化测试的同时还不影响自己处理其他工作。在实际应用的过程中,我们还发现无头浏览器比普通浏览器在执行自动化测试的速度上更有优势,以作者个人的经验来说时间上能节约5%左右。
最早的时候PhantomJS无头浏览器非常流行,但随着Chrome和Firefox相继推出无头浏览器模式,PhantomJS的用户量渐渐减少,新版的Selenium已经不再支持PhantomJS。接下来,我们看一个Chrome使用无头浏览器的代码示例。
test16_1.py:
from selenium import webdriver
from time import sleep
# 创建出启动浏览器所需要的配置,即实例化ChromeOptions浏览器选项对象
chrome_options = webdriver.ChromeOptions()
# 构建配置信息,即通过浏览器选项对象调用配置方法
# 设置浏览器为无头模式
chrome_options.headless = True
# 将配置信息加入浏览器启动,即实例化浏览器驱动对象添加属性option值
driver = webdriver.Chrome(options=chrome_options)
driver.get("http://www.baidu.com")
sleep(2)
driver.quit()实现方式非常简单,只是在浏览器初始化的时候增加一个headless参数。
2. 不关闭浏览器
在自动化测试过程中,每执行一个测试用例都会打开浏览器、登录浏览器、退出浏览器,这些步骤占用了不少的时间。于是部分团队在实践过程中采取如下策略:执行完一个测试用例后并不关闭浏览器,从而避免下一个测试用例再重复打开浏览器。
这里给大家提供一个示例。
针对test_001_login.py文件,我们做如下调整:将setup和teardown分别用setup_class和teardown_class来代替。
修改后的代码如下所示:
from selenium import webdriver
import pytest
# 导入本用例用到的页面对象文件
from Chapter_14.Test.PageObject import login_page
from Chapter_14.Common.parse_csv import parse_csv
from Chapter_14.Common.parse_yml import parse_yml
host = parse_yml("../../Config/redmine.yml", "websites", "host")
# host = parse_yml("D:\Love\Chapter_13\Config\\redmine.yml", "websites", "host")
url = "http://"+host+"/redmine/login"
data = parse_csv("../../Data/test_01_login.csv")
# data = parse_csv("D:\Love\Chapter_13\Data\\test_01_login.csv")
# print(data)
# data = [('admin', 'error', '0'), ('admin', 'rootroot', '1')]
@pytest.mark.parametrize(("username", "password", "status"), data)
class TestLogin():
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
# self.driver.implicitly_wait(20)
# 访问"登录"页面
self.driver.get(url)
def teardown_class(self):
self.driver.quit()
def test_001_login(self, username, password, status):
# 登录的3个操作用业务场景方法一条语句代替
login_page.LoginScenario(self.driver).login(username,password)
if status == '0':
# 登录失败后的提示信息,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_failed_info()
assert text == '无效的用户名或密码'
elif status == '1':
# 登录成功后显示的用户名,通过封装的元素操作来代替
text = login_page.LoginOper(self.driver).get_login_name()
assert username in text
# 增加一个断言
assert "我的工作台" in self.driver.page_source
else:
print('参数化的状态只能传入0或1')
if __name__ == '__main__':
# pytest.main(['-s', '-q', '--alluredir', '../report/'])
pytest.main(['-s', 'test_001_login.py'])
# pytest.main(['-s', '-q', '--alluredir', '../../Report/report'])再次执行代码。第一个用例执行完成之后(登录失败)并不会退出浏览器,而是会继续执行第二个测试用例(登录成功)。这样就省去了重复启动、初始化浏览器的动作,整体测试的执行时间会节省30%左右。
但细心的朋友应该会发现,要达到这样的效果是有前提条件的。首先,第一个测试必须登录失败,此时被测页面仍然停留在“登录”页面,这样才能无缝衔接第二个测试用例的执行,否则就会因为找不到“用户名”或“密码”文本框,而无法执行第二个测试用例;其次,这种情况只适用于测试用例中做了参数化(通过数据文件读取)的情况,无法在多个测试用例文件之间执行。
实际上,该方法违背了自动化测试设计的基础原则,即自动化测试用例不应依赖于其他用例的成败。所以并不推荐使用这种方法。
十六、Docker DevOps实战
基于docker搭建jenkins+gitlab环境,集成python+pytest+gitlab+jenkins+allure实现自动化持续集成测试,最终达到pycharm一键提交代码,触发整个测试流程,测试人员只需要接收分析测试报告的目标。
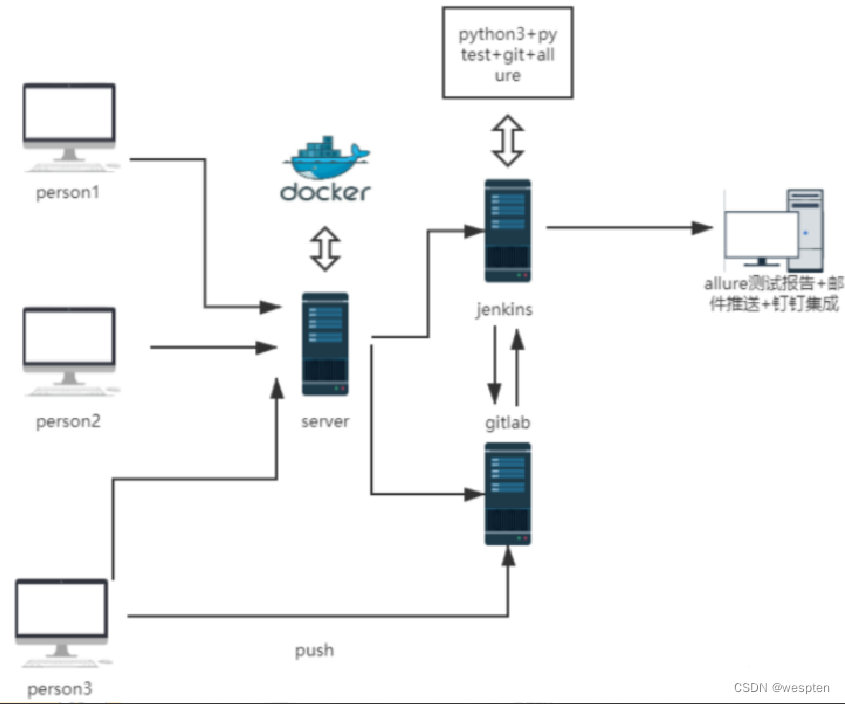
目标:
- 安装docker
- 使用jenkins镜像创建容器,并搭建python+pytest+allure的自动化测试环境
- 在Jenkins 容器上的搭建持续集成环境和完成自动化测试
- 搭建Gitlab容器并上传本地项目代码
- 结合Jenkins + Gitlab完成自动化测试的持续集成实战
1、Pytest 自动化测试框架搭建
文件目录如下所示:
1. common
- assertion.py 封装的断言
- casefiletemplate.py 用于根据 params 文件夹下的测试数据文件自动生成.py 的测试用例
- consts.py 定义发送报告用的全局变量
- email.py 封装的发送 email 报告功能
- get_casedate.py 读取 params 文件夹下的测试数据文件,返回接口可以直接用的字典数据
- httprequest.py 封装的 requests 的 get 和 post 请求,其他请求方法有需要可以后期添加
- lop.py 封装的记录日志功能
- readconfig.py 封装的读取 config 文件夹下配置文件的功能
- shell.py 封装的执行 shell 命令的功能
2. config

- baseconfig.ini 用于存放基本配置,比如数据库连接信息、发送邮件的信息等
- interfaceconfig.ini 用于保存被测接口的配置信息
3. log
logs.log 记录的日志文件。
4. params
存放 excel 或者 yaml 格式的测试数据,文件名称需要和 interfaceconfig.ini 配置文件中的 section 名称保持一致。
5. report
存放 allure 生成的测试报告。
6. testcase&testcase_backup
- testcase 下面存放需要执行的测试用例
- testcase_backup 下面存放不需要执行的测试用例
此处需要注意测试用例的名称是 params 文件夹下测试数据文件名前面加 test_,后面加.py 组成的,文件间的名称对应关系如下:
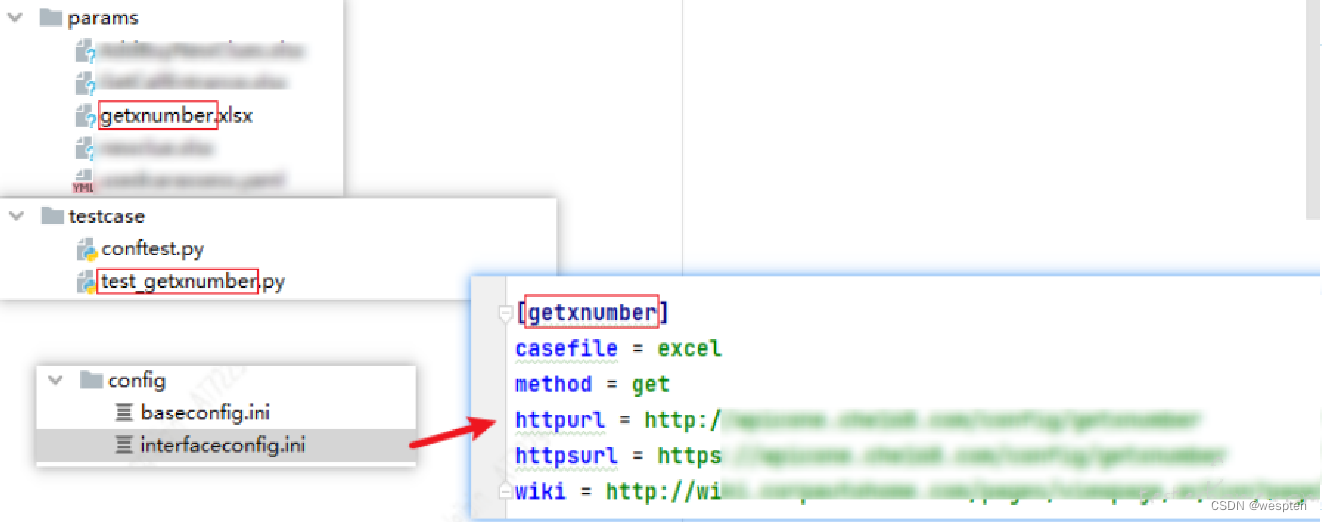
这样命名的目的是为增加新用例的时候尽可能少的减少重复操作,同时根据文件名称可以更便捷的获取所需要的参数。
7. run.py
执行测试的主入口。
8. 使用说明
- 当有新的接口需要测试的时候需要按照固定格式,先创建测试数据文件,可以是 excel 或者 yaml,具体格式可以参考 parmas 下的测试数据文件,例如创建的文件为 mywork.xlsx
- 配置 interfaceconfig.ini,配置文件的 section 用 mywork
- 执行 common 下的 casefiletemplate.py 会自动在 testcase 文件夹下生成 test_mywork.py 的文件
- 然后编辑 test_mywork.py,添加需要的断言
- 运行 run.py
9. 其他说明
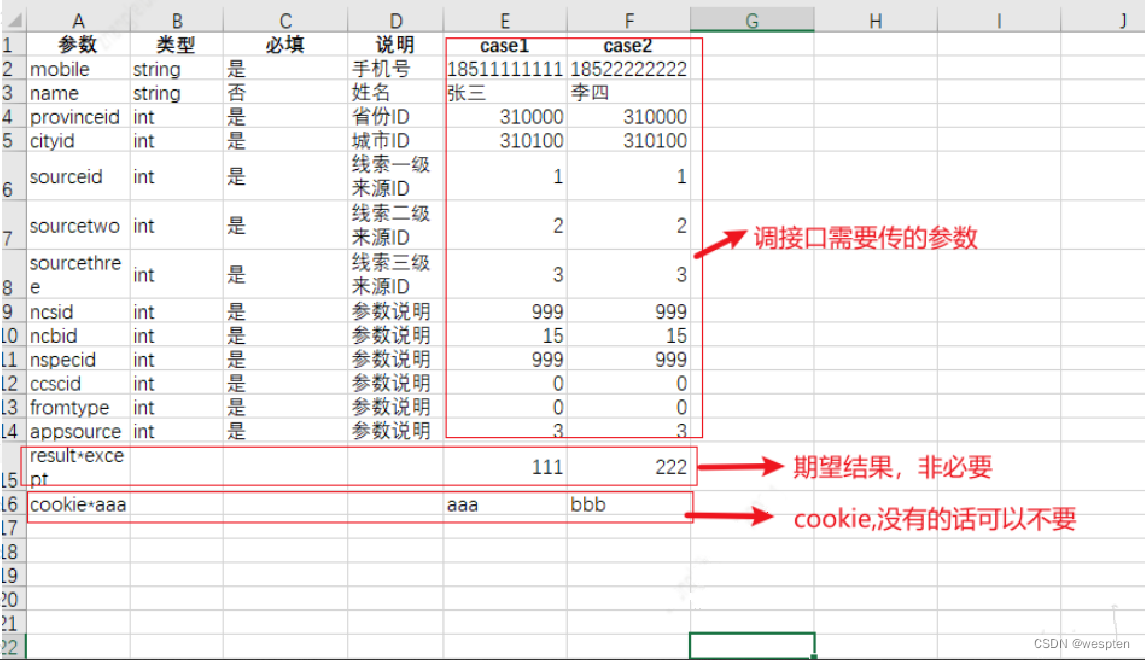
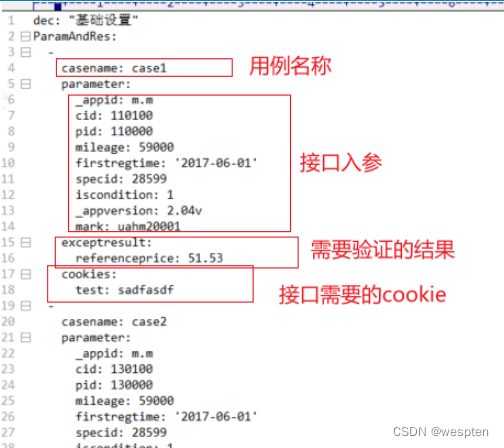
2、安装Docker
首先我们需要卸载旧版本Docker:
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine注意:
- /var/lib/docker/ 下的内容(包括 images,containers,volumes,networks)被保留
- Docker Engine 软件包现在称为 docker-ce
安装docker:
# step 1: 安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息,国内 Repository 更加稳定
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3: 更新
sudo yum makecache fast安装最新版本的 Docker Engine 和 Container:
sudo yum install docker-ce docker-ce-cli containerd.io安装指定版本的 Docker Engine:
sudo yum list docker-ce --showduplicates | sort -r
安装最新版本:
sudo yum -y install docker-ce
启动 Docker:
sudo systemctl start docker
验证 Docker Engine 是否已正确安装:
通过运行 hello-world 映像来验证。
sudo docker run hello-world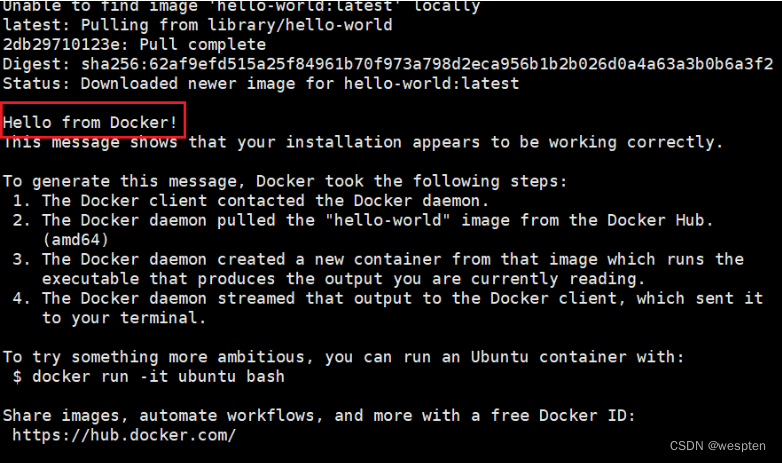
验证hello-world是否安装成功:
docker images配置docker镜像加速:
# 1.创建一个目录
sudo mkdir -p /etc/docker
# 2.编写配置文件
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://reg-mirror.qiniu.com"
]
}
EOF
# 3.重启服务
sudo systemctl daemon-reload
sudo systemctl restart docker3、安装Jenkins
搜索 jenkins 镜像:
docker search jenkins
下载 jenkins 镜像:
docker pull jenkins/jenkins查看本地镜像:
docker images 
创建 Jenkins 容器:
在主机下创建一个目录,用于挂载目录。
mkdir -p /var/jenkins_node给挂载目录一个最高权限:
可读可写可执行。
chmod -R 777 /var/jenkins_node创建与启动 jenkins 容器:
- -d:守护模式
- -uroot:使用 root 身份进入容器,推荐加上,避免容器内执行某些命令时报权限错误
- -p:主机 80 端口映射容器的 8080 端口,后面访问 jenkins 直接访问主机 ip 就行了,不需要加 8080 端口
- -v:目录映射
- --name:自定义一个容器名称
使用上面推荐的 jenkins/jenkins 镜像:
docker run -d -uroot -p 80:8080 --name jenkins1 -v /var/jenkins_node:/var/jenkins_home jenkins/jenkins查看容器是否运行:
docker ps
进入 jenkins 容器 CLI 界面:
docker exec -it -uroot jenkins1 bash这里也可以指定 root 身份进入容器:
# 获取最新的软件包
apt-get update
apt-get install vim
apt-get install wget
# 升级已安装的软件包
apt-get upgrade
# 提前安装,以便接下来的配置操作
apt-get -y install gcc automake autoconf libtool make
apt-get -y install make*
apt-get -y install zlib*
apt-get -y install openssl libssl-dev
apt-get install sudo访问jenkins:
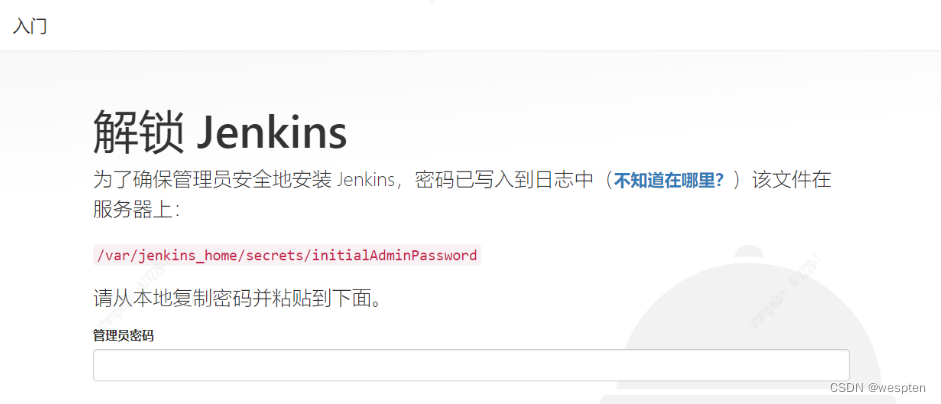
按照上图提示 首先在指定目录下找到管理员密码:
cat /var/jenkins_home/secrets/initialAdminPassword然后粘贴到输入框中,之后新手入门中先安装默认的插件即可,完成后出现如下界面。
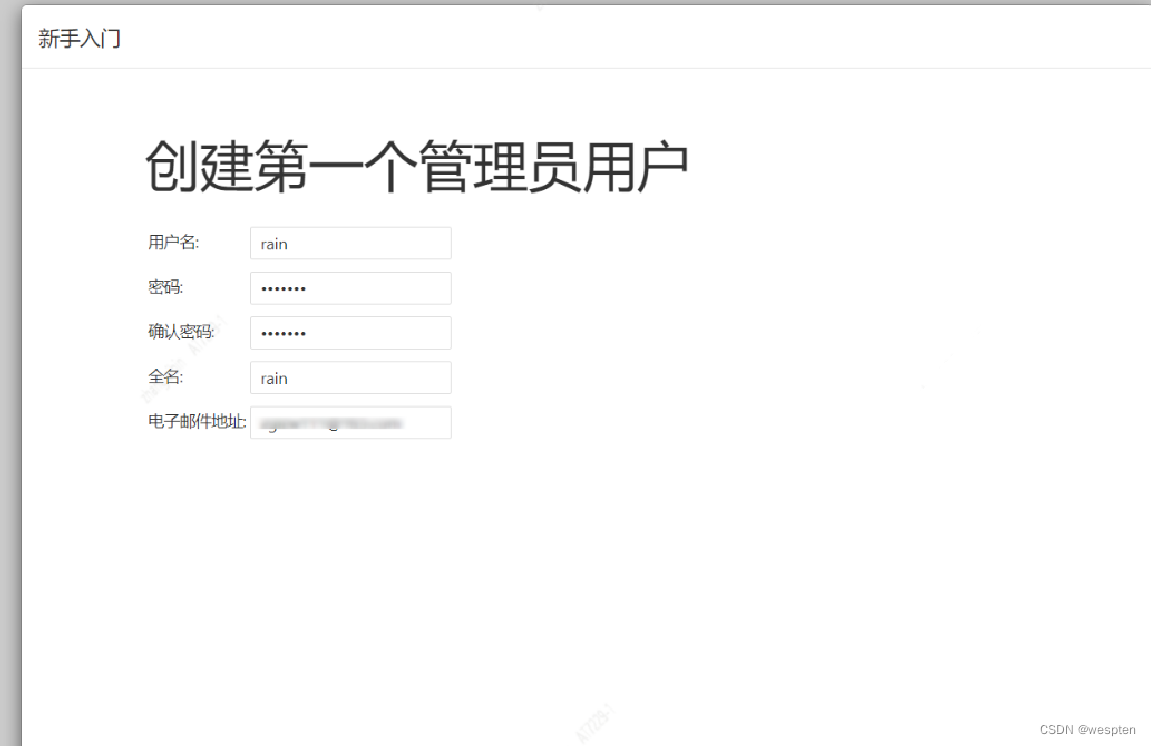
保存完成后会让配置实例地址,默认就行,配置完成后,点击开始使用jenkins。
最后将插件源切换成国内镜像地址:
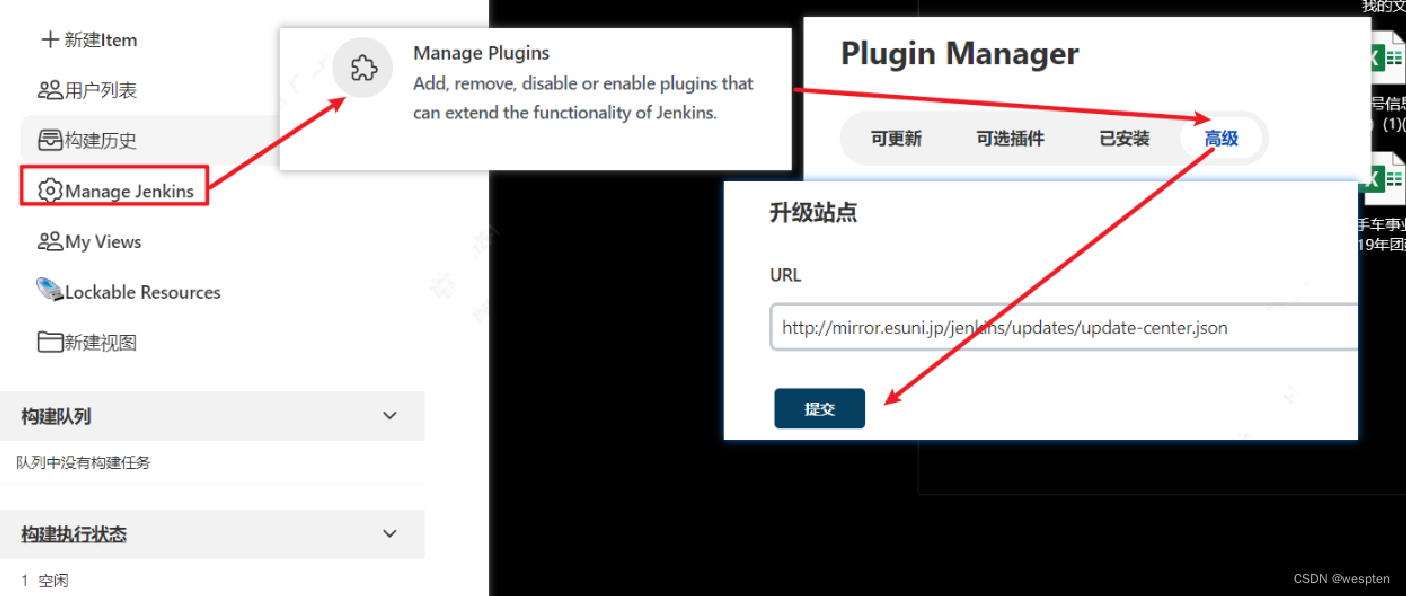
url填入下面地址,然后提交:
http://mirror.esuni.jp/jenkins/updates/update-center.json4、安装Python
下载 python:
cd /usr/local/src
wget https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tgz
tar -zxvf Python-3.6.8.tgz
mv Python-3.6.8 py3.6
cd py3.6
pwdmake 编译安装:
在 /usr/local/src/py3.6 安装目录下执行下面的命令。
./configure --prefix=/usr/local/src/py3.6
make && make install添加软链接:
添加 python3 软链接。
ln -s /usr/local/src/py3.6/bin/python3.6 /usr/bin/python3添加pip3软链接。
ln -s /usr/local/src/py3.6/bin/pip3 /usr/bin/pip3验证 python3 环境:
敲 python3 和 pip3 有下图的结果就是正常了。
5、安装Allure
将压缩包传送到容器内:
- 先将包上传到主机
- 然后从主机复制到容器内
docker cp allure-2.19.0.zip jenkins:/usr/local/src进入容器解压包:
unzip allure-2.19.0.zip 赋予文件夹所有内容最高权限:
mv allure-2.13.6 allure
chmod -R 777 allure配置 allure 和 py 环境变量:
cat >> /root/.bashrc << "EOF"
export PATH=/usr/local/src/allure/bin:$PATH
export PATH=/usr/local/src/py3.6/bin:$PATH
EOF更新环境变量配置文件:
source /root/.bashrc验证环境变量:
allure --version
python3 --version配置 JDK 环境变量:
cat >> /root/.bashrc<< "EOF"
export PATH=$JAVA_HOME/bin:$PATH
EOF更新环境变量配置文件:
source /root/.bashrc查看当前的系统已配置的环境变量:
export
6、Jenkins配置与项目部署
配置JDK、Git、allure,然后从gitlab拉取代码,执行pytest命令、最后生成allure报告。
jenkins初始化完成之后需要安装需要的插件:
下载DevOps环节需要的插件:gitlab、gitlab hook、allure。
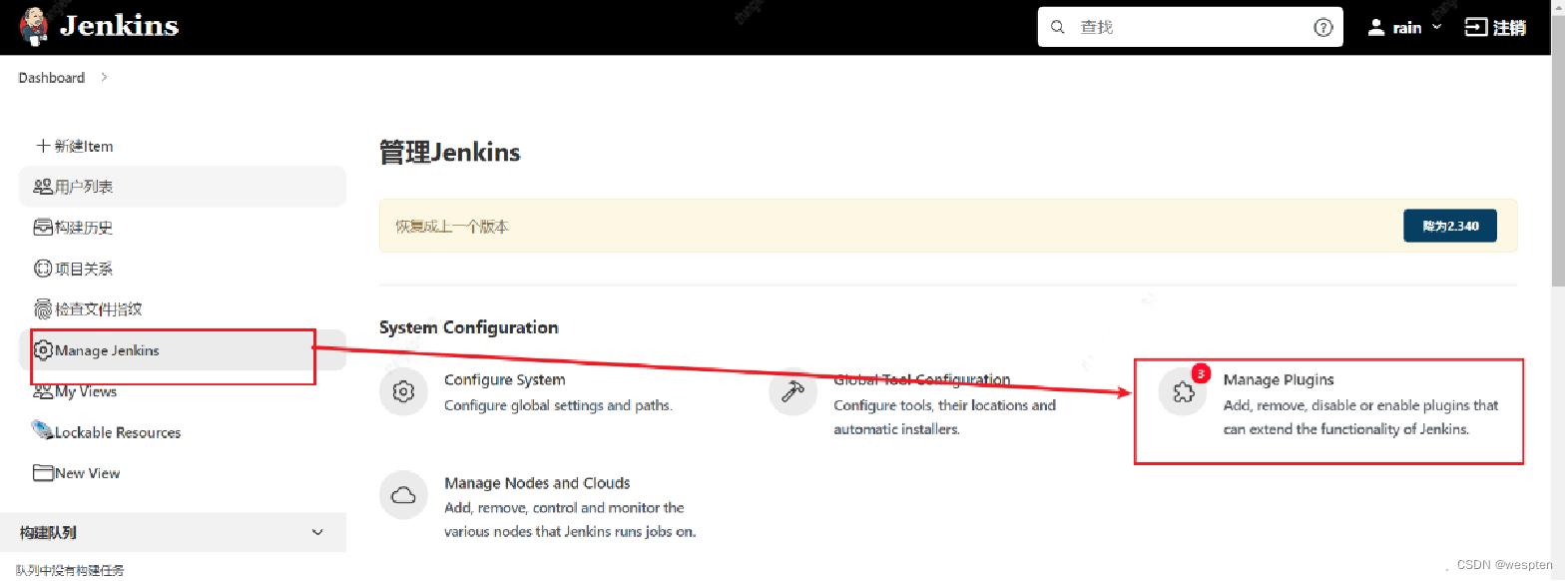
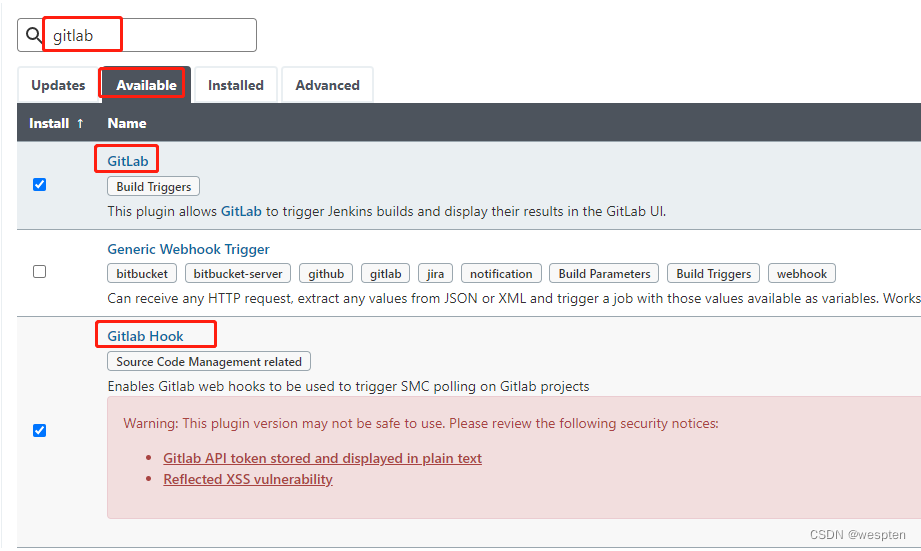
汉化插件:
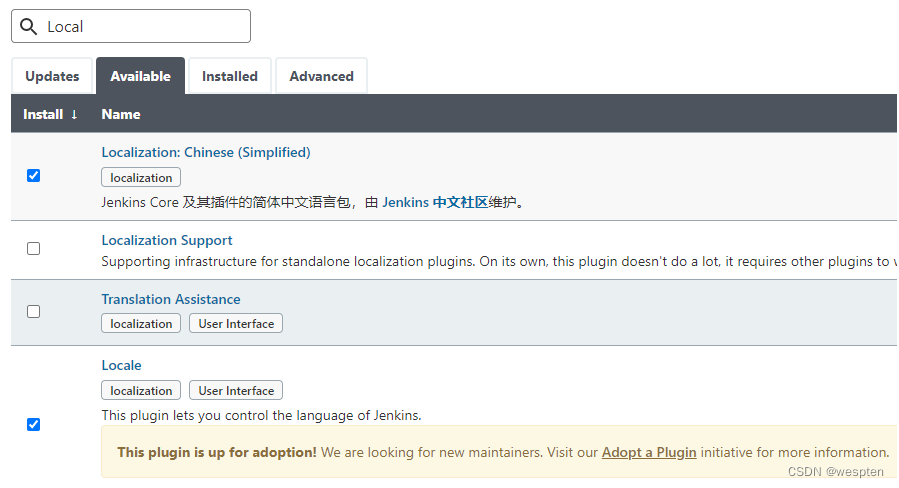
汉化配置,保存后如果没有生效重启以下容器就好了:
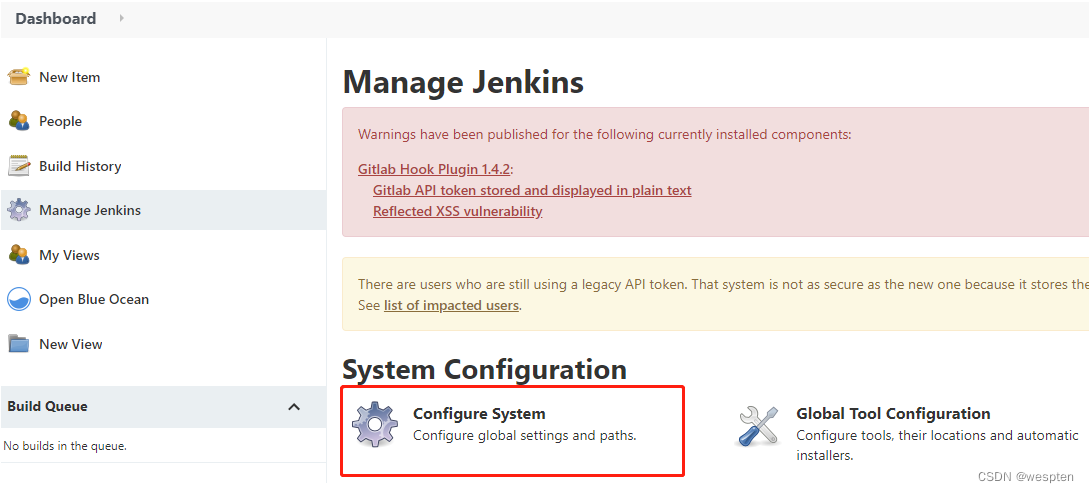
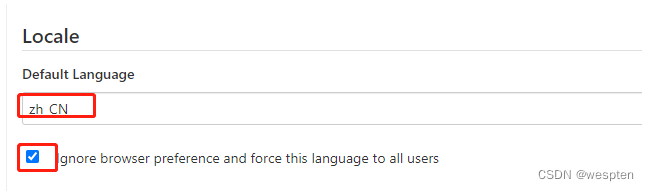
选中上面的插件之后点击(我已经安装完成,正常没有安装的情况可以在可选插件tab下搜出需要的插件选中)。
下载好之后,重启Jenkins容器:
[root@localhost ~]# docker restart jenkins1
jenkins1也可以出现的页面中选中安装完成后重启:
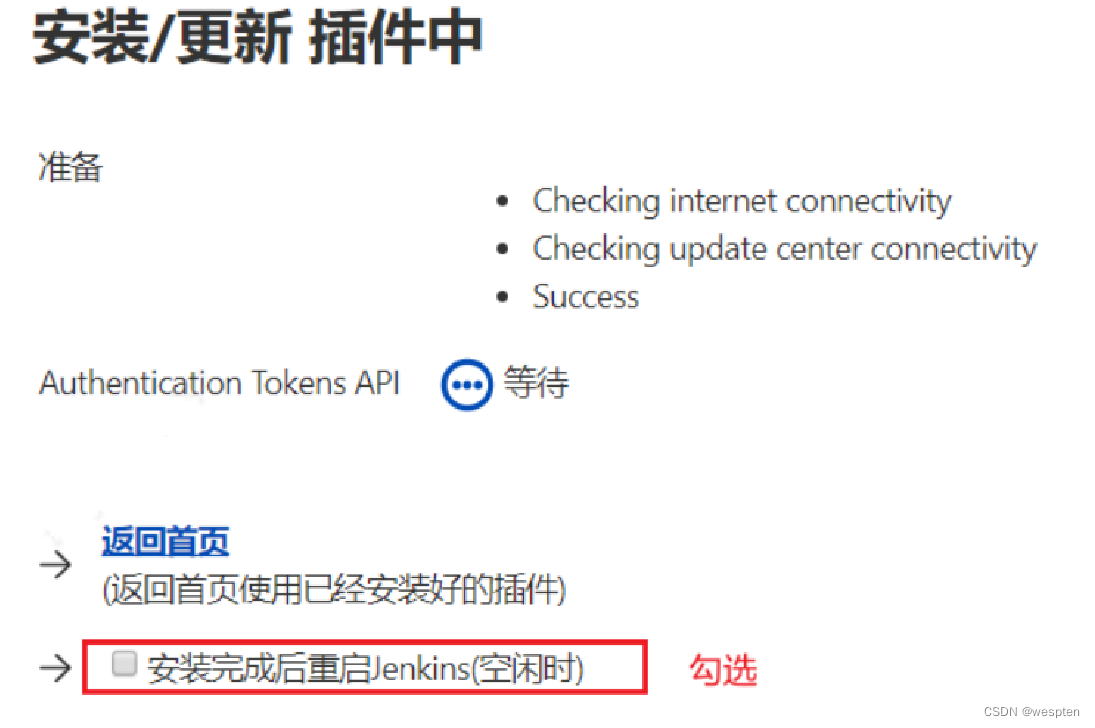
Jenkins 全局工具设置:
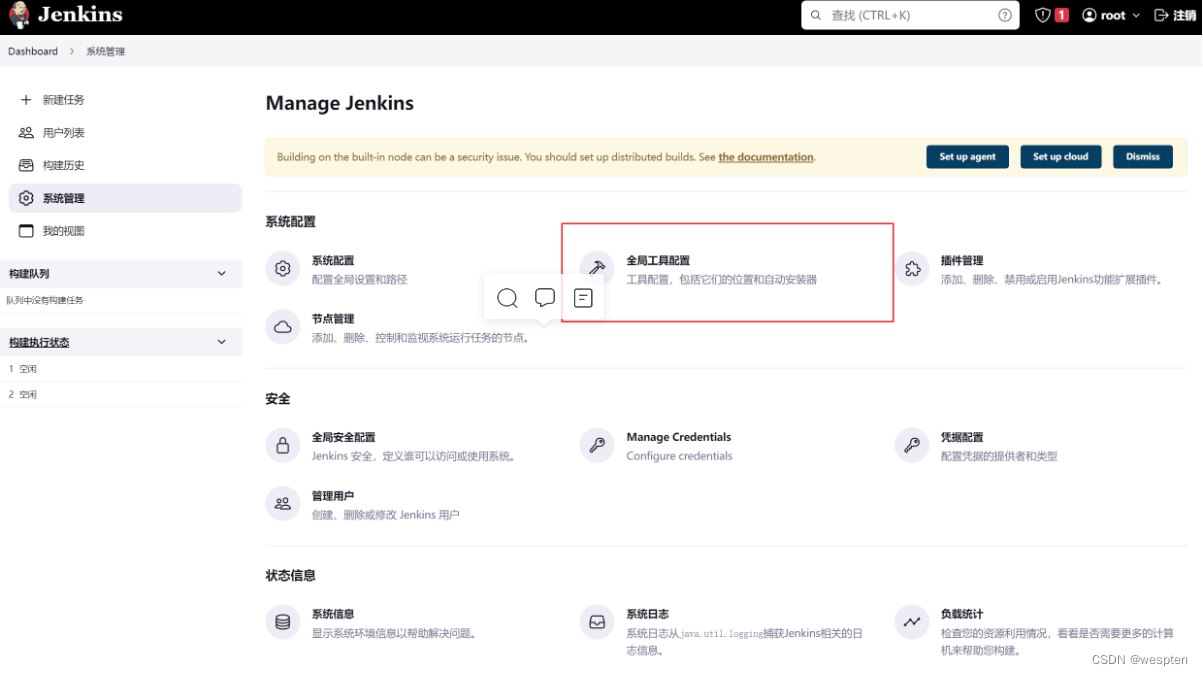
配置 JDK:
JAVA_HOME的路径可以用echo $JAVA_HOME查看。
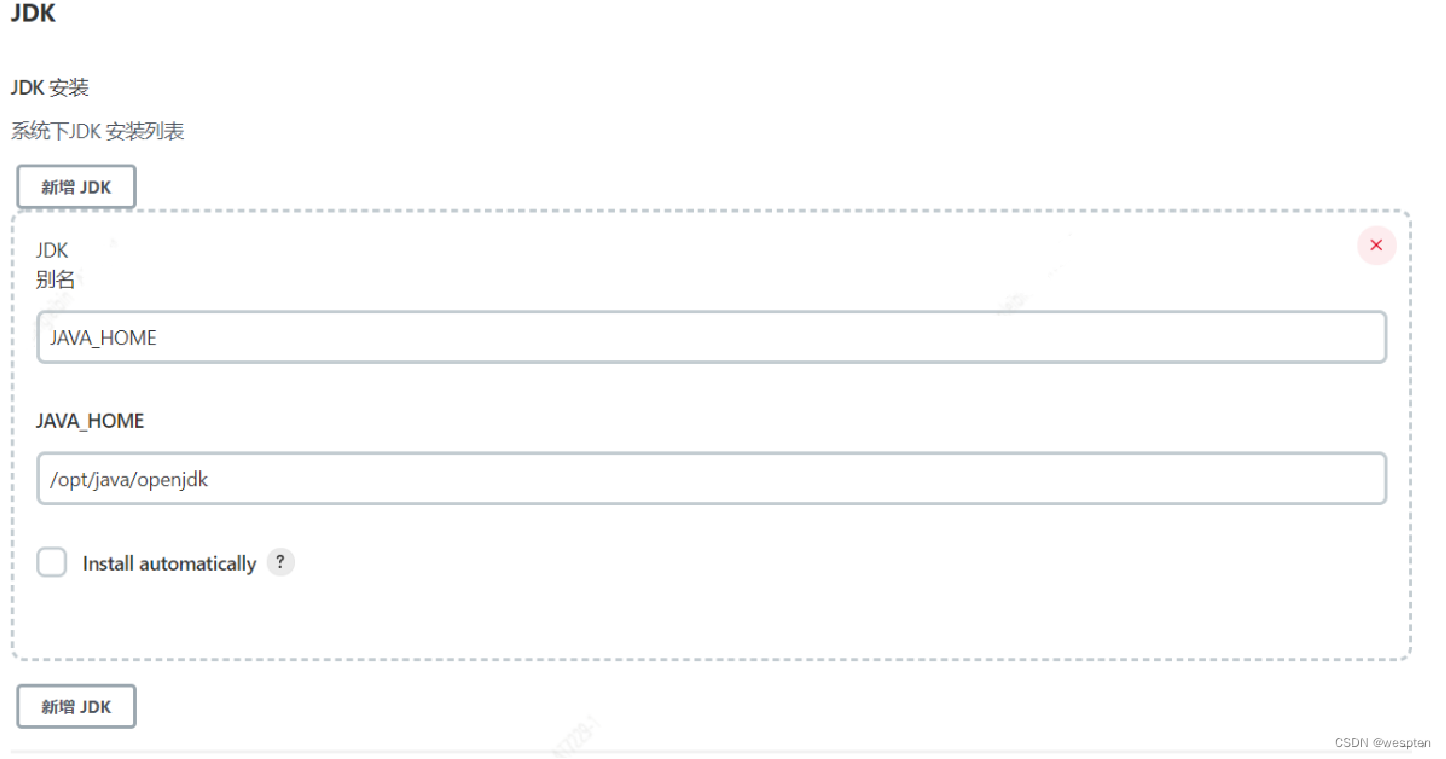
配置 Git :
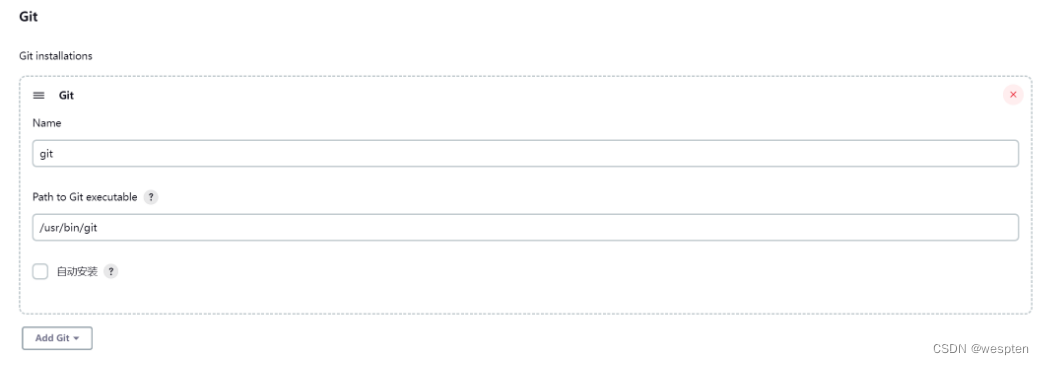
alllure的安装目录为jenkins容器下安装allure时的安装目录:
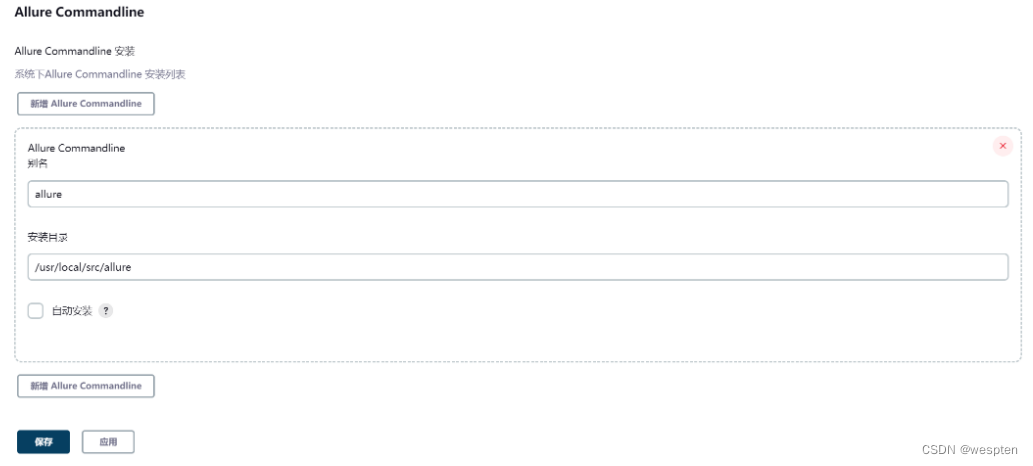
应用!保存!
邮箱:
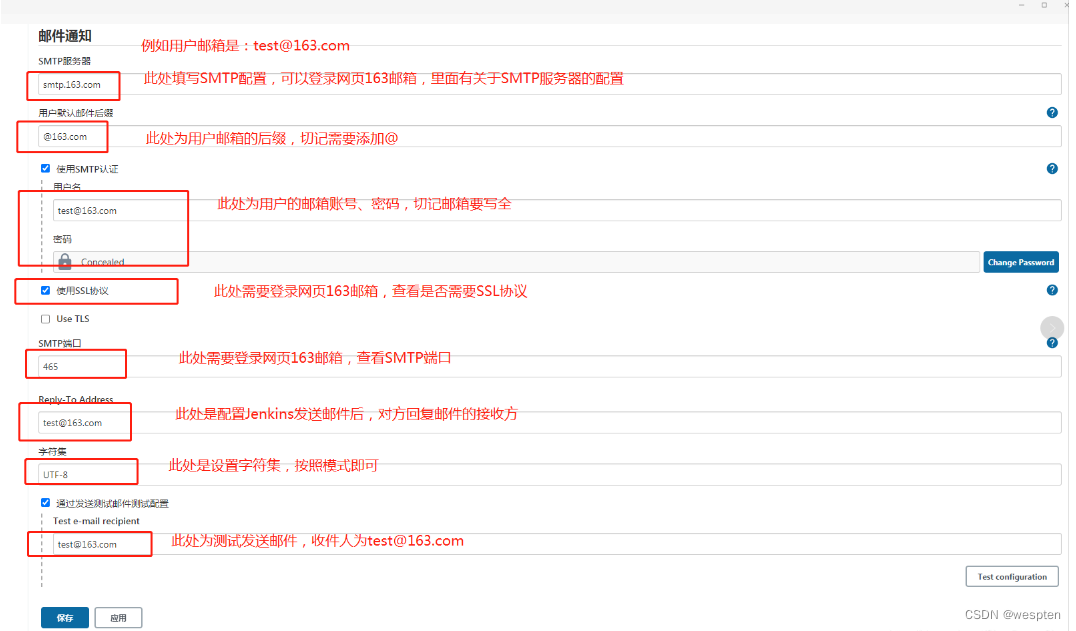
下图为SMTP服务器开启的方法:

邮件插件配置,常用的插件为“Extended E-mail Notification”。
滑动到Extended E-mail Notification通知部分,然后进行配置,如下图。
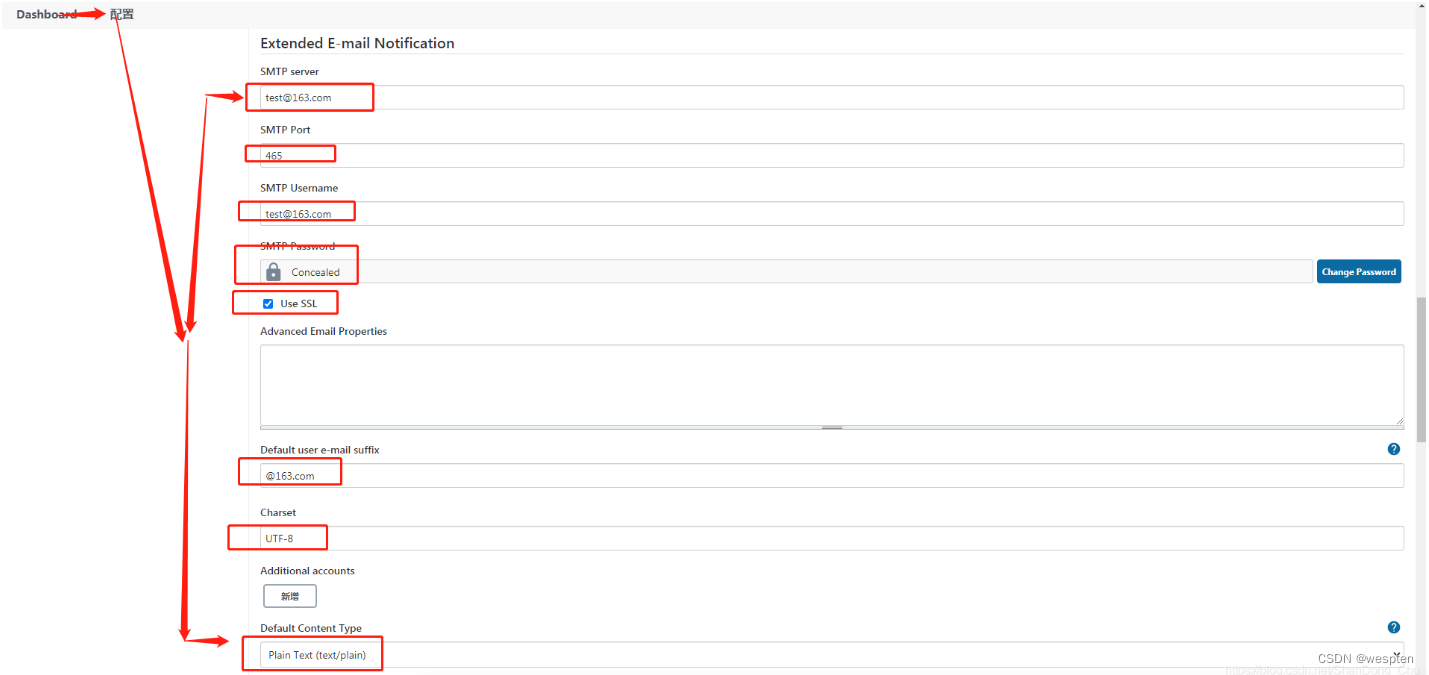
上图中除了邮件服务器和发送账号配置,其他的配置项即为默认配置,然后在具体的Jenkins项目中,可以使用该默认配置,也可以进行自定义配置,例如:收件人、收件标题、收件内容等等。
接下来创建任务:
创建完成项目之后返回jenkins首页然后选择创建好的项目点击,如下图所示:
然后点配置:
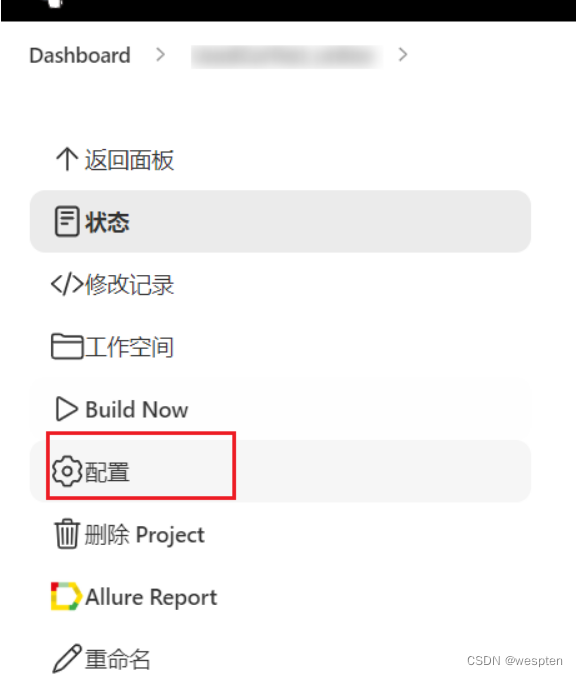
源码管理tab签下设置从gitlab拉取代码,配置好从gitlab拉取代码之后再配置执行pytest命令。
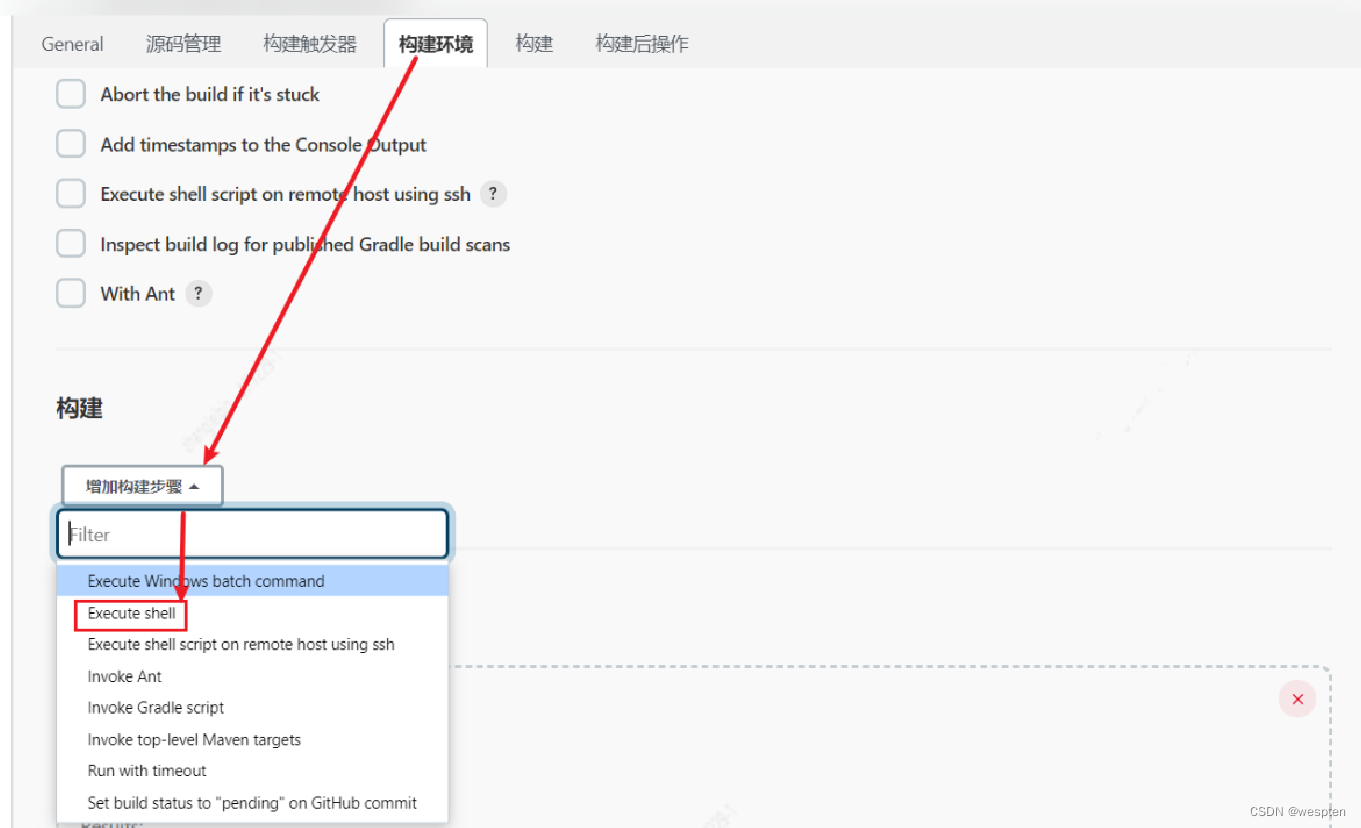
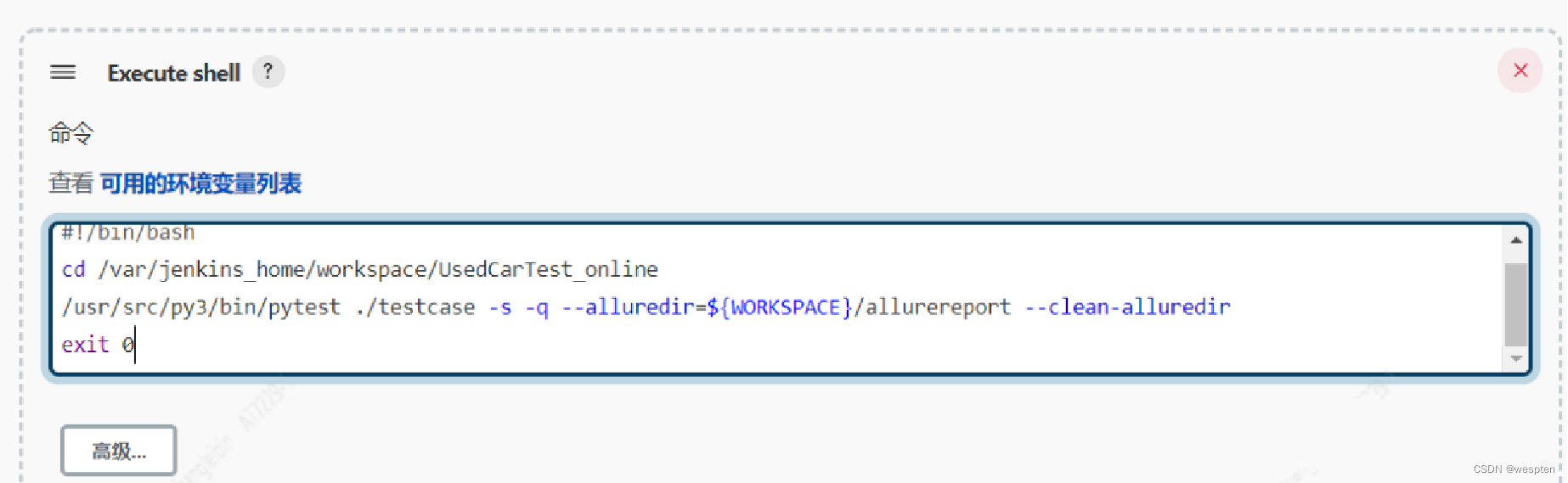
上图中的命令下面两种方式都可以:
#!/bin/bash -ilex
cd /var/jenkins_home/workspace/UsedCarTest_online
pytest ./testcase -s -q --alluredir=${WORKSPACE}/allurereport --clean-alluredir
exit 0
#!/bin/bash
cd /var/jenkins_home/workspace/UsedCarTest_online
/usr/src/py3/bin/pytest ./testcase -s -q --alluredir=${WORKSPACE}/allurereport --clean-alluredir
exit 0最后生成allure报告:
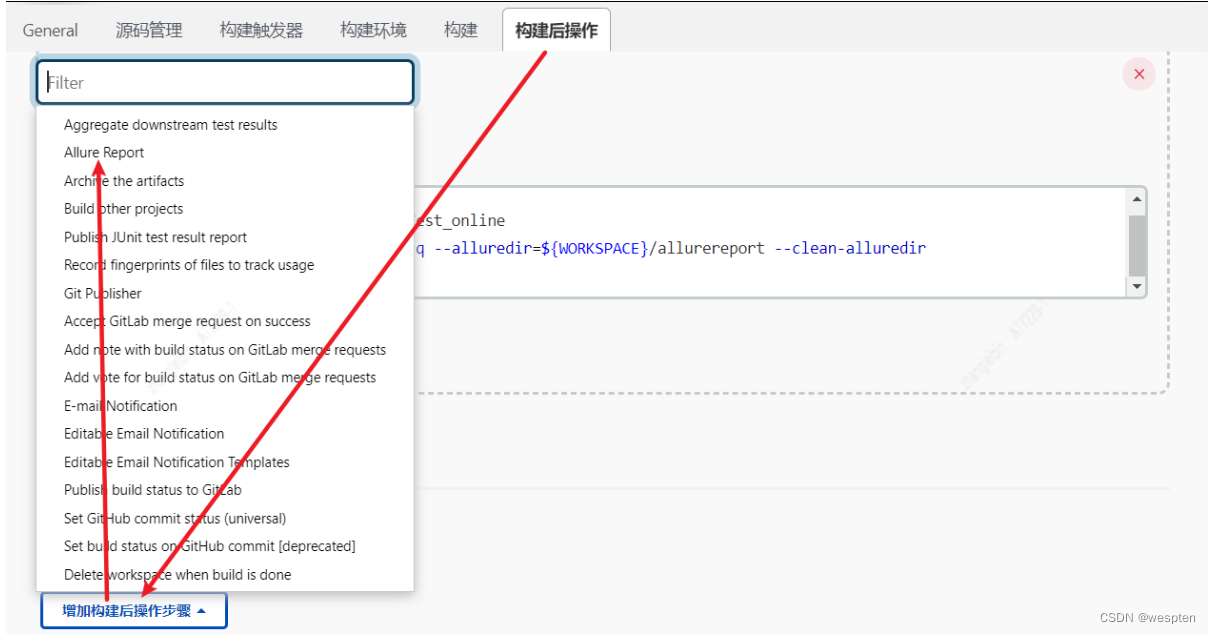
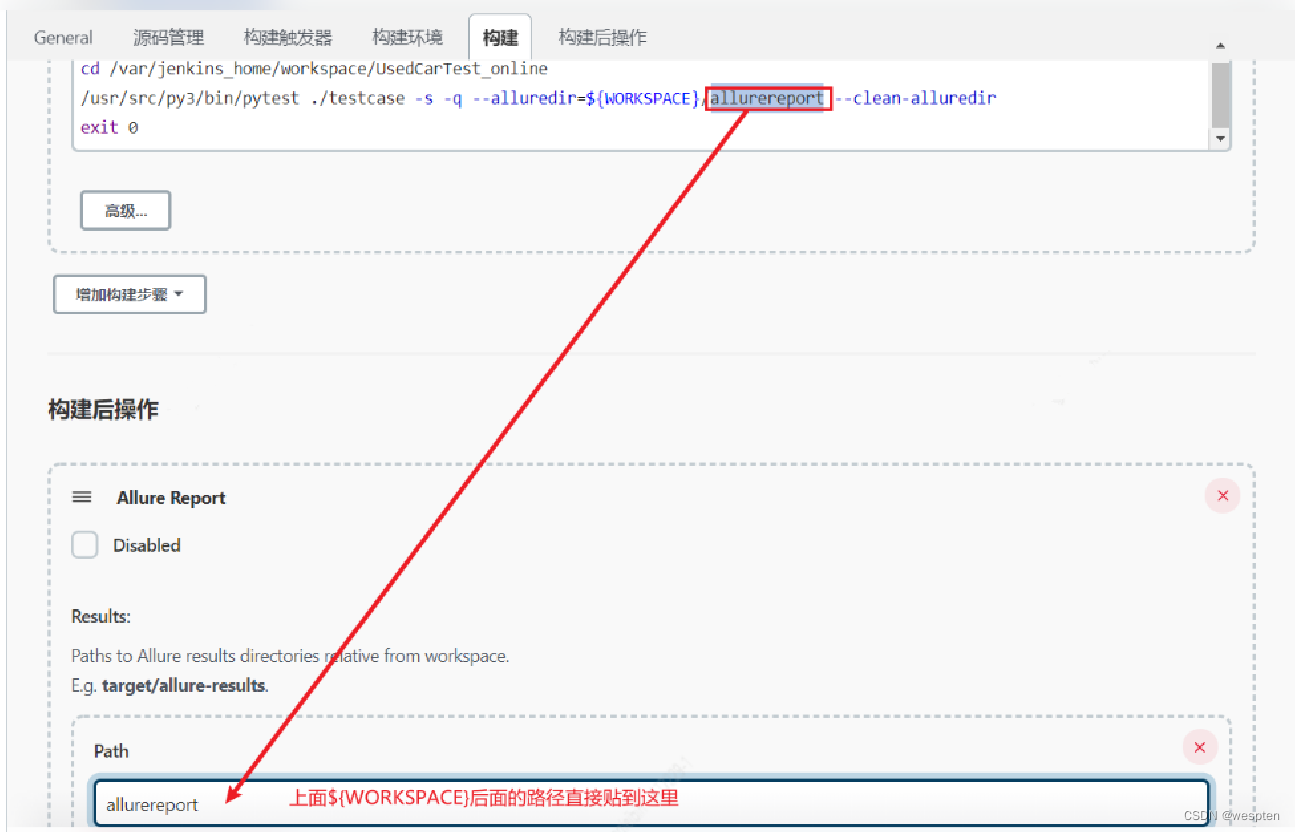
最后挨个点击应用、保存:

保存之后点击构建,则可以执行测试并生成allure报告。

7、安装Gitlab
搜索 gitlab 镜像:
docker search gitlab
创建 gitlab 容器:
由于是 docker 镜像运行, 所以我们需要把 gitlab 容器的配置、数据、日志存到容器外面,即将其目录映射到主机上,先准备三个目录。
#切到srv目录
cd /srv
#创建gitlab文件夹
mkdir gitlab
cd gitlab
mkdir config logs data创建容器:
docker run -d -p 443:443 -p 9001:80 -p 8022:22 \
--name gitlab \
--restart always \
--privileged=true \
-v /srv/gitlab/config:/etc/gitlab \
-v /srv/gitlab/logs:/var/log/gitlab \
-v /srv/gitlab/data:/var/opt/gitlab \
-v /etc/localtime:/etc/localtime:ro \
gitlab/gitlab-ce访问 gitlab 网站:
ip+9001
首次登陆需要账号密码:
cat /etc/gitlab/initial_root_password创建一个项目:
修改地址。
进入容器:
docker exec -it gitlab bash
vim /etc/gitlab/gitlab.rb将这个 external_url 改成主机的 IP,不需要加端口哦。
重启 gitlab 容器:
docker restart gitlab在windows上安装git环境:
打开git-bash。
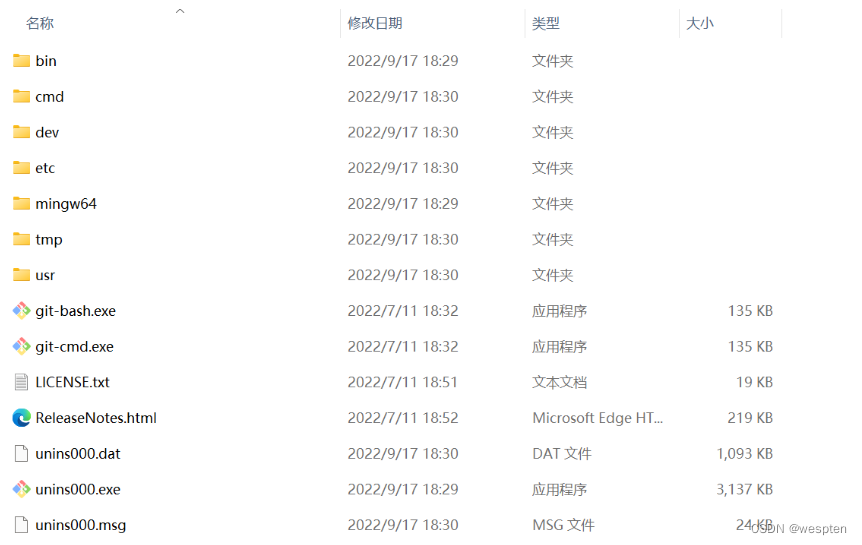
输入以下命令,即可将你的用户信息绑定到本地:
git config --global user.name "你的用户名"
git config --global user.email "你的邮箱"生成SSH公钥:
首先输入命令查看电脑是否已有公钥。
cd ~/.ssh若无法进入文件夹,代表没有公钥,输入命令生成公钥;这里可以一直敲Enter,不需要加密码了。
ssh-keygen -t rsa -C "你的邮箱"查看公钥:

添加本地公钥到 Gitlab 中:
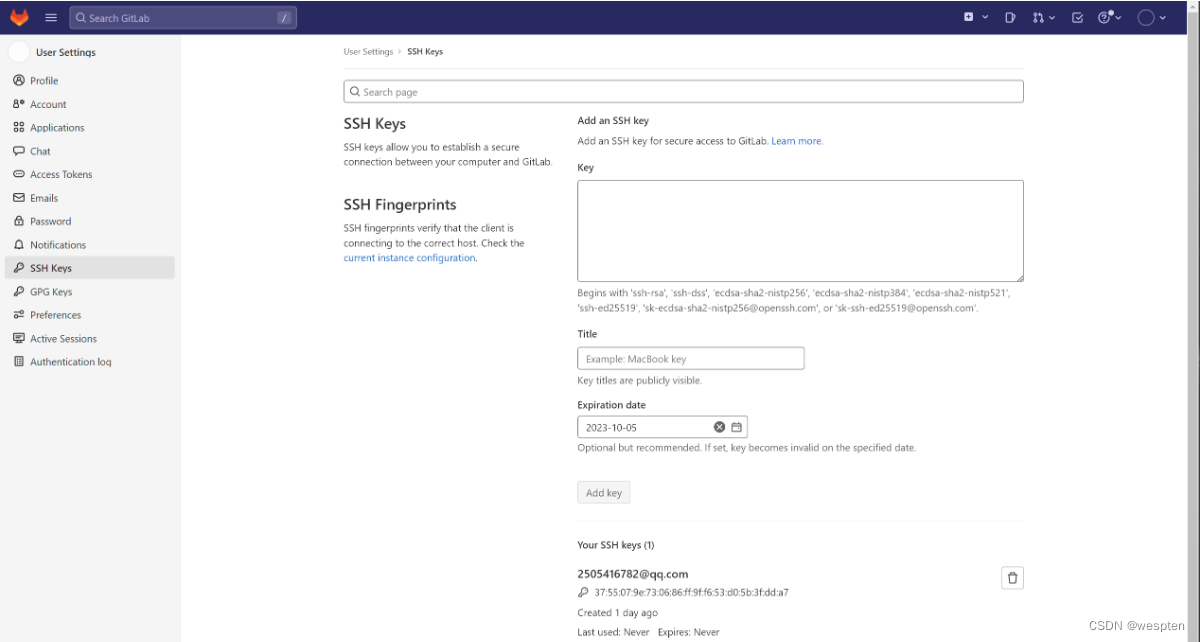
本地项目关联 Gitlab 项目并上传代码:
cd 项目目录
git init
git remote add origin http://主机IP:9001..
git add .
git commit -m "Initial commit"
git push -u origin master重点:
因为是在 docker 上部署的 Gitlab,且容器 80 端口映射到主机的 9001 端口;
所以执行 git remote 命令关联项目时,需要用 http 形式,且需要指定 9001 端口,否则会不成功;
注意事项:
执行 git push 的时候可能会出现Git Credential Manager for Windows的弹窗,此时输入 root 用户名和一开始登录的密码就行了。
8、Jenkins 关联 Gitlab
进入 Jenkins 任务的配置页面:
点击“高级”->“generate”->生成一个token
记住:webhook URL 和token,并配置到git仓库得到项目中。
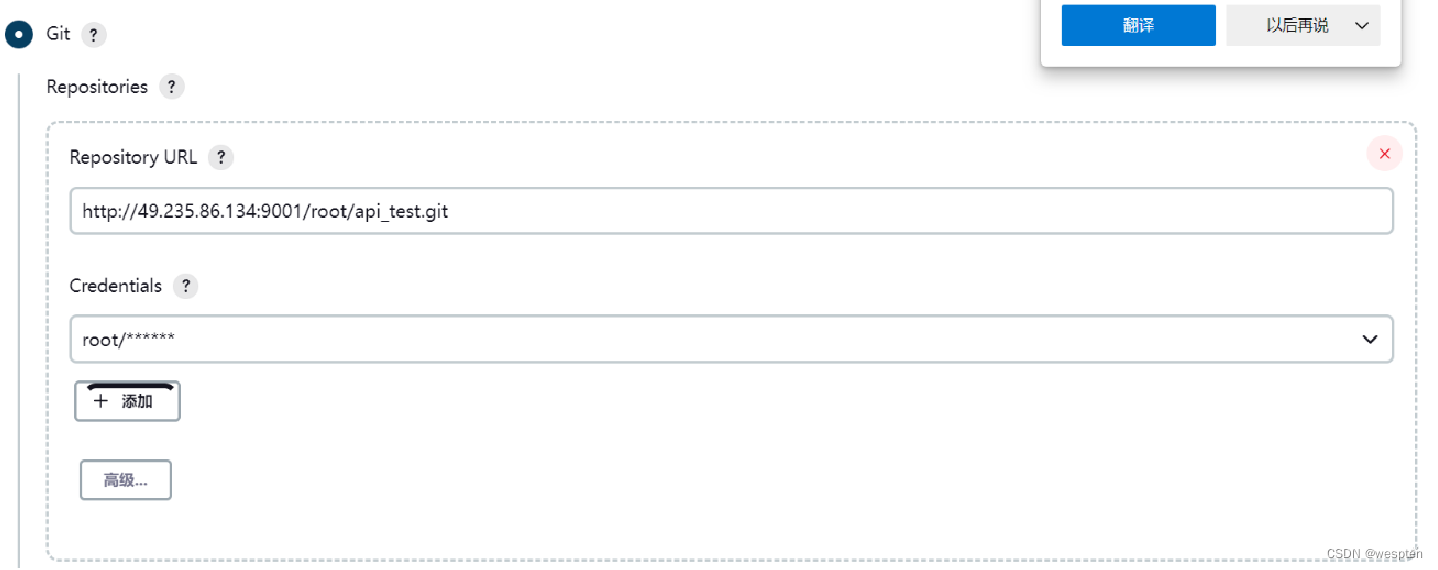
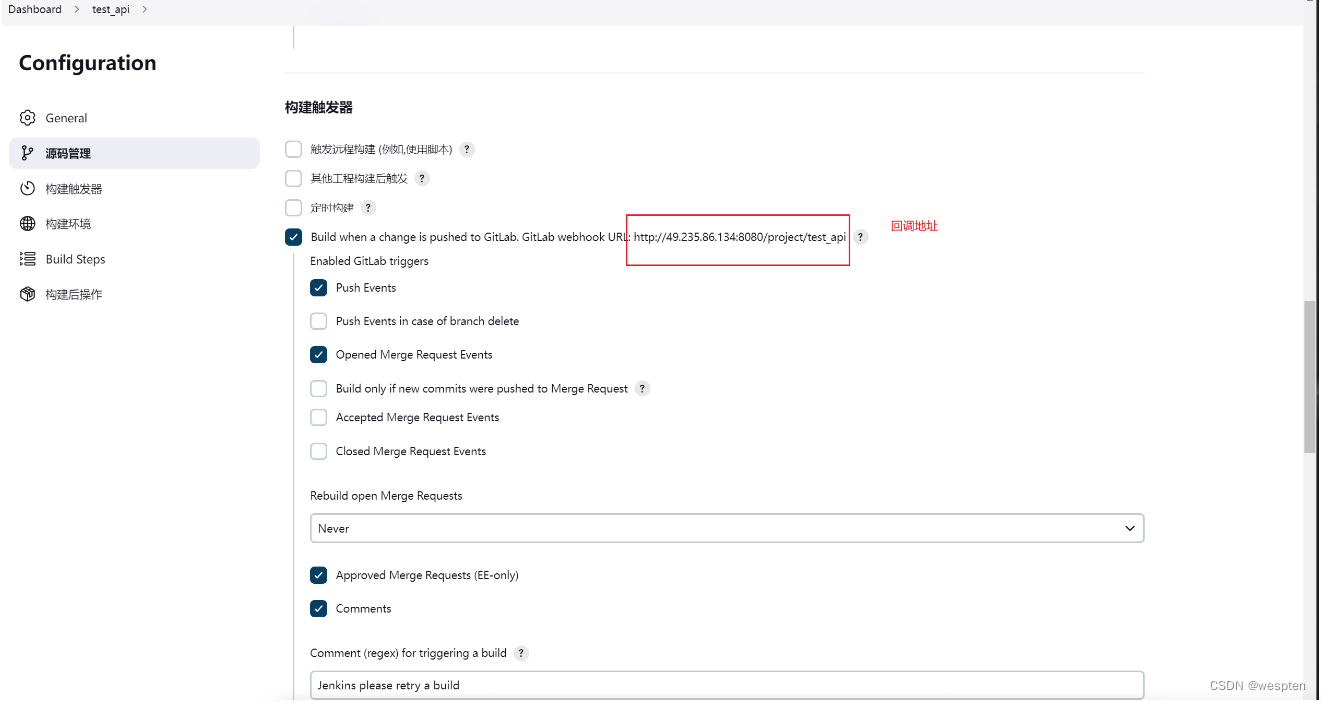

源码管理和构建触发器都配置好就能保存了。
9、Gitlab 仓库配置 Webhooks
进入 Gitlab 仓库对应的项目:
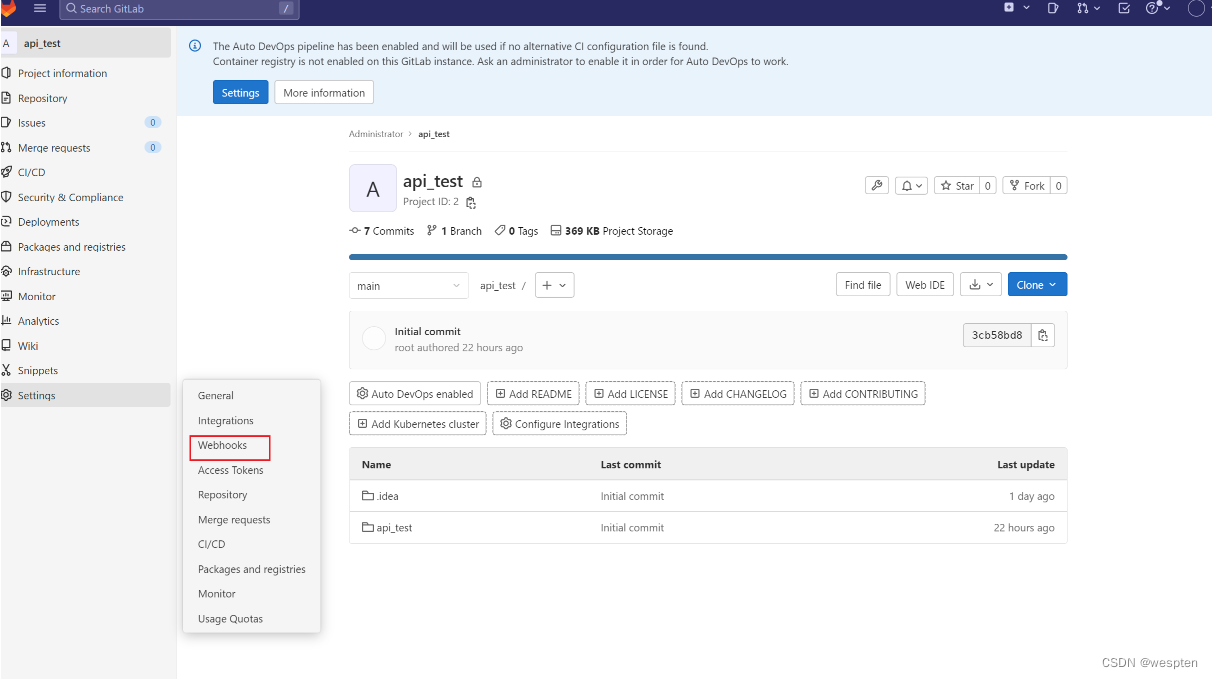
将jenkins上的webhook URL 和token黏贴过来,生成一个web hook:
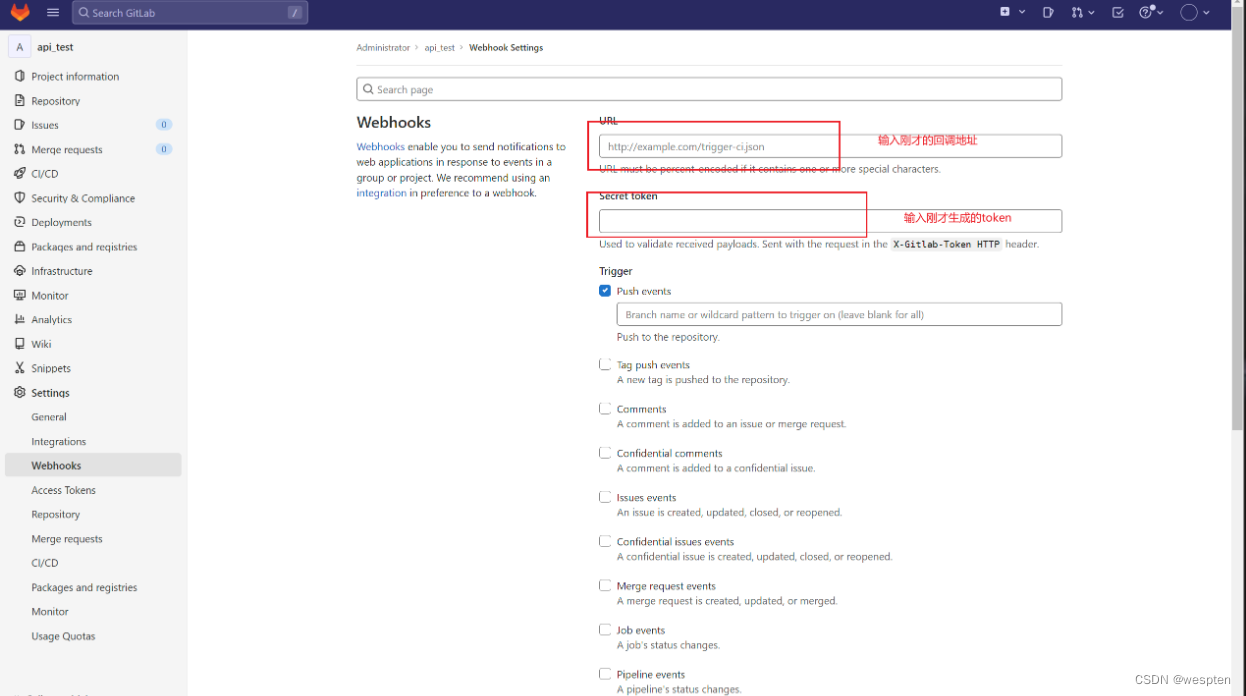
点击新生成的web hook的 ‘push events’,查看web 钩子是否可以和jenkins连接成功。
http 200,表示连接成功。
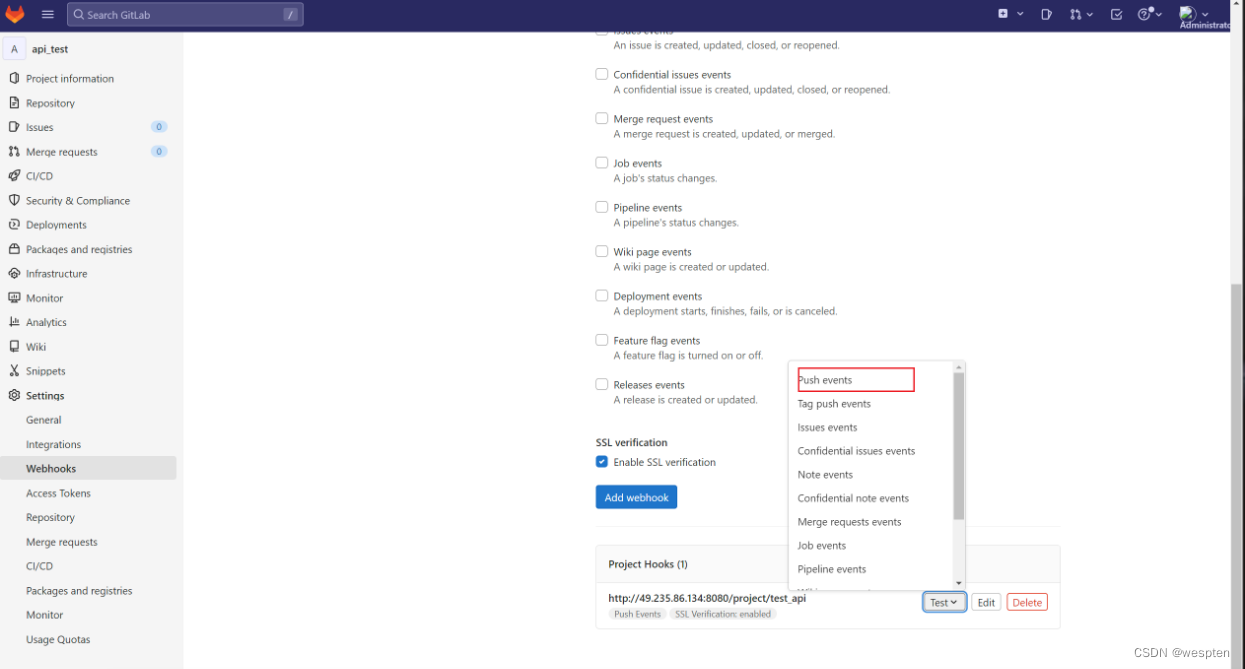
点击push event,可以看jenkins:
我们也可以看allure报告:
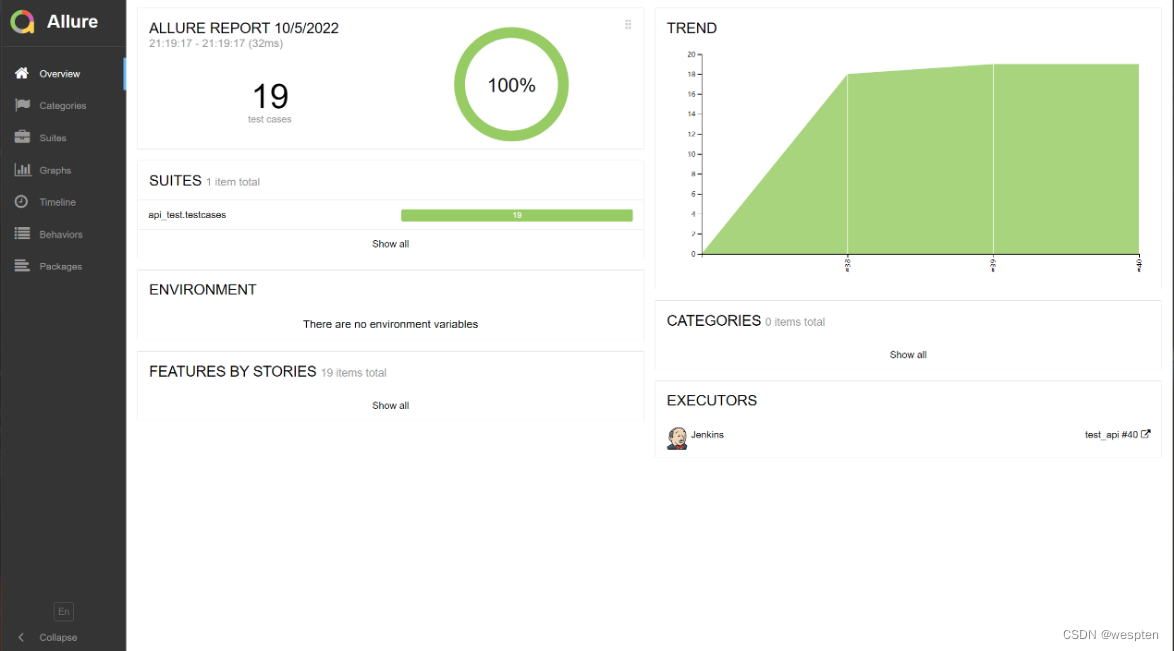
在构建时,报错:找不到项目下的子目录文件:
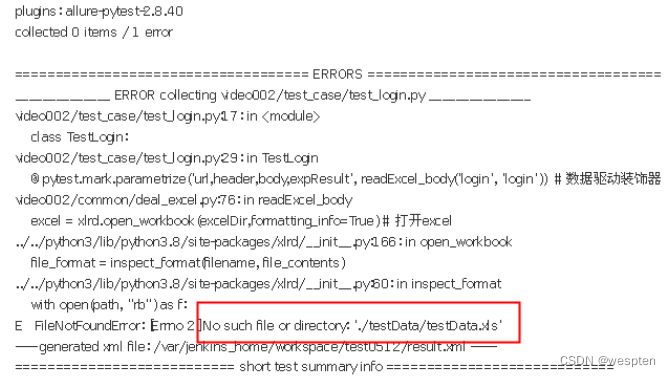
jenkins 下默认的执行文件的目录是在{worksapce},整个项目的文件是在放在{workspace}下的,将整个项目的文件路径添加进去之后就可以了。
回到jenkins上继续配置-》“构建”:
#!/bin/sh
python3 -m pytest -s --junit-xml=result.xml --alluredir ${WORKSPACE}/allure-results --clean-alluredir
exit 0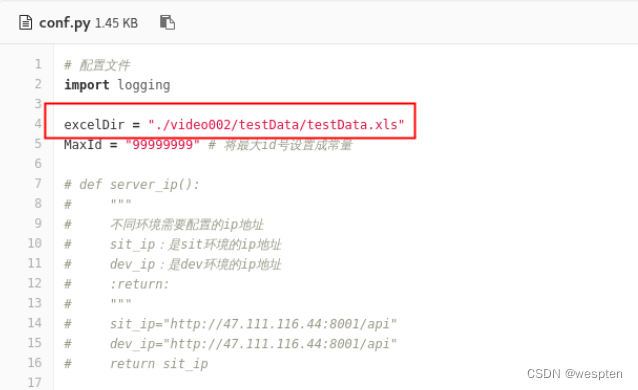
最后再配置allure-results和“高级”-》“allure-reports”:
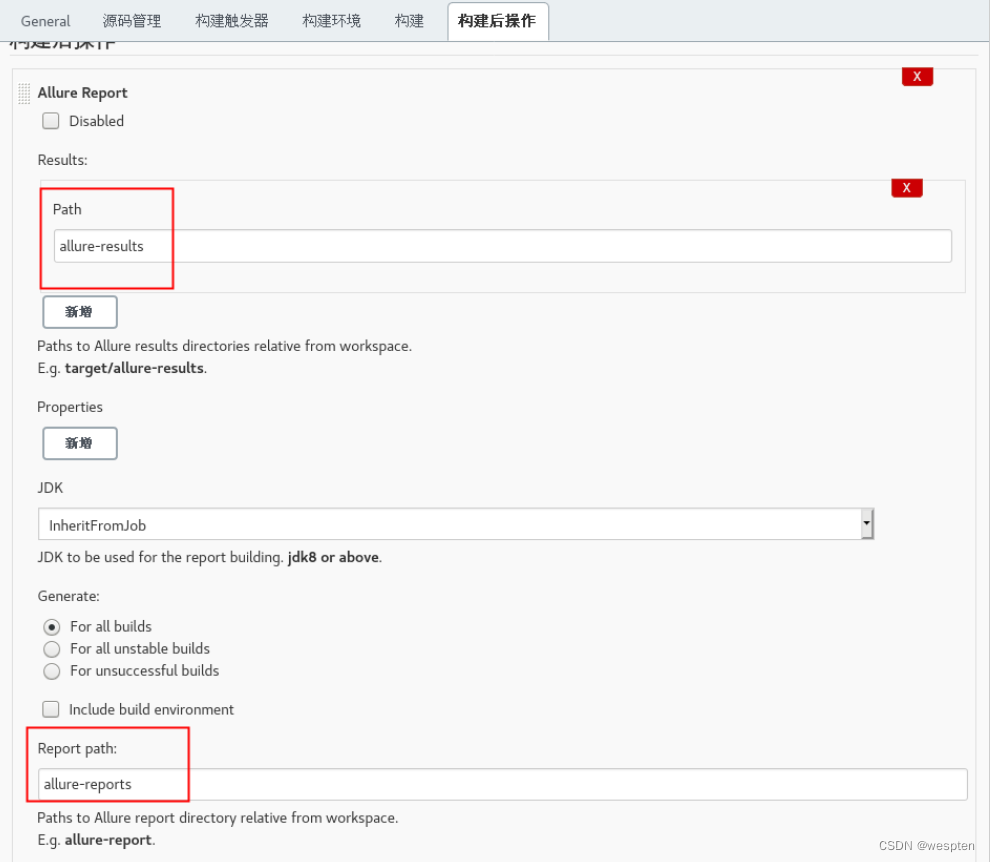
配置完成-》保存-》立即构建。
10、其他补充
1. 安装项目依赖的类库
Python项目中,一般都会有一个 requirements.txt 文件。这个文件主要是用于记录当前项目下的所有依赖包及其精确的版本号,以方便在一个新环境下更快的进行部署。
如何生成 requirements.txt:
方式一:进入项目根目录,执行以下命令。
pip3 freeze > requirements.txt方式二:进入项目根目录,执行以下命令。
python.exe -m pip freeze > requirements1.txt使用 requirement.txt 安装第三方库:
pip3 install -r requirement.txt需要在 python 项目生成一个 requirement.txt:
# 将requirement.text放到宿主机/root目录下
# 从宿主机复制到容器内
[root@localhost ~]# docker cp /root/requirements.txt jenkins1:/usr/local/src/
#cd到src目录下,pip3安装项目依赖的相关类库
root@7db4335f0dd4:/usr/local/src/py3.6# cd ../
root@7db4335f0dd4:/usr/local/src/py3.6# pip3 install -r requirements.txt2. 安装Allure报告插件
下载,放到宿主机/root目录下:Releases · allure-framework/allure2 · GitHub
也可从网盘下载:
百度网盘 请输入提取码
提取码:pb5e
# 从宿主机复制到容器内
[root@localhost ~]# docker cp /root/allure-2.14.0.zip jenkins1:/usr/local/src/
# 解压缩
root@7db4335f0dd4:/usr/local/src/py3.6# cd ../
root@7db4335f0dd4:/usr/local/src/# unzip allure-2.14.0.zip
# 目录重命名
root@7db4335f0dd4:/usr/local/src/# mv allure-2.14.0 allure
# 赋予文件夹内所有内容最高权限
root@7db4335f0dd4:/usr/local/src/# chmod -R 777 allure
# 配置allure 和 py 环境变量
root@7db4335f0dd4:/usr/local/src# cat >> /root/.bashrc << "EOF"
> export PATH=/usr/local/src/allure/bin:$PATH
> export PATH=/usr/local/src/py3.6/bin:$PATH
> EOF
# 更新环境变量配置文件
root@7db4335f0dd4:/usr/local/src# source /root/.bashrc
# 验证环境变量
root@7db4335f0dd4:/usr/local/src# allure --version
2.14.0
root@7db4335f0dd4:/usr/local/src# python3 --version
Python 3.6.83. 配置JDK环境变量
root@7db4335f0dd4:/usr/local/src# cat >> /root/.bashrc<< "EOF"
> export PATH=$JAVA_HOME/bin:$PATH
> EOF
# 更新环境变量配置文件
root@7db4335f0dd4:/usr/local/src# source /root/.bashrc4. 容器中进行自动化测试
将项目放到容器目录下:
因为当时run jenkins1的时候,设置了路径挂载,因此只需要将项目放到宿主机的/var/jenkins_node/目录下就可以。
项目文件同步到在容器的/var/jenkins_home/目录下。
Jenkins创建任务工程:
Jenkins任务配置构建、构建后操作:
#!/bin/bash
cd /var/jenkins_home/python_selenium/case
pytest -s -q --alluredir=${WORKSPACE}/allure-reports --clean-alluredir
exit 0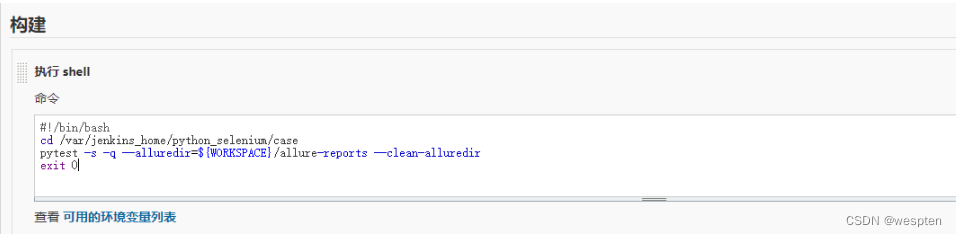
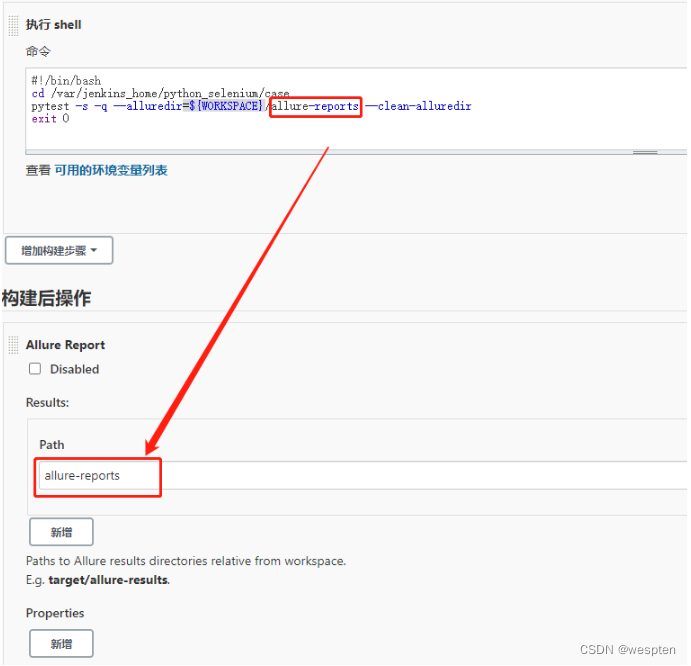
应用保存,构建Jenkins任务,查看allure报告。
5. 使用 Pycharm 需要注意的地方
每个人使用 pycharm 都会创建很多个项目,而每个项目都需要有自己的 python 依赖环境,在 pycharm 里面叫做 Project Interpreter。
有时候为了方便,这个 Interpreter 会设置为本机安装的 python 路径,如下图,这样依赖库装一遍就行。
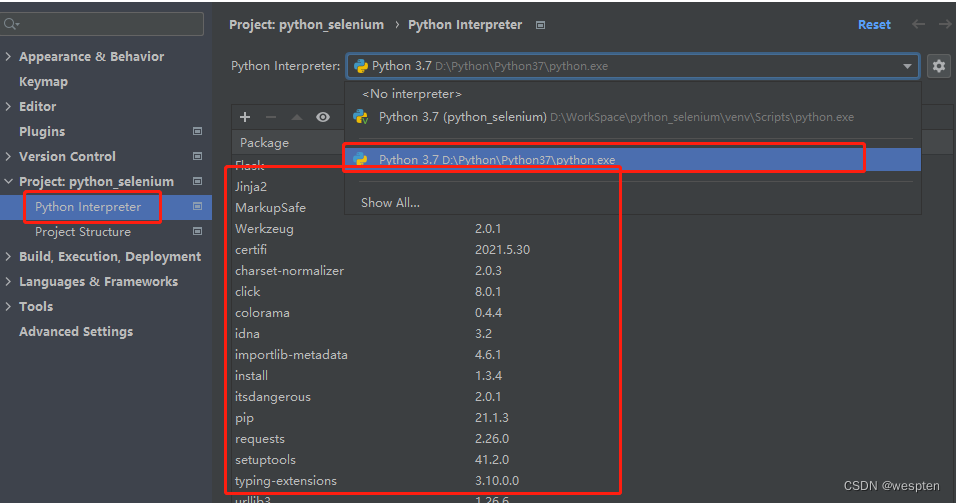
这样一来,这个依赖环境的第三方库就会有非常多,然而在某个项目的第三方库并不需要很多时,如果此时用这个 interpreter 生成 requirement.txt 就会有很多无关紧要的库。
如何解决这个问题?
给这个项目分配一个单独的 project interceptor,点击【Show All】:
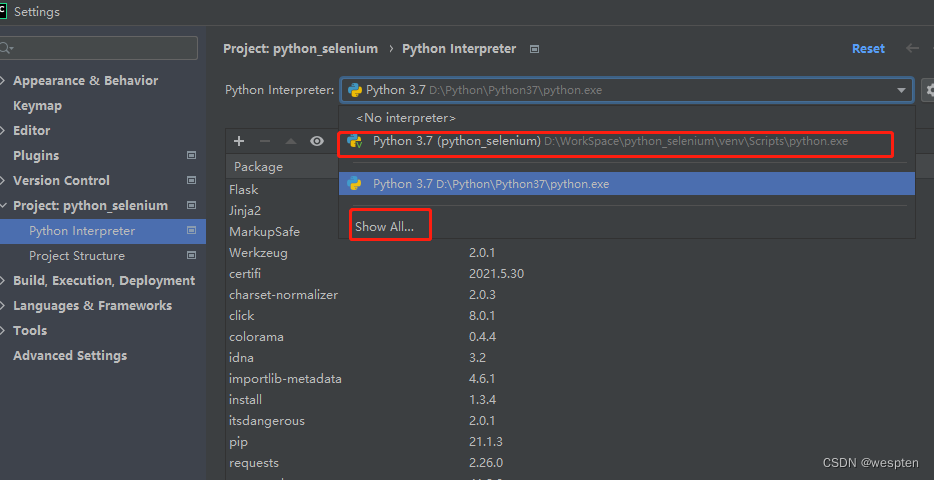
点击【+】:
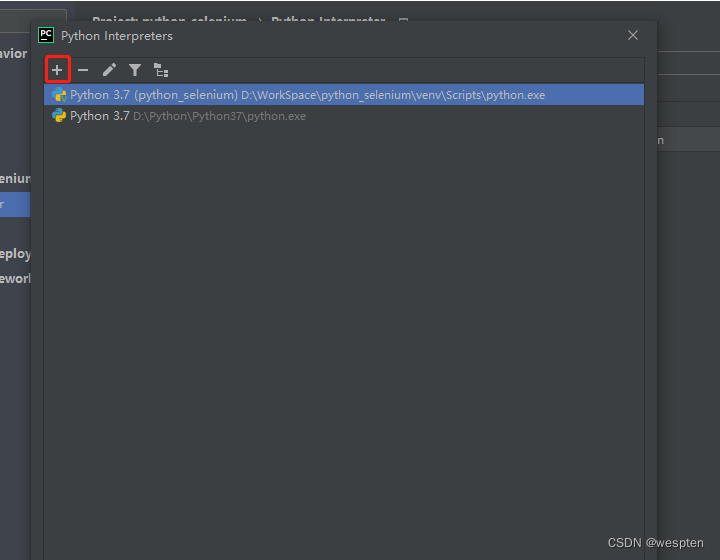
选择你的项目,点击【OK】:
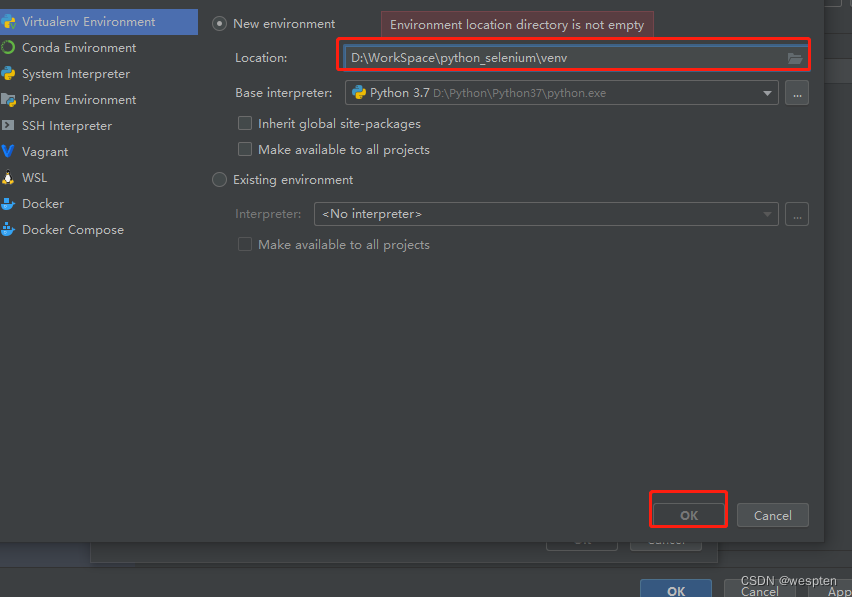
项目目录下会出现一个 venv 文件夹,这个项目依赖的 py 环境就是这里面的东西,而 python.exe 就在 Scripts 目录下。
生成 requirement.txt:
利用 venv/Scripts 下的 python.exe 生成 requirement.txt。
D:\WorkSpace\python_selenium\venv\Scripts>python.exe -m pip freeze > ../../requirements3.text
现在的 requirement.txt 就只包含这个项目所需的第三方库了。




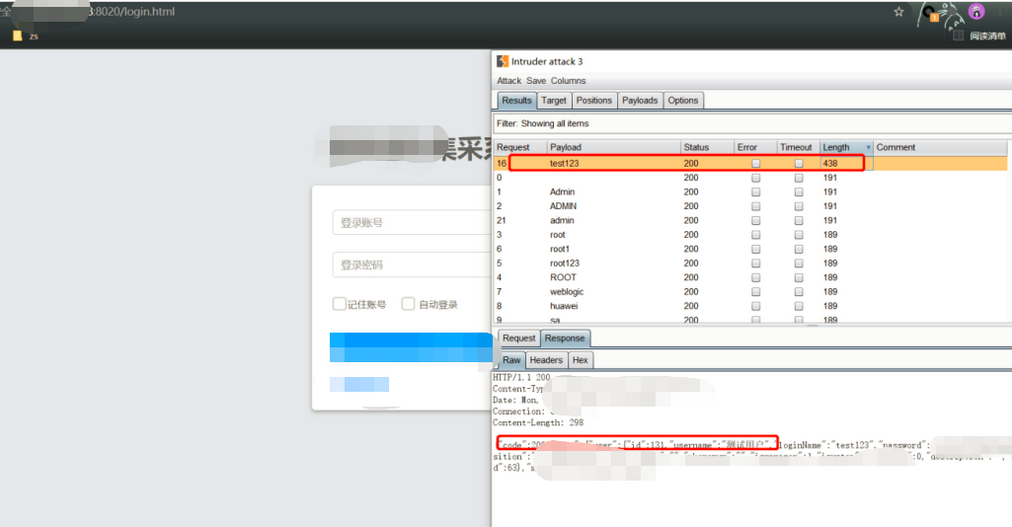
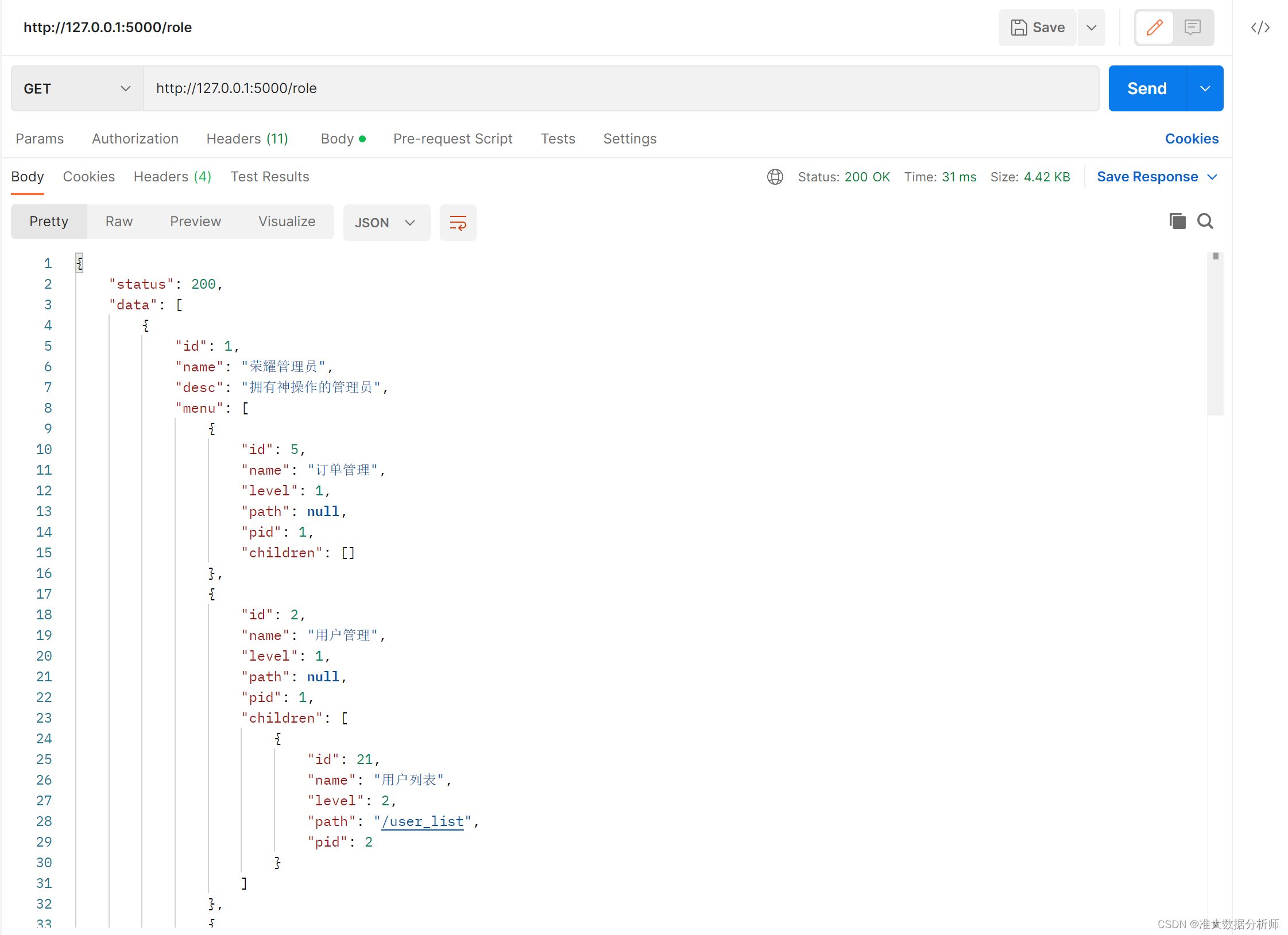
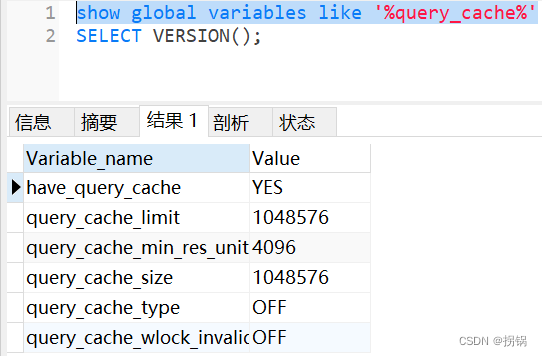
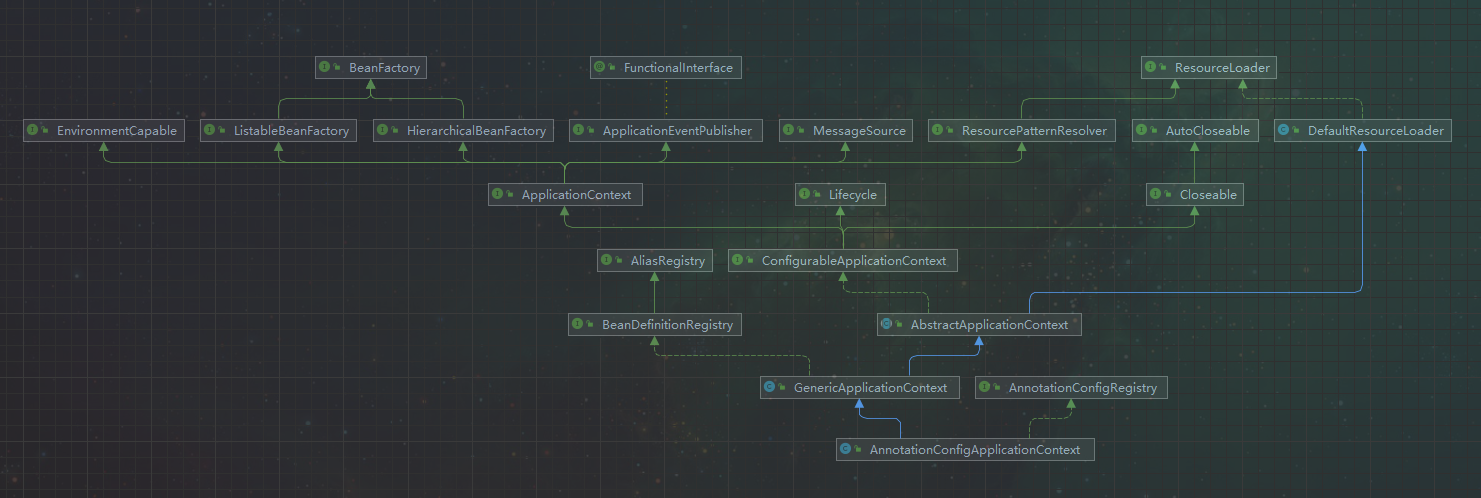

![【C语言】移位操作符 位操作符 - 对二进制位进行精准操作【+面试题目】_[初阶篇]](https://img-blog.csdnimg.cn/2df7227933834ee6b0c82ef0fb0be6e7.png)