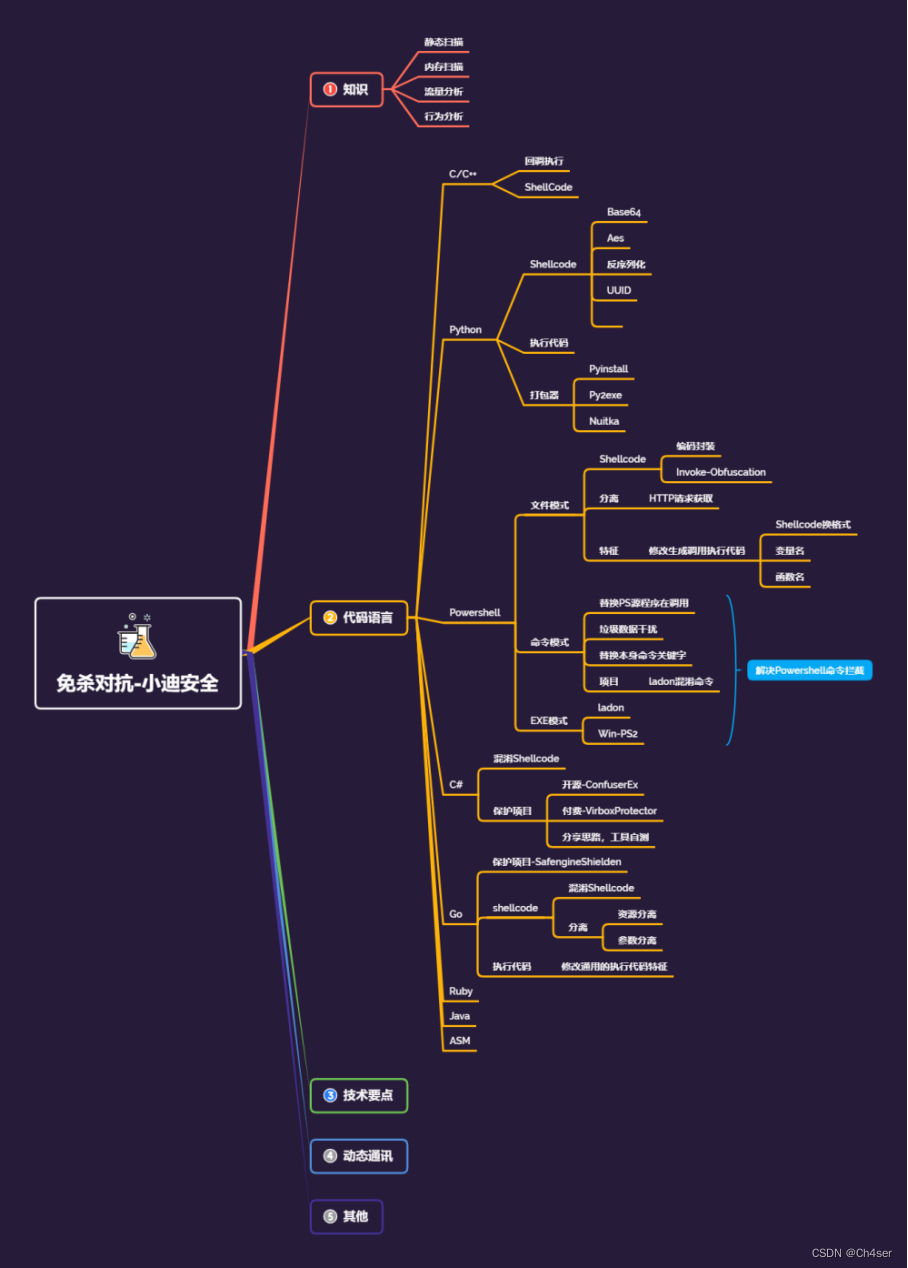
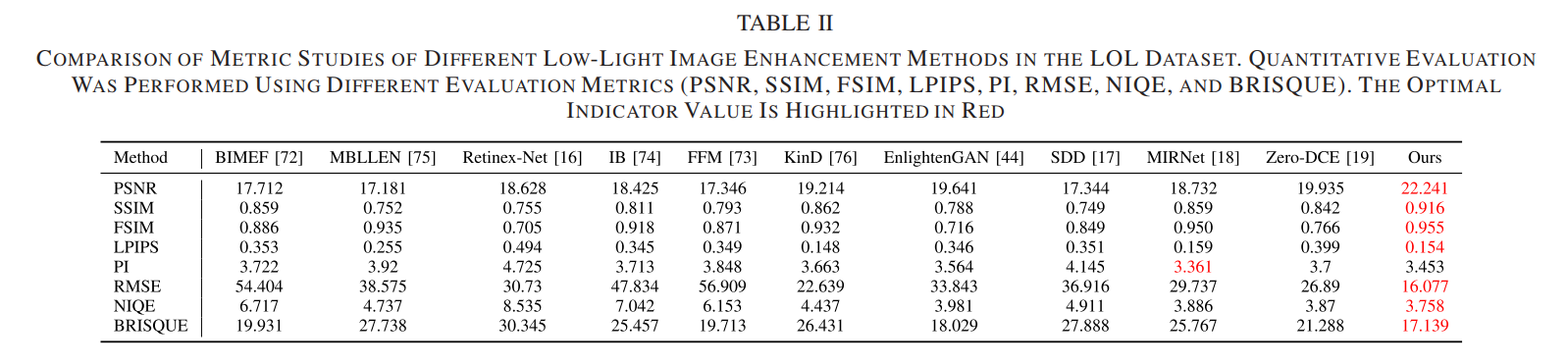
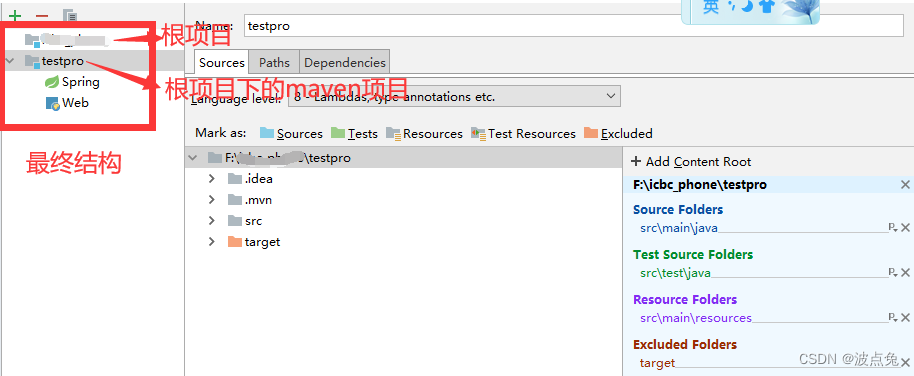
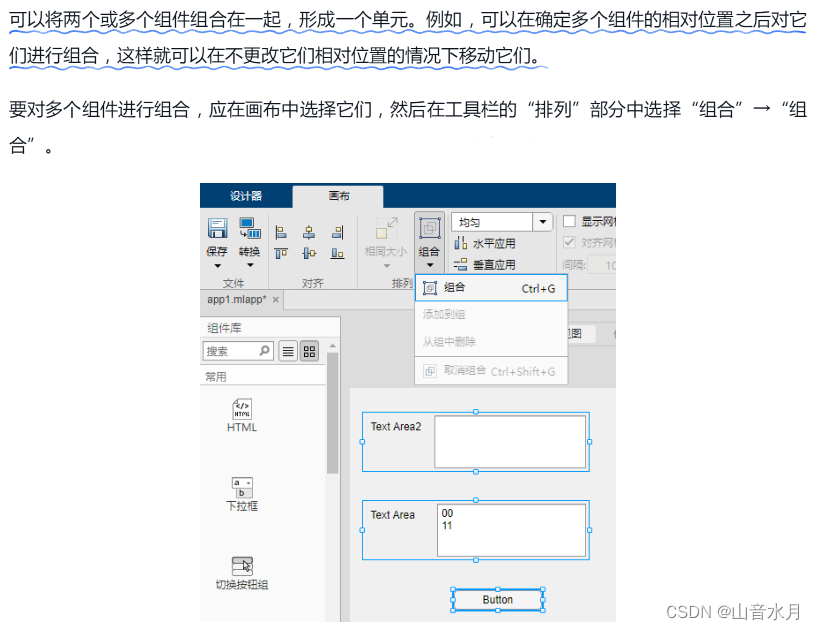
前段时间写了一篇关于顺序表的博客,http://t.csdn.cn/0gCRp
顺序表在某些时候存在着一些不可避免的缺点:
问题:1. 中间 / 头部的插入删除,时间复杂度为 O(N)2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。3. 增容一般是呈 2 倍的增长,势必会有一定的空间浪费。例如当前容量为 100 ,满了以后增容到 200,我们再继续插入了 5 个数据,后面没有数据插入了,那么就浪费了 95 个数据空间。
一.单链表的概念、结构和优缺点
1.1概念
1.2单链表的结构
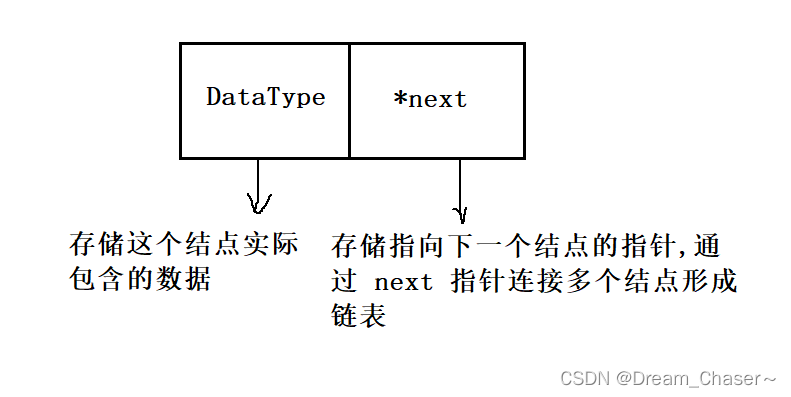
单链表是由一系列结点组成的线性结构,每个结点包含两个域:数据域和指针域。
数据域用来存储数据,指针域用来存储下一个结点的指针。单链表的头结点指向第一个结点,最后一个结点的指针域为空。
一个结点的结构:
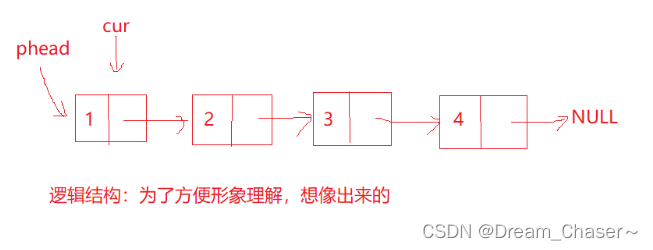
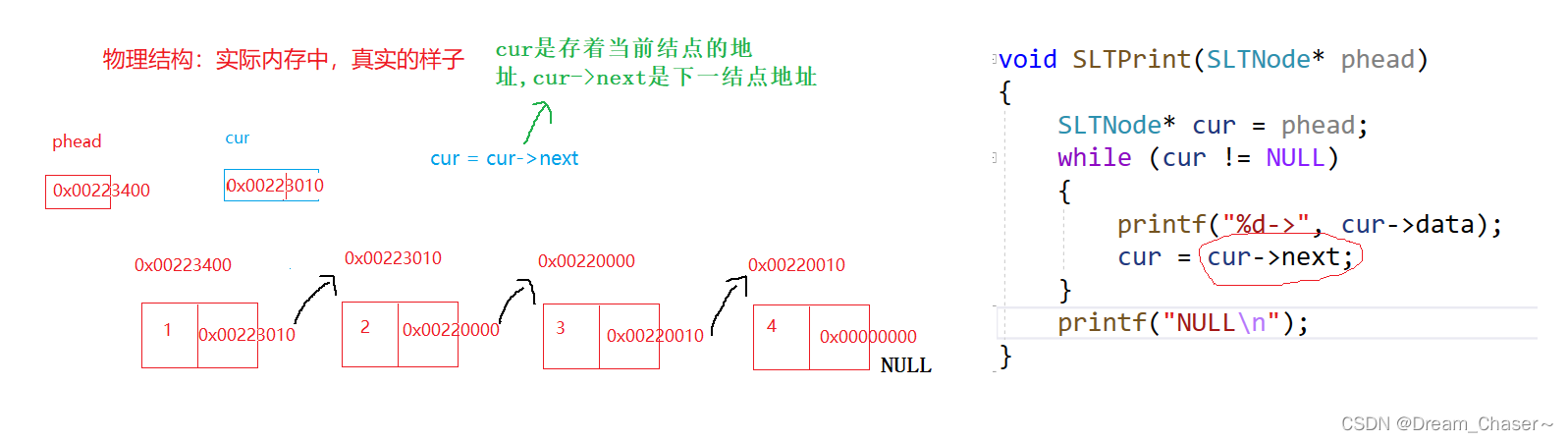
物理结构: 实际内存中,真实的样子。
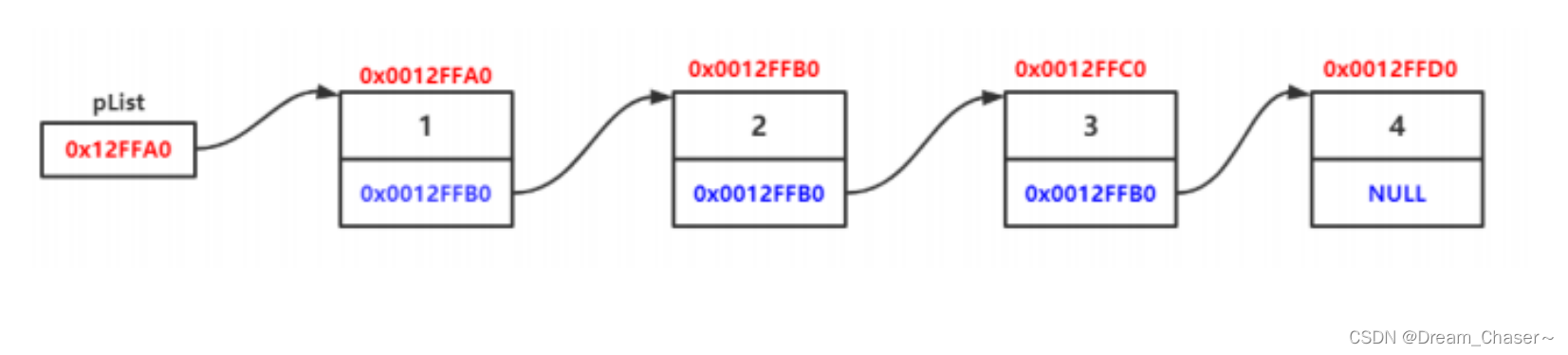 1.3单链表的优缺点
1.3单链表的优缺点
单链表是一种常见的数据结构,它具有以下优缺点:
优点:
- 插入和删除操作效率高:由于单链表的节点包含指向下一个节点的指针,因此在插入和删除节点时,只需要修改指针的指向,不需要移动大量的数据元素,因此效率较高。
- 空间利用率高:单链表的节点只包含数据和指针两部分,不需要预先分配内存空间,因此空间利用率相对较高。
- 长度可变:单链表的长度可以根据需要动态增长或缩小,不需要预先定义数组大小,具有较好的灵活性。
缺点:
- 随机访问效率低:由于单链表的节点只包含指向下一个节点的指针,因此无法直接访问某个节点之前的节点,需要从头节点开始遍历到该节点,因此随机访问效率较低。
- 存储空间浪费:由于单链表的每个节点都需要存储下一个节点的指针,因此在存储相同数据量的情况下,单链表需要更多的存储空间。
- 链接信息的丢失:单链表中只有指向下一个节点的指针,无法直接访问前一个节点,因此在需要反向遍历链表或者删除节点时,需要保存前一个节点的指针,否则将无法完成操作。
二.单链表的实现
单链表各接口函数
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;//这样做的目的是为了增加代码的可读性和可维护性,以及提高代码的可移植性,
//因为如果将来需要更改 SLTDataType 的类型,只需要在 typedef 语句中修改一处即可,
// 如果我们在程序的其他地方需要修改 SLTDataType 的类型,
//只需在 typedef 语句中修改 int 为其他类型即可,不需要修改其他代码。
//typedef int SLTADataType;
typedef struct SListNode //--single Linked List
{
SLTDataType data;//成员变量
struct SListNode* next;
}SLTNode;
void SLTPrint(SLTNode* phead);
//void SLPushFront(SLTNode* pphead,SLTDataType x);
void SLPushFront(SLTNode** pphead, SLTDataType x);//头部插入
//void SLPushBack(SLTNode* phead, SLTDataType x);
void SLPushBack(SLTNode** pphead, SLTDataType x);//尾部插入
void SLPopFront(SLTNode** pphead);//头部删除
void SLPopBack(SLTNode** pphead);//尾部删除
//单链表查找
SLTNode* STFind(SLTNode* phead, SLTDataType x);
//单链表pos之前插入
void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//单链表pos之后插入
void SLInsertAfter(SLTNode* pos, SLTDataType x);
//单链表pos位置删除
void SLErase(SLTNode** pphead, SLTNode* pos);
//单链表pos之后删除
void SLEraseAfter(SLTNode* phead);2.1结点的定义
英文简写:
单链表的英文为:Single linked list --简写为SL
而顺序表的英文是:Sequence table -- 简写为Seq
结点的英文为:node
typedef的主要作用有:主要用于提高代码的可读性和可维护性,这样代码的可读性会更好,因为SLTDataType这个名字说明了变量x的类型含义,可以为这个数据类型创建一个更简洁、更明了的别名,这样可以使代码更易读、更易维护。
typedef int SLTDataType;
typedef struct SListNode //--single Linked List
{
SLTDataType data;//成员变量
struct SListNode* next;
}SLTNode;定义了一个单链表节点的结构体 SLTNode,其中包含了两个成员变量:一个名为 data 的int变量 SLTDataType,和一个名为 next 的指向下一个节点的指针。
2.2链表的打印
“指针赋值的本质是将一个指针变量的地址复制给另一个指针变量”
int *p1, *p2;
p1 = (int*)malloc(sizeof(int)); // 为p1分配内存
*p1 = 10; // 设置p1指向的内存的值为10
p2 = p1; // 将p1的地址赋值给p2上面代码中,p1和p2都是指针变量。p1被分配了内存,并指向该内存。p2 = p1这行代码将p1的地址复制给了p2,使p2也指向p1所指向的内存。
所以指针赋值后,两个指针变量指向同一块内存,通过任一指针变量访问内存的值都会相同。
指针赋值不会复制指针指向的内存内容,仅仅是将指针变量中的地址值进行复制。
画图:
 代码实现:
代码实现:
//函数的作用是遍历单链表,并将每个节点的数据元素打印到屏幕上。
void SLTPrint(SLTNode* phead)//参数是一个指向 SLTNode 类型的指针 phead,表示单链表的头节点。
{
SLTNode* cur = phead;//头结点存储的地址给cur指针。
while (cur != NULL)//使用一个while循环对单链表进行遍历,循环条件为 cur 不为 NULL。
{ //cur 可以表示当前正在处理的节点的地址,
//通过访问 cur->data 和 cur->next 成员变量,可以获取当前节点的数据元素和下一个节点的地址
printf("%d->", cur->data);
cur = cur->next;//cur是存着当前结点的地址,cur->next是下一结点地址
}
printf("NULL\n");
}
2.3创建一个新结点
SLTNode* BuyLTNode(SLTDataType x)//表示要创建的节点的数据元素。
//函数的作用是创建一个新的单链表节点,并将其初始化为包含数据元素 x 的节点。
{
//SLTNode node;//这样是不行,处于不同的空间,出了作用域是会销毁的。
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//使用malloc函数动态分配了一个大小为SLTNode的内存块,
//并将其强制转换为 SLTNode 指针类型,即创建了一个新的节点。
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
//需要注意的是,在使用 malloc 函数动态分配内存时,需要手动释放内存,否则会导致内存泄漏
//因此,在创建单链表节点后,我们应该在适当的时候使用 free 函数释放节点所占用的内存
newnode->data = x;
newnode->next = NULL;
return newnode;//返回的是一个结点的地址
}该函数的作用是创建一个新的单链表节点,并将其初始化为包含数据元素 x 的节点。具体实现过程是通过使用 malloc 函数动态分配内存块,然后将其强制转换为 SLTNode 指针类型,即创建了一个新的节点。然后将该节点的 data 成员设置为 x,next 成员设置为 NULL,最后返回新节点的指针地址。
需要注意的是,在使用 malloc 函数动态分配内存时,需要手动释放内存,否则会导致内存泄漏。因此,在创建单链表节点后,我们应该在适当的时候使用 free 函数释放节点所占用的内存。
2.4单链表尾插
错误代码1:
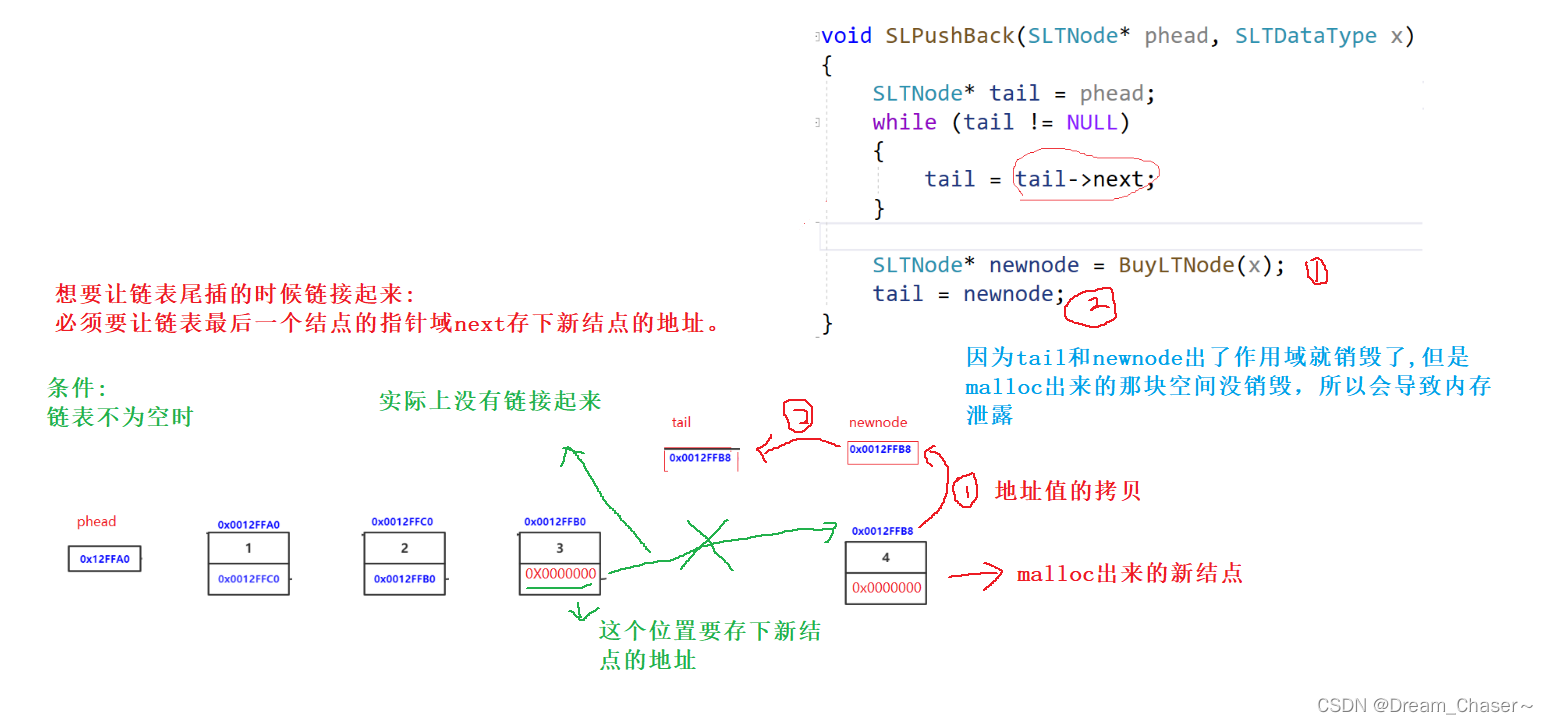
void SLPushBack(SLTNode* phead, SLTDataType x)
{
SLTNode* tail = phead;
while (tail != NULL)
{
tail = tail->next;
}SLTNode* newnode = BuyLTNode(x);
tail = newnode;//这个地方没有链接起来
}
1.链表没有链接起来
2.出了作用域指针变量销毁,内存泄露
补充一下内存泄露的知识:
如果没有使用free函数释放通过malloc函数分配的内存空间,这些内存空间将一直占用着系统资源,直到程序结束或者操作系统重启。
当程序结束时,操作系统会回收该程序使用的所有内存空间,包括没有通过free函数释放的空间。但是,在程序运行期间,这些没有释放的内存空间会一直占用着系统资源,可能导致系统的内存资源耗尽,从而影响系统的稳定性和性能。
因此,为了避免内存泄漏问题,开发人员需要在程序中显式地使用free函数来释放不再使用的内存空间,以确保系统资源的有效利用。
错误代码2:
void SLPushFront(SLTNode** pphead, SLTDataType x);
void SLPushBack(SLTNode* phead, SLTDataType x);
void TestSList1()
{
SLTNode* plist = NULL;
SLPushFront(&plist,1);
SLPushFront(&plist,2);
SLPushFront(&plist,3);
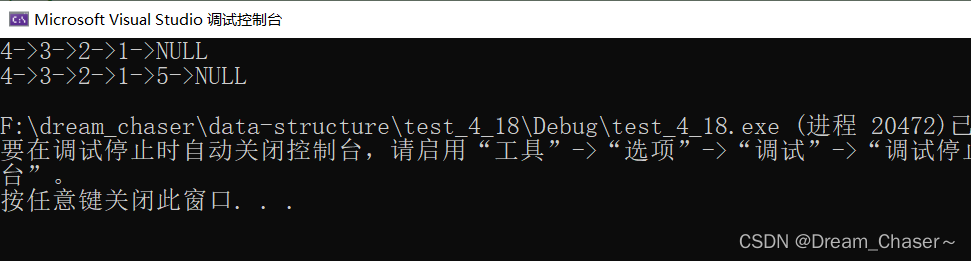
SLPushFront(&plist,4);SLTPrint(plist);
SLPushBack(plist, 5);//这里传了一级指针
SLTPrint(plist);}
void SLPushBack(SLTNode* phead, SLTDataType x)
{
SLTNode* tail = phead;
while (tail->next!= NULL)
{
tail = tail->next;
}SLTNode* newnode = BuyLTNode(x);
tail->next = newnode;
}
这种情况是先头插然后再尾插,头插每次都需要二级指针,然而尾插需要第一次是传二级指针,后面可以传一级指针,但是参数是统一的,无法实现写两个相同的函数,第一次传一级指针,后面传二级指针。
所以一致传二级指针。
这种情况前提条件是链表不为空,可以直接修改结构体的next,存下新结点的地址。
执行:
错误代码3:
画图:
void SLPushFront(SLTNode** pphead, SLTDataType x);
void SLPushBack(SLTNode* phead, SLTDataType x);void TestSList2()
{
SLTNode* plist = NULL;
SLPushBack(plist, 1);
SLPushBack(plist, 2);
SLTPrint(plist);
}void SLPushBack(SLTNode* phead, SLTDataType x)
{
SLTNode* newnode = BuyLTNode(x);
if (phead == NULL)
{
phead = newnode;
}
else
{
SLTNode* tail = phead;
while (tail->next != NULL)
{
tail = tail->next;
}tail->next = newnode;
}
}
输出:
列举了这么多错误案例接下来到正确案例:
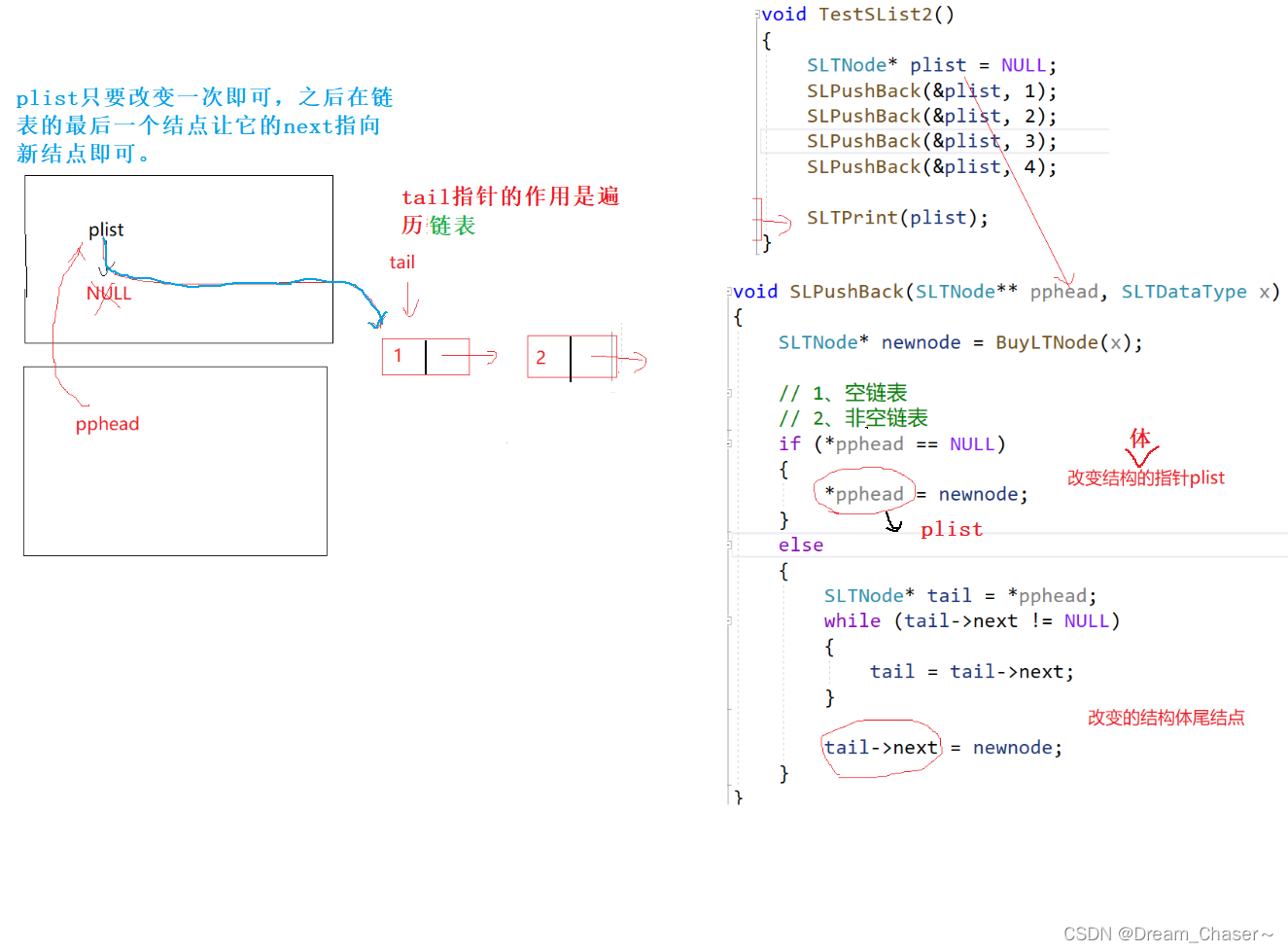
void SLPushBack(SLTNode** pphead, SLTDataType x)
void TestSList2()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
}
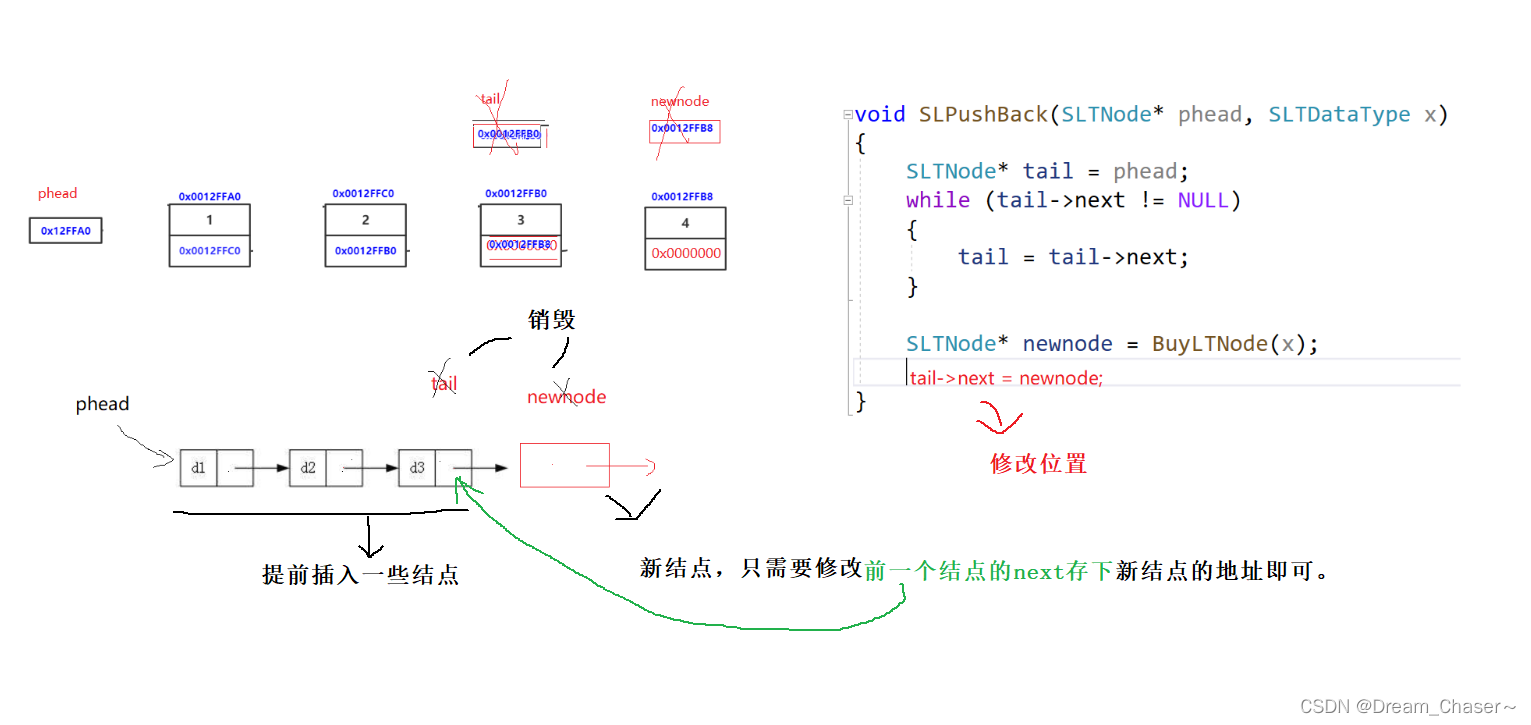
//要让新节点和tail链接起来,一定要去改tail的next
void SLPushBack(SLTNode** pphead, SLTDataType x)//尾插的本质是让上一个结点链接下一个结点
{
SLTNode* newnode = BuyLTNode(x);
// 1、空链表
// 2、非空链表
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}代码执行:

2.5单链表头插
头插思路:

头插第二个节点思路:
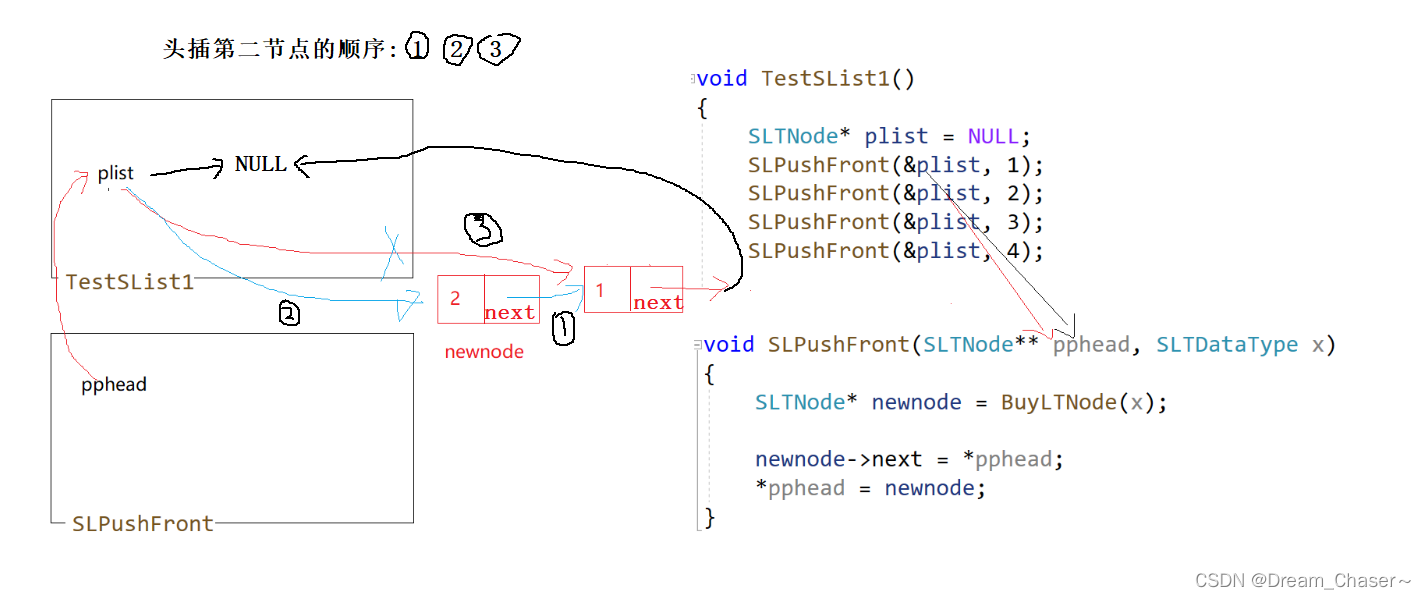
头插的代码可以写成这样
void SLPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//使用malloc函数动态分配了一个大小为SLTNode的内存块,
//并将其强制转换为 SLTNode 指针类型,即创建了一个新的节点。
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
//需要注意的是,在使用 malloc 函数动态分配内存时,需要手动释放内存,否则会导致内存泄漏
//因此,在创建单链表节点后,我们应该在适当的时候使用 free 函数释放节点所占用的内存
newnode->data = x;
newnode->next = NULL;
//return newnode;//返回的是一个结点的地址
newnode->next = *pphead;
*pphead = newnode;//将头节点*pphead 更新为新节点的地址,以使新节点成为新的头节点。
}但是为了避免创建新节点的程序重复编写,可以利用上面的BuyLTNode(x)函数定义新节点达成简写的目的,也可以头插的函数也可以写成这样:
void SLPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}在
SLPushFront函数中,我们首先调用BuyLTNode(x)函数创建一个新的节点,然后将新节点的next指针指向当前链表头节点,接着将链表头指针指向新节点,从而完成了在链表头部插入新节点的操作。
代码执行:
2.6单链表尾删
错误案例:

方法1:
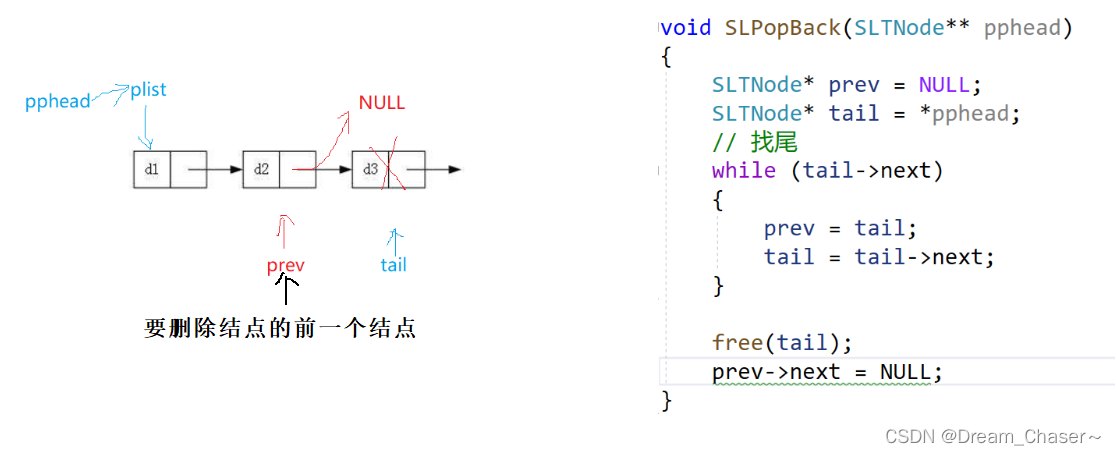
方法2:
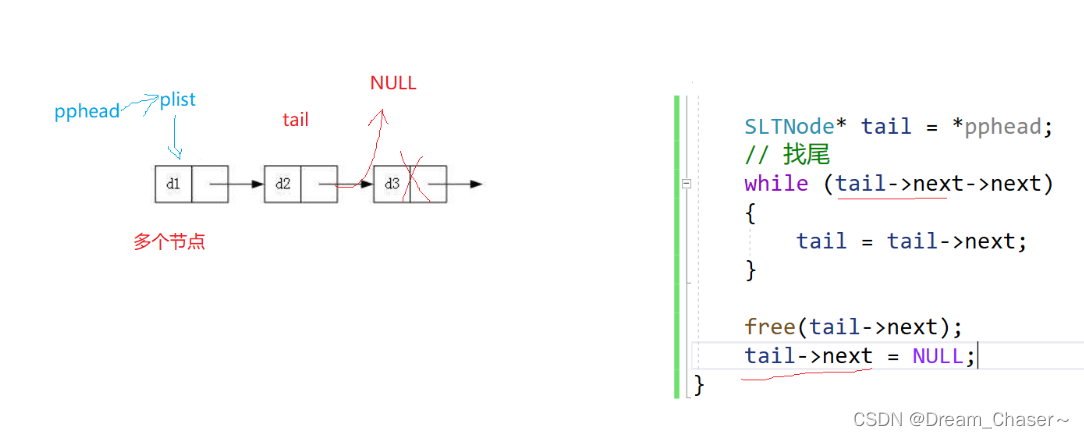
代码实例:
void SLPopBack(SLTNode** pphead)
{
//没有节点(空链表)
//暴力检查
assert(*pphead);
//温柔检查
if (*pphead == NULL)
{
return;
}
//一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}//多个节点
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
//找尾
//方法一
/*while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;*/
//方法二
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}执行:
2.7单链表头删
思路:
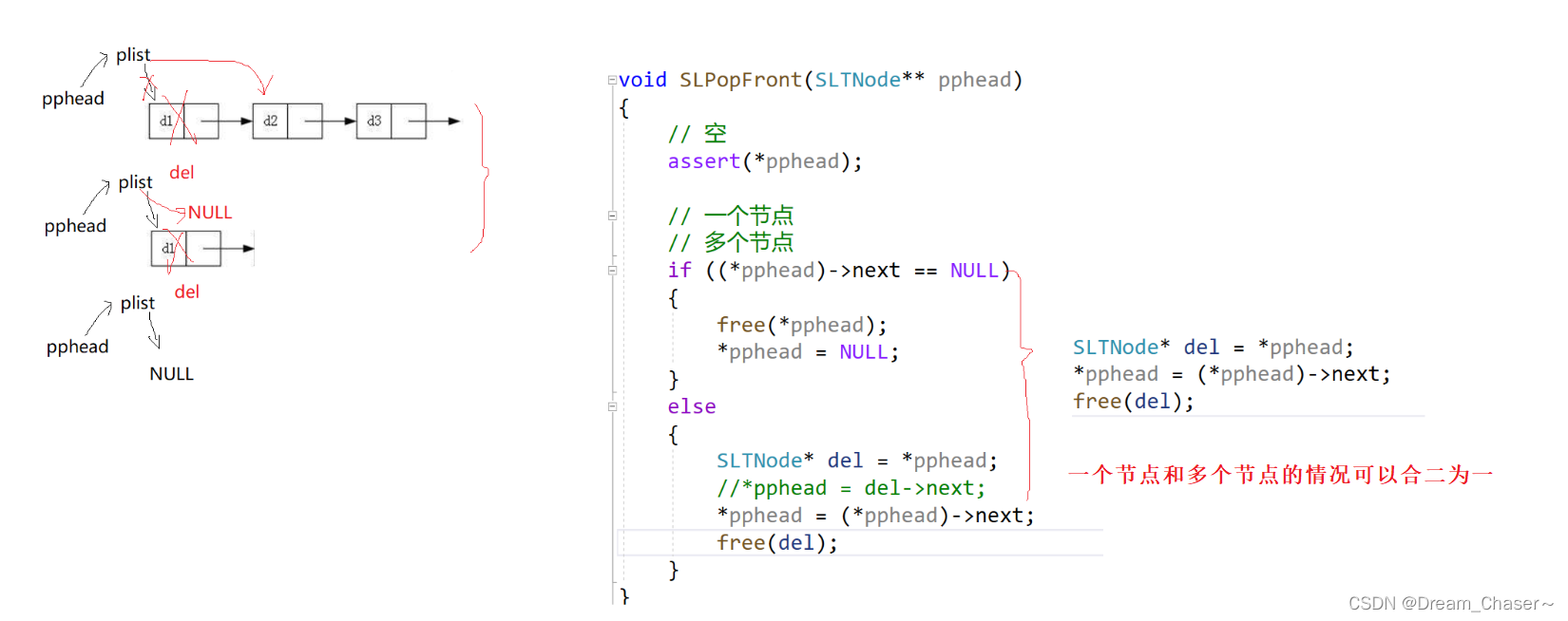
void SPopFront(SLTNode** pphead)
{
//没有节点
//暴力检查
assert(*pphead);
//温柔检查
if (*pphead == NULL)
return;// 一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//多个节点
else
{
SLTNode* del = *pphead;//相当于一个标记,删掉的标记
//写法一
//*pphead = del->next;
//写法二
*pphead = (*pphead)->next;
free(del);
}
}执行:

2.8单链表查找/修改某个值
使用尾插将1,2,3,4按先后顺序分别插入链表中,接着找到链表中值为3的元素,并把其改为30(可以通过定义结构体类型的指针访问data为3的结点,并直接通过pos->next=30修改)
注意:直接在main函数内定义一个test函数修改值即可,不必另定义新函数。
SLTNode* STFind(SLTNode* phead, SLTDataType x)
{
//assert(phead);
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}执行:

2.9单链表在pos之前插入
思路:

void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);//&plist
assert(pos);
//assert(*pphead);
//一个节点
if (*pphead == NULL)
{
SLPushFront(pphead, x);
}
else//多个节点
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuyLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
}执行:

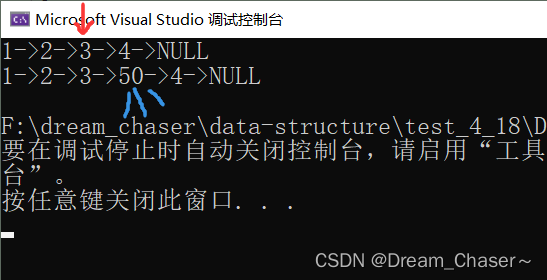
2.10单链表在pos之后插入
思路:
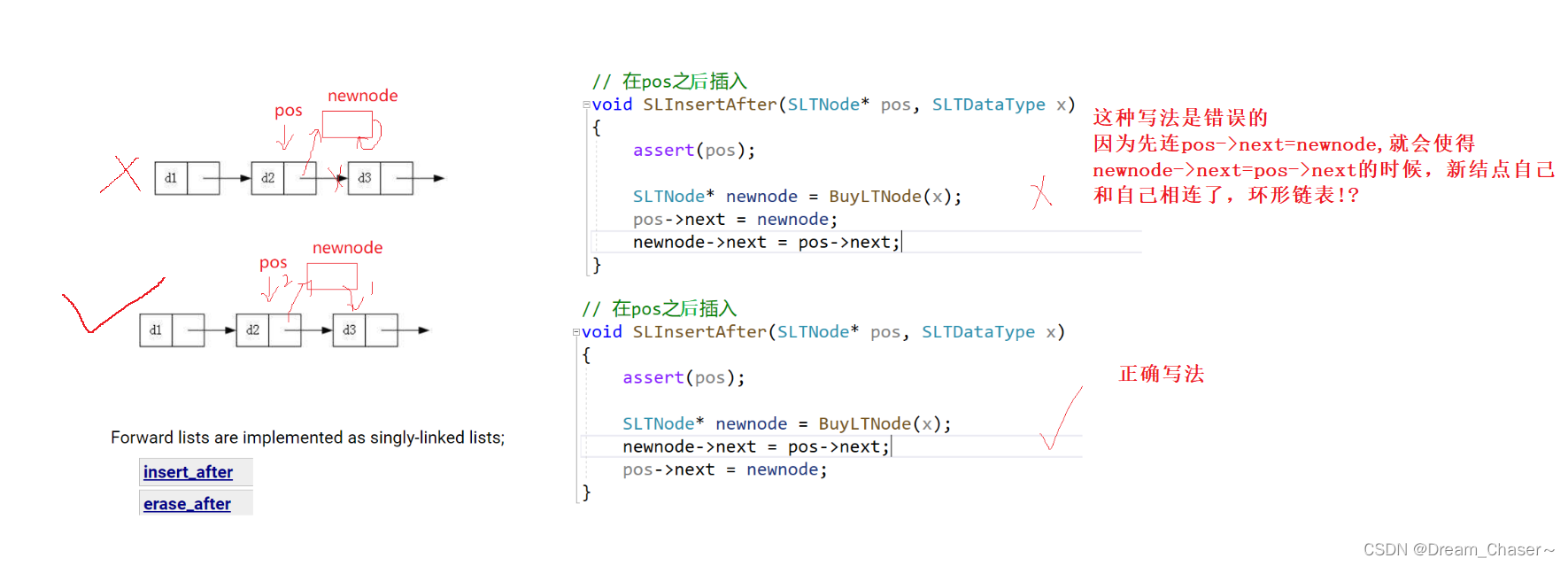
void SLInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuyLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
2.11单链表删除pos的值
思路:
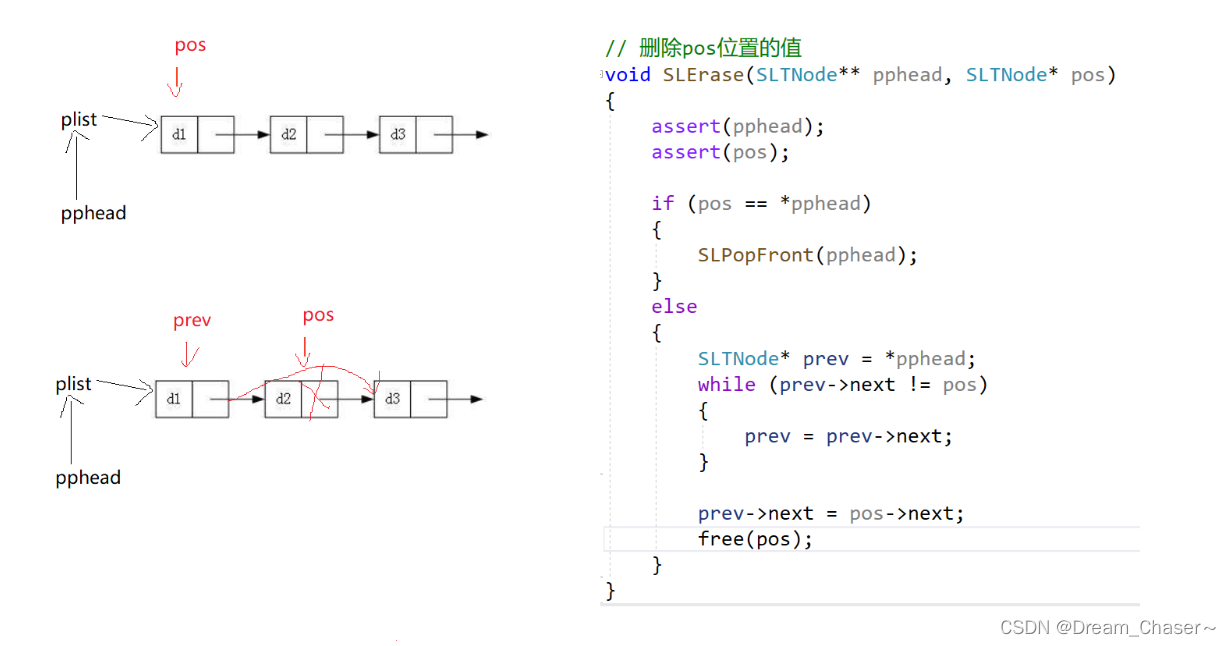
void SLErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next!=pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
2.12单链表删除pos之后的值
思路:
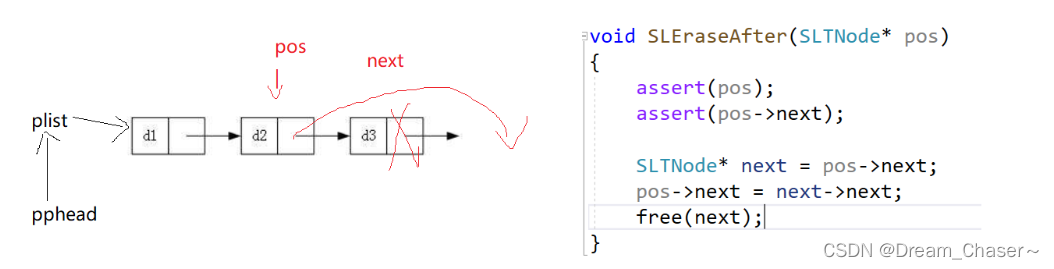
void SLEraseAfter(SLTNode* pos)
{
assert(pos);
SLTNode* next= pos->next;
pos->next = next->next;
free(next);
} 
三.案例函数实现
3.1测试
void TestSList1()
{
SLTNode* plist = NULL;
SLPushFront(&plist,1);
SLPushFront(&plist,2);
SLPushFront(&plist,3);
SLPushFront(&plist,4);
SLTPrint(plist);
SLPushBack(plist, 5);
SLTPrint(plist);
}3.2头插
void TestSList2()
{
SLTNode* plist = NULL;
SLPushFront(&plist, 1);
SLPushFront(&plist, 2);
SLPushFront(&plist, 3);
SLPushFront(&plist, 4);
SLTPrint(plist);
SLPushBack(&plist, 5);
SLTPrint(plist);
}3.3尾插
void TestSList3()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLTPrint(plist);
SLPushBack(&plist, 2);
SLTPrint(plist);
SLPushBack(&plist, 3);
SLTPrint(plist);
SLPushBack(&plist, 4);
SLTPrint(plist);
}3.4头删
void TestSList4()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
//头删
SLPopFront(&plist);
SLTPrint(plist);
SLPopFront(&plist);
SLTPrint(plist);
SLPopFront(&plist);
SLTPrint(plist);
SLPopFront(&plist);
SLTPrint(plist);
}3.5尾删
void TestSList5()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLPopBack(&plist);
SLTPrint(plist);
SLPopBack(&plist);
SLTPrint(plist);
SLPopBack(&plist);
SLTPrint(plist);
}3.6查找/修改某值
void TestSList6()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist,3);
if (pos)
pos->data = 30;
SLTPrint(plist);
}3.7在pos之前插入
void TestSList7()//pos之前插入
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist,3);
if (pos)
{
SLInsert(&plist, pos, 30);
}
SLTPrint(plist);
}3.8在pos之后插入
void TestSList8()//pos之后插入
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist, 3);
if (pos)
{
SLInsertAfter(pos, 50);
}
SLTPrint(plist);
}3.9删除pos位置的值
void TestSList9() {
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist, 3);
if (pos)
{
SLErase(&plist,pos);
}
SLTPrint(plist);
}3.10删除pos之后的值
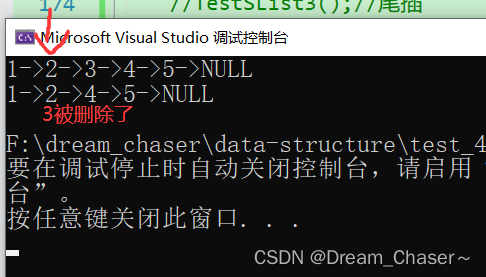
void TestSList10() {
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLPushBack(&plist, 5);
SLTPrint(plist);
SLTNode* pos = STFind(plist, 2);
if (pos)
{
SLEraseAfter(pos);
}
SLTPrint(plist);
}本章完,如有错误欢迎各位大佬指点,感谢你的来访。