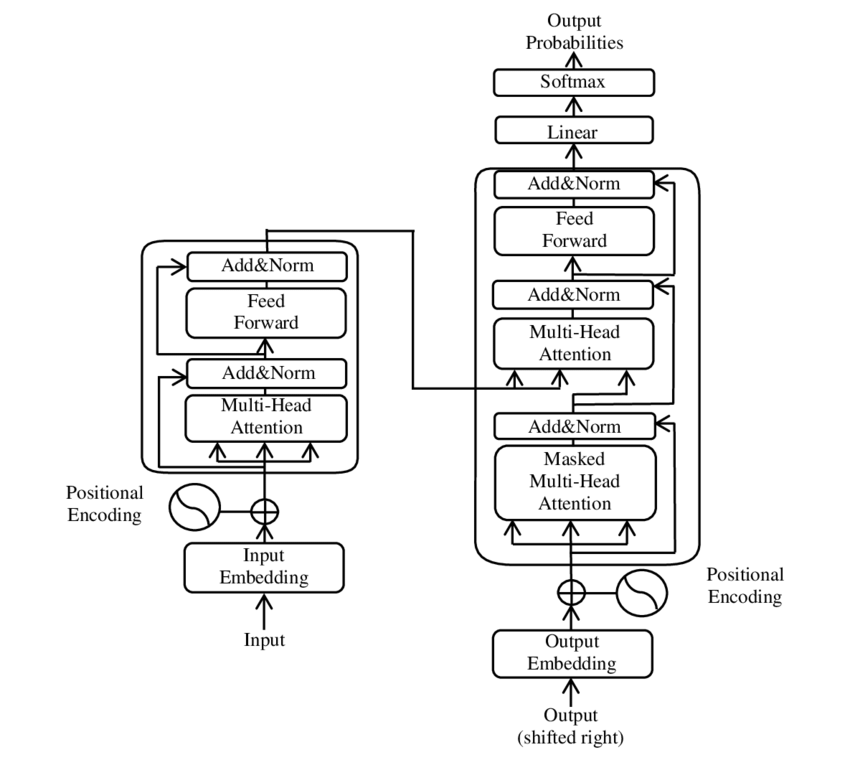
前言
曾在游戏世界挥洒创意,也曾在前端和后端的浪潮间穿梭,如今,而立的我仰望AI的璀璨星空,心潮澎湃,步履不停!愿你我皆乘风破浪,逐梦星辰!
Activation Checkpointing(激活检查点),在 DeepSpeed 里是一个非常实用的显存优化技术。简单来说,它的核心目标就是:
“节省显存,代价是多做点计算。”
下面我给你讲明白它是啥、怎么干的、为什么有效、啥时候该用。
🧠 一句话解释
Activation Checkpointing 就是:
在前向传播时不保存所有中间激活(activation),而是只保存“关键点”的激活;
等到反向传播需要时,再重新计算中间丢掉的部分。
📦 举个例子(以 Transformer 为例)
假设你有一个 12 层的 Transformer:
-
正常训练时,前向传播完 12 层,会保存 每一层的激活输出(用于反向传播时算梯度)。
-
这些激活可能占你一大半的显存!
💡 但是,如果你设置了 activation checkpointing:
-
你只保存第 0、4、8、12 层的激活(比如每隔 4 层存一个“检查点”)。
-
当反向传播需要第 2 层激活时,Deepspeed 会:
-
重新从第 0 层开始计算到第 2 层。
-
得到激活,然后继续正常反传。
-
-
这样就省下了很多显存,但代价是计算时间会稍微变长(因为要“回头重算”)。
🔍 技术实现机制
| 步骤 | 做了什么 |
|---|---|
| 前向传播 | 只保存“检查点”处的激活,其他层的激活丢掉 |
| 反向传播 | 当需要中间层激活时,重新从上一个检查点 forward 一遍 |
| PyTorch 实现 | 通常使用 torch.utils.checkpoint.checkpoint(function, *inputs) 来做 |
| Deepspeed 支持 | 可以自动为模型的某些模块启用 checkpoint,比如 TransformerBlock |
🧮 显存节省 vs 计算开销
| 优点 | 缺点 |
|---|---|
| 大幅减少激活存储显存(最多可省 50%+) | 增加前向传播的计算量(因为反向时要重算一部分) |
| 可以训练更大的模型 / 更大 batch | 训练速度略慢(但通常接受) |
典型使用场景:
-
显存紧张,训练不了大的 batch 或模型。
-
训练 GPT/BERT 这类“块状重复”的模型时特别有效(容易切分 block)。
✅ 在 Deepspeed 中如何启用?
在 deepspeed_config.json 中这样配:
{
"activation_checkpointing": {
"partition_activations": true,
"contiguous_memory_optimization": true,
"cpu_checkpointing": false,
"number_checkpoints": 4
}
}
| 配置项 | 含义 |
|---|---|
partition_activations | 按 rank 切分激活,进一步省显存 |
contiguous_memory_optimization | 内存优化,避免碎片化 |
cpu_checkpointing | 是否把 checkpoint 存 CPU(更慢,慎用) |
number_checkpoints | 控制多少层之间插一个 checkpoint(类似“每几层存一次”) |
📌 总结一句话
Activation Checkpointing 是一种“用时间换空间”的策略,省显存的同时代价是略微增加计算。对于大模型(如 GPT、BERT)训练来说是非常常见的标配技术。
如果你要训练 13B、30B 这种大模型或者 batch 太大撑不住,那这技术几乎是必开项了。


![[王阳明代数讲义]具身智能才气等级分评价排位系统领域投射模型讲义](https://i-blog.csdnimg.cn/direct/5593a120ff514d058e96f601782d6d1c.jpeg#pic_center)








![线代[12]|《高等几何》陈绍菱(1984.9)(文末有对三大空间的分析及一个合格数学系毕业生的要求)](https://i-blog.csdnimg.cn/direct/c3824a02d3094a648f7adf08f2cb137f.jpeg#pic_center)