神经网络作为机器学习中的核心算法之一,其灵感来源于生物神经系统。在本文中,我们将带领大家手把手学习神经网络的基本原理、结构和训练过程,并通过详细的 Python 代码实例让理论与实践紧密结合。无论你是编程新手还是机器学习爱好者,这篇文章都将帮助你轻松入门!
你是否曾好奇,那些看似智能的AI是如何“思考”和“学习”的?比如,它们如何识别图片中的猫咪,如何听懂你说的话,又如何下出让你惊叹的棋局?在众多AI背后的“大脑”中,有一种非常重要且强大的算法——神经网络。
别听到“神经”两个字就觉得高深莫测!今天,我们就用最简单有趣的方式,一层层揭开神经网络的神秘面纱,让你也能轻松入门,甚至亲手搭建自己的第一个神经网络!
一、 什么是神经网络?
想象一下我们的大脑。里面布满了数以亿计的神经元,它们相互连接,传递着各种信息,让我们能够思考、学习和感知世界。神经网络的灵感正是来源于此。
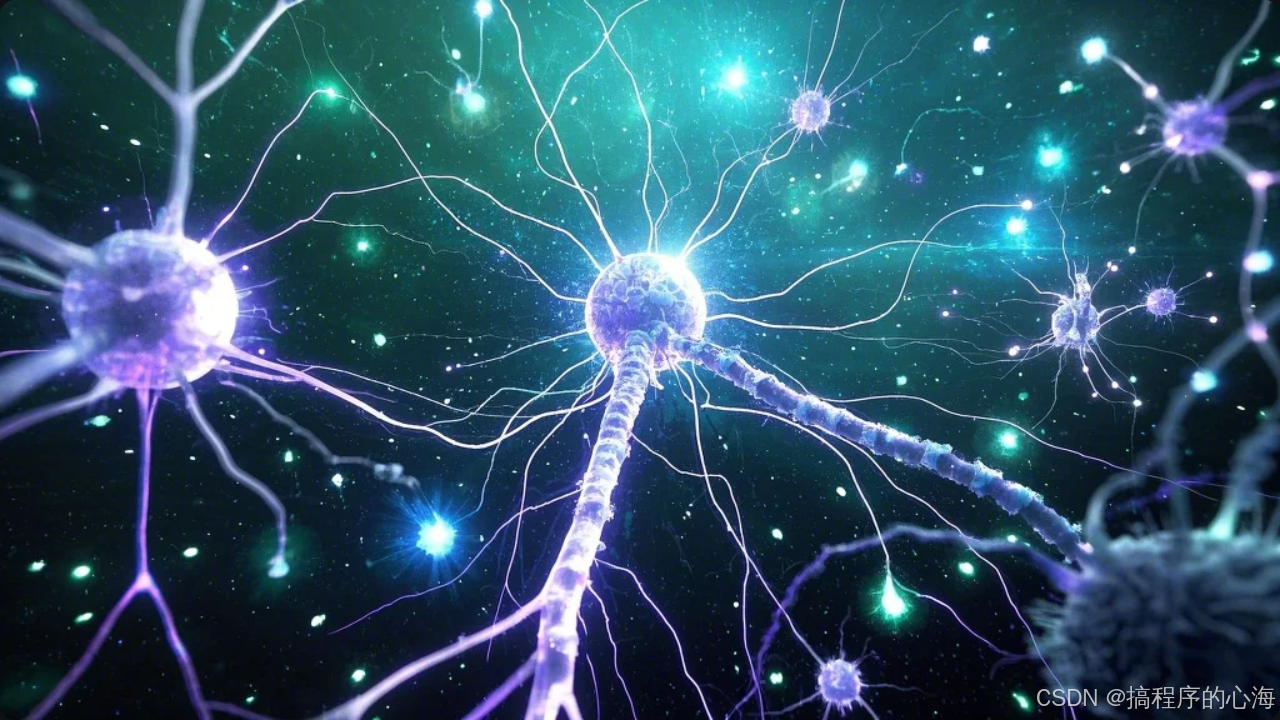
神经网络模拟人脑神经元之间的连接方式,由大量的人工神经元(也称节点或单元)按层次结构组成。每个神经元会接收输入,经过加权求和和激活函数的处理后,将信号传递到下一层。整个网络由输入层、隐藏层和输出层构成,每一层都有特定的功能:
-
输入层:负责接收数据。
-
隐藏层:执行大量的非线性变换,是模型表达能力的关键。
-
输出层:输出最终预测结果。
这种层层传递、不断调整权重的过程就是神经网络“学习”的过程。
🌰 生活中的神经网络
- 图像识别:帮你从相册中找出所有猫的照片
- 语音助手:听懂你的 "豆包,今天天气如何?"
- 自动驾驶:识别交通标志和行人
二、 神经网络的基本结构
2.1 神经元模型
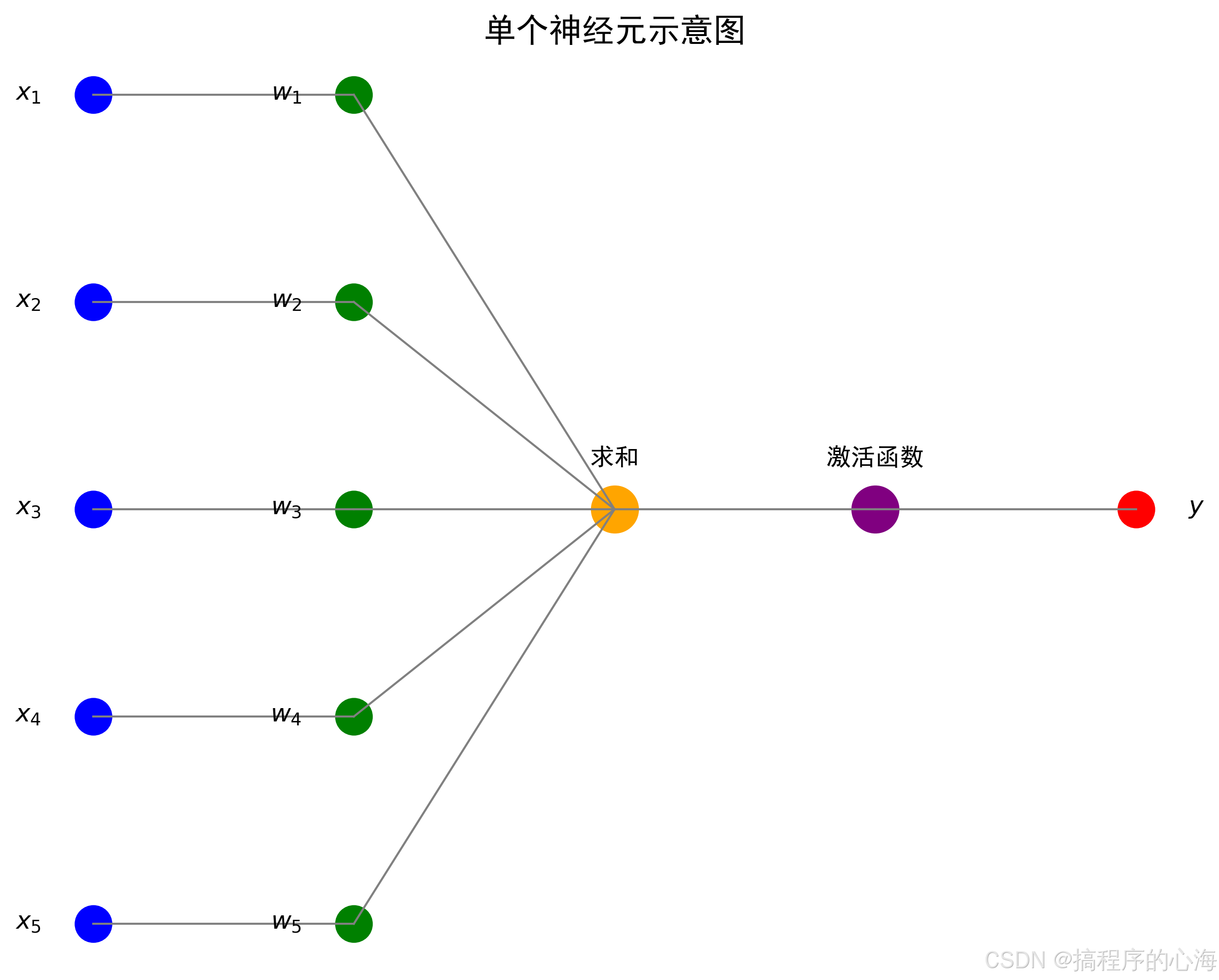
让我们先来认识一下神经网络中最基本的单元——人工神经元。一个人工神经元通常包含以下几个部分:
-
输入 (Inputs): 神经元接收到的信息。可以是一个或多个数值。想象一下,你正在判断一个水果是不是苹果,颜色、形状、大小、气味等都是输入的信息。
-
权重 (Weights): 每个输入都带有一个权重,表示该输入对神经元输出的重要性。比如,颜色和形状可能比气味在判断苹果时更重要,所以它们的权重会更高。
-
求和 (Summation): 神经元将所有输入与它们对应的权重相乘后求和。这个过程相当于对各种输入信息进行加权汇总。
-
偏置 (Bias,可选): 一个额外的常数项,可以调整神经元的激活阈值。相当于给神经元一个“预启动”或者“延迟启动”的倾向。
-
激活函数 (Activation Function): 求和后的结果会通过一个激活函数,决定神经元是否“激活”并输出。激活函数引入了非线性,这使得神经网络能够学习复杂的模式。常见的激活函数有Sigmoid、ReLU等,我们稍后会详细介绍。
-
输出 (Output): 神经元处理后的结果,可以传递给下一个神经元。
你可以把一个神经元想象成一个小型的信息处理中心:接收信息(带权重的)、汇总信息、然后根据一定的规则(激活函数)决定是否发出信号。
2.2 神经网络的结构:层层递进的信息处理
多个相互连接的神经元就组成了神经网络。一个典型的神经网络通常由以下几层组成:
-
输入层 (Input Layer): 接收原始数据的输入。每个输入特征通常对应一个输入神经元。例如,如果我们要识别一张28x28像素的手写数字图片,那么输入层就会有784个神经元(28 * 28)。
-
隐藏层 (Hidden Layer): 位于输入层和输出层之间。可以有一个或多个隐藏层。隐藏层中的神经元会从上一层接收信息,进行处理,并将结果传递给下一层。隐藏层是神经网络学习复杂特征的关键。
-
输出层 (Output Layer): 输出最终结果。输出层神经元的数量取决于要解决的问题。例如,如果我们要进行10个数字的分类,输出层通常会有10个神经元,每个神经元代表一个数字的概率。
信息在神经网络中是单向流动的,通常从输入层开始,经过一个或多个隐藏层,最终到达输出层。每一层都对输入信息进行某种形式的变换和提取。
三、神经网络是如何学习的?—— “反向传播”的魔法
神经网络之所以强大,在于它能够通过学习数据来自动优化自身的参数(主要是神经元之间的连接权重和偏置),从而完成特定的任务。那么,它是如何学习的呢?这就要提到神经网络的核心学习算法——反向传播 (Backpropagation)。
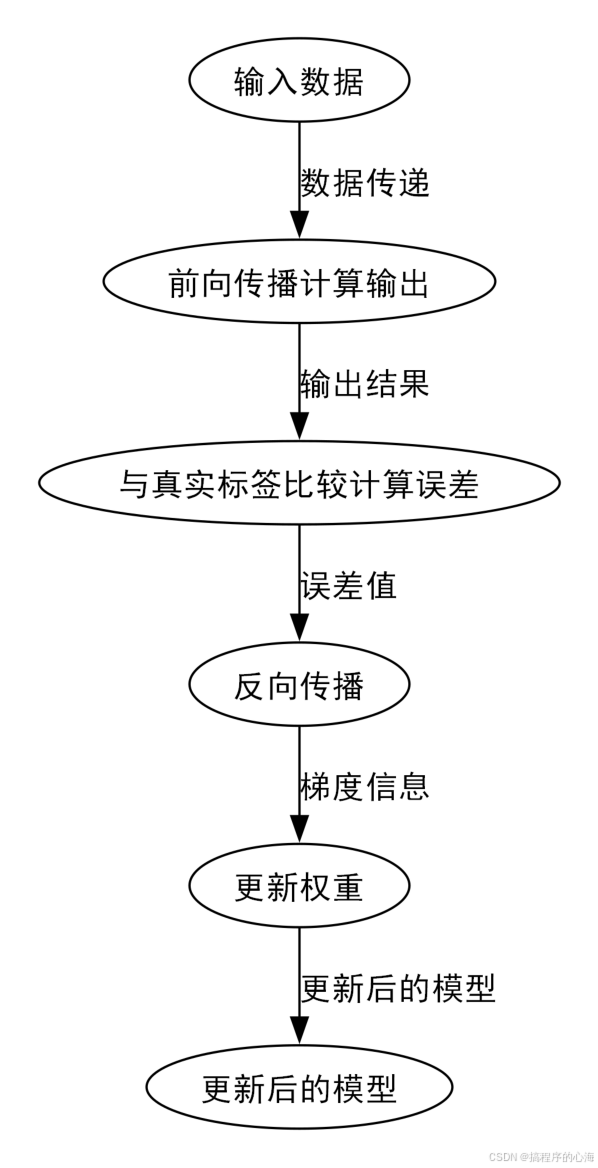
3.1 前向传播:计算预测结果
首先,当一条数据输入到神经网络时,信息会从输入层开始,逐层向前传递,直到输出层,最终得到一个预测结果。这个过程被称为前向传播 (Forward Propagation)。
在每一层中,每个神经元都会接收来自上一层神经元的输出,乘以各自的权重,加上偏置,然后通过激活函数计算出自己的输出,并传递给下一层。
3.2 损失函数:衡量预测的“好坏”
得到预测结果后,我们需要知道这个结果与真实的标签(我们期望的答案)之间的差距有多大。损失函数 (Loss Function) 就是用来衡量这个差距的。损失函数的输出值越小,表示神经网络的预测越准确。
常见的损失函数有均方误差 (Mean Squared Error, MSE) 和交叉熵损失 (Cross-Entropy Loss) 等,具体选择取决于我们要解决的问题类型。
3.3 反向传播:调整神经网络的“大脑”
关键的一步来了!如果我们的预测结果不够好(损失函数的值很大),神经网络就需要调整它的参数(权重和偏置)来减小这个误差。反向传播就是用来高效地计算出每个参数应该如何调整的。
反向传播的原理基于微积分中的链式法则。它从输出层开始,计算损失函数对输出层每个神经元输出的梯度(即变化率),然后逐层向后传播这些梯度。通过梯度信息,我们可以知道稍微调整哪个权重或偏置,能够对减小损失函数的影响最大。
3.4 梯度下降:寻找最优参数
有了梯度信息,我们就可以使用梯度下降 (Gradient Descent) 等优化算法来更新神经网络的参数。梯度指向的是损失函数增长最快的方向,所以我们沿着梯度的相反方向调整参数,就能使损失函数的值逐渐减小,直到找到一个“谷底”,即损失函数最小的点,这时候神经网络的性能也达到了最优。
你可以把梯度下降想象成一个在山谷中寻找最低点的盲人。他会不断地沿着感觉上坡度最大的反方向走一步,直到走到一个四周都是上坡的地方。
这个不断进行前向传播计算预测、计算损失、反向传播计算梯度、梯度下降更新参数的过程,就是神经网络学习的核心循环。
四、激活函数:为神经网络注入非线性
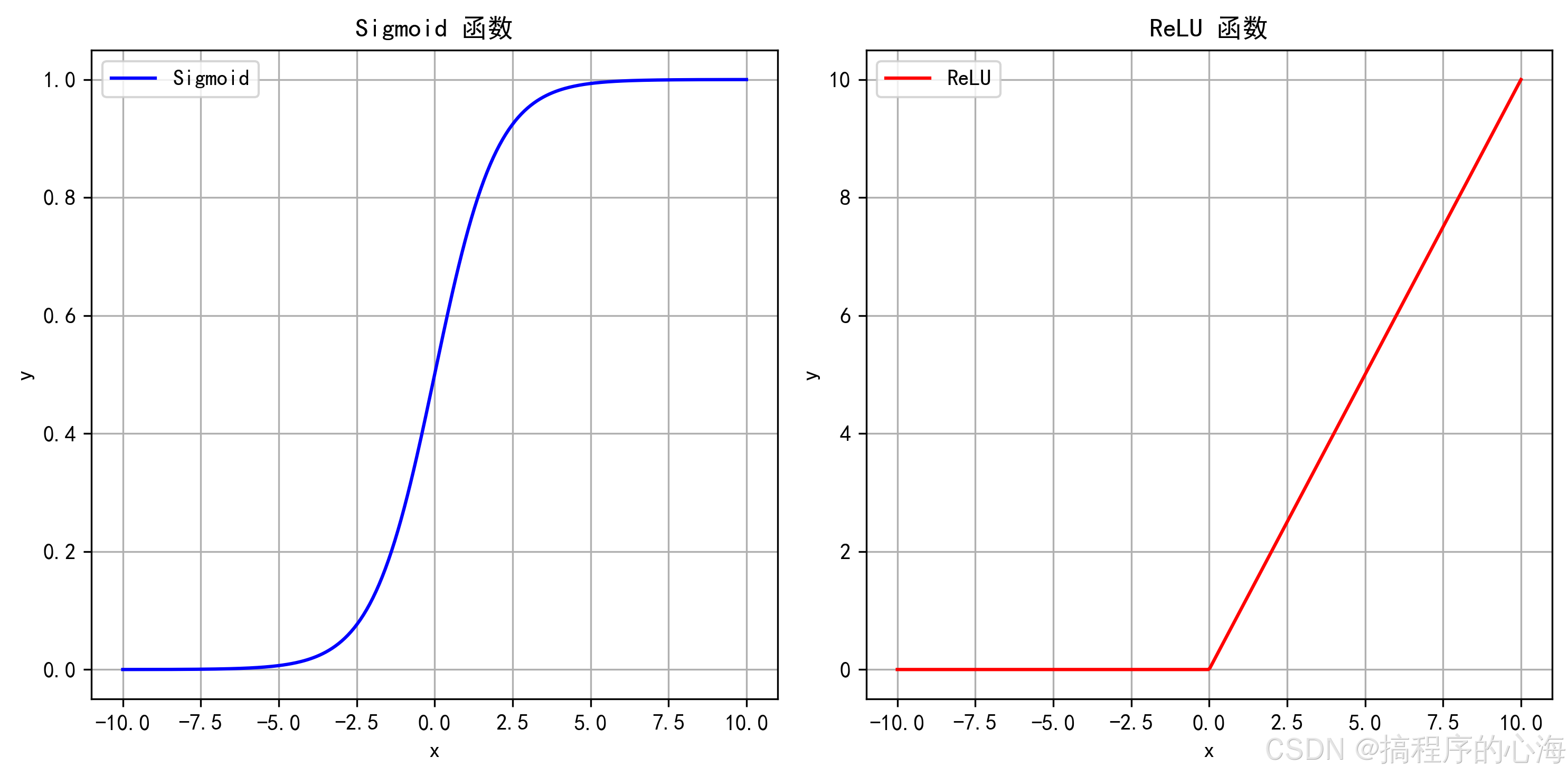
前面我们提到了激活函数,它是神经网络中非常重要的组成部分,赋予了神经网络学习复杂模式的能力。如果没有激活函数,无论神经网络有多少层,它都只能进行线性变换,无法解决非线性问题。
常见的激活函数有:
-
Sigmoid 函数: 将输入值压缩到0和1之间。常用于二分类问题的输出层,可以表示概率。但容易出现梯度消失问题(在输入值非常大或非常小时,梯度接近于0,导致参数更新缓慢)。
-
Tanh 函数 (Hyperbolic Tangent): 将输入值压缩到-1和1之间。与Sigmoid类似,但也存在梯度消失问题。
-
ReLU 函数 (Rectified Linear Unit): 当输入大于0时,输出等于输入;当输入小于等于0时,输出为0。ReLU简单高效,是目前最常用的激活函数之一,能够有效缓解梯度消失问题。但也可能出现“死亡ReLU”问题(当神经元的输入总是负数时,输出始终为0,导致该神经元不再学习)。
-
Softmax 函数: 通常用于多分类问题的输出层。它将每个类别的原始输出转换为概率分布,所有类别的概率之和为1。
选择合适的激活函数对于神经网络的性能至关重要,需要根据具体的问题和网络结构进行考虑。
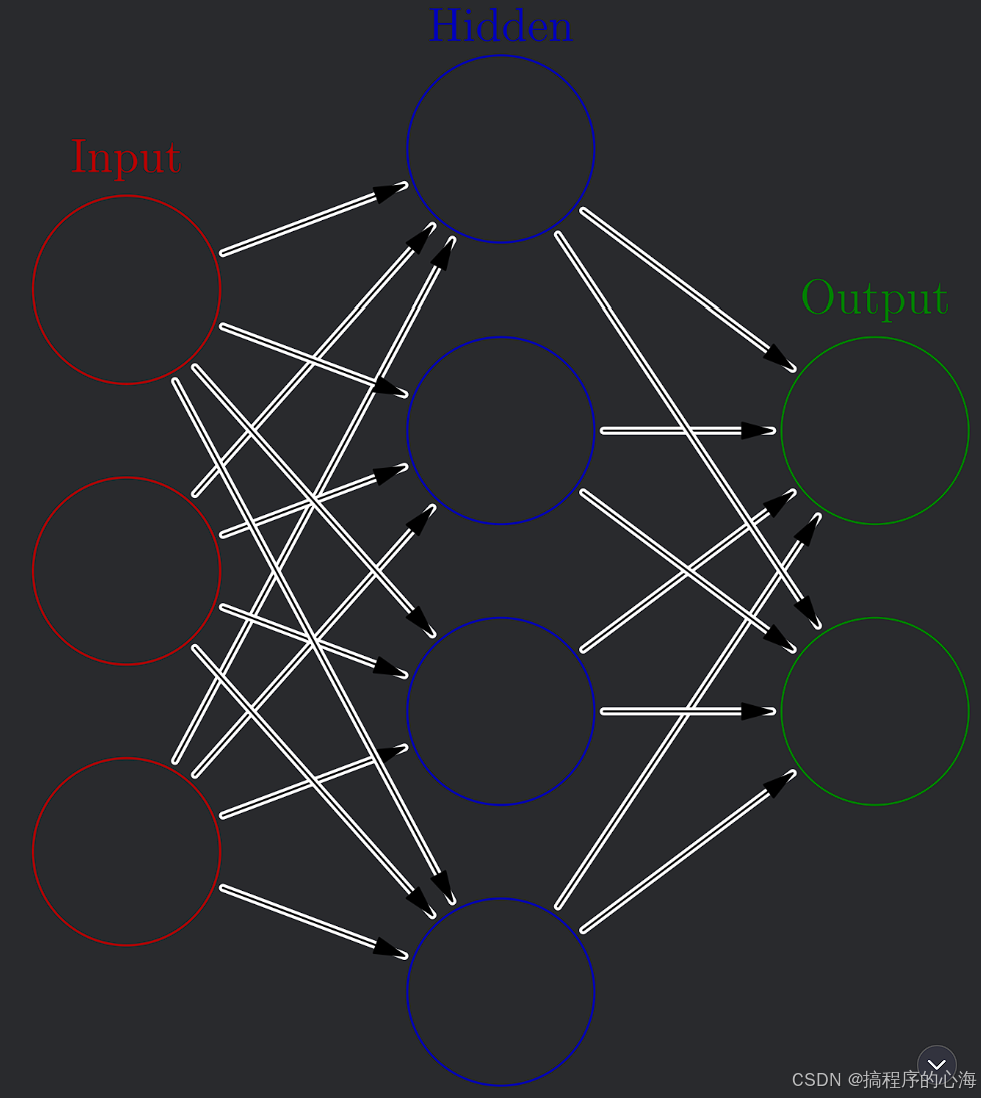
五、简单神经网络结构图
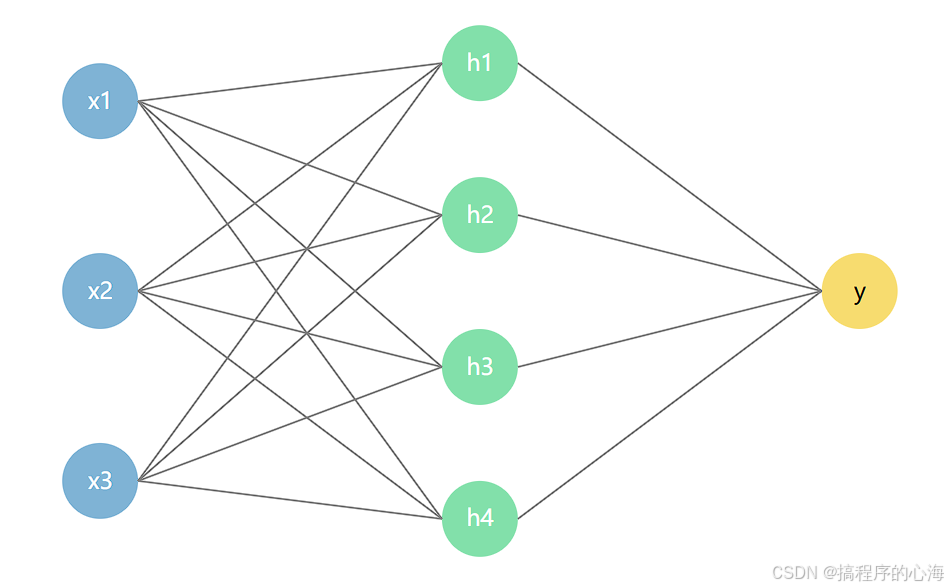
图中左侧为输入层(三个节点分别代表输入变量 x1、x2 和 x3),中间为隐藏层(四个节点 h1~h4),右侧为输出层(单个节点 y)。
节点间用灰色线条连接,表示神经元之间的全连接关系。
六、Python 实战案例:构建一个简单的神经网络
接下来,我们通过一个简单案例来手把手构建一个具有单隐藏层的神经网络,用于解决二分类问题。为了便于理解,我们使用 NumPy 实现前向传播与反向传播的基本算法。
6.1 案例目标
假设我们有一个简单的数据集,每个样本有两个特征,通过神经网络学习后预测输出(0 或 1)。
6.2 Python 代码详解
下面代码包括以下部分:
-
数据生成:生成一些随机样本数据。
-
网络结构定义:初始化权重和偏置。
-
前向传播:计算隐藏层和输出层的激活值。
-
损失计算:使用均方误差(MSE)。
-
反向传播:根据误差调整权重。
-
训练循环:多次迭代更新参数。
import numpy as np
# 设置随机种子,保证结果可重复
np.random.seed(42)
# 1. 生成数据:简单的二分类数据
# 输入数据:100个样本,每个样本2个特征
X = np.random.randn(100, 2)
# 目标:根据简单规则生成标签(例如:如果两个特征之和大于0,则为1,否则为0)
y = (np.sum(X, axis=1) > 0).astype(np.float32).reshape(-1, 1)
# 2. 定义网络参数
input_dim = 2 # 输入特征数
hidden_dim = 4 # 隐藏层神经元个数
output_dim = 1 # 输出层(1个节点)
# 初始化权重和偏置
W1 = np.random.randn(input_dim, hidden_dim) # 输入到隐藏层权重
b1 = np.zeros((1, hidden_dim))
W2 = np.random.randn(hidden_dim, output_dim) # 隐藏层到输出层权重
b2 = np.zeros((1, output_dim))
# 定义激活函数:ReLU 和 Sigmoid
def relu(x):
return np.maximum(0, x)
def relu_derivative(x):
return (x > 0).astype(np.float32)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
s = sigmoid(x)
return s * (1 - s)
# 学习率
learning_rate = 0.01
# 训练次数
epochs = 10000
# 训练循环
for epoch in range(epochs):
# 前向传播
z1 = np.dot(X, W1) + b1 # 隐藏层加权和
a1 = relu(z1) # 隐藏层激活
z2 = np.dot(a1, W2) + b2 # 输出层加权和
a2 = sigmoid(z2) # 输出层激活(预测值)
# 计算损失(均方误差)
loss = np.mean((a2 - y) ** 2)
# 反向传播
# 输出层梯度
d_loss_a2 = 2 * (a2 - y) / y.size # 均方误差对输出的导数
d_a2_z2 = sigmoid_derivative(z2)
dz2 = d_loss_a2 * d_a2_z2 # 输出层加权和的梯度
# 隐藏层梯度
dW2 = np.dot(a1.T, dz2)
db2 = np.sum(dz2, axis=0, keepdims=True)
da1 = np.dot(dz2, W2.T)
dz1 = da1 * relu_derivative(z1)
dW1 = np.dot(X.T, dz1)
db1 = np.sum(dz1, axis=0, keepdims=True)
# 更新权重和偏置
W2 -= learning_rate * dW2
b2 -= learning_rate * db2
W1 -= learning_rate * dW1
b1 -= learning_rate * db1
# 每1000次输出一次损失
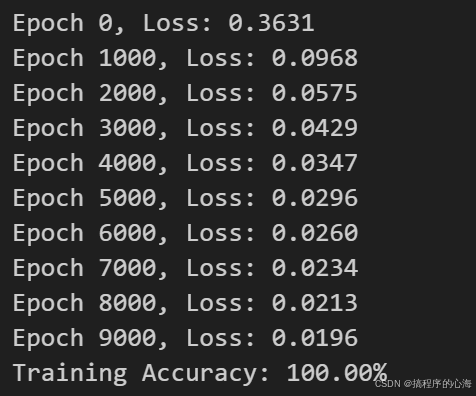
if epoch % 1000 == 0:
print(f"Epoch {epoch}, Loss: {loss:.4f}")
# 训练完成后对训练数据进行预测
predictions = (a2 > 0.5).astype(np.int32)
accuracy = np.mean(predictions == y)
print(f"Training Accuracy: {accuracy * 100:.2f}%")
代码讲解:
数据生成:我们随机生成 100 个样本,每个样本有 2 个特征,并通过简单规则(两个特征和大于 0 则标记为 1)生成标签。
网络初始化:设置输入层、隐藏层、输出层的维度,随机初始化权重,偏置初始化为 0。
激活函数:使用 ReLU 作为隐藏层激活函数,Sigmoid 作为输出层激活函数。
前向传播:计算每一层的加权和与激活值,得到预测输出。
反向传播:计算输出与实际标签之间的误差,再通过链式法则求出各层梯度,更新权重和偏置。
训练循环:重复迭代更新参数,每隔一段时间输出一次当前的损失。最终,根据预测结果计算训练准确率。
七、 总结
本文详细介绍了神经网络的基本原理和结构,从神经元模型、激活函数、前向传播到反向传播的全过程,并通过 SVG 图展示了网络的层级结构。最后,我们使用 Python 和 NumPy 从零实现了一个简单的神经网络案例,带你一步步体验了模型训练的过程。
通过本文的学习,相信你对神经网络有了更深入的理解。接下来,可以尝试扩展网络结构、改进激活函数或使用其他优化算法,进一步探索深度学习的无限可能!


![[王阳明代数讲义]具身智能才气等级分评价排位系统领域投射模型讲义](https://i-blog.csdnimg.cn/direct/5593a120ff514d058e96f601782d6d1c.jpeg#pic_center)








![线代[12]|《高等几何》陈绍菱(1984.9)(文末有对三大空间的分析及一个合格数学系毕业生的要求)](https://i-blog.csdnimg.cn/direct/c3824a02d3094a648f7adf08f2cb137f.jpeg#pic_center)