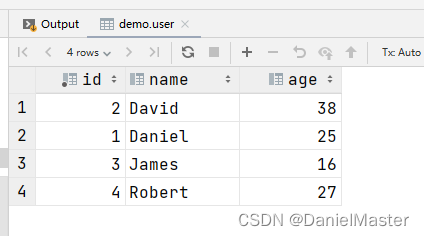
seatunnel hive source 未设置分隔符导致多个字段没有切分全保存在一个字段中了,翻看源码发现分隔符是是通过delimiter设置的,只要设置这个delimiter=","就可以了。

设置这个属性 delimiter=“,”
他的默认值是\u0001,如果没有设置delimiter属性则会根据文件类型判断,如果是csv则使用”,”,其他的不会处理,也就是不会切分。
env {
spark.sql.catalogImplementation = "hive"
spark.app.name = "SeaTunnel-spark3-hive"
spark.executor.instances = 4
spark.executor.cores = 2
spark.executor.memory = "5g"
spark.yarn.queue = "aiops"
spark.ui.enabled = true
}
source {
Hive {
table_name = "default.zc_hive_500_id_int"
metastore_uri = "thrift://cdh129130:9083"
kerberos_principal = "hive/cdh129144@MYCDH"
kerberos_keytab_path = "/home/aiops/keytab/hive.keytab"
hdfs_site_path = "/etc/hadoop/conf/hdfs-site.xml"
parallelism = 1
read_columns = ["nid","date_id","mm","latn_id","email","ctime","address"],
fetch_size = 10000
delimiter=","
}
}
transform {
}
sink {
Console{
}
}
源码分析过程:
根据抛异常的地方找打读记录行的位置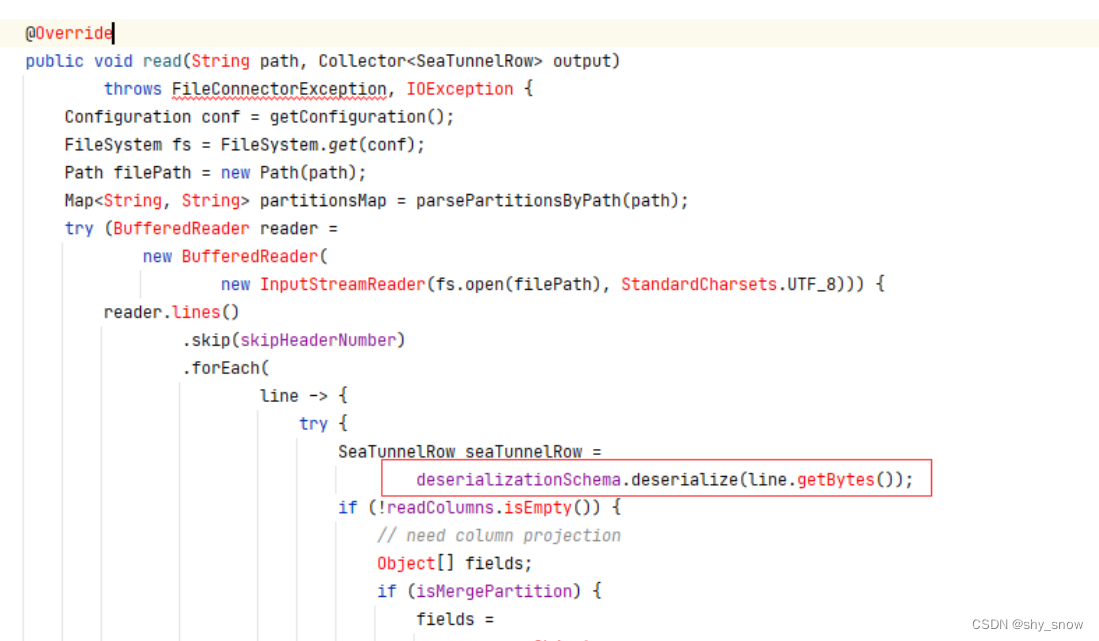
这里有多种实现

根据获取的字段列表转换行到SeaTunnelRow对象, 这里将line按separators[level]进行split切割为多列的值(这里很关键, 分隔符是什么?), 最后将字段index和value放到map,然后使用SeaTunnelRow对象封装map。
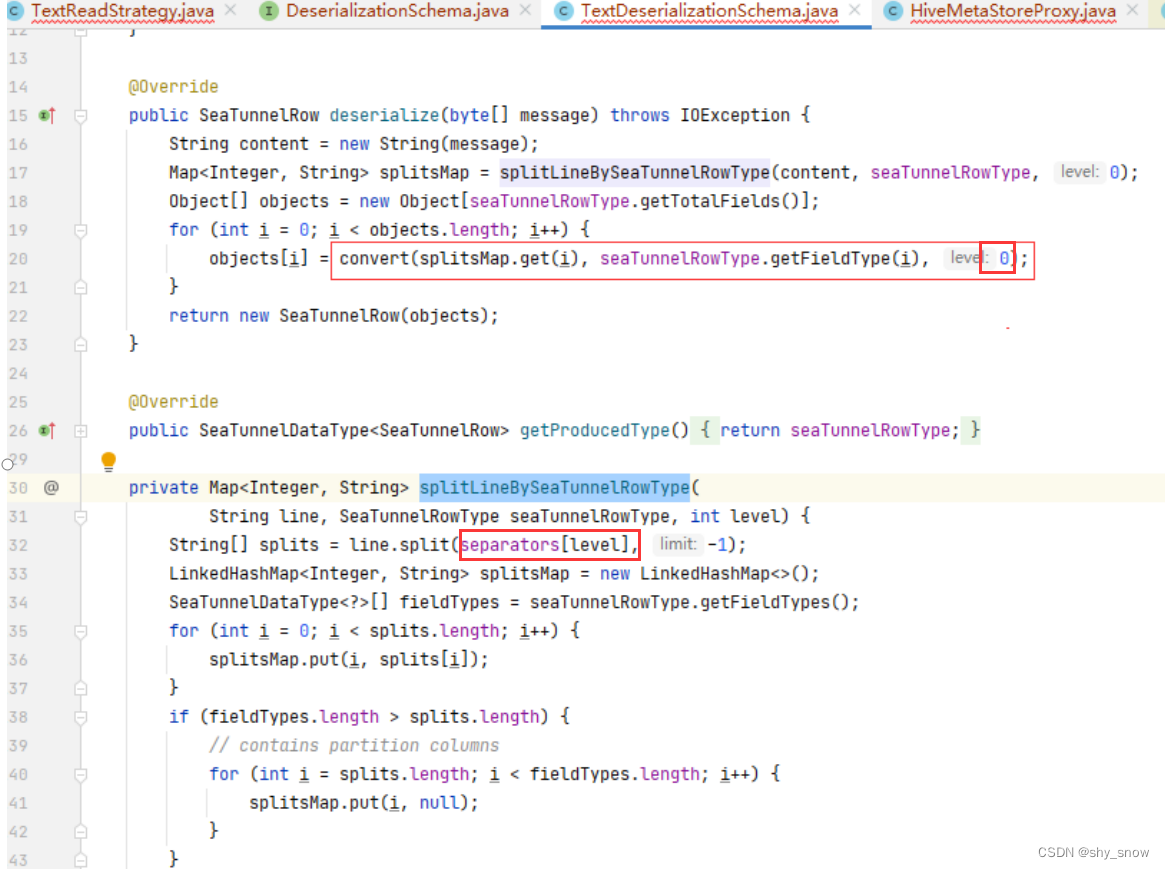
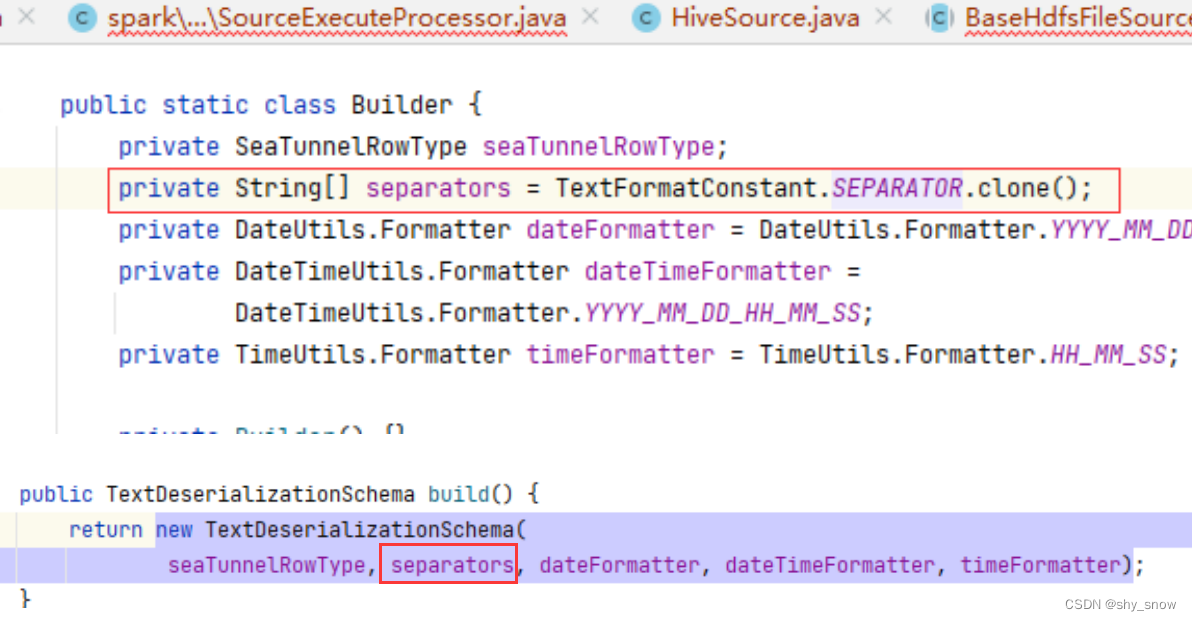
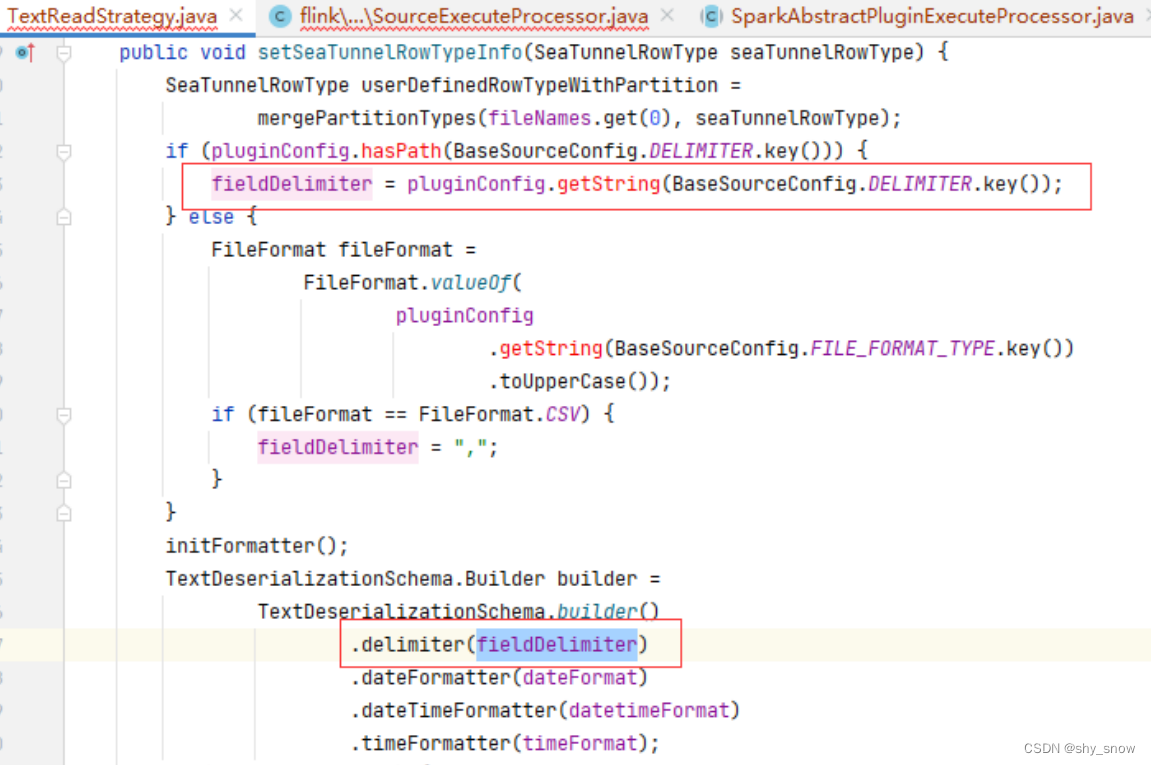
分隔符在build中被赋值
Build中的fieldDelimiter来自于BaseSourceConfig.DELIMITER.key(),如果没有值则获取FILE_FORMAT_TYPE进行判断,如果是csv格式则是逗号分隔。
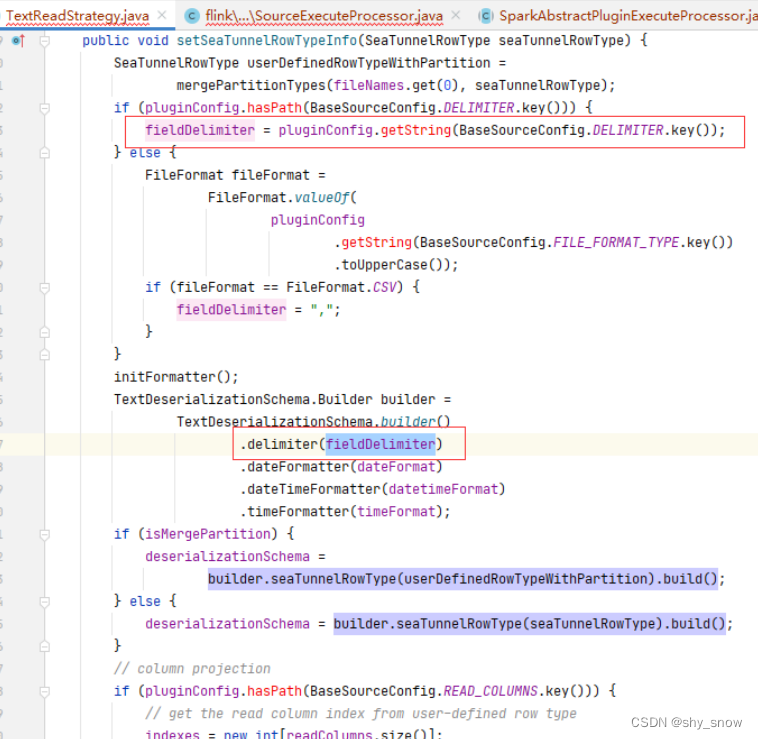
字段分隔符被设置到separators[0]
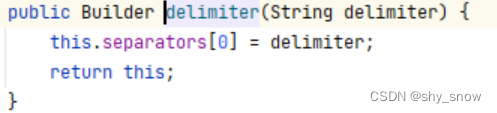
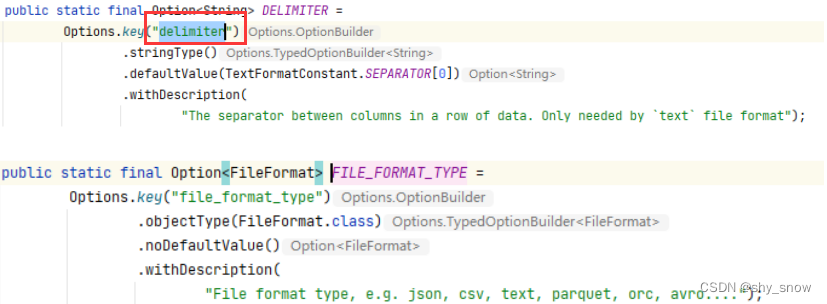
如何能配置指定的分隔符呢?
设置这个delimiter, 他是读取自这个属性的。
source {
Hive {
table_name = "default.zc_hive_500_id_int"
metastore_uri = "thrift://cdh129130:9083"
kerberos_principal = "hive/cdh129144@MYCDH"
kerberos_keytab_path = "/home/aiops/keytab/hive.keytab"
hdfs_site_path = "/etc/hadoop/conf/hdfs-site.xml"
parallelism = 1
read_columns = ["nid","date_id","mm","latn_id","email","ctime","address"],
fetch_size = 10000
delimiter=","
}
}
参考
https://github.com/apache/seatunnel/issues/4731
本文链接 https://blog.csdn.net/shy_snow/article/details/131845117