文章目录
- 1. 音频输出模块
- 1.1 音频输出流程
- 1.2 音频输出模型图
- 2. 打开SDL音频设备
- audio_open详解
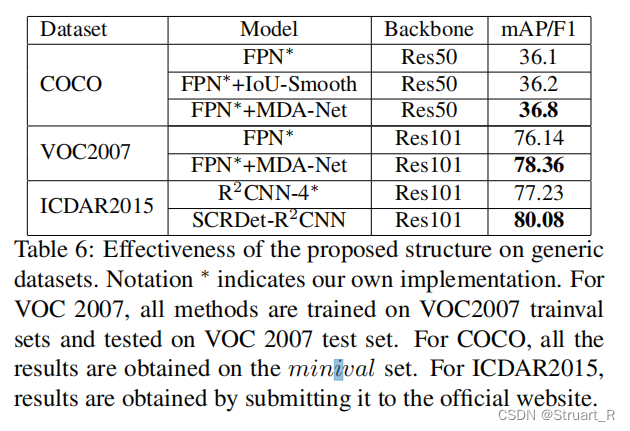
- sdl_audio_callback
- audio_decode_frame
- 3. 音频重采样
- 样本补偿
1. 音频输出模块
1.1 音频输出流程
- 打开SDL音频设备,设置参数
- 启动SDL音频设备播放
- SDL音频回调函数读取数据,也就是从FrameQueue中读取Frame到SDL回调函数中的Buffer中
audio的输出在SDL下是被动的,即开启SDL音频后,当SDL需要数据输出时则通过回调函数的方式告诉应用者改传入多少数据,但是这里存在问题:
-
ffmpeg解码一个AVPacket音频到AVFrame后,AVFrame中存储的音频数据大小与SDL回调需要的数据不一定相等 (回调函数每次获取的数据量是固定的)
-
特别是如果实现声音的变速功能,那么每一帧AVFrame做变速后大小概率和SDL回调所需要的数据大小不一致.
这就需要再添加一级缓冲区来解决问题了,即是从FrameQueue中获取Frame数据后,先存到一个Buffer中,如果再从这个Buffer中读取数据给SDL的回调函数.
1.2 音频输出模型图
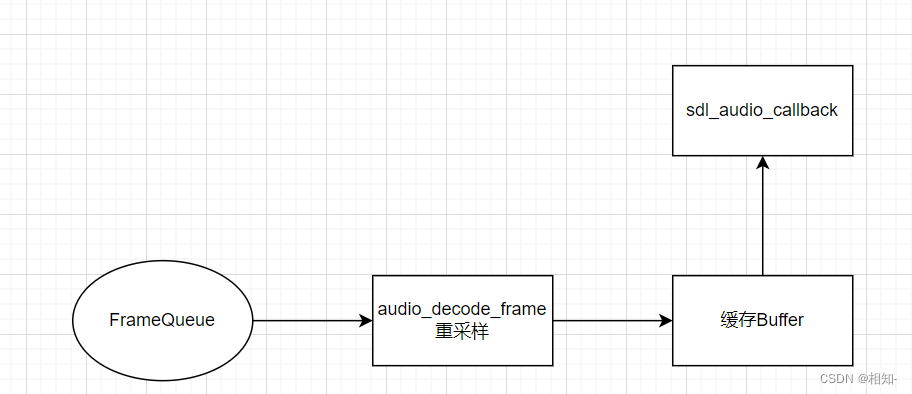
注意:aduio_decode_frame这个函数没有解码,而是将数据放入缓存Buffer中去,最多只是执行了重采样而已(输出源和输入参数不一致时要重采样!)
2. 打开SDL音频设备
SDL音频输出参数是一开始就设置好的!!! 当码流解出来的参数和预设参数不一致时需要重采样成SDL音频输出的参数,这样才能正常播放.
音频设备打开其实是在解复用线程中实现的.解复用线程先打开音频设备,设定音频回调函数供SDL音频播放线程回调使用,然后创建解码线程!
main()->
stream_open()->
read_thread()->
stream_component_open()->
audio_open(is, channel_layout, nb_channels, sample_rate, &is->audio_tgt)
case AVMEDIA_TYPE_AUDIO:
//从avctx(即AVCodecContext)中获取音频格式参数
sample_rate = avctx->sample_rate;
nb_channels = avctx->channels;
channel_layout = avctx->channel_layout;
#endif
/* prepare audio output 准备音频输出*/
//调用audio_open打开sdl音频输出,实际打开的设备参数保存在audio_tgt,返回值表示输出设备的缓冲区大小
if ((ret = audio_open(is, channel_layout, nb_channels, sample_rate, &is->audio_tgt)) < 0)
goto fail;
is->audio_hw_buf_size = ret;
is->audio_src = is->audio_tgt; //暂且将数据源参数等同于目标输出参数
//初始化audio_buf相关参数
is->audio_buf_size = 0;
is->audio_buf_index = 0;
/* init averaging filter 初始化averaging滤镜, 非audio master时使用 */
is->audio_diff_avg_coef = exp(log(0.01) / AUDIO_DIFF_AVG_NB); //0.794 exp,高等数学里以自然常数e为底的指数函数
is->audio_diff_avg_count = 0;
/* 由于我们没有精确的音频数据填充FIFO,故只有在大于该阈值时才进行校正音频同步*/
is->audio_diff_threshold = (double)(is->audio_hw_buf_size) / is->audio_tgt.bytes_per_sec;
is->audio_stream = stream_index; // 获取audio的stream索引
is->audio_st = ic->streams[stream_index]; // 获取audio的stream指针
// 初始化ffplay封装的音频解码器
decoder_init(&is->auddec, avctx, &is->audioq, is->continue_read_thread);
if ((is->ic->iformat->flags & (AVFMT_NOBINSEARCH | AVFMT_NOGENSEARCH | AVFMT_NO_BYTE_SEEK)) && !is->ic->iformat->read_seek) {
is->auddec.start_pts = is->audio_st->start_time;
is->auddec.start_pts_tb = is->audio_st->time_base;
}
// 启动音频解码线程
if ((ret = decoder_start(&is->auddec, audio_thread, "audio_decoder", is)) < 0)
goto out;
SDL_PauseAudioDevice(audio_dev, 0);
break;
通过audio_open获取输出设备参数audio_tgt,然后将audio_tgt赋值给audio_src,如果audio_src参数和输入参数一致的话则不需要进行重采样操作,否则将引入重采样机制.
最后初始化了几个audio_buf相关参数(也就是上图的缓存Buffer):
- audio_buf:从要输出的AVFrame中取得音频数据(PCM),必要时进行重采样.
- audio_buf_size:audio_buf总大小
- audio_buf_index:下一次可读大的audio_buf位置.
- audio_write_buf_size:audio_buf剩余的buffer长度,也就是audio_buf_size-dudio_buf_index
在audio_open中,通过SDL_OpenAudioDevice注册sdl_audio_callback函数为音频输出的回调函数,这样音频输出的总逻辑就是sdl_audio_callback了
audio_open详解
audio_open的工作就是获取输出设备的参数,并且为音频输出线程设置回调函数.
static int audio_open(void *opaque, int64_t wanted_channel_layout,
int wanted_nb_channels, int wanted_sample_rate,
struct AudioParams *audio_hw_params)
{
SDL_AudioSpec wanted_spec, spec;
const char *env;
static const int next_nb_channels[] = {0, 0, 1, 6, 2, 6, 4, 6};
static const int next_sample_rates[] = {0, 44100, 48000, 96000, 192000};
int next_sample_rate_idx = FF_ARRAY_ELEMS(next_sample_rates) - 1;
env = SDL_getenv("SDL_AUDIO_CHANNELS");
if (env) { // 若环境变量有设置,优先从环境变量取得声道数和声道布局
wanted_nb_channels = atoi(env);
wanted_channel_layout = av_get_default_channel_layout(wanted_nb_channels);
}
if (!wanted_channel_layout || wanted_nb_channels != av_get_channel_layout_nb_channels(wanted_channel_layout)) {
wanted_channel_layout = av_get_default_channel_layout(wanted_nb_channels);
wanted_channel_layout &= ~AV_CH_LAYOUT_STEREO_DOWNMIX;
}
// 根据channel_layout获取nb_channels,当传入参数wanted_nb_channels不匹配时,此处会作修正
wanted_nb_channels = av_get_channel_layout_nb_channels(wanted_channel_layout);
wanted_spec.channels = wanted_nb_channels;
wanted_spec.freq = wanted_sample_rate;
if (wanted_spec.freq <= 0 || wanted_spec.channels <= 0) {
av_log(NULL, AV_LOG_ERROR, "Invalid sample rate or channel count!\n");
return -1;
}
while (next_sample_rate_idx && next_sample_rates[next_sample_rate_idx] >= wanted_spec.freq)
next_sample_rate_idx--; // 从采样率数组中找到第一个不大于传入参数wanted_sample_rate的值
// 音频采样格式有两大类型:planar和packed,假设一个双声道音频文件,一个左声道采样点记作L,一个右声道采样点记作R,则:
// planar存储格式:(plane1)LLLLLLLL...LLLL (plane2)RRRRRRRR...RRRR
// packed存储格式:(plane1)LRLRLRLR...........................LRLR
// 在这两种采样类型下,又细分多种采样格式,如AV_SAMPLE_FMT_S16、AV_SAMPLE_FMT_S16P等,
// 注意SDL2.0目前不支持planar格式
// channel_layout是int64_t类型,表示音频声道布局,每bit代表一个特定的声道,参考channel_layout.h中的定义,一目了然
// 数据量(bits/秒) = 采样率(Hz) * 采样深度(bit) * 声道数
wanted_spec.format = AUDIO_S16SYS;
wanted_spec.silence = 0;
/*
* 一次读取多长的数据
* SDL_AUDIO_MAX_CALLBACKS_PER_SEC一秒最多回调次数,避免频繁的回调
* Audio buffer size in samples (power of 2)
*/
wanted_spec.samples = FFMAX(SDL_AUDIO_MIN_BUFFER_SIZE,
2 << av_log2(wanted_spec.freq / SDL_AUDIO_MAX_CALLBACKS_PER_SEC));
wanted_spec.callback = sdl_audio_callback;
wanted_spec.userdata = opaque;
// 打开音频设备并创建音频处理线程。期望的参数是wanted_spec,实际得到的硬件参数是spec
// 1) SDL提供两种使音频设备取得音频数据方法:
// a. push,SDL以特定的频率调用回调函数,在回调函数中取得音频数据
// b. pull,用户程序以特定的频率调用SDL_QueueAudio(),向音频设备提供数据。此种情况wanted_spec.callback=NULL
// 2) 音频设备打开后播放静音,不启动回调,调用SDL_PauseAudio(0)后启动回调,开始正常播放音频
// SDL_OpenAudioDevice()第一个参数为NULL时,等价于SDL_OpenAudio()
while (!(audio_dev = SDL_OpenAudioDevice(NULL, 0, &wanted_spec, &spec, SDL_AUDIO_ALLOW_FREQUENCY_CHANGE | SDL_AUDIO_ALLOW_CHANNELS_CHANGE))) {
av_log(NULL, AV_LOG_WARNING, "SDL_OpenAudio (%d channels, %d Hz): %s\n",
wanted_spec.channels, wanted_spec.freq, SDL_GetError());
wanted_spec.channels = next_nb_channels[FFMIN(7, wanted_spec.channels)];
if (!wanted_spec.channels) {
wanted_spec.freq = next_sample_rates[next_sample_rate_idx--];
wanted_spec.channels = wanted_nb_channels;
if (!wanted_spec.freq) {
av_log(NULL, AV_LOG_ERROR,
"No more combinations to try, audio open failed\n");
return -1;
}
}
wanted_channel_layout = av_get_default_channel_layout(wanted_spec.channels);
}
// 检查打开音频设备的实际参数:采样格式
if (spec.format != AUDIO_S16SYS) {
av_log(NULL, AV_LOG_ERROR,
"SDL advised audio format %d is not supported!\n", spec.format);
return -1;
}
// 检查打开音频设备的实际参数:声道数
if (spec.channels != wanted_spec.channels) {
wanted_channel_layout = av_get_default_channel_layout(spec.channels);
if (!wanted_channel_layout) {
av_log(NULL, AV_LOG_ERROR,
"SDL advised channel count %d is not supported!\n", spec.channels);
return -1;
}
}
// wanted_spec是期望的参数,spec是实际的参数,wanted_spec和spec都是SDL中的结构。
// 此处audio_hw_params是FFmpeg中的参数,输出参数供上级函数使用
// audio_hw_params保存的参数,就是在做重采样的时候要转成的格式。
audio_hw_params->fmt = AV_SAMPLE_FMT_S16;
audio_hw_params->freq = spec.freq;
audio_hw_params->channel_layout = wanted_channel_layout;
audio_hw_params->channels = spec.channels;
/* audio_hw_params->frame_size这里只是计算一个采样点占用的字节数 */
audio_hw_params->frame_size = av_samples_get_buffer_size(NULL, audio_hw_params->channels,
1, audio_hw_params->fmt, 1);
audio_hw_params->bytes_per_sec = av_samples_get_buffer_size(NULL, audio_hw_params->channels,
audio_hw_params->freq,
audio_hw_params->fmt, 1);
if (audio_hw_params->bytes_per_sec <= 0 || audio_hw_params->frame_size <= 0) {
av_log(NULL, AV_LOG_ERROR, "av_samples_get_buffer_size failed\n");
return -1;
}
// 比如2帧数据,一帧就是1024个采样点, 1024*2*2 * 2 = 8192字节
return spec.size; /* SDL内部缓存的数据字节, nb_samples * channels *byte_per_sample */
}
bytes_per_sec就说一秒钟音频字节数=采样率 * 声道数 * 采样格式大小(bit) /8
音频一帧大小=一帧采样点数(AAC为1024)*声道数 * 采样格式大小(bit)/8
spec.size取的是两帧数据大小
sdl_audio_callback
/**
* @brief sdl_audio_callback
* @param opaque 指向user的数据
* @param stream 拷贝PCM的地址
* @param len 需要拷贝的长度
*/
static void sdl_audio_callback(void *opaque, Uint8 *stream, int len)
{
VideoState *is = opaque;
int audio_size, len1;
audio_callback_time = av_gettime_relative(); // while可能产生延迟
while (len > 0) { // 循环读取,直到读取到足够的数据
/* (1)如果is->audio_buf_index < is->audio_buf_size则说明上次拷贝还剩余一些数据,
* 先拷贝到stream再调用audio_decode_frame
* (2)如果audio_buf消耗完了,则调用audio_decode_frame重新填充audio_buf
*/
if (is->audio_buf_index >= is->audio_buf_size) {
audio_size = audio_decode_frame(is);
if (audio_size < 0) {
/* if error, just output silence */
is->audio_buf = NULL;
is->audio_buf_size = SDL_AUDIO_MIN_BUFFER_SIZE / is->audio_tgt.frame_size
* is->audio_tgt.frame_size;
} else {
if (is->show_mode != SHOW_MODE_VIDEO)
update_sample_display(is, (int16_t *)is->audio_buf, audio_size);
is->audio_buf_size = audio_size; // 讲字节 多少字节
}
is->audio_buf_index = 0;
}
//根据缓冲区剩余大小量力而行
len1 = is->audio_buf_size - is->audio_buf_index;
if (len1 > len) // len = 3000 < len1 4096
len1 = len;
//根据audio_volume决定如何输出audio_buf
/* 判断是否为静音,以及当前音量的大小,如果音量为最大则直接拷贝数据 */
if (!is->muted && is->audio_buf && is->audio_volume == SDL_MIX_MAXVOLUME)
memcpy(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1);
else {
memset(stream, 0, len1);
// 3.调整音量
/* 如果处于mute状态则直接使用stream填0数据, 暂停时is->audio_buf = NULL */
if (!is->muted && is->audio_buf)
SDL_MixAudioFormat(stream, (uint8_t *)is->audio_buf + is->audio_buf_index,
AUDIO_S16SYS, len1, is->audio_volume);
}
len -= len1;
stream += len1;
/* 更新is->audio_buf_index,指向audio_buf中未被拷贝到stream的数据(剩余数据)的起始位置 */
is->audio_buf_index += len1;
}
is->audio_write_buf_size = is->audio_buf_size - is->audio_buf_index;
/* Let's assume the audio driver that is used by SDL has two periods. */
if (!isnan(is->audio_clock)) {
set_clock_at(&is->audclk, is->audio_clock -
(double)(2 * is->audio_hw_buf_size + is->audio_write_buf_size)
/ is->audio_tgt.bytes_per_sec,
is->audio_clock_serial,
audio_callback_time / 1000000.0);
sync_clock_to_slave(&is->extclk, &is->audclk);
}
}
首先解释sdl_audio_callback的参数含义:
- opaque就是指向VideoPlayer大管家,由wanted_spec.userdata = opaque;设置
- stream这个就是回调缓冲区,我们回调得到的数据都会存放到这个缓冲区中
- len是回调缓冲区需要的数据量,也就是需要拷贝的长度
while(len>0)就是一直读取数据,直到读满为止
if (is->audio_buf_index >= is->audio_buf_size)这个意思是说我们用户设置的缓冲区没有数据了,得通过audio_decode_frame函数进行获取数据
len1是缓冲区大小,如果缓冲区len1<=len的话就全部读取,否则就读取len长度,剩余留在缓冲区中待下次读取.
if (!is->muted && is->audio_buf && is->audio_volume == SDL_MIX_MAXVOLUME)
memcpy(stream, (uint8_t *)is->audio_buf + is->audio_buf_index, len1);
else {
memset(stream, 0, len1);
// 3.调整音量
/* 如果处于mute状态则直接使用stream填0数据, 暂停时is->audio_buf = NULL */
if (!is->muted && is->audio_buf)
SDL_MixAudioFormat(stream, (uint8_t *)is->audio_buf + is->audio_buf_index,
AUDIO_S16SYS, len1, is->audio_volume);
}
这段代码很容易读懂,就是如果不是静音,并且缓冲区不为空且音量为最大值 那么就直接将数据拷贝到stream中
否则如果音量为0就直接写入0数据即可,不然就要调用SDL_MixAudioFormat设置音量,然后写入.
audio_decode_frame
static int audio_decode_frame(VideoState *is)
{
int data_size, resampled_data_size;
int64_t dec_channel_layout;
av_unused double audio_clock0;
int wanted_nb_samples;
Frame *af;
if (is->paused)
return -1;
do {
#if defined(_WIN32)
while (frame_queue_nb_remaining(&is->sampq) == 0) {
if ((av_gettime_relative() - audio_callback_time) > 1000000LL * is->audio_hw_buf_size / is->audio_tgt.bytes_per_sec / 2)
return -1;
av_usleep (1000);
}
#endif
// 若队列头部可读,则由af指向可读帧
if (!(af = frame_queue_peek_readable(&is->sampq)))
return -1;
frame_queue_next(&is->sampq);
} while (af->serial != is->audioq.serial);
// 根据frame中指定的音频参数获取缓冲区的大小 af->frame->channels * af->frame->nb_samples * 2
data_size = av_samples_get_buffer_size(NULL,
af->frame->channels,
af->frame->nb_samples,
af->frame->format, 1);
// 获取声道布局
dec_channel_layout =
(af->frame->channel_layout &&
af->frame->channels == av_get_channel_layout_nb_channels(af->frame->channel_layout)) ?
af->frame->channel_layout : av_get_default_channel_layout(af->frame->channels);
// 获取样本数校正值:若同步时钟是音频,则不调整样本数;否则根据同步需要调整样本数
wanted_nb_samples = synchronize_audio(is, af->frame->nb_samples);
// is->audio_tgt是SDL可接受的音频帧数,是audio_open()中取得的参数
// 在audio_open()函数中又有"is->audio_src = is->audio_tgt""
// 此处表示:如果frame中的音频参数 == is->audio_src == is->audio_tgt,
// 那音频重采样的过程就免了(因此时is->swr_ctr是NULL)
// 否则使用frame(源)和is->audio_tgt(目标)中的音频参数来设置is->swr_ctx,
// 并使用frame中的音频参数来赋值is->audio_src else {
// 未经重采样,则将指针指向frame中的音频数据
/*
重采样代码后面单独分析
*/
is->audio_buf = af->frame->data[0]; //将audio_buf指向帧数据
resampled_data_size = data_size;
audio_clock0 = is->audio_clock;
/* update the audio clock with the pts */
if (!isnan(af->pts))
is->audio_clock = af->pts + (double) af->frame->nb_samples / af->frame->sample_rate;
else
is->audio_clock = NAN;
is->audio_clock_serial = af->serial;
#ifdef DEBUG
{
static double last_clock;
printf("audio: delay=%0.3f clock=%0.3f clock0=%0.3f\n",
is->audio_clock - last_clock,
is->audio_clock, audio_clock0);
last_clock = is->audio_clock;
}
#endif
return resampled_data_size;
}
audio_decode_frame函数就是冲FrameQueue中获取Frame数据,然后判断是否需要重采样(下面详解,这边忽略),然后将audio_buf指向帧中的buff,这里可以看出audio_buf并不是直接申请一段空间,而是直接复用帧的缓冲区而已,最重要的是考虑下面时钟代码的原理!!!
is->audio_clock = af->pts + (double) af->frame->nb_samples / af->frame->sample_rate;
时钟为什么这样设置呢???
我们知道af->pts(单位为秒,在存入队列前就设置过了)是指向audio_buf一开始的位置,而(double) af->frame->nb_samples / af->frame->sample_rate;是计算一帧的时间,也就是说这里的audio_clock时钟现在是指向这一帧结尾的位置;如下图所示
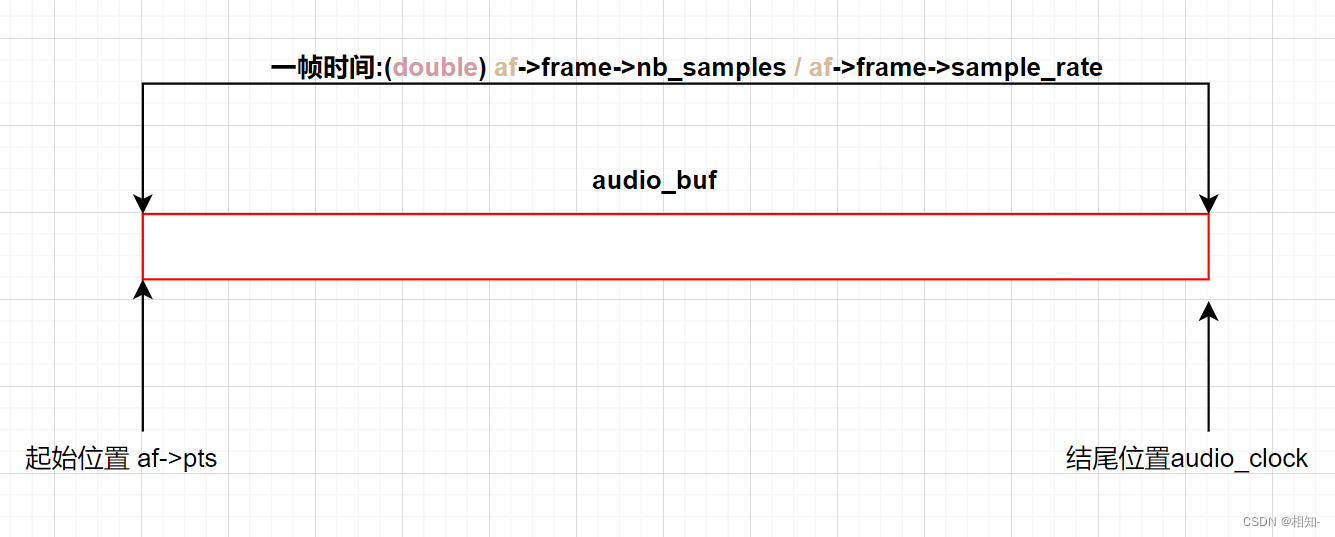
那么这样具体有什么用呢???
我们看sdl_audio_callback结尾的一段代码:
is->audio_write_buf_size = is->audio_buf_size - is->audio_buf_index;
/* Let's assume the audio driver that is used by SDL has two periods. */
if (!isnan(is->audio_clock)) {
set_clock_at(&is->audclk, is->audio_clock -
(double)(2 * is->audio_hw_buf_size + is->audio_write_buf_size)
/ is->audio_tgt.bytes_per_sec,
is->audio_clock_serial,
audio_callback_time / 1000000.0);
sync_clock_to_slave(&is->extclk, &is->audclk);
}
audio_write_buf_size是计算的是未读的字节数
我们现在时钟需要设置播放位置的pts,但是我们只知道audio_clock也就是audio_buf的pts,然后我们通过每秒钟为多少字节来计算sdl播放的pts,看图:

3. 音频重采样
static int audio_decode_frame(VideoState *is)
{
int data_size, resampled_data_size;
int64_t dec_channel_layout;
av_unused double audio_clock0;
int wanted_nb_samples;
Frame *af;
if (is->paused)
return -1;
do {
#if defined(_WIN32)
while (frame_queue_nb_remaining(&is->sampq) == 0) {
if ((av_gettime_relative() - audio_callback_time) > 1000000LL * is->audio_hw_buf_size / is->audio_tgt.bytes_per_sec / 2)
return -1;
av_usleep (1000);
}
#endif
// 若队列头部可读,则由af指向可读帧
if (!(af = frame_queue_peek_readable(&is->sampq)))
return -1;
frame_queue_next(&is->sampq);
} while (af->serial != is->audioq.serial);
// 根据frame中指定的音频参数获取缓冲区的大小 af->frame->channels * af->frame->nb_samples * 2
data_size = av_samples_get_buffer_size(NULL,
af->frame->channels,
af->frame->nb_samples,
af->frame->format, 1);
// 获取声道布局
dec_channel_layout =
(af->frame->channel_layout &&
af->frame->channels == av_get_channel_layout_nb_channels(af->frame->channel_layout)) ?
af->frame->channel_layout : av_get_default_channel_layout(af->frame->channels);
// 获取样本数校正值:若同步时钟是音频,则不调整样本数;否则根据同步需要调整样本数
wanted_nb_samples = synchronize_audio(is, af->frame->nb_samples);
// is->audio_tgt是SDL可接受的音频帧数,是audio_open()中取得的参数
// 在audio_open()函数中又有"is->audio_src = is->audio_tgt""
// 此处表示:如果frame中的音频参数 == is->audio_src == is->audio_tgt,
// 那音频重采样的过程就免了(因此时is->swr_ctr是NULL)
// 否则使用frame(源)和is->audio_tgt(目标)中的音频参数来设置is->swr_ctx,
// 并使用frame中的音频参数来赋值is->audio_src
if (af->frame->format != is->audio_src.fmt || // 采样格式
dec_channel_layout != is->audio_src.channel_layout || // 通道布局
af->frame->sample_rate != is->audio_src.freq || // 采样率
// 第4个条件, 要改变样本数量, 那就是需要初始化重采样
(wanted_nb_samples != af->frame->nb_samples && !is->swr_ctx) // samples不同且swr_ctx没有初始化
) {
swr_free(&is->swr_ctx);
is->swr_ctx = swr_alloc_set_opts(NULL,
is->audio_tgt.channel_layout, // 目标输出
is->audio_tgt.fmt,
is->audio_tgt.freq,
dec_channel_layout, // 数据源
af->frame->format,
af->frame->sample_rate,
0, NULL);
if (!is->swr_ctx || swr_init(is->swr_ctx) < 0) {
av_log(NULL, AV_LOG_ERROR,
"Cannot create sample rate converter for conversion of %d Hz %s %d channels to %d Hz %s %d channels!\n",
af->frame->sample_rate, av_get_sample_fmt_name(af->frame->format), af->frame->channels,
is->audio_tgt.freq, av_get_sample_fmt_name(is->audio_tgt.fmt), is->audio_tgt.channels);
swr_free(&is->swr_ctx);
return -1;
}
is->audio_src.channel_layout = dec_channel_layout;
is->audio_src.channels = af->frame->channels;
is->audio_src.freq = af->frame->sample_rate;
is->audio_src.fmt = af->frame->format;
}
if (is->swr_ctx) {
// 重采样输入参数1:输入音频样本数是af->frame->nb_samples
// 重采样输入参数2:输入音频缓冲区
const uint8_t **in = (const uint8_t **)af->frame->extended_data; // data[0] data[1]
// 重采样输出参数1:输出音频缓冲区尺寸
uint8_t **out = &is->audio_buf1; //真正分配缓存audio_buf1,指向是用audio_buf
// 重采样输出参数2:输出音频缓冲区
int out_count = (int64_t)wanted_nb_samples * is->audio_tgt.freq / af->frame->sample_rate
+ 256;
int out_size = av_samples_get_buffer_size(NULL, is->audio_tgt.channels,
out_count, is->audio_tgt.fmt, 0);
int len2;
if (out_size < 0) {
av_log(NULL, AV_LOG_ERROR, "av_samples_get_buffer_size() failed\n");
return -1;
}
// 如果frame中的样本数经过校正,则条件成立
if (wanted_nb_samples != af->frame->nb_samples) {
int sample_delta = (wanted_nb_samples - af->frame->nb_samples) * is->audio_tgt.freq
/ af->frame->sample_rate;
int compensation_distance = wanted_nb_samples * is->audio_tgt.freq / af->frame->sample_rate;
// swr_set_compensation
if (swr_set_compensation(is->swr_ctx,
sample_delta,
compensation_distance) < 0) {
av_log(NULL, AV_LOG_ERROR, "swr_set_compensation() failed\n");
return -1;
}
}
av_fast_malloc(&is->audio_buf1, &is->audio_buf1_size, out_size);
if (!is->audio_buf1)
return AVERROR(ENOMEM);
// 音频重采样:返回值是重采样后得到的音频数据中单个声道的样本数
len2 = swr_convert(is->swr_ctx, out, out_count, in, af->frame->nb_samples);
if (len2 < 0) {
av_log(NULL, AV_LOG_ERROR, "swr_convert() failed\n");
return -1;
}
if (len2 == out_count) {
av_log(NULL, AV_LOG_WARNING, "audio buffer is probably too small\n");
if (swr_init(is->swr_ctx) < 0)
swr_free(&is->swr_ctx);
}
// 重采样返回的一帧音频数据大小(以字节为单位)
is->audio_buf = is->audio_buf1;
resampled_data_size = len2 * is->audio_tgt.channels * av_get_bytes_per_sample(is->audio_tgt.fmt);
} else {
// 未经重采样,则将指针指向frame中的音频数据
is->audio_buf = af->frame->data[0]; // s16交错模式data[0], fltp data[0] data[1]
resampled_data_size = data_size;
}
audio_clock0 = is->audio_clock;
/* update the audio clock with the pts */
if (!isnan(af->pts))
is->audio_clock = af->pts + (double) af->frame->nb_samples / af->frame->sample_rate;
else
is->audio_clock = NAN;
is->audio_clock_serial = af->serial;
#ifdef DEBUG
{
static double last_clock;
printf("audio: delay=%0.3f clock=%0.3f clock0=%0.3f\n",
is->audio_clock - last_clock,
is->audio_clock, audio_clock0);
last_clock = is->audio_clock;
}
#endif
return resampled_data_size;
}
样本补偿
/**
*@}
*
*@name低级选项设置功能
*这些功能提供了一种设置不可能的低级选项的方法
*使用AVOption API。
*@{
*/
/**
*激活重采样补偿(“软”补偿)。这个功能是
*在swr_next_pts()中需要时内部调用。
*
*@参数[in, out]s分配的Swr上下文。如果没有初始化,
*或SWR_FLAG_RESAMPLE未设置,swr_init()是
*使用设置的标志调用。
*@参数[in]每个样品的PTSsample_delta增量
*@参数[in]compensation_distance要补偿的样本数
*@return>=0成功,AVERROR错误代码如果:
*@li@c s为NULL,
*@li@ccompensation_distance小于0,
*@li@ccompensation_distance是0但sample_delta不是,
*@li重新取样器不支持的补偿,或
*@liswr_init()调用时失败。
*/
int swr_set_compensation(struct SwrContext *s, int sample_delta, int compensation_distance);