目录
一、概述
二、三个挑战
三、网络结构
1、SF-Net
2、MDA-Net(Multi-Dimensional Attention Network)
3、Rotation Branch
四、损失函数
五、实验
一、概述
SCRDet(Towards More Robust Detection for Small,Cluttered and Rotated Objects)来自ICCV2019,two-stage 网络,在对于小尺寸、任意方向、密集分布下的物体提出多类别旋转检测器,设计了一种将多层特征与有效锚定采样相结合的采样融合网络SF-Net,以提高对小物体的灵敏度。
本文为了抑制噪声和突出目标特征,引入了通道注意力网络和像素点注意力机制网络MDA-Net(这里包含了SE-Net)。
为了准确的目标估计,在SmoothL1Loss中加入IoU常数因子,解决旋转边界框回归问题。
二、三个挑战
由于大多数场景下没有关注鲁棒性目标检测中的小物体,杂乱排列,任意方向的问题,在现实中由于相机分辨率问题,很多场景下的对象可能是非常小的尺寸,可能以密集形式排列且方向不一,例如商店中的商品和高分辨率图片中街道上的人脸。所以本文提出目标检测中的三个挑战:
(1)小物体:遥感图像中的小物体经常被复杂的环境所覆盖。本文设计一种采样融合网络,将多层特征融合到有效anchor采样中,以提高对于小型目标的检测灵敏度。
(2)杂乱排列:由于被检测物体经常是紧密排列的。本文使用有监督的像素注意力网络和通道注意力网络,来抑制噪声和突出物体的特征,提高对于小而杂乱的目标检测。
(3)任意方向:由于遥感图片中的物体以不同方向出现。本文为保证准确进行旋转估计,提出将IoU常数因子引入Smooth L1 Loss中,来解决旋转边界框回归问题。
三、网络结构
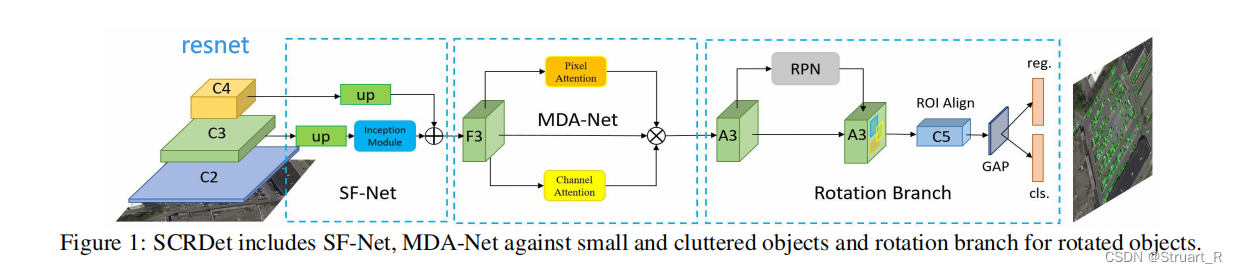
本文SCRDet以ResNet作为bacebone,由SF-Net,MDA-Net,Rotation Branch组成。
SF-Net:用于多层特征融合和有效锚框采样,解决目标信息不足和锚框样本不足问题。
MDA-Net:通过生成权重的方法对目标进行强化,背景进行弱化,增强错误检测和减少漏检的问题。
Rotation Branch:对于新的特征图feature map进行检测,进行RPN提取候选框,候选框映射到特征图后进行ROI Align,对目标进行分类和回归,对每个方案进行改进的单元参数回归和旋转非最大抑制(R-NMS)操作。
1、SF-Net
首先本文提出检测小物体的主要障碍:物体特征信息不足和锚框采样不足。
原因:
(1)使用了池化层,使得小对象在深层网络下丢失了大部分特征信息。(池化操作会使区域内的特征值聚合,减少特征图大小,减少区域内特征点的数量,而对于小目标而言,本身特征点就较少,池化后会进一步减少特征点数量,另外池化操作也会使特征图分辨率降低,限制对小目标特征信息的提取)
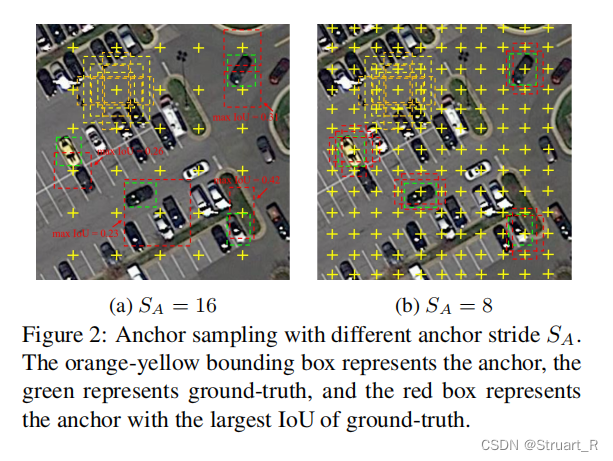
(2) 高阶特征图的采样步幅较大,容易跳过小的目标,导致采样不足。如下图所示,步长大的a图,效果非常不好,但不可否认采样点增多也会带来参数量增大的问题。
本文提出了两个解决方案:
(1)特征融合:低阶特征图可以保存目标较小的特征信息,而高阶特征图可以包含更高层次的语义线索(这也忽视了小目标的特征),常见的特征融合方法有FPN、TDM、ROM,本文只是进行列举,没有使用。
(2)更好的抽样,训练样本不足和不平衡会导致影响检测性能,所以引入期望最大重叠(EMO)分数,通过计算锚框与对象之间的期望最大交集(IoU),发现步幅越小,EMO得分越高。(类似上图的数学解释)
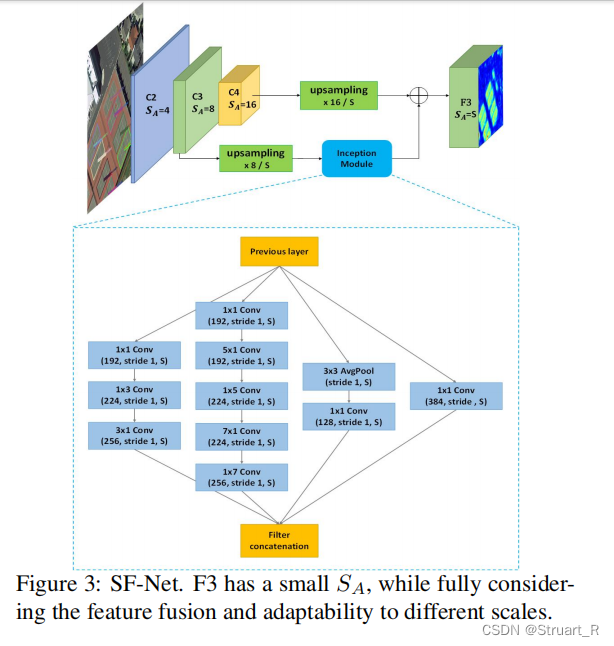
SF-Net网络结构如下:
输入一张图片,根据缩放因子不同,提取不同尺寸C2、C3、C4的特征图,将C3、C4在SF-Net中进行特征融合得到特征图F3。
2、MDA-Net(Multi-Dimensional Attention Network)
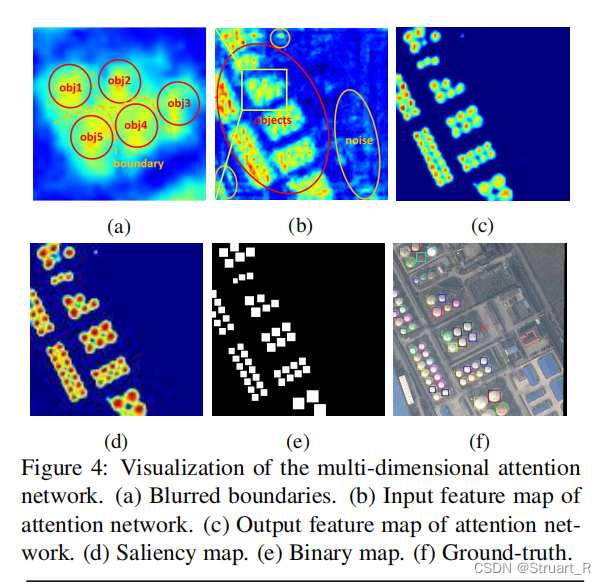
由于航拍图像等真实数据的复杂性,RPN提供的方案会引入大量的噪声信息。过多的噪声会淹没目标信息,使目标信息边界模糊,导致漏检,如下图(a)。下面其余各图为(b)输入注意力网络的特征图(c)输出注意力网络的特征图(d)显著性图(e)二值化图(f)真实图
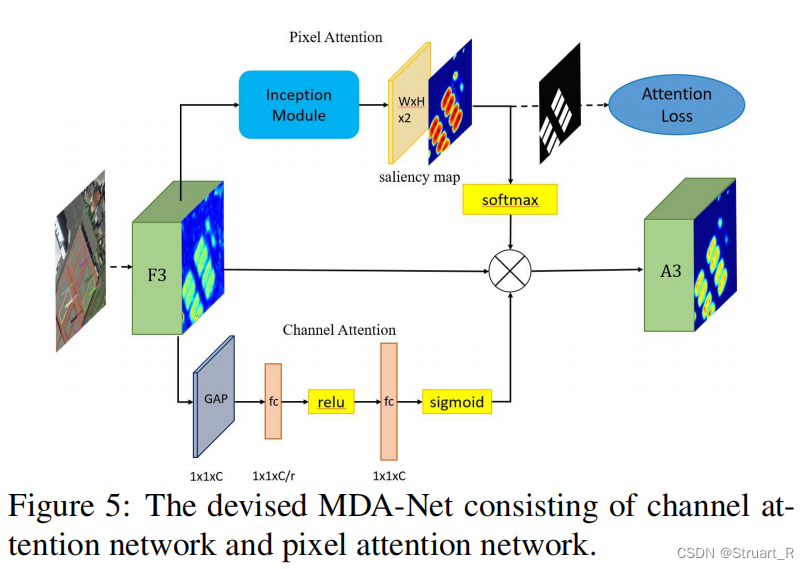
由于当前的解决噪声、遮挡的注意力网络都是无监督的,本文提出一个有监督多维注意力网络(MDA-Net),由通道注意力网络(SE-Net)和像素注意力网络(Pixel Attention)组成。
像素注意力网络
流程:F3经过Inception(具有不同比值的卷积核的模块),用于对不同尺度的特征进行提取,然后经过两个卷积得到双通道的显著性映射(上图(d)),使用softmax对显著性映射(范围处理为[0,1],降低噪声,增强目标特征信息)进行处理,将其中一个通道与F3融合(论文就用了其中一个)。
注意力损失:将双通道的显著性映射进行二值化处理,得到含有目标区域的二值化图,显著性高和显著性低的区域分别赋值0和1,进行二值交叉熵损失作为注意力损失。
通道注意力网络
流程:将F3使用GAP输出C个特征通道的数值分布,全连接将特征维度降低到输入的1/r,进入ReLU激活后,再经过全连接层变回原维度,再用Sigmoid进行激活,获得[0,1]之间的归一化权重,最后将输出与F3融合。
3、Rotation Branch
从旋转框的参数计算来看,还是与R3Det相同的,可以参考上一个博文。
本文提出了一个R-NMS(旋转非最大抑制)的算法,对于集中数据的方向的多样,设定不同的阈值。避免出现使用水平NMS而导致破坏bounding box的预测。
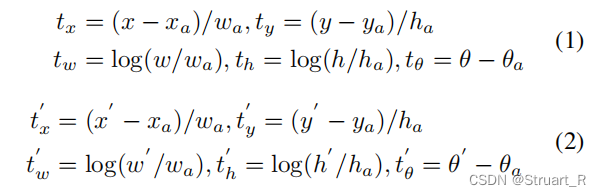
四、损失函数
SCR-Det的多任务损失如下,分为边界框回归损失、注意力损失、分类损失三个部分。
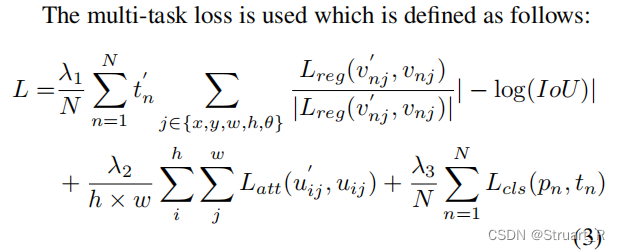
边界框回归损失
N:候选框数量,:控制权重的超参数,
:二进制数,表示背景和前景,
真实框偏移向量(对于x,y,w,h,θ五个参数),
预测框偏移向量。
边界框回归损失使用Smooth L1损失。
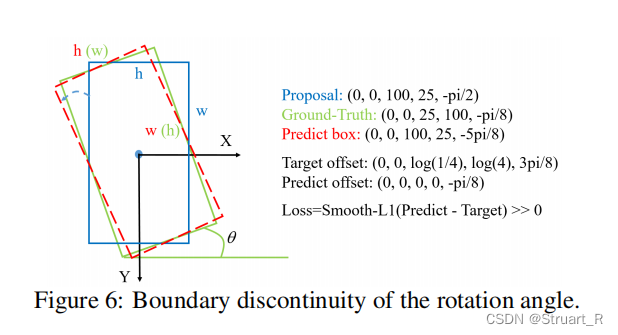
添加IoU常数因子:文中提出,由于旋转框角度存在周期性,在大角度下,存在较大的损失,增大了回归的多样性,所以提出引入IoU常数因子,避免骤降为0,
作为梯度下降的大小。
:控制梯度方向。
下图为Smooth L1损失和使用IoU的Smooth IoU损失的预测框。

注意力损失
:表示GT框的高和宽,
:控制权重的超参数,
代表mask后的标记值和预测值。
注意力损失使用softmax交叉熵。
分类损失
N:候选框数量,:控制权重的超参数,
:用softmax函数计算的各类别对应的概率分布,
:各类别的标签
分类损失使用softmax交叉熵。
五、实验
对于不同的缩放因子在DOTA的OBB(任意四边形)和HBB(一般水平四边形)两种标注的数据集下进行测试,可以看到缩放因子
在6的时候mAP最高,用时也是最高。(感觉也是考虑了DOTA数据集的物体的分布,最后选择了6)
HBB:horizontal bounding box,通常为(x,y,w,h)
OBB:oriented bounding box,通常为(x,y,w,θ)或者(x1,y1,x2,y2,x3,y3,x4,y4)的四个角点坐标的形式。
对于使用SCRDet的不同模块做了对比,backbone貌似是RetinaNet做的,可以看到SCR-Det的每一个分支都是不可替代的,还是相对还好的,但是最后一行添加的P不是很懂什么意思。

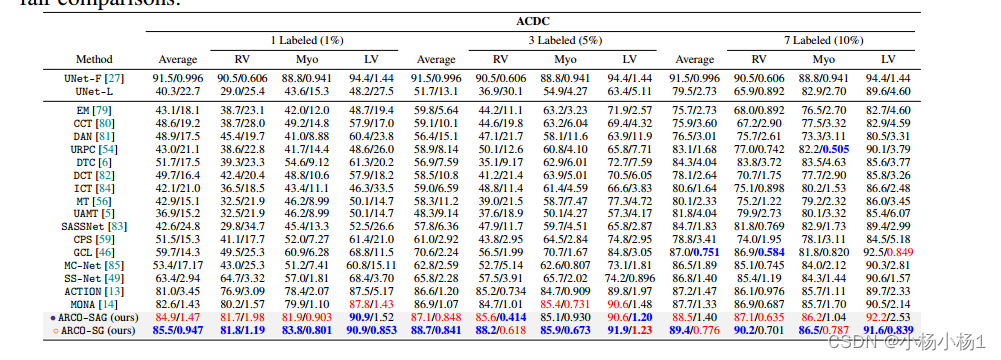
对于OBB和HBB类型数据集下的主流模型进行对比,backbone也是RetinaNet,可以看到mAP提升还是很可观的,但是速度方面就不太清楚了,感觉RoI-Transformer这种trick极度倾向简化方向和YOLOV2这类one-stage的应该会快于SCRDet。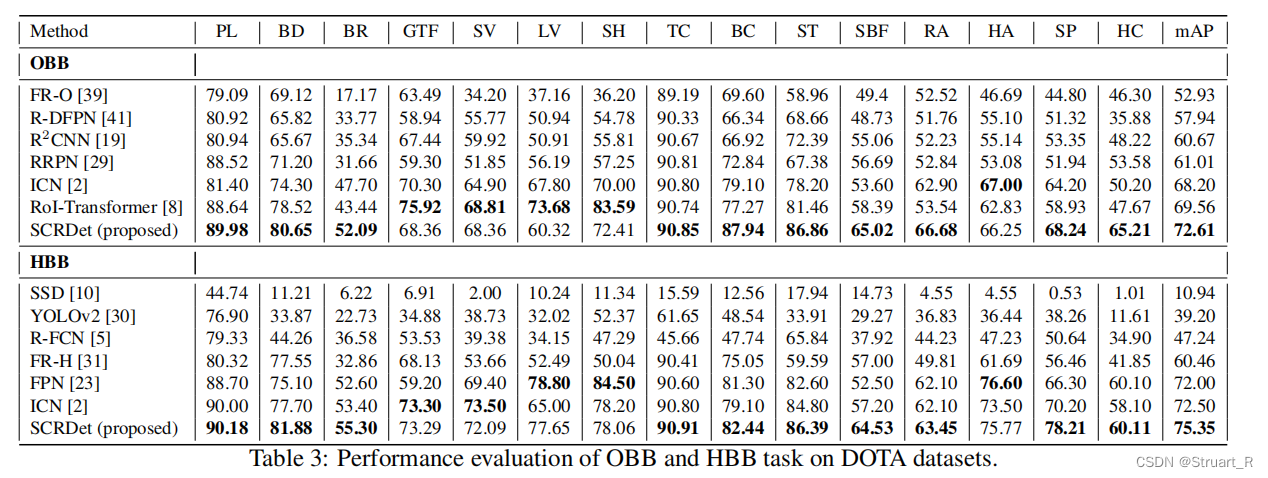
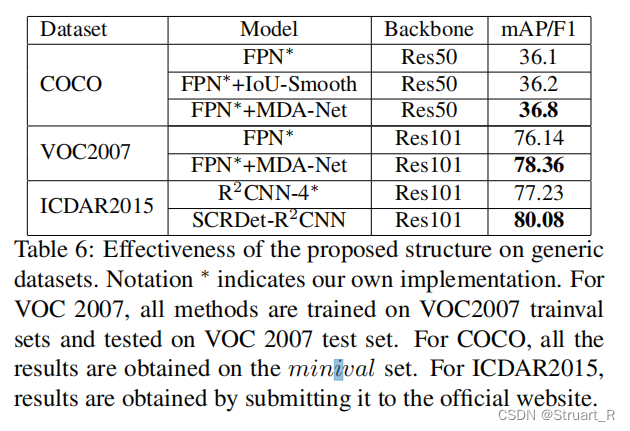
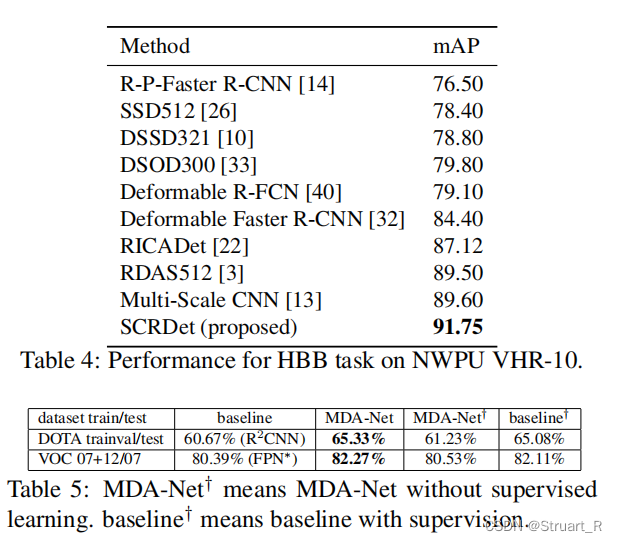
下图是对于不同数据集上,与其他two-stage的模型进行对比。另外进行MDA-Net的有监督和无监督模块的对比,有监督学习的mAP仍要高于无监督学习。
下面对于COCO、VOC2007、ICDAR2015的通用数据集使用MDA-Net、IoU-Smooth模块测试模块的通用性,在密集对象和小目标上性能具有显著提升。