文章目录
- Rethinking Semi-Supervised Medical Image Segmentation: A Variance-Reduction Perspective
- 摘要
- 本文方法
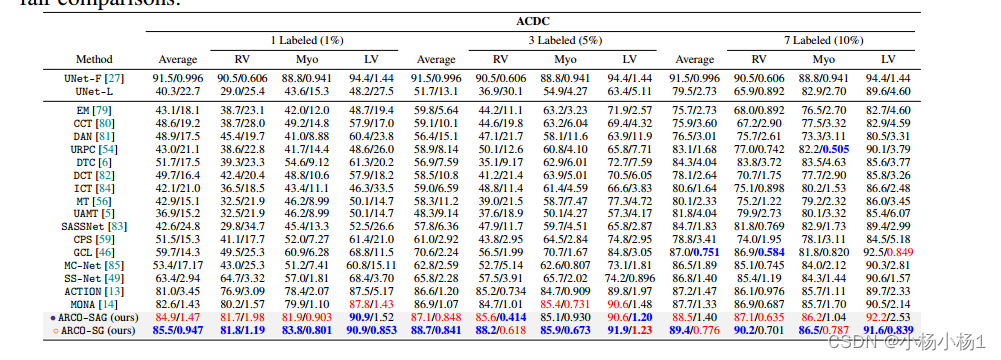
- 实验结果
Rethinking Semi-Supervised Medical Image Segmentation: A Variance-Reduction Perspective
摘要
在医学图像分割中,对比学习是通过对比语义相似和不相似的样本对来提高视觉表征质量的主要方法。这是通过观察来实现的,在不访问地面真值标签的情况下,具有真正不同解剖特征的负例,如果采样,可以显着提高性能。然而,在现实中,这些样本可能来自相似的解剖区域,模型可能难以区分少数尾类样本,从而使尾类更容易被错误分类,这两种情况通常都会导致模型崩溃。
本文提出了一种基于分层群理论的半监督对比学习框架ARCO,用于医学图像分割。特别是,我们首先提出了通过方差减少估计的概念构建ARCO,并表明某些方差减少技术在标签极其有限的像素/体素级分割任务中特别有益。此外,我们从理论上证明了这些采样技术在方差缩减方面是通用的。最后,我们在8个基准上实验验证了我们的方法,即5个2D/3D医学数据集和3个语义分割数据集,具有不同的标签设置,我们的方法始终优于最先进的半监督方法。此外,我们用这些采样技术增强了CL框架,并演示了与以前的方法相比的显著增益。我们相信我们的工作是迈向半监督医学图像分割的重要一步,通过量化当前自我监督目标的局限性来完成这些具有挑战性的安全关键任务
本文方法
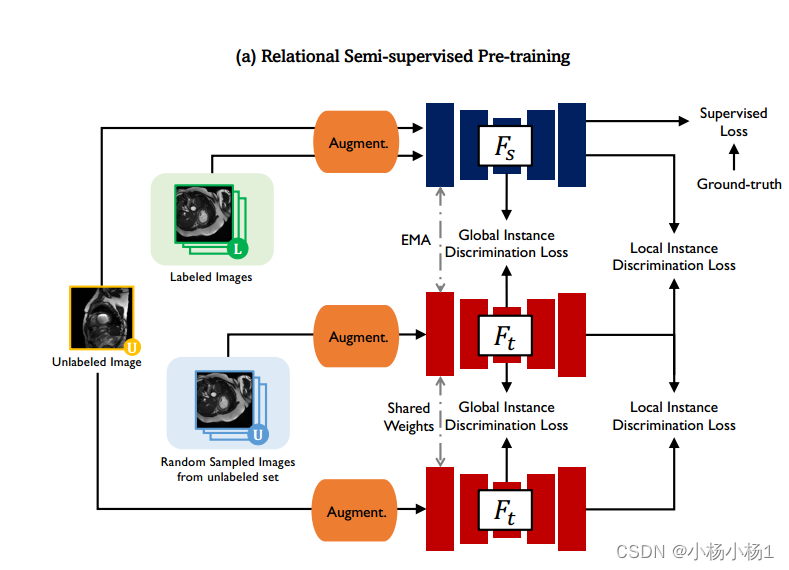
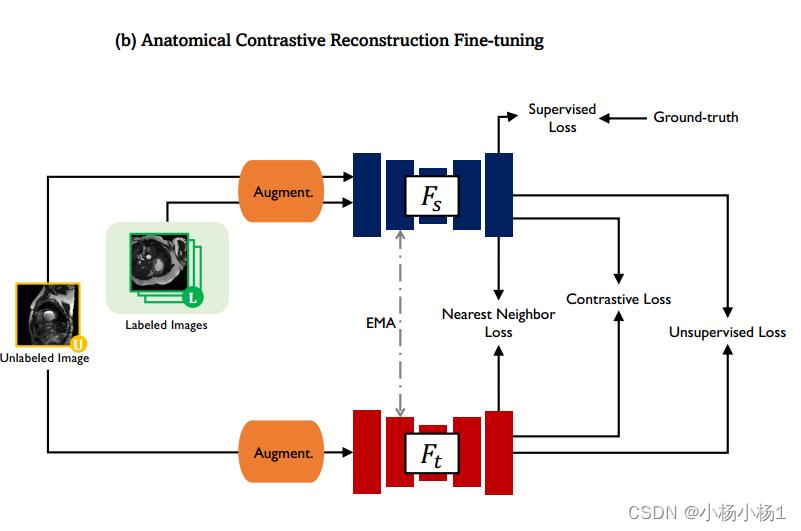
由两个阶段组成:(1)关系半监督预训练:在标记数据上,学生网络通过具有监督损失Lsup的真值标签进行训练;(2)解剖对比重构微调:在标记数据上,使用带监督损失Lsup的真值标签对学生网络进行训练;而对于未标记数据,学生网络从EMA老师那里获取表示映射和伪标签,更加重视尾类Lcontrast,利用实例间关系Lnn,计算无监督损失Lunsup。

在实践中,我们首先根据不同的类别将图像划分为具有相同大小的网格,然后在同一网格内以高概率对语义上彼此接近的像素进行采样,同时使用最小的额外内存占用
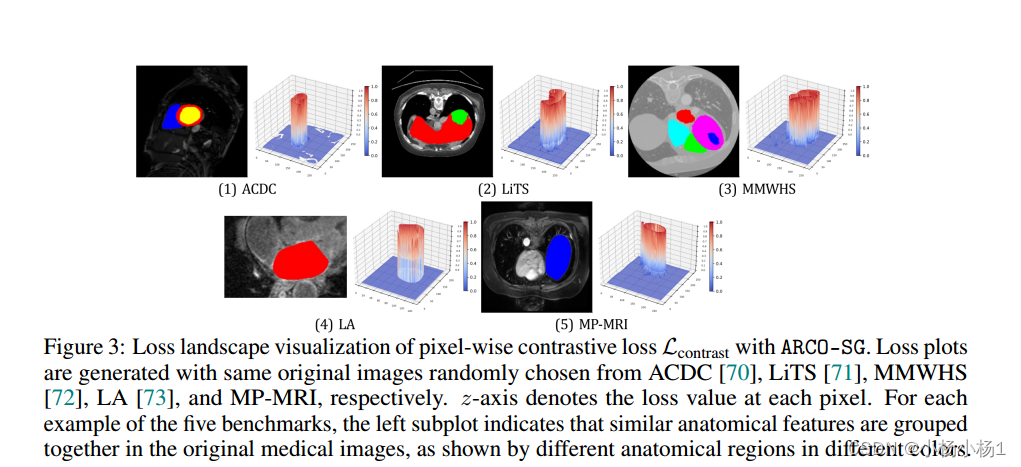
实验结果