简介
- ddt 提供了一种方便的方法来实现数据驱动测试(Data-Driven Testing)。
- 数据驱动测试是一种测试方法,通过将测试数据与测试逻辑分开,可以使用不同的数据集来运行相同的测试用例。这样可以提高测试的灵活性和可维护性,减少代码的重复编写。
目录
1. 常用方法说明
2. 数据驱动测试
2.1. 基本结构介绍
2.2. 简单的使用方法
2.3. 读取csv文件测试
2.4. 读取Excel文件测试
1. 常用方法说明
ddt.data(*args)
- 装饰器,用于指定测试方法的数据来源。
- *args 可以接受多个数据集,每个数据集会生成一个独立的测试用例。
ddt.unpack(data)
- 装饰器,用于解压数据集。
- 通常与 ddt.data(*args) 一起使用,将传入的数据集解压为多个参数,以便用于测试方法的参数化调用。
ddt.file_data(file_path)
- 装饰器,用于读取文件中的测试数据。
- file_path 参数指定要读取的文件路径,文件可以是CSV、Excel等格式。
2. 数据驱动测试
2.1. 基本结构介绍
1、ddt 用于数据驱动,测试还需要导入 unittest 模块
import ddt
import unittest
2、创建一个继承自测试框架的类(使用 @ddt.ddt 装饰器来标记该类为数据驱动测试类)
@ddt.ddt
class MyDataDrivenTest(unittest.TestCase):
print("测试方法1")
print("测试方法2")
print("测试方法3")
3、测试方法中,使用 @ddt.data 装饰器来指定测试数据集
'''指定多个数据作为测试用例'''
@ddt.data((1, 2), (3, 6), (4, 8))
'''解压缩数据元组'''
@ddt.unpack
'''定义测试方法'''
def test_example(self, input_data, expected_result):
# 运行另一个测试函数(test_func),代入输入数据,并返回结果
result = test_func(input_data)
# 对返回结果断言(预期为指定的预期结果)
self.assertEqual(result, expected_result)
4、执行数据驱动测试
if __name__ == '__main__':
unittest.main()
2.2. 简单的使用方法
通过 ddt.data 传入数据,测试方法根据数据个数依次调度,通过预期和实际结果进行断言。
import unittest
import ddt
'''继承自测试的框架,定义为数据驱动类'''
@ddt.ddt
class MyDataDrivenTest(unittest.TestCase):
# 准备驱动数据 ([输入,预期] , [输入,预期]...)
@ddt.data([1, 2], [2, 4], [3, 6])
@ddt.unpack # 解压数据
def test_func1(self, input, expect):
# 简单的测试方法
result = input * 2
# 打印数据信息
print(f'输入数据:{input},输出数据:{result},预期结果:{expect}')
# 断言输出数据和预期结果
self.assertEqual(result, expect)
if __name__ == '__main__':
unittest.main() # 执行注意:这里的 result = input * 2 只是一个简单的测试方法,一般对于实际场景会把这里改成一个专门的测试函数。
例如:测试Linux某个目录下有多少文件,则将输入数据定义为路径,预期结果定义为文件数量。通过一个专门的方法去获取文件数据,则 result = get_filenum(input) 通过 get_filenum 去获取文件数量,再将返回结果断言。

举一个异常的输出例子
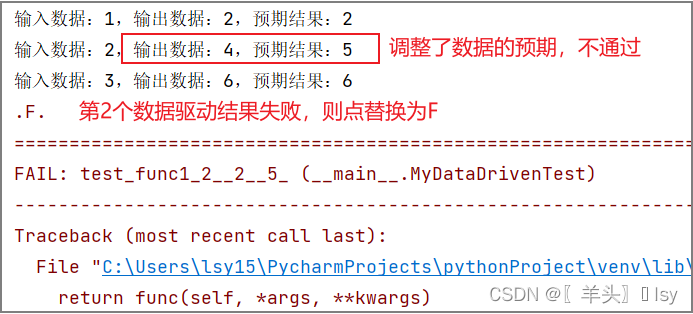
2.3. 读取csv文件测试
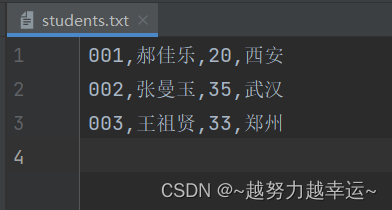
csv文件内容如下
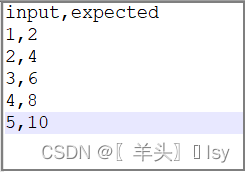
ddt.file_data 方法可以直接读取文件,但是打开文件出错,没有找到解决的方法。
使用 csv 模块自己封装一个读取文件的方法。
import csv
file_path = r'E:\test.csv'
def get_csv(file):
'''定义一个读取csv文件内容的方法'''
with open(file, encoding='utf-8') as f:
# 创建读取对象
csv_reader = csv.reader(f)
# 跳过第一行(next() 函数用于获取迭代器的下一个元素)
next(csv_reader)
# 将文件内容赋值给变量
csv_value = [v for v in csv_reader]
# 返回结果
return csv_value
'''调用方法'''
result = get_csv(file_path)
print(result)结果如下

套入方法,执行测试
import ddt
import csv
import unittest
# 指定测试文件路径
file_path = r'E:\test.csv'
def multiplication(input_data):
'''定义一个测试方法,这里的名称不能以test开头,否则会被读取为框架方法'''
return input_data * 2
def get_csv(file):
'''定义一个读取csv文件内容的方法'''
with open(file, encoding='utf-8') as f:
csv_reader = csv.reader(f)
next(csv_reader)
csv_value = [v for v in csv_reader]
return csv_value
@ddt.ddt
class MyDataDrivenTest(unittest.TestCase):
'''封装一个数据驱动测试框架'''
# 获取csv文件内容
csv_data = get_csv(file_path)
# 将内容当做数据传入驱动
@ddt.data(*csv_data)
@ddt.unpack # 解压数据
def test_func(self, *test_data):
# 读取传入的两个数据
input,expect = test_data
# 因为测试方法是计算,将结果转换为int类型
input = int(input); expect = int(expect)
# 执行测试,将返回结果赋值
result = multiplication(input)
# 打印测试信息
print(f'输入数据:{input},输出数据:{result},预期结果:{expect}')
# 断言输出数据和预期结果
self.assertEqual(result, expect)
if __name__ == '__main__':
unittest.main()输出结果
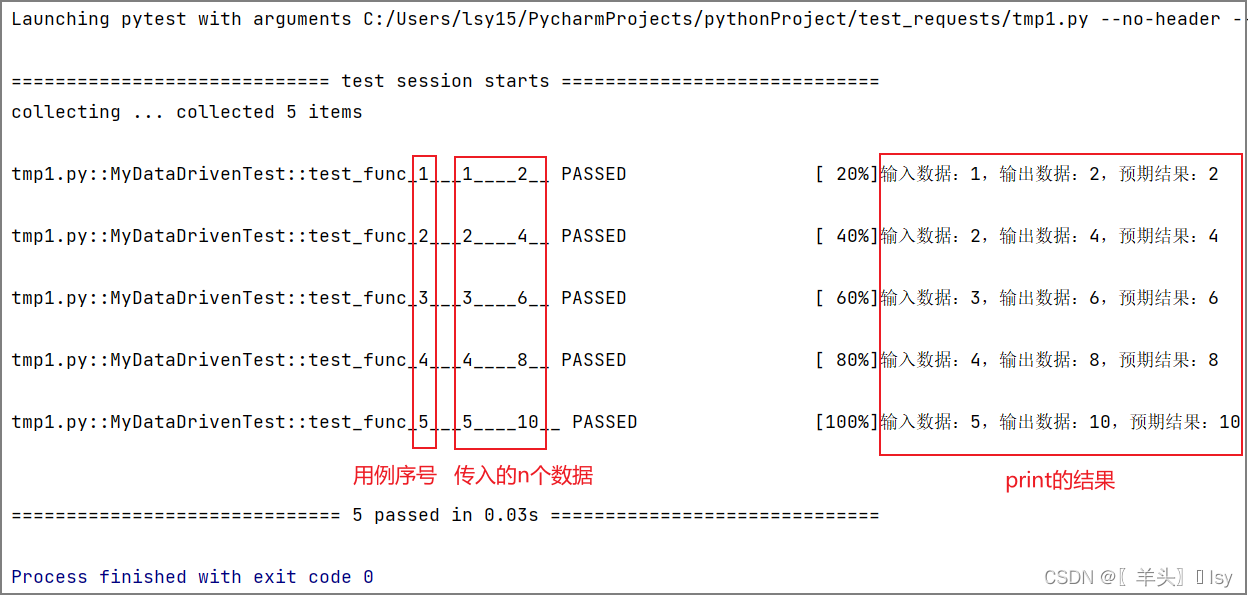
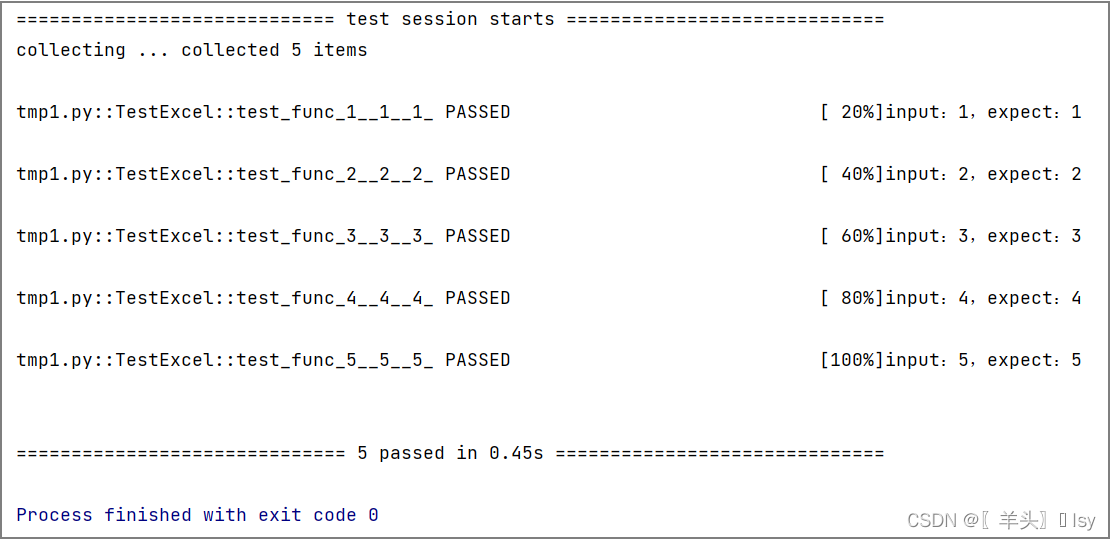
2.4. 读取Excel文件测试
Excel 文件内容如下
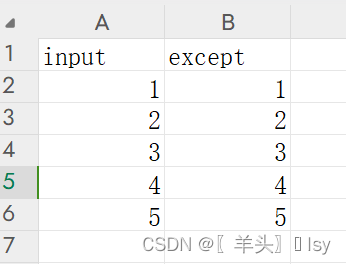
通过 openpyxl 去读取数据(不读第1行)
import openpyxl
file_path = r'E:\test.xlsx'
def get_excel(file):
'''定义一个读取Excel文件内容的方法'''
# 打开文件
wb = openpyxl.load_workbook(file)
# 指定工作表
wb_sheet = wb['Sheet1']
# 指定读取行、列(行:第2-最大行,列:第1-2列)
wb_data = wb_sheet.iter_rows(min_row=2, min_col=1, max_col=2, values_only=True)
# 通过行去遍历列的值(不需要手动关闭文件,load_workbook()自动关闭)
return [i for i in wb_data]
'''调用方法'''
result = get_excel(file_path)
print(result)结果如下

套入方法,执行测试
import ddt
import openpyxl
import unittest
# 指定测试文件路径
file_path = r'E:\test.xlsx'
def get_excel(file):
'''定义一个读取Excel文件内容的方法'''
wb = openpyxl.load_workbook(file)
wb_sheet = wb['Sheet1']
wb_data = wb_sheet.iter_rows(min_row=2, min_col=1, max_col=2, values_only=True)
return [i for i in wb_data]
@ddt.ddt
class TestExcel(unittest.TestCase):
'''封装一个数据驱动的测试框架'''
# 读取Excel文件数据
excel_data = get_excel(file_path)
# 将数据传入驱动
@ddt.data(*excel_data)
@ddt.unpack
def test_func(self, *test_data):
# 仅设定了2列数据,所以结果只需要2个
input,expect = test_data
# 输出获取到的结果
print(f'input:{input},expect:{expect}')
# 执行测试、断言
pass
if __name__ == '__main__':
unittest.main()结果如下