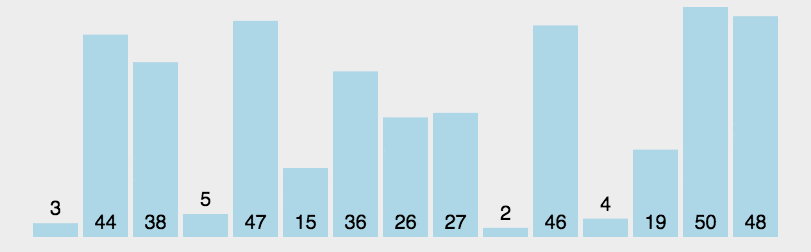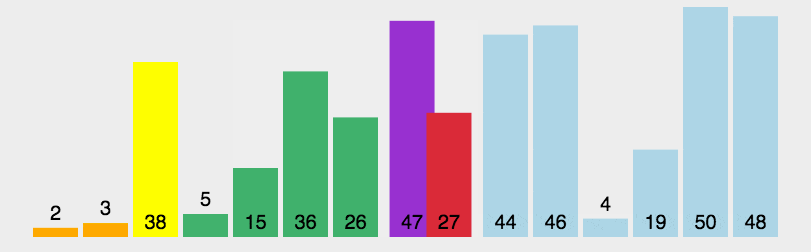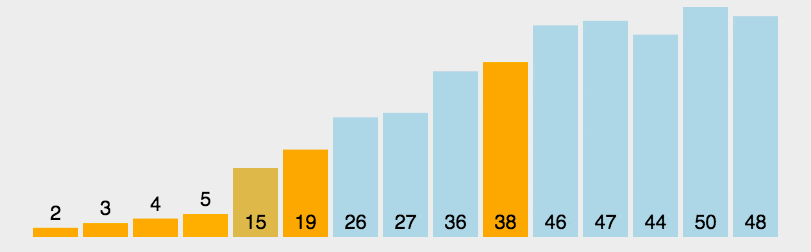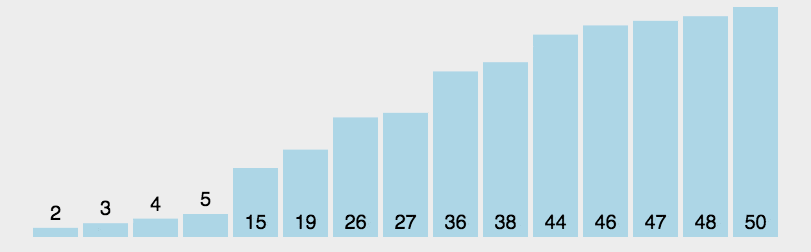
二叉树是一种常见的树状数据结构,每个节点最多有两个子节点,称为左子节点
和右子节点。它可以为空树(没有任何节点),或者由根节点及其子节点组成。
具有层级结构,其中顶层的节点被称为根节点(root)。根节点没有父节点,而其
他节点都有且只有一个父节点。叶子节点是指没有子节点的节点,它们位于树的
最底层。
节点(Node):二叉树的基本单位。每个节点包含三个主要部分:
数据/值域:节点中存储的具体数据,可以是任何类型,例如整数、字符、对
象等。
左子节点:指向当前节点的左侧子节点的指针。如果没有左子节点,指针的值
为None或null。
右子节点:指向当前节点的右侧子节点的指针。如果没有右子节点,指针的值
为None或null。
根节点(Root Node):二叉树的顶层节点,没有父节点。根节点是整个二叉树
的起点。
子节点(Child Node):每个节点可以有零个、一个或两个子节点。左子节点和
右子节点是相对于父节点而言的。
叶子节点(Leaf Node):没有子节点的节点被称为叶子节点。叶子节点位于二叉
树的最底层。
父节点(Parent Node):一个节点的直接上层节点被称为其父节点。
兄弟节点(Sibling Node):具有相同父节点的节点之间称为兄弟节点。
节点之间的连接(Edges):边是连接节点的线条或指针,它表示一个节点与其子
节点之间的关系。
空树(Empty Tree):没有任何节点的二叉树被称为空树。在空树中,根节点为
None 或 null。
二叉树(Binary Tree):是一种有序树结构,其中每个节点最多有两个子节点,
即左子节点和右子节点。左子节点和右子节点的顺序是固定的。
二叉树的形态:二叉树可以具有不同的形态和结构,它可以是平衡的或非平衡
的,可以是满二叉树、完全二叉树或非完全二叉树等。
二叉树的高度(Height):二叉树的高度是指从根节点到最深叶子节点的层数。
空树的高度为0,只有根节点的树的高度为1。
最大节点数量:
在二叉树的第n层,最多有2^(n-1)个节点。
在高度为h的二叉树中,最多有2^h - 1个节点。
最小高度:
对于含有n个节点的二叉树,它的最小高度为 log2(n+1)。
如果二叉树是平衡树,那么它的最小高度为 floor(log2(n+1))。
树的高度:
树的高度是指从根节点到最深叶子节点的路径上的边数。
对于n个节点的二叉树,它的高度最大为n,最小为log2(n+1)。
子树的高度:
二叉树的任意子树的高度不会超过整个二叉树的高度。叶子节点数和度为2
的节点数:
在二叉树中,度为2的节点数等于叶子节点数加1。
完全二叉树是一种特殊的二叉树,除了最后一层外,其他层的节点都必须是满的。
在完全二叉树中,叶子节点从左到右依次排列,不会出现在左侧缺少叶子节点的
情况。
完全二叉树可以使用数组来表示,节点按照层序遍历的顺序依次存放在数组中。
二叉搜索树(Binary Search Tree,BST)是一种特殊的二叉树,满足以下性质:
左子树上的所有节点的值都小于根节点的值。
右子树上的所有节点的值都大于根节点的值。
左右子树也分别是二叉搜索树。
在二叉搜索树中,通过比较节点的值可以快速地搜索、插入和删除节点。
二叉树可以使用不同的存储结构来表示其节点和连接关系。常见的二叉树存储结
构包括链式存储和数组存储。下面对这两种存储结构进行详细讲解:
链式存储使用节点来表示二叉树的各个部分,每个节点包含数据和指向左右子节
点的指针。链式存储可以通过类、结构体或节点对象实现。其中,每个节点由数
据域、左子节点指针和右子节点指针组成。
数组存储使用数组来表示二叉树的节点和连接关系。数组的索引可以代表节点在
二叉树中的位置,节点的值存储在数组对应位置上。
灵活性高:链表存储结构可以动态地插入和删除节点,不需要提前确定存储空间
的大小。
支持任意形态的二叉树:链表存储结构可以直接表示任意形态的二叉树,包括不
平衡和不完全的二叉树。
内存利用效率高:链表存储结构只需要为每个节点分配内存,不会浪费空间。
额外的指针开销:链表存储结构需要为每个节点维护两个指针(左子节点和右子
节点),增加了额外的指针开销。
空间开销较大:相比数组存储结构,链表存储结构会占用更多的存储空间来存储
指针信息。
内存连续、访问高效:数组存储结构的节点在内存中是连续存储的,可以通过索
引快速访问节点,访问效率较高。
空间利用效率高:对于满二叉树或完全二叉树这种特殊形态的二叉树,数组存储
结构可以节省存储空间。
大小固定:数组存储结构需要提前确定二叉树的大小,当二叉树的节点数超过数
组大小时,需要重新分配内存,导致性能下降。
插入和删除困难:对于数组存储结构,插入和删除节点的操作相对复杂且耗时,
需要进行元素的移动和调整。
综上所述,链表存储结构适用于频繁的修改操作和不规则形态的二叉树,它具有
灵活性和动态性的优势。而数组存储结构适用于满二叉树或完全二叉树这种特殊
形态的二叉树,它具有内存连续和访问高效的优势。
搜索和排序算法:
二叉搜索树(Binary Search Tree,BST)是一种常用的数据结构,基于二叉树
实现。它具有快速的搜索、插入和删除操作,广泛用于搜索和排序算法,如二叉
搜索、二叉查找、二叉排序等。BST还可以根据中序遍历得到有序的数据序列。
文件系统的组织:
文件系统常常被组织成一棵树,其中每个节点代表一个目录或文件。使用二叉树
的方式可以方便地进行文件的搜索和管理操作,例如快速查找、遍历和删除文
件等。
表达式表示与求值:
二叉树可以用于表示数学表达式,其中每个节点表示操作符或操作数。通过遍历
二叉树,可以对表达式进行求值或转换。例如,通过后序遍历可以实现表达式求
值,通过中序遍历可以进行中缀表达式转换为后缀表达式。
解析和编译器设计:
编译器和解析器常常使用二叉树来解析源代码,并将其转换为语法树或抽象语法
树(Abstract Syntax Tree,AST)。语法树可以方便地对源代码进行分析、优
化和生成中间代码等。
网络和路由算法:
二叉树在网络和路由算法中有应用。例如,用于安全路由的Patricia树或前缀
树(Prefix Tree)是一种特殊的二叉树,可以高效地存储和查询路由信息。
Huffman编码:
Huffman编码是一种无损数据压缩算法,通过构建二叉树并对每个字符进行编码,
实现有效地压缩。二叉树中的叶子节点表示不同的字符,路径和编码表示字符的
编码。
数据库索引结构:
数据库中的索引结构常常使用二叉树的变种来实现,例如平衡二叉树、B 树和
B+树等。这些树结构可以加速数据库的查询和检索操作。
图形学和游戏开发:
在图形学和游戏开发中,二叉树可以用于场景图的构建和管理。场景图是一种用
于表示物体之间层次关系的树结构,便于进行碰撞检测、渲染优化和对象的空间
关系操作。
除此以外
二叉树还可以在许多其他领域中使用,如人工智能中的决策树和神经网络,
网络协议等方面
class Node {
int key;
Node left, right;
public Node ( int item) {
key = item;
left = right = null ;
}
}
public class BinaryTree {
Node root;
public BinaryTree ( int key) {
root = new Node ( key) ;
}
public BinaryTree ( ) {
root = null ;
}
public void insert ( int key) {
root = insertNode ( root, key) ;
}
private Node insertNode ( Node root, int key) {
if ( root == null ) {
root = new Node ( key) ;
return root;
}
if ( key < root. key)
root. left = insertNode ( root. left, key) ;
else if ( key > root. key)
root. right = insertNode ( root. right, key) ;
return root;
}
public void delete ( int key) {
root = deleteNode ( root, key) ;
}
private Node deleteNode ( Node root, int key) {
if ( root == null )
return root;
if ( key < root. key)
root. left = deleteNode ( root. left, key) ;
else if ( key > root. key)
root. right = deleteNode ( root. right, key) ;
else {
if ( root. left == null )
return root. right;
else if ( root. right == null )
return root. left;
root. key = getMinValue ( root. right) ;
root. right = deleteNode ( root. right, root. key) ;
}
return root;
}
private int getMinValue ( Node root) {
int minVal = root. key;
while ( root. left != null ) {
minVal = root. left. key;
root = root. left;
}
return minVal;
}
public Node search ( Node root, int key) {
if ( root == null || root. key == key)
return root;
if ( key < root. key)
return search ( root. left, key) ;
return search ( root. right, key) ;
}
public void preorderTraversal ( Node node) {
if ( node != null ) {
System . out. print ( node. key + " " ) ;
preorderTraversal ( node. left) ;
preorderTraversal ( node. right) ;
}
}
public void inorderTraversal ( Node node) {
if ( node != null ) {
inorderTraversal ( node. left) ;
System . out. print ( node. key + " " ) ;
inorderTraversal ( node. right) ;
}
}
public void postorderTraversal ( Node node) {
if ( node != null ) {
postorderTraversal ( node. left) ;
postorderTraversal ( node. right) ;
System . out. print ( node. key + " " ) ;
}
}
public static void main ( String [ ] args) {
BinaryTree tree = new BinaryTree ( ) ;
tree. insert ( 50 ) ;
tree. insert ( 30 ) ;
tree. insert ( 20 ) ;
tree. insert ( 40 ) ;
tree. insert ( 70 ) ;
tree. insert ( 60 ) ;
tree. insert ( 80 ) ;
tree. delete ( 20 ) ;
Node searchNode = tree. search ( tree. root, 40 ) ;
if ( searchNode != null )
System . out. println ( "节点 40 找到了" ) ;
else
System . out. println ( "节点 40 未找到" ) ;
System . out. println ( "前序遍历:" ) ;
tree. preorderTraversal ( tree. root) ;
System . out. println ( "\n中序遍历:" ) ;
tree. inorderTraversal ( tree. root) ;
System . out. println ( "\n后序遍历:" ) ;
tree. postorderTraversal ( tree. root) ;
}
}