文章目录
- 一、基础入门
- 1. 示例程序
- 2. 安装与环境变量设置
- 3. 项目构建和编译发布
- 3.1 go build和go install对比
- 3.2 跨平台编译
- 二、数据类型
- 1. 基础类型
- 1.1 整型
- 1.2 浮点数
- 1.3 布尔型
- 1.4 字符串
- 1.5 零值
- 2. 变量
- 2.1 变量声明
- 2.1.1 指定变量类型
- 2.1.2 根据值自行判定变量类型
- 2.1.3 简短声明
- 2.1.4 多变量声明
- 2.2 指针
- 3. 常量
- 3.1 定义
- 3.2 iota
- 4. 字符串
- 4.1 字符串和数字互转
- 4.2 Strings包
- 三、控制结构
- 1. if条件语句
- 2. switch选择语句
- 3. for循环语句
- 四、集合类型
- 1. Array(数组)
- 1.1 数组声明
- 1.2 数组循环
- 2. Slice(切片)
- 2.1 切片的定义与生成
- 2.1.1 基于数组生成切片
- 2.1.2 make 函数声明
- 2.1.3 字面量初始化
- 2.2 切片修改
- 2.3 Append
- 3. Map(映射)
- 3.1 声明初始化
- 3.2 取值和删除
- 3.3 遍历Map
- 3.4 Map的大小
- 4. String 和 []byte
- 五、函数和方法
- 1. 函数
- 1.1 函数声明
- 1.2 多值返回
- 1.3 命名返回参数
- 1.4 可变参数
- 1.5 包级函数
- 1.6 匿名函数和闭包
- 2. 方法
- 2.1 方法声明
- 2.2 值类型接收者和指针类型接收者
- 2.3 方法赋值变量
- 六、struct 和 interface
- 1. 结构体
- 1.1 定义
- 1.2 声明使用
- 1.3 字段结构体
- 2. 接口
- 2.1 定义
- 2.2 接口实现
- 2.3 值接收者和指针接收者
- 3. 工厂函数
- 3.1 创建自定义结构体
- 3.2 创建接口
- 4. 继承和组合
- 5. 类型断言
- 七、错误处理
- 1. 错误(error)
- 1.1 error 接口
- 1.2 error工厂函数
- 1.3 自定义 error
- 1.4 error 断言
- 2. error错误嵌套
- 2.1 Error Wrapping
- 2.2 errors.Unwrap 函数
- 2.3 errors.Is 函数
- 2.4 errors.As 函数
- 2. Deferred 函数
- 3. Panic 异常
- 3.1 定义
- 3.2 Recover 捕获 Panic 异常
一、基础入门
1. 示例程序
package main
import "fmt"
func main() {
fmt.Println("Hello, 世界")
}
- 第一行的 package main 代表当前的文件属于哪个包,其中 package 是 Go 语言声明包的关键字,main 是要声明的包名。在 Go 语言中 main 包是一个特殊的包,代表你的 Go 语言项目是一个可运行的应用程序,而不是一个被其他项目引用的库。
- 第二行的 import “fmt” 是导入一个 fmt 包,其中 import 是 Go 语言的关键字。
- 第三行的 func main() 是定义了一个函数,其中 func 是 Go 语言的关键字。
- 第四行的 fmt.Println(“Hello, 世界”) 是通过 fmt 包的 Println 函数打印文本。
2. 安装与环境变量设置
检查安装的Go语言版本
$ go version
go version go1.20.5 darwin/arm64
GOPATH和GO VENDOR是旧的包管理机制,已不建议使用,目前使用的均为Go Modules模式。
从 v1.11 开始,go env 多了个环境变量: GO111MODULE ,这里的 111,其实就是 v1.11 的象征标志, go 里好像很喜欢这样的命名方式,比如当初 vendor 出现的时候,也多了个 GO15VENDOREXPERIMENT环境变量,其中 15,表示的vendor 是在 v1.5 时才诞生的。
GO111MODULE 是一个开关,通过它可以开启或关闭 go mod 模式。
它有三个可选值:off、on、auto,默认值是auto。
GO111MODULE=off禁用模块支持,编译时会从GOPATH和vendor文件夹中查找包。
GO111MODULE=on启用模块支持,编译时会忽略GOPATH和vendor文件夹,只根据 go.mod下载依赖。
GO111MODULE=auto,当项目在$GOPATH/src外且项目根目录有go.mod文件时,自动开启模块支持。
3. 项目构建和编译发布
执行如下命令创建一个 Go Module 项目:
$ go mod init [模块名称]
执行成功后,会生成一个 go.mod 文件。
3.1 go build和go install对比
- go build:用于测试编译包,在项目目录下生成可执行文件(有main包)。
- go install:主要用来生成库和工具。一是编译包文件(无main包),将编译后的包文件放到 pkg 目录下($GOPATH/pkg)。二是编译生成可执行文件(有main包),将可执行文件放到 bin 目录($GOPATH/bin)。
相同点:都能生成可执行文件
不同点:
- go build 不能生成包文件, go install 可以生成包文件
- go build 生成可执行文件在当前目录下, go install 生成可执行文件在bin目录下($GOPATH/bin)
go build示例:
$ go build ./main.go
回车执行后会在当前目录生成 main 可执行文件
$ ./main
Hello, 世界
3.2 跨平台编译
Go 语言通过两个环境变量来控制跨平台编译,它们分别是 GOOS 和 GOARCH 。
- GOOS:代表要编译的目标操作系统,常见的有 Linux、Windows、Darwin 等。
- GOARCH:代表要编译的目标处理器架构,常见的有 386、AMD64、ARM64 等。
这样通过组合不同的 GOOS 和 GOARCH,就可以编译出不同的可执行程序。比如我现在的操作系统是 macOS AMD64 的,我想编译出 Linux AMD64 的可执行程序,只需要执行 go build 命令即可,如以下代码所示:
$ GOOS=linux GOARCH=amd64 go build ./ch01/main.go
关于 GOOS 和 GOARCH 更多的组合,参考官方文档的 $GOOS and $GOARCH 这一节即可。
二、数据类型
1. 基础类型
常用的有:整型、浮点数、布尔型和字符串
1.1 整型
整型分为:
- 有符号整型:如 int、int8、int16、int32 和 int64。
- 无符号整型:如 uint、uint8、uint16、uint32 和 uint64。
它们的差别在于,有符号整型表示的数值可以为负数、零和正数,而无符号整型只能为零和正数。
除了有用“位”(bit)大小表示的整型外,还有 int 和 uint 这两个没有具体 bit 大小的整型,它们的大小可能是 32bit,也可能是 64bit,和硬件设备 CPU 有关。
在整型中,如果能确定 int 的 bit 就选择比较明确的 int 类型,因为这会让你的程序具备很好的移植性。
在 Go 语言中,还有一种字节类型 byte,它其实等价于 uint8 类型,可以理解为 uint8 类型的别名,用于定义一个字节,所以字节 byte 类型也属于整型。
1.2 浮点数
Go 语言提供了两种精度的浮点数,分别是 float32 和 float64。项目中最常用的是 float64,因为它的精度高,浮点计算的结果相比 float32 误差会更小。
1.3 布尔型
Go 语言中的布尔型使用关键字 bool 定义。一个布尔型的值只有两种:true 和 false。
布尔值可以用于一元操作符 !,表示逻辑非的意思,也可以用于二元操作符 &&、||,它们分别表示逻辑和、逻辑或。
1.4 字符串
在 Go 语言中,字符串通过类型 string 声明:
var s1 string = "Hello"
var s2 string = "世界"
fmt.Println("s1 is",s1,",s2 is",s2)
可以通过操作符 + 把字符串连接起来,得到一个新的字符串,比如将上面的 s1 和 s2 连接起来,如下所示:
fmt.Println("s1+s2=",s1+s2)
字符串也可以通过 += 运算符操作。
1.5 零值
零值其实就是一个变量的默认值,在 Go 语言中,如果声明了一个变量,但是没有对其进行初始化,那么 Go 语言会自动初始化其值为对应类型的零值。比如数字类的零值是 0,布尔型的零值是 false,字符串的零值是 “” 空字符串等。
示例:
var zi int
var zf float64
var zb bool
var zs string
fmt.Println(zi,zf,zb,zs)
还有一种数据类型——复数,它不常用,是用 complex 这个内置函数创建的。
2. 变量
2.1 变量声明
2.1.1 指定变量类型
在 Go 语言中,通过 var 声明语句来定义一个变量,定义的时候需要指定这个变量的类型,然后再为它起个名字,并且设置好变量的初始值。
var 变量名 类型 = 表达式
示例
package main
import "fmt"
func main() {
var i int = 10
fmt.Println(i)
}
Go 语言中定义的变量必须使用,否则无法编译通过,这也是 Go 语言比较好的特性,防止定义了变量不使用,导致浪费内存的情况。
2.1.2 根据值自行判定变量类型
因为 Go 语言具有类型推导功能,所以也可以不去刻意地指定变量的类型,而是让 Go 语言自己推导,比如变量 i 也可以用如下的方式声明:
var i = 10
这样变量 i 的类型默认是 int 类型。
不止 int 类型,float64、bool、string 等基础类型都可以被自动推导。
2.1.3 简短声明
借助类型推导,Go 语言提供了变量的简短声明 :=,结构如下:
变量名:=表达式
在实际的项目实战中,如果你能为声明的变量初始化,那么就选择简短声明方式,这种方式也是使用最多的。
如果变量已经使用 var 声明过了,再使用 := 声明变量,就产生编译错误
2.1.4 多变量声明
//类型相同多个变量, 非全局变量
var vname1, vname2, vname3 type
vname1, vname2, vname3 = v1, v2, v3
var vname1, vname2, vname3 = v1, v2, v3 // 和 python 很像,不需要显示声明类型,自动推断
vname1, vname2, vname3 := v1, v2, v3 // 出现在 := 左侧的变量不应该是已经被声明过的,否则会导致编译错误
声明全局变量一般把要声明的多个变量放到一个括号中,如下面的代码所示:
var (
j int= 0
k int= 1
)
同理因为类型推导,以上多个变量声明也可以用以下代码的方式书写:
var (
j = 0
k = 1
)
2.2 指针
指针对应的是变量在内存中的存储位置,也就说指针的值就是变量的内存地址。通过 & 可以获取一个变量的地址,也就是指针。
在以下的代码中,pi 就是指向变量 i 的指针。要想获得指针 pi 指向的变量值,通过*pi这个表达式即可。
pi:=&i
fmt.Println(*pi)
3. 常量
在程序中,常量的值是指在编译期就确定好的,一旦确定好之后就不能被修改,这样就可以防止在运行期被恶意篡改。
3.1 定义
常量的定义和变量类似,只不过它的关键字是 const。
因为 Go 语言可以类型推导,所以在常量声明时也可以省略类型。
const i int = 10
const name = "hello"
在 Go 语言中,只允许布尔型、字符串、数字类型这些基础类型作为常量。
3.2 iota
iota 是一个常量生成器,它可以用来初始化相似规则的常量,避免重复的初始化。假设我们要定义 one、two、three 和 four 四个常量,对应的值分别是 1、2、3 和 4,如果不使用 iota,则需要按照如下代码的方式定义:
const(
one = 1
two = 2
three =3
four =4
)
以上声明都要初始化,会比较烦琐,因为这些常量是有规律的(连续的数字),所以可以使用 iota 进行声明,如下所示:
const(
one = iota+1
two
three
four
)
fmt.Println(one,two,three,four)
iota 的初始值是 0,它的能力就是在每一个有常量声明的行后面 +1,下面我来分解上面的常量:
- one=(0)+1,这时候 iota 的值为 0,经过计算后,one 的值为 1。
- two=(0+1)+1,这时候 iota 的值会 +1,变成了 1,经过计算后,two 的值为 2。
- three=(0+1+1)+1,这时候 iota 的值会再 +1,变成了 2,经过计算后,three 的值为 3。
- four=(0+1+1+1)+1,这时候 iota 的值会继续再 +1,变成了 3,经过计算后,four 的值为 4。
如果定义更多的常量,就依次类推,其中 () 内的表达式,表示 iota 自身 +1 的过程。
4. 字符串
4.1 字符串和数字互转
Go 语言是强类型的语言,所以不同类型的变量在进行赋值或者计算前,需要先进行类型转换。
字符串和数字互转
i2s:=strconv.Itoa(i) // Itoa is equivalent to FormatInt(int64(i), 10)
s2i,err:=strconv.Atoi(i2s) // Atoi is equivalent to ParseInt(s, 10, 0), converted to type int.
fmt.Println(i2s,s2i,err)
通过包 strconv 的 Itoa 函数可以把一个 int 类型转为 string,Atoi 函数则用来把 string 转为 int。
同理对于浮点数、布尔型,Go 语言提供了 strconv.ParseFloat、strconv.ParseBool、strconv.FormatFloat 和 strconv.FormatBool 进行互转。
数字类型互转
i2f:=float64(i)
f2i:=int(f64)
fmt.Println(i2f,f2i)
这种使用方式比简单,采用“类型(要转换的变量)”格式即可。
4.2 Strings包
标准包 strings 是用于处理字符串的工具包,里面有很多常用的函数,帮助我们对字符串进行操作,比如查找字符串、去除字符串的空格、拆分字符串、判断字符串是否有某个前缀或者后缀等。
示例:
//判断s1的前缀是否是H
fmt.Println(strings.HasPrefix(s1,"H"))
//在s1中查找字符串o
fmt.Println(strings.Index(s1,"o"))
//把s1全部转为大写
fmt.Println(strings.ToUpper(s1))
关于strings包的详细文档可参考:https://pkg.go.dev/strings@go1.20.5
三、控制结构
1. if条件语句
示例:
func main() {
i:=6
if i >10 {
fmt.Println("i>10")
} else if i>5 && i<=10 {
fmt.Println("5<i<=10")
} else {
fmt.Println("i<=5")
}
}
关于 if 条件语句的使用有一些规则:
- if 后面的条件表达式不需要使用 (),这和有些编程语言不一样,也更体现 Go 语言的简洁;
- 每个条件分支(if 或者 else)中的大括号是必须的,哪怕大括号里只有一行代码(如示例);
- if 紧跟的大括号 { 不能独占一行,else 前的大括号 } 也不能独占一行,否则会编译不通过。
和其他编程语言不同,在 Go 语言的 if 语句中,可以有一个简单的表达式语句,并将该语句和条件语句使用分号 ; 分开。
func main() {
if i:=6; i >10 {
fmt.Println("i>10")
} else if i>5 && i<=10 {
fmt.Println("5<i<=10")
} else {
fmt.Println("i<=5")
}
}
通过 if 简单语句声明的变量,只能在整个 if……else if……else 条件语句中使用,比如以上示例中的变量 i。
2. switch选择语句
switch 语句同样也可以用一个简单的语句来做初始化,同样也是用分号 ; 分隔。每一个 case 就是一个分支,分支条件为 true 该分支才会执行,而且 case 分支后的条件表达式也不用小括号 () 包裹。
switch i:=6;{
case i>10:
fmt.Println("i>10")
case i>5 && i<=10:
fmt.Println("5<i<=10")
default:
fmt.Println("i<=5")
}
在 Go 语言中,switch 的 case 从上到下逐一进行判断,一旦满足条件,立即执行对应的分支并返回,其余分支不再做判断。也就是说 Go 语言的 switch 在默认情况下,case 最后自带 break。这和其他编程语言不一样,Go 语言的这种设计就是为了防止忘记写 break 时,下一个 case 被执行。
如果我们需要执行后面的 case,可以使用 fallthrough 。
switch j:=1;j {
case 1:
fallthrough
case 2:
fmt.Println("1")
default:
fmt.Println("没有匹配")
}
当 switch 之后有表达式时,case 后的值就要和这个表达式的结果类型相同,比如这里的 j 是 int 类型,那么 case 后就只能使用 int 类型,如示例中的 case 1、case 2。如果是其他类型,比如使用 case “a” ,会提示类型不匹配,无法编译通过。
而对于 switch 后省略表达式的情况,整个 switch 结构就和 if……else 条件语句等同了。
switch 后的表达式也没有太多限制,是一个合法的表达式即可,也不用一定要求是常量或者整数。
3. for循环语句
Go 语言的 For 循环有 3 种形式
(1)for init; condition; post { }
示例:
sum:=0
for i:=1;i<=100;i++ {
sum+=i
}
fmt.Println("the sum is",sum)
需要特别留意的是,Go 语言里的 for 循环非常强大,以上介绍的三部分组成都不是必须的,可以被省略。
(2)for condition { }
在 Go 语言中没有 while 循环,但是可以通过 for 达到 while 的效果,如以下代码所示:
sum:=0
i:=1
for i<=100 {
sum+=i
i++
}
fmt.Println("the sum is",sum)
这个示例和上面的 for 示例的效果是一样的,但是这里的 for 后只有 i<=100 这一个条件语句,也就是说,它达到了 while 的效果。
在 Go 语言中,同样支持使用 continue、break 控制 for 循环。
(3)for { }
无限循环示例:
sum:=0
i:=1
for {
sum+=i
i++
if i>100 {
break
}
}
fmt.Println("the sum is",sum)
这个示例使用的是没有任何条件的 for 循环,也称为 for 无限循环。
Go语言只有后置的自增自减,没有前置的自增自减。
四、集合类型
在 Go 语言中,数组(array)、切片(slice)、映射(map)这些都是集合类型,用于存放同一类元素。
1. Array(数组)
1.1 数组声明
在下面的代码示例中声明了一个字符串数组,长度是 5,所以其类型定义为 [5]string,其中大括号中的元素用于初始化数组。
array:=[5]string{"a","b","c","d","e"}
注意:[5]string 和 [4]string 不是同一种类型,也就是说长度也是数组类型的一部分。
在定义数组的时候,数组的长度可以省略,这个时候 Go 语言会自动根据大括号 {} 中元素的个数推导出长度,所以以上示例也可以像下面这样声明:
array:=[...]string{"a","b","c","d","e"}
如果设置了数组的长度,我们还可以通过指定下标来初始化特定索引元素:
array1:=[5]string{1:"b",3:"d"}
示例中的「1:“b”,3:“d”」的意思表示初始化索引 1 的值为 b,初始化索引 3 的值为 d,整个数组的长度为 5。如果这个例子中省略长度 5,那么整个数组的长度只有 4。
此外,没有初始化的索引,其默认值都是数组类型的零值,也就是 string 类型的零值 “” 空字符串。
1.2 数组循环
使用传统的 for 循环遍历数组,输出对应的索引和对应的值,这种方式很烦琐,一般不使用,大部分情况下使用的是 for range 这种 Go 语言的新型循环,如下面的代码所示:
for i,v:=range array{
fmt.Printf("数组索引:%d,对应值:%s\n", i, v)
}
这种方式和传统 for 循环的结果是一样的。对于数组,range 表达式返回两个结果:
- 第一个是数组的索引;
- 第二个是数组的值。
相比传统的 for 循环,for range 要更简洁,如果返回的值用不到,可以使用 _ 下划线丢弃,如下面的代码所示:
for _,v:=range array{
fmt.Printf("对应值:%s\n", v)
}
2. Slice(切片)
切片和数组类似,可以把它理解为动态数组。切片是基于数组实现的,它的底层就是一个数组。对数组任意分隔,就可以得到一个切片。
在 Go 语言开发中,切片是使用最多的,尤其是作为函数的参数时,相比数组,通常会优先选择切片,因为它高效,内存占用小。
2.1 切片的定义与生成
2.1.1 基于数组生成切片
//基于数组生成切片,包含索引start,但是不包含索引end
slice:=array[start:end]
示例:
array:=[5]string{"a","b","c","d","e"}
slice:=array[2:5]
fmt.Println(slice)
在数组 array 中,元素 c 的索引其实是 2,但是对数组切片后,在新生成的切片 slice 中,它的索引是 0,这就是切片。虽然切片底层用的也是 array 数组,但是经过切片后,切片的索引范围改变了。
切片是一个具备三个字段的数据结构,分别是指向数组的指针 data,长度 len 和容量 cap:
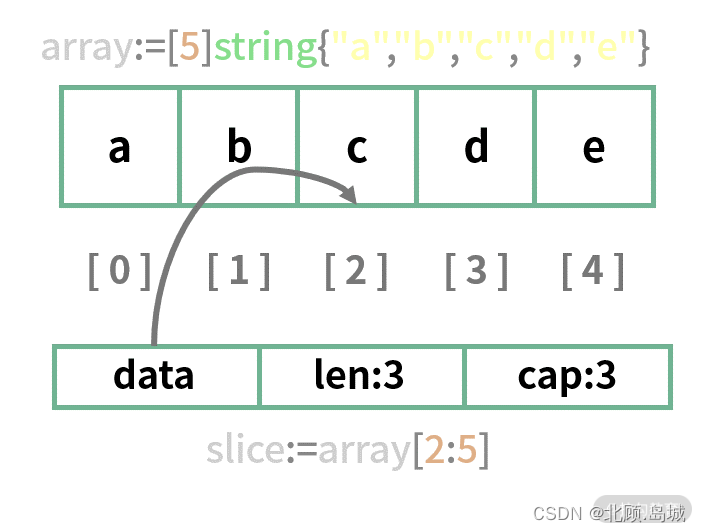
2.1.2 make 函数声明
make 函数可以传入一个长度和容量参数:
slice1:=make([]string,4,8) // 声明了一个元素类型为 string 的切片,长度是 4,容量是 8
切片的容量不能比切片的长度小
上面的示例说明,Go 语言在内存上划分了一块容量为 8 的内容空间(容量为 8),但是只有 4 个内存空间才有元素(长度为 4),其他的内存空间处于空闲状态,当通过 append 函数往切片中追加元素的时候,会追加到空闲的内存上,当切片的长度要超过容量的时候,会进行扩容。
2.1.3 字面量初始化
slice1:=[]string{"a","b","c","d","e"}
fmt.Println(len(slice1),cap(slice1))
切片和数组的字面量初始化方式,差别就是中括号 [] 里的长度。此外,通过字面量初始化的切片,长度和容量相同。
2.2 切片修改
对切片相应的索引元素赋值就是修改,在下面的代码中,把切片 slice 索引 1 的值修改为 f,然后打印输出数组 array:
slice:=array[2:5]
slice[1] ="f"
fmt.Println(array)
可以看到如下结果:
[a b c f e]
数组对应的值已经被修改为 f,所以这也证明了基于数组的切片,使用的底层数组还是原来的数组,一旦修改切片的元素值,那么底层数组对应的值也会被修改。
2.3 Append
可以通过内置的 append 函数对一个切片追加元素,返回新切片
//追加一个元素
slice2:=append(slice1,"f")
//多加多个元素
slice2:=append(slice1,"f","g")
//追加另一个切片
slice2:=append(slice1,slice...)
append 函数可以有以上三种操作,你可以根据自己的实际需求进行选择,append 会自动处理切片容量不足需要扩容的问题。
小技巧:在创建新切片的时候,最好要让新切片的长度和容量一样,这样在追加操作的时候就会生成新的底层数组,从而和原有数组分离,就不会因为共用底层数组导致修改内容的时候影响多个切片。
3. Map(映射)
map 是一个无序的 K-V 键值对集合,结构为 map[K]V。其中 K 对应 Key,V 对应 Value。map 中所有的 Key 必须具有相同的类型,Value 也同样,但 Key 和 Value 的类型可以不同。此外,Key 的类型必须支持 == 比较运算符,这样才可以判断它是否存在,并保证 Key 的唯一。
如果 map 的 Key 的类型是整型,并且集合中的元素比较少,应该尽量选择切片,因为效率更高。
3.1 声明初始化
创建一个 map 可以通过内置的 make 函数,如下面的代码所示:
nameAgeMap:=make(map[string]int)
除了可以通过 make 函数创建 map 外,还可以通过字面量的方式。
nameAgeMap:=map[string]int{"item":20}
在创建 map 的同时添加键值对,如果不想添加键值对,使用空大括号 {} 即可,要注意的是,大括号一定不能省略。
3.2 取值和删除
Go 语言的 map 可以获取不存在的 K-V 键值对,如果 Key 不存在,返回的 Value 是该类型的零值,比如 int 的零值就是 0。所以很多时候,需要先判断 map 中的 Key 是否存在。
map 的 [] 操作符可以返回两个值:
- 第一个值是对应的 Value;
- 第二个值标记该 Key 是否存在,如果存在,它的值为 true。
nameAgeMap:=make(map[string]int)
nameAgeMap["item"] = 20
age,ok:=nameAgeMap["item1"]
if ok {
fmt.Println(age)
}
在示例中,age 是返回的 Value,ok 用来标记该 Key 是否存在,如果存在则打印 age。
如果要删除 map 中的键值对,使用内置的 delete 函数即可。
delete(nameAgeMap,"item")
delete 有两个参数:第一个参数是 map,第二个参数是要删除键值对的 Key。
3.3 遍历Map
对于 map,for range 返回两个值:
- 第一个是 map 的 Key;
- 第二个是 map 的 Value。
需要注意的是 map 的遍历是无序的,也就是说每次遍历,键值对的顺序可能会不一样。如果想按顺序遍历,可以先获取所有的 Key,并对 Key 排序,然后根据排序好的 Key 获取对应的 Value。
小技巧:for range map 的时候,也可以使用一个值返回。使用一个返回值的时候,这个返回值默认是 map 的 Key。
3.4 Map的大小
和数组切片不一样,map 是没有容量的,它只有长度,也就是 map 的大小(键值对的个数)。要获取 map 的大小,使用内置的 len 函数即可
fmt.Println(len(nameAgeMap))
4. String 和 []byte
字符串 string 也是一个不可变的字节序列,所以可以直接转为字节切片 []byte
s:="Hello小明小红"
bs:=[]byte(s)
string 不止可以直接转为 []byte,还可以使用 [] 操作符获取指定索引的字节值
s:="Hello小明小红"
bs:=[]byte(s)
fmt.Println(bs)
fmt.Println(s[0],s[1],s[15])
上例中因为字符串是字节序列,每一个索引对应的是一个字节,而在 UTF8 编码下,一个汉字对应三个字节,所以字符串 s 的长度其实是 17。
运行下面的代码,就可以看到打印的结果是 17。
fmt.Println(len(s))
如果想把一个汉字当成一个长度计算,可以使用 utf8.RuneCountInString 函数。
fmt.Println(utf8.RuneCountInString(s))
而使用 for range 对字符串进行循环时,也恰好是按照 unicode 字符进行循环的,所以对于字符串 s 来说,循环了 9 次。
在下面示例的代码中,i 是索引,r 是 unicode 字符对应的 unicode 码点,这也说明了 for range 循环在处理字符串的时候,会自动地隐式解码 unicode 字符串。
for i,r:=range s{
fmt.Println(i,r)
}
五、函数和方法
在 Go 语言中,虽然存在函数和方法两个概念,但是它们基本相同,不同的是所属的对象。函数属于一个包,方法属于一个类型,所以方法也可以简单地理解为和一个类型关联的函数。
1. 函数
1.1 函数声明
格式:
func funcName(params) result {
body
}
一个函数的签名定义,它包含以下几个部分:
- 关键字 func;
- 函数名字 funcName;
- 函数的参数 params,用来定义形参的变量名和类型,可以有一个参数,也可以有多个,也可以没有;
- result 是返回的函数值,用于定义返回值的类型,如果没有返回值,省略即可,也可以有多个返回值;
- body 就是函数体,可以在这里写函数的代码逻辑。
函数中形参的定义和定义变量是一样的,都是变量名称在前,变量类型在后,只不过在函数里,变量名称叫作参数名称,也就是函数的形参,形参只能在该函数体内使用。函数形参的值由调用者提供,这个值也称为函数的实参。
一个函数示例:
func sum(a int,b int) int{
return a+b
}
如果 a 和 b 形参的类型是一样的,可以省略其中一个类型的声明
func sum(a, b int) int {
return a + b
}
像这样使用逗号分隔变量,后面统一使用 int 类型,这和变量的声明是一样的,多个相同类型的变量都可以这么声明。
1.2 多值返回
Go 语言的函数可以返回多个值,也就是多值返回。在 Go 语言的标准库中,可以看到很多这样的函数:第一个值返回函数的结果,第二个值返回函数出错的信息,这种就是多值返回的经典应用。
对于 sum 函数,假设我们不允许提供的实参是负数,可以这样改造:在实参是负数的时候,通过多值返回,返回函数的错误信息,如下面的代码所示:
func sum(a, b int) (int,error){
if a<0 || b<0 {
return 0,errors.New("a或者b不能是负数")
}
return a + b,nil
}
如果函数有多个返回值,返回值部分的类型定义需要使用小括号括起来,也就是 (int,error)。这代表函数 sum 有两个返回值,第一个是 int 类型,第二个是 error 类型,在函数体中使用 return 返回结果的时候,也要符合这个类型顺序。
提示:这里使用的 error 是 Go 语言内置的一个接口,用于表示程序的错误信息。
1.3 命名返回参数
不止函数的参数可以有变量名称,函数的返回值也可以,也就是说可以为每个返回值都起一个名字,这个名字可以像参数一样在函数体内使用。
示例:
func sum(a, b int) (sum int,err error){
if a<0 || b<0 {
return 0,errors.New("a或者b不能是负数")
}
sum=a+b
err=nil
return
}
返回值的命名和参数、变量都是一样的,名称在前,类型在后。
通过下面示例中的这种方式直接为命名返回参数赋值,也就等于函数有了返回值,所以就可以忽略 return 的返回值了,也就是说,示例中只有一个 return,return 后没有要返回的值。
sum=a+b
err=nil
虽然 Go 语言支持函数返回值命名,但是并不是太常用,根据自己的需求情况,酌情选择是否对函数返回值命名。
1.4 可变参数
同样一个函数,可以不传参数,也可以传递一个参数,也可以两个参数,也可以是多个等等,这种函数就是具有可变参数的函数。
下面是 Println 函数的声明,从中可以看到,定义可变参数,只要在参数类型前加三个点 … 即可:
func Println(a ...interface{}) (n int, err error)
示例:
func sum1(params ...int) int {
sum := 0
for _, i := range params {
sum += i
}
return sum
}
可变参数的类型其实就是切片,比如示例中 params 参数的类型是 []int,所以可以使用 for range 进行循环。
需要注意,如果你定义的函数中既有普通参数,又有可变参数,那么可变参数一定要放在参数列表的最后一个,比如 sum1(tip string,params …int) ,params 可变参数一定要放在最末尾。
1.5 包级函数
几个关键点:
-
函数名称首字母小写代表私有函数,只有在同一个包中才可以被调用;
-
函数名称首字母大写代表公有函数,不同的包也可以调用;
-
任何一个函数都会从属于一个包。
Go 语言没有用 public、private 这样的修饰符来修饰函数是公有还是私有,而是通过函数名称的大小写来代表,这样省略了烦琐的修饰符,更简洁。
1.6 匿名函数和闭包
顾名思义,匿名函数就是没有名字的函数,这是它和正常函数的主要区别。
func main() {
sum2 := func(a, b int) int {
return a + b
}
fmt.Println(sum2(1, 2))
}
上例中的 sum2 只是一个函数类型的变量,并不是函数的名字。
有了匿名函数,就可以在函数中再定义函数(函数嵌套),定义的这个匿名函数,也可以称为内部函数。更重要的是,在函数内定义的内部函数,可以使用外部函数的变量等,这种方式也称为闭包。
示例:
func main() {
cl:=colsure()
fmt.Println(cl())
fmt.Println(cl())
fmt.Println(cl())
}
func colsure() func() int {
i:=0
return func() int {
i++
return i
}
}
输出:
1
2
3
在 Go 语言中,函数也是一种类型,它也可以被用来声明函数类型的变量、参数或者作为另一个函数的返回值类型。
2. 方法
2.1 方法声明
方法必须要有一个接收者,这个接收者是一个类型,这样方法就和这个类型绑定在一起,称为这个类型的方法。
在下面的示例中,type Age uint 表示定义一个新类型 Age,该类型等价于 uint,可以理解为类型 uint 的重命名。其中 type 是 Go 语言关键字,表示定义一个类型。
type Age uint
func (age Age) String(){
fmt.Println("the age is",age)
}
和函数不同,定义方法时会在关键字 func 和方法名 String 之间加一个接收者 (age Age) ,接收者使用小括号包围。
接收者的定义和普通变量、函数参数等一样,前面是变量名,后面是接收者类型。接收者就是函数和方法的最大不同。
定义了接收者的方法后,就可以通过点操作符调用方法,如下面的代码所示:
func main() {
age:=Age(25)
age.String()
}
因为 25 也是 unit 类型,unit 类型等价于定义的 Age 类型,所以 25 可以强制转换为 Age 类型。
2.2 值类型接收者和指针类型接收者
方法的接收者除了可以是值类型,也可以是指针类型。
定义的方法的接收者类型是指针时,对指针的修改是有效的,如果不是指针,修改就没有效果,如下所示:
func (age *Age) Modify(){
*age = Age(30)
}
调用一次 Modify 方法后,再调用 String 方法查看结果,会发现已经变成了 30,说明基于指针的修改有效。
age:=Age(25)
age.String()
age.Modify()
age.String()
在调用方法的时候,传递的接收者本质上都是副本,只不过一个是这个值副本,一是指向这个值指针的副本。指针具有指向原有值的特性,所以修改了指针指向的值,也就修改了原有的值。可以简单地理解为值接收者使用的是值的副本来调用方法,而指针接收者使用实际的值来调用方法。
示例中调用指针接收者方法的时候,使用的是一个值类型的变量,并不是一个指针类型,其实这里使用指针变量调用也是可以的,如下面的代码所示:
(&age).Modify()
这就是 Go 语言编译器自动做的事情:
- 如果使用一个值类型变量调用指针类型接收者的方法,Go 语言编译器会自动取指针调用,以满足指针接收者的要求。
- 同样的原理,如果使用一个指针类型变量调用值类型接收者的方法,Go 语言编译器会自动解引用调用,以满足值类型接收者的要求。
总之,方法的调用者,既可以是值也可以是指针,Go 语言会自动转义。
不管是使用值类型接收者,还是指针类型接收者,要先确定需求:在对类型进行操作的时候是要改变当前接收者的值,还是要创建一个新值进行返回?这些就可以决定使用哪种接收者。
2.3 方法赋值变量
方法赋值给变量称为方法表达式,如下面的代码所示:
age:=Age(25)
//方法赋值给变量,方法表达式
sm:=Age.String
//通过变量,要传一个接收者进行调用也就是age
sm(age)
方法 String 其实是没有参数的,但是通过方法表达式赋值给变量 sm 后,在调用的时候,必须要传一个接收者,这样 sm 才知道怎么调用。
不管方法是否有参数,通过方法表达式调用,第一个参数必须是接收者,然后才是方法自身的参数。
如果使用已经声明的类型变量的方法赋值给一个变量,则在调用的时候无需传递接收者。
age:=Age(25)
sm:=age.String
sm()
六、struct 和 interface
结构体是对现实世界的描述,接口是对某一类行为的规范和抽象。通过它们可以实现代码的抽象和复用,同时可以面向接口编程,把具体实现细节隐藏起来,让写出来的代码更灵活,适应能力也更强。
1. 结构体
1.1 定义
结构体定义的表达式,如下面的代码所示:
type structName struct{
fieldName typeName
....
....
}
其中:
- type 和 struct 是 Go 语言的关键字,二者组合就代表要定义一个新的结构体类型。
- structName 是结构体类型的名字。
- fieldName 是结构体的字段名,而 typeName 是对应的字段类型。
- 字段可以是零个、一个或者多个。
示例:
type person struct {
name string
age uint
}
1.2 声明使用
结构体类型和普通的字符串、整型一样,也可以使用同样的方式声明和初始化。
声明了一个 person 类型的变量 p,因为没有对变量 p 初始化,所以默认会使用结构体里字段的零值。
var p person
在声明一个结构体变量的时候,也可以通过结构体字面量的方式初始化。
p:=person{"小明",30}
在 Go 语言中,访问一个结构体的字段和调用一个类型的方法一样,都是使用点操作符“.”。
采用字面量初始化结构体时,初始化值的顺序很重要,必须和字段定义的顺序一致。
如果不按照顺序初始化,则需要指出字段名称,如下所示:
p:=person{age:30,name:"小明"}
这种方式和 map 类型的初始化很像,都是采用冒号分隔。Go 语言尽可能地重用操作,不发明新的表达式,便于记忆和使用。
也可以只初始化部分字段,其余字段会自动使用默认的零值。
1.3 字段结构体
结构体的字段可以是任意类型,也包括自定义的结构体类型,比如下面的代码:
type person struct {
name string
age uint
addr address
}
type address struct {
province string
city string
}
对于嵌套结构体字段的结构体,其初始化和正常的结构体大同小异,只需要根据字段对应的类型初始化即可,如下面的代码所示:
p:=person{
age:30,
name:"飞雪无情",
addr:address{
province: "北京",
city: "北京",
},
}
如果需要访问结构体最里层的字段的值,同样也可以使用点操作符,只不过需要使用多个点。
2. 接口
2.1 定义
接口的定义和结构体稍微有些差别,虽然都以 type 关键字开始,但接口的关键字是 interface,表示自定义的类型是一个接口。也就是说 Stringer 是一个接口,它有一个方法 String() string,整体如下面的代码所示:
type Stringer interface {
String() string
}
Stringer 是 Go SDK 的一个接口,属于 fmt 包。
针对 Stringer 接口来说,它会告诉调用者可以通过它的 String() 方法获取一个字符串,这就是接口的约定。至于这个字符串怎么获得的,长什么样,接口不关心,调用者也不用关心,因为这些是由接口实现者来做的。
2.2 接口实现
接口的实现者必须是一个具体的类型,以 person 结构体为例,让它来实现 Stringer 接口,如下代码所示:
func (p person) String() string{
return fmt.Sprintf("the name is %s,age is %d",p.name,p.age)
}
给结构体类型 person 定义一个方法,这个方法和接口里方法的签名(名称、参数和返回值)一样,这样结构体 person 就实现了 Stringer 接口。
注意:如果一个接口有多个方法,那么需要实现接口的每个方法才算是实现了这个接口。
实现接口后就可以使用了。定义一个可以打印 Stringer 接口的函数,如下所示:
func printString(s fmt.Stringer){
fmt.Println(s.String())
}
函数 printString 接收一个 Stringer 接口类型的参数,然后打印出 Stringer 接口的 String 方法返回的字符串。它的优势就在于它是面向接口编程的,只要一个类型实现了 Stringer 接口,都可以打印出对应的字符串,而不用管具体的类型实现。
person 实现了 Stringer 接口,所以变量 p 可以作为函数 printString 的参数。
printString(p)
面向接口的好处是,只要定义和调用双方满足约定,就可以使用,而不用管具体实现。接口的实现者也可以更好的升级重构,而不会有任何影响,因为接口约定没有变。
2.3 值接收者和指针接收者
定义一个方法,有值类型接收者和指针类型接收者两种。二者都可以调用方法,因为 Go 语言编译器自动做了转换,所以值类型接收者和指针类型接收者是等价的。但是在接口的实现中,值类型接收者和指针类型接收者不一样。
printString(&p)
上述代码编译运行都正常。这就证明了以值类型接收者实现接口的时候,不管是类型本身,还是该类型的指针类型,都实现了该接口。
示例中值接收者(p person)实现了 Stringer 接口,那么类型 person 和它的指针类型*person就都实现了 Stringer 接口。
如果在方法中把接收者改成指针类型,如下代码所示:
func (p *person) String() string{
return fmt.Sprintf("the name is %s,age is %d",p.name,p.age)
}
代码编译会不通过,提示如下错误:
./main.go:17:13: cannot use p (type person) as type fmt.Stringer in argument to printString:
person does not implement fmt.Stringer (String method has pointer receiver)
意思就是类型 person 没有实现 Stringer 接口。这就证明了以指针类型接收者实现接口的时候,只有对应的指针类型才被认为实现了该接口。
两种接收者类型的接口实现规则对比:
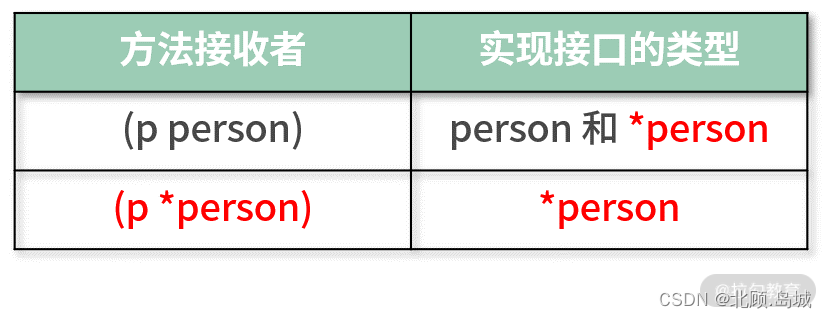
- 当值类型作为接收者时,person 类型和*person类型都实现了该接口。
- 当指针类型作为接收者时,只有*person类型实现了该接口。
3. 工厂函数
3.1 创建自定义结构体
工厂函数一般用于创建自定义的结构体,便于使用者调用。以 person 类型为例,用如下代码进行定义:
func NewPerson(name string) *person {
return &person{name:name}
}
通过工厂函数创建自定义结构体的方式,可以让调用者不用太关注结构体内部的字段,只需要给工厂函数传参就可以了。
用下面的代码,即可创建一个*person 类型的变量 p1:
p1:=NewPerson("张三")
3.2 创建接口
工厂函数也可以用来创建一个接口,它的好处就是可以隐藏内部具体类型的实现,让调用者只需关注接口的使用即可。
以 errors.New 这个 Go 语言自带的工厂函数为例,演示如何通过工厂函数创建一个接口,并隐藏其内部实现,如下代码所示:
//工厂函数,返回一个error接口,其实具体实现是*errorString
func New(text string) error {
return &errorString{text}
}
//结构体,内部一个字段s,存储错误信息
type errorString struct {
s string
}
//用于实现error接口
func (e *errorString) Error() string {
return e.s
}
其中,errorString 是一个结构体类型,它实现了 error 接口,所以可以通过 New 工厂函数,创建一个 *errorString 类型,通过接口 error 返回。
面向接口的编程,假设重构代码,哪怕换一个其他结构体实现 error 接口,对调用者也没有影响,因为接口没变。
4. 继承和组合
在 Go 语言中没有继承的概念,所以结构、接口之间也没有父子关系,Go 语言提倡的是组合,利用组合达到代码复用的目的,这也更灵活。
以 Go 语言 io 标准包自带的接口为例讲解类型的组合(也可以称之为嵌套),如下代码所示:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
//ReadWriter是Reader和Writer的组合
type ReadWriter interface {
Reader
Writer
}
ReadWriter 接口就是 Reader 和 Writer 的组合,组合后,ReadWriter 接口具有 Reader 和 Writer 中的所有方法,这样新接口 ReadWriter 就不用定义自己的方法了。
不止接口可以组合,结构体也可以组合,现在把 address 结构体组合到结构体 person 中,而不是当成一个字段,如下所示:
type person struct {
name string
age uint
address
}
直接把结构体类型放进来,就是组合,不需要字段名。组合后,被组合的 address 称为内部类型,person 称为外部类型。修改了 person 结构体后,声明和使用也需要一起修改,如下所示:
p:=person{
age:30,
name:"飞雪无情",
address:address{
province: "北京",
city: "北京",
},
}
//像使用自己的字段一样,直接使用
fmt.Println(p.province)
类型组合后,外部类型不仅可以使用内部类型的字段,也可以使用内部类型的方法,就像使用自己的方法一样。如果外部类型定义了和内部类型同样的方法,那么外部类型的会覆盖内部类型,这就是方法的覆写。
方法覆写不会影响内部类型的方法实现。
5. 类型断言
类型断言用来判断一个接口的值是否是实现该接口的某个具体类型中的所有方法。
语法格式如下:
value, ok := x.(T)
其中,x 表示一个接口的类型,T 表示一个具体的类型(也可为接口类型)。
如果检查成功,类型断言返回的结果是 x 的动态值,其类型是 T。
示例:
func (p *person) String() string{
return fmt.Sprintf("the name is %s,age is %d",p.name,p.age)
}
func (addr address) String() string{
return fmt.Sprintf("the addr is %s%s",addr.province,addr.city)
}
*person 和 address 都实现了接口 Stringer,可以进行如下类型断言调用:
var s fmt.Stringer
s = p1
p2:=s.(*person)
fmt.Println(p2)
如上所示,接口变量 s 称为接口 fmt.Stringer 的值,它被*person类型的变量 p1 赋值。然后使用类型断言表达式 s.(*person),尝试返回一个*person类型变量 p2。如果接口的值 s 是一个*person,那么类型断言正确,可以正常返回 p2。如果接口的值 s 不是一个 *person,那么在运行时就会抛出异常,程序终止运行。
这里返回的 p2 已经是 *person 类型了,也就是在类型断言的时候,同时完成了类型转换。
如果对 s 进行 address 类型断言,就会出现一些问题:
a:=s.(address)
fmt.Println(a)
这个代码在编译的时候不会有问题,因为 address 实现了接口 Stringer,但是在运行的时候,会抛出如下异常信息:
panic: interface conversion: fmt.Stringer is *main.person, not main.address
Go 语言也为我们提供了类型断言的多值返回,如下所示:
a,ok:=s.(address)
if ok {
fmt.Println(a)
}else {
fmt.Println("s不是一个address")
}
类型断言返回的第二个值“ok”就是断言是否成功的标志,如果为 true 则成功,否则失败。
七、错误处理
在 error、panic 这两种错误机制中,Go 语言更提倡 error 这种轻量错误,而不是 panic。
1. 错误(error)
在 Go 语言中,错误是可以预期的,并且不是非常严重,不会影响程序的运行。对于这类问题,可以用返回错误给调用者的方法,让调用者自己决定如何处理。
1.1 error 接口
在 Go 语言中,错误是通过内置的 error 接口表示的。它非常简单,只有一个 Error 方法用来返回具体的错误信息。
type error interface {
Error() string
}
以函数 strconv.Atoi 的定义为例:
func Atoi(s string) (int, error)
一般而言,error 接口用于当方法或者函数执行遇到错误时进行返回,而且是第二个返回值。通过这种方式,可以让调用者自己根据错误信息决定如何进行下一步处理。
1.2 error工厂函数
自己定义的函数也可以返回错误信息给调用者,如下面的代码所示:
func add(a,b int) (int,error){
if a<0 || b<0 {
return 0,errors.New("a或者b不能为负数")
}else {
return a+b,nil
}
}
调用者可以通过错误信息是否为 nil 进行判断。
errors.New 就是errors包提供的创建符合error接口错误对象的工厂函数,它接收一个字符串参数,返回一个 error 接口对象。
1.3 自定义 error
在错误信息中如果想要携带更多信息(比如错误码信息),就需要自定义 error 。
自定义 error 其实就是先自定义一个新类型,比如结构体,然后让这个类型实现 error 接口,如下面的代码所示:
type commonError struct {
errorCode int //错误码
errorMsg string //错误信息
}
func (ce *commonError) Error() string{
return ce.errorMsg
}
改造上面的例子,返回刚刚自定义的 commonError,如下所示:
return 0, &commonError{
errorCode: 1,
errorMsg: "a或者b不能为负数"}
上例通过字面量的方式创建一个 *commonError 返回。
1.4 error 断言
使用自定义的 error,需要先把返回的 error 接口转换为自定义的错误类型,使用的是类型断言。
下面代码中的 err.(*commonError) 就是类型断言在 error 接口上的应用,也可以称为 error 断言。
sum, err := add(-1, 2)
if cm,ok:=err.(*commonError);ok{
fmt.Println("错误代码为:",cm.errorCode,",错误信息为:",cm.errorMsg)
} else {
fmt.Println(sum)
}
如果返回的 ok 为 true,说明 error 断言成功,正确返回了 *commonError 类型的变量 cm,所以就可以像示例中一样使用变量 cm 的 errorCode 和 errorMsg 字段信息了。
2. error错误嵌套
在 Go 语言提供的 Error Wrapping 能力下,我们写的代码要尽可能地使用 Is、As 这些函数做判断和转换。
2.1 Error Wrapping
假如有这样的需求:基于一个存在的 error 再生成一个 error,就需要错误嵌套。比如调用一个函数,返回了一个错误信息 error,在不想丢失这个 error 的情况下,又想添加一些额外信息返回新的 error。
这种场景可以自定义一个 struct,实现 error 接口,然后在初始化 MyError 的时候传递存在的 error 和新的错误信息。
type MyError struct {
err error
msg string
}
func (e *MyError) Error() string {
return e.err.Error() + e.msg
}
func main() {
//err是一个存在的错误,可以从另外一个函数返回
newErr := MyError{err, "数据上传问题"}
}
这个结构体有两个字段,其中 error 类型的 err 字段用于存放已存在的 error,string 类型的 msg 字段用于存放新的错误信息,这种方式就是 error 的嵌套。这种方式可以满足我们的需求,但是非常烦琐。
从 Go 语言 1.13 版本开始,Go 标准库新增了 Error Wrapping 功能,让我们可以基于一个存在的 error 生成新的 error,并且可以保留原 error 信息,如下面的代码所示:
e := errors.New("原始错误e")
w := fmt.Errorf("Wrap了一个错误:%w", e)
fmt.Println(w)
Go 语言没有提供 Wrap 函数,而是扩展了 fmt.Errorf 函数,然后加了一个 %w,通过这种方式,便可以生成 wrapping error。
2.2 errors.Unwrap 函数
Go 语言提供了 errors.Unwrap 用于获取被嵌套的 error,比如以上例子中的错误变量 w ,就可以对它进行 unwrap,获取被嵌套的原始错误 e。
fmt.Println(errors.Unwrap(w))
输出:
原始错误e
2.3 errors.Is 函数
有了 Error Wrapping 后,原来判断两个 error 是不是同一个 error 的方法失效了,比如 Go 语言标准库经常用到的如下代码中的方式:
if err == os.ErrExist
上述情况是由于 Go 语言的 Error Wrapping 功能,令人不知道返回的 err 是否被嵌套,又嵌套了几层。Go 语言为我们提供了 errors.Is 函数,用来判断两个 error 是否是同一个,如下所示:
func Is(err, target error) bool
说明:
- 如果 err 和 target 是同一个,那么返回 true。
- 如果 err 是一个 wrapping error,target 也包含在这个嵌套 error 链中的话,也返回 true。
总结就是两个 error 相等或 err 包含 target 的情况下返回 true,其余返回 false。
可以用上面的示例判断错误 w 中是否包含错误 e:
fmt.Println(errors.Is(w,e))
2.4 errors.As 函数
有了 error 嵌套后,error 断言也不能用了,因为不知道一个 error 是否被嵌套,又嵌套了几层。所以 Go 语言为解决这个问题提供了 errors.As 函数。
var cm *commonError
if errors.As(err,&cm){
fmt.Println("错误代码为:",cm.errorCode,",错误信息为:",cm.errorMsg)
} else {
fmt.Println(sum)
}
errors.As() 函数的主要功能就是用于从一个错误链中查找特定类型的错误,并将其赋值给目标变量。
2. Deferred 函数
defer函数是golang语言中的一种特殊函数,它可以在函数执行结束后执行一些操作,本质上是一种延迟执行机制。
下面的代码是 Go 语言标准包 ioutil 中的 ReadFile 函数,它需要打开一个文件,然后通过 defer 关键字确保在 ReadFile 函数执行结束后,f.Close() 方法被执行,这样文件的资源才一定会释放。
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.Close()
//省略无关代码
return readAll(f, n)
}
defer 关键字用于修饰一个函数或者方法,使得该函数或者方法在返回前才会执行,也就说被延迟,但又可以保证一定会执行。
以上面的 ReadFile 函数为例,被 defer 修饰的 f.Close 方法延迟执行,也就是说会先执行 readAll(f, n),然后在整个 ReadFile 函数 return 之前执行 f.Close 方法。
defer 语句常被用于成对的操作,如文件的打开和关闭,加锁和释放锁,连接的建立和断开等。不管多么复杂的操作,都可以保证资源被正确地释放。
两个关键点:
- 在一个方法或者函数中,可以有多个 defer 语句;
- 多个 defer 语句的执行顺序依照后进先出的原则。
示例:
func moreDefer(){
defer fmt.Println("First defer")
defer fmt.Println("Second defer")
defer fmt.Println("Three defer")
fmt.Println("函数自身代码")
}
func main(){
moreDefer()
}
输出:
函数自身代码
Three defer
Second defer
First defer
defer 有一个调用栈,越早定义越靠近栈的底部,越晚定义越靠近栈的顶部,在执行这些 defer 语句的时候,会先从栈顶弹出一个 defer 然后执行它。
3. Panic 异常
3.1 定义
Go 语言是一门静态的强类型语言,很多问题都尽可能地在编译时捕获,但是有一些只能在运行时检查,比如数组越界访问、不相同的类型强制转换等,这类运行时的问题会引起 panic 异常。
除了运行时可以产生 panic 外,也可以主动抛出 panic 异常。panic 是 Go 语言内置的函数,可以接受 interface{} 类型的参数,也就是任何类型的值都可以传递给 panic 函数,如下所示:
func panic(v interface{})
interface{} 是空接口的意思,在 Go 语言中代表任意类型。
panic 异常是一种非常严重的情况,会让程序中断运行,使程序崩溃,所以如果是不影响程序运行的错误,不要使用 panic,使用普通错误 error 即可。
3.2 Recover 捕获 Panic 异常
通常情况下,不需要对 panic 异常做任何处理,因为既然它是影响程序运行的异常,就让它直接崩溃即可。但是也的确有一些特例,比如在程序崩溃前做一些资源释放的处理,这时候就需要从 panic 异常中恢复,才能完成处理。
在 Go 语言中,可以通过内置的 recover 函数恢复 panic 异常。因为在程序 panic 异常崩溃的时候,只有被 defer 修饰的函数才能被执行,所以 recover 函数要结合 defer 关键字使用才能生效。
recover函数只有在defer函数中调用才有效
示例:
func recoverFunc() {
if r := recover(); r != nil {
// 处理panic异常
// ...
}
}
func exampleFunc() {
defer recoverFunc()
// 可能会引发panic异常的代码
// ...
}
recover 函数返回的值就是通过 panic 函数传递的参数值。