目录
前言
一、list 类型
1.1、操作命令
lpush / rpush(插入元素)
lrange(查看范围元素)
lpushx / rpushx (有约束的插入)
lpop / rpop(头删尾删)
lindex(获取下标元素)
llen(长度)
lrem(删除指定元素)
ltrim(保留区间)
lset (根据下标修改元素)
blpop / brpop(阻塞删除)
1.2、内部编码方式
1.3、使用场景
表示多表之间的关联关系
一般消息对列
频道(多列表)消息队列
微博列表
前言
redis 中所有的 key 都是字符串,value 的类型是存在差异的,因此出现了操控不同 value 的命令,接下来,就一起来学习一下吧~
Ps1:接下来,我给出的指令都是按照 Redis 官方文档的语法格式来解析的,[ ] 相当于一个独立的单元,表示可选项(可有可无),其中 | 表示 “或者” 的意思,多个只能出现一个,[ ] 和 [ ] 之间是可以同时存在的.
Ps2:一个快速失去年终奖的小技巧 —— 清除 redis 上所有的数据 =》 FLUSHALL,这个操作可以把 redis 上所有的键值对全部带走.
一、list 类型
1.1、操作命令

list 的内部结构类似于 “双端队列”(deque),元素是有序的,并且允许元素重复,因此头插和尾插的效率很高,可以当作一个 栈 / 队列 来使用,约定最左侧元素下标是 0,并且是是支持负数下标.
Redis 早期作为消息队列就是通过 List 来实现的,后面又提供了一种 stream 这种功能更加强大的类型来实现.
Ps:"有序" 的含义一定要根据上下文来区分,有的时候谈到有序指的是 “升序” 和 “降序” ,有的时候,指的是顺序很关键(如果把元素位置颠倒,顺序调换,那么新的 list 和之前的 list 是不对等的)~
就像面试的时候问你谈谈对 “栈 / 堆” 的理解,那么一定不要一上来就回答,而是要问清楚,到底是问数据结构中的,还是操作系统中的,还是 JVM 中.
lpush / rpush(插入元素)
lpush 和 rpush 都是用来插入元素的,分别是从左右两侧插入元素,一次可以一个或多个,例如插入 1 2 3 4 ,按照顺序使用 lpush 插入,插入完毕后,4 就是开头元素.(时间复杂度 O(1))
LPUSH key element [element ...]
lrange(查看范围元素)
查看 list 中指定范围的元素,区间为 闭区间(Redis 中的区间都是 闭区间),同样支持负数下标.
LRANGE key start stop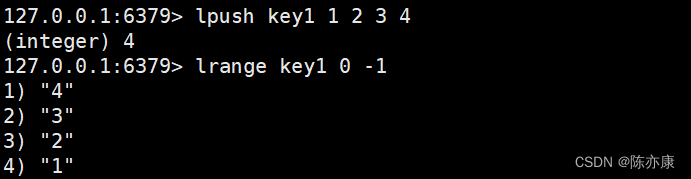
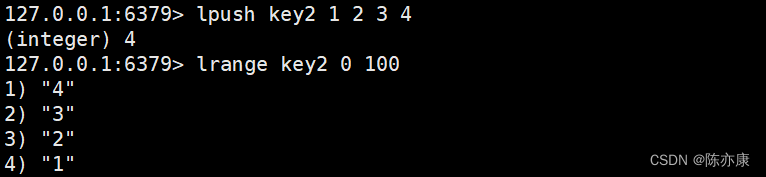
Ps:Redis 中使用 lrange 如果下标超出范围,不会像 java 那样抛出异常,而是尽可能的获取到对应内容(有多少获取多少,超出的不管)
lpushx / rpushx (有约束的插入)
lpushx 表示有约束的从左侧插入一个或多个元素,只有当 key 存在时,才能将元素插入成功,不存在则插入失败,返回值为插入元素的个数(返回 0 表示插入失败).
rpushx 与 lpushx 同理,rpushx 只是从右侧插入元素.
LPUSHX key element [element ...]
lpop / rpop(头删尾删)
lpop 表示从最左侧删除一个元素.
rpop 同理,从右侧删除一个元素.
LPOP keyPs:在 redis 6.2 之后新增了一个 count 参数, count 就描述了这次要删除的元素个数.

Ps:Redis 中 list 是一个双端队列,从两头插入 / 删除元素 都是非常高效的,因此
搭配使用 rpush 和 lpop ,就相当于队列.
搭配使用 rpush 和 rpop ,就相当于栈.
lindex(获取下标元素)
获取给定下标的对应元素,时间复杂度为 O(N),此处的 N 指的是 list 中元素个数.
LINDEX key index
Ps:如果下标非法,返回 nil.
llen(长度)
获取 list 元素个数.
LLEN key
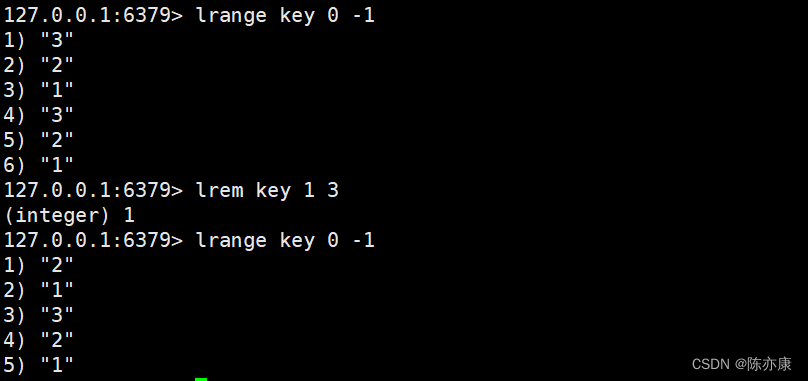
lrem(删除指定元素)
用来删除指定元素,并可以根据 count 来指定删除元素(element)的个数(list 中允许出现重复元素).
LREM key count element当 count > 0 时,从最左侧删除元素 count 个 element 的元素
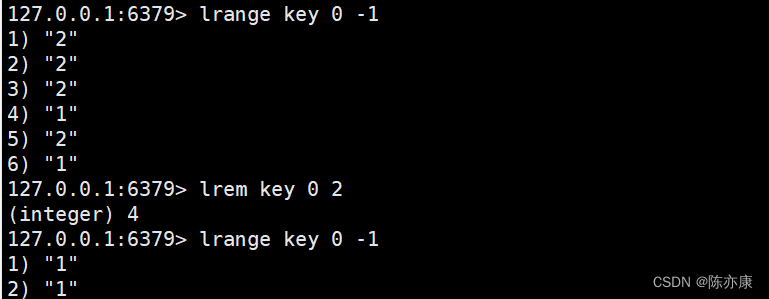
当 count < 0 时,从最右侧删除元素 count 个 element 的元素

当 count = 0 时,删除所有的 element 元素.
ltrim(保留区间)
LTRIM key start stop保留 start 到 stop 之间的元素(闭区间,并且删除 闭区间 之外的所有元素)

Redis 的官方文档中还给出了访问控制列表(redis 6 及以上版本支持),acl 就是给每一个命令都打上标签,这样管理员就可以给每一个 redis 用户配置不同的权限(允许该用户可以执行哪些命令).这不是一个知识点,只是用到的时候查一下配置怎么写.

lset (根据下标修改元素)
用来根据指定下标修改元素,处理的时间复杂度为 O(N).
LSET key index element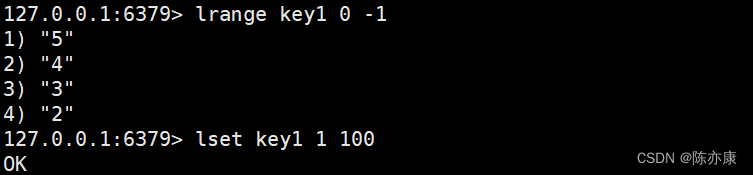
Ps:这里不会像 lindex 那样下标越界能很好的处理,lset 下标越界就会报错.

blpop / brpop(阻塞删除)
这类似于阻塞队列(BlockingQueue)实现生产者消费者模型,阻塞就表示当前的线程不再往后执行了,满足一定条件以后才被唤醒.
在 redis 中的 list 只支持 "队列为空" 的情况,不考虑 "队列满",具体规则如下:
- 如果 list 中 存在元素, blpop 和 brpop 就和 lpop 以及 rpop 作用完全相同.
- 如果 list 中为空,blpop 和 brpop 就会产生阻塞,一直阻塞到队列不为空为止.
- 可以显式设置阻塞时间,并且阻塞期间可以执行其他命令(阻塞期间并不会对 redis 服务器产生负面影响).
- 命令中若设置了多个键,那么会从左向右进行遍历,一旦有一个键对应列表中可以弹出的元素,命令立即返回.
- 如果有多个客户端同时执行 blpop,则先执行命令的客户端得到弹出的元素((这就像是有一个女神,但是有多个屌丝去追,当女神有空了以后,哪个先约的,哪个人就能先约到女神).
blpop 和 brpop 两个阻塞命令,主要用途就是用来做 "消息队列",但是这两命令的功能还是比较有限的(实现消息队列我们一般不用 redis).
BLPOP key [key ...] timeoutPs:此处的超时时间,单位是 秒(redis 5), redis 6 超时时间允许设置成小数.
1.针对一个空队列进行操作,就阻塞住了~
2.再开启一个 redis 客户端,向 key1 中再塞一个元素阻塞就解除了.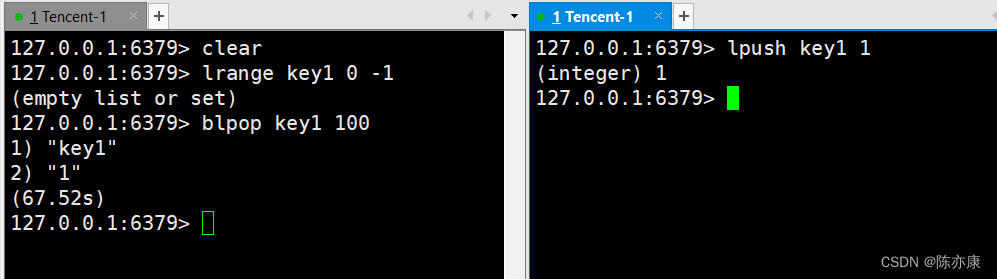
针对多个 key 进行操作,哪个 key 先放入元素,就取哪个~
1.2、内部编码方式
在 redis 早期的版本中,有以下两种编码方式:
- linkedlist:双向链表,当一个 list 包含了数量比较多的元素,又或者 list 中包含的元素都是比较长的字符串时,Redis就会使用 linkedlist 作为 list 的底层实现。
- ziplist:压缩列表,当哈希表里的元素比较少的时候,就优化成了 ziplist 了,能够节省空间(压缩的原因:redis 上有很多 key,可能某些 key 的 value 是 hash,此时如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不是特别大的情况下,就尽量去压缩,让整体占用内存更小了);
现在的 redis 中 list 内部编码为 quicklist,包含了以上两种编码方式的有优点.
quick 相当于是 链表 和 压缩列表 的结合,整体还是一个双向链表,链表的每一个节点是一个压缩列表(控制链表每个节点不能过大).
之前的 list-max-ziplist-entries 配置 和 list-max-ziplist-value 都不在使用了,现在使用的配置是 list-max-ziplist-size .
1.3、使用场景
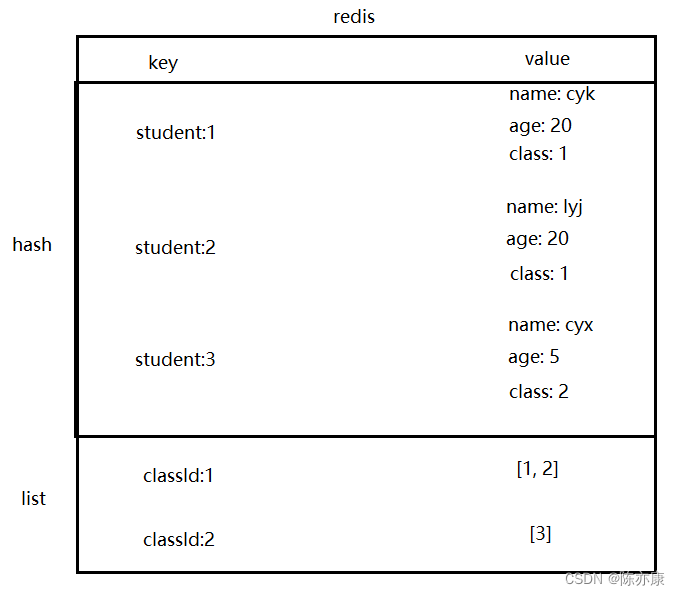
表示多表之间的关联关系
可以将 list 作为 "数组" 这样的结构来存储多个元素,例如现在有学生和班级两张表,使用 hash + list 的方式就可以将 学生和班级信息关联起来.
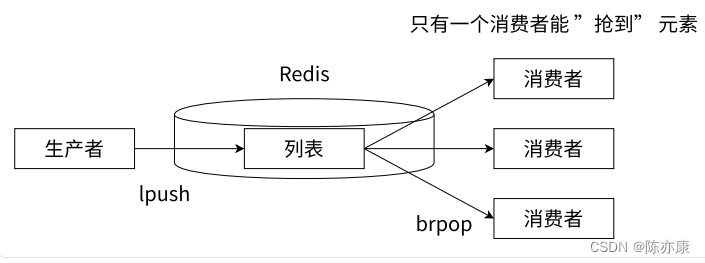
一般消息对列
通过 blpop / brpop 就可以实现生产者消费者模型.
当有多个消费者时,谁先执行 brpop 命令,谁就能先拿到元素,像这样的设定,就能构成一个 “轮询” 的效果~
假设消费者执行顺序执行的顺序是1、2、3,当新的元素到来的时候,消费者1 就可以先拿到元素,之后 消费者1 还想继续消费,就需要重新执行 brpop ,执行后就意味 消费者1 的执行顺序被排到了最后,之后每个消费者都依次轮询...
频道(多列表)消息队列
多列表这种场景也是很常见的,例如抖音这个软件,一个通道来了可以传输短视频、另一个通道来了,可以传输弹幕、还有...这样多个通道就实现了解耦操作,互不干扰.

微博列表
每个用户都有属于⾃⼰的 Timeline(微博列表),现需要分页展示列表。此时可以考虑使用 列表,因为列表不但是有序的,同时⽀持按照索引范围获取元素。
分页获取用户用户前 10 个文章伪代码,如下:
keylist = lrange user:1:mblogs 0 9
for key in keylist {
hgetall key
}每一页有多少数据是不确定的,有可能触发很多 hgetall 操作,导致过多的网路请求
正确的解决办法就是分流水线去做,假设某个用户发了 1w 个微博,长度就是 1w ,我们就可以把中 1w 数据拆成 10 份,每个就是 1k .