文章目录
- 27 Deep Belief Network——深度信念网络
- 27.1 DBN是什么?
- 27.2 为什么要使用DBN
- 27.2.1 DBN的思想是怎么来的?
- 27.2.2 RBM的叠加可以提高ELBO
- 27.3 训练方式
27 Deep Belief Network——深度信念网络
27.1 DBN是什么?
DBN(Deep Belief Network)是由RBM(Restricted Boltzmann Machine)和SBN(Sigmoid Belief Network)两层结构所组成,其图形可以画成如下形式:
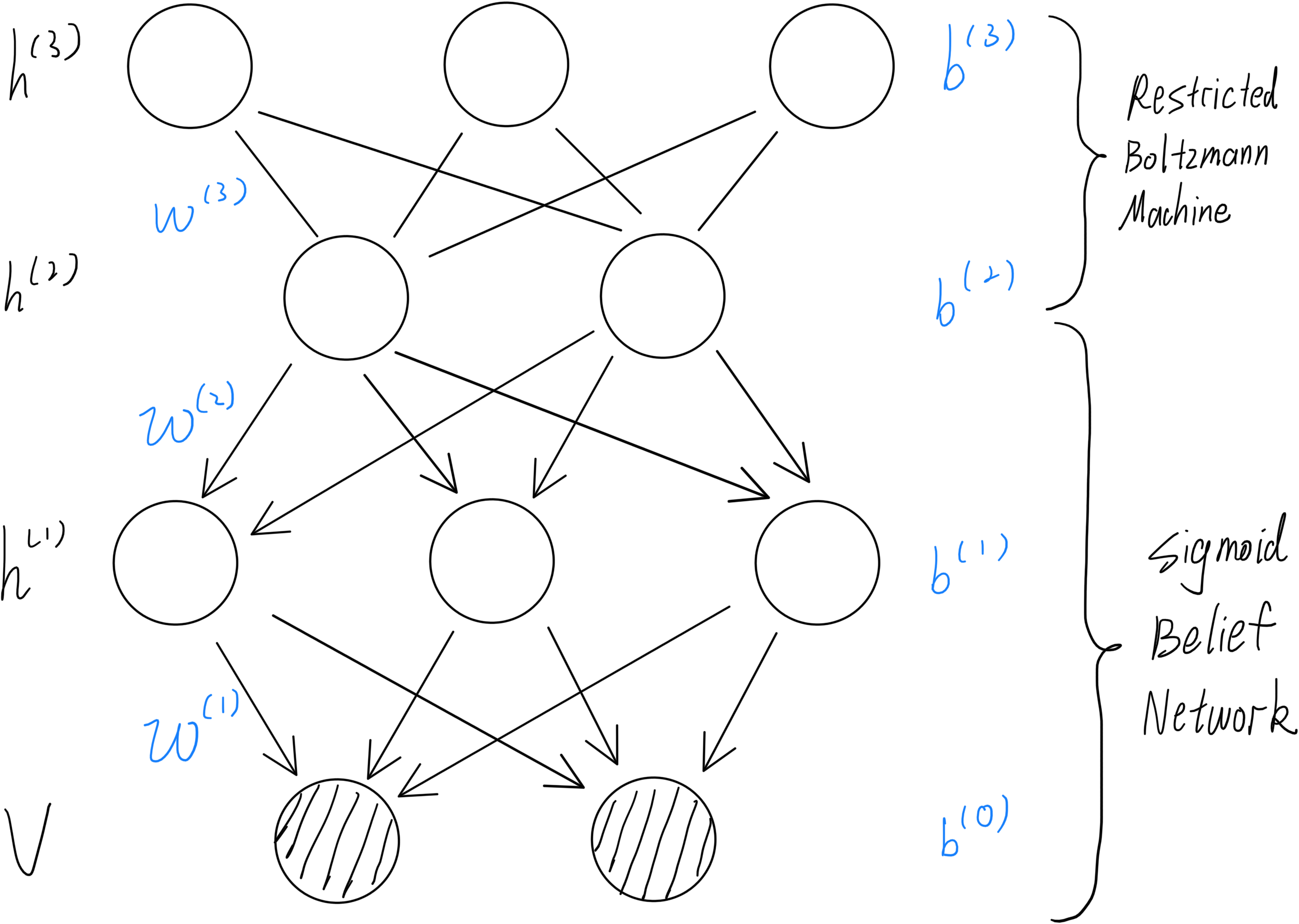
根据其图性质、节点的关联性及分层相互独立的性质,我们可以将联合概率写出来:
P
(
V
,
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
=
P
(
V
∣
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
⋅
P
(
h
(
1
)
,
h
(
2
)
,
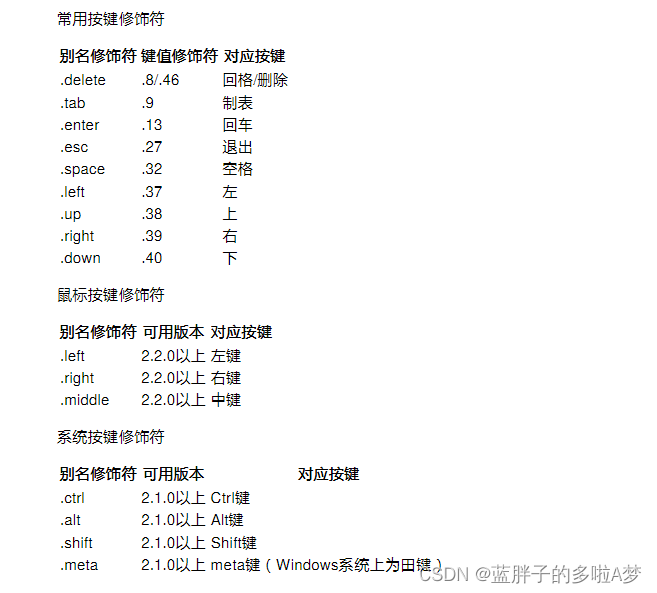
h
(
3
)
)
=
P
(
V
∣
h
(
1
)
)
⋅
P
(
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
=
P
(
V
∣
h
(
1
)
)
⋅
P
(
h
(
1
)
∣
h
(
2
)
)
⋅
P
(
h
(
2
)
,
h
(
3
)
)
=
∑
i
P
(
v
∣
h
(
1
)
)
⋅
∑
j
P
(
h
j
(
1
)
∣
h
(
2
)
)
⋅
P
(
h
(
2
)
,
h
(
3
)
)
\begin{align} P(V, h^{(1)}, h^{(2)}, h^{(3)}) &= P(V| h^{(1)}, h^{(2)}, h^{(3)}) \cdot P(h^{(1)}, h^{(2)}, h^{(3)}) \\ &= P(V| h^{(1)}) \cdot P(h^{(1)}, h^{(2)}, h^{(3)}) \\ &= P(V| h^{(1)}) \cdot P(h^{(1)}| h^{(2)}) \cdot P(h^{(2)}, h^{(3)}) \\ &= \sum_i P(v| h^{(1)}) \cdot \sum_j P(h_j^{(1)}| h^{(2)}) \cdot P(h^{(2)}, h^{(3)}) \\ \end{align}
P(V,h(1),h(2),h(3))=P(V∣h(1),h(2),h(3))⋅P(h(1),h(2),h(3))=P(V∣h(1))⋅P(h(1),h(2),h(3))=P(V∣h(1))⋅P(h(1)∣h(2))⋅P(h(2),h(3))=i∑P(v∣h(1))⋅j∑P(hj(1)∣h(2))⋅P(h(2),h(3))
根据SBN的性质我们可以得到:
- P ( v ∣ h ( 1 ) ) = s i g m o i d ( w : , i ( 1 ) T ⋅ h ( 1 ) + b i ( 0 ) ) P(v| h^{(1)}) = sigmoid({w_{:,i}^{(1)}}^T \cdot h^{(1)} + b_i^{(0)}) P(v∣h(1))=sigmoid(w:,i(1)T⋅h(1)+bi(0))
- P ( h j ( 1 ) ∣ h ( 2 ) ) = s i g m o i d ( w : , j ( 2 ) T ⋅ h ( 2 ) + b j ( 1 ) ) P(h_j^{(1)}| h^{(2)}) = sigmoid({w_{:,j}^{(2)}}^T \cdot h^{(2)} + b_j^{(1)}) P(hj(1)∣h(2))=sigmoid(w:,j(2)T⋅h(2)+bj(1))
根据RBM的性质我们可以得到:
- P ( h ( 2 ) , h ( 3 ) ) = 1 Z exp { h ( 3 ) T w ( 3 ) h ( 2 ) + h ( 2 ) T b ( 2 ) + h ( 3 ) T b ( 3 ) } P(h^{(2)}, h^{(3)}) = \frac{1}{Z} \exp{\lbrace {h^{(3)}}^T w^{(3)} h^{(2)} + {h^{(2)}}^T b^{(2)} + {h^{(3)}}^T b^{(3)} \rbrace} P(h(2),h(3))=Z1exp{h(3)Tw(3)h(2)+h(2)Tb(2)+h(3)Tb(3)}
通过以上内容我们就可以得到一个DBN的联合概率公式
27.2 为什么要使用DBN
27.2.1 DBN的思想是怎么来的?
DBN是在RBM的基础上叠加而来,一个基础的RBM应该是如下结构:

我们用该结构求解
P
(
V
)
P(V)
P(V)会通过引入
h
(
1
)
h^{(1)}
h(1)的方法,再用修正的Gibbs采样的方法(CD-k)进行求解,可以得到:
P
(
V
)
=
∑
h
(
1
)
P
(
h
(
1
)
)
⏟
p
r
i
o
r
P
(
V
∣
h
(
1
)
)
⏟
f
i
x
e
d
P(V) = \sum_{h^{(1)}} \underbrace{P(h^{(1)})}_{prior} \underbrace{P(V|h^{(1)})}_{fixed}
P(V)=h(1)∑prior
P(h(1))fixed
P(V∣h(1))
其中我们可以将其中的
P
(
V
∣
h
(
1
)
)
P(V|h^{(1)})
P(V∣h(1))固定住,并添加一层RBM用于提高prior(提高的原理再下一节),如下图所示:

原先最下层的无向图变为有向图是因为我们的条件是固定住 P ( V ∣ h ( 1 ) ) P(V|h^{(1)}) P(V∣h(1)),所以去掉了从 V V V到 h ( 1 ) h^{(1)} h(1)的方向,如此我们可以叠加很多层。
27.2.2 RBM的叠加可以提高ELBO
如果我们想要将结果的精度再进行提升,我们肯定要将
log
P
(
V
)
\log P(V)
logP(V)中的一部分提高,则我们可以写出的
log
P
(
V
)
\log P(V)
logP(V)ELBO:
log
P
(
v
)
=
log
∑
h
(
1
)
P
(
V
,
h
(
1
)
)
=
log
∑
h
(
1
)
q
(
h
(
1
)
∣
V
)
P
(
V
,
h
(
1
)
)
q
(
h
(
1
)
∣
V
)
=
log
E
q
(
h
(
1
)
∣
V
)
[
P
(
V
,
h
(
1
)
)
q
(
h
(
1
)
∣
V
)
]
≥
E
q
(
h
(
1
)
∣
V
)
[
log
P
(
V
,
h
(
1
)
)
q
(
h
(
1
)
∣
V
)
]
=
E
q
(
h
(
1
)
∣
V
)
[
log
P
(
h
(
1
)
)
⏟
重新建模
+
log
P
(
V
∣
h
(
1
)
)
⏟
可以通过
w
1
求解
−
log
q
(
h
(
1
)
∣
V
)
⏟
固定
]
\begin{align} \log P(v) &= \log \sum_{h^{(1)}} P(V, h^{(1)}) \\ &= \log \sum_{h^{(1)}} q(h^{(1)} | V) \frac{P(V, h^{(1)})}{q(h^{(1)} | V)} \\ &= \log E_{q(h^{(1)} | V)} \left[ \frac{P(V, h^{(1)})}{q(h^{(1)} | V)} \right] \\ &\geq E_{q(h^{(1)} | V)} \left[ \log \frac{P(V, h^{(1)})}{q(h^{(1)} | V)} \right] \\ &= E_{q(h^{(1)} | V)} \left[ \underbrace{\log P(h^{(1)})}_{重新建模} + \underbrace{\log P(V | h^{(1)})}_{可以通过w_1求解} - \underbrace{\log q(h^{(1)} | V)}_{固定} \right] \\ \end{align}
logP(v)=logh(1)∑P(V,h(1))=logh(1)∑q(h(1)∣V)q(h(1)∣V)P(V,h(1))=logEq(h(1)∣V)[q(h(1)∣V)P(V,h(1))]≥Eq(h(1)∣V)[logq(h(1)∣V)P(V,h(1))]=Eq(h(1)∣V)
重新建模
logP(h(1))+可以通过w1求解
logP(V∣h(1))−固定
logq(h(1)∣V)
根据(以上变换)+(上文所说我们可以固定
P
(
V
∣
h
(
1
)
)
P(V|h^{(1)})
P(V∣h(1))实现叠加RBM——固定表示为定值),可以得到:
log
P
(
v
)
≥
∑
h
(
1
)
q
(
h
(
1
)
∣
V
)
⏟
f
i
x
e
d
log
P
(
h
(
1
)
)
+
C
\begin{align} \log P(v) &\geq \sum_{h^{(1)}} \underbrace{q(h^{(1)} | V)}_{fixed} \log P(h^{(1)}) + C \\ \end{align}
logP(v)≥h(1)∑fixed
q(h(1)∣V)logP(h(1))+C
若此时我们对
h
(
1
)
h^{(1)}
h(1)重新建模,在上面加一层
h
(
2
)
h^{(2)}
h(2),此时
h
(
1
)
h^{(1)}
h(1)就是prior,我们会求得
h
(
1
)
h^{(1)}
h(1)的最大值。通过这种方法我们就可以提高
log
P
(
V
)
\log P(V)
logP(V)的ELBO
27.3 训练方式
通过计算我们已知公式可以写作:
log
P
(
v
)
≥
∑
h
(
1
)
q
(
h
(
1
)
∣
V
)
log
P
(
h
(
1
)
)
+
C
\begin{align} \log P(v) &\geq \sum_{h^{(1)}} q(h^{(1)} | V) \log P(h^{(1)}) + C \\ \end{align}
logP(v)≥h(1)∑q(h(1)∣V)logP(h(1))+C
其中我们固定的
q
(
h
(
1
)
∣
V
)
q(h^{(1)} | V)
q(h(1)∣V)可以计算得出:
q
(
h
(
1
)
∣
V
)
=
∏
i
q
(
h
i
(
1
)
∣
V
)
=
∏
i
s
i
g
m
o
i
d
(
w
i
,
:
(
1
)
⋅
v
+
b
i
(
1
)
)
q(h^{(1)} | V) = \prod_i q(h_i^{(1)} | V) = \prod_i sigmoid(w_{i,:}^{(1)} \cdot v + b_i^{(1)})
q(h(1)∣V)=i∏q(hi(1)∣V)=i∏sigmoid(wi,:(1)⋅v+bi(1))
其中的v就是我们的训练样本。
通过这种方法最后的得到的DBN方便采样:可以在最上层的RBM使用Gibbs采样,再通过SBN对有向图的方法采样下来。








![get请求传入[ ]这类字符 返回400错误解决](https://img-blog.csdnimg.cn/8b5f56b7b1f7422583923489d9685640.png)