muduo 库里的日志打印比较复杂,跟标准库 std::cout << 似乎比较像吧,库里自己实现了“流”式的日志打印,今天一起来看一下。
int main(int argc, char* argv[])
{
CLogger::setLogLevel(CLogger::INFO);
LOG_INFO << "loggingTest!";
return 0;
}这个就是一个简单的打印,首先设置了打印等级,然后就可以调用 LOG_INFO 或其他的宏进行打印。这些宏完整的定义如下:
#define LOG_TRACE if (CLogger::logLevel() <= CLogger::TRACE) \
CLogger(__FILE__, __LINE__, CLogger::TRACE, __func__).stream()
#define LOG_DEBUG if (CLogger::logLevel() <= CLogger::DEBUG) \
CLogger(__FILE__, __LINE__, CLogger::DEBUG, __func__).stream()
#define LOG_INFO if (CLogger::logLevel() <= CLogger::INFO) \
CLogger(__FILE__, __LINE__).stream()
#define LOG_WARN CLogger(__FILE__, __LINE__, CLogger::WARN).stream()
#define LOG_ERROR CLogger(__FILE__, __LINE__, CLogger::ERROR).stream()
#define LOG_FATAL CLogger(__FILE__, __LINE__, CLogger::FATAL).stream()
#define LOG_SYSERR CLogger(__FILE__, __LINE__, false).stream()
#define LOG_SYSFATAL CLogger(__FILE__, __LINE__, true).stream()截止到这里,是不是有人感到疑惑?因为从上面看,似乎没有调用什么接口进行输出啊,那它这个日志是怎么输出的呢?执行结果就是这样一句:
20230720 15:51:59.942668 tid: 13398 INFO loggingTest! - LoggingTest.cpp:67
其实这里涉及到了一个知识点:匿名对象调用完就析构了。可以参考 这里。其实我们可以用 GDB 单步跟踪看它具体的执行步骤。如下:
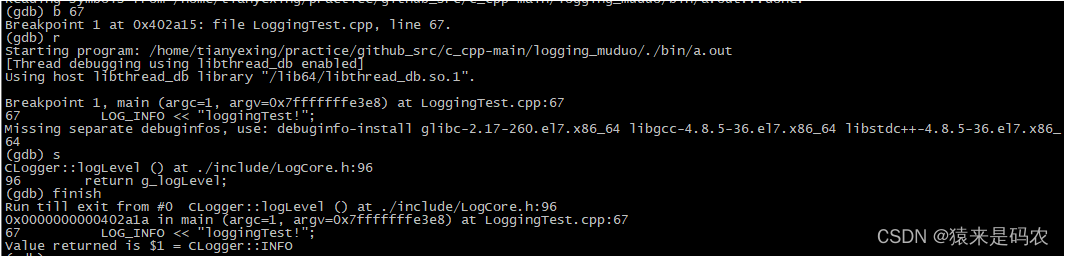
调用到了 CLogger::logLevel() 获取当前的打印等级,其返回值是 CLogger::INFO,正是main函数开头设置的打印等级。
接着构造 CLogger 对象,调用的是这个构造函数:
CLogger::CLogger(SourceFile file, int line): mImpl(INFO, 0, file, line)
{
}
然而在这个构造函数里,首先去构造了 SourceFile 对象:
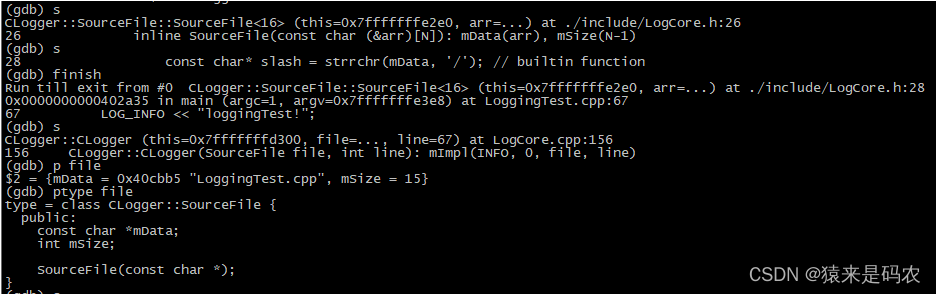
所以传递过来的 file 就是一个 SourceFile 对象。那紧接着就是构造 Impl 对象了。
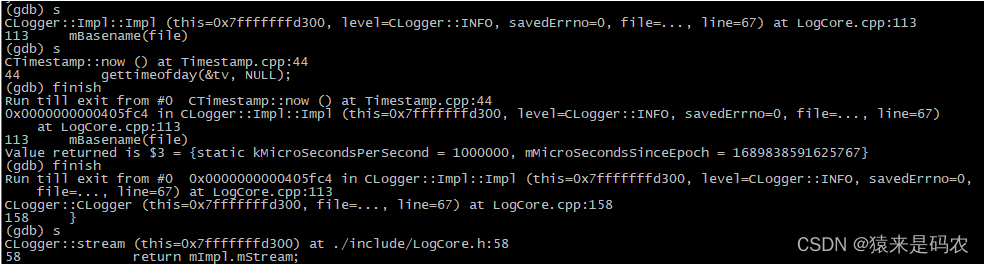
所以呢,LOG_INFO 宏得到的最终产物就是 mImpl.mStream,其类型就是 class CLogStream
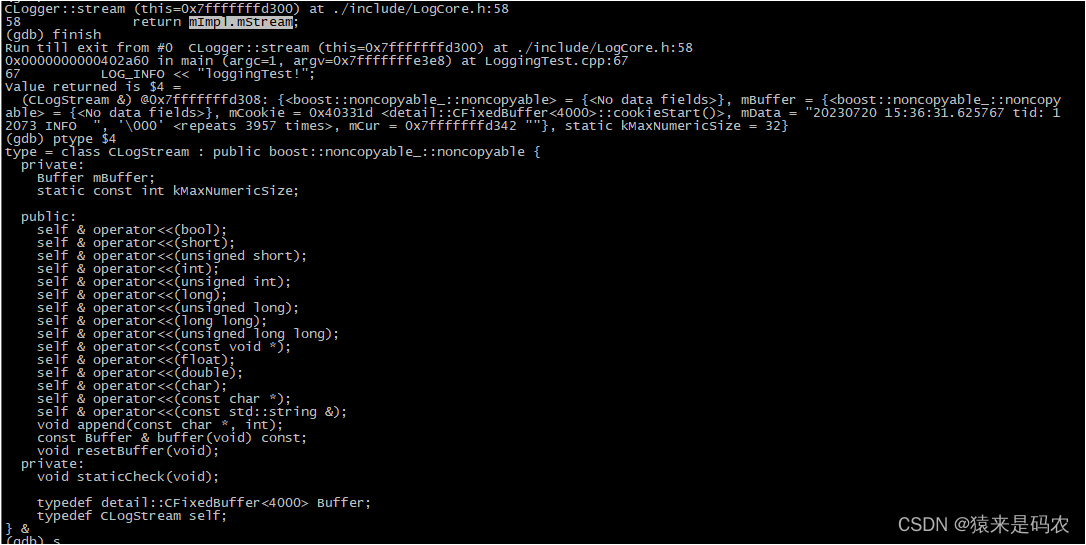
在得到 CLogStream 后,接着就是调用了重载符号 <<
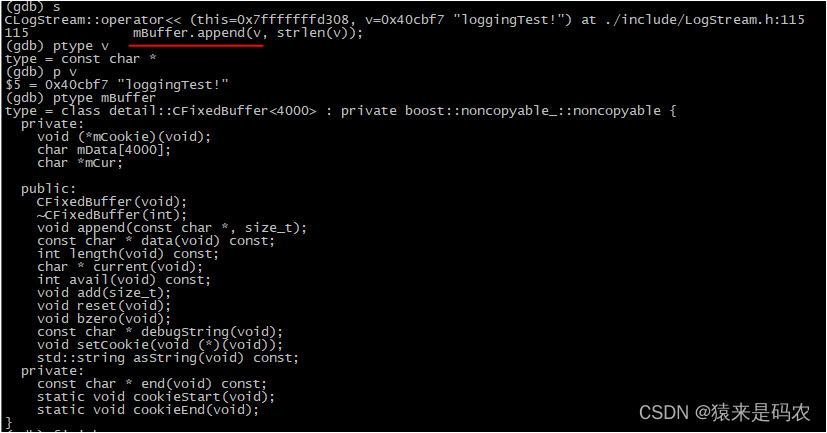
重载符号 << 里做的就是往 mBuffer 里添加内容,可以看到这个 mBuffer 的类型是一个模板类,
///固定缓存区类
template<int SIZE>
class CFixedBuffer: boost::noncopyable
{
public:
CFixedBuffer(): mCur(mData)
{
setCookie(cookieStart);
}
~CFixedBuffer()
{
setCookie(cookieEnd);
}
void append(const char* /*restrict*/ buf, size_t len)
{
// FIXME: append partially
if (static_cast<size_t>(avail()) > len)
{
memcpy(mCur, buf, len);
mCur += len;
}
}
const char* data() const { return mData; }
int length() const { return static_cast<int>(mCur - mData); }
// write to mData directly
char* current() { return mCur; }
int avail() const { return static_cast<int>(end() - mCur); }
void add(size_t len) { mCur += len; }
void reset() { mCur = mData; }
void bzero() { ::bzero(mData, sizeof mData); }
// for used by GDB
const char* debugString();
void setCookie(void (*cookie)()) { mCookie = cookie; }
// for used by unit test
std::string asString() const { return std::string(mData, length()); }
private:
const char* end() const { return mData + sizeof(mData); }
// Must be outline function for cookies.
static void cookieStart();
static void cookieEnd();
void (*mCookie)();
char mData[SIZE];
char* mCur;
};这个类里直接定义了 mData[SIZE] 大小的字符数组,这个 SIZE = 4000,所以这个mBuffer 可以容纳4000个字符。所以调用 mBuffer.append() 其实就是拷贝字符:
void append(const char* /*restrict*/ buf, size_t len)
{
// FIXME: append partially
if (static_cast<size_t>(avail()) > len)
{
memcpy(mCur, buf, len);
mCur += len;
}
}最后就调用到了 CLogger 的析构函数了:

析构函数里做了什么呢?
CLogger::~CLogger()
{
mImpl.finish();
const CLogStream::Buffer& buf(stream().buffer());
g_output(buf.data(), buf.length());
if (mImpl.mLevel == FATAL)
{
g_flush();
abort();
}
}mImpl.finish() 里只是打印了文件名和行号,这个mBasename 和 mLine 在构造Impl的时候已经传递进去了:
void CLogger::Impl::finish()
{
///日志输出最后输出文件名、行号
mStream << " - " << mBasename << ':' << mLine << '\n';
}然后用 g_output() 进行输出,输出的内容就是 stream().buffer()。而 g_output 是一个函数指针,其指向的是 defaultOutput() 函数,这个函数里就是向标准输出设备输出内容:
void defaultOutput(const char* msg, int len)
{
size_t n = fwrite(msg, 1, len, stdout);
//FIXME check n
(void)n;
}
void defaultFlush()
{
fflush(stdout);
}
CLogger::OutputFunc g_output = defaultOutput;
CLogger::FlushFunc g_flush = defaultFlush;


![解决Vue2中控制台报错 [WDS] Disconnected! 问题](https://img-blog.csdnimg.cn/1b8b9f309d7540639aa1dc1641e0ff09.png)