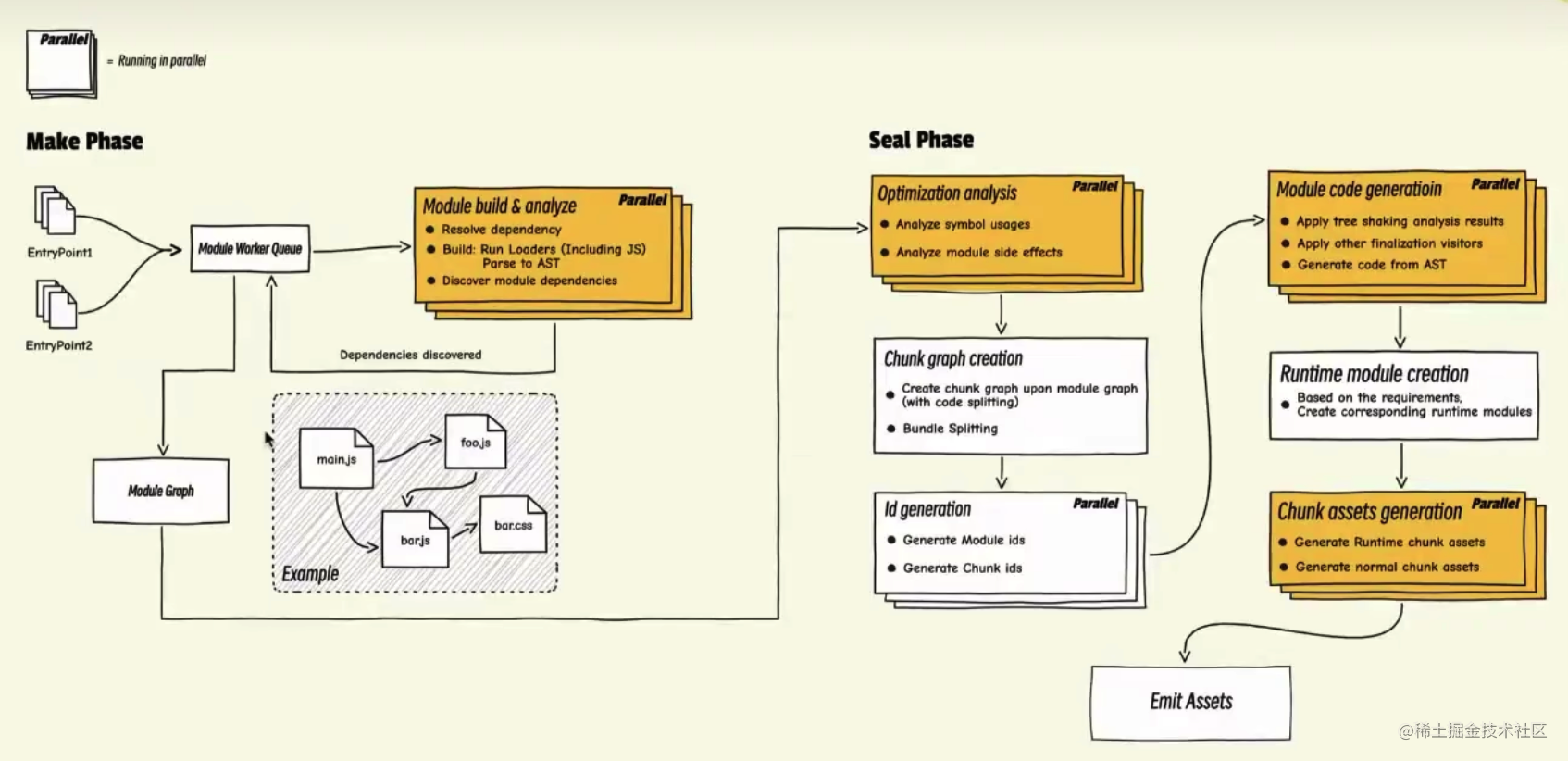
1、Elasticsearch 故障探测及熔断背景
探究Elasticsearch7.10.2 节点之间的故障探测以及熔断故障是怎么做的,思考生产上的最佳实践。
服务端故障场景:
单个master挂掉
除了断点断网,状态同步异常,主master也会认为自己已经失败,会退出,然后选举新的master
Elasticsearch 是一种基于点对点的系统,其中节点直接相互通信。主节点的职责是维护全局集群状态并在节点加入或离开集群时重新分配分片。每次集群状态更改时,新状态都会发布到集群中的所有节点。
主master挂掉
备master挂掉
单个datanode挂掉
单个datanode 和active master 同时挂掉
服务端发生熔断
从服务端如何应对这些场景以及客户端如何应对这些场景。
2、集群故障探测认知
Elasticsearch 故障监测官方文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/cluster-fault-detection.html
leader check 和 follower check

leader check 和 follower check 实际上都是线程,由 same 线程池执行,same 线程池是一种DIRECTl类型的线程池,当某个任务不需要在独立的线程执行,又想被线程池管理时,于是诞生了这种特殊类型的线程池:
在调用者线程中执行任务,这个same线程池是对用户不可见的,所以通过_cat/thread_pool看不到这个线程池。
map.put(Names.SAME, ThreadPoolType.DIRECT);
static final ExecutorService DIRECT_EXECUTOR = EsExecutors.newDirectExecutorService();
executors.put(Names.SAME, new ExecutorHolder(DIRECT_EXECUTOR, new Info(Names.SAME, ThreadPoolType.DIRECT)));关于DirectExecutorService的关键定义:
@Override
public void execute(Runnable command) {
command.run(); // 直接运行,并没有实际的线程池
rethrowErrors(command);
}follower check
选出的主节点会定期检查集群中的每个节点,以确保它们仍然保持连接且健康
对应实现在org.elasticsearch.cluster.coordination.FollowersChecker.FollowerChecker#handleWakeUp
leader检查
集群中的每个节点也会定期检查选出的主节点的健康状况
对应实现在:org.elasticsearch.cluster.coordination.LeaderChecker.CheckScheduler#handleWakeUp
相关配置
Elasticsearch 允许这些检查偶尔失败或超时而不采取任何行动。只有在连续多次检查失败后,才认为节点出现故障。
cluster.fault_detection. settings 相关配置如下:
cluster.fault_detection.follower_check.interval
静态
设置follower_checker的间隔, 默认1s一次
cluster.fault_detection.follower_check.timeout
静态
follower_checker的超时时间,默认10s
cluster.fault_detection.follower_check.retry_count
静态
follower_check 失败多少次会认为follower 检测失败, 默认3次, 超过这个次数之后,当选的主节点认为该节点出现故障并将其从集群中删除
cluster.fault_detection.leader_check.interval
静态
设置leader_checker的间隔, 默认1s一次
cluster.fault_detection.leader_check.timeout
静态
leader_checker的超时时间,默认10s
cluster.fault_detection.leader_check.retry_count
静态
leader_check 失败多少次会认为leader检测失败, 默认3次, 超过这个次数之后,节点认为当选的主节点有故障并尝试查找或选举新的主节点
💡 注意事项:
选出的主节点检测到某个节点已断开连接,这种情况会被立即认为是故障,主节点绕过超时和重试设置值并尝试从集群中删除节点。
类似地,如果节点检测到选出的主节点已断开连接,则这种情况将被视为立即故障。节点绕过超时和重试设置并重新启动其发现阶段以尝试查找或选举新的主节点。
3、选举认知
因为 master节点挂掉的时候,可能有两种情况, 主master挂掉和备master挂掉。如果主master挂掉就会触发选举。
所以分析一下相关选举配置如下:
discovery.cluster_formation_warning_timeout
静态
多久没选举完成就会打印出”master not discovered”
discovery.find_peers_interval
静态
设置节点在尝试另一轮discovery选举 之前等待的时间。
discovery.probe.connect_timeout
静态
设置尝试连接到每个地址时等待的时间。默认为 3 秒
discovery.probe.handshake_timeout
静态
设置尝试通过握手识别远程节点时等待的时间,默认为 1 秒。
discovery.request_peers_timeout
静态
设置节点认为向对等方发送请求失败之前的超时时间,默认3s
discovery.seed_resolver.max_concurrent_resolvers
静态
指定解析种子节点地址时要执行的并发 DNS 查找数量。默认为 10。
discovery.seed_resolver.timeout
静态
指定解析种子节点地址时执行的每次 DNS 查找的等待时间。默认为 5 秒。
cluster.auto_shrink_voting_configuration
动态
控制投票配置是否自动删除离开的节点,只要它仍然包含至少 3 个节点。默认值是true。如果设置为 false,投票配置永远不会自动收缩。
cluster.election.back_off_time
静态
设置每次选举失败后选举前等待时间上限的增加量。请注意,这是线性退避。默认为 100 毫秒。更改此默认设置可能会导致集群无法选择主节点。
cluster.election.duration
静态
设置每次选举在节点认为失败并安排重试之前允许进行的时间。默认为 500 毫秒。更改此默认设置可能会导致集群无法选择主节点。
cluster.election.initial_timeout
静态
设置节点最初等待的时间上限,或者在当选的主节点失败后,在尝试第一次选举之前等待的时间上限。默认为 100 毫秒。更改此默认设置可能会导致集群无法选择主节点。
cluster.election.max_timeout
静态
设置节点在尝试第一次选举之前等待的时间的最大上限,以便长时间持续的网络分区不会导致选举过于稀疏。默认为 10 秒。更改此默认设置可能会导致集群无法选择主节点。
cluster.no_master_block
动态
指定当集群中没有活动主节点时拒绝哪些操作。此设置具有三个有效值.
all , 节点上的所有操作(读和写操作)都会被拒绝。这也适用于 API 集群状态读取或写入操作
write (默认) 写入操作被拒绝。根据最后已知的集群配置,读取操作成功。这种情况可能会导致部分读取过时数据,因为该节点可能与集群的其余部分隔离。
metadata_write, 仅元数据写入操作(例如映射更新、路由表更改)被拒绝,但常规索引操作继续工作。根据最后已知的集群配置,读取和写入操作成功。这种情况可能会导致部分读取过时数据,因为该节点可能与集群的其余部分隔离
4、分片主从切换是如何做的
在节点被判断离开集群的时候,会触发一个node-left的状态更新任务。
this.followersChecker = new FollowersChecker(settings, transportService, this::onFollowerCheckRequest, this::removeNode,
nodeHealthService);
private void removeNode(DiscoveryNode discoveryNode, String reason) {
synchronized (mutex) {
if (mode == Mode.LEADER) {
// 提交一个node-left状态更新任务
masterService.submitStateUpdateTask("node-left",
new NodeRemovalClusterStateTaskExecutor.Task(discoveryNode, reason),
ClusterStateTaskConfig.build(Priority.IMMEDIATE),
nodeRemovalExecutor,
nodeRemovalExecutor);
}
}
}之后就进入到状态更新阶段:org.elasticsearch.cluster.service.MasterService#runTasks:

这里对应的线程池为 org.elasticsearch.cluster.coordination.NodeRemovalClusterStateTaskExecutor,于是进入到其的execute方法:
@Override
public ClusterTasksResult<Task> execute(final ClusterState currentState, final List<Task> tasks) throws Exception {
final DiscoveryNodes.Builder remainingNodesBuilder = DiscoveryNodes.builder(currentState.nodes());
boolean removed = false;
// 如果任务指定的节点存在于当前集群状态中,则从DiscoveryNodes.Builder对象中删除该节点,
// 并将removed标志设置为true。如果该任务指定的节点不存在于当前集群状态中,则记录一条调试级别的日志,表示忽略该任务。
for (final Task task : tasks) {
if (currentState.nodes().nodeExists(task.node())) {
remainingNodesBuilder.remove(task.node());
removed = true;
} else {
logger.debug("node [{}] does not exist in cluster state, ignoring", task);
}
}
// 如果没有删除任何节点,则返回当前的集群状态
if (!removed) {
// no nodes to remove, keep the current cluster state
return ClusterTasksResult.<Task>builder().successes(tasks).build(currentState);
}
// 剩余节点
final ClusterState remainingNodesClusterState = remainingNodesClusterState(currentState, remainingNodesBuilder);
return getTaskClusterTasksResult(currentState, tasks, remainingNodesClusterState);
}
protected ClusterTasksResult<Task> getTaskClusterTasksResult(ClusterState currentState, List<Task> tasks,
ClusterState remainingNodesClusterState) {
ClusterState ptasksDisassociatedState = PersistentTasksCustomMetadata.disassociateDeadNodes(remainingNodesClusterState);
final ClusterTasksResult.Builder<Task> resultBuilder = ClusterTasksResult.<Task>builder().successes(tasks);
return resultBuilder.build(allocationService.disassociateDeadNodes(ptasksDisassociatedState, true, describeTasks(tasks)));
}随后调用 org.elasticsearch.cluster.routing.allocation.AllocationService#disassociateDeadNodes(org.elasticsearch.cluster.ClusterState, boolean, java.lang.String)
private void disassociateDeadNodes(RoutingAllocation allocation) {
for (Iterator<RoutingNode> it = allocation.routingNodes().mutableIterator(); it.hasNext(); ) {
RoutingNode node = it.next();
// 如果该节点的ID存在于RoutingAllocation对象的数据节点列表中,则表示该节点是活动节点,继续遍历下一个节点
if (allocation.nodes().getDataNodes().containsKey(node.nodeId())) {
// its a live node, continue
continue;
}
// 否则,这个节点就离线。
// 对于每个已离线的节点,该方法遍历该节点上的所有分片,并为每个分片创建一个UnassignedInfo对象,表示该分片未分配的原因是节点离线。
// 然后,该方法调用failShard方法,将该分片标记为失败,并将其移动到未分配状态。该方法还会从RoutingNode列表中删除已离线的节点
// now, go over all the shards routing on the node, and fail them
for (ShardRouting shardRouting : node.copyShards()) {
final IndexMetadata indexMetadata = allocation.metadata().getIndexSafe(shardRouting.index());
boolean delayed = INDEX_DELAYED_NODE_LEFT_TIMEOUT_SETTING.get(indexMetadata.getSettings()).nanos() > 0;
UnassignedInfo unassignedInfo = new UnassignedInfo(UnassignedInfo.Reason.NODE_LEFT, "node_left [" + node.nodeId() + "]",
null, 0, allocation.getCurrentNanoTime(), System.currentTimeMillis(), delayed, AllocationStatus.NO_ATTEMPT,
Collections.emptySet());
allocation.routingNodes().failShard(logger, shardRouting, unassignedInfo, indexMetadata, allocation.changes());
}
// its a dead node, remove it, note, its important to remove it *after* we apply failed shard
// since it relies on the fact that the RoutingNode exists in the list of nodes
it.remove();
}
}org.elasticsearch.cluster.routing.RoutingNodes#failShard, 将分片移动到未分配状态或完全删除分片(如果是重分配relocation目标分片),具体的逻辑如下:
如果分片是主分片,则会先失败初始化副本
如果分片是活动主分片,则会将一个活动副本升级为主分片(如果存在这样的副本)
如果分片是正在分配relocation的主分片,则会删除主分片重分配relocation目标分片
如果分片是正在重分配relocation的副本,则会将副本重分配relocation目标升级为完全初始化的副本,并删除重定位源信息。这是因为对等恢复始终是从主分片进行的。
如果分片是(主分片或副本)分配relocation目标,则还会清除源分片上的重分配relocation信息。
这里我们关注一下,怎么做的主从切换, 具体进入到如下逻辑:
// fail actual shard
if (failedShard.initializing()) {
if (failedShard.relocatingNodeId() == null) {
if (failedShard.primary()) {
// promote active replica to primary if active replica exists (only the case for shadow replicas)
unassignPrimaryAndPromoteActiveReplicaIfExists(failedShard, unassignedInfo, routingChangesObserver);
} else {
// initializing shard that is not relocation target, just move to unassigned
moveToUnassigned(failedShard, unassignedInfo);
}
}org.elasticsearch.cluster.routing.RoutingNodes#unassignPrimaryAndPromoteActiveReplicaIfExists
private void unassignPrimaryAndPromoteActiveReplicaIfExists(ShardRouting failedShard, UnassignedInfo unassignedInfo,
RoutingChangesObserver routingChangesObserver) {
assert failedShard.primary();
// 这里会从所有副本分片中找最高版本的副本
ShardRouting activeReplica = activeReplicaWithHighestVersion(failedShard.shardId());
if (activeReplica == null) {
moveToUnassigned(failedShard, unassignedInfo);
} else {
// 将主分片移动到未分配状态,并将其降级为副本, 这里还会将主分片加入到unassignedShards列表中, 根据索引的配置会做分片恢复
movePrimaryToUnassignedAndDemoteToReplica(failedShard, unassignedInfo);
// 将活动副本升级为主分片,并通知路由变更观察器进行相应的处理
promoteReplicaToPrimary(activeReplica, routingChangesObserver);
}
}做好路由的变更之后,master会同步集群状态给各个节点,至此就完成了主副本分片切换。
总的来说,只要探测到data-node离线肯定就会进行主从切换,所以这部分的耗时主要在同步集群状态上,在网络等资源良好的情况下,基本是秒级的。
5、客户端重试机制
以 java 客户端为例,当配置多个 IP , 客户端会自动执行负载均衡, 默认是轮询存活的节点。
意味着每个新的请求都会发送到下一个 IP 地址,当所有的 IP 地址都被使用后,再从头开始。
这样可以确保所有的 Elasticsearch 节点都有均等的机会处理请求,避免了某个节点过载的问题。
当一个节点失败了,会加入到blaklist:
private void onFailure(Node node) {
while(true) {
DeadHostState previousDeadHostState =
blacklist.putIfAbsent(node.getHost(), new DeadHostState(DeadHostState.DEFAULT_TIME_SUPPLIER));
if (previousDeadHostState == null) {
if (logger.isDebugEnabled()) {
logger.debug("added [" + node + "] to blacklist");
}
break;
}
if (blacklist.replace(node.getHost(), previousDeadHostState,
new DeadHostState(previousDeadHostState))) {
if (logger.isDebugEnabled()) {
logger.debug("updated [" + node + "] already in blacklist");
}
break;
}
}
failureListener.onFailure(node);
}在发送请求的时候,selectNodes 会过滤出活跃的节点(没有被列入黑名单或已经到了重试时间的节点),然后使用一个 NodeSelector 对象对这些节点进行选择。
可以看出是轮询的方式。
static Iterable<Node> selectNodes(NodeTuple<List<Node>> nodeTuple, Map<HttpHost, DeadHostState> blacklist,
AtomicInteger lastNodeIndex, NodeSelector nodeSelector) throws IOException {
/*
* Sort the nodes into living and dead lists.
*/
List<Node> livingNodes = new ArrayList<>(Math.max(0, nodeTuple.nodes.size() - blacklist.size()));
List<DeadNode> deadNodes = new ArrayList<>(blacklist.size());
for (Node node : nodeTuple.nodes) {
DeadHostState deadness = blacklist.get(node.getHost());
// 没有被列入黑名单或已经到了重试时间的节点 , 默认是1min重试间隔, 只有1min之后才会再次访问这个节点, 无法修改,写死的
if (deadness == null || deadness.shallBeRetried()) {
livingNodes.add(node);
} else {
deadNodes.add(new DeadNode(node, deadness));
}
}注意:一些客户端有“节点嗅探”功能,但是这种在 k8s 场景下并不友好,而且违背了仅协调节点的部署架构,对以后 VIP 规划也有影响,所以并不太建议开启。
6、故障梳理
注:这里的挂掉都是指网卡挂了,并不是被kill或者关机,这里两者有本质区别:
网卡下线,需要探测时间。
如果进程被kill ,被kill的es 节点会立即断开连接,不需要探测时间,会被立即移出集群,从而触发node-left,故障恢复
这里搭建 6 个节点, 其中 3 个节点为 master 角色, 3 个节点为 data 角色,使用的是虚拟机部署
6.1 故障一:主 master 挂掉

第一次检测失败:2023-07-14T20:40:52

第二次检测失败:2023-07-14T20:41:03

第三次检测失败:2023-07-14T20:41:14

2023-07-14T20:41:14,427 选举结束,再发布集群状态。

值得注意的是,客户端不断使用非挂掉机器的ip 访问es, 只有选举期间是无法写入的,其他时间都可以写入,但是无法更新集群状态(比如创建索引等),因为这个时候master已经挂了。
6.2 故障二:备master挂掉

直接看最后一次的 timeout:2023-07-14T21:04:54 ,耗时就是大概30s。

值得注意的是,客户端不断使用非挂掉机器的ip 访问es, 因为只是关闭了备master节点,所以期间集群状态一直都是green的。对客户端新的请求是没有影响的。
6.3 故障三:单个datanode挂掉


直接看最后一次check失败:2023-07-14T21:17:58 , 相差大概也是30s,这个时候标记这个数据节点的分片为failed(会做主从分片切换), 并计划恢复那些丢失的分片,这个时候集群为Yellow状态


由于使用的是默认配置index.unassigned.node_left.delayed_timeout 为1m, 而且索引的数据量很小,所以集群很快恢复了分片,转入到GREEN状态

6.4 故障四:活跃master节点和一个datanode 同时挂掉
这个场景其实是故障一和故障三的结合, 从服务端流程可以看出来,先进行了master重选举,再然后是处理数据节点的离线。原因很简单,因为只有active master 节点才有follower 检测,所以有这个顺序。

2023-07-14T21:34:54 选举出新 master

2023-07-14T21:35:26 探测到 data 节点

6.5 故障五:服务端熔断
这块主要看客户端怎么做的容错,以java客户端为例,
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.2</version>
</dependency>在服务端熔断的情况下,服务端会直接返回异常,客户端会抛出异常, 这个时候需要判断返回码429, 并判断熔断类型是否为TRANSIENT, 如果是需要不断重试, 如果是PERMANENT 则可以放弃重试。

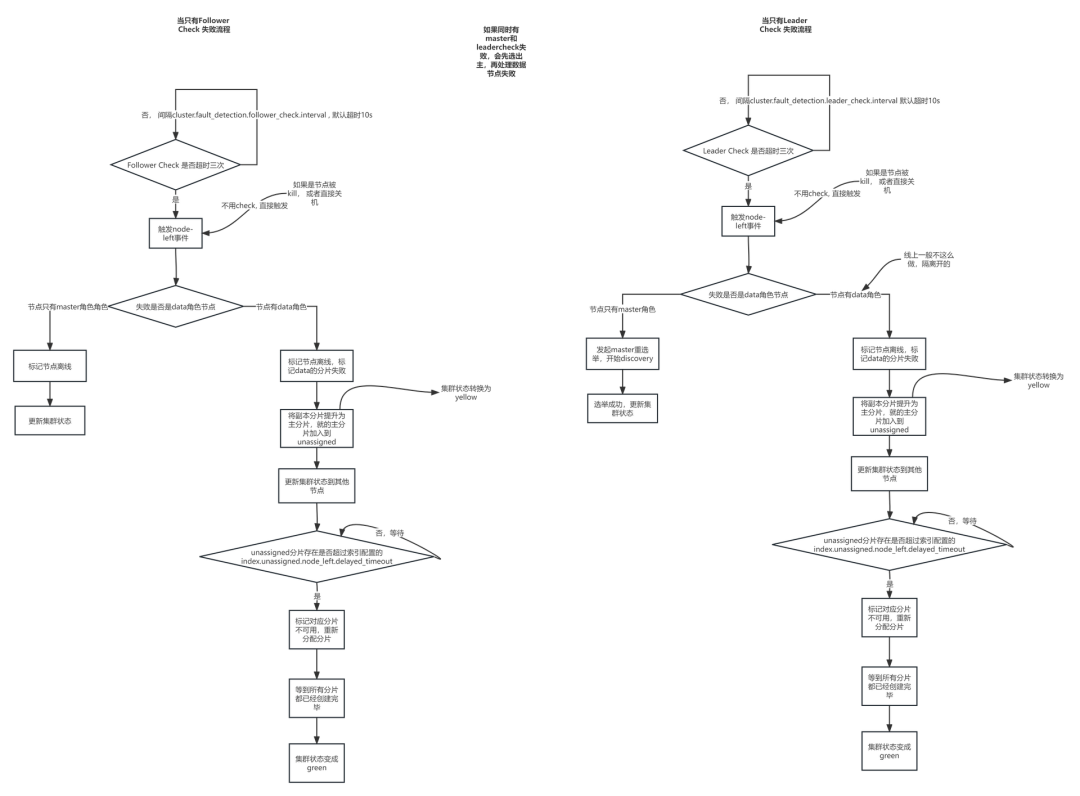
6.6 故障恢复流程图
7、故障总结
注:这里的挂掉都是指网卡挂了,并不是被 kill 或者关机,这里两者有本质区别:
网卡下线,需要探测时间。
如果进程被 kill ,被 kill 的 es 节点会立即断开连接,不需要探测时间,会被立即移出集群,从而触发 node-left,故障恢复
| 故障场景 | 客户端影响 | 大概恢复时长 | 优化手段以及对应时长 |
|---|---|---|---|
| 场景一:单个 active master 挂掉 | 1.访问故障节点的请求都失败 探测active 故障之前: 2.可对已有索引进行读写,但是无法更新集群状态,比如创建索引等 选举期间: 3.其他读请求可以成功进行,但是可能会读到旧数据 | 1. 取决故障节点恢复时间, 这个对客户端没影响,只要客户端能重试请求到其他存活es节点就可以 2.探测master挂掉需要30s, 期间可读写索引,但是无法更新集群状态 3. 3个master节点 选举只需要几s,具体看网络环境和节点个数,未选举出新的master时,只能读取 | 可以降低节点的探测超时时间,改成每次探测超时时间为3s,而不是10s,这样就可以将探测时间降低到9s |
| 场景二:单个备用master挂掉 | 1.访问故障节点的请求都失败 | 1. 取决故障节点恢复时间, 这个对客户端没影响,只要客户端能重试请求到其他存活es节点就可以,不会发生重选举 | |
| 场景三:单个data node挂掉 | 1.访问故障节点的请求都失败 2. 访问这个数据节点的分片的请求都失败 | 1. 取决故障节点恢复时间, 这个对客户端没影响,只要客户端能重试请求到其他存活es节点就可以 2.需要探测数据节点掉线30s,所以30s之内的这个数据节点负责的分片都无法写入和读取。 3.主副本分片切换之后,同步集群状态大概几s,具体看网络环境和节点个数 | 可以降低节点的探测超时时间,改成每次探测超时时间为3s,而不是10s,这样就可以将探测时间降低到9s |
| 场景四:active master节点和data node 节点同时挂掉 | 场景一和场景三的结合,会先经历场景一,然后发生场景三 | 1.探测master挂掉需要30s, 期间可读写索引,但是无法更新集群状态,选举需要秒级时间(3个master在集群压力小的情况下,通常1s之内) 2.需要探测数据节点掉线30s,所以30s之内的这个数据节点负责的分片都无法写入 | 可以降低节点的探测超时时间,改成每次探测超时时间为3s,而不是10s,这样就可以将探测时间降低到18s |
| 场景五:服务端熔断 | 1. 访问熔断节点的请求都失败 | 1.取决服务端内存释放情况,如果只是临时熔断,理论上几s钟就能释放一些 | 客户端应该判断服务端异常是否为熔断,如果是临时熔断应该做重试处理,理论上重试多少次都没关系,只要临时熔断,总会自动恢复 |
8、最佳实践思考总结
8.1 客户端实践复盘
客户端地址不能只设置成1个, 尤其是在虚拟机部署的es集群情况下,这种情况下一旦设置的 ip 地址挂了,就算 es 集群恢复,业务也无法恢复, 就算是 k8s 部署的 es 节点也需要填写多个 k8s master 地址 + svc nodeport。
如果是k8s的部署场景,需要注意pod的健康检测,不应该仅仅只是探测自身服务,还要探测和其他节点的网络连通性。
想象发生了故障二,理论上是对业务没有影响的,但是如果只单纯 curl 127.0.0.1:9200 的话,这样会造成svc的endpoint里较长时间还保留着已经挂掉的 pod ip。k8s在负载均衡的时候就会将流量转发到出问题的 pod,这样就会导致请求失败,实际上对于es服务来讲,几乎对客户端没有影响。
客户端需要参考 java sdk 做容错处理(如果该语言sdk没有实现的话), 实现配置多个节点ip,划分2个列表,存活列表和黑名单,对于存活列表轮询访问,失败过的节点就加到黑名单,一段时间之后(1,2,4s…退避式)重试。
在服务端熔断的情况下,服务端会直接返回异常,客户端会抛出异常, 需要客户端对这个异常进行cath 然后重试。这个时候需要判断返回码429, 并判断熔断类型是否为TRANSIENT, 如果是需要不断重试, 如果是PERMANENT 则可以放弃重试。
8.2 服务端实践复盘
默认的故障探测耗时为30s, 耗时较长, 在网络等资源良好的情况下,可以考虑缩短超时。
默认情况下,这个配置index.unassigned.node_left.delayed_timeout 为1m, 太短了,一般都有systemctl或者 k8s pod 漂移保活,这个可以考虑设置较长时间,比如1d,另外可以考虑索引的这个配置设置的都一样,不然会造成大量索引同时恢复,对es稳定性造成影响。
作者介绍
He Chengbo,互联网安全独角兽公司资深工程师,死磕 Elasticsearch 星球资深活跃技术专家。
在此,感谢铭毅老师提供这个宝贵的平台发表文章,也感谢您给予的指导和鼓励!
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!