文章目录
- 认识动静态库
- 静态库
- 动态库
- 静态的打包
- 静态库的使用
- 动态库的打包
- 动态库的使用
动静态库的本质就是可执行程序的"半成品"。
需要完成一个可执行程序需要经历以下四个步骤:
预处理:完成头文件的展开,去掉注释,宏替换,条件编译等,最终形成***.i文件
编译:完成语法分析,词法分析,语义分析,符号汇总等,检查无误后将代码翻译成汇编指令,最终形成***.s文件
汇编:将汇编指令转换成二进制指令,最终形成***.o文件
链接:将生成的各个***.o文件进行链接,最终形成可执行程序
例如,用test1.c,test2.c以及main1.c形成可执行文件,需要先得到各个文件的目标文test1.o,test2.o以及main1.o,然后将这些目标文件链接起来,最终形成一个可执行程序。

对于可能频繁用到的源文件,比如这里的test1.c,test2.c,可以将他们的目标文件test1.o,test2.o进行打包,之后需要用到这两个目标文件就可以直接链接这个包当中的目标文件即可,上面的打包就可以称为一个库。库的本质就是一堆***.O集合,库的文件当中并不包含主函数而只是包含了大量写好的方法以供调用,因此,我们说动静态库是可执行程序的"半成品".
认识动静态库
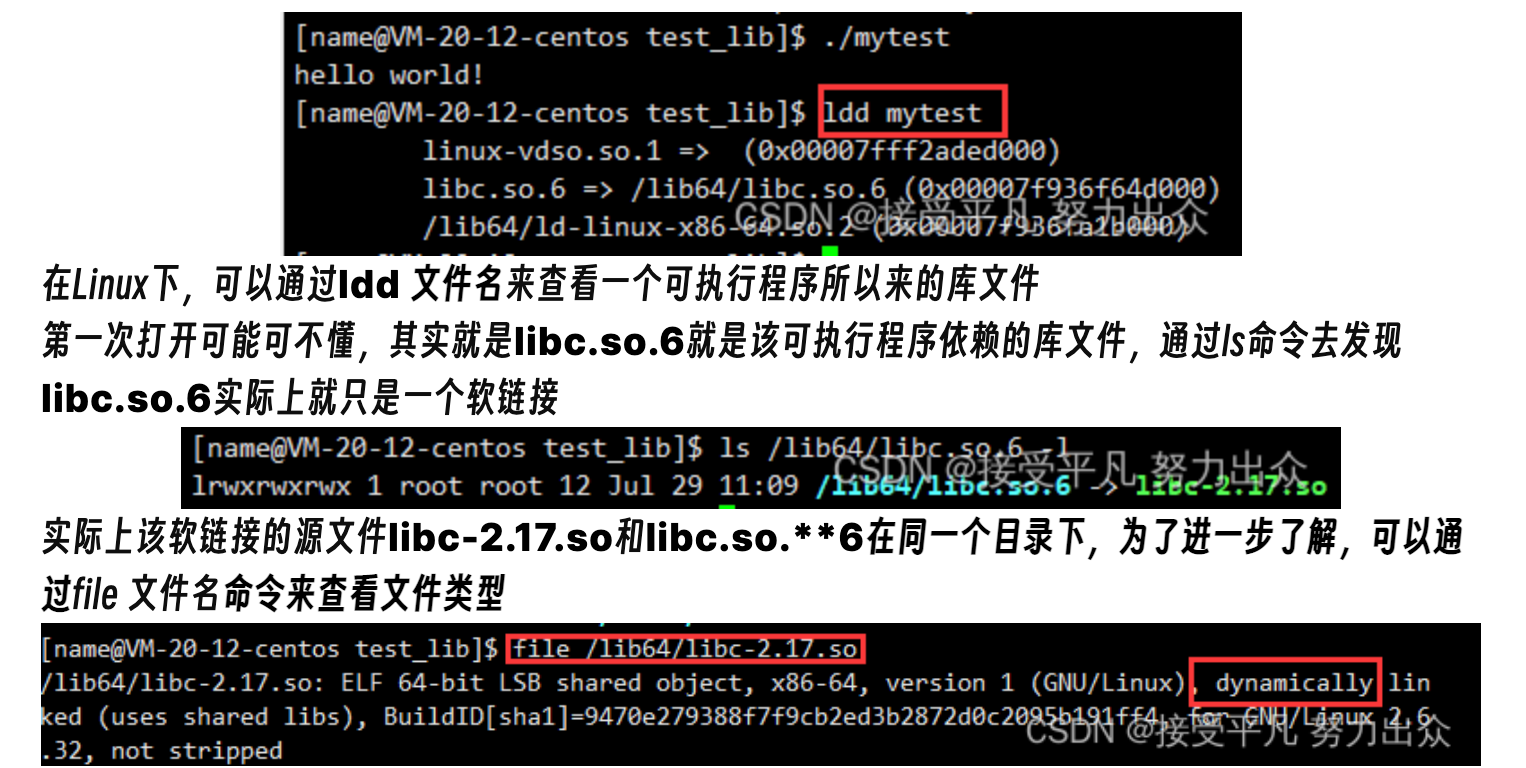
可以看到,实际上libc-2.17.so就是一个共享的目标文件库,准确来说,这还是一个动态库。说一下:
- 在Linux中,以.so为后缀的是动态库,以.a为后缀的是静态库。
- 在Windows中,以.dll为后缀的是动态库,以.lib为后缀的是静态库
- 这里的libc.so.6实际上就是C动态库,库的名字就是,去掉前缀lib,再去掉后缀**.so或.a**及其后面的版本。
而g++编译器一般都是默认是动态链接的,若想进行静态链接,可以携带一个 —static
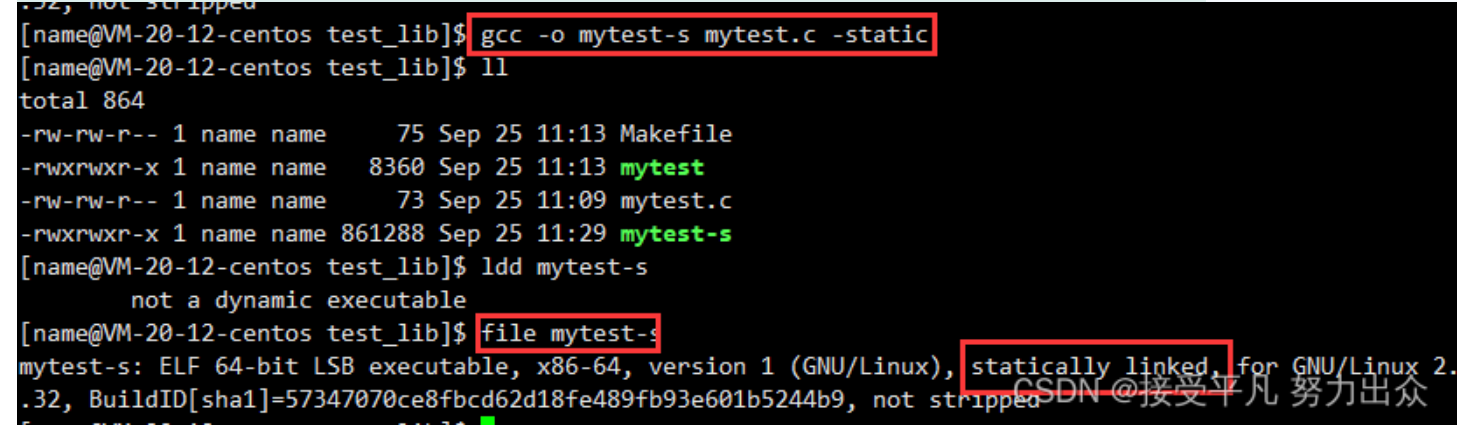
此时生产的可执行程序就是静态链接了,可以明显观察到静态链接生成的可执行程序文件的大小,要比动态的要大的多。主要原因下面详细介绍。
静态库
Linux下,以.a为后缀的文件。程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候不再需要静态库。本质是在编译时把静态库中的代码复制到进程的代码中。因此使用静态库生成的可执行程序要比一般的程序大。
优点:程序运行的时候不再需要静态库
缺点:生成的可执行程序较大。如果多个使用静态链接生成的程序同时运行会占用大量的内存空间
动态库
Linux下,以.so为后缀的文件。程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。一个动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码。
在可执行文件开始运行前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程叫做动态链接。动态库在多个程序间共享,节省了磁盘空间,操作系统采用虚拟内存机制允许物理内存中的一份动态库被调用到该库的所有进程共用,节省了内存和磁盘空间。
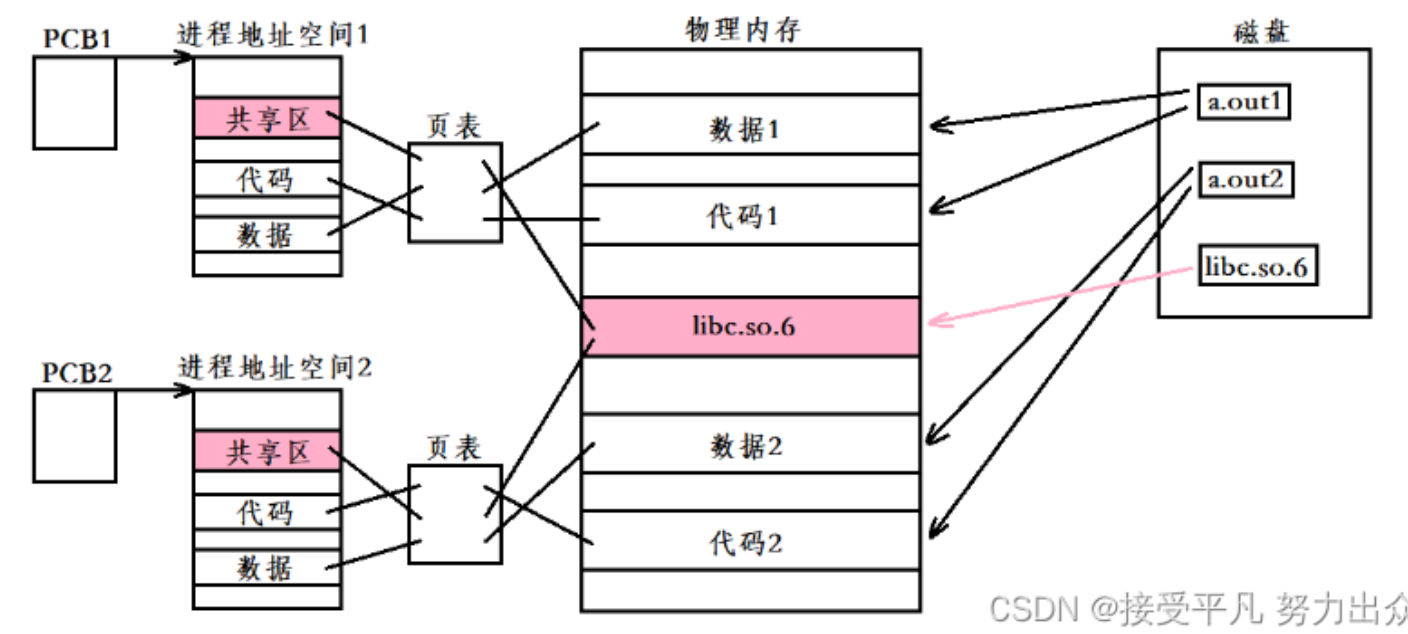
- **优点:*节省磁盘空间,且多个用到相同动态库的程序同时运行时,库文件会通过进程地址空间进行共享,内存当中不会存在重复代码
- 缺点:必须依赖动态库,否则无法运行
静态的打包
本质就是将代码编译成.o的二进制文件,然后进行打包。
为了更好的演示这个过程,创建add.c,add.h,sub.c和sub.h四个文件,内容如下所示:
#pragma once
extern int my_add(int x, int y);
//add.h
#include "add.h"
int my_add(int x, int y)
{
return x + y;
}
//add.c
#pragma once
extern int my_sub(int x, int y);
//sub.h
#include "sub.h"
int my_sub(int x, int y)
{
return x - y;
}
//sub.c
第一步:将所有源文件生成对应的目标文件
第二步:使用ar命令将所有目标文件打包为静态库
ar命令是gnu的归档工具,常用于将目标文件打包为静态库,下面我们使用ar命令的**-r选项和-c**选项进行打包。
- -r(replace):若静态库文件当中的目标文件有更新,则用新的目标文件替换旧的目标文件
- -c(create):建立静态库文件。
第三步:将头文件和生成的静态库组织起来
当我们把自己的库给别人用的时候,实际上需要给别人两个文件夹,一个文件夹下面放的是一堆头文件的集合,另一个文件夹下面放的是所有库文件
因此,在这里我们可以将add.h和sub.h这两个头文件放到一个名为Include的目录下,将生成的静态库文件libmymath.a放到一个名为lib的目录下,然后将这两个目录放到myliba下,此时就可以将myliba给别人使用了。
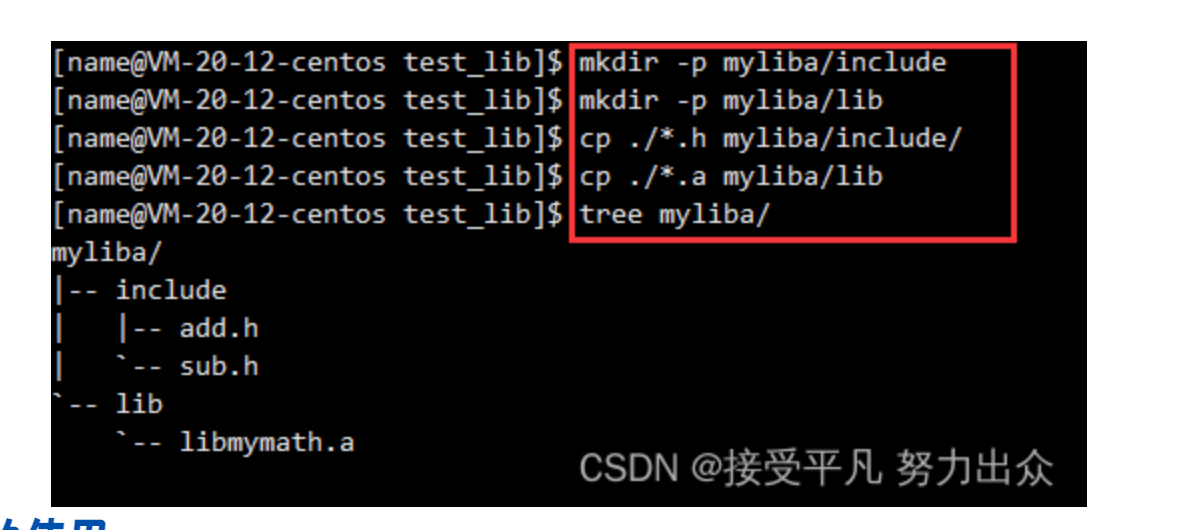
静态库的使用
创建源文件main.c,编写下面这边简单的程序尝试使用我们打包好的静态库。
#include <stdio.h>
#include <add.h>
#include<sub.h>
int main()
{
int x = 20;
int y = 10;
int z = my_add(x, y);
int q=my_sub(x,y);
printf("%d + %d = %d\n", x, y, z);
printf("%d+%d=%d\n",x,y,q);
return 0;
}
经过调整后目录下只有main.c和我们刚刚打包好的静态库。
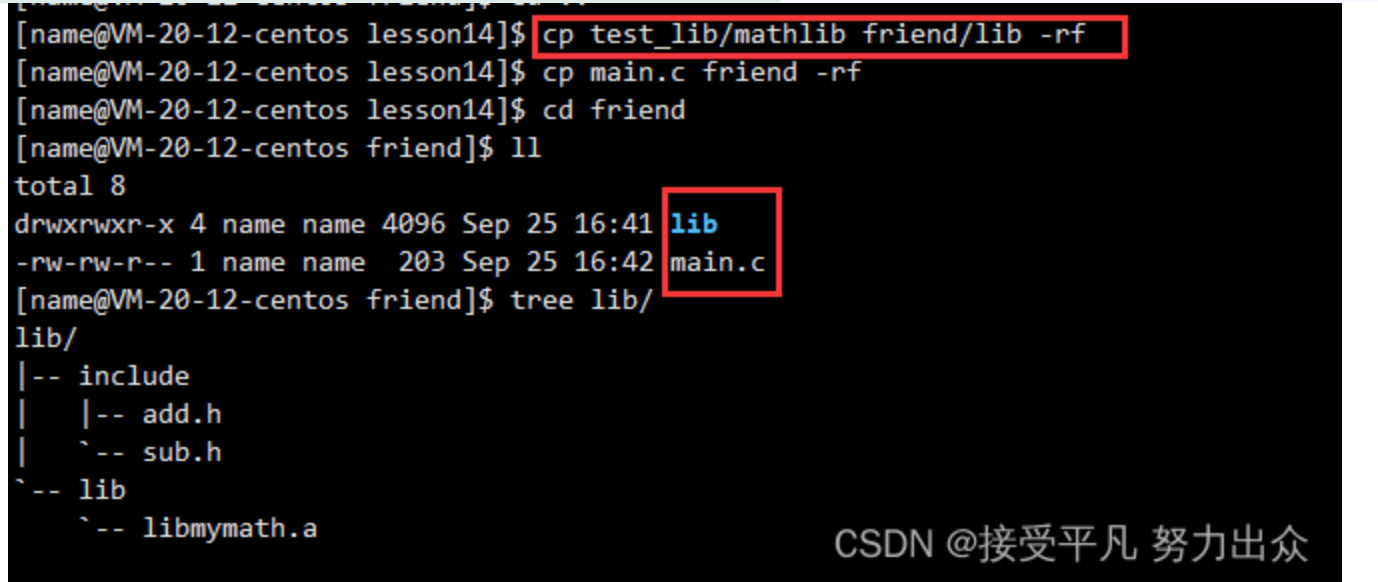
此时使用gcc编译main.c生成可执行程序时需要携带三个选项:
- -I:指定头文件搜索路径
- -L: 指定库文件搜索路径
- -l: 指明需要链接库文件路径下的哪一个库
- 具体操作如下:
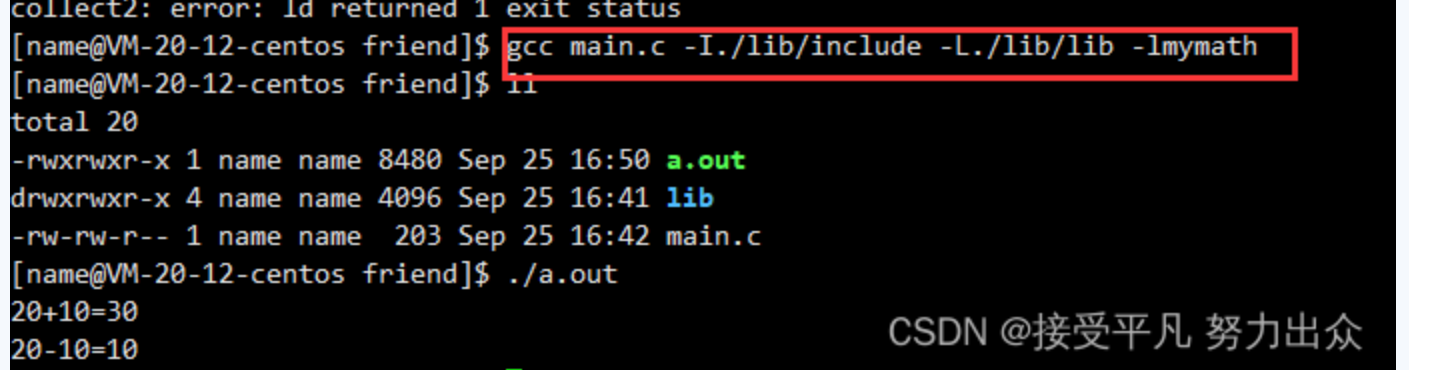
- 因为编译器不知道你所包含的头文件add.h在哪里,所以需要指定头文件的搜索路径。
因为头文件add.h当中只有my_add函数声明,并没有该函数的定义,所以还需要指定所要链接库文件的搜索路径。
实际中,在库文件的Lib目录下可能会有大量的库文件,因此我们需要指明需要链接库文件路径下的哪一个库,库文件名需要去掉前缀lib,再去掉后缀.so或者.a以及后面的版本号,剩下的就是这个库的真正名字。
为什么之前使用gcc编译的时候没有指明过库的名字?
因为我们使用的gcc编译的是C语言,而gcc就是用来编译C程序的,所以gcc编译的时候默认就找的是C库,但此时我们要链接的是哪一个库编译器是不知道的,因此我们需要使用选项,指明需要链接库文件路径下的哪一个库。
动态库的打包
动态库的打包相对于静态库来说有一点点差别,但大致相同,还是以上面的四个文件为例子:
第一步:让所有源文件生成对应的目标文件
此时用源文件生成目标文件时需要携带**-fPIC**选项:
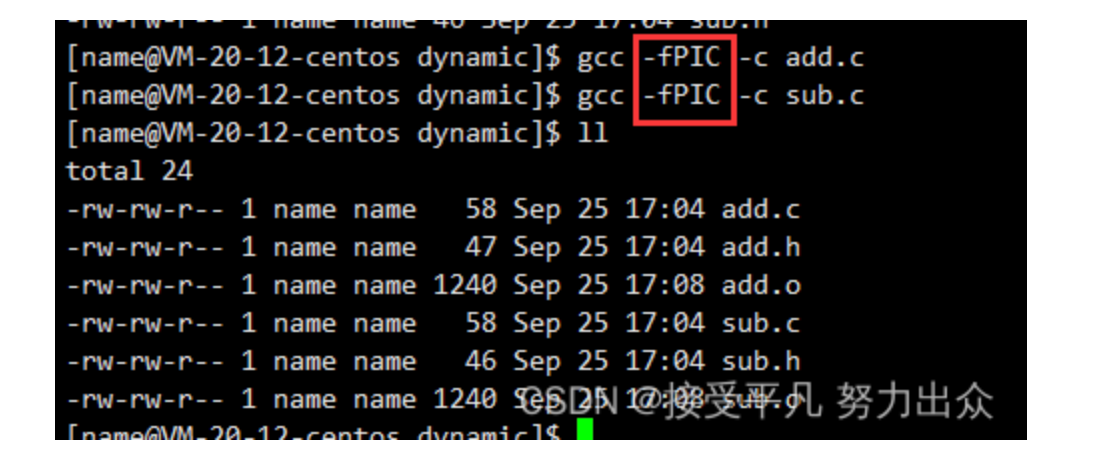
说明:
-
-fPIC:产生位置无关码
-
-fPIC作用域编译阶段,告诉编译器产生于位置无关的代码,此时产生的代码中没有绝对地址,全部都使用相对地址,从而代码可以被加载器加载到内存的任意位置都可以正确的执行。这正是共享库所要求的,共享库被加载时, 在内存的位置不是固定的。
-
如果不加-fPIC选项,则加载.so文件的代码段时,代码段引用的数据对象需要重定位,重定位会修改代码段的内容,这就造成了每个使用这个.so文件代码段的进程在内核里都会生成这个.so文件代码段的拷贝,并且每个拷贝都不一样,取决于这个.so文件代码段和数据段内存映射的位置。
-
不加-fPIC编译出来的.so是要在加载时根据加载到的位置再次重定位的,因为它里面的代码BBS位置无关代码。如果该.so文件被多个应用程序共同使用,那么它们必须每个程序维护一份.so的代码副本(因为.so被每个程序加载的位置都不同,显然这些重定位后的代码也不同,当然不能共享)。
-
我们总是用-fPIC来生成.so,但从来不用-fPIC来生成.a,但是.so一样可以不用-fPIC选项进行编译,只是这样的.so必须要在加载到用户程序的地址空间时重定向所有表目。
第二步:使用-shared选项将所有目标文件打包成动态库
与生成静态库不同的是,生成动态库时我们不必使用ar命令,只需使用gcc的-shared选项即可。
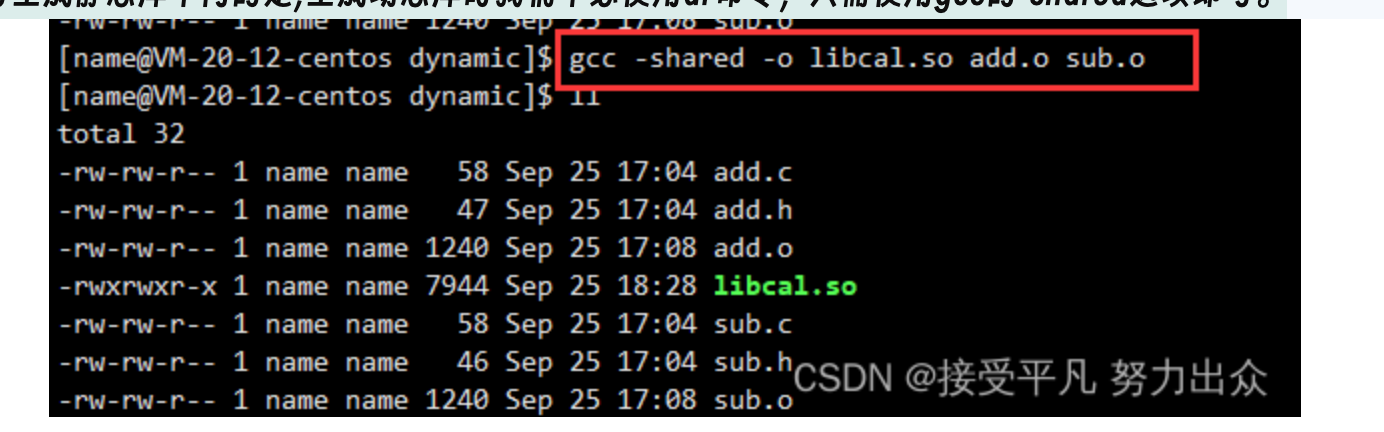
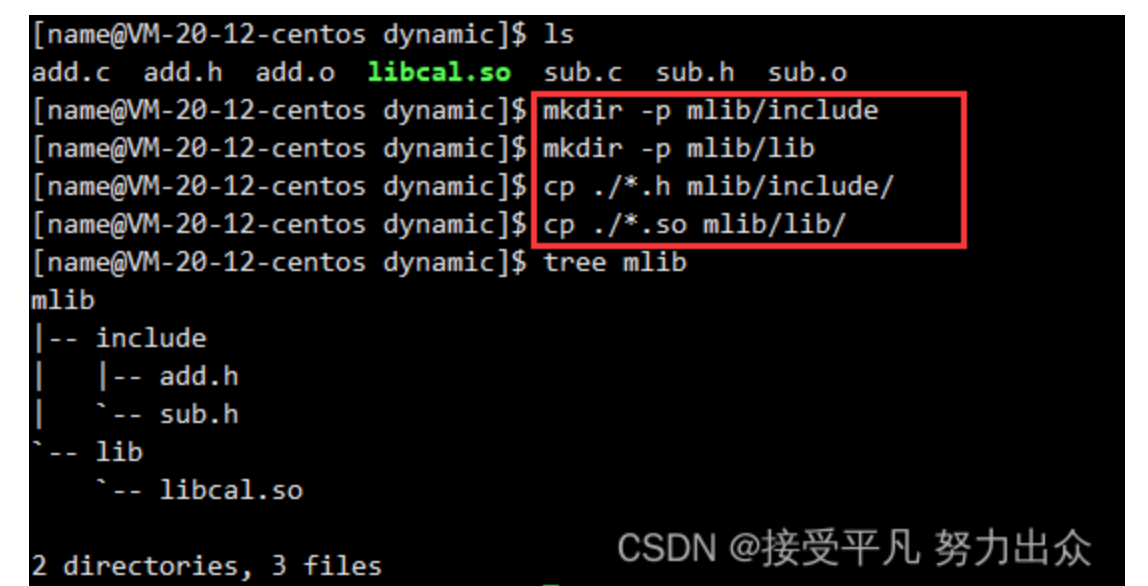
第三步: 将头文件和生成的动态库组织起来
与生成静态库时一样,为了方便别人使用,在这里可以将add.h和sub.h这两个头文件放到一个名为include的目录下,将生成的的动态库文件libcal.so放在一个名为lib的目录下,然后将这两个目录都放在mlib下。
动态库的使用
使用main.c来演示动态库的使用和我们刚打包好的动态库
使用该动态库的方法与刚才我们使用静态库的方法一样,我们既可以用-I,-L,-l这三个选项来生成可执行程序,也可以先将头文件和库文件拷贝到系统目录下,然后仅使用-l选项指明需要链接的库名字来生成可执行程序。下面仅以第一种方法为例进行演示。
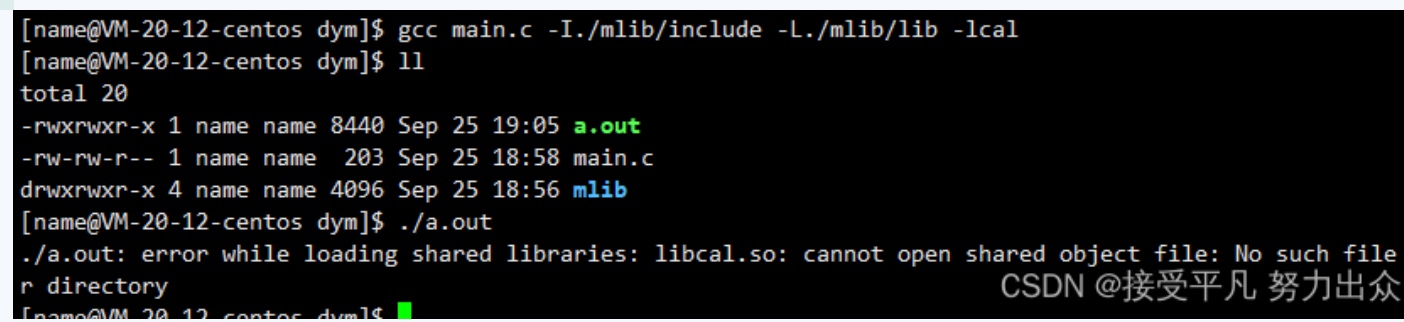
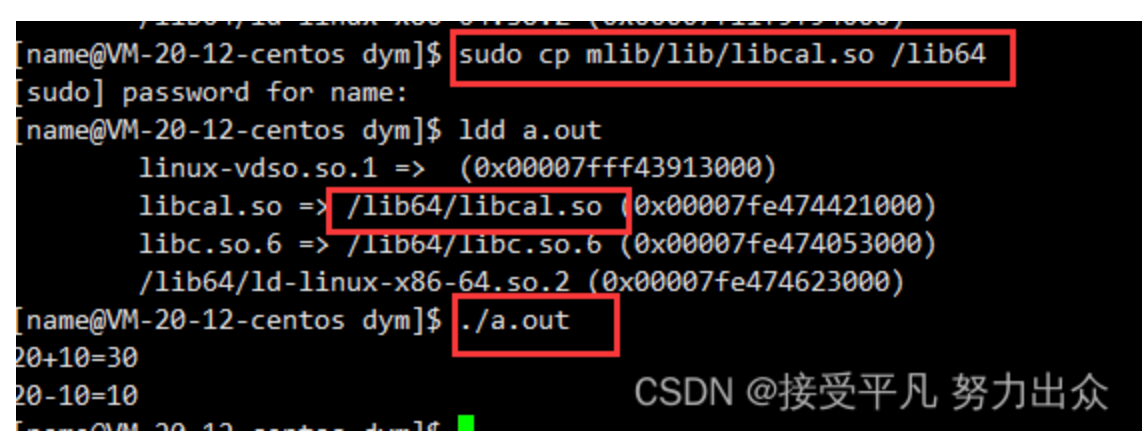
与静态库不同的是,这里无法直接运行。
需要注意,这里使用-I,-L,-l这三个选项都是在编译期间告诉编译器我们使用的头文件和库文件在哪里以及是谁,但是当生成的可执行程序生成后就与编译器没有关系了,此后该可执行程序运行起来后,操作系统找不到该可执行程序所依赖的动态库。
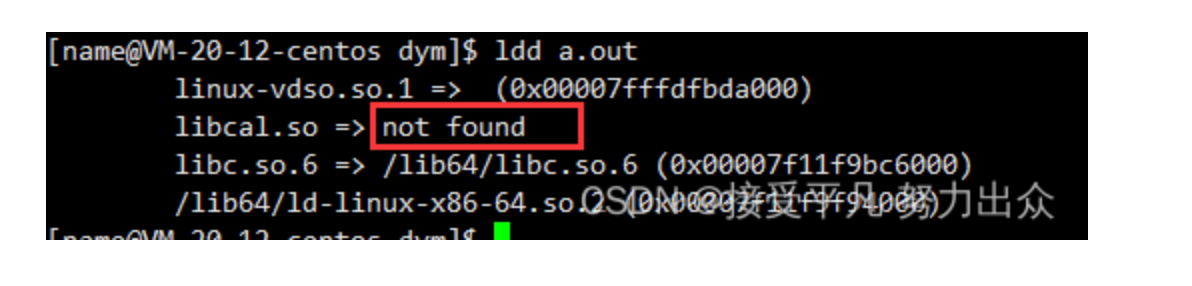
既然找不到我们的库文件,那么我们直接将库文件拷贝到系统共享的库路径下,这样一来系统就能找到对应的库文件了。