前言
R-CNN系列算法(R-CNN、SPPNet、Fast R-CNN、Faster R-CNN)均是采用two-stage的方法(1.提取region proposal 2.分类+边框回归),主要是对region proposal进行识别定位。虽然这类方法检测精度很高,但由于需要一个单独的网络进行提取region proposal,因此在速度上无法突破瓶颈。
而YOLOV1算法作为YOLO系列算法的开篇之作,作为One Stage目标检测算法的杰出代表,其重要性不言而喻。可以说,其具有着开天辟地的作用,今天我们便来一睹第一代YOLO算法的风采。
论文下载地址:https://arxiv.org/abs/1506.02640
YOLOV1创新点
作为YOLO系列的开篇之作,其主要是针对Two Stage目标检测算法的创新。
将detection视为回归问题,仅使用一个neural network同时预测bounding box的位置和类别,因此速度很快。
由于不需提取region proposal,而是直接在整幅图像进行检测,因此YOLOv1可以联系上下文信息和特征,减少将背景检测为物体的错误。
YOLOv1学习到的是目标的泛化表示(generalizable representations),泛化能力非常强,更容易应用于新的领域或输入。
设计思路
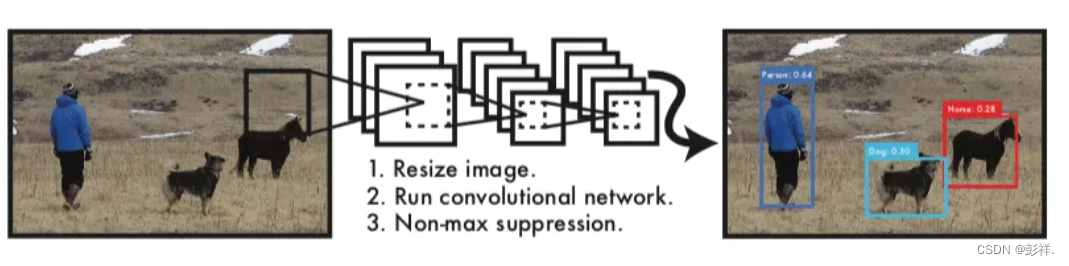
由于不需提取region proposal,则YOLOv1的检测流程很简单:
**Resize image:**将输入图片resize到448x448。
**Run ConvNet:**使用CNN提取特征,FC层输出分类和回归结果。
**Non-max Suppression:**非极大值抑制筛选出最终的结果。
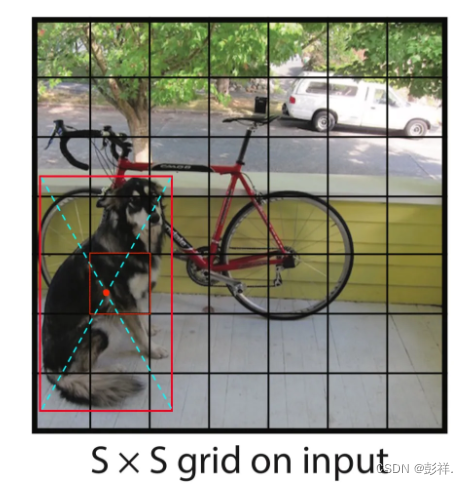
没有region proposal,那应该怎么定位那些包含目标的区域并固定输出呢?简单来说,YOLOv1的做法是:**CNN网络将resize后的图像分割成S x S(7 x 7)的单元格,若目标的中心点落在某一单元格,则该单元格负责检测该目标,输出该目标的类别和边框坐标。**例如:下图中狗的中心落在红色单元格内,则这个单元格负责预测狗。
网络结构
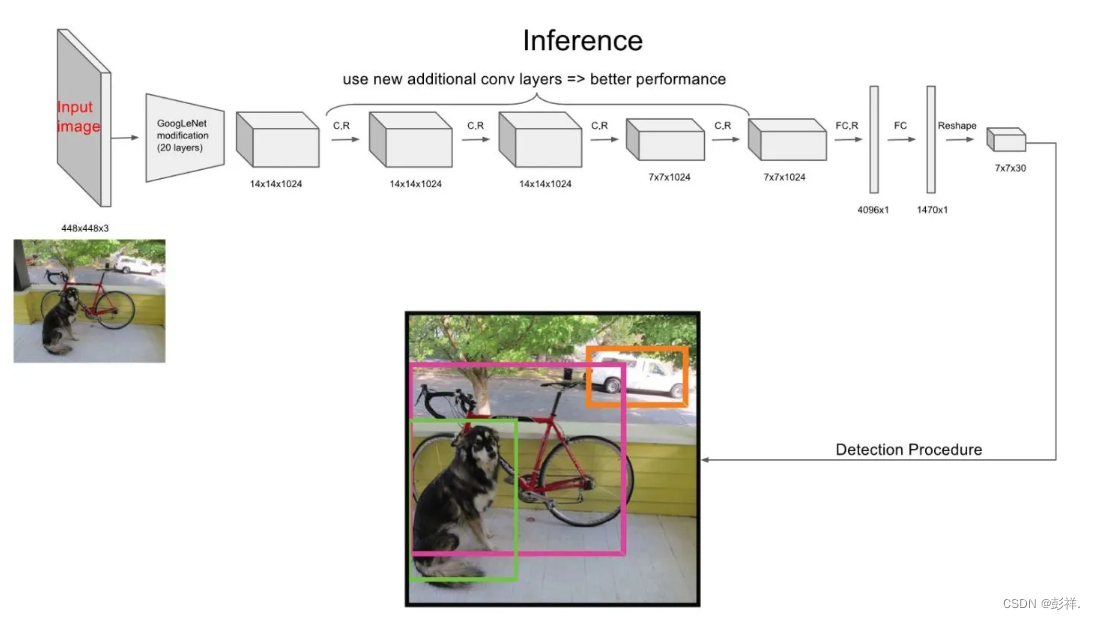
YOLOv1的网络结构很简单,借鉴了GooLeNet设计,共包含24个卷积层,2个全链接层(前20层中用1×1 reduction layers 紧跟 3×3 convolutional layers 取代GooLeNet的 inception modules,GooLeNet有20层)。
1.输入:448 x 448 x 3,由于网络的最后需要接入两个全连接层,全连接层需要固定尺寸的输入,故需要将输入resize。
2.Conv + FC:主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:max(x,0.1x) ,但是最后一层采用线性激活函数。
3.输出:最后一个FC层得到一个1470 x 1的输出,将这个输出reshape一下,得到 7 x 7 x 30 的一个tensor,即最终每个单元格都有一个30维的输出,代表预测结果。具体如下:
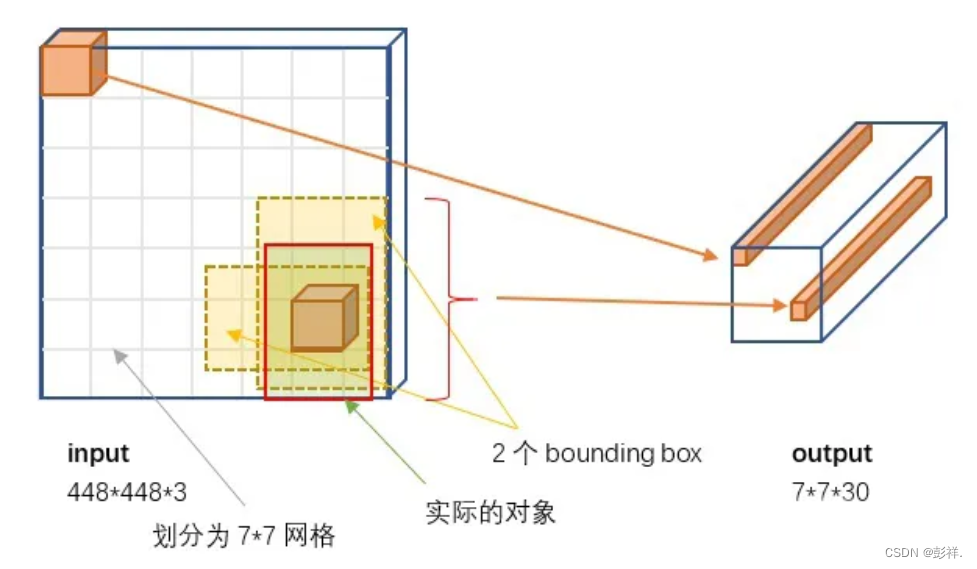
7 x 7 (网格):
输入图像被划分为 7 x 7 的单元格(grid),输出tensor中的 7 x 7 对应着输入图像的 7 x 7 个单元格,每个单元格对应输出30维的向量。如上图所示,输入图像左上角的网格对应到输出张量中左上角的向量。要注意的是,并不是说仅仅网格内的信息被映射到一个30维向量。经过神经网络对输入图像信息的提取和变换,网格周边的信息也会被识别和整理,最后编码到那个30维向量中。
30维向量:
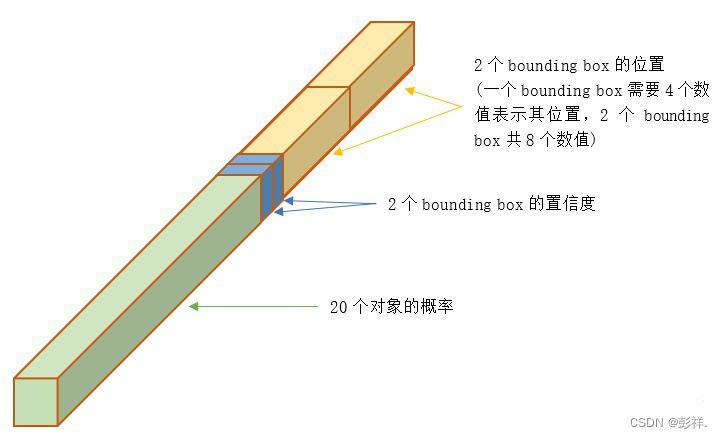
① 2个bounding box的位置:对于每个单元格,YOLOv1会预测出2个bounding box,每个bounding box需要4个数值(x, y, w, h)来表示其位置,2个bounding box共需要8个数值来表示其位置,(x,y) 是bbox的中心点的位置,这个位置值相对于单元格归一化到0-1之间,例如图片的宽为width,高为height,上图红框中的单元格坐标为(5, 5),那 x=bbox 的实际坐标x/(width/S)-5,y=bbox 的实际坐标 y/(height/S)-5。(w,h) 是bbox的宽和高,这个是相对于整张图片的,即w=bbox实际的宽/图片的宽,h=bbox实际的高/图片的高,这样做可以将w和h归一到0-1之间,这有利于之后的回归。
② 2个bounding box的置信度:对于每个单元格,YOLOv1会预测出2个置信度,分别对应该单元格预测两个bounding box。每一个置信度包含两个方面,一是该边界框含有目标的可能性大小,二是该边界框的准确度。前者记为 Pr(object),当该边界框是背景时(即不包含目标),此时Pr(object)=0;当该边界框包含目标时,Pr(object)=1。后者即边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为IOU。因此置信度可以定义为Pr(object)*IOU。
③20类对象分类的概率:对于每个单元格,YOLOv1预测出20个类别概率值(对于PASCAL VOC数据集),其表征的是由该单元格负责预测的两个边界框中的目标属于各个类别的概率。注意这些概率值其实是在各个边界框置信度下的条件概率,即Pr(classi/object),也就是说不管一个单元格预测多少个边界框,该单元格只预测一组类别概率值(YOLOv1的一大缺点)。
总结:输入图片被分成 7 x 7 个单元格,每个单元格预测输出2个bounding box,每个bounding box包含5个值(4个坐标+1置信度),另外每个单元格预测20个类别,所以最终预测输出7 x 7 (4 + 1 + 20) = 7 x 7 x 30 的tensor。
训练过程
首先在ImageNet上对网络中的前20层进行预训练,之后再在这20层后连上4层卷积和2层全连接层进行训练。所以,前20层是用预训练网络初始化,最后的这6层是随机初始化的并在训练过程中更新权重。此外,因为detection需要更多图片细节的信息,所以在训练时,统一将输入图片的size从224224调整为448448。对于loss函数,是通过ground truth和输出之间的sum-squared error(SSE,误差平方和)进行计算的,所以相当于把分类问题也当成回归问题来计算loss。下面分析loss函数:
LOSS计算
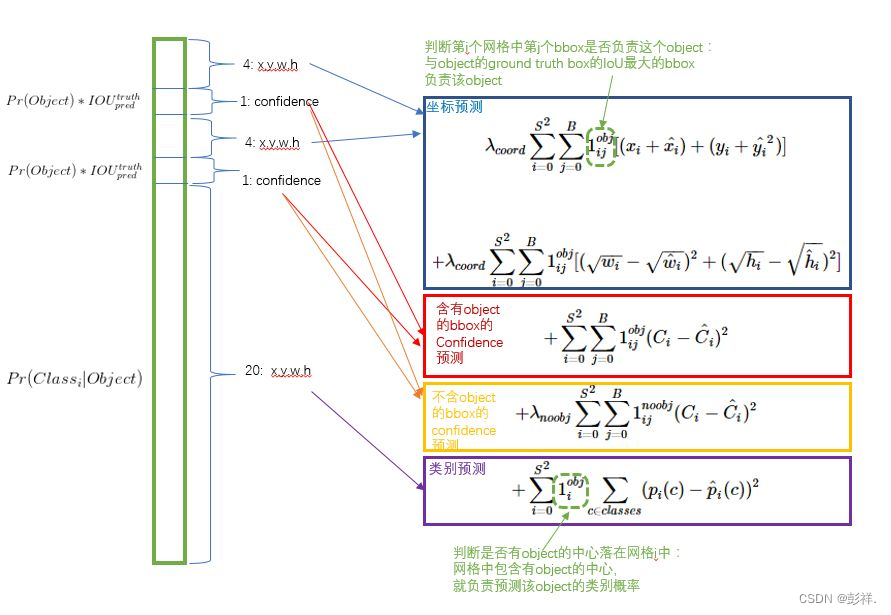
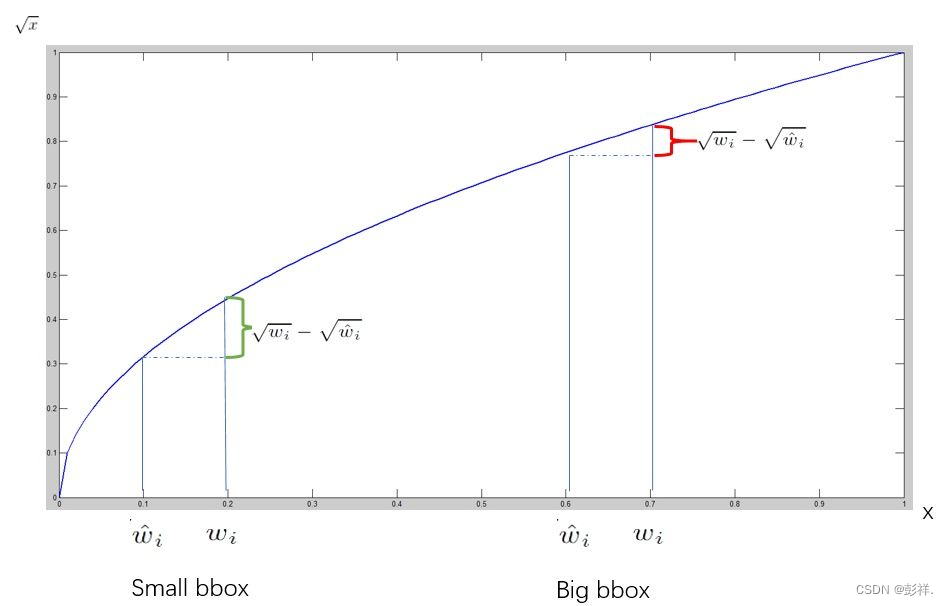
**位置误差:**主要是计算bbox的 (x,y,w,h) 和对应的ground truth box的 (x,y,w,h) 之间的sum-squared error,需要注意的是并不是所有的bbox都参与loss的计算,首先必须是第i个单元格中存在object,并且该单元格中的第j个bbox和ground truth box有最大的IoU值,那么这个bbox j才参与loss的计算,其他的不满足条件的bbox不参与。此外,因为误差在小的box上体现的更明显,即一点点小的位置上的偏差可能对大的box影响不是很大,但是对小的box的影响就比较明显了,所以为了给不同size的box的位置loss赋予不同的‘权重’,需要对w和h开方后才进行计算。根据 y=
x
2
\sqrt[2]{x}
2x 的函数图像可知,当x较小时,x的一点小的变化都会导致y大的变化,而当x较大的时候,x的一点儿小的变化不会让y的变化太大。 但这个方法只能减弱这个问题,并不能彻底解决这个问题。
**置信度误差:**分两种情况,一是有object的单元格的置信度计算,另一种是没有object的单元格的置信度计算。两种情况都是单元格中所有的bbox都参与计算。对于有object的单元格中的bbox的置信度的ground truth就是1IOU。需要注意的是这个IOU是在训练过程中不断计算出来的,因为网络在训练过程中每次预测的bbox是变化的,所以bbox和ground truth计算出来的IOU每次也会不一样。而对于没有object的单元格中的bbox的置信度的ground truth为0IOU=0,因为不包含物体。
**分类误差:**当作回归误差来计算,使用sum-squared error来计算分类误差,需要注意的是只有包含object的单元格才参与分类loss的计算,即有object中心点落入的单元格才进行分类loss的计算,而这个单元格的ground truth label就是该物体的label。
此外,为了使得三种误差达到平衡,就需要给不同的误差赋予不同的权重。
1.更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为
λ
\lambda
λcoord ,在pascal VOC训练中取5。(上图蓝色框)
2.对没有object的bbox的confidence loss,赋予小的loss weight,记为
λ
\lambda
λnoobj,在pascal VOC训练中取0.5。(上图橙色框)
3.有object的bbox的confidence loss (图6红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
总结起来就是:
对于有object的cell,那么计算cell的分类误差,然后cell中两个bbox的置信度误差,然后cell中和ground truth box的IoU最大的bbox的位置误差。
对于没有object的cell,那就只计算cell中两个bbox的置信度误差。
测试过程
将一张图输入到网络中,然后得到一个 7730 的预测结果。然后将计算结果中的每个单元格预测的类别信息 Pr(classi/Object) 和每个bbox的置信度信息 Pr(object)*IOU 相乘即可得到每个bbox的class-specific confidence score:
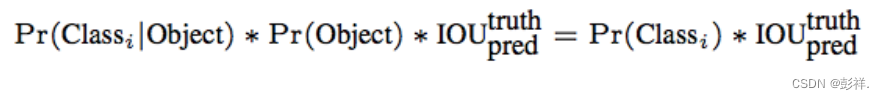
如下图所示:
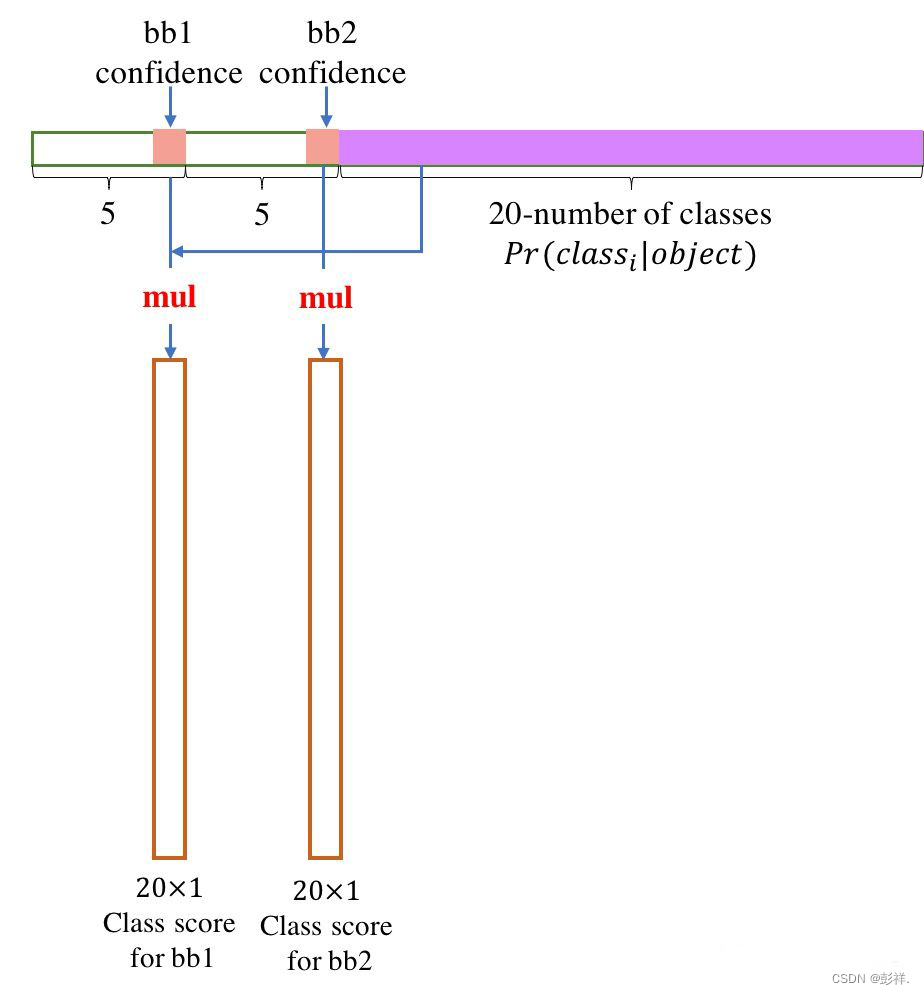
根据同样的方法可以计算得到7 x 7 x 2 = 98个bbox的confidence score,然后根据confidence score对预测得到的98个bbox进行非极大值抑制,得到最终的检测结果。
YOLOv1缺点
因为YOLO中每个cell只预测两个bbox和一个类别,这就限制了能预测重叠或邻近物体的数量,比如说两个物体的中心点都落在这个cell中,但是这个cell只能预测一个类别。
此外,不像Faster R-CNN一样预测offset,YOLO是直接预测bbox的位置的,这就增加了训练的难度。
YOLO是根据训练数据来预测bbox的,但是当测试数据中的物体出现了训练数据中的物体没有的长宽比时,YOLO的泛化能力低
同时经过多次下采样,使得最终得到的feature的分辨率比较低,就是得到coarse feature,这可能会影响到物体的定位。
损失函数的设计存在缺陷,使得物体的定位误差有点儿大,尤其在不同尺寸大小的物体的处理上还有待加强。
值得注意的是,YOLOV1的局限主要是由于其没有anchor导致的,而在之后的YOLO项目中为了克服这个问题也都引入了Anchor



![[附源码]JAVA毕业设计校园失物招领管理系统(系统+LW)](https://img-blog.csdnimg.cn/263507da4c1f42d9929222d1dda90125.png)