文章目录
- 一、 实验目的和要求
- 二、实验环境(实验设备)
- 三、实验原理及内容
- (一)设计概要
- 1、C++语言子集
- 2、单词及编码
- 3、状态转换图
- (二)实现分析
- (三)结果分析
- 四、实验小结(包括问题和解决方法、心得体会、意见与建议等)
- (一)实验中遇到的主要问题及解决方法
- (二)实验心得
- (三)意见与建议(没有可省略)
一、 实验目的和要求
设计、编制、调试一个词法分析程序,对单词进行识别和编码,加深对词法分析原理的理解。
二、实验环境(实验设备)
硬件:微型计算机
软件:Windows 操作系统、Visual Studio 2019
三、实验原理及内容
(一)设计概要
1、C++语言子集
(1) 关键字:
void、int、main、return、if、else
(2) 运算符和界限符:
+、-、*、/、%、=
;、(、)、[、]、{、}
(3) 整型常数(INT)和标识符(ID)通过正规文法定义
:= |
:= letter||(||)
2、单词及编码
| 基本符号 | 类型 | 类型说明 |
|---|---|---|
| void | 1 | 关键字 |
| int | 1 | 关键字 |
| main | 1 | 关键字 |
| return | 1 | 关键字 |
| if | 1 | 关键字 |
| else | 1 | 关键字 |
| ; | 2 | 界限符 |
| ( | 2 | 界限符 |
| ) | 2 | 界限符 |
| [ | 2 | 界限符 |
| ] | 2 | 界限符 |
| { | 2 | 界限符 |
| } | 2 | 界限符 |
| + | 3 | 运算符 |
| - | 3 | 运算符 |
| * | 3 | 运算符 |
| / | 3 | 运算符 |
| % | 3 | 运算符 |
| = | 3 | 运算符 |
| 标识符 | 4 | 标识符 |
| 整常数 | 5 | 常量 |
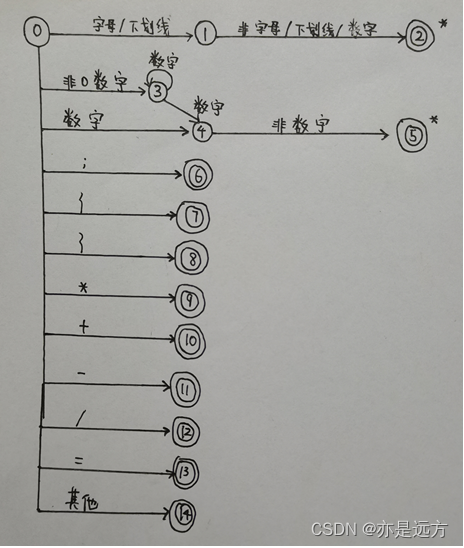
3、状态转换图
(二)实现分析
1、代码
#include <iostream>
#include<fstream>
#define KEYWORD 1
#define DELIMITER 2
#define OPERATOR 3
#define IDENTIFIER 4
#define CONSTINTEGRAL 5
#define ELSE 0
// 关键词列表,界限符列表、运算符列表
std::string keyWord[] = { "void", "int", "char", "main", "return", "if", "else"};
std::string delimiter[] = { "(", ")", "[", "]", "{", "}", ";", "," };
std::string operator0[] = { "+", "-", "*", "/", "%", "=" };
// 检测 char 中字符是否为字母
bool Letter(char c)
{
if (c >= 'A' && c <= 'Z' || c >= 'a' && c <= 'z')
{
return true;
}
return false;
}
// 检测单词是否为关键字
bool KeyWord(std::string str)
{
for (std::string p : keyWord)
{
if (p == str)
return true;
}
return false;
}
// 判断单词是否是界限符
bool Delimiter(std::string str)
{
for (std::string p : delimiter)
{
if (p == str)
return true;
}
return false;
}
// 判断单词是否是运算符
bool Operator(std::string str)
{
for (std::string p : operator0)
{
if (p == str)
return true;
}
return false;
}
// 判断字符是否为数字
bool Digit(char c)
{
if (c >= '0' && c <= '9')
{
return true;
}
return false;
}
// 由 token 查保留字表,若 token 中字符串为保留字符则返回其类别编码,否则返回值为0
int Reserve(std::string str)
{
int type = ELSE;
if (KeyWord(str))
type = KEYWORD;
else if (Delimiter(str))
type = DELIMITER;
else if (Operator(str))
type = OPERATOR;
else if (Digit(str[0]))
type = CONSTINTEGRAL;
// 标识符
else if (str[0] == '_' || Letter(str[0]))
{
type = IDENTIFIER;
{
for (int i = 1; i < str.length(); i++)
{
// 若不符合标识符规则,则type=0
if (!(str[i] == '_' || Letter(str[i]) || Digit(str[i])))
{
type = ELSE;
break;
}
}
}
}
else
type = ELSE;
return type;
}
// 读取源代码文本文件
std::string ReadFile(std::string url)
{
std::string token = "";
char ch;
std::ifstream infile;
infile.open(url, std::ios::in);
if (!infile.is_open())
{
std::cout << "文件无法打开!";
return "";
}
infile >> ch;
while (!infile.eof())
{
token = token + ch;
infile >> ch;
}
infile.close();
return token;
}
int main()
{
// 读取源代码文本文件,将空格和回车删除
std::string token = ReadFile("code.txt");
// 打印处理后的源代码
std::cout << "token = " << token << std::endl;
// str 存入一个单词
std::string str = "";
int i = 0;
// 依次遍历源代码中的每一个字符
while(i < token.length())
{
str = "";
// 数字开头
if (Digit(token[i]))
{
while (Digit(token[i]))
str = str + token[i++];
// 打印分类结果
std::cout << "(" << Reserve(str) << ", " << "\"" << str << "\"" << ")" << std::endl;
}
// 下划线或者字母开头的单词,即标识符或者关键字
else if (token[i] == '_' || Letter(token[i]))
{
while (token[i] == '_' || Letter(token[i]) || Digit(token[i]))
{
str = str + token[i++];
// 如果是关键字,立即结束
if (Reserve(str) == KEYWORD)
break;
}
std::cout << "(" << Reserve(str) << ", " << "\"" << str << "\"" << ")" << std::endl;
}
// 运算符
else {
str = str + token[i++];
std::cout << "(" << Reserve(str) << ", " << "\"" << str << "\"" << ")" << std::endl;
}
}
}
1、时间复杂度分析
时间复杂度为O(n)
(三)结果分析
1、 实验使用的源代码文本文件内容如下

2、实验结果
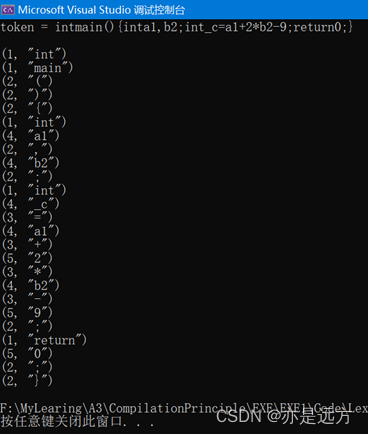
3、结果分析
各种单词均识别分类正确,实验正确
实 验 报 告
四、实验小结(包括问题和解决方法、心得体会、意见与建议等)
(一)实验中遇到的主要问题及解决方法
1、 在编译时,只有第一个标识符识别正确,从第二个标识符开始被识别成非法单词,后来经过调试,发现是在循环过程中,应该首先假设下划线或者字母开头的任意单词是标识符,然后再判断单词中是否出现其他非法字符
2、 在读取源代码文本文件时,无法读取到最后一个字符,后来通过调试,发现读取每个字符时,不能使用string类型变量保存读取到的字符,改用char类型变量读取后,能够正常读取文件内所有的字符。
(二)实验心得
1、熟悉了词法分析的过程
2、加深了对编译器分析源代码词法的理解



![[附源码]计算机毕业设计的花店售卖系统的设计与实现Springboot程序](https://img-blog.csdnimg.cn/f7120909fcc843e48dafb0a828db689e.png)