目录
1. 探索参数空间
1.1 学习曲线
1.2. 决策树对象Tree
2. 使用网格搜索在随机森林上进行调参
1. 探索参数空间
随机森林集成算法的超参数种类繁多、取值丰富,且参数之间会相互影响、共同作用于算法的最终结果,因此集成算法的调参是一个难度很高的过程。在超参数优化还未盛行的时候,随机森林的调参是基于方差-偏差理论(variance-bias trade-off)和学习曲线完成的,而现在可以依赖于网格搜索来完成自动优化。在对任意算法进行网格搜索时,需要明确两个基本事实:一是参数对算法结果的影响力大小,二是用于进行搜索的参数空间。
对随机森林来说,各个参数对算法的影响排列大致如下:
| 影响力 | 参数 |
|---|---|
| ⭐⭐⭐⭐⭐ 几乎总是具有巨大影响力 | n_estimators(整体学习能力) max_depth(粗剪枝) max_features(随机性) |
| ⭐⭐⭐⭐ 大部分时候具有影响力 | max_samples(随机性) class_weight(样本均衡) |
| ⭐⭐ 可能有大影响力 大部分时候影响力不明显 | min_samples_split(精剪枝) min_impurity_decrease(精剪枝) max_leaf_nodes(精剪枝) criterion(分枝敏感度) |
| ⭐ 当数据量足够大时,几乎无影响 | random_state ccp_alpha(结构风险) |
随机森林在剪枝方面的空间总是很大的,因为默认参数下树的结构基本没有被影响(也就是几乎没有剪枝),因此当随机森林过拟合的时候,我们可以尝试粗、精、随机等各种方式来影响随机森林。通常在网格搜索当中,我们会考虑所有有巨大影响力的参数、以及1~2个影响力不明显的参数。
虽然随机森林调参的空间较大,但大部分时候在调参过程中依然难以突破,因为树的集成模型的参数空间非常难以确定。当没有数据支撑时,人们很难通过感觉或经验来找到正确的参数范围。举例来说,我们也很难直接判断究竟多少棵树对于当前的模型最有效,同时,我们也很难判断不剪枝时一棵决策树究竟有多深、有多少叶子、或者一片叶子上究竟有多少个样本,更不要谈凭经验判断树模型整体的不纯度情况了。可以说,当森林建好之后,我们简直是对森林一无所知。对于网格搜索来说,新增一个潜在的参数可选值,计算量就会指数级增长,因此找到有效的参数空间非常重要。此时我们就要引入两个工具来帮助我们:学习曲线 and 决策树对象Tree的属性。
1.1 学习曲线
学习曲线是以参数的不同取值为横坐标,模型的结果为纵坐标的曲线。当模型的参数较少、且参数之间的相互作用较小时,我们可以直接使用学习曲线进行调参。但对于集成算法来说,学习曲线更多是探索参数与模型关系的关键手段。许多参数对模型的影响是确定且单调的,例如n_estimators,树越多模型的学习能力越强,再比如ccp_alpha,该参数值越大模型抗过拟合能力越强,因此我们可能通过学习曲线找到这些参数对模型影响的极限,并围绕这些极限点来构筑参数空间。
Option = [1,*range(5,101,5)]
#生成保存模型结果的arrays
trainRMSE = np.array([])
testRMSE = np.array([])
trainSTD = np.array([])
testSTD = np.array([])
for n_estimators in Option:
#按照当下的参数,实例化模型
reg_f = RFR(n_estimators=n_estimators,random_state=1412)
#实例化交叉验证方式,输出交叉验证结果
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_f = cross_validate(reg_f,x,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True)
#根据输出的MSE进行RMSE计算
train = abs(result_f["train_score"])**0.5
test = abs(result_f["test_score"])**0.5
#将本次交叉验证中RMSE的均值、标准差添加到arrays中进行保存
trainRMSE = np.append(trainRMSE,train.mean())
testRMSE = np.append(testRMSE,test.mean())
trainSTD = np.append(trainSTD,train.std())
testSTD = np.append(testSTD,test.std())def plotCVresult(Option,trainRMSE,testRMSE,trainSTD,testSTD):
#一次交叉验证下,RMSE的均值与std的绘图
xaxis = Option
plt.figure(figsize=(8,6),dpi=80)
#RMSE
plt.plot(xaxis,trainRMSE,color="k",label = "RandomForestTrain")
plt.plot(xaxis,testRMSE,color="red",label = "RandomForestTest")
#标准差 - 围绕在RMSE旁形成一个区间
plt.plot(xaxis,trainRMSE+trainSTD,color="k",linestyle="dotted")
plt.plot(xaxis,trainRMSE-trainSTD,color="k",linestyle="dotted")
plt.plot(xaxis,testRMSE+testSTD,color="red",linestyle="dotted")
plt.plot(xaxis,testRMSE-testSTD,color="red",linestyle="dotted")
plt.xticks([*xaxis])
plt.legend(loc=1)
plt.show()
plotCVresult(Option,trainRMSE,testRMSE,trainSTD,testSTD)
当绘制学习曲线时,可以很容易找到泛化误差开始上升或转变为平稳趋势的转折点。因此我们可以选择转折点或转折点附近的n_estimators取值,例如20。然而,n_estimators会受到其他参数的影响,例如:单棵决策树的结构更简单时(依赖剪枝时),或单棵决策树训练的数据更简单时(依赖随机性时),可能需要更多树。因此n_estimators的参数空间可以被确定为range(20,100,5),如果比较保守,甚至可以确认为是range(15,25,5)。
1.2. 决策树对象Tree
在sklearn中,树模型是单独的一类对象,每个树模型背后都有一套完整的属性供我们调用,包括树的结构、树的规模等众多细节。随机森林是树组成的算法,因此也可以调用这些属性。
#训练一个随机森林
reg_f = RFR(n_estimators=10,random_state=1412)
reg_f = reg_f.fit(x,y) 属性
.estimators_
reg_f.estimators_ #返回一片随机森林中所有的树[DecisionTreeRegressor(max_features=1.0, random_state=1608637542), DecisionTreeRegressor(max_features=1.0, random_state=1273642419), DecisionTreeRegressor(max_features=1.0, random_state=1935803228), DecisionTreeRegressor(max_features=1.0, random_state=787846414), DecisionTreeRegressor(max_features=1.0, random_state=996406378), DecisionTreeRegressor(max_features=1.0, random_state=1201263687), DecisionTreeRegressor(max_features=1.0, random_state=423734972), DecisionTreeRegressor(max_features=1.0, random_state=415968276), DecisionTreeRegressor(max_features=1.0, random_state=670094950), DecisionTreeRegressor(max_features=1.0, random_state=1914837113)]
reg_f.estimators_[0] #使用索引单独提取一棵树DecisionTreeRegressor(max_features=1.0, random_state=1608637542)
属性
.max_depth
reg_f.estimators_[0].tree_.max_depth #查看第一棵树的实际深度21
#对随机森林中所有树查看实际深度
for t in reg_f.estimators_:
print(t.tree_.max_depth)21 23 24 19 22 25 21 21 22 22
如果树的数量较多,也可以查看平均或分布
reg_f = RFR(n_estimators=100,random_state=1412)
reg_f = reg_f.fit(x,y)
d = pd.Series([],dtype="int64")
for idx,t in enumerate(reg_f.estimators_):
d[idx] = t.tree_.max_depth
d.describe()count 100.000000 mean 22.250000 std 1.955954 min 19.000000 25% 21.000000 50% 22.000000 75% 23.000000 max 30.000000 dtype: float64
假设现在随机森林过拟合,max_depth的最大深度范围设置在[15,25]之间就会比较有效,如果希望激烈地剪枝,则可以设置在[10,15]之间。
相似的,也可以调用其他属性来辅助我们调参:
| 参数 | 参数含义 | 对应属性 | 属性含义 |
|---|---|---|---|
| n_estimators | 树的数量 | reg.estimators_ | 森林中所有树对象 |
| max_depth | 允许的最大深度 | .tree_.max_depth | 树实际的深度 |
| max_leaf_nodes | 允许的最大 叶子节点量 | .tree_.node_count | 树实际的总节点量 |
| min_sample_split | 分枝所需最小样本量 | .tree_.n_node_samples | 每片叶子上实际的样本量 |
| min_weight_fraction_leaf | 分枝所需最小 样本权重 | tree_.weighted_n_node_samples | 每片叶子上实际的样本权重 |
| min_impurity_decrease | 分枝所需最小 不纯度下降量 | .tree_.impurity .tree_.threshold | 每片叶子上的实际不纯度 每个节点分枝后不纯度下降量 |
属性
.tree_.node_count
#所有树上的总节点数
for t in reg_f.estimators_:
print(t.tree_.node_count)1807 1777 1763 1821 1777 1781 1811 1771 1753 1779
属性
.tree_.threshold
#每个节点上的不纯度下降量,为负数则表示该节点是叶子节点
reg_f.estimators_[0].tree_.threshold.tolist()[:20][6.5, 5.5, 327.0, 214.0, 0.5, 1.0, 104.0, 0.5, -2.0, -2.0, -2.0, 105.5, 28.5, 0.5, 1.5, -2.0, -2.0, 11.0, 1212.5, 2.5]
#min_impurity_decrease的范围设置多少会剪掉多少叶子?
pd.Series(reg_f.estimators_[0].tree_.threshold).value_counts().sort_index()-2.0 904
0.5 43
1.0 32
1.5 56
2.0 32
...
1118.5 1
1162.5 1
1212.5 2
1254.5 1
1335.5 1
Length: 413, dtype: int64
根据结果显示:对于第一棵树,有904个叶子节点;有43个节点不纯度下降为0.5;依此类推……
pd.set_option("display.max_rows",None)
np.cumsum(pd.Series(reg_f.estimators_[0].tree_.threshold).value_counts().sort_index()[1:])从这棵树反馈的结果来看,min_impurity_decrease在现有数据集上至少要设置到[2,10]的范围才可能对模型有较大的影响。
更多属性可以参考:
from sklearn.tree._tree import Tree
help(Tree) 现在模型正处于过拟合的状态,需要抗过拟合,且整体数据量不是非常多,随机抽样的比例不宜减小,因此我们挑选以下五个参数进行搜索:n_estimators,max_depth,max_features,min_impurity_decrease,criterion。
2. 使用网格搜索在随机森林上进行调参
import numpy as np
import pandas as pd
import sklearn
import matplotlib as mlp
import matplotlib.pyplot as plt
import time #计时模块time
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.model_selection import cross_validate, KFold, GridSearchCV
data=pd.read_csv('F:\\Jupyter Files\\机器学习进阶\\集成学习\\datasets\\House Price\\train_encode.csv',encoding='utf-8')
data.drop('Unnamed: 0', axis=1, inplace=True)
x=data.iloc[:,:-1]
y=data.iloc[:,-1]step1 :建立benchmark
reg = RFR(random_state=1412)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_pre_adjusted = cross_validate(reg,x,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True)def RMSE(cvresult,key):
return (abs(cvresult[key])**0.5).mean()RMSE(result_pre_adjusted,"train_score")11177.272008319653
RMSE(result_pre_adjusted,"test_score")30571.26665524217
step2:创建参数空间
param_grid_simple = {"criterion": ["squared_error","poisson"]
, 'n_estimators': [*range(20,100,5)]
, 'max_depth': [*range(10,25,2)]
, "max_features": ["log2","sqrt",16,32,64,"auto"]
, "min_impurity_decrease": [*np.arange(0,5,10)]
}step3:实例化用于搜索的评估器、交叉验证评估器与网格搜索评估器
reg = RFR(random_state=1412,verbose=True)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
search = GridSearchCV(estimator=reg
,param_grid=param_grid_simple
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv)step4:训练网格搜索评估器
start = time.time()
search.fit(x,y)
print(time.time() - start)ps:这部分代码跑了将近一个小时,但菜菜老师在实例化随机森林和网格搜索评估器的时候都加了参数n_jobs=-1,即调用全部线程,花了7分钟左右的时间。而我实例化的时候加n_jobs这个参数会报错(试了很多种方法都没法解决😅),最终只能不写,默认n_jobs=1,即只调用一个线程,跑了将近一个小时。(有没有小伙伴知道如何解决这个问题的欢迎来dd😊)
step5:查看结果
search.best_estimator_
ad_reg = RFR(n_estimators=85, max_depth=23, max_features=16, random_state=1412)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_post_adjusted = cross_validate(ad_reg,x,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True)RMSE(result_post_adjusted,"train_score")11000.81099038192
RMSE(result_post_adjusted,"test_score")28572.070208366855
axis = range(1,6)
plt.figure(figsize=(8,6),dpi=80)
plt.plot(xaxis,abs(result_pre_adjusted["train_score"])**0.5,color="green",label = "RF_pre_ad_Train")
plt.plot(xaxis,abs(result_pre_adjusted["test_score"])**0.5,color="green",linestyle="--",label = "RF_pre_ad_Test")
plt.plot(xaxis,abs(result_post_adjusted["train_score"])**0.5,color="orange",label = "RF_post_ad_Train")
plt.plot(xaxis,abs(result_post_adjusted["test_score"])**0.5,color="orange",linestyle="--",label = "RF_post_ad_Test")
plt.xticks([1,2,3,4,5])
plt.xlabel("CVcounts",fontsize=16)
plt.ylabel("RMSE",fontsize=16)
plt.legend()
plt.show()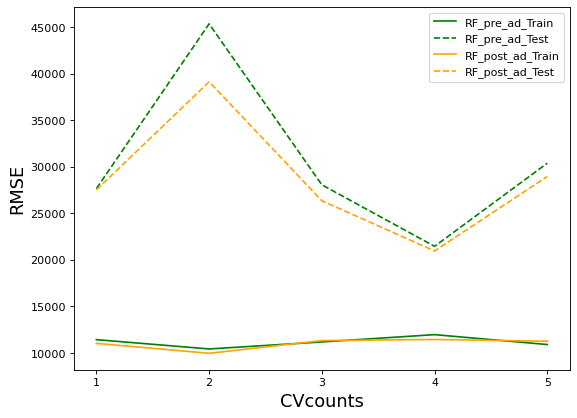
不难发现,网格搜索之后的模型过拟合程度减轻,且在训练集与测试集上的结果都有提高,可以说从根本上提升了模型的基础能力。