后端编译与优化
- 解释器和编译器
- 编译器
- 即时编译器
- 分层编译
- 热点代码
- 热点探测
- 计数器
- 编译过程
- 查看及分析即时编译结果
- 提前编译器
- jaotc的提前编译
- 后端编译优化
- 总览
- 优化演示
- 方法内联(最重要的优化技术之一)
- 逃逸分析(最前沿的优化技术之一)
- 公共子表达式消除(语言无关的经典优化技术之一)
- 数组边界检查消除(语言相关的经典优化技术之一)
解释器和编译器
Java最初都是通过解释器解释执行,随后引入编译器将频繁调用的代码编译成本地代码
- 当程序需要迅速启动和执行时,解释器先发挥作用,省去编译的时间,立即运行
- 当程序启动后,编译器把代码编译成本地代码,以获得更高效率
- 当运行内存有限,可用解释执行节约内存,反之可用编译执行来提升效率
- 解释器可作为编译器激进优化时的逃生门,当激进优化的假设不成立时退回到解释执行
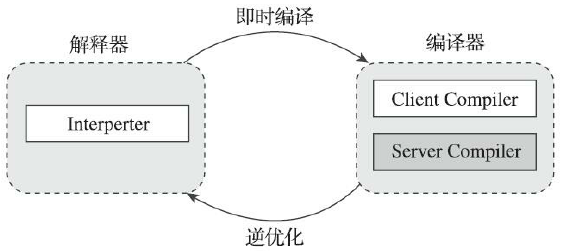
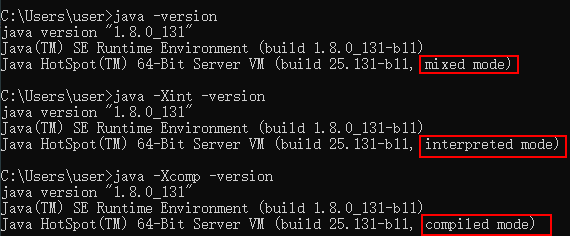
在JDK7分层编译工作模式出现之前,可使用
- -Xmixed 混合模式,解释器与编译器搭配使用
- -Xint 解释模式,编译器不介入工作,代码都使用解释执行
- -Xcomp 编译模式,优先采用编译执行,但解释器要在无法编译时介入
《Java虚拟机规范》中并未规定编译器是JVM必需的组成部分,接下来依据HotSpot中的实现讲解
编译器
字节码转为本地机器码称为后端编译,分为
-
即时编译器(JIT,Just In Time Compiler),如HotSpot的C1、C2、Graal
-
提前编译器(AOT,Ahead Of Time Compiler),如JDK的Jaotc、GNU Compiler for the Java(GCJ)、Excelsior JET
即时编译器
即时编译器在运行时将热点代码编译成本地机器码并优化,分为
- 客户端编译器(Client Compiler),C1编译器
- 服务端编译器(Server Compiler),C2编译器(或叫Opto)
- JDK 10时出现用于替换C2的Graal编译器
分层编译
即时编译器编译本地代码需要占用程序运行时间,且优化程度越高所需时间越长,想要编译出优化程度高的代码,还需让解释器收集性监控信息,同时制约了解释执行速度
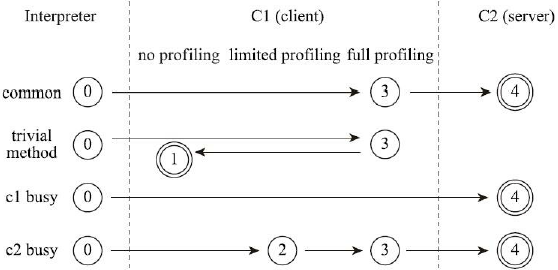
为了达到平衡,JDK7引入分层编译
- 第0层:纯解释执行,不开启性能监控
- 第1层:使用客户端编译器将字节码编译为本地代码来运行,进行简单可靠的稳定优化,不开启性能监控
- 第2层:仍使用客户端编译器执行,仅开启方法及回边次数统计等有限的性能监控功能
- 第3层:仍使用客户端编译器执行,开启全部性能监控,除了第2层的统计信息外,还会收集如分支跳转、虚方法调用版本等全部的统计信息
- 第4层:使用服务端编译器将字节码编译为本地代码,会启用更多编译耗时更长的优化,还会根据性能监控信息进行激进优化
以上层次并非固定不变,根据不同的运行参数和版本,虚拟机可以调整分层的数量。各层次编译之间的交互、转换关系如下
热点代码
即时编译器的编译对象是热点代码,包括
- 被多次调用的方法
- 被多次执行的循环体
上述两种情况,编译的目标对象都是方法体,而不是循环体,当热点代码的编译发生在方法执行的过程中,称为栈上替换(On Stack Replacement,OSR)
热点探测
确定热点代码的行为称为热点探测(Hot Spot Code Detection),分为
- 基于采样的热点探测:周期性检查各个线程的栈顶,经常出现在栈顶的方法即是热点方法,J9采用
- 基于计数器的热点探测:为方法(甚至是代码块)建立计数器,统计执行次数,超过一定的阈值就认定为热点方法,HotSpot采用
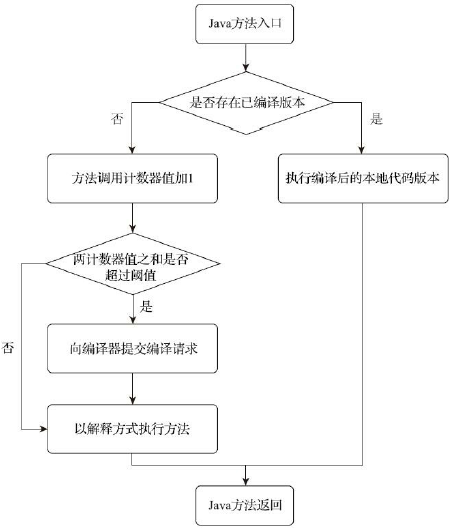
计数器
HotSpot为每个方法建立了方法调用计数器和回边计数器
对于方法调用计数器
- 统计的并不是调用的绝对次数,而是相对的执行频率,即一段时间内调用的次数
- 若超过一定的时间,调用次数未达到即时编译阈值(Client是1500次,Service是10000次,-XX:CompileThreshold),计数器减半,称为热度衰减,而这段时间称为半衰周期
- 热度衰减是在gc时进行,可使用-XX:-UseCounterDecay关闭,以此统计方法调用的绝对次数,当系统运行时间足够长,绝大部分方法都会被编译成本地代码
- -XX:CounterHalfLifeTime可设置半衰周期,单位是秒
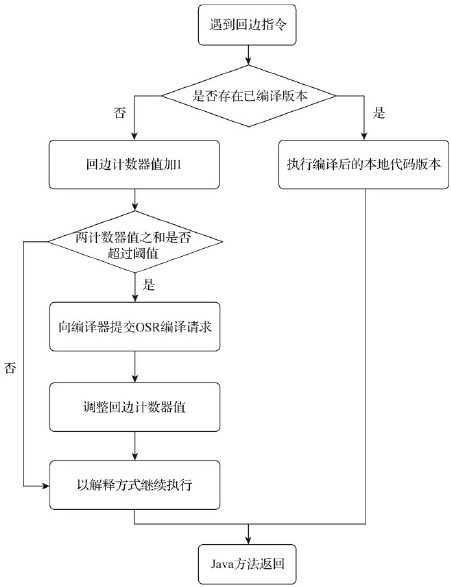
对于回边计数器
- 统计方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令就称为回边
- Client下,默认阈值 = (-XX:CompileThreshold,1500) * (-XX:OnStackReplacePercentage, 933) / 100 = 13995
- Service下,默认阈值 = (-XX:CompileThreshold,1500) * ((-XX:OnStackReplacePercentage,140) - (-XX:InterpreterProfilePercentage, 33) / 100 = 10700
编译过程
即时编译在后台的编译线程中进行
- 可通过-XX:-BackgroundCompilation禁止后台编译
- 禁止后,当达到即时编译条件时,执行线程向JVM提交编译请求
- 随后一直阻塞等待,直到编译完成再开始执行编译出的本地代码
Client的编译过程如下
- 一个平台独立的前端将字节码构造成一种高级中间代码表示(High-Level Intermediate Representation,HIR)
- 一个平台相关的后端从HIR中产生低级中间代码表示(Low-Level Intermediate Representation,LIR)
- 在平台相关的后端使用线性扫描算法在LIR上分配寄存器,并在LIR上做窥孔(Peephole)优化,产生机器代码
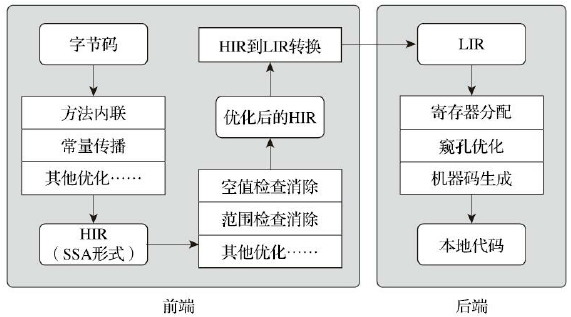
Service编译过程类似Client,但提供更多的优化
查看及分析即时编译结果
对于如下程序
public class Test {
public static final int NUM = 15000;
public static int doubleValue(int i) {
for (int j = 0; j < 100000; j++) ; //空循环用于演示即时编译优化
return i * 2;
}
public static long calcSum() {
long sum = 0;
for (int i = 1; i <= 100; i++) {
sum += doubleValue(i);
}
return sum;
}
public static void main(String[] args) {
for (int i = 0; i < NUM; i++) {
calcSum();
}
}
}
若想在即时编译时打印被编译成本地代码的方法名,可使用
-XX:+PrintCompilation
输出如下,带有%的输出说明是由回边计数器触发的栈上替换编译,可看到calcSum()和doubleValue()被编译
242 110 % 3 Test::doubleValue @ 5 (18 bytes)
242 111 3 Test::doubleValue (18 bytes)
242 112 % 4 Test::doubleValue @ 5 (18 bytes)
242 110 % 3 Test::doubleValue @ -2 (18 bytes) made not entrant
242 113 4 Test::doubleValue (18 bytes)
243 111 3 Test::doubleValue (18 bytes) made not entrant
243 114 3 Test::calcSum (26 bytes)
243 115 % 4 Test::calcSum @ 7 (26 bytes)
244 116 4 Test::calcSum (26 bytes)
245 114 3 Test::calcSum (26 bytes) made not entrant
若想要输出方法内联信息,可使用
-XX:+PrintCompilation (-XX:+UnlockDiagnosticVMOptions) -XX:+PrintInlining
输出如下,可看到doubleValue()内联到calcSum(),JVM下一次执行calcSum()时,doubleValue()不会被实际调用
74 25 % 3 Test::doubleValue @ 5 (18 bytes)
75 26 3 Test::doubleValue (18 bytes)
75 27 % 4 Test::doubleValue @ 5 (18 bytes)
75 25 % 3 Test::doubleValue @ -2 (18 bytes) made not entrant
75 28 4 Test::doubleValue (18 bytes)
75 26 3 Test::doubleValue (18 bytes) made not entrant
76 29 3 Test::calcSum (26 bytes)
@ 9 Test::doubleValue (18 bytes) inlining prohibited by policy
76 30 % 4 Test::calcSum @ 7 (26 bytes)
@ 9 Test::doubleValue (18 bytes) inline (hot)
77 31 4 Test::calcSum (26 bytes)
@ 9 Test::doubleValue (18 bytes) inline (hot)
78 29 3 Test::calcSum (26 bytes) made not entrant
若要进一步查看生成的中间代码表示,可使用
-XX:+PrintOptoAssembly //用于Service
-XX:+PrintLIR //用于Client
如下为calcSum()部分伪汇编代码
000 N221: # B1 <- BLOCK HEAD IS JUNK Freq: 1
000 # breakpoint
nop # 11 bytes pad for loops and calls
010 B1: # B12 B2 <- BLOCK HEAD IS JUNK Freq: 1
010 # stack bang (112 bytes)
pushq rbp # Save rbp
subq rsp, #32 # Create frame
01c movl RBP, [RSI] # int
01e movq RBX, [RSI + #8 (8-bit)] # long
022 movq RDI, RSI # spill
025 call_leaf,runtime OSR_migration_end
No JVM State Info
#
032 cmpl RBP, #100
035 jg B12 P=0.009901 C=100498.000000
想再进一步跟踪本地代码生成过程,可使用
-XX:+PrintCFGToFile //用于Client
-XX:PrintIdealGraphFile //用于Service
将编译过程中的数据输出到文件中,可使用如下工具分析
- Java HotSpot Client Compiler Visualizer用于Client
- Ideal Graph Visualizer用于Service
Service编译器的中间代码称为理想图,如下使用
-XX:PrintIdealGraphLevel=2 -XX:PrintIdealGraphFile=ideal.xml
生成一个包含编译代码过程信息的ideal.xml文件,用Ideal Graph Visualizer打开,如下左侧为编译过的方法列表和优化过程,右侧为理想图,节点表示程序的元素,边表示数据或控制流
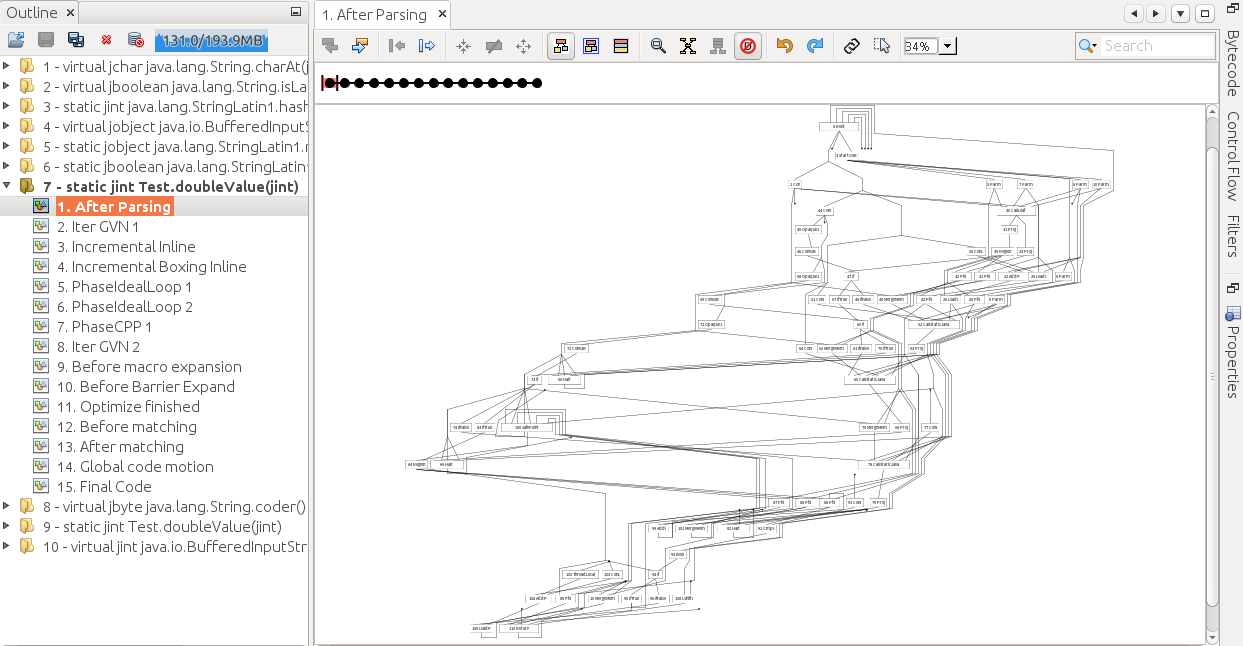
对于doubleValue(),若忽略语言安全检查的基本块,可简化为
- 程序入口,建立栈帧
- 设置j=0,进行安全点(Safepoint)轮询,跳转到4的条件检查
- 执行j++
- 条件检查,如果j<100000,跳转到3
- 设置i=i*2,进行安全点轮询,函数返回
而for (int j = 0; j < 100000; j++) ;空循环路径流程对应下图
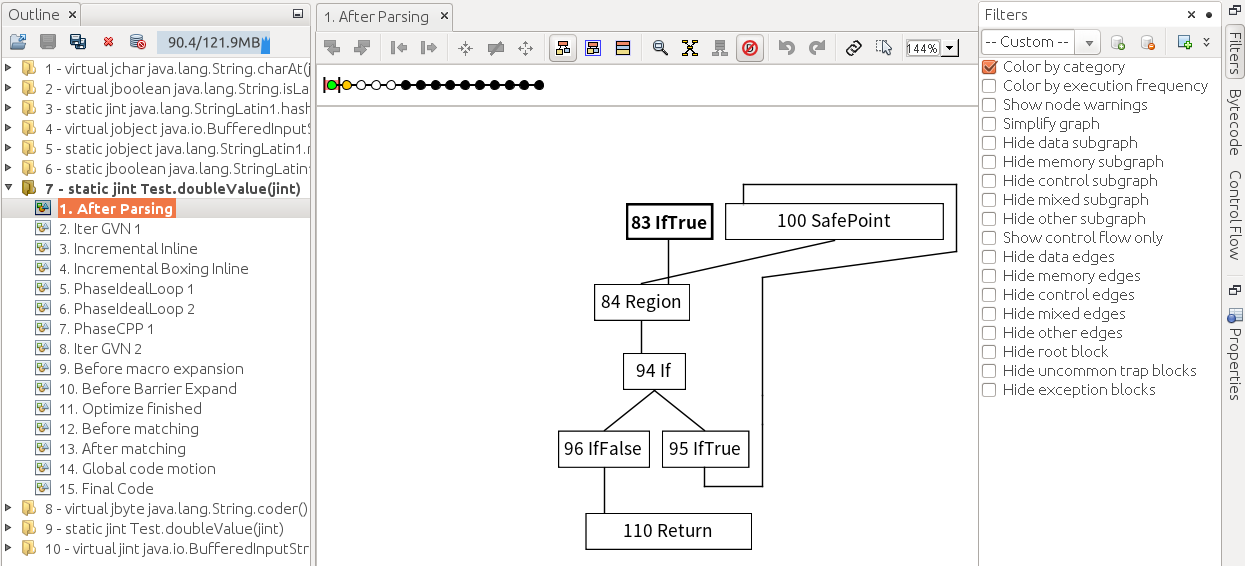
Outline右击Difference to current graph(或拖动小圆圈),软件自动分析两阶段理想图的差异,若被消除则为红色
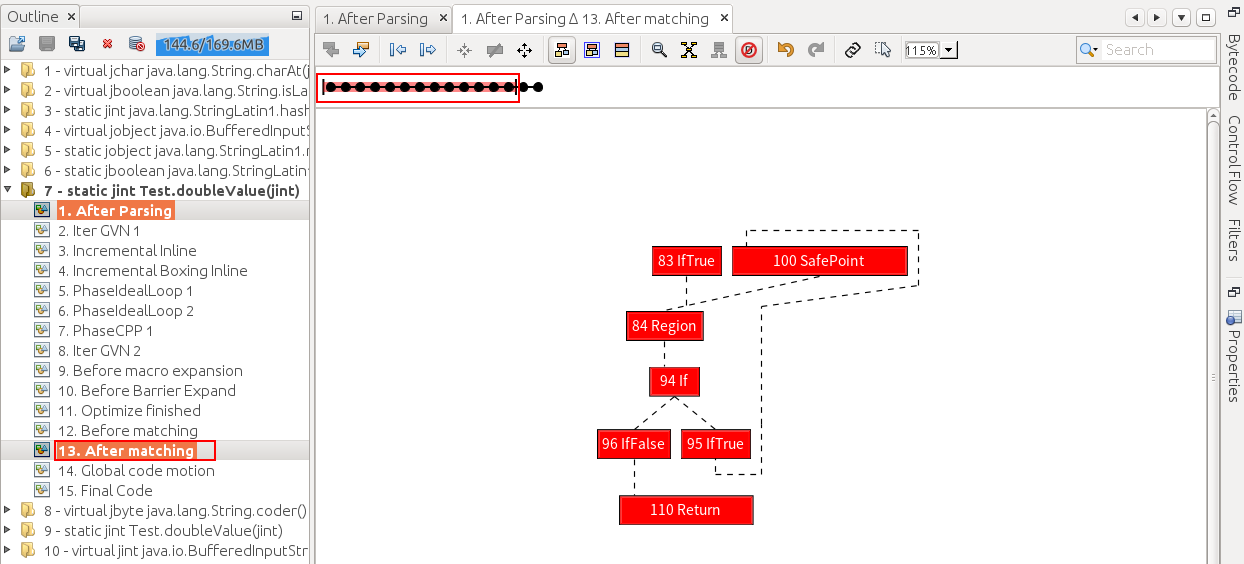
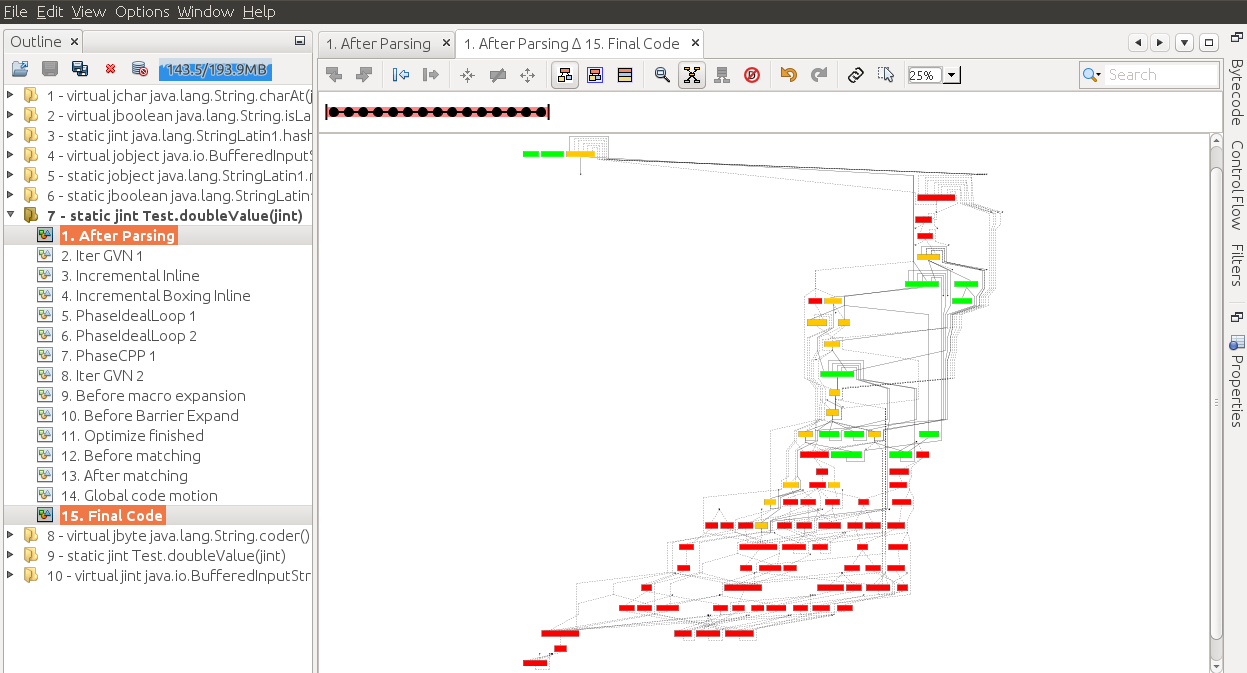
可看到在After matching阶段,空循环已被优化掉了,而到Final Code阶段,许多语言安全保障措施和GC安全点的轮询操作也被一起消除了
提前编译器
提前编译的主要有两大分支
- 在程序运行前把代码编译成机器码,如Substrate VM
- 把即时编译器在运行时要做的工作提前做好并保存,下次运行时直接加载使用,称为动态提前编译或即时编译缓存,如Jaotc
分别解决以下问题
- 即时编译需要占用程序运行时间和运算资源的问题
- Java程序的启动时间慢及需要一段时间预热后才能到达最高性能的问题
但提前编译仍无法取代即时编译的以下优势
- 性能分析制导优化,在解释执行时会不断收集性能监控信息,其在静态分析时是无法得到的
- 激进预测性优化,静态优化需保证优化前后对程序影响(不仅仅是执行结果)是等效的,而即时编译可做预测优化,若优化失败退回到解释执行,不会出现无法挽救的后果
- 链接时优化,Class文件在运行时动态链接加载到JVM,然后在即时编译器优化成本地代码,而对于C/C++,主程序与动态链接库的代码在编译时是独立的,各自编译、优化代码,难以实现跨链接库调用的优化
jaotc的提前编译
JDK9 引入Jaotc,用于对Class文件和模块提前编译,以减少程序的启动时间和到达全速性能的预热时间,如对于以下程序
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
先编译为class,再生成so
javac HelloWorld.java
jaotc --output libHelloWorld.so HelloWorld.class
通过如下方式调用
java -XX:AOTLibrary=./libHelloWorld.so HelloWorld

下面演示用Jaotc编译java.base模块,有些方法还不支持提前编译,新建文件java.base-list.txt将其排除
# jaotc: java.lang.StackOverflowError
exclude sun.util.resources.LocaleNames.getContents()[[Ljava/lang/Object;
exclude sun.util.resources.TimeZoneNames.getContents()[[Ljava/lang/Object;
exclude sun.util.resources.cldr.LocaleNames.getContents()[[Ljava/lang/Object;
exclude sun.util.resources..*.LocaleNames_.*.getContents\(\)\[\[Ljava/lang/Object;
exclude sun.util.resources..*.LocaleNames_.*_.*.getContents\(\)\[\[Ljava/lang/Object;
exclude sun.util.resources..*.TimeZoneNames_.*.getContents\(\)\[\[Ljava/lang/Object;
exclude sun.util.resources..*.TimeZoneNames_.*_.*.getContents\(\)\[\[Ljava/lang/Object;
# java.lang.Error: Trampoline must not be defined by the bootstrap classloader
exclude sun.reflect.misc.Trampoline.<clinit>()V
exclude sun.reflect.misc.Trampoline.invoke(Ljava/lang/reflect/Method;Ljava/lang/Object;[Ljava/lang/Object;)Ljava/# JVM asserts
exclude com.sun.crypto.provider.AESWrapCipher.engineUnwrap([BLjava/lang/String;I)Ljava/security/Key;
exclude sun.security.ssl.*
exclude sun.net.RegisteredDomain.<clinit>()V
# Huge methods
exclude jdk.internal.module.SystemModules.descriptors()[Ljava/lang/module/ModuleDescriptor;
使用如下命令编译,-J后接JVM参数
jaotc -J-XX:+UseCompressedOops -J-XX:+UseG1GC -J-Xmx4g --compile-for-tiered --info --compile-commands java.base-list.txt --output libjava.base-coop.so --module java.base
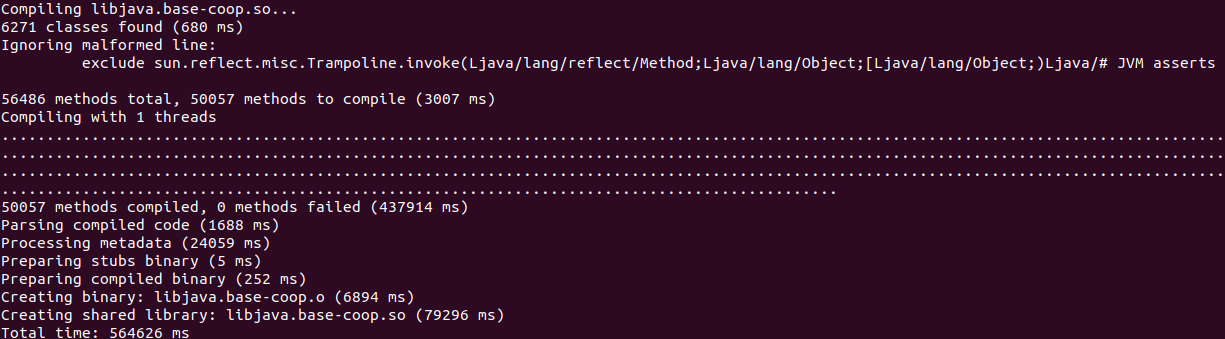
接下来即可使用提前编译版本的java.base模块来运行Java程序

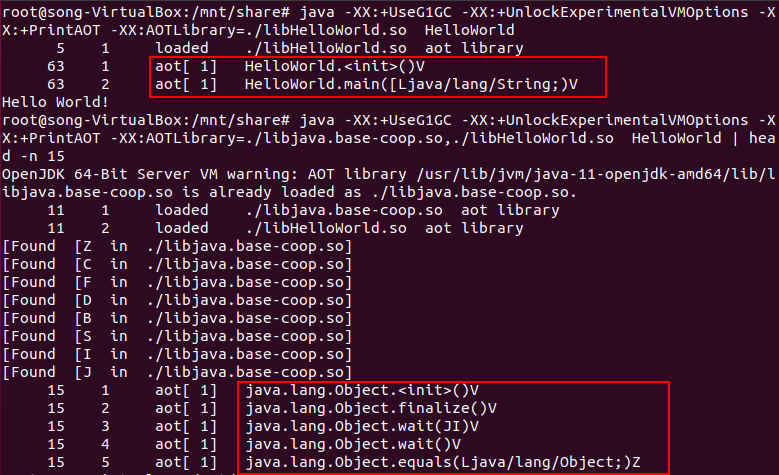
可使用如下参数,确认哪些方法使用了提前编译的版本
-XX:+PrintAOT
若不使用libjava.base-coop.so,就只有HelloWord的构造函数和main()方法是提前编译,加上后使用的API都是提前编译好的
后端编译优化
总览


优化演示
代码优化建立在代码的中间表示或者是机器码之上,如下为方便讲解,使用Java演示
static class B {
int value;
final int get() {
return value;
}
}
public void foo() {
y = b.get();
...
z = b.get();
sum = y + z;
}
第一步进行方法内联
- 去除方法调用成本,如查找方法版本、建立栈帧等
- 为其他优化建立基础(内联通常优先进行)
public void foo() {
y = b.value;
...
z = b.value;
sum = y + z;
}
第二步进行冗余访问消除
- 若中间代码不改变b.value,则可直接将y赋值给z,避免访问对象b的局部变量
- 若把b.value看作一个表达式,也可把这项优化看作公共子表达式消除
public void foo() {
y = b.value;
..
z = y;
sum = y + z;
}
第三步进行复写传播,程序没必要使用额外的变量z,因为和y相等,所以用y代替z
public void foo() {
y = b.value;
...
y = y;
sum = y + y;
}
第四步进行无用代码消除,无用代码是不会被执行或没有意义的代码,如上面的y=y
public void foo() {
y = b.value;
...
sum = y + y;
}
优化代码和原代码效果一致,但省略了许多语句,转换的字节码和机器码更少,效率更高
方法内联(最重要的优化技术之一)
只有以下方法会在编译期进行解析
- invokespecial指令调用的私有方法、实例构造器、父类方法
- invokestatic指令调用的静态方法
- nvokevirtual指令调用的final方法
其他Java方法调用都必须在运行时进行多态选择,可能存在多个版本的方法调用
即Java语言中默认的实例方法都是虚方法,故编译器无法静态内联确定方法版本
为此,JVM引入了类型继承关系分析,用于确定已加载的类或接口是否有多个实现、是否存在子类、子类是否覆盖了父类的虚方法等信息
- 非虚方法,直接内联
- 虚方法,但现阶段只有一个版本,守护内联,当未加载到令继承关系发生变化的类时继续内联,反之,需丢弃已编译代码,退回解释执行或重新编译
- 虚方法,但有多个版本,使用内联缓存减少方法调用开销,当第一次调用时记录方法版本,在之后的调用都比较版本,若都一致则称单态内联缓存,若不一致则退化成超多态内联缓存(相当于查找虚方法表来进行方法分派)
逃逸分析(最前沿的优化技术之一)
用于分析对象动态作用域,当对象定义在方法里
- 可能被外部方法所引用,如作为参数传递到其他方法中,称为方法逃逸
- 还有可能被外部线程访问,如赋值给可以在其他线程中访问的实例变量,称为线程逃逸
- 不逃逸-方法逃逸-线程逃逸,逃逸程度由低到高
- -XX:+DoEscapeAnalysis开启逃逸分析
- -XX:+PrintEscapeAnalysis查看逃逸分析结果
对于不会线程逃逸的对象,可采取栈上分配和同步消除
- 将原分配在堆中线程共享的对象转为栈上分配,所用内存随栈帧出栈而销毁,避免GC
- 若一个变量无法被其他线程访问,则可安全消除对该变量的同步措施,+XX:+EliminateLocks开启同步消除
对于不会方法逃逸的对象,可采取标量替换
- 无法再分解的数据称为标量(如原始数据类型),反之称为聚合量(如对象)
- 把对象拆散,将其用到的成员变量恢复为原始类型来访问,称为标量替换,避免对象实际创建
- -XX:+EliminateAllocations开启标量替换
- -XX:+PrintEliminateAllocations查看标量的替换情况
如下模拟逃逸分析过程,Point是包含x和y坐标的对象
public int test(int x) {
int xx = x + 2;
Point p = new Point(xx, 42);
return p.getX();
}
第一步,将构造函数和getX()内联
public int test(int x) {
int xx = x + 2;
Point p = point_memory_alloc(); // 在堆中分配P对象的示意方法
p.x = xx;
p.y = 42
return p.x;
}
第二步,经过逃逸分析,对象Point不会发生逃逸,进行标量替换
public int test(int x) {
int xx = x + 2;
int px = xx;
int py = 42
return px;
}
第三步,通过数据流分析,进行无用代码消除xx、px、py
public int test(int x) {
return x + 2;
}
公共子表达式消除(语言无关的经典优化技术之一)
若表达式E已经被计算过,且E中变量的值未改变,则下次使用时无需再次计算,可直接用之前的结果代替
int d = (c * b) * 12 + a + (a + b * c);
若存在如上代码,计算期间b与c的值不变,可转为
int d = E * 12 + a + (a + E);
在此基础进一步进行代数化简
int d = E * 13 + a + a;
数组边界检查消除(语言相关的经典优化技术之一)
对于数组arr[i],在Java中访问会自动进行范围检查,若 i 不在 [0, arr.length)范围内,则抛出ArrayIndexOutOfBoundsException
数组检查可避免溢出,但若每次读写时都进行判断会在一定程度上影响性能,若能分析出数组下标不会越界,则可以消除检查



![[附源码]计算机毕业设计的高校车辆租赁管理系统Springboot程序](https://img-blog.csdnimg.cn/8446bc8eadeb4699a046129b32333c53.png)