概念:
Concept:
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
Subject: Topic. A topic is a logical container that carries messages. In practice, it is often used to distinguish specific services.
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
Partition: Partition. An ordered, unchanging sequence of messages. You can have multiple sections under each topic.
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值
Message Offset: Offset. Represents the location information for each message in the partition, and is a monotonically increasing, constant value
副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。读数据以及写数据的时候,只在leader副本进行。
Copy: Replica. The same message in Kafka can be copied to multiple places to provide data redundancy, which are called replicas. There are also instances of leaders and followers, each with different roles. Replicas are at the partition level, i.e. each partition can be configured with multiple replicas to achieve high availability. When reading data and writing data, it is only performed in the leader copy.
生产者:Producer。向主题发布新消息的应用程序。
Producer: Producer. An application that publishes new messages to a topic.
消费者:Consumer。从主题订阅新消息的应用程序。
Consumer: Consumer. An application that subscribes to new messages from a topic.
消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
Consumer Offset. Represents the consumer's consumption progress, each consumer has its own consumer displacement.
消费者组:是由多个消费者实例组成的,消费者组可以可以消费多个分区里面的数据,但是一个消费者组只能对应一个topic
Consumer group: It is composed of multiple consumer instances. A consumer group can consume data in multiple partitions, but one consumer group can only correspond to one topic
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Rebalance: Rebalance. The process of automatically reassigning subscription topic partitions to other consumer instances when a consumer instance in a consumer group dies. Rebalance is an important means for Kafka to achieve high availability on the consumer side.
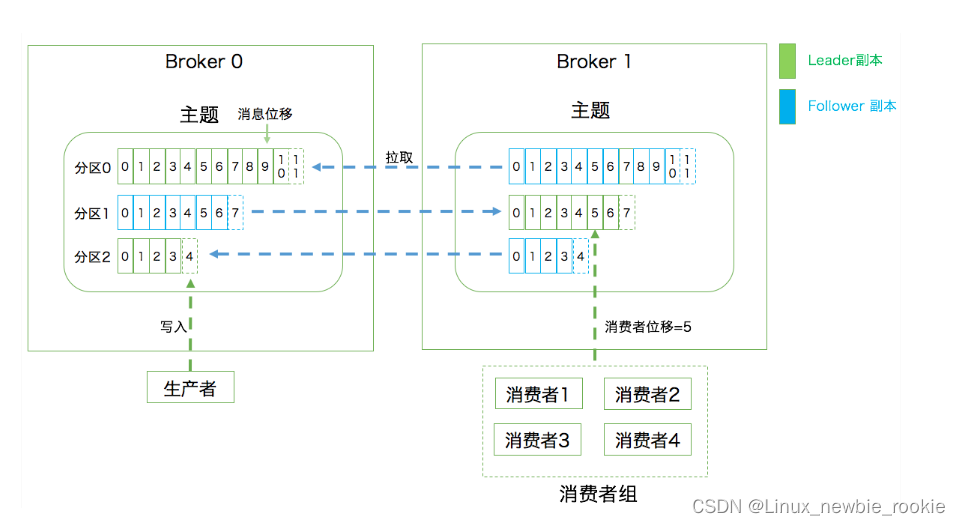
kafak读或者写的时候,都在副本的leader进行。
When kafak reads or writes, it does so in the copy's leader.
参数(重要参数释义)
Parameters (Interpretation of Important Parameters)
Broker端参数:
Broker terminal parameters:
log.dirs:这是非常重要的参数,指定了 Broker 需要使用的若干个文件目录路径。 : This is a very important parameter that specifies several file directory paths that the Broker needs to use.
在线上生产环境中一定要为log.dirs配置多个路径,具体格式是一个 CSV 格式,也就是用逗号分隔的多个路径,比如/home/kafka1,/home/kafka2,/home/kafka3这样。- 如果有条件的话你最好保证这些目录挂载到不同的物理磁盘上。这样做有两个好处: You'd better make sure that these directories are mounted on different physical disks if possible. This has two advantages:
- (1)提升读写性能:比起单块磁盘,多块物理磁盘同时读写数据有更高的吞吐量。 (1) Improve read-write performance: Compared with a single disk, multiple physical disks can read and write data at the same time with higher throughput.
- (2)能够实现故障转移:即 Failover。这是 Kafka 1.1 版本新引入的强大功能。要知道在以前,只要 Kafka Broker 使用的任何一块磁盘挂掉了,整个 Broker 进程都会关闭。但是自 1.1 开始,这种情况被修正了,坏掉的磁盘上的数据会自动地转移到其他正常的磁盘上,而且 Broker 还能正常工作。 (2) Enable failover: i. e. Failover. This is a powerful new feature in Kafka 1.1. Remember that in the old days, if any of the disks used by Kafka Broker died, the entire Broker process would shut down. However, since 1.1, this has been fixed, and the data on the broken disk is automatically transferred to the other healthy disk, and the Broker still works normally.
Broker端的zookeeper参数:
Broker side zookeeper parameter:
- 一个kafka集群连接一个zk集群,zookeeper.connect参数配置:zookeeper.connect=zk1:2181,zk2:2181,zk3:2181 A kafka cluster connects to a zk cluster, and the zookeeper.connect parameter is configured: zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
- 多个 Kafka 集群使用同一套 ZooKeeper 集群,假设分别叫它们 kafka1 和 kafka2,zookeeper.connect参数配置: Multiple Kafka clusters use the same ZooKeeper cluster, assuming they are called kafka1 and kafka2 respectively, and the zookeeper.connect parameter is configured:
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181/kafka1和zookeeper.connect=zk1:2181,zk2:2181,zk3:2181/kafka2 - 切记 chroot 只需要写一次,而且是加到最后的。 Remember that chroot only needs to be written once, and it is added last.
Broker端的Topic参数:
Topic parameter of Broker side:
auto.create.topics.enable:是否允许自动创建 Topic。 : Whether to allow automatic creation of Topics.
建议false,可以避免出现一些乱七八糟的topic。 Suggest false to avoid some messy topics.unclean.leader.election.enable:是否允许 Unclean Leader 选举。 : Whether to allow Unclean Leader election.
建议false,kafka每个分区中有多个副本提供高可用性,多个副本中只有leader提供服务,假如leader挂掉,会从其他副本中进行选举leader(选举leader条件是:只有保存数据比较多的那些副本才有资格竞选,落后进度太多的副本没有资格去竞选)
假如保存数据比较多的副本都挂掉了,这个参数设置为false,则会坚持之前原则,会阻止进度落后的副本去选举,会造成该分区不可用,若参数为true,落后的副本会进行选举,则会造成数据丢失。auto.leader.rebalance.enable:是否允许定期进行 Leader 选举。 : Whether regular Leader election is allowed.
建议false。设置它的值为 true 表示允许 Kafka 定期地对一些 Topic 分区进行 Leader 重选举,当然这个重选举不是无脑进行的,它要满足一定的条件才会发生。严格来说它与上一个参数中 Leader 选举的最大不同在于,它不是选 Leader,而是换 Leader!比如 Leader A 一直表现得很好,但若auto.leader.rebalance.enable=true,那么有可能一段时间后 Leader A 就要被强行卸任换成 Leader B。
Broker端数据保存参数:
Broker data saving parameters:
log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小。 This is the size of the total disk capacity saved by the specified Broker for messages.
默认是 -1,表明你想在这台 Broker 上保存多少数据都可以,不受容量限制。message.max.bytes:控制 Broker 能够接收的最大消息大小。 Controls the maximum message size that the Broker can receive.
默认是1m,可以调大,毕竟现实场景中消息大于1m的很多,它仅仅衡量 Broker 能够处理的最大消息大小,即使设置大一点也不会耗费什么磁盘空间的。log.retention.{hour|minutes|ms}:控制一条消息数据被保存多长时间。 : Controls how long a message's data is saved.
从优先级上来说 ms 设置最高、minutes 次之、hour 最低。默认情况下,使用hour比较多,比如数据保存7天(168h)。
Topic级别参数:
Topic Level Parameters:
当同时设置了broker端参数和Topic级别参数的时候,Topic级别的参数会覆盖broker端的参数。
When both broker side parameters and Topic level parameters are set, Topic level parameters will override broker side parameters.
retention.ms:规定了该 Topic 消息被保存的时长。默认是 7 天,即该 Topic 只保存最近 7 天的消息。一旦设置了这个值,它会覆盖掉 Broker 端的全局参数值。 : specifies the duration for which the Topic message is saved. The default is 7 days, that is, the Topic only saves the messages of the last 7 days. Once this value is set, it overrides the global parameter value on the Broker side.retention.bytes:规定了要为该 Topic 预留多大的磁盘空间。和全局参数作用相似,这个值通常在多租户的 Kafka 集群中会有用武之地。当前默认值是 -1,表示可以无限使用磁盘空间。 : specifies how much disk space to reserve for the Topic. similar to that global paramete, this value is often useful in a multi-tenant Kafka cluster. The current default is -1, which means unlimited disk space.
如何设置topic参数:
To set the topic parameter:
- 创建Topic的时候设置 Set when creating Topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic transaction --partitions 1 --replication-factor 1 --config retention.ms=15552000000 --config max.message.bytes=5242880 - 修改Topic配置的时候设置 Set when modifying Topic configuration
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name transaction --alter --add-config max.message.bytes=10485760
JVM参数:
< strong > JVM parameters:
设置kafka的jvm参数:
Set the jvm parameters for kafka:
KAFKA_HEAP_OPTS:指定堆大小。 : Specifies the heap size.KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 参数。 : Specify GC parameters.
在kafka启动之前,设置环境变量,(或者修改kafka-server-start.sh脚本)
Before starting kafka, set the environment variables,(or modify the kafka-server-start.sh script)
$> export KAFKA_HEAP_OPTS=--Xms6g --Xmx6g
$> export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
$> bin/kafka-server-start.sh config/server.properties避免消费端多次rebalance的参数:
Parameters to avoid multiple rebalances at the consumer end:
避免消费端多次rebalance,可以增强Consumer 端的TPS。在消费端进行配置(该配置主要是避免造成rebalance时候的一种方法,即避免消费组里面的实例被Coordinator剔除)
Avoiding multiple rebalances at the consumer end can enhance TPS at the Consumer end. Configure at the consumer end (this configuration is mainly a method to avoid causing rebalance, that is, to avoid the instances in the consumer group being eliminated by Coordinator)
- session.timeout.ms 请求超时时间,默认值10s(如果 Coordinator 在 10 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了) Request timeout, default 10s (if the Coordinator does not receive a heartbeat from a Consumer instance under the Group within 10 seconds, it will consider that the Consumer instance has been hung)
- heartbeat.interval.ms 发送心跳请求频率。 how often heartbeat request are sent.
- max.poll.interval.ms 控制 Consumer 实际消费能力对 Rebalance 的影响。 Control the impact of the actual spending power of the Consumer on Rebalance.
(限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔。它的默认值是 5 分钟,表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起“离开组”的请求,Coordinator 也会开启新一轮 Rebalance。) - GC 参数 GC Parameters
案列:
Case:
如何规划 Kafka 集群的存储容量呢?
How do you plan the storage capacity of your Kafka cluster?
假如:有个业务每天需要向 Kafka 集群发送 1 亿条消息,每条消息保存两份以防止数据丢失,另外消息默认保存两周时间。现在假设消息的平均大小是 1KB,
Suppose: a business needs to send 100 million messages to the Kafka cluster every day. Each message is saved in two copies to prevent data loss, and the messages are saved for two weeks by default. Now assume that the average size of a message is 1KB.
所用总空间:
Total space used:
总的空间大小就等于 1 亿 * 1KB * 2 / 1000 / 1000 = 200GB。一般情况下 Kafka 集群除了消息数据还有其他类型的数据,比如索引数据等,故我们再为这些数据预留出 10% 的磁盘空间,因此总的存储容量就是 220GB。既然要保存两周,那么整体容量即为 220GB * 14,大约 3TB 左右。Kafka 支持数据的压缩,假设压缩比是 0.75,那么最后你需要规划的存储空间就是 0.75 * 3 = 2.25TB。
The total space is 100 million * 1KB * 2 / 1000 / 1000 = 200GB. In general, Kafka cluster has other types of data besides message data, such as index data, so we reserve 10% disk space for these data, so the total storage capacity is 220GB. Since you 're saving for two weeks, the total capacity is 220GB * 14, which is about 3TB. Kafka supports data compression, assuming a compression ratio of 0.75, then the final storage space you need to plan is 0.75 * 3 = 2.25TB.
总之在规划磁盘容量时你需要考虑下面这几个元素:
In summary, you need to consider the following elements when planning disk capacity:
- 新增消息数 Number of new messages
- 消息留存时间 message age
- 平均消息大小 Average Message Size
- 备份数 Number of backups
- 是否启用压缩 Enable Compression
带宽:
Wide: Wide, wide.
假设使用的是千兆网络举,来说明一下如何进行带宽资源的规划。
Assume that the network is gigabit network, to explain how to plan bandwidth resources.
假设你公司的机房环境是千兆网络,即 1Gbps,现在你有个业务,其业务目标或 SLA 是在 1 小时内处理 1TB 的业务数据。那么问题来了,你到底需要多少台 Kafka 服务器来完成这个业务呢?
Let's say your company's computer room environment is a gigabit network, or 1Gbps, and you have a business with a business goal or SLA of processing 1TB of business data in 1 hour. So the question is, how many Kafka servers do you need to do this?
来计算一下,由于带宽是 1Gbps,即每秒处理 1Gb 的数据,假设每台 Kafka 服务器都是安装在专属的机器上,也就是说每台 Kafka 机器上没有混布其他服务,毕竟真实环境中不建议这么做。通常情况下你只能假设 Kafka 会用到 70% 的带宽资源,因为总要为其他应用或进程留一些资源。
To calculate, since the bandwidth is 1Gbps, i.e. processing 1Gb of data per second, assume that each Kafka server is installed on a dedicated machine, which means that there are no other services mixed on each Kafka machine, which is not recommended in the real world. Normally you can only assume that Kafka is using 70% of its bandwidth, as there is always some resource left for other applications or processes.
根据实际使用经验,超过 70% 的阈值就有网络丢包的可能性了,故 70% 的设定是一个比较合理的值,也就是说单台 Kafka 服务器最多也就能使用大约 700Mb 的带宽资源。
According to practical experience, there is a possibility of network packet loss if the threshold exceeds 70%. Therefore, the setting of 70% is a reasonable value, that is, a single Kafka server can use about 700Mb of bandwidth resources at most.
稍等,这只是它能使用的最大带宽资源,你不能让 Kafka 服务器常规性使用这么多资源,故通常要再额外预留出 2/3 的资源,即单台服务器使用带宽 700Mb / 3 ≈ 240Mbps。需要提示的是,这里的 2/3 其实是相当保守的,你可以结合你自己机器的使用情况酌情减少此值。
Wait a minute, this is just the maximum bandwidth it can use. You can't expect Kafka servers to use this much on/regular basis, so you usually have to reserve an extra two-thirds of the resources, or 700Mb / 3 ≈ 240Mbps per server. Note that this two-thirds is quite conservative, and you can reduce it to suit your own machine.
好了,有了 240Mbps,我们就可以计算 1 小时内处理 1TB 数据所需的服务器数量了。根据这个目标,我们每秒需要处理 2336Mb(1TB%3600*8) 的数据,除以 240,约等于 10 台服务器。如果消息还需要额外复制两份,那么总的服务器台数还要乘以 3,即 30 台。
OK, with 240Mbps, we can calculate the number of servers needed to process 1TB of data in 1 hour. With this goal, we need to process 2336Mb (1TB%3600*8) of data per second, which is roughly 10 servers divided by 240. If two additional copies of the message are required, the total number of servers is multiplied by three, or 30.
![[附源码]计算机毕业设计的高校车辆租赁管理系统Springboot程序](https://img-blog.csdnimg.cn/8446bc8eadeb4699a046129b32333c53.png)