论文标题:GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
论文链接:https://arxiv.org/abs/1811.06965
论文来源:Google
一、概述
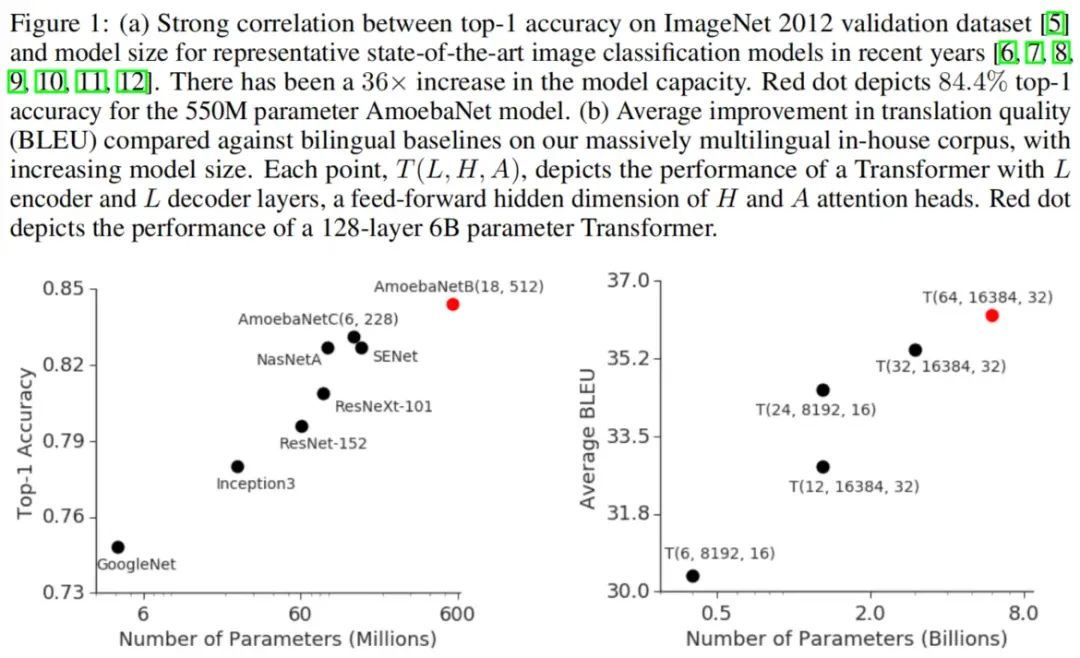
如下图所示,近过去十年中,由于开发了促进神经网络有效容量扩大的方法,深度学习取得了巨大进步。这种趋势在图像分类中表现得尤为明显,就像ImageNet的模型容量增加带来的精度提升一样。在自然语言处理的背景下也可以观察到类似的现象,简单的浅层句子表示模型被其更深更大的对应模型超越。
然而,虽然更大的模型为许多领域带来了显著的质量提升,但扩大神经网络也带来了重大的实践挑战。包括内存限制和加速器(GPU或TPU)的通信带宽在内的硬件约束,迫使用户将更大的模型划分为多个部分,并将不同的部分分配给不同的加速器。然而,高效的模型并行算法非常难以设计和实现,这通常要求实践者在扩大容量、灵活性(或特定于特定任务和架构)和训练效率之间做出艰难的选择。结果,大多数高效的模型并行算法都是针对特定架构和任务的。随着深度学习应用的不断增多,人们对可靠且灵活的基础设施的需求也在不断增长,这些基础设施可以让研究者轻松地将神经网络扩大到大量的机器学习任务。
为了解决这些挑战,我们引入了GPipe,这是一个灵活的库,可以实现大型神经网络的有效训练。通过在不同的加速器上分割模型并在每个加速器上支持re-materialization,GPipe可以扩大任意深度神经网络架构,超越单个加速器的内存限制。在GPipe中,每个模型都可以被定义为一系列的层,连续的层群可以被分割成单元。每个单元然后被放置在一个单独的加速器上。基于这种划分设置,我们提出了一个新的流水线并行算法,通过批量分割。我们首先将训练样例的一个小批量划分为更小的微批量,然后将每组微批量的执行在各个单元中流水线化。我们采用同步的小批量梯度下降方法进行训练,其中的梯度在一个小批量的所有微批量中累积,并在小批量结束时应用。因此,使用GPipe的梯度更新不会因为划分的数量不同而不同,这使得研究者可以通过部署更多的加速器来轻松训练越来越大的模型。GPipe还可以与数据并行结合,进一步扩大训练规模。
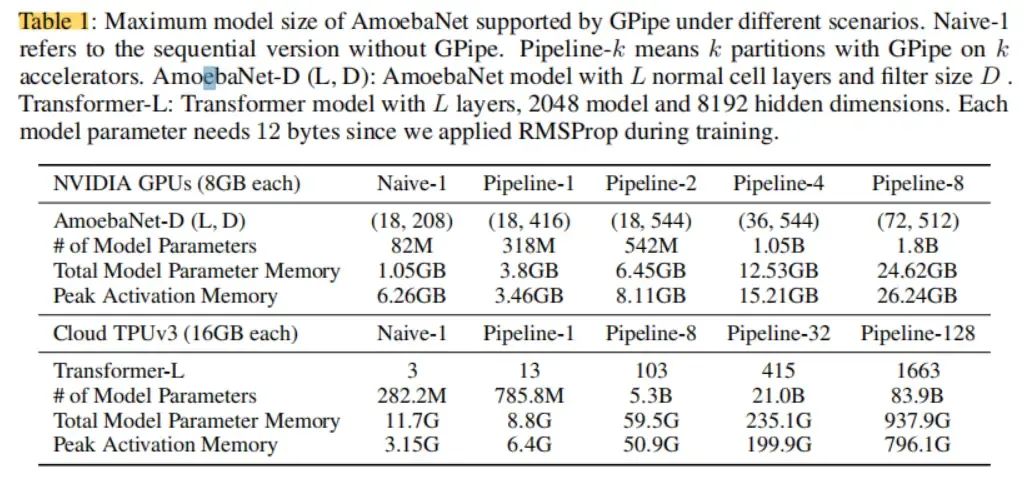
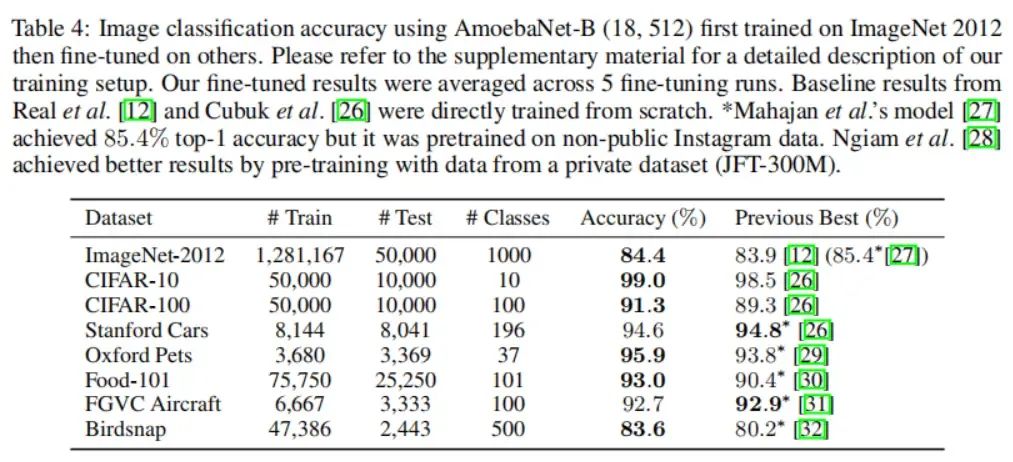
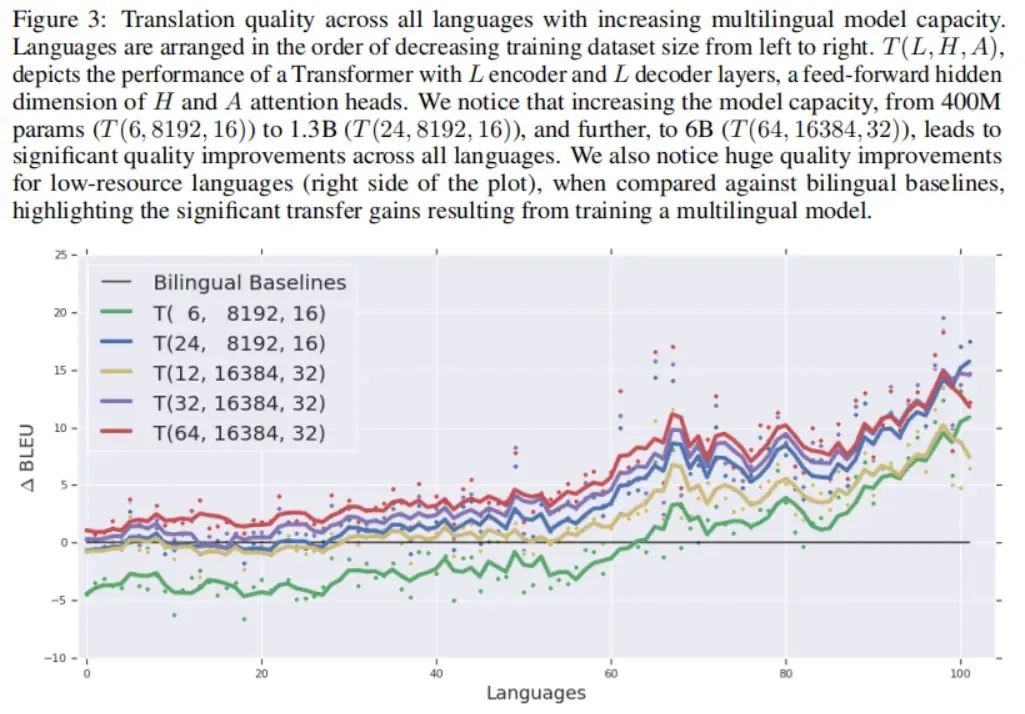
我们在图像分类和机器翻译上展示了GPipe的灵活性和效率。对于图像分类,我们在ImageNet 2012数据集上,训练了AmoebaNet模型,并将输入调整为480×480。通过增加模型的宽度,我们将参数数量扩大到5.57亿,并实现了84.4%的最高验证精度。在机器翻译上,我们训练了一个有128层、60亿参数的多语言Transformer模型,支持103种语言(102种语言到英语)。我们展示了该模型能够超越单独训练的3.5亿参数的双语Transformer Big模型在100个语言对上的表现。
二、方法
GPipe开源库是以Lingvo框架为基础实现的,不过它的核心设计思路是通用的,可以与其他框架结合。
接口
一个深度神经网络可以被定义为层的一个序列,每一层包括一个前向传播计算函数和参数集合。GPipe额外允许用户为每一层指定一个可选的计算花销评估函数。对于一个给定的划分数量,这个神经网络的层序列可以被划分为个复合层(或者叫做单元)。我们用来代表从到之间的连续层。对应于的参数集合为的并集,其前向传播函数为,相应的反向传播函数可以通过从使用自动符号微分获得,另外花销估计函数为。
GPipe的接口非常地简单和直观,只需要用户指定:①模型划分的数量;②微批量的数量;③模型的层的序列与定义。
算法
在GPipe中,用户定义他们网络中的层序列,包括模型参数,前向计算函数和成本估计函数。然后,GPipe将网络分割成个单元,并将第个单元放在第个加速器上。在分割的边界,GPipe自动插入了通信原语,允许邻近分割之间的数据传输。分割算法会试图最小化所有单元的估计成本的差异,从而通过同步所有分割的计算时间,以最大化流水线的效率。
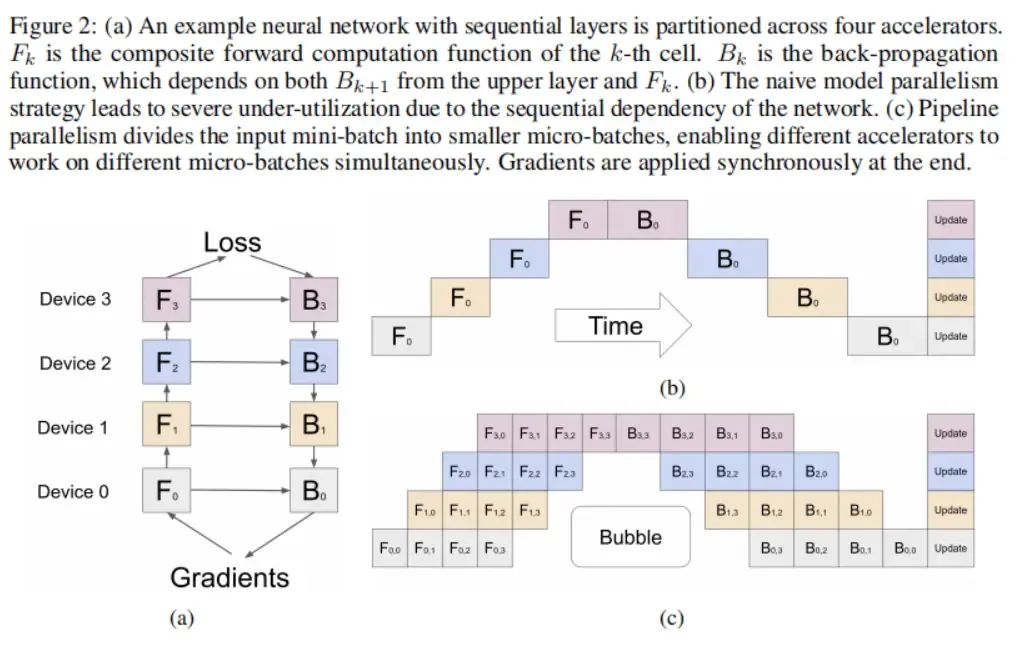
在前向传播过程中,GPipe首先将大小为的每个小批量(mini-batch)划分为个相等的微批量(micro-batch),并通过个加速器进行流水线传输。在反向传播过程中,每个微批量的梯度都基于用于前向传播的相同模型参数来计算。在每个小批量结束时,所有个微批量的梯度都被累积起来,并用于更新所有加速器上的模型参数。这个过程如下图(c)所示。
如果在网络中使用了批量归一化(batch normalization),那么在训练期间,输入的充分统计量将在每个微批量以及在必要的情况下的复制品(replica)上计算。我们还会跟踪整个小批量的充分统计量的移动平均值,以供在评估期间使用。
性能优化
为了减少激活(activation)的内存需求,GPipe支持re-materialization。在前向计算的过程中,每个加速器只保存在单元边界处的输出激活。在反向传播的过程中,第个加速器重新计算复合前向传播函数。在这样的处理下,峰值激活内存需求减少到了,这里的是微批量大小,是每个单元的层数。作为对比,没有re-materialization的情况下内存需求为,这是因为在计算梯度需要上层梯度以及缓存的激活。
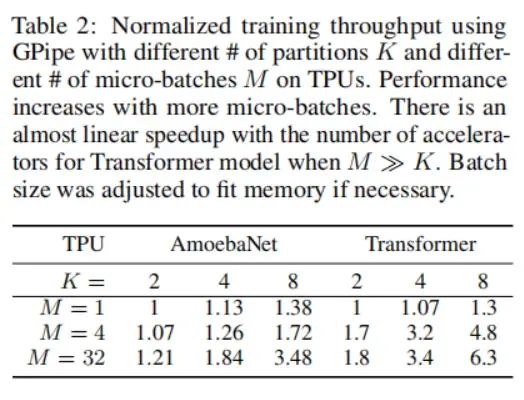
上图(c)中所示的分割过程会引入一些加速器的空闲时间,被称为气泡开销(bubble overhead)。这个气泡时间在每个微批量上的平摊开销为。在实验中,当微批量数时,我们发现气泡开销可以忽略不计。这部分原因是在反向传播期间可以提前调度re-materialization,而无需等待来自前面层的梯度。
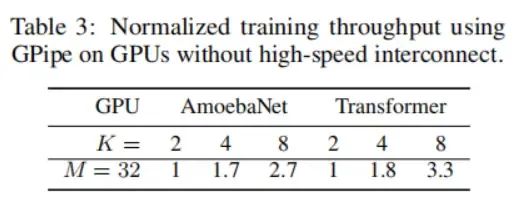
GPipe引入了较低的通信开销,因为我们只需要在加速器之间的分割边界传递激活张量。因此,即使在没有高速互联的加速器上,我们也可以实现高效的扩展性性能。
上图(c)假设分割是均衡的。然而,不同层的内存需求和计算量通常是不均衡的。在这种情况下,不完美的分割算法可能导致负载不平衡。更好的分割算法有可能改善我们启发式方法的性能。
这一部分关于这一系列复杂度是如何得到的,可以参看李沐视频(https://www.bilibili.com/video/BV1v34y1E7zu)。
三、实验