文章目录
- 分布式缓存
- Redis持久化
- RDB持久化
- AOF持久化
- Redis主从
- Redis数据同步原理
- 全量同步
- 增量同步
- Redis哨兵
- 哨兵的作用和原理
- sentinel(哨兵)的三个作用是什么?
- sentinel如何判断一个Redis实例是否健康?
- master出现故障后,新的master选择过程是怎样的?
- 故障转移的步骤有哪些?
- 项目中配置RedisTemplate哨兵模式
- Redis分片集群
- Redis散列插槽
- Redis集群伸缩
- 项目中RedisTemplate配置访问分片集群
- Redis多级缓存
- JVM进程缓存
- Caffeine
- Caffeine实现本地进程缓存案例
- Redis实战经验
- Redis键值设计
- 优雅的key结构
- 解决BigKey
- 选择恰当的数据类型
- 批处理优化
- pipeline
- 集群下的批处理
- 服务端优化
- 持久化配置
- 慢查询
- 内存配置
- Redis实现原理
- 数据结构
分布式缓存
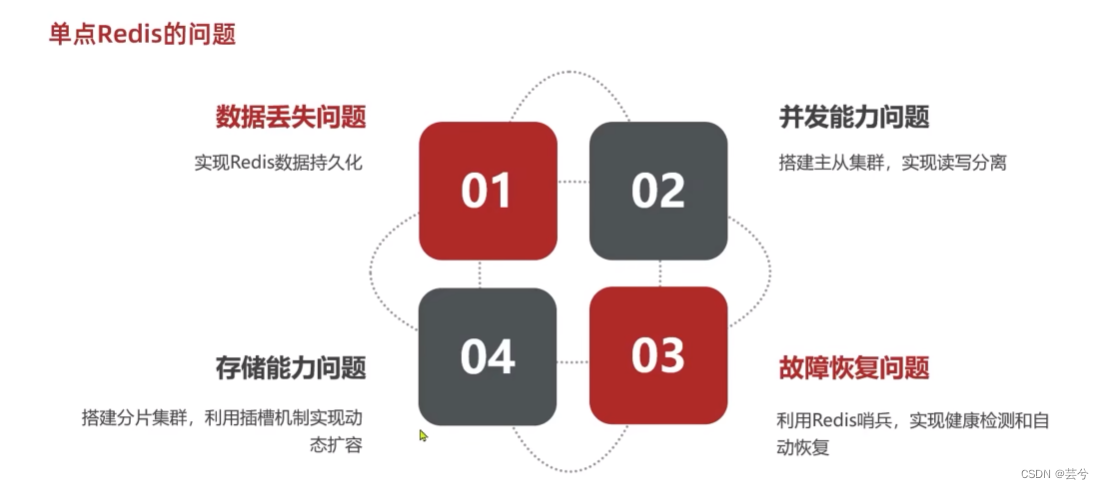
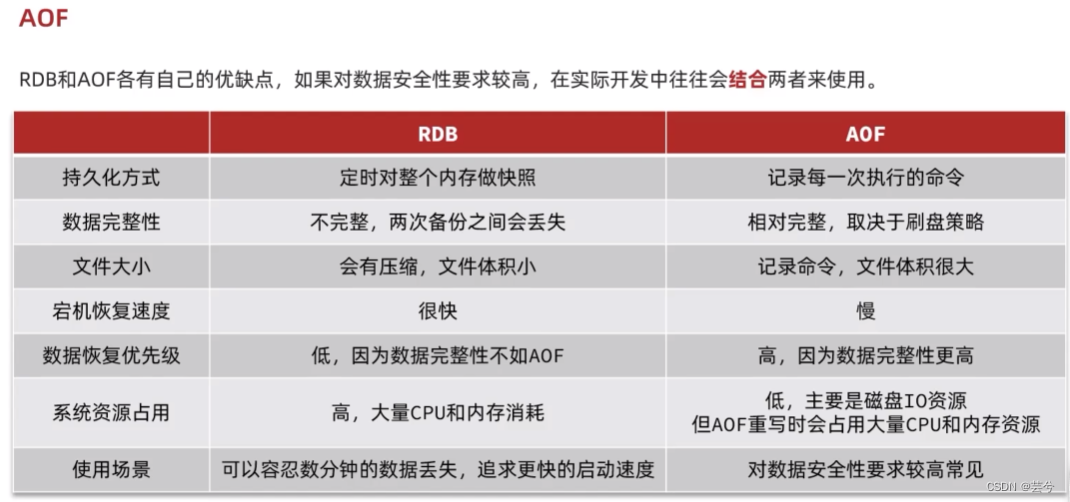
单节点Redis存在着:
- 数据丢失问题:单节点宕机,数据就丢失了。
- 并发能力和存储能力问题:单节点能够满足的并发量、能够存储的数据量有限。
- 故障恢复问题:如果Redis宕机,服务不可用,需要一种自动的故障恢复手段。
Redis持久化
RDB持久化
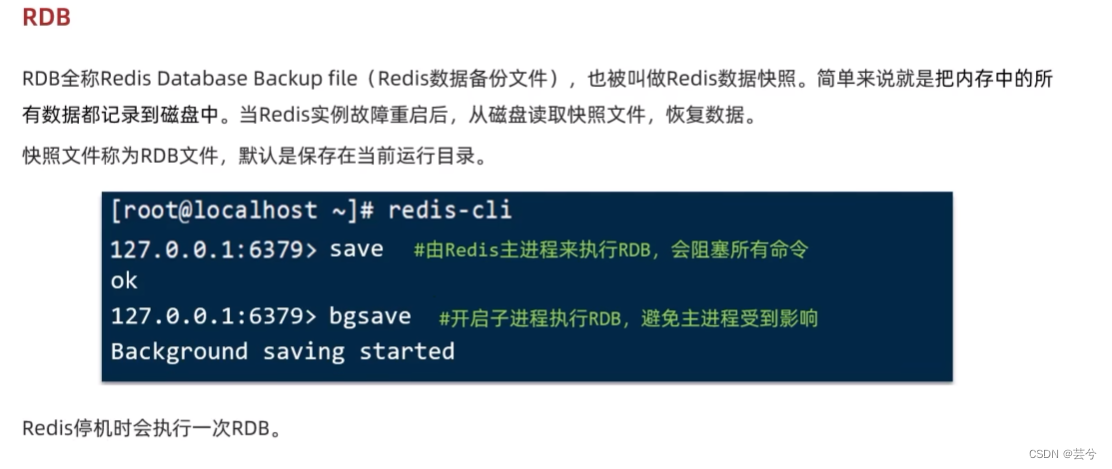
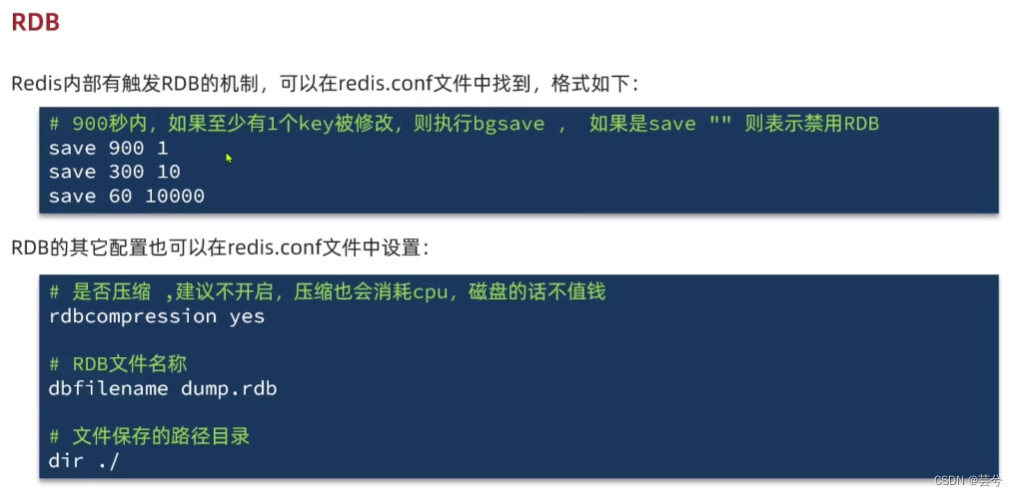
RDB(Redis database backup file,Redis数据库备份文件)
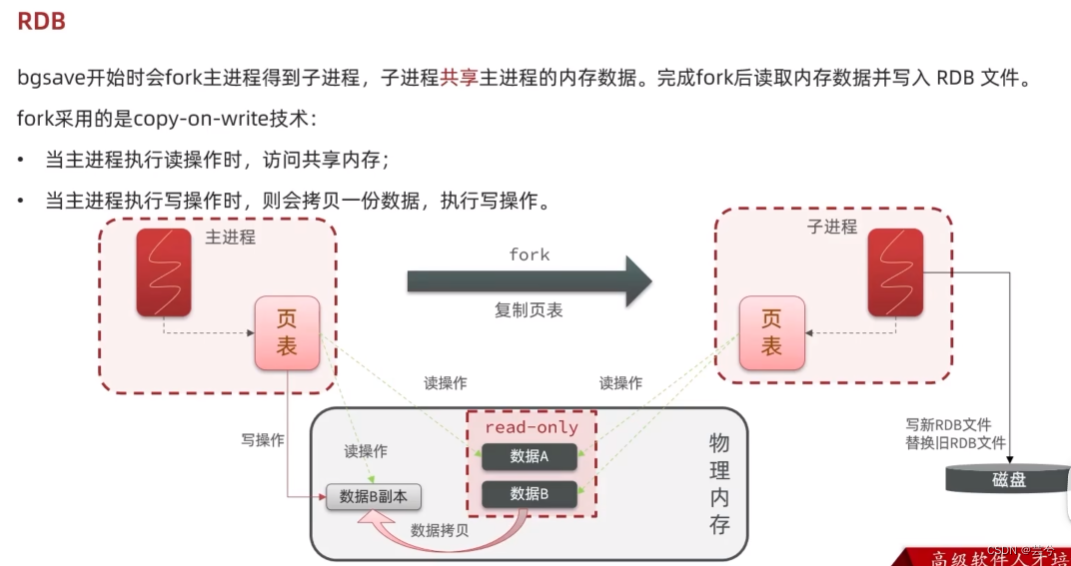
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后,读取内存数据并写入RDB文件。fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。

AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。


Redis主从

Redis数据同步原理
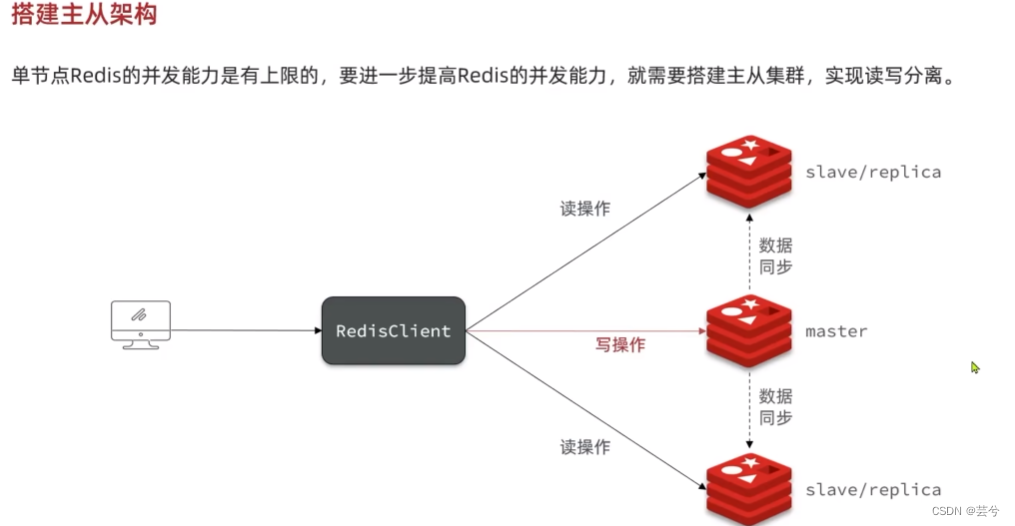
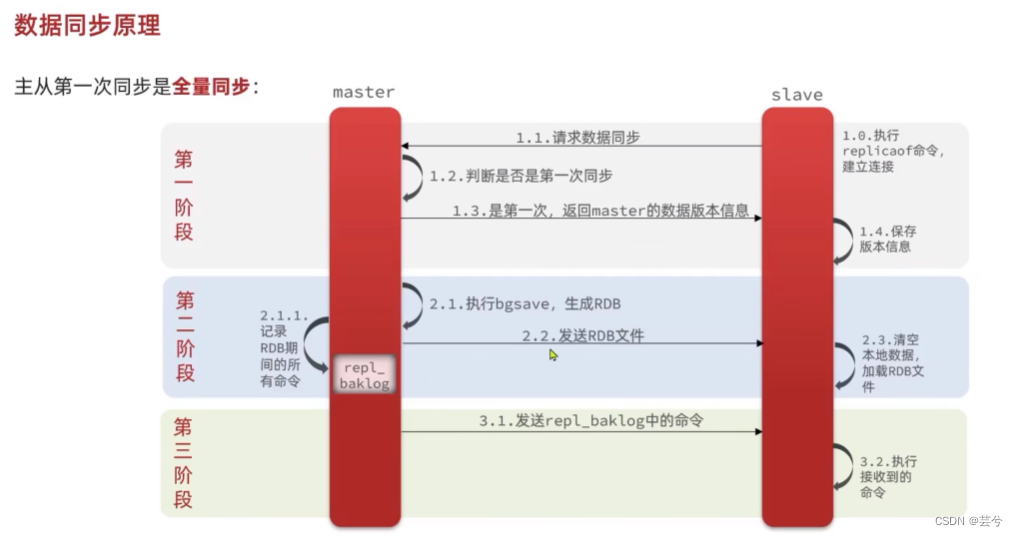
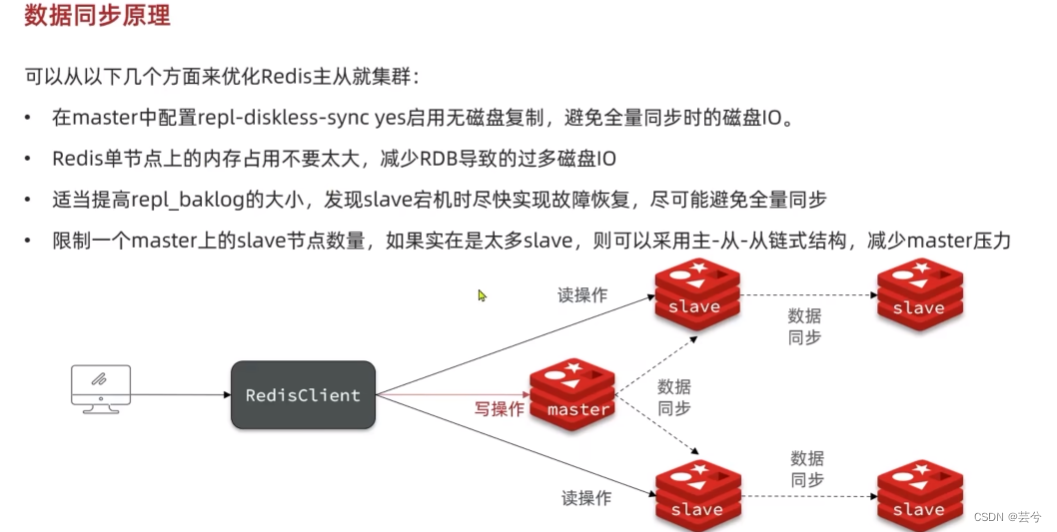
全量同步
主从节点间的第一次同步采用的是全量同步,全量同步的流程如下:
- slave节点请求增量同步
- master节点判断replid,如果发现id不一致拒绝增量同步,id不一致说明是第一次同步,master会返回master的数据版本信息,尝试建立全量同步。
- slave收到后,保存版本信息。
- master节点执行bgsave,生成RDB,生成RDB期间的所有命令会保存在repl-backlog中,随后向slave发送RDB文件。
- slave收到RDB文件后,清空本地数据,加载master节点发来的RDB文件。
- 后序master节点会发送repl-baklog文件,slave收到后执行其中的命令,保持与master的数据同步。
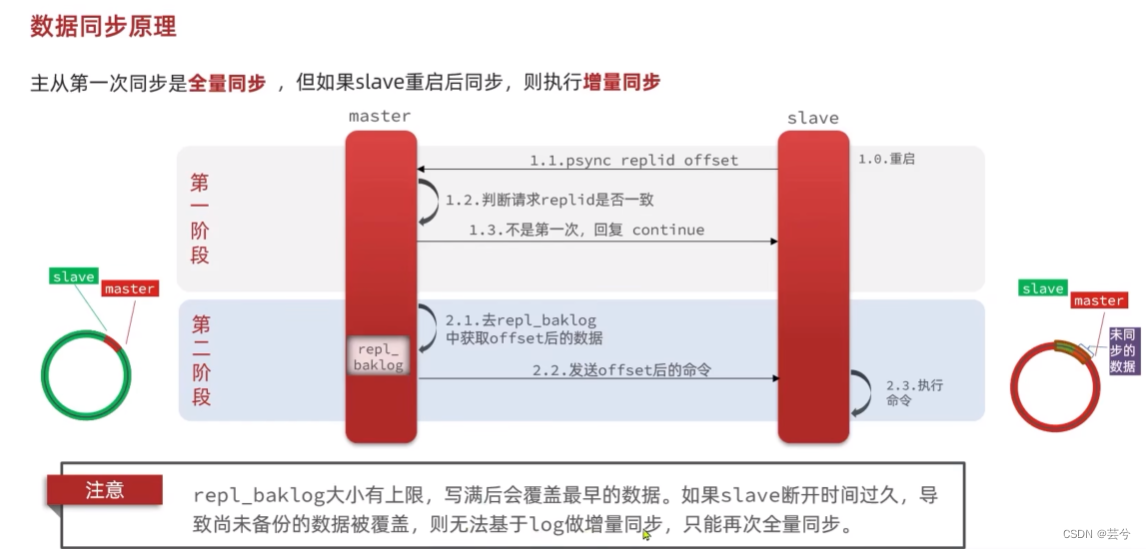
增量同步
主从第一次同步是全量同步,但如果slave重启后同步,则执行增量同步。
Redis哨兵
哨兵的作用和原理
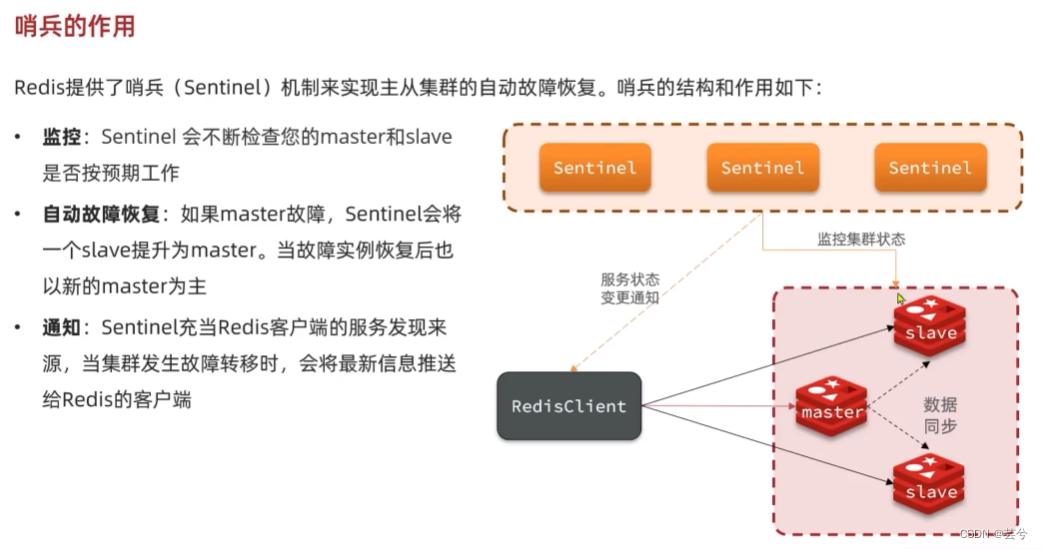

sentinel(哨兵)的三个作用是什么?
- 监控
- 故障转移
- 通知
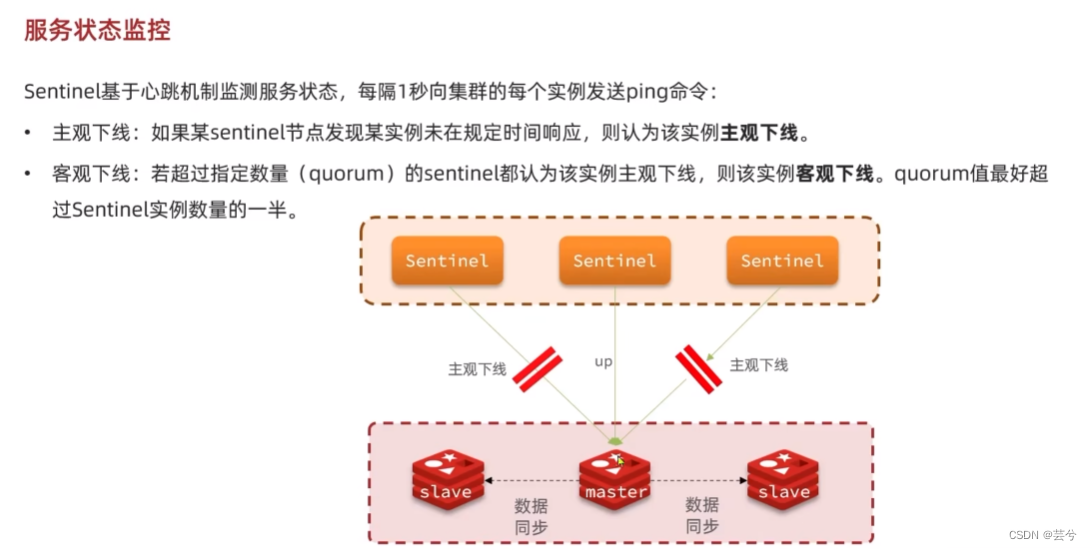
sentinel如何判断一个Redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没响应,认为是主观下线
- 如果超过一半的sentinel都认为实例主观下线,则判断服务客观下线。
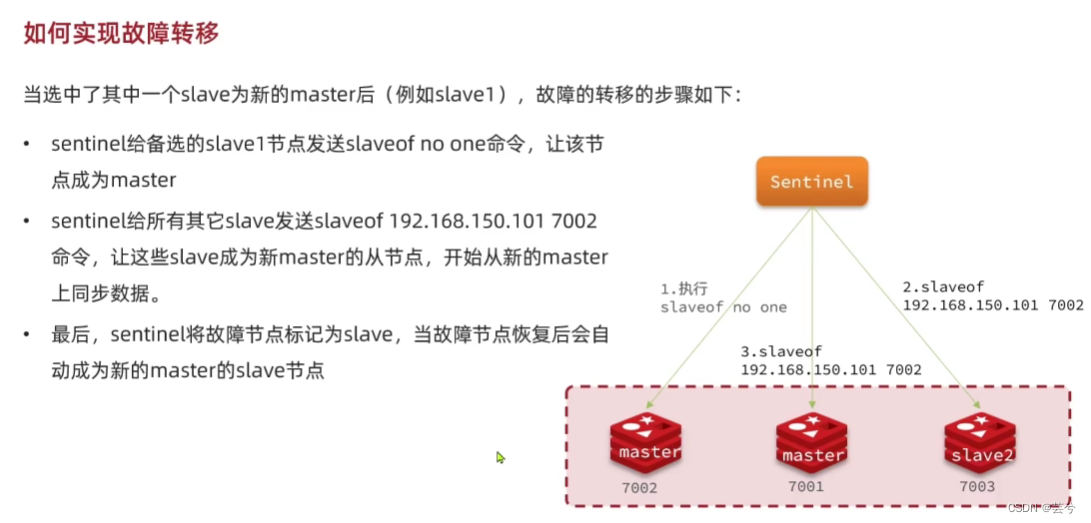
master出现故障后,新的master选择过程是怎样的?
故障转移的步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有的节点都执行slaveof 新的master
- 修改故障节点配置,添加slaveof 新的master
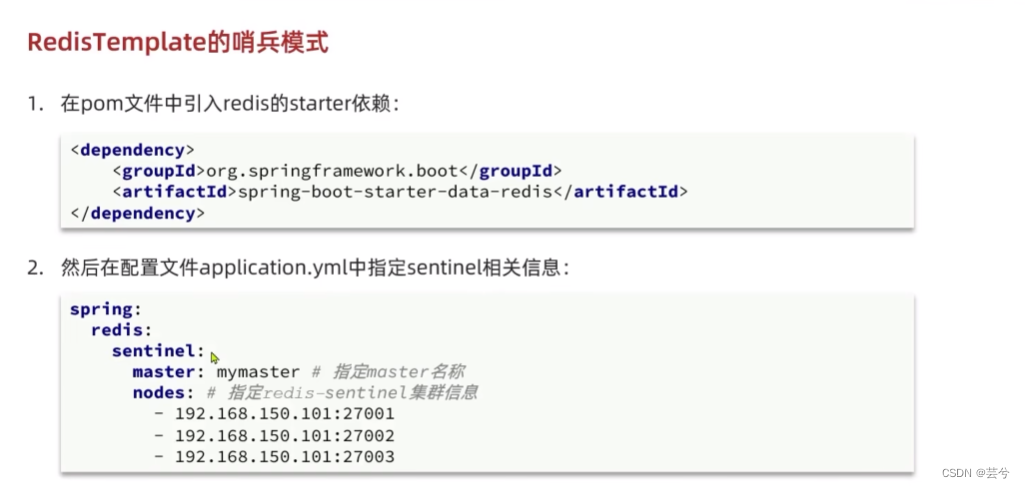
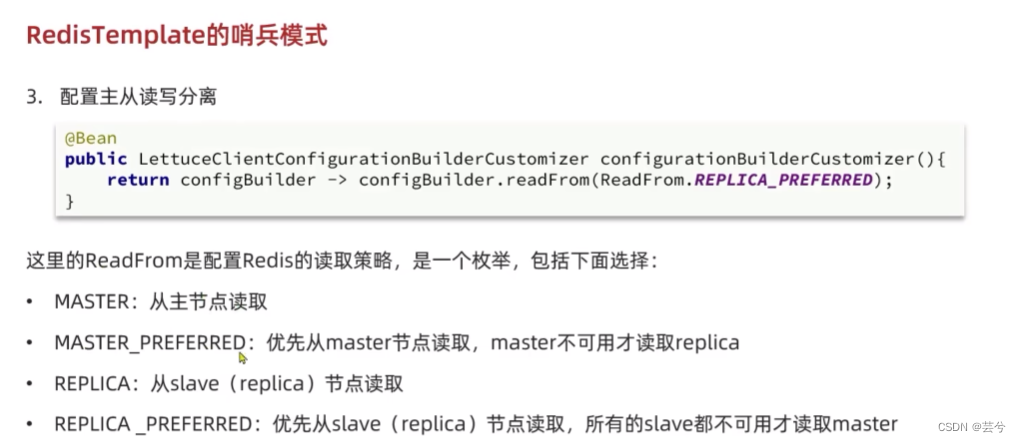
项目中配置RedisTemplate哨兵模式
步骤:
Redis分片集群
主从和哨兵可以解决高可用、高并发持续的问题,但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发读写的问题
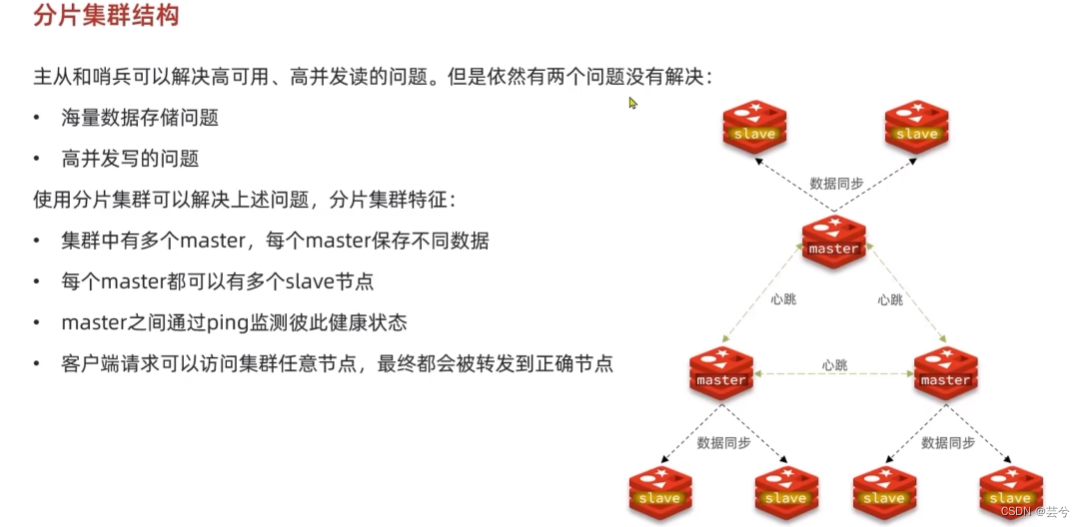
分片集群中有多个master,每个master都可以有多个slave节点,master间通过ping监测彼此健康状态,此时就不再需要哨兵机制了。
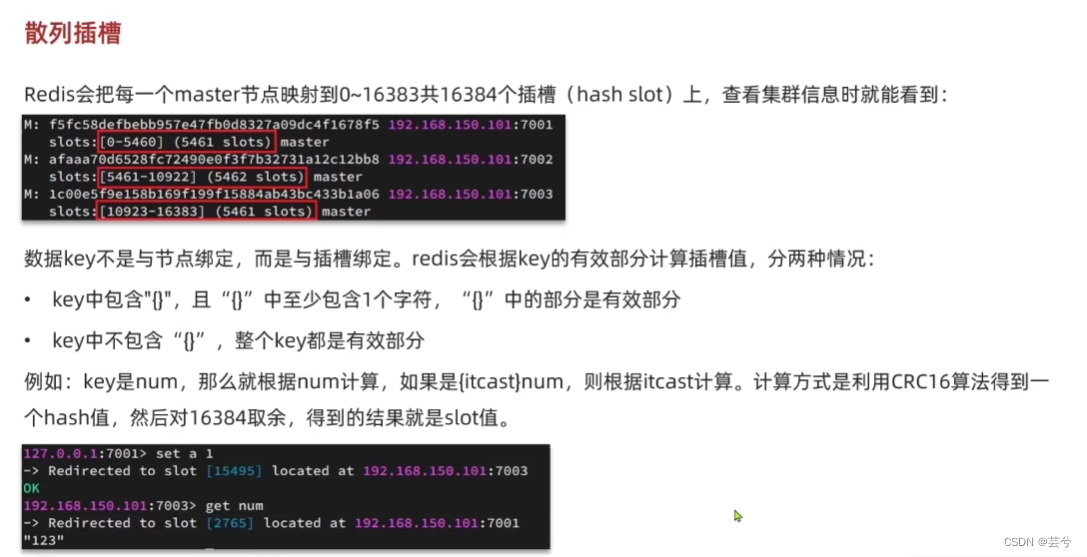
Redis散列插槽
Redis会把一个master的节点映射到 0 - 16383个插槽上,数据的key不是与节点绑定,而是与插槽绑定。
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例。
- 根据key的有效部分计算哈希值,对16384取余。
- 余数作为插槽,寻找插槽所在的实例即可。
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeid}为前缀。
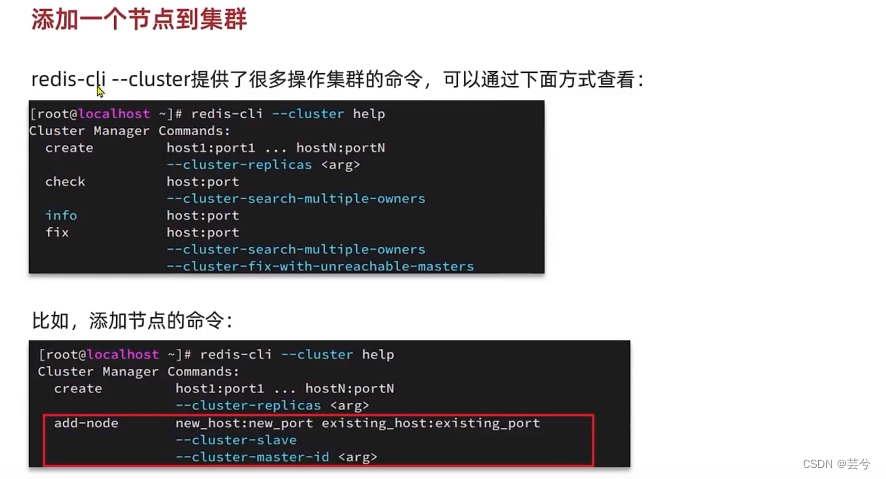
Redis集群伸缩
集群伸缩的概念就是动态添加和移除节点
项目中RedisTemplate配置访问分片集群

Redis多级缓存
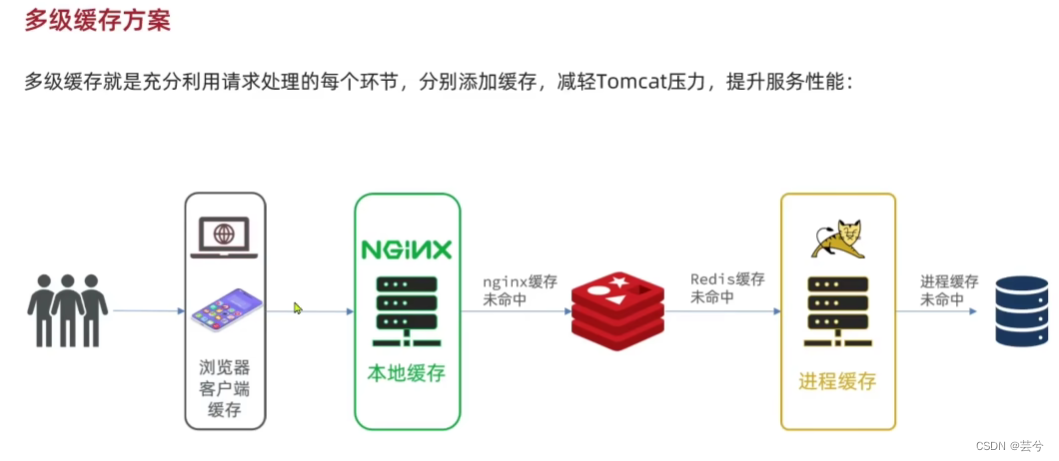
多级缓存就是充分利用请求处理的各个环节,分别添加缓存,减轻Tomcat压力,提升服务性能。
- 浏览器、客户端缓存
- Nginx本地缓存
- Redis缓存
- Tomcat进程缓存

JVM进程缓存

Caffeine
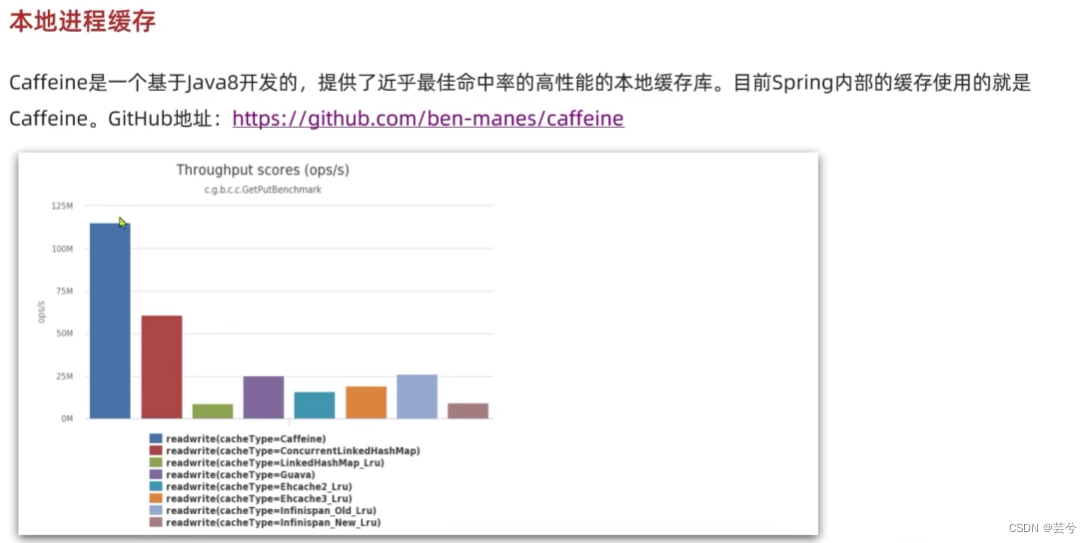


Caffeine实现本地进程缓存案例

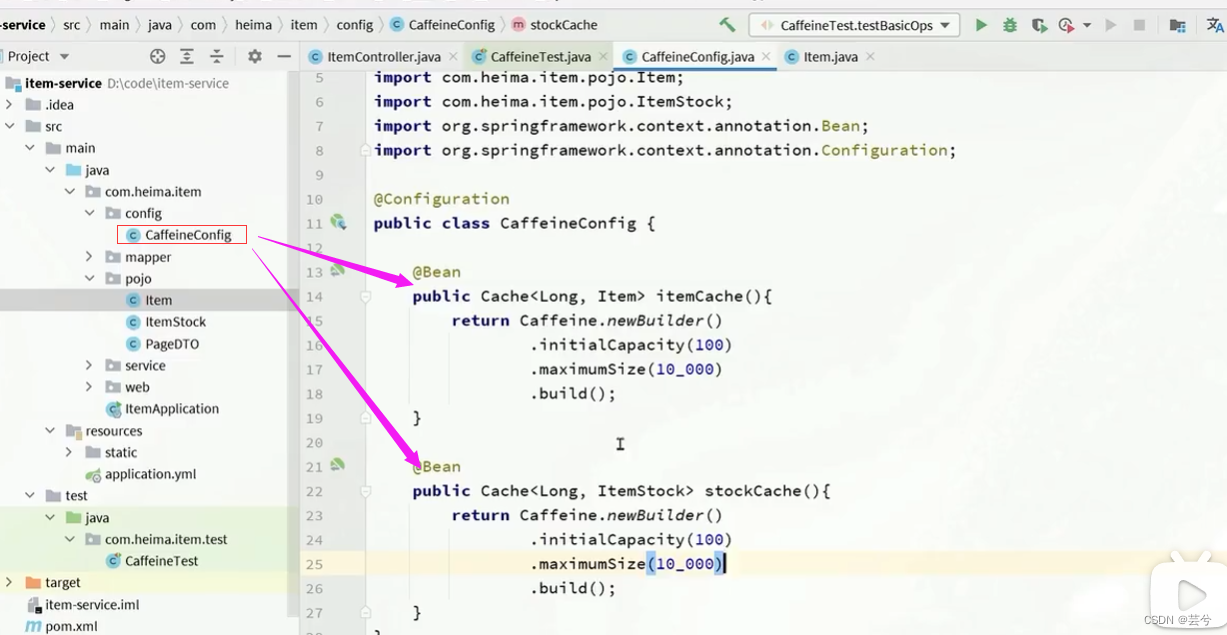
第一步:
构建缓存配置类,创建2个缓存的Bean对象:
第二步:
在使用的地方,将缓存对象注入,编写缓存查询和缓存未命中业务逻辑。

Redis实战经验
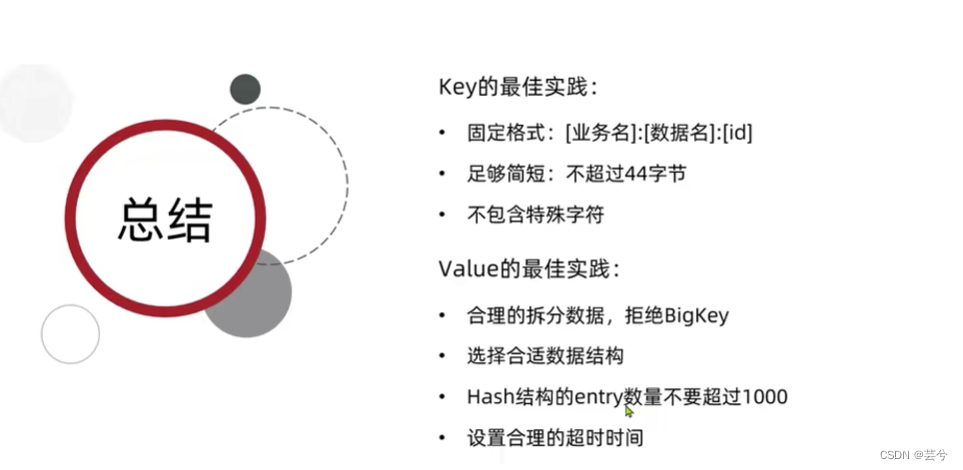
Redis键值设计
优雅的key结构

解决BigKey



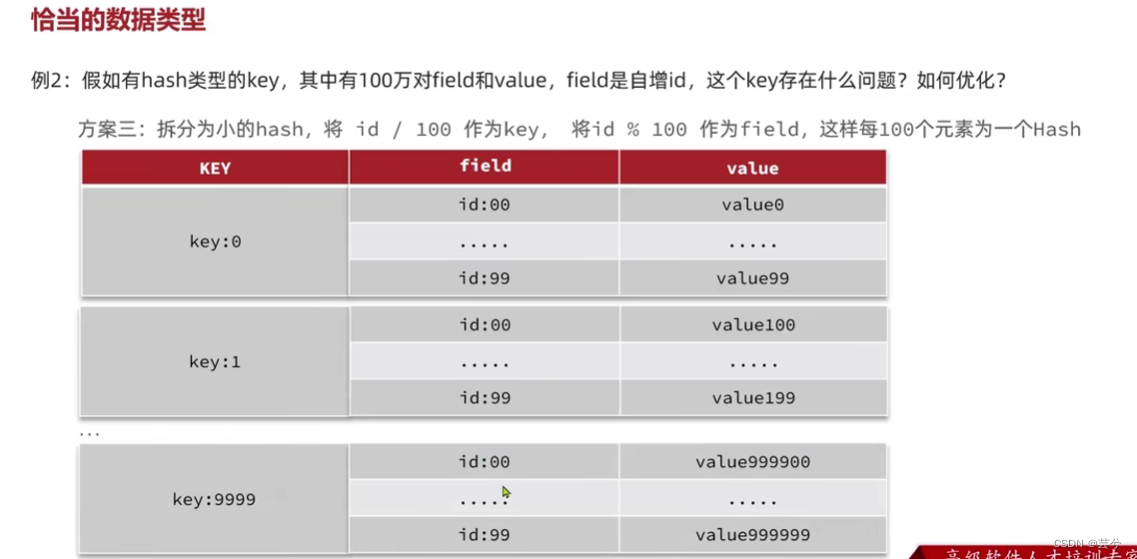
选择恰当的数据类型
将大型的哈希表,进行拆表,拆解为小型的哈希表:

批处理优化
通过批处理执行,减少网络传输耗时。

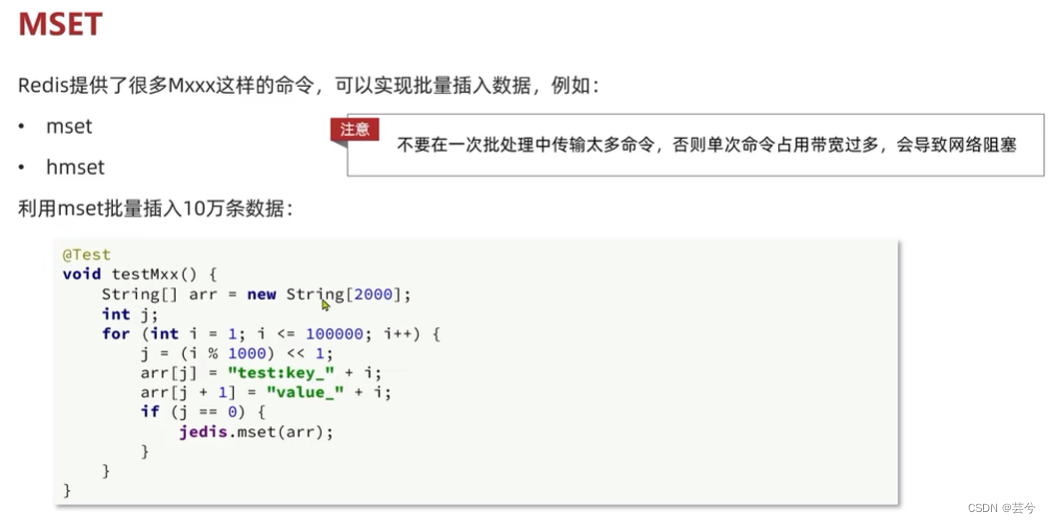
pipeline


集群下的批处理
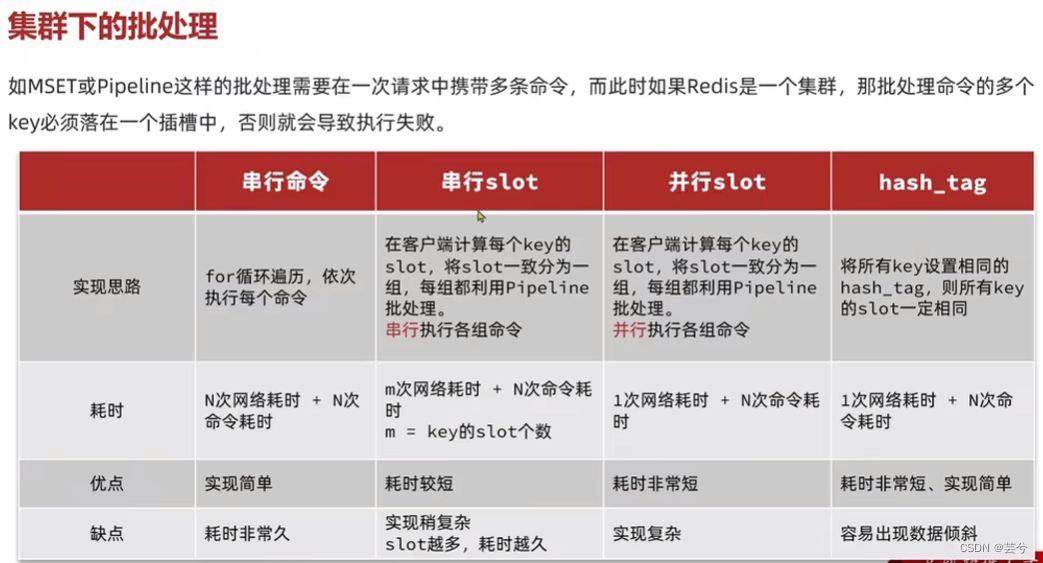
spring的Redistemplate已经提供了并行slot的集群下的批处理实现。
服务端优化
持久化配置
Redis持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
- 用来做缓存的Redis实例尽量不要开启持久化,因为做缓存的数据只是为了加快响应速度,重要性没那么高。但是对于用来做分布式锁的数据,必须开启持久化,保证数据安全。
- 建议关闭RDB持久化功能,使用AOF持久化。RDB持久化虽然文件占用更小,恢复更快,但是RDB在fork进程,生成RDB文件过程中,可能导致数据丢失。
- 利用脚本定期在slave节点做RDB,实现数据备份。

慢查询


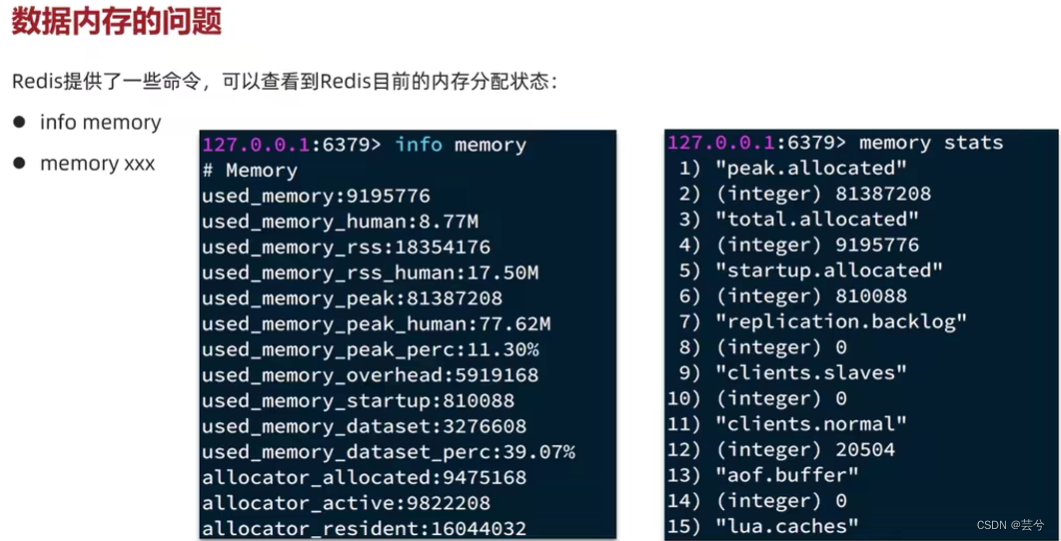
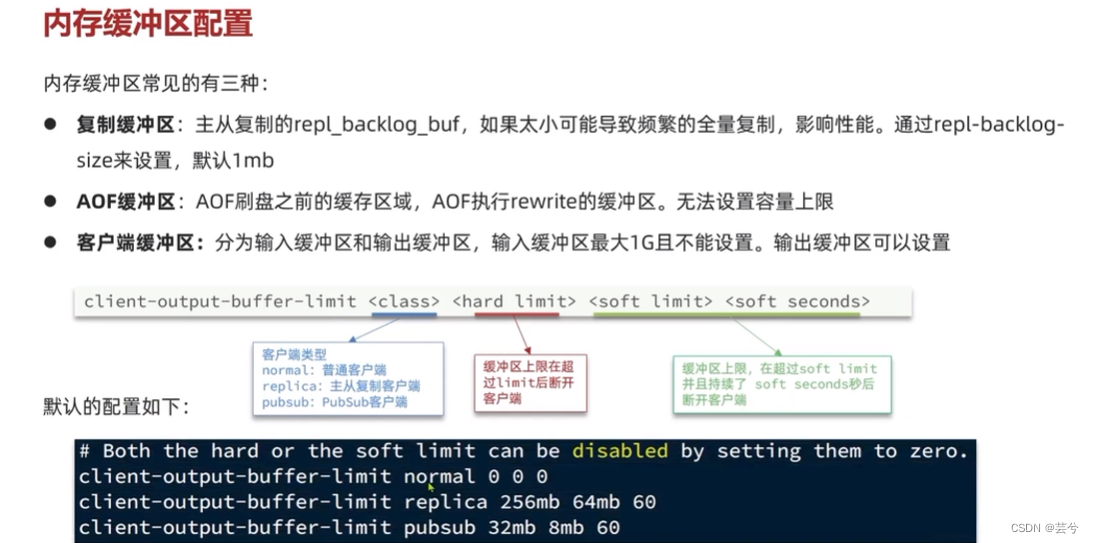
内存配置