1、准备工作
用Python编写的访问网页的程序中,有很多是调用 requests 库模块中的函数来进行操作,这个库模块把网页请求和操作等多项功能进行了高度封装,使其可以轻而易举完成浏览器的许多操作。
requests库是第三方模块,需要进行安装,安装命令如下所示。
| pip install requests |
2、网络爬虫基础知识
(1)robots 协议:网站往往通过授权,声明允许用户爬取哪部门数据、不允许爬取哪些数据,这些授权写在robots.txt 中,称为 robots 协议。
(2)HTTP协议
(3)HTTPS协议:该协议被称为是安全的HTTP协议,就是在HTTP协议增加了安全协议。HTTPS采取证书密钥加密方式,加密方式有对称密钥加密、非对称密钥和证书加密三种方式。
3、利用 get() 函数获取网页的内容
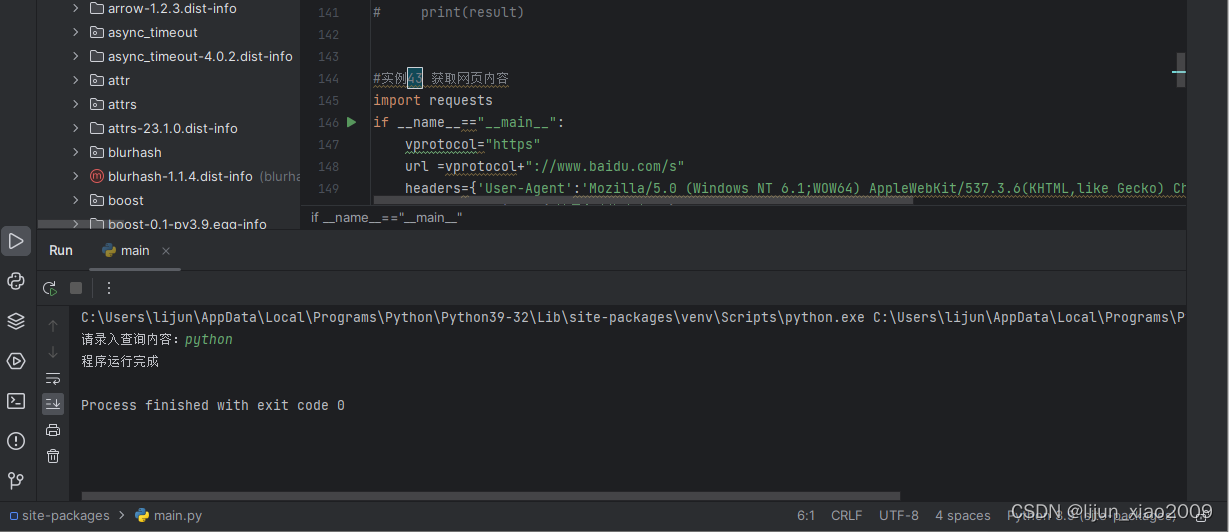
本节编程实例主要利用 Requests 库中的 get() 函数发送 GET 请求,获取网页的内容。样例代码如下所示。
import requests
if __name__=="__main__":
vprotocol="https"
url =vprotocol+"://www.baidu.com/s"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1;WOW64) AppleWebKit/537.3.6(KHTML,like Gecko) Chrome/63.0.3239.132 Safari/537 QIHU 360SE'}
queryword = input("请录入查询内容:")
parm={'q':queryword}
res=requests.get(url,params=parm,headers=headers)
txt=res.text
with open("./test1.html","w",encoding="utf-8") as fs:
fs.write(txt)
print("程序运行完成")4、运行结果