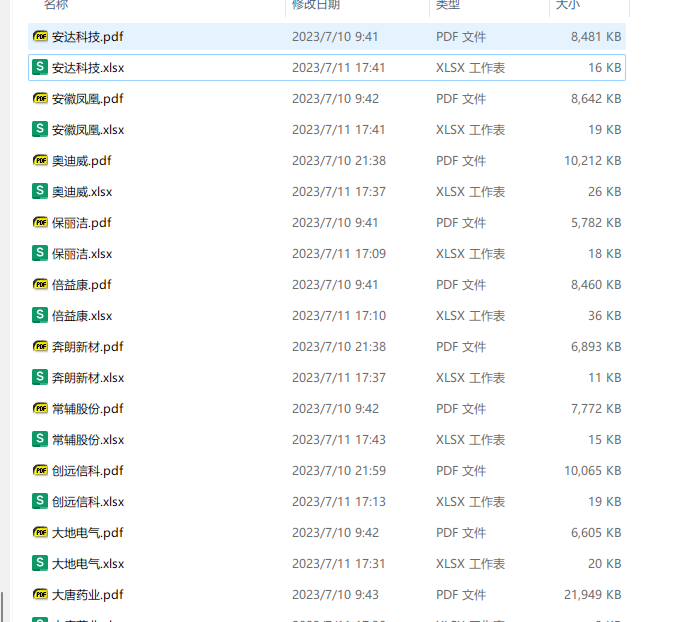
上市公司招股说明书通常会详细列明公司的发明专利,而通过企业的发明专利可以了解企业未来的业务布局情况,怎么把这些发明专利列表都批量提取出来呢?
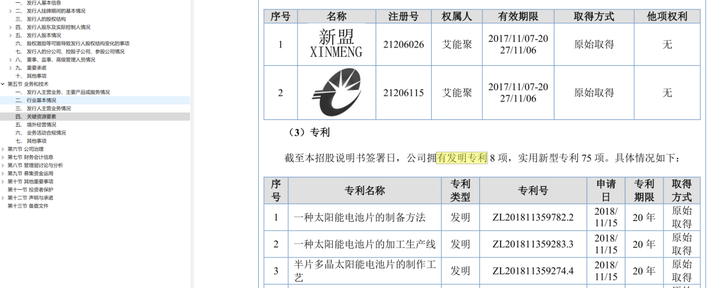
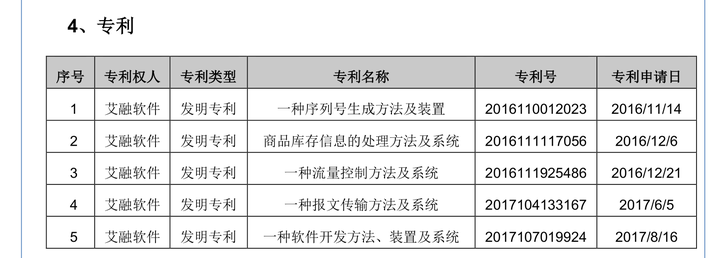
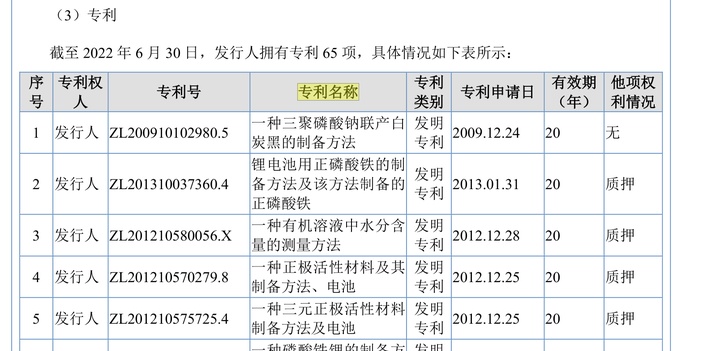
随机打开几个上市公司的招股说明书,可以看到发明专利这一内容,共同的特征是都有关键词:专利号。
所以,可以在ChatGPT中输入提示词如下:
写一段Python程序:
读取“F:\北交所全部上市公司的招股说明书20230710”下所有的PDF文件标题名,设为变量:zhaogushuname;
用Pdfplumber读取“F:\北交所全部上市公司的招股说明书20230710”下所有的PDF文件,定位到包含“专利号”的表格,然后提取这个表格内容,保存到“F:\北交所全部上市公司的招股说明书20230710”的“{zhaogushuname}.xlsx”;
然后判断这个表格是否跨页,如果跨页,就提取下一页的表格内容,添加到“F:\北交所全部上市公司的招股说明书20230710”的“{zhaogushuname}.xlsx”;
重复上面步骤,一直到表格结束;
注意:
每一步都要输出信息;
合并数据之前检查并修改重复的列名,确保列名是唯一的;
添加一个检查条件:有些PDF文件中包含没有“专利号”的表格,遇到这种情况就跳过,然后读取下一个PDF文件;
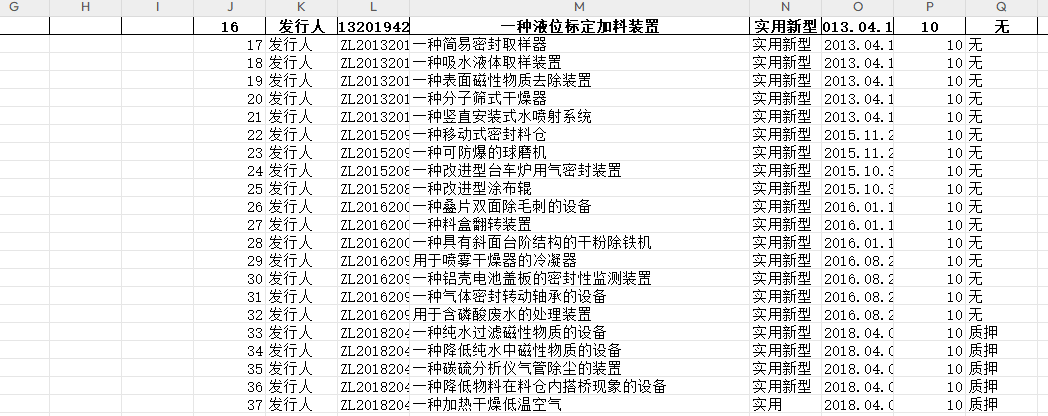
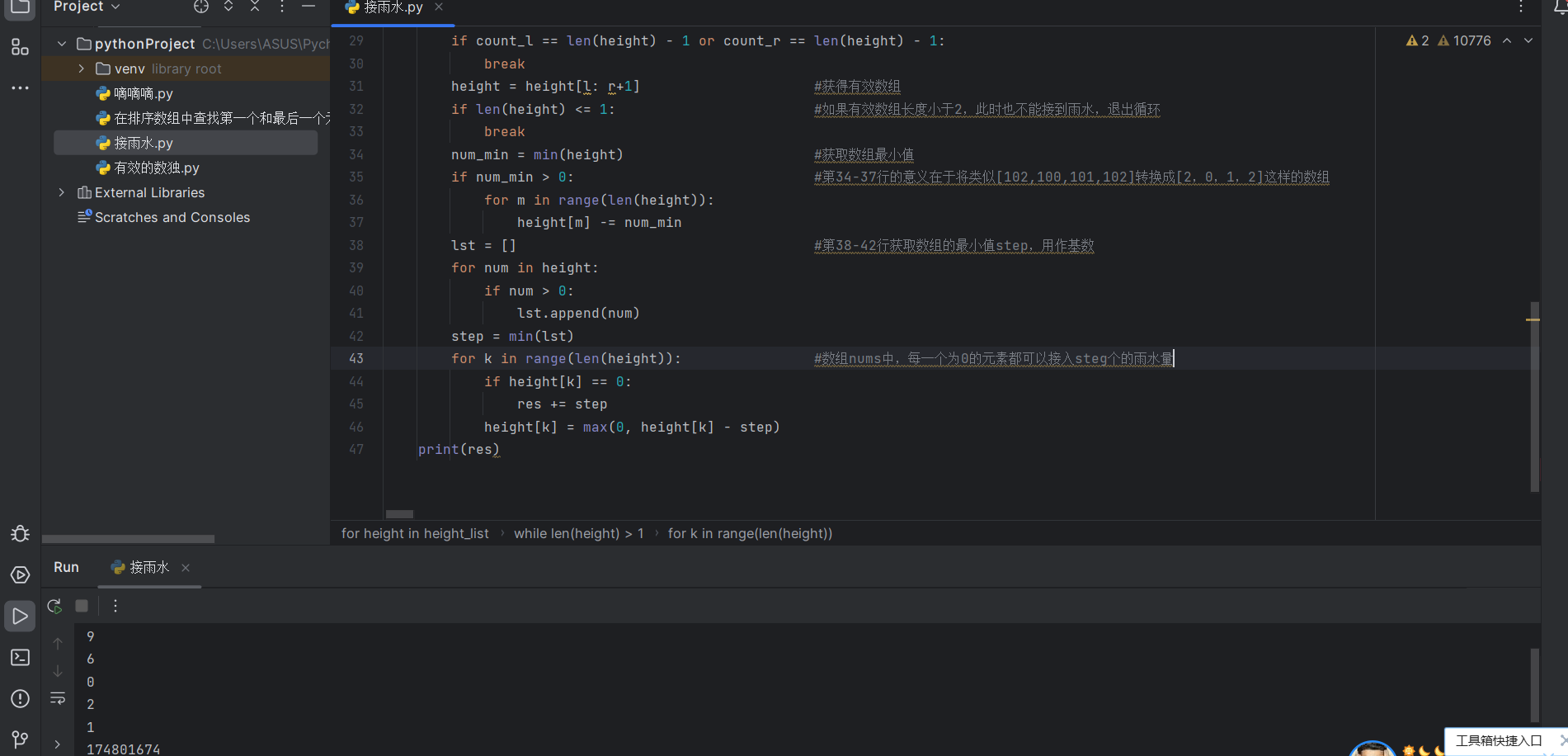
程序运行,发明专利被成功提取出来: