GLM-130B
一、预训练
采用双向注意力机制,对被遮挡的部分及逆行预测,
可以自由设置单词mask,句子smask,文章gmask,可以根据任务的不同设置mask,文本理解设置单词级别mask,文本生成色湖之句子级别的gmask,glm130B中设置的师70%句子级别gmask,30%词级别mask,
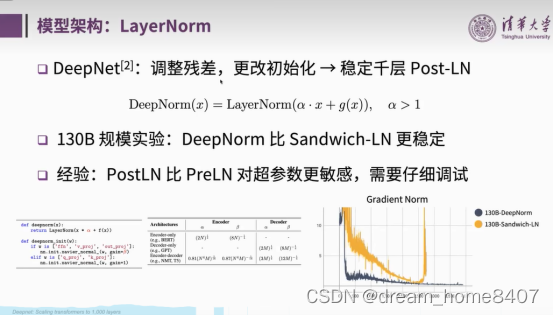
二、模型架构LayerNorm
不同于bert采用transformer架构中attention后进行layernorm,glm采用attention前后进行归一化
用DeepNorm(x) = LayerNorm(α · x + Network(x)),其中α = (2N) 二分之一,
是的模型训练更具稳定性,
Positional Embedding
1,绝对位置编码,三角式,可学习式,
2,相对位置编码,attention中建模单词两两之间的相对距离,
3,RoPE旋转式编码,绝对编码实现相对编码,主要就是对每个位置token中的q, k向量乘以矩阵,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了

三、混合精度训练,

整个流程,相当于forward 参数的计算都是fp16,,更新梯度使用fp32,有更长的表示范围,
转换机制使用float2hat,
四、数据并行,ZeRO优化器
模型并行,流水线并行,将每个stage分别放置到不同的显卡上计算,
五、训练稳定性,
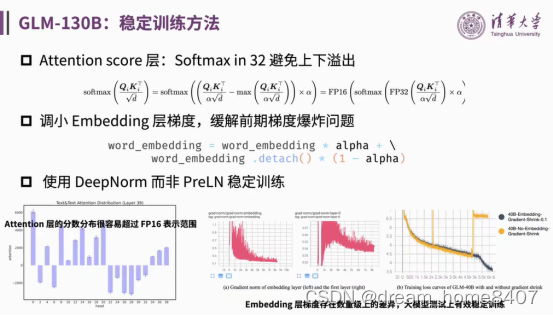
1,attention中在softmax处理之前,乘以一个系数阿尔法,
2,调小embedding层的梯度,缓解梯度爆炸,
3,使用deepnorm归一化,
激活函数,改进transformer中的FFN,使用GeGLu代替relu
六、扩充词表,tockernizer,收集语料,然后用SentencePiece训练后,再拼接词表
七、GLM是一种基于transformer架构的语言模型,利用其空白填空作为其训练目标,对于文本序列x{x1…xm}和文本片段{s1,…sm}从其中采样,每个si表示一个连续标记片段[si,1,…si,li]
并用单个掩码标记替换,形成x,模型要求对它进行自回归回复,
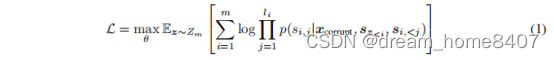
八、预训练数据:包括1.2T Pile (Gao et al., 2020)英语语料库、1.0T汉语五道语料库(Yuan et al.,从网上爬取的250G中文语料库(包括在线论坛、百科全书和问答),形成了中英文数据集
九、Chatglm2-6B,具体信息,
模型结构是,堆叠了28层transformer结构,输入维度是4096,mutil-attention-head是32头
Tokenizer: ChatGLMTokenizer(name_or_path=‘/home/.cache/huggingface/hub/models–THUDM–chatglm2-6b/snapshots/31d45da2d8f14e55f459e15da7e5e57e32dd1e93’, vocab_size=64794, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side=‘left’, truncation_side=‘right’, special_tokens={})
config:
ChatGLMConfig {
“_name_or_path”: “/home/.cache/huggingface/hub/models–THUDM–chatglm2-6b/snapshots/31d45da2d8f14e55f459e15da7e5e57e32dd1e93”,
“add_bias_linear”: false,
“add_qkv_bias”: true,
“apply_query_key_layer_scaling”: true,
“apply_residual_connection_post_layernorm”: false,
“architectures”: [
“ChatGLMModel”
],
“attention_dropout”: 0.0,
“attention_softmax_in_fp32”: true,
“auto_map”: {
“AutoConfig”: “configuration_chatglm.ChatGLMConfig”,
“AutoModel”: “modeling_chatglm.ChatGLMForConditionalGeneration”,
“AutoModelForSeq2SeqLM”: “modeling_chatglm.ChatGLMForConditionalGeneration”
},
“bias_dropout_fusion”: true,
“eos_token_id”: 2,
“ffn_hidden_size”: 13696,
“fp32_residual_connection”: false,
“hidden_dropout”: 0.0,
“hidden_size”: 4096,
“kv_channels”: 128,
“layernorm_epsilon”: 1e-05,
“model_type”: “chatglm”,
“multi_query_attention”: true,
“multi_query_group_num”: 2,
“num_attention_heads”: 32,
“num_layers”: 28,
“original_rope”: true,
“pad_token_id”: 0,
“padded_vocab_size”: 65024,
“post_layer_norm”: true,
“pre_seq_len”: 128,
“prefix_projection”: false,
“quantization_bit”: 0,
“rmsnorm”: true,
“seq_length”: 32768,
“tie_word_embeddings”: false,
“torch_dtype”: “float16”,
“transformers_version”: “4.27.1”,
“use_cache”: true,
“vocab_size”: 65024
}
model: ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
(prefix_encoder): PrefixEncoder(
(embedding): Embedding(128, 14336)
)
(dropout): Dropout(p=0.1, inplace=False)
)
)