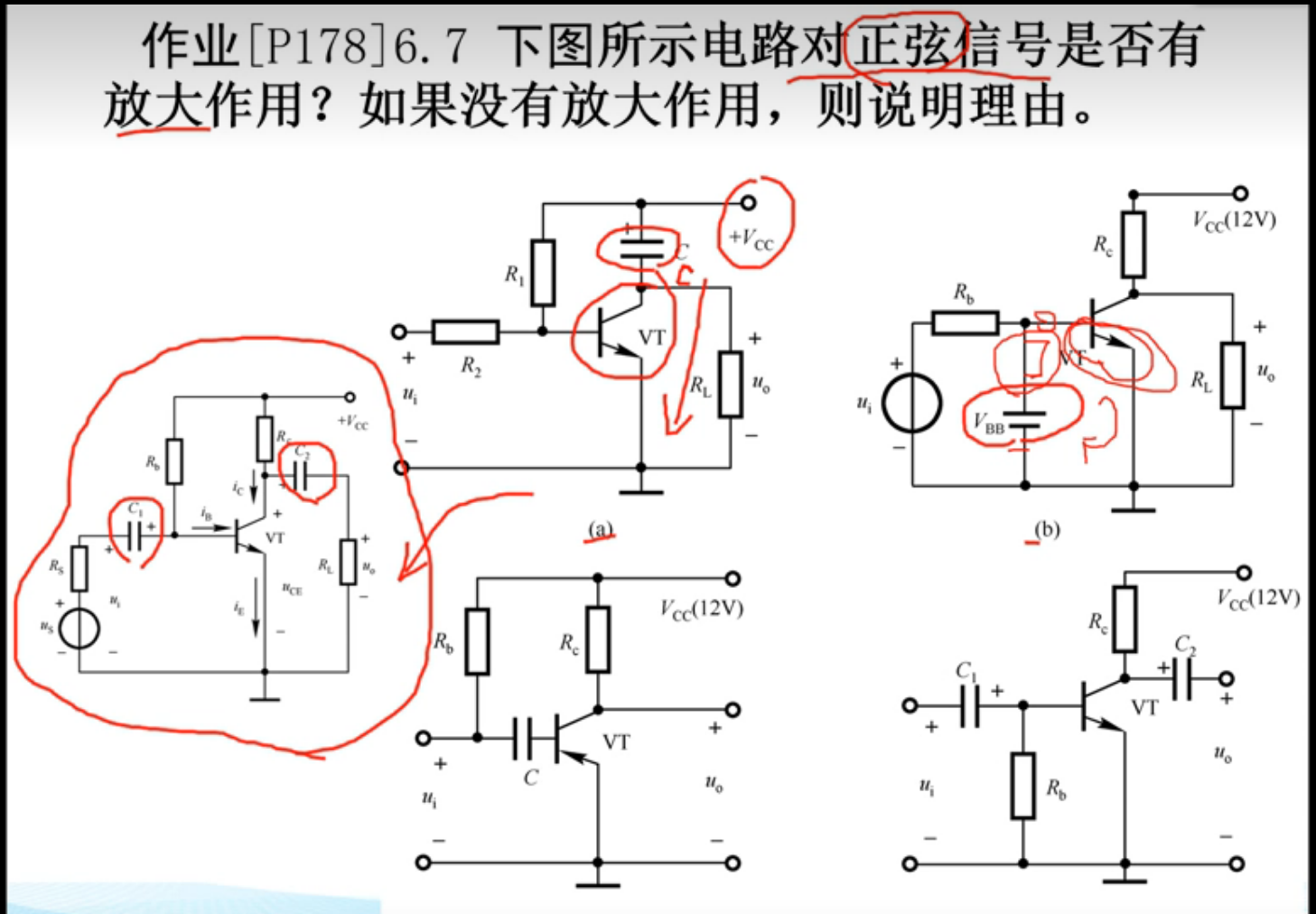
前言
- 这个专栏将会用纯C实现常用的数据结构和简单的算法;
- 有C基础即可跟着学习,代码均可运行;
- 准备考研的也可跟着写,个人感觉,如果时间充裕,手写一遍比看书、刷题管用很多,这也是本人采用纯C语言实现的原因之一;
- 欢迎收藏 + 关注,本人将会持续更新。
文章目录
- 什么是队列
- 队列基本操作
- 队列的数组实现
- 队列的链表实现
- 双端队列
- 优先队列简介
什么是队列
队列(Queue)也是一种运算受限的线性表,它限定在表的一端进行插入操作,在表的另一端进行删除操作。队列的结构特性是:先进先出FIFO ( First In First Out)。队列又被称为先进先出表。
队尾:允许插入的一端称作队尾(Rear)
队首:允许删除的一端称作队首(Front)

队列为空的时候 队头front和队尾tail都是0的位置,入队的时候队尾tail往后移动,出队的时候front往队列tail靠拢
因为front的移动,导致数组队列存在伪溢出现象,可以通过循环队列的方式解决伪溢出问题。
伪溢出:不是实际的的内存越界,只是队头下标比队尾下标前。

链式队列可以通过无表头链表记录头尾的方式实现,插入队列用表尾法插入,遍历表头法删除写法
队列基本操作
- 创建栈
- 入队
- 出队
- 获取队头元素
- 队列是否为空
- 队列元素个数
队列的数组实现
数组队列,就是数组模拟队列,实现方法有很多,这里也只是一种方法。
🚸队列封装
- 数组队列实现是用过移动队头、队尾的
下标实现的,故核心在于:front、tail的理解。 - 数组采用扩容的方法存储数组。
typedef int DataType;
typedef struct Queue {
DataType* data;
int front, tail;
int capacity;
}Queue;
🖍 创建队列(初始化)
这一步就是创建队列,为队列申请一块内存,并且初始化队列,注意,这里需要将tail赋值为-1, 为什么呢? 这个可以随着看代码体会。
Queue* create_queue()
{
Queue* queue = (Queue*)calloc(1, sizeof(Queue));
assert(queue);
queue->tail = -1;
return queue;
}
🌓 入队
- ++tail,采用后置++的方法从队尾巴插入,这里应该就能理解为什么要将tail赋值为-1;
- 注意:容量不够需要扩容。
void push(Queue* queue, DataType data)
{
assert(queue);
// 扩容
if (queue->front == -1 || (queue->front >= queue->capacity)) {
DataType* temp = (DataType*)realloc(queue->data, queue->capacity + 10);
assert(temp);
queue->data = temp;
queue->capacity += 10;
}
queue->data[++queue->tail] = data;
}
✴️ 出队
- 就是移动front,因为数组无法单独删除一个元素;
- 注意:队列为空的情况,front>tail
void pop(Queue* queue)
{
assert(queue);
if (queue->front <= queue->tail) {
queue->front++;
}
}
🤕 获取对头元素
- 这个就是通过数组下标直接获取即可。
DataType top(Queue* queue)
{
assert(queue);
return queue->data[queue->front];
}
🚄 万金油函数:队列大小、是否为空
- 获取大小:注意获取的是大小,不是下标;
- 判断是否为空:就是对头和队尾的下标对比。
int size(Queue* queue)
{
assert(queue);
return queue->tail + 1;
}
bool empty(Queue* queue)
{
assert(queue);
return queue->tail < queue->front;
}
⚗️ 总代码
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <assert.h>
typedef int DataType;
typedef struct Queue {
DataType* data;
int front, tail;
int capacity;
}Queue;
Queue* create_queue()
{
Queue* queue = (Queue*)calloc(1, sizeof(Queue));
assert(queue);
queue->tail = -1;
return queue;
}
void push(Queue* queue, DataType data)
{
assert(queue);
// 扩容
if (queue->front == -1 || (queue->front >= queue->capacity)) {
DataType* temp = (DataType*)realloc(queue->data, queue->capacity + 10);
assert(temp);
queue->data = temp;
queue->capacity += 10;
}
queue->data[++queue->tail] = data;
}
DataType top(Queue* queue)
{
assert(queue);
return queue->data[queue->front];
}
void pop(Queue* queue)
{
assert(queue);
if (queue->front <= queue->tail) {
queue->front++;
}
}
int size(Queue* queue)
{
assert(queue);
return queue->tail + 1;
}
bool empty(Queue* queue)
{
assert(queue);
return queue->tail < queue->front;
}
int main()
{
Queue* queue = create_queue();
for (int i = 1; i <= 10; i++) {
push(queue, i);
}
while (!empty(queue)) {
printf("%d ", top(queue));
pop(queue);
}
return 0;
}
队列的链表实现
链表这里采用的是无头单链表实现,其中:
- 入栈:插入队头
- 出栈:弹出队头
🌛 队列封装
这个部分就是正常的节点封装,队列封装。
// 无头链表,封装写法,尾插法
typedef int DataType;
typedef struct Node {
DataType* data;
struct Node* next;
}Node;
typedef struct Queue {
Node* queueHead;
// Node* tailHead; // 添加这个节点会更简单一点
int size;
}Queue;
👤 创建队列(初始化)
这一部分也是正常的创建节点、队列,然后申请内存。
Node* create_node(DataType data)
{
Node* node = (Node*)calloc(1, sizeof(Node));
assert(node);
node->data = data;
return node;
}
Queue* create_queue()
{
Queue* queue = (Queue*)calloc(1, sizeof(Queue));
assert(queue);
return queue;
}
📌 入队
入队就是在链表头插入,但是要注意,再插入的时候需要判断是否为空表:
- 空表:插入节点作为头;
- 不为空,则头插。
void push(Queue* queue, DataType data)
{
assert(queue);
if (queue->size == 0) {
queue->queueHead = create_node(data);
}
else {
Node* temp = queue->queueHead;
while (temp->next) {
temp = temp->next;
}
temp->next = create_node(data);
}
queue->size++;
}
🏤 出队
出队就是弹出头节点,但是要注意提前判断链表是否为空的情况。
void pop(Queue* queue)
{
assert(queue);
if (queue->size == 0) {
return;
}
Node* temp = queue->queueHead;
queue->queueHead = temp->next;
free(temp);
temp = NULL;
queue->size--;
}
🍿 获取对头元素
这个就是获取头节点的元素值,要注意的是空表的情况,这里空表是直接断言了。
DataType top(Queue* queue)
{
assert(queue);
assert(queue->size != 0); // 队列为空,不能获取栈顶元素
return queue->queueHead->data;
}
🔌 万金油函数:队列大小、是否为空
这个没有什么好说的,看代码吧。
bool empty(Queue* queue)
{
assert(queue);
return queue->size == 0;
}
int size(Queue* queue)
{
assert(queue);
return queue->size;
}
⏰ 总代码
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <assert.h>
// 无头链表,封装写法,尾插法
typedef int DataType;
typedef struct Node {
DataType* data;
struct Node* next;
}Node;
typedef struct Queue {
Node* queueHead;
// Node* tailHead; // 添加这个节点会更简单一点
int size;
}Queue;
Node* create_node(DataType data)
{
Node* node = (Node*)calloc(1, sizeof(Node));
assert(node);
node->data = data;
return node;
}
Queue* create_queue()
{
Queue* queue = (Queue*)calloc(1, sizeof(Queue));
assert(queue);
return queue;
}
void push(Queue* queue, DataType data)
{
assert(queue);
if (queue->size == 0) {
queue->queueHead = create_node(data);
}
else {
Node* temp = queue->queueHead;
while (temp->next) {
temp = temp->next;
}
temp->next = create_node(data);
}
queue->size++;
}
DataType top(Queue* queue)
{
assert(queue);
assert(queue->size != 0); // 队列为空,不能获取栈顶元素
return queue->queueHead->data;
}
void pop(Queue* queue)
{
assert(queue);
if (queue->size == 0) {
return;
}
Node* temp = queue->queueHead;
queue->queueHead = temp->next;
free(temp);
temp = NULL;
queue->size--;
}
bool empty(Queue* queue)
{
assert(queue);
return queue->size == 0;
}
int size(Queue* queue)
{
assert(queue);
return queue->size;
}
int main()
{
Queue* queue = create_queue();
for (int i = 1; i <= 10; i++) {
push(queue, i);
}
while (!empty(queue)) {
printf("%d ", top(queue));
pop(queue);
}
return 0;
}
双端队列
双端队列(Deque)是一种具有队列和栈性质的数据结构,它允许我们从两端添加或删除元素。这种灵活性使得双端队列在多种场景下都非常有用。
双端队列支持的基本操作包括:
- 入队:在队列的前端或后端添加元素。
- 出队:从队列的前端或后端移除元素。
- 访问:访问队列的前端或后端元素而不移除它们。
🉑 实现:
- 采用无头双向链表实现
📦 节点封装
这个就是封装数据节点,双向链表节点,和之前一样,代码如下:
typedef int DataType;
typedef struct Node {
DataType data;
struct Node* prev;
struct Node* next;
}Node;
typedef struct Deque {
Node* head;
Node* tail;
int count;
}Deque;
📇 初始化节点
这个也是和上面一样,封装创建节点、创建队列的节点。
Node* create_node(DataType data)
{
Node* node = (Node*)calloc(1, sizeof(Node));
assert(node);
node->data = data;
return node;
}
Deque* create_deque()
{
Deque* deque = (Deque*)calloc(1, sizeof(Deque));
assert(deque);
return deque;
}
🎧 头插
头插这个要注意的就是判断链表是否为空。
void push_front(Deque* deque, DataType data)
{
assert(deque);
if (deque->count == 0) {
deque->head = deque->tail = create_node(data);
}
else {
Node* node = create_node(data);
node->next = deque->head;
deque->head->prev = node;
deque->head = node;
}
deque->count++;
}
🎉 尾插
尾插这个也是要注意的就是判断链表是否为空。
void push_back(Deque* deque, DataType data)
{
assert(deque);
if (deque->count == 0) {
deque->head = deque->tail = create_node(data);
}
else {
Node* node = create_node(data);
node->prev = deque->tail;
deque->tail->next = node;
deque->tail = node;
}
deque->count++;
}
👟 头删
删除要注意几个点:
- 空不能删;
- 删除后,如果是一个节点删除,则要将指向尾节点指针赋值为NULL,如果不是,则需要将新的对头元素前指针赋值为NULL。
void pop_front(Deque* deque)
{
assert(deque);
assert(deque->count != 0); // 空,不能弹出
Node* temp = deque->head;
deque->head = temp->next;
free(temp);
temp = NULL;
(deque->head) ? (deque->head->prev = NULL) : (deque->tail = NULL); // 这个写法
deque->count--;
}
🚖 尾删
删除要注意几个点:
- 空不能删;
- 删除后,如果是一个节点删除,则要将指向头节点指针赋值为NULL,如果不是,则需要将新队尾的下一个指针赋值为NULL。
void pop_tail(Deque* deque)
{
assert(deque);
assert(deque->count != 0);
Node* temp = deque->tail;
deque->tail = temp->prev;
(deque->tail) ? (deque->tail->next = NULL) : (deque->head = NULL);
free(temp);
temp = NULL;
deque->count--;
}
📑 获取对头、队尾大小
这个就是获取对于节点的元素值,但是要注意的是没有元素的情况。
DataType top_front(Deque* deque)
{
assert(deque);
assert(deque->count != 0);
return deque->head->data;
}
DataType top_tail(Deque* deque)
{
assert(deque);
assert(deque->count != 0);
return deque->tail->data;
}
🆎 总代码
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <assert.h>
/*
C++: deque
实现:双向链表
*/
typedef int DataType;
typedef struct Node {
DataType data;
struct Node* prev;
struct Node* next;
}Node;
typedef struct Deque {
Node* head;
Node* tail;
int count;
}Deque;
Node* create_node(DataType data)
{
Node* node = (Node*)calloc(1, sizeof(Node));
assert(node);
node->data = data;
return node;
}
Deque* create_deque()
{
Deque* deque = (Deque*)calloc(1, sizeof(Deque));
assert(deque);
return deque;
}
void push_back(Deque* deque, DataType data)
{
assert(deque);
if (deque->count == 0) {
deque->head = deque->tail = create_node(data);
}
else {
Node* node = create_node(data);
node->prev = deque->tail;
deque->tail->next = node;
deque->tail = node;
}
deque->count++;
}
void push_front(Deque* deque, DataType data)
{
assert(deque);
if (deque->count == 0) {
deque->head = deque->tail = create_node(data);
}
else {
Node* node = create_node(data);
node->next = deque->head;
deque->head->prev = node;
deque->head = node;
}
deque->count++;
}
// 简单代码的思路,记住
void pop_front(Deque* deque)
{
assert(deque);
assert(deque->count != 0); // 空,不能弹出
Node* temp = deque->head;
deque->head = temp->next;
free(temp);
temp = NULL;
(deque->head) ? (deque->head->prev = NULL) : (deque->tail = NULL); // 这个写法
deque->count--;
}
void pop_tail(Deque* deque)
{
assert(deque);
assert(deque->count != 0);
Node* temp = deque->tail;
deque->tail = temp->prev;
(deque->tail) ? (deque->tail->next = NULL) : (deque->head = NULL);
free(temp);
temp = NULL;
deque->count--;
}
DataType top_front(Deque* deque)
{
assert(deque);
assert(deque->count != 0);
return deque->head->data;
}
DataType top_tail(Deque* deque)
{
assert(deque);
assert(deque->count != 0);
return deque->tail->data;
}
void print_deque(Deque* deque)
{
assert(deque);
Node* temp = deque->head;
while (temp != NULL) {
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}
int main()
{
Deque* deque = create_deque();
for (int i = 1; i <= 10; i++) {
push_front(deque, i);
}
print_deque(deque);
for (int i = 20; i <= 30; i++) {
push_back(deque, i);
}
print_deque(deque);
pop_front(deque);
pop_tail(deque);
print_deque(deque);
return 0;
}
优先队列简介
优先队列,我们第一反应是堆,没错,堆应该是应用最广泛的优先队列,但是从优先队列的定义来看,堆也只是其一种实现方式,优先队列的定义是:按照权值出队。
这里实现了一个简单的优先队列,出队的时候按照优先权最高出队,代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <assert.h>
// 优先队列,按照权值出队,这里只是实现一个简易版本
#define MAX 100
typedef struct Data {
int key; // 比较准则
char name[20];
}Data;
typedef struct PriQueue {
Data data[MAX]; // 简单版本,不扩容
int curSize;
}PriQueue;
PriQueue* create_priqueue()
{
PriQueue* queue = (PriQueue*)calloc(1, sizeof(PriQueue));
assert(queue);
queue->curSize = -1; /// 头为 -1
return queue;
}
bool empty(PriQueue* queue)
{
assert(queue);
return queue->curSize == -1;
}
size_t size(PriQueue* queue)
{
assert(queue);
return queue->curSize + 1;
}
void push(PriQueue* queue, Data data)
{
assert(queue);
if (queue->curSize == MAX)
return;
queue->data[++queue->curSize] = data;
}
// 这里规定:权重最大的优先权最高,故弹出优先权最大的
void pop(PriQueue* queue, Data* temp) // temp:存储需弹出的元素
{
assert(queue);
Data t = queue->data[0];
int max = 0;
for (int i = 1; i <= queue->curSize; i++) {
if (queue->data[i].key > t.key) {
t = queue->data[i];
max = i;
}
}
// 存储
*temp = queue->data[max];
for (int i = max; i <= queue->curSize - 1; i++) {
queue->data[i] = queue->data[i + 1];
}
queue->curSize--;
}
int main()
{
PriQueue* queue = create_priqueue();
Data arr[5] = { {1,"小美"},{5,"小丽"},{3,"小芳"},{4,"coco"},{2,"花花"} };
for (int i = 0; i < 5; i++) {
push(queue, arr[i]);
}
while (!empty(queue)) {
Data temp;
pop(queue, &temp);
printf("key: %d, value: %s\n", temp.key, temp.name);
}
return 0;
}