What‘s HLS?
HLS(High-Level Synthesis)高层次综合。何谓高层次?意味着我们可以使用高层次的语言来对设计进行描述,如C,C++,System C等;那何谓综合呢?HLS在其中起了重要的转换作用,将高层次的抽象语言转换为寄存器传输级语言(register transfer level,RTL),这样我们可以将其映射到FPGA的器件中,进行硬件实现,此谓综合。
简单来说,我们通过HLS工具,可以将C,C++等高级语言描述的算法转换为可以进行硬件部署的代码,缩短我们的开发时间。那有同学就兴奋了:“硬件开发真简单,把算法思路拿C语言验证一下,再用HLS工具转换一下代码就ok了,我上我也行。”这种说法对,也不对。开发的流程是对的,先用高级语言对算法进行验证,再进行硬件实现,不对的地方在于没那么简单(手动狗头),或者说想要高效的硬件实现没那么简单。
Why HLS?
讲完What就该讲Why了,说到Why其实就是说说HLS有哪些优势值得我们选择呢?在这里我搬运一下Xilinx官方文档里面“自夸”的部分:
High-level synthesis bridges hardware and software domains, providing the following primary benefits:
Improved productivity for hardware designers:Hardware designers can work at a higher level of abstraction while creating high-performance hardware.
Improved system performance for software designers:Software developers can accelerate the computationally intensive parts of their algorithms on a new compilation target, the FPGA.
Using a high-level synthesis design methodology allows you to:
Develop algorithms at the C-level:Work at a level that is abstract from the implementation details, which consume development time.
Verify at the C-level:Validate the functional correctness of the design more quickly than with traditional hardware description languages.
Control the C synthesis process through optimization directives:Create specific high-performance hardware implementations.
Create multiple implementations from the C source code using optimization directives:Explore the design space, which increases the likelihood of finding an optimal implementation.
Create readable and portable C source code:Retarget the C source into different devices as well as incorporate the C source into new projects.
我来给大家省流一下,HLS工具对硬件开发者的抽象程度更高,对于软件开发者而言,更方便把算法放FPGA上进行加速了。也就是硬件开发软件化,降低了软件工作者使用FPGA平台进行算法加速的门槛。
那HLS的设计方法有哪些过人之处呢?1、设计的层次更高,不用过多关注设计细节;2、在C-Level就可以进行设计的验证工作;3、使用一些HLS的优化约束语句就可以控制综合结果的性能;4、基于同一套C Code,使用不同组合的优化约束可以生成性能不同的综合结果,来探索设计空间;5、同一套C Code可以映射到不同的硬件平台中,重塑性强。
说了那么多,那HLS用起来方便不,又是C代码,又是约束的。我们看一下官方文档里对HLS输入输出的说明:

输入主要包括:用C、C++、SystemC编写的函数;设计约束,包括时钟频率、时钟不确定度、目标平台等信息;优化指示,来引导HLS工具做综合方面的优化,如面积优先or速度优先;C语言的testbench以及相关的测试文件;
输出主要包括:使用HDL描述的设计;报告文件;
其实各方向的知识基本都符合二八定律,即掌握20%的知识就可以解决80%的问题,其余80%的知识主要用来fix各种corner的情况,本文希望能把20%最重要的东西讲明白,让大家能对HLS有个初步印象,那我们开始吧。
Optimizing the Design
本章主要介绍一些优化技巧,来指导HLS进行综合。通过了解如何对设计进行优化,来提升大家对HLS工具的兴趣。
NOTE:后续所述知识需要同学具有如下基础:了解FPGA基本组成结构,了解 BRAM 资源特性,了解 真双口/伪双口 RAM 的区别,有一定的 C 语言基础,了解指针等基础概念。
时钟、复位和RTL输出
指定时钟频率
对于 C 和 C++ 设计,仅支持单一时钟。对设计中的所有函数将应用同一个时钟。
对于 SystemC 语言设计,每个 SC_MODULE 都必须使用不同时钟来指定。要在 SystemC 语言设计中指定多个时钟,需要使用 create_clock 命令的 -name 选项来创建多个指定时钟,并使用 CLOCK 指令或编译指示来指定哪个函数包含将以指定时钟进行综合的 SC_MODULE。
时钟周期(以 ns 为单位)在“Solutions” → “Solutions Setting”中设置。Vivado HLS 使用时钟不确定性概念来提供用户定义的时序裕度。通过使用时钟频率和器件目标信息,Vivado HLS 可估算设计中的操作时序,但无法确定最终组件布局和信号线布线:这些操作由输出 RTL 的逻辑综合来执行。
为计算用于综合的时钟周期,Vivado HLS 会从时钟周期减去时钟不确定性,如下图所示。
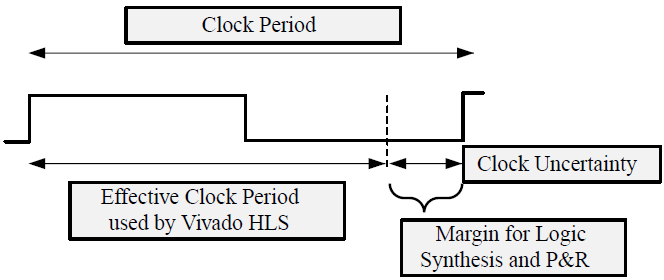
这样可为用户提供指定裕度以确保下游进程(例如,逻辑综合与布局布线)具有足够的时序裕度来完成其操作。如果FPGA 器件利用率过高,那么单元的布局以及用于连接单元的信号线的布线可能无法达成理想状态,并且可能导致设计的时序延迟大于期望值。对于此类情况,增加时序裕度可避免 Vivado HLS 所创建的设计在每个时钟周期内综合过多的逻辑运算,并在布局布线选项不太理想的情况下使 RTL 综合仍能满足时序。默认时钟不确定性为周期时间的 12.5%,设计者可以在时钟周期设置的旁边显式指定该值。
NOTE:综合后复查约束的报告至关重要:实际上虽然 Vivado HLS 可生成输出设计,但并不能保证设计满足所有性能约束。请复查设计报告的“性能估算 (Performance Estimates)”部分。
指定复位
通常 RTL 配置中最重要的操作即选择复位行为。对于复位行为,重要的是理解初始化与复位之间的差异。
初始化行为,指在 C 中,以静态限定符定义的变量,以及全局作用域中定义的变量默认都初始化为 0。对于这些变量,可赋予特定初始值。对于这两种类型的变量,C 语言代码中的初始值在编译时(时序为 0 时)进行赋值,并且不再进行赋值。上述两种情况下,在 RTL 中实现的初始值相同。
- 在 RTL 仿真期间,为这些变量设置的初始值与 C 语言代码中相同。
- 在用于对 FPGA 进行编程的比特流中同样会对这些变量进行初始化。当器件上电时,变量将以其初始状态启动。
变量启动时的初始状态与 C 语言代码中相同,但无法强制返回此初始状态。要返回初始状态,必须通过复位来实现。
那么我们如何控制复位行为呢?复位端口在 FPGA 中用于在应用复位信号时,立即将连接到复位端口的寄存器和 BRAM 还原为初始值。config_rtl 配置可用于控制 RTL 复位端口是否存在及其行为,如下图所示。要访问此配置,请选择“Solution” → “Solution Settings” → “General” → “Add” → “config_rtl”。
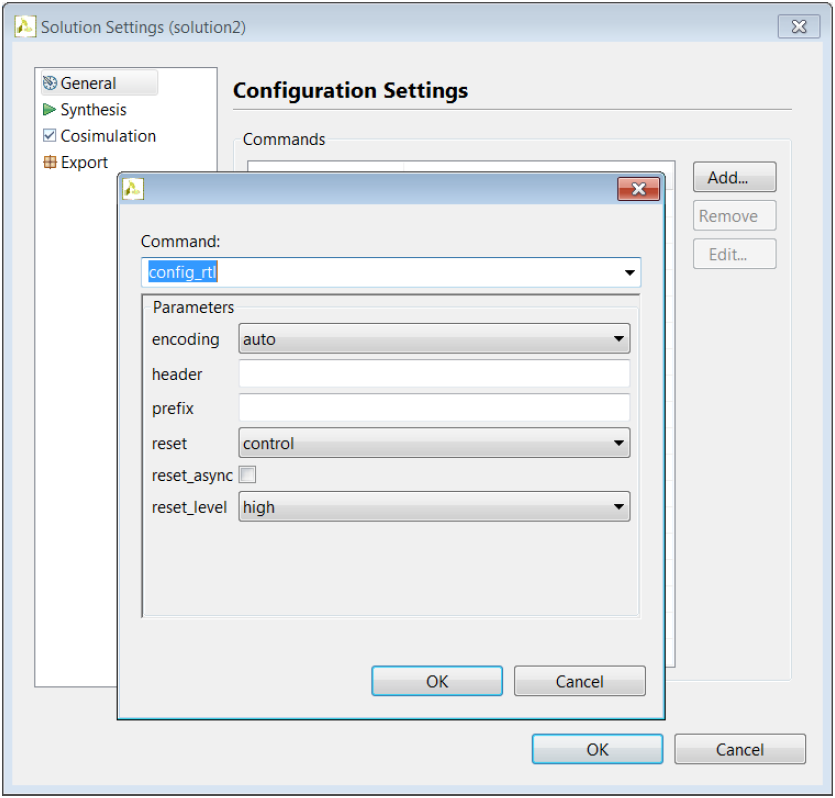
复位设置包含设置复位极性以及使用同步复位还是异步复位的功能,但更重要的是,它可通过“reset”选项来控制应用复位信号时要复位的寄存器。“reset”选项包含 4 项设置:
- “none”:不向设计添加任何复位。
- “control”:这是默认设置,用于确保将所有控制寄存器复位。控制寄存器即状态机中使用的寄存器,用于生成 I/O 协议信号。此设置可确保设计可立即启动其操作状态。
- “state”:该选项可为控制寄存器添加复位(与“control”设置相同),并且还可为衍生自 C 语言代码中的静态变量和全局变量的任意寄存器或memory添加复位。此设置可确保应用复位后,C 语言代码中初始化的静态变量和全局变量均复位为其初始值。
- “all”:为设计中的所有寄存器和memory添加复位。
通过 RESET 指令可提供更精细的复位控制。对于静态变量或全局变量,RESET 指令可用于为其显式添加复位,或者可将该变量从使用 RESET 指令的 off 选项复位的变量中移除。当设计中存在静态数组或全局数组时,该选项非常实用。
NOTE:当在设计上使用 AXI4 接口时,复位极性会自动更改为低电平有效,而与 config_rtl 配置中的设置无关。这与 AXI4 标准的要求有关。
对数组而言,其通常定义为静态变量,这表明所有元素都将初始化为 0,且数组通常使用 BRAM 来实现。使用复位选项 state 或 all 时,会强制将用 BRAM 实现的所有数组在复位后都返回初始化状态。这可能导致 RTL 设计中出现不好的现象:
- 不同于上电初始化,显式复位要求 RTL 设计对 BRAM 中的每个地址进行迭代以设置值:如果 N 较大,这可能导致复位所需的时钟周期数量显著增加,并增加资源占用。
- 设计中的每个数组中都有复位信号。
为防止在此类 BRAM 上都放置复位逻辑,并避免因复位 BRAM 中的所有元素而产生的周期开销,建议执行以下操作:
- 使用默认 control 复位模式,并使用 RESET 指令来指定要复位的每个静态变量或全局变量。
- 或者,使用 state 复位模式,并使用 RESET 指令的 off 选项从特定静态变量或全局变量中移除复位。
RTL输出
可使用 config_rtl 配置来控制 Vivado HLS 的各种 RTL 输出特性:
- 指定 RTL 状态机中使用的 FSM 编码类型。
- 使用 -header 选项可向所有 RTL 文件添加任意注释字符串(例如,版权声明)。
- 使用 prefix 选项可指定要添加到所有 RTL 输出文件名的唯一名称。
- 强制 RTL 端口使用小写名称。
默认 FSM 编码样式为 onehot。其它可用选项包括 auto、binary 和 gray。如果选择 auto,Vivado HLS 可使用onehot 默认设置来实现编码样式,但 Vivado Design Suite 可在逻辑综合期间提取并重新实现 FSM 样式。
最优化设计的吞吐量
使用以下约束来提高吞吐量,或降低函数的启动时间间隔。首先对于函数和循环,可以进行流水线设计,提高数据的吞吐率;其次对于内存读写端口受限的场景,设计者通过对数组进行合适的分区,来将其分布到不同的 BRAM 中,解决读写端口受限的问题;然后对于数据依赖的问题,要仔细分析是否为假性的数据依赖;最后对循环进行适当的展开以改善流水线性能,并在任务级别进行并行化处理。
函数与循环流水线化
流水线化允许并行执行操作:每个执行步骤无需等待完成所有操作后再开始下一项操作。流水线化适用于函数和循环。下图显示了通过函数流水线化实现的吞吐量提升。

如果不使用流水线化,上述示例中的函数将每隔 3 个时钟周期读取一次输入,并在 2 个时钟周期后输出值。该函数启动时间间隔 (Initiation Interval,II) 为 3,时延为 3。使用流水线化后,对于此示例,每个周期都会读取 1 次新输入 (II=1),且不更改输出时延。
循环流水线化支持以重叠方式来实现循环中的操作。在下图中,(A) 显示了默认顺序操作,每次输入读操作间存在 3 个时钟周期 (II=3),需要经过 8 个时钟周期才会执行最后一次输出写操作。
在 (B) 所示的循环的流水线版本中,每个周期都会读取一次新输入样本 (II=1),仅需 4 个时钟周期后即可写入最终输出,在使用相同硬件资源的前提下显著改善 II 和时延。
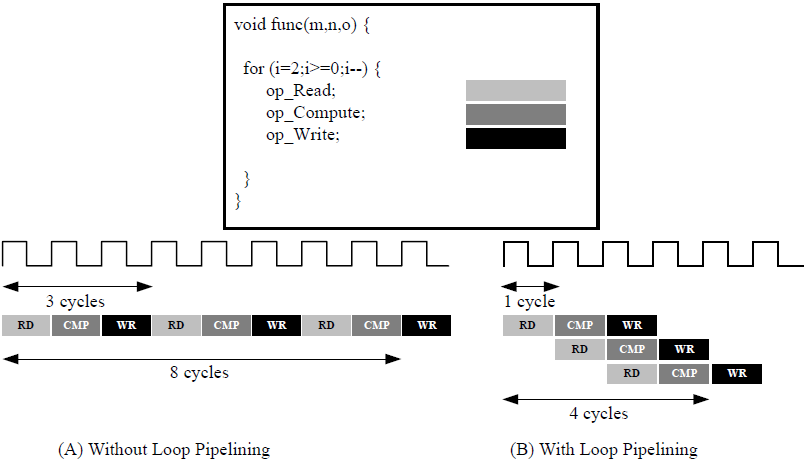
函数或循环使用 PIPELINE 指令来实现流水线化。该指令需要在函数或循环主体区域中进行指定。启动时间间隔如果不指定,则默认为 1,但也可设置为其它值。
流水线化仅应用于指定区域,而不应用于下层层级。但下层层级内所有循环都会自动展开。指定函数的下层层级内的所有子函数都必须单独流水线化。如果将子函数流水线化,其上层的已流水线化的函数即可充分发挥流水线性能。反之,已流水线化的顶层函数下层的任意子函数如果不采用流水线化,则可能限制流水线性能。
已流水线化的函数与已流水线化的循环之间行为存在差异。对于函数,流水线将永久运行,永不终止。对于循环,流水线将持续执行直至循环的所有迭代完成为止。在下图中总结了行为差异。

行为差异会影响流水线输入和输出的处理方式。如上图所示,已流水线化的函数将持续读取新输入和写入新输出。相比之下,由于循环必须首先完成循环中的所有操作,然后才能启动下一次循环,已流水线化的循环会导致数据流传输中出现“气泡”;即,当循环完成最终迭代后不读取任何输入数据的时间点,以及当开始新循环迭代时没有输出数据的时间点。
Rewind已流水线化的循环以保障性能
为避免前图中所示的问题,PIPELINE 编译指示具有可选 rewind 命令。此命令支持将后续调用的迭代进行重叠执行,前提是此循环为数据流进程顶层函数的最外层的构造(并且多次调用数据流区域)。
下图显示了对循环进行流水线化时使用 rewind 选项的操作。循环迭代计数结束时,循环将开始重新执行。虽然一般情况下它立即重新执行,但也可能出现延迟。

NOTE:如果在 DATAFLOW 区域周围使用循环,Vivado HLS 会自动将其实现以允许后续迭代进行重叠。
自动循环流水线化
config_compile 配置支持根据迭代计数对循环进行自动流水线化。此配置可通过菜单“Solution” → “Solution Setting” → “General” → “Add” → “config_compile”访问。
pipeline_loops 选项可用于设置循环边界的限制。低于此限制的单一迭代计数内的所有循环都将自动流水线化。默认值为0:不执行自动循环流水线化。
给定以下示例代码:
for (y = 0; y < 480; y++) {
for (x = 0; x < 640; x++) {
for (i = 0; i < 5; i++) {
// do something 5 times
...
}
}
}
如果 pipeline_loops 选项设置为 6,那么以上代码片段中最内层的 for 循环将自动流水线化。这等同于以下代码片段:
for (y = 0; y < 480; y++) {
for (x = 0; x < 640; x++) {
for (i = 0; i < 5; i++) {
#pragma HLS PIPELINE II=1
// do something 5 times
...
}
}
}
如果设计中有部分无需使用自动流水线化的循环,请对此类循环应用含 off 选项的 PIPELINE 指令。off 选项可阻止自动循环流水线化。
NOTE:Vivado HLS 会在执行所有用户指定的指令后应用 config_compile pipeline_loops 选项。例如,如果 Vivado HLS 向循环应用用户指定的 UNROLL 指令,那么将首先展开该循环,但无法应用自动循环流水线化。
流水线化失败的问题
将函数流水线化时,下层层级内所有循环都会自动展开。这是继续执行流水线化的前提。如果循环的边界是一个变量,则无法展开。这将导致无法对函数进行流水线化。
其次是数据依赖的问题,静态变量用于在循环迭代间保留数据,这通常在导致最终实现时生成寄存器。如果在用流水线实现的函数中遇到此变量,vivado_hls 可能无法对设计进行充分最优化,这可能导致启动时间间隔超过所需的时间。下面给出代码示例:
function_foo()
{
static bool change = 0
if (condition_xyz){
change = x; // store
}
y = change; // load
}
如果 vivado_hls 无法最优化此代码,则存储操作需要 1 个周期,加载操作也需要 1 个周期。如果此函数包含在流水线中,那么流水线必须以最小启动时间间隔 2 来实现,因为数据间存在依赖关系。
用户可通过重写代码来避免此问题,如下例所示。它可确保在循环的每次迭代中仅存在读操作或写操作,这样即可以II=1 来调度设计。
function_readstream()
{
static bool change = 0
bool change_temp = 0;
if (condition_xyz)
{
change = x; // store
change_temp = x;
}
else
{
change_temp = change; // load
}
y = change_temp;
}
通过数组分区来改善流水线化
以下消息显示了对函数进行流水线化时常见的问题:
INFO: [SCHED 204-61] Pipelining loop 'SUM_LOOP'.
WARNING: [SCHED 204-69] Unable to schedule 'load' operation ('mem_load_2',bottleneck.c:62) on array 'mem' due to limited memory ports.
WARNING: [SCHED 204-69] The resource limit of core:RAM:mem:p0 is 1, current assignments:
WARNING: [SCHED 204-69] 'load' operation ('mem_load', bottleneck.c:62) on array 'mem',
WARNING: [SCHED 204-69] The resource limit of core:RAM:mem:p1 is 1, current assignments:
WARNING: [SCHED 204-69] 'load' operation ('mem_load_1', bottleneck.c:62) on array 'mem',
INFO: [SCHED 204-61] Pipelining result: Target II: 1, Final II: 2, Depth: 3.
在此示例中,Vivado HLS 声明它无法达成指定的初始时间间隔 (II) 值 1,因为它受内存端口所限,无法在内存上调度 load(读取)操作 (mem_load_2)。以上消息指出了第 62 行上的 mem_load 操作所使用的“core:RAM:mem:p0 is 1”的资源限制。BRAM 的第 2 个端口同样仅含 1 项资源,该资源同样供 mem_load_1 操作使用。由于存在此内存端口争用,Vivado HLS 报告的最终 II 为 2,而不是所期望的值 1。
此问题通常是由数组所导致的。数组作为最多只含有 2 个数据端口的 BRAM 来实现。这可能限制读写(或加载/存储)密集型算法的吞吐量。通过将该数组(单一 BRAM 资源)拆分为多个更小的数组(多个 BRAM)从而有效增加端口数量,即可改善带宽。
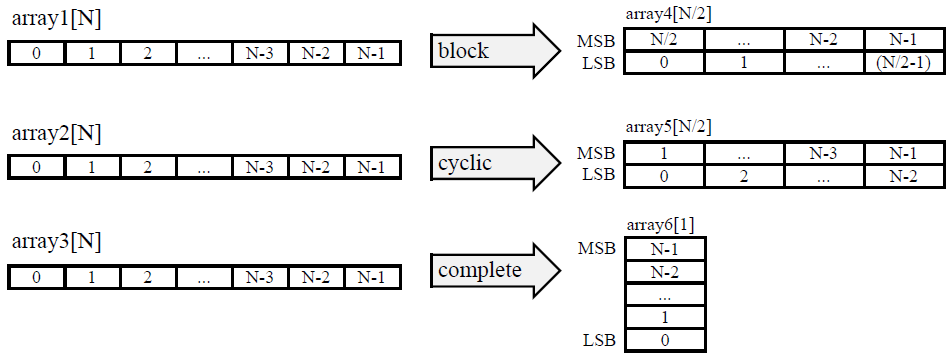
数组可使用 ARRAY_PARTITION 指令来进行分区。Vivado HLS 可提供 3 种类型的数组分区,如下图所示。这 3 种分区样式分别是:
- block:原始数组分割为原始数组的连续元素块(大小相同)。
- cyclic:原始数组分割多个大小相同的块,这些块交织成原始数组的元素。
- complete:默认操作是将数组按其独立元素进行拆分。这对应于将内存解析为寄存器。
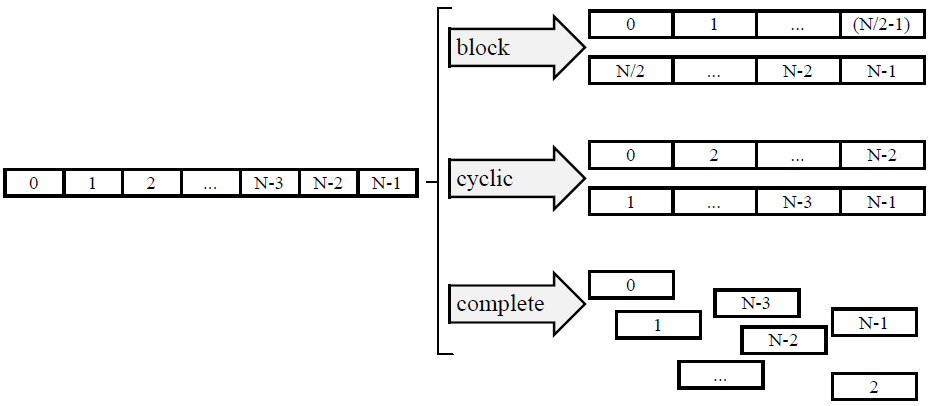
对于 block 和 cyclic 分区,factor 选项可指定要创建的数组数量。在前图中,使用因子 2,即将数组分割为 2 个更小的数字。如果数组的元素数量并非该因子的整数倍,那么最后一个数组所含元素数量较少。
对多维数组进行分区时,dimension 选项可用于指定对哪个维度进行分区。下图显示了使用 dimension 选项对以下代码示例进行分区的方式:
void foo (...) {
int my_array[10][6][4];
...
}
此图中的示例演示了如何通过对 dimension 3 进行分区来生成 4 个独立数组,以及如何对 dimension 1 进行分组以生成 10 个独立分区。如果针对 dimension 指定 0,则将对所有维度进行分区。
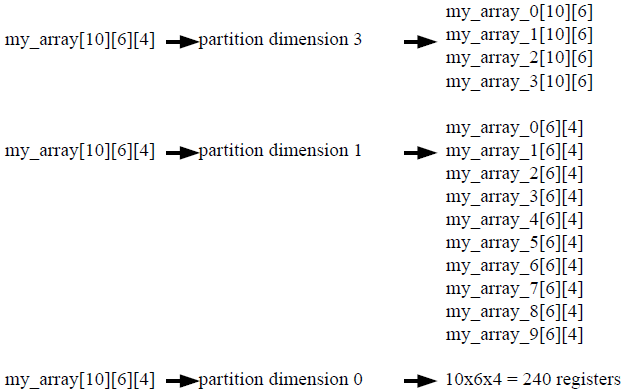
自动数组分区
config_array_partition 配置可根据元素数量判定数组的自动分区方式。此配置可通过菜单“Solution” →“Solution Settings” → “General” → “Add” → “config_array_partition”访问。
通过 throughput_driven 选项可对分区阈值进行调整,并且可完全实现自动分区。选中 throughput_driven 选项时,Vivado HLS 会自动对数组进行分区以实现指定的吞吐量。
与Vivado HLS之间的依赖关系
Vivado HLS 会构造对应于 C 语言源代码的硬件数据路径。
如果没有流水线指令,将按顺序执行,并且不考虑任何依赖关系。但对设计进行流水线时,该工具仍需对 Vivado HLS生成的硬件的处理器架构中发现的依赖关系进行处理。
数据依赖关系或内存依赖关系的典型用例是在完成上一次读操作或写操作后再次发生读操作或写操作。
-
先写后读 (RAW) 操作也称为真性依赖关系,它表示指令(及其读取/使用的数据)从属于前一次操作的结果。
- I1: t = a * b;
- I2: c = t + 1;
语句 I2 中的读操作取决于语句 I1 中的 t 的写操作。如果对指令进行重新排序,它会使用 t 的前一个值,导致结果错误。
-
先读后写 (WAR) 操作也称为反依赖关系,它表示当前一条指令完成数据读取后,下一条指令才能更新寄存器或内存(通过写操作)。
- I1: b = t + a;
- I2: t = 3;
语句 I2 中的写操作无法在语句 I1 之前执行,否则 b 的结果无效。
-
先写后写 (WAW) 依赖关系表示必须按特定顺序写入寄存器或内存,否则可能破坏其它指令。
- I1: t = a * b;
- I2: c = t + 1;
- I3: t = 1;
语句 I3 中的写操作必须晚于语句 I1 中的写操作。否则,语句 I2 结果将出错。
-
先读后读不含任何依赖关系,因为只要变量未声明为volatile,即可随意对指令进行重新排序。如果变量声明为volatile,则必须保留指令顺序不变。
例如,生成流水线时,工具需确保后续阶段读取的寄存器或内存位置没有被之前的写操作修改。这属于真性依赖关系或先写后读 (RAW) 依赖关系。具体示例如下:
int top(int a, int b) {
int t,c;
I1: t = a * b;
I2: c = t + 1;
return c;
}
在语句 I1 完成前,无法对语句 I2 求值,因为与 t 变量之间存在依赖关系。在硬件中,如果乘法需耗时 3 个时钟周期,那么 I2 将发生等同于此时间量的延迟。如果对以上函数进行流水线化,那么 HLS 会将其检测为真性依赖关系,并对操作进行相应调度,因此函数可按 II =1 来运行,但Latency无法进行优化。
当此示例应用于数组而不仅是变量时,就会出现内存依赖关系。
int top(int a) {
int r=1,rnext,m,i,out;
static int mem[256];
L1: for(i=0;i<=254;i++) {
#pragma HLS PIPELINE II=1
I1: m = r * a; mem[i+1] = m; // line 7
I2: rnext = mem[i]; r = rnext; // line 8
}
return r;
}
在以上示例中,L1 循环的调度导致出现调度警告消息:
WARNING: [SCHED 204-68] Unable to enforce a carried dependency constraint (II = 1, distance = 1) between 'store' operation (top.cpp:7) of variable 'm', top.cpp:7 on array 'mem' and 'load' operation ('rnext', top.cpp:8) on array 'mem'.
INFO: [SCHED 204-61] Pipelining result: Target II: 1, Final II: 2, Depth: 3.
只要写入的索引不同于读取的索引,那么循环的同一次迭代内就不会发生任何问题。而 2 条指令可同时并行执行。但请观测多次迭代中的读写操作:
// Iteration for i=0
I1: m = r * a; mem[1] = m; // line 7
I2: rnext = mem[0]; r = rnext; // line 8
// Iteration for i=1
I1: m = r * a; mem[2] = m; // line 7
I2: rnext = mem[1]; r = rnext; // line 8
// Iteration for i=2
I1: m = r * a; mem[3] = m; // line 7
I2: rnext = mem[2]; r = rnext; // line 8
当考虑到 2 次连续迭代时,来自 I1 语句的乘法结果 m(时延 = 2)将写入某一位置,而循环的下一次迭代的 I2 语句将把位于该位置的结果读取到 rnext 中。在此情况下,存在 RAW 依赖关系,因为上一次计算的写操作完成后,下一次循环迭代才能开始读取 mem[i]。
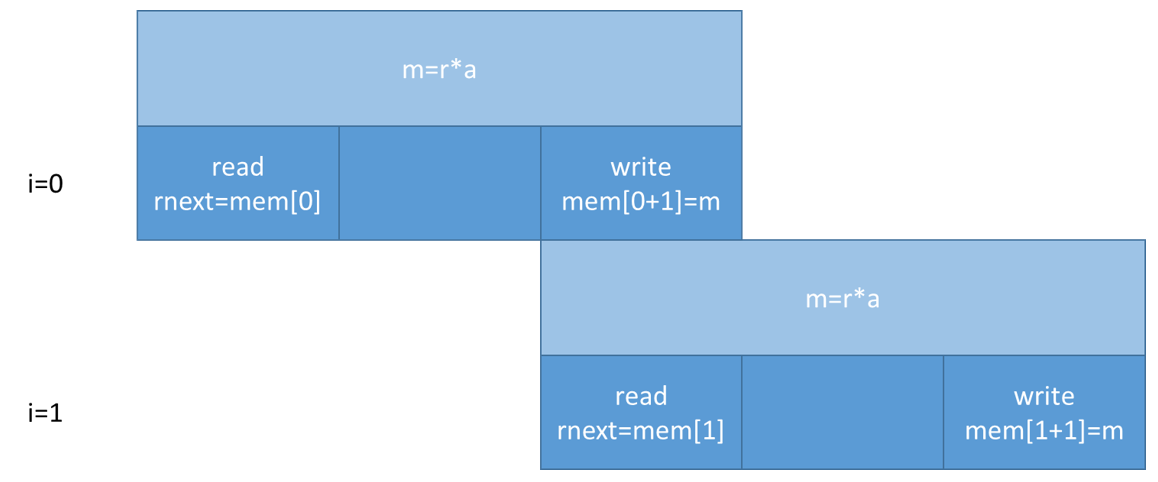
请注意,如果增大时钟频率,那么乘法器将需要更多流水线阶段,从而导致时延增加。这也将迫使 II 增大。
请注意以下代码,其中操作已发生交换,导致功能发生更改。
int top(int a) {
int r,m,i;
static int mem[256];
L1: for(i=0;i<=254;i++) {
#pragma HLS PIPELINE II=1
I1: r = mem[i]; // line 7
I2: m = r * a , mem[i+1]=m; // line 8
}
return r;
}
调度警告为:
INFO: [SCHED 204-61] Pipelining loop 'L1'.
WARNING: [SCHED 204-68] Unable to enforce a carried dependency constraint (II = 1, distance = 1) between 'store' operation (top.cpp:8) of variable 'm', top.cpp:8 on array 'mem' and 'load' operation ('r', top.cpp:7) on array 'mem'.
WARNING: [SCHED 204-68] Unable to enforce a carried dependency constraint (II = 2, distance = 1) between 'store' operation (top.cpp:8) of variable 'm', top.cpp:8 on array 'mem' and 'load' operation ('r', top.cpp:7) on array 'mem'.
WARNING: [SCHED 204-68] Unable to enforce a carried dependency constraint (II = 3, distance = 1) between 'store' operation (top.cpp:8) of variable 'm', top.cpp:8 on array 'mem' and 'load' operation ('r', top.cpp:7) on array 'mem'.
INFO: [SCHED 204-61] Pipelining result: Target II: 1, Final II: 4, Depth: 4.
请观测多次迭代中的连续读写操作:
Iteration with i=0
I1: r = mem[0]; // line 7
I2: m = r * a , mem[1]=m; // line 8
Iteration with i=1
I1: r = mem[1]; // line 7
I2: m = r * a , mem[2]=m; // line 8
Iteration with i=2
I1: r = mem[2]; // line 7
I2: m = r * a , mem[3]=m; // line 8
所需 II 延长,因为存在如下 RAW 依赖关系,从 mem[i] 读取 r、执行乘法并写入 mem[i+1]。
移除假性依赖关系以改善循环流水线化
假性依赖关系,即编译器过于保守时出现的依赖关系。这些依赖关系在真实代码中并不存在,但无法由编译器来判定。这些依赖关系可能阻碍循环流水线化。
假性依赖关系如下示例所示。在此示例中,针对相同循环迭代内的 2 个不同地址执行读写访问。这 2 个地址均依赖于输入数据,可指向 hist 数组中的任一元素。有鉴于此,Vivado HLS 假定这 2 个地址可访问同一个位置。因此,它安排按交替周期对数组执行读写操作,导致循环 II 为 2。但代码显示 hist[old] 和 hist[val] 永远无法访问相同地址,因为这两者包含在 if(old == val) 条件的 else 分支中。
void histogram(int in[INPUT SIZE], int hist[VALUE SIZE]) f
int acc = 0;
int i, val;
int old = in[0];
for(i = 0; i < INPUT SIZE; i++)
{
#pragma HLS PIPELINE II=1
val = in[i];
if(old == val)
{
acc = acc + 1;
}
else
{
hist[old] = acc;
acc = hist[val] + 1;
}
old = val;
}
hist[old] = acc;
为克服这一缺陷,我们可以使用 DEPENDENCE 指令,为 Vivado HLS 提供这些依赖关系的附加信息。
void histogram(int in[INPUT SIZE], int hist[VALUE SIZE]) {
int acc = 0;
int i, val;
int old = in[0];
#pragma HLS DEPENDENCE variable=hist intra RAW false
for(i = 0; i < INPUT SIZE; i++)
{
#pragma HLS PIPELINE II=1
val = in[i];
if(old == val)
{
acc = acc + 1;
}
else
{
hist[old] = acc;
acc = hist[val] + 1;
}
old = val;
}
hist[old] = acc;
NOTE:在实际上依赖关系并非 FALSE 的情况下指定 FALSE 依赖关系可能导致硬件错误。指定依赖关系前,请确认它是否正确(TRUE 或 FALSE)。
指定依赖关系时,有 2 种主要类型:
-
Inter:指定相同循环的不同迭代之间的依赖关系。
如指定为 FALSE,则当循环已流水线化、已展开或已部分展开时,允许 Vivado HLS 并行执行运算,指定为 TRUE 时则阻止此类并行运算。
-
Intra:指定循环的相同迭代内的依赖关系,例如,在相同迭代开始和结束时访问的数组。
当 intra 依赖关系指定为 FALSE 时,Vivado HLS 可在循环内自由移动运算、提升运算移动性,从而可能改善性能或面积。当此依赖关系指定为 TRUE 时,必须按指定顺序执行运算。
标量依赖关系
部分标量依赖关系较难以解析,且通常需要更改源代码。标量数据依赖关系如下所示:
while (a != b) {
if (a > b) a -= b;
else b -= a;
}
此循环的当前迭代完成 a 和 b 的更新值计算后才能启动下一次迭代,如下图所示。

如果必须得到上一次循环迭代结果后才能开始当前迭代,则无法进行循环流水线化。如果 Vivado HLS 无法以指定的启动时间间隔进行流水线化,那么它会增加启动时间间隔。如果完全无法流水线化,则它会停止流水线化并继续输出非流水线化设计。
最优化循环展开以改善流水线
默认情况下,在 Vivado HLS 中循环保持处于收起状态。这些收起的循环会生成硬件资源,供循环的每次迭代使用。虽然这样可以节省硬件资源,但有时可能导致性能瓶颈。
Vivado HLS 可提供使用 UNROLL 指令来展开或部分展开 for 循环的功能。
下图显示了循环展开的优势以及展开循环时必须考量的影响。此示例假定 a[i]、b[i] 和 c[i] 数组已映射到 BRAM 。此示例显示只需直接应用UNROLL约束即可同时创建大批不同的实现方式。

- 循环未展开:当循环未展开时,每次迭代都在单独的时钟周期内执行。此实现需耗时 4 个时钟周期,只需 1 个乘法器并且每个 BRAM 均可为单端口 BRAM。
- 循环部分展开:在此示例中,循环已按因子 2 进行展开。此实现需 2 个乘法器和双端口 RAM ,以支持在同一个时钟周期内读取或写入每个 RAM。但此实现只需 2 个时钟周期即可完成:相比于循环未展开的版本,启动时间间隔和时延均减半。
- 循环全部展开:在完全展开的版本中,可在单一时钟周期内执行所有循环操作。但此实现需 4 个乘法器。更重要的是,此实现需在同一个时钟周期内执行 4 次读操作和 4 次写操作的功能。由于 BRAM 最多仅有 2 个端口,因此该实现方式需对数组进行分区。
要执行循环展开,可向设计中的每个循环应用 UNROLL 指令。或者,可向函数应用 UNROLL 指令,以展开函数作用域内的所有循环。
如果循环已完全展开,那么只要数据依赖关系和资源允许,即可并行执行所有操作。如果某一循环迭代中的操作需要上一次循环的结果,则这两次迭代无法并行执行,但一旦数据可用即可立即执行。
以下示例演示了如何使用循环展开来创建最优化的设计。在此示例中,数据作为交织式通道存储在数组中。如果按 II=1 来对循环进行流水线化,则每经过 8 个时钟周期才会对每个通道执行依次读取和写入。
// Array Order : 0 1 2 3 4 5 6 7 8 9 10 etc. 16
etc...
// Sample Order: A0 B0 C0 D0 E0 F0 G0 H0 A1 B1 C1 etc. A2
etc...
// Output Order: A0 B0 C0 D0 E0 F0 G0 H0 A0+A1 B0+B1 C0+C1 etc. A0+A1+A2
etc...
#define CHANNELS 8
#define SAMPLES 400
#define N CHANNELS * SAMPLES
void foo (dout_t d_out[N], din_t d_in[N]) {
int i, rem;
// Store accumulated data
static dacc_t acc[CHANNELS];
// Accumulate each channel
For_Loop: for (i=0;i<N;i++) {
rem=i%CHANNELS;
acc[rem] = acc[rem] + d_in[i];
d_out[i] = acc[rem];
}
}
按 factor 为 8 来对循环进行部分展开将允许并行处理每个通道(每 8 个样本为一组),前提是输入数组和输出数组同样按 cyclic 方式进行分区,以便在每个时钟周期内进行多次访问。如果此循环同时采用 rewind 选项来进行流水线化,那么此设计将持续并行处理全部 8 个通道,前提是要以流水线方式(即在顶层或者在数据流区域中)调用这些通道。
void foo (dout_t d_out[N], din_t d_in[N]) {
#pragma HLS ARRAY_PARTITION variable=d_i cyclic factor=8 dim=1 partition
#pragma HLS ARRAY_PARTITION variable=d_o cyclic factor=8 dim=1 partition
int i, rem;
// Store accumulated data
static dacc_t acc[CHANNELS];
// Accumulate each channel
For_Loop: for (i=0;i<N;i++) {
#pragma HLS PIPELINE rewind
#pragma HLS UNROLL factor=8
rem=i%CHANNELS;
acc[rem] = acc[rem] + d_in[i];
d_out[i] = acc[rem];
}
}
部分循环展开不要求展开因子为最大迭代计数的整数倍。Vivado HLS 会添加出口检查以确保部分展开的循环的功能与原始循环相同。例如,给定以下代码:
for(int i = 0; i < N; i++) {
a[i] = b[i] + c[i];
}
按因子 2 展开的循环可将代码有效变换为如下示例所示形式,其中 break 构造器用于确保功能保持不变:
for(int i = 0; i < N; i += 2) {
a[i] = b[i] + c[i];
if (i+1 >= N) break;
a[i+1] = b[i+1] + c[i+1];
}
由于 N 为变量,Vivado HLS 可能无法判定其最大值(它可能受输入端口驱动)。如果展开因子(在此例中为 2)是最大迭代计数 N 的整数因子,那么 skip_exit_check 选项会移除出口检查和关联的逻辑。展开的效果现在可表示为:
for(int i = 0; i < N; i += 2) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
}
这有助于最大限度降低面积并简化控制逻辑。
利用任务级别并行化:数据流最优化
数据流最优化对于一系列顺序任务(例如,函数或循环)很实用,如下图所示。

上图显示了连续 3 个任务的特定情况,但通信结构比所示情况可能更复杂。
通过使用这一系列顺序任务,数据流最优化可以创建并发进程架构,如下所示。数据流最优化是可用于改进设计吞吐量和时延的强大方法。

下图显示了数据流最优化允许重叠执行任务的方式,由此可提升总体设计吞吐量并降低时延。
在以下图示和示例中,(A) 表示无数据流最优化的情况。实现需经历 8 个周期后,func_A 才能处理新输入,还需要 8 个周期后 func_C 才能写入输出。
对于同样的示例,(B) 表示应用数据流最优化的情况。func_A 每隔 3 个时钟周期即可开始处理新输入(启动时间间隔更低),只需 5 个时钟即可输出最终值(时延更短)。

这种类型的并行化势必伴随着硬件开销。将某个特定区域(例如,函数主体或循环主体)识别为要应用数据流最优化的区域时,Vivado HLS 会分析此函数主体或循环主体,并创建独立通道以对数据流进行建模,用于将每项任务的结果存储在数据流区域中。这些通道对于标量变量而言可能只是简单的 FIFO,而对于数组之类非标量变量,则可能是乒乓缓存。其中每个通道还都包含用于指示 FIFO 或乒乓缓存已满或已空的信号。这些信号表示完全数据驱动的握手接口。通过采用独立 FIFO 和/或乒乓缓存,Vivado HLS 可使每项任务按其自己的步调执行,吞吐量仅受输入和输出缓存的可用性限制。由此实现的任务执行交织比正常流水线化实现更好,但导致增加 FIFO 或 BRAM 寄存器(用于乒乓缓存)成本。前图所示的数据流区域实现的结构与下图中相同示例所示结构相同。

数据流最优化的性能可能比静态流水线化解决方案的性能更好。它将严格集中控制的流水线停滞理念替换为更灵活的分布式握手架构,后者使用 FIFO 或乒乓缓存。
时延最优化
主要思路如下:首先使用时延约束指明HLS工具的优化方向,然后针对循环进行优化,是否可以对循环进行合并以减少时延,是否可以将嵌套的循环扁平化,避免进出循环的时延。
使用时延约束
Vivado HLS 支持对任意作用域使用时延约束。时延约束是使用 LATENCY 指令来指定的。
对作用域施加最大和/或最小 LATENCY 约束时,Vivado HLS 会尝试确保函数内的所有运算都在指定的时钟周期范围内完成。
应用于循环的时延指令可指定单次循环迭代所需的时延:它指定循环主体的时延,如以下示例所示:
Loop_A: for (i=0; i<N; i++) {
#pragma HLS latency max=10
..Loop Body...
}
如果要限制所有循环迭代的总时延,应将时延指令应用于包含整个循环的区域,如以下示例所示:
Region_All_Loop_A: {
#pragma HLS latency max=10
Loop_A: for (i=0; i<N; i++)
{
..Loop Body...
}
}
在此情况下,即使展开循环,时延指令仍会对所有循环操作设置最大限制。
如果 Vivado HLS 无法满足最大时延约束,它会放宽时延约束,并尝试尽可能实现最佳结果。
如果设置最小时延约束,并且 Vivado HLS 生成的设计时延低于所需的最小值,它会插入虚拟时钟周期以满足最小时延(笔者理解这边就是强行打拍)。
合并顺序循环以减少时延
所有收起的循环都在设计 FSM 中指明并创建至少一种状态。当存在多个顺序循环时,它可能会创建其它不必要的时钟周期,并阻止进一步的最优化。
下图显示了一个简单的示例,其中看似直观的编码样式对 RTL 设计的性能产生了负面影响。
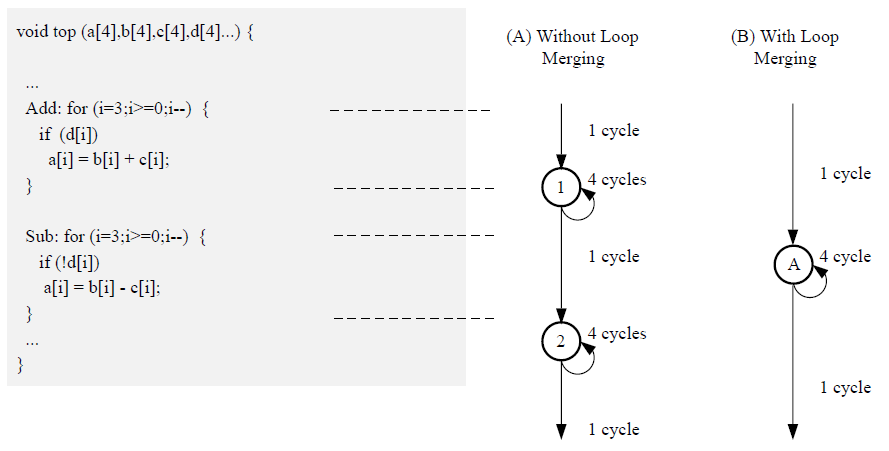
在上图中,(A) 显示了默认情况下设计中的每个收起的循环如何在 FSM 中创建至少一种状态。在这些状态之间移动需耗费多个时钟周期:假设每个循环迭代需要 1 个时钟周期,则执行两个循环总共需要 11 个周期:
- 需要 1 个时钟周期进入 ADD 循环。
- 需要 4 个时钟周期执行加法循环。
- 需要 1 个时钟周期退出 ADD 并进入 SUB。
- 需要 4 个时钟周期执行 SUB 循环。
- 需要 1 个时钟周期退出 SUB 循环。
- 总共 11 个时钟周期。
在这个简单的示例中,很明显,ADD 循环中的 else 分支也可以解决该问题,但是在更复杂的示例中,它可能不那么明显,更直观的编码方式可能具有更大的优势。
LOOP_MERGE 最优化指令用于自动合并循环。LOOP_MERGE 指令将尝试合并应用范围内的所有循环。在上面的示例中,合并循环将创建类似于上图 (B) 所示的控制结构,完成它只需要 6 个时钟周期。
合并循环允许将循环内的逻辑组合在一起进行最优化。在上面的示例中,使用真双口 BRAM 可以并行执行加减运算。
当前在 Vivado HLS 中合并循环具有以下限制:
- 如果循环边界都是变量,则它们必须具有相同的值。
- 如果循环边界为常量,那么最大常量值用作为合并循环的边界。
- 具有变量边界和常量边界的循环无法合并。
- 要合并的循环之间的代码不得产生不同结果:多次执行此代码应生成相同的结果(允许使用 a = b,不允许使用 a = a + 1)。
- 包含 FIFO 访问的循环无法合并:合并将更改 FIFO 上的读写顺序:这些循环必须始终按顺序进行。
将嵌套循环扁平化以改善时延
已展开的嵌套循环之间的移动需要额外的时钟周期,这与前述章节中所述的连续循环间移动方式相似。从外层循环移至内层循环需要一个时钟周期,从内层循环移至外层循环同样如此。
在此处所示小型示例中,这暗示执行 Outer 循环需 200 个额外时钟周期。
void foo_top { a, b, c, d} {
...
Outer: while(j<100){
Inner: while(i<6){ // 1 cycle to enter inner
...
LOOP_BODY
...
} // 1 cycle to exit inner
}
...
}
Vivado HLS 提供的 set_directive_loop_flatten 命令允许将已标记为完美和半完美的嵌套循环扁平化,这样就无需重新编码来提升硬件性能,并且还可减少执行循环中的运算所需的周期数。
- 完美循环嵌套:仅限最内层的循环才有循环主体内容,逻辑语句之间未指定任何逻辑,所有循环边界均为常量。
- 半完美循环嵌套:仅限最内层的循环才有循环主体内容,逻辑语句之间未指定任何逻辑,除最外层循环外所有循环边界均为常量。
对于非完美循环嵌套,即内层循环具有变量边界或者循环主体未完全包含在内层循环内,设计人员应尝试重构代码或者将循环主体中的循环展开以创建完美循环嵌套。
将该指令应用于一组嵌套循环时,应将其应用于最内层循环。
set_directive_loop_flatten top/Inner
循环扁平化还可使用 GUI 中的“Vivado HLS Directive Editor”选项执行,可将其单独应用于各循环,或者通过在函数级别应用该指令来将其应用于函数中的所有循环。
面积最优化
主要可以从下面几个角度考虑:更精准地对数据的类型和位宽进行设置,避免资源的浪费;通过函数的内联来复用模块;通过对函数进行精准的例化来减少函数的通用性,降低资源占用;对于数组而言,首先考虑数据的存取需求,在满足吞吐率的情况下考虑是否可以对数据进行合并,节省存储的 BRAM 资源;此外,对一些复杂运算而言,通过显式制定硬件核可以节省较多的片上逻辑资源,并改善性能。
数据类型和位宽
C 语言函数中的变量位宽会直接影响 RTL 实现中使用的存储元素和运算符。如果变量只需 12 位但指定为整数类型(32 位),这会导致HLS使用更大且运算更慢的 32 位运算符,从而减少一个时钟周期内可执行的运算数量,并可能增大启动时间间隔和时延。为此请特别注意如下几点:
- 使用适合数据类型的相应精度。
- 确认要使用 RAM 还是寄存器来实现数组。任何过大的元素都会影响面积,从而导致硬件资源浪费。
- 请特别注意乘法、除法、取模或其它复杂算术运算。如果这些变量过大,则会对面积和性能都产生负面影响。
函数内联
函数内联会移除函数层级。函数可使用 INLINE 指令进行内联。内联函数可以支持函数中的逻辑共享,以更高效的方式调用函数中的逻辑,从而改善面积。Vivado HLS 也会自动执行此类型的函数内联。小型函数可自动内联。
内联支持对函数共享进行更有效的控制。对于要共享的函数,必须在相同层级内使用。在此代码示例中,foo_top 函数会对 foo 进行 2 次调用,并调用 foo_sub 函数。
foo_sub (p, q) {
int q1 = q + 10;
foo(p1,q); // foo_3
...
}
void foo_top { a, b, c, d} {
...
foo(a,b); //foo_1
foo(a,c); //foo_2
foo_sub(a,d);
...
}
将函数 foo_sub 内联并使用 ALLOCATION 指令指定仅使用 foo 函数的 1 个实例,这样生成的设计仅含 1 个 foo 函数的实例:面积为以上示例的三分之一。
foo_sub (p, q) {
#pragma HLS INLINE
int q1 = q + 10;
foo(p1,q); // foo_3
...
}
void foo_top { a, b, c, d} {
#pragma HLS ALLOCATION instances=foo limit=1 function
...
foo(a,b); //foo_1
foo(a,c); //foo_2
foo_sub(a,d);
...
}
INLINE 指令可选择使用 recursive 选项来允许位于指定函数下层的所有函数以递归方式进行内联。如果对顶层函数使用 recursive 选项,那么将移除设计中的所有函数层级。
可选择对函数应用 INLINE off 选项以阻止对这些函数进行内联。该选项可用于阻止 Vivado HLS 自动进行函数内联。
INLINE 指令是大幅修改代码结构而不对源代码执行任何实际修改的强大方法,并可提供强大的架构探索方法。
将大量数组映射到单一大型数组
当 C 语言代码中存在大量小型数组时,将其映射到单一大型数组通常可减少所需的 BRAM 数量。
受器件支持的前提下,每个数组都映射到 1 个块 RAM 或 UltraRAM。任一 FPGA 中提供的基本块 RAM 单元为 18K。如有大量小型数组且占用资源不足 18K,那么为了更有效地利用 BRAM 资源,可将大量小型数组映射到单一大型数组。如果 BRAM 大于 18K,则会自动将其映射到多个 18K 单元。在综合报告中,请复查“Utilization Report” →“Details” → “Memory”,以便详细了解设计中 BRAM 的使用情况。
ARRAY_MAP 指令支持通过 2 种方式将多个小型数组映射到单一大型数组:
- 水平映射:从数组的深度方向进行合并,通过并置原始数组来创建新阵列。实际上,这作为含更多元素的单一数组来实现。
- 垂直映射:从数组的位宽方向进行合并,通过并置数组中的字词来创建新阵列。实际上,这作为含较大位宽的单一数组来实现。
水平数组映射
以下代码示例包含 2 个数组,这些数组将生成 2 个 RAM 组件。
void foo (...) {
int8 array1[M];
int12 array2[N];
...
loop_1: for(i=0;i<M;i++) {
array1[i] = ...;
array2[i] = ...;
...
}
...
}
数组 array1 和 array2 可组合为单一数组,在以下示例中指定为 array3:
void foo (...) {
int8 array1[M];
int12 array2[N];
#pragma HLS ARRAY_MAP variable=array1 instance=array3 horizontal
#pragma HLS ARRAY_MAP variable=array2 instance=array3 horizontal
...
loop_1: for(i=0;i<M;i++) {
array1[i] = ...;
array2[i] = ...;
...
}
...
}
在此示例中,ARRAY_MAP 指令按下图所示方式对数组进行变换。
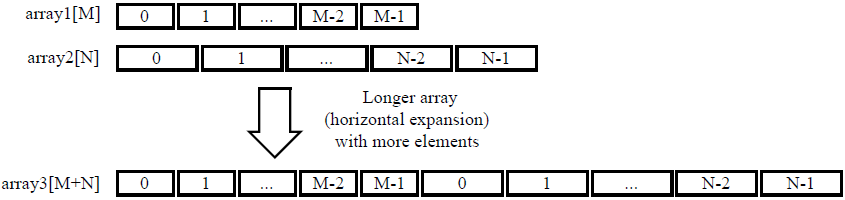
使用水平映射时,多个较小的数组将映射到单一较大的数组。映射从较大的数组中的位置 0 开始,并遵循指定命令的顺序执行映射。
使用下图所示的水平映射时,BRAM 中的实现如下图所示。

ARRAY_MAP 指令的 offset 选项用于指定使用 horizontal 选项时后续数组添加到的位置。重复先前示例,但反转命令顺序(先指定 array2,然后指定 array1)并添加 offset,如下所示:
void foo (...) {
int8 array1[M];
int12 array2[N];
#pragma HLS ARRAY_MAP variable=array2 instance=array3 horizontal
#pragma HLS ARRAY_MAP variable=array1 instance=array3 horizontal offset=2
...
loop_1: for(i=0;i<M;i++) {
array1[i] = ...;
array2[i] = ...;
...
}
...
}
这将导致如下图所示的变换。

映射后,新构成的数组(即以上示例中的 array3)可通过向映射到新实例的任意变量应用 RESOURCE 指令来定向到特定 BRAM 或 UltraRAM。
虽然水平映射可能导致使用的块 RAM 组件数量减少从而改善面积,但它确实会影响吞吐量和性能,因为当前 BRAM端口数量有所减少。为克服此限制,Vivado HLS 还提供了垂直映射。
映射垂直数组
在垂直映射中,通过并置多个数组来生成位宽更高的单个数组。下图显示了应用垂直映射模式时,前述示例所发生的变化。
void foo (...) {
int8 array1[M];
int12 array2[N];
#pragma HLS ARRAY_MAP variable=array2 instance=array3 vertical
#pragma HLS ARRAY_MAP variable=array1 instance=array3 vertical
...
loop_1: for(i=0;i<M;i++) {
array1[i] = ...;
array2[i] = ...;
...
}
...
}
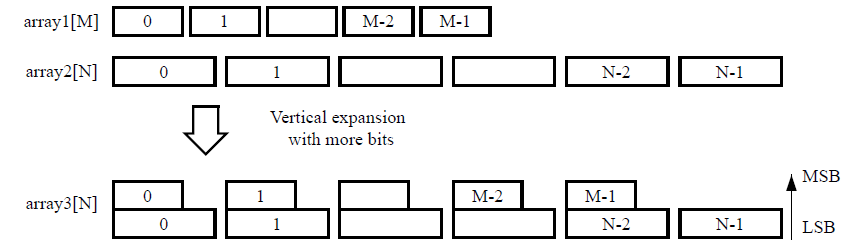
在垂直映射中,按命令指定顺序并置各数组,指定的数组排序顺序为从 LSB 开始到 MSB 结束。完成垂直映射后,新组成的数组将在单一BRAM 组件内实现,如下图所示。

数组映射以及注意事项
NOTE:数组变换的优化指令在代码中放置的位置必须先于其它任何与数组相关的优化指令。
要将元素从已分区的数组映射到含 horizontal 映射的单一数组中,必须在 ARRAY_MAP 指令中指定数组的每个要分区的元素。例如,以下 Tcl 命令用于对 accum 数组进行分区,并将生成的元素重新映射到一起。
#pragma HLS array_partition variable=m_accum cyclic factor=2 dim=1
#pragma HLS array_partition variable=v_accum cyclic factor=2 dim=1
#pragma HLS array_map variable=m_accum[0] instance=mv_accum horizontal
#pragma HLS array_map variable=v_accum[0] instance=mv_accum horizontal
#pragma HLS array_map variable=m_accum[1] instance=mv_accum_1 horizontal
#pragma HLS array_map variable=v_accum[1] instance=mv_accum_1 horizontal
可对全局数组进行映射。但生成的数组实例为全局实例,映射到该数组实例的任何局部数组都会变为全局数组。当不同函数的局部数组映射到同一目标数组时,目标数组实例就会变为全局实例。
数组重塑
ARRAY_RESHAPE 指令将 ARRAY_PARTITIONING 与 ARRAY_MAP 的垂直模式相结合,用于减少 BRAM 数量,同时仍支持分区的有利特性:并行访问数据。
给定以下示例代码:
void foo (...) {
int array1[N];
int array2[N];
int array3[N];
#pragma HLS ARRAY_RESHAPE variable=array1 block factor=2 dim=1
#pragma HLS ARRAY_RESHAPE variable=array2 cycle factor=2 dim=1
#pragma HLS ARRAY_RESHAPE variable=array3 complete dim=1
...
}
ARRAY_RESHAPE 指令可将数组转换为下图所示形式。
ARRAY_RESHAPE 指令支持在单一时钟周期内访问更多数据。只要能在单一时钟周期内访问更多数据,Vivado HLS 即可自动展开使用此数据的所有循环,前提是这样有助于提升吞吐量。循环可全部或部分展开以提高数据的吞吐率。此功能可使用 config_unroll 命令和 tripcount_threshold 选项来加以控制。在以下示例中,循环次数小于 16 的任何循环都将自动展开(前提是可提高吞吐量)。
config_unroll -tripcount_threshold 16
函数例化
函数例化是一种最优化技巧,不仅具有维持函数层级的面积优势,还可提供另一个强大的选项:在函数的特定实例上执行针对性局部最优化。这样可以简化围绕函数调用的控制逻辑,也可能改进时延和吞吐量。
鉴于调用函数时部分函数输入可能是常量,FUNCTION_INSTANTIATE 指令可借此简化周围控制结构,并生成进一步优化的、更小的函数块。这可通过示例来细化解释。
给定如下代码:
void foo_sub(bool mode){
#pragma HLS FUNCTION_INSTANTIATE variable=mode
if (mode) {
// code segment 1
} else {
// code segment 2
}
}
void foo(){
#pragma HLS FUNCTION_INSTANTIATE variable=select
foo_sub(true);
foo_sub(false);
}
很明显,函数 foo_sub 的功能为执行单一重复性运算(根据 mode 是否为 true)。函数 foo_sub 的每个实例均以相同方式实现:这非常适合函数复用和面积最优化,但也意味着函数内部的控制逻辑必须更加复杂。
FUNCTION_INSTANTIATE 最优化允许对每个实例进行独立最优化,从而减少功能和面积。完成FUNCTION_INSTANTIATE 最优化后,以上代码可有效转换为 2 个独立函数,每个函数都针对模式的不同可能值来完成最优化,如下所示:
void foo_sub1() {
// code segment 1
}
void foo_sub2() {
// code segment 2
}
void A(){
foo_sub1();
foo_sub2();
}
在不进行大幅内联或代码修改的情况下,在不同层级使用该函数会导致函数难以共享,那么函数例化约束可提供改进面积的最佳方法:大量小型局部最优化的函数副本比大量无法共享的大型函数副本更有效。
控制硬件资源
综合期间,Vivado HLS 会执行以下基本任务:
-
首先,将 C、C++ 或 SystemC 语言源代码细化为包含运算符的内部数据库。
运算符表示 C 语言代码中的运算,如加法、乘法、数组读取和写入等。
-
然后,将运算符映射到实现硬件操作的核上。
核为用于创建设计的特定硬件组件(例如,加法器、乘法器、流水线化的乘法器和 BRAM)。
作为设计者,我们可以控制其中每个步骤,从而对硬件实现进行精细化的控制。
限制运算符数量
显式限制运算符的数量以减小某些情况下所需的面积:Vivado HLS 的默认操作是首先最大限度提升性能。限制设计中的运算符数量是一项减小面积的实用技巧:它通过强制共享运算来减小面积。
ALLOCATION 指令允许设计者限制设计中使用的运算符、核或函数数量。例如,名为 foo 的设计包含 317 次乘法,但FPGA 仅有 256 项乘法器资源 (DSP48)。以下所示 ALLOCATION 指令可指示 Vivado HLS 创建含最多 256 个乘法 (mul) 运算符的设计:
dout_t array_arith (dio_t d[317]) {
static int acc;
int i;
#pragma HLS ALLOCATION instances=mul limit=256 operation
for (i=0;i<317;i++) {
#pragma HLS UNROLL
acc += acc * d[i];
}
return acc;
}
NOTE:如果指定的 ALLOCATION 限制超出所需数量,Vivado HLS 会尝试使用此项限制指定的资源数量,导致减少共享量。
设计者可使用 type 选项来指定 ALLOCATION 指令是否限制运算、核和函数数量。下表列出了可使用 ALLOCATION 指令控制的所有运算。
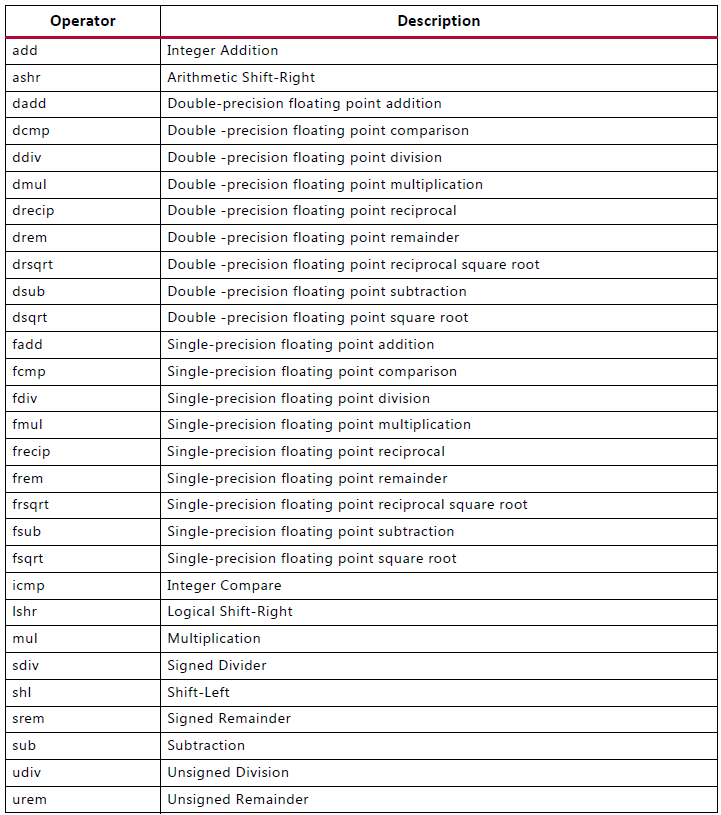
全局最大限度减少运算符
ALLOCATION 指令与所有其它指令一样,都是在某一作用域内指定的:函数、循环或区域。config_bind 配置允许在整个设计中最大限度减少运算符。
在设计中要最大限度减少运算符,可执行 config_bind 配置中的 min_op 选项。前表中列出的任意运算符均可按此方式加以限制。
应用配置后,它将应用于解决方案中执行的所有综合操作:如果关闭再重新打开解决方案,那么指定的配置仍适用于所有新综合运算。
随 config_bind 配置一起应用的任意配置均可使用 reset 选项来移除,或者使用 open_solution -reset 以打开解决方案。
控制硬件核
执行综合时,Vivado HLS 会使用由时钟指定的时序约束、由目标器件指定的延迟以及由您指定的任意指令来判定使用哪个核来实现运算符。例如,要实现乘法运算,Vivado HLS 可使用组合乘法器核或使用流水线乘法器核。
综合期间映射到运算符的核可采用与运算符相同的方式来加以限制。您无需限制乘法运算总数,而可改为选择限制组合乘法器核的数量以强制使用流水线化乘法器来执行所有剩余乘法(或反之亦然)。这是通过将 ALLOCATION 指令 type 选项指定为 core 来实现的。
RESOURCE 指令用于显式指定要用于特定操作的核。在以下示例中指定使用 2 阶流水线化乘法器以实现变量的乘法运算。以下命令会告知 Vivado HLS 针对变量 c 使用 2 阶流水线化乘法器。由 Vivado HLS 判定用于变量 d 的核。
int foo (int a, int b) {
int c, d;
#pragma HLS RESOURCE variable=c latency=2
c = a*b;
d = a*c;
return d;
}
在以下示例中,RESOURCE 指令指定变量 temp 的加法运算,并使用 AddSub_DSP 核来实现。这样可确保在最终设计中使用 DSP48 原语来实现此运算 - 默认情况下加法运算是使用 LUT 来实现的。
void apint_arith(dinA_t inA, dinB_t inB, dout1_t *out1) {
dout2_t temp;
#pragma HLS RESOURCE variable=temp core=AddSub_DSP
temp = inB + inA;
*out1 = temp;
}
list_core 命令用于获取有关库中可用的核的详细信息。list_core 只能在 Tcl 命令界面中使用,并且必须使用set_part 命令指定器件。如果未选中器件,此命令将无效。list_core 命令的 -operation 选项列出了库中可通过指定运算实现的所有核。下表列出了用于实现标准 RTL 逻辑运算(例如,加法、乘法和比较)的核。

除标准核外,当运算使用浮点类型时还可使用以下浮点核。请参阅每个器件的文档以判定在器件中是否支持浮点核。
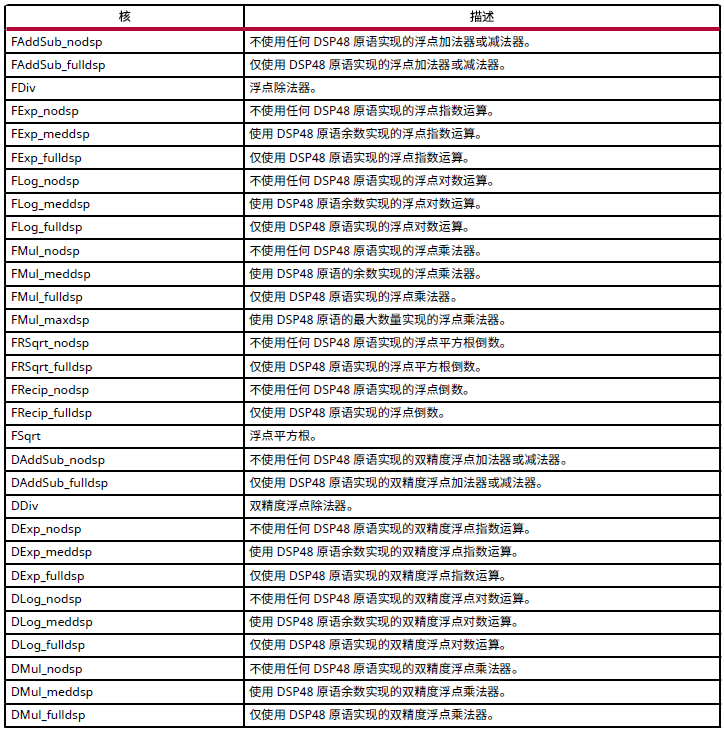

下表列出了用于实现存储元素的核。


RESOURCE 指令使用已赋值的变量作为资源目标。给定代码的情况下,RESOURCE 指令可指定 out1 的乘法使用 3 阶流水线化乘法器来实现。
void foo(...) {
#pragma HLS RESOURCE variable=out1 latency=3
// Basic arithmetic operations
*out1 = inA * inB;
*out2 = inB + inA;
*out3 = inC / inA;
*out4 = inD % inA;
}
如果赋值指定多个相同的运算符,则必须修改此代码以确保针对要控制的每个运算符都存在单一变量。例如,此示例中,如果仅使用流水线化乘法器来实现首个乘法 (inA * inB):
*out1 = inA * inB * inC;
那么应使用 Result_tmp 变量上指定的指令来将代码更改为:
#pragma HLS RESOURCE variable=Result_tmp latency=3
Result_tmp = inA * inB;
*out1 = Result_tmp * inC;
全局最优化硬件核
config_bind 配置项使开发者能改变将核与运算符绑定时所需的工作量。默认情况下,Vivado HLS 会选择能在时序与面积间实现最佳平衡的核。config_bind 能影响所使用的运算符。
config_bind -effort [low | medium | high] -min_op <list>
config_bind 命令只能在处于活动状态的解决方案内发出。绑定运算的默认运行策略是 medium。
- low 工作量:减少共享时间,运行时间更短,但最终 RTL 占用的资源可能更大。适用案例为设计人员已知几乎不可能存在运算共享或者几乎没有符合期望的运算共享,并且不希望将 CPU 周期浪费在探寻运算共享可能性上。
- medium 工作量:默认设置,Vivado HLS 会尝试共享运算,但尽力在合理时间内完成运算。
- high 工作量:尝试最大限度共享运算,不限制运行时间。Vivado HLS 不断尝试直至完成所有可能的运算共享组合为止。
最优化逻辑
主要考虑运算符的流水线以及是否可以进行表达式平衡的工作。
控制运算符流水线化
Vivado HLS 会自动判定用于内部运算的流水线化级别。设计者可将 RESOURCE 指令与 -latency 选项配合使用,以显式指定流水线阶段的数量,并覆盖由 Vivado HLS 判定的数量。
RTL 综合可使用多个额外流水线寄存器来帮助改善布局布线后可能导致的时序问题。在模块的输出信号中添加寄存器通常有助于改善输出数据路径中的时序。在模块的输入信号中添加寄存器通常有助于改善输入数据路径和来自 FSM 的控制逻辑中的时序。
添加这些额外的流水线阶段的规则是:
- 如果指定的时延比由 Vivado HLS 判定的时延多 1 个周期,Vivado HLS 会向运算输出添加新的输出寄存器。
- 如果指定的时延比由 Vivado HLS 判定的时延多 2 个周期,Vivado HLS 会向运算输出以及运算的输入侧添加寄存器。
- 如果指定的时延比由 Vivado HLS 判定的时延多 3 个或 3 个以上周期,Vivado HLS 会向运算的输出以及运算的输入侧添加寄存器。Vivado HLS 会自动判定任何附加的寄存器的位置。
您可使用 config_core 配置对设计中特定核的具有相同流水线深度的所有实例进行流水线化。要设置此配置,请执行以下操作:
-
选择“Solutions” → “Solution Settings”。
-
在“解决方案设置 (Solution Settings)”对话框中,选择“General”类别,然后单击“Add”。
-
在“添加命令 (Add Command)”对话框中,选择 config_core 命令,并指定参数。
例如,以下配置指定使用 DSP48 核实现的所有运算均采用流水线化,且时延设置为 3,这是该核允许的最大时延:
config_core DSP48 -latency 3以下配置指定随 RAM_1P_BRAM 核实现的所有 BRAM 均采用流水线化,且时延设置为 3:
config_core RAM_1P_BRAM -latency 3NOTE:Vivado HLS 仅将此核配置应用于含显式 RESOURCE 指令的 BRAM,该指令可指定用于实现数组的核。如果使用默认核来实现数组,那么核配置不影响 BRAM。
最优化逻辑表达式
在综合期间会执行多次最优化(例如,强度折减和位宽最小化)。在自动最优化列表中也包括表达式平衡。
NOTE:强度折减个人理解是用简单的算子来实现复杂的算子。下面把维基百科的解释搬运一下:
In compiler construction, strength reduction is a compiler optimization where expensive operations are replaced with equivalent but less expensive operations. The classic example of strength reduction converts “strong” multiplications inside a loop into “weaker” additions – something that frequently occurs in array addressing.
Examples of strength reduction include:
- replacing a multiplication within a loop with an addition
- replacing an exponentiation within a loop with a multiplication
表达式平衡会重新排列运算符以构造平衡的树结构并降低时延。
- 对于整数运算,默认情况下表达式平衡处于开启状态,但可将其禁用。
- 对于浮点运算,默认情况下表达式平衡处于关闭状态,但可将其启用。
对于使用如下示例所示的 += 和 *= 之类的赋值运算符的高度循序代码:
data_t foo_top (data_t a, data_t b, data_t c, data_t d)
{
data_t sum;
sum = 0;
sum += a;
sum += b;
sum += c;
sum += d;
return sum;
}
如果不使用表达式平衡并且假定每个加法都需要 1 个时钟周期,那么完整计算 sum 需要 4 个时钟周期,如下图所示。
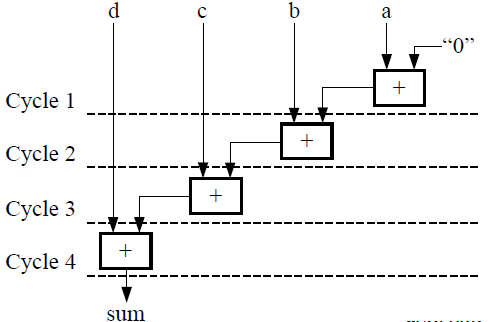
但加法 a+b 和 c+d 可并行执行以缩减时延。经过平衡后,计算可在 2 个时钟周期内完成,如下图所示。

对于整数,您可使用 EXPRESSION_BALANCE 最优化指令配合 off 选项来禁用表达式平衡。默认情况下,Vivado HLS 对于 float 类型或 double 类型的运算不执行 EXPRESSION_BALANCE 最优化。对 float 和 double 类型进行综合时,Vivado HLS 会保留 C 语言代码中执行的运算顺序,以确保结果与 C 语言仿真相同。例如,在以下代码示例中,所有变量类型均为 float 或 double。O1 和 O2 即使看似执行相同的基本操作,其值也并不同。

该行为是 C 语言标准中执行 float 或 double 类型的运算时饱和和舍入所导致的结果。因此,存在类型为 float 或 double 的函数时,Vivado HLS 始终保留运算顺序不变,并且默认不执行表达式平衡。
您可使用 config_compile 配置选项对 float 和 double 类型启用表达式平衡,如下所示:
- 选择“Solution” → “Solution Settings”。
- 在“解决方案设置 (Solution Settings)”对话框中,单击“General”类别,然后单击“Add”。
- 在“添加命令 (Add Command)”对话框中,选择“config_compile”,并启用“unsafe_math_operations”。
启用此设置后,Vivado HLS 即可更改运算顺序,以生成更优化的设计。但 C/RTL 协同仿真的结果可能与 C 语言仿真不同。
unsafe_math_operations 功能还支持 no_signed_zeros 最优化。no_signed_zeros 最优化可确保以下表达式配合浮点类型和双精度类型使用时结果完全相同:
x - 0.0 = x;
x + 0.0 = x;
0.0 - x = -x;
x - x = 0.0;
x*0.0 = 0.0;
如果不使用 no_signed_zeros 最优化,由于舍入,以上表达式结果将不同。通过在 config_compile 配置中仅选中该选项,即可选择在不使用表达式平衡的情况下执行此最优化。
NOTE:使用 unsafe_math_operations 和 no_signed_zero 最优化时,RTL 实现结果将不同于 C 语言仿真。测试激励文件应可忽略结果中的轻微差异:检查范围,不执行精确比对。
Managing Interfaces
在基于 C 语言的设计中,通过函数实参即可立即执行所有输入和输出操作。在 RTL 设计中,同样这些输入和输出操作必须通过设计接口中的端口来执行,并且通常使用特定 I/O(输入/输出)协议来进行操作。
Vivado HLS 支持使用以下解决方案来指定要使用的 I/O 协议类型:
- 接口综合,其中端口接口基于高效的业界标准接口来创建。
接口综合
对顶层函数进行综合时,函数的实参(或参数)将综合到 RTL 端口中。此流程称为“接口综合 (interface synthesis)”。
接口综合概述
以下代码提供了接口综合的完整概述。
#include "sum_io.h"
dout_t sum_io(din_t in1, din_t in2, dio_t *sum) {
dout_t temp;
*sum = in1 + in2 + *sum;
temp = in1 + in2;
return temp;
}
以上代码示例包括:
- 2 个输入:in1 和 in2。
- 可供读取和写入的指针 sum。
- return 函数,值为 temp。
通过默认接口综合设置,设计将综合到含端口的 RTL 块中,如下图所示。

Vivado HLS 会在 RTL 设计上创建 3 种类型的端口:
- 时钟和复位端口:ap_clk 和 ap_rst。
- 块级接口协议。在前图中已显示并展开这些端口:ap_start、ap_done、ap_ready 和 ap_idle。
- 端口级接口协议。这些端口是针对顶层函数和函数返回(如果函数有返回值)中的每个实参创建的。在此示例中,这些端口包括:in1、in2、sum_i、sum_o、sum_o_ap_vld 和 ap_return。
时钟和复位端口
如果设计耗时超过 1 个周期才能完成操作,则会引入时钟与复位端口。
(可选)可使用“Solution” → “Solution Settings” → “General”和 config_interface 配置将芯片使能端口添加到整个块中。
复位操作由 config_rtl 配置控制。
块级接口协议
默认情况下,块级接口协议会添加到设计中。这些信号用于控制模块,与任意端口级 I/O 协议无关。这些端口用于控制模块开始处理数据的时间 (ap_start)、指示它是否已准备好开始接受新输入 (ap_ready) 以及指示设计是处于空闲状态(ap_idle) 还是已完成操作 (ap_done)。
端口级接口协议
最后一组信号是数据端口。创建的 I/O 协议取决于 C 语言实参的类型和默认值。使用块级协议启动块操作后,端口级 I/O 协议用于对进出模块的数据进行排序。
默认情况下,输入按值传递 (pass-by-value) 实参和指针作为简单的线型端口来实现,无需关联的握手信号。因此在以上示例中,实现的输入端口不含 I/O 协议,仅为数据端口。如果此端口不含默认或按设计指定的 I/O 协议,那么输入数据必须保持稳定直至读取为止。
默认输出指针实现时含关联的输出有效信号,用于指示何时输出数据有效。在上述示例中,输出端口实现时含关联的输出有效端口 (sum_o_ap_vld) 以指示何时端口上的数据有效并且可供读取。如果不存在与输出端口关联的 I/O 协议,那么将难以确定何时读取数据。最好始终在输出上使用 I/O 协议。
同时支持读取和写入的函数实参将拆分为独立的输入端口和输出端口。在以上示例中,sum 作为输出端口 sum_i 和输出端口 sum_o 来实现,并具有关联的 I/O 协议端口 sum_o_ap_vld。
如果函数具有返回值,则实现输出端口 ap_return 以提供返回值。当设计完成 1 项传输事务时(等同于执行 1 次 C 语言函数),块级协议会以 ap_done 信号来表明函数已完成。这也表示 ap_return 端口上的数据有效且可读。
对于所示的示例代码,时序行为如下图所示(假定目标技术和时钟频率允许每个时钟周期执行一次加法)。
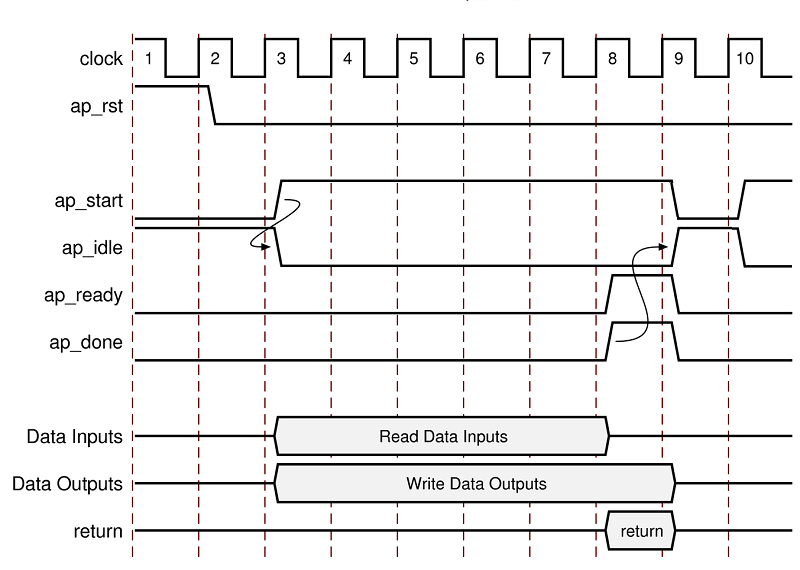
- 当 ap_start 断言为 High 时,即模块开始工作。
- ap_idle 信号断言为 Low 以表示设计正在运行。
- 输入数据可在首个周期后的任意时钟内读取。Vivado HLS 会调度读取发生的时间。读取所有输入后,ap_ready信号即断言为高位有效 (high)。
- 计算输出 sum 时,关联的输出握手 (sum_o_ap_vld) 表示数据有效。
- 当函数完成时,即断言 ap_done 有效。这也表示 ap_return 上的数据有效。
- 端口 ap_idle 断言为 High 以表示设计正在等待再次启动。
接口综合I/O协议
由接口综合所创建的接口类型取决于 C 语言实参的类型、默认接口模式以及 INTERFACE 最优化指令。下图显示了设计者可在每一种 C 语言实参类型上指定的接口协议模式。此图使用以下首字母缩略词:
-
D:每一种类型的默认接口模式。
-
I:输入实参(只读)。
-
O:输出实参(只写)。
-
I/O:输入/输出实参(可读写)。

在接口综合参考章节中包含有关接口协议的完整信息(包括波形图),下面提供每个接口模式的概述。
块级接口协议
块级接口协议包括 ap_ctrl_none、ap_ctrl_hs 和 ap_ctrl_chain。这些协议只能在函数或函数返回值处指定。在 GUI 中指定该指令时,会将这些协议应用于函数返回值。即使函数没有返回值,也可在函数返回值处指定块级协议。
前述示例中所述的 ap_ctrl_hs 模式是默认协议。ap_ctrl_chain 协议类似于 ap_ctrl_hs,但具有额外的输入端口 ap_continue 以提供数据回压功能。如果函数完成时 ap_continue 端口为逻辑 0,此模块将停止操作,并且不会继续执行下一项传输事务。仅当 ap_continue 断言为逻辑 1 时,才会继续执行下一项传输事务。
ap_ctrl_none 模式用于实现不含任何块级 I/O 协议的设计。
如果函数返回值同时指定为 AXI4-Lite 接口 (s_axilite),那么块级接口中的所有端口都将分组到此 AXI4-Lite 接口中。我们在使用其它器件(如 CPU)来配置和控制模块的开始和停止操作时间时,常用此方法。
端口级接口协议:AXI4协议
Vivado HLS 支持的 AXI4 接口包括 AXI4-Stream 接口 (axis)、AXI4-Lite 从接口 (s_axilite) 和 AXI4 主接口 (m_axi),这些接口可按以下方式指定:
- AXI4-Stream 接口:仅在input实参或output实参上指定,而不在inout实参上指定。
- AXI4-Lite 接口,在任何类型的实参上指定,但是array类型除外。设计者可以将多个实参分组到同一 AXI4-Lite 接口中。
- AXI4 主接口:仅在数组和指针(以及 C++ 中的引用)上指定。设计者可以将多个实参分组到同一 AXI4 接口中。
端口级接口协议:无I/O协议
ap_none 和 ap_stable 模式可指定不向端口添加任何 I/O 协议。指定这些模式时,实参作为不含任何其它关联信号的数据端口来实现。ap_none 模式是标量输入的默认模式。ap_stable 模式用于仅当器件处于复位模式时才可更改的配置输入。
端口级接口协议:握手协议
接口模式 ap_hs 包含与数据端口的双向握手信号。此握手属于业界标准的有效和确认握手。ap_vld 模式同样如此,但仅含有效端口,ap_ack 仅含确认端口。
ap_ovld 模式用于inout参数。将inout数据类型拆分为独立输入端口和输出端口时,ap_none 模式适用于其中的输入端口,ap_vld 适用于其中的输出端口。这是支持读写的指针实参的默认类型。
ap_hs 模式可应用于按顺序读写的数组。如果 Vivado HLS 可判定读访问或写访问为无序访问,它将停止综合并报错。如果无法判定访问顺序,Vivado HLS 将发出警告。
端口级接口协议:内存接口
默认情况下,数组实参作为 ap_memory 接口来实现。这是含数据、地址、芯片使能和写使能端口的标准 BRAM 接口。
ap_memory 接口可作为单端口接口或双端口接口来实现。如果 Vivado HLS 可判定使用双端口接口可以缩短启动时间间隔,那么它将自动实现双端口接口。RESOURCE 指令用于指定内存资源,如果在含单端口 BRAM 的数组上指定该指令,那么将实现单端口接口。相反,如果使用 RESOURCE 指令指定双端口接口,并且 Vivado HLS 判定此接口并无益处,那么它将自动实现单端口接口。
bram 接口模式的运作方式与 ap_memory 接口相同。唯一差异是在 Vivado IP integrator 中使用设计时,端口的实现方式。
- ap_memory 接口显示为多个独立端口。
- bram 接口显示为单个组合端口,可使用单一点对点连接来连接到赛灵思 BRAM。
如果按顺序访问数组,可使用 ap_fifo 接口。就像 ap_hs 接口一样,如果 Vivado HLS 判定未按顺序进行数据访问,那么它将停止;如果无法判定是否采用顺序访问,则将发出警告;如果判定已采用顺序方式访问,则不发出任何消息。ap_fifo 接口只能用于读取或写入,不能用于同时读写。
ap_bus 接口可与总线网桥进行通信。此接口不遵循任何特定总线标准,但鉴于其泛用性,可配合总线网桥一起使用,从而与系统总线进行仲裁。总线网桥必须能够将所有突发写操作进行缓存。
接口综合和多次访问指针
使用多次访问的指针可能会在综合后引发意外行为。在以下示例中,对指针 d_i 执行了 4 次读取,对指针 d_o 执行了 2 次写入:指针执行了多次访问。
#include "pointer_stream_bad.h"
void pointer_stream_bad ( dout_t *d_o, din_t *d_i) {
din_t acc = 0;
acc += *d_i;
acc += *d_i;
*d_o = acc;
acc += *d_i;
acc += *d_i;
*d_o = acc;
}
综合后,此代码产生的 RTL 设计将读取 1 次输入端口,写入 1 次输出端口。与任何标准 C 语言编译器一样,Vivado HLS 将优化掉多余的指针访问。要按“预期”实现上述代码,即对 d_i 读取 4 次,对 d_o 写入 2 次,必须将指针指定为 volatile,如以下示例所示。
#include "pointer_stream_better.h"
void pointer_stream_better ( volatile dout_t *d_o, volatile din_t *d_i) {
din_t acc = 0;
acc += *d_i;
acc += *d_i;
*d_o = acc;
acc += *d_i;
acc += *d_i;
*d_o = acc;
}
即使此段 C 语言代码也有问题。实际上,在测试激励文件上,除了为 d_i 提供一个值之外,无法执行任何其它操作,或者除了最终写入之外,也不能验证任何对 d_o 的写入。尽管支持多次访问指针,但Xilinx官方还是强烈建议使用 hls::stream 类实现所需的行为。
指定接口
接口综合可通过 INTERFACE 指令或使用配置设置来加以控制。要在端口上指定接口模式,请在 GUI 的“Directives”选项卡中选择端口,右键单击并选择“Insert Directive”以打开“Vivado HLS Directive Editor”,如下图所示。
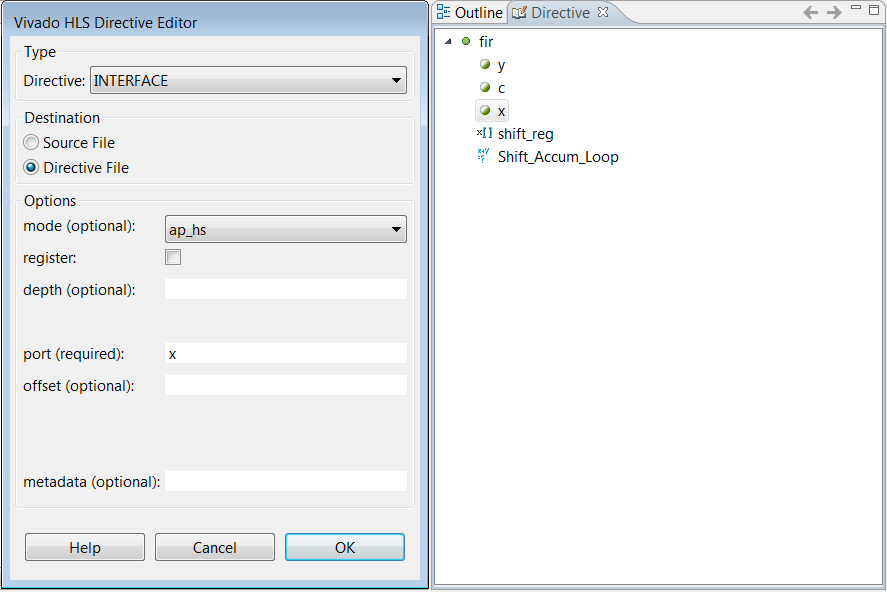
在“Vivado HLS Directives Editor”中,设置以下选项:
-
“mode”
从下拉菜单中选择接口模式。
-
“register”
如果选择该选项,对输入数据会使用register进行暂存,对于输出端口,“register”选项可保证对输出进行寄存。设计者可将“register”选项应用于设计中的任意函数。对于内存、FIFO 和 AXI4 接口,“register”选项无效。
-
“depth”
该选项用于指定测试激励文件向设计提供的样本数量以及测试激励文件必须存储的输出值数量。以更大的数值为准。(与综合无关)
如果“depth”选项设置过小,那么 C/RTL 协同仿真可能出现死锁,如下所示:
- 读取输入数据的操作可能停滞并等待数据,而测试激励文件无法提供这些数据。
- 在尝试写出输出数据时可能停滞,因为存储空间已满。
-
“port”
该选项为必需,指明约束的目标。默认情况下,Vivado HLS 不对端口进行寄存。
-
“offset”
该选项适用于 AXI4 接口,指明地址偏移量。
要设置接口配置,请选择“Solution” → “Solution Settings” → “General” → “config_interface”。您可使用配置设置来执行如下操作:
- 向 RTL 设计添加全局时钟使能。
- 移除无关联的端口,例如,由设计中不使用的元素所创建的端口。
- 为任意全局变量创建 RTL 端口。
任何 C 语言函数均可使用全局变量:即定义的作用域超出任意函数作用域的变量。默认情况下,全局变量不会导致创建 RTL 端口:Vivado HLS 假定全局变量位于最终设计内。config_interface 配置设置 expose_global 会指示Vivado HLS 为全局变量创建端口。
使用AXI接口
这边就不展开说了,AMBA AXI可以单独写一篇文章来细说了。需要的同学可以自行去ARM官网查阅AXI的协议,并结合UG902查看各配置项的含义。
Interface Synthesis Reference
此参考部分对每一种 Vivado HLS 接口模式进行了解释。
块级I/O协议
Vivado HLS 使用接口类型 ap_ctrl_none、ap_ctrl_hs 和 ap_ctrl_chain 来指定是否使用块级握手信号实现RTL。块级握手信号可指定:
- 设计何时开始执行操作
- 操作何时终止
- 设计何时处于空闲状态以及何时准备好处理新输入
设计者可在函数上或函数返回时指定块级 I/O 协议。如果 C 语言代码不返回值,您仍可在函数返回时指定块级 I/O 协议。如果 C 语言代码使用函数返回,那么 Vivado HLS 会为返回值创建 ap_return 输出端口。
在块级 I/O 协议中 ap_ctrl_hs (handshake) 为默认协议。下图显示了 Vivado HLS 对函数实现 ap_ctrl_hs 时生成的 RTL 端口和行为。在此示例中,函数使用 return 语句返回值,Vivado HLS 在 RTL 设计中创建 ap_return 输出端口。如果在 C 语言代码中不包含函数 return 语句,则不会创建此端口。

ap_ctrl_chain 接口模式类似于 ap_ctrl_hs,但可提供额外的 ap_continue 输入信号以应用反压。赛灵思建议使用 ap_ctrl_chain 块级 I/O 协议将 Vivado HLS IP链接在一起。
ap_ctrl_none
如果指定 ap_ctrl_none 块级 I/O 协议,则不创建块级 I/O 协议中所示的握手信号端口(ap_start、ap_idle、ap_ready 和 ap_done)。如果在设计上不指定块级 I/O 协议,那么使用 C/RTL 协同仿真来验证 RTL 设计时,必须遵守接口综合要求中所述条件。
ap_ctrl_hs
下图显示了由 ap_ctrl_hs I/O 协议为非流水线化设计创建的块级握手信号的行为。

复位后,将执行以下操作:
-
此模块会等待 ap_start 达到高电平,然后再开始操作。
-
ap_idle 输出会立即变为低电平,以指示设计不再处于空闲状态。
-
ap_start 信号必须保持处于高电平状态,直至 ap_ready 达到高电平状态。当 ap_ready 达到高电平状态后:
- 如果 ap_start 保持高电平,设计将启动下一项传输事务。
- 如果 ap_start 变为低电平,设计将完成当前传输事务,然后停止操作。
-
可读取输入端口上的数据。
-
可将数据写入输出端口。
-
当模块完成操作后,ap_done 输出会变为高电平状态。
-
当模块准备好接受新输入后,ap_ready 信号会变为高电平状态。以下是有关 ap_ready 信号的其它信息:
- ap_ready 信号处于不活动状态,直至模块开始操作为止。
- 在非流水线化设计中,ap_ready 信号与 ap_done 同时断言有效。
- 在流水线化设计中,当 ap_start 采样结果为高电平后,ap_ready 信号可能在任意周期变为高电平状态。这取决于设计流水线化的启动间隔。
- 如果 ap_start 信号为低电平状态,而 ap_ready 为高电平状态,那么设计将持续执行操作,直至 ap_done变为高电平状态后停止操作。
- 如果 ap_start 信号为高电平状态,且 ap_ready 为高电平状态,那么下一项传输事务将立即启动,且模块将继续操作。
-
ap_idle 信号可用于指示设计何时处于空闲且不执行操作状态。以下是有关 ap_idle 信号的其它信息:
- 如果 ap_start 信号为低电平状态,而 ap_ready 为高电平状态,那么设计将停止操作,而 ap_idle 信号将在达成 ap_done 后,再经过 1 个周期后变为高电平状态。
- 如果 ap_start 信号为高电平状态,且 ap_ready 为高电平状态,那么设计将继续操作,且 ap_idle 信号保持处于低电平状态。
ap_ctrl_chain
下面介绍 ap_ctrl_chain 的接口协议。该块级 I/O 协议类似于 ap_ctrl_hs 协议,但可提供 1 个额外输入端口,名为 ap_continue。处于高电平有效状态的 ap_continue 信号,可指示使用输出数据的下游块已准备好处理新的数据输入。如果下游块无法使用新数据输入,那么 ap_continue 信号处于低电平状态,这将阻止上游块生成更多数据。
下游块的 ap_ready 端口可直接驱动 ap_continue 端口。以下是有关 ap_continue 端口的其它信息:
- 如果 ap_continue 信号为高电平状态,且 ap_done 为高电平状态,那么设计将继续操作。其它块级 I/O 信号的行为与 ap_ctrl_hs 块级 I/O 协议中描述的行为相同。
- 如果 ap_continue 信号为低电平状态,而 ap_done 为高电平状态,那么设计将停止操作,ap_done 信号将保持高电平状态,并且如果存在 ap_return 端口,那么 ap_return 端口上的数据将保持有效。
在下图中,第 1 项传输事务已完成,第 2 项传输事务立即启动,因为 ap_continue 为高电平状态,且 ap_done 为高电平状态。但设计在第 2 项传输事务结束后将暂停,直至 ap_continue 断言为高电平有效为止。

端口级I/O协议
ap_none
ap_none 端口级 I/O 协议是最简单的接口类型,没有与之关联的其它信号。输入和输出数据信号都没有关联的控制端口以指示何时读取或写入数据。RTL 设计中仅有的端口是源代码中指定的端口。
ap_none 接口无需额外硬件开销。但是,ap_none 接口需满足以下条件:
- 生产者模块执行以下操作之一:
- 在正确的时间向输入端口提供数据
- 在执行传输事务期间保留数据,直到设计完成
- 使用者模块在正确的时间读取输出端口
ap_stable
与 ap_none 一样,ap_stable 端口级 I/O 协议不会向设计添加任何接口控制端口。ap_stable 类型通常用于可更改但在正常操作期间保持稳定的数据,例如提供配置数据的端口。ap_stable 类型向 Vivado HLS 发送下列通知:
- 应用于端口的数据在正常操作期间应保持稳定,但不是可以被优化掉的常量值。
- 此端口的扇出无需寄存。
ap_hs(ap_ack、ap_vld和ap_ovld)
ap_hs 端口级 I/O 协议在开发过程中提供了最大的灵活性,允许采用自下而上和自上而下的设计流程。双向握手可安全执行所有模块间通信,无需人为干预或假设即可正确执行。ap_hs 端口级 I/O 协议提供以下信号:
- 数据端口
- 用于指示何时使用数据的确认信号
- 用于指示何时读取数据的 valid 信号
下图显示了 ap_hs 接口对应输入和输出端口的行为。在此示例中,输入端口名为 in,输出端口名为 out。
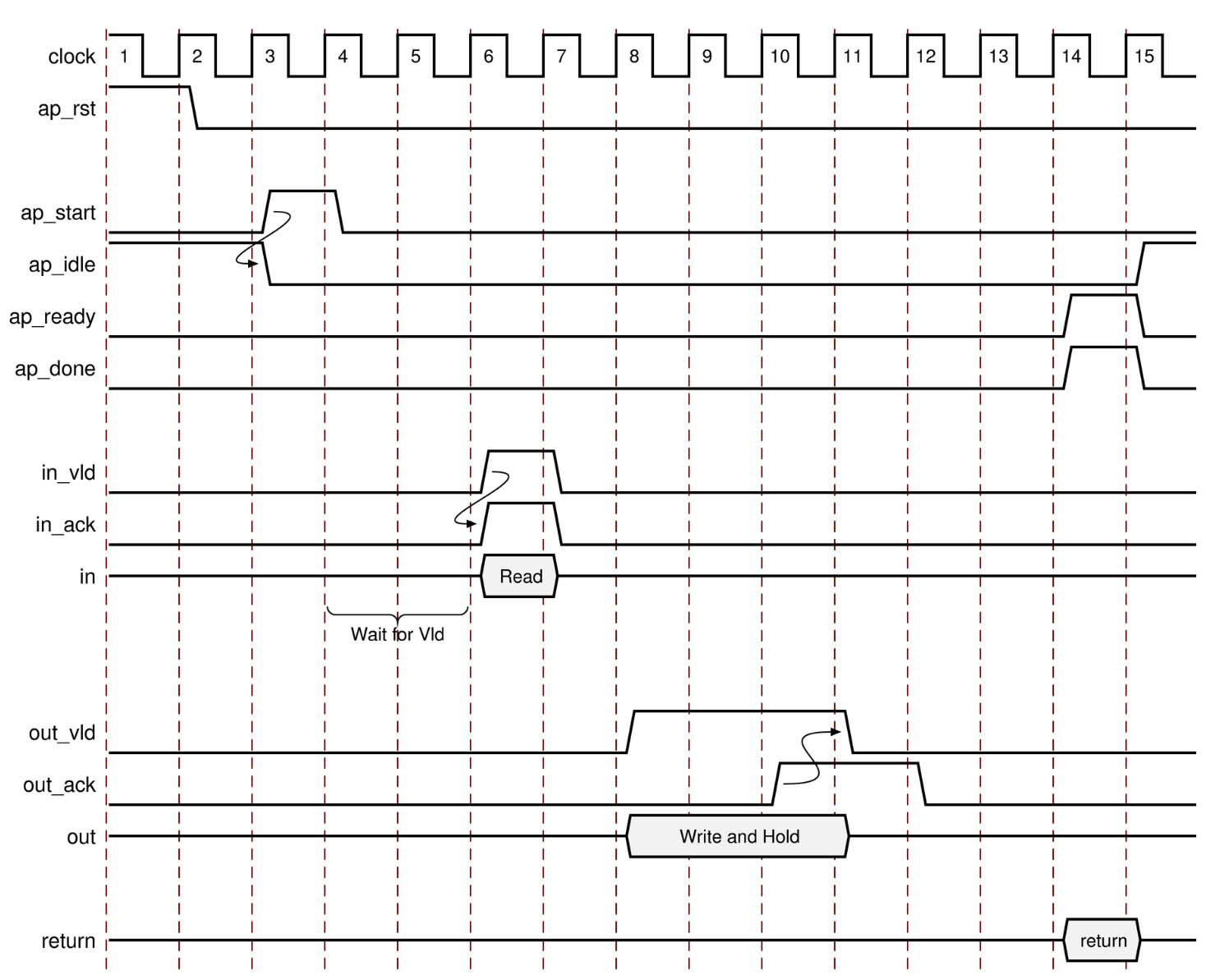
对于输入,将执行以下操作:
-
应用 start 后,该模块开始正常操作。
-
如果设计已准备好输入数据,但输入 valid 处于低电平状态,则设计将停滞并等待断言输入 valid 有效以指示存在新的输入值。
-
当输入 valid 断言为高电平有效 (High) 时,in_ack 将断言为高电平有效 (High),表明已读取数据。
对于输出,将执行以下操作:
- 应用 start 后,该模块开始正常操作。
- 写入输出端口时,将同时断言其关联的输出 valid 信号有效,以指示端口上存在 valid 数据。
- 如果关联的 out_ack 为低电平,则设计将停滞并等待断言 out_ack 有效。
- 当 out_ack 确认有效后,将在下一个时钟沿断言 out_valid 无效。
ap_ack
ap_ack 端口级 I/O 协议是 ap_hs 接口类型的子集。ap_ack 端口级 I/O 协议提供以下信号:
-
数据端口
-
用于指示何时使用数据的ack信号(删去了ap_hs中的in_vld和out_vld信号,仅保留input和output端口的ack信号)
-
对于输入实参,设计会在读取输入的周期中生成高电平ack信号进行确认。
-
对于输出实参,Vivado HLS 会实现ack端口来确认已读取输出。
-
ap_vld
ap_vld 是 ap_hs 接口类型的子集。ap_vld 端口级 I/O 协议提供以下信号:
- 数据端口
- 用于指示何时读取数据的 valid 信号(删去了ap_hs中的ack信号,仅保留vld信号)
- 对于输入实参,模块在 valid 端口有效后立即读取数据端口。即使模块尚未准备好读取新数据,也会对数据端口进行采样并在内部保留数据,直到需要时为止。
- 对于输出实参,Vivado HLS 会实现输出 valid 端口以指示输出端口上的数据何时为 valid。
ap_ovld
ap_ovld 是 ap_hs 接口类型的子集。ap_ovld 端口级 I/O 协议提供以下信号:
- 数据端口
- 用于指示何时读取数据的 valid 信号
- 对于输入实参和inout类型参数中的输入部分,设计默认为 ap_none 类型。
- 对于输出实参和inout类型参数中的输出部分,设计实现 ap_vld 类型。
ap_memory, bram
ap_memory 和 bram 接口端口级 I/O 协议用于实现数组实参。当实现要求随机访问内存地址位置时,这种类型的端口级 I/O 协议可以与内存元件(例如,RAM 和 ROM)通信。
ap_memory 和 bram 接口端口级 I/O 协议相同。唯一的区别是 Vivado IP integrator 显示模块的方式:
- ap_memory 接口显示为离散端口。
- bram 接口显示为单一端口(已组合)。在 IP integrator 中,可使用单一连接来创建到所有端口的连接。
使用 ap_memory 接口时,请使用 RESOURCE 指令指定数组目标。如果没有为数组指定目标,则 Vivado HLS 会决定是使用单端口还是双端口 RAM 接口。
下图显示了一个名为 d 的数组,该数组指定为单端口 BRAM。端口名称基于 C 语言函数实参。例如,如果 C 语言实参为 d,则根据 BRAM 的 output/q 端口,芯片使能为 d_ce,输入数据为 d_q0。
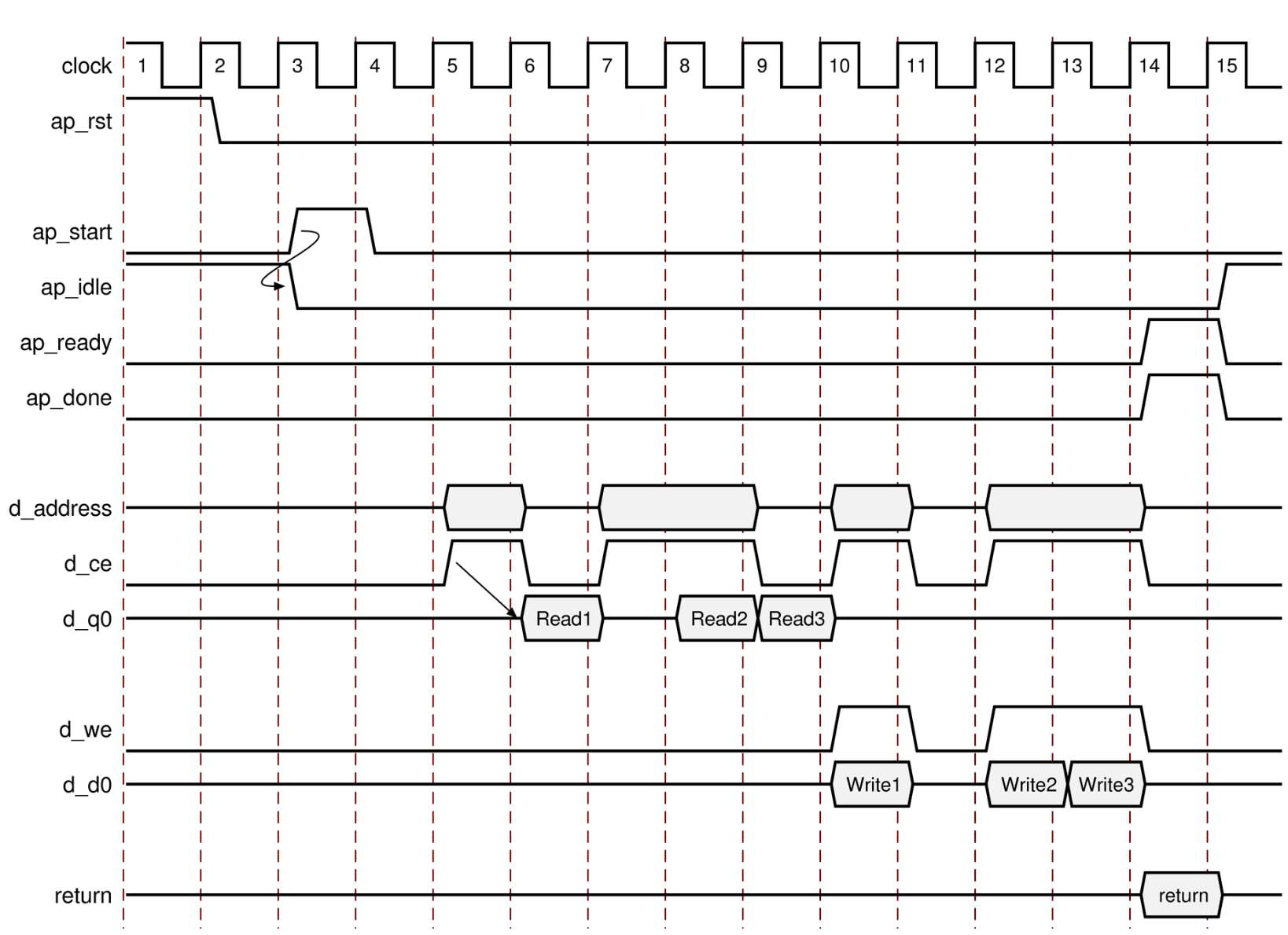
复位后,将执行以下操作:
-
断言 ap_start 后,该模块开始正常操作。
-
通过在断言输出信号 d_ce 有效的同时在输出地址端口上应用地址来执行读取。
-
通过断言输出端口 d_ce 和 d_we 有效并同时应用地址和输出数据 d_d0 来执行写操作。
ap_fifo
写入输出端口时,当设计需要访问内存元件并且访问始终以顺序方式执行时,即不需要随机访问,则ap_fifo接口是最节省资源的方法。ap_fifo 端口级 I/O 协议支持以下操作:
- 允许端口连接到 FIFO
- 启用完整的双向 empty-full 通信
- 适用于数组、指针和按引用传递实参类型
在下图示例中,in1 是一个指针,该指针访问当前地址,然后访问当前地址上面的两个地址,最后访问下面的一个地址。
void foo(int* in1, ...) {
int data1, data2, data3;
...
data1= *in1;
data2= *(in1+2);
data3= *(in1-1);
...
}
如果将 in1 指定为 ap_fifo 接口,则 Vivado HLS 会检查访问、判定访问并非按顺序进行,随即发出错误消息并中止。要从非顺序地址读取,请使用 ap_memory 或 bram 接口。
不能在同时支持读取和写入的实参上指定 ap_fifo 接口。您只能在输入或输出实参上指定 ap_fifo 接口。含输入实参 in 和输出实参 out(指定为 ap_fifo 接口)的设计的行为如下图所示。
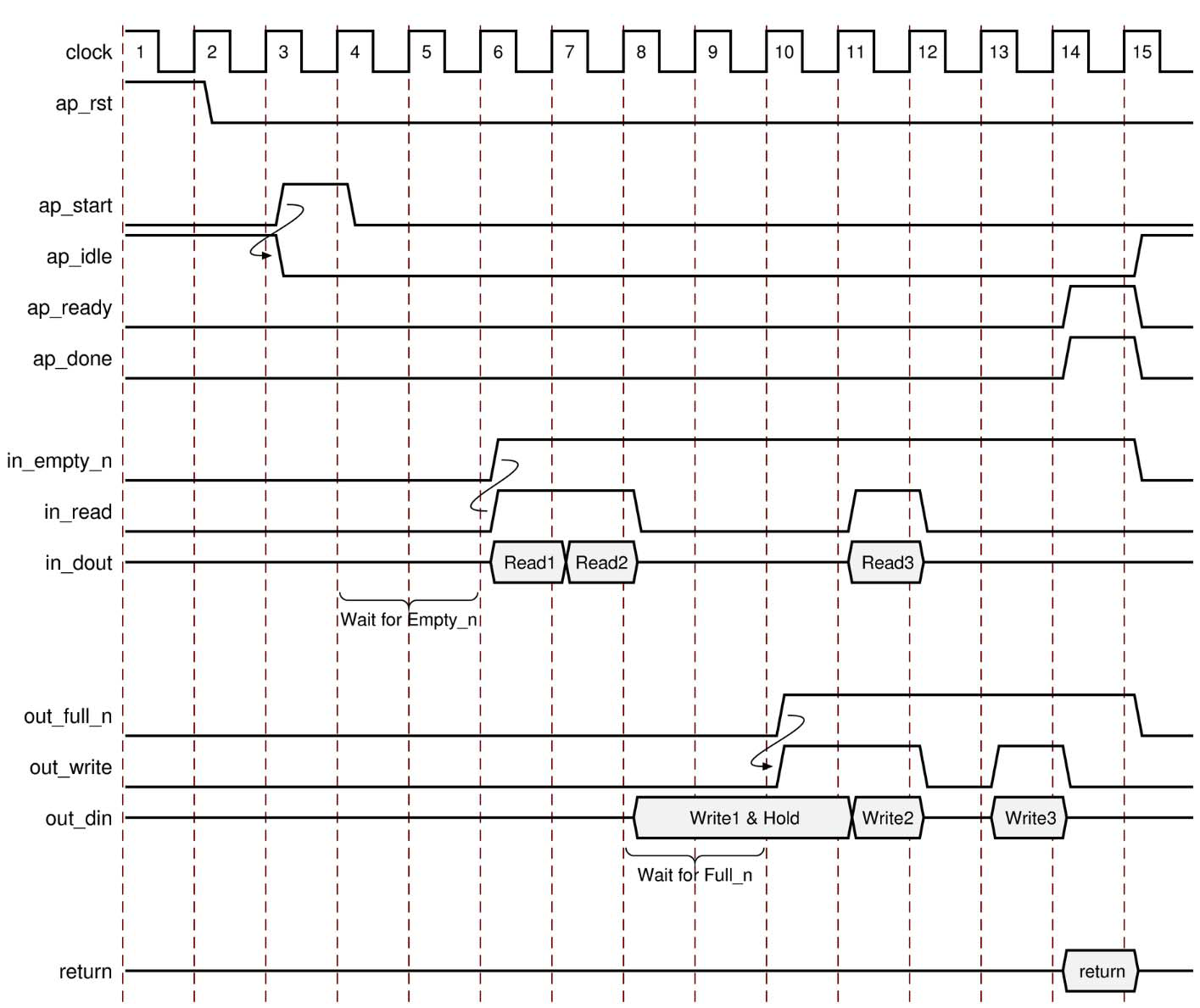
对于输入,将执行以下操作:
- 断言 ap_start 后,该模块开始正常操作。
- 如果输入端口已准备好读取,但输入端口 in_empty_n 处于低电平状态,指示 FIFO 为空,则设计将停滞并等待数据可用。
- 当输入端口 in_empty_n 处于高电平状态,指示 FIFO 包含数据时,将断言输出确认 in_read 为高电平有效以指示当前周期中已读取数据。
对于输出,将执行以下操作:
-
断言 ap_start 后,该模块开始正常操作。
-
如果输出端口已准备好写入,但 out_full_n 处于低电平状态,指示 FIFO 已满,则数据将置于输出端口上,但设计将停滞并等待 FIFO 中的空间可用。
-
当 out_full_n 处于高电平状态,指示 FIFO 中有可用空间时,将断言输出确认信号 out_write 有效以指示输出数据为 valid。
-
如果顶层函数或顶层循环已使用 -rewind 选项进行流水线化,则 Vivado HLS 将创建另一个后缀为 lwr 的输出端口。当最后一次写入 FIFO 接口完成时,lwr 端口将变为高电平有效。
ap_bus
ap_bus 接口可以与总线桥通信。由于 ap_bus 接口未遵循特定的总线标准,因此可将此接口用于与系统总线进行通信的总线桥。总线桥必须能够对所有突发写入进行高速缓存。
设计者可以通过以下方式使用 ap_bus 接口:
-
标准模式:此模式执行单独的读操作和写操作,并为每项操作指定地址。
-
突发模式:如果在 C 语言源代码中使用了 C 语言函数 memcpy,则此模式将执行数据传输。在突发模式下,该接口指示基址和传输大小。然后以连续的周期传输数据样本。
以下示例显示了将 ap_bus 接口应用于实参 d 时,标准模式下的读写操作的行为。
void foo (int *d) {
static int acc = 0;
int i;
for (i=0;i<4;i++) {
acc += d[i+1];
d[i] = acc;
}
}
以下示例显示了使用 C memcpy 函数和突发模式时的行为。
void bus (int *d) {
int buf1[4], buf2[4];
int i;
memcpy(buf1,d,4*sizeof(int));
for (i=0;i<4;i++) {
buf2[i] += buf1[1+i];
}
memcpy(d,buf2,4*sizeof(int));
}
ap_bus标准读取和写入的时序图如下所示:
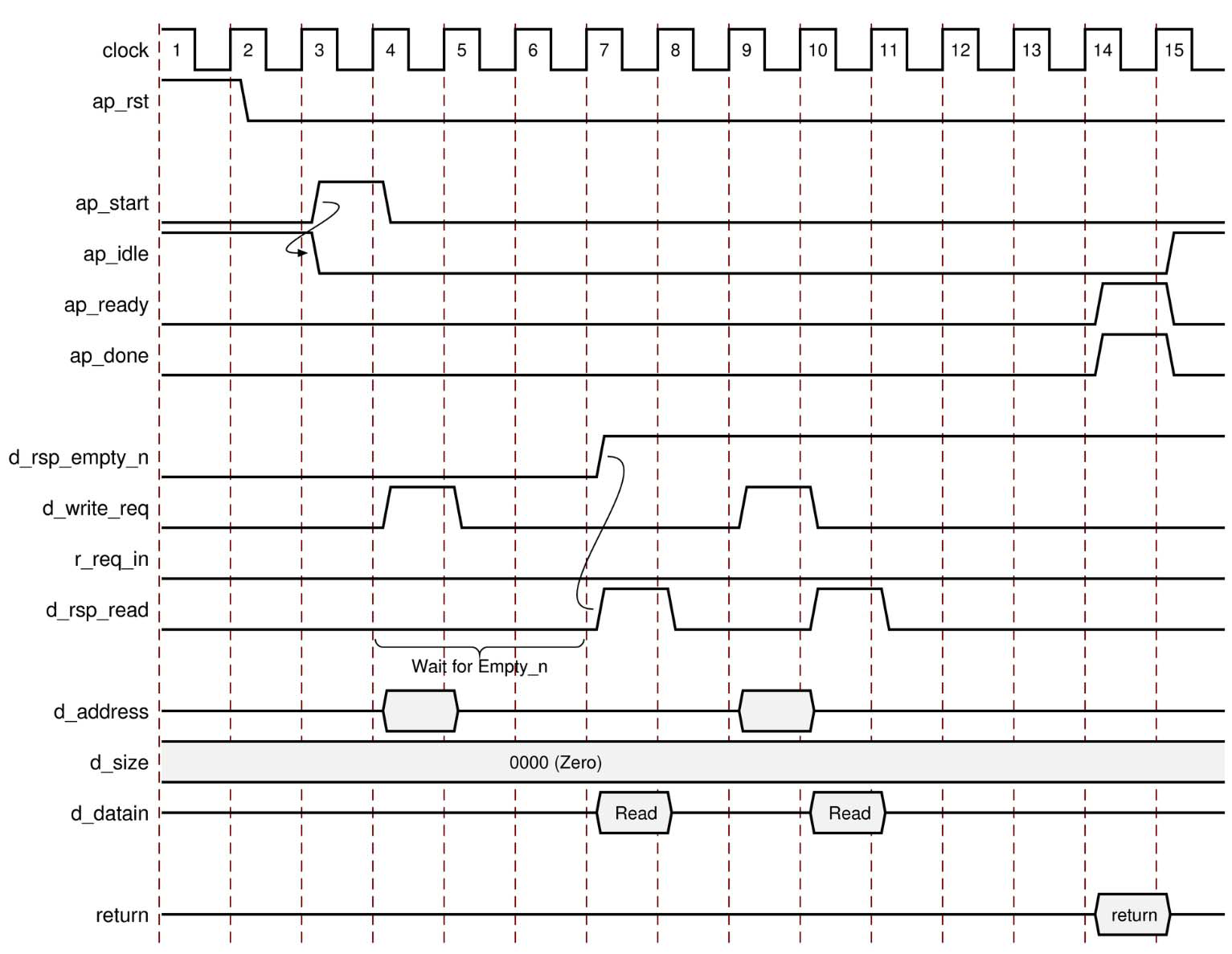
对于ap_bus的标准读过程,在复位后将执行下列操作:
-
断言 ap_start 后,该模块开始正常操作。
-
如果执行读取时 d_rsp_empty_n 为低电平,指示总线桥 FIFO 中没有数据,则会执行以下操作:
- 断言输出端口 d_write_req 有效,并断言端口 r_req_in 无效,以指示读取操作。
- 输出地址。
- 设计停滞并等待数据可用。
-
当数据可用于读取输出信号时,立即断言 d_rsp_read 有效并在下一个时钟沿读取数据。
-
如果执行读取时 d_rsp_empty_n 为高电平,指示总线桥 FIFO 中有可用数据,则会执行以下操作:
-
断言输出端口 d_write_req 有效,并断言端口 r_req_in 无效,以指示读取操作。
-
输出地址。
-
在下一个时钟周期断言输出信号 d_rsp_read 有效,并在下一个时钟沿读取数据。
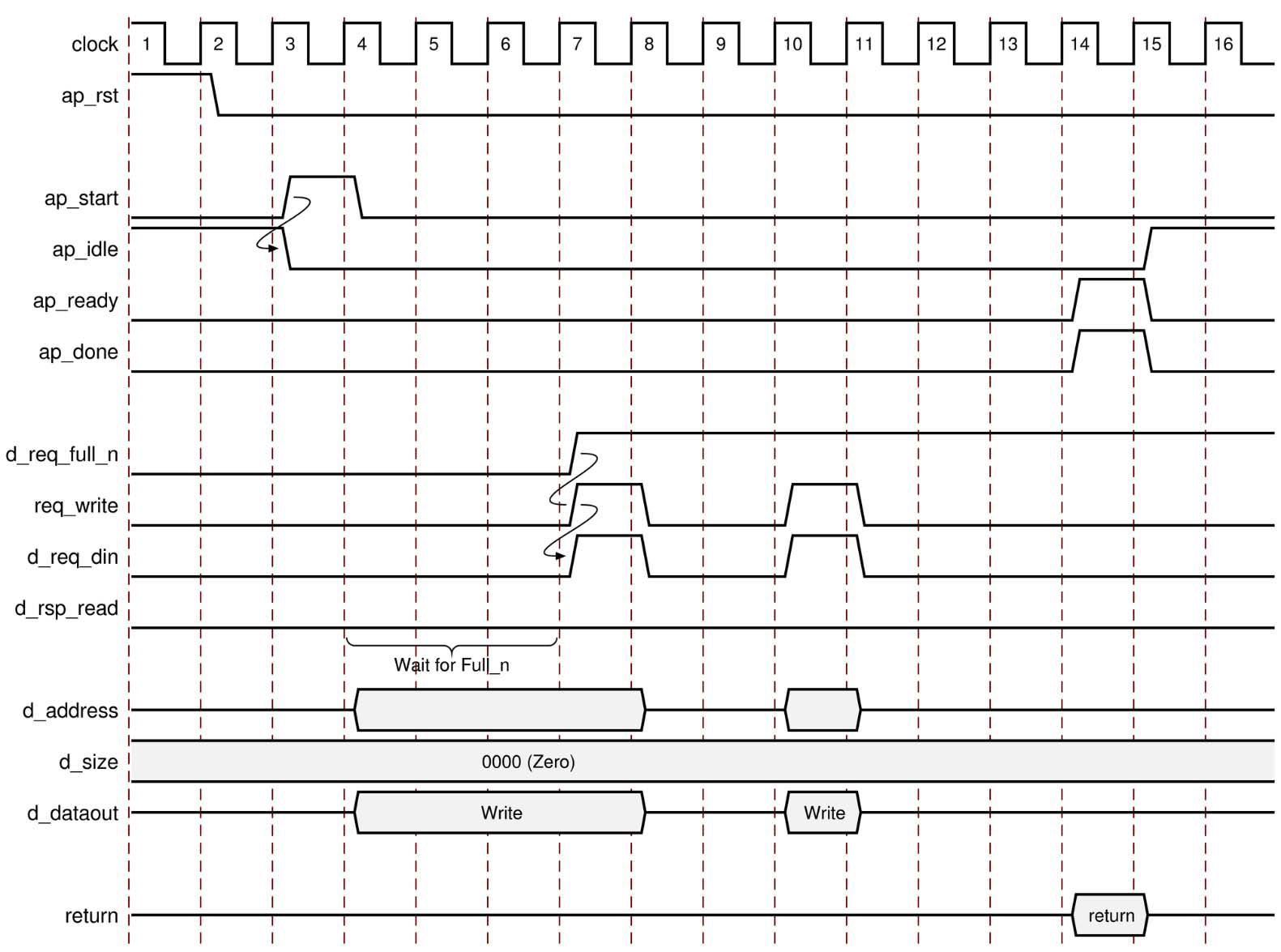
-
对于ap_bus的标准写过程,在复位后将执行下列操作:
- 断言 ap_start 后,该模块开始正常操作。
- 如果执行写入时 d_req_full_n 为低电平,指示总线桥 FIFO 中没有空间可用,则会执行以下操作:
- 输出地址和数据。
- 设计停滞并等待空间可用。
- 当有空间可用于写入时,将执行以下操作:
- 断言输出端口 req_write 和 d_req_din 有效,以指示写操作。
- 立即断言输出信号 d_req_din 有效以指示该数据在下一个时钟沿有效。
- 如果执行写入时d_req_full_n 为高电平,指示总线桥 FIFO 中有可用空间,则会执行以下操作:
- 断言输出端口 req_write 和 d_req_din 有效,以指示写操作。
- 输出地址和数据。
- 断言输出信号 d_req_din 有效以指示该数据在下一时钟沿有效。
ap_bus突发读取和写入的时序图如下所示:

对于ap_bus的突发读过程,在复位后将执行下列操作:
- 断言 ap_start 后,该模块开始正常操作。
- 如果执行读取时 d_rsp_empty_n 为低电平,指示总线桥 FIFO 中没有数据,则会执行以下操作:
- 断言输出端口 d_req_write 有效,并断言端口 d_req_din 无效,以指示读取操作。
- 输出传输的基地址和传输长度。
- 设计停滞并等待数据可用。
- 当数据可用于读取输出信号时,立即断言 d_rsp_read 有效,并在接下来的 N 个时钟沿读取数据,其中 N 是d_size的值。
- 如果总线桥 FIFO 的值已清空,数据传输将立即停止,并等待数据可用后再继续。

对于ap_bus的突发写过程,在复位后将执行下列操作:
- 断言 ap_start 后,该模块开始正常操作。
- 如果执行写入时d_req_full_n 为低电平,指示总线桥 FIFO 中没有空间可用,则会执行以下操作:
- 输出基址、传输大小和数据。
- 设计停滞并等待空间可用。
- 当有空间可用于写入时,将执行以下操作:
- 断言输出端口 d_req_write 和 d_req_din 有效,以指示写操作。
- 立即断言输出信号 d_req_din 有效以指示该数据在下一个时钟沿有效。
- 如果 FIFO 已满,则会立即断言输出信号 d_req_din 无效,并在空间可用时重新断言。
- 传输于完成 N 个数据值后停止,其中 N 是d_size的值。
- 如果执行写入时 d_rsp_full_n 为高电平,指示总线桥 FIFO 中有可用空间,则传输开始,设计停滞并等待直到 FIFO 已满。
axi_s
axis 模式指定 AXI4-Stream I/O 协议。
s_axilite
s_axilite 模式指定 AXI4-Lite 从接口 I/O 协议。
m_axi
m_axi 模式指定 AXI4 主接口 I/O 协议。
How to use HLS?
这边本文不展开说了,本文主要目的是带大家熟悉HLS中基本的约束情况。工具的详细使用教程请大家参考官方例程文档UG871,跟着教程做完实验基本就可以熟悉HLS的设计、验证以及后续导出RTL设计的流程了,其中与结果分析相关的实验需要好好学习,在后续实际使用中遇到问题时才有调试的思路。
What’s more?
虽然我们思考问题尽量要从源头出发,但解决问题时如果有一些前人的成果可以参考的话那就再好不过了,本章简要介绍一下HLS中自带的各种算法库,其中有些笔者使用过,有些并没有用过。只能对着官方文档"省流"一波,更多细节的内容大家可以去UG902自行查阅。
1、Arbitrary Precision Data Types Library:顾名思义,扩展了数据的类型。Then,Why?原生的基于C的数据类型都是字节对齐的,如8,16,32,64bits。但RTL的数据类型是支持任意宽度的,所以HLS需要设计一种机制来满足任意位宽的数据的声明,而不能像C语言一样有Byte对齐的要求。假设如果没有该库,我们需要用HLS实现一个17bit的乘法器,那么HLS会将其强制实现为32bit的乘法器。总而言之,该库可以让我们更高效地利用硬件资源,以bit为单位给数据设置位宽。
2、HLS Stream Library:Stream是一种数据类型,Stream中的数据都是依序采样后发送,没有地址的概念,可以借助FIFO的概念来辅助理解。在C语言中对Stream类型的数据进行建模比较困难,C中一般是基于指针对数据进行存取,因此使用HLS Stream Lib对构建Stream数据类型的设计与仿真贡献较大。
3、HLS Math Library:顾名思义,可以实现一些高效的数学运算,如指数、对数、三角、幂函数、取整、乘除、比较等等函数。
4、其余的笔者目前没怎么用到过,还有HLS Video Library,HLS IP Libraries,HLS Linear Algebra Library,HLS DSP Library等,大家需要的话可以自行查阅原文档。
Reference
UG902-Vivado Design Suite User Guide: High-Level Synthesis
UG871-Vivado Design Suite Tutorial: High-Level Synthesis
UG1197-UltraFast Vivado HLS Methodology Guide