本文将从btbuild函数作为入口从源码角度进行讲解btree文件的创建流程,执行SQL对应为CREATE TABLE wp_shy(id int primary key, name carchar(20))。知识回顾见:postgres源码解析41 btree索引文件的创建–1
执行流程图梳理

_bt_spools_heapscan 执行流程
1)首先定义并初始化BTBuildState结构体;
2)如果允许并行模式,则调用 _bt_begin_parallel 创建 parallel context上下文,并启动工作线程;
3)调用 tuplesort_begin_index_btree 构建 Tuplesortstate结构体,该结构体记录元组排序转态的关键信息;
存放目标扫描的元组数组,对应数据类型的比较函数,索引和扫描键信息,
4)如果该索引为唯一索引,则需构造spools2结构用以存放死堆表元组对应的索引元组,便利之处在于这些索引均不是最新的,对于唯一索引来就无须检查这些元组是否唯一,可以直接插入索引结构中。
5)上述步骤完成后,将 spools2 空间释放
/*
* Create and initialize one or two spool structures, and save them in caller's
* buildstate argument. May also fill-in fields within indexInfo used by index
* builds.
*
* Scans the heap, possibly in parallel, filling spools with IndexTuples. This
* routine encapsulates all aspects of managing parallelism. Caller need only
* call _bt_end_parallel() in parallel case after it is done with spool/spool2.
*
* Returns the total number of heap tuples scanned.
*/
static double
_bt_spools_heapscan(Relation heap, Relation index, BTBuildState *buildstate,
IndexInfo *indexInfo)
{
BTSpool *btspool = (BTSpool *) palloc0(sizeof(BTSpool));
SortCoordinate coordinate = NULL;
double reltuples = 0;
/*
* We size the sort area as maintenance_work_mem rather than work_mem to
* speed index creation. This should be OK since a single backend can't
* run multiple index creations in parallel (see also: notes on
* parallelism and maintenance_work_mem below).
*/
btspool->heap = heap;
btspool->index = index;
btspool->isunique = indexInfo->ii_Unique;
btspool->nulls_not_distinct = indexInfo->ii_NullsNotDistinct;
/* Save as primary spool */
buildstate->spool = btspool;
/* Report table scan phase started */
pgstat_progress_update_param(PROGRESS_CREATEIDX_SUBPHASE,
PROGRESS_BTREE_PHASE_INDEXBUILD_TABLESCAN);
/* Attempt to launch parallel worker scan when required */
if (indexInfo->ii_ParallelWorkers > 0)
_bt_begin_parallel(buildstate, indexInfo->ii_Concurrent,
indexInfo->ii_ParallelWorkers);
/*
* If parallel build requested and at least one worker process was
* successfully launched, set up coordination state
*/
if (buildstate->btleader)
{
coordinate = (SortCoordinate) palloc0(sizeof(SortCoordinateData));
coordinate->isWorker = false;
coordinate->nParticipants =
buildstate->btleader->nparticipanttuplesorts;
coordinate->sharedsort = buildstate->btleader->sharedsort;
}
/*
* Begin serial/leader tuplesort.
*
* In cases where parallelism is involved, the leader receives the same
* share of maintenance_work_mem as a serial sort (it is generally treated
* in the same way as a serial sort once we return). Parallel worker
* Tuplesortstates will have received only a fraction of
* maintenance_work_mem, though.
*
* We rely on the lifetime of the Leader Tuplesortstate almost not
* overlapping with any worker Tuplesortstate's lifetime. There may be
* some small overlap, but that's okay because we rely on leader
* Tuplesortstate only allocating a small, fixed amount of memory here.
* When its tuplesort_performsort() is called (by our caller), and
* significant amounts of memory are likely to be used, all workers must
* have already freed almost all memory held by their Tuplesortstates
* (they are about to go away completely, too). The overall effect is
* that maintenance_work_mem always represents an absolute high watermark
* on the amount of memory used by a CREATE INDEX operation, regardless of
* the use of parallelism or any other factor.
*/
buildstate->spool->sortstate =
tuplesort_begin_index_btree(heap, index, buildstate->isunique,
buildstate->nulls_not_distinct,
maintenance_work_mem, coordinate,
TUPLESORT_NONE);
/*
* If building a unique index, put dead tuples in a second spool to keep
* them out of the uniqueness check. We expect that the second spool (for
* dead tuples) won't get very full, so we give it only work_mem.
*/
if (indexInfo->ii_Unique)
{
BTSpool *btspool2 = (BTSpool *) palloc0(sizeof(BTSpool));
SortCoordinate coordinate2 = NULL;
/* Initialize secondary spool */
btspool2->heap = heap;
btspool2->index = index;
btspool2->isunique = false;
/* Save as secondary spool */
buildstate->spool2 = btspool2;
if (buildstate->btleader)
{
/*
* Set up non-private state that is passed to
* tuplesort_begin_index_btree() about the basic high level
* coordination of a parallel sort.
*/
coordinate2 = (SortCoordinate) palloc0(sizeof(SortCoordinateData));
coordinate2->isWorker = false;
coordinate2->nParticipants =
buildstate->btleader->nparticipanttuplesorts;
coordinate2->sharedsort = buildstate->btleader->sharedsort2;
}
/*
* We expect that the second one (for dead tuples) won't get very
* full, so we give it only work_mem
*/
buildstate->spool2->sortstate =
tuplesort_begin_index_btree(heap, index, false, false, work_mem,
coordinate2, TUPLESORT_NONE);
}
/* Fill spool using either serial or parallel heap scan */
if (!buildstate->btleader)
reltuples = table_index_build_scan(heap, index, indexInfo, true, true,
_bt_build_callback, (void *) buildstate,
NULL);
else
reltuples = _bt_parallel_heapscan(buildstate,
&indexInfo->ii_BrokenHotChain);
/*
* Set the progress target for the next phase. Reset the block number
* values set by table_index_build_scan
*/
{
const int progress_index[] = {
PROGRESS_CREATEIDX_TUPLES_TOTAL,
PROGRESS_SCAN_BLOCKS_TOTAL,
PROGRESS_SCAN_BLOCKS_DONE
};
const int64 progress_vals[] = {
buildstate->indtuples,
0, 0
};
pgstat_progress_update_multi_param(3, progress_index, progress_vals);
}
/* okay, all heap tuples are spooled */
if (buildstate->spool2 && !buildstate->havedead)
{
/* spool2 turns out to be unnecessary */
_bt_spooldestroy(buildstate->spool2);
buildstate->spool2 = NULL;
}
return reltuples;
}
_bt_leafbuild 执行流程
该函数的主要功能是将_bt_spools_heapscan扫描的索引元组(位于BTBuildState结构体中的 spool/spool2数据类型,该类型是一个数组,每个元素为索引元组)插入叶子结点中,如果叶子不存在,则会新建。
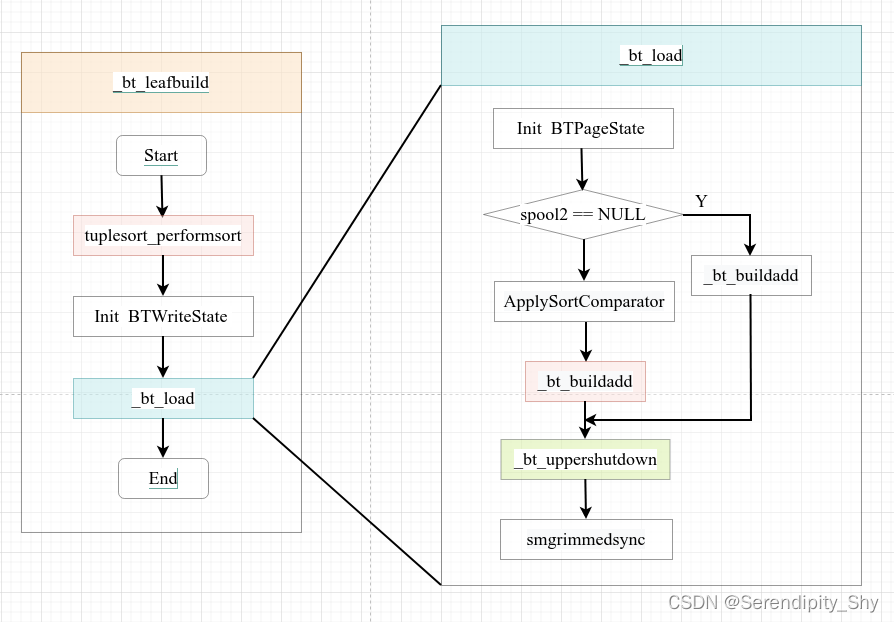
执行流程
1 调用 tuplesort_performsort对spool/spool2存放的索引元组进行排序(单独进行);
2 构建并初始化 BTWriteState结构体信息;
3 调用 _bt_load 函数将spool与spool2中的元组进行合并排序,将其填充至btree叶子节点中;
_bt_load 函数的工作流程如图:
1)根据入参初始化 BTPageState结构体
2)循环遍历spool/spool2中的元组,如果spool2为空,则直接调用_bt_buildadd将spool中的元组插入索引叶子结点中,反 之会先调用相应的排序函数确定两者的偏序关系,在调用_bt_buildadd函数进行上述插入操作;
3)紧接着完善叶子节点与父节点的link关系,并写入元页信息,同时记录WAL日志,该操作由_bt_uppershutdown函数完成;
4)将生成的索引页持久化至磁盘中,目的是防止发生崩溃重启时重放不了检查点之前的日志条目。[因为此相关的WAL日志只是在WAL buffer中构建好,并没有刷盘(未调用XLOGFlush),假设检查点发生时此日志条目落盘,但是对应的索引页却未持久化(索引页是在进程的私有内存中构建的)],如发生奔溃;此后重启根据检查点的规则便不会去回放WAL日志条目。
_bt_buildadd 工作流程
该函数的功能是将指定的索引元组插入到索引页结构中,在索引页结构空间不足时,会申请一个页面作为它的右兄弟,继续插入操作,最后会更新兄弟或者父子关系。

- 首先检查索引元组大小是否超过索引页大小的1/3,若超过则打印出错信息,反之转至步骤2;
2)如果当前页能够容纳所要插入的元组,则转至步骤 6;
3)将当前页面置为opage,申请一个新页面为npage,将opage最大的索引last_off元组复制到npage中,后续经整理使其成为oage的Highkey; - 紧接着通过BTPagestate.btps_next判断是否有父节点,若没有则创建一个父节点,并将opage中的min key复制到父节点中,更新opage与npage间的链接关系;
5)此时旧页opage已经完成填充不会再修改,此后调用 _bt_blwritepage将opage写入索引文件;
6)最后将带插入元祖添加至当前页,并更新BTPageState结构信息。
_bt_uppershutdown执行流程
该函数的主要功能是将完成的btree进行持久化,在此过程会更新父子页的链接关系

/*
* Finish writing out the completed btree.
*/
static void
_bt_uppershutdown(BTWriteState *wstate, BTPageState *state)
{
BTPageState *s;
BlockNumber rootblkno = P_NONE;
uint32 rootlevel = 0;
Page metapage;
/*
* Each iteration of this loop completes one more level of the tree.
*/
for (s = state; s != NULL; s = s->btps_next)
{
BlockNumber blkno;
BTPageOpaque opaque;
blkno = s->btps_blkno;
opaque = BTPageGetOpaque(s->btps_page);
/*
* We have to link the last page on this level to somewhere.
*
* If we're at the top, it's the root, so attach it to the metapage.
* Otherwise, add an entry for it to its parent using its low key.
* This may cause the last page of the parent level to split, but
* that's not a problem -- we haven't gotten to it yet.
*/
if (s->btps_next == NULL)
{
opaque->btpo_flags |= BTP_ROOT;
rootblkno = blkno;
rootlevel = s->btps_level;
}
else
{
Assert((BTreeTupleGetNAtts(s->btps_lowkey, wstate->index) <=
IndexRelationGetNumberOfKeyAttributes(wstate->index) &&
BTreeTupleGetNAtts(s->btps_lowkey, wstate->index) > 0) ||
P_LEFTMOST(opaque));
Assert(BTreeTupleGetNAtts(s->btps_lowkey, wstate->index) == 0 ||
!P_LEFTMOST(opaque));
BTreeTupleSetDownLink(s->btps_lowkey, blkno);
_bt_buildadd(wstate, s->btps_next, s->btps_lowkey, 0);
pfree(s->btps_lowkey);
s->btps_lowkey = NULL;
}
/*
* This is the rightmost page, so the ItemId array needs to be slid
* back one slot. Then we can dump out the page.
*/
_bt_slideleft(s->btps_page);
_bt_blwritepage(wstate, s->btps_page, s->btps_blkno);
s->btps_page = NULL; /* writepage freed the workspace */
}
/*
* As the last step in the process, construct the metapage and make it
* point to the new root (unless we had no data at all, in which case it's
* set to point to "P_NONE"). This changes the index to the "valid" state
* by filling in a valid magic number in the metapage.
*/
metapage = (Page) palloc(BLCKSZ);
_bt_initmetapage(metapage, rootblkno, rootlevel,
wstate->inskey->allequalimage);
_bt_blwritepage(wstate, metapage, BTREE_METAPAGE);
}