参考:线程池的基本用法 - 简书
1、为什么要用线程池?
在java中,开启线程的方式一般分为以下三种:
a. 继承Thread,实现其run方法;
b. 实现Runnabler接口,通过Thread来实现线程;
c. 实现 Callable 接口(创建线程较复杂)。
但无论哪种方式,当线程执行完成后,生命周期就结束了。在Linux系统中,线程的创建是一种很耗资源和时间的工作,因此,实现线程的复用便可以极大的减小资源的消耗,因此,有了线程池的出现。
2.初始化线程池的参数问题
java内置的线程池:
构造方法(最完整的)
代码示例:
public ThreadPoolExecutor(int corePoolSize, //核心线程数量
int maximumPoolSize, //最大线程数
long keepAliveTime, //最大空闲时间
TimeUnit unit, //时间单位
BlockingQueue<Runnable> workQueue, //任务队列
ThreadFactory threadFactory, //线程工厂
RejectedExecutionHandler handler //饱和处理机制
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}当核心线程数满了,并且任务队列也已经满的时候,此时最大线程数就要创建新的线程。

3、参数间的关系
在上面七个参数中,我们重点要关注的是 参数1,2,5,7间的关系。
corePoolSize,核心线程池大小。当我们添加的任务小于该值时,每添加一个任务,但会开启一个线程;一旦任务量大于了corePoolSize,则新添加的任务就会进入workQueue中,这是一个阻塞队列,当队列填满时,如果再添加任务,此时,新添加的任务就会触发新的线程的初始化(创建新的线程?)。此时持续添加任务,便会持续造成新的线程产生,但总共的线程不能超过maximumPoolSize。当总共开启的线程超过maximumPoolSize时,会便启动handler,对新任务进行拒绝。因此,workQueue在传入时,要设定一个大小,否则队列不满,则线程总数只会有corePoolSize个。
如果线程空闲时间超过了keepAliveTime后,线程就会自动销毁。注意,这里销毁的线程不包括核心线程。
4、如何实现线程复用
线程的生命周期在运行完run方法之后就结束了,因此,没办法将Thread拿过来重新用。想实现复用,只能让run方法无法结束,这时workQueue就起到了作用。
在线程池中,所用的队列为阻塞队列。当队列中无数据时,当前线程就会阻塞,直到有数据进入,线程才会运行。因此当线程运行完一个任务后,去队列中获取下一个,如果无法取到新任务,则会阻塞,进而完成一个线程中运行多个任务,即复用的功能。
5、代码验证
package test1;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* @auther zhoulz
* @description: 线程池的基础用法
*/
public class ThreadPoolTest {
public static void main(String[] args){
int corePoolSize = 2;
int maximumPoolSize = 5;
int keepAliveTime = 10 * 1000;
int workQueueSize = 10;
int taskSize = 4; // 输入不同的任务
ExecutorService pool = new ThreadPoolExecutor(corePoolSize,maximumPoolSize,keepAliveTime,
TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(workQueueSize));
for (int i = 1; i <= taskSize; i++) {
pool.execute(new MyThread(i));
}
pool.shutdown();
}
}
class MyThread extends Thread{
private int addNum;
MyThread(int addNum){
this.addNum = addNum;
}
@Override
public void run() {
try {
sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "正在执行。。。" + addNum);
}
}corePoolSize(2),maximumPoolSize(5),blockQueueSize(10)的值不变,我们测试taskSize不同时,输出的结果。
(1) taskSize = 2

结果:只创建了两个核心线程(pool-1-thread-1、pool-1-thread-2)。
(2)taskSize = 12, workQueue有数据,但不满或刚满

结果:还是只创建了两个核心线程(pool-1-thread-1、pool-1-thread-2),其他的任务均会进入队列中,当 thread1 和 thread2 运行完成后,进行复用执行其他任务。
(3)taskSize =15, taskSize = (maximumPoolSize+workQueueSize)阻塞队列填满,且线程正好开启到最大值

结论:可以看到任务1,2以及最后添加的13,14,15先运行了。这是因为,3到12之间的任务,会填入workQueue中,当workQueue填满时,还有任务进入,就会创建新的线程(这里新创建了3个,因为workQueue填满后多出来3个任务),运行后续加入的任务,直到所有线程数达到maximumPoolSize(5)。我们这种情况正好wrokQueue填满,而线程开启到最大值maximumPoolSize,任务刚刚与两个值一样。
(4)taskSize = 18 taskSize>(maximumPoolSize+workQueueSize), 任务超出最大线程数与队列等待数之和
结果:从上面可以看出,任务15之后的就看不到了且出现了异常,这说明超出的线程池的处理能力,如果我们传RejectedExecutionHandler handler,也就是拒绝策略,此时就会接到任务。
(并且程序一直阻塞着)
(5)corePoolSize=0,maximumPoolSize=3,blockQueueSize=90,taskSize=10
这是一个特殊情况,就是如果我们把corePoolSize置为0,且所有的任务不超过等待对列的大小会如何?按上面理的理解,因为队列不满,所以除了核心线程外,不会创建新线程,但此时corePoolSize为0?难道任务就一直在队列里无法执行吗?
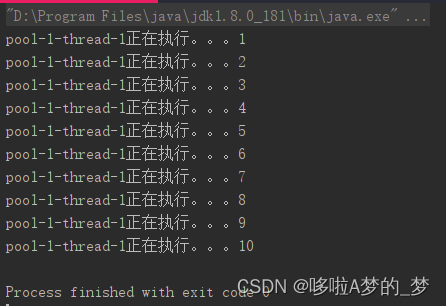
实际这种情况下,任务依然执行了,但线程只有一个。这个和我们设置 corePoolSize=1运行结果是一样的,原因呢?
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0) //****注意这里 1
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}注意代码中标有注释的 1处,当corePoolSize==0时,会走到此处,引发创建线程的操作,所以当corePoolSize=0时,也会运行任务。关于 addWorker()代码的说明,可以参照 手撕ThreadPoolExecutor线程池源码,在Android OkHttp框架中,核心线程池就是0,且使用到的了个无容量的队列(相当于系统提供的newCachedThreadPool),有兴趣的可以去看一下。
6、参考值
在使用中,corePoolSize可根据业务来定,另一参数maximumPoolSize则比较重要了,其具体值可根据任务类型来定:
a.CPU密集型
此类的任务,特点为需要大量的使用cpu进行大量的计算,此时的最大线程数,最大值不能超过CPU核心数+1,之所以加1,考虑到cpu计算时,如果有数据在虚拟内存上,需要将其挪到内存上,此过程较为耗时,cpu在等待过程中,可能出现空闲,为了保证其不会空闲,所以+1。
b.IO密集型
当任务中存在大量的网络读取或磁盘文件读取时,maximumPoolSize最大值不要超过 cpu核心数2。因为IO密集型,在等待网络数据或文件读取时,是不需要cpu的,采用DMS机制,此时cpu会空闲下来,因此有了2的操作。
c.cpu+io混合型
如果任务中涉及到cpu计算以及IO操作,如果cpu计算与io操作所用的时间相差不大,则考虑将其拆分成两个任务;如果相差较大,一般是IO操作比较耗时,则可以忽略cpu任务,将其当成IO操作的任务即可。
7、4个参数的设计
1. 核心线程数(corePoolSize)
核心线程数的设计需要依据任务的处理时间和每秒产生的任务数量来确定,例如:执行一个任务需要0.1秒,系统百分之80的时间每秒都会产生100个任务,那么要想在1秒内处理完这100个任务,就需要10个线程,此时我们就可以设计核心线程数为10;当然实际情况不可能这么平均,所以我们一般按照8020原则设计即可,既按照百分之80的情况设计核心线程数,剩下的百分之20可以利用最大线程数处理。
2. 任务队列长度(workQueue)
任务队列长度一般设计为:核心线程数/单个任务执行时间*2即可;例如上面的场景中,核心线程数设计为10,单个任务执行时间为0.1秒,则队列长度可以设计为200。
3. 最大线程数(maximumPoolSize)
最大线程数的设计除了需要参照核心线程数的条件外,还需要参照系统每秒产生的最大任务数决定:例如:上述环境中,如果系统每秒最大产生的任务是1000个,那么,最大线程数=(最大任务数-任务队列长度)*单个任务执行时间;既: 最大线程数=(1000-200)*0.1=80个.
4. 最大空闲时间(keepAliveTime)
这个参数的设计完全参考系统运行环境和硬件压力设定,没有固定的参考值,用户可以根据经验和系统产生任务的时间间隔合理设置一个值即可。
注:上面4个参数的设置只是一般的设计原则,并不是固定的,用户也可以根据实际情况灵活调整!







![[synchronized ]关键字详解](https://img-blog.csdnimg.cn/0e28df8c50aa4105809c4c89b1ec1971.png)