作者|BBuf
很高兴为大家带来One-YOLOv5的最新进展,在《一个更快的YOLOv5问世,附送全面中文解析教程》发布后收到了很多算法工程师朋友的关注,十分感谢。
不过,可能你也在思考一个问题:虽然OneFlow的兼容性做得很好,可以很方便地移植YOLOv5并使用OneFlow后端来进行训练,但为什么要用OneFlow?能缩短模型开发周期吗?解决了任何痛点吗?本篇文章将尝试回答这几个问题。
我曾经也是一名算法工程师,开发机器也只有两张RTX 3090消费级显卡而已,但实际上大多数由我上线的检测产品也就是靠这1张或者2张RTX 3090完成的。
由于成本问题,很多中小公司没有组一个A100集群或者直接上数十张卡来训练检测模型的实力,所以这个时候在单卡或者2卡上将目标检测模型做快显得尤为重要。模型训练速度提升之后可以降本增效,提高模型生产率。
所以,近期我和实习生小伙伴一起凭借对YOLOv5的性能分析以及几个简单的优化,将单RTX 3090 FP32 YOLOv5s的训练速度提升了近20%。对于需要迭代300个Epoch的COCO数据集来说,One-YOLOv5相比Ultralytics/YOLOv5缩短了11.35个小时的训练时间。
本文将分享我们的所有优化技术,如果你是一名PyTorch和OneFlow的使用者,尤其日常和检测模型打交道但资源相对受限,那么本文的优化方法将对你有所帮助。
One-YOLOv5链接:
https://github.com/Oneflow-Inc/one-yolov5
欢迎你给我们在GitHub上点个Star,我们会用更多高质量技术分享来回馈社区。对 One-YOLOv5 感兴趣的小伙伴可以添加bbuf23333进入One-YOLOv5微信交流群。
1
结果展示
我们展示一下分别使用One-YOLOv5以及Ultralytics/YOLOv5在RTX 3090单卡上使用YOLOv5s FP32模型训练COCO数据集的一个Epoch所需的耗时:

可以看到,在单卡模式下,经过优化后的One-YOLOv5相比Ultralytics/YOLOv5的训练速度提升了20%左右。
然后我们再展示一下2卡DDP模式YOLOv5s FP32模型训练COCO数据集一个Epoch所需的耗时:
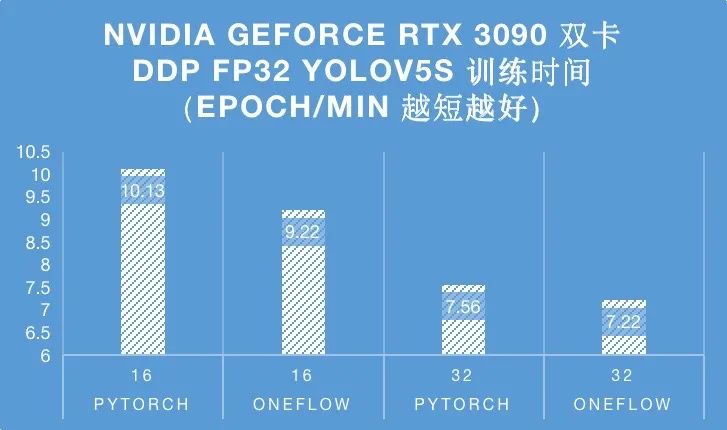
在DDP模式下,One-YOLOv5的性能依然领先,但还需要进一步,猜测可能是通信部分的开销比较大,后续我们会再研究一下。
2
优化手段
我们深度分析了PyTorch的YOLOv5的执行序列,发现当前YOLOv5主要存在3个优化点。
第一,对于Upsample算子的改进,由于YOLOv5使用上采样是规整的最近邻2倍插值,所以我们可以实现一个特殊Kernel降低计算量并提升带宽。
第二,在YOLOv5中存在一个滑动更新模型参数的操作,这个操作启动了很多碎的CUDA Kernel,而每个CUDA Kernel的执行时间都非常短,所以启动开销不能忽略。我们使用水平并行CUDA Kernel的方式(MultiTensor)对其完成了优化,基于这个优化,One-YOLOv5获得了9%的加速。
第三,通过对YOLOv5nsys执行序列的观察发现,在ComputeLoss部分出现的bbox_iou是整个Loss计算部分的比较大的瓶颈,我们在bbox_iou函数部分完成了多个垂直的KernelFuse,使得它的开销从最初的3.xms降低到了几百个us。接下来将分别详细阐述这三种优化。
2.1 对UpsampleNearest2D的特化改进
这里直接展示我们对UpsampleNearest2D进行调优的技术总结,大家可以结合下面的PR链接来对应下面的知识点进行总结。我们在A100 40G上测试了UpsampleNearest2D算子的性能表现,这块卡的峰值带宽在1555Gb/s , 我们使用的CUDA版本为11.8。
进行 Profile 的程序如下:
import oneflow as flow
x = flow.randn(16, 32, 80, 80, device="cuda", dtype=flow.float32).requires_grad_()
m = flow.nn.Upsample(scale_factor=2.0, mode="nearest")
y = m(x)
print(y.device)
y.sum().backward()https://github.com/Oneflow-Inc/oneflow/pull/9415 & https://github.com/Oneflow-Inc/oneflow/pull/9424 这两个 PR 分别针对 UpsampleNearest2D 这个算子(这个算子是 YOLO 系列算法大量使用的)的前后向进行了调优,下面展示了在 A100 上调优前后的带宽占用和计算时间比较:
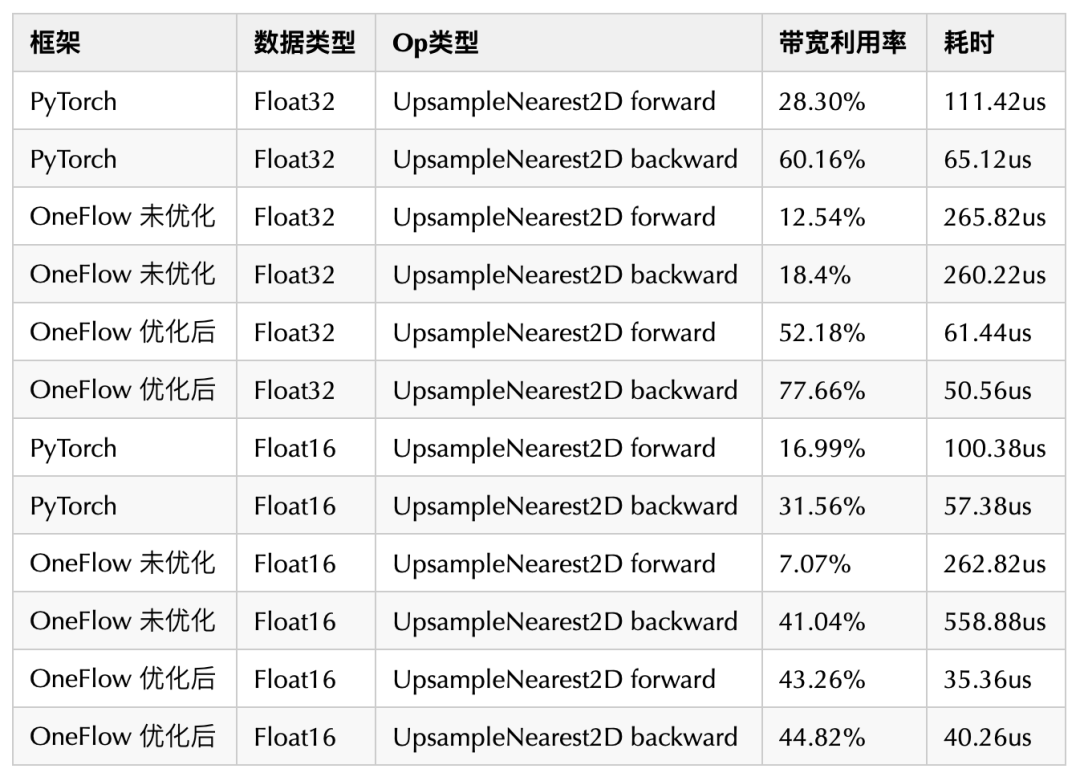
上述结果使用 /usr/local/cuda/bin/ncu -o torch_upsample /home/python3 debug.py 得到profile文件后使用Nsight Compute打开记录。
基于上述对 UpsampleNearest2D 的优化,OneFlow 在 FP32 和 FP16 情况下的性能和带宽都大幅超越之前未经优化的版本,并且相比于 PyTorch 也有较大幅度的领先。
本次优化涉及到的知识点总结如下(by OneFlow 柳俊丞):
-
为常见的情况写特例,比如这里就是为采样倍数为2的Nearest插值写特例,避免使用NdIndexHelper带来的额外计算开销,不用追求再一个kernel实现中同时拥有通用型和高效性;
-
整数除法开销大(但是编译器有的时候会优化掉一些除法),nchw中的nc不需要分开,合并在一起计算减少计算量;
-
int64_t除法的开销更大,用int32满足大部分需求,其实这里还有一个快速整数除法的问题;
-
反向Kernel计算过程中循环dx相比循环dy ,实际上将坐标换算的开销减少到原来的1/4;
-
CUDA GMEM的开销的也比较大,虽然编译器有可能做优化,但是显式的使用局部变量更好;
-
一次Memset的开销也很大,和写一次一样,所以反向Kernel中对dx使用Memset清零的时机需要注意;
-
atomicAdd开销很大,即使抛开为了实现原子性可能需要的锁总线等,atomicAdd需要把原来的值先读出来,再写回去;另外,half的atomicAdd 巨慢无比,慢到如果一个算法需要用到atomicAdd,那么相比于用half ,转成float ,再atomicAdd,再转回去还要慢很多;
-
向量化访存。
对这个Kernel进行特化是优化的第一步,基于这个优化可以给YOLOv5的单卡 PipLine 带来1%的提升。
2.2 对bbox_iou函数进行优化 (垂直Fuse优化)
通过对nsys的分析,我们发现无论是One-YOLOv5还是Ultralytics/YOLOv5,在计算Loss的阶段都有一个耗时比较严重的bbox_iou函数,这里贴一下bbox_iou部分的代码:
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
if CIoU or DIoU or GIoU:
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
return iou # IoU以One-YOLOv5的原始执行序列图为例,我们发现bbox_iou函数这部分每一次运行都需要花2.6ms左右,并且可以看到这里有大量的小Kernel被调度,虽然每个小Kernel计算很快,但访问GlobalMemory以及多次KernelLaunch的开销也比较大,所以我们做了几个fuse来降低Kernel Launch的开销以及减少访问Global Memrory来提升带宽。
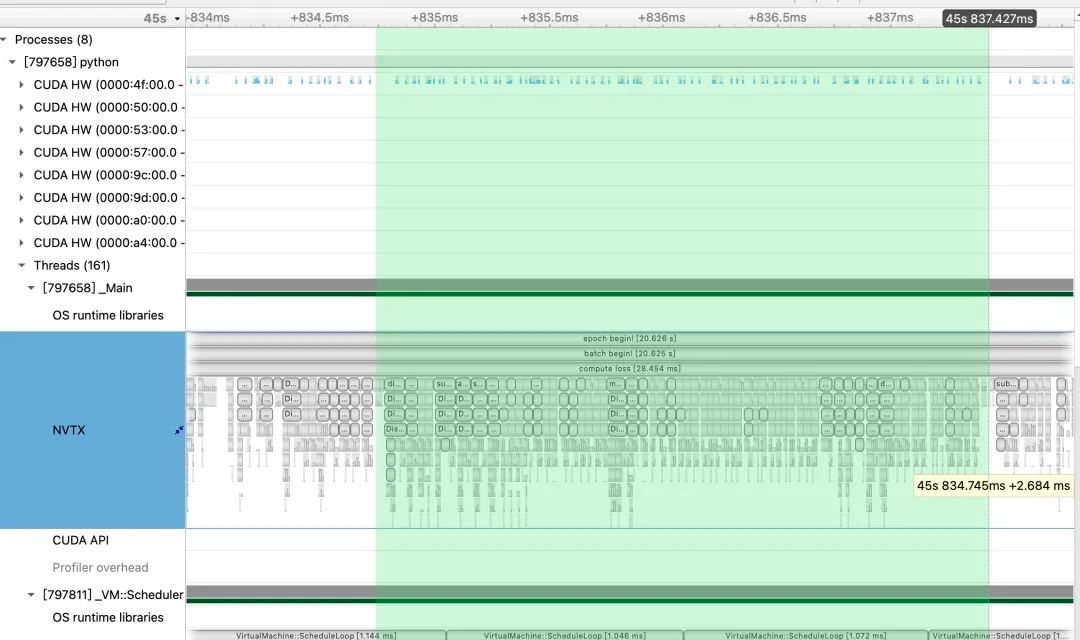
经过我们的Kernel Fuse之后的耗时只需要600+us。
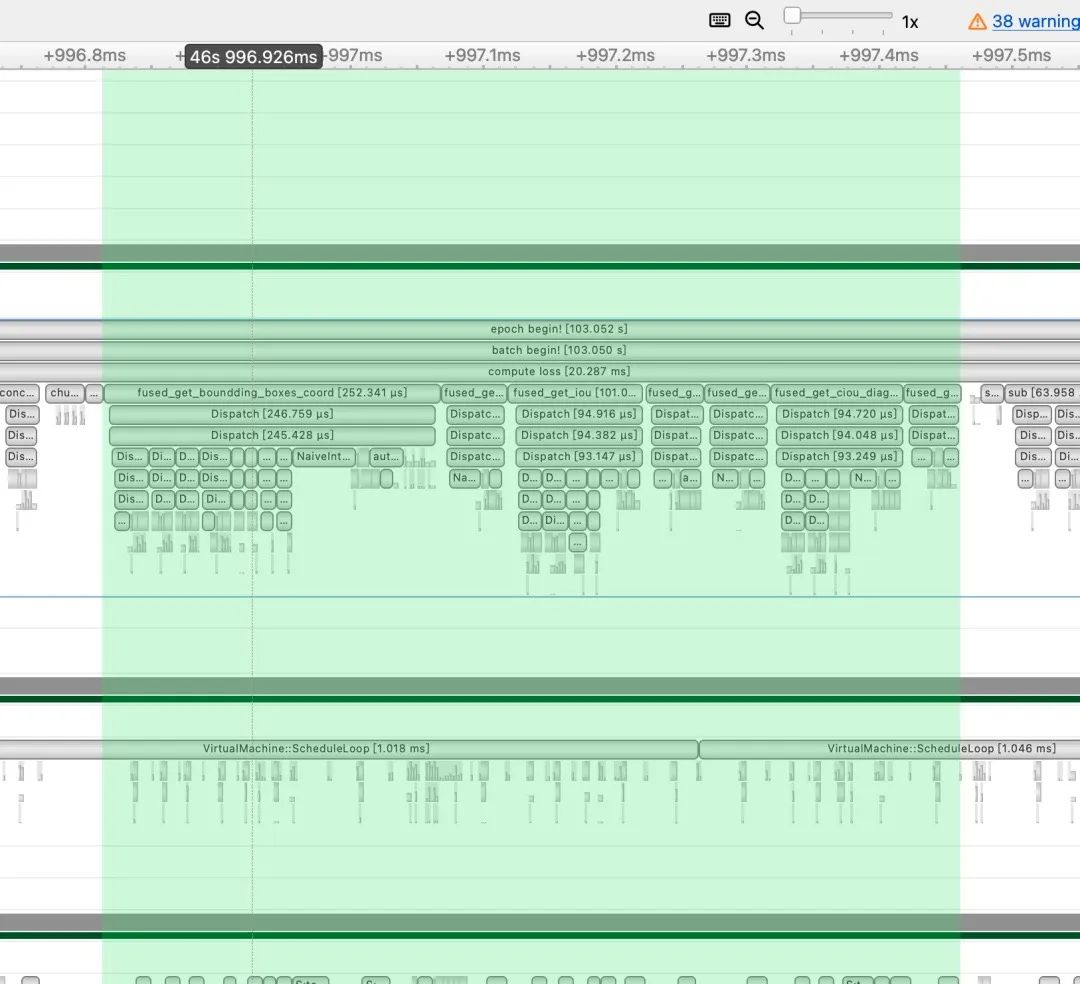
具体来说我们这里做了如下的几个fuse:
-
fused_get_boundding_boxes_coord:https://github.com/Oneflow-Inc/oneflow/pull/9433
-
fused_get_intersection_area: https://github.com/Oneflow-Inc/oneflow/pull/9485
-
fused_get_iou: https://github.com/Oneflow-Inc/oneflow/pull/9475
-
fused_get_convex_diagonal_squared: https://github.com/Oneflow-Inc/oneflow/pull/9481
-
fused_get_center_dist: https://github.com/Oneflow-Inc/oneflow/pull/9446
-
fused_get_ciou_diagonal_angle: https://github.com/Oneflow-Inc/oneflow/pull/9465
-
fused_get_ciou_result: https://github.com/Oneflow-Inc/oneflow/pull/9462
然后我们在One-YOLOv5的train.py中扩展了一个 --bbox_iou_optim 选项,只要训练的时候带上这个选项就会自动调用上面的fuse kernel来对bbox_iou函数进行优化了,具体请看:https://github.com/Oneflow-Inc/one-yolov5/blob/main/utils/metrics.py#L224-L284 。对bbox_iou这个函数的一系列垂直Fuse优化使得YOLOv5整体的训练速度提升了8%左右,是一个十分有效的优化。
2.3 对模型滑动平均更新进行优化(水平Fuse优化)
在 YOLOv5 中会使用EMA(指数移动平均)对模型的参数做平均, 一种给予近期数据更高权重的平均方法, 以求提高测试指标并增加模型鲁棒。这里的核心操作如下代码所示:
def update(self, model):
# Update EMA parameters
self.updates += 1
d = self.decay(self.updates)
msd = de_parallel(model).state_dict() # model state_dict
for k, v in self.ema.state_dict().items():
if v.dtype.is_floating_point: # true for FP16 and FP32
v *= d
v += (1 - d) * msd[k].detach()
# assert v.dtype == msd[k].dtype == flow.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'以下是未优化前的这个函数的时序图:
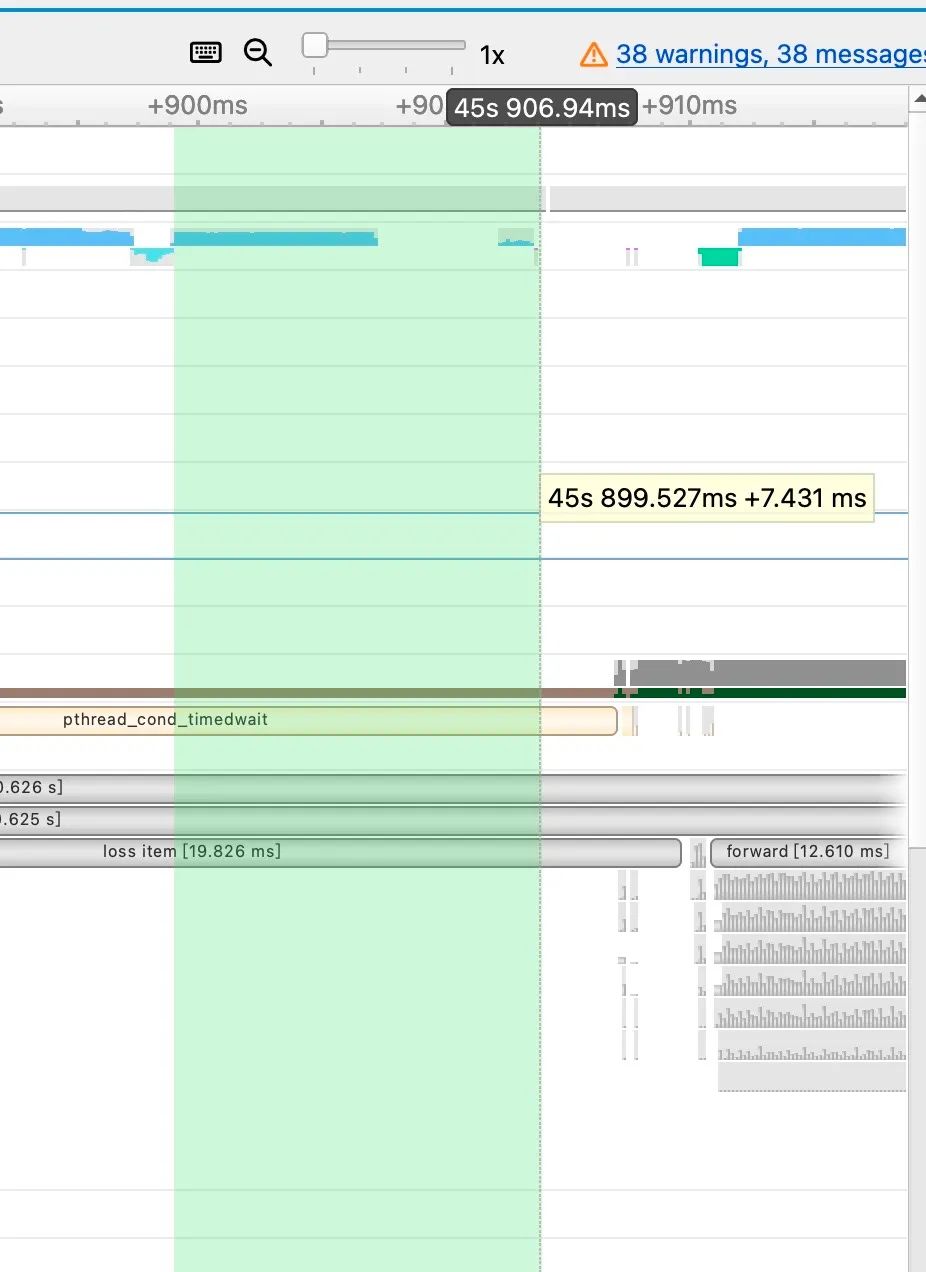
这部分的CUDAKernel的执行速度大概为7.4ms,而经过我们水平Fuse优化(即MultiTensor),这部分的耗时情况降低了127us。
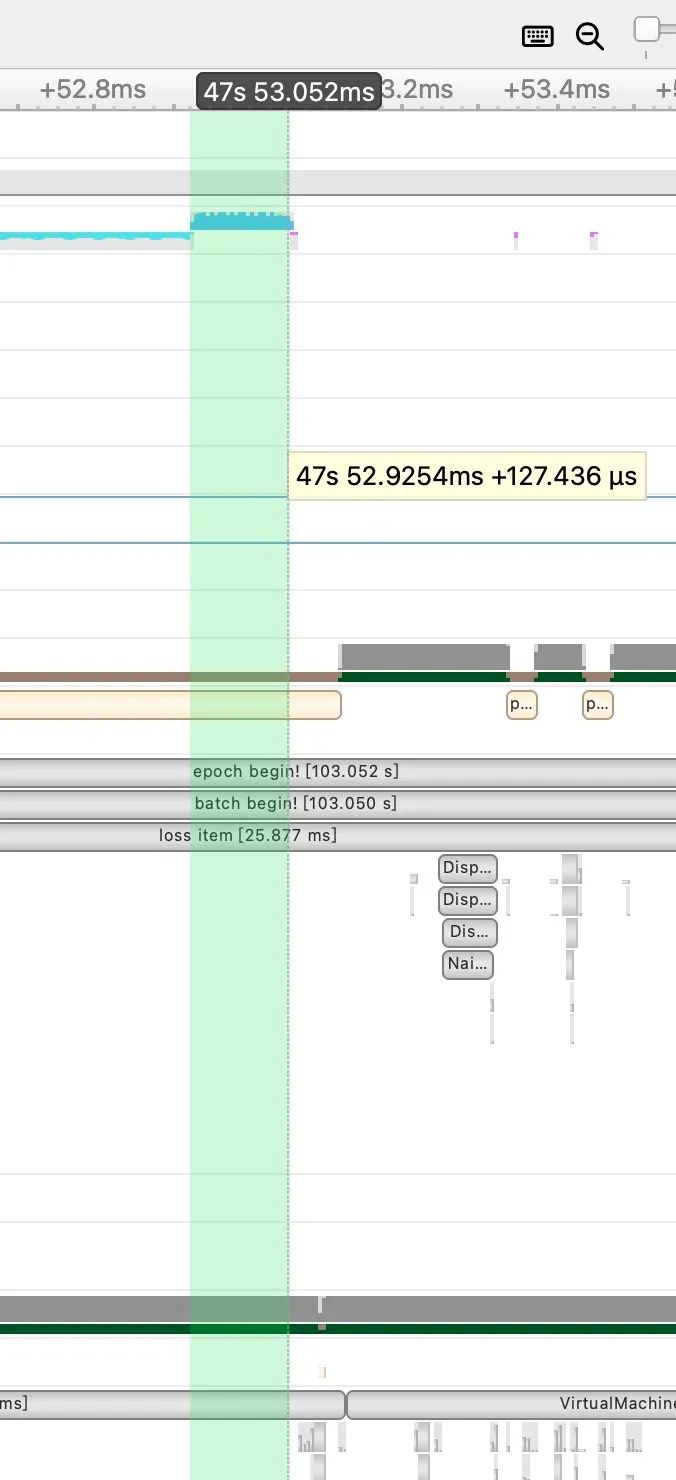
并且水平方向的Kernel Fuse也同样降低了Kernel Launch的开销,使得前后2个Iter的间隙也进一步缩短了。最终这个优化为YOLOv5的整体训练速度提升了10%左右。本优化实现的pr如下:https://github.com/Oneflow-Inc/oneflow/pull/9498
此外,对于Optimizer部分同样可以水平并行,所以我们在One-YOLOv5里设置了一个multi_tensor_optimizer标志,打开这个标志就可以让 optimizer 以及 EMA 的 update以水平并行的方式运行。
关于MultiTensor这个知识可以看 zzk 的这篇文章:https://zhuanlan.zhihu.com/p/566595789。zzk 在 OneFlow 中也实现了一套 MultiTensor 方案,上面的 PR 9498 也是基于这套 MultiTensor 方案实现的。介于篇幅原因我们就不展开MultiTensor的代码实现了,感兴趣朋友的可以留言后续单独讲解。
3
使用方法
上面已经提到所有的优化都集中于 bbox_iou_optim 和 multi_tensor_optimizer 这两个扩展的Flag,只要我们训练的时候打开这两个Flag就可以享受到上述优化了。其他的运行命令和One-YOLOv5没有变化,以One-YOLOv5在RTX 3090上训练YOLOv5为例,命令为:
python train.py
--batch 16
--cfg models/yolov5s.yaml
--weights ''
--data coco.yaml
--img 640
--device 0
--epoch 1
--bbox_iou_optim
--multi_tensor_optimizer4
总结
目前,YOLOv5s网络当以BatchSize=16的配置在GeForce RTX 3090上(这里指定BatchSize为16时)训练COCO数据集时,OneFlow相比PyTorch可以节省 11.35 个小时。希望这篇文章提到的优化技巧可以对更多的从事目标检测的工程师带来启发。
欢迎Star One-YOLOv5项目:
https://github.com/Oneflow-Inc/one-yolov5
One-YOLOv5的优化工作实际上不仅包含性能,我们目前也付出了很多心血在文档和源码解读上,后续会继续放出《YOLOv5全面解析教程》的其他文章,并将尽快发布新版本。
5
致谢
感谢同事柳俊丞在这次调优中提供的 idea 和技术支持,感谢胡伽魁同学实现的一些fuse kernel,感谢郑泽康和宋易承的MultiTensorUpdate实现,感谢冯文的精度验证工作以及文档支持,以及小糖对One-YOLOv5的推广,以及帮助本项目发展的工程师如赵露阳、梁德澎等等。本项目未来会继续发力做出更多的成果。
直播现在约!!!
12月8日(本周四)20:00,OneFlow框架开发工程师、ONNX核心成员分享ONNX最新特性和最佳实践,欢迎围观。
其他人都在看
-
OneFlow-ONNX v0.6.0正式发布
-
OneFlow源码解析:自动微分机制
-
下载量突破10亿,MinIO的开源启示录
-
更快的YOLOv5问世,附送全面中文解析教程
-
李白:你的模型权重很不错,可惜被我没收了
-
比快更快,开源Stable Diffusion刷新作图速度
-
OneEmbedding:单卡训练TB级推荐模型不是梦
 https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/