文章目录
- 一、 什么是线程池
- 二、Java中线程池的运用
- 1. 创建线程池中的问题
- 2. 标准库中线程池的使用
- 三、自主实现一个简单的线程池
一、 什么是线程池
所谓线程池,其实和字符串常量池,数据库连接池十分相似,就是设定一块区域,提前放好一些已经成型的线程,当需要使用的时候,直接进行调用不需要经历复杂的创建过程,销毁线程时也不需要经历复杂过程,直接将线程返还给线程池即可线程池最大的优势就是减少了每次启动、销毁线程的损耗!
为什么引入线程池后创建/销毁会更加高效?
其实,创建/销毁线程这个操作时由操作系统内核完成的。而从线程池获取/放回用户代码即可实现,无需交给操作系统内核。
解释操作系统内核:
对于操作系统内核,下面我通过一个场景进行简单的介绍。
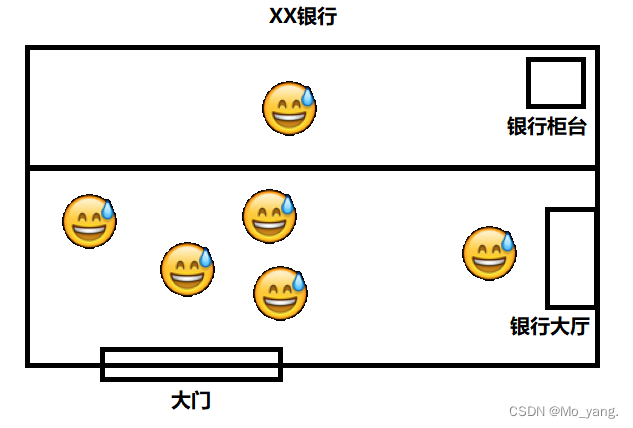
如上图所示,假设一个银行,有很多人要办业务,这些人大致分为两类,同样也对应两种不同的需求:
- 第一类,这些人不是要在柜台办理什么业务,而是取钱(取款机),看银行项目等其他事务的,是自由的,类似于程序中的 用户态 用户态执行的是程序员自己实现的代码,在这里代码想干什么,怎么干都是程序员自主决定的。
- 第二类,就是要办理业务的人,像是办理银行卡,更改用户名等。此时这些操作是需要在银行柜台后进行,你不能进入其中,需要通过工作人员间接执行。这就像是程序中的 内核态 内核态中的操作都是在操作系统内核中完成的,内核会为程序员提供一些 api,即,系统调用。 程序员通过这些系统调用来驱使内核完成工作,但是,这里面的工作是不受程序员控制,是内核自行完成的。
总的来讲,用户态中程序的行为是可控的,比较快速整洁。但是,内核态就需要过另外一个人 (操作系统内核) 的手续,就不可控了。
二、Java中线程池的运用
1. 创建线程池中的问题
创建一个线程池

如上图所示,这样就创建了一个数目固定为10的一个线程池。需要注意的是,这里划红线的地方,此处的 new 是方法名字的一部分,不是 new 关键字。
这个操作,就是使用某个静态的方法,直接构造一个对象出来(相当于将 new 方法隐藏在这个方法里)
这种方法称之为“工厂方法”,即利用“工厂模式”设计出的方法。
解释工厂模式:
所谓 工厂模式 简单来讲就是,使用普通的方法来代替构造方法创建对象。会出现这种模式的主要原因就是构造方法中有很多不便之处。
例如,现在有个类要表示平面上的一点,如图所示:

此时很明显就出了问题,正常来讲,多个构造方法是通过 “重载” 的形式提供的。但是,我们要明确的是,重载的要求是,方法名相同,参数的 个数/类型 不相同。 在这里很明显都不满足。
因此,这里才需要引入工厂模式,如图:
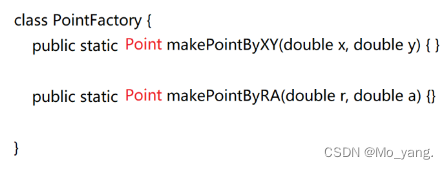
这样问题就得以解决了。
2. 标准库中线程池的使用
代码展示:
public static void main(String[] args) {
ExecutorService poll = Executors.newFixedThreadPool(10);
for (int i = 0; i < 1000; i++) {
int n = i;
poll.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello"+n);
}
});
}
}
这里的 submit 方法可以给线程池提供若干个任务。
运行之后不难发现,main 线程结束但是整个进程没有结束,在这里,线程池中的线程都是前台线程,因此会阻止进程结束。
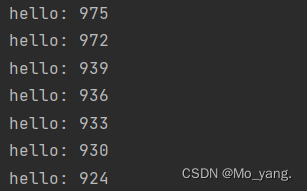
这里要注意的是,当前线程池中存放了 1000 个任务。这 10 个线程分别分配执行,执行结束后就到线程池中获取,但是,不一定是平均分配,可能有的多有的少。
思考:

如上图所示,我们知道,这里的 n 就是起到一个中介的作用,但是为什么直接使用 i 却不行?
其实不难理解,这里主线程 for 中的 i 是一个局部变量,主线程执行的速度很快,这里的 for 执行完了,但是当前 run 的任务在线程池中还没有排到,此时 i 已经销毁了
解决这个问题的思路其实也不难理解,这里其实就是一个变量捕获。我们知道,这里的 run 方法属于 runnable。这个方法的执行不是立刻马上,而是在未来的某个节点才去执行。
所以,为了避免作用域的差异,导致后续执行时 i 已经被销毁,于是也就有了变量捕获,即就是在定义 run 方法时,将 i 的值记录下来。后续执行的时候将其复制过去即可。
Executors创建线程的几种方式:
对于创建线程池,大致有下面几种类型:
- newCachedThreadPool() : 线程数量是动态变化的,根据任务多少的情况来创建线程。
- newFixedThreadPool() : 设定一个恒定大小数量的线程池。
- newSingleThreadExecutor() : 线程池中只有一个线程。
- newScheduleThreadPool() : 类似于定时器,让任务延时执行,只是在执行的时候不使用扫描线程,而是使用单独的线程池来执行。
创建形式示例:
ExecutorService poll = Executors.newFixedThreadPool(10);
理解 ThreadPoolExecutor 构造方法参数

如上图所示,我们可以看到该构造方法中有很多参数,下面我来进行简单的解释。
首先,将创建一个线程池设想成开公司。每一个员工相当于一个线程。
- corePoolSize: 正式员工数量(一旦录用,永不辞退)—— 核心线程数。
- maximumPoolSize: 正式员工 + 临时工数目。(临时工:一段时间不干活,就被辞退)
- keepAliveTime: 临时工允许空闲的时间。
- unit: keepAliveTime 的时间单位是秒,分钟,其他值…
- workQueue: 传递任务的阻塞队列
- threadFactory: 创建线程的工厂,参与具体创建线程的工作。
- RejectedExecutionHandler: 拒绝策略, 如果任务量超出公司的负荷了接下来怎么处理.
AbortPolicy(): 超过负荷, 直接抛出异常.
CallerRunsPolicy(): 调用者负责处理
DiscardOldestPolicy(): 丢弃队列中最老的任务.
DiscardPolicy(): 丢弃新来的任务.
创建形式示例:
ExecutorService pool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
三、自主实现一个简单的线程池
根据前面的示例我们可以知道,实现一个线程池内部至少有两大部分。
- 阻塞队列,用于保存任务。
- 实现若干个工作线程
代码展示
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
class MyThreadPool{
//创建一个阻塞队列
private BlockingDeque<Runnable> queue = new LinkedBlockingDeque<>();
// n 表示线程的数量
public void MyThreadPool(int n){
for (int i = 0; i < n; i++) {
Thread t = new Thread(()->{
//不断尝试获取队列中的元素
while(true){
try {
Runnable runnable = queue.take();
//调用 runnable 方法中的 run
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
//添加元素到线程池(阻塞队列)
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
}
public class ThreadDemo {
public static void main(String[] args) throws InterruptedException {
MyThreadPool myThreadPool = new MyThreadPool();
//设定线程池的数量
myThreadPool.MyThreadPool(10);
for (int i = 0; i < 1000; i++) {
int n = i;
//创建任务放到线程池
myThreadPool.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello: "+n);
}
});
}
}
}
运行结果: