一、标记混合预测器
分支预测的目的是根据历史信息来预测分支指令的跳转方向和目标地址,从而提高流水线的效率。不同的分支预测方法有不同的优缺点,因此有人提出了一种将多种预测方法结合起来的方案,混合预测器。这种方案可以根据不同的分支情况选择最合适的预测方法,提高预测的准确性。
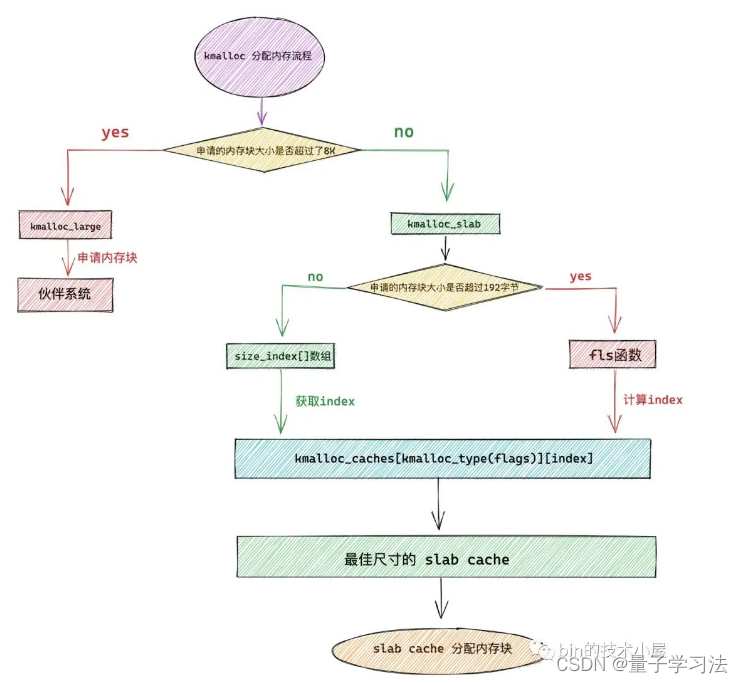
其中一种重要的混合预测器是基于一种统计压缩算法PPM(Prediction by Partial Matching)的思想,叫做带标签的混合预测器(Tagged Hybrid Predictor)。这种预测器使用了一系列的全局预测器,每个全局预测器使用不同长度的历史信息来索引。例如,一个五部分的带标签混合预测器有五个预测表:P(0),P(1),…,P(4),其中P(i)使用分支指令的地址和最近i条分支指令的历史(保存在一个移位寄存器h中,就像gshare一样)进行哈希运算来索引。使用多个历史长度来索引不同的预测器是第一个关键的区别。
第二个关键的区别是在表P(1)到P(4)中使用了标签。标签可以很短,因为不需要100%匹配:一个4-8位的小标签就可以获得大部分优势。一个来自P(1),…,P(4)的预测只有在标签和分支地址和全局分支历史的哈希值匹配时才会被使用。P(0)总是匹配,因为它不使用标签,它成为了如果没有P(1)到P(n)匹配时的默认预测。每个P(0…n)中的预测器可以是一个标准的2位预测器。
给定分支指令的预测是具有最长分支历史并且也有匹配标签的预测器。带标签混合版本的这个预测器还包括了一个2位使用域,在历史索引预测器中的每一个。使用域表示一个预测是否最近被使用并且因此可能更准确;使用域可以周期性地在所有条目中重置,以便清除旧的预测。实现这种风格的预测器涉及许多更多细节,特别是如何处理错误预测。最优化预测器的搜索空间也非常大,因为预测器数量、用于索引的确切历史和每个预测器大小都是可变化的。
带标签混合预测器(有时称为TAGE——TAgged GEometric predictors)和早期基于PPM的预测器已经成为最近年度国际分支预测竞赛中获胜者。这样的预测器以适度数量(32-64 KiB)内存超越了gshare和锦标赛式(tournament) 预测器,并且此外,这类预测器似乎能够有效地利用更大规模的缓存来提供改进后准确性。
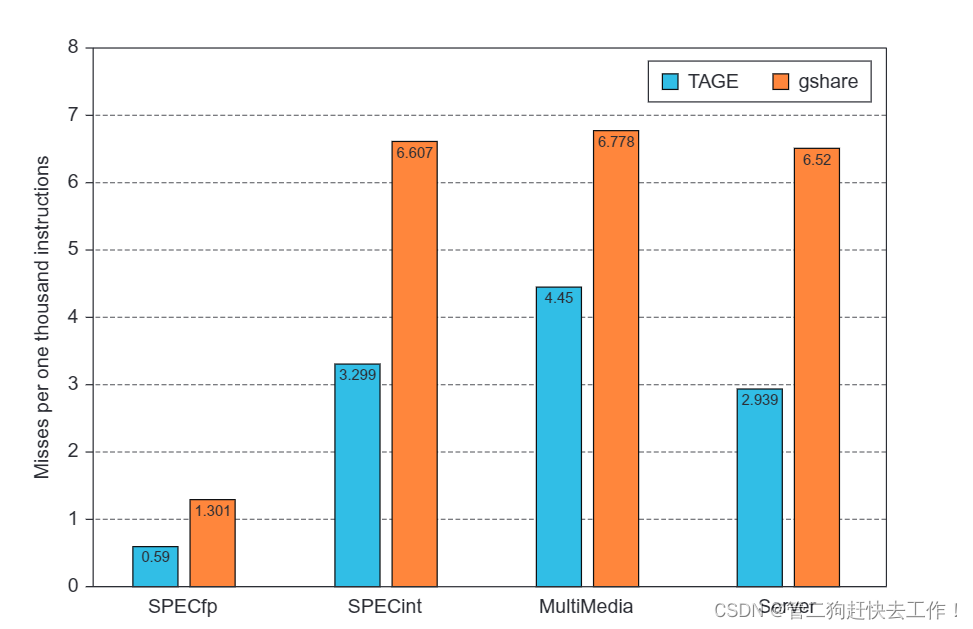
标记混合与 gshare 的误预测率(以每执行 1000 条指令的误预测来衡量)的比较。 两个预测器使用相同的总位数,尽管标记混合使用一些标签存储,而 gshare 不包含标签。 这些基准测试由 SPECfp 和 SPECint(一系列多媒体和服务器基准测试)的跟踪组成。 后两者的行为更像 SPECint。
二、英特尔酷睿 i7 分支预测器的演变
2008 年(使用 Nehalem 微架构的 Core i7 920)到 2016 年(使用 Skylake 微架构的 Core i7 6700)期间,Intel Core i7 处理器已经出现了六代。 由于深度流水线和每个时钟多个问题的结合,i7 一次有许多指令在运行(最多 256 条,通常至少 30 条)。 这使得分支预测变得至关重要,这也是英特尔一直在不断改进的领域。 也许是因为分支预测器对性能至关重要的性质,英特尔倾向于对其分支预测器的细节保密。
Core i7 920使用了二级预测器,其中一个较小的第一级预测器旨在满足每个时钟周期预测一个分支的周期约束,并有一个较大的第二级预测器作为备份。 每个预测器结合了三个不同的预测器:(1)简单的2位预测器,; (2)全球历史预测器; (3)循环退出预测器。 循环退出预测器使用计数器来预测被检测为循环分支的分支所采用的分支的确切数量(即循环迭代的数量)。 对于每个分支,通过跟踪每个预测的准确性从三个预测器中选择最佳预测,就像锦标赛预测器一样。 除了这个多级主预测器之外,还使用单独的单元预测间接分支的目标地址,并且还使用堆栈来预测返回地址。