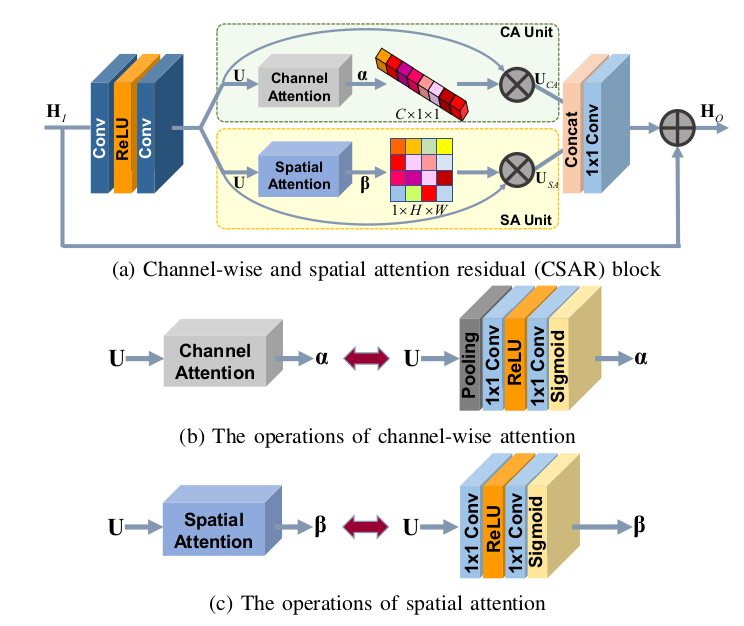
在机器视觉任务中,每一张图片都有重点区域,而非每一个像素对模型理解图片都同等重要。
在自然语言处理任务中,每一段文字都有重点词语,而非每一个字对模型理解语句都同等重要。
如此,在神经网络模型中引入注意力,让模型把握重点,必是能提升模型的理解能力的!
SE模块
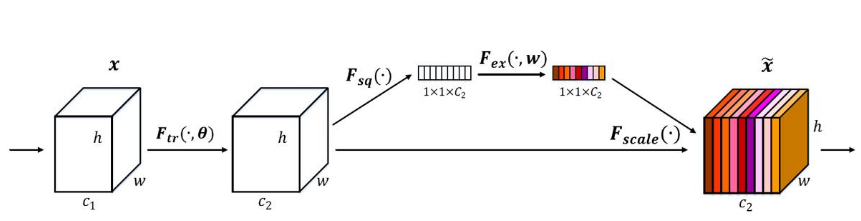
SE(Squeeze-and-Excitation:压缩与激活)模块:通过卷积操作将特征图压缩成11C的通道注意力向量,在将该注意力向量作用到之前的特征图。
import torch.nn as nn
import torch
class SELayer(nn.Module):
def __init__(self,channel,reduction=16):
super(SELayer,self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel,channel//reduction,bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel//reduction,channel,bias=False),
nn.Sigmoid())
def forward(self,x):
b,c,_,_ = x.size()
y = self.avg_pool(x).view(b,c)
y = self.fc(y).view(b,c,1,1)
return x*y.expand_as(x)
a = torch.randn(1,8,64,64)
SE = SELayer(8)
print(SE(a).shape)
CBAM模块
CBAM(Convolutional Block Attention Module:卷积注意力)模块:首先经过一个通道注意力模块,之后再经过一个空间注意力模块。

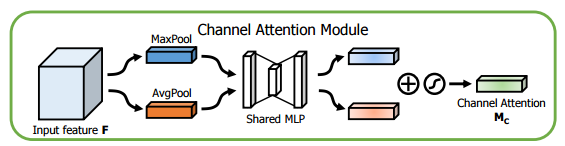
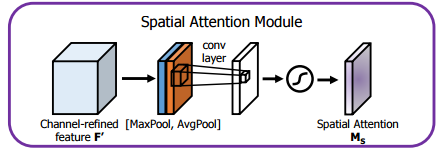
其中通道注意力模块便是一个SE模块;空间注意力模块是将经过通道注意力加权后的特征图与其经卷积操作获得的空间注意力向量进行乘法运算。
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
#基础的卷积模块 由卷积层+BN+激活函数
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
#展平层
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
#通道注意
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
)
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type=='avg':
avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( avg_pool )
elif pool_type=='max':
max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( max_pool )
elif pool_type=='lp':
lp_pool = F.lp_pool2d( x, 2, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( lp_pool )
elif pool_type=='lse':
# LSE pool only
lse_pool = logsumexp_2d(x)
channel_att_raw = self.mlp( lse_pool )
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw
scale = F.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
def logsumexp_2d(tensor):
tensor_flatten = tensor.view(tensor.size(0), tensor.size(1), -1)
s, _ = torch.max(tensor_flatten, dim=2, keepdim=True)
outputs = s + (tensor_flatten - s).exp().sum(dim=2, keepdim=True).log()
return outputs
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
#空间注意力部分
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = F.sigmoid(x_out) # broadcasting
return x * scale
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
if not self.no_spatial:
x_out = self.SpatialGate(x_out)
return x_out
a = torch.randn(1,8,16,16)
cbam = CBAM(8)
print(cbam(a).shape)
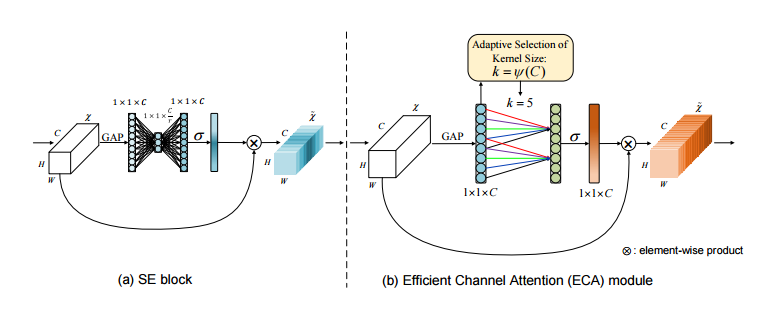
ECA模块
ECA(Effificient Channel Attention:高效通道注意力)模块:其与SE模块唯一的区别就在于:没有将通道注意力向量压缩后再放大的全连接层,而是之间将其与特征图进行加权运算。
import torch
import torch.nn
from torch.nn.parameter import Parameter
class eca_layer(nn.Module):
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
a = torch.randn(1,4,32,32)
eca = eca_layer(8)
print(eca(a).shape)
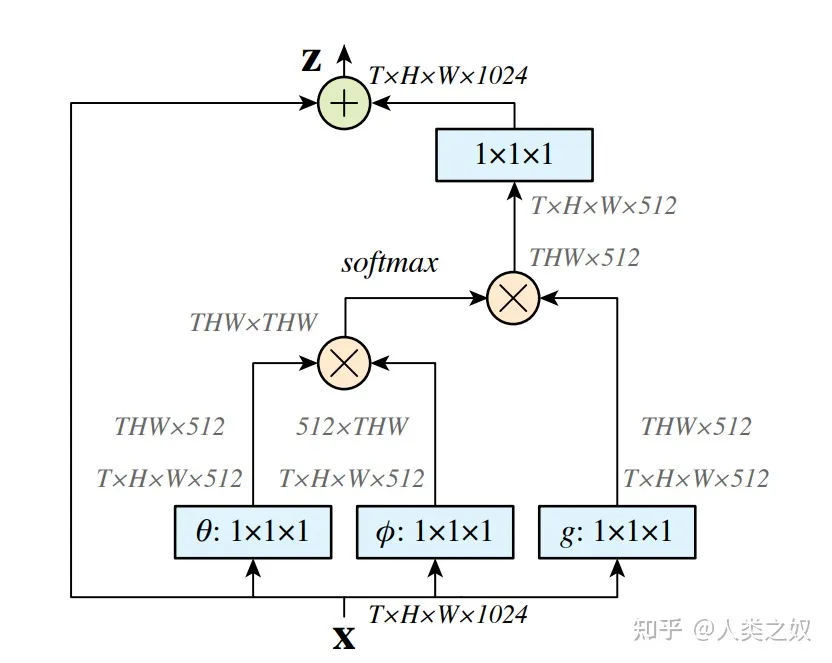
Non- Local模块
Non-Local(非全局)模块
import torch
from torch import nn
from torch.nn import functional as F
class NonLocal(nn.Module):
def __init__(self,in_channels,inter_channels=None,dimension=3,sub_sample=True,bn_layer=True):
super(NonLocal,self).__init__()
assert dimension in [1,2,3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1,2,2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2,2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels,out_channels=self.inter_channels,kernel_size=1,stride=1,padding=0)
if bn_layer:
self.W = nn.Sequential(conv_nd(in_channels=self.inter_channels,out_channels=self.in_channels,kernel_size=1,stride=1,padding=0),bn(self.in_channels))
nn.init.constant_(self.W[1].weight,0)
nn.init.constant_(self.W[1].bias,0)
else:
self.W = conv_nd(in_channels=self.inter_channels,out_channels=self.in_channels,kernel_size=1,stride=1,padding=0)
nn.init.constant_(self.W[1].weight,0)
nn.inti.constant_(self.W[1].bias,0)
self.theta = conv_nd(in_channels=self.in_channels,out_channels=self.inter_channels,kernel_size=1,stride=1,padding=0)
self.phi = conv_nd(in_channels=self.in_channels,out_channels=self.inter_channels,kernel_size=1,stride=1,padding=0)
if sub_sample:
self.g = nn.Sequential(self.g,max_pool_layer)
self.phi = nn.Sequential(self.phi,max_pool_layer)
def forward(self,x):
batch_size = x.size(0)
g_x = self.g(x).view(batch_size,self.inter_channels,-1)
g_x = g_x.permute(0,2,1)
theta_x = self.theta(x).view(batch_size,self.inter_channels,-1)
theta_x = theta_x.permute(0,2,1)
phi_x = self.phi(x).view(batch_size,self.inter_channels,-1)
f = torch.matmul(theta_x,phi_x)
print(f.shape)
f_div_C = F.softmax(f,dim=-1)
y = torch.matmul(f_div_C,g_x)
y = y.permute(0,2,1).contiguous()
y = y.view(batch_size,self.inter_channels,*x.size()[2:])
W_y = self.W(y)
z = W_y + x
return z
a = torch.randn(1,6,6,32,32)
no = NonLocal(6)
print(no(a).shape)
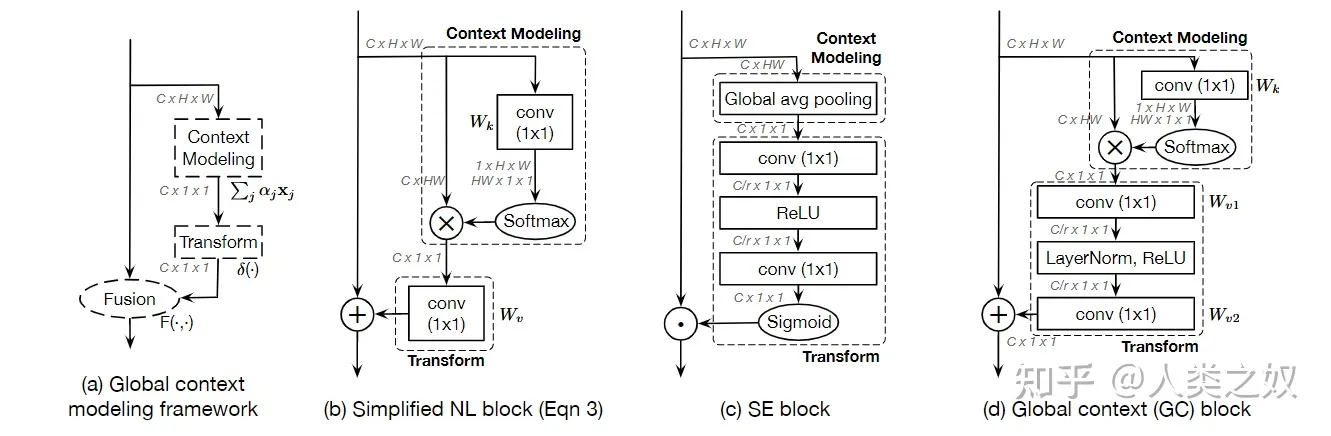
GC模块
GC(Global Context:全局纹理)模块:
from __future__ import absolute_import
import torch
from torch import nn
from mmcv.cnn import constant_init, kaiming_init
import math
def last_zero_init(m):
if isinstance(m, nn.Sequential):
constant_init(m[-1], val=0)
m[-1].inited = True
else:
constant_init(m, val=0)
m.inited = True
class ContextBlock2d(nn.Module):
def __init__(self, inplanes, planes, pool, fusions):
super(ContextBlock2d, self).__init__()
assert pool in ['avg', 'att']
assert all([f in ['channel_add', 'channel_mul'] for f in fusions])
assert len(fusions) > 0, 'at least one fusion should be used'
self.inplanes = inplanes
self.planes = planes
self.pool = pool
self.fusions = fusions
if 'att' in pool:
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusions:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1)
)
else:
self.channel_add_conv = None
if 'channel_mul' in fusions:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.planes, self.inplanes, kernel_size=1)
)
else:
self.channel_mul_conv = None
self.reset_parameters()
def reset_parameters(self):
if self.pool == 'att':
kaiming_init(self.conv_mask, mode='fan_in')
self.conv_mask.inited = True
if self.channel_add_conv is not None:
last_zero_init(self.channel_add_conv)
if self.channel_mul_conv is not None:
last_zero_init(self.channel_mul_conv)
def spatial_pool(self, x):
batch, channel, height, width = x.size()
if self.pool == 'att':
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(3)
# [N, 1, C, 1]
# 汇集全文的信息 对应的像素点进行匹配,整个图像的像素点全部相加
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
else:
# [N, C, 1, 1]
context = self.avg_pool(x)
return context
def forward(self, x):
# [N, C, 1, 1]
context = self.spatial_pool(x)
if self.channel_mul_conv is not None:
# [N, C, 1, 1]
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = x * channel_mul_term
else:
out = x
if self.channel_add_conv is not None:
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out
if __name__ == "__main__":
inputs = torch.randn(1,16,300,300)
block = ContextBlock2d(16,4,"att",["channel_add"])
out = block(inputs)
print(out.size())
SimAM模块
SimAM模块:受SE模块和CBAM模块启发,SimAM模块直接通过公式计算出CHW的三维注意力矩阵的解析解。
import torch
import torch.nn as nn
class SimAM_module(torch.nn.Module):
def __init__(self,channels=None,e_lambda=1e-4):
super(SimAM_module,self).__init__()
self.activation = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambad=%f)'%self.e_lambda)
return s
@staticmethod
def get_module_name():
return 'simam'
def forward(self,x):
b,c,h,w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3],keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3],keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activation(y)
class Bottleneck_SimAM(nn.Module):
def __init__(self,c1,c2,shortcut=True,g=1,e=0.5):
super(Bottleneck_SimAM,self).__init__()
c_ = int(c2*e)
self.cv1 = Conv(c1,c_,1,1)
self.cv2 = Conv(c_,c2,3,1,g=g)
self.add = shortcut and c1 == c2
self.attention = SimAM_module(channels=c2)
def forward(self,x):
return x + self.attention(self.cv2(self.cv1(x))) if self.add else self.cv2(self.cv1(x))
a = torch.randn(1,4,32,32)
sim = SimAM_module()
print(sim(a).shape)
CASR模块