21.String、StringBuffer和StringBuilder的区别是什么?
线程安全:
- String中的对象是不可变的,线程安全
- StringBuffer对方法加了同步锁,所以是线程安全的
- StringBuilder没有对方法加同步锁,所以是非线程安全的
使用效率:
- String进行操作时,每次都会生成一个新的String对象,然后将指针指向新的String对象。
- 而StringBuffer和StringBuilder每次都会对本身进行操作而不是生成新对象。StringBuilder比StringBuffer使用效率较高,但线程不安全
可变性:
String:
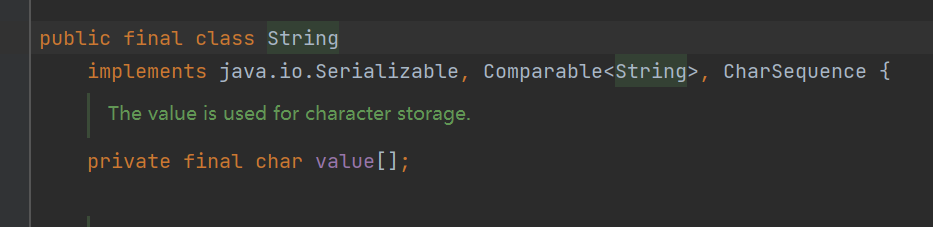
fianl修饰的类不能被继承,修饰的方法不能被重写,修饰的基本类型数据不能改变,修饰的引用类型则不能在指向其他对象。因为final修饰的数组并不是String不可变的根本原因,因为这个数组保存的内部数据是可变的,真正的原因有以下几点:
- 字符串数组被final修饰并且为私有,并且String没有提供修改这个字符串的方法
- String类被final修饰导致不能被继承,避免了子类破坏String不可变
StringBuilder与StringBuffer:

StringBuilder与StringBuffer都继承于AbstractStringBuilder,该抽象类也是使用字符数组保存字符串,但没有使用final和private修饰。而且还提供很多操作字符串的方法
如何选择三者:
- 少量操作使用String
- 单线程下大量操作使用StringBuilder
- 多线程下大量操作使用StringBuffer
字符串拼接使用 + 还是StringBuilder?
public static void main(String[] args) {
String str = "";
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
str += "a";
}
long end = System.currentTimeMillis();
System.out.println("String拼接100000次花费时间: " + (end - start));
StringBuilder stringBuilder = new StringBuilder();
start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
stringBuilder.append("a");
}
end = System.currentTimeMillis();
System.out.println("StringBuilder拼接100000次花费时间: " + (end - start));
}
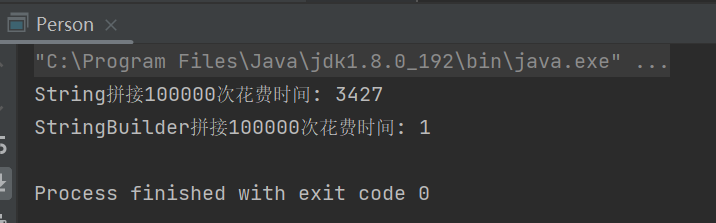
首先我们可以得出当数据量很大时,StringBuilder的拼接效率远远高于String拼接,那么为什么呢?
因为String通过"+“进行拼接时,实现会先创建StringBuilder然后调用append()调用toString()得到一个String对象。当我们在循环里使用”+"进行拼接时,会创建大量的StringBuilder对象,每循环一次就会创建一个
字符串常量池:
字符串常量池主要是为了提升性能并减少内存消耗,给字符串专门开辟了一块区域,为了防止字符串重复创建
public static void main(String[] args) {
// 将字符串"abc"保存在字符串常量池
String s1 = "abc";
// 从字符串常量池直接返回"abc"的引用
String s2 = "abc";
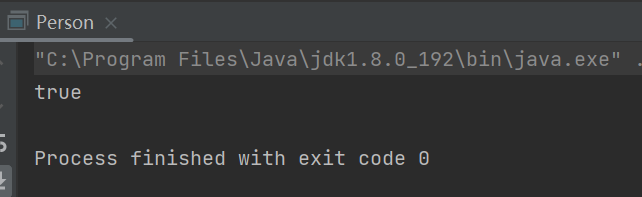
System.out.println(s1 == s2);
}
String s = new String(“a”) 会创建几个对象?
这里分两种情况:
- 常量池存在"abc"的引用,那么只会在堆空间中创建一个对象
- 常量池中不存在"abc"的引用,首先会在字符串常量池中创建,然后再堆中创建,那么共创建2个字符串对象
intern()是做什么的?
intern()是一个native方法,作用是将字符串保存在常量池中,也分为以下两种情况:
- 字符串常量池存在该字符串的引用,直接返回该引用
- 字符串常量池不存在该字符串的引用,就在常量池创建一个指向该字符串对象并将引用返回
String变量与常量做+运算时发生了什么?
public static void main(String[] args) {
String str1 = "abc";
String str2 = "efg";
String str3 = "abc" + "efg";
String str4 = str1 + str2;
String str5 = "abcefg";
System.out.println(str3 == str4);
System.out.println(str3 == str5);
System.out.println(str4 == str5);
}
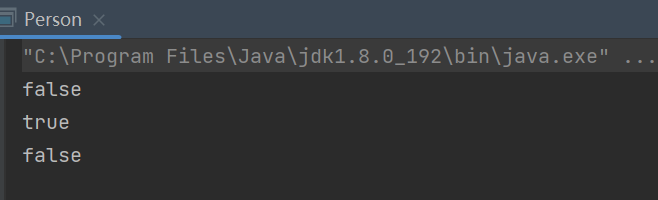
为什么会出现这种情况呢?
因为对于编译器可以确定的字符串,也就是字符串常量,JVM会将其存入字符串常量池。也会将拼接后的字符串常量在编译器就存入字符串常量池,得益于编译器优化。
例如:
String str3 = "abc" + "efg";
String str3 = "abcefg";
大家需要注意不是所有常量都可以进行折叠(常量折叠是将常量表达式的值嵌入在最终代码中,这是Javac编译器堆源代码做的优化),只有在编译器可以确定的常量才可以:
- final修饰的基本数据类型和字符串变量
- 基本数据类型基于字符串常量
上述str4是引用的值在编译器是无法确定的,所以我们编译器无法对其进行优化
它相当于:
String str4 = new StringBuilder().append(str1).append(str2).toString();
但是如果我们给字符串变量加上final修饰后,就可以让编译器将其当作常量来处理
public static void main(String[] args) {
final String str1 = "abc";
final String str2 = "efg";
String str3 = "abc" + "efg";
String str4 = str1 + str2;
String str5 = "abcefg";
System.out.println(str3 == str4);
System.out.println(str3 == str5);
System.out.println(str4 == str5);
}
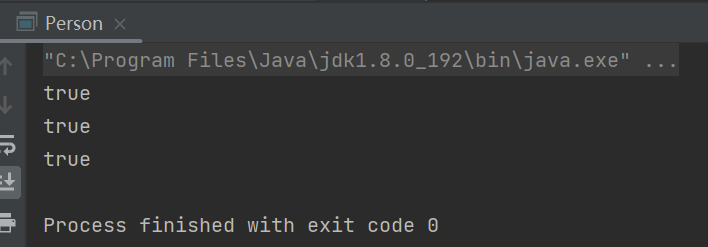
我们给str1,str2加上final修饰后,String会被编译器当作常量进行处理,在编译期就可以确定它的值,相当于常量访问。
22.方法常见知识
静态方法为什么不能调用非静态成员?
1.静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员是属于实例对象的,只有对象实例化之后才存在,需要通过类的实例对象去访问
2.在类的非静态成员不存在时静态方法就已经存在了,此时调用内存中不存在的非静态成员是非法的
静态方法和实例方法有什么不同?
1.调用方式:
在调用静态方法时,可以使用类名.方法名 ,也可以使用对象.方法名 的方式,而实例方法只能使用后面这种方法,静态方法不依赖对象
但是我们为了避免混淆静态方法和非静态方法,我们一般建议使用类名.方法名的方式来调用静态方法
2.访问类成员是否存在限制
静态方法在访问本类成员时,只需要访问静态成员和方法,不能访问实例成员和方法。
什么是可变长参数?
从Java5开始,Java支持可变长参数,也就是允许调用方法时可以传入不定长度的参数,比如:
public static int add(int... n) {
int sum = 0;
for (int i : n) {
sum += i;
}
return sum;
}
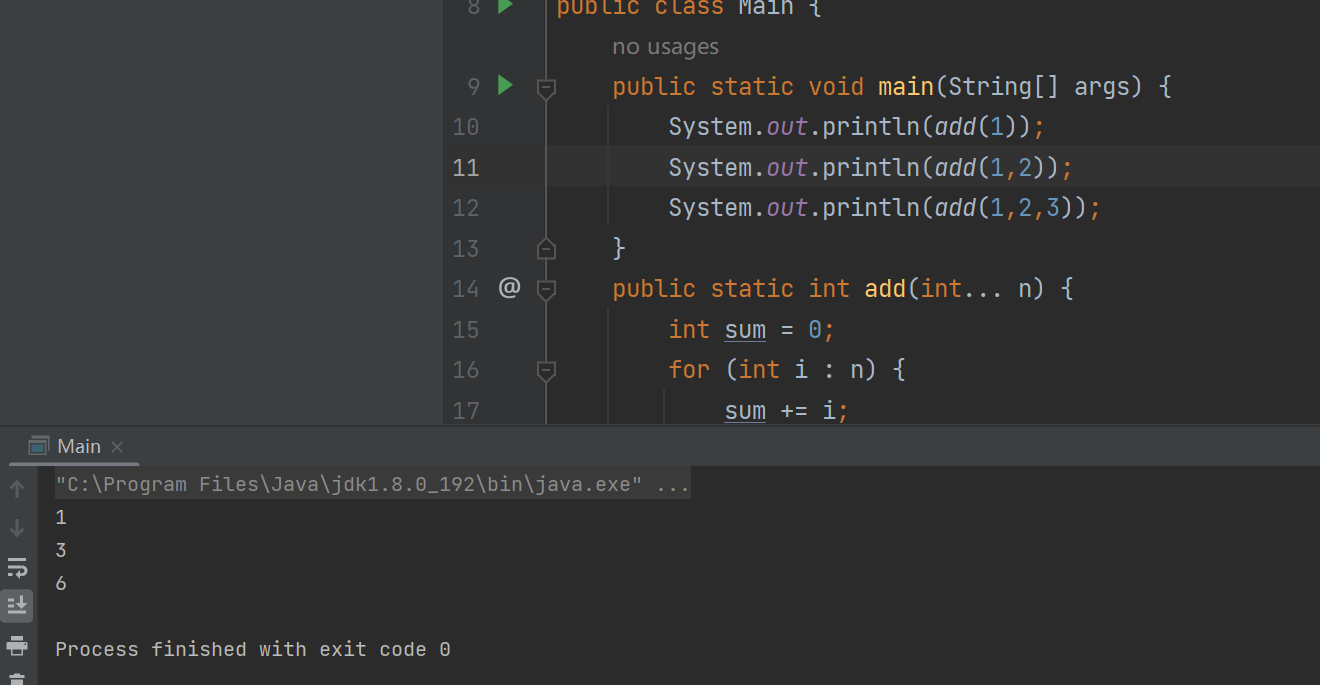
需要注意的是,可变参数只能作为函数的最后一个参数,前面可以有任意个参数,包含0个
public static int add(String name,int... n) {
}
如果方法重载了,优先调用固定参数还是可变参数呢?
这里是会优先匹配固定参数的方法,因为固定参数的方法匹配度更高
public static int add(int n) {
return 0;
}
public static int add(int... n) {
return 1;
}
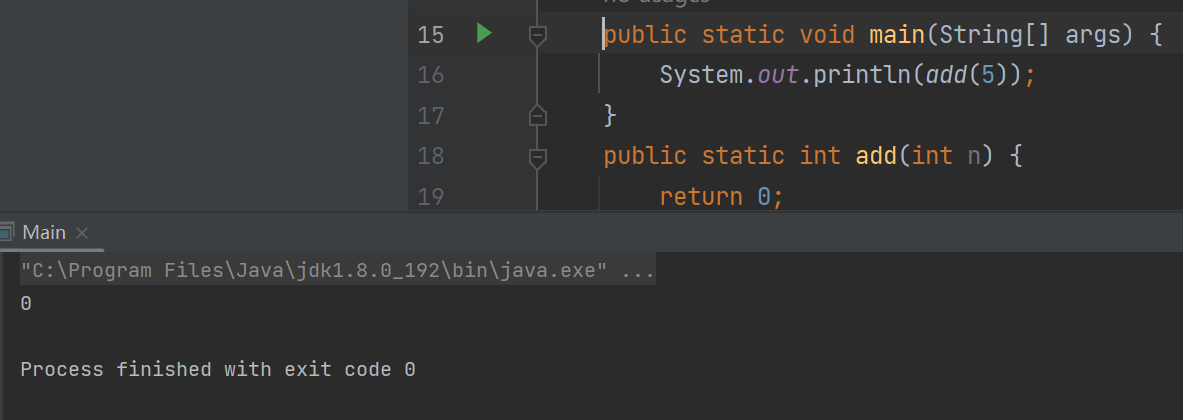
实际上,我们Java中的可变参数在编译后会被转换成一个数组
23.数值运算精度问题
为什么浮点数运算的时候会有精度丢失问题?
public static void main(String[] args) {
float a = 2.6f - 1.7f;
float b = 1.6f - 0.7f;
System.out.println(a);
System.out.println(b);
System.out.println(a == b);
}
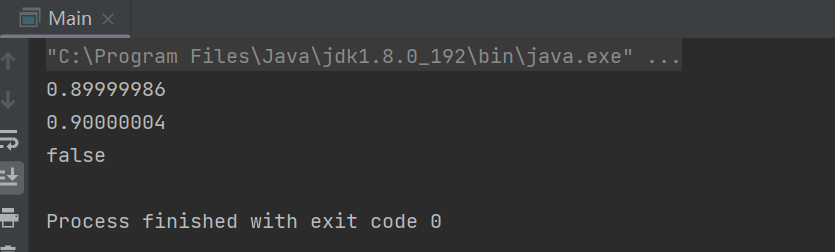
与计算机在保存浮点数的方式有关系。我们计算机是二进制表示的,计算一个数字时宽度是有限的,无限循环的小树存储在计算机时只能被截断,这也是为什么浮点数没有办法用二进制精确表示
如何解决浮点数运算精度丢失问题?
我们可以使用BigDecimal来实现对浮点数的运算,大部分对运算精度要求比较高的业务场景,都是通过BigDecimal来做的
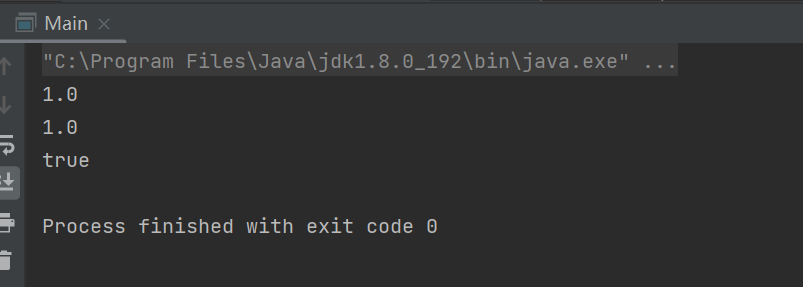
public static void main(String[] args) {
BigDecimal a = new BigDecimal("3.0");
BigDecimal b = new BigDecimal("2.0");
BigDecimal c = new BigDecimal("1.0");
System.out.println(a.subtract(b));
System.out.println(b.subtract(c));
System.out.println(a.subtract(b).equals(b.subtract(c)));
}
超过long整型的数据应该如何表示?
在Java中,64位long整型是最大的整型类型,但如果超过这个范围就会有数值溢出的风险
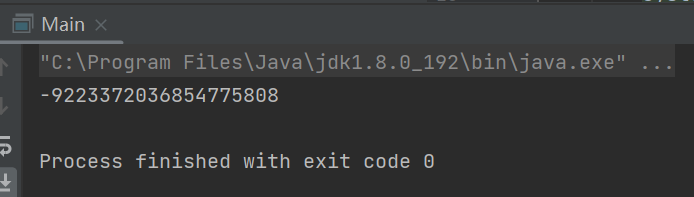
public static void main(String[] args) {
long a = Long.MAX_VALUE;
System.out.println(a+1);
}
我们可以使用BigInteger来表示:
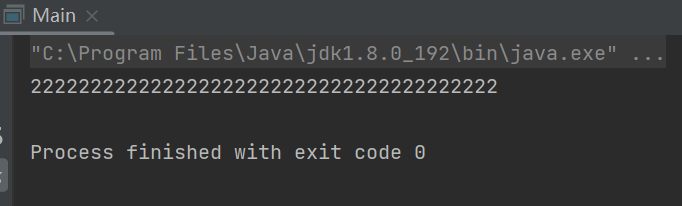
public static void main(String[] args) {
BigInteger a = new BigInteger("111111111111111111111111111111111111111");
BigInteger b = new BigInteger("111111111111111111111111111111111111111");
System.out.println(a.add(b));
}
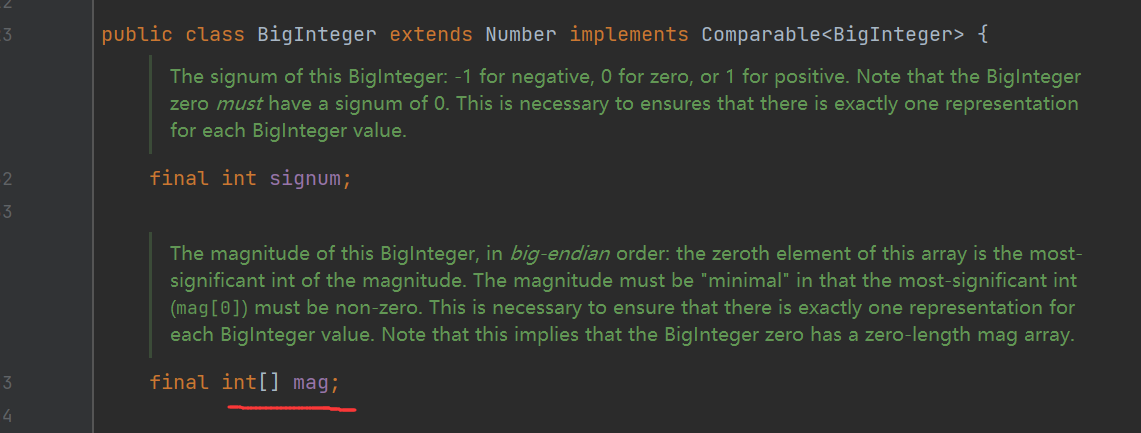
我们可以发现BigInteger内部使用int[ ]数组来存储任意大小的整型数据,但BigInteger的运算效率相对较低
24.异常
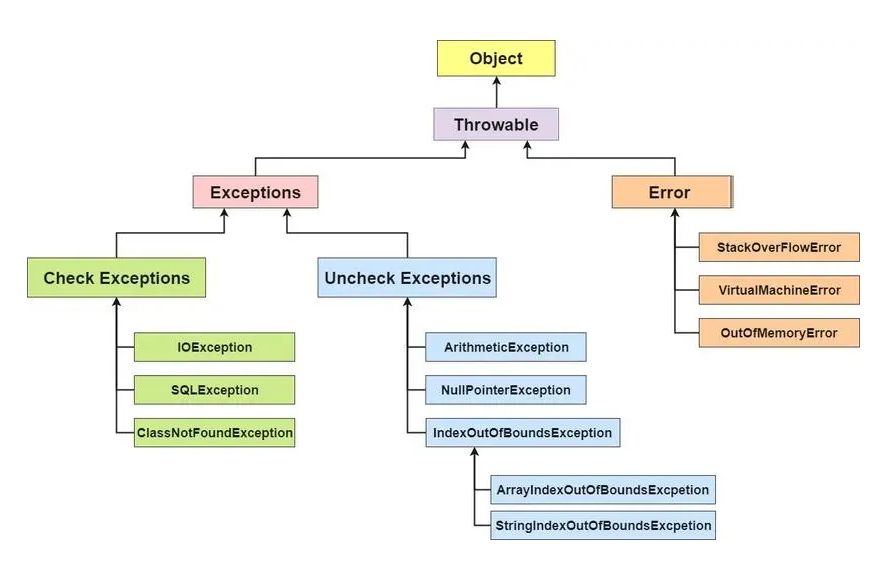
Java(Throwable)的结构可分为三种类型:错误(Error)、被检查的异常(CheckedException)、运行时异常(RuntimeException)
Exception和Error有什么关系?
Java中,所有的异常都有一个公共祖先:java.lang包中的Throwable类,而Exception和Error为Throwable类中两个重要子类:
Error: 当资源不足,约束失败,或者是其他程序无法继续运行的条件发生时,就产生Error,程序无法处理的错误。比如:虚拟机内存不够错误(OutOfMemoryError)、虚拟机运行错误(Virtual MachineError)、类加载错误(NoClassDefFoundError)等。当发生这些异常时,JVM会选择终止该线程
Exception: 程序本身可以处理的异常,我们可以通过try - catch进行捕获异常,Exception可以分为必须处理的受检查异常(Checked Exception) 和 可以不处理的非受查异常(Unchecked Exception)
Checked Exception 和 Unchecked Exception 有什么区别?
Unchecked Exception: 该种类型的错误,Java编译器不会检查,当出现该种异常时,即使没有通过throws声明抛出它,也没有使用try-catch语句捕捉它,仍然会编译通过。
RuntimeException及子类都统称为非受查异常,比如:
- NullPointerException:空指针异常
- illegalArgumentException:参数异常
- ArrayIndexOutOfBoundsException:数组越界异常
- ClassCastException:类型转换异常
- ArithmeticException:算数异常
- SecurityException:安全异常
- IllegalStateException:非法状态异常
- UnsupportedOperationException:不支持的操作异常
- NumberFormatException:数值格式异常
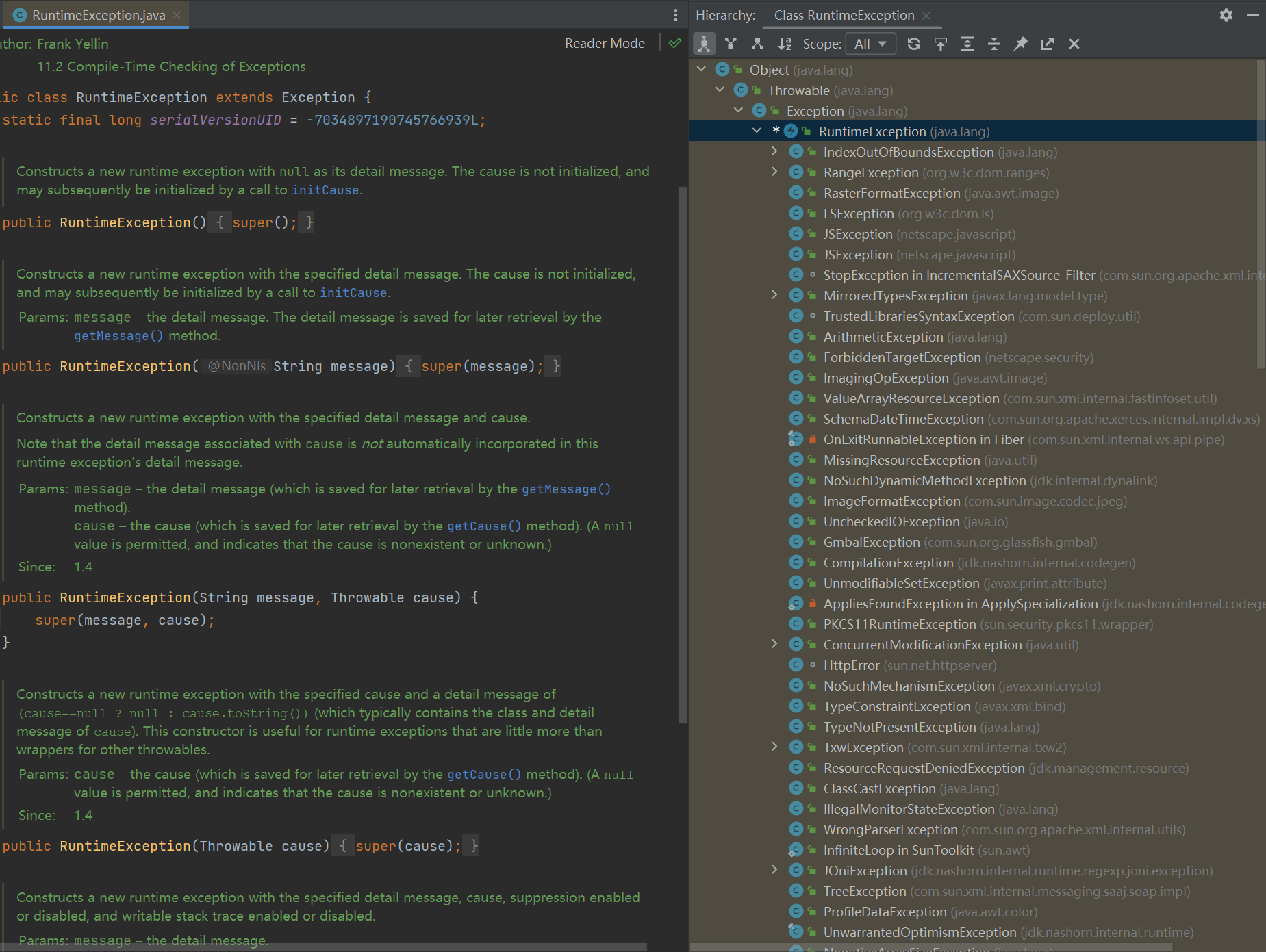
Checked Exception: 受查异常,如果没有被catch或者throws处理的话,就无法通过编译器。除了RuntimeException及子类外,其他Exception类及子类都属于受查异常,常见的有:
- ClassNotFoundException
- IOException
- FileNotFoundException
- SQLException
总结:受查异常通常不是程序引起的错误,比如:读取文件时文件不存在引发的:FileNotFoundException。而非受查异常通常是因为糟糕的编程引起的,比如:在没有确保对象引用非空时就使用而引起的:NullPointerException
Throwable有哪些常见方法?
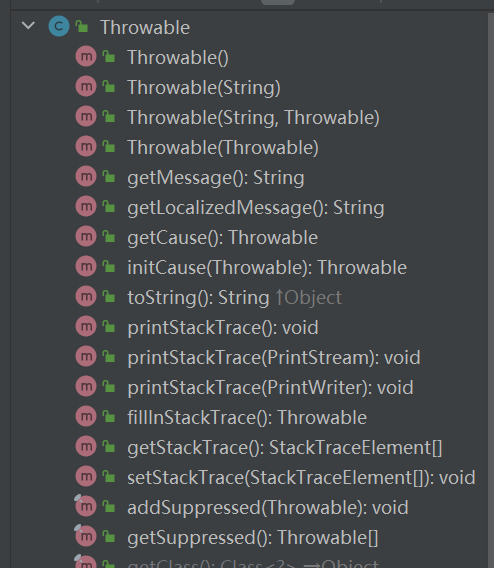
- String getMessage():返回异常的简要描述
- String toString():返回异常的详细信息
- void printStackTrace():在控制台打印Throwable对象封装的异常信息
- String getLocalizedMessage():返回异常对象的本地化信息。使用Throwable子类重写该方法,可以生成本地化信息。如果没有重写,那么与getMessage()返回结果相同
25.OOM你遇到过哪些情况,SOF你遇到过哪些情况
OOM
1.OutOfMemoryError异常:
除了程序计算器外,虚拟机内存的其他几个区域都有可能发生OOM异常的可能。
Java Heap溢出:一般异常信息为java.lang.OutOfMemoryError:Java heap spacess
Java堆用于存储对象实例,只要我们不断地创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制来清理这些对象,就会在对象数量达到最大堆容量限制后产生内存溢出异常,当出现该异常时,我们一般先通过内存映像分析工具(Eclipse Memory Analyzer) 堆dump除了的对转存快照进行分析,重点是确认内存中的对象是否是必要的,分清是因为内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)
如果内存泄漏,可进一步通过工具查看泄露对象到GCRoots的引用链,排查是怎样的路径与GCRoots关联导致垃圾收集器无法自动回收
如果不存在泄露,就检查虚拟机参数(-Xmx与-Xms)是否合适
2.虚拟机和本地方法栈溢出:
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError,如果虚拟机在扩展栈时无法申请到足够的内存空间,抛出OutOfMemoryError异常
3.方法区溢出:
方法区用于存放Class的相关信息,如类名、访问修饰符、字段描述、方法描述等。异常信息为:java.lang.OutOfMemoryError:PermGenspace,有可能是方法区保存的class对象没有被及时回收或者class信息占用的内存超出了我们的配置
方法区溢出也是一种我们常见的内存溢出异常,一个类如果要被垃圾收集器回收,判定条件是比较苛刻的。
SOF(StackOverflow栈溢出溢出):
该异常一般当应用程序递归太深而发生堆栈溢出时会抛出该错误
需要注意的是,栈溢出错误往往意味着代码存在问题,过于深的调用层次可能会导致性能和可维护性问题。因此,在解决 StackOverflowError 时,建议对代码进行仔细检查和优化,确保代码的健壮性和性能。
26.语法糖
语法糖:语法糖是指编程语言为了方便程序员开发而设计的一种特殊语法,这种语法对编译语言的功能并没有影响,实现一个相同的功能,基于语法糖写出的代码往往更加简洁。
常见的语法糖有哪些:
泛型、lambda表达式、自动拆装箱、try-with-resources语法、变长参数、增强for循环等
比如:Java中的for-each
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6,7};
for (int i : arr) {
System.out.println(i);
}
}
我们的JVM本身是不能识别语法糖的,Java的语法糖要想被正确执行,需要先通过编译器进行解糖,在编译阶段讲语法糖转为JVM认识的语法。也说明真正支持语法糖的是Java编译器而不是JVM,在compile()中有一部就是desugar(),复负责语法糖解糖的。
27.Java反射的作用与原理
反射:在运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意个对象,都能够调用它的任意一个方法。在java中,只要给定类的名字,就可以通过反射来获得类的所有信息。这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制
哪里会用到反射机制?
jdbc就是典型的反射:
Class.for("com.mysql.jdbc.Drivice.class");//加载MySQL的驱动类
这就是反射。我们大部分都在写业务代码,很少接触到直接使用反射的场景,这并不代表反射没有用,相反,正是因为反射,我们才能这么轻松的使用各种框架。Spring/Spring Boot、MyBatis等框架中都大量使用了反射机制
反射的实现方式:
- 获取Class对象:一共有四种方法: 1) Class.forName(“类路径”);2) 类名.class;3)对象名.getClass();4)基本类型的包装类,可以调用包装类的Type属性类获取该包装类的Class对象
Class<?> clazz = Class.forName("com.example.zd")。
- 获取类的字段:getField(“filename”)方法:可以获取public修饰的字段。getDeclaredField(“filedName”)可以获取指定名称的字段,无论修饰符是什么
Field field = clazz.getDeclaredField("fieldName")。
- 获取类的方法信息:getMethod(“methodName”,parameterTypes),可获取指定名称和参数类型的公共(public)方法;使用getDeclaredMethod(“methodName”,parameterTypes)方法,可以获取指定名称和参数类型的方法,无论修饰符是什么
Method method = clazz.getDeclaredMethod("methodName", String.class, int.class)。
- 创建对象实例:使用newInstance()方法,可以通过无参构造函数创建一个对象实例,例如:
Object obj = clazz.newInstance()。
使用getConstructor(parameterTypes).newInstacne(arguments)方法可以通过指定构造方法和参数创建对象
Constructor<?> constructor = clazz.getConstructor(String.class, int.class);
Object obj = constructor.newInstance("arg1", 123)。
反射的优缺点:
反射可以让我们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利。不过,反射让我们在运行时有了分析操作类的能力同时,也增加了安全问题,比如:可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍微差点,不过对框架影响不大