目录
- ELK架构
- 背景需求
- 架构
- logstash
- 核心概念
- 配置文件结构
- 插件
- Codec Plugin-Multiline
- 输出:elasticsearch
- 输入:jdbc
- Grok插件
- Grok语法
- mutate插件
- Date插件
- Logstash Queue
- Beats
- 配置步骤
- ELK整合
- 步骤1:日志采集
- 步骤2:配置Logstash接收
- 步骤3:输出数据到Elasticsearch
ELK架构
背景需求
收集信息,汇总展示
架构
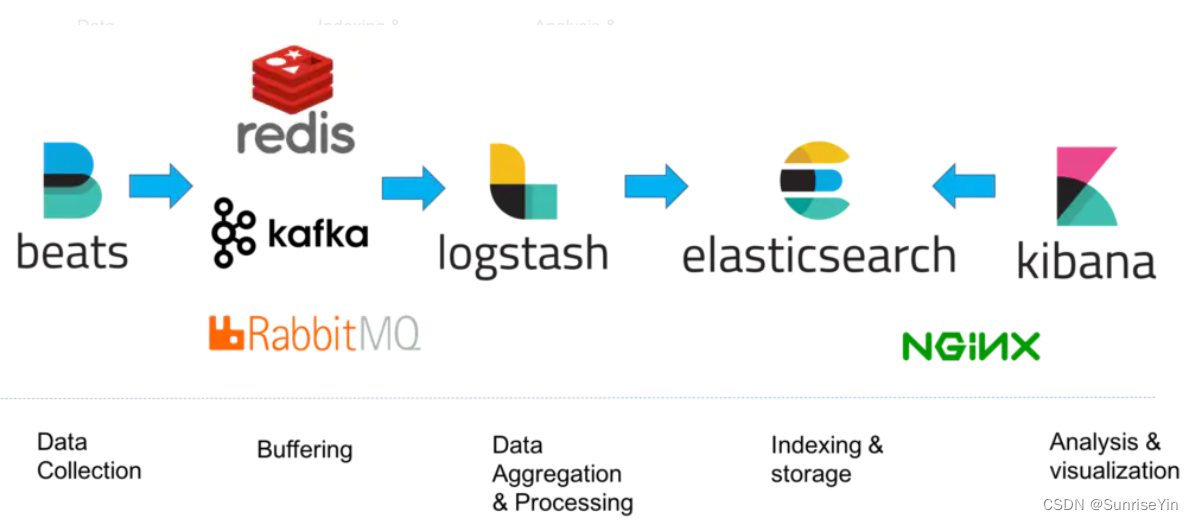
beats:收集,不依赖java环境
Buffering:避免收集过快导致后边的应用支撑不了
logstash:数据清洗、提供各种插件、开发人员主要维护就是清晰规则配置
logstash
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的存储库中。
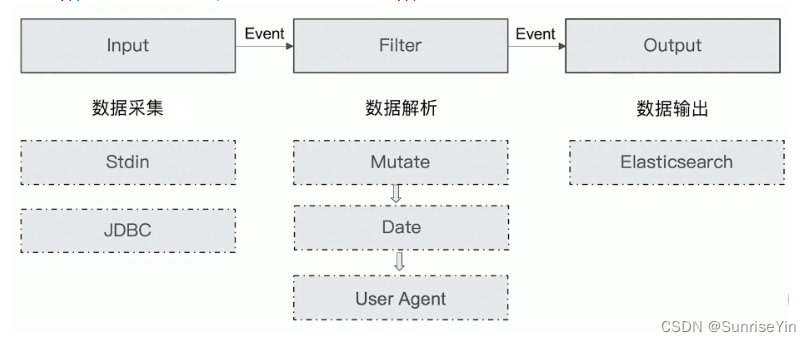
其实就是接受输入、处理数据、输出
核心概念
- Pipeline
包含了input—filter-output三个阶段的处理流程
插件生命周期管理
队列管理 - Logstash Event
数据在内部流转时的具体表现形式。数据在input 阶段被转换为Event,在 output被转化成目标格式数据
Event 其实是一个Java Object,在配置文件中,对Event 的属性进行增删改查 - Codec (Code / Decode)
将原始数据decode成Event;将Event encode成目标数据
配置文件结构
编写配置文件:logstash-demo.conf
input {
stdin { }
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
grok {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { hosts => ["localhost:9200"]}
stdout { codec => rubydebug }
}
启动使用指定配置文件
input 、filter、output 为数据处理流程的三个步骤
stdin、grok、elasticsearch、stdout 就是数据处理的插件
官网有每个插件的详细使用方法和示例
插件
Codec Plugin-Multiline
参数
- pattern: 设置行匹配的正则表达式
- what : 如果匹配成功,那么匹配行属于上一个事件还是下一个事件
previous / next - negate : 是否对pattern结果取反
true / false
在异常堆栈时往往会自动换行
如果不进行处理则日志有可能同步散乱
通过Multiline就可以将异常堆栈和为一行,就是指定不是字符串开头的就组合起来
# 示例: 多行数据,异常
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
# multiline-exception.conf
input {
stdin {
codec => multiline {
pattern => "^\s"
what => "previous"
}
}
}
filter {}
output {
stdout { codec => rubydebug }
}
#执行管道
bin/logstash -f multiline-exception.conf
输出:elasticsearch
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
user => "elastic"
password => "123456"
}
stdout {}
}
#输出到es指定索引
#注意:index名称中,不能出现大写字符
output {
elasticsearch {
index => "tomcat_web_log_%{+YYYY-MM}"
hosts => ["http://localhost:9200"]
user => "elastic"
password => "123456"
}
stdout{
codec => rubydebug
}
}
输入:jdbc
1)拷贝jdbc依赖到logstash-7.17.3/drivers目录下
2)准备mysql-demo.conf配置文件
input {
jdbc {
jdbc_driver_library => "/home/es/logstash-7.17.3/drivers/mysql-connector-java-5.1.49.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/test?useSSL=false"
jdbc_user => "root"
jdbc_password => "123456"
#启用追踪,如果为true,则需要指定tracking_column
use_column_value => true
#指定追踪的字段,
tracking_column => "last_updated"
#追踪字段的类型,目前只有数字(numeric)和时间类型(timestamp),默认且推荐是数字类型、timestamp有可能有时区问题
tracking_column_type => "numeric"
#记录最后一次运行的结果
record_last_run => true
#上面运行结果的保存位置
last_run_metadata_path => "jdbc-position.txt"
statement => "SELECT * FROM user where last_updated >:sql_last_value;"
schedule => " * * * * * *"
}
}
Grok插件
读取到的日志各有各的格式,如果希望对其进行清洗则可使用Grok
Grok是一种将非结构化日志解析为结构化的插件。
Grok语法
Grok是通过模式匹配的方式来识别日志中的数据
默认Logstash拥有120个模式。
%{SYNTAX:SEMANTIC}
#SYNTAX(语法)指的是Grok模式名称,SEMANTIC(语义)是给模式匹配到的文本字段名。
#举例:
%{NUMBER:duration} %{IP:client}
#duration表示:匹配一个数字,client表示匹配一个IP地址。
#在Grok中,所有匹配到的的数据类型都是字符串,如果要转换成int类型(目前只支持int和float),可以这样:%{NUMBER:duration:int} %{IP:client}
再logstash中配置示例
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
# 解析tomcat日志
#192.168.10.128 - - [23/Jun/2022:22:37:23 +0800] "GET /docs/images/docs-stylesheet.css HTTP/1.1" 200 5780
#指定模式:
%{IP:ip} - - \[%{HTTPDATE:date}\] \"%{WORD:method} %{PATH:uri} %{DATA:protocol}\" %{INT:status} %{INT:length}
mutate插件
使用mutate插件过滤掉不需要的字段
mutate {
enable_metric => "false"
remove_field => ["message", "log", "tags", "input", "agent", "host", "ecs", "@version"]
}
Date插件
日期格式化 并修改target属性来重新定义输出字段。
filter {
date {
match => ["date","dd/MMM/yyyy:HH:mm:ss Z","yyyy-MM-dd HH:mm:ss"]
target => "date"
}
}
Logstash Queue
- In Memory Queue
进程Crash,机器宕机,都会引起数据的丢失 - Persistent Queue
机器宕机,数据也不会丢失; 数据保证会被消费; 可以替代 Kafka等消息队列缓冲区的作用(低并发)
queue.type: persisted (默认是memory)
queue.max_bytes: 4gb
Beats
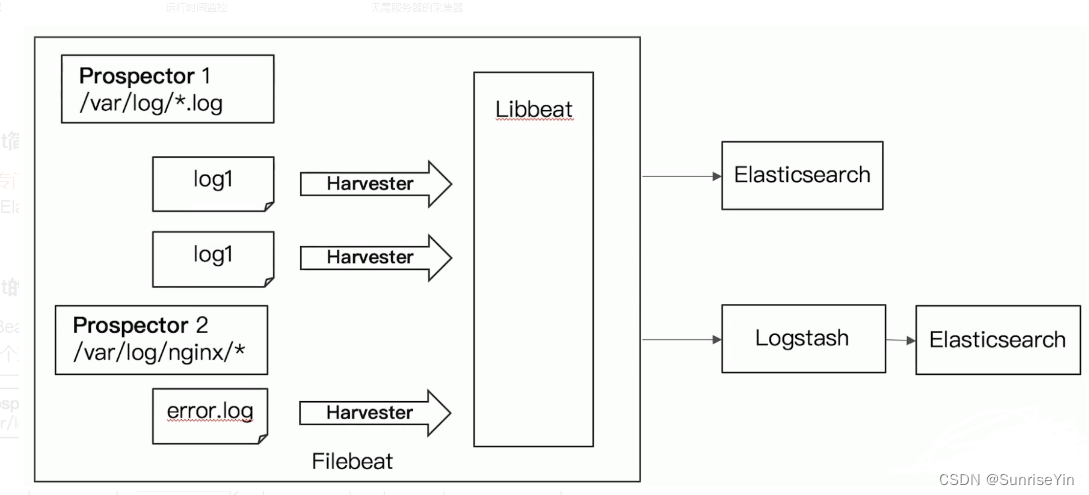
轻量型数据采集器
在官网有很多数据采集的示例配置
监听指定的日志,FileBeat将新的日志发发送到libbeat
再一块发送给输出(output)
配置步骤
- 下载并安装
- 修改配置文件 filebeat.yml
output.elasticsearch:
hosts: ["esHost1:9200","esHost2:9200","esHost3:9200"]
username: "elastic"
password: "123456"
setup.kibana:
host: "kibanaHost:5601"
- 启用和配置数据收集模块
从安装目录中,运行:
# 查看可以模块列表
./filebeat modules list
#启用nginx模块
./filebeat modules enable nginx
#如果需要更改nginx日志路径,修改modules.d/nginx.yml
- module: nginx
access:
var.paths: ["/var/log/nginx/access.log*"]
#启用 Logstash 模块
./filebeat modules enable logstash
#在 modules.d/logstash.yml 文件中修改设置
- module: logstash
log:
enabled: true
var.paths: ["/home/es/logstash-7.17.3/logs/*.log"]
- 启动
# setup命令加载Kibana仪表板。 如果仪表板已经设置,则忽略此命令。
./filebeat setup
# 启动Filebeat
./filebeat -e
ELK整合
模拟场景:
通过Logstash采集tomcat日志并存储至ElasticSearch中
步骤1:日志采集
创建配置文件filebeat-logstash.yml,配置FileBeats将数据发送到Logstash
vim filebeat-logstash.yml
chmod 644 filebeat-logstash.yml
#因为Tomcat的web log日志都是以IP地址开头的,所以我们需要修改下匹配字段。
# 不以ip地址开头的行追加到上一行
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/es/apache-tomcat-8.5.33/logs/*access*.*
multiline.pattern: '^\\d+\\.\\d+\\.\\d+\\.\\d+ '
multiline.negate: true
multiline.match: after
output.logstash:
enabled: true
hosts: ["192.168.65.204:5044"]
pattern:正则表达式
negate:true 或 false;默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
match:after 或 before,合并到上一行的末尾或开头
启动FileBeat,并指定使用指定的配置文件
./filebeat -e -c filebeat-logstash.yml
步骤2:配置Logstash接收
vim config/filebeat-console.conf
# 配置从FileBeat接收数据
input {
beats {
port => 5044
}
}
output {
stdout {
codec => rubydebug
}
}
启动logstash
# reload.automatic:修改配置文件时自动重新加载
bin/logstash -f config/filebeat-console.conf --config.reload.automatic
步骤3:输出数据到Elasticsearch
修改Logstash的output配置。
vim config/filebeat-elasticSearch.conf
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
user => "elastic"
password => "123456"
}
stdout{
codec => rubydebug
}
}
启动logstash
bin/logstash -f config/filebeat-elasticSearch.conf --config.reload.automatic