1 论文解读
paper:VIT
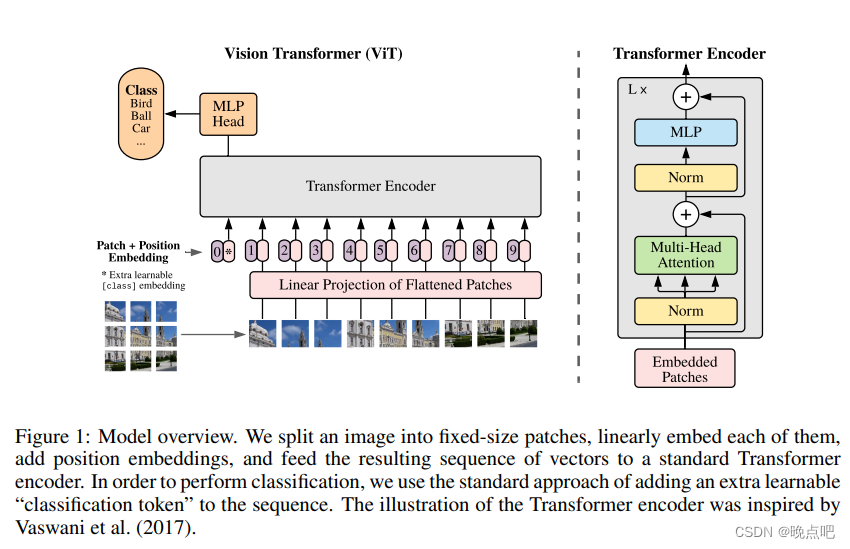
1.1 VIT模型架构如下图所示:
- 图片原始输入维度 H * W * C
- 在H和W按像素P切分,则H 、W可分割为 NPP, N=HW/(PP),N为输入transform序列的长度。
- x ∈ R H ∗ W ∗ C = > x ∈ R N ∗ P 2 ∗ C x \in R^{H*W*C} => x\in R^{N*P^2*C} x∈RH∗W∗C=>x∈RN∗P2∗C
- 固定每层的维度D不变,The Transformer uses constant latent vector size D through all of its layers, so we flatten the patches and map to D dimensions with a trainable linear projection
- 在N序列长度的基础上,增加一个Class token,类似bert用于分类任务学习
- 增加位置信息,使用拉长后的一维数据作为位置编码信息。(使用图片的二维坐标位置,模型效果没有明显改善)
VIT模型公式
输入
x
∈
N
∗
p
2
∗
C
输入 x \in N*p^2*C
输入x∈N∗p2∗C
x
p
1
∈
P
2
∗
C
x_p^1 \in P^2*C
xp1∈P2∗C
E
∈
(
P
2
∗
C
)
∗
D
E \in (P^2*C) *D
E∈(P2∗C)∗D
其中E对序列N中的每一个xi都是一样的,z0的维度为(N+1)* D
公式(2)MSA(多头注意力)不改变z0的维度
公式(3)经过MLP层后与原始z相加,类似残差网络
公式(4)只取z的第一个值(之前在第一个位置手动添加了一个class标识)用于分类任务,进行模型学习
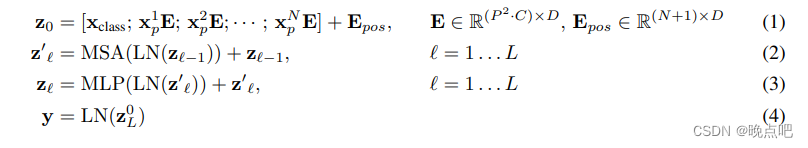
2 代码实现
2.1 embedding 层
- 模型输入x.shape=[16,3,224,224] #16为batch_size
- x输入patch_embedding 后,shape =[16,768,14,14]
- 将上面的patch_embedding最后两位(H,W)拉平后,与channel调换位置,shape=[16,196,768]
- 然后与手动的cls_token拼接 shape=[16,197,768]
- 加入位置信息后,即可得到embdeeing的输出,shape=[16,197,768]
self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=config.hidden_size,
kernel_size=16,
stride=16)
- cls_token shape=[1,1,768]
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
#备注:n_patches=14*14 ,config.hidden_size=768
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches+1, config.hidden_size))
2.2 block层
- 输入为Embedding层输入的x ;shape=[16,197,768]
- 通过layer_norm层,,shape不变
- 通过attn层,构建多头注意力,query,key,value的shape都为shape=[16,12,197,64]
- 加上原始的x,纪委multi-head的输出,shape=[16,197,768]
- 再经过layer_norm和全连接层,加上上层x,即为block的输出,shape=[16,197,768]
layer_norm层
self.attention_norm = LayerNorm(config.hidden_size, eps=1e-6)
2.3Encoder层
经过L个Block层,输出结果即为encoder层,shape=[16,197,768]
2.4 模型输出
- transform最后的输出层为 shape=[16,197,768]
- 取序列197的第一个作为输出x,x shape=[16,768]
- 输出x,经过全连接层,shape=[16,num_class]
- 模型loss为交叉熵损失
3 transformer 结构
(embeddings): Embeddings(
(patch_embeddings): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): Encoder(
(layer): ModuleList(
(0): Block(
(attention_norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(ffn_norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(ffn): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(attn): Attention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(out): Linear(in_features=768, out_features=768, bias=True)
(attn_dropout): Dropout(p=0.0, inplace=False)
(proj_dropout): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
)
... 省略10层Block
(11): Block(
(attention_norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(ffn_norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(ffn): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(attn): Attention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(out): Linear(in_features=768, out_features=768, bias=True)
(attn_dropout): Dropout(p=0.0, inplace=False)
(proj_dropout): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
)
)
(encoder_norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
)
)
3 代码总览
3.1 Embedding类
class Embeddings(nn.Module):
"""Construct the embeddings from patch, position embeddings.
"""
def __init__(self, config, img_size, in_channels=3):
super(Embeddings, self).__init__()
self.hybrid = None
img_size = _pair(img_size)
if config.patches.get("grid") is not None:
grid_size = config.patches["grid"]
patch_size = (img_size[0] // 16 // grid_size[0], img_size[1] // 16 // grid_size[1])
n_patches = (img_size[0] // 16) * (img_size[1] // 16)
self.hybrid = True
else:
patch_size = _pair(config.patches["size"])
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])
self.hybrid = False
if self.hybrid:
self.hybrid_model = ResNetV2(block_units=config.resnet.num_layers,
width_factor=config.resnet.width_factor)
in_channels = self.hybrid_model.width * 16
self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=config.hidden_size,
kernel_size=patch_size,
stride=patch_size)
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches+1, config.hidden_size))
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
self.dropout = Dropout(config.transformer["dropout_rate"])
def forward(self, x):
print(x.shape)
B = x.shape[0]
cls_tokens = self.cls_token.expand(B, -1, -1)
print(cls_tokens.shape)
if self.hybrid:
x = self.hybrid_model(x)
x = self.patch_embeddings(x)
print(x.shape)
x = x.flatten(2)
print(x.shape)
x = x.transpose(-1, -2)
print(x.shape)
x = torch.cat((cls_tokens, x), dim=1)
print(x.shape)
embeddings = x + self.position_embeddings
print(embeddings.shape)
embeddings = self.dropout(embeddings)
print(embeddings.shape)
return embeddings
3.2 Block层
class Block(nn.Module):
def init(self, config, vis):
super(Block, self).init()
self.hidden_size = config.hidden_size
self.attention_norm = LayerNorm(config.hidden_size, eps=1e-6)
self.ffn_norm = LayerNorm(config.hidden_size, eps=1e-6)
self.ffn = Mlp(config)
self.attn = Attention(config, vis)
def forward(self, x):
print(x.shape)
h = x
x = self.attention_norm(x)
print(x.shape)
x, weights = self.attn(x)
x = x + h
print(x.shape)
h = x
x = self.ffn_norm(x)
print(x.shape)
x = self.ffn(x)
print(x.shape)
x = x + h
print(x.shape)
return x, weights
3 encoder层
class Encoder(nn.Module):
def __init__(self, config, vis):
super(Encoder, self).__init__()
self.vis = vis
self.layer = nn.ModuleList()
self.encoder_norm = LayerNorm(config.hidden_size, eps=1e-6)
for _ in range(config.transformer["num_layers"]):
layer = Block(config, vis)
self.layer.append(copy.deepcopy(layer))
def forward(self, hidden_states):
print(hidden_states.shape)
attn_weights = []
for layer_block in self.layer:
hidden_states, weights = layer_block(hidden_states)
if self.vis:
attn_weights.append(weights)
encoded = self.encoder_norm(hidden_states)
return encoded, attn_weights
attention 层
class Attention(nn.Module):
def __init__(self, config, vis):
super(Attention, self).__init__()
self.vis = vis
self.num_attention_heads = config.transformer["num_heads"]
self.attention_head_size = int(config.hidden_size / self.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = Linear(config.hidden_size, self.all_head_size)
self.key = Linear(config.hidden_size, self.all_head_size)
self.value = Linear(config.hidden_size, self.all_head_size)
self.out = Linear(config.hidden_size, config.hidden_size)
self.attn_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.proj_dropout = Dropout(config.transformer["attention_dropout_rate"])
self.softmax = Softmax(dim=-1)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
print(new_x_shape)
x = x.view(*new_x_shape)
print(x.shape)
print(x.permute(0, 2, 1, 3).shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states):
print(hidden_states.shape)
mixed_query_layer = self.query(hidden_states)
print(mixed_query_layer.shape)
mixed_key_layer = self.key(hidden_states)
print(mixed_key_layer.shape)
mixed_value_layer = self.value(hidden_states)
print(mixed_value_layer.shape)
query_layer = self.transpose_for_scores(mixed_query_layer)
print(query_layer.shape)
key_layer = self.transpose_for_scores(mixed_key_layer)
print(key_layer.shape)
value_layer = self.transpose_for_scores(mixed_value_layer)
print(value_layer.shape)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
print(attention_scores.shape)
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
print(attention_scores.shape)
attention_probs = self.softmax(attention_scores)
print(attention_probs.shape)
weights = attention_probs if self.vis else None
attention_probs = self.attn_dropout(attention_probs)
print(attention_probs.shape)
context_layer = torch.matmul(attention_probs, value_layer)
print(context_layer.shape)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
print(context_layer.shape)
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
print(context_layer.shape)
attention_output = self.out(context_layer)
print(attention_output.shape)
attention_output = self.proj_dropout(attention_output)
print(attention_output.shape)
return attention_output, weights