进入了AI 大数据时代,无论是工业自动化系统,还是物联网系统,对大数据的采集,存储和分析都十分重要。大数据被称为工业的石油,未来制造业的持续改善离不开大数据。
传统的应用中,历史数据的存储是特定的数据结构来存储历史数据的,不同厂商,不同应用的数据存储格式都各不相同。在工业控制和物联网应用项目中,数据库的工作量占据了很大一部分设计工作
开放自动化的观点下,倾向系统的数据采纳开放的,标准化的数据模型。例如OPCUA 信息模型。基于标准化的数据模型,实现不同厂商的设备和软件实现互操作。
在开放性系统中,构建一个通用的,基于模型的历史数据库显得十分重要。本博文探讨OPCUA 历史数据库的相关话题。
在前面的博文中,我曾经介绍过聚合服务器和历史数据服务器,可以阅读:
OPCUA 聚合服务器和历史数据服务器
本文我们进一步探讨实现历史数据库具体的细节。
OPCUA 历史数据的访问的内容
在OPCUA 规范的多个部分提及历史数据访问。
- OPC 10000-5: UA Part 5: Information Model 5.3 Variables
- OPC 10000-11: UA Part 11: Historical Access
- OPC 10000-4: UA Part 4: Services
Historizing 属性
在 UA Part5 5.3 变量规范中指出 信息模型中每一个变量可以有一个Historizing 属性 当该属性为true 表示该变量具有历史数据。

这里表明该属性的值是与服务器相关的,不知道什么意思。在Open62541 中是这样设置historizing 属性的。
UA_VariableAttributes attr = UA_VariableAttributes_default;
UA_UInt32 myUint32 = 0;
UA_Variant_setScalar(&attr.value, &myUint32, &UA_TYPES[UA_TYPES_UINT32]);
attr.description = UA_LOCALIZEDTEXT("en-US","myUIntValue");
attr.displayName = UA_LOCALIZEDTEXT("en-US","myUIntValue");
attr.dataType = UA_TYPES[UA_TYPES_UINT32].typeId;
/* We set the access level to also support history read
* This is what will be reported to clients */
attr.accessLevel = UA_ACCESSLEVELMASK_READ | UA_ACCESSLEVELMASK_WRITE | UA_ACCESSLEVELMASK_HISTORYREAD;
/* We also set this node to historizing, so the server internals also know from it. */
attr.historizing = true;
历史数据的读写
OPC 10000-4: UA Part 4: Services 中规范了HistoryRead和HistoryUpdate
5.10.3 HistoryRead
允许client 端读取节点的值和事件。
5.10.5 HistoryUpdate
允许Server 更新历史数据和事件。
在OPC 10000-11: UA Part 11: Historical Access中·规定了参数的细节。
maxAge
timesStampsTo Return 返回时间标签格式。
在Open62641 中是使用UA_Client_HistoryRead_raw 调用
UA_StatusCode
UA_Client_HistoryRead_raw(UA_Client *client, const UA_NodeId *nodeId,
const UA_HistoricalIteratorCallback callback,
UA_DateTime startTime, UA_DateTime endTime,
UA_String indexRange, UA_Boolean returnBounds, UA_UInt32 numValuesPerNode,
UA_TimestampsToReturn timestampsToReturn, void *callbackContext)
OPCUA Server与历史数据库的融合
历史数据存储在哪里?采取什么样的数据格式存储在数据库中呢?这并不是OPCUA 规范的内容,与系统架构和产品有关。它们大致分为两种:
历史数据库嵌入现场设备中
许多工业控制器和仪表中嵌入的历史数据存储功能,例如,在智能电表中,会存储几百个波形数据值,上层软件能够分析波形数据,分析恶意负载等现象。工业控制器一般使用小型SD 卡存储现场数据,容量比较小,存储的时间短,通常不采用数据库,而是一种特殊格式的文件系统实现数据存储。这种嵌入式历史数据存储的优点是存储数据非常块。缺点是上层软件通过读取历史数据的比较慢。而且读取大量历史数据会打扰实时控制的正常操作。特别是需要同时读取多个设备的历史数据时,占用的网络带宽更是无法容忍的。
此外,并不是所有的现场设备都支持嵌入式存储。
云端或边缘设备中构建历史数据存储
另一种方式是在云端或者现场设置一个独立的数据库设备中。例如独立的计算机安装influxDB,MySQL ,mongoDB 等数据库。所有现场设备将更新数据发送到历史数据库中。应用软件可以直接访问历史数据库。
这种架构类似与著名的OSISoft(现在是施耐德AVEVA的一部分)的PI 服务器。OSISoft 的PI 服务器已经具有30多年的历史,OSIsoft 的业务主要面向石油和天然气、公用事业、生命科学和生物制药、金属和采矿、纸浆和造纸、水务六个核心市场。

PI 服务器基于所谓的资产架构(AF) 服务器和PI 数据库两大部分。所谓的AF 是一个模型库,通过·访问·AF服务器可以找到对于的数据指针,读取PI中的历史数据。
但是可惜的是PI 系统的AF 模型并非OPCUA 模型。如果设计一个类似PI System,同时支持OPCUA 的历史数据服务器,可以使用OPCUA 信息模型替代AF 资产架构。这样我们就可以构建一个开放性历史数据库系统。
实现的系统架构如下所示:
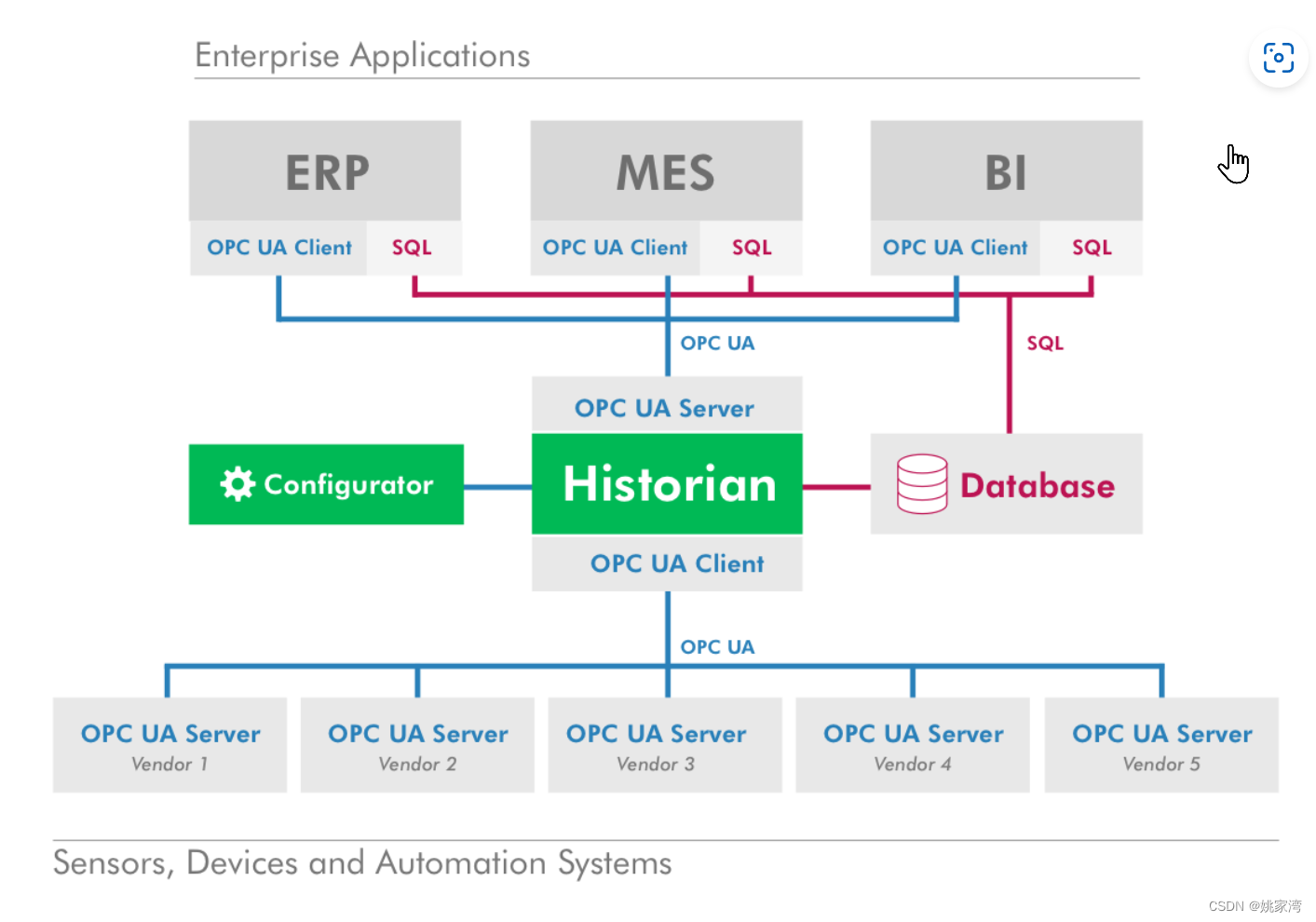
注意: Historian 服务器和Database 可以部署在同一的计算机上,或者云端。这台计算机提供了三个接口:
OPC UA Client
通过了现场OPC UA Server 的数据读取
OPCUA Server
应用软件能够访问工业现场的实时数据,也可以访问历史数据。
数据库访问接口
为了使历史数据的访问更加高效,可以直接数据库的接口访问数据。同时能够避免访问历史数据库影响现场网络的实时性。
聚合服务器
历史数据库往往会与聚合服务器结合在一起。我在博文谈谈OPCUA 聚合服务器 中介绍了背景知识。聚合服务器+历史服务器形成了一个工业现场的完整的大模型。是控制现场的一个全景快照。它们是TI应用程序能够访问控制现场的全部数据。
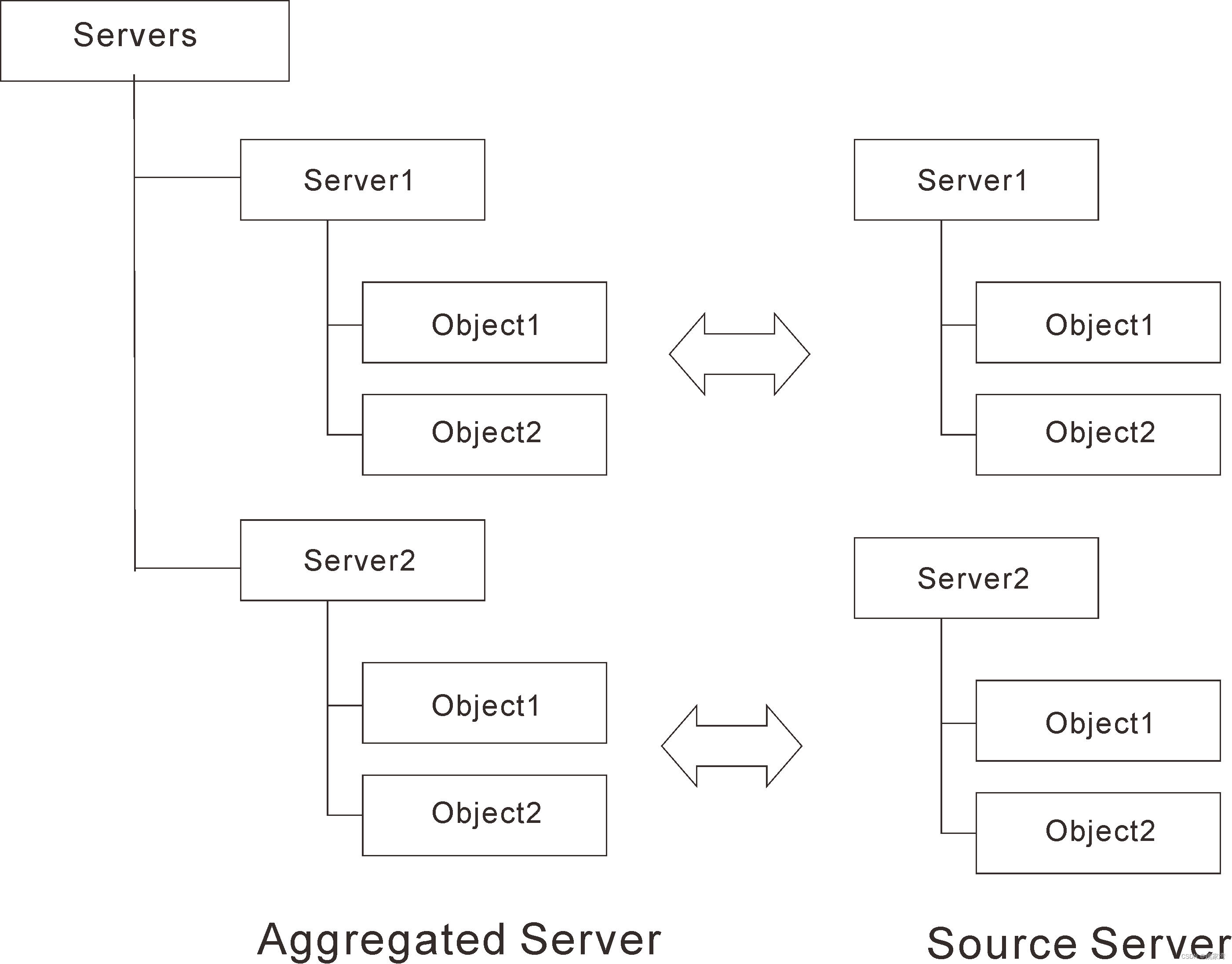
从OPCUA 聚合服务器的规范中看,实现服务器的聚合貌似很复杂。基本的模型如下:
在聚合服务器中包含了多个Aggregated Server 。有些应用建立了Servers 文件夹,将所有的源服务器放在内部,它们包含了ServerUrl,EndPoint 等参数。在每个Server 中,包含了需要聚合的对象。这些对象的名称的名称应该和源服务器中对应的对象是相同的。当需要读取这些对象的值时,通过OPCUA Client 到源服务器中读取。
下图中左边是聚合服务器,右边是源服务器
研究国外的一些聚合服务器产品,他们采用了一些简单的方式。
采用配置文件实现
采用用户的配置文件,可以将需要聚合的对象完全描述出来,并且包括服务器的URI,Endpoint 参数。有些项目还规定了那些对象需要轮询,那些需要订阅,那些需要Monitor。一般使用json 作为配置文件格式。
Prosys 公司的实现
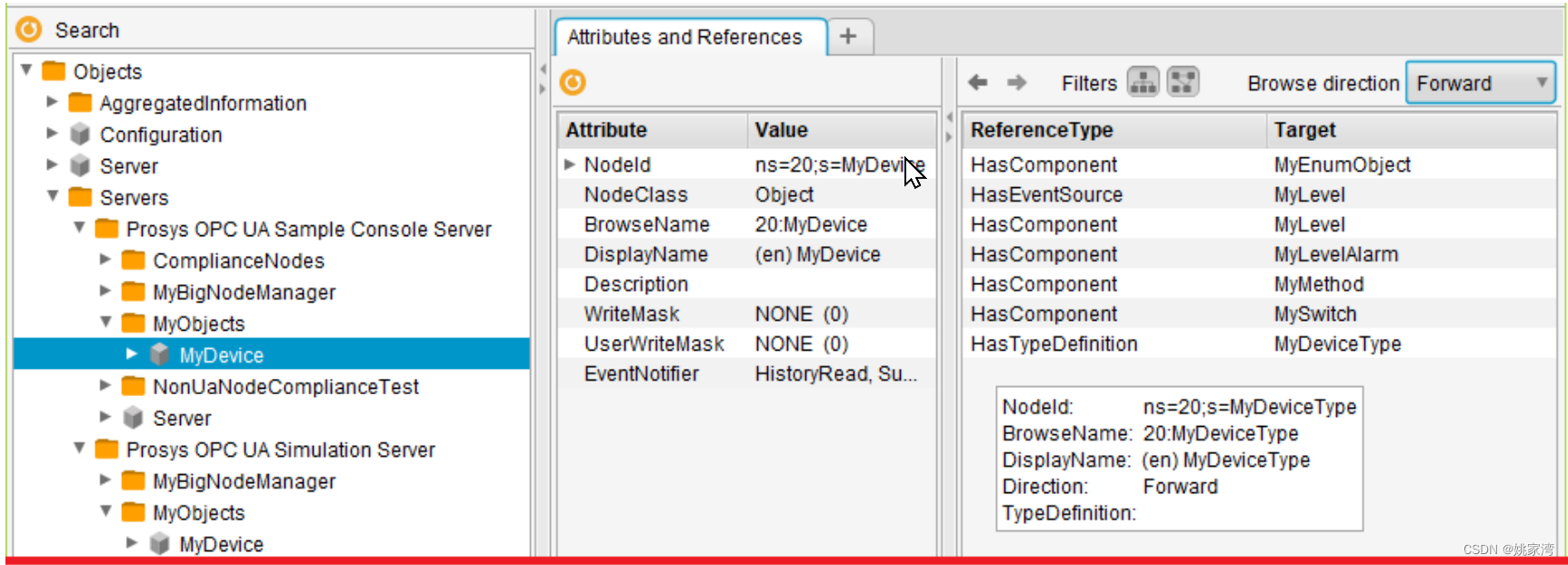
在聚合服务器中将所有现场的源服务器建立一个副本服务器实例。例如在下图中,就建立了两个源服务器的副本:
’Prosys OPC UA Sample Console Server
’Prosys OPC UA Simulation Server
聚合的方法
程序扫描Servers 中的变量和属性等,以相同的名称去访问源服务器中的值。写入到聚合服务器相应的变量中去。
但是这会遇到一个问题,比如两个服务器实例中有相同名称的对象,如上图中MyDevice。他们采取的方式是使用不同的地址空间Index。

在上图中一个MyDevice的ns=20,另一个ns=26.
当然,还有事件和方法的聚合问题。想必采取类似的方式去解决。
此外,在聚合服务器中要保留所有的服务器的入口(Endpoint)。
许多问题看文本是一回事,编程是另一回事。只有深化,问题才会浮现出来。
数据库的数据格式
为了实现一个通用的数据库格式,需要设计一种通用的数据库格式,包含必需的tag。下面几项是必需的:
源服务器
- 对象的browserName
- 对象的DisplayName
- 对象的NodeId
- 显示路径
- 时间标签
- 值
实例:
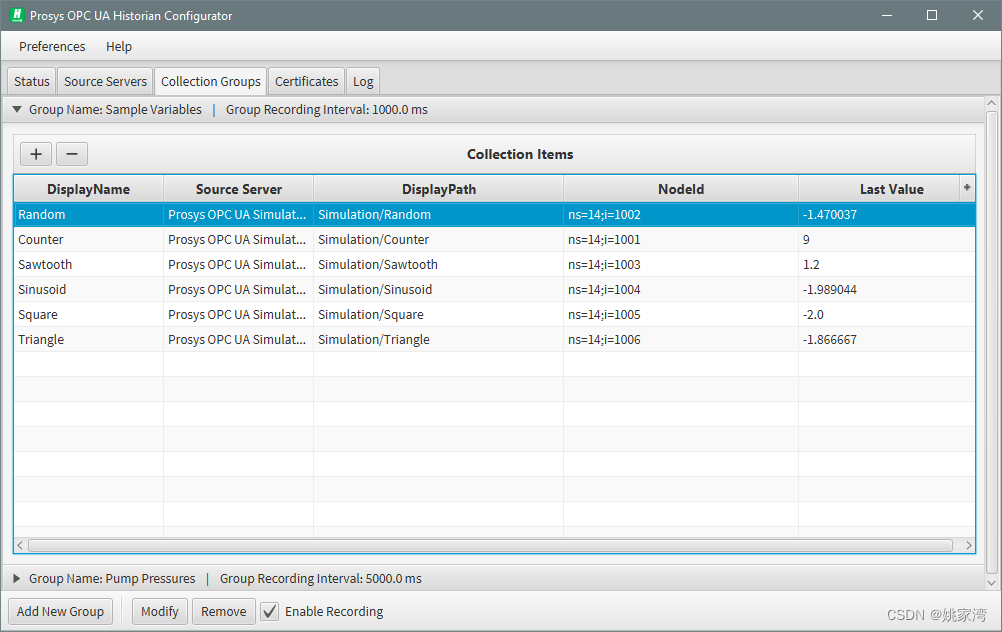
应用软件借助于这些tag 和OPCUA 服务器中的信息模型,获取历史数据的完整信息。
数据库可以采用influxDB,mongoDB和MySQL 等多种数据库,本人倾向使用influxDB。
OPCUA大模型架构的优点
在实际应用中,构建一个聚合现场设备OPCUA 服务器的UPCUA 大模型系统的是十分有效的。它的优点
- 为所有的数据建立一个统一的接入点
- 建立一个IT/OT 的接口
- 简单统一的方式访问历史数据
自动化线的安全性,可靠性十分重要,一个小小的操作失误可能造成巨大的财产损失和人员丧亡。所以,要在不影响生产线安全和可靠运行的前提下,才能够将生产线向IT 开放,简单地将生产设备与云端服务互联是一种不安全的做法。比较合适的方法是通过一个公共的,安全的节点向IT结合。
实验项目
正在编写中。
编写一个OPCUA Server,建立聚合服务器模型。
client 采取多线程方式。与现场设备连接。
结束语
OPCUA 很重要,也很复杂。实现开放自动化和工业4.0 还有漫长的道路。如何采纳这些为明天准备的技术来解决现在的问题,采取渐进的方式推行开放自动化的实现是可行的道路。