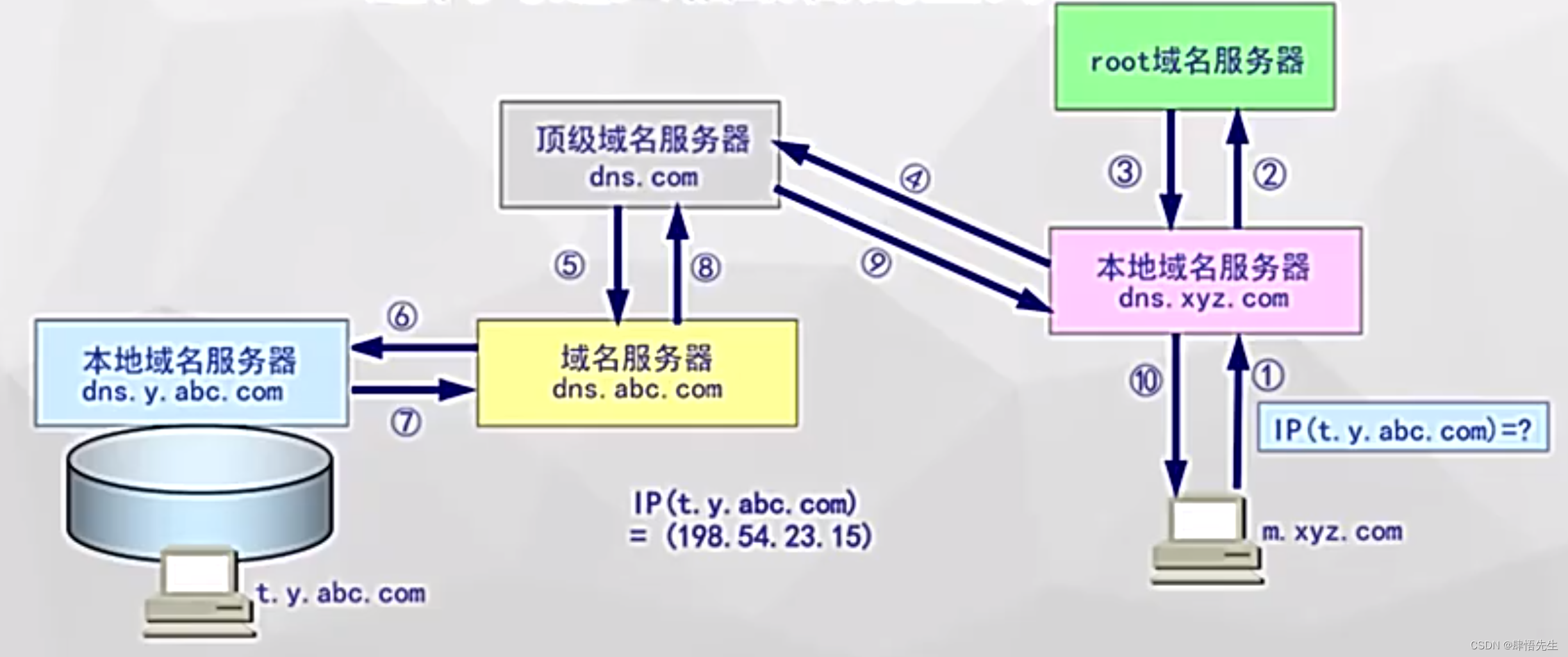
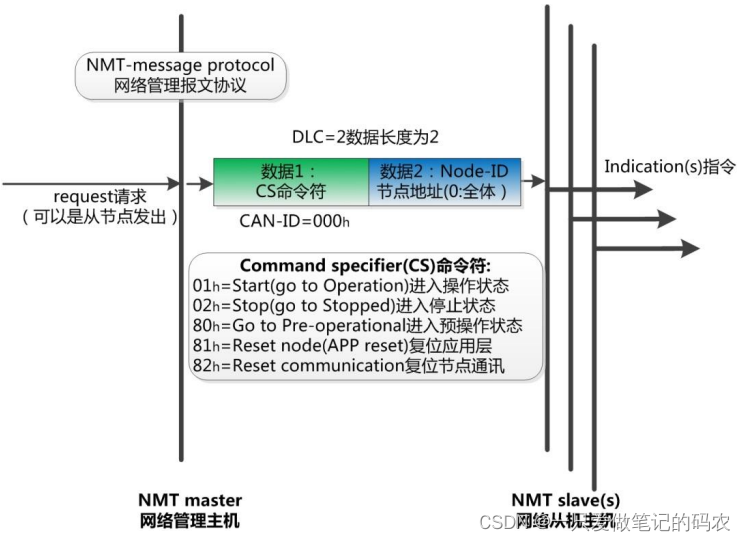
在性能设计的时候,其实主要的三板斧就是数据库(读写分离、分库分表),缓存(提升读性能),异步处理(提升写性能)以及相关的秒杀设计以及边缘设计等。
本篇主要介绍异步处理的哪些事,我们知道对于一个系统来说,网络请求相应都是同步处理,一个Request和Response,而这种同步请求,一个会受限制下游系统的整体吞吐量,也就是上游系统不能发送超过下游系统的处理能力,否则下游系统一定会出现响应超时。而另一个就是一旦下游系统出现服务宕机,不可用。那么整个链路就会收到影响。比如订单系统请求支付系统,如果支付系统不能及时处理请求,那么整个链路就是断了,整体服务不可用。所以引入异步处理设计,对于互联网应用来说是必须的,主要的话就是异步、消峰、解耦。
- 即时响应,更好的用户体验。
- 控制消费速度,合适的负载压力。
- 异步主要优化写操作。
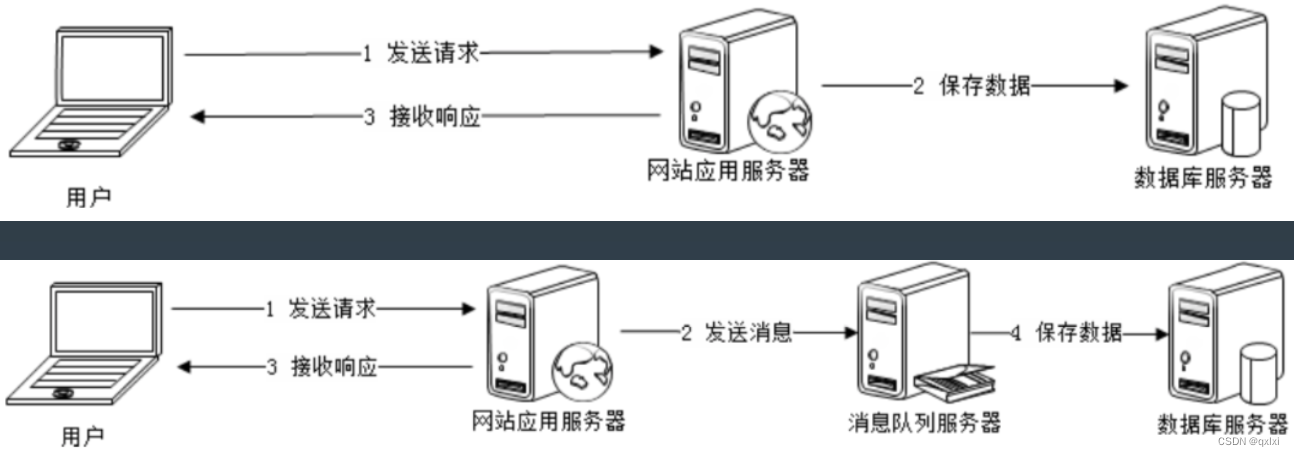
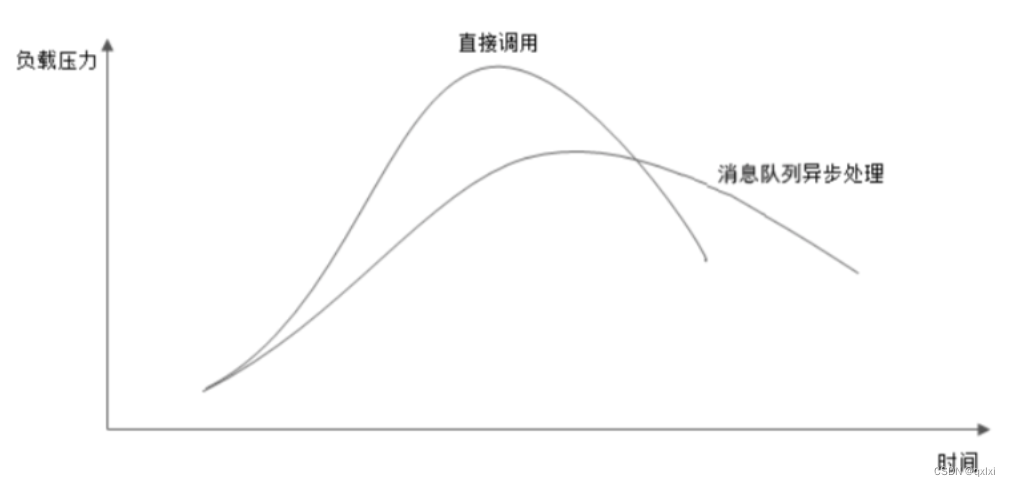
为什么需要异步设计
异步处理不仅仅可以提高系统的稳定性和容错能力,也可以提高系统的吞吐能力,提高并发能力。
其实在工作中,如果有人不断的打扰你去处理别的事情,那么没办法合理的利用时间和资源更快的处理工作。但是如果使用邮件这样的方式,不会打扰别人,类似于异步通信。就可以先处理优先级高的事情,
在分布式系统中,一般都是多个系统之间互相调用。比如金融领域中,订单、支付、三方系统等。所以统一地规划和统筹整体,可以达到整体的最优。
在计算机中,异步到处可见,网络中可以TCP发送网络包,并不是每次都发送一次,而是将数据包积累到一起,然后发送。
操作系统中,文件读写的时候,当前线程读写文件的时候,并不会同步等待文件,而是异步处理。
存储系统Mysql中,修改操作也是先写到change buffer中,然后异步刷回到磁盘中。框架中,Spring、Netty中等都是这样的操作。
异步处理的设计
通常来说,一般都是系统间采用异步处理,异步订单系统处理完毕订单,开始推送支付系统进行处理。而支付系统需要保证异步处理的幂等性。而订单系统也可能会发起重试,所以重试和幂等需要一起做好。
通常有两种模式,一种是push,一种是pull。push的话 需要主动告诉下游系统有任务处理,而pull,则不需要,下游系统有任务就会处理。大多数都是采用pull的方式。
异步处理的分布式事务
对于分布式事务,在强一致性下,在业务层上只能做两阶段提交,而在数据层面上需要使用 Raft/Paxos 的算法。
异步处理会设计到分布式事务的操作,但是大多数场景并不需要强一致性,最终一致性即可。比如饭店支付和拿货物分开的,可以有效提高并发吞吐量。而其中需要保护好凭证、幂等性,补偿机制等。
异步处理的设计要点
出现故障
异步处理中,三大问题,消息丢失、无序、。所以当下游系统处理完毕之后需要ACK回传消息系统。发起方需要有定时任务,把没有处理的消息重试,所以下游需要幂等性处理。
合理分析业务,是否需要强一致性
**生产问题:出现消息挤压,需要快速扩容,不过不能整个系统可能挂掉。
**
异步处理系统的本质是把被动的任务处理变成主动的任务处理,其本质是在对任务进行调度和统筹管理。
总结
本篇主要介绍了消息系统的设计要点和分布式场景下,分布式事务的处理。目前主流的异步处理消息队列,就是Kafka、RabbitMQ、RockketMQ,所以熟练掌握其基本原理和业务场景的实际运用非常重要。