ChatGPT开启大模型“军备赛”,存储作为计算机重要组成部分明显受益:
ChatGPT开启算力军备赛,大模型参数呈现指数规模,引爆海量算力需求,模型计算量增长速度远超人工智能硬件算力增长速度,同时也对数据传输速度提出了更高的要求。XPU、内存、硬盘组成完整的冯诺依曼体系,以一台通用服务器为例,芯片组+存储的成本约占70%以上,芯片组、内部存储和外部存储是组成核心部件;存储是计算机的重要组成结构,“内存”实为硬盘与CPU之间的中间人,存储可按照介质分类为ROM和RAM两部分。
存算一体,后摩尔时代的必然发展:
过去二十年中,算力发展速度远超存储,“存储墙”成为加速学习时代下的一代挑战,原因是在后摩尔时代,存储带宽制约了计算系统的有效带宽,芯片算力增长步履维艰。因此存算一体有望打破冯诺依曼架构,是后摩时代下的必然选择,存算一体即数据存储与计算融合在同一个芯片的同一片区之中,极其适用于大数据量大规模并行的应用场景。存算一体优势显著,被誉为AI芯片的“全能战士”,具有高能耗、低成本、高算力等优势;存算一体按照计算方式分为数字计算和模拟计算,应用场景较为广泛,SRAM、RRAM有望成为云端存算一体主流介质。
存算一体前景广阔、渐入佳境:
存算一体需求旺盛,有望推动下一阶段的人工智能发展,原因是我们认为现在存算一体主要AI的算力需求、并行计算、神经网络计算等;大模型兴起,存算一体适用于从云至端各类计算,端测方面,人工智能更在意及时响应,即“输入”即“输出”,目前存算一体已经可以完成高精度计算;云端方面,随着大模型的横空出世,参数方面已经达到上亿级别,存算一体有望成为新一代算力因素;存算一体适用于人工智能各个场景,如穿戴设备、移动终端、智能驾驶、数据中心等。我们认为存算一体为下一代技术趋势并有望广泛应用于人工智能神经网络相关应用、感存算一体,多模态的人工智能计算、类脑计算等场景。
01. 存算一体,开启算力新篇章
1.1 ChatGPT开启大模型“军备赛”,算力呈现明显缺口
ChatGPT开启算力军备赛: 我们已经在《ChatGPT: 百度文心一言畅想》中证明数据、平台、算力是打造大模型生态的必备基础,且算力是训练大模型的底层动力源泉,一个优秀的算力底座在大模型(AI算法)的训练和推理具备效率优势;同时,我们在《ChatGPT打响AI算力“军备战”》中证明算力是AI技术角逐“入场券”,其中AI服务器、AI芯片等为核心产品;此外,我们还在《ChatGPT ,英伟达DGX引爆AI “核聚变”》中证明以英伟达为代表的科技公司正在快速补足全球AI算力需求,为大模型增添必备“燃料”。
大模型参数呈现指数规模,引爆海量算力需求: 根据财联社和OpenAI数据,ChatGPT浪潮下算力缺口巨大,根据OpenAI数据,模型计算量增长速度远超人工智能硬件算力增长速度,存在万倍差距。运算规模的增长,带动了对AI训练芯片单点算力提升的需求,并对数据传输速度提出了更高的要求。根据智东西数据,过去五年,大模型发展呈现指数级别,部分大模型已达万亿级别,因此对算力需求也随之攀升。

1.2 深度拆解服务器核心硬件组成部分
服务器的组成: 我们以一台通用服务器为例,服务器主要由主板、内存、芯片组、磁盘、网卡、显卡、电源、主机箱等硬件设备组成;其中芯片组、内部存储和外部存储是组成核心部件。
GPU服务器优势显著: GPU服务器超强的计算功能可应用于海量数据处理方面的运算,如搜索、大数据推荐、智能输入法等,相较于通用服务器,在数据量和计算量方面具有成倍的效率优势。此外,GPU可作为深度学习的训练平台,优势在于1、GPU 服务器可直接加速计算服务,亦可直接与外界连接通信;2、GPU服务器和云服务器搭配使用,云服务器为主,GPU服务器负责提供计算平台;3、对象存储COS 可以为GPU 服务器提供大数据量的云存储服务。
AI服务器芯片组价值成本凸显: 以一台通用服务器为例,主板或芯片组占比最高,大约占成本50%以上,内存(内部存储+外部存储)占比约为20%。此外,根据Wind及芯语的数据,AI服务器相较于高性能服务器、基础服务器在芯片组(CPU+GPU)的价格往往更高,AI服务器(训练)芯片组的成本占比高达83%、AI服务器(推理)芯片组占比为50%,远远高于通用服务器芯片组的占比。

1.3 存储,计算机的重要组成结构
存储是计算机的重要组成结构: 存储器是用来存储程序和数据的部件,对于计算机来说,有了存储器才有记忆功能,才能保证正常工作。存储器按其用途可分为主存储器和辅助存储器,主存储器又称内存储器(简称内存),辅助存储器又称外存储器(简称外存)。
内存: 主板上的存储结构,与CPU直接沟通,并用其存储数据的部件,存放当前正在使用的(即执行中)的数据和程序,一旦断电,其中的程序和数据就会丢失;
外存: 磁性介质或光盘,像硬盘,软盘,CD等,能长期保存信息,并且不依赖于电力来保存信息。
XPU、内存、硬盘组成完整的冯诺依曼体系: “内存”实为硬盘与CPU之间的中间人,CPU如果直接从硬盘中抓数据,时间会太久。所以“内存”作为中间人,从硬盘里面提取数据,再让CPU直接到内存中拿数据做运算。这样会比直接去硬盘抓数据,快百万倍;CPU里面有一个存储空间Register(寄存器),运算时,CPU会从内存中把数据载入Register, 再让Register中存的数字做运算,运算完再将结果存回内存中,因此运算速度Register > 内存> 硬盘,速度越快,价格越高,容量越低。

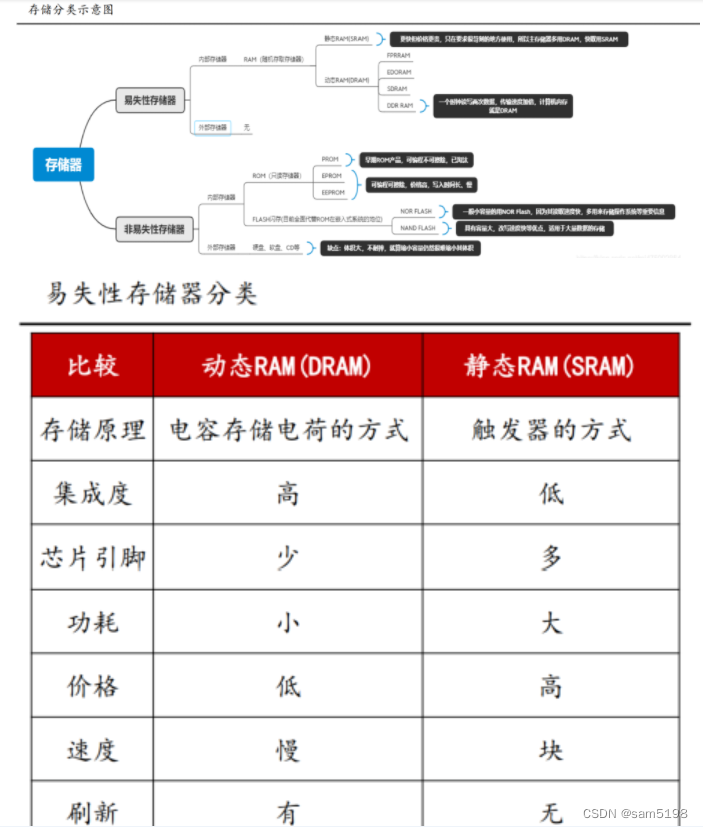
存储按照易失性分类: 分别为ROM(只读存储器)是Read Only Memory的缩写,RAM(随机存取存储器)是Random Access Memory的缩写。ROM在系统停止供电的时候仍然可以保持数据,而RAM通常都是在掉电之后就丢失数据,典型的RAM就是计算机的内存。
RAM(随机存取存储器)作为内存架构广泛应用于计算机中:是与中央处理器直接交换数据的内部存储器。可以随时读写且速度很快,通常作为操作系统或其他正在运行中的程序的临时资料存储介质。RAM可分为静态SRAM与动态DRAM,SRAM速度非常快,是目前读写最快的存储设备了,但是价格昂贵,所以只在要求很苛刻的地方使用,譬如CPU的一级缓冲,二级缓冲;DRAM保留数据的时间很短,速度也比SRAM慢,不过比任何的ROM都要快,但从价格上来说DRAM相比SRAM要便宜,因此计算机内存大部分为DRAM架构;
ROM(只读存储器)作为硬盘介质广泛使用: Flash内存的存储特性相当于硬盘,它结合了ROM和RAM的长处,不仅具备了电子可擦除可编程的性能,还不会断电丢失数据同时可以快速读取数据,近年来Flash已经全面替代传统ROM在嵌入式系统的定位,目前Flash主要有两种NOR Flash和NAND Flash。Nand-flash存储器具有容量较大,改写速度快等优点,适用于大量数据的存储,因此被广泛应用在各种存储卡,U盘,SSD,eMMC等等大容量设备中;NOR-Flash则由于特点是芯片内执行,因此应用于众多消费电子领域。
1.4 存算一体,后摩尔时代的必然发展
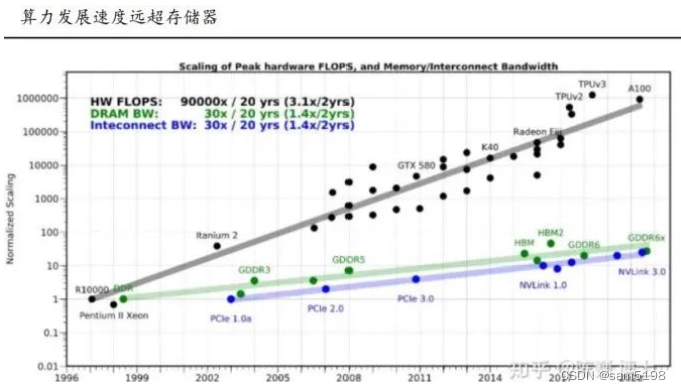
算力发展速度远超存储,存储带宽限制计算系统的速度: 在过去二十年,处理器性能以每年大约55%的速度提升,内存性能的提升速度每年只有10%左右。因此,目前的存储速度严重滞后于处理器的计算速度。能耗方面,从处理单元外的存储器提取所需的时间往往是运算时间的成百上千倍,因此能效非常低;“存储墙”成为加速学习时代下的一代挑战,原因是数据在计算单元和存储单元的频繁移动。
存储墙、带宽墙和功耗墙成为首要限制关键: 在传统计算机架构中,存储与计算分离,存储单元服务于计算单元,因此会考虑两者优先级;如今由于海量数据和AI加速时代来临,不得不考虑以最佳的配合方式为数据采集、传输、处理服务,然而存储墙、带宽墙和功耗墙成为首要挑战,虽然多核并行加速技术也能提升算力,但在后摩尔时代,存储带宽制约了计算系统的有效带宽,芯片算力增长步履维艰。
存算一体有望打破冯诺依曼架构,是后摩时代下的必然选择: 存算一体是在存储器中嵌入计算能力,以新的运算架构进行二维和三维矩阵乘法/加法运算。存内计算和存内逻辑,即存算一体技术优势在于可直接利用存储器进行数据处理或计算,从而把数据存储与计算融合在同一个芯片的同一片区之中,可以彻底消除冯诺依曼计算架构瓶颈,特别适用于深度学习神经网络这种大数据量大规模并行的应用场景。
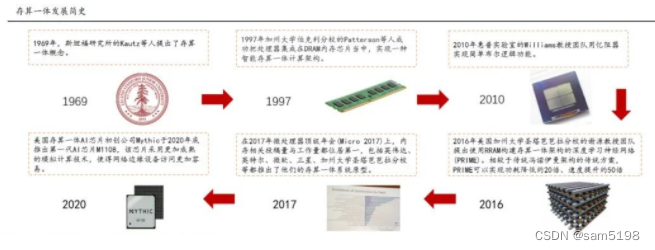
存算一体概念已有50年历史:早在1969年,斯坦福研究所的Kautz等人提出了存算一体计算机的概念。但受限于当时的芯片制造技术和算力需求的匮乏,那时存算一体仅仅停留在理论研究阶段,并未得到实际应用。然而为了打破冯诺依曼架构,降低“存储-内存-处理单元”过程数据搬移带来的开销, 业内广泛采用3D封装技术实现3D堆叠提供更大带宽,但是并没有改变数据存储与数据处理分离的问题;
近年来,存算一体随着人工智能的驱动得到较快发展: 随着半导体制造技术突破,以及AI等算力密集的应用场景的崛起,为存算一体技术提供新的制造平台和产业驱动力。2016年,美国加州大学团队提出使用RRAM构建存算一体架构的深度学习神经网络(PRIME)。相较于传统冯诺伊曼架构的传统方案,PRIME可以实现功耗降低约20倍、速度提升约50倍;此外,2017年,英伟达、微软、三星等提出存算一体原型;同年起,国产存算一体芯片企业开始“扎堆”入场,例如千芯科技、智芯微、亿铸科技、后摩时代、苹芯科技等。
1.5 存算一体: AI芯片的“全能战士”
存算一体优势显著,被誉为AI芯片的“全能战士”其优势如下:
1、成百上千倍的提高计算效率,降低成本:存算一体的优势是打破存储墙,消除不必要的数据搬移延迟和功耗,使用存储单元提升算力;
2、特定领域提供更高算力与能效:存算一体架构消除了计算与存储的界限,直接在存储器内完成计算,因此属于非冯诺伊曼架构,在特定领域可以提供更大算力(1000TOPS以上)和更高能效(超过10-100TOPS/W),明显超越现有ASIC算力芯片;
3、存算一体代表了未来AI计算芯片的主流架构: 除AI计算外,存算技术也可用于感存算一体芯片和类脑芯片,可减少不必要的数据搬运与使用存储单元参与逻辑计算提升算力,原因在于等效于在面积不变的情况下规模化增加计算核心数。
目前存算技术按照历史路线顺序演进:
A、查存计算: GPU中对于复杂函数就采用了这种计算方法,通过在存储芯片内部查表来完成计算操作,目前应用较为广阔,且技术相较成熟;
B、近存计算: 计算操作由位于存储区域外部的独立计算芯片/模块完成。这种架构设计的代际设计成本较低,适合传统架构芯片转入。例如AMD的Zen系列CPU、三星的HBM-PIM、特斯拉Dojo(AI训练计算机)、阿里达摩院等,近存计算技术早已成熟,被广泛应用在各类CPU和GPU上;
C、存内计算: 计算操作由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟的也可以是数字的。这种路线一般用于算法固定的场景算法计算,典型代表如Mythic、千芯科技、闪亿、知存、九天睿芯等;
D、存内逻辑: 这种架构数据传输路径最短,同时能满足大模型的计算精度要求。通过在内部存储中添加计算逻辑,直接在内部存储执行数据计算。典型代表为TSMC和千芯科技等。
存算一体按照计算方式分为数字计算和模拟计算:
模拟计算: 模拟存算一体通常使用FLASH、RRAM、PRAM等非易失性介质作为存储器件,存储密度大,并行度高,但是对环境噪声和温度非常敏感。模拟存算一体模型权重保持在存储器中,输入数据流入存储器内部基于电流或电压实现模拟乘加计算,并由外设电路对输出数据实现模数转换。由于模拟存算一体架构能够实现低功耗低位宽的整数乘加计算,因此非常适合边缘端AI场景。
数字计算: 随着AI任务的复杂性和应用范围增加,高精度的大规模AI模型不断涌现。这些模型需要在数据中心等云端AI场景完成训练和推理,产生巨大的算力需求,相比于边缘端AI场景,云端AI场景具有更多样的任务需求,因此云端AI芯片必须兼顾能效、精度、灵活性等方面以保证各种大规模AI推理和训练;数字存算一体主要以SRAM和RRAM作为存储器件,采用先进逻辑工艺,具有高性能高精度的优势,且具备很好的抗噪声能力和可靠性,因此较为适合在云端大算力高能效的商用场景。
02. 存算一体,打开海量应用空间
存算一体需求旺盛,有望推动下一阶段的人工智能发展: 我们认为现在存算一体主要AI的算力需求、并行计算、神经网络计算等,因此存算一体需求旺盛;以数据中心为例,百亿亿次(E级)的超级计算机成为各国比拼算力的关键点,为此美国能源部启动了“百亿亿次计算项目”,我国则联合国防科大、中科曙光等机构推出首台E级超算,而E级超算面临的主要问题为功耗过高、现有技术超算功率高达千兆瓦,需要一个专门的核电站来给它供电,而其中50%以上的功耗都来源于数据的“搬运”,本质原因是计算与存储分离所致。
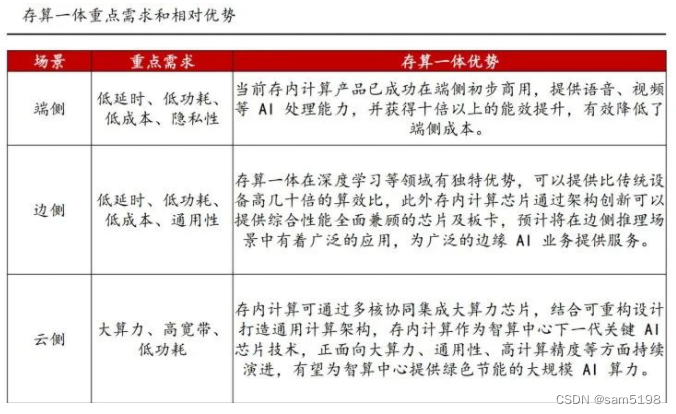
大模型兴起,存算一体适用于从云至端各类计算: ChatGPT等“大模型”兴起,本质即为神经网络、深度学习等计算,因此,我们认为对算力需求旺盛;端测方面,人工智能更在意及时响应,即“输入”即“输出”,同时,随着存算一体发展,存内计算和存内逻辑,已经可以完成高精度计算;云端方面,随着大模型的横空出世,参数方面已经达到上亿级别,因此对算力的能耗方面考核更加严格,随着SRAM和PRAM等技术进一步成熟,存算一体有望成为新一代算力因素,从而推动人工智能产业的发展。