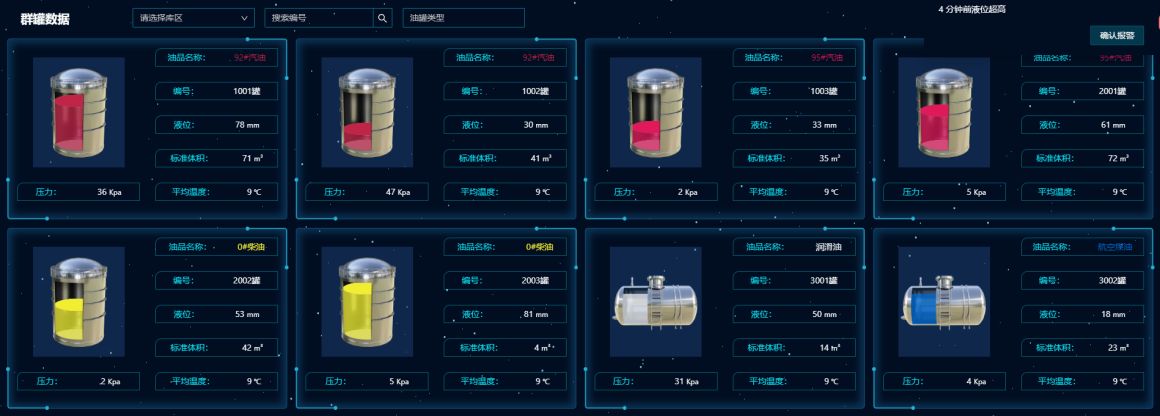
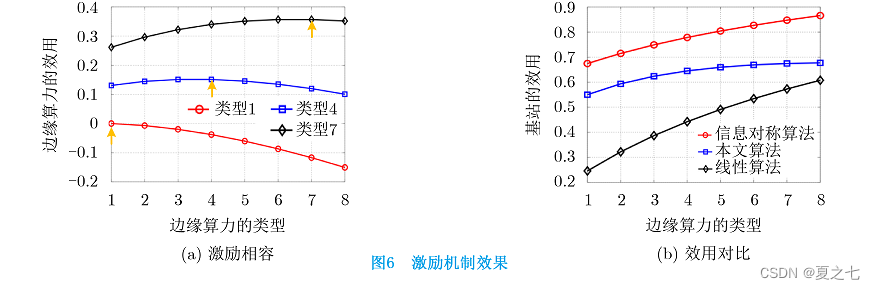
GoogLeNet中基本的卷积块是Inception块。
1.Inception块:4个路径从不同的层面抽取信息,然后在输出通道合并
①1*1的卷积层,减少通道数,降低模型的复杂度
② 1*1的卷积层,减少通道数,降低模型复杂度。然后使用3*3的卷积层提取信息,输出
③1*1的卷积层,减少通道数,降低模型复杂度。然后使用5*5的提取信息卷积层,输出
④3*3的最大池化层,然后1*1卷积层
通过padding最后4条路径的输出的尺寸都一样,然后进行合并。
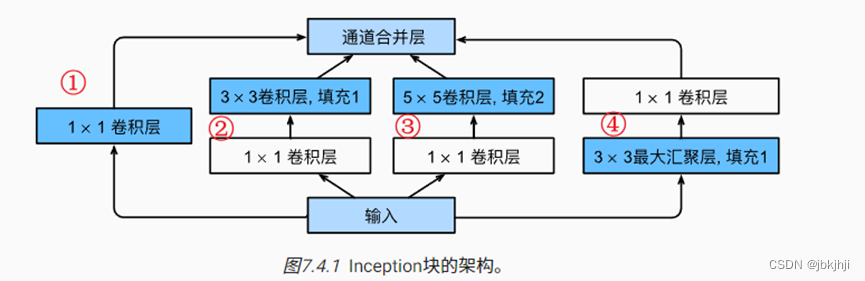
2.Inception块的通道数:通道数是个超参数
白色框是1*1的卷积是通过降低通道数来控制模型的复杂度
蓝色框的卷积是提取信息的
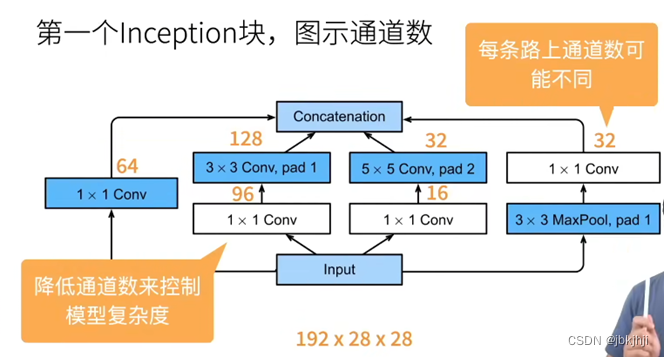
3.Inception块的优点
跟单3*3卷积层或者5*5卷积层相比,Inception块的参数个数少和计算复杂度低。
4.GoogLeNet的架构:有5段,9个Inception块
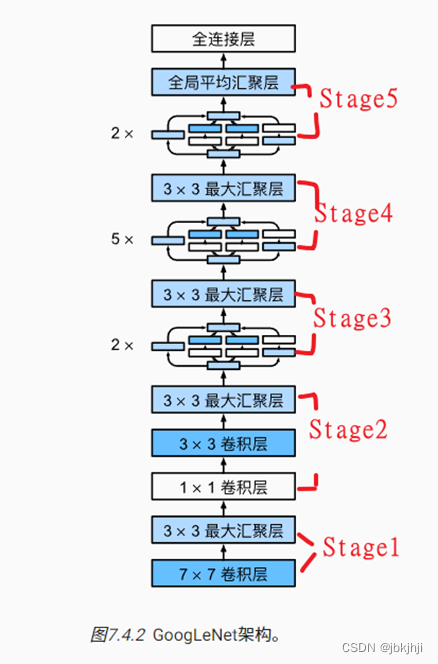
【总结】
①Inception块用4条有不同超参数的卷积层和池化层的路来抽取不同的信息,优点是模型参数小,计算复杂度低
②GoogleNet使用了9个Inception块,是第一个达到上百层的网络
【代码实现】
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# Inception块
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs) # **kwargs是将除了前面显式参数外的其他参数
# 线路1 单层1*1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2 1*1卷积层后按3*3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3 1*1卷积后按5*5卷积
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4 3*3最大池化层后按1*1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
# GoogLeNet模型搭建
# 第一个模块使用64个通道,7*7卷积层
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 第二个模块是使用 第一个卷积层是64个通道 1*1 第二个卷积层是192个通道 3*3
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第三个模块是 2个Inception块
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第四个模块是 5个Inception块
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第五个模块是 2个Inception块
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
# 网络搭建
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
# 模型测试
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
# 模型训练
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()