前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐

开发环境:
-
python 3.8
-
pycharm
模块使用:
-
requests --> pip install requests
-
re
-
base64
-
docx --> pip install python-docx
第三方模块安装方法:
win + R 输入cmd 输入安装命令 pip install 模块名
(如果你觉得安装速度比较慢, 你可以切换国内镜像源)
准备工作
在写代码之前,你需要先在Baidu开发者平台申请权限,

步骤如下:
1. 登录百度智能云
-
「https://cloud.baidu.com/?from=console」,没有Baidu账号的注册一个;
-
第一次进入会有这样一个页面,你自己随意填
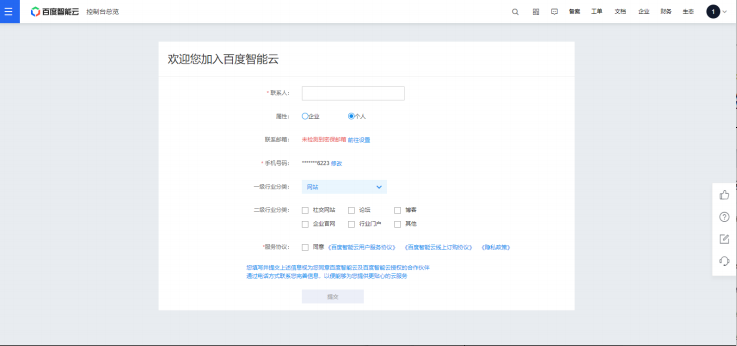
2. 通过界面右上角进入控制台
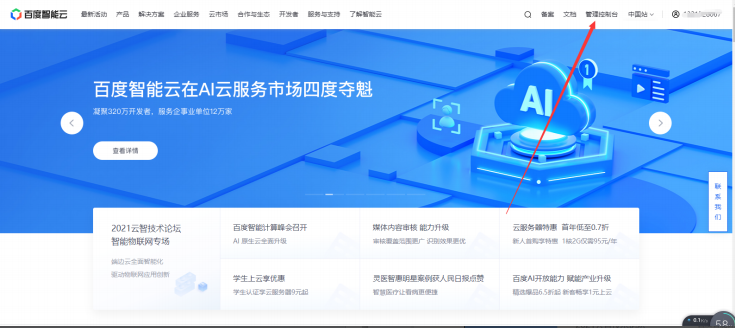
3. 进入控制台后点击左上角的菜单栏
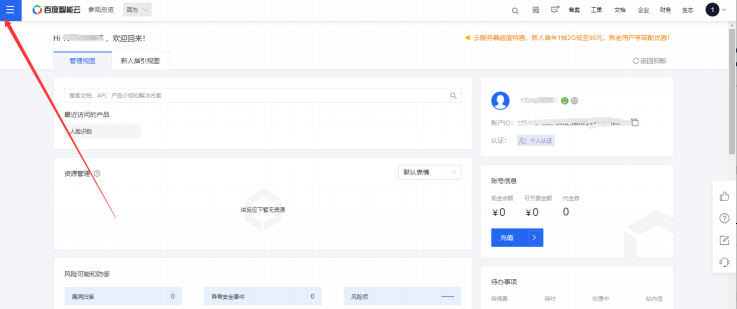
3. 选中产品服务
搜索人脸识别

4. 点击创建应用
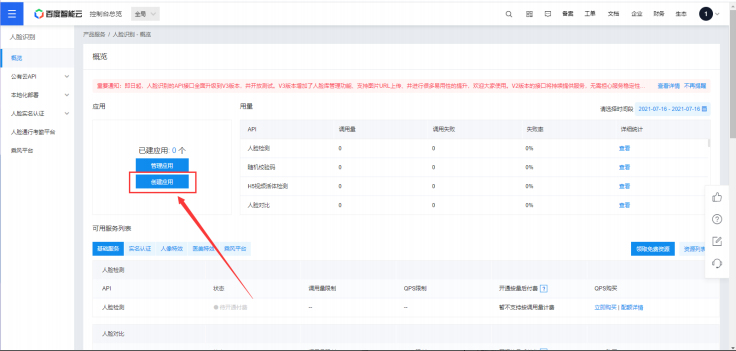
应用名称随便填
接口选择默认
应用归属选个人
应用描述随便填
然后点击立即创建
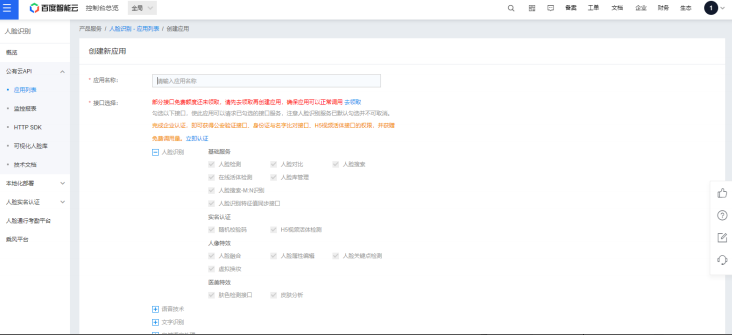
5. 创建完毕后点击返回应用列表
重点点击领取免费资源
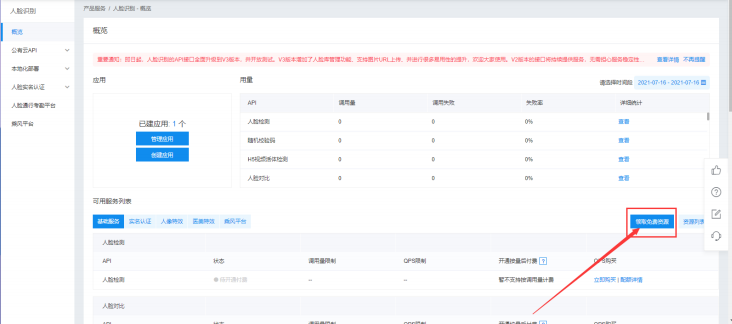
6. 进行实名认证后领取服务类型里面的所有内容
实名认证需要一定时间
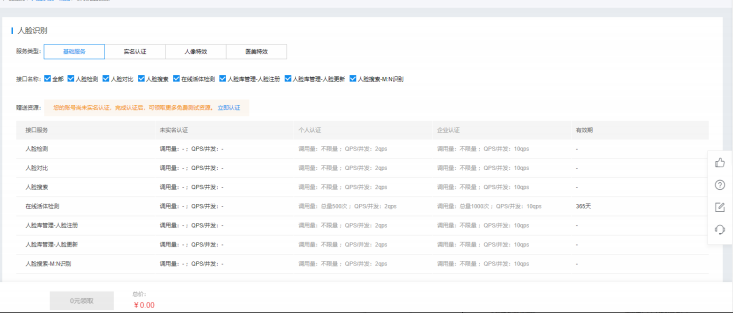
7. 领取完毕之后回到应用列表

复制API Key和Secret Key里的内容,用于后期的接口认证
👇 👇 👇 更多精彩机密、教程,尽在下方,赶紧点击了解吧~
素材、视频教程、完整代码、插件安装教程我都准备好了,直接在文末名片自取就可

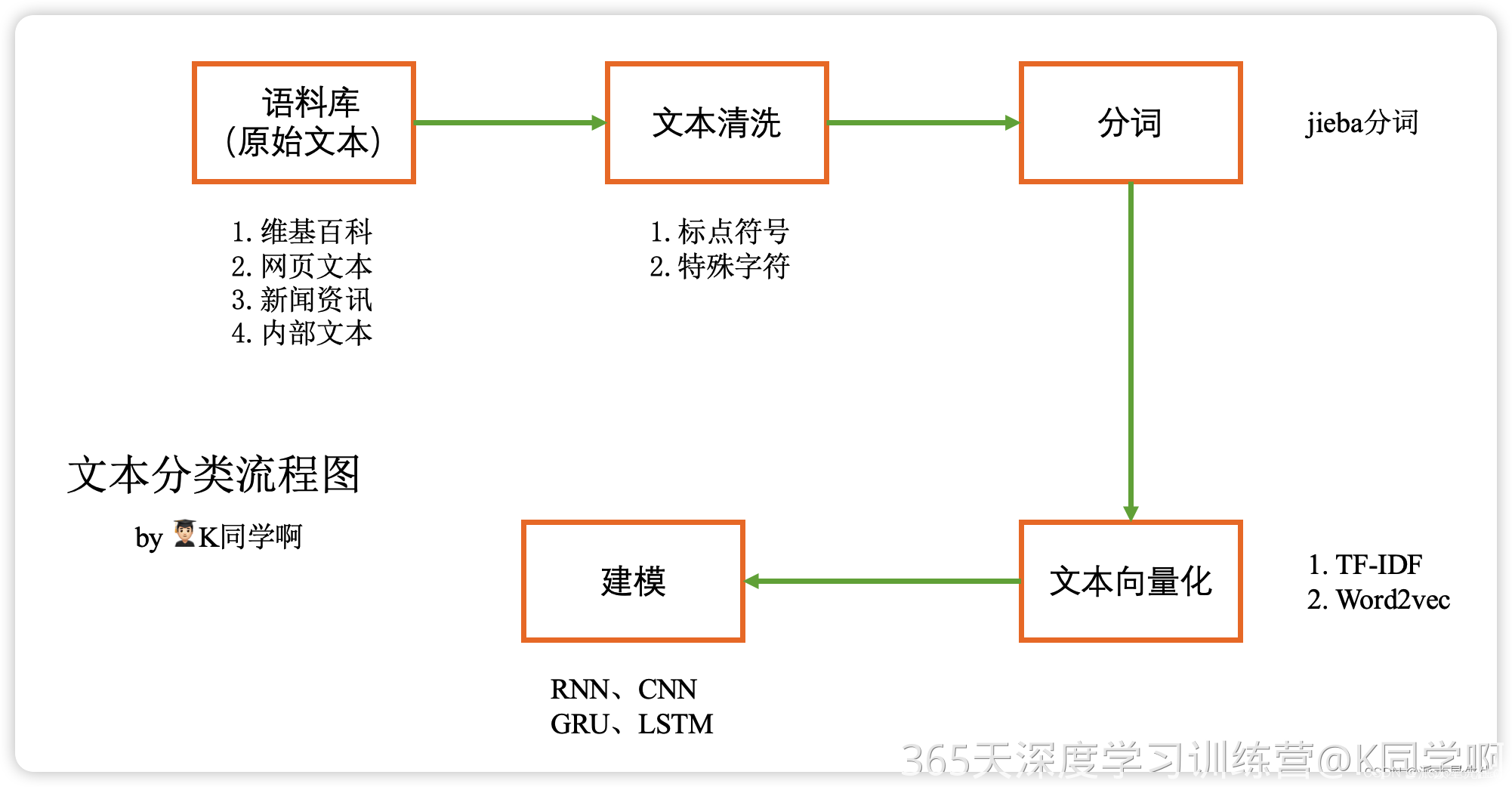
代码实现步骤
-
发送请求, 模拟浏览器对于 文档页面url地址 发送请求
-
获取数据, 获取服务器返回响应数据
-
解析数据, 提取我们需要的内容:
sid参数 / 文档页数 / 文档名称
构建文档图片链接
-
保存数据, 把文档图片内容保存下来
代码展示
# 导入数据请求模块
import requests
# 导入正则模块
import re
import base64
from docx import Document
doc = Document()
def Content(content):
url = "https://****/oauth/2.0/token?grant_type=client_credentials&client_id=xxxx&client_secret=xxxx"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
access_token = response.json()['access_token']
'''
通用文字识别(高精度版)
'''
request_url = "https://****/rest/2.0/ocr/v1/accurate_basic"
# 二进制方式打开图片文件
# f = open('img\\1 计算机概述1.jpg', 'rb')
img = base64.b64encode(content)
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
json_data = requests.post(request_url, data=params, headers=headers).json()
words_result = '\n'.join([i['words'] for i in json_data['words_result']])
print(words_result)
# 模拟浏览器 --> 字典数据类型 --> 键:值
headers = {
# User-Agent 用户代理 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 请求链接
url = 'https://****/p-3282300896.html'
# 发送请求
response = requests.get(url=url, headers=headers)
# 获取网页数据
html_data = response.text
# 提取sid参数
sid = re.findall('flash_param_hzq:"(.*?)",', html_data)[0]
# 提取名字
name = re.findall('productName:"(.*?)",', html_data)[0]
# 提取页码
num = re.findall('<em>(\d+)</em>页</span>', html_data)[0]
# 构建完整图片链接
content_list = []
for page in range(1, int(num)+1):
# 字符串格式化方法
img = f'http://221.122.117.73/docinpic.jsp?sid={sid}&file=3282300896&width=942&pageno={page}'
# 发送请求, 获取二进制数据<图片内容>
img_content = requests.get(url=img, headers=headers).content
words = Content(img_content)
doc.add_paragraph(words)
doc.save(f'{name}.docx')
正则表达式提取数据内容
-
re.findall(‘数据’, ‘地方’) 调用re模块里面findall方法
查找所有我们需要的数据内容