前言:
本文讲述使用python将需要处理的文件夹内多个excel文件内容进行合并,并输出为xlsx格式的总表。就比如一个文件夹里又有许多子文件夹,这些子文件夹里分布有excel文件,这里的python文件就能将这个文件夹内的所有excel文件进行合并成总表,不管里面是否还有其他文件格式就比如dox、jpg、py等,更不用说这个文件夹内只含有excel文件。
本文还使用了GUI界面使操作更加简洁,并介绍了将其打包成exe可执行文件的步骤,让它使用的更广泛了。由于进行了模块化设计,各个步骤使用了函数封装。
流程:
1.引入库
2.获取excel文件的路径
3.对excel文件内容的读取
4.写入excel总表
5.设置GUI界面
6.打包成exe可执行文件
正文:
引入库:
需要引入5个库,分别如下。其中xlrd库是用于xls格式的读取,openpyxl库是用于xlsx格式的读取,而openpyxl库既可以用于xls格式的写入,又可以用于xlsx格式的写入。os是操作系统的库,python自带库。tkinter是GUI界面的库,其中filedialog是tkinter中的文件对话框,它的作用类似我们下载一个东西需选择下在哪个地方的界面。
import xlrd
import os
import openpyxl
import tkinter as tk
import tkinter.filedialog获取excel文件的路径:
这一部分总的代码如下。
root_files_Global = []
def find_excel():#定义获取excel文件路径
for root, dirs, files in os.walk('{}'.format(filename)):
for i in range(len(files)):
if 'xls' in files[i] or 'xlsx' in files[i]:
root_files_Global.append(root+'/'+files[i])
然后分开来单独看各个代码的作用
filename = 'C:/Users/86182/Desktop/需要处理的文件夹'
for root, dirs, files in os.walk('{}'.format(filename)):
print(root)
print(files)filename为需要处理的文件夹的绝对路径,就比如C:/Users/86182/Desktop/需要处理的文件夹,可以自己查看自己电脑某个文件的路径,这里使用filename是为了之后与其它模块衔接。可以看下输出的结果:
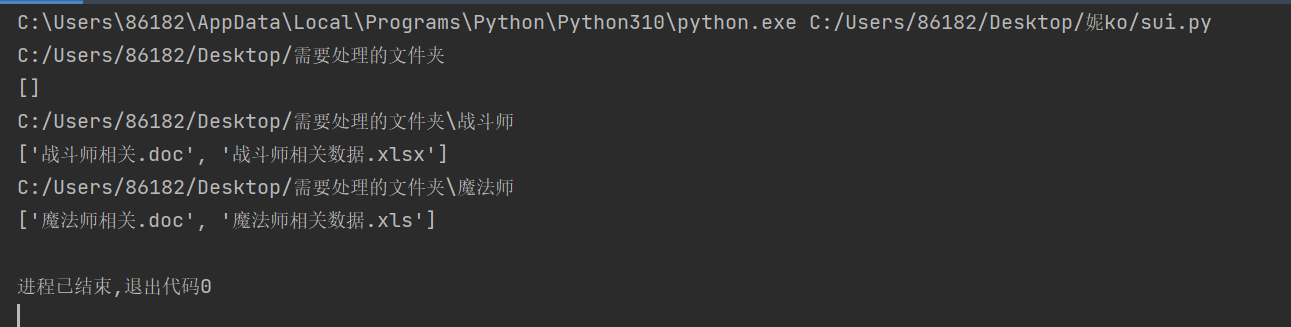
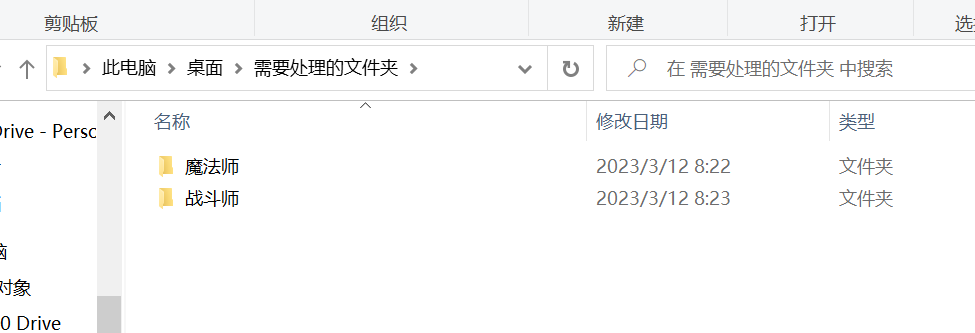
这串代码的作用是遍历需要处理文件夹内所有文件,root的作用是返回文件的路径,而file的作用是以列表形式返还文件名。父文件夹’需要处理的文件夹‘内只有两个子文件夹,分别为’战斗师‘,’魔法师‘。战斗师文件夹里有'战斗师相关.doc', '战斗师相关数据.xlsx'这两个文件。魔法师文件夹里有'魔法师相关.doc', '魔法师相关数据.xls'这两个文件,直观如下。注意对于root,需要处理的文件夹\战斗师,中间是反斜杠\与其他不同,后面会利用这个性质。
接下来:
root_files_Global = []
def find_excel():#定义获取excel文件路径
for root, dirs, files in os.walk('{}'.format(filename)):
for i in range(len(files)):
if 'xls' in files[i] or 'xlsx' in files[i]:
root_files_Global.append(root+'/'+files[i])
find_excel()
print(root_files_Global)对于for i in range(len(files))循环下,如果files列表内第i个元素中有'xls'、'xlsx'字符串在内(即判断excel文件),则在root_files_Global列表内添加文件的路径加名称。这样在整个循环内,就能把需要处理的文件夹内的所有excel文件的路径加名称全部添加到root_files_Global列表内。可以看一下这一部分运行的结果:

对excel文件内容的读取
由于对excel文件的读取分xls与xlsx格式的读取,所以需要分别引用xlrd库与openpyxl库,不过他们读取内容的过程相似,可以仿照。这一部分的总代码如下:
row = []
column = []
value = []
f0 = 0
def read_excel_xls():#定义读取xls文件格式函数
global f0
wb = xlrd.open_workbook(root_files_Global[t])
sheet_names = wb.sheet_names()
sheet = wb.sheet_by_name(sheet_names[0])
for r in range(sheet.nrows):
for c in range(sheet.ncols):
va = sheet.cell(r, c).value
row.append(r+f0)
column.append(c)
value.append(va)
f0 = f0 + sheet.nrows
def read_excel_xlsx():#定义读取xlsx文件格式的函数,使用openpyxl
global f0
wb = openpyxl.load_workbook(root_files_Global[t])
ws = wb.worksheets[0]
for r in range(ws.max_row):
for c in range(ws.max_column):
va = ws.cell(r+1, c+1).value
row.append(r + f0)
column.append(c)
value.append(va)
f0 = f0 + ws.max_row
这一部分我们就主要看read_excel_xls()这个定义的函数,read_excel_xlsx()可以仿照。9-11行作用是打开excel表格内第一个sheet表格(具体可以查看xlrd库相关内容)。sheet.nrows表示表格的行数,sheet.ncols表示表格的列数,第24行至25行表示在每一行遍历每一列;va = ws.cell(r+1, c+1).value的作用为获取第r+1行、c+1列的内容并返还对象va。将内容行数信息和列数信息分别储存在row=[]、column=[]这两个列表里,将内容信息储存在value=[]列表里。这里f0的使用是比较重要的,如果没有f0,当循环到下一个文件,行数与列数的信息就又重0开始了,而我们之后需要写入一个总表,行数信息就应该自上个文件的最大行数再往下。f0的作用就是让行数信息接着往下。
为了使按照顺序读取多个excel文件,可以使用如下代码:
for t in range(len(root_files_Global)):
if 'xlsx' in root_files_Global[t]:
read_excel_xlsx()
elif 'xls' in root_files_Global[t]:
read_excel_xls()写入excel总表
这一部分就比较简单了,总的代码如下:
def write_excel_xlsx():#定义写入xlsx文件格式的函数,使用openpyxl
wb = openpyxl.Workbook()
ws = wb.worksheets[0]
for i in range(len(row)):
ws.cell(row[i]+1,column[i]+1).value = value[i]
wb.save('总表.xlsx')openpyxl.Workbook()创建一个xlsx格式excel文件并返还wb对象,打开这个文件的第一个sheet表格,第4行到第5行代码为按照行的信息和数的信息写入内容,wb.save('总表.xlsx')最后保存总表。
到这里大致python代码就完成了。接下来引入GUI、打包exe可执行化文件。
设置GUI界面
这一步分总的代码如下:
def askfile():#选择文件夹
global filename
filename = tk.filedialog.askdirectory()
if filename !='':
label2.config(text=filename)
print(filename)
else:
label2.config(text='您没有选择任何文件夹')
def GUI_excel():
global label2
window = tk.Tk()
window.geometry('600x300')
window.title('excel合成')
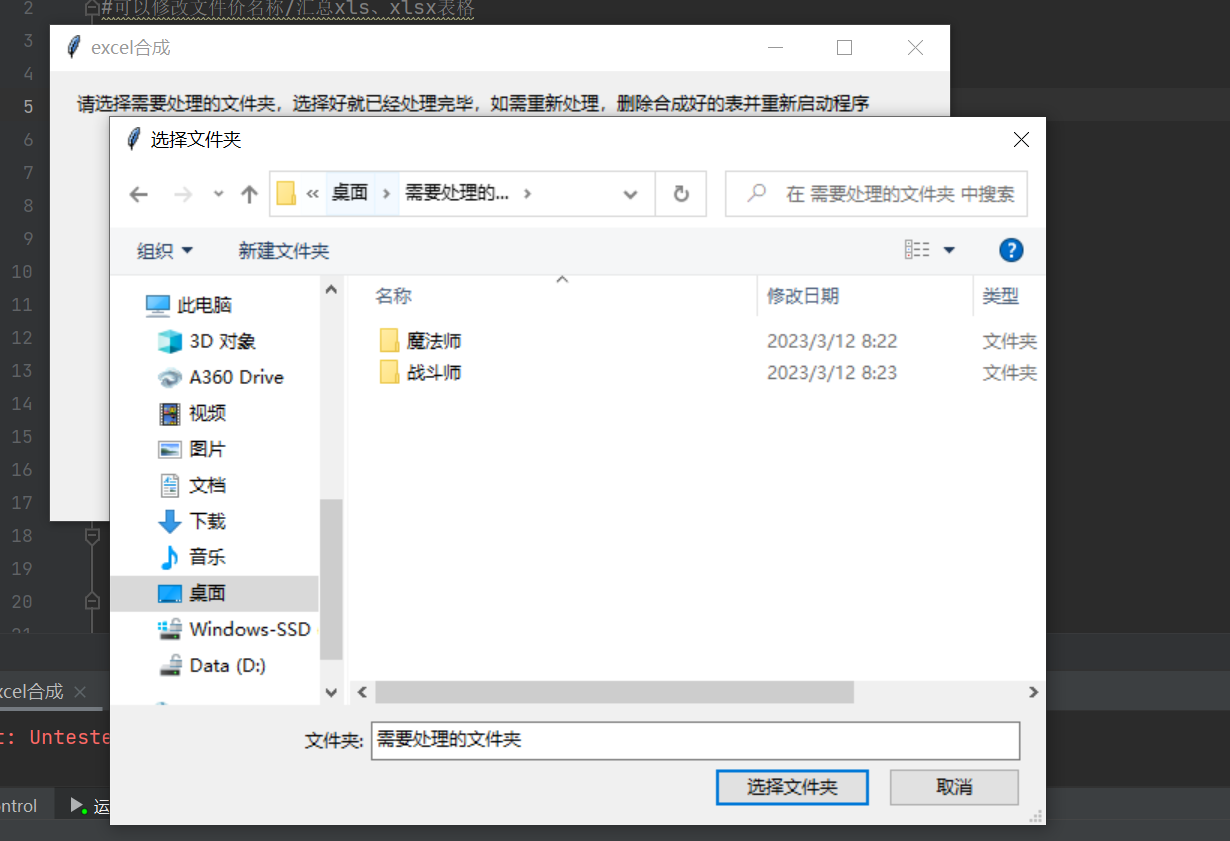
label1 = tk.Label(window,text='请选择需要处理的文件夹,选择好就已经处理完毕,如需重新处理,删除合成好的表并重新启动程序')
label1.place(x=15,y=10)
label2 = tk.Label(window,text='')
label2.place(x=15,y=30)
button1 = tk.Button(window,text='选择文件夹',bg='blue',fg='white',command=askfile())
button1.place(x=15,y=60)
window.mainloop()
window = tk.Tk()
window.geometry('600x300')
window.title('excel合成')
这三行代码用于创建一个大小为’600*300‘GUI界面,标题名称为excel合成,label1是一个标签用为提示相关信息,label2主要是为了搭配askfile()函数使用。
再设置一个按钮button1,它的功能就是askfile(),而askfile()的作用类似我们下载一个东西需选择下在哪个地方的界面,就如下:
到现在所有代码都已经完成,我把总的代码写在下面,需要自取:
#只针对sheet1/支持xls、xlsx/最后输出xlsx格式总表
#可以修改文件价名称/汇总xls、xlsx表格
import xlrd
import os
import openpyxl
import tkinter as tk
import tkinter.filedialog
root_files_Global = []
row = []
column = []
value = []
f0 = 0
def askfile():#选择文件夹
global filename
filename = tk.filedialog.askdirectory()
if filename !='':
label2.config(text=filename)
print(filename)
else:
label2.config(text='您没有选择任何文件夹')
def GUI_excel():
global label2
window = tk.Tk()
window.geometry('600x300')
window.title('excel合成')
label1 = tk.Label(window,text='请选择需要处理的文件夹,选择好就已经处理完毕,如需重新处理,删除合成好的表并重新启动程序')
label1.place(x=15,y=10)
label2 = tk.Label(window,text='')
label2.place(x=15,y=30)
button1 = tk.Button(window,text='选择文件夹',bg='blue',fg='white',command=askfile())
button1.place(x=15,y=60)
window.mainloop()
GUI_excel()
def find_excel():#定义获取excel文件路径
for root, dirs, files in os.walk('{}'.format(filename)):
for i in range(len(files)):
if 'xls' in files[i] or 'xlsx' in files[i]:
root_files_Global.append(root+'/'+files[i])
find_excel()
print(root_files_Global)
def read_excel_xls():#定义读取xls文件格式函数
global f0
wb = xlrd.open_workbook(root_files_Global[t])
sheet_names = wb.sheet_names()
sheet = wb.sheet_by_name(sheet_names[0])
for r in range(sheet.nrows):
for c in range(sheet.ncols):
va = sheet.cell(r, c).value
row.append(r+f0)
column.append(c)
value.append(va)
f0 = f0 + sheet.nrows
def read_excel_xlsx():#定义读取xlsx文件格式的函数,使用openpyxl
global f0
wb = openpyxl.load_workbook(root_files_Global[t])
ws = wb.worksheets[0]
for r in range(ws.max_row):
for c in range(ws.max_column):
va = ws.cell(r+1, c+1).value
row.append(r + f0)
column.append(c)
value.append(va)
f0 = f0 + ws.max_row
for t in range(len(root_files_Global)):
if 'xlsx' in root_files_Global[t]:
read_excel_xlsx()
elif 'xls' in root_files_Global[t]:
read_excel_xls()
def write_excel_xlsx():#定义写入xlsx文件格式的函数,使用openpyxl
wb = openpyxl.Workbook()
ws = wb.worksheets[0]
for i in range(len(row)):
ws.cell(row[i]+1,column[i]+1).value = value[i]
wb.save('总表.xlsx')
write_excel_xlsx()
打包成exe可执行文件
如果直接使用install进行打包会使压缩包达到两、三百兆的样子。传输起来会非常不方便。所以这里需要python创建虚拟环境,由于我使用的是Anaconda,所以在这里只介绍相关内容,大家可以上网搜如何下载,这里我就不过多介绍了。
先介绍几个conda命令
conda create -n 虚拟环境名字 python==3.1 #创建虚拟环境
conda activate 虚拟环境名字 #激活虚拟环境
conda deactivate #退出虚拟环境
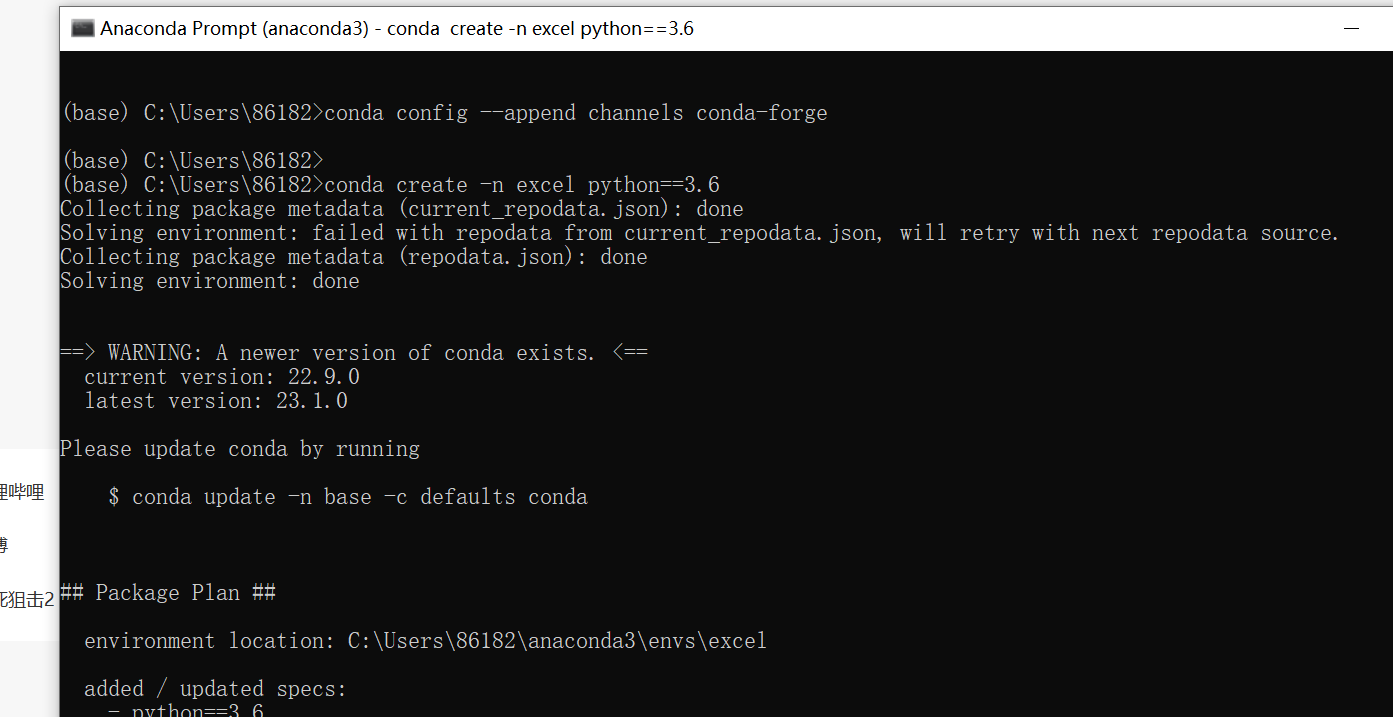
下载好后,从开始菜单运行“Anaconda Prompt”,使用上述第一个命令创建名为‘excel’的虚拟环境,如下:
在创建过程中需要回复(y/n),Yes,再激活虚拟环境
使用conda activate 虚拟环境名字 #激活虚拟环境,刚刚我们创建的虚拟环境名字为excel,结果如下:
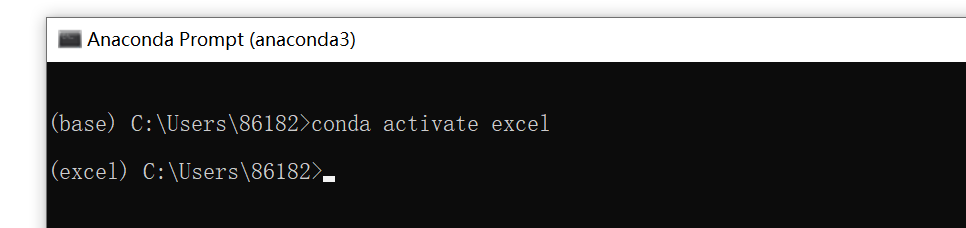
这样就代表激活好了,现在可以使用conda list来看下这个虚拟环境所安装的一些库:
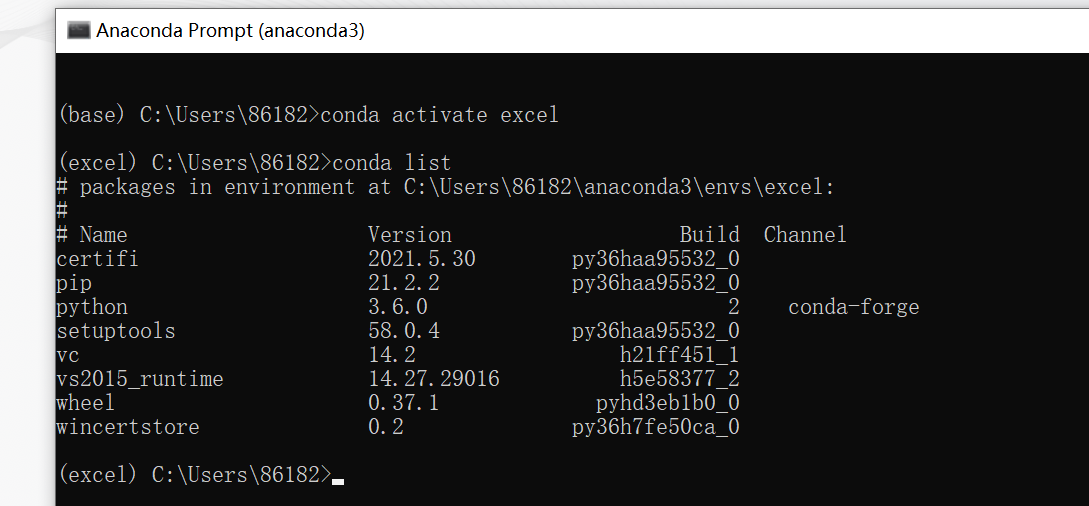
由于我们脚本还需要使用xlrd、openpyxl这两个库,而tkinter库和os库是python自带库,所以只需要将这两个库加载到虚拟环境中,当然还必不可打包的库pyinstaller;使用如下安装库(直接输入就好):
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyinstaller
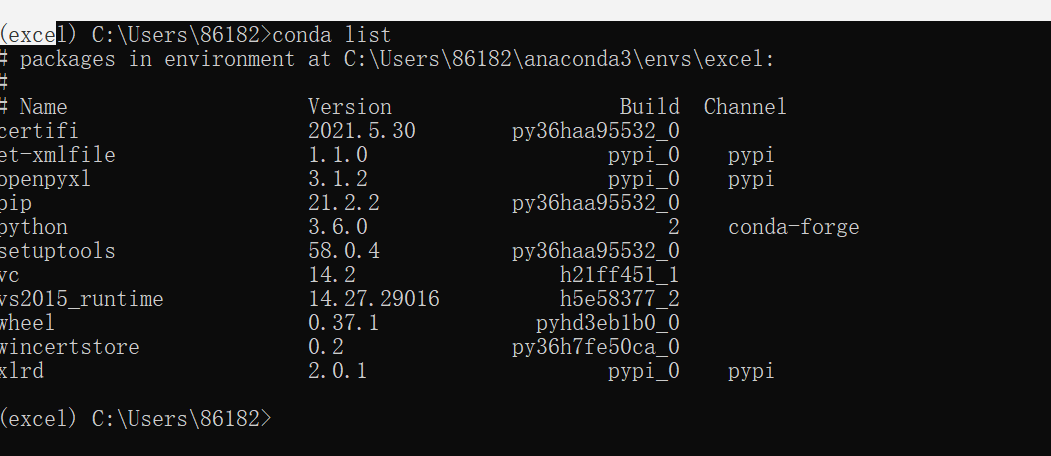
现在我已经安装好了。现在只需你新建个文件夹,将py文件放进去,在进行如下操作就好了

我的py文件名称为excel合成,并将它放在了excel合成总表这个文件夹里了,
所以cd C:/Users/86182/Desktop/excel合成总表这边转到自己的路径就好了,这样文件就打包好了,可执行化文件在刚刚那个文件夹中的dist里面
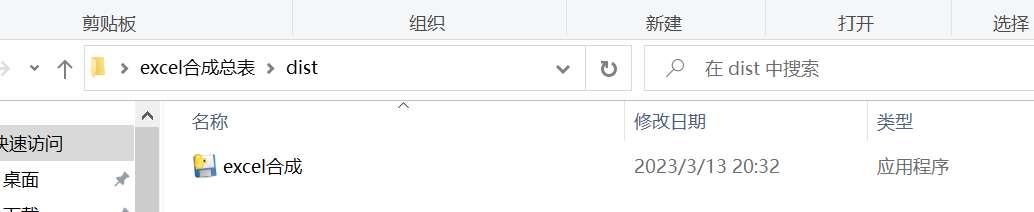
到现在就结束了。
总结:
虽然此方法将多个excel表格内的内容进行了合并,但是还存在一个问题就是,并不能将excel的格式一起合并起来,不过后面我会在学习以下,看能不能解决。
谢谢你的观看!我是小白,如有问题请指出😊!





![[MySQL]数据类型(图文详解)](https://img-blog.csdnimg.cn/img_convert/88c03c46b32d8103d27bfcbd2d0eba41.png)