文章目录
- Docker DNS配置
- Linux Docker DNS设置
- Windows、MacOs Docker DNS设置
- 打包Hadoop
- Dockerfile打包文件
- 参数声明和基础镜像引入
- 安装相关依赖库
- 创建普通用户
- 下载或导入软件包
- 环境变量配置
- 初始化脚本
- 参数配置
- `${HADOOP_CONF_DIR}/workers`工作节点
- `${HADOOP_CONF_DIR}/hadoop-env.sh`环境变量配置
- `${HADOOP_CONF_DIR}/core-site.xml`Hadoop核心设置
- 启动SSH,设置SSH免密登录
- 设置启动服务
- 主函数
在使用学习Hadoop等相关大数据产品时,为更好的学习和理解分布式的理念和操作,在学习时一般采用多机器的方式进行学习。一般情况下,可以采用通过虚拟机和云服务器等方式满足机器不足等问题。考虑到,云服务器成本过高,虚拟机资源性能等问题,博主决定采用容器的方法来学习搭建Hadoop集群。以便更好的学习Hadoop、容器、Shell等相关概念。
Docker DNS配置
在基于基础镜像进行Hadoop打包时,默认的基础镜像缺失很多库,所以需要在打包时下载相关依赖库,考虑到外网的相关镜像站连接不稳定,可以使用设置DNS的方式来加快访问。
Linux Docker DNS设置
修改/etc/docker/daemon.json文件:
{
"dns": [
"8.8.8.8",
"114.114.114.114"
]
}
重启docker:
systemctl daemon-reload
systemctl restart docker
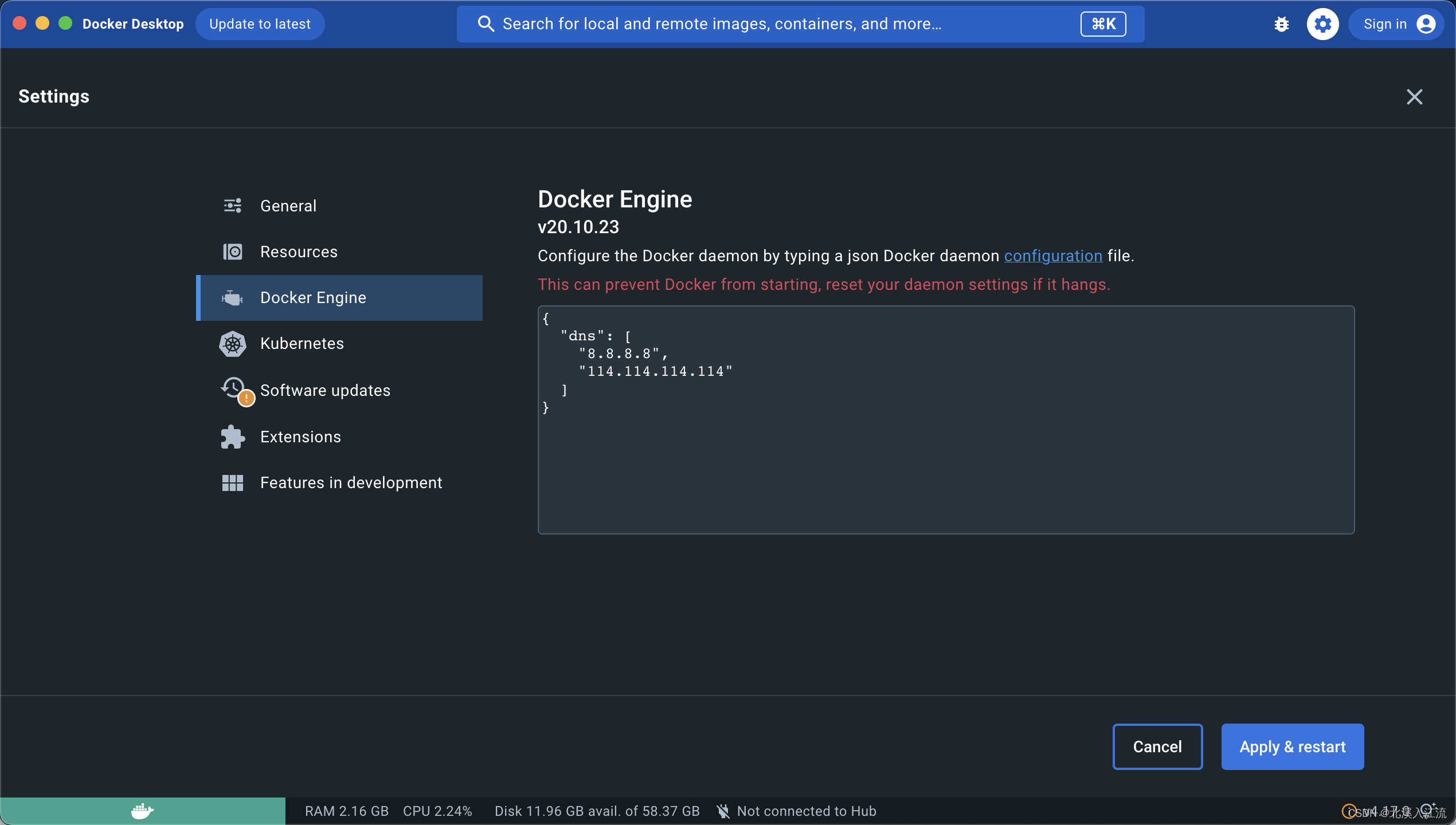
Windows、MacOs Docker DNS设置
Windows或者MacOs一般采用Docker Desktop的方式按照Docker。在Docker Desktop的设置界面的Docker Engine界面对Docker DNS进行设置。
打包Hadoop
在打包博客中,综合考虑,博主选择ubuntu:22.04作为基础镜像进行Hadoop打包。
Dockerfile打包文件
参数声明和基础镜像引入
# 初始化添加普通用户
ARG USER="focus"
# 用户默认密码
ARG PASSWORD="0000"
# 用户默认路径
ARG USER_HOME="/data"
# root用户密码,默认为普通用户密码
ARG ROOT_PASSWORF=${PASSWORD}
# 基础镜像版本
ARG BASE_IMAGE_VERSION="0.1"
# 基础镜像发行商
ARG BASE_IMAGE_DISTRO="ubuntu"
# 基础镜像架构,缺省为amd64
ARG BASE_IMAGE_ARCH="amd64"
# 基础镜像环境,缺省为dev
ARG BASE_IMAGE_ENV="dev"
# 引入基础镜像
FROM ubuntu:22.04
# 重新声明进所有参数以继承入口的参数传递
ARG USER
ARG PASSWORD
ARG USER_HOME
ARG ROOT_PASSWORF
ARG BASE_IMAGE_VERSION
ARG BASE_IMAGE_DISTRO
ARG BASE_IMAGE_ARCH
ARG BASE_IMAGE_ENV
- 在开始部分,通过
ARG声明后续需要的参数信息。ARG参数声明可以在打包镜像时指定具体值覆盖默认值
- 通过
FROM命令导入需要的基础镜像,在此基础上进行打包 - Dockerfile基于层的概念进行打包,引入基础镜像后,前面
ARG声明的参数信息将会失效,所以在之后需要重新声明相关参数
安装相关依赖库
RUN \
echo "install system library" && \
apt update && \
apt -y upgrade && \
apt -y install sudo openssh-client openssh-server sshpass iputils-ping telnet lsof curl wget vim
- 由于Dockerfile基于层的概念进行打包,所以在执行如
RUN等操作时,尽量在一个语句里面执行多个操作- 假设我们在一层中打包了我们不需要的文件,但是在后面的层将此文件删除,但是在打包时,这一层是仍有这个文件的,所以导致执行删除操作并没有使打包镜像减少,文件也并没有被删除,只是被标记为删除了而已。因为这个文件在之前的层中仍存在
-y:表示在执行upgrade和install时遇到需要确认的地方默认执行确认操作,避免因无法确认而在终端阻塞- 其中
sudo、openssh、sshpass为必要文件,在之后的脚本和开发中需要,其他的根据自己的需求选择依赖库
创建普通用户
RUN \
# 设置时区
echo "Asia/Shanghai" > /etc/timezone && \
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
# root sudo设置
echo "root ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers && \
echo "root:${ROOT_PASSWORF}" | sudo chpasswd && \
# 创建默认组
groupadd -g 1001 ${USER} && \
# 创建默认用户
mkdir -p ${USER_HOME} && \
useradd -u 1001 -g 1001 --no-create-home -d ${USER_HOME} --no-log-init --shell /bin/bash ${USER} && \
echo "${USER}:${PASSWORD}" | sudo chpasswd && \
# 赋予sudo权限
echo "${USER} ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
echo "${USER} ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers:赋予用户免密执行sudo特权操作的权限echo "${USER}:${PASSWORF}" | sudo chpasswd:免交互模式下修改用户密码groupadd:添加用户组-g:用户组ID
useradd:添加用户-u:设置用户ID-g:设置用户组ID--no-create-home:不创建默认用户文件夹-d:指定用户默认文件夹--no-log-init:不要将此用户添加到最近登录和登录失败数据库--shell:指定用户的默认shell
下载或导入软件包
# 修改当前用户
USER ${USER}
# 修改当前工作目录
WORKDIR ${USER_HOME}
COPY ./init_server.sh .
RUN \
# 修改用户路径下文件权限
sudo chown -R "${USER}:${USER}" ${USER_HOME} && \
# JDK
mkdir -p "${USER_HOME}/software/jdk" && \
wget https://download.java.net/openjdk/jdk8u43/ri/openjdk-8u43-linux-x64.tar.gz && \
tar -xzvf openjdk-8u43-linux-x64.tar.gz --strip-components 1 -C ${USER_HOME}/software/jdk && \
rm openjdk-8u43-linux-x64.tar.gz && \
# Hadoop
mkdir -p "${USER_HOME}/software/hadoop" && \
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz && \
tar -xzvf hadoop-3.3.6.tar.gz --strip-components 1 -C ${USER_HOME}/software/hadoop && \
rm hadoop-3.3.6.tar.gz && \
mkdir -p "${USER_HOME}/software/hadoop/data/logs" && \
# code-server
mkdir -p "${USER_HOME}/software/code-server" && \
wget https://github.com/coder/code-server/releases/download/v4.14.1/code-server-4.14.1-linux-amd64.tar.gz && \
tar -xzvf code-server-4.14.1-linux-amd64.tar.gz --strip-components 1 -C ${USER_HOME}/software/code-server && \
rm code-server-4.14.1-linux-amd64.tar.gz
USER、WORKDIR:切换当前的执行用户和工作目录COPY ${SRC_PATH} ${CONTAINER_PATH}:将本地的文件复制到镜像中chown:修改文件的用户和用户组,确保新创建的用户可以操作工作路径- 在这里的脚本中通过
wget命令来下载镜像,但在实际应用中,建议先将软件下载下来,然后通过COPY命令拷贝到容器中,避免因为打包失败或其他因素还需要重新下载 - 解压后建议及时删除不需要的压缩包
–strip-components Number:解压时清除Number个引导目录,一般情况下,Number为1表示不包含打包前原目录-C:指定解压路径
环境变量配置
ENV USER_HOME="${USER_HOME}"
# JDK
ENV JAVA_HOME="${USER_HOME}/software/jdk"
ENV PATH="${JAVA_HOME}/bin:${PATH}"
# HADOOP
ENV HADOOP_HOME="${USER_HOME}/software/hadoop"
# hadoop配置文件位置
ENV HADOOP_CONF_DIR="${HADOOP_HOME}/etc/hadoop"
# hadoop运行文件位置
ENV HADOOP_LOG_DIR="${HADOOP_HOME}/data/logs"
# hadoop数据存储位置
ENV HADOOP_DATA_HOME="${HADOOP_HOME}/data"
# hadoop执行脚本路径
ENV PATH="${HADOOP_HOME}/bin:${PATH}"
ENV PATH="${HADOOP_HOME}/sbin:${PATH}"
# 匿名卷声明
VOLUME [ ${USER_HOME} ]
# 端口声明
# SSH远程登录端口
EXPOSE 22
# code-server访问端口
EXPOSE 8080
CMD ["/bin/bash"]
ENV:设置镜像的环境变量。通过ENV设置环境变量后,可以不需要写入export到环境变量配置文件中VOLUME:声明匿名卷EXPOSE:声明可用端口- 在设置
VOLUME和EXPOSE参数后,不是说只能挂载指定的目录和端口,只是指明了本镜像可能需要哪些工作目录和端口
初始化脚本
在如上设置好打包镜像脚本内容,并打包脚本的情况下,我们的镜像未配置完成,关于Hadoop的集群化,我们仍需添加配置相关的参数才可以集群化,所以,需要在启动镜像是通过参数信息设置Hadoop的集群数量,并启动集群。这里将初始化脚本内容写进${USER_HOME}/init_server.sh脚本中,在打包镜像时打包进去。
在ubuntu镜像中,sh程序是不完整的,所以在这里基于bash程序进行脚本的编写,在执行脚本时,需要使用bash程序执行
参数配置
nodeNum=${1:-1}
集群化设置,主要的操作就是能够根据参数信息获取到集群的数量,所以首先需要根据传入的参数获取集群量
${HADOOP_CONF_DIR}/workers工作节点
workers主要功能为记录所有的数据节点的主机名或IP地址。将集群的所有节点的主机名或者IP地址写入workers文件即可。
function setWorkers() {
for ((i = 1; i < $nodeNum; i++))
do
echo "node$i" >> ./workers
done
echo -n "node${nodeNum}" >> ./workers
}
-n:不在末尾追加\n- worker时文件不要有空行,否则在启动集群时,可能会在本地创建多个从节点
${HADOOP_CONF_DIR}/hadoop-env.sh环境变量配置
在Hadoop中,一些环境变量无法读取系统的环境变量,所以需要配置在hadoop-env.sh文件中,理论上讲,只需要配置JAVA_HOME路径,其他的可以采用默认路径。
function setEnv() {
echo "export JAVA_HOME=${JAVA_HOME}" >> ${HADOOP_CONF_DIR}/hadoop-env.sh
echo "export HADOOP_HOME=${HADOOP_HOME}" >> ${HADOOP_CONF_DIR}/hadoop-env.sh
echo "export HADOOP_CONF_DIR=${HADOOP_CONF_DIR}" >> ${HADOOP_CONF_DIR}/hadoop-env.sh
echo "export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}" >> ${HADOOP_CONF_DIR}/hadoop-env.sh
}
${HADOOP_CONF_DIR}/core-site.xmlHadoop核心设置
function setCoreSite() {
# fs.defaultFS:整个hadoop的通讯路径,设置NameNode的通讯路径
# io.file.buffer.size:IO缓冲池大小
coreSiteContent="""
<property>\n
\t\t<name>fs.defaultFS</name>\n
\t\t<value>hdfs://node1:9001</value>\n
\t</property>\n
\n
\t<property>\n
\t\t<name>io.file.buffer.size</name>\n
\t\t<value>131072</value>\n
\t</property>
"""
# 对需要sed写入core-site.xml文件中的内容进行转义
coreSiteContent=$(echo -E ${coreSiteContent} | sed -e 's/[]/$*.^[]/\\&/g')
# 获取<configuration>所在行
begin_line=$(sed -n '/<configuration/=' ${HADOOP_CONF_DIR}/core-site.xml)
# 讲内容写入<configuration>所在行后
sed -i "${begin_line}a${coreSiteContent}" ${HADOOP_CONF_DIR}/core-site.xml
}
- 在bash中调用echo,需要添加
-E参数使\t、\n等转义符进行转义 $(echo -E ${} | sed -e 's/[]/$*.^[]/\\&/g'):主要为对sed中的内容进行转义,否则输出内容将错误无法识别
启动SSH,设置SSH免密登录
function setSSH() {
USER=`whoami`
echo "${USER}:${USER_PASSWORD:-0000}" | sudo chpasswd
echo "Start SSH"
sudo /etc/init.d/ssh start
# 无交互模式生成ssh密钥
ssh-keygen -t rsa -b 4096 -f ${USER_HOME}/.ssh/id_rsa -N "" -q
# 解决第一次ssh登录需要输入yes的问题
sudo sed -i '/StrictHostKeyChecking/c StrictHostKeyChecking no' /etc/ssh/ssh_config
# sleep 15s
for ((i = 1; i <= $nodeNum; i++))
do
sshpass -p ${USER_PASSWORD:-0000} ssh-copy-id "node$i"
done
}
- 可在启动镜像时,设置环境变量
#{USER_PASSWORD}来修改用户密码。若是在打包时修改了默认密码,请修改${USER_PASSWORD:-0000}的默认密码
设置启动服务
function startServers() {
echo "Start Server"
${USER_HOME}/software/code-server/bin/code-server --auth none --bind-addr 0.0.0.0:8080 --extensions-dir ${USER_HOME}/software/code-server/extensions ${USER_HOME}
}
- Docker镜像在启动时需要启动一个守护进程,否则镜像无法正常启动,这里以
code-server为守护进程
主函数
function main() {
if [${HAVE_INIT} == ""] ; then
setWorker
setEnv
setCoreSite
setSSH
startServers
echo "export HAVE_INIT=1" >> ~/.bash_profile
source ~/.bash_profile
else
sudo /etc/init.d/ssh start
${USER_HOME}/software/code-server/bin/code-server --auth none --bind-addr 0.0.0.0:8080 --extensions-dir ${USER_HOME}/software/code-server/extensions ${USER_HOME}
fi
}
main
未完待续