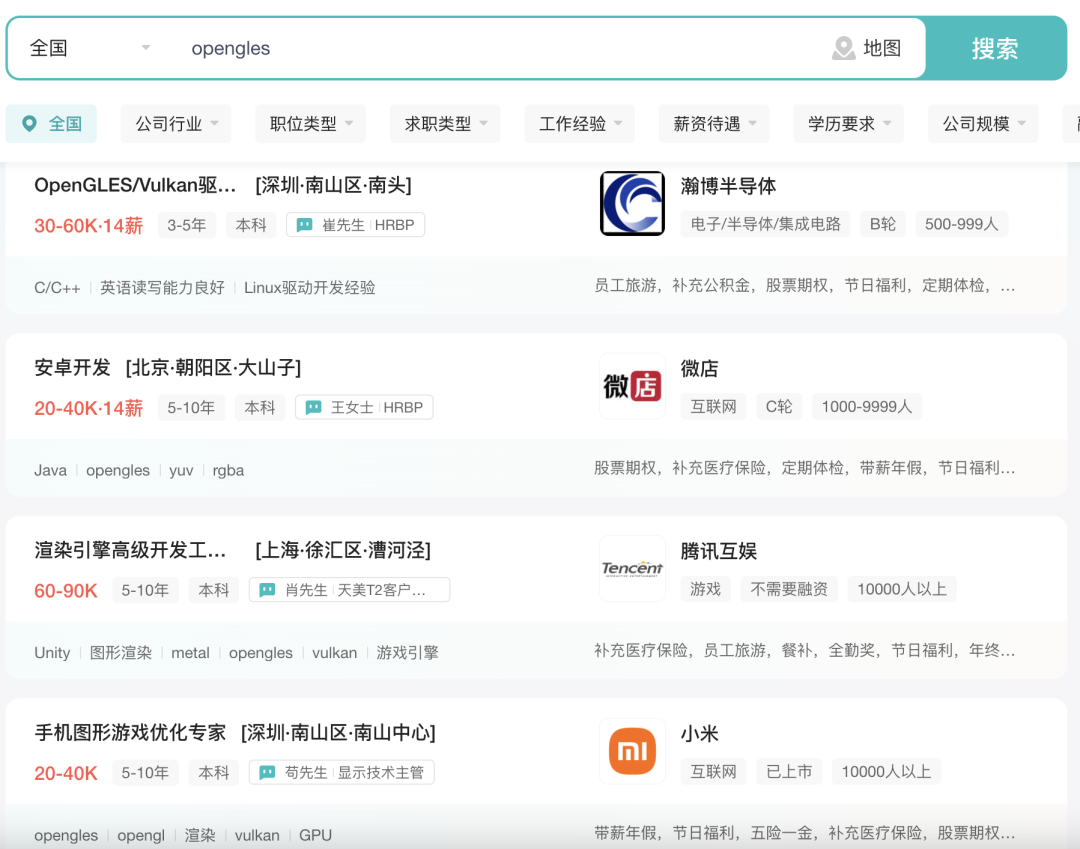
yolo代码自动标注
- 1.引言
- 1.初阶“自动标注”,给每个图像都生成一个固定的标注文件,进而在labglimg中对矩形框进行微调,减少标注的工作量
- 2.高阶自动标注,利用我们训练好的(但是没有特别精准的)yolo文件先对每张图进行检测,再手动微调
- 3.总结
1.引言
在图像处理与机器视觉领域,标注数据的质量和数量对于模型的训练至关重要。然而,手动标注大量图像是一项繁琐且耗时的工作。为了解决这个问题,自动标注技术应运而生。本文将介绍如何使用YOLOv10结合传统图像处理算法进行验证码图像的自动标注,从初步的自动标注到高阶的基于检测结果的自动标注。
1.初阶“自动标注”,给每个图像都生成一个固定的标注文件,进而在labglimg中对矩形框进行微调,减少标注的工作量
在初步的自动标注阶段,我们首先为每张图像生成一个固定的标注文件,这些文件的内容通常是预设的,矩形框的位置并不精确,因此适合用作标注的初步框架。
import os
# 图像文件夹路径
image_folder = 'D:'
# 标注文件即txt文件路径
txt_folder = 'D:'
# 基于上述两个路径检索图像和txt即yolo格式的标注文件
image_files = [f.split('.')[0] for f in os.listdir(image_folder) if f.lower().endswith(('jpg', 'jpeg', 'png', 'bmp'))]
txt_files = [f.split('.')[0] for f in os.listdir(txt_folder) if f.lower().endswith('txt')]
# 遍历图像文件名
for img_name in image_files:
# 如果某图像没有对应的标签文件即txt文件
if img_name not in txt_files:
# 写入txt文件
txt_content = """0 0.808621 0.945652 0.072414 0.073913
0 0.250000 0.604348 0.093103 0.078261
0 0.660345 0.584783 0.086207 0.100000
0 0.613793 0.160870 0.117241 0.139130
0 0.293103 0.184783 0.103448 0.117391"""
with open(os.path.join(txt_folder, img_name + '.txt'), 'w') as f:
f.write(txt_content)
print("Process complete.")
由于我们对每张图都生成的是一份固定的标注txt文件,所以生成的文件一般都是这种的,矩形框 不在正确的位置上,虽然能够降低一定的标注工作量,但是我们还是想让它更精准一点,那就需要使用训练好的模型了。
局限性:
矩形框位置不准确,标注结果可能与实际物体位置存在偏差。
无法自动识别图像中的所有物体,可能遗漏检测。

2.高阶自动标注,利用我们训练好的(但是没有特别精准的)yolo文件先对每张图进行检测,再手动微调
为了提高自动标注的精度,我们可以使用YOLOv10模型对每张图像进行目标检测,并根据检测结果生成标注文件。这种方式能够提供较为准确的初步标注,用户只需要对检测框进行微调即可,减少了大量的手动标注工作。
import os
from ultralytics import YOLOv10
# Folder paths
image_folder = 'D:'
txt_folder = 'D:'
# Load a pretrained YOLOv10n model
model = YOLOv10("\weights\\best.pt")
image_files = [f for f in os.listdir(image_folder) if f.lower().endswith(('jpg', 'jpeg', 'png', 'bmp'))]
# Perform object detection on each image file
for img_name in image_files:
img_path = os.path.join(image_folder, img_name)
# Perform prediction
results = model.predict(img_path)
# Extract detection results (assuming results[0] contains the detection)
detections = results[0].boxes.xywh # Get bounding box coordinates (xywh format)
# If no .txt file exists, create a new one
txt_path = os.path.join(txt_folder, img_name.split('.')[0] + '.txt')
if not os.path.exists(txt_path): # Check if .txt file already exists
# Write detection results to the .txt file
with open(txt_path, 'w') as f:
for detection in detections:
# Assuming you want the format: class_id x_center y_center width height (normalized)
# Convert coordinates from pixels to normalized values by dividing by image width/height
x_center, y_center, width, height = detection
x_center /= results[0].orig_img.shape[1] # Normalize by image width
y_center /= results[0].orig_img.shape[0] # Normalize by image height
width /= results[0].orig_img.shape[1] # Normalize by image width
height /= results[0].orig_img.shape[0] # Normalize by image height
# Write to file (Assuming class id is 0 here, change based on your model)
f.write(f"0 {x_center} {y_center} {width} {height}\n")
print("Process complete.")
代码详解:
1.加载YOLOv10模型:使用YOLOv10模型进行物体检测。通过model.predict()函数对每张图像进行检测。
2.提取检测结果:模型返回的结果中包含了检测到的目标的坐标信息,采用boxes.xywh提取出目标的位置。
3.坐标归一化:将检测结果的坐标从像素值转换为相对图像大小的比例(即归一化值),以符合YOLO标注格式。
4.生成标注文件:根据模型检测结果生成标注文件,格式为class_id x_center y_center width height。
这种方式得到的数据一般是下图这样的,1.会有一些框不准,2.有一些框是重复的,3.有一些代码没有检测到。此时我们只需要微调这三种情况的框即可,显著降低了工作量。

3.总结
本文介绍了基于YOLOv10的自动标注方法,从初阶的固定标注到高阶的基于YOLO检测结果的自动标注。两者相比,高阶方法显著提高了标注的准确性,并减少了人工操作的时间。
初阶方法:快速生成标注文件,适用于初步标注,但需要人工微调和修正。
高阶方法:通过YOLOv10检测得到较为精准的标注结果,适合更高精度要求的任务,但仍需要人工微调。
希望这些代码能帮助大家提升标注工作的效率和精度,降低人工标注的成本。在未来的工作中,我们可以继续优化和扩展该方法,进一步提高自动标注的精度和适用范围。

![边缘提取函数 [OPENCV--2]](https://i-blog.csdnimg.cn/direct/0d172bb166794fb28761b733653e29a8.png)